1. Introduction
Object detection from satellite imagery has considerable importance in areas, such as defense and military applications, urban studies, airport surveillance, vessel traffic monitoring, and transportation infrastructure determination. Remote sensing images obtained from satellite sensors are much complex than computer vision images since these images are obtained from high altitudes, including interference from the atmosphere, viewpoint variation, background clutter, and illumination differences [
1]. Moreover, satellite images cover larger areas (at least 10kmx10km for one image frame) and represent the complex landscape of the Earth’s surface (different land categories) with two-dimensional images with less spatial details compared to digital photographs obtained from cameras. As a result, the data size and areal coverage of satellite images are also bigger compared to natural images. In object detection studies with satellite imagery, the visual interpretation approach that benefits from experts’ knowledge for the identification of different objects/targets is still widely used. The accuracy of this approach is dependent on the level of expertise and the approach is time consuming due to the manual process [
2].
Several studies have been conducted on the automatic identification of different targets, such as buildings, aircraft, ships, etc., to reduce human-induced errors and save time and effort [
1,
3,
4]. However, the complexity of the background; differences in data acquisition geometry, topography, and illumination conditions; and the diversity of objects make automatic detection challenging for satellite images. The object detection task can be considered as a combination of two fundamental tasks, which are the classification of the objects and determination of their location on the images. Studies conducted so far have focused on improving these two tasks separately or together [
1,
5].
In the early studies, the majority of the studies were conducted with unsupervised methods using different attributes. For example, the scale-invariant feature transform (SIFT) key points and the graph theorem were used for building detection from panchromatic images [
6]. Alternatively, a wavelet transform was utilized in ship detection from synthetic aperture radar (SAR) images [
7]. However, such unsupervised methods generally provided efficient results for simple structure types, and the results were successful for a limited variety of objects. Later studies focused on supervised learning methods so that objects with different constructions could be identified with high performance from more complex scenes [
8,
9]. The main reason behind the more successful results with supervised learning is that the learning process during the training phase is performed with previously manually labeled samples. Before the use of convolutional neural network (CNN) structures became widespread, different supervised learning methods were utilized with handcrafted features. In previous research, a spatial sparse coding bag-of-words (BOW) model was developed for aircraft recognition through the SVM classifier and the results were better than the traditional BOW model [
10]. Gabor filters with SVM were used to detect aircraft, and achieved a 91% detection rate (DR) with a 7.5% false alarm rate (FAR) [
11]. A deformation model representing the relation of the roots and parts of the objects by utilizing an extracted histogram of oriented gradient (HOG) features at different scales of images was developed and trained in a discriminatory manner as a framework for object recognition using a mixed model [
12]. In another study, a probabilistic latent semantic analysis model (pLSA) and a K-Nearest Neighbor (k-NN) classifier with bag-of-visual-words (BoVW) was used for landslide detection [
13]. In a more recent research, visually saliency and sparse coding methods were combined to efficiently and simultaneously recognize the multi-layered targets from optical satellite images [
14].
In summary, the location of objects on the image is generally determined by scanning the entire image with a sliding window approach and a classifier, which may be selected from the abovementioned methods, which does the recognition task. The classifiers trained with these methods have a low size of parameters. Therefore, scanning the entire image with small strides allows an acceptable pace at object detection.
In 2012, following the remarkable success of AlexNet’s [
15] at the ImageNet Large-Scale Visual Recognition Challenge [
16], the CNN architectures, which are also known as deep learning methods, have begun to be used in different image processing problems. After the evolution of AlexNet, which can be accepted as a milestone for deep learning, deeper architectures, such as visual geometry group (VGG) [
17], GoogleNet [
18], which came up with inception modules, and residual network (ResNet) [
19], were developed and the error rate in the competition decreased gradually. Along with these advancements, researchers started to use CNN structures in object classification with satellite images [
20,
21,
22,
23,
24]. Although the remote sensing images have less spatial details and complex background, these methods can achieve highly accurate results near the visual interpretation performance.
In the challenges for object detection from natural images, competitors have tended to use state-of-the-art deep learning architectures, such as PASCAL VOC (Pattern Analysis, Statistical Modelling and Computational Learning Visual Object Classes) and COCO (Common Objects in Context) as a base network with a large amount of labeled data to beat the previous results. They applied different approaches, fine-tuning the base networks and performing some modifications; not only for increasing the accuracy of the classification part of the object detection task but also for improving the localization performance.
For the classification stage of object detection, the success of deep architectures is promising, but as they include a large number of parameters, direct use of the sliding window method, which has a high computational cost, is being abandoned. New architectures, such as the R-CNN (regions with CNN features), SPP-NET (Spatial Pyramid Pooling), Fast R-CNN, and Faster R-CNN, have emerged to overcome the computational cost disadvantage of the sliding window approach. These architectures use CNN networks as a base network for classification and solve the problem of localization by creating object candidates from the image [
25,
26,
27,
28]. With these structures, high performance and high speed could be achieved in real-time applications, such as object detection from a video stream. Additionally, object proposal approaches have become more widely used in remote sensing applications, with improvements in speed and performance [
29,
30,
31,
32,
33]. Detection by producing an object proposal achieved successful results, but there is a trade-off between the detection performance and processing speed according to the number of proposals produced. The number and the accuracy of the object candidates could directly affect the precision of the trained model or reduce the detection speed [
34].
In recent years, You Only Look Once (YOLO) [
35] and Single Shot MultiBox Detector (SSD) [
36] networks, which convert the classification and localization steps of the object detection task into a regression problem, can perform object detection tasks with a single neural network structure. These new methods have also overwhelmed the object proposal techniques in major competitions, such as PASCAL VOC (Pattern Analysis, Statistical Modelling and Computational Learning Visual Object Classes) [
37] and COCO (Common Objects in Context) [
38], where objects are detected from natural images. However, few studies have implemented these techniques on remotely sensed images. This is mainly due to an imbalanced dataset, where there are a large number of labeled natural images for detection tasks but less for remote sensing images. In addition, unlike the natural images, some of the objects that should be detected in satellite images are represented with few numbers of pixels due to the limitations of the sensor’s spatial resolution. Moreover, the presence of a multi-perspective data set is important to obtain highly accurate detection results. Although it is not a difficult task to create multi-perspective data sets using natural images, this could be challenging with satellite sensors. This challenge could be partially overcome by using satellite images obtained with different incidence angles to account for perspective differences in the training phase. Lastly, the atmospheric conditions and sun angle should be considered for satellite images as they affect the spectral response of the objects. Cheng et al. proposed the creation of a large-sized dataset named NWPU-RESISC45 to overcome the lack of training samples that are derived from satellite images. Their network consists of 31,500 image chips related to 45 land classes and they reported an obvious improvement in scene classification by implementing this dataset on pre-trained networks [
22]. Radovic et al. worked on the detection of aircraft from unmanned aerial vehicle (UAV) imageries with YOLO and achieved a 99.6% precision rate [
39]. Nie et al. used SSD to detect the various sizes of ships inshore and offshore areas using a transfer-learned SSD model with 87.9% average precision and outperformed the Faster R-CNN model, which provided an 81.2% average precision [
40]. Wang et al. tried two sizes of detectors (SSD300 and SSD512) with SAR images for the same purpose and achieved 92.11% and 91.89% precisions, respectively [
41].
The main objective of this research was to develop a framework with a comparative evaluation of the state-of-the-art CNN-based object detection models, which are Faster R-CNN, SSD, and YOLO, to increase the speed and accuracy of the detection of aircraft objects. To increase the detection accuracy, VHR satellite images obtained from different incidence angles and atmospheric conditions were introduced into the evaluation. As mentioned above, the trained data availability for the satellite images is limited, which is an important drawback in CNN-based architectures. Thus, this research proposes the use of a pre-trained network as a base, and improves the training data by comparatively less number of samples obtained from satellite images. In addition, default bounding boxes are generated with six different aspect ratios at every feature map layer to detect objects more accurately and faster. The detection models were trained with a labeled dataset produced from satellite images with different acquisition characteristics and by the use of the transfer learning approach. The training processes were performed repeatedly with different optimization methods and hyper-parameters. Although the accuracy is very important, it must be taken into account that the framework needs to process very large-scale satellite images quickly. Thus, a detection flow was developed to use trained models in the simultaneous detection of multiple objects from satellite images with large coverage. This research aimed to significantly contribute to the CNN-based object detection field by:
- Improving the performance of state-of-the-art object detectors on the satellite image domain by improving the learning with a patched and augmented “A Large-scale Dataset for Object DeTection in Aerial Images (DOTA)” satellite dataset (transfer learning) and hyperparameter tuning.
- Providing a detection flow that includes the slide-and-detect approach and non-Maximum suppression algorithm, to enable fast and accurate detection on large-scale satellite images.
- Providing a comparative evaluation of object detection models across different object sizes and different IOUs and preform an independent evaluation with full-sized (large-scale) Pleiades satellite images that have different resolution specs than the training dataset to investigate the transferability.
2. Data and Methods
In this section, information about the used satellite images and data augmentation process are given initially. Next, a detailed description of the evaluated network architectures is provided. Lastly, the steps and parameterization of the training process are explained.
2.1. Data and Augmentation
The DOTA dataset was used for training and testing purposes. It is an open-source dataset for object detection purposes from remote sensing images. The dataset includes satellite image patches obtained from the Google Earth
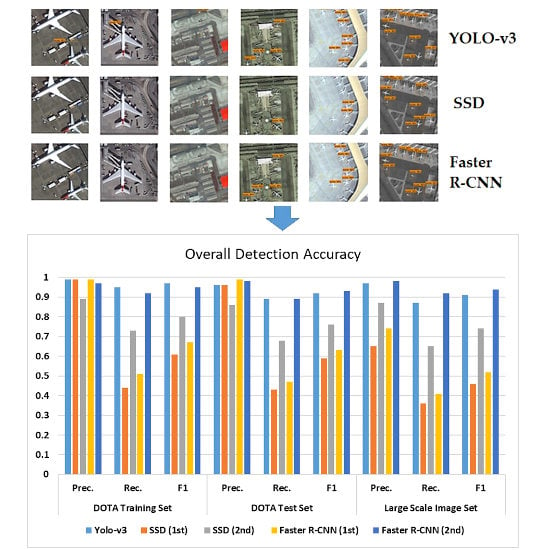
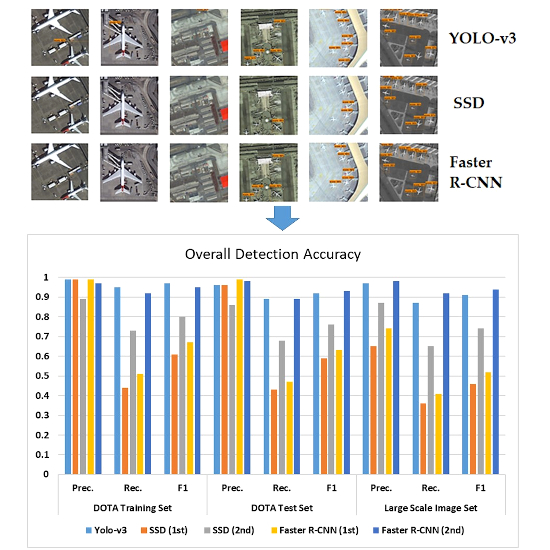
© platform, and Jilin 1 (JL-1) and Gaofen 2 (GF-2) satellites. It contains 15 object categories as airplane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field, and swimming pool. The image sizes are in the range of 800 × 800 to 4000 × 4000. In this study, airplane detection was aimed for; therefore, 1631 images that contained 5209 commercial airplane objects were selected from the dataset. The images were split to the size of 1024 × 1024 patches to train Faster R-CNN and 608 × 608 for training SSD and YOLO-v3 detectors. The spatial resolution of the images varies in range 0.11 to 2 m and they contain various orientations, aspect ratios, and pixel sizes of the objects. In addition, the images vary according to the altitude, nadir-angles of the satellites, and the illumination conditions. The selected images were separated as 90% for training and the rest for testing. The DOTA training and test sets also include different samples in terms of airplane dimensions, background complexity, and illuminance conditions. Some image patches have some cropped objects, and some examples are black and white panchromatic images. These variations in the DOTA dataset enable the trained object detection architectures to achieve a similar performance in different image conditions (
Figure 1).
Moreover, independent testing was performed with five image scenes obtained from very high-resolution pan-sharpened Pleiades 1A&1B satellite images with a 0.5-m spatial resolution and four spectral channels. In this research, Red/Green/Blue (RGB) bands of the Pleiades images were used. Satellite images were acquired in different atmospheric conditions but mostly at cloudless days and at different times in daylight. Images were collected between 2015 and 2017 in different seasons except for the winter. The images contain the Istanbul Ataturk, Istanbul Sabiha Gokcen, Izmir Adnan Menderes, Ankara Esenboga, and Antalya airport districts. They cover about a 53 km² area and contain 280 commercial airplanes. Properties of the Pleiades VHR images are provided in
Table 1.
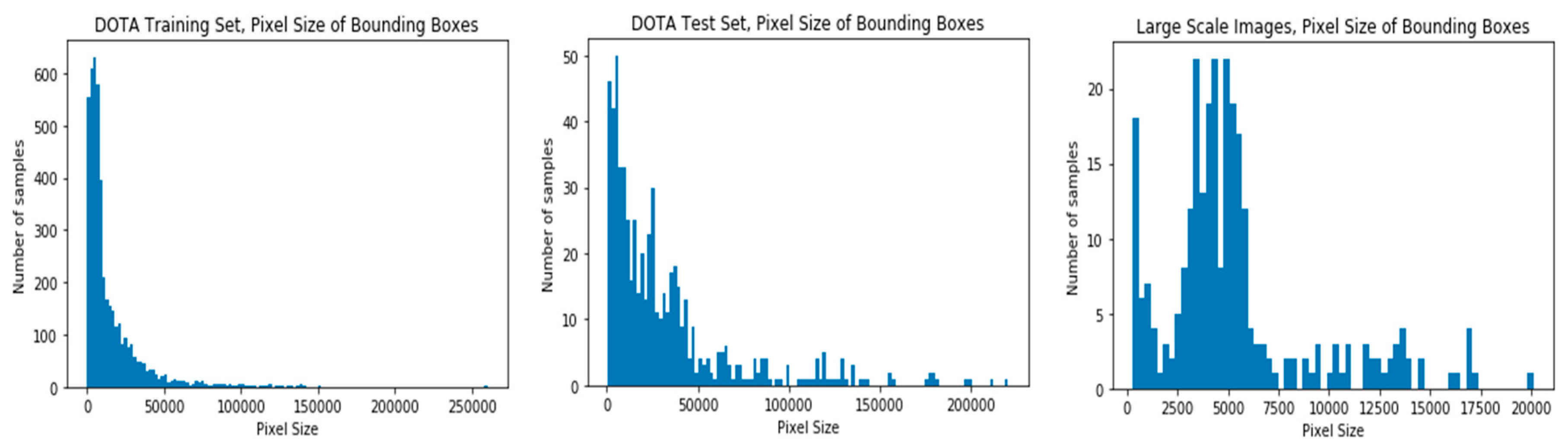
When the bounding box area distributions of aircraft samples were investigated for the DOTA training, DOTA test, and Pleiades image datasets, it was revealed that the DOTA train set includes almost the same distribution as the DOTA test set, with areas between 0 and 15,000 pixels, while it differs slightly from the samples in the large-scale Pleiades image data set. There is no object sample over 20,000 pixels in the large-scale test set and the areas of the samples are mostly between 3000 and 6000 pixels (
Figure 2).
In deep architectures, a large number of labeled data is significant. Thus, the data augmentation has vital importance to cope with a lack of labeled data and to have robustness in the training step. Horizontal rotation and random cropping were applied as augmentation techniques. Besides, the image chips were scaled in HSV (hue-saturation-value) to imitate atmospheric and lighting conditions (
Figure 3).
2.2. SSD Network Framework
In this sub-section, the general architecture of the SSD framework is presented initially. After, the default bounding box and negative sample generation procedures are explained. Next, the loss function and detection flow steps are presented.
2.2.1. General Architecture
The SSD is an object detector in the form of a single convolutional neural network. The SSD architecture works with the corporation of extracted feature maps and generated bounding boxes, which are called default bounding boxes. The network simply performs the loss calculation by comparing the offsets of the default bounding boxes and predicted classes with the ground truth values of the training samples at every iteration by the use of different filters. After that, it updates all the parameters according to that calculated loss value with the back propagation algorithm. In this way, it tries to learn best filter structures that can detect the features of the objects and generalize the training samples to reduce the loss value, thus attaining high accuracy at the evaluation phase [
36].
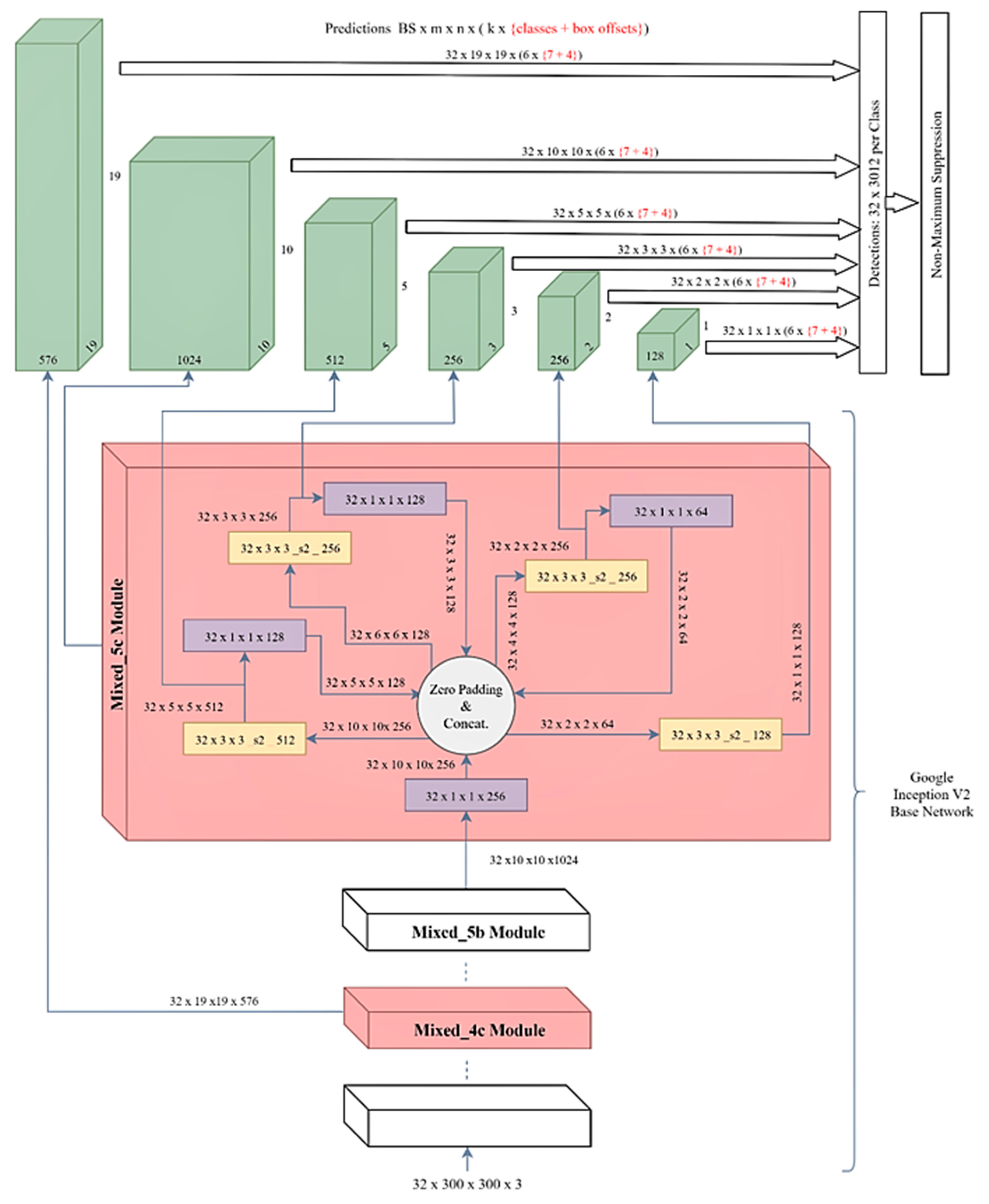
In the SSD method, a state-of-the-art CNN architecture was used as a base network for feature extraction with additional convolution layers, which produce smaller feature maps to detect the objects with different scales. Also, SSD allows more aspect ratios for generating default bounding boxes. In this way, SSD boxes can wrap around the objects in a tighter and more accurately. Lastly, the SSD network used in this research has a smaller input size, which positively affects the detection speed compared to YOLO architectures (
Figure 4). Besides, YOLO has just two fully connected layers instead of additional convolution layers. These modifications are the main differences of SSD from the YOLO and they help to obtain a higher precision rate and faster detection [
36].
In the original SSD research, the VGG-16 model was used as a base network. In this research, the InceptionV2 model was used to reach a higher precision and faster detection as it has a deeper structure than the VGG models. In addition, it uses fewer parameters than VGG models thanks to the inception modules that are composed of multiple connected convolution layers [
42]. As an example, GoogleNet, which is one of the first networks with inception modules, employed only 5 million parameters, which represented a 12x reduction compared to AlexNet and it gives slightly more accurate results than VGG. Furthermore, VGGNet has 3x more parameters than AlexNet [
18].
2.2.2. Default Bounding Boxes and Negative Sample Generation
In the initial phase of training, it is necessary to find out which default bounding box matches well with the bounding boxes of the ground truth samples. The default generated bounding boxes vary with the location and aspect ratio, and a scale process is applied by matching each ground truth box to a default box with the best jaccard overlapping value, which should be higher than 0.5 threshold. This condition facilitates the learning process and allows the network to predict high scores for multiple overlapping default boxes, rather than selecting only those that have the maximum overlap.
To handle different object scales, SSD utilizes feature maps that were extracted from several different layers in a single network. For this aim, a fixed number of default bounding boxes should be produced at different scales and aspect ratios in each region of the extracted feature maps. Six levels of aspect ratios were set supposing
∈ {1, 2, 3, 1/2, 1/3} and
is the scale of the
k-th square feature map for generating default boxes. The sixth one is generated for the aspect ratio of 1 with the scale of
=
. Therefore, the width (
=
) and height (
=
) can be computed for each default box.
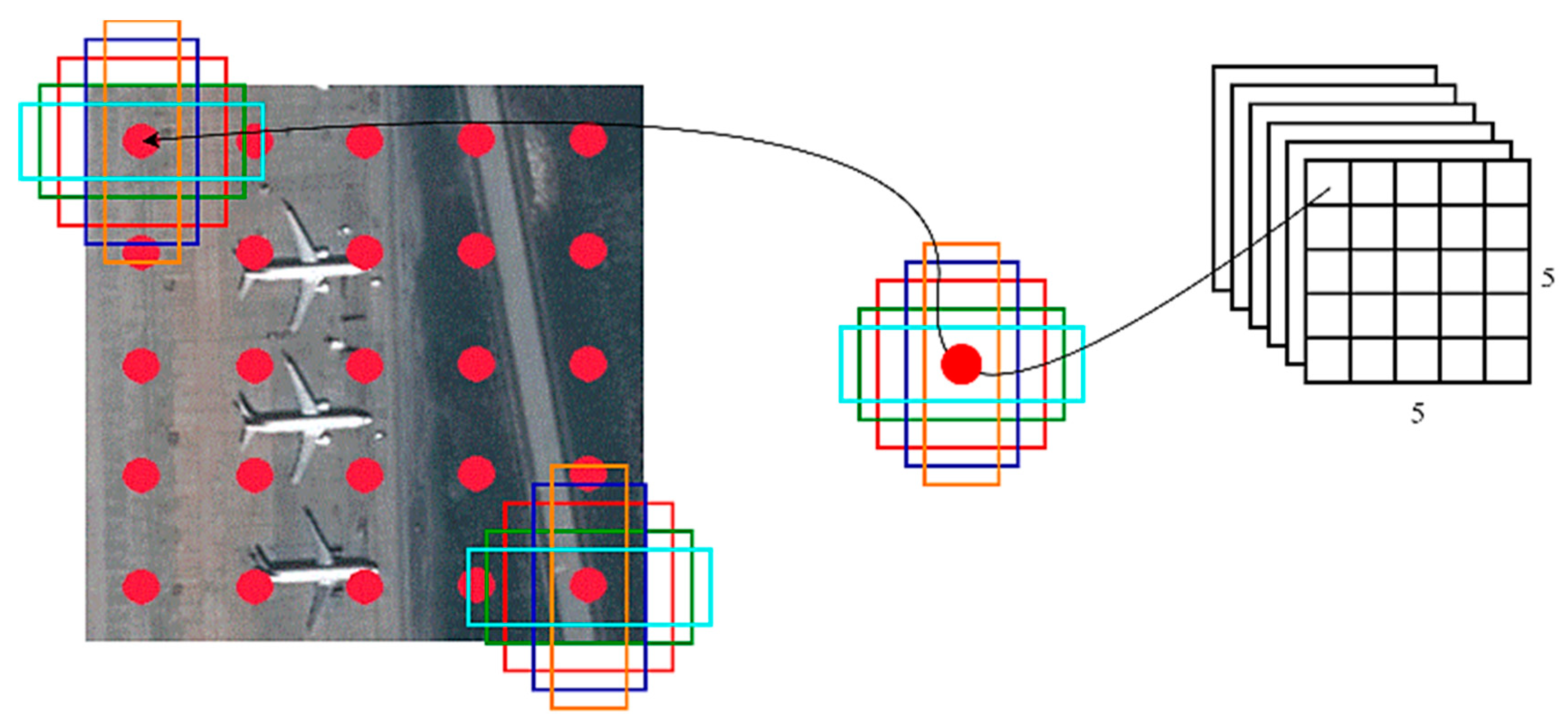
Figure 3 illustrates how the generated default bounding boxes on a 5 × 5-feature map are represented on the input image and overlap with the possible objects (
Figure 5). For this research, 150 bounding boxes were generated. At the same time, each of them represents the predictions in the evaluation step.
After the matching phase, which is performed at the beginning of the training, most of the default boxes are set as negatives. Instead of using all the negative examples to protect the balance with the positive examples, the confidence loss for each default box was calculated and three of them with the highest scores were selected, so the ratio between the negatives and positives is not more than 3:1. This ratio is found to provide faster optimization and training with higher accuracy [
36].
2.2.3. Loss Function
The loss (objective) value was calculated as a combination of the confidence of the predicted class scores and the accuracy of the location. The total loss value (localization loss + confidence loss) given in Equation (1) is an indication of the pairing of the
i-th default box with
j-th ground truth box of class
p, such that
:
where
N corresponds to the number of matching default boxes. If there is no match (
N = 0), the total loss is determined as zero directly. The
value is the balance of two types of losses, and it is equal to 1 during the cross-validation phase. The localization loss is calculated as the Smooth L1 loss between the offsets of the predicted box (
l) and the ground truth box (
g). If the center location of the boxes denoted as
cx,
cy, the default boxes
d, width
w, and height as
h:
in which:
Additionally, the confidence loss (
c) was calculated as a softmax loss of the predicted class relative to other classes:
The above-mentioned equations are detailed in Liu et al.’s article [
37].
2.2.4. Detection Flow
While the usual sliding window technique slides the whole image at a fixed sliding step, it cannot ensure that the windows cover the objects exactly. Moreover, small sliding steps result in huge computation costs and larger window sizes, thus decreasing the accuracy. As shown in
Figure 6, a detection flow was created with the sliding window approach and an optimized sliding step to achieve higher accuracy and faster detection [
43]. As an example schema, when the sliding was performed with a 300-pixel size over a 500 × 500 pixel image patch, the objects at the edges of the window could not be detected or the bounding box offsets of them would be incorrect. To tackle this problem, an overlapping area between two windows was determined as 100 pixels, which covers the object size for this research. In the sliding process for an image with a certain overlap, k × l windows were obtained to detect by the object detector for the horizontal and vertical directions, respectively:
After the sliding and detection step, the non-maximum suppression (NMS) algorithm [
44] (
Appendix A) was used to eliminate multiple detection occurrences over an object in the overlapping regions and a score threshold was also applied to decrease the number of false detections (
Figure 7).
2.3. You Look Only Once (YOLO) v3 Network Framework
Yolo-v3 is grounded upon the custom CNN architecture, which is called DarkNet-53 [
45]. The initial Yolo v1 architecture was inspired by GoogleNet, and it performs downsampling of the image and produces final predictions from a tensor. This tensor is obtained in a similar way as in the ROI pooling layer of the Faster R-CNN network. The next-generation Yolo v2 architecture uses a 30-layer architecture, which consists of 19 layers from Darknet-19 and an additional 11 layers adopted for object detection purposes. This new architecture provides more accurate and faster object detection results, but it often struggles with the detection of small objects in the region of interest. Moreover, it does not benefit from the advantages of the residual blocks or upsampling operations while Yolo v3 does.
Yolo v3 consists of a fully convolutional architecture, which uses a variant of Darknet, which has 53 layers trained with the Imagenet classification dataset. For the object detection tasks, an additional 53 layers were added onto it, and the improved architecture trained with the Pascal VOC dataset. With this structural design, the Yolo v3 outperformed most of the detection algorithms, while it is still fast enough for the real-time applications. With the help of the residual connections and upsampling, the architecture can perform detections at three different scales from the specific layers of the structure [
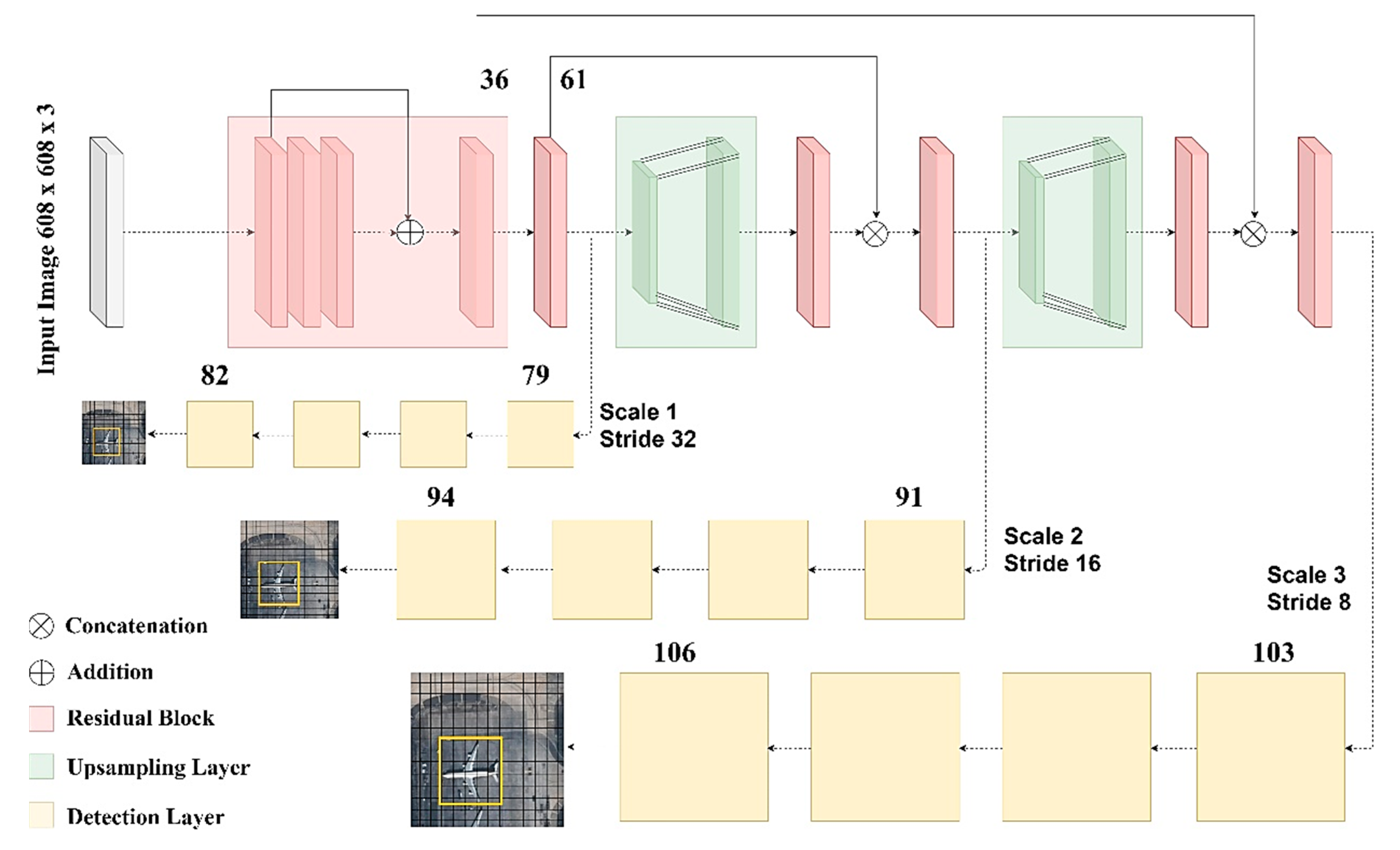
45]. This makes the architecture more efficient at the detection of smaller objects but results in slower processing than the previous versions due to the complexity of the framework (
Figure 8).
The shape of the detection kernel is 1 × 1 × (B × (5 + C)). In the v3 network, 3 pieces of an anchor are used for detection for each scale. Here, B is the number of the anchors on the feature map, 5 is for the 4 bounding box offsets, and one for object confidence. C is the number of categories. In the current research, the Yolo v3 network was used and the class was the only airplane, so the detection kernel shape was designed as 1 × 1 × (3 × (5 + 1)) for each scale. The first detection process was performed from the 82nd layer, as the first 81 layers downsampled the input image by the size of 32 strides. If the input image has a size of 608 × 608 pixels, that will be output as a feature map of 18 × 18 pixels in that layer. This corresponds to 18 × 18 × 18 detection features being obtained from this layer. After the first detection operation, the feature map was upsampled by a factor of 2. This upsampled feature map is was with the feature map arising from the 61st layer. Then, a few 1 × 1 convolution operations were performed to fuse features and reduce the depth dimension. After that, the second detection is performed from the 94th layer, which returns a detection feature map of 36 × 36 × 18. The same procedure was performed for the third scale at the 106th layer, which yields a feature map of the 72 × 72 × 18 size. This means it produced 20,412 predicted boxes for each image. As in the SSD network, the final predictions were proposed after the NMS algorithm was applied.
2.4. Faster R-CNN Network Framework
In this sub-section, the general architecture of the faster R-CNN framework is presented initially. After, the loss function and residual blocks are explained in detail.
2.4.1. General Architecture
Faster R-CNN is one of the most used object detection networks, which achieves accurate and quick results with CNN structures. It was initially used for nearly real-time applications, such as video indexing tasks, due to these capabilities. Faster R-CNN has developed progressively over time. The first version of it, the R-CNN, uses a selective search algorithm that utilizes a hierarchical grouping method to produce object proposals. It produces 2000 objects as the rectangular boxes, and they are passed to a pre-trained CNN model. Then, the feature maps of them are extracted from the CNN model to pass them to an SVM for classification [
25].
In 2015, Girshick R. et al. [
27] came up again with the Fast R-CNN, which moves the R-CNN solution one step forward. The main advantage of Fast R-CNN over the R-CNN is gained by producing the object proposals from the feature map of the CNN, instead of getting them from the complete input image. In this way, there is no need to apply the CNN process 2000 times to extract feature maps. In the next step, the region of interest (ROI) pooling is applied to ensure a standard and pre-defined output size is obtained. Finally, the future maps are classified with a softmax classifier and bounding box localizations are performed with linear regression.
In the Faster R-CNN, the selective search method is replaced by a region proposal network (RPN). This network aims to learn the proposal od an object from the feature maps. The RPN is the first stage of this object detection method. The feature maps extracted from a CNN are passed to the RPN for proposing the regions. For each location of the feature maps, k anchor boxes are used to generate region proposals. The anchor box number k is defined as 9 considering the 3 different scales and 3 aspect ratios in the original research [
36]. With a size of W × H feature map, there are W × H × k anchor boxes in total, which are comprised of the negative (not object) and positive (object) samples. This means that there are many negative anchor boxes for an image, and to prevent bias occurring due to this imbalance, the negative and positive samples are chosen randomly by a 1:1 ratio (128 negative and 128 positives) as a mini-batch. The RPN learns to generate the region proposals at the training phase by utilizing these anchor boxes by comparing the ground truth boxes of the objects. The bounding box classification layer (cls) of the RPN outputs 2 × k scores whether there is an object or not for k boxes. A regression layer is used to predict the 4 × k coordinates (center coordinates of box, width, and height) of k boxes. After generation of the region proposals, the ROI pooling operation is performed as in the Fast R-CNN at the second stage of the network. Again, as in Fast R-CNN, a ROI feature vector is obtained from fully connected layers and this vector is classified by softmax to determine which category it belongs. A box regressor is applied to it to adapt the bounding box of that object. In the current research, the Faster R-CNN was used with a residual neural network (ResNet) that was comprised of 101 residual layers. This network won the COCO 2015 challenge by utilizing the ResNet-101, instead of VGG-16 in Faster R-CNN. Moreover, one additional scale parameter was added for generating the anchor boxes to detect smaller airplanes (4 scales, 3 aspect ratios, k = 12).
2.4.2. Loss Function
The loss function of the RPN network for an image was defined as:
where
is the index of an anchor,
is the prediction probability of anchor
being an object, and
is the ground truth label and it is 1 if the anchor is an object; otherwise, it is 0.
and
represent the classification loss, respectively, which is a log loss over two classes (object or not object) and the regression loss is the smooth
function used for the
and
parameters.
is a vector representation of the predicted bounding box, and
is a ground truth bounding box associated with a positive anchor. Lastly, the parameter
is used for balancing the loss function terms, and
and
are the normalization parameters of the classification and regression losses according to the mini-batch size and anchor locations.
2.4.3. Residual Blocks
When the CNN networks are designed with a deeper structure, degradation problems can occur. As the architecture becomes deeper, the layers of the higher level can act simply as an identity function. The output of them, which are the feature maps, becomes more similar to the input data. This phenomenon causes saturation in the accuracy, which is followed by fast degradation. To solve this problem, the residual blocks can be used. Instead of learning from a direct mapping of × → y with a function H(x), the residual blocks can be used to modify the function as H(x) = F(x) + x, where F(x) and × represent the stacked non-linear layers and identity function, respectively.
2.5. Training
In this work, all the experiments were performed with the Tensorflow and Keras open-source deep learning framework, which was developed by the Google research team [
46]. The transfer learning technique was applied by using the pre-trained network with the COCO dataset. Additionally, fine-tuning of the parameters and extending the training set with the sample collection were performed to improve the performance as much as possible.
Through the transfer learning approach, the training was started with the implementation of the pre-trained parameters to include the useful information gathered from a previously trained network with different data used for another problem in the computer vision area. Although the COCO dataset contains natural images, the pre-trained model of the networks, which was utilized from COCO, can be used for the current research as well, because features, such as the edge, corner, shape, and color, can be implemented, which form the basis of all of the vision tasks. After starting the network with the parameters of the pre-trained model, it was fed with training examples from the produced DOTA image chips.
For Faster R-CNN, 1024 × 1024 sized image patches were used to train the model. For the RPN stage, the bounding box scales were defined as 0.25, 0.5, 1.0, and 2.0 with 0.5, 1.0, and 2.0 aspect ratios, which ensured that the network generated 12 anchor boxes for each location of the feature maps. The batch size was defined as 1 to prevent memory allocation errors. For the first attempt of the training, the process continued until 400,000 iterations, which took 72 h. The learning rate was started at 0.003 and was reduced to half of it in each further 75,000 step. The training loss did not decrease more, thus a new training process was initialized, with the learning rate corresponding to a tenth of the previous value, and the process continued for 900,000 iterations by reducing the learning rate to a quarter for each 50,000 step after the 150,000th iteration.
For the SSD network, 608 × 608-sized image patches were used for training. The sizes and aspect ratios of the default bounding boxes of each feature map layers remained the same as the original SSD research [
36]. The RMSProp optimization method was used for gradient calculations with a 0.001 learning rate and 0.9 decay factor for each 25,000 iteration. The batch size was defined as 16 and the training process was continued till the 200,000th step, which took 60 h. The first attempt at the SSD training provided unsatisfactory results similar to Faster R-CNN. Therefore, a new training process initialized with a 0.0004 learning rate value and the same decay factor for each 50,000th iteration along with 450,000 iterations.
The Yolo-v3 architecture was trained with the Adam optimizer by a learning rate of 5 × 10−5 with a decay factor of 0.1 for every 3 epochs, with which the validation loss did not decrease. We used 9 anchor boxes with different sizes, 3 for each stage of the network, as in the original paper. Before the training, the bounding boxes of the entire data were clustered according to their sizes with the k-means clustering algorithm to find 9 optimum anchor box sizes. In the next step, bounding boxes were sorted from smallest to largest. For the validation purpose, 10% of the training data was split for monitoring the validation loss during the training process. The batch size was defined as 8 and the whole training was continued for 80 epochs. One epoch means the feed forward and back propagation processes are completed for the whole training dataset. Training of the Yolo-v3 took about 36 h.
4. Conclusions
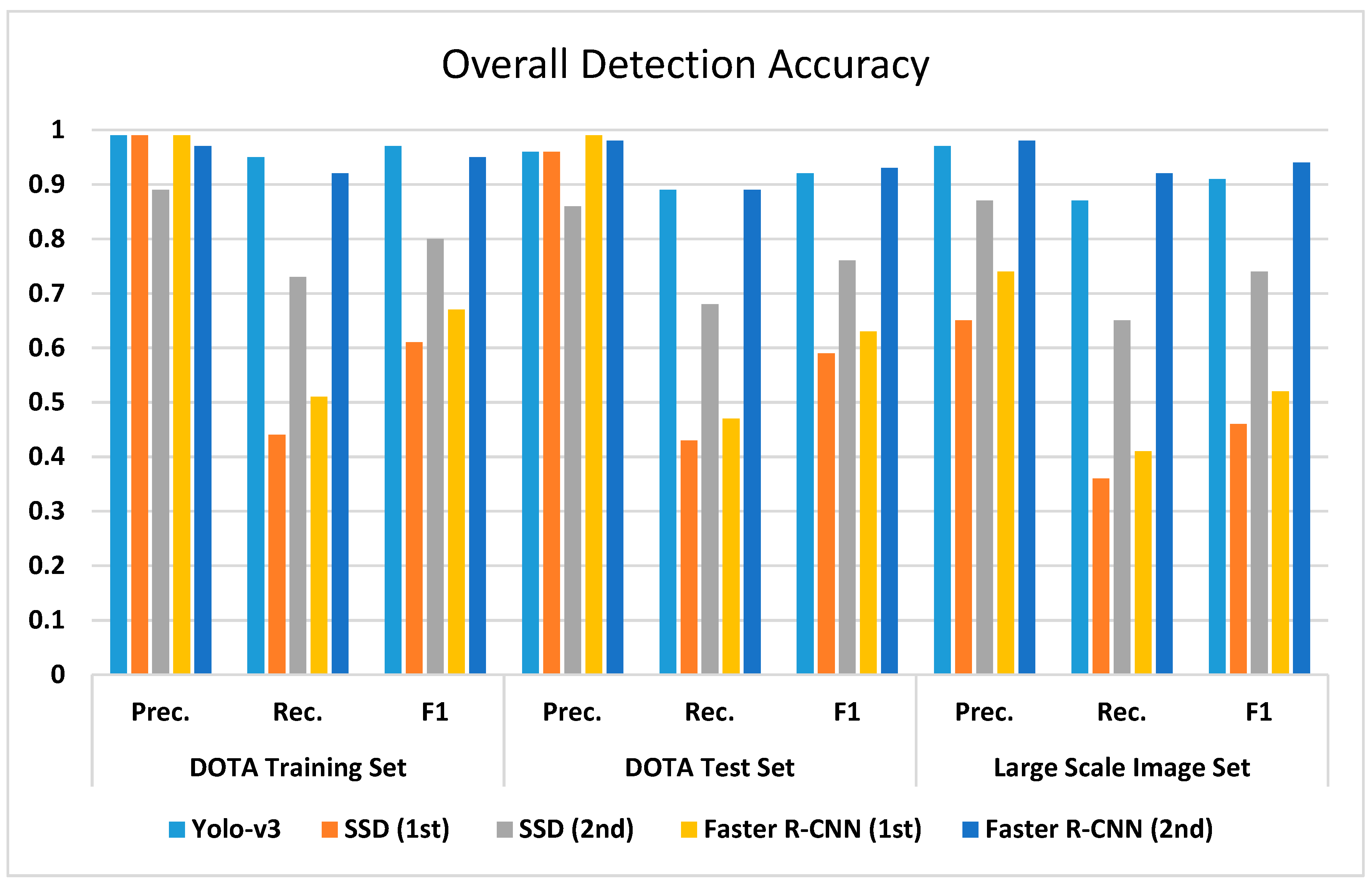
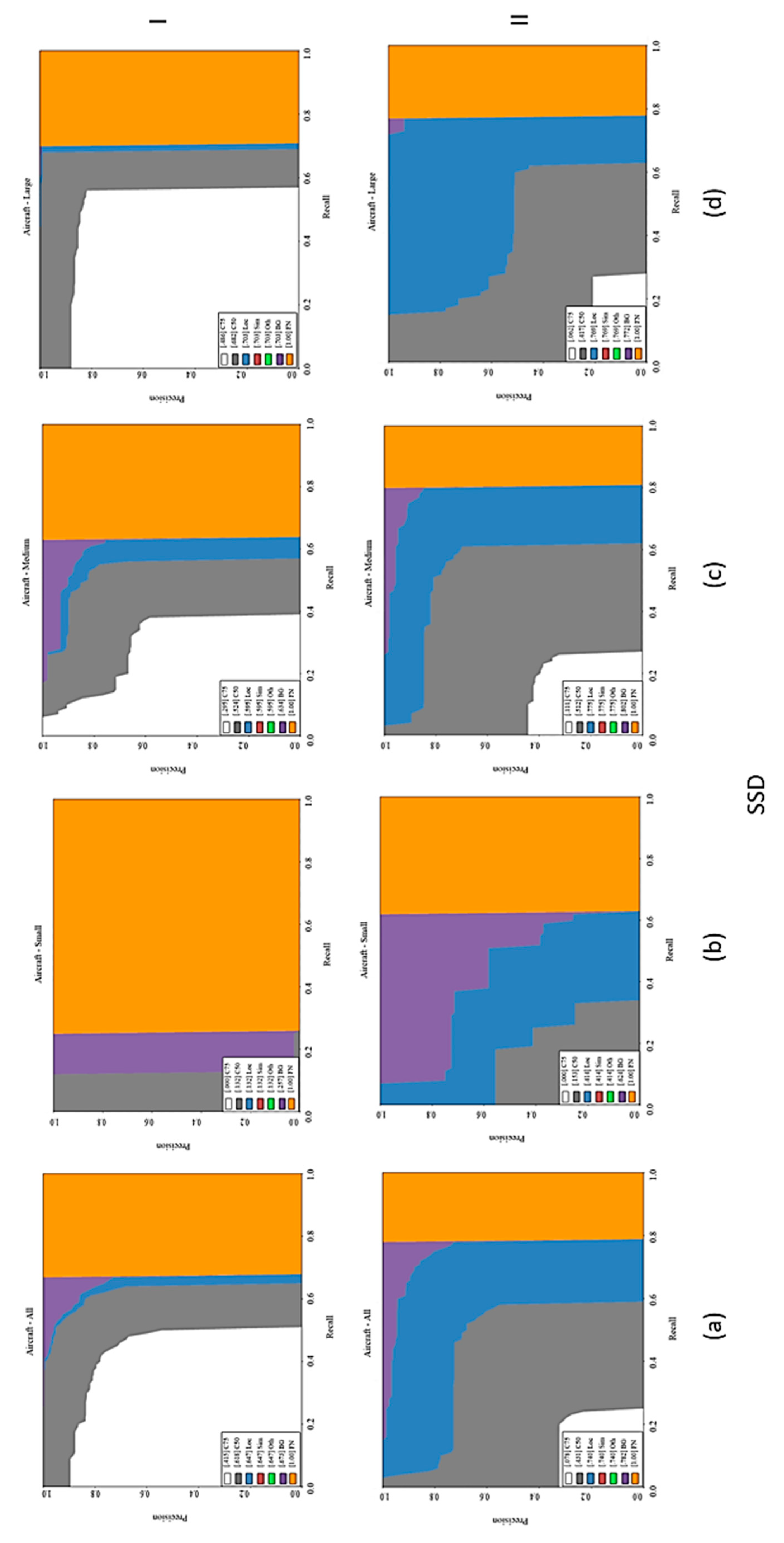
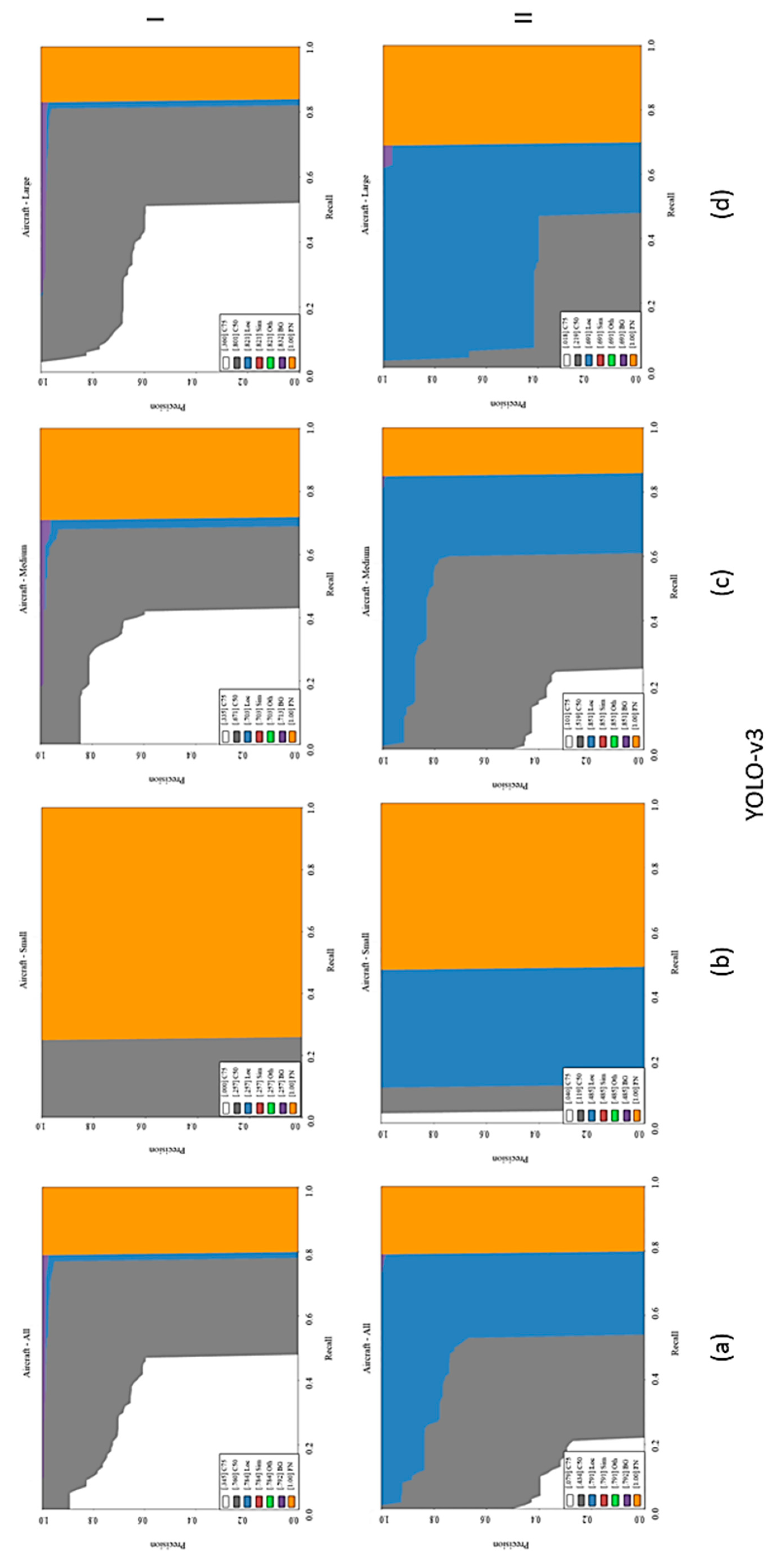
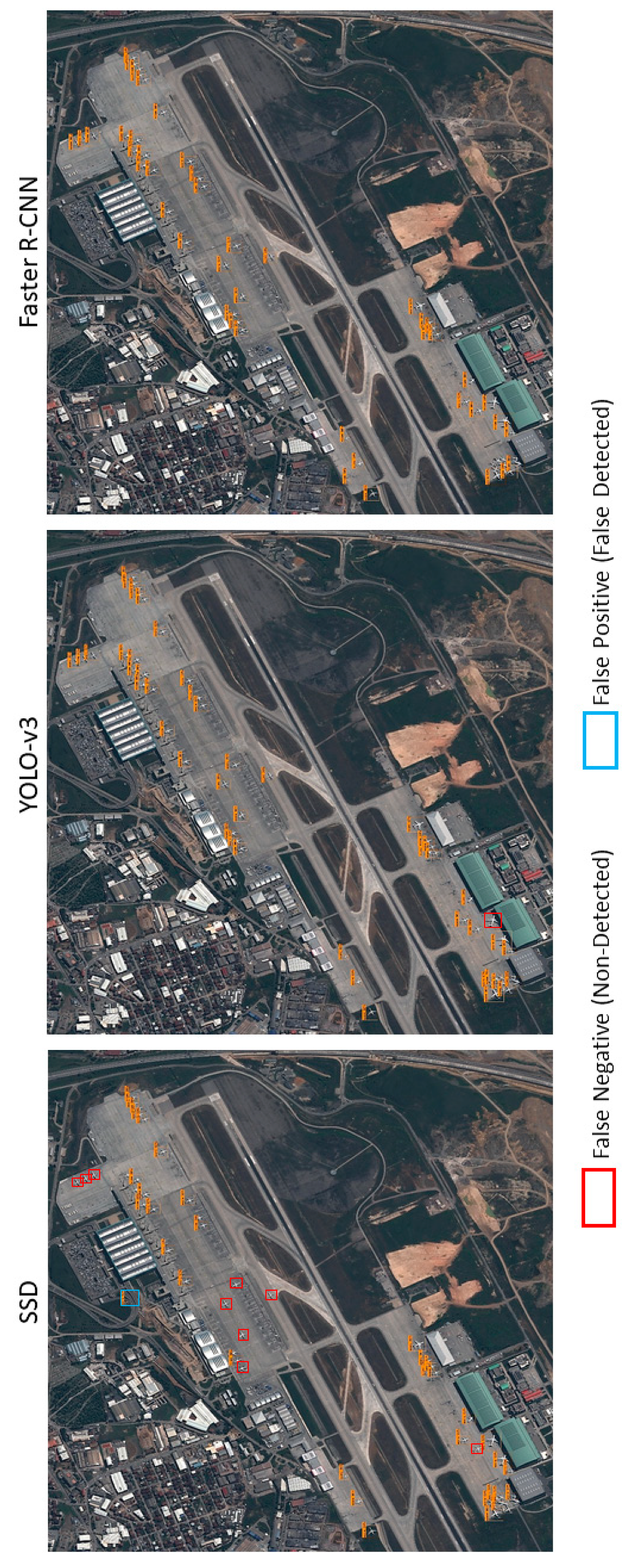
This article presented a comparative evaluation of state-of-the-art CNN-based object detection models for determining airplanes from satellite images. The networks were trained with the DOTA dataset and the performance of them was evaluated with both the DOTA dataset and independent Pleiades satellite images. The best results were obtained with the Faster R-CNN network according to the COCO metrics and F1 scores. The Yolo-v3 architecture also provided promising results with a lower processing time, but SSD could not converge the training data well with low iterations. All of the networks tended to learn more with different parameters and more iterations. It can be asserted that Yolo-v3 has a faster convergence capability when compared with the other networks; however, the optimization methods also play an important role in the process. Although SSD provided the worst detection performance, it was better in object localization. The imbalance between the object sizes and the diversities also affected the results. In the training of deep learning architectures, imbalances should be avoided, or the categories should be divided into finer grains, such as airplanes, gliders, small planes, jet planes, and warplanes. In summary, transfer learning and parameter tuning approaches on pre-trained object detection networks provided promising results for airplane detection from satellite images. Besides, the proposed slide and detect and non-maximum suppression-based detection flow enabled algorithms to be run on full-sized (large-scale) satellite images.
For future work, the anchor box sizes can be defined by weighted clustering according to the sample size of the datasets. Moreover, all of the networks can be used together to define the offsets of the bounding boxes by averaging the predicted bounding boxes, to prevent false positives and increase the recall ratio. In this way, the localization errors could be decreased as well. Finding a way to use the ensemble learning methods for object detection architectures could be another improvement. In addition, the object detection networks often use R, G, and B bands, as they are mostly developed for natural images. However, satellite imageries can contain more spectral bands. Therefore, further studies are planned to integrate the additional spectral bands of the satellite images, to increase the number of labels and train the model more accurately.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}