Water Identification from High-Resolution Remote Sensing Images Based on Multidimensional Densely Connected Convolutional Neural Networks


Abstract
1. Introduction
2. Materials and Methods
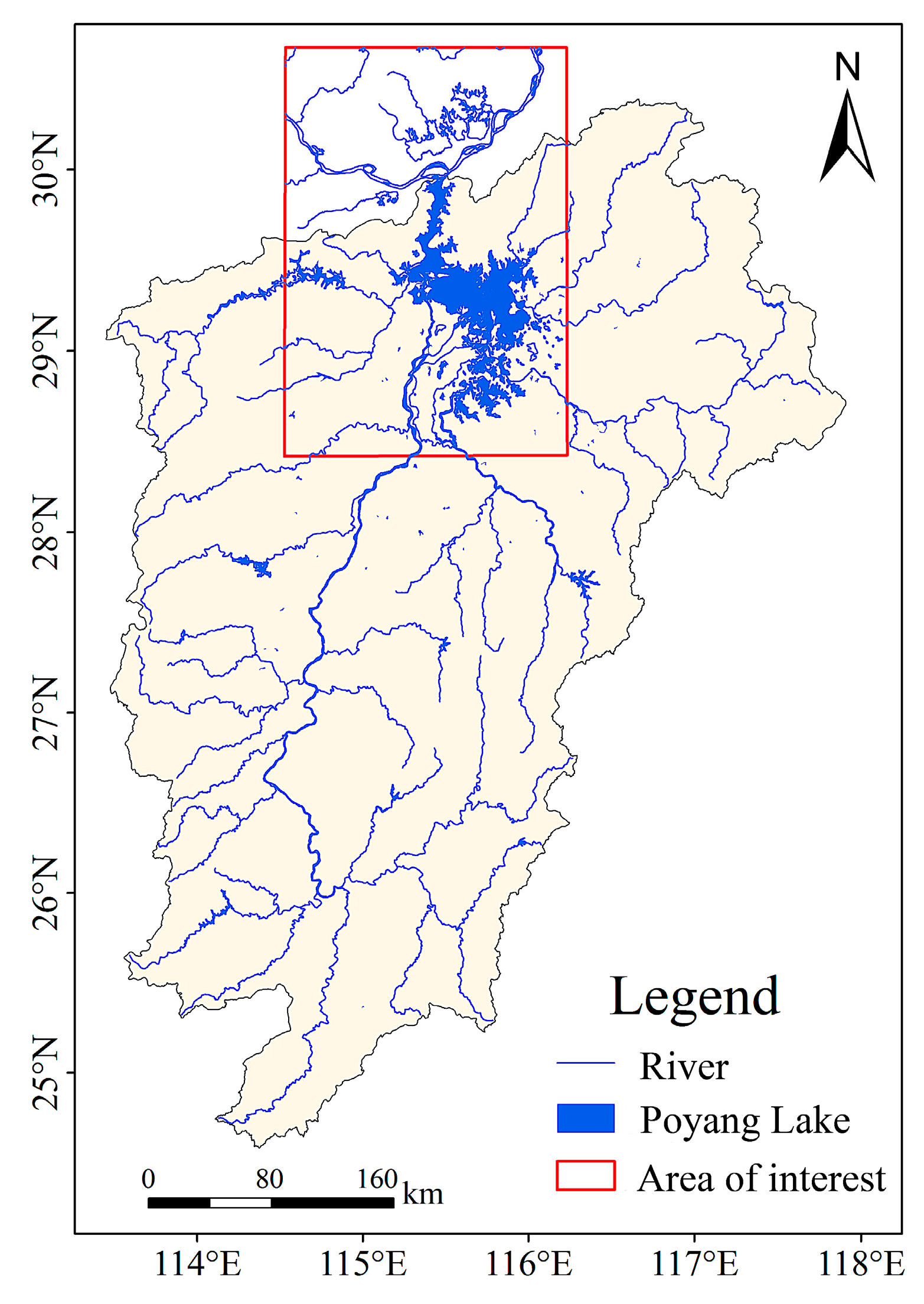
2.1. Study Area
2.2. Data
2.3. Methods
2.3.1. The Normalized Difference Water Index (NDWI)
2.3.2. Evolution of Convolutional Neural Network
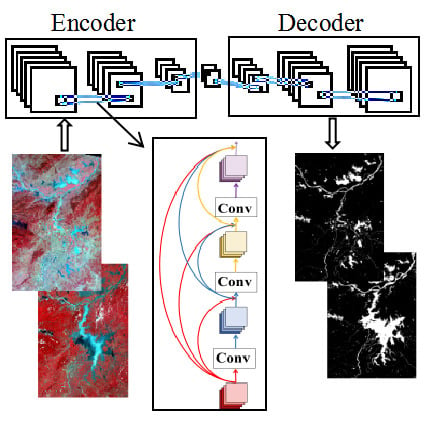
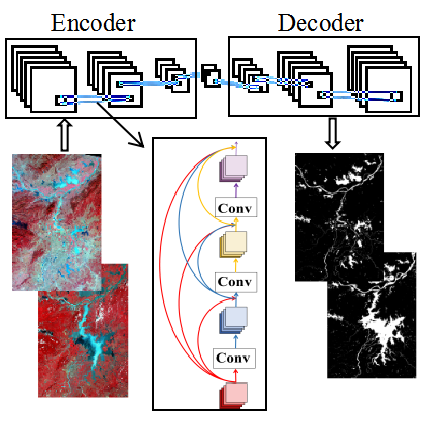
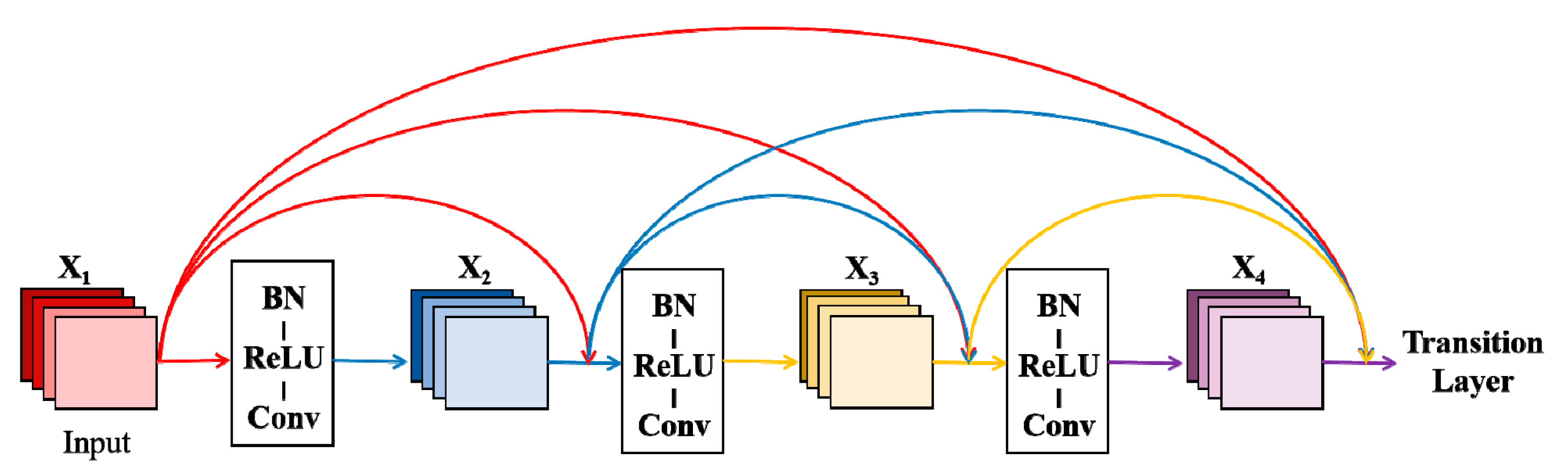
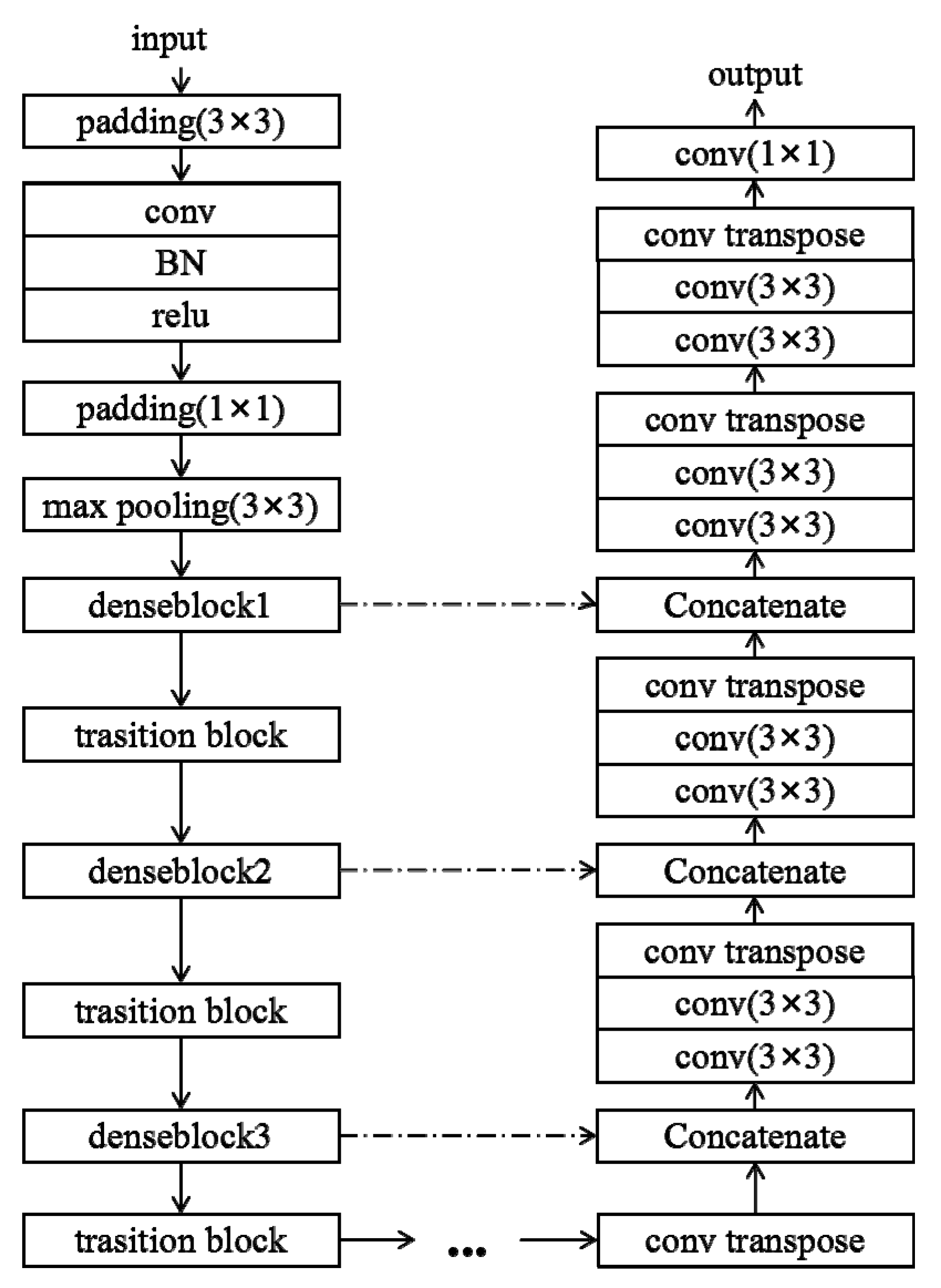
2.3.3. Model-Based on DenseNet
3. Results
3.1. The Image Preprocessing
3.2. Water Identification Result of DenseNet
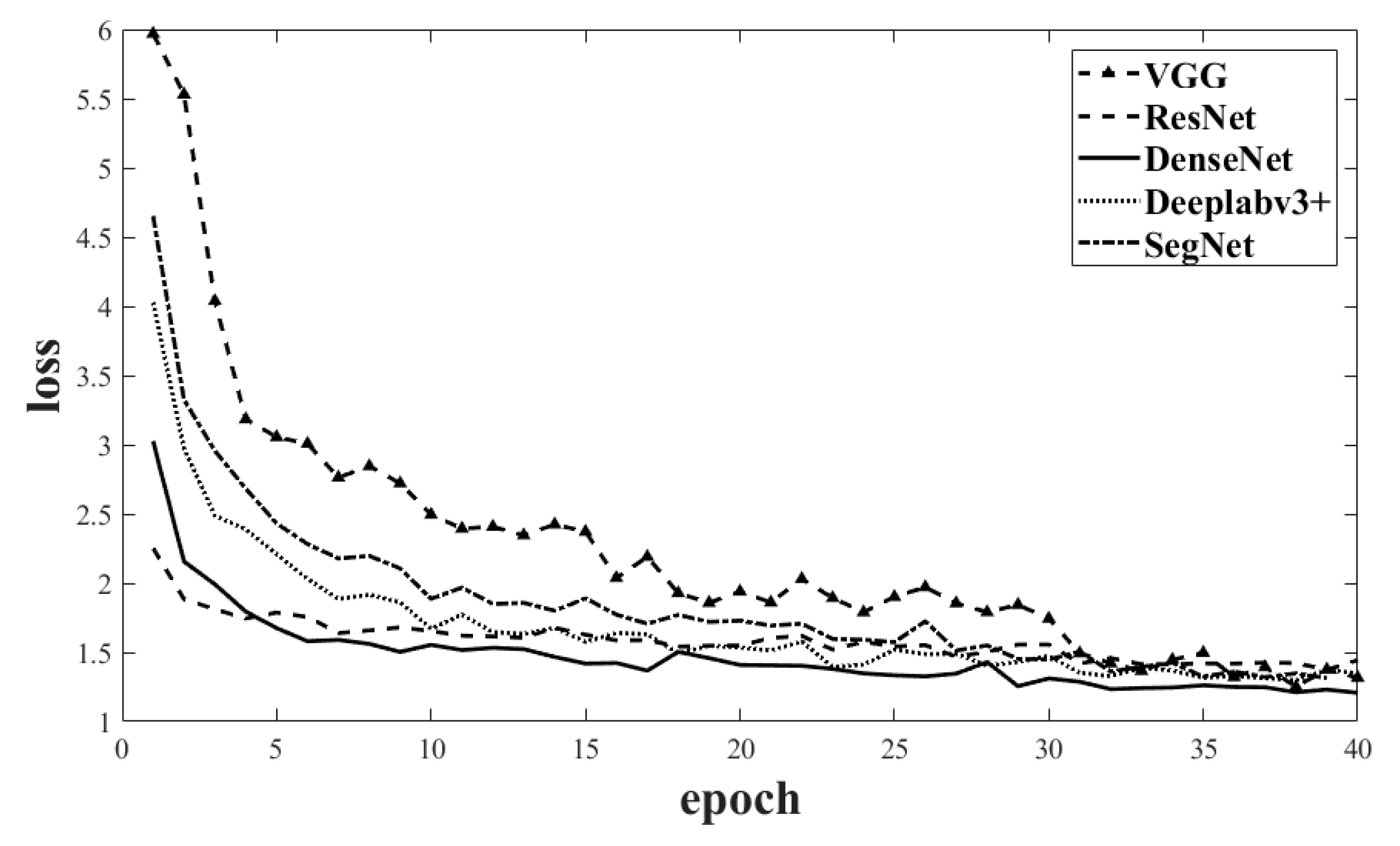
3.3. Working Efficiency of DenseNet, ResNet, VGG, SegNet and DeepLab v3+ Models
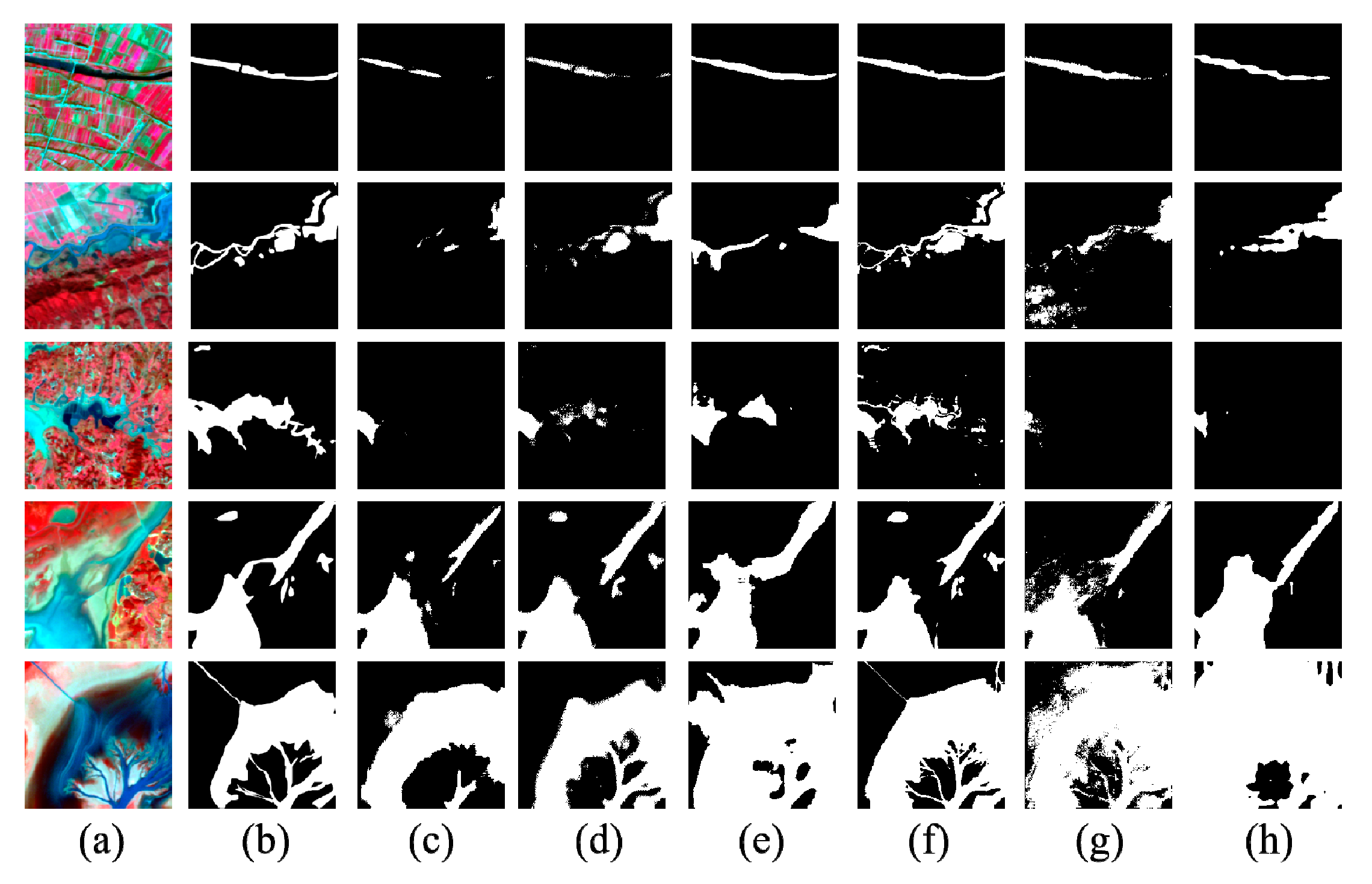
3.4. Comparison of Identification Results
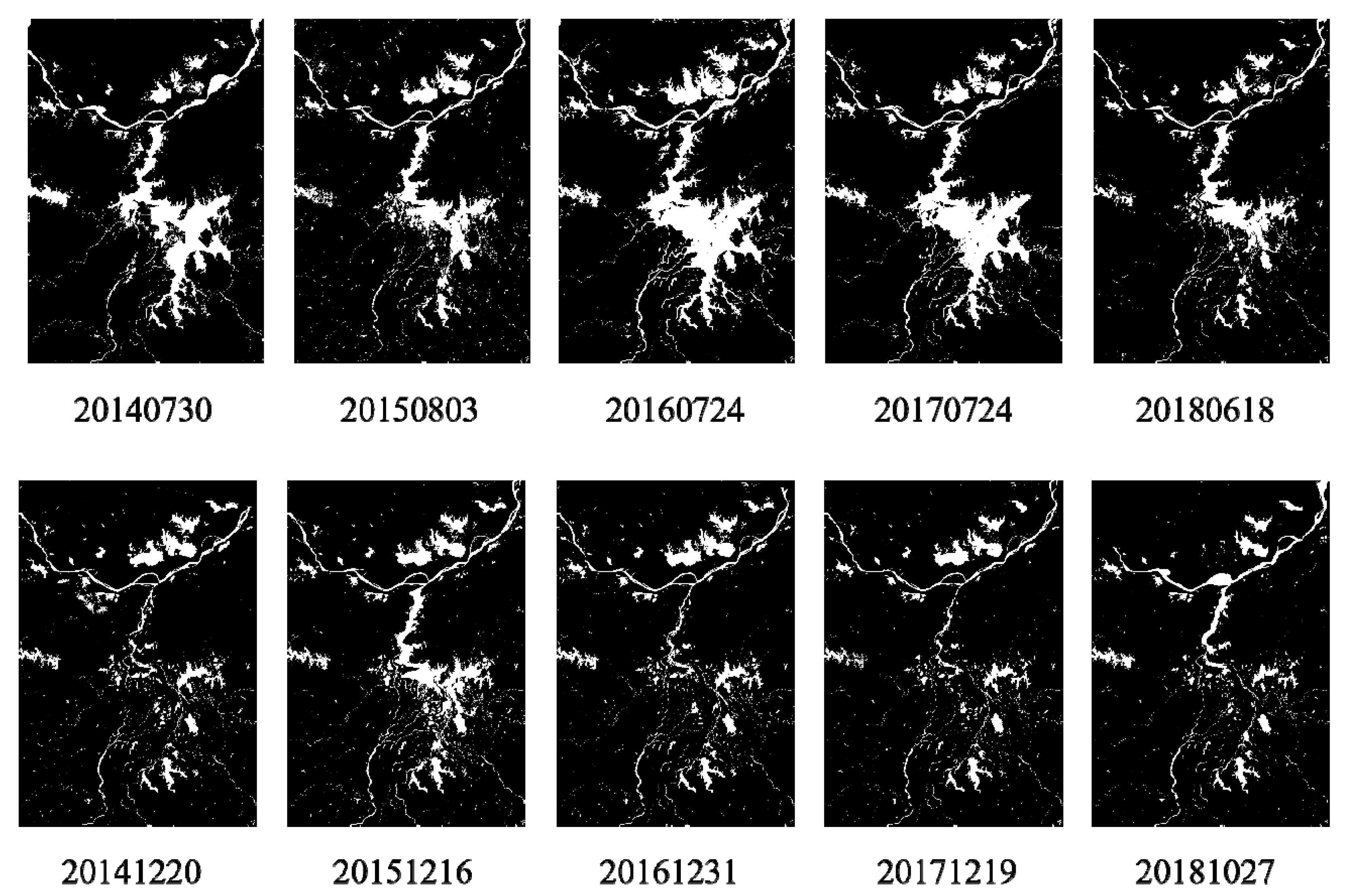
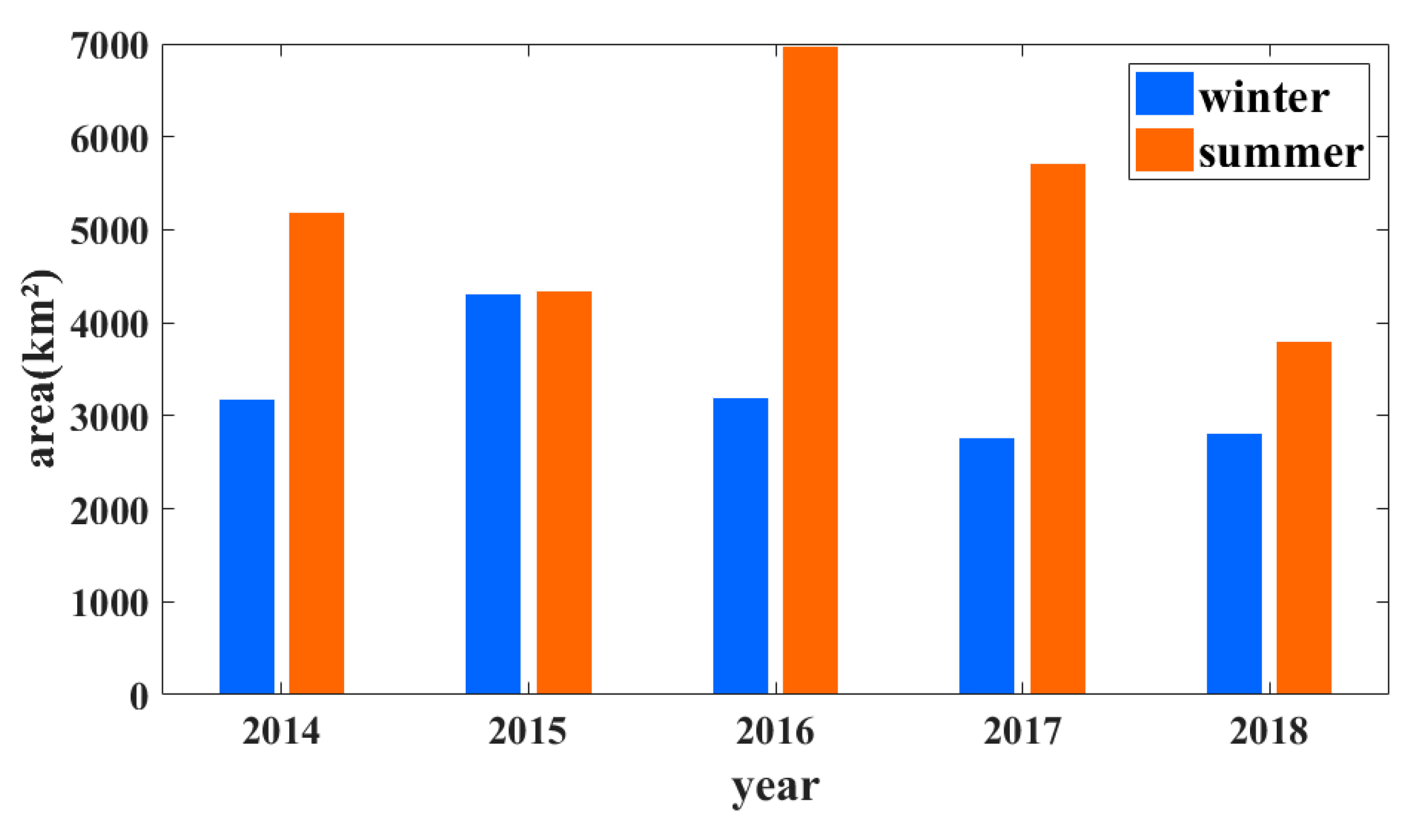
3.5. Interannual Variations of the Water Areas
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tri, A.; Dong, L.; In, Y.; In, Y.; Jae, L. Identification of Water Bodies in a Landsat 8 OLI Image Using a J48 Decision Tree. Sensors 2016, 16, 1075. [Google Scholar]
- Shevyrnogov, A.P.; Kartushinsky, A.V.; Vysotskaya, G.S. Application of Satellite Data for Investigation of Dynamic Processes in Inland Water Bodies: Lake Shira (Khakasia, Siberia), A Case Study. Aquat. Ecol. 2002, 36, 153–164. [Google Scholar] [CrossRef]
- Famiglietti, J.S.; Rodell, M. Water in the Balance. Science 2013, 340, 1300–1301. [Google Scholar] [CrossRef] [PubMed]
- Feng, L.; Hu, C.; Han, X.; Chen, X. Long-Term Distribution Patterns of Chlorophyll-a Concentration in China’s Largest Freshwater Lake: MERIS Full-Resolution Observations with a Practical Approach. Remote Sens. 2015, 7, 275–299. [Google Scholar] [CrossRef]
- Ye, Q.; Zhu, L.; Zheng, H.; Naruse, R.; Zhang, X.; Kang, S. Glacier and lake variations in the Yamzhog Yumco basin, southern Tibetan Plateau, from 1980 to 2000 using remote-sensing and GIS technologies. J. Glaciol. 2007, 53, 183. [Google Scholar] [CrossRef]
- Zhang, F.; Zhu, X.; Liu, D. Blending MODIS and Landsat images for urban flood mapping. Int. J. Remote Sens. 2014, 35, 3237–3253. [Google Scholar] [CrossRef]
- Barton, I.J.; Bathols, J.M. Monitoring flood with AVHRR. Remote Sens. Environ. 1989, 30, 89–94. [Google Scholar] [CrossRef]
- Sheng, Y.; Gong, P.; Xiao, Q. Quantitative dynamic flood monitoring with NOAA AVHRR. Int. J. Remote Sens. 2001, 22, 1709–1724. [Google Scholar] [CrossRef]
- Davranche, A.; Lefebvre, G.; Poulin, B. Wetland monitoring using classification trees and SPOT-5 seasonal time series. Remote Sens. Environ. 2012, 114, 552–562. [Google Scholar] [CrossRef]
- Kelly, M.; Tuxen, K.A.; Stralberg, D. Mapping changes to vegetation pattern in a restoring wetland: Finding pattern metrics that are consistent across spatial scale and time. Ecol. Indic. 2011, 11, 263–273. [Google Scholar] [CrossRef]
- Zhao, G.; Xu, Z.; Pang, B.; Tu, T.; Xu, L.; Du, L. An enhanced inundation method for urban flood hazard mapping at the large catchment scale. J. Hydrol. 2019, 571, 873–882. [Google Scholar] [CrossRef]
- Jamshed, A.; Rana, I.A.; Mirza, U.M.; Birkmann, J. Assessing relationship between vulnerability and capacity: An empirical study on rural flooding in Pakistan. Int. J. Disaster Risk Reduct. 2019, 36, 101109. [Google Scholar] [CrossRef]
- Minaee, S.; Wang, Y. An ADMM Approach to Masked Signal Decomposition Using Subspace Representation. IEEE Trans. Image Process. 2019, 28, 3192–3204. [Google Scholar] [CrossRef] [PubMed]
- Frazier, P.S.; Page, K.J. Water body detection and delineation with Landsat TM data. Photogramm. Eng. Remote Sens. 2000, 66, 1461–1467. [Google Scholar]
- Berthon, J.F.; Zibordi, G. Optically black waters in the northern Baltic Sea. Geophys. Res. Lett. 2010, 37, 232–256. [Google Scholar] [CrossRef]
- Karpatne, A.; Khandelwal, A.; Chen, X.; Mithal, V.; Faghmous, J.; Kumar, V. Global Monitoring of Inland Water Dynamics: State-of-the-Art, Challenges, and Opportunities; Lässig, J., Kersting, K., Morik, K., Eds.; Computational Sustainability, Springer International Publishing: Cham, Switzerland, 2016; pp. 121–147. [Google Scholar]
- Bischof, H.; Schneider, W.; Pinz, A.J. Multispectral classification of Landsat-images using neural networks. IEEE Trans. Geosci. Remote Sens. 1992, 30, 482–490. [Google Scholar] [CrossRef]
- Hughes, M.J.; Hayes, D.J. Automated detection of cloud and cloud shadow in single-date Landsat imagery using neural networks and spatial post-processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef]
- Mcfeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S.R. Automated water extraction index: A new technique for surface water mapping using Landsat imagery. Remote Sens. Environ. 2014, 40, 23–35. [Google Scholar] [CrossRef]
- Zhu, C.; Luo, J.; Shen, Z.; Li, J. River Linear Water Adaptive Auto-extraction on Remote Sensing Image Aided by DEM. Acta Geodaetica et Cartographica Sinica 2013, 42, 277–283. [Google Scholar]
- Tesfa, T.K.; Tarboton, D.G.; Watson, D.W.; Schreuders, K.A.T.; Baker, M.E.; Wallace, R.M. Extraction of hydrological proximity measures from DEMs using parallel processing. Environ. Modell. Softw. 2011, 26, 1696–1709. [Google Scholar] [CrossRef]
- Turcotte, R.; Fortin, J.P.; Rousseau, A.N.; Massicotte, S.; Villeneuve, J.P. Determination of the drainage structure of a watershed using a digital elevation model and a digital river and lake network. J. Hydrol. 2001, 240, 225–242. [Google Scholar] [CrossRef]
- Chen, C.; Fu, J.; Sui, X.; Lu, X.; Tan, A. Construction and application of knowledge decision tree after a disaster for water body information extraction from remote sensing images. J. Remote Sens. 2018, 2, 792–801. [Google Scholar]
- Xia, X.; Wei, Y.; Xu, N.; Yuan, Z.; Wang, P. Decision tree model of extracting blue-green algal blooms information based on Landsat TM/ETM + imagery in Lake Taihu. J. Lake Sci. 2014, 26, 907–915. [Google Scholar]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Available online: https://www.arxiv-vanity.com/papers/1409.1556/ (accessed on 18 December 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Santoro, A.; Faulkner, R.; Raposo, D.; Rae, J.; Chrzanowski, M.; Weber, T.; Wierstra, D.; Vinyals, O.; Pascanu, R.; Lillicrap, T. Relational Recurrent Neural Networks. Available online: https://arxiv.org/abs/1806.01822 (accessed on 18 December 2019).
- Ronneberger, O.; Fisher, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Clipolla, R. A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refine Net: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. Available online: https://arxiv.org/abs/1611.06612 (accessed on 18 December 2019).
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. Available online: https://arxiv.org/abs/1412.7062 (accessed on 10 February 2020).
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Concolution, and Fully Connected CRFs. Available online: https://arxiv.org/abs/1606.00915 (accessed on 10 February 2020).
- Chen, L.C.; Papandreou, G.; Schroff, F.; Papandreou, G. Rethinking Atrous Convolution for Semantic Image Segmentation. Available online: https://arxiv.org/abs/1706.05587 (accessed on 10 February 2020).
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Papandreou, G. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrel, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. Available online: https://arxiv.org/abs/1311.2524 (accessed on 10 February 2020).
- Girshick, R. Fast R-CNN. In Proceedings of the International Conference on Computer Vision, Santiago, MN, USA, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. Available online: https://arxiv.org/abs/1703.06870 (accessed on 10 February 2020).
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid Task Cascade for Instance Segmentation. Available online: https://arxiv.org/abs/1901.07518 (accessed on 19 February 2020).
- Chen, L.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to Scale: Scale-Aware Semantic Image Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 3640–3649. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Marquez-Neila, P.; Baumela, L.; Alvarez, L. A Morphological Approach to Curvature-Based Evolution of Curves and Surfaces. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2–17. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. Available online: https://arxiv.org/abs/2001.05566 (accessed on 19 February 2020).
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Feng, M.; Sexton, J.O.; Channan, S.; Townshend, J.R. A global, 30-m resolution land-surface water body dataset for 2000: first results of a topographic-spectral classification algorithm. Int. J. Digit. Earth 2016, 9, 113–133. [Google Scholar] [CrossRef]
- Guo, H.; Hu, Q.; Zhang, Q. Changes in Hydrological Interactions of the Yangtze River and the Poyang Lake in China during 1957–2008. Acta Geographica Sinica 2011, 66, 609–618. [Google Scholar]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Liu, D.; Wang, L. Fast Threshold Image Segmentation Based on 2D Fuzzy Fisher and Random Local Optimized QPSO. IEEE Trans. Image Process. 2017, 26, 1355–1362. [Google Scholar] [CrossRef] [PubMed]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable Object Detection using Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 2155–2162. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway Networks. Available online: https://arxiv.org/abs/1505.00387 (accessed on 15 December 2019).
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K. Deep Networks with Stochastic Depth. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 10–16 October 2016; pp. 646–661. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. FractalNet: Ultra-Deep Neural Networks without Residuals. Available online: https://arxiv.org/abs/1605.07648 (accessed on 15 December 2019).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. Available online: https://arxiv.org/abs/1412.6980 (accessed on 10 October 2019).
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation. J. Mach. Learn. Tch. 2011, 2, 37–63. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. Available online: https://arxiv.org/abs/1704.04861 (accessed on 10 December 2019).
- Hu, Q.; Feng, S.; Guo, H.; Chen, G.; Jiang, T. Interactions of the Yangtze River flow and hydrologic progress of the Poyang Lake, China. J. Hydrol. 2007, 347, 90–100. [Google Scholar] [CrossRef]
- Zhou, Y.; Jeppesen, E.; Li, J.; Zhang, X.; Li, X. Impacts of Three Gorges Reservoir on the sedimentation regimes in the downstream-linked two largest Chinese freshwater lakes. Sci. Rep. 2016, 6, 35396. [Google Scholar] [CrossRef]
- Yang, Z.; Mu, X.D.; Zhao, F.A. Scene Classification of Remote Sensing Image Based on Deep Network Grading Transferring. Optik 2018, 168, 127–133. [Google Scholar] [CrossRef]
- Gao, H.; Birkett, C.; Lettenmaier, D.P. Global monitoring of large reservoir storage from satellite remote sensing. Water Resour. Res. 2012, 48, W09504. [Google Scholar] [CrossRef]
- Liu, P.; Du, P.; Tan, K. A novel remotely sensed image classification based on ensemble learning and feature integration. J. Infrared Millim. Waves 2014, 33, 311–317. [Google Scholar]
- Teimouri, M.; Mokhtarzade, M.; Zoej, M.J.V. Optimal fusion of optical and SAR high-resolution images for semiautomatic building detection. GISci. Remote Sens. 2016, 53, 45–62. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Time | P | R | F1 | mIoU |
|---|---|---|---|---|---|
| DenseNet63 | 15,463 s | 0.959 | 0.900 | 0.928 | 0.867 |
| DenseNet79 | 16,377 s | 0.961 | 0.904 | 0.931 | 0.872 |
| DenseNet121 | 20,611 s | 0.957 | 0.901 | 0.928 | 0.866 |
| DenseNet169 | 24,018 s | 0.964 | 0.896 | 0.928 | 0.867 |
| DenseNet201 | 27,121 s | 0.960 | 0.899 | 0.929 | 0.867 |
| Network | Time |
|---|---|
| DenseNet | 16,377 s |
| ResNet | 19,436 s |
| VGG | 21,471 s |
| SegNet | 19,021 s |
| DeepLab v3+ | 11,924 s |
| DenseNet | ResNet | VGG | SegNet | DeepLab v3+ | NDWI | |
|---|---|---|---|---|---|---|
| P | 0.961 ± 0.011 | 0.936 ± 0.014 | 0.914 ± 0.016 | 0.911 ± 0.017 | 0.922 ± 0.016 | 0.702 ± 0.027 |
| R | 0.904 ± 0.017 | 0.902 ± 0.017 | 0.915 ± 0.016 | 0.934 ± 0.015 | 0.917 ± 0.016 | 0.983 ± 0.007 |
| F1 | 0.931 ± 0.015 | 0.919 ± 0.016 | 0.914 ± 0.016 | 0.922 ± 0.016 | 0.919 ± 0.016 | 0.819 ± 0.023 |
| mIoU | 0.872 ± 0.020 | 0.850 ± 0.021 | 0.842 ± 0.021 | 0.856 ± 0.021 | 0.850 ± 0.021 | 0.767 ± 0.025 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Wu, M.; Wei, X.; Song, H. Water Identification from High-Resolution Remote Sensing Images Based on Multidimensional Densely Connected Convolutional Neural Networks. Remote Sens. 2020, 12, 795. https://doi.org/10.3390/rs12050795
Wang G, Wu M, Wei X, Song H. Water Identification from High-Resolution Remote Sensing Images Based on Multidimensional Densely Connected Convolutional Neural Networks. Remote Sensing. 2020; 12(5):795. https://doi.org/10.3390/rs12050795
Chicago/Turabian StyleWang, Guojie, Mengjuan Wu, Xikun Wei, and Huihui Song. 2020. "Water Identification from High-Resolution Remote Sensing Images Based on Multidimensional Densely Connected Convolutional Neural Networks" Remote Sensing 12, no. 5: 795. https://doi.org/10.3390/rs12050795
APA StyleWang, G., Wu, M., Wei, X., & Song, H. (2020). Water Identification from High-Resolution Remote Sensing Images Based on Multidimensional Densely Connected Convolutional Neural Networks. Remote Sensing, 12(5), 795. https://doi.org/10.3390/rs12050795