SAR Image Despeckling by Deep Neural Networks: from a Pre-Trained Model to an End-to-End Training Strategy



Abstract

1. Introduction
2. Related Works
2.1. Additive Gaussian Noise Eeduction by Deep Learning
2.2. Speckle Reduction by Deep Learning
3. SAR Despeckling Using CNNs
3.1. Statistics of SAR Images
3.2. Despeckling Using Pre-Trained CNN Models
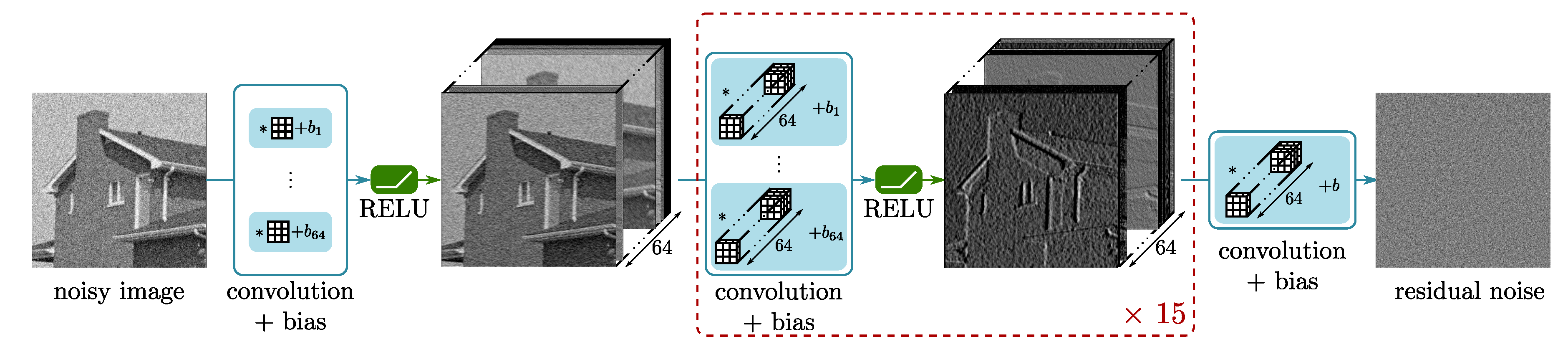
3.2.1. Architecture of the CNN
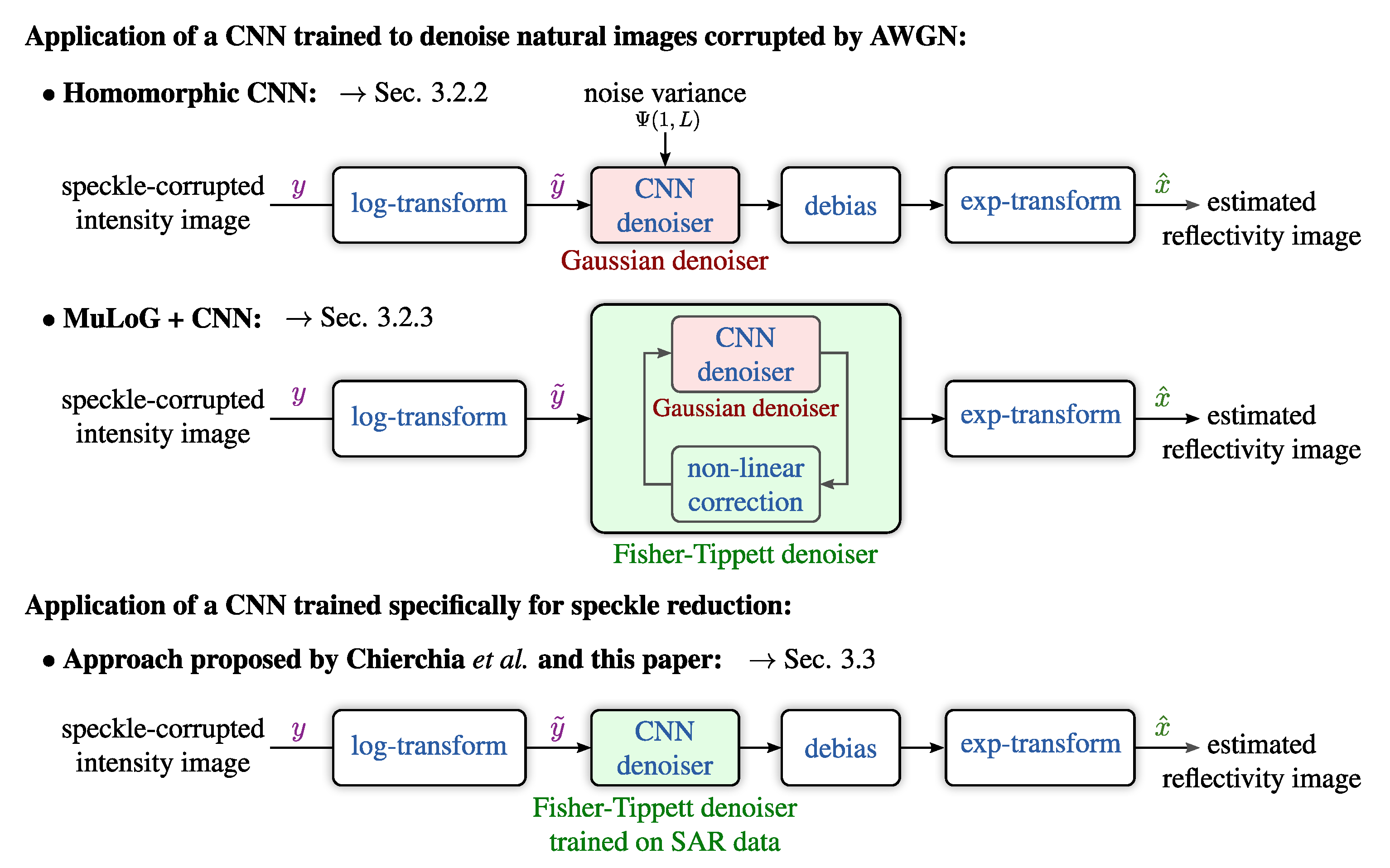
3.2.2. Homomorphic Filtering with a Pre-Trained CNN
3.2.3. Iterative Filtering with MuLoG and a Pre-Trained Model
3.3. Despeckling with a CNN Specifically Trained on SAR Images
3.3.1. Training-Set Generation
3.3.2. Network Architecture and the Effect of the Loss Function
3.3.3. The Training of the Network
3.4. Hybrid Approach: MuLoG + Trained CNN
4. Experimental Results
4.1. Influence of the Loss Function and of the Network Depth
4.2. Quantitative Comparisons on Images with Simulated Speckle
4.3. Despeckling of Real Single-Look SAR Images: How to Handle Correlations
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.P. A tutorial on synthetic aperture radar. IEEE Trans. Geosci. Remote Sens. 2013, 1, 6–43. [Google Scholar] [CrossRef]
- Lee, J.S.; Jurkevich, L.; Dewaele, P.; Wambacq, P.; Oosterlinck, A. Speckle filtering of synthetic aperture radar images: A review. Remote Sens. Rev. 1994, 8, 313–340. [Google Scholar] [CrossRef]
- Goodman, J.W. Some fundamental properties of speckle. JOSA 1976, 66, 1145–1150. [Google Scholar] [CrossRef]
- Touzi, R. A review of speckle filtering in the context of estimation theory. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2392–2404. [Google Scholar] [CrossRef]
- Argenti, F.; Lapini, A.; Bianchi, T.; Alparone, L. A tutorial on speckle reduction in Synthetic Aperture Radar images. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–35. [Google Scholar] [CrossRef]
- Lee, J.S.; Grunes, M.R.; De Grandi, G. Polarimetric SAR speckle filtering and its implication for classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2363–2373. [Google Scholar]
- Lopes, A.; Nezry, E.; Touzi, R.; Laur, H. Structure detection and statistical adaptive speckle filtering in SAR images. Int. J. Remote Sens. 1993, 14, 1735–1758. [Google Scholar] [CrossRef]
- Feng, H.; Hou, B.; Gong, M. SAR image despeckling based on local homogeneous-region segmentation by using pixel-relativity measurement. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2724–2737. [Google Scholar] [CrossRef]
- Deledalle, C.A.; Denis, L.; Tupin, F. Iterative weighted maximum likelihood denoising with probabilistic patch-based weights. IEEE Trans. Image Process. 2009, 18, 2661–2672. [Google Scholar] [CrossRef] [PubMed]
- Deledalle, C.A.; Denis, L.; Tupin, F. NL-InSAR: Nonlocal interferogram estimation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1441–1452. [Google Scholar] [CrossRef]
- Chen, J.; Chen, Y.; An, W.; Cui, Y.; Yang, J. Nonlocal filtering for polarimetric SAR data: A pretest approach. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1744–1754. [Google Scholar] [CrossRef]
- Deledalle, C.A.; Denis, L.; Tupin, F.; Reigber, A.; Jäger, M. NL-SAR: A unified nonlocal framework for resolution-preserving (Pol)(In) SAR denoising. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2021–2038. [Google Scholar] [CrossRef]
- Baraldi, A.; Parmiggiani, F. A refined Gamma MAP SAR speckle filter with improved geometrical adaptivity. IEEE Trans. Geosci. Remote Sens. 1995, 33, 1245–1257. [Google Scholar] [CrossRef]
- Kuruoglu, E.E.; Zerubia, J. Modeling SAR images with a generalization of the Rayleigh distribution. IEEE Trans. Image Process. 2004, 13, 527–533. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Figueiredo, M.A. Multiplicative noise removal using variable splitting and constrained optimization. IEEE Trans. Image Process. 2010, 19, 1720–1730. [Google Scholar] [CrossRef]
- Aubert, G.; Aujol, J.F. A variational approach to removing multiplicative noise. Siam J. Appl. Math. 2008, 68, 925–946. [Google Scholar] [CrossRef]
- Darbon, J.; Sigelle, M.; Tupin, F. The use of levelable regularization functions for MRF restoration of SAR images while preserving reflectivity. In Computational Imaging V; International Society for Optics and Photonics: Bellingham, WA, USA, 2007; Volume 6498, p. 64980T. [Google Scholar]
- Shi, J.; Osher, S. A nonlinear inverse scale space method for a convex multiplicative noise model. Siam J. Imaging Sci. 2008, 1, 294–321. [Google Scholar] [CrossRef]
- Denis, L.; Tupin, F.; Darbon, J.; Sigelle, M. SAR image regularization with fast approximate discrete minimization. IEEE Trans. Image Process. 2009, 18, 1588–1600. [Google Scholar] [CrossRef]
- Argenti, F.; Alparone, L. Speckle removal from SAR images in the undecimated wavelet domain. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2363–2374. [Google Scholar] [CrossRef]
- Dai, M.; Peng, C.; Chan, A.K.; Loguinov, D. Bayesian wavelet shrinkage with edge detection for SAR image despeckling. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1642–1648. [Google Scholar]
- Bianchi, T.; Argenti, F.; Alparone, L. Segmentation-based MAP despeckling of SAR images in the undecimated wavelet domain. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2728–2742. [Google Scholar] [CrossRef]
- Li, H.C.; Hong, W.; Wu, Y.R.; Fan, P.Z. Bayesian wavelet shrinkage with heterogeneity-adaptive threshold for SAR image despeckling based on generalized Gamma distribution. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2388–2402. [Google Scholar] [CrossRef]
- Xie, H.; Pierce, L.E.; Ulaby, F.T. Statistical properties of logarithmically transformed speckle. IEEE Trans. Geosci. Remote Sens. 2002, 40, 721–727. [Google Scholar] [CrossRef]
- Parrilli, S.; Poderico, M.; Angelino, C.V.; Verdoliva, L. A nonlocal SAR image denoising algorithm based on LLMMSE wavelet shrinkage. IEEE Trans. Geosci. Remote Sens. 2012, 50, 606–616. [Google Scholar] [CrossRef]
- Achim, A.; Tsakalides, P.; Bezerianos, A. SAR image denoising via Bayesian wavelet shrinkage based on heavy-tailed modeling. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1773–1784. [Google Scholar] [CrossRef]
- Solbo, S.; Eltoft, T. Homomorphic wavelet-based statistical despeckling of SAR images. IEEE Trans. Geosci. Remote Sens. 2004, 42, 711–721. [Google Scholar] [CrossRef]
- Xie, H.; Pierce, L.E.; Ulaby, F.T. SAR speckle reduction using wavelet denoising and Markov random field modeling. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2196–2212. [Google Scholar] [CrossRef]
- Bhuiyan, M.I.H.; Ahmad, M.O.; Swamy, M. Spatially adaptive wavelet-based method using the Cauchy prior for denoising the SAR images. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 500–507. [Google Scholar] [CrossRef]
- Deledalle, C.A.; Denis, L.; Tabti, S.; Tupin, F. MuLoG, or how to apply Gaussian denoisers to multi-channel SAR speckle reduction? IEEE Trans. Image Process. 2017, 26, 4389–4403. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; NIPS: Montreal, QC, Canada, 2015; pp. 91–99. [Google Scholar]
- Sun, Y.; Chen, Y.; Wang, X.; Tang, X. Deep learning face representation by joint identification-verification. In Advances in Neural Information Processing Systems; NIPS: Montreal, QC, Canada, 2014; pp. 1988–1996. [Google Scholar]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; NIPS: Lake Tahoe, NV, USA, 2012; pp. 1097–1105. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dong, B.; Ji, H.; Li, J.; Shen, Z.; Xu, Y. Wavelet frame based blind image inpainting. Appl. Comput. Harmon. Anal. 2012, 32, 268–279. [Google Scholar] [CrossRef]
- Wang, G.; Pan, Z.; Zhang, Z. Deep CNN Denoiser prior for multiplicative noise removal. Multimed. Tools Appl. 2019, 78, 29007–29019. [Google Scholar] [CrossRef]
- Xie, J.; Xu, L.; Chen, E. Image denoising and inpainting with deep neural networks. In Advances in Neural Information Processing Systems; NIPS: Lake Tahoe, NV, USA, 2012; pp. 341–349. [Google Scholar]
- Chierchia, G.; Cozzolino, D.; Poggi, G.; Verdoliva, L. SAR image despeckling through convolutional neural networks. In Proceedings of the Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5438–5441. [Google Scholar]
- Wang, P.; Zhang, H.; Patel, V.M. Generative adversarial network-based restoration of speckled SAR images. In Proceedings of the 2017 IEEE 7th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), Curacao, The Netherlands, 10–13 December 2017; pp. 1–5. [Google Scholar]
- Zhang, Q.; Yuan, Q.; Li, J.; Yang, Z.; Ma, X. Learning a dilated residual network for SAR image despeckling. Remote Sens. 2018, 10, 196. [Google Scholar] [CrossRef]
- Boulch, A.; Trouvé, P.; Koeninguer, E.; Janez, F.; Le Saux, B. Learning speckle suppression in SAR images without groundtruth: Application to Sentinel-1 time series. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2366–2369. [Google Scholar]
- Chan, S.H.; Wang, X.; Elgendy, O.A. Plug-and-play ADMM for image restoration: Fixed-point convergence and applications. IEEE Trans. Comput. Imaging 2017, 3, 84–98. [Google Scholar] [CrossRef]
- Combettes, P.L.; Pesquet, J.C. Proximal splitting methods in signal processing. In Fixed-Point Algorithms for Inverse Problems in Science and Engineering; Springer: Berlin/Heidelberg, Germany, 2011; pp. 185–212. [Google Scholar]
- Parikh, N.; Boyd, S. Proximal algorithms. Found. Trends Optim. 2014, 1, 127–239. [Google Scholar] [CrossRef]
- Elad, M.; Milanfar, P.; Rubinstein, R. Analysis versus synthesis in signal priors. Inverse Probl. 2007, 23, 947. [Google Scholar] [CrossRef]
- Roth, S.; Black, M.J. Fields of experts: A framework for learning image priors. In Proceedings of the Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 860–867. [Google Scholar]
- Chen, Y.; Ranftl, R.; Pock, T. Insights into analysis operator learning: From patch-based sparse models to higher order MRFs. IEEE Trans. Image Process. 2014, 23, 1060–1072. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Non-local sparse models for image restoration. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2272–2279. [Google Scholar]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar]
- Jain, V.; Seung, S. Natural image denoising with convolutional networks. In Advances in Neural Information Processing Systems; NIPS: Vancouver, BC, Canada, 2009; pp. 769–776. [Google Scholar]
- Burger, H.C.; Schuler, C.J.; Harmeling, S. Image denoising: Can plain neural networks compete with BM3D? In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 26 July 2012; pp. 2392–2399. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Sun, M.; Hu, K. Dilated deep residual network for image denoising. In Proceedings of the 2017 IEEE 29th International Conference on Tools with Artificial Intelligence (ICTAI), Boston, MA, USA, 6–8 November 2017; pp. 1272–1279. [Google Scholar]
- Wang, T.; Qin, Z.; Zhu, M. An ELU network with total variation for image denoising. In International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2017; pp. 227–237. [Google Scholar]
- Isogawa, K.; Ida, T.; Shiodera, T.; Takeguchi, T. Deep shrinkage convolutional neural network for adaptive noise reduction. IEEE Signal Process. Lett. 2018, 25, 224–228. [Google Scholar] [CrossRef]
- Liu, P.; Fang, R. Wide inference network for image denoising. arXiv 2017, arXiv:1707.05414. [Google Scholar]
- Bae, W.; Yoo, J.J.; Ye, J.C. Beyond deep residual learning for image restoration: Persistent homology-guided manifold simplification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1141–1149. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Wang, P.; Zhang, H.; Patel, V.M. SAR image despeckling using a convolutional neural network. IEEE Signal Process. Lett. 2017, 24, 1763–1767. [Google Scholar] [CrossRef]
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions: With Formulas, Graphs, and Mathematical Tables; Courier Corporation: North Chelmsford, MA, USA, 1965; Volume 55. [Google Scholar]
- Goodman, J.W. Speckle Phenomena in Optics: Theory and Applications; Roberts & Company: Greenwood Village, CO, USA, 2007. [Google Scholar]
- Eltoft, T. The Rician Inverse Gaussian Distribution: A New Model for Non-Rayleigh Signal Amplitude Statistics. IEEE Trans. Image Process. 2005, 14, 1722–1735. [Google Scholar] [CrossRef]
- Nicolas, J.M.; Tupin, F. A new parametrization for the Rician distribution. IEEE Geosci. Remote Sens. Lett. 2019. [Google Scholar] [CrossRef]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss functions for Image Restoration with Neural Networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- Pastina, D.; Colone, F.; Lombardo, P. Effect of apodization on SAR image understanding. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3533–3551. [Google Scholar] [CrossRef]
- Stankwitz, H.C.; Dallaire, R.J.; Fienup, J.R. Nonlinear apodization for sidelobe control in SAR imagery. IEEE Trans. Aerosp. Electron. Syst. 1995, 31, 267–279. [Google Scholar] [CrossRef]
- Abergel, R.; Denis, L.; Ladjal, S.; Tupin, F. Subpixellic Methods for Sidelobes Suppression and Strong Targets Extraction in Single Look Complex SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 759–776. [Google Scholar] [CrossRef]
- Dalsasso, E.; Denis, L.; Tupin, F. How to Handle Spatial Correlations in SAR Despeckling? Resampling Strategies and Deep Learning Approaches. hal-02538046. 2020. Available online: https://hal.archives-ouvertes.fr/hal-02538046/ (accessed on 7 August 2020).
- Zhao, W.; Deledalle, C.A.; Denis, L.; Maître, H.; Nicolas, J.M.; Tupin, F. Ratio-Based Multitemporal SAR Images Denoising: RABASAR. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3552–3565. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Configuration | |
|---|---|---|
| Layer 1 | 64 | CONV, ReLU |
| Layer 2 to (D-1) | 64 | CONV, Batch Norm., ReLU |
| Layer D | 1 | CONV |
| Images | Number of Dates | Number of Patches |
|---|---|---|
| Marais 1 | 45 | 40194 |
| Limagne | 53 | 40194 |
| Saclay | 69 | 7227 |
| Lely | 25 | 14850 |
| Rambouillet | 69 | 39168 |
| Risoul | 72 | 9648 |
| Marais 2 | 45 | 40194 |
| Algorithm | MuLoG+CNN | MuLoG+CNN (Pretrained on SAR) | SAR-CNN |
|---|---|---|---|
| Input | Natural images | SAR dataset | SAR dataset |
| Noise type | Gaussian | Gaussian | Speckle |
| Architecture | DnCNN, | DnCNN, | DnCNN, |
| Loss function |
| Images | Noisy | SAR-BM3D | NL-SAR | MuLoG+BM3D | MuLoG+CNN | MuLoG+CNN (Pretrained on SAR) | SAR-CNN |
|---|---|---|---|---|---|---|---|
| Marais 1 | 10.05 ± 0.0141 | 23.56 ± 0.1335 | 21.71 ± 0.1258 | 23.46 ± 0.0794 | 23.39 ± 0.0608 | 23.63 ± 0.0678 | 24.65 ± 0.0860 |
| Limagne | 10.87 ± 0.0469 | 21.47 ± 0.3087 | 20.25 ± 0.1958 | 21.47 ± 0.2177 | 21.16 ± 0.0249 | 21.85 ± 0.1273 | 22.65 ± 0.2914 |
| Saclay | 15.57 ± 0.1342 | 21.49 ± 0.3679 | 20.40 ± 0.2696 | 21.67 ± 0.2445 | 21.88 ± 0.2195 | 22.77 ± 0.2403 | 23.47 ± 0.2276 |
| Lely | 11.45 ± 0.0048 | 21.66 ± 0.4452 | 20.54 ± 0.3303 | 22.25 ± 0.4365 | 22.17 ± 0.2702 | 22.97 ± 0.3671 | 23.79 ± 0.4908 |
| Rambouillet | 8.81 ± 0.0693 | 23.78 ± 0.1977 | 22.28 ± 0.1132 | 23.88 ± 0.1694 | 23.30 ± 0.1140 | 23.30 ± 0.1630 | 24.73 ± 0.0798 |
| Risoul | 17.59 ± 0.0361 | 29.98 ± 0.2638 | 28.69 ± 0.2011 | 30.99 ± 0.3760 | 30.85 ± 0.1844 | 31.03 ± 0.2008 | 31.69 ± 0.2830 |
| Marais 2 | 9.70 ± 0.0927 | 20.31 ± 0.7833 | 20.07 ± 0.7553 | 21.59 ± 0.7573 | 21.00 ± 0.4886 | 22.12 ± 0.6792 | 23.36 ± 0.8068 |
| Average | 12.00 | 23.17 | 21.99 | 23.62 | 23.39 | 23.95 | 24.91 |
| Images | Noisy | SAR-BM3D | NL-SAR | MuLoG+BM3D | MuLoG+CNN | MuLoG+CNN (Pretrained on SAR) | SAR-CNN |
|---|---|---|---|---|---|---|---|
| Marais 1 | 0.3571 ± 0.0015 | 0.8053 ± 0.0018 | 0.7471 ± 0.0029 | 0.8003 ± 0.0020 | 0.7955 ± 0.0027 | 0.8072 ± 0.0024 | 0.8333 ± 0.0016 |
| Limagne | 0.4060 ± 0.0021 | 0.8091 ± 0.0027 | 0.7493 ± 0.0033 | 0.8011 ± 0.0030 | 0.8055 ± 0.0027 | 0.8147 ± 0.0023 | 0.8327 ± 0.0029 |
| Saclay | 0.5235 ± 0.0019 | 0.8031 ± 0.0032 | 0.7478 ± 0.0040 | 0.7734 ± 0.0034 | 0.7956 ± 0.0033 | 0.8156 ± 0.0030 | 0.8314 ± 0.0024 |
| Lely | 0.3654 ± 0.0013 | 0.8473 ± 0.0023 | 0.8062 ± 0.0023 | 0.8552 ± 0.0025 | 0.8659 ± 0.0019 | 0.8703 ± 0.0018 | 0.8856 ± 0.0019 |
| Rambouillet | 0.2886 ± 0.0017 | 0.7831 ± 0.0028 | 0.7364 ± 0.0031 | 0.7798 ± 0.0029 | 0.7706 ± 0.0095 | 0.7821 ± 0.0073 | 0.8002 ± 0.0026 |
| Risoul | 0.4362 ± 0.0017 | 0.8306 ± 0.0024 | 0.7671 ± 0.0028 | 0.8345 ± 0.0030 | 0.8291 ± 0.0027 | 0.8341 ± 0.0024 | 0.8493 ± 0.0018 |
| Marais 2 | 0.2628 ± 0.0017 | 0.8506 ± 0.0026 | 0.8222 ± 0.0022 | 0.8561 ± 0.0025 | 0.8594 ± 0.0111 | 0.8677 ± 0.0097 | 0.8866 ± 0.0025 |
| Average | 0.3771 | 0.8184 | 0.7680 | 0.8143 | 0.8173 | 0.8273 | 0.8460 |
| Images | SAR-BM3D | NL-SAR | MuLoG+BM3D | MuLoG+CNN | MuLoG+CNN (Pretrained on SAR) | SAR-CNN |
|---|---|---|---|---|---|---|
| Sentinel-1: | ||||||
| Marais 1 | 226.48 | 165.24 | 132.30 | 288.70 | 210.17 | 177.72 |
| Lely | 166.60 | 75.19 | 349.32 | 82.24 | 145.07 | 289.03 |
| Rambouillet | 262.47 | 171.42 | 139.62 | 413.09 | 383.81 | 295.30 |
| Marais 2 | 119.99 | 213.45 | 84.67 | 146.33 | 182.44 | 206.93 |
| TerraSAR-X: | ||||||
| Saint Gervais | 40.01 | 39.70 | 39.37 | 45.18 | 129.66 | 59.21 |
| SAR-BM3D | NL-SAR | MuLoG+BM3D | MuLoG+CNN | SAR-CNN |
|---|---|---|---|---|
| 73.89 s | 116.28 s | 59.82 s | 80.43 s | 0.19 s |
| MuLoG+CNN | Pros |
|
| Cons |
| |
| SAR-CNN | Pros |
|
| Cons |
|
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dalsasso, E.; Yang, X.; Denis, L.; Tupin, F.; Yang, W. SAR Image Despeckling by Deep Neural Networks: from a Pre-Trained Model to an End-to-End Training Strategy. Remote Sens. 2020, 12, 2636. https://doi.org/10.3390/rs12162636
Dalsasso E, Yang X, Denis L, Tupin F, Yang W. SAR Image Despeckling by Deep Neural Networks: from a Pre-Trained Model to an End-to-End Training Strategy. Remote Sensing. 2020; 12(16):2636. https://doi.org/10.3390/rs12162636
Chicago/Turabian StyleDalsasso, Emanuele, Xiangli Yang, Loïc Denis, Florence Tupin, and Wen Yang. 2020. "SAR Image Despeckling by Deep Neural Networks: from a Pre-Trained Model to an End-to-End Training Strategy" Remote Sensing 12, no. 16: 2636. https://doi.org/10.3390/rs12162636
APA StyleDalsasso, E., Yang, X., Denis, L., Tupin, F., & Yang, W. (2020). SAR Image Despeckling by Deep Neural Networks: from a Pre-Trained Model to an End-to-End Training Strategy. Remote Sensing, 12(16), 2636. https://doi.org/10.3390/rs12162636