Object Detection in Remote Sensing Images Based on Improved Bounding Box Regression and Multi-Level Features Fusion


Abstract
1. Introduction
- (1)
- A new metric (i.e., GIoU) for ODRSIs is adopted to replace the existing metric (i.e., IoU). The GIoU overcomes the problem that the IoU cannot measure the distance when the predicted bounding box and the ground truth box are nonoverlapping.
- (2)
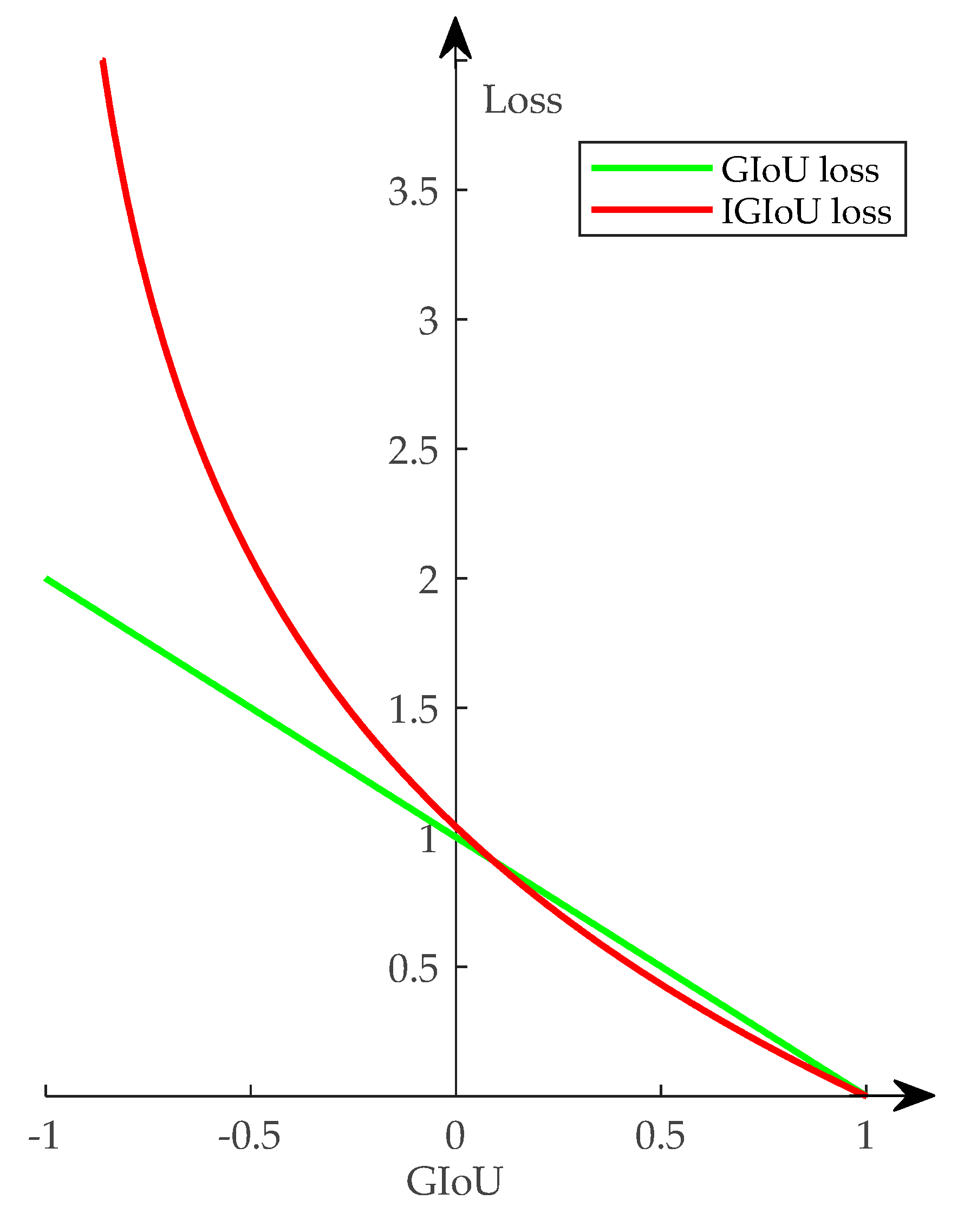
- A novel bounding box regression loss named IGIoU loss is proposed. The proposed IGIoU loss can optimize the new metric (i.e., GIoU) directly, which thus solves the problem that the existing bounding box regression loss cannot directly optimize the metric in ODRSIs. Furthermore, it can overcome the problem that existing GIoU loss [43] cannot adaptively change the gradient based on the GIoU value.
- (3)
- A multi-level features fusion module named MLFF module is proposed. The proposed MLFF can be incorporated into the existing hierarchical deep network, which can address the problem that the existing methods which adopt a hierarchical deep network do not make full use of the advantages of multi-level features for the feature extraction of region proposals.
2. Materials and Methods
2.1. Methods
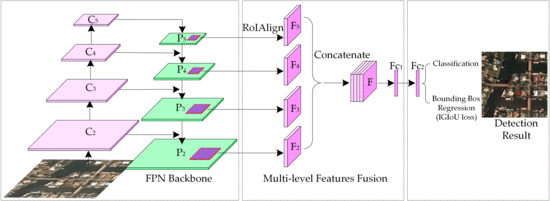
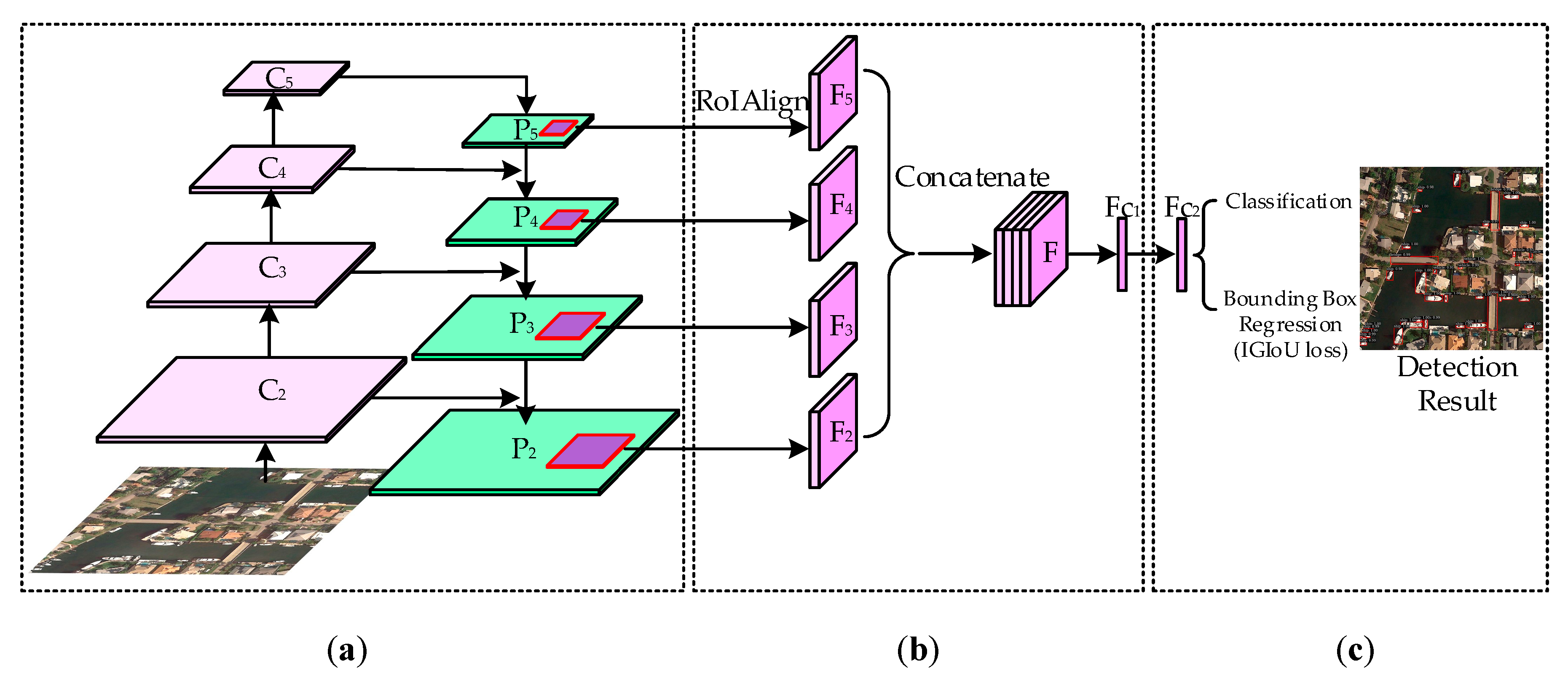
2.1.1. Multi-Level Features Fusion
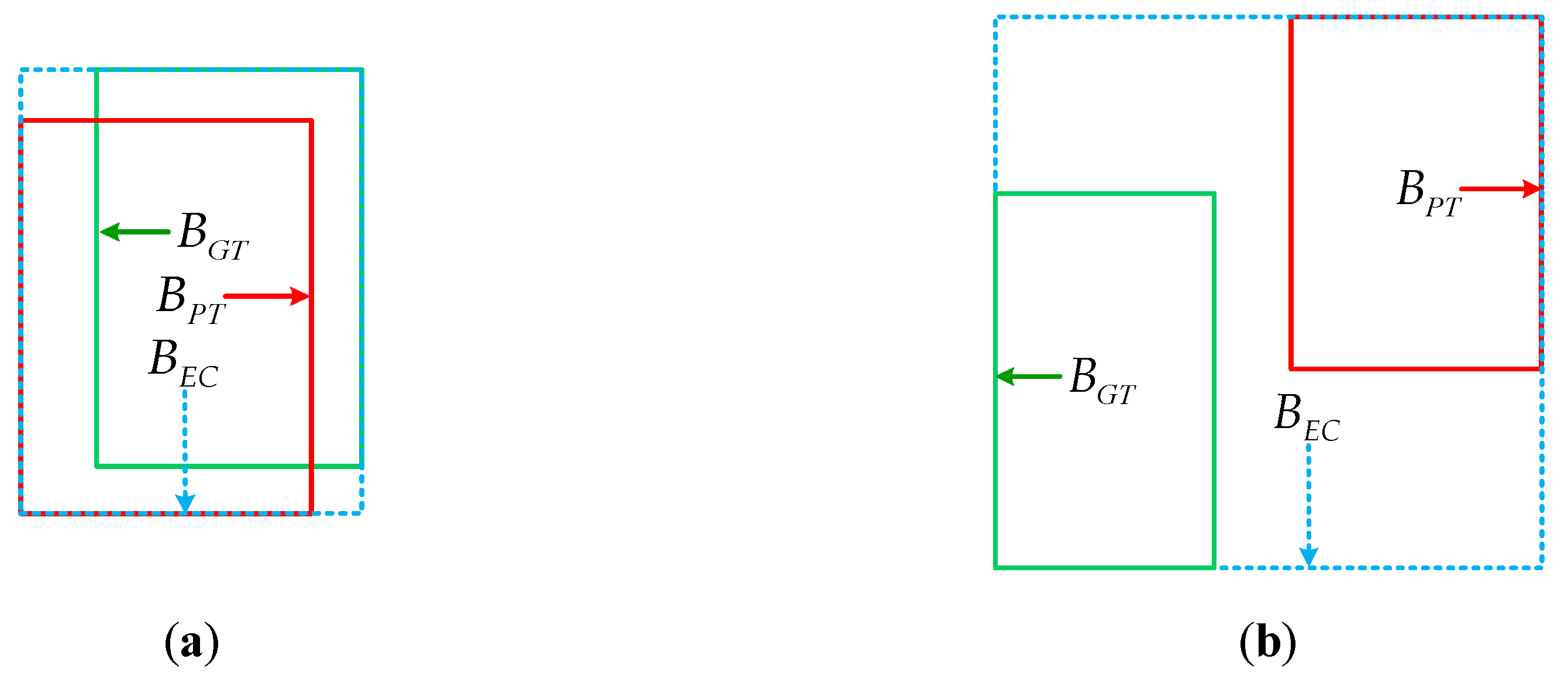
2.1.2. Generalized Intersection over Union
2.1.3. Bounding Box Regression Based on IGIoU Loss
2.2. Experimental Materials
2.2.1. Dataset
2.2.2. Evaluation Metrics
2.2.3. Implementation Details
2.2.4. Comparison Methods
3. Results
3.1. Evaluation on NWPU VHR-10 Dataset
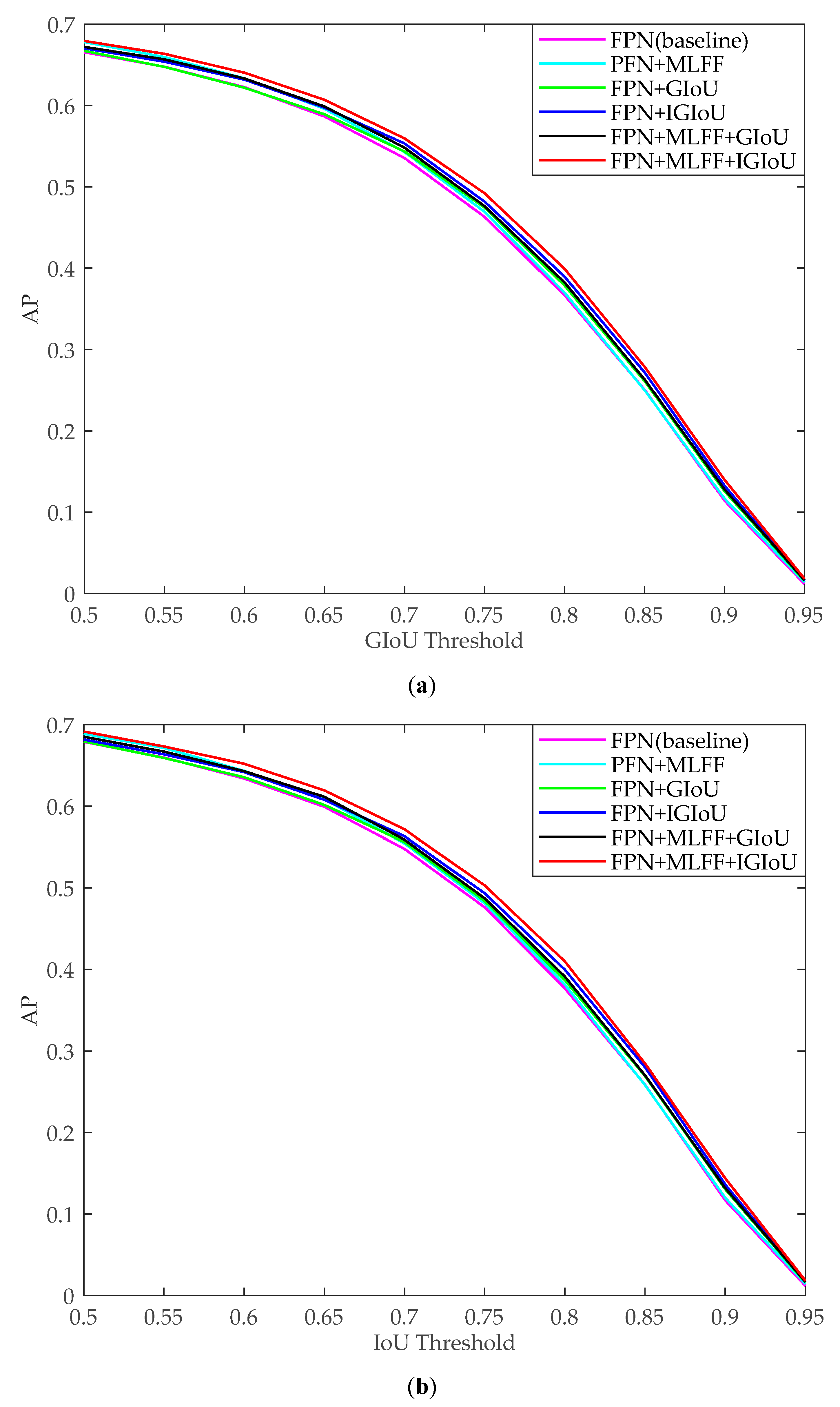
3.1.1. Evaluation of Proposed IGIoU Loss and MLFF Module
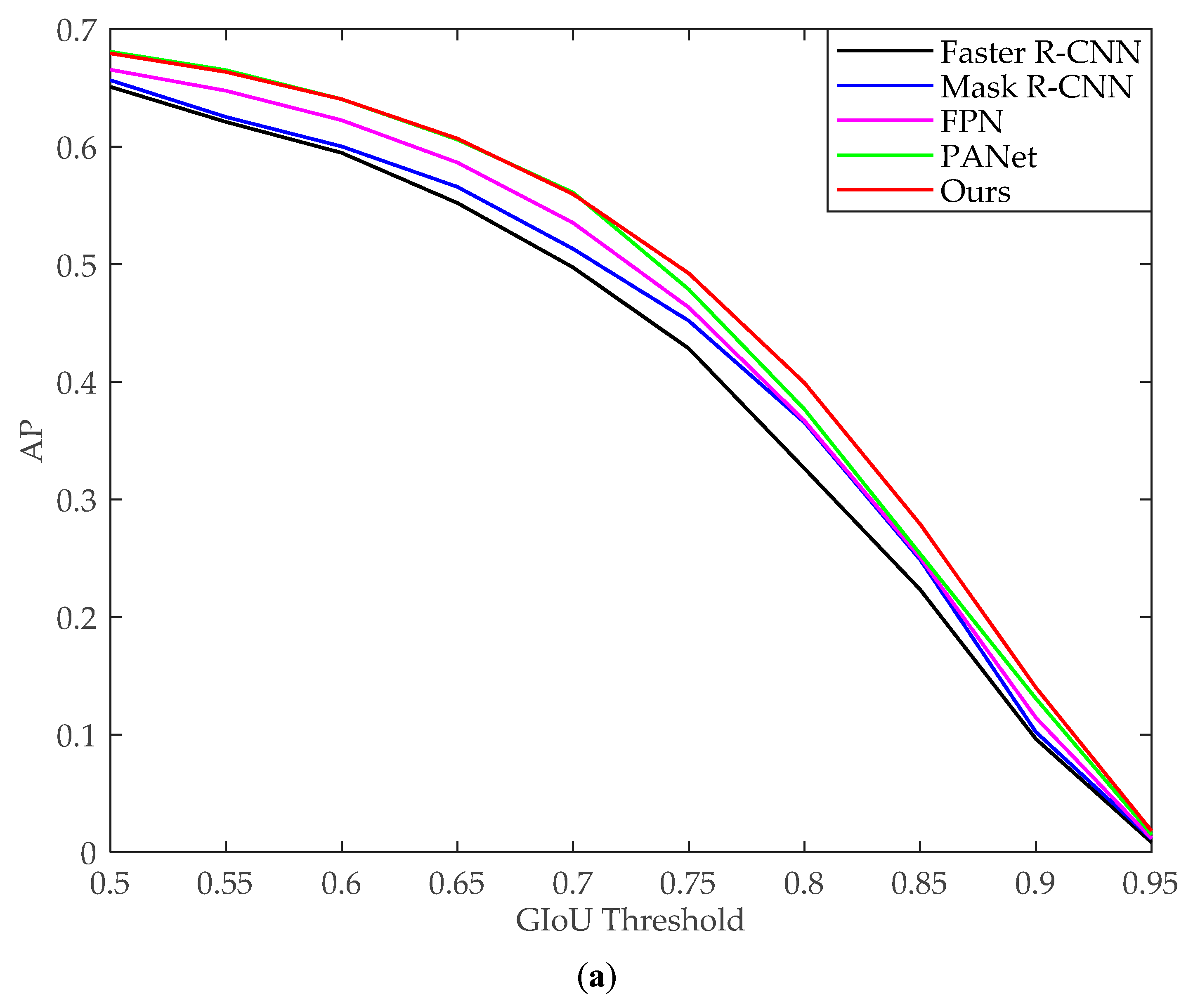
3.1.2. Comparison with the State-of-the-Art Methods
3.2. Evaluation on DIOR Dataset
3.2.1. Evaluation of Proposed IGIoU Loss and MLFF Module
3.2.2. Comparison with the State-of-the-Art Methods
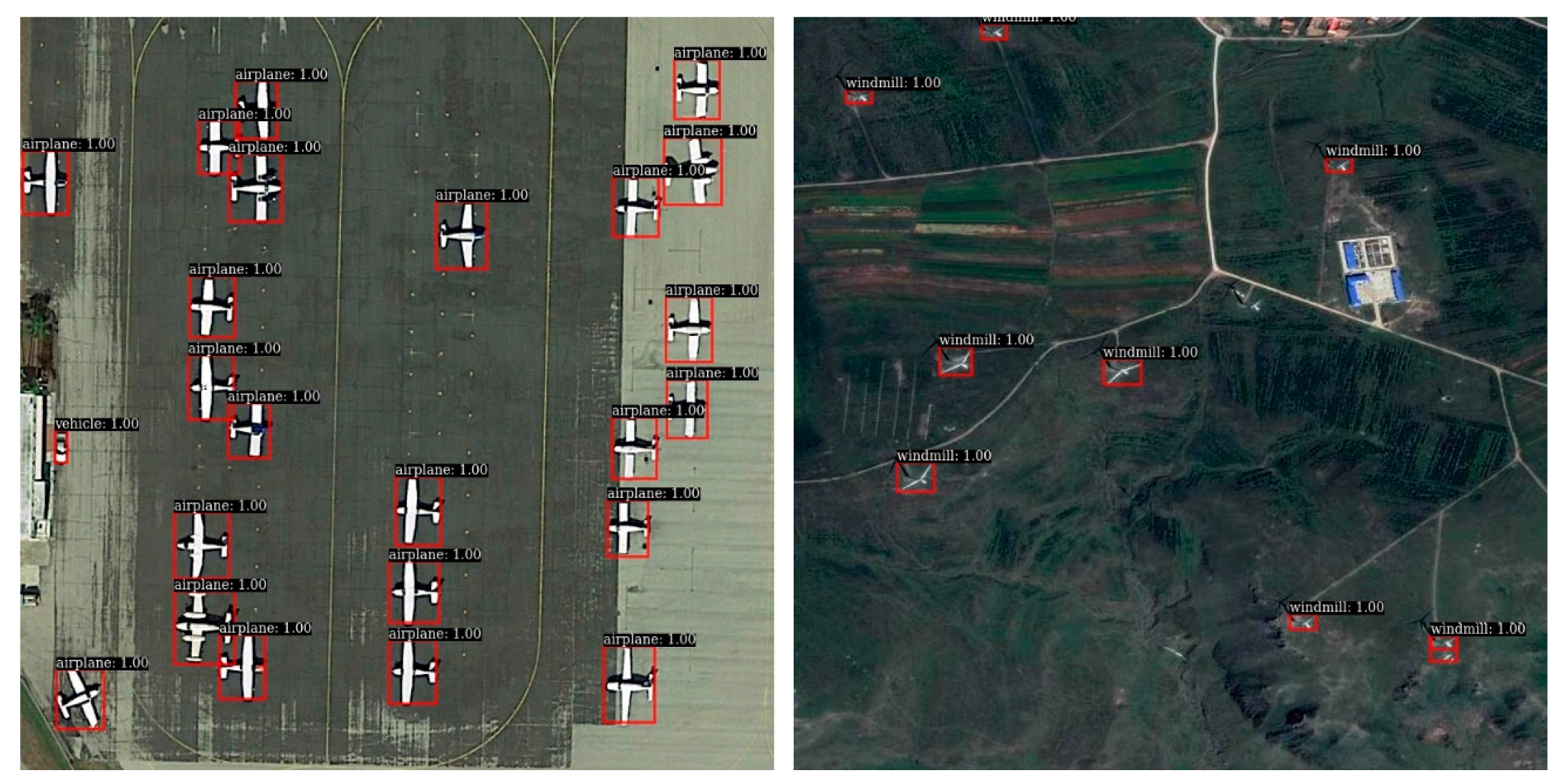
3.3. Subjective Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liao, W.; Vancoillie, F.; Gao, L.; Li, L.; Zhang, B.; Chanussot, J. Deep learning for fusion of APEX hyperspectral and full-waveform LiDAR remote sensing data for tree species mapping. IEEE Access 2018, 6, 68716–68729. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, J.; Wei, W.; Zhang, Y. Learning Discriminative Compact Representation for Hyperspectral Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8276–8289. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Lu, T.; Zhou, K.; Wang, M.; Bao, H. A new method for region-based majority voting CNNs for very high resolution image classification. Remote Sens. 2018, 10, 1946. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Chen, Y.; Wang, M. Very high resolution remote sensing image classification with SEEDS-CNN and scale effect analysis for superpixel CNN classification. Int. J. Remote Sens. 2019, 40, 506–531. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced Deep-Learning Techniques for Salient and Category-Specific Object Detection: A Survey. IEEE Signal Process Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Xu, D. Learning Rotation-Invariant and Fisher Discriminative Convolutional Neural Networks for Object Detection. IEEE Trans. Image Process. 2019, 28, 265–278. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Y.; Yan, H.; Gao, Y.; Wei, W. Salient object detection in hyperspectral imagery using multi-scale spectral-spatial gradient. Neurocomputing 2018, 291, 215–225. [Google Scholar] [CrossRef]
- Liao, W.; Bellens, R.; Pizurica, A.; Philips, W.; Pi, Y. Classification of hyperspectral data over urban areas using directional morphological profiles and semi-supervised feature extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1177–1190. [Google Scholar] [CrossRef]
- Gao, L.; Zhao, B.; Jia, X.; Liao, W.; Zhang, B. Optimized Kernel Minimum Noise Fraction Transformation for Hyperspectral Image Classification. Remote Sens. 2017, 9, 548. [Google Scholar] [CrossRef]
- Du, L.; You, X.; Li, K.; Meng, L.; Cheng, G.; Xiong, L.; Wang, G. Multi-modal deep learning for landform recognition. ISPRS J. Photogramm. Remote Sens. 2019, 158, 63–75. [Google Scholar] [CrossRef]
- Zhang, L.; Shi, Z.; Wu, J. A hierarchical oil tank detector with deep surrounding features for high-resolution optical satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4895–4909. [Google Scholar] [CrossRef]
- Stankov, K.; He, D. Detection of buildings in multispectral very high spatial resolution images using the percentage occupancy hit-or-miss transform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4069–4080. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Zhang, L. An Efficient and Robust Integrated Geospatial Object Detection Framework for High Spatial Resolution Remote Sensing Imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Li, F.; Perona, P. A bayesian hierarchical model for learning natural scene categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 21–23 September 2005; pp. 524–531. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 21–23 September 2005; pp. 886–893. [Google Scholar]
- Felzenszwalb, P.; Girshick, R.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.; Sun, X.; Wang, H.; Li, Y.; Li, X. Automatic target detection in high-resolution remote sensing images using spatial sparse coding bag-of-words model. IEEE Geosci. Remote Sens. Lett. 2011, 9, 109–113. [Google Scholar] [CrossRef]
- Hyvärinen, A.; Oja, E. Independent component analysis: Algorithms and applications. Neural Netw. 2000, 13, 411–430. [Google Scholar] [CrossRef]
- Zhang, D.; Meng, D.; Han, J. Co-saliency detection via a self-paced multiple-instance learning framework. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 865–878. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Hu, X.; Guo, L.; Ren, J.; Wu, F. Background prior-based salient object detection via deep reconstruction residual. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 1309–1321. [Google Scholar]
- Han, J.; Yao, X.; Cheng, G.; Feng, X.; Xu, D. P-CNN: Part-Based Convolutional Neural Networks for Fine-Grained Visual Categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Han, J.; Ji, X.; Hu, X.; Zhu, D.; Li, K.; Jiang, X.; Cui, G.; Guo, L.; Liu, T. Representing and retrieving video shots in human-centric brain imaging space. IEEE Trans. Image Process 2013, 22, 2723–2736. [Google Scholar] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Victoria, BC, Canada, 1–3 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Las Vegas, NV, USA, 27–30 June 2016; pp. 21–37. [Google Scholar]
- Liu, W.; Ma, L.; Wang, J. Detection of Multiclass Objects in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 791–795. [Google Scholar] [CrossRef]
- Chen, S.; Zhan, R.; Zhang, J. Geospatial object detection in remote sensing imagery based on multiscale single-shot detector with activated semantics. Remote Sens. 2018, 10, 820. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Lei, L.; Zou, H. Arbitrary-oriented vehicle detection in aerial imagery with single convolutional neural networks. Remote Sens. 2017, 9, 1170. [Google Scholar] [CrossRef]
- Tayara, H.; Chong, K. Object detection in very high-resolution aerial images using one-stage densely connected feature pyramid network. Sensors 2018, 18, 3341. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, T.; Ouyang, C. End-to-end airplane detection using transfer learning in remote sensing images. Remote Sens. 2018, 10, 139. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2117–2125. [Google Scholar]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-insensitive and context-augmented object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2337–2348. [Google Scholar] [CrossRef]
- Zhong, Y.; Han, X.; Zhang, L. Multi-class geospatial object detection based on a position-sensitive balancing framework for high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2018, 138, 281–294. [Google Scholar] [CrossRef]
- Chen, C.; Gong, W.; Chen, Y.; Li, W. Object Detection in Remote Sensing Images Based on a Scene-Contextual Feature Pyramid Network. Remote Sens. 2019, 11, 339. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 1492–1500. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2961–2969. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Cramer, M. The DGPF-test on digital airborne camera evaluation–overview and test design. Photogramm. Fernerkund. Geoinf. 2010, 2010, 73–82. [Google Scholar] [CrossRef] [PubMed]
- Yao, X.; Han, J.; Cheng, G.; Qian, X.; Guo, L. Semantic Annotation of High-Resolution Satellite Images via Weakly Supervised Learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3660–3671. [Google Scholar] [CrossRef]
- Morsier, F.; Tuia, D.; Borgeaud, M.; Gass, V.; Thiran, J. Semi-Supervised Novelty Detection Using SVM Entire Solution Path. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1939–1950. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object Detection in Optical Remote Sensing Images: A Survey and A New Benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2849–2858. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Guo, W.; Yang, W.; Zhang, H.; Hua, G. Geospatial object detection in high resolution satellite images based on multi-scale convolutional neural network. Remote Sens. 2018, 10, 131. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Everingham, M.; Vangool, L.; Williams, C.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning representations by back-propagating errors. Nature 1988, 323, 696–699. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | GIoU | IoU | ||||
|---|---|---|---|---|---|---|
| mAP (%) | AP50 (%) | AP75 (%) | mAP (%) | AP50 (%) | AP75 (%) | |
| FPN(baseline) | 55.3 | 88.8 | 64.0 | 56.5 | 89.3 | 65.9 |
| FPN+MLFF | 56.2 | 89.6 | 64.2 | 57.5 | 90.4 | 66.7 |
| FPN+GIoU | 56.2 | 88.9 | 65.9 | 57.5 | 89.3 | 67.5 |
| FPN+IGIoU | 57.3 | 89.8 | 66.6 | 58.5 | 90.7 | 68.5 |
| FPN+MLFF+GIoU | 57.0 | 89.5 | 66.1 | 58.2 | 90.8 | 67.8 |
| FPN+MLFF+IGIoU(Ours) | 58.0 | 90.5 | 67.5 | 59.2 | 91.4 | 69.6 |
| Method | GIoU | IoU | ||||
|---|---|---|---|---|---|---|
| mAP (%) | AP50 (%) | AP75 (%) | mAP (%) | AP50 (%) | AP75 (%) | |
| Faster R-CNN | 53.5 | 86.8 | 61.0 | 54.6 | 87.1 | 62.6 |
| Mask R-CNN | 54.7 | 88.8 | 62.6 | 55.8 | 89.4 | 64.2 |
| FPN | 55.3 | 88.8 | 64.0 | 56.5 | 89.3 | 65.9 |
| PANet | 56.3 | 90.5 | 63.9 | 57.8 | 91.8 | 65.8 |
| Ours | 58.0 | 90.5 | 67.5 | 59.2 | 91.4 | 69.6 |
| Method | GIoU | IoU | ||||
|---|---|---|---|---|---|---|
| mAP (%) | AP50 (%) | AP75 (%) | mAP (%) | AP50 (%) | AP75 (%) | |
| FPN(baseline) | 42.6 | 66.5 | 46.3 | 43.6 | 67.9 | 47.6 |
| FPN+MLFF | 43.3 | 67.8 | 46.9 | 44.2 | 68.9 | 48.1 |
| FPN+GIoU | 43.3 | 66.7 | 47.5 | 44.2 | 67.9 | 48.4 |
| FPN+IGIoU | 44.0 | 67.0 | 48.2 | 44.8 | 68.2 | 49.3 |
| FPN+MLFF+GIoU | 43.8 | 67.2 | 47.6 | 44.6 | 68.5 | 48.7 |
| FPN+MLFF+IGIoU(Ours) | 44.8 | 67.9 | 49.2 | 45.7 | 69.2 | 50.3 |
| Method | GIoU | IoU | ||||
|---|---|---|---|---|---|---|
| mAP (%) | AP50 (%) | AP75 (%) | mAP (%) | AP50 (%) | AP75 (%) | |
| Faster R-CNN | 40.0 | 65.1 | 42.8 | 41.3 | 66.4 | 44.2 |
| Mask R-CNN | 41.4 | 65.7 | 45.2 | 42.9 | 67.0 | 46.6 |
| FPN | 42.6 | 66.5 | 46.3 | 43.6 | 67.9 | 47.6 |
| PANet | 44.1 | 68.1 | 47.8 | 44.8 | 69.3 | 49.0 |
| Ours | 44.8 | 67.9 | 49.2 | 45.7 | 69.2 | 50.3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, X.; Lin, S.; Cheng, G.; Yao, X.; Ren, H.; Wang, W. Object Detection in Remote Sensing Images Based on Improved Bounding Box Regression and Multi-Level Features Fusion. Remote Sens. 2020, 12, 143. https://doi.org/10.3390/rs12010143
Qian X, Lin S, Cheng G, Yao X, Ren H, Wang W. Object Detection in Remote Sensing Images Based on Improved Bounding Box Regression and Multi-Level Features Fusion. Remote Sensing. 2020; 12(1):143. https://doi.org/10.3390/rs12010143
Chicago/Turabian StyleQian, Xiaoliang, Sheng Lin, Gong Cheng, Xiwen Yao, Hangli Ren, and Wei Wang. 2020. "Object Detection in Remote Sensing Images Based on Improved Bounding Box Regression and Multi-Level Features Fusion" Remote Sensing 12, no. 1: 143. https://doi.org/10.3390/rs12010143
APA StyleQian, X., Lin, S., Cheng, G., Yao, X., Ren, H., & Wang, W. (2020). Object Detection in Remote Sensing Images Based on Improved Bounding Box Regression and Multi-Level Features Fusion. Remote Sensing, 12(1), 143. https://doi.org/10.3390/rs12010143