Exploration for Object Mapping Guided by Environmental Semantics using UAVs

 , , ,
, , ,
Abstract
:1. Introduction
- A 3D, semantically-aware, colored annotated mapping method that uses a deep learning model to semantically segment the objects in 2D images and project the annotated objects in a 3D, semantically-aware occupancy map. This includes a novel data structure that extends the volumetric occuapancy grid representations to include more semantic specific information.
- Development of a multi-objective utility function that encapsulates the quantified information generated from the semantic map and volumetric map to allow the robot to explore the unknown space and to direct the robot to visit the objects and label them effectively.
- An overall exploration strategy that utilizes rapidly exploring random tree (RRT) for viewpoint sampling, and the next-best-view approach with the proposed semantic utility functions to iteratively explore the unknown environment and label all the objects there.
2. Related Work
2.1. Object Detection and Classification
2.2. Semantic Mapping
2.3. Exploration
3. Materials and Methods
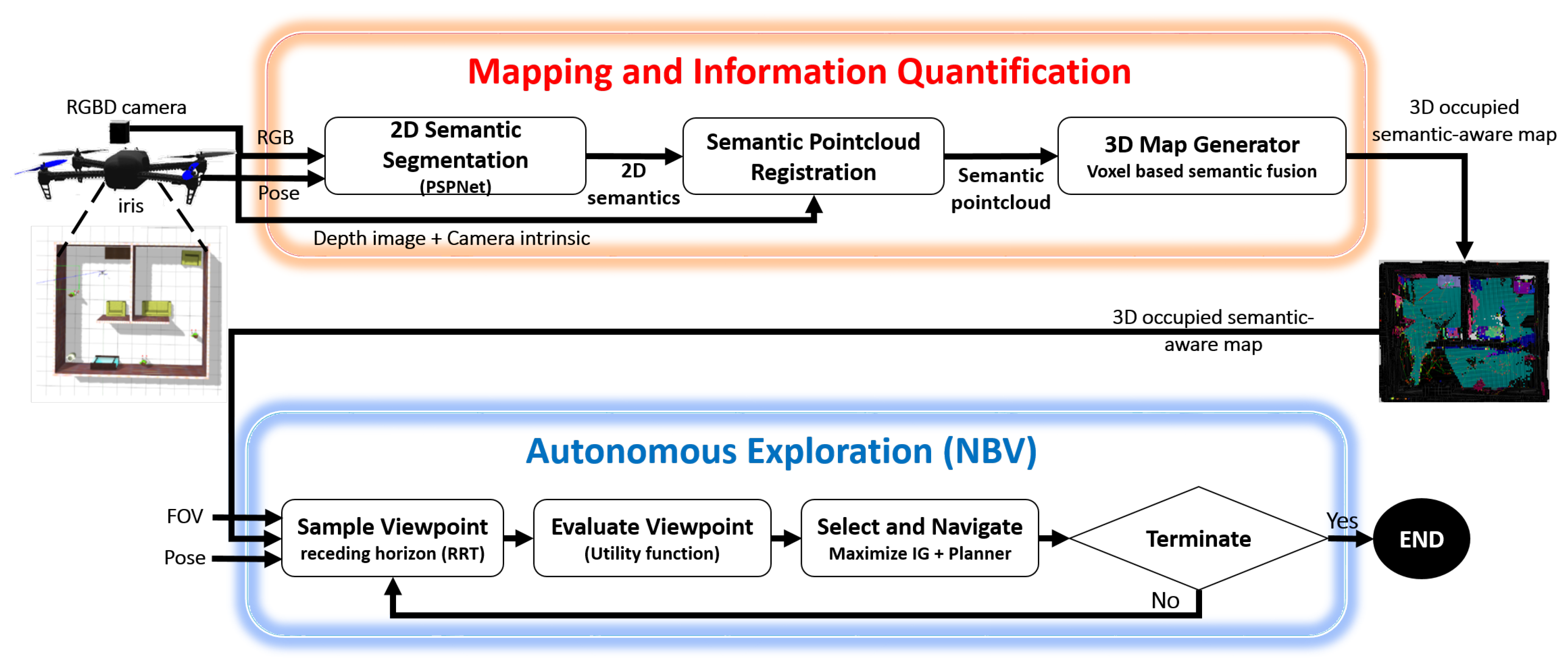
3.1. Proposed Approach
3.2. Mapping and Information Quantification
3.2.1. 2D-Image-Based Semantic Segmentation and Semantic Fusion
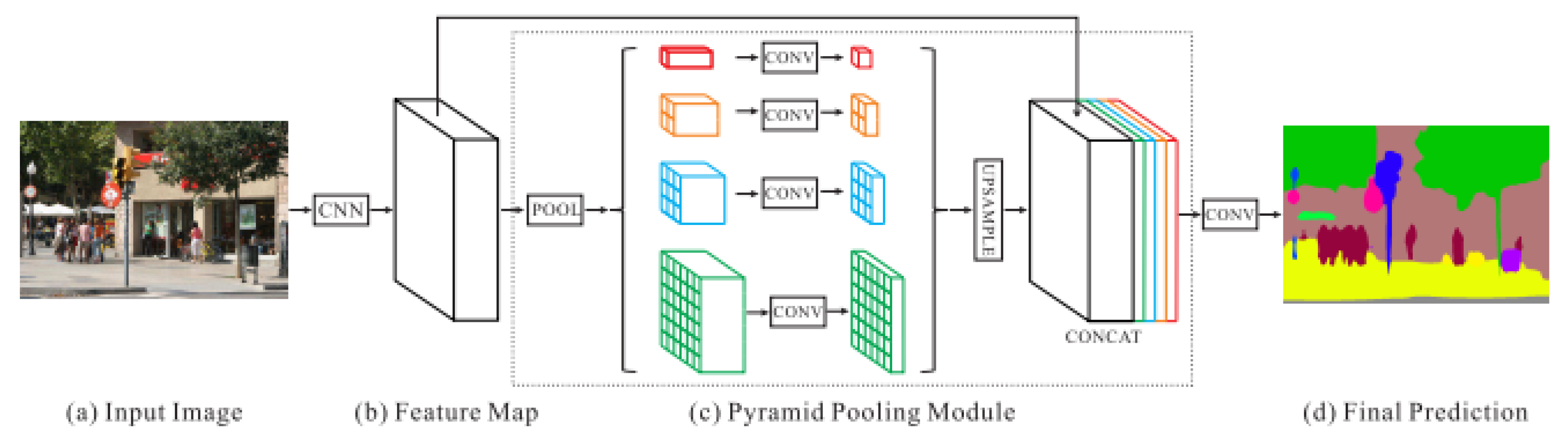
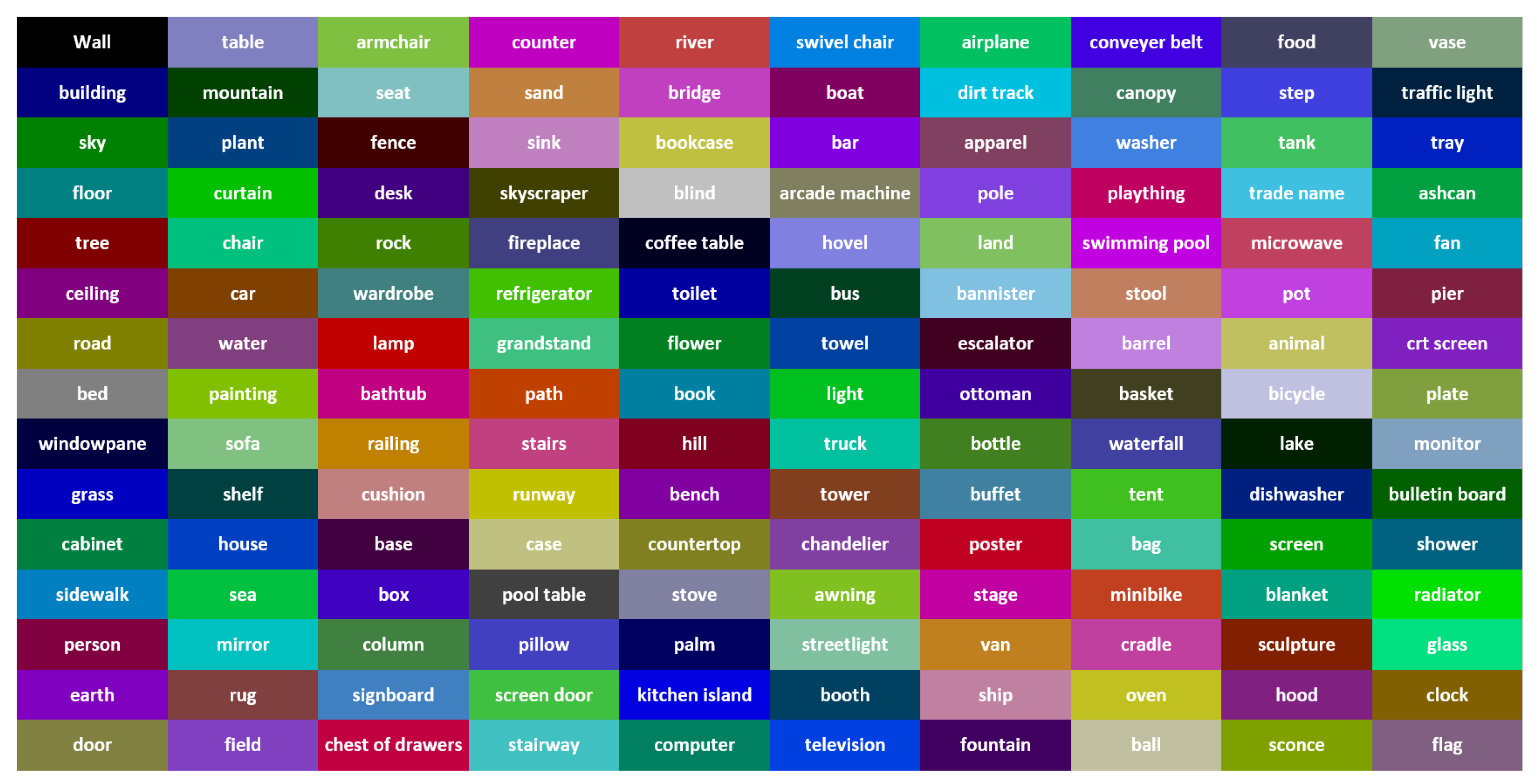
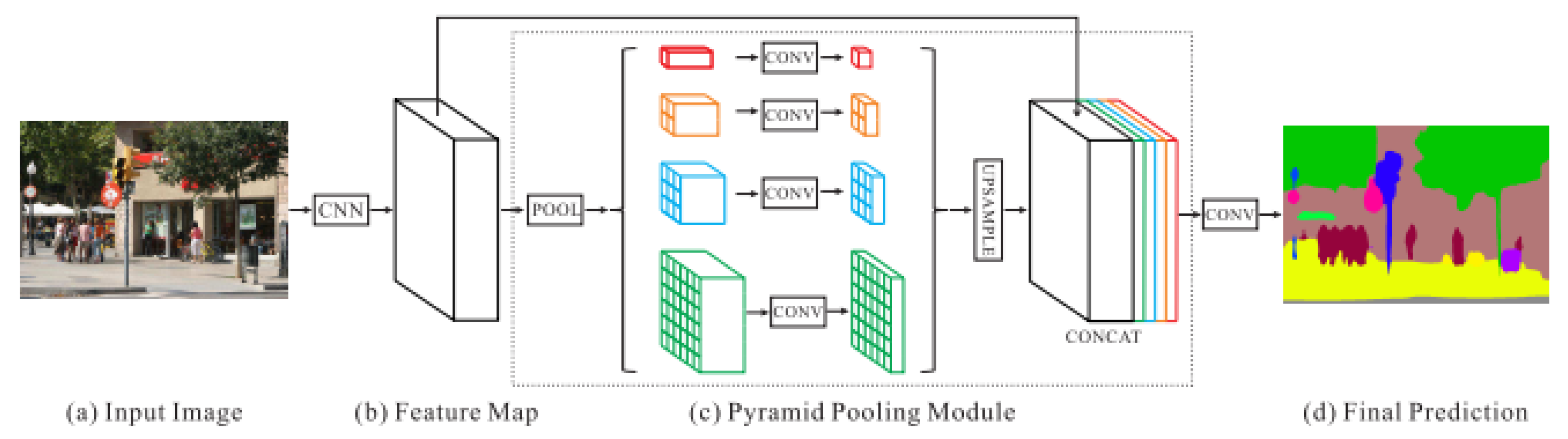
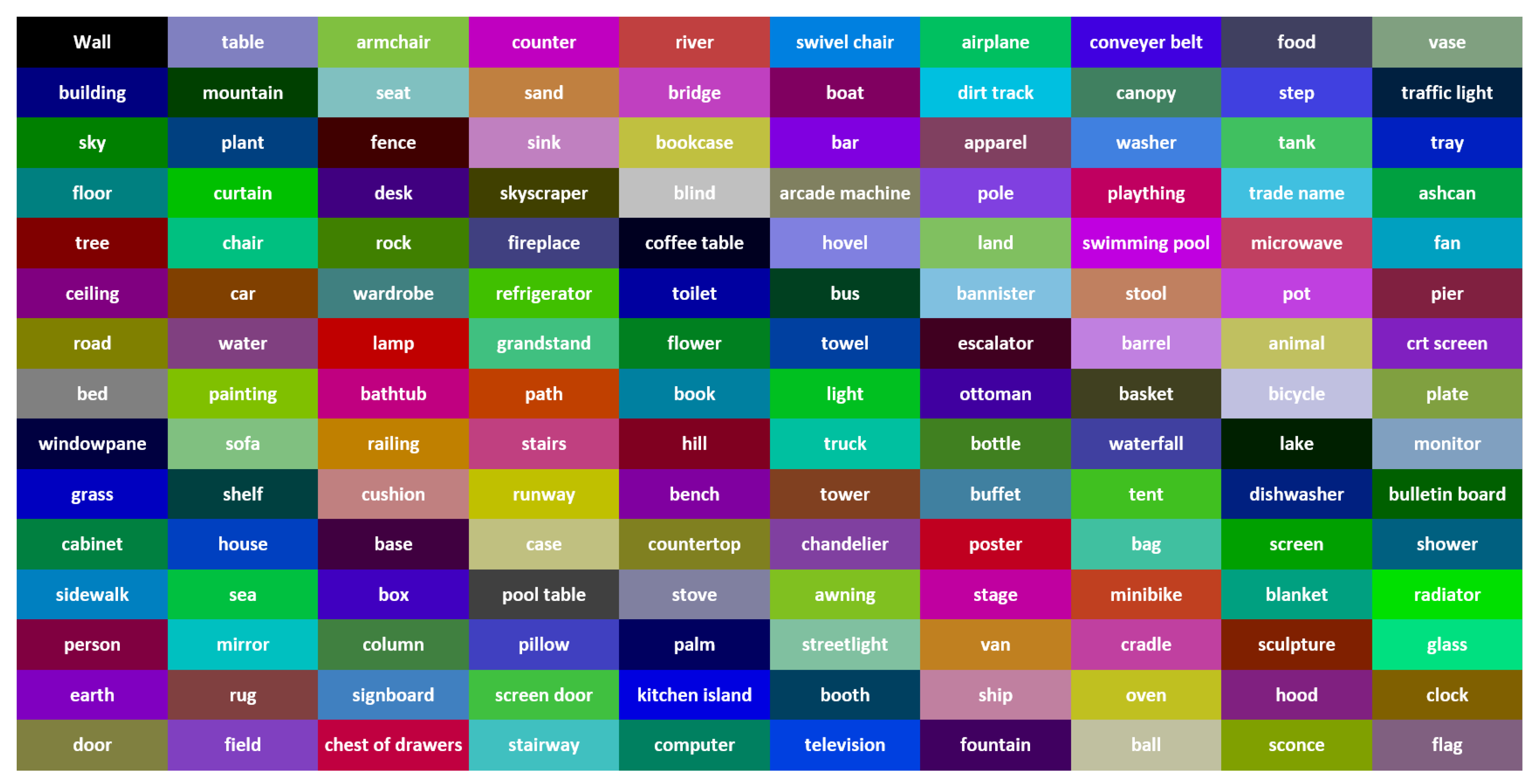
- Semantic SegmentationThe deep neural network pyramid scene parsing network (PSPNet) based on semantic segmentation [28] is employed to provide semantic segments for the different objects in 2D images. The network architecture is shown in Figure 2. PSPNet operates in five steps as follows: (i) create a feature map using resnet, (ii) apply pyramid pooling on the created feature map to produce feature maps at varying resolutions, (iii) perform convolution on each pooled feature map, (iv) create a final feature map by upsampling the feature maps and concatenate them, and (v) generate a class score map by employing final convolutions.The PSPNet model is trained [28] on two datasets, the SUNRGB [38] and ADE20K [39]. The ADE20K dataset includes a large vocabulary of 150 classes from both indoor and outdoor objects. However, the SUNRGBD data set contains 38 semantic classes for indoor scenes. The fact that the ADE20K dataset contains a larger number of objects made it a preferable choice to segment an unknown environment with a diversity of objects. Examples of 2D images with semantic segments are shown in Figure 3a,b respectively. The RGB images are obtained using the simulated sensor in the Gazebo simulator that mimics the characteristics of an actual camera. In this work, only ADE20K dataset is used and the semantic labels of ADE20K dataset are shown in Figure 4.
- Semantic FusionSemantic information encapsulated in the point cloud is fused using the “max fusion” approach [40]. In the max fusion approach, the semantic color that corresponds to the highest confidence value generated from the CNN model is included in the generated point cloud. In addition, the same value of the confidence and the label color are saved in the corresponding voxel of octomap.
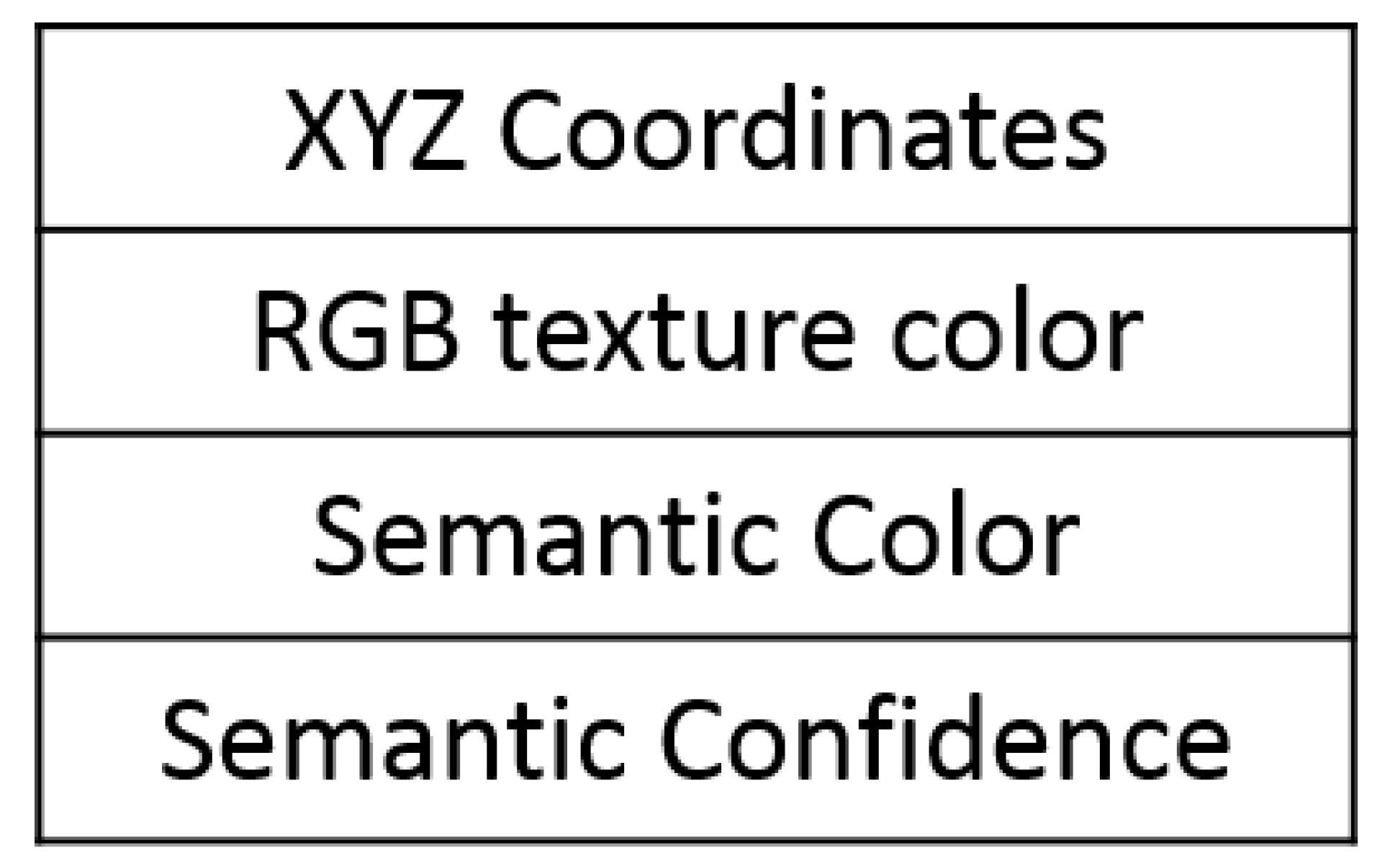
3.2.2. Annotated Point Cloud Generation
3.2.3. 3D Semantic Map Generation
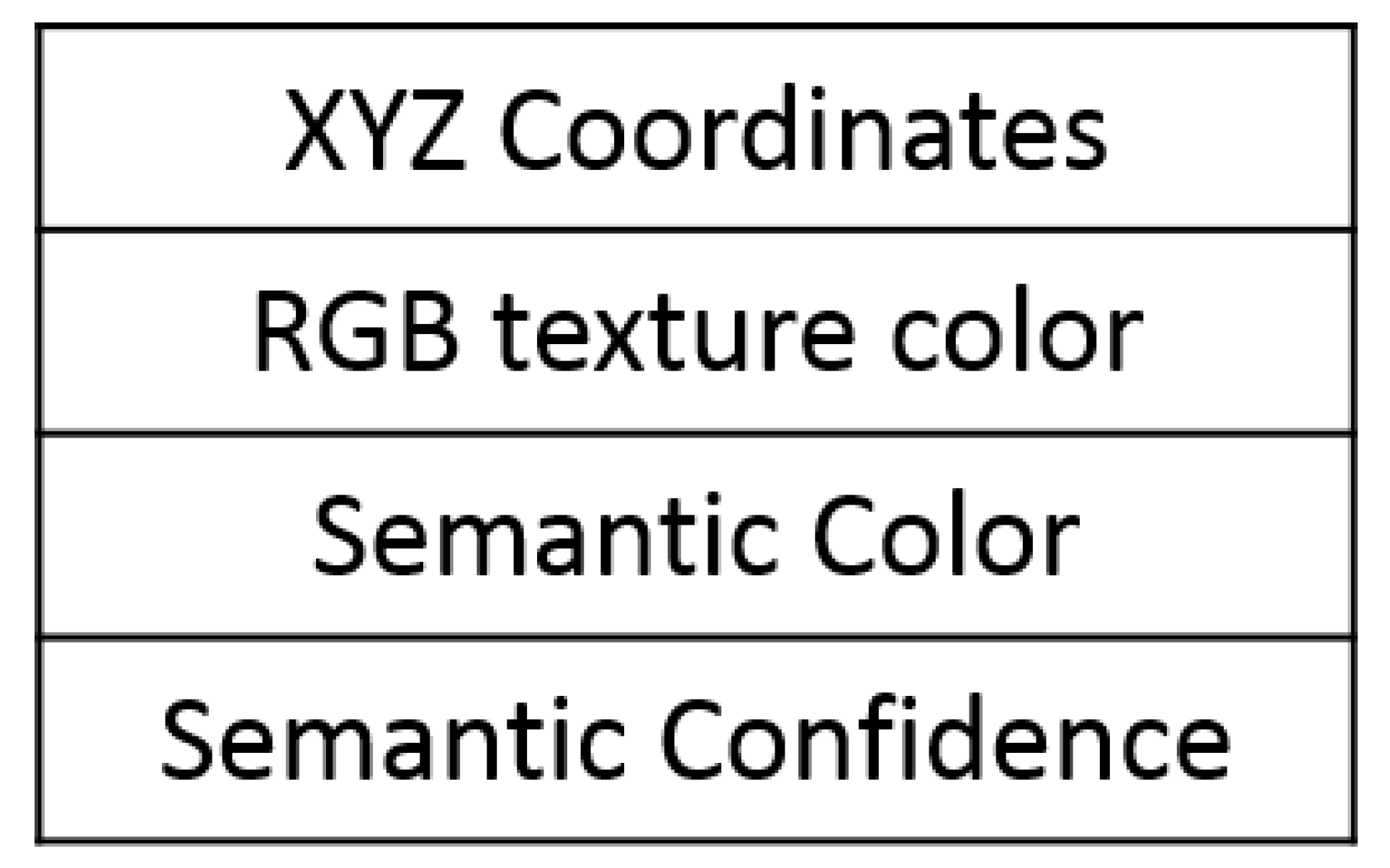
- Position ;
- Probability of being occupied (value) ;
- Semantic color ;
- Confidence value from class type ;
- Number of visits.
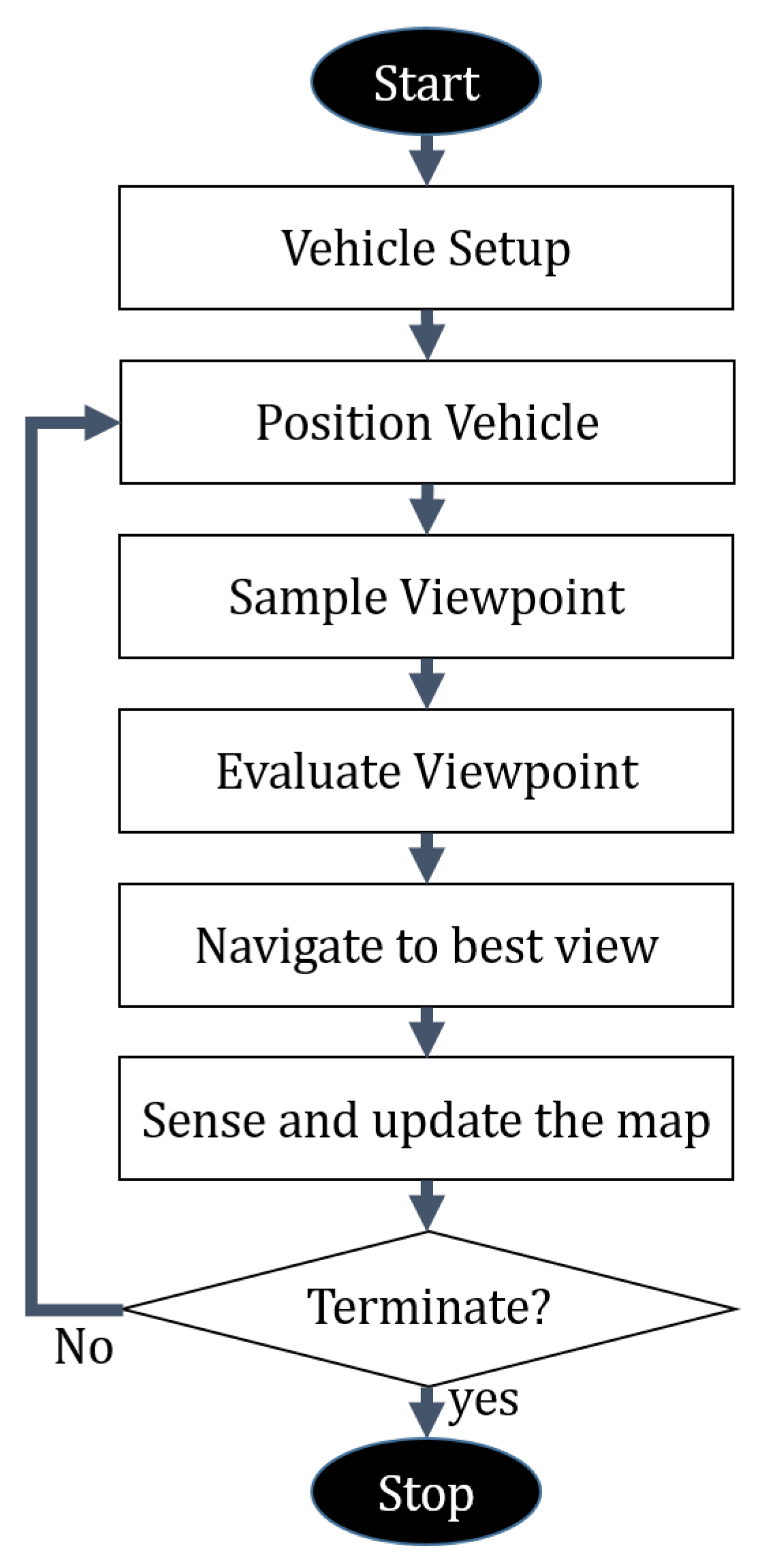
3.3. Semantically-Aware Exploration
| Algorithm 1 Proposed planner—iterative step. |
| 1: current robot configuration |
| 2: Initialize T with |
| 3: |
| 4: |
| 5: Number of initial Nodes in T |
| 6: while or do |
| 7: Incrementally build T by adding |
| 8: |
| 9: if InformationGain() then |
| 10: InformationGain() |
| 11: |
| 12: end if |
| 13: if then |
| 14: Terminate |
| 15: end if |
| 16: ExtractBestSegment() |
| 17: end while |
| 18: return |
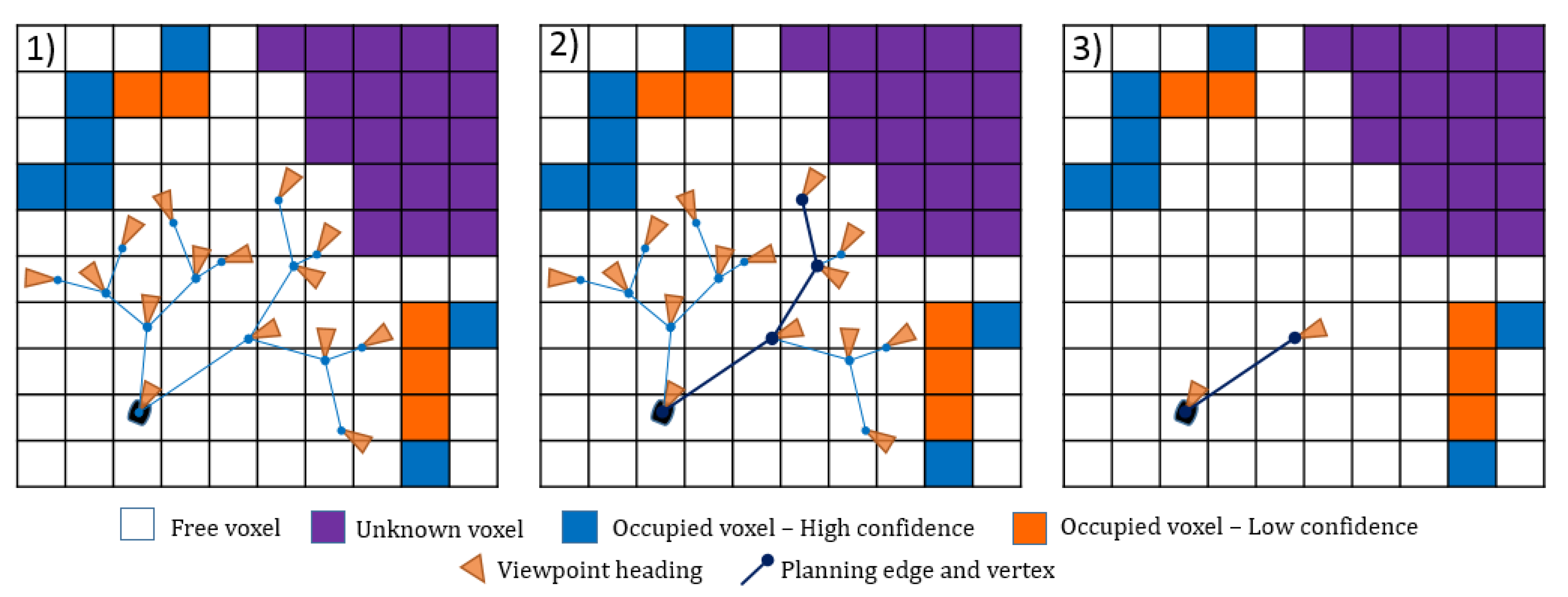
3.3.1. Viewpoint Sampling
3.3.2. Viewpoint Evaluation
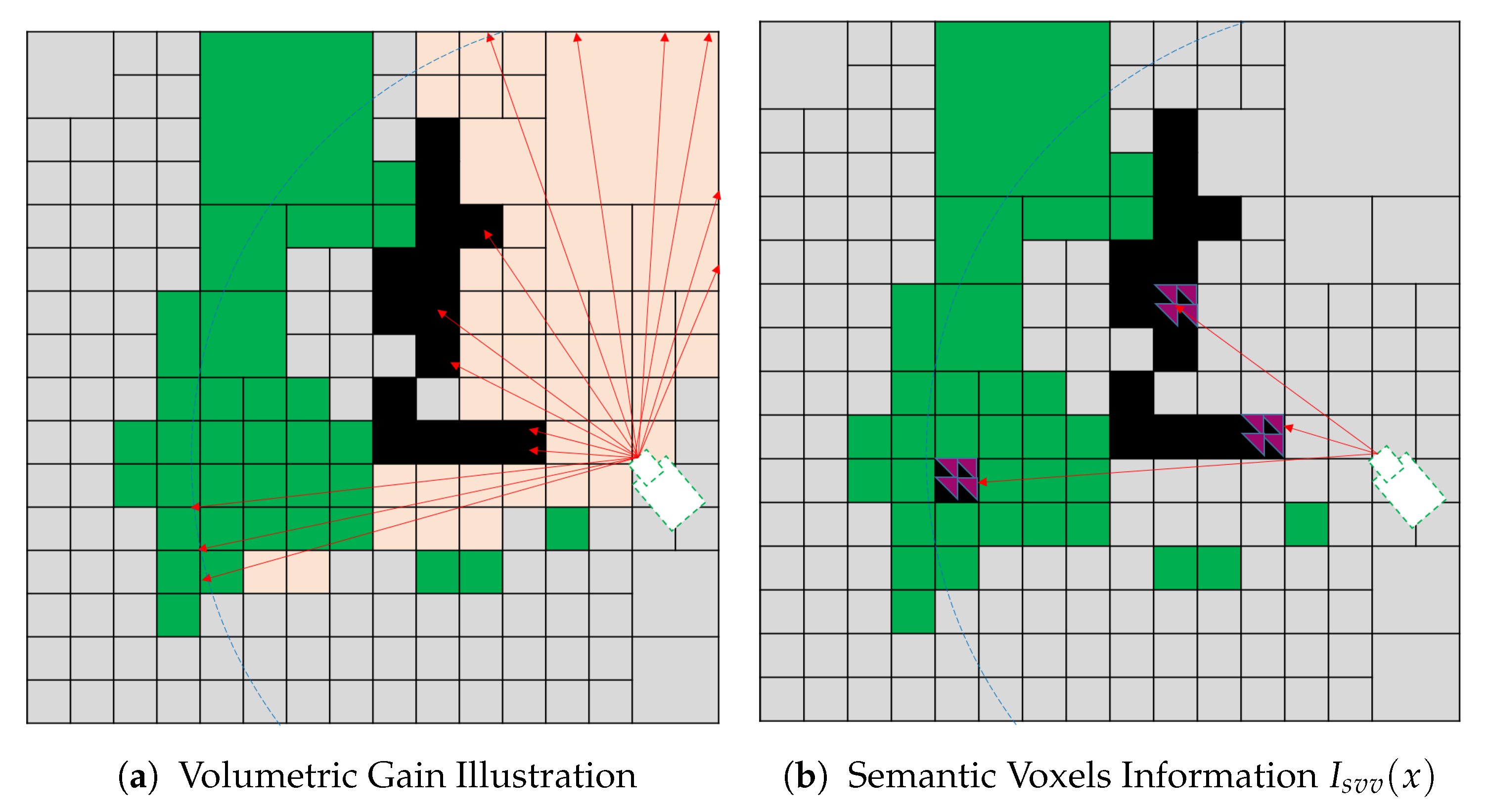
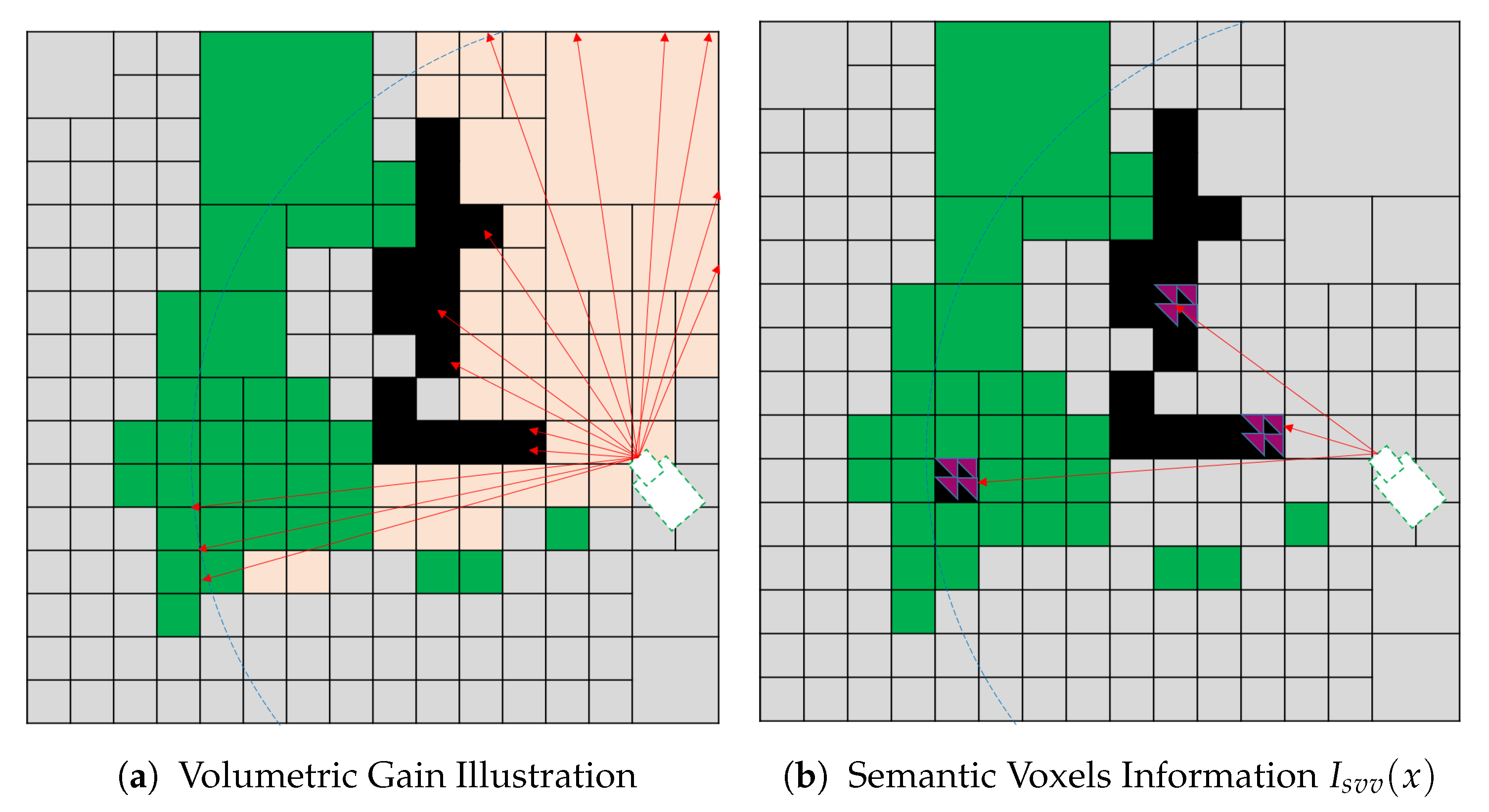
- Semantic Visible Voxel (SVV)The proposed SVV multi-objective function tends to direct the robot towards the views that contain known occupied voxels with a small confidence value to label all the objects in the scene. The confidence value is obtained from CNN, and it is the maximum confidence value for the corresponding class out of 150 objects. Let be the indicator if the semantic confidence value assigned to a voxel is less than a predefined threshold:where is the semantic confidence value fused by the deep learning model, and is a predefined confidence threshold.We propose semantic information for a single voxel as a voxel that is visible, semantically labeled, and its confidence value less than a predefined threshold. The is defined as:Finally, the gain obtained from the proposed utility function is calculated by substituting into in Equation (1), where and . The total gain for a single view combines the volumetric and semantic info for all the voxels in the view. Figure 10 illustrates the SVV function which is a combination(accumulation) of both the volumetric in formation in Figure 10a and semantic information in Figure 10b.
- Semantic Visited Object Of Interest Visible Voxel (SVOI)The proposed SVOI multi-objective function tends to direct the robot toward the views that contain occupied voxels classified as an object of interest but not visited sufficiently. In this function, the number of visits for each voxel is recorded to be used in the semantic information calculation. Let be the indicator if the object belongs to the set of interest object S as follows:Each voxel in the semantic map holds a value that represents the number of times it has been visited. In addition, let be the indicator of visiting threshold:where is a predefined threshold for the sufficient number of visiting.We propose semantic information for a single voxel as a voxel that visible voxels, semantically labeled, belongs to object of interest, and their visiting value is less than a predefined threshold. It is defined as:Finally, the gain obtained from the proposed utility function is calculated by substituting into in Equation (1) where and . The total gain for a single view combines the volumetric and semantic info for all the voxels in the view.
3.3.3. Termination
4. Experimental Setup and Results
4.1. Experimental Setup
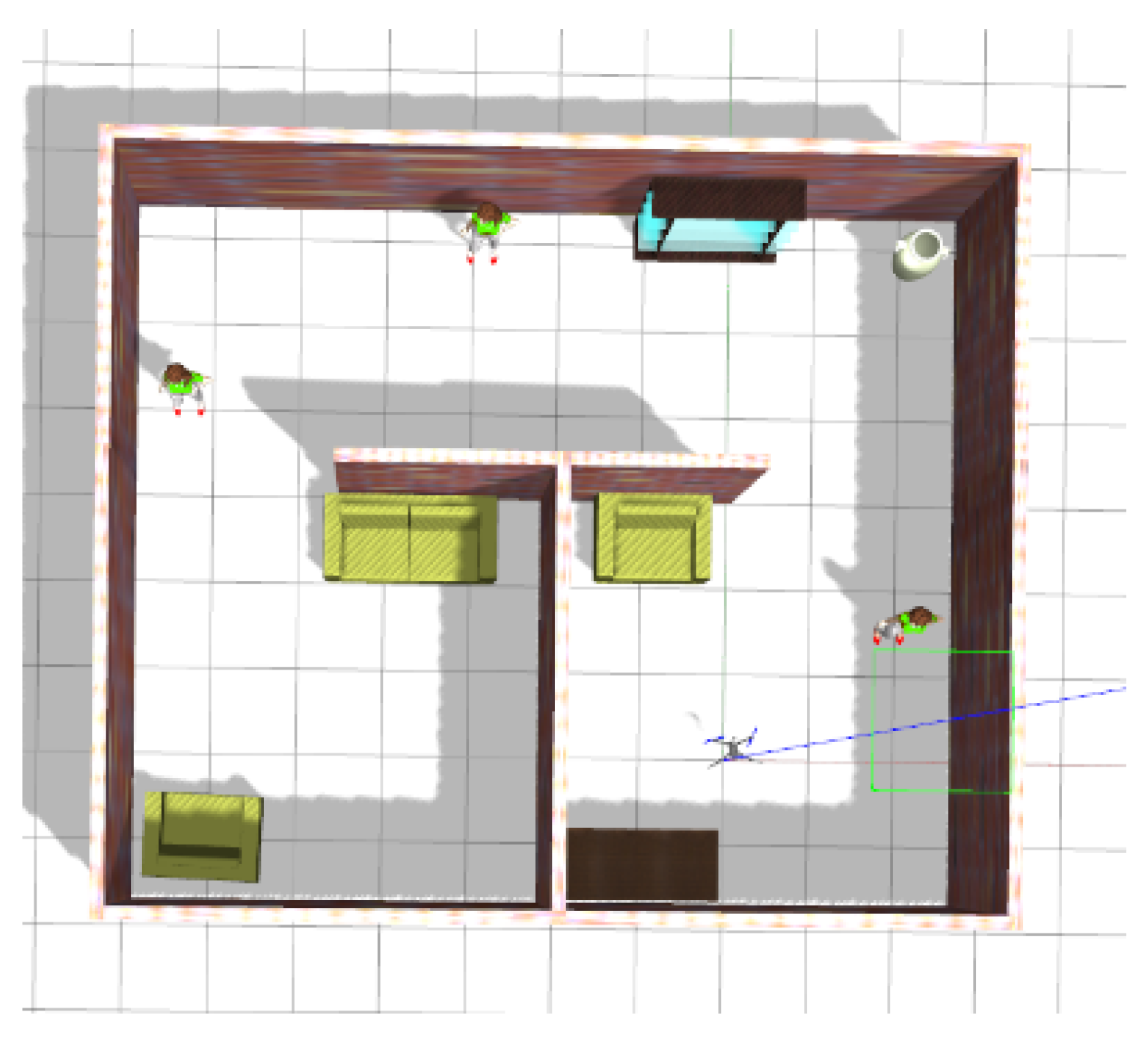
4.1.1. Scenario
4.1.2. Simulation
- The position of the robot was considered entirely known from the gazebo.
- The explored environment is unknown with known boundaries only.
4.1.3. Baselines for Comparison
4.1.4. Evaluation Metrics
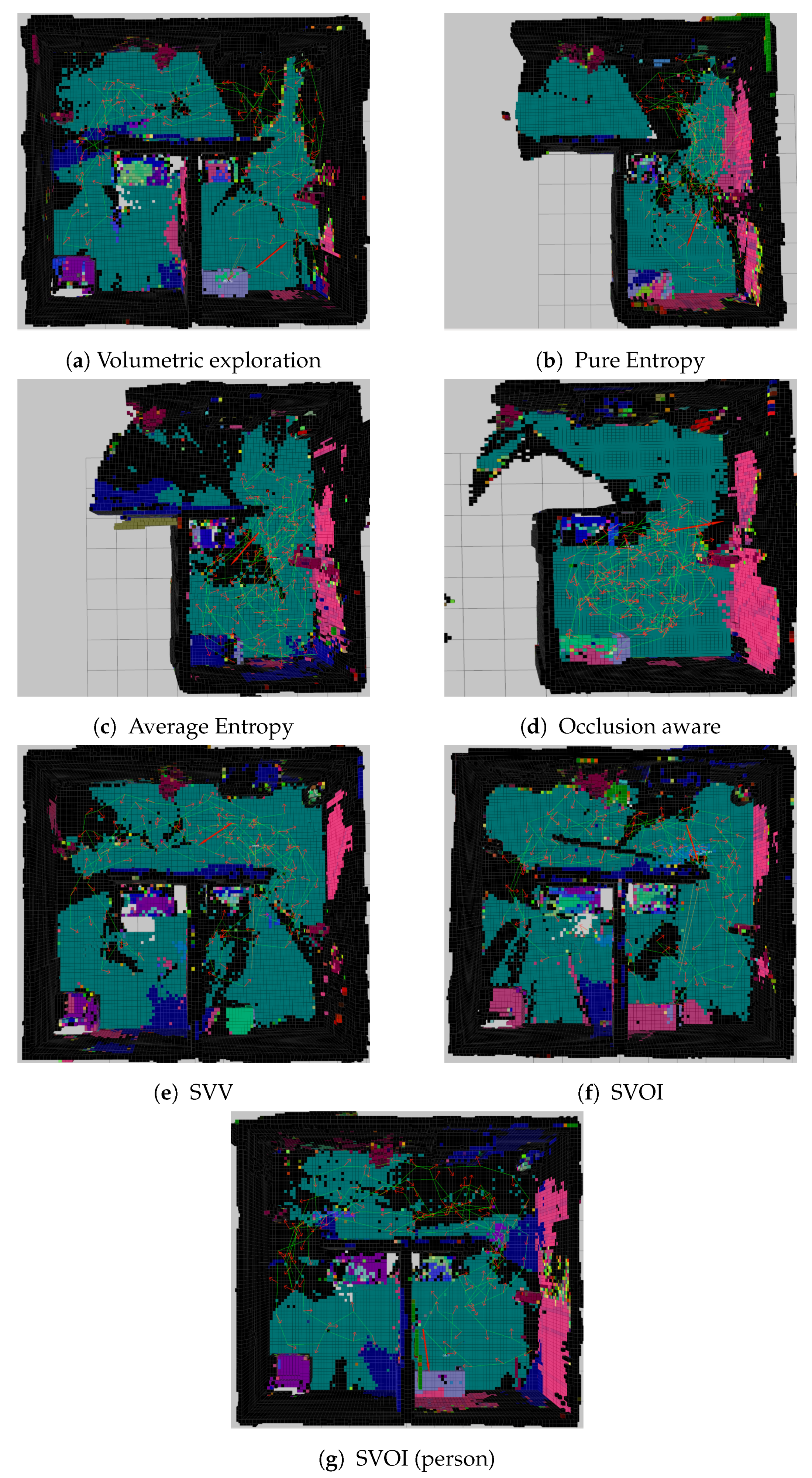
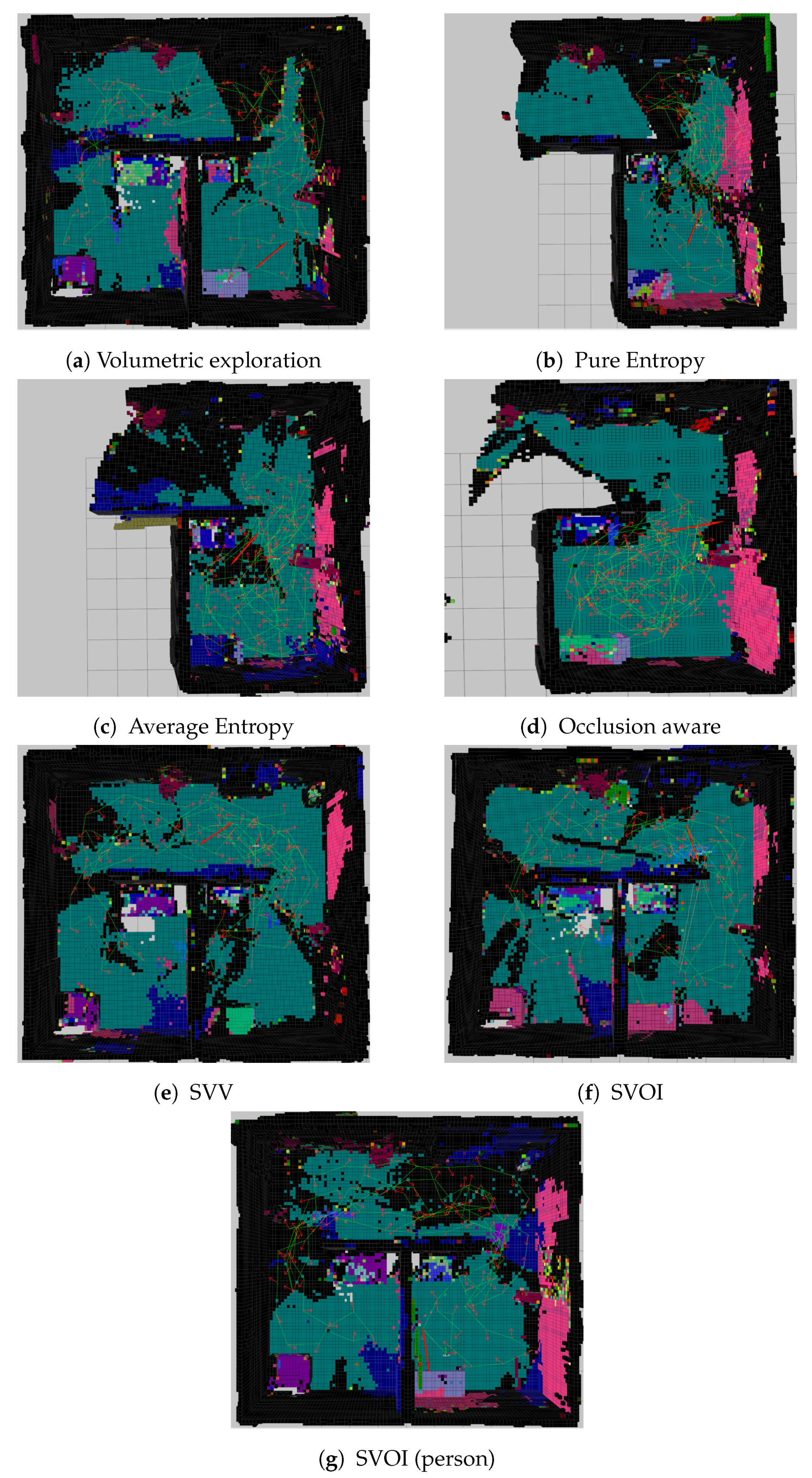
4.2. Experiment Results and Analysis
4.2.1. Mapping Evaluation
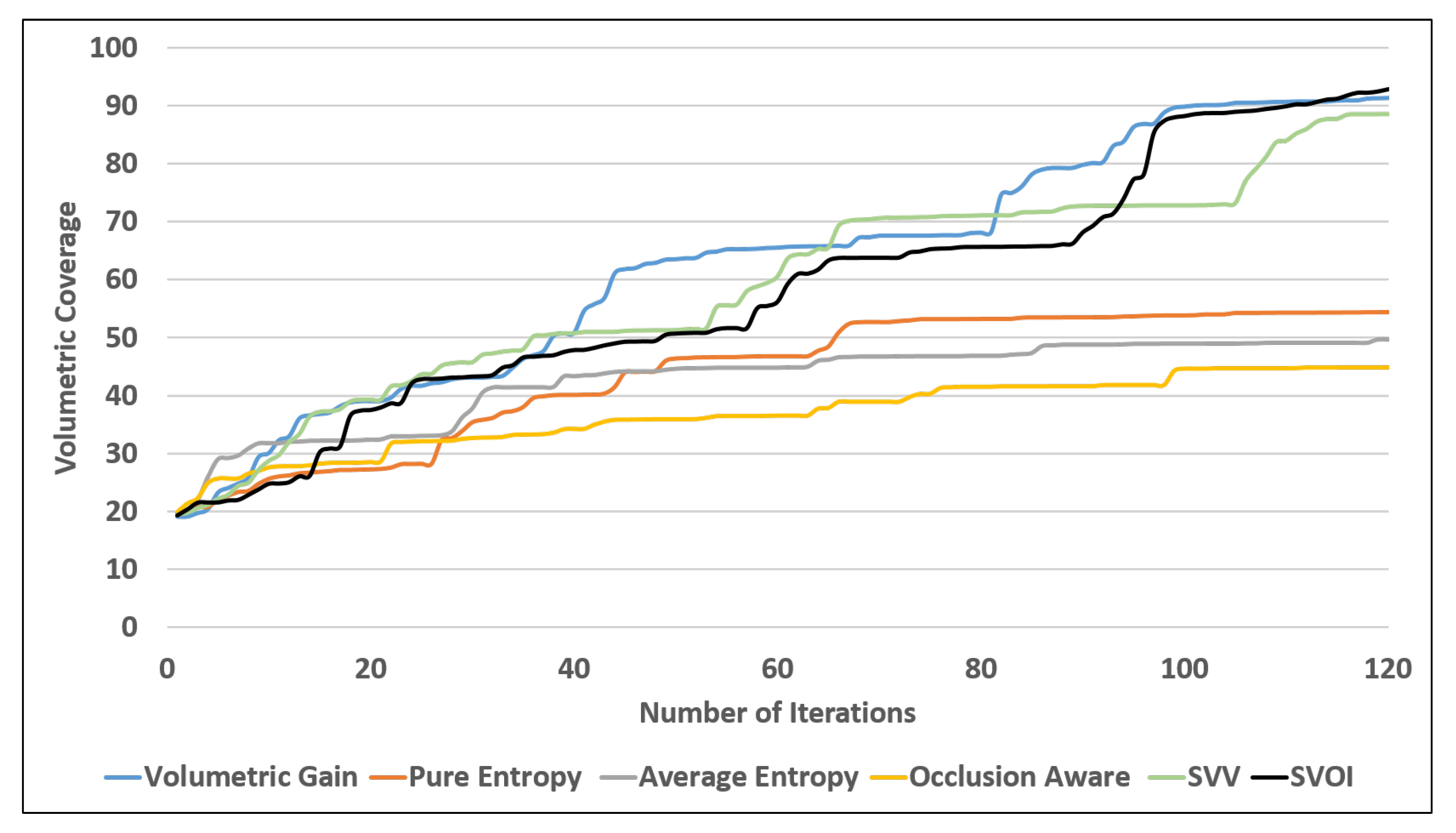
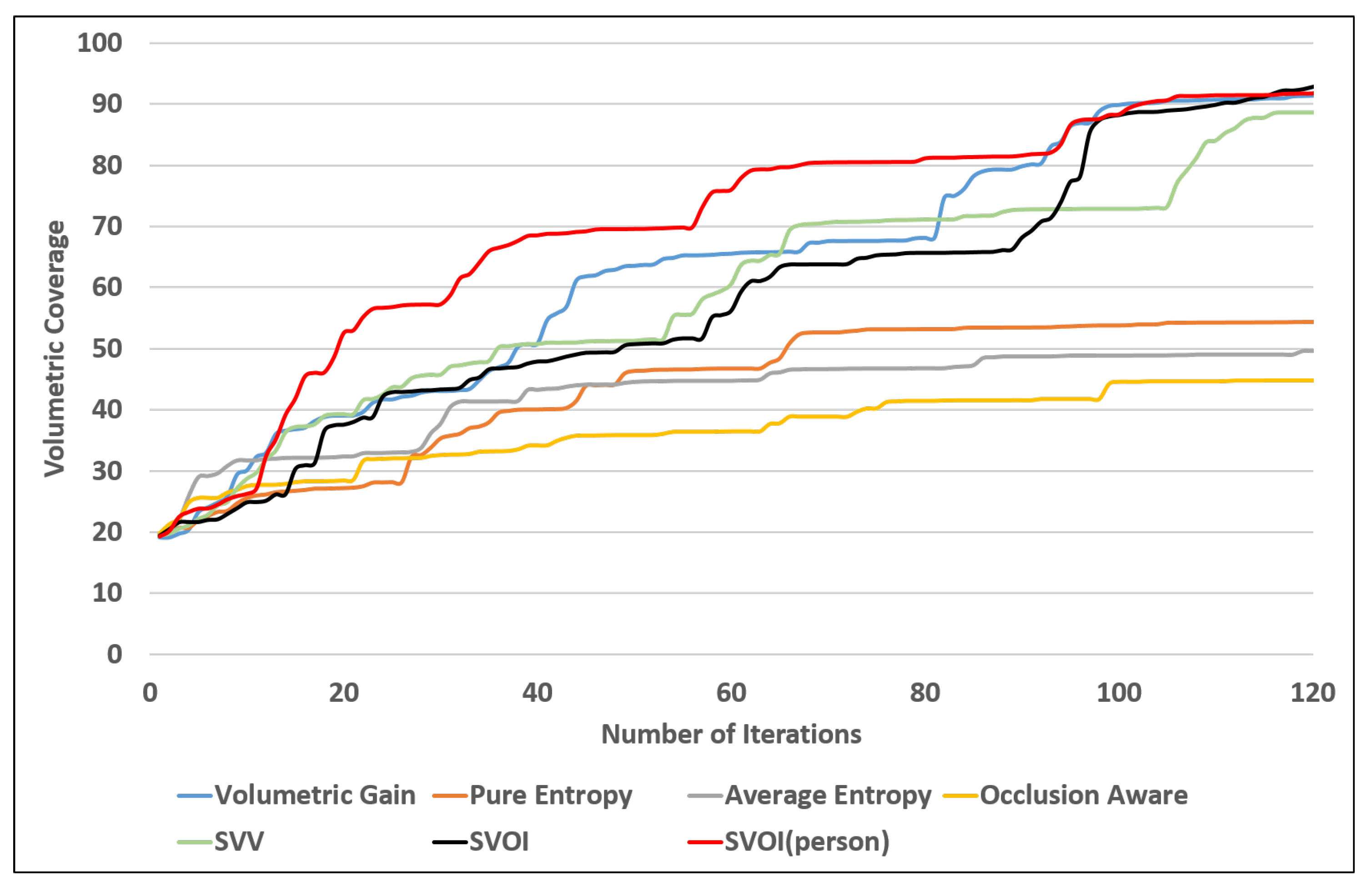
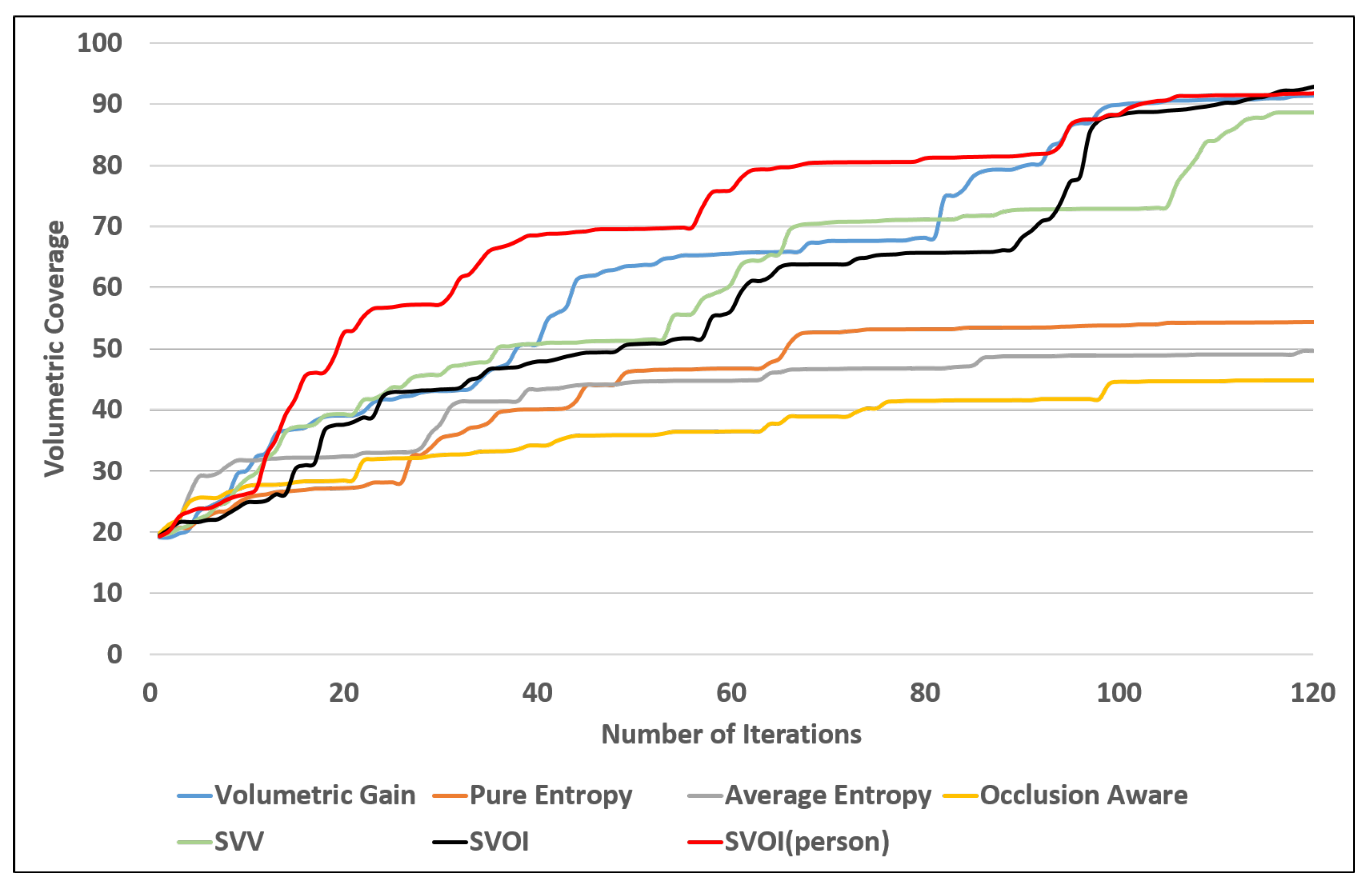
4.2.2. Area Coverage Over Number of Iteration
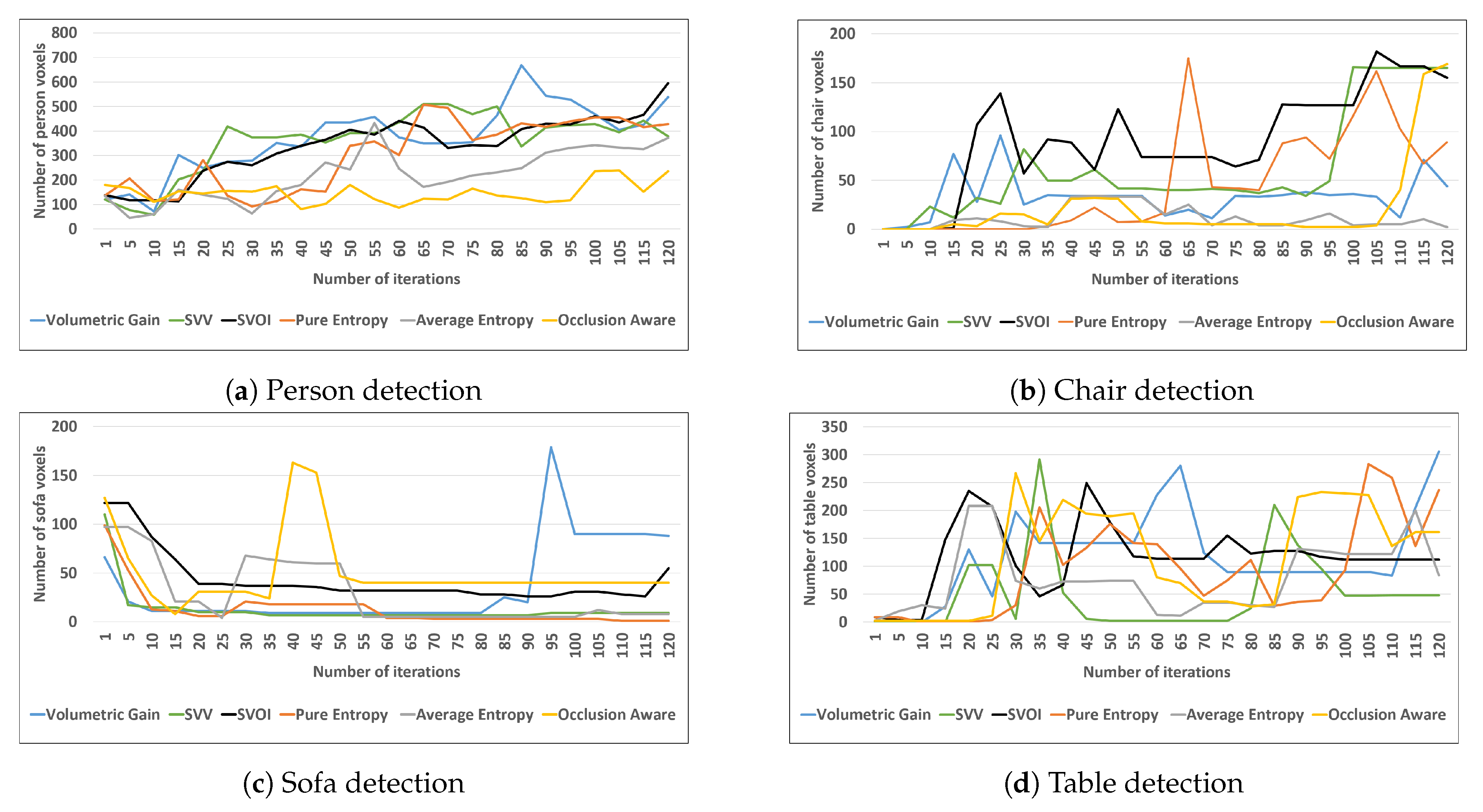
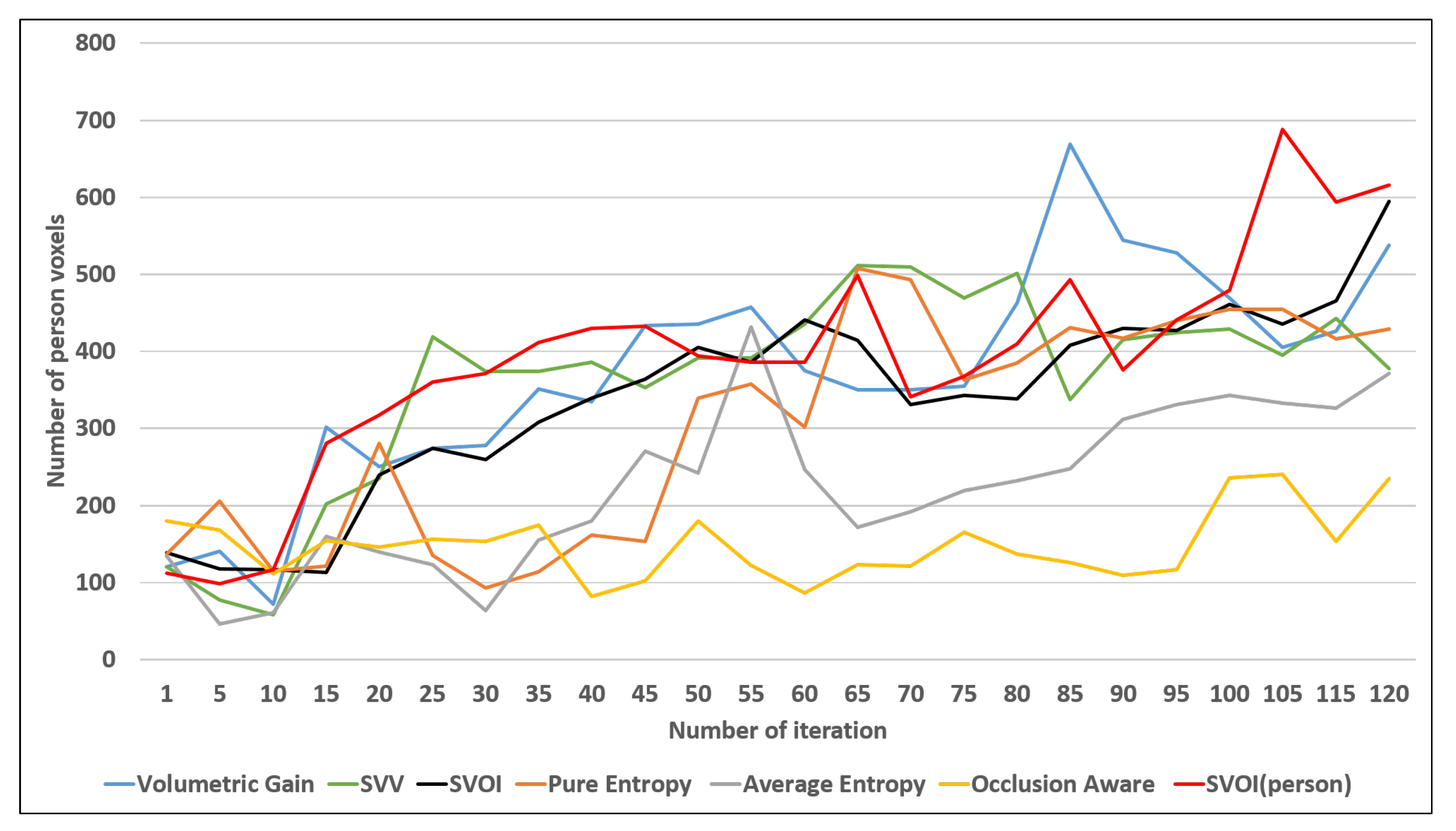
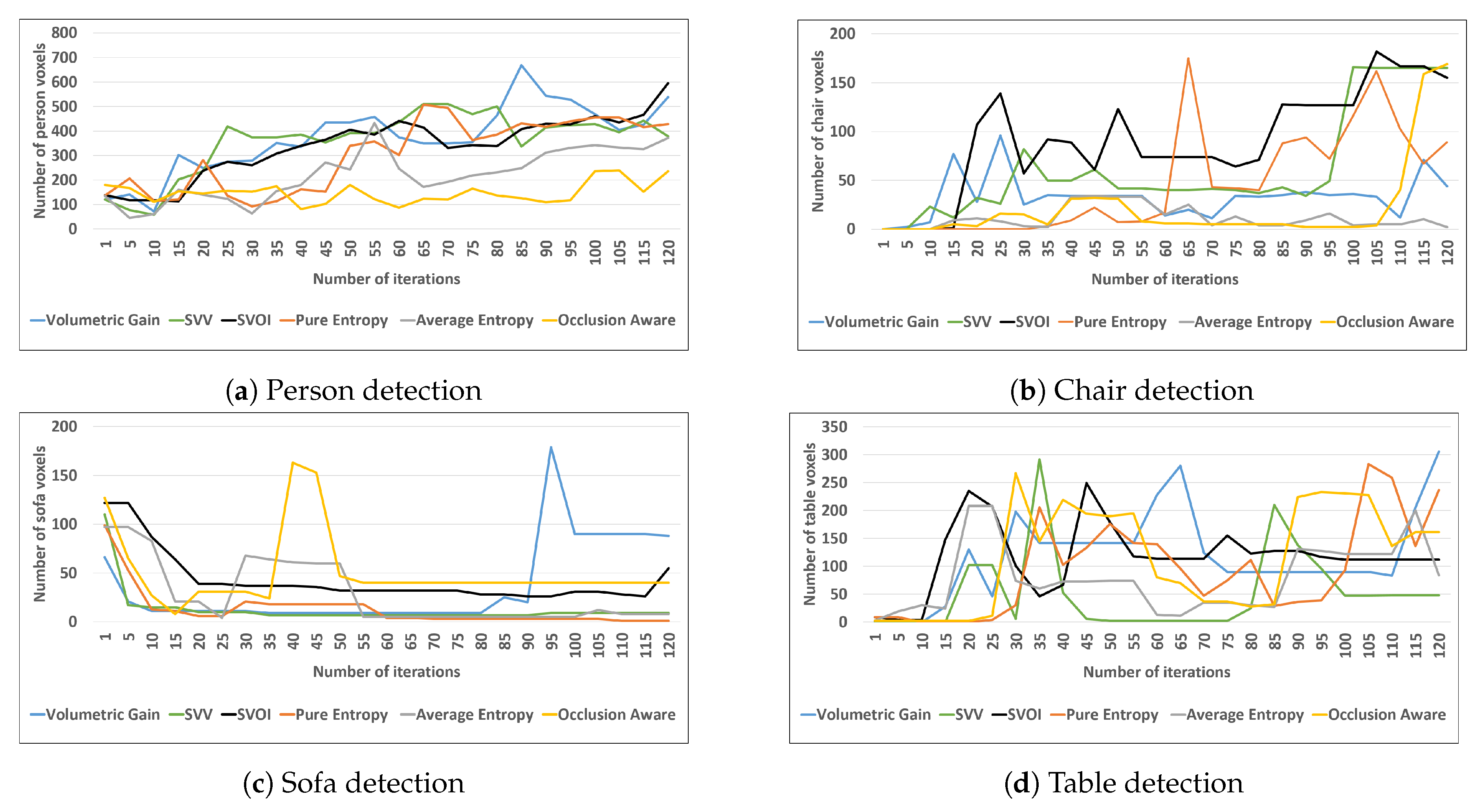
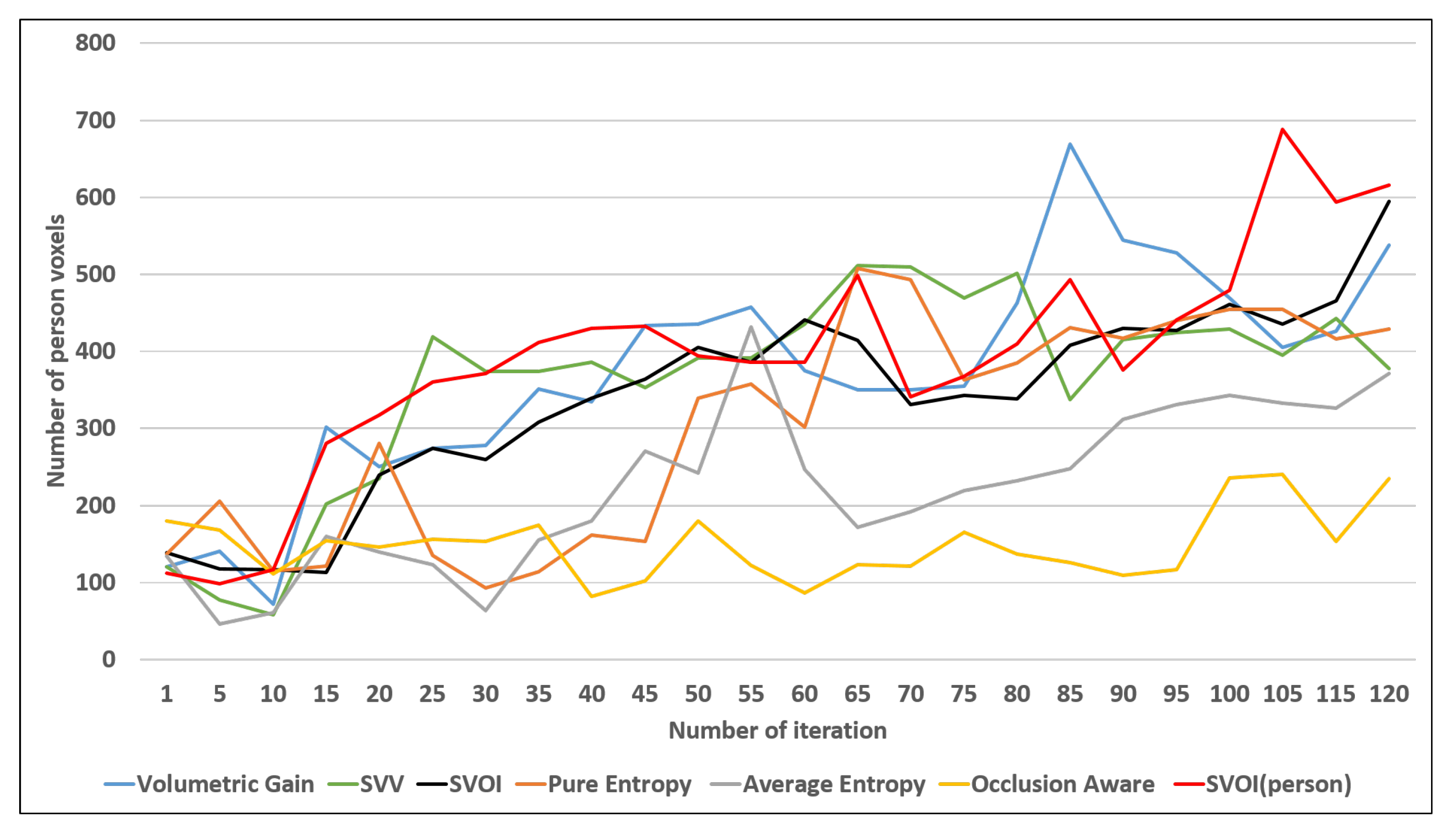
4.2.3. Object Detection and Labeling
4.3. Object Search Application
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Naidoo, Y.; Stopforth, R.; Bright, G. Development of an UAV for search & rescue applications. In Proceedings of the IEEE Africon’11, Livingstone, Zambia, 13–15 September 2011; pp. 1–6. [Google Scholar]
- Erdelj, M.; Natalizio, E.; Chowdhury, K.R.; Akyildiz, I.F. Help from the sky: Leveraging UAVs for disaster management. IEEE Pervasive Comput. 2017, 16, 24–32. [Google Scholar]
- Waharte, S.; Trigoni, N. Supporting search and rescue operations with UAVs. In Proceedings of the 2010 International Conference on Emerging Security Technologies, Canterbury, UK, 6–7 September 2010; pp. 142–147. [Google Scholar]
- Hallermann, N.; Morgenthal, G. Visual inspection strategies for large bridges using Unmanned Aerial Vehicles (UAV). In Proceedings of the 7th IABMAS, International Conference on Bridge Maintenance, Safety and Management, Shangai, China, 7–11 July 2014; pp. 661–667. [Google Scholar]
- Wada, A.; Yamashita, T.; Maruyama, M.; Arai, T.; Adachi, H.; Tsuji, H. A surveillance system using small unmanned aerial vehicle (UAV) related technologies. NEC Tech. J. 2015, 8, 68–72. [Google Scholar]
- Lang, D.; Paulus, D. Semantic Maps for Robotics. In Proceedings of the Workshop” Workshop on AI Robotics” at ICRA, Chicago, IL, USA, 14–18 September 2014. [Google Scholar]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar]
- Kostavelis, I.; Gasteratos, A. Semantic mapping for mobile robotics tasks: A survey. Robot. Auton. Syst. 2015, 66, 86–103. [Google Scholar]
- Wurm, K.M.; Hornung, A.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: A probabilistic, flexible, and compact 3D map representation for robotic systems. In Proceedings of the ICRA 2010 workshop on Best Practice in 3D Perception and Modeling for Mobile Manipulation, Anchorage, AS, USA, 3–7 May 2010; Volume 2. [Google Scholar]
- Lai, K.; Bo, L.; Fox, D. Unsupervised feature learning for 3d scene labeling. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 3050–3057. [Google Scholar]
- Pillai, S.; Leonard, J. Monocular slam supported object recognition. arXiv 2015, arXiv:1506.01732. [Google Scholar]
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.; Davison, A.J. Slam++: Simultaneous localisation and mapping at the level of objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1352–1359. [Google Scholar]
- Vineet, V.; Miksik, O.; Lidegaard, M.; Nießner, M.; Golodetz, S.; Prisacariu, V.A.; Kähler, O.; Murray, D.W.; Izadi, S.; Pérez, P.; et al. Incremental dense semantic stereo fusion for large-scale semantic scene reconstruction. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 75–82. [Google Scholar]
- Kostavelis, I.; Charalampous, K.; Gasteratos, A.; Tsotsos, J.K. Robot navigation via spatial and temporal coherent semantic maps. Eng. Appl. Artif. Intell. 2016, 48, 173–187. [Google Scholar]
- Yamauchi, B. A frontier-based approach for autonomous exploration. In Proceedings of the Proceedings 1997 IEEE International Symposium on Computational Intelligence in Robotics and Automation CIRA’97. ’Towards New Computational Principles for Robotics and Automation’, Monterey, CA, USA, 10–11 July 1997; pp. 146–151. [Google Scholar]
- Elfes, A. Using occupancy grids for mobile robot perception and navigation. Computer 1989, 22, 46–57. [Google Scholar] [CrossRef]
- Connolly, C. The determination of next best views. In Proceedings of the 1985 IEEE International Conference on Robotics and Automation, St. Louis, MO, USA, 25–28 March 1985; Volume 2, pp. 432–435. [Google Scholar]
- Półka, M.; Ptak, S.; Kuziora, Ł. The use of UAV’s for search and rescue operations. Procedia Eng. 2017, 192, 748–752. [Google Scholar]
- Tang, J.; Zhu, K.; Guo, H.; Liao, C.; Zhang, S. Simulation optimization of search and rescue in disaster relief based on distributed auction mechanism. Algorithms 2017, 10, 125. [Google Scholar]
- Goian, A.; Ashour, R.; Ahmad, U.; Taha, T.; Almoosa, N.; Seneviratne, L. Victim Localization in USAR Scenario Exploiting Multi-Layer Mapping Structure. Remote Sens. 2019, 11, 2704. [Google Scholar]
- Lindeberg, T. Scale invariant feature transform. Scholarpedia 2012, 7, 10491. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Wang, L. Support Vector Machines: Theory and Applications; Springer Science & Business Media: Berlin, Germany, 2005; Volume 177. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Amsterdam, The Netherlands, 8–16 October 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2017; pp. 5099–5108. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 918–927. [Google Scholar]
- Rosinol, A.; Abate, M.; Chang, Y.; Carlone, L. Kimera: An Open-Source Library for Real-Time Metric-Semantic Localization and Mapping. arXiv 2019, arXiv:1910.02490. [Google Scholar]
- Dang, T.; Papachristos, C.; Alexis, K. Visual Saliency-Aware Receding Horizon Autonomous Exploration with Application to Aerial Robotics. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2526–2533. [Google Scholar] [CrossRef]
- Dang, T.; Papachristos, C.; Alexis, K. Autonomous exploration and simultaneous object search using aerial robots. In Proceedings of the 2018 IEEE Aerospace Conference, Big Sky, MT, USA, 3–10 March 2018. [Google Scholar]
- Heng, L.; Gotovos, A.; Krause, A.; Pollefeys, M. Efficient visual exploration and coverage with a micro aerial vehicle in unknown environments. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1071–1078. [Google Scholar]
- Fraundorfer, F.; Heng, L.; Honegger, D.; Lee, G.H.; Meier, L.; Tanskanen, P.; Pollefeys, M. Vision-based autonomous mapping and exploration using a quadrotor MAV. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 4557–4564. [Google Scholar]
- Cieslewski, T.; Kaufmann, E.; Scaramuzza, D. Rapid Exploration with Multi-Rotors: A Frontier Selection Method for High Speed Flight. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 567–576. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]
- Xuan, Z.; David, F. Real-Time Voxel Based 3D Semantic Mapping with a Hand Held RGB-D Camera. 2018. Available online: https://github.com/floatlazer/semantic_slam (accessed on 3 March 2020).
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: An efficient probabilistic 3D mapping framework based on octrees. Auton. Robots 2013, 34, 189–206. [Google Scholar]
- Bircher, A.; Kamel, M.; Alexis, K.; Oleynikova, H.; Siegwart, R. Receding Horizon “Next-Best-View” Planner for 3D Exploration. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1462–1468. [Google Scholar]
- Burgard, W.; Moors, M.; Stachniss, C.; Schneider, F.E. Coordinated multi-robot exploration. IEEE Trans. Robot. 2005, 21, 376–386. [Google Scholar]
- Stachniss, C.; Grisetti, G.; Burgard, W. Information Gain-based Exploration Using Rao-Blackwellized Particle Filters. Robot. Sci. Syst. 2005, 2, 65–72. [Google Scholar]
- Paul, G.; Webb, S.; Liu, D.; Dissanayake, G. Autonomous robot manipulator-based exploration and mapping system for bridge maintenance. Robot. Auton. Syst. 2011, 59, 543–554. [Google Scholar]
- Al khawaldah, M.; Nuchter, A. Enhanced frontier-based exploration for indoor environment with multiple robots. Adv. Robot. 2015, 29. [Google Scholar] [CrossRef]
- Karaman, S.; Frazzoli, E. Sampling-based algorithms for optimal motion planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar]
- Lavalle, S.M. Rapidly-Exploring Random Trees: A New Tool for Path Planning; Technical Report; Iowa State University: Ames, IA, USA, 1998. [Google Scholar]
- Delmerico, J.A.; Isler, S.; Sabzevari, R.; Scaramuzza, D. A comparison of volumetric information gain metrics for active 3D object reconstruction. Auton. Robot. 2018, 42, 197–208. [Google Scholar]
- Kriegel, S.; Rink, C.; Bodenmüller, T.; Suppa, M. Efficient next-best-scan planning for autonomous 3D surface reconstruction of unknown objects. J. Real-Time Image Process. 2015, 10, 611–631. [Google Scholar]
- Batista, N.C.; Pereira, G.A.S. A Probabilistic Approach for Fusing People Detectors. J. Control Autom. Electr. Syst. 2015, 26, 616–629. [Google Scholar] [CrossRef]
- Isler, S.; Sabzevari, R.; Delmerico, J.; Scaramuzza, D. An information gain formulation for active volumetric 3D reconstruction. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3477–3484. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specification | Value |
|---|---|
| Horizontal FOV | 60° |
| Vertical FOV | 45° |
| Resolution | 0.1 m |
| Range | 5 m |
| Mounting orientation | |
| (Roll, Pitch, Yaw) | (0, 0, 0) |
| Utility Function | ||
|---|---|---|
| Volumetric gain | [42] | 0 |
| Pure Entropy | [49] | 0 |
| Average Entropy | [50] | 0 |
| Occlusion Aware | [49] | 0 |
| Unobserved Voxels | [49] | 0 |
| Proposed SVV | [42] | Equation (5) |
| Proposed SVOI | [42] | Equation (8) |
| Coverage | Percentage of the number of known voxels compared with the total number of voxels the environment can cover. After each iteration, the coverage is calculated as follows |
| Detected objects | Counting the number of detected objects in the environment |
| Sufficiently labeled objects | Counting the number of objects that are sufficiently labeled using the semantic color table |
| Total voxel type | Count the voxel for each category
|
| NUM | View Point Generation | Utility | Volumetric Coverage (%) | Num of Detected Objects | Num of Sufficiently Visited |
|---|---|---|---|---|---|
| 1 | Receding Horizon RRT | Volumetric Gain | 91.396 | 11 | 8 |
| 2 | Pure Entropy | 54.3802 | 8 | 5 | |
| 3 | Average Entropy | 49.7883 | 8 | 5 | |
| 4 | Occlusion Aware | 44.8293 | 8 | 5 | |
| 5 | Unobserved Voxel | 75.8496 | 10 | 6 | |
| 6 | SVV | 88.5718 | 11 | 7 | |
| 7 | SVOI | 93.1325 | 11 | 8 | |
| 8 | SVOI (person detection) | 92.0332 | 11 | 9 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ashour, R.; Taha, T.; Dias, J.M.M.; Seneviratne, L.; Almoosa, N. Exploration for Object Mapping Guided by Environmental Semantics using UAVs. Remote Sens. 2020, 12, 891. https://doi.org/10.3390/rs12050891
Ashour R, Taha T, Dias JMM, Seneviratne L, Almoosa N. Exploration for Object Mapping Guided by Environmental Semantics using UAVs. Remote Sensing. 2020; 12(5):891. https://doi.org/10.3390/rs12050891
Chicago/Turabian StyleAshour, Reem, Tarek Taha, Jorge Manuel Miranda Dias, Lakmal Seneviratne, and Nawaf Almoosa. 2020. "Exploration for Object Mapping Guided by Environmental Semantics using UAVs" Remote Sensing 12, no. 5: 891. https://doi.org/10.3390/rs12050891
APA StyleAshour, R., Taha, T., Dias, J. M. M., Seneviratne, L., & Almoosa, N. (2020). Exploration for Object Mapping Guided by Environmental Semantics using UAVs. Remote Sensing, 12(5), 891. https://doi.org/10.3390/rs12050891