A Fast Three-Dimensional Convolutional Neural Network-Based Spatiotemporal Fusion Method (STF3DCNN) Using a Spatial-Temporal-Spectral Dataset



Abstract
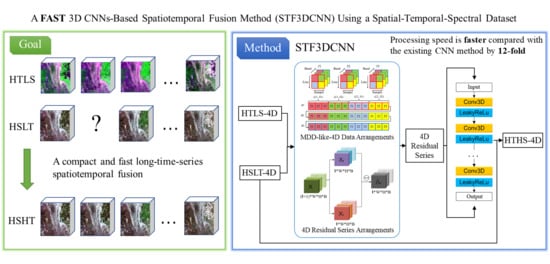
1. Introduction
2. Materials and Methods
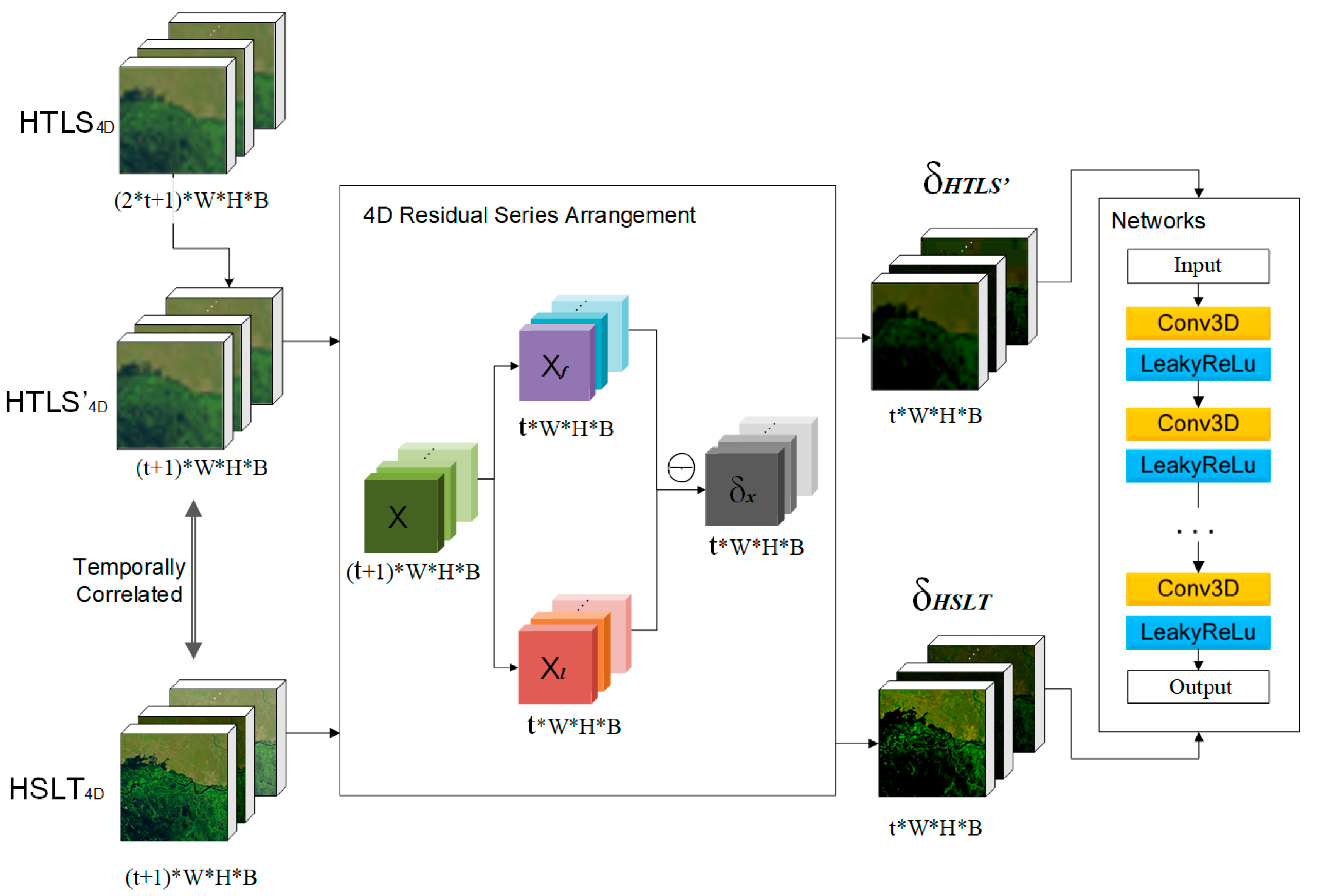
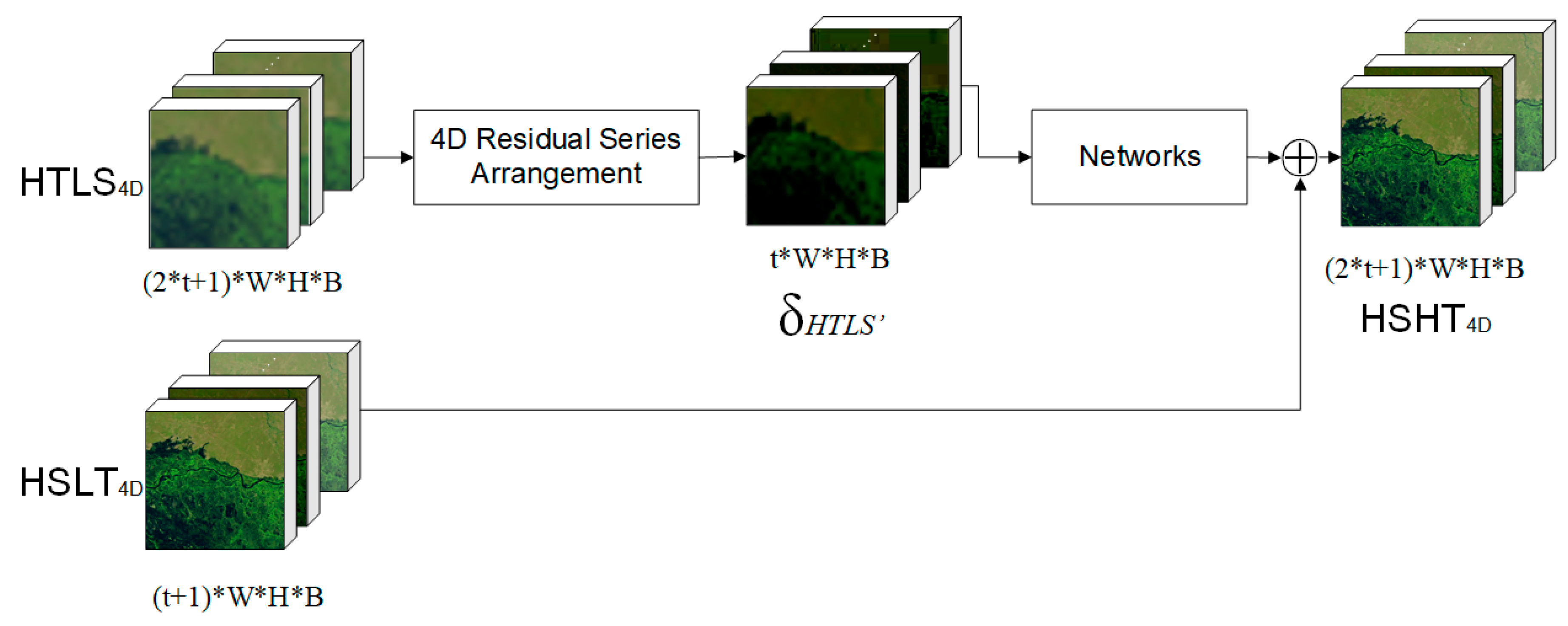
2.1. Four-Dimensional (4D) Residual Series
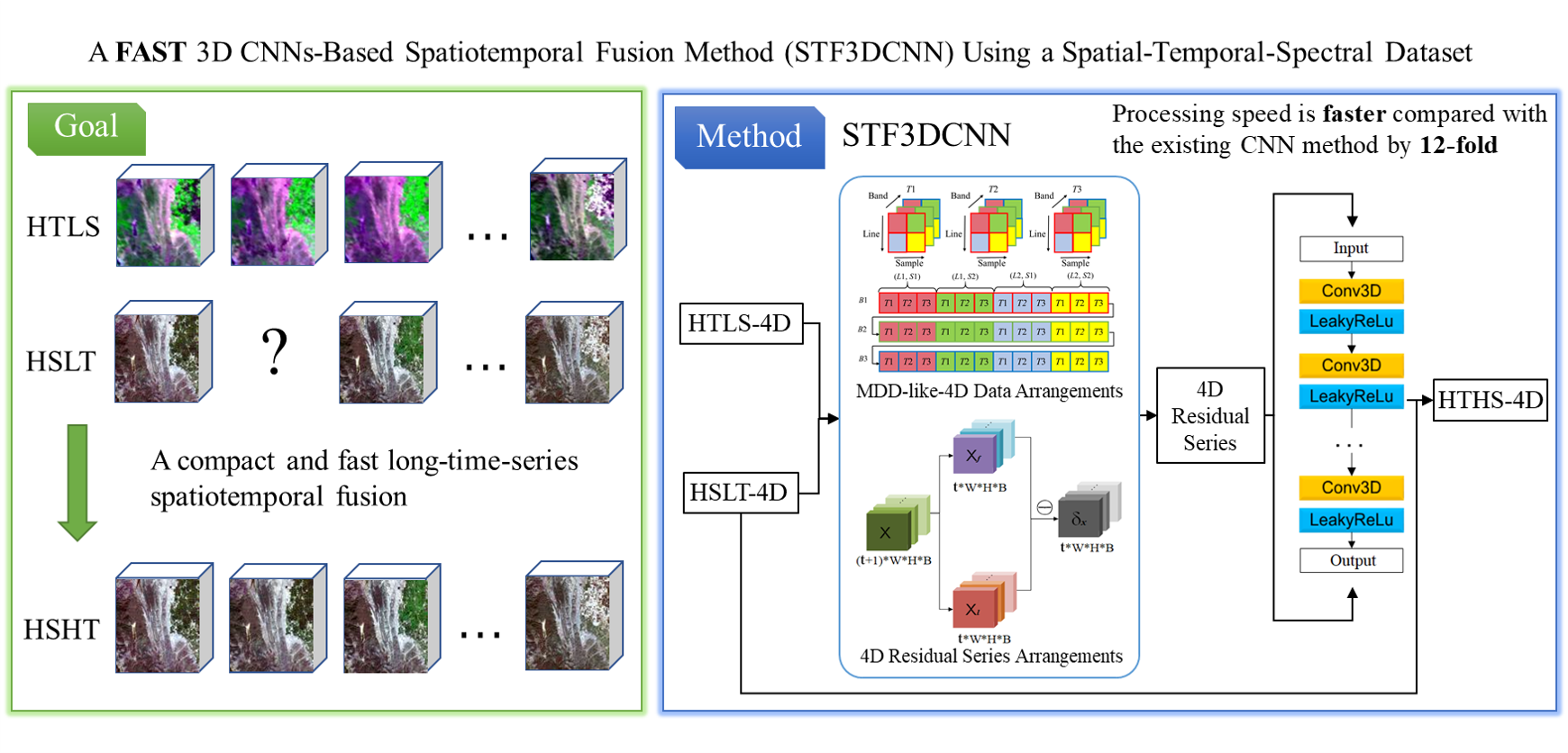
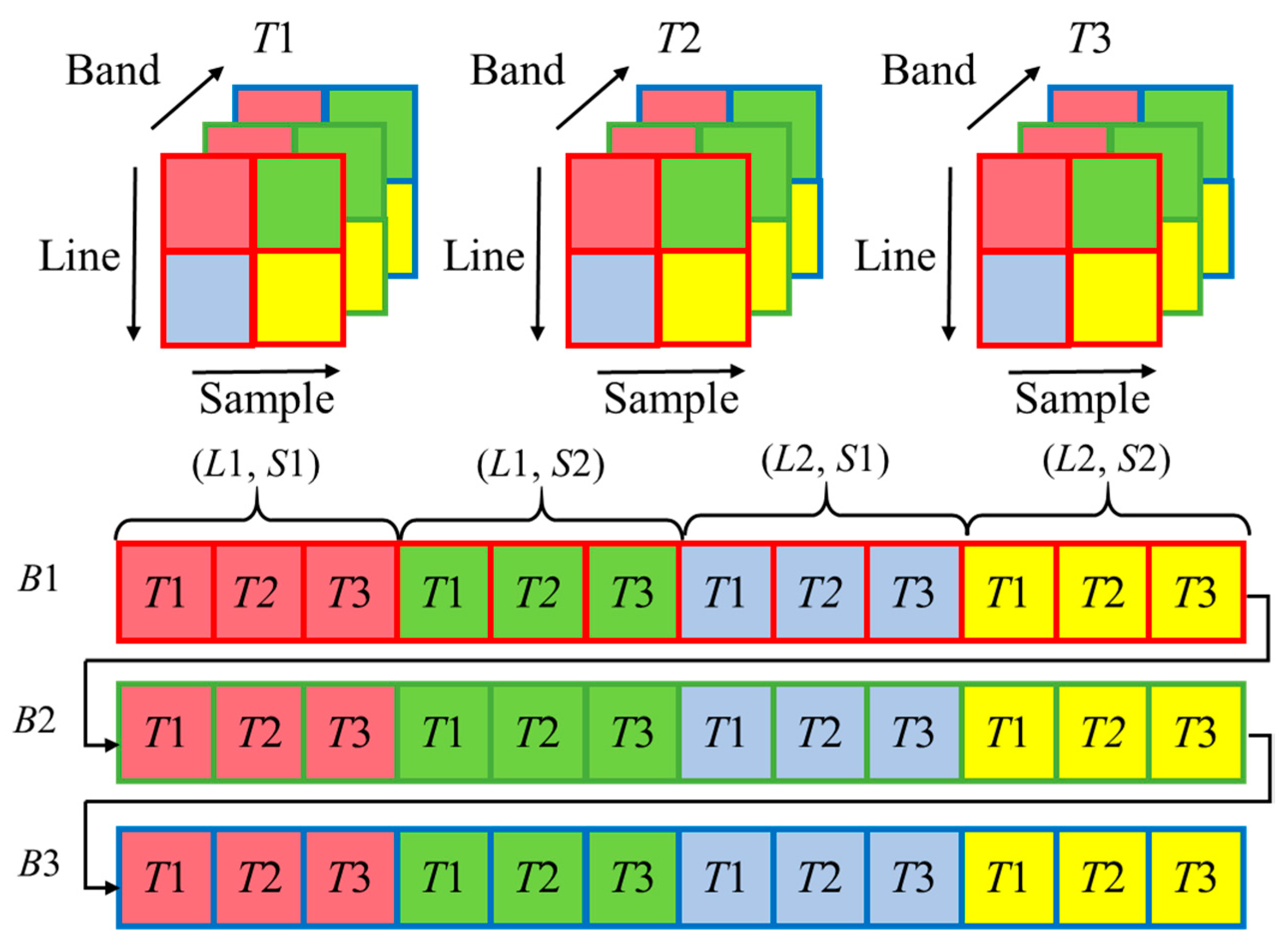
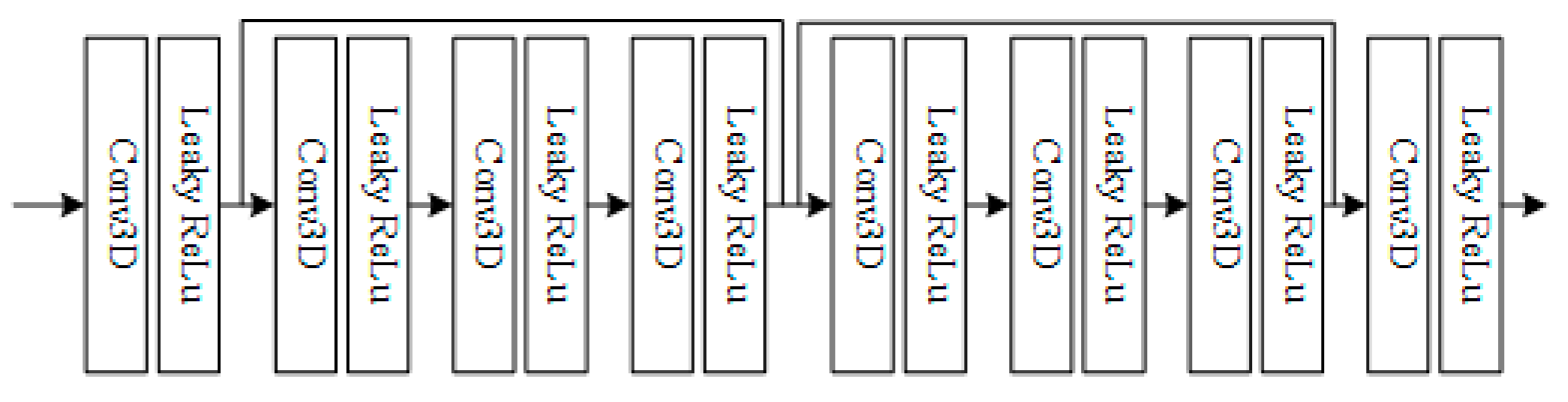
2.2. 3D CNNs for 4D Residual Series
2.3. Overall Frame
3. Experiments and Datasets
3.1. Datasets
3.2. Data Preprocessing and Experimental Settings
- (1)
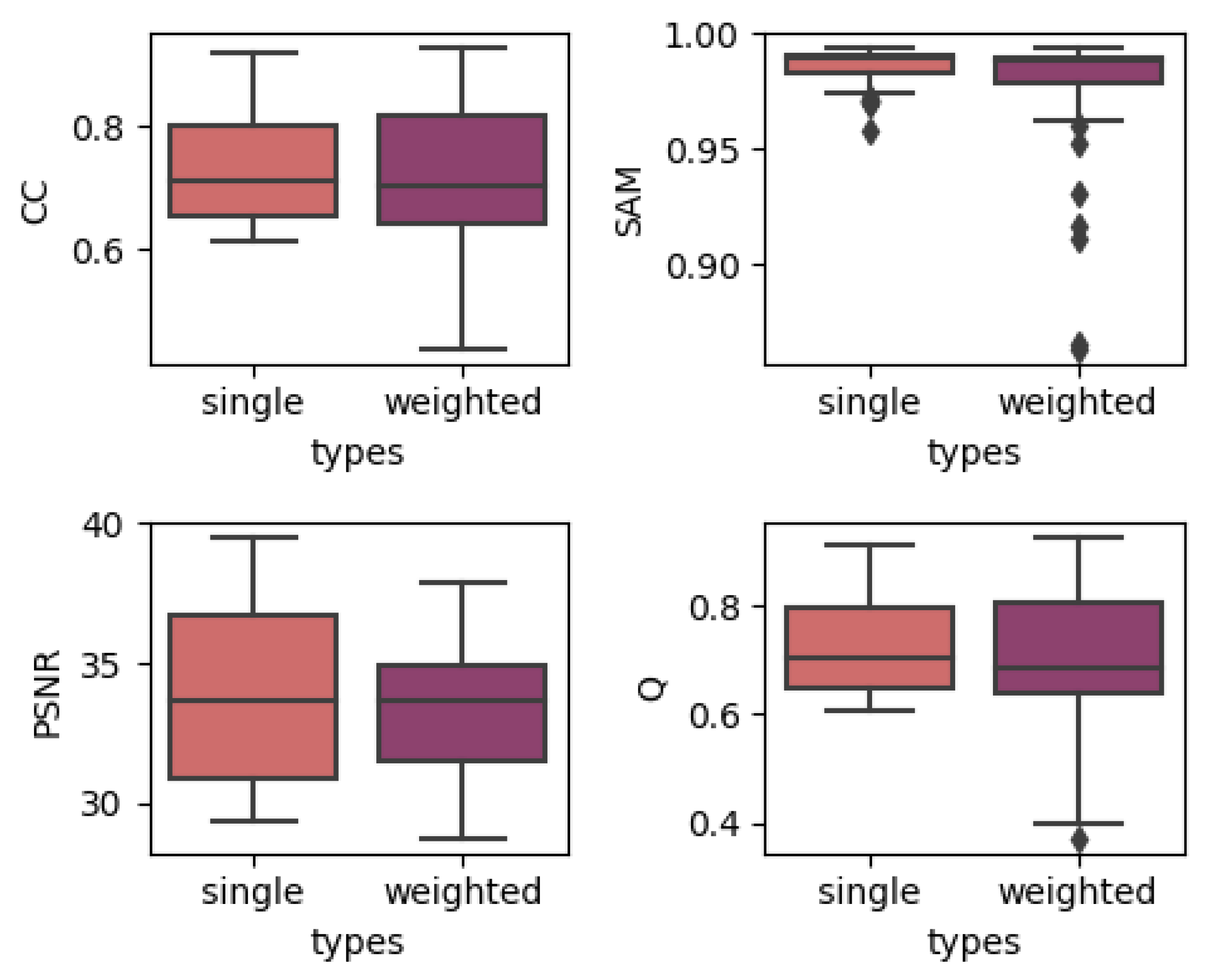
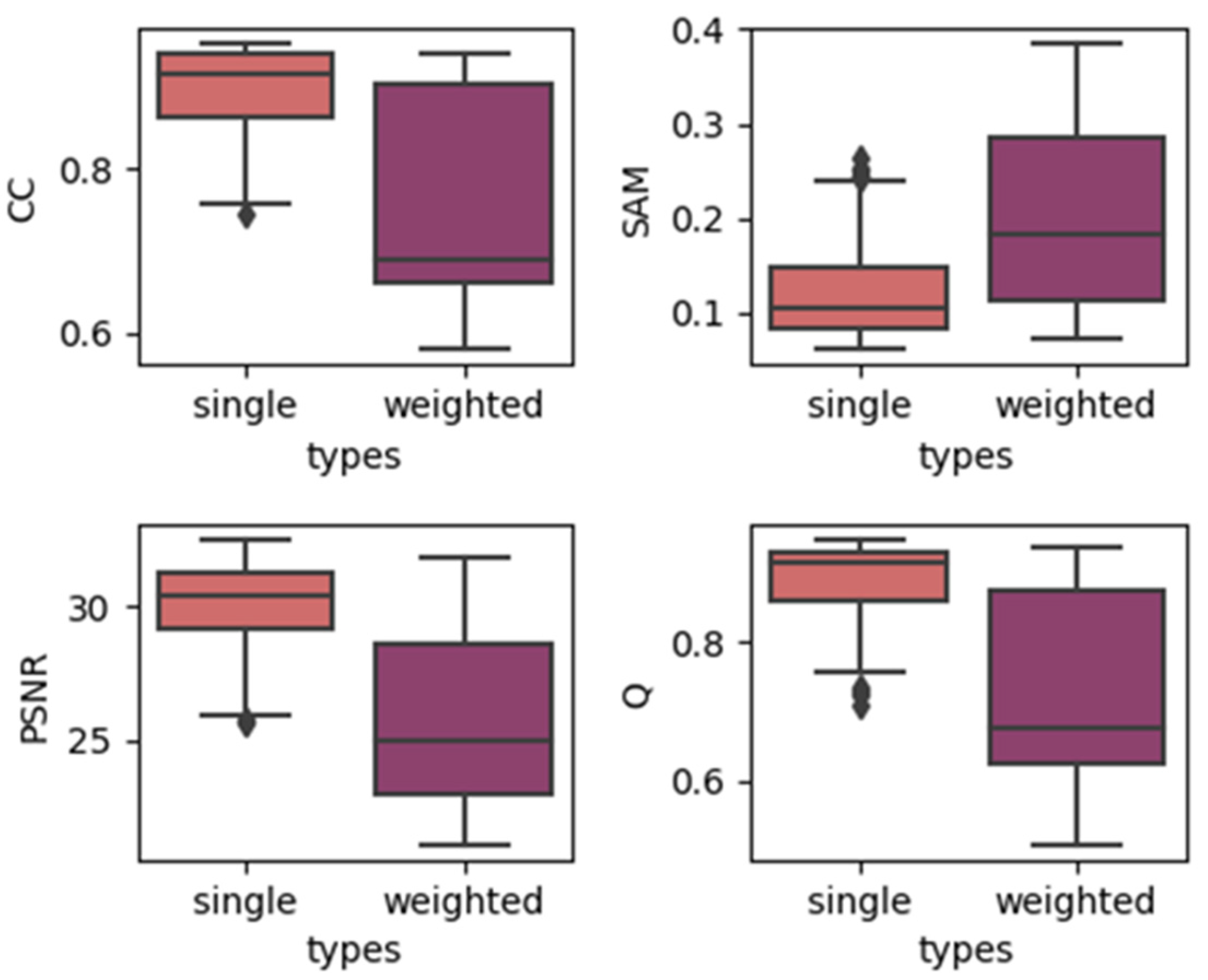
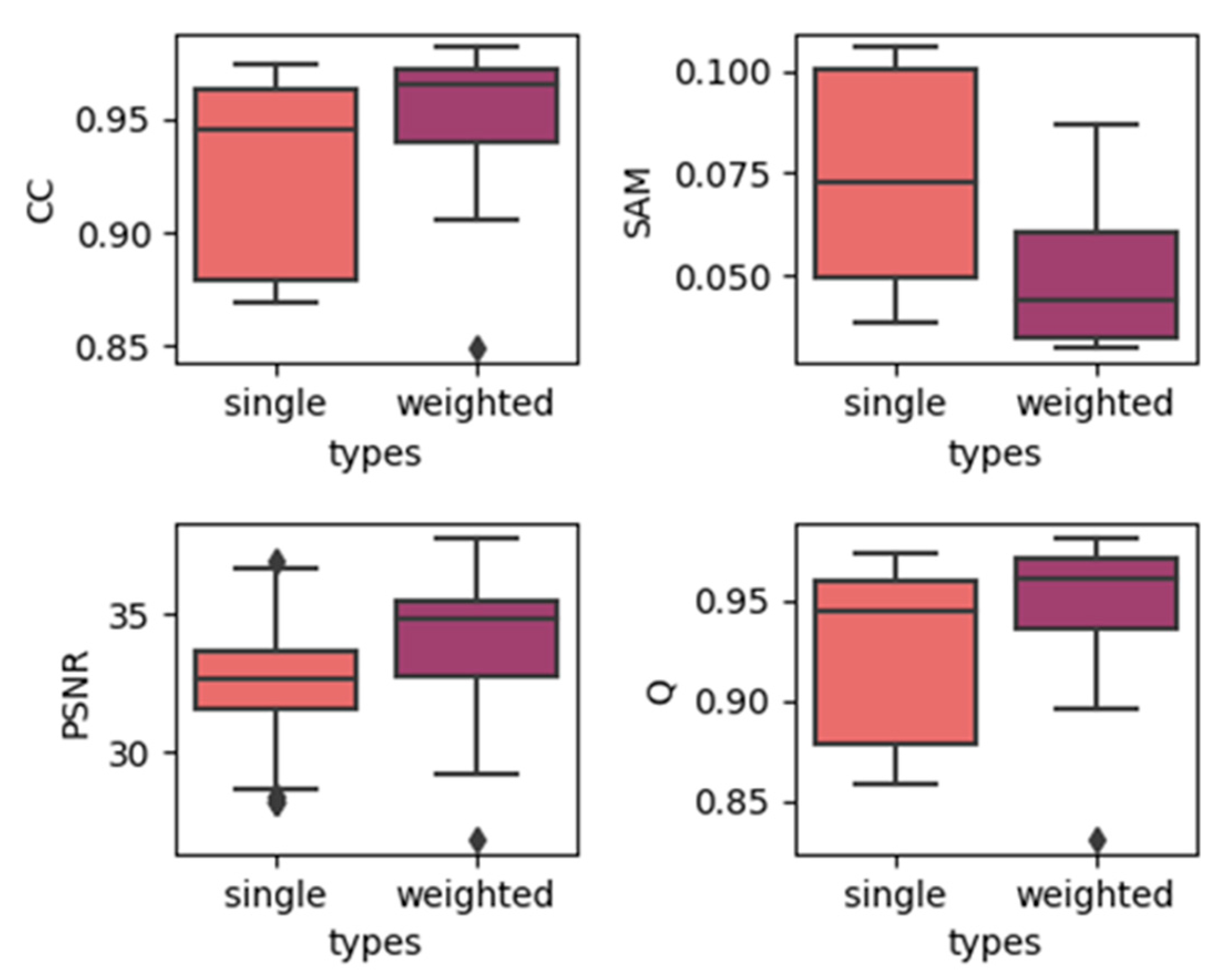
- Correlation coefficient (CC) [23]: CC is an important indicator for measuring the relevance between two images. The CC, , for band k can be represented as:where represents the pixel value at the k-th band at the (i, j) position of the real reference image, represents the pixel value at the k-th band at the (i, j) position of the fused image and and respectively, represent the average gray values of the two images in the band k. The closer the CC is to 1, the better relevance between the two images.
- (2)
- Spectral angle mapper (SAM) [24]: SAM is a common index used to measure the spectral similarity between two spectral vectors or remote sensing images. The SAM of the (i, j)th pixel between the two images is as follows:where and represent the two spectral vectors of the (i, j)th pixel of the two images, respectively. The smaller the spectral angle, the greater the similarity between the spectra. The perfectly matched spectral angle is 0. For the evaluation of the fusion image, the average spectral angle between the fusion image and the real reference image can be obtained by averaging the spectral angle of every pixel to evaluate the preservation of the spectral characteristics of the fusion image.
- (3)
- Peak signal-to-noise ratio (PSNR) [25]: PSNR is one of the most commonly used evaluation indices for image fusion evaluation. It evaluates whether the effective information of the fused image is enhanced compared to the original image, and it characterizes the quality of the spatial information reconstruction of the image. The PSNR of band k can be represented as:where represents the maximum possible value of the k-th band of the image. The larger the PSNR, the better the quality of the spatial information of the image.
- (4)
- Universal image quality index (UIQI, Q) [26]: The UIQI is a fusion evaluation index related to the correlation, brightness difference, and contrast difference between images. The formula for calculating the UIQI index of the k-th band of the image before and after fusion is:where represents the co-standard deviation between the corresponding bands of the two images. The ideal value of UIQI is 1. The closer the index is to 1, the better the fusion effect is.
4. Discussion
4.1. Effects of Utilizing Temporal Weights
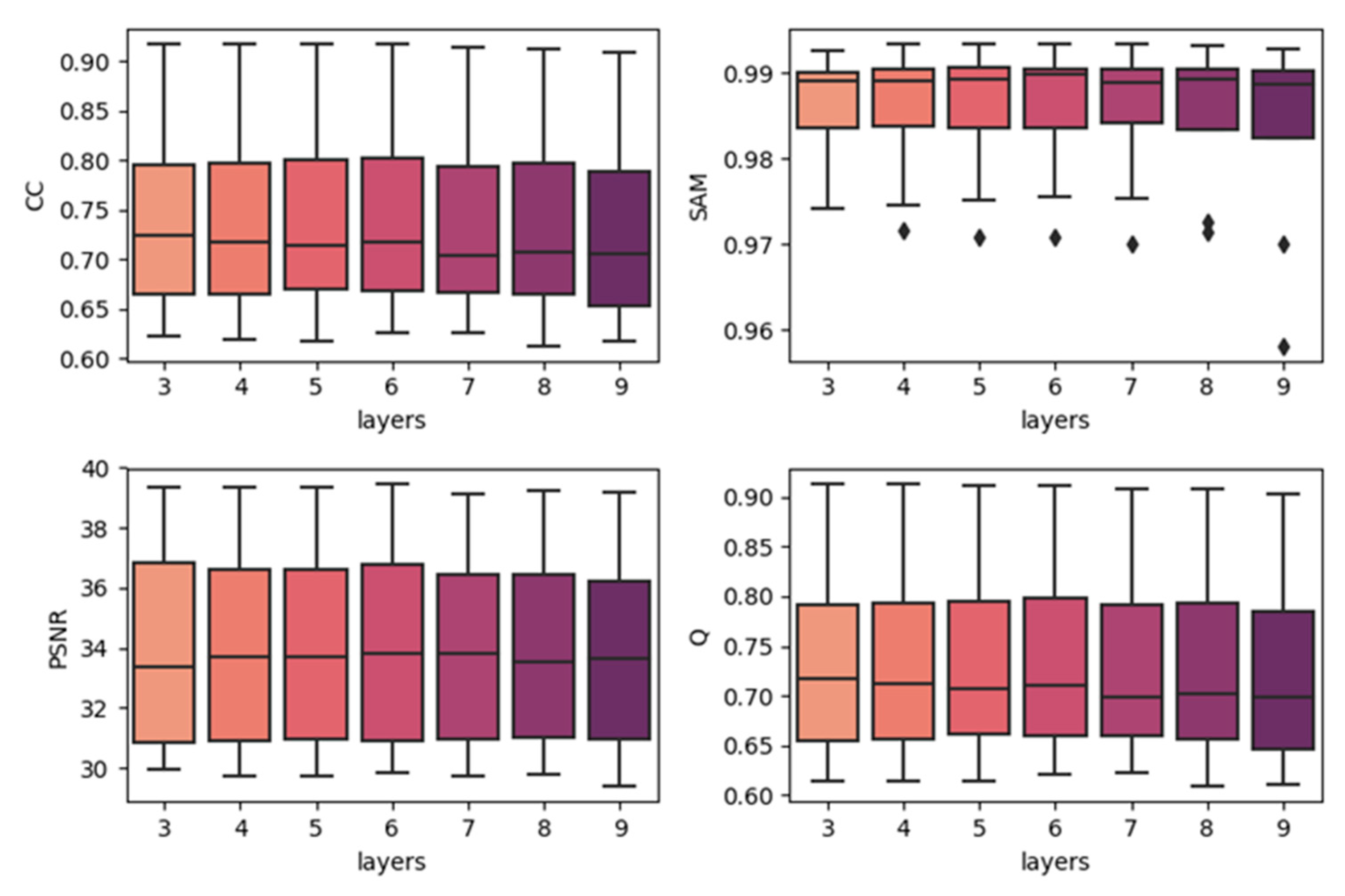
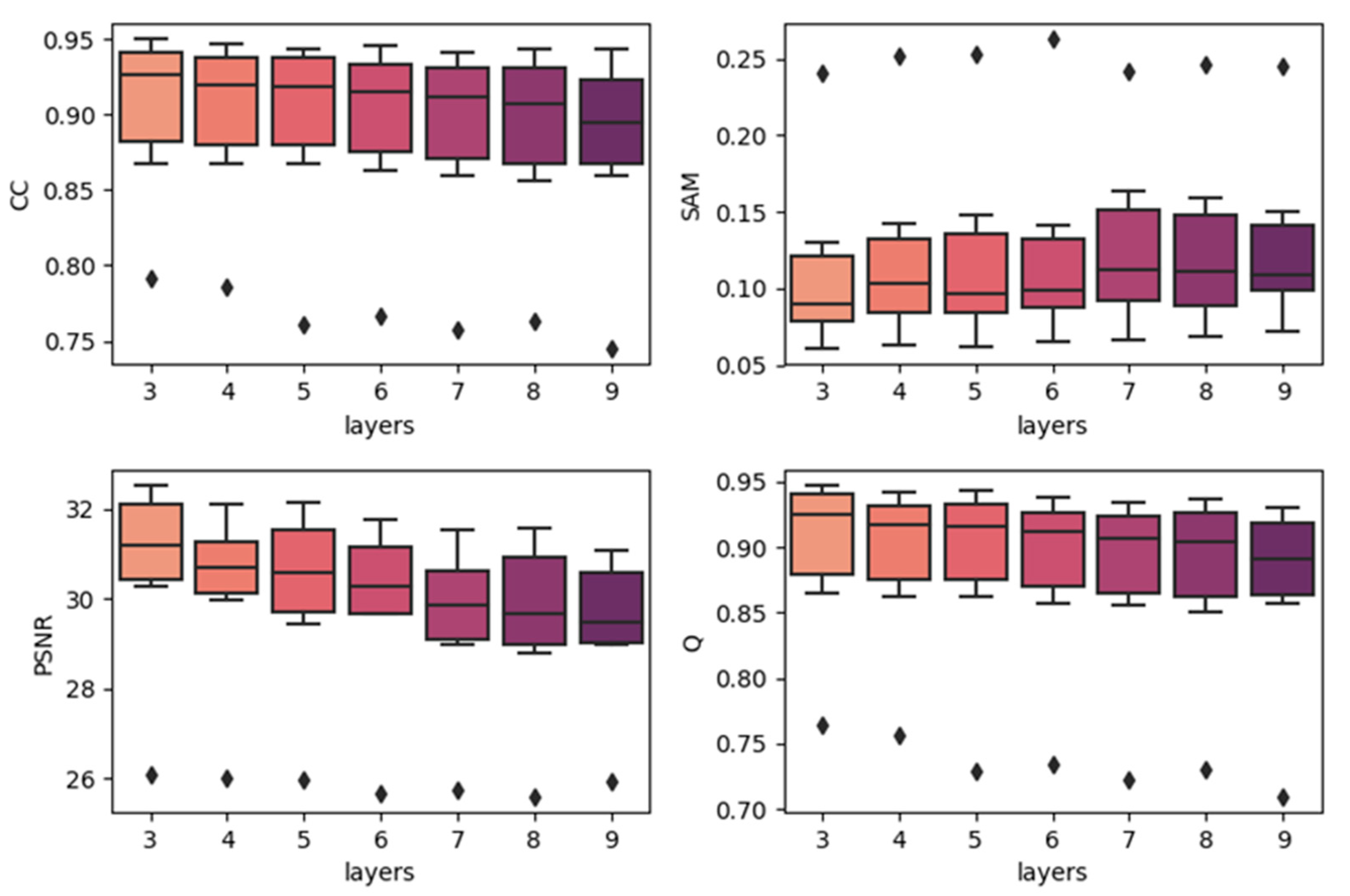
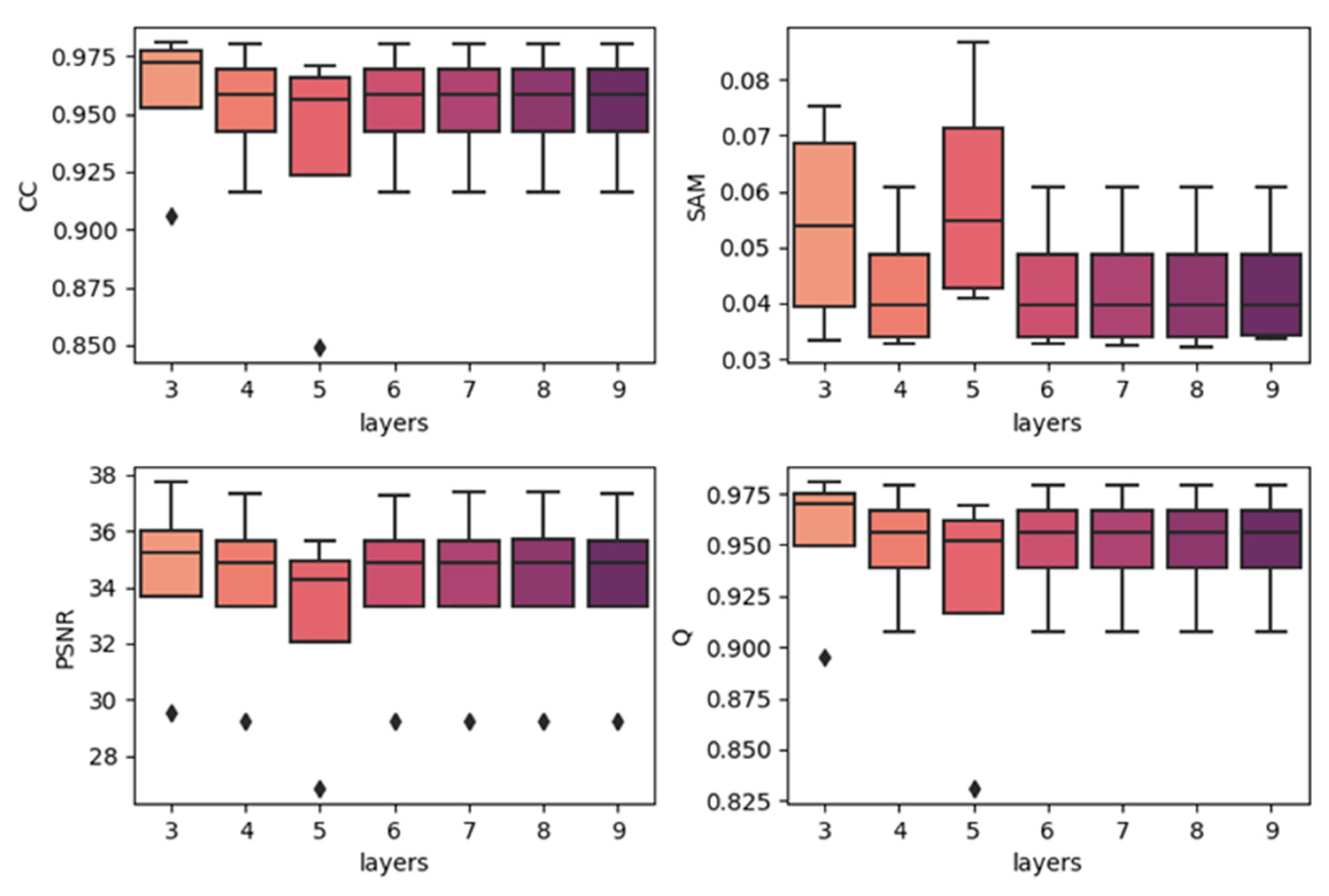
4.2. Effects of Network Depth
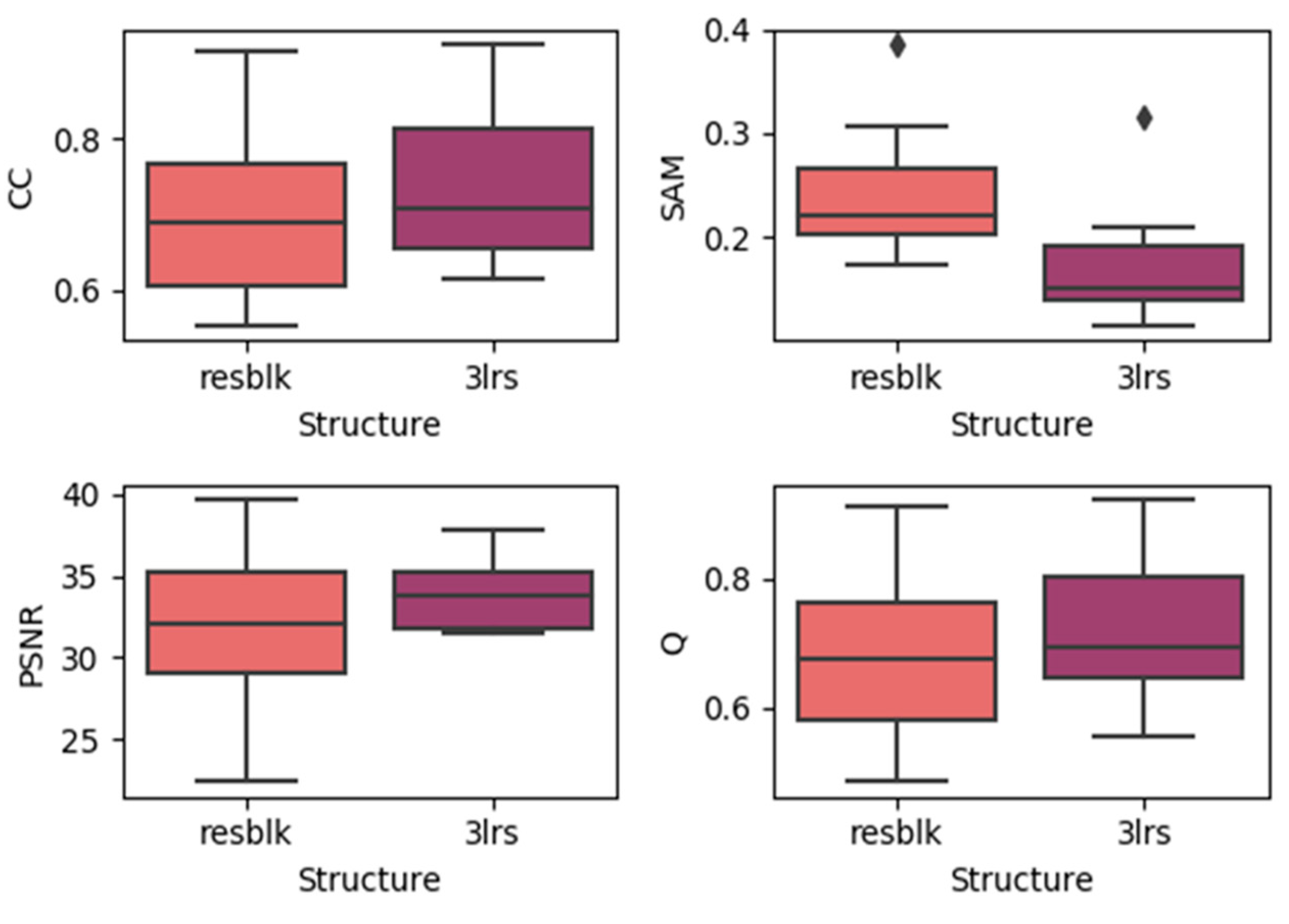
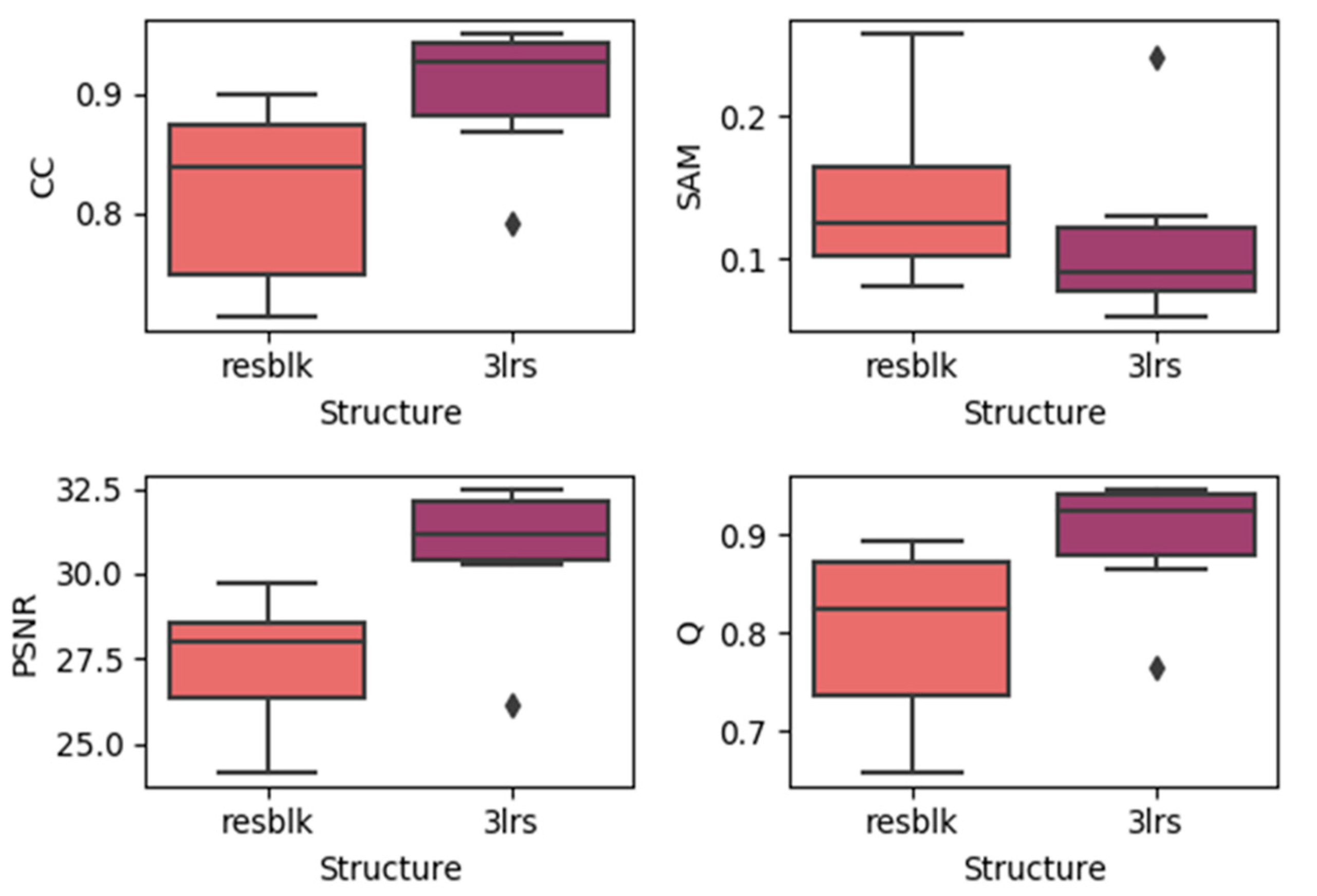
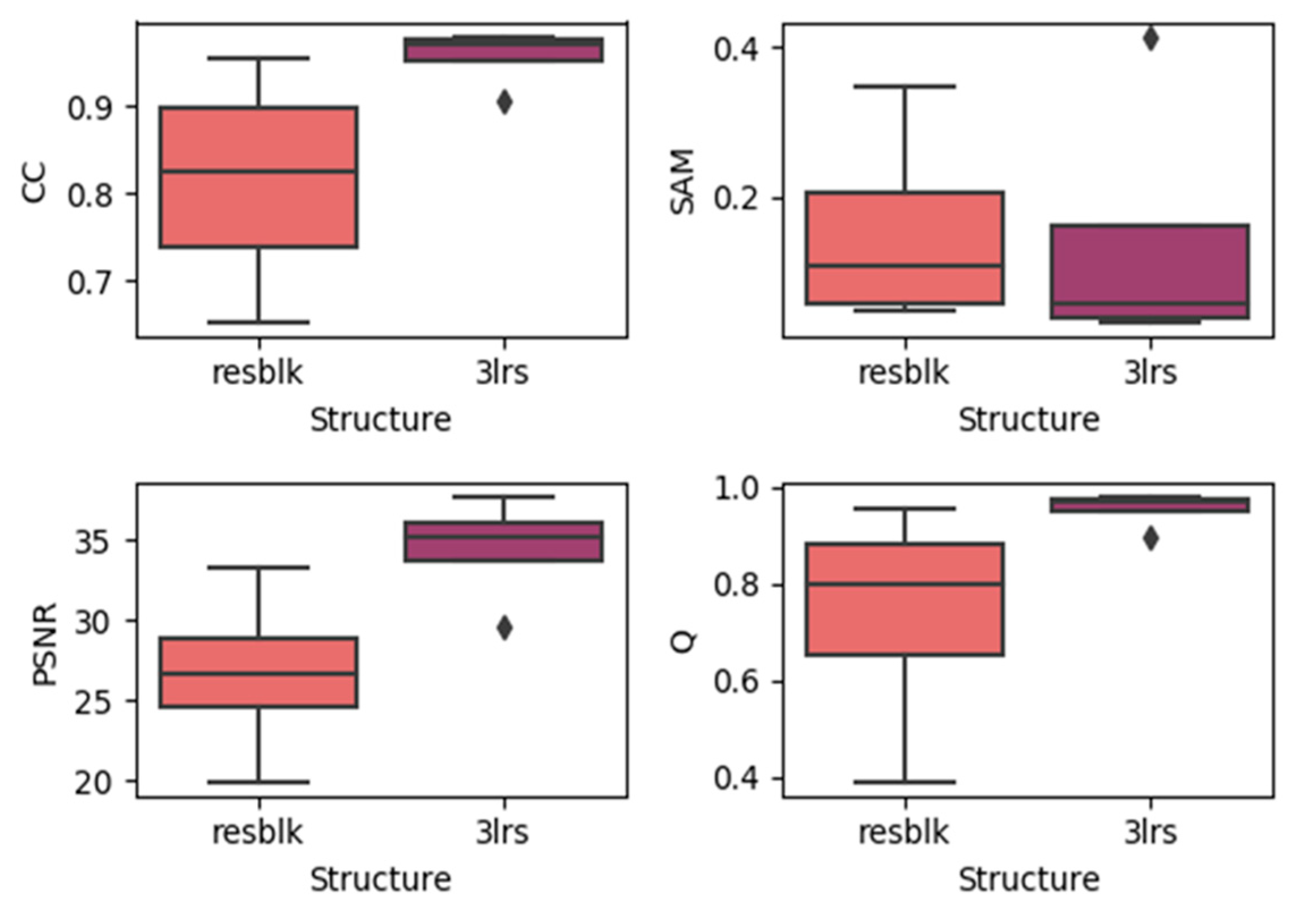
4.3. Effects of Utilizing Residual Blocks
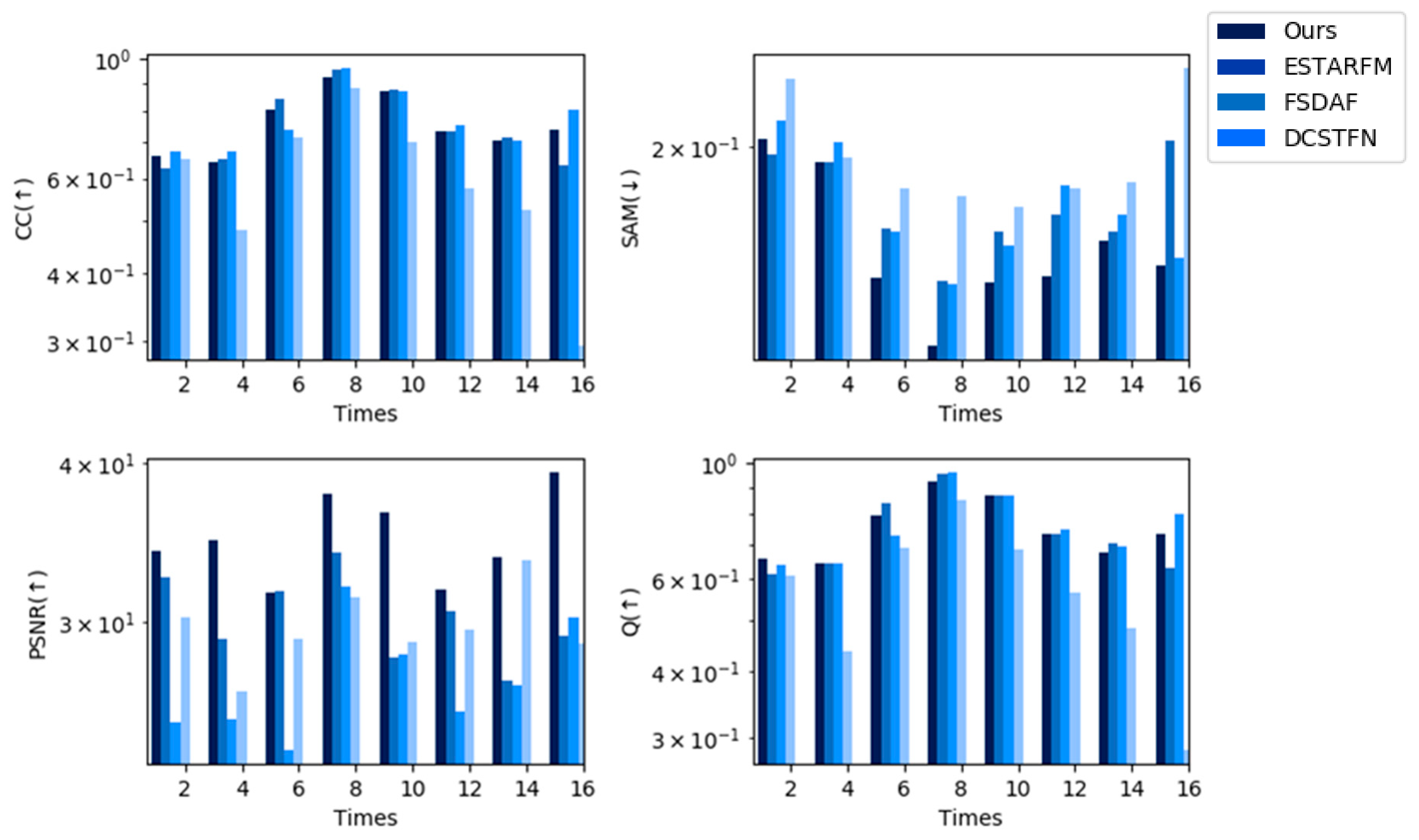
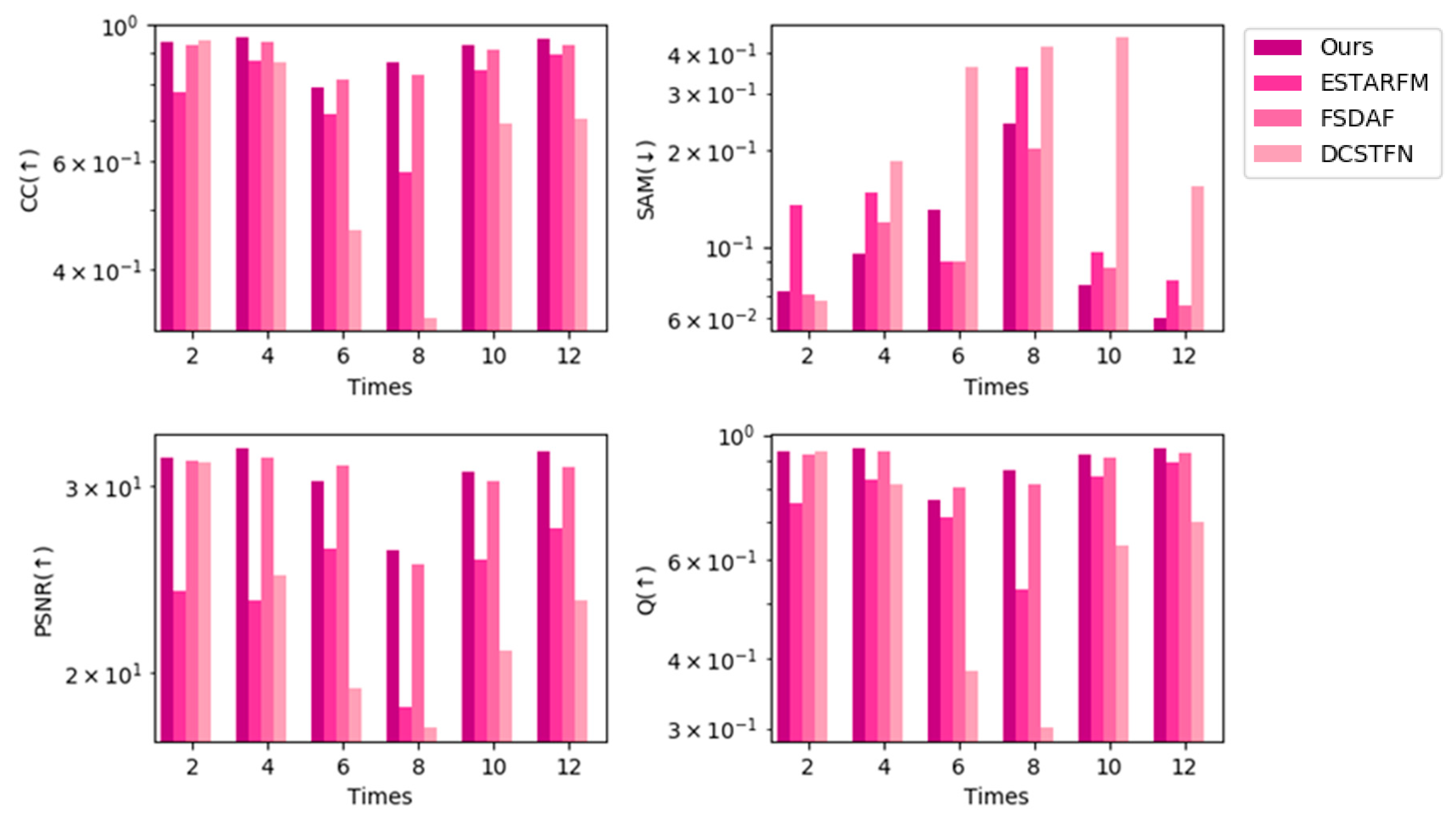
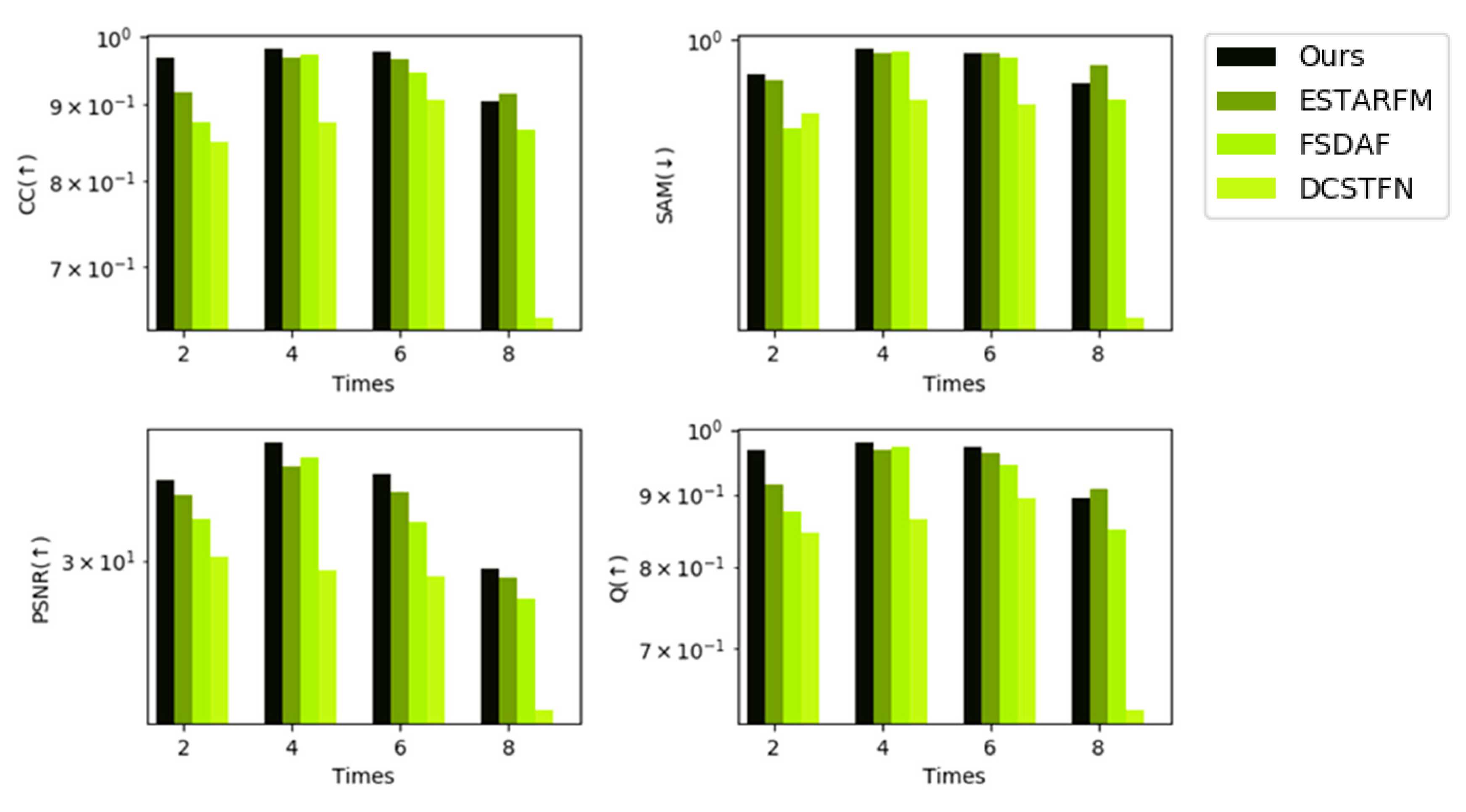
4.4. Comparison with State-of-the-Art Spatiotemporal Fusion Methods
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, L.; Peng, M.; Sun, X.; Cen, Y.; Tong, Q. Progress and bibliometric analysis of remote sensing data fusion methods (1992–2018). J. Remote Sens. 2019, 23, 1993–2002. [Google Scholar] [CrossRef]
- Gao, F.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: Predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar]
- Hilker, T.; Wulder, M.A.; Coops, N.C.; Linke, J.; Mcdermid, G.; Masek, J.G.; Gao, F.; White, J.C. A new data fusion model for high spatial- and temporal-resolution mapping of forest disturbance based on Landsat and MODIS. Remote Sens. Environ. 2009, 113, 1613–1627. [Google Scholar] [CrossRef]
- Zhu, X.; Jin, C.; Feng, G.; Chen, X.; Masek, J.G. An enhanced spatial and temporal adaptive reflectance fusion model for complex heterogeneous regions. Remote Sens. Environ. 2010, 114, 2610–2623. [Google Scholar] [CrossRef]
- Fu, D.; Chen, B.; Wang, J.; Zhu, X.; Hilker, T. An Improved Image Fusion Approach Based on Enhanced Spatial and Temporal the Adaptive Reflectance Fusion Model. Remote Sens. 2013, 5, 6346–6360. [Google Scholar] [CrossRef]
- Wang, J.; Huang, B. A Rigorously-Weighted Spatiotemporal Fusion Model with Uncertainty Analysis. Remote Sens. 2017, 9, 990. [Google Scholar] [CrossRef]
- Zhukov, B.; Oertel, D.; Lanzl, F.; Reinhackel, G. Unmixing-based multisensor multiresolution image fusion. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1212–1226. [Google Scholar] [CrossRef]
- Zhu, X.; Helmer, E.H.; Gao, F.; Liu, D.; Chen, J.; Lefsky, M.A. A flexible spatiotemporal method for fusing satellite images with different resolutions. Remote Sens. Environ. 2016, 172, 165–177. [Google Scholar] [CrossRef]
- Mingquan, W.; Zheng, N.; Changyao, W.; Chaoyang, W.; Li, W. Use of MODIS and Landsat time series data to generate high-resolution temporal synthetic Landsat data using a spatial and temporal reflectance fusion model. J. Appl. Remote Sens. 2012, 6, 063507. [Google Scholar] [CrossRef]
- Zhang, W.; Li, A.; Jin, H.; Bian, J.; Zhengjian, Z.; Lei, G.; Qin, Z.; Huang, C. An Enhanced Spatial and Temporal Data Fusion Model for Fusing Landsat and MODIS Surface Reflectance to Generate High Temporal Landsat-Like Data. Remote Sens. 2013, 5, 5346–5368. [Google Scholar] [CrossRef]
- Wu, P.; Shen, H.; Zhang, L.; Gottsche, F.M. Integrated fusion of multi-scale polar-orbiting and geostationary satellite observations for the mapping of high spatial and temporal resolution land surface temperature. Remote Sens. Environ. 2015, 156, 169–181. [Google Scholar] [CrossRef]
- Amorós-López, J.; Gómez-Chova, L.; Alonso, L.; Guanter, L.; Zurita-Milla, R.; Moreno, J.; Camps-Valls, G. Multitemporal fusion of Landsat/TM and ENVISAT/MERIS for crop monitoring. Int. J. Appl. Earth Obs. Geoinf. 2013, 23, 132–141. [Google Scholar] [CrossRef]
- Lu, M.; Chen, J.; Tang, H.; Rao, Y.; Yang, P.; Wu, W. Land cover change detection by integrating object-based data blending model of Landsat and MODIS. Remote Sens. Environ. 2016, 184, 374–386. [Google Scholar] [CrossRef]
- Moosavi, V.; Talebi, A.; Mokhtari, M.H.; Shamsi, S.R.F.; Niazi, Y. A wavelet-artificial intelligence fusion approach (WAIFA) for blending Landsat and MODIS surface temperature. Remote Sens. Environ. 2015, 169, 243–254. [Google Scholar] [CrossRef]
- Song, H.; Liu, Q.; Wang, G.; Hang, R.; Huang, B. Spatiotemporal Satellite Image Fusion Using Deep Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 821–829. [Google Scholar] [CrossRef]
- Tan, Z.; Peng, Y.; Di, L.; Tang, J. Deriving High Spatiotemporal Remote Sensing Images Using Deep Convolutional Network. Remote Sens. 2018, 10, 1066. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, H.; Sun, X.; Fu, D.; Tong, Q. Designing spatial-temporal-spectral integrated storage structure of multi-dimensional remote sensing images. Yaogan Xuebao J. Remote Sens. 2017, 21, 62–73. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Sebastianelli, A.; Del Rosso, M.P.; Ullo, S. Automatic Dataset Builder for Machine Learning Applications to Satellite Imagery; 2020. Available online: https://arxiv.org/abs/2008.01578 (accessed on 18 September 2020).
- Sun, Z.; Wang, J.; Lei, P.; Qin, Z. Multiple Walking People Classification with Convolutional Neural Networks Based on Micro-Doppler. In Proceedings of the 2018 10th International Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 18–20 October 2018; pp. 1–4. [Google Scholar]
- Emelyanova, I.V.; McVicar, T.R.; Van Niel, T.G.; Li, L.T.; van Dijk, A.I.J.M. Assessing the accuracy of blending Landsat–MODIS surface reflectances in two landscapes with contrasting spatial and temporal dynamics: A framework for algorithm selection. Remote Sens. Environ. 2013, 133, 193–209. [Google Scholar] [CrossRef]
- Salomonson, V.V.; Guenther, B.; Masuoka, E. A summary of the status of the EOS Terra mission Moderate Resolution Imaging Spectroradiometer (MODIS) and attendant data product development after one year of on-orbit performance. In Proceedings of the Scanning the Present and Resolving the Future, Proceedings. IEEE 2001 International Geoscience and Remote Sensing Symposium (Cat. No.01CH37217), Sydney, Australia, 9–13 July 2001; Volume 1193, pp. 1197–1199. [Google Scholar]
- Alparone, L.; Wald, L.; Chanussot, J.; Thomas, C.; Gamba, P.; Bruce, L. Comparison of Pansharpening Algorithms: Outcome of the 2006 GRS-S Data Fusion Contest. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3012–3021. [Google Scholar] [CrossRef]
- Zhang, Y.; De Backer, S.; Scheunders, P. Noise-Resistant Wavelet-Based Bayesian Fusion of Multispectral and Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3834–3843. [Google Scholar] [CrossRef]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Dan, L.; Hao, M.; Zhang, J.Q.; Bo, H.; Lu, Q. A universal hypercomplex color image quality index. In Proceedings of the IEEE Instrumentation & Measurement Technology Conference, Graz, Austria, 13–16 May 2012. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Sub-Categories | Representative Methods |
|---|---|---|
| Weight function methods | STARFM, ESTARFM, mESTARFM, RWSTFM | |
| Linear optimization decomposition methods | Spectral-unmixing method | MMT, STDFM, enhanced STDFM, soft clustering, OBIA |
| Bayesian method | ||
| Sparse representation method | ||
| Nonlinear optimization methods | ANN, DCSTFN, STFDCNN | |
| CIA | LGC | RDT | ||||||
|---|---|---|---|---|---|---|---|---|
| Image # | Date | Intervals | Image # | Date | Intervals | Image # | Date | Intervals |
| 1 | 8-Oct-2001 | 1 | 16-Apr-2004 | 1 | 3-Jun-2013 | |||
| 2 | 17-Oct-2001 | 9 | 2 | 2-May-2004 | 16 | 2 | 19-Jun-2013 | 16 |
| 3 | 2-Nov-2001 | 16 | 3 | 5-Jul-2004 | 64 | 3 | 5-Jul-2013 | 16 |
| 4 | 9-Nov-2001 | 7 | 4 | 6-Aug-2004 | 32 | 4 | 21-Jul-2013 | 16 |
| 5 | 25-Nov-2001 | 16 | 5 | 22-Aug-2004 | 16 | 5 | 22-Aug-2013 | 32 |
| 6 | 4-Dec-2001 | 9 | 6 | 25-Oct-2004 | 64 | 6 | 7-Sep-2013 | 16 |
| 7 | 5-Jan-2002 | 32 | 7 | 26-Nov-2004 | 32 | 7 | 23-Sep-2013 | 16 |
| 8 | 12-Jan-2002 | 7 | 8 | 12-Dec-2004 | 16 | 8 | 9-Oct-2013 | 16 |
| 9 | 13-Feb-2002 | 32 | 9 | 28-Dec-2004 | 16 | 9 | 25-Oct-2013 | 16 |
| 10 | 22-Feb-2002 | 9 | 10 | 13-Jan-2005 | 16 | |||
| 11 | 10-Mar-2002 | 16 | 11 | 29-Jan-2005 | 16 | |||
| 12 | 17-Mar-2002 | 7 | 12 | 14-Feb-2005 | 16 | |||
| 13 | 2-Apr-2002 | 16 | 13 | 2-Mar-2005 | 16 | |||
| 14 | 11-Apr-2002 | 9 | 14 | 3-Apr-05 | 32 | |||
| 15 | 18-Apr-2002 | 7 | ||||||
| 16 | 27-Apr-2002 | 9 | ||||||
| 17 | 4-May-2002 | 7 | ||||||
| CIA | LGC | RDT | |||
|---|---|---|---|---|---|
| Band Names | Wavelengths | Band Names | Wavelengths | Band Names | Wavelengths |
| Band 1 Visible | 0.45–0.52 µm | Band 1 Visible | 0.45–0.52 µm | Band 2 Visible | 0.450–0.51 µm |
| Band 2 Visible | 0.52–0.60 µm | Band 2 Visible | 0.52–0.60 µm | Band 3 Visible | 0.53–0.59 µm |
| Band 3 Visible | 0.63–0.69 µm | Band 3 Visible | 0.63–0.69 µm | Band 4 Red | 0.64–0.67 µm |
| Band 4 Near-Infrared | 0.77–0.90 µm | Band 4 Near-Infrared | 0.76–0.90 µm | Band 5 Near-Infrared | 0.85–0.88 µm |
| Band 5 Short-wave Infrared | 1.55–1.75 µm | Band 5 Near-Infrared | 1.55–1.75 µm | ||
| Band 7 Mid-Infrared | 2.08–2.35 µm | Band 7 Mid-Infrared | 2.08–2.35 µm | ||
| CC (↑) | SAM (↓) | PSNR (↑) | Q (↑) | |
|---|---|---|---|---|
| STF3DCNN | 0.8740 | 0.1201 | 33.3709 | 0.8684 |
| ESTARFM | 0.8255 | 0.1471 | 29.2558 | 0.8158 |
| FSDAF | 0.8595 | 0.1266 | 29.9007 | 0.8525 |
| DCSTFN | 0.6969 | 0.2227 | 26.8396 | 0.6715 |
| CIA | LGC | RDT | |
|---|---|---|---|
| STF3DCNN | 552 | 987 | 77 |
| ESTARFM | 65,871.94 | 109,361.795 | 14,435.744 |
| FSDAF | 27,626.017 | 51,858.298 | 7595.211 |
| DCSTFN | 6910 | 12,278 | 489.4740 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, M.; Zhang, L.; Sun, X.; Cen, Y.; Zhao, X. A Fast Three-Dimensional Convolutional Neural Network-Based Spatiotemporal Fusion Method (STF3DCNN) Using a Spatial-Temporal-Spectral Dataset. Remote Sens. 2020, 12, 3888. https://doi.org/10.3390/rs12233888
Peng M, Zhang L, Sun X, Cen Y, Zhao X. A Fast Three-Dimensional Convolutional Neural Network-Based Spatiotemporal Fusion Method (STF3DCNN) Using a Spatial-Temporal-Spectral Dataset. Remote Sensing. 2020; 12(23):3888. https://doi.org/10.3390/rs12233888
Chicago/Turabian StylePeng, Mingyuan, Lifu Zhang, Xuejian Sun, Yi Cen, and Xiaoyang Zhao. 2020. "A Fast Three-Dimensional Convolutional Neural Network-Based Spatiotemporal Fusion Method (STF3DCNN) Using a Spatial-Temporal-Spectral Dataset" Remote Sensing 12, no. 23: 3888. https://doi.org/10.3390/rs12233888
APA StylePeng, M., Zhang, L., Sun, X., Cen, Y., & Zhao, X. (2020). A Fast Three-Dimensional Convolutional Neural Network-Based Spatiotemporal Fusion Method (STF3DCNN) Using a Spatial-Temporal-Spectral Dataset. Remote Sensing, 12(23), 3888. https://doi.org/10.3390/rs12233888