PercepPan: Towards Unsupervised Pan-Sharpening Based on Perceptual Loss



Abstract
1. Introduction
- How can the framework and loss be designed to train pan-sharpening model G directly?
- Could supervised pre-training offer gains in the SPUF training paradigm?
- Could the unsupervised perspective outperform its supervised counterpart?
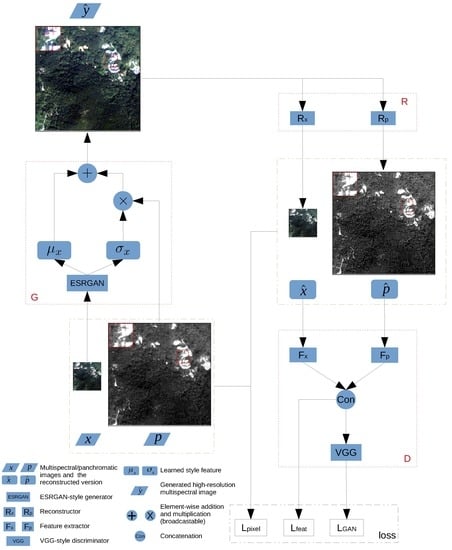
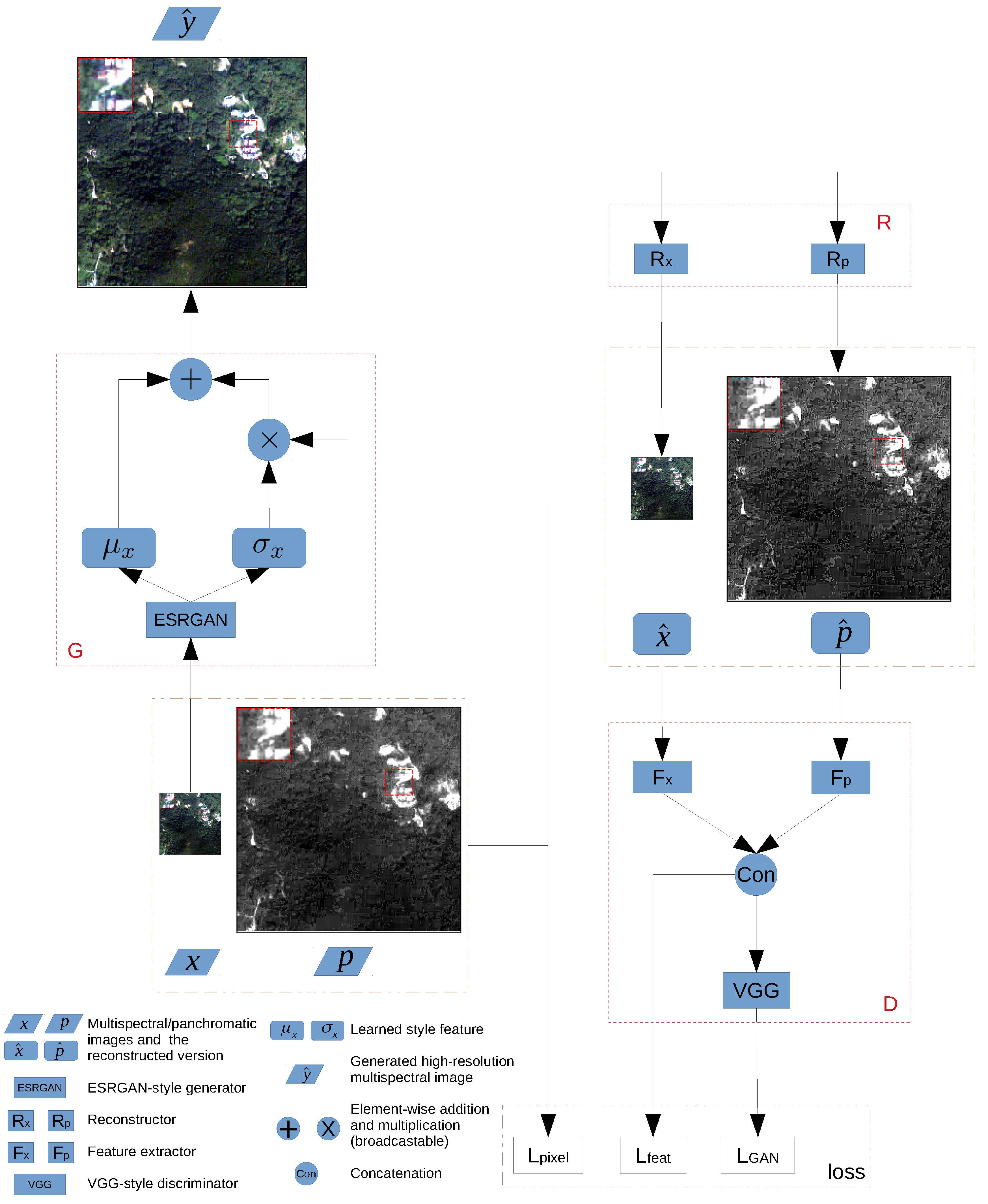
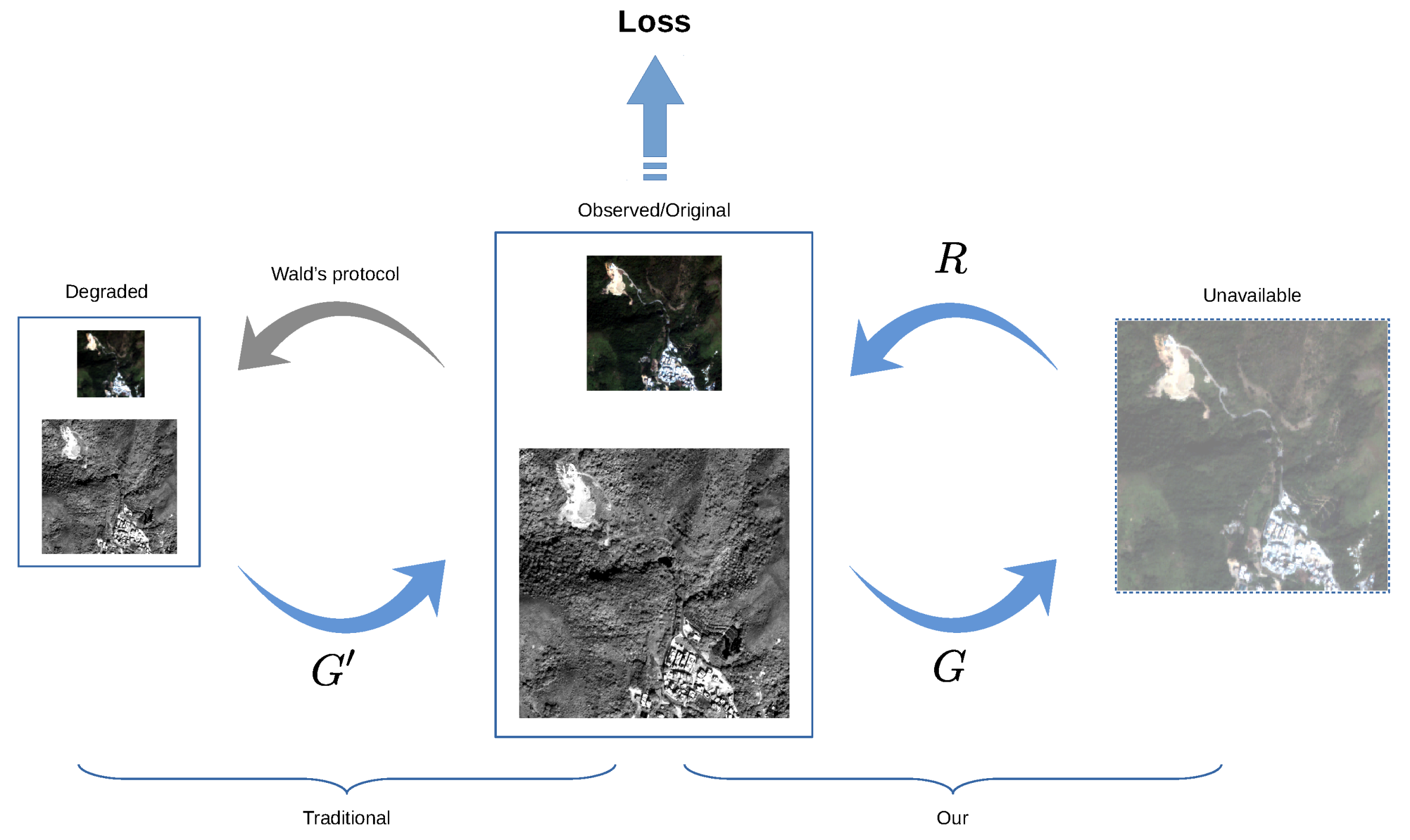
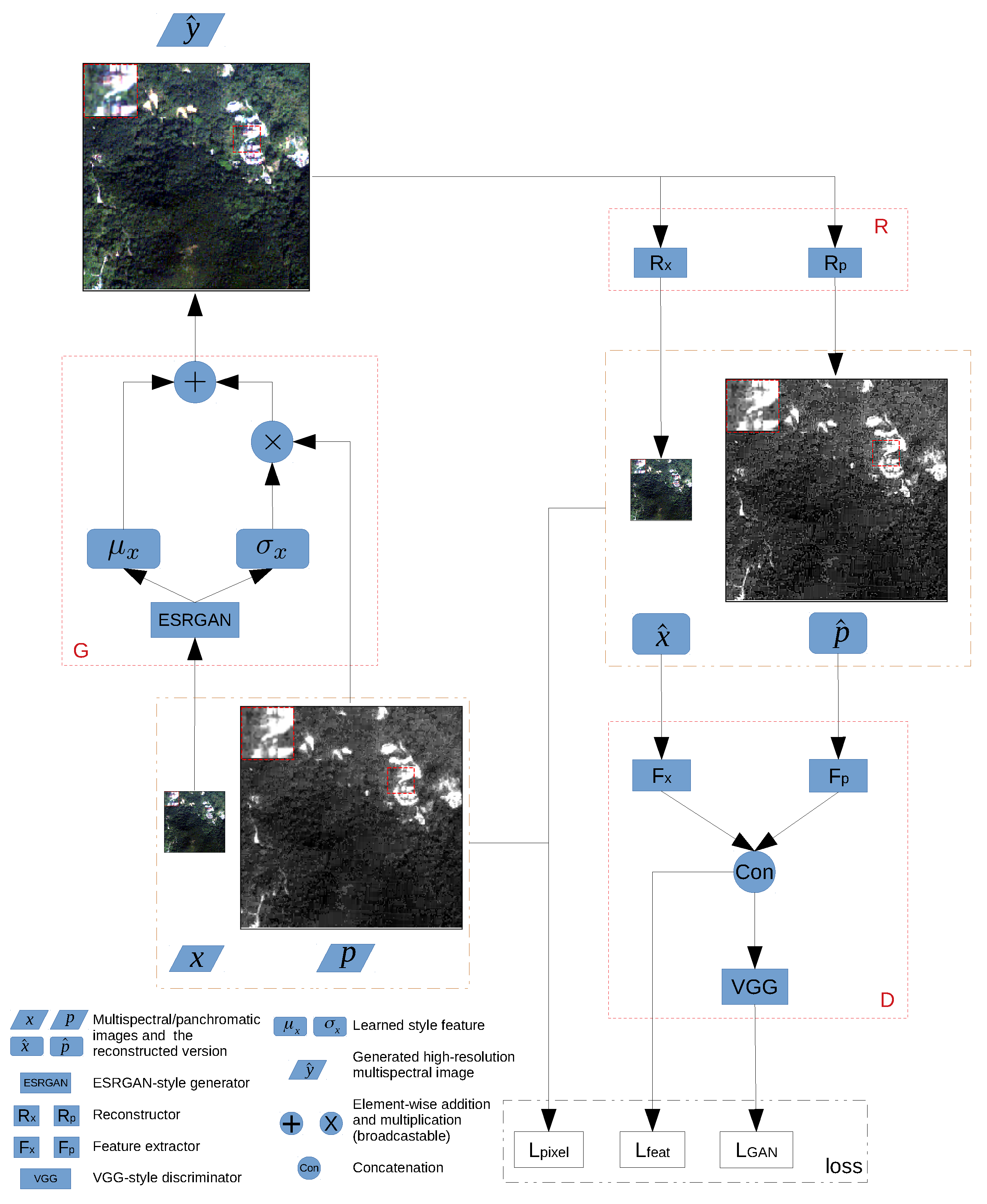
- A novel unsupervised learning framework “perceptual pan-sharpening (PercepPan)” is proposed, which does not need the degradation step anymore. The framework consists of a generator, a reconstructor, and a discriminator. The generator takes responsibility for generating HRMS images, the reconstructor takes advantage of prior knowledge to imitate the observation model from HRMS images to LRMS-PAN image pairs, and the discriminator extracts features from LRMS-PAN image pairs to compute feature loss and GAN loss.
- A perceptual loss is adopted as the objective function. The loss consists of three parts, with one computed in pixel space, another computed in feature space and the last computed in GAN space. The hybrid loss is beneficial for improving perceptual quality of generated HRMS images.
- A novel training paradigm, called SPUF, is adopted to train the proposed PercepPan. Experiments show that SPUF could usually outperform random initialization.
- Experiments show that PercepPan could cooperate with several different generators. Experiments on the QuickBird dataset show that the unsupervised results are comparable to the supervised ones. When generalizing to the IKONOS dataset, similar conclusions still hold.
2. Perceptual Loss
3. Methodology
3.1. Pan-Sharpening Formula
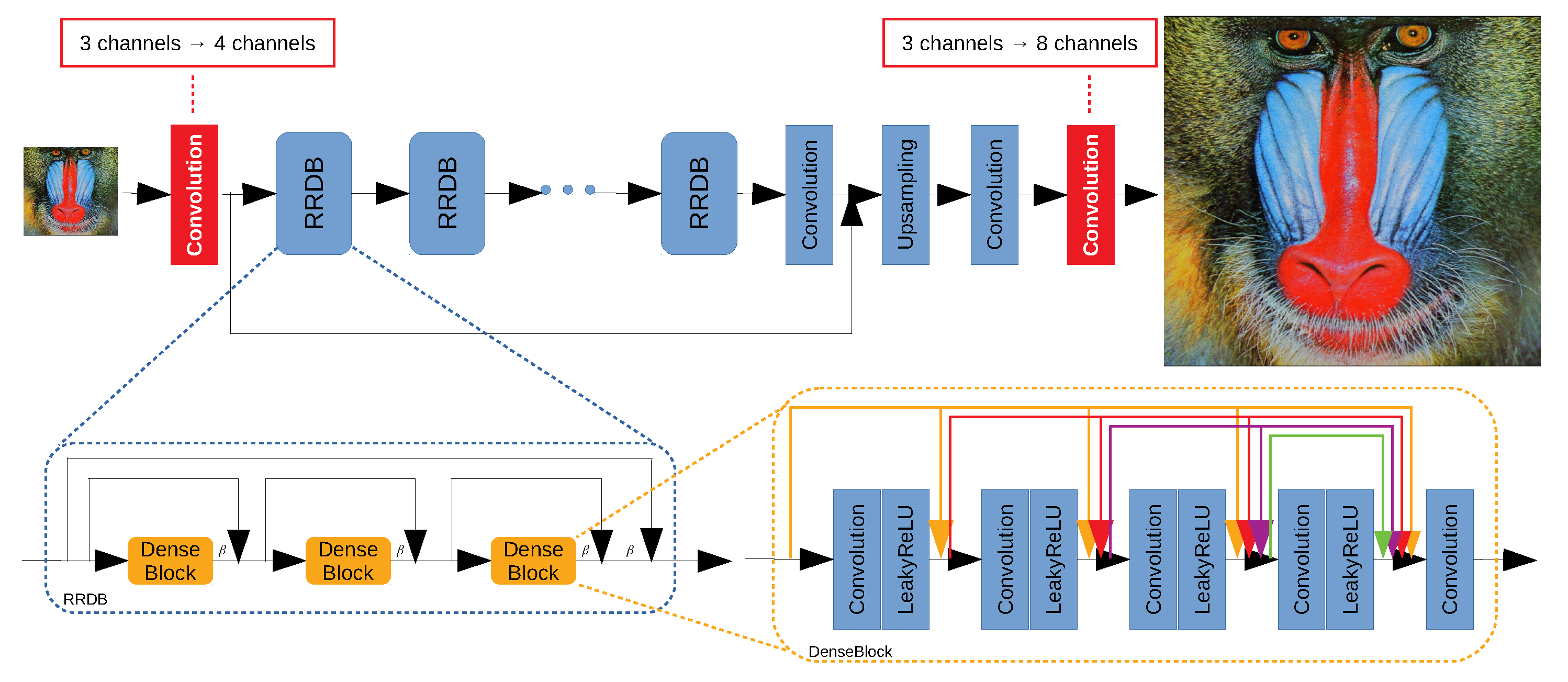
3.2. Network Architecture
- A generator G which takes as input a LRMS-PAN image pair to generate a HRMS image ;
- A reconstructor R which takes as input a generated HRMS image to reconstruct the corresponding LRMS-PAN image pair, with the output denoted as and , respectively;
- A discriminator D which takes as input real/reconstructed LRMS-PAN image pairs to calculate feature loss and GAN loss.
3.3. Initialization
3.4. Training Strategy
3.5. Datasets and Algorithms
| Algorithm 1 Full-scale SPUF training algorithm. |
| Require: Full-scale training dataset, number of training iterations , batch size , learning rates and , hyper-parameters , and . 1: Initializing G, R and D 2: for do 3: Sampling a mini-batch of image pairs, , from full-scale training dataset 4: Computing loss 5: Computing Gradient 6: Updating weights 7: Sampling a mini-batch of image pairs, , from full-scale training dataset 8: Computing loss 9: Computing Gradient 10: Updating weights 11: end for |
| Algorithm 2 Reduced-scale SPSF training algorithm. |
| Require: Reduced-scale training dataset, number of training iterations , batch size , learning rates and , hyper-parameters , and . 1: Initializing G and D 2: for do 3: Sampling a mini-batch of image pairs, , from reduced-scale training dataset 4: Computing loss 5: Computing Gradient 6: Updating weights 7: Sampling a mini-batch of image pairs, , from reduced-scale training dataset 8: Computing loss 9: Computing Gradient 10: Updating weights 11: end for |
4. Experiments
4.1. Experiment Settings
- The QuickBird bundle product is composed of two kinds of images, with one MS image at m resolution and another PAN images at m resolution, and the pixel is recorded in 11 bits. The images used in this paper come from the area of Sha Tin, Hong Kong, China, with geographic coordinates N() E(), and the image of this area is shown in Figure 4. The whole size is 7364 × 7713 for MS images, and 29,456 × 30,852 for PAN images.
- The IKONOS bundle product is composed of two kinds of images as well, with one MS image at 4 m resolution and another PAN image at 1 m resolution, and again pixel is recorded in 11 bits. The images used in this paper come from the area of Wenchuan, Sichuan, China, with geographic coordinates N() E(). Due to the license issue, the image of this area is not shown here. The whole size is for MS image, and 12,944 for PAN image.
4.2. Image Quality Assessment
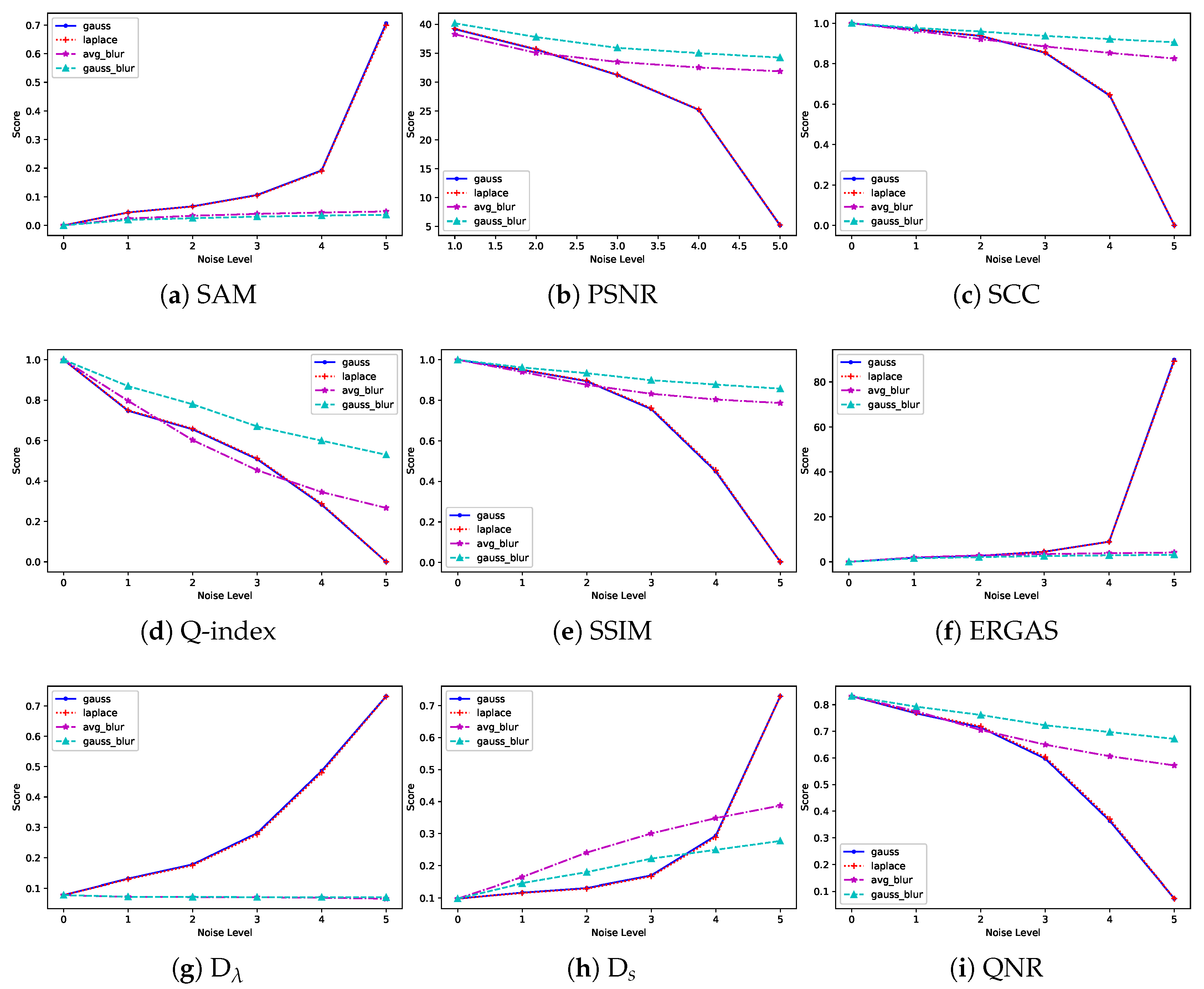
- SAM is a measurement of spectral distortion. Denote as vectors at pixel position of and I, respectively, thenwhere is the inner product operator.
- PSNR is a commonly used image quality assessment method,where is the maximum possible pixel value of I, and stands for the root of mean squared error. It is the same below.
- SCC is a spatial quality index. Denote as the c-th band of and I, respectively. Then,where is the covariance and is the standard deviation. It is the same below.
- Q-index gathers image luminance, contrast, and structure for quality assessment. After dividing and into B patches pairs , Q-index is computed as follows:where stands for mean value. It is the same below.
- SSIM is a famous image quality assessment method and it is an extension of Q-index,where , , and .
- ERGAS is another common method of image quality assessment. Denote the spatial resolution ratio between MS images and the corresponding PAN images by r. Then,
- QNR is a no-reference method for image quality assessment. It consists of a spectral distortion index , and a spatial distortion index . Here, denote an LRMS image with C spectral bands as , the corresponding generated HRMS image as , PAN image with only one spectral band as , and its degraded counterpart as , thenwhere and usually.
4.3. Model Evaluation with Different Settings
4.4. Generalization: Generator
4.5. Generalization: Dataset
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

References
- Carper, W.; Lillesand, T.; Kiefer, R. The use of intensity-hue-saturation transformations for merging SPOT panchromatic and multispectral image data. Photogramm. Eng. Remote Sens. 1990, 56, 459–467. [Google Scholar]
- Gillespie, A.R.; Kahle, A.B.; Walker, R.E. Color enhancement of highly correlated images. II. Channel ratio and “chromaticity” transformation techniques. Remote Sens. Environ. 1987, 22, 343–365. [Google Scholar] [CrossRef]
- Zhang, Y.; Hong, G. An IHS and wavelet integrated approach to improve pan-sharpening visual quality of natural colour IKONOS and QuickBird images. Inf. Fusion 2005, 6, 225–234. [Google Scholar] [CrossRef]
- Khan, M.M.; Chanussot, J.; Condat, L.; Montanvert, A. Indusion: Fusion of Multispectral and Panchromatic Images Using the Induction Scaling Technique. IEEE Geosci. Remote Sens. Lett. 2008, 5, 98–102. [Google Scholar] [CrossRef]
- Otazu, X.; González-Audícana, M.; Fors, O.; Núñez, J. Introduction of sensor spectral response into image fusion methods. Application to wavelet-based methods. IEEE Trans. Geosci. Remote Sens. 2005, 43, 2376–2385. [Google Scholar] [CrossRef]
- Guo, M.; Zhang, H.; Li, J.; Zhang, L.; Shen, H. An Online Coupled Dictionary Learning Approach for Remote Sensing Image Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1284–1294. [Google Scholar] [CrossRef]
- Zhu, X.; Bamler, R. A Sparse Image Fusion Algorithm With Application to Pan-Sharpening. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2827–2836. [Google Scholar] [CrossRef]
- Ghassemian, H. A review of remote sensing image fusion methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Meng, X.; Shen, H.; Li, H.; Zhang, L.; Fu, R. Review of the pansharpening methods for remote sensing images based on the idea of meta-analysis: Practical discussion and challenges. Inf. Fusion 2019, 46, 102–113. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Garzelli, A. A Review of Image Fusion Algorithms Based on the Super-Resolution Paradigm. Remote Sens. 2016, 8, 797. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar] [CrossRef]
- Lu, T.; Wang, J.; Zhang, Y.; Wang, Z.; Jiang, J. Satellite Image Super-Resolution via Multi-Scale Residual Deep Neural Network. Remote Sens. 2019, 11, 1588. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by Convolutional Neural Networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef]
- Shao, Z.; Cai, J. Remote Sensing Image Fusion With Deep Convolutional Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1656–1669. [Google Scholar] [CrossRef]
- Yang, J.; Fu, X.; Hu, Y.; Huang, Y.; Ding, X.; Paisley, J.W. PanNet: A Deep Network Architecture for Pan-Sharpening. In Proceedings of the IEEE International Conference on Computer Vision ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 1753–1761. [Google Scholar] [CrossRef]
- Liu, X.; Wang, Y.; Liu, Q. Psgan: A Generative Adversarial Network for Remote Sensing Image Pan-Sharpening. In Proceedings of the 2018 IEEE International Conference on Image Processing, ICIP 2018, Athens, Greece, 7–10 October 2018; pp. 873–877. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Hong, D.; Yokoya, N.; Chanussot, J.; Zhu, X.X. CoSpace: Common Subspace Learning from Hyperspectral-Multispectral Correspondences. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4349–4359. [Google Scholar] [CrossRef]
- Yao, J.; Meng, D.; Zhao, Q.; Cao, W.; Xu, Z. Nonconvex-Sparsity and Nonlocal-Smoothness-Based Blind Hyperspectral Unmixing. IEEE Trans. Image Process. 2019, 28, 2991–3006. [Google Scholar] [CrossRef]
- Hong, D.; Yokoya, N.; Chanussot, J.; Zhu, X.X. An Augmented Linear Mixing Model to Address Spectral Variability for Hyperspectral Unmixing. IEEE Trans. Image Process. 2019, 28, 1923–1938. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G.E. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hong, D.; Yokoya, N.; Xia, G.; Chanussot, J.; Zhu, X. X-ModalNet: A Semi-Supervised Deep Cross-Modal Network for Classification of Remote Sensing Data. arXiv 2020, arXiv:2006.13806. [Google Scholar]
- Hong, D.; Yokoya, N.; Ge, N.; Chanussot, J.; Zhu, X.X. Learnable manifold alignment (LeMA): A semi-supervised cross-modality learning framework for land cover and land use classification. ISPRS J. Photogramm. Remote Sens. 2019, 147, 193–205. [Google Scholar] [CrossRef]
- Hong, D.; Wu, X.; Ghamisi, P.; Chanussot, J.; Yokoya, N.; Zhu, X.X. Invariant attribute profiles: A spatial-frequency joint feature extractor for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3791–3808. [Google Scholar] [CrossRef]
- Wald, L.; Ranchin, T.; Mangolini, M. Fusion of satellite images of different spatial resolutions: Assessing the quality of resulting images. Photogramm. Eng. Remote Sens. 1997, 63, 691–699. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy Layer-Wise Training of Deep Networks. In Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 153–160. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.C.; Manzagol, P.; Vincent, P.; Bengio, S. Why Does Unsupervised Pre-training Help Deep Learning? J. Mach. Learn. Res. 2010, 11, 625–660. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014—13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, À.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 Million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems 2012., Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Rasti, B.; Hong, D.; Hang, R.; Ghamisi, P.; Kang, X.; Chanussot, J.; Benediktsson, J.A. Feature Extraction for Hyperspectral Imagery: The Evolution from Shallow for Deep (Overview and Toolbox). IEEE Geosci. Remote Sens. Mag. 2020. [Google Scholar] [CrossRef]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Chanuoost, J.; Tao, R.; Wang, Y. Fourier-based Rotation- invariant Feature Boosting: An Efficient Framework for Geospatial Object Detection. IEEE Geosci. Remote Sens. Lett. 2020, 17, 302–306. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Gao, L.; Hong, D.; Yao, J.; Zhang, B.; Gamba, P.; Chanussot, J. Spectral Superresolution of Multispectral Imagery with Joint Sparse and Low-Rank Learning. IEEE Trans. Geosci. Remote Sens. 2020. [Google Scholar] [CrossRef]
- He, K.; Girshick, R.B.; Dollár, P. Rethinking ImageNet Pre-training. arXiv 2018, arXiv:1811.08883. [Google Scholar]
- Kornblith, S.; Shlens, J.; Le, Q.V. Do Better ImageNet Models Transfer Better? arXiv 2018, arXiv:1805.08974. [Google Scholar]
- Hendrycks, D.; Lee, K.; Mazeika, M. Using Pre-Training Can Improve Model Robustness and Uncertainty. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 2712–2721. [Google Scholar]
- Yosinski, J.; Clune, J.; Nguyen, A.M.; Fuchs, T.J.; Lipson, H. Understanding Neural Networks Through Deep Visualization. arXiv 2015, arXiv:1506.06579. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin, Germany, 2016; Volume 9906, pp. 694–711. [Google Scholar] [CrossRef]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York, NY, USA, 19–24 June 2016; pp. 1558–1566. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the Computer Vision—ECCV 2018 Workshops, Munich, Germany, 8–14 September 2018; pp. 63–79. [Google Scholar] [CrossRef]
- Jolicoeur-Martineau, A. The relativistic discriminator: a key element missing from standard GAN. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Blau, Y.; Mechrez, R.; Timofte, R.; Michaeli, T.; Zelnik-Manor, L. The 2018 PIRM Challenge on Perceptual Image Super-Resolution. In Proceedings of the Computer Vision—ECCV 2018 Workshops, Munich, Germany, 8–14 September 2018; pp. 334–355. [Google Scholar] [CrossRef]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V.S. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Huang, X.; Belongie, S.J. Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 1510–1519. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Bengio, Y.; Courville, A.C. Deep Learning; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2016; pp. 499–523. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Li, S.; Yin, H.; Fang, L. Remote Sensing Image Fusion via Sparse Representations Over Learned Dictionaries. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4779–4789. [Google Scholar] [CrossRef]
- Hong, D.; Zhu, X. SULoRA: Subspace Unmixing with Low-Rank Attribute Embedding for Hyperspectral Data Analysis. IEEE J. Sel. Top. Signal Process. 2018, 12, 1351–1363. [Google Scholar] [CrossRef]
- Mishkin, D.; Matas, J. All you need is a good init. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A.; Selva, M. MTF-tailored multiscale fusion of high-resolution MS and Pan imagery. Photogramm. Eng. Remote Sens. 2006, 72, 591–596. [Google Scholar] [CrossRef]
- Vivone, G.; Alparone, L.; Chanussot, J.; Mura, M.D.; Garzelli, A.; Licciardi, G.; Restaino, R.; Wald, L. A Critical Comparison Among Pansharpening Algorithms. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2565–2586. [Google Scholar] [CrossRef]
- Li, Z.; Leung, H. Fusion of Multispectral and Panchromatic Images Using a Restoration-Based Method. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1482–1491. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Salimans, T.; Goodfellow, I.J.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. In Proceedings of the Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 2226–2234. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 6626–6637. [Google Scholar]
- Wang, L.; Sousa, W.P.; Gong, P.; Biging, G.S. Comparison of IKONOS and QuickBird images for mapping mangrove species on the Caribbean coast of Panama. Remote Sens. Environ. 2004, 91, 432–440. [Google Scholar] [CrossRef]
- Parente, C.; Santamaria, R. Increasing geometric resolution of data supplied by quickbird multispectral sensors. Sens. Transducers 2013, 156, 111. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R., Eds.; pp. 8024–8035. [Google Scholar]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the Summaries 3rd Annual JPL Airborne Geoscience Workshop, 1992, Pasadena, CA, USA, 1–5 June 1992; Jet Propulsion Laboratory Publication: Pasadena, CA, USA, 1992; Volume 1, pp. 147–149. [Google Scholar]
- Zhou, J.; Civco, D.; Silander, J. A wavelet transform method to merge Landsat TM and SPOT panchromatic data. Int. J. Remote Sens. 1998, 19, 743–757. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C. A universal image quality index. IEEE Signal Process. Lett. 2002, 9, 81–84. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Ranchin, T.; Wald, L. Fusion of high spatial and spectral resolution images: the ARSIS concept and its implementation. Photogramm. Eng. Remote Sens. 2000, 66, 49–61. [Google Scholar]
- Alparone, L.; Aiazzi, B.; Baronti, S.; Garzelli, A.; Nencini, F.; Selva, M. Multispectral and panchromatic data fusion assessment without reference. Photogramm. Eng. Remote Sens. 2008, 74, 193–200. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite | Item | Blue | Green | Red | Near Infrared |
|---|---|---|---|---|---|
| QuickBird | Nyquist | ||||
| Weight | |||||
| IKONOS | Nyquist | ||||
| Weight |
| Dataset | Training Paradigm | HRMS Patches | LRMS Patches | PAN Patches | Training Type | Quality Assessment |
|---|---|---|---|---|---|---|
| Full-scale | SPUF | None | Original MS patches | Original PAN patches | Unsupervised | No-reference |
| Reduced-scale | SPSF | Original MS patches | Degraded MS patches | Degraded PAN patches | Supervised | Full-reference |
| Satellite | Wave Length (nm) | Spatial Resolution (m) | |||||
|---|---|---|---|---|---|---|---|
| Blue | Green | Red | Near Infrared | Panchromatic | Multispectral | Panchromatic | |
| QuickBird | 450–520 | 520–600 | 630-690 | 780–900 | 450–900 | ||
| IKONOS | 445–516 | 506–595 | 632–698 | 757–853 | 450–900 | 4 | 1 |
| Satellite | Dataset Type | Patch Size | #Training | #Validation | #Test | |
|---|---|---|---|---|---|---|
| Multispectral | Panchromatic | |||||
| QuickBird | Full-scale | 13,494 | 4498 | 4499 | ||
| Reduced-scale | 820 | 274 | 274 | |||
| IKONOS | Full-scale | 1574 | 525 | 525 | ||
| Reduced-scale | 90 | 30 | 30 | |||
| Initialization | Hyper-Parameter | Reduced-Scale | Full-Scale | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SAM (0) | PSNR (∞) | SCC (1) | Q-index (1) | SSIM (1) | ERGAS (0) | (0) | (0) | QNR (1) | ||||||
| Random | 1 | 0 | 0 | 1 × 10−4 | — | |||||||||
| 1 × 10−5 | — | |||||||||||||
| 0 | 1 | 1 × 10−4 | 1 × 10−4 | |||||||||||
| 1 × 10−4 | 1 × 10−5 | |||||||||||||
| 1 × 10−5 | 1 × 10−4 | |||||||||||||
| 1 | 1 | 1 × 10−4 | 1 × 10−4 | |||||||||||
| 1 × 10−4 | 1 × 10−5 | |||||||||||||
| 1 × 10−5 | 1 × 10−4 | |||||||||||||
| PSNR | 1 | 0 | 0 | 1 × 10−4 | — | |||||||||
| 1 × 10−5 | — | |||||||||||||
| 0 | 1 | 1 × 10−4 | 1 × 10−4 | |||||||||||
| 1 × 10−4 | 1 × 10−5 | |||||||||||||
| 1 × 10−5 | 1 × 10−4 | |||||||||||||
| 1 | 1 | 1 × 10−4 | 1 × 10−4 | |||||||||||
| 1 × 10−4 | 1 × 10−5 | |||||||||||||
| 1 × 10−5 | 1 × 10−4 | |||||||||||||
| ESRGAN | 1 | 0 | 0 | 1 × 10−4 | — | |||||||||
| 1 × 10−5 | — | |||||||||||||
| 0 | 1 | 1 × 10−4 | 1 × 10−4 | |||||||||||
| 1 × 10−4 | 1 × 10−5 | |||||||||||||
| 1 × 10−5 | 1 × 10−4 | |||||||||||||
| 1 | 1 | 1 × 10−4 | 1 × 10−4 | |||||||||||
| 1 × 10−4 | 1 × 10−5 | |||||||||||||
| 1 × 10−5 | 1 × 10−4 | |||||||||||||
| Methods | Reduced-Scale | Full-Scale | |||||||
|---|---|---|---|---|---|---|---|---|---|
| SAM (0) | PSNR (∞) | SCC (1) | Q-Index (1) | SSIM (1) | ERGAS (0) | (0) | (0) | QNR (1) | |
| PNN [14] | |||||||||
| RSIFNN [15] | |||||||||
| PanNet [16] | |||||||||
| PSGAN [17] | |||||||||
| PercePan | |||||||||
| Methods | Reduced-Scale | Full-Scale | |||||||
|---|---|---|---|---|---|---|---|---|---|
| SAM (0) | PSNR (∞) | SCC (1) | Q-Index (1) | SSIM (1) | ERGAS (0) | (0) | (0) | QNR (1) | |
| PNN [14] | |||||||||
| RSIFNN [15] | |||||||||
| PanNet [16] | |||||||||
| PSGAN [17] | |||||||||
| PercepPan | |||||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, C.; Zhang, J.; Liu, J.; Zhang, C.; Fei, R.; Xu, S. PercepPan: Towards Unsupervised Pan-Sharpening Based on Perceptual Loss. Remote Sens. 2020, 12, 2318. https://doi.org/10.3390/rs12142318
Zhou C, Zhang J, Liu J, Zhang C, Fei R, Xu S. PercepPan: Towards Unsupervised Pan-Sharpening Based on Perceptual Loss. Remote Sensing. 2020; 12(14):2318. https://doi.org/10.3390/rs12142318
Chicago/Turabian StyleZhou, Changsheng, Jiangshe Zhang, Junmin Liu, Chunxia Zhang, Rongrong Fei, and Shuang Xu. 2020. "PercepPan: Towards Unsupervised Pan-Sharpening Based on Perceptual Loss" Remote Sensing 12, no. 14: 2318. https://doi.org/10.3390/rs12142318
APA StyleZhou, C., Zhang, J., Liu, J., Zhang, C., Fei, R., & Xu, S. (2020). PercepPan: Towards Unsupervised Pan-Sharpening Based on Perceptual Loss. Remote Sensing, 12(14), 2318. https://doi.org/10.3390/rs12142318