A Spectral Unmixing Method by Maximum Margin Criterion and Derivative Weights to Address Spectral Variability in Hyperspectral Imagery


Abstract
:1. Introduction
2. Theoretical Methodology
2.1. Linear Mixture Model
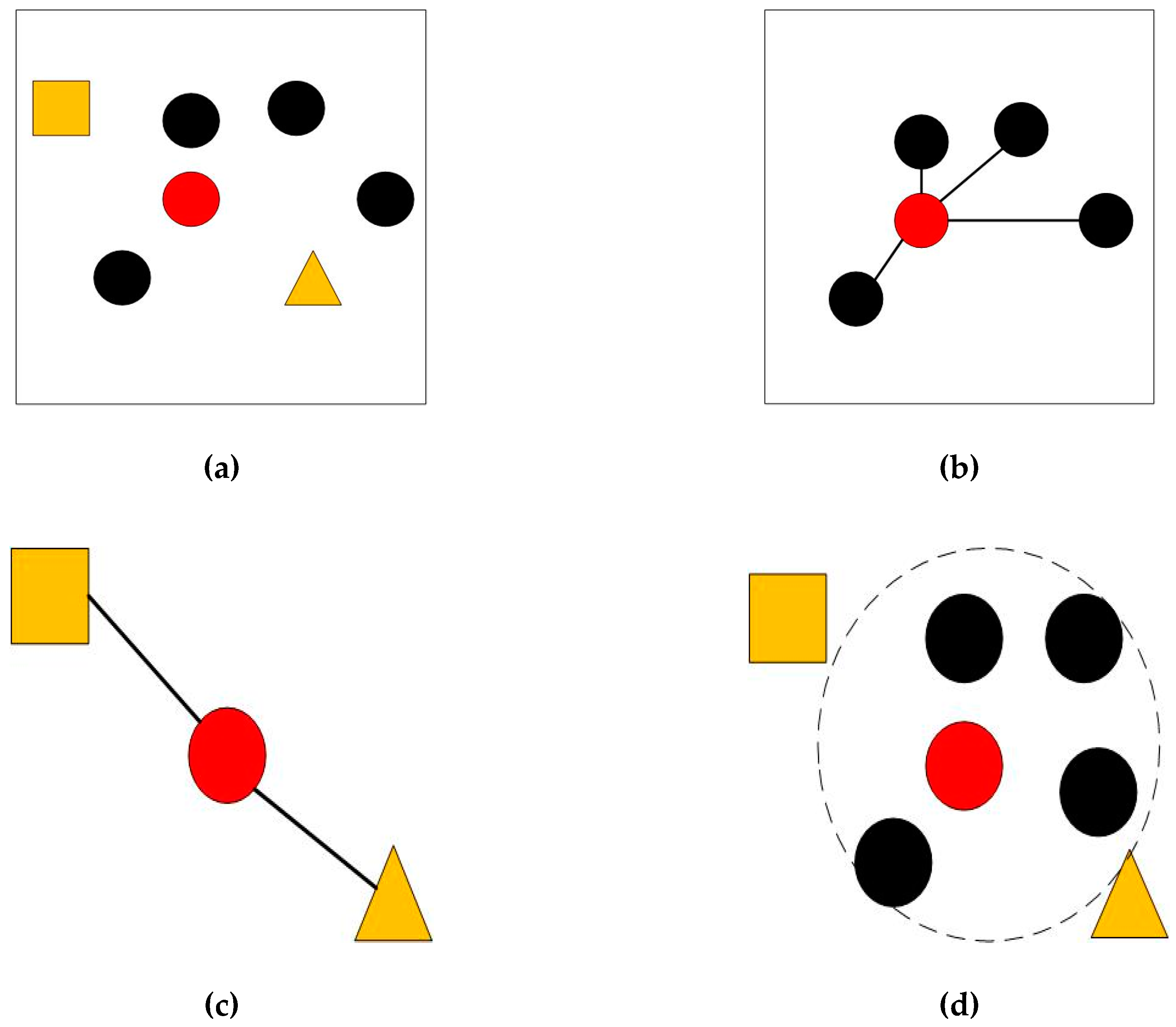
2.2. Modeling Endmember Spectral Library
- Step (1)
- Determine that the class number of endmembers is m and the number of spectra contained in each endmember is t.
- Step (2)
- Initialize the endmember matrix by VCA algorithm.
- Step (3)
- For each endmember k = 1, …, m, the algorithm constructs the new endmember set that removes the kth endmember . The new endmember set is marked as . According to the Equations (3)–(5), the algorithm generates the projection matrix orthogonal to the endmembers set , projects all the pixels of the hyperspectral image onto the matrix, and records the pixels of the first t maximum projection length as the spectrum library of the kth endmember. The average of the t pixels is regarded as the improved spectrum of the kth endmember. The kth endmember is replaced with in the initial endmember matrix .
- Step (4)
- Repeat step (3) until the spectral library and the improved spectra of all the endmembers are found.
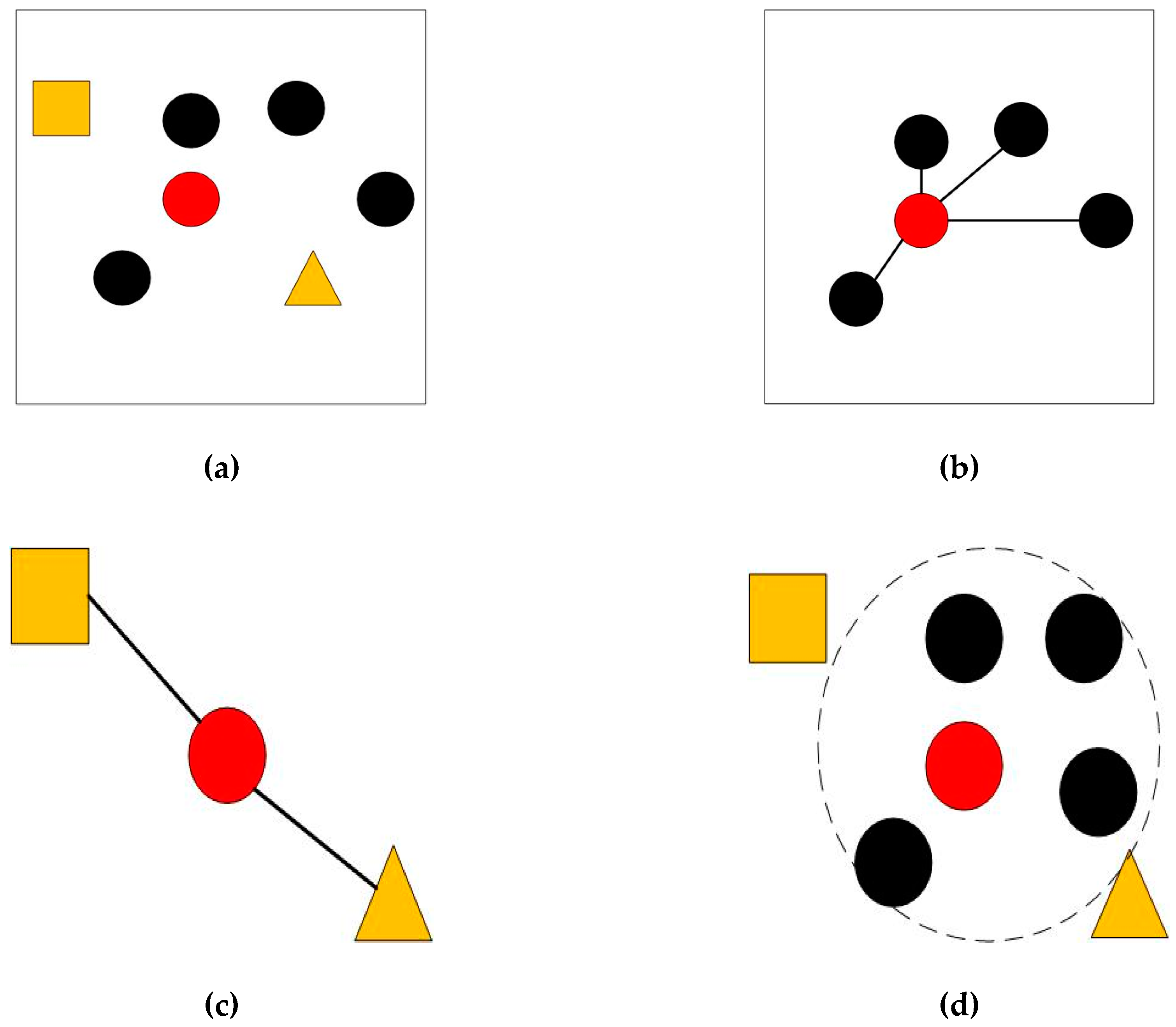
2.3. Spectral Weighting Matrix
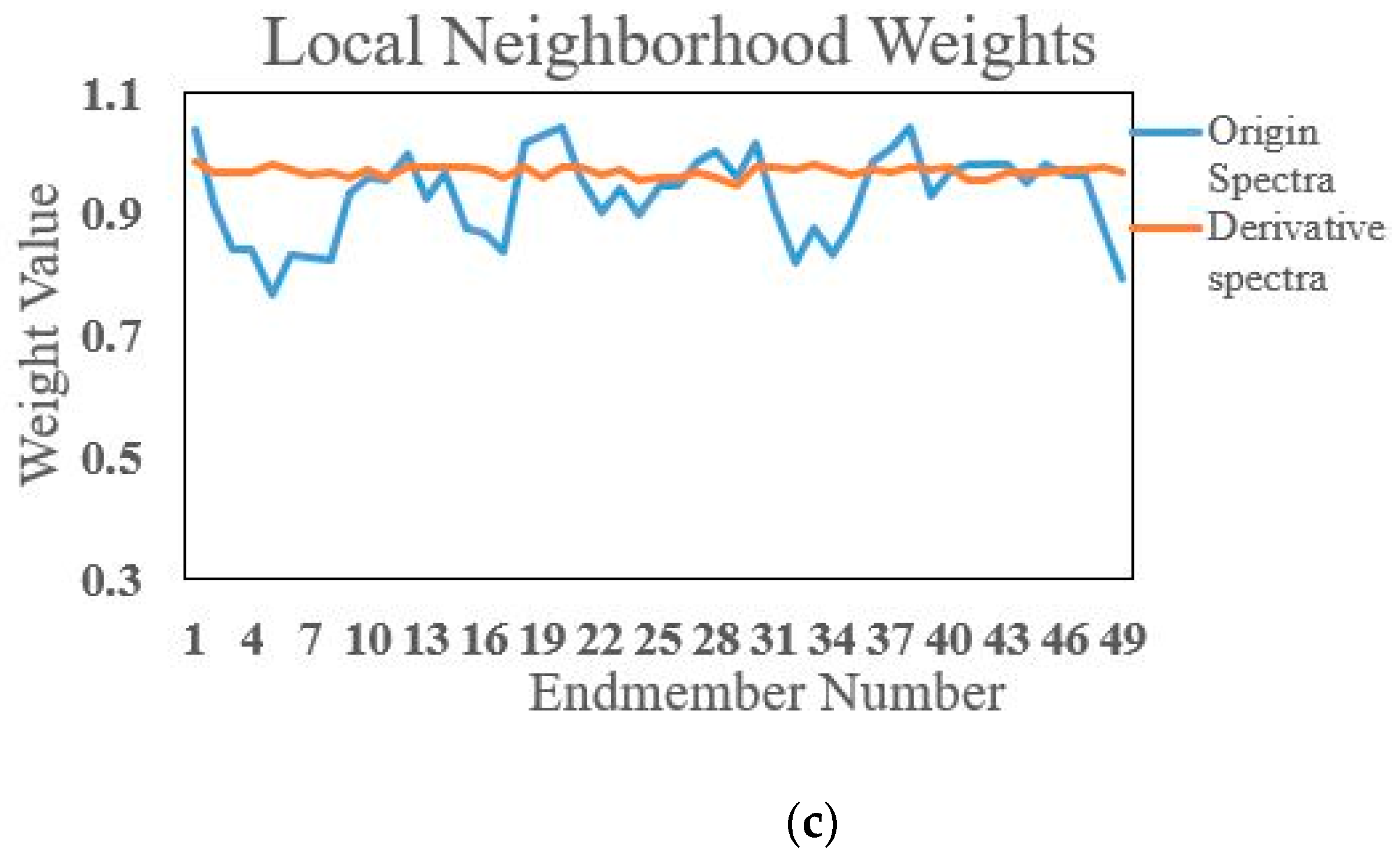
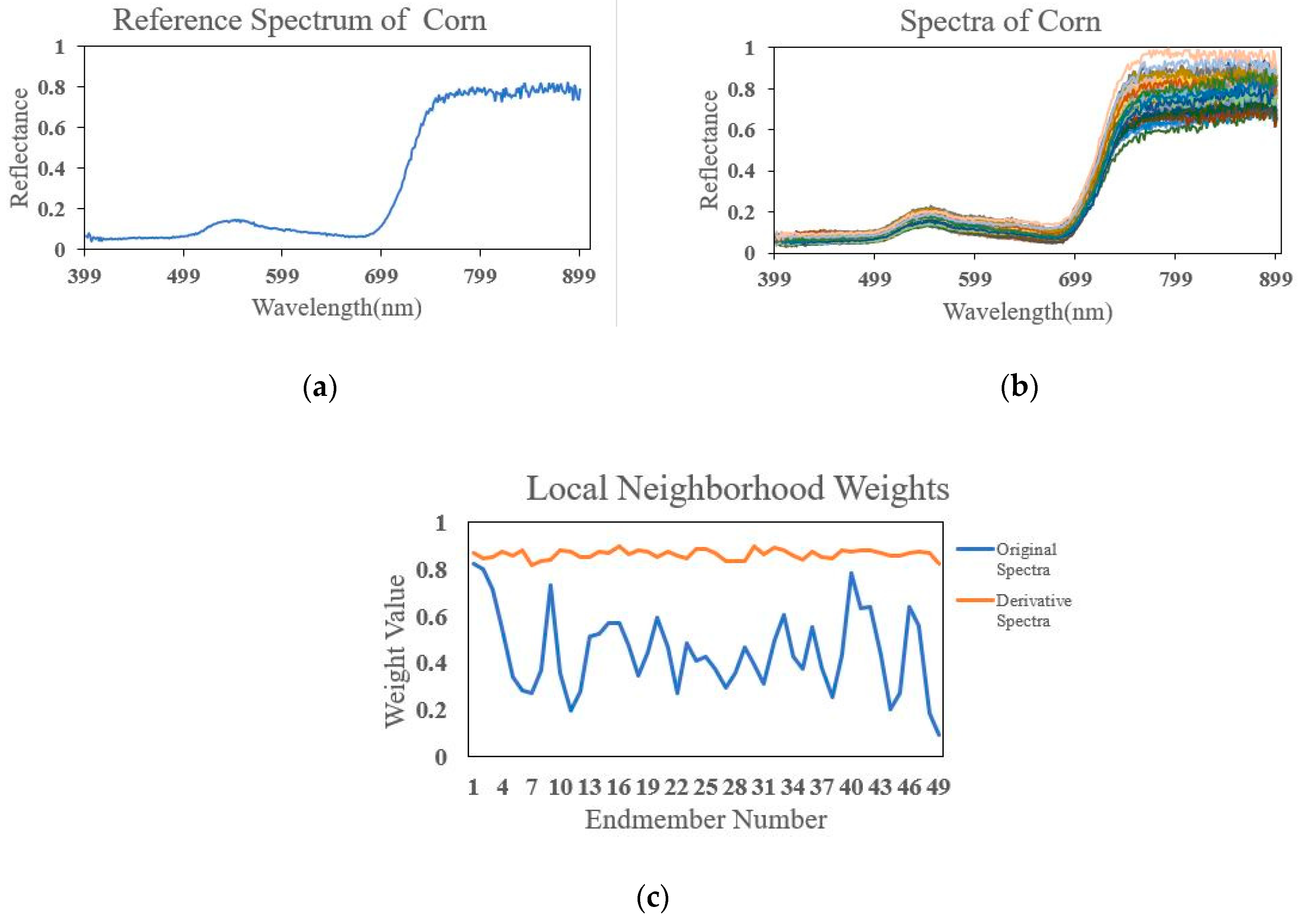
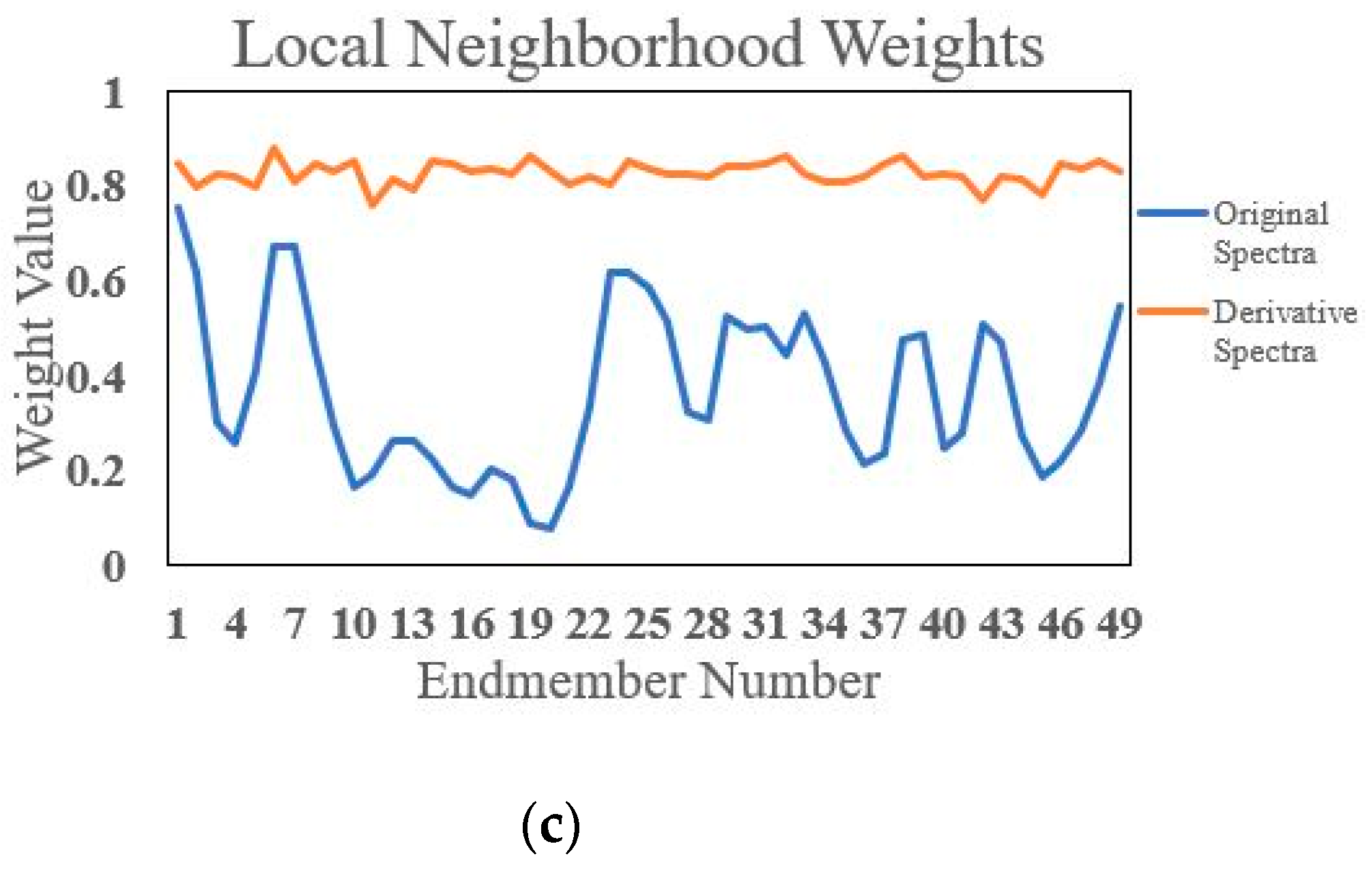
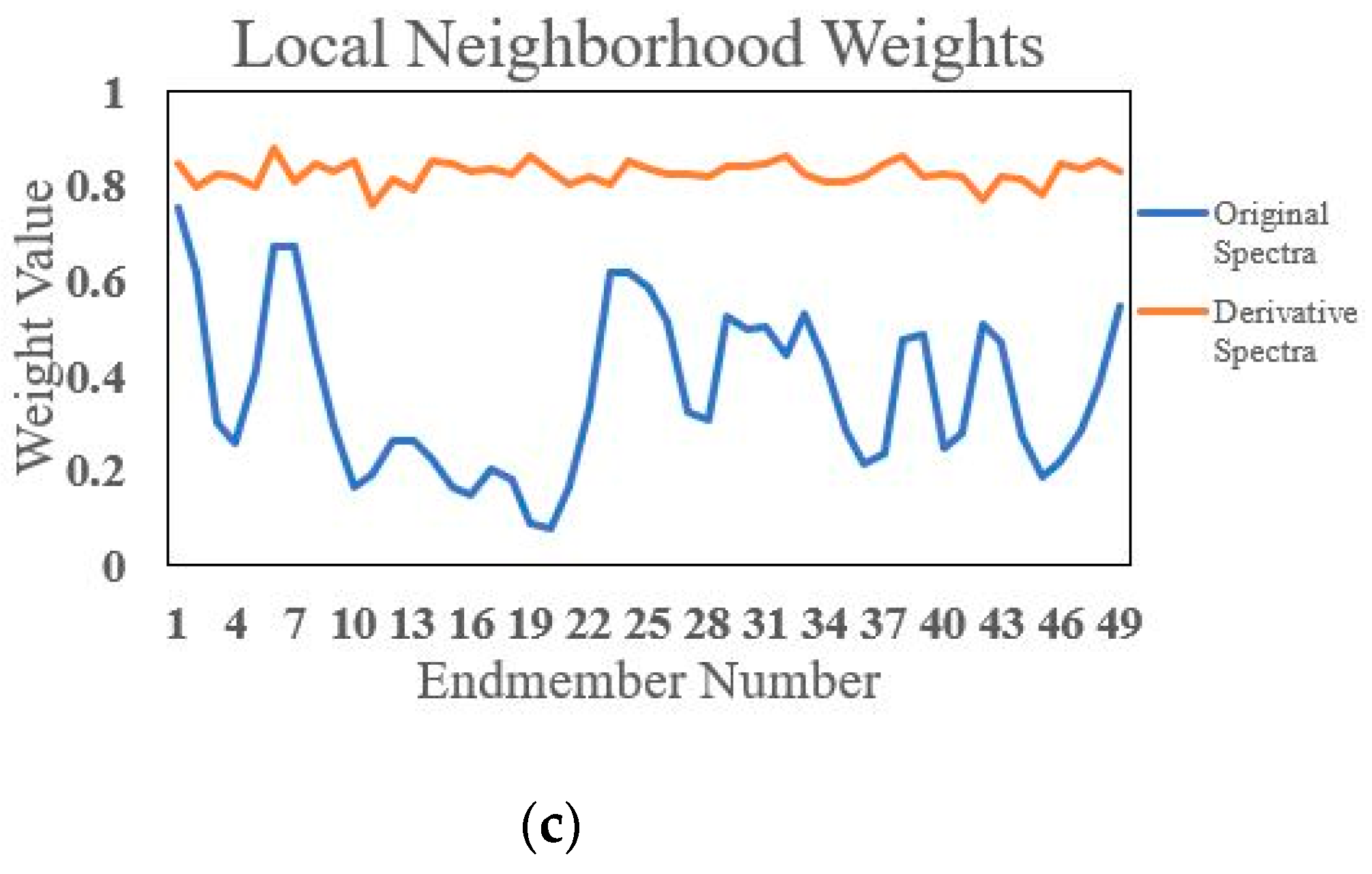
2.4. Local Neighborhood Derivative Weights
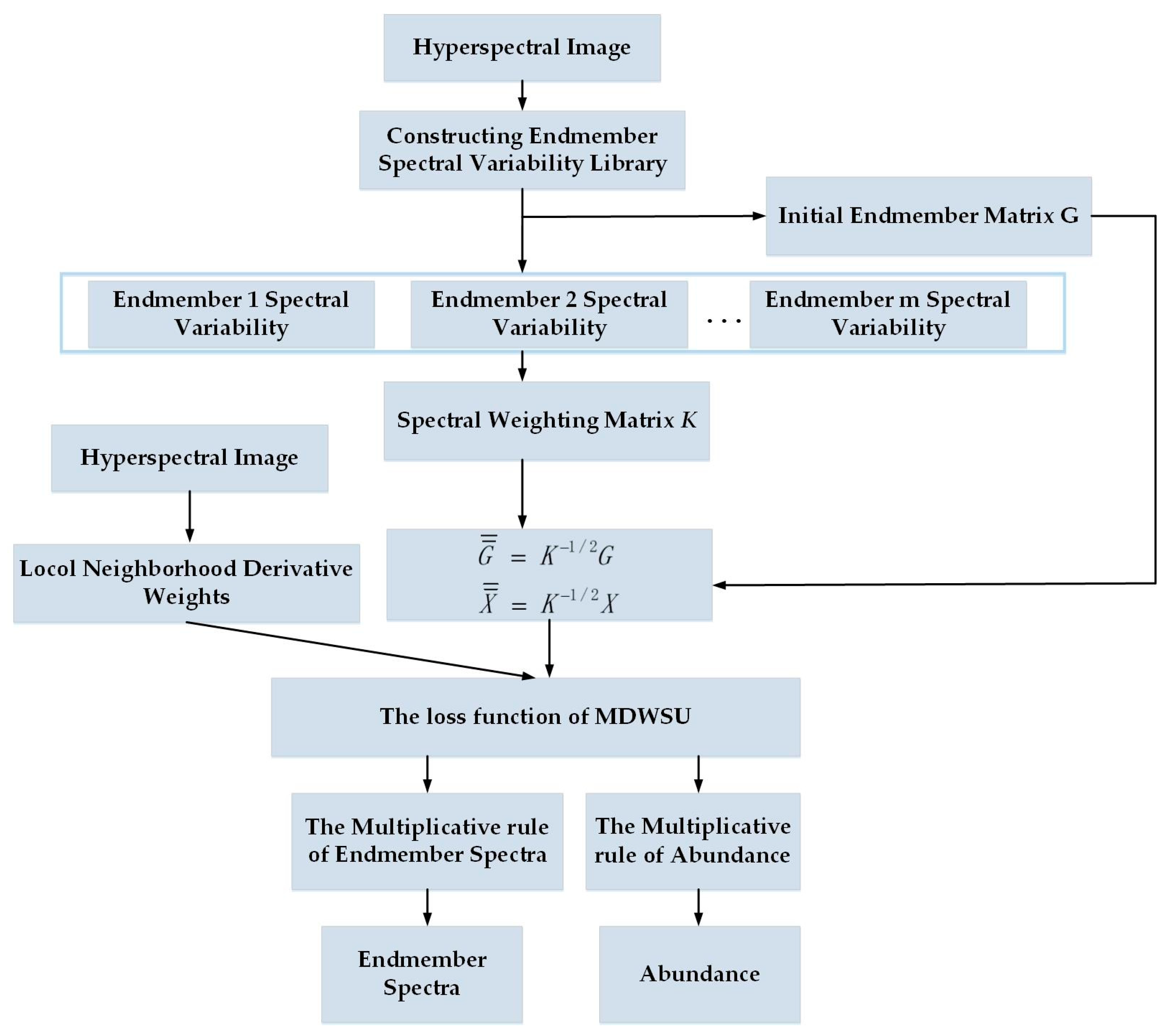
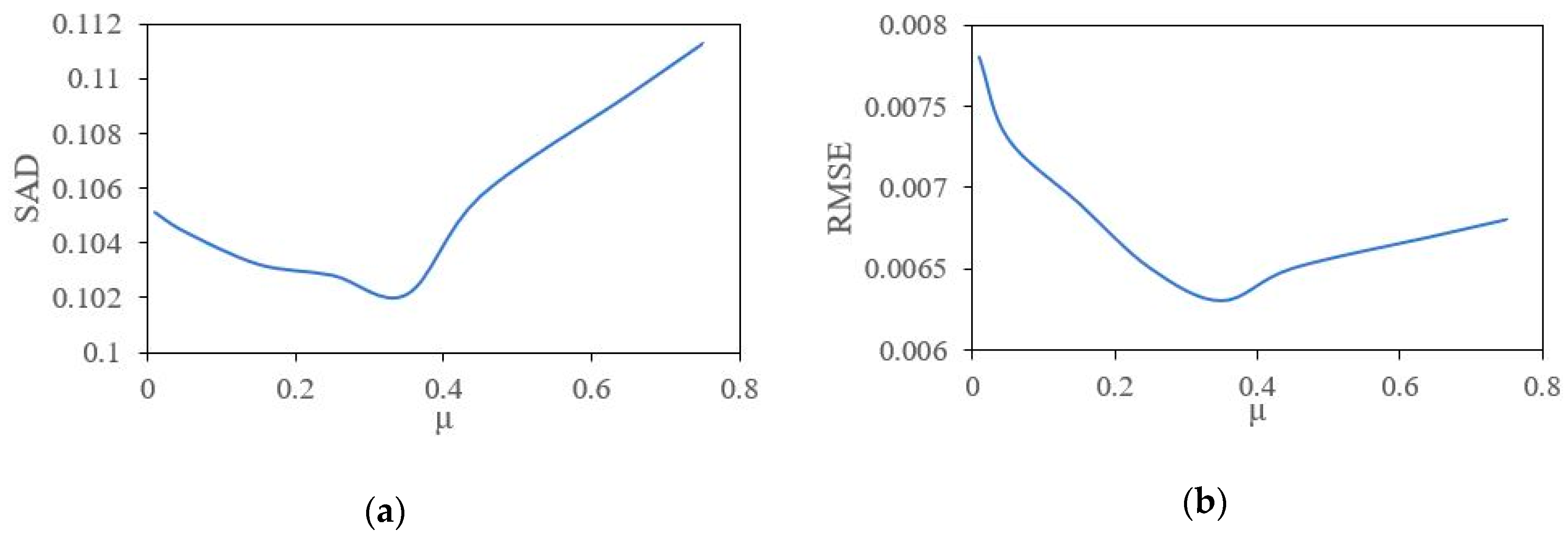
2.5. The Proposed MDWSU Algorithm Model
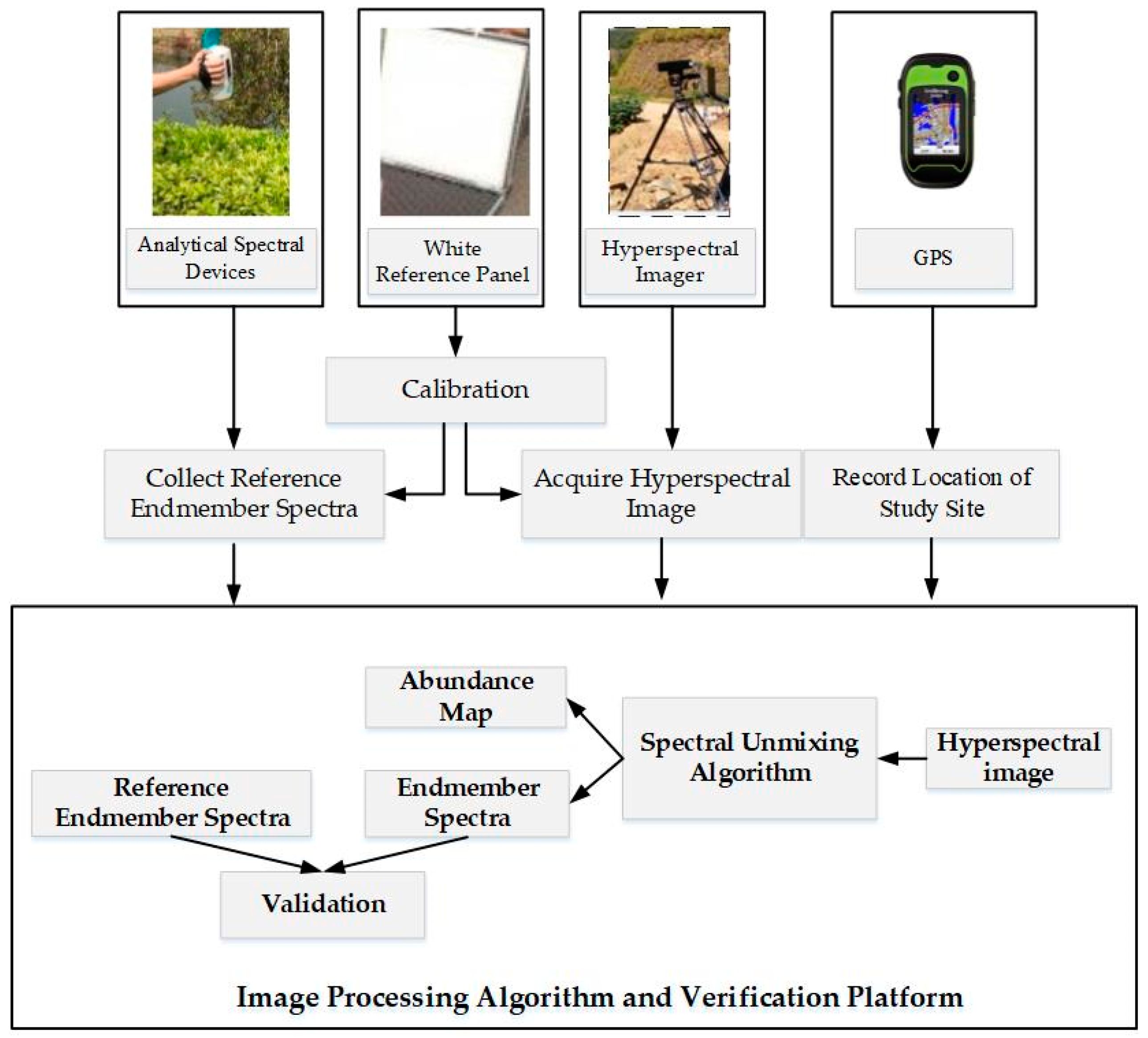
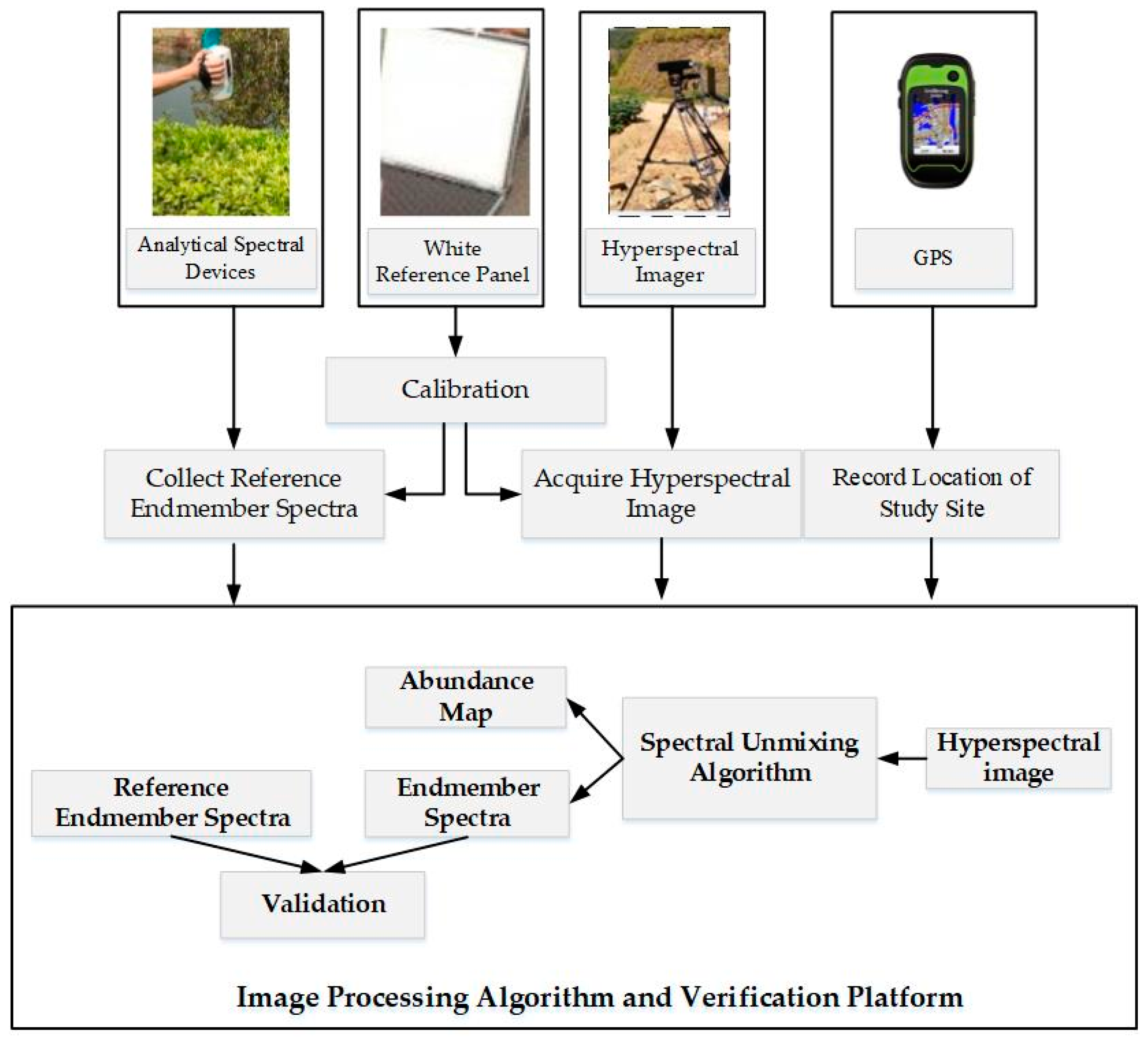
3. Data Acquisition
4. Experimental Results and Analysis
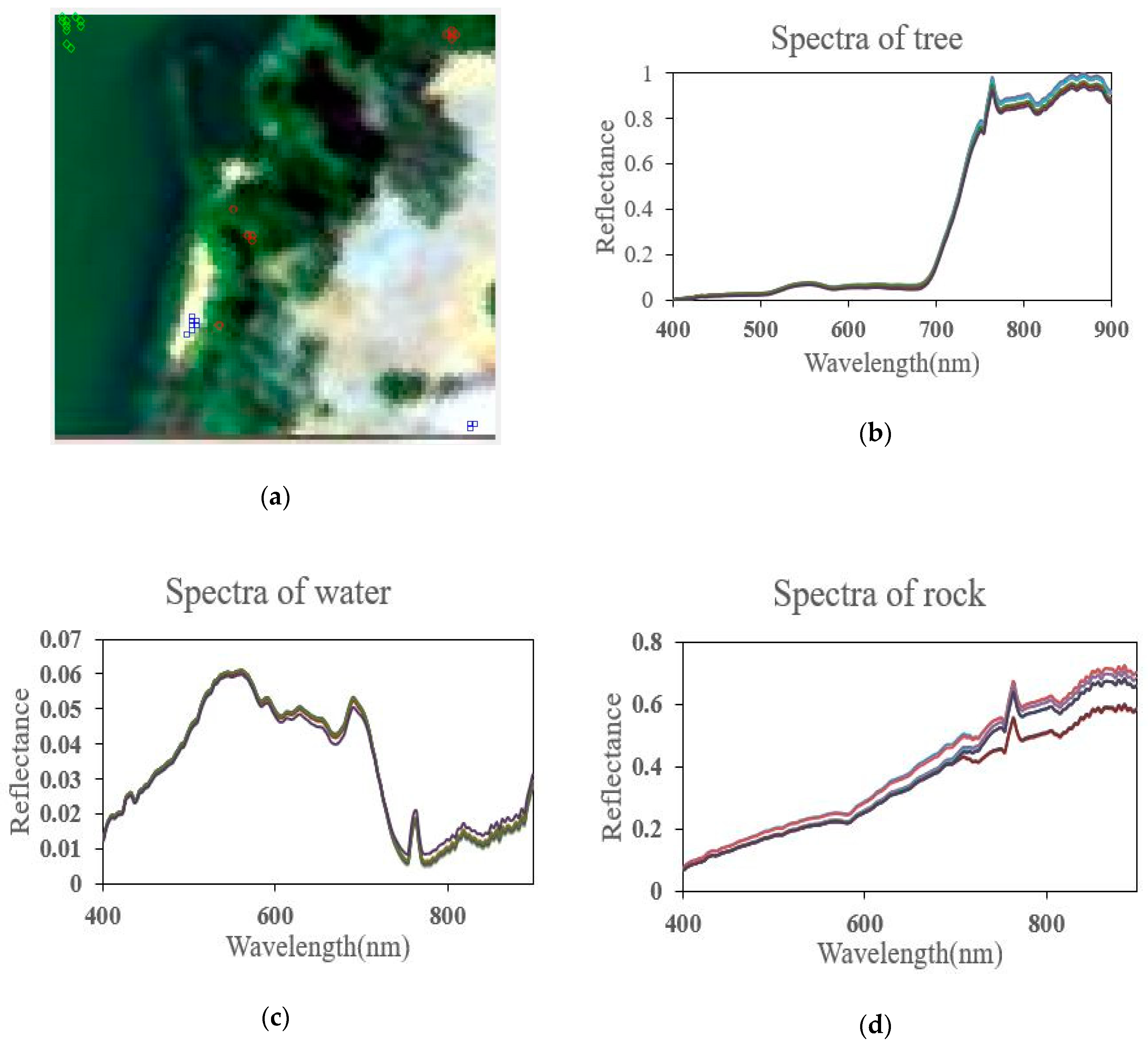
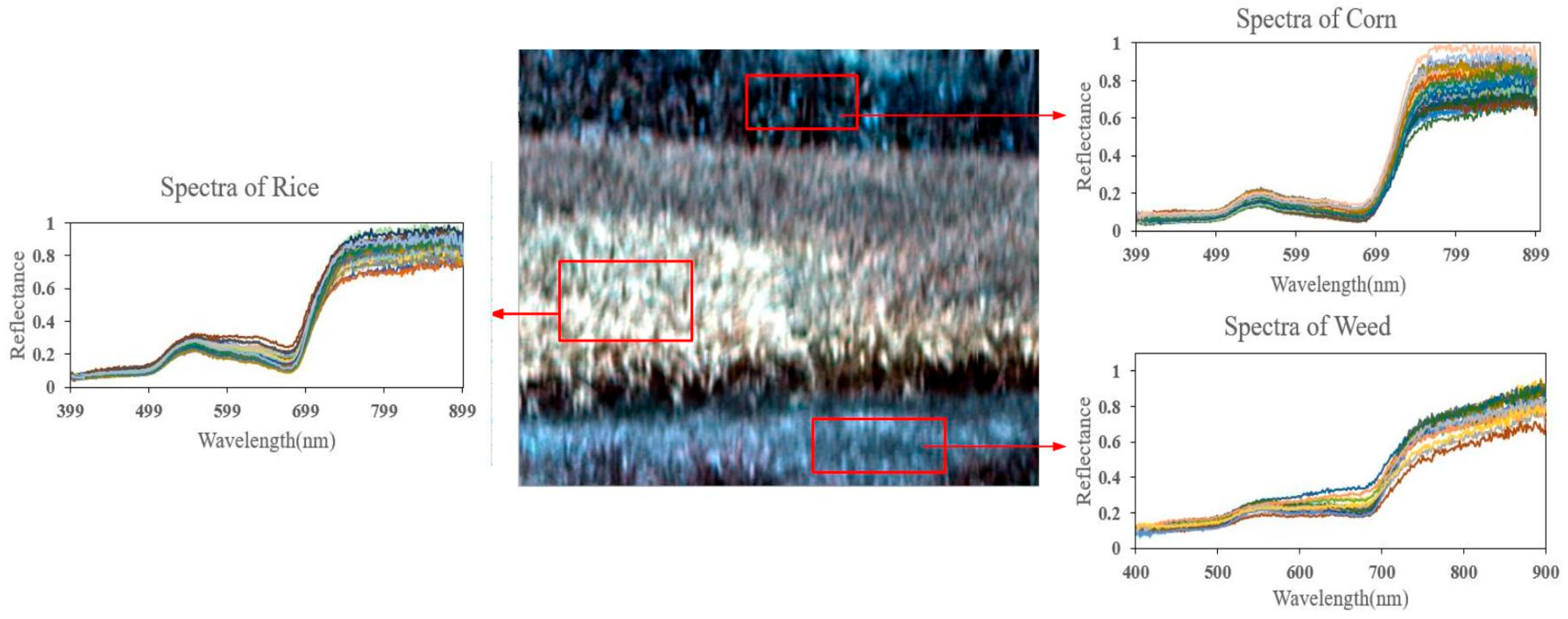
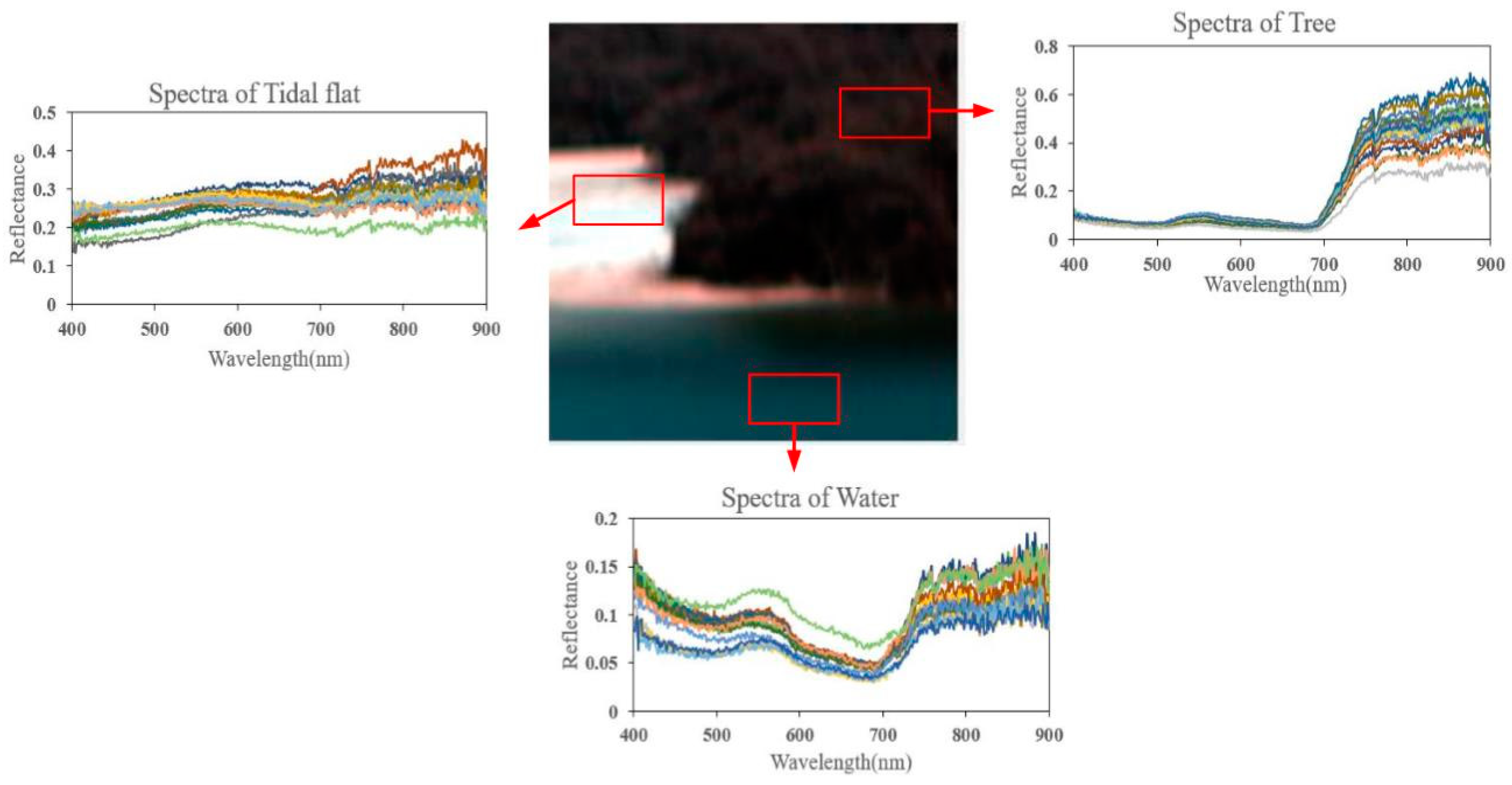
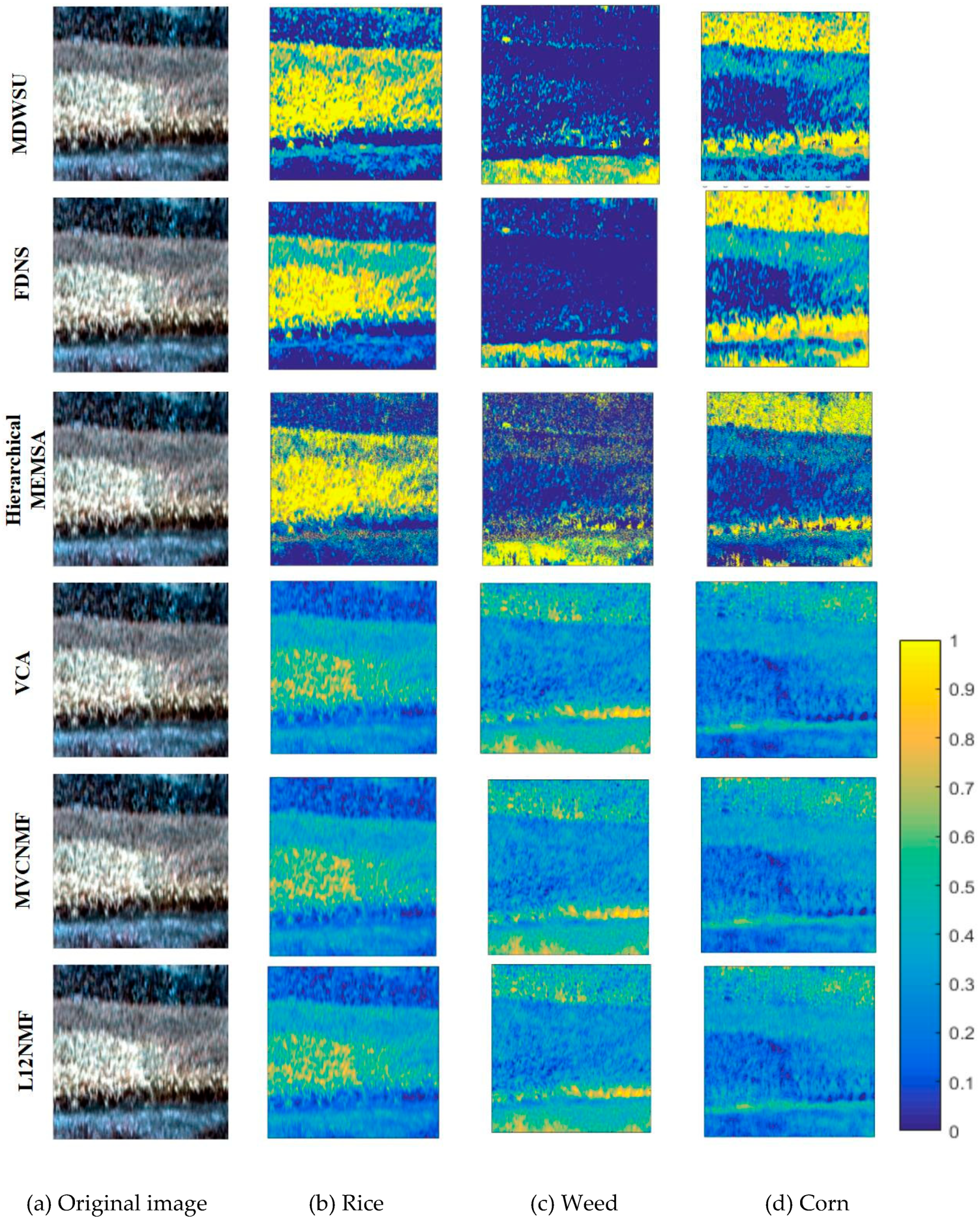
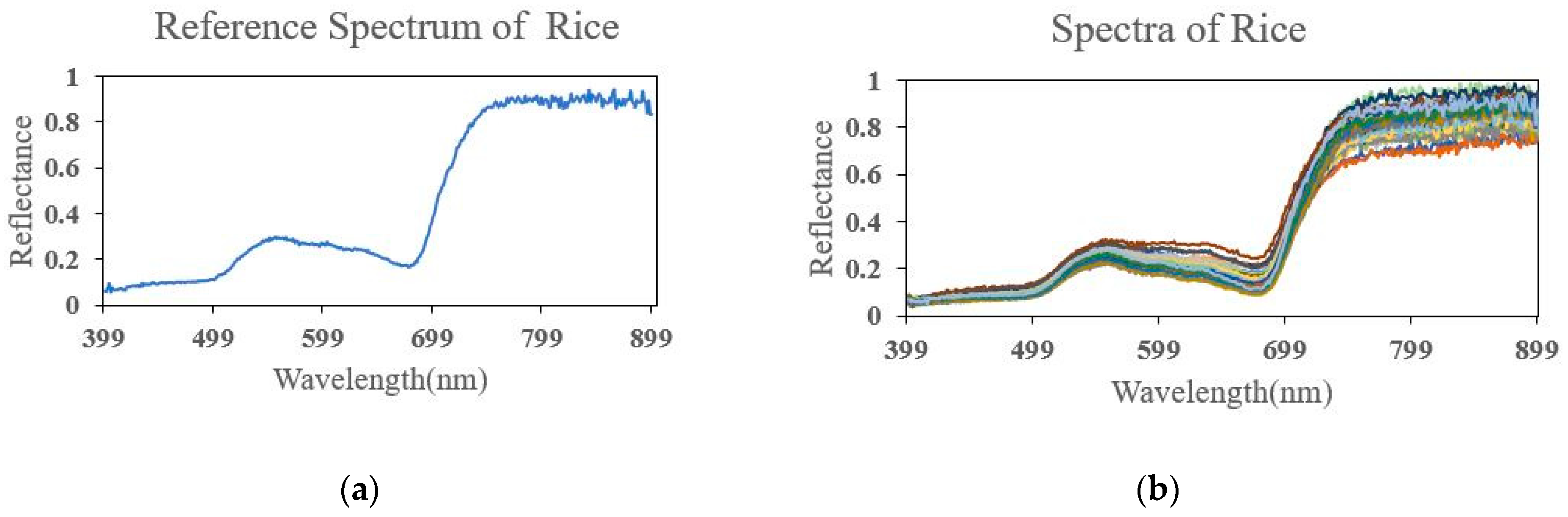
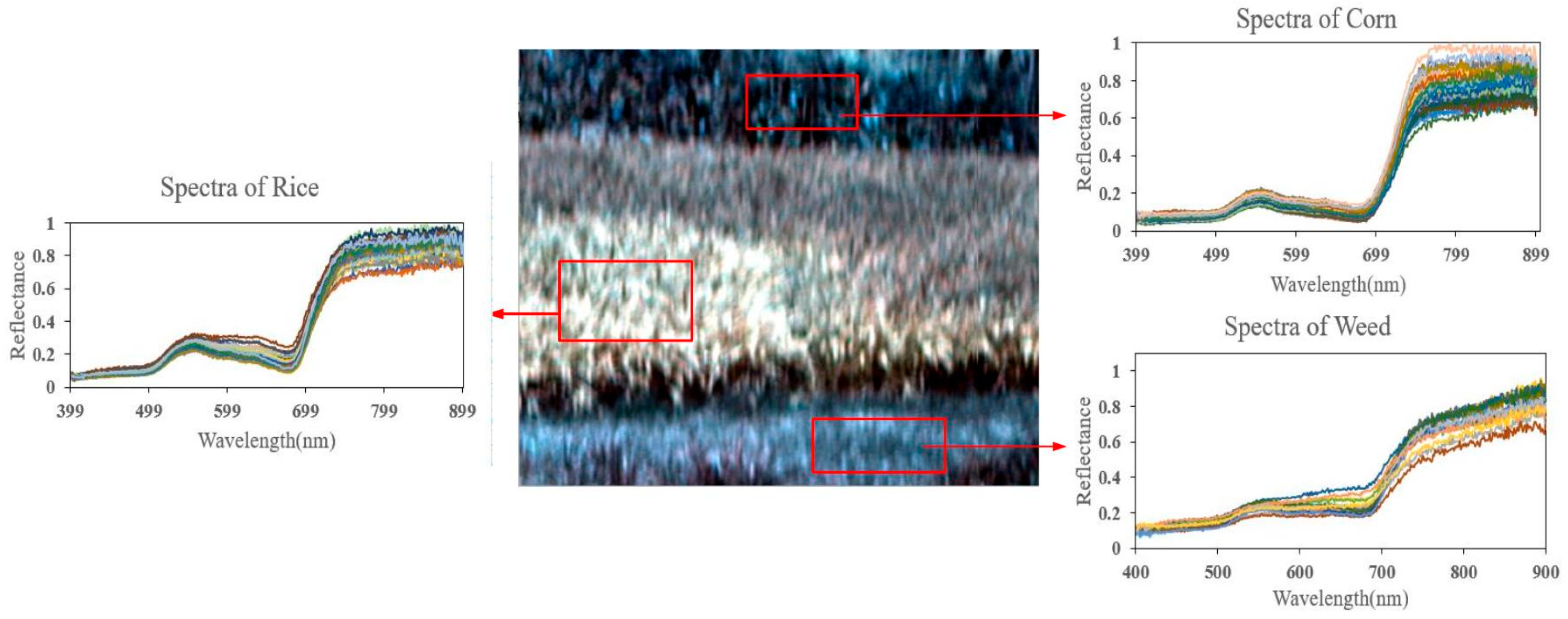
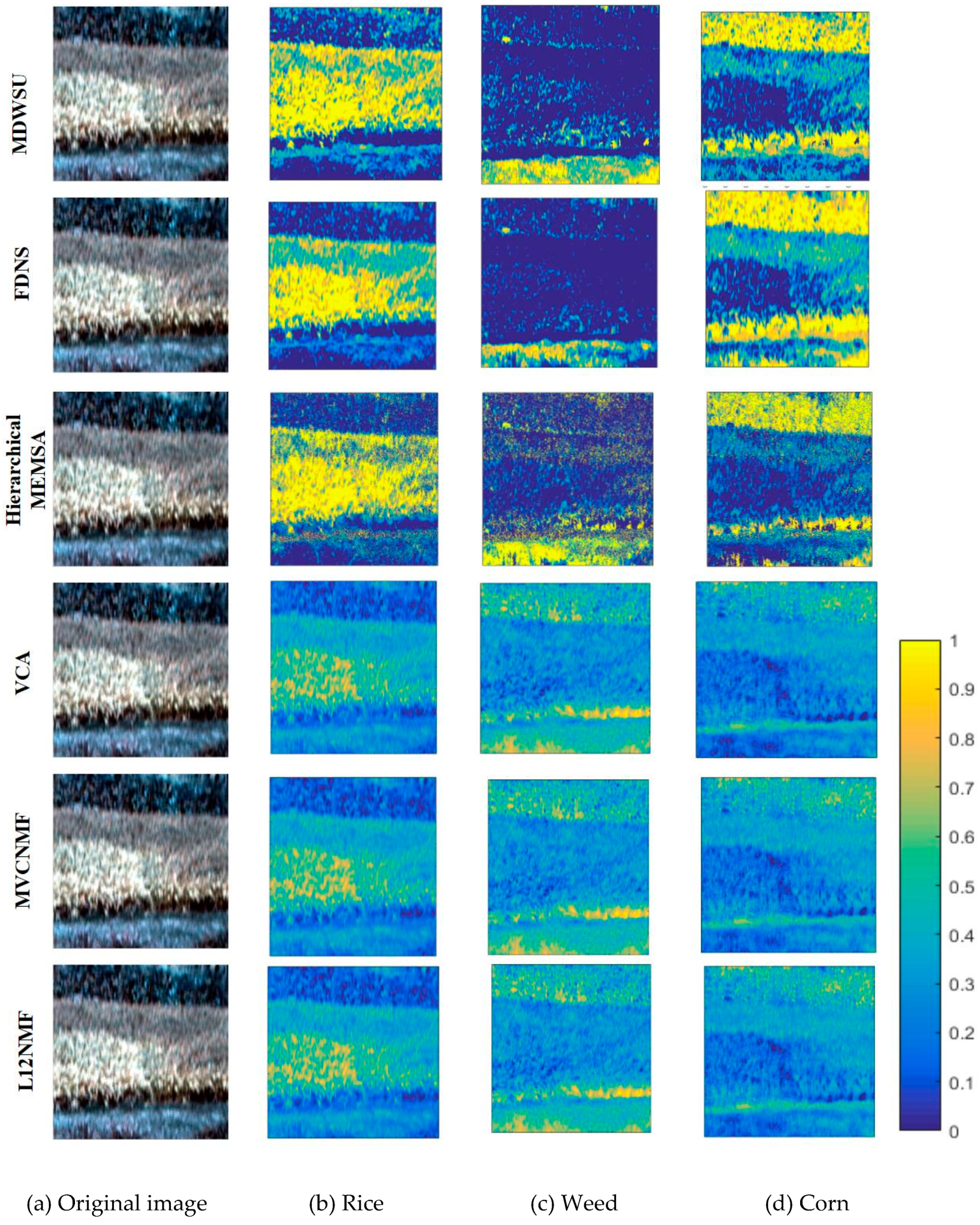
4.1. Real Hyperspectral Data Experiments
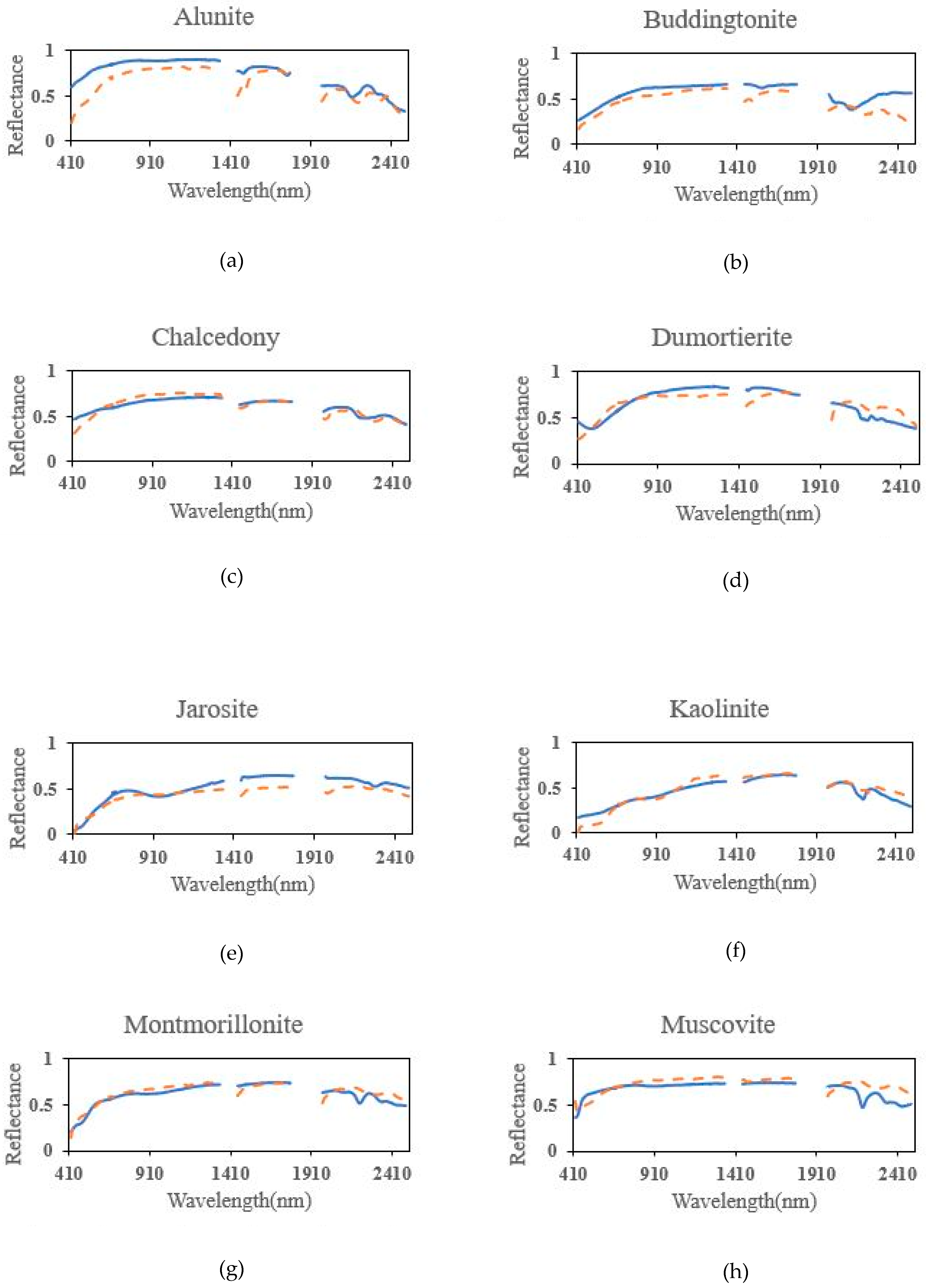
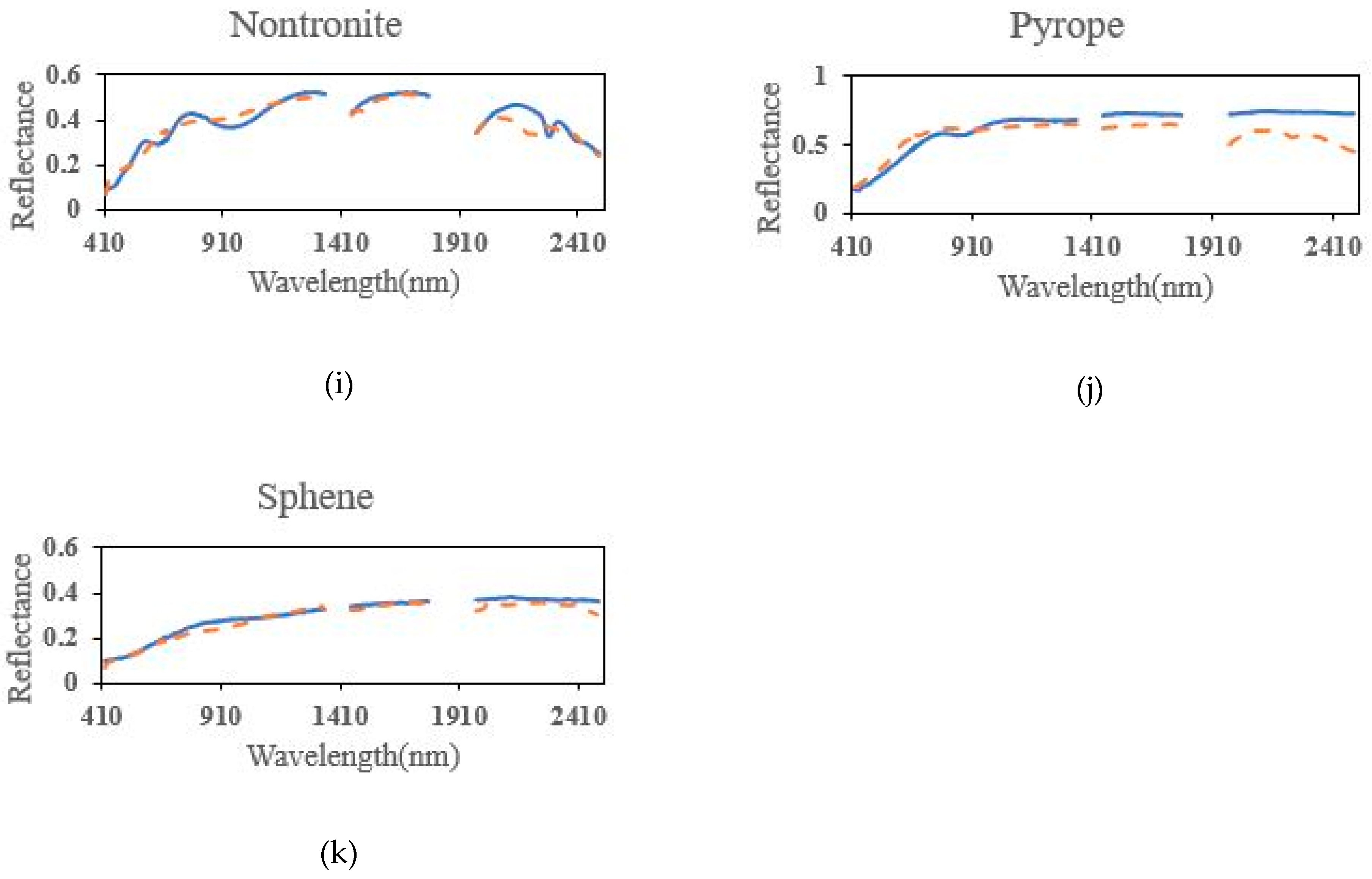
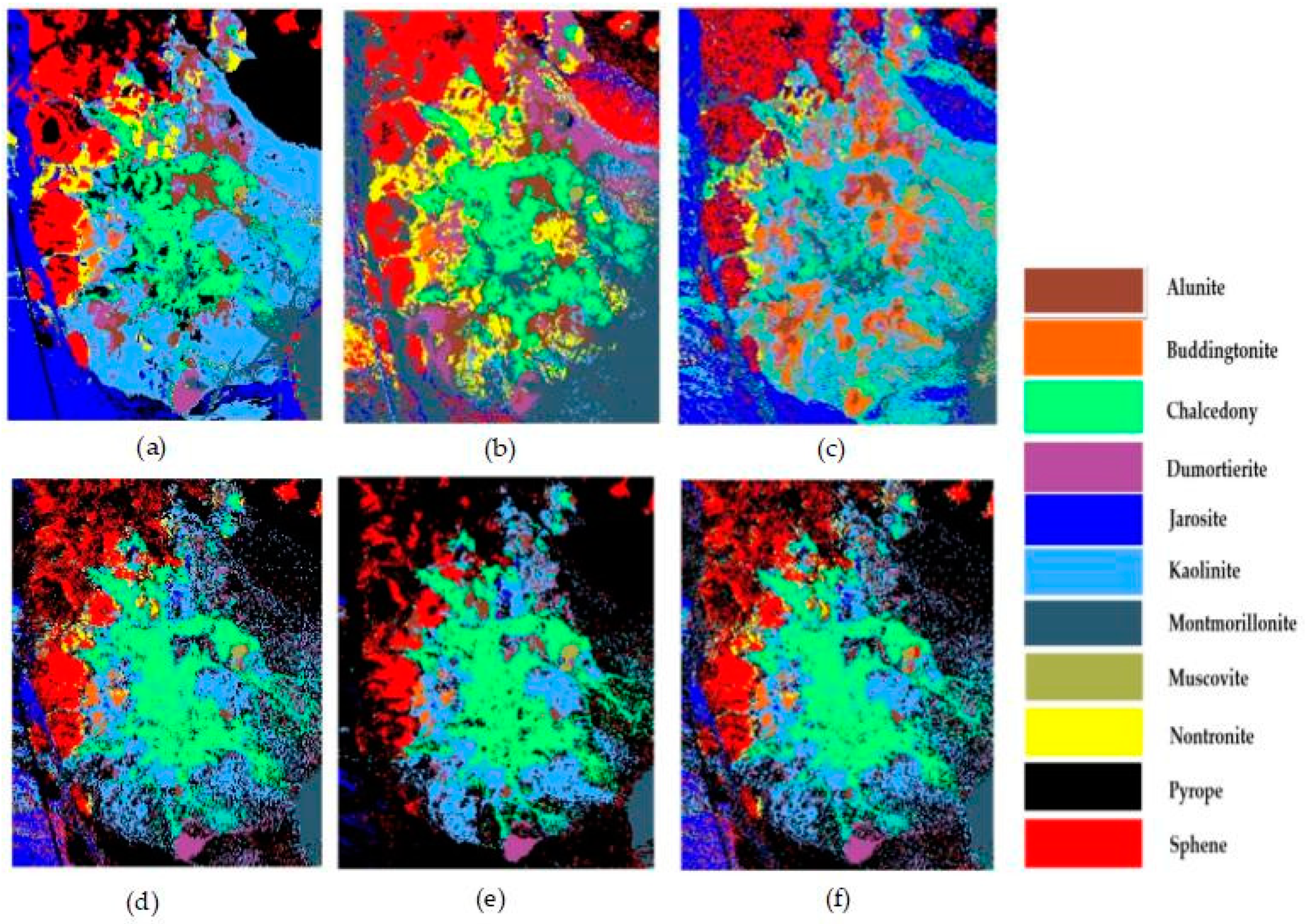
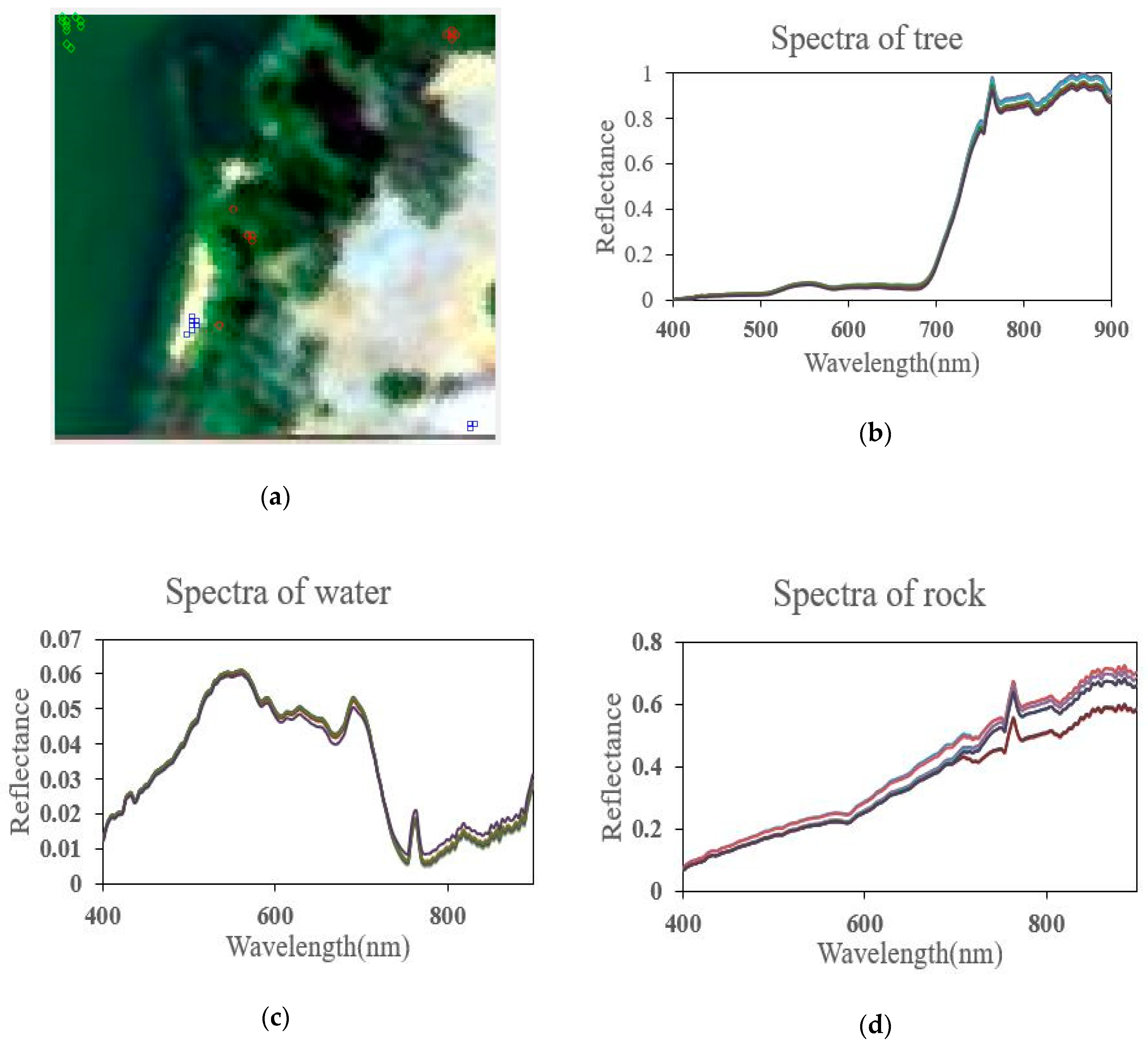
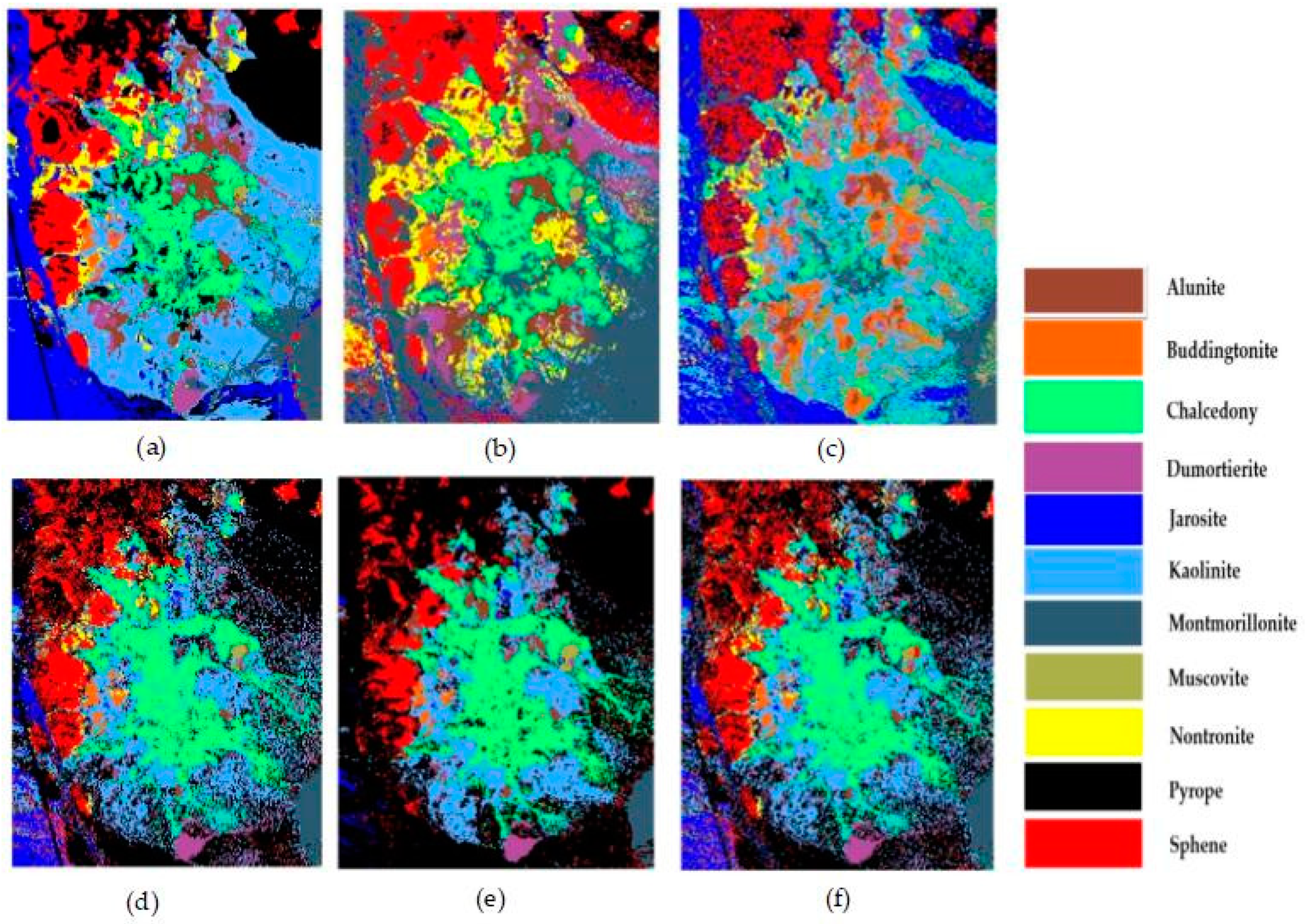
4.2. Experimental Results of the AVIRIS Cuprite Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Zhang, H.; Gong, M.; Zhao, D.; Yan, P.; Cui, R.; Jia, W. Super-resolution technique of microzooming in electro-optical imaging systems. J. Mod. Opt. 2001, 48, 2161–2167. [Google Scholar] [CrossRef]
- Keshava, N. A survey of spectral unmixing algorithms. Linc. Lab. J. 2003, 14, 55–78. [Google Scholar]
- Zou, J.; Lan, J. A multiscale hierarchical model for sparse hyperspectral unmixing. Remote Sens. 2019, 11, 500. [Google Scholar] [CrossRef]
- Halimi, A.; Honeine, P.; Bioucas-Dias, J.M. Hyperspectral unmixing in presence of endmember variability, nonlinearity, or mismodeling effects. IEEE Trans. Image Process. 2016, 25, 4565–4579. [Google Scholar] [CrossRef] [PubMed]
- Somers, B.; Asner, G.P.; Tits, L.; Coppin, P. Endmember variability in spectral mixture analysis: A review. Remote Sens. Environ. 2011, 115, 1603–1616. [Google Scholar] [CrossRef]
- Zare, A.; Ho, K.C. Endmember variability in hyperspectral analysis: Addressing spectral variability during spectral unmixing. IEEE Signal Process. Mag. 2014, 31, 95–104. [Google Scholar] [CrossRef]
- Ghaffari, O.; Zoej, M.J.V.; Mokhtarzade, M. Reducing the effect of the endmembers’ spectral variability by selecting the optimal spectral bands. Remote Sens. 2017, 9, 884. [Google Scholar] [CrossRef]
- Costanzo, D.J. Hyperspectral imaging spectral variability experiment results. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 24–28 July 2000. [Google Scholar]
- Drumetz, L.; Veganzones, M.A.; Henrot, S.; Phlypo, R.; Chanussot, J.; Jutten, C. Blind hyperspectral unmixing using an extended linear mixing model to address spectral variability. IEEE Trans. Image Process. 2016, 25, 3890–3905. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Rivard, B.; Sánchez-Azofeifa, A.; Castro-Esau, K. Intra- and inter-class spectral variability of tropical tree species at La Selva, Costa Rica: Implications for species identification using HYDICE imagery. Remote Sens. Environ. 2006, 105, 129–141. [Google Scholar] [CrossRef]
- Roberts, D.A.; Gardner, M.; Church, R.; Ustin, S.; Scheer, G.; Green, R.O. Mapping chaparral in the santa monica mountains using multiple endmember spectral mixture models. Remote Sens Environ. 1998, 65, 267–279. [Google Scholar] [CrossRef]
- Franke, J.; Roberts, D.A.; Halligan, K.; Menz, G. Hierarchical multiple endmember spectral mixture analysis (MESMA) of hyperspectral imagery for urban environments. Remote Sens Environ. 2009, 113, 1712–1723. [Google Scholar] [CrossRef]
- Powell, R.L.; Roberts, D.A.; Dennison, P.E.; Hess, L.L. Sub-pixel mapping of urban land cover using multiple endmember spectral mixture analysis: Manaus, Brazil. Remote Sens Environ. 2007, 106, 253–267. [Google Scholar] [CrossRef]
- Somers, B.; Zortea, M.; Plaza, A.; Asner, G.P. Automated extraction of image-based endmember bundles for improved spectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 396–408. [Google Scholar] [CrossRef]
- Veganzones, M.A.; Drumetz, L.; Tochon, G.; Mura, M.D.; Plaza, A.; Bioucas-Dias, J.-M.; Chanussot, J. A new extended linear mixing model to address spectral variability. In Proceedings of the 6th IEEE Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Lausanne, Switzerland, 24–27 June 2014. [Google Scholar]
- Chang, C.I.; Wang, S. Constrained band selection for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1575–1585. [Google Scholar] [CrossRef]
- Guo, B.; Gunn, S.R.; Damper, R.I.; Nelson, J.D.B. Band selection for hyperspectral image classification using mutual information. IEEE Geosci. Remote Sens. Lett. 2006, 3, 522–526. [Google Scholar] [CrossRef]
- Somers, B.; Verbesselt, J.; Ampe, E.M.; Sims, N.; Verstraeten, W.W.; Coppin, P. Spectral mixture analysis to monitor defoliation in mixed-aged Eucalyptus globulus Labill plantations in southern Australia using Landsat 5-TM and EO-1 Hyperion data. Int. J. Appl. Earth Obs. 2010, 12, 270–277. [Google Scholar] [CrossRef]
- Asner, B.; Delalieux, S.; Verstraeten, W.W.; Verbesselt, J.; Lhermitte, S.; Coppin, P. Magnitude- and shape-related feature integration in hyperspectral mixture analysis to monitor weeds in Citrus Orchards. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3630–3642. [Google Scholar]
- Mahhi, A.; Gao, R.X. PCA-based feature selection scheme for machine defect classification. IEEE Trans. Instrum. Meas. 2004, 53, 1517–1525. [Google Scholar]
- Li, J. Wavelet-based feature extraction for improved endmember abundance estimation in linear unmixing of hyperspectral signals. IEEE Trans. Geosci. Remote Sens. 2004, 42, 644–649. [Google Scholar] [CrossRef]
- Zhang, J.; Rivard, B.; Sanchez-Azofeifa, A. Derivative spectral unmixing of hyperspectral data applied to mixtures of lichen and rock. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1934–1940. [Google Scholar] [CrossRef]
- Asner, G.P.; Lobell, D.B. A biogeophysical approach for automated SWIR unmixing of soils and vegetation. Remote Sens. Environ. 2000, 74, 99–112. [Google Scholar] [CrossRef]
- Zou, J.; Lan, J.; Shao, Y. A hierarchical sparsity unmixing method to address endmember variability in hyperspectral image. Remote Sens. 2018, 10, 738. [Google Scholar] [CrossRef]
- Jin, J.; Wang, B.; Zhang, L. A Novel Approach Based on Fisher Discriminant Null Space for Decomposition of Mixed Pixels in Hyperspectral Imagery. IEEE Geosci. Remote Sens. Lett. 2010, 7, 699–703. [Google Scholar] [CrossRef]
- Boardman, J.W.; Kruse, F.A.; Green, R.O. Mapping Target Signatures via Partial Unmixing of AVIRIS Data. In Proceedings of the 5th Annual JPL Airborne Earth Science Workshop, Pasadena, CA, USA, 9–14 December 1995; Volume 1, pp. 23–26. [Google Scholar]
- Li, H.; Jiang, T.; Zhang, K. Efficient and Robust Feature Extraction by Maximum Margin Criterion. IEEE Trans. Neural Netw. 2006, 17, 157–165. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, J.; Gao, Y.; Zhang, C.; Li, Z. Enhancing spectral unmixing by local neighborhood weights. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1545–1552. [Google Scholar] [CrossRef]
- Miao, X.; Gong, P.; Swope, S.; Pu, R.; Carruthers, R.; Anderson, G.L.; Heaton, J.S.; Tracy, C.R. Estimation of yellow starthistle abundance through CASI-2 hyperspectral imagery using linear spectral mixture models. Remote Sens. Environ. 2006, 101, 329–341. [Google Scholar] [CrossRef]
- Karnieli, A. A review of mixture modeling techniques for sub-pixel land cover estimation. Remote Sens. Rev. 1996, 13, 161–186. [Google Scholar]
- Keshava, N.; Mustard, J.F. Spectral unmixing. IEEE Signal Process. Mag. 2002, 19, 44–57. [Google Scholar] [CrossRef]
- Nascimento, J.M.P.; Dias, J.M.B. Vertex component analysis: A fast algorithm to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef]
- Neville, R.A.; Staenz, K.; Szeredi, T.; Lefebvre, J.; Hauff, P. Automatic endmember extraction from hyperspectral data for mineral exploration. In Proceedings of the International Airborne Remote Sensing Conference and Exhibition, 4th/21st Canadian Symposium on Remote Sensing, Ottawa, ON, Canada, 21–24 June 1999; pp. 891–897. [Google Scholar]
- Opticks. Available online: http://opticks.org/confluence/display/opticks/Sample+Data (accessed on 27 November 2015).
- Chang, C.I.; Ji, B. Weighted abundance-constrained linear spectral mixture analysis. IEEE Trans. Geosci. Remote Sens. 2006, 44, 378–388. [Google Scholar] [CrossRef]
- Tsai, F.; Philpot, W.D. A derivative-aided hyperspectral image analysis system for land-cover classification. IEEE Trans. Geosci. Remote Sens. 2002, 40, 416–425. [Google Scholar] [CrossRef]
- Tsai, F.; Philpot, W.D. Derivative analysis of hyperspectral data. Remote Sens. Environ. 1998, 66, 41–51. [Google Scholar] [CrossRef]
- Chen, Z.; Curran, P.J.; Hansom, J.D. Derivative reflectance spectroscopy to estimate suspended sediment concentration. Remote Sens. Environ. 1992, 40, 67–77. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1964, 7, 1627–1639. [Google Scholar] [CrossRef]
- Tobler, W. A computer movie simulating urban growth in the Detroit region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps and spectral techniques for embedding and clustering. Adv. Neural Inf. Process. Syst. 2001, 14, 585–591. [Google Scholar]
- Qian, Y.; Jia, S.; Zhou, J.; Robles-Kelly, A. Hyperspectral unmixing via L1/2 sparsity-constrained nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2014, 49, 4282–4297. [Google Scholar] [CrossRef]
- Miao, L.; Qi, H. Endmember extraction from highly mixed data using minimum volume constrained nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2007, 45, 765–777. [Google Scholar] [CrossRef]
- Lu, X.; Wu, H.; Yuan, Y.; Yan, P.; Li, X. Manifold Regularized Sparse NMF for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2815–2826. [Google Scholar] [CrossRef]
- Hoyer, P.O. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 2004, 5, 1457–1469. [Google Scholar]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Heinz, D.; Chang, C.-I. Fully constrained least squares linear mixture analysis for material quantification in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2000, 39, 529–545. [Google Scholar] [CrossRef]
- Zhou, G.X.; Xie, S.L.; Ding, S.X.; Yang, J.M.; Zhang, J. Blind spectral unmixing based on sparse nonnegative matrix factorization. IEEE Trans. Image Process. 2011, 20, 1112–1125. [Google Scholar]
- SpecLab. Available online: http://speclab.cr.usgs.gov/cuprite.html (accessed on 20 September 2018).
- Swayze, G.; Clark, R.; Sutley, S.; Gallagher, A. Ground-truthing AVIRIS mineral mapping at Cuprite, Nevada. In Proceedings of the 3rd Annual JPL Airborne Geoscience Workshop, Pasadena, CA, USA, 1–5 June 1992. [Google Scholar]
- Swayze, G.A. The Hydrothermal and Structural History of the Cuprite Mining District, Southwestern Nevada: An Integrated Geological and Geophysical Approach; Stanford University: Stanford, CA, USA, 1997. [Google Scholar]
- USGS. Available online: https://speclab.cr.usgs.gov/spectral-lib.html (accessed on 17 January 2019).
- Li, J.; Bioucas-Dias, J.; Plaza, A.; Liu, L. Robust Collaborative Nonnegative Matrix Factorization for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6076–6090. [Google Scholar] [CrossRef]
- Chang, C.I.; Du, Q. Estimation of number of spectrally distinct signal sources in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2004, 42, 608–619. [Google Scholar] [CrossRef]
- Revel, C.; Deville, Y.; Achrad, V.; Briottet, X.; Weber, C. Inertia-Constrained Pixel-by-Pixel Nonnegative Matrix Factorisation: A Hyperspectral Unmixing Method Dealing with Intra-Class Variability. Remote Sens. 2017, 10, 1706. [Google Scholar] [CrossRef]
- Bateson, C.A.; Asner, G.P.; Wessman, C.A. Endmember Bundles: A New Approach to Incorporating Endmember Variability into Spectral Mixture Analysis. IEEE Trans. Geosci. Remote Sens. 2000, 38, 1083–1094. [Google Scholar] [CrossRef]
- Winter, M.E. N-FINDR: An algorithm for fast autonomous spectral endmember determination in hyperspectral data. In Proceedings of the SPIE’s International Symposium on Optical Science, Engineering, and Instrumentation, Denver, CO, USA, 18–23 July 1999; pp. 266–275. [Google Scholar]
- Li, J.; Bioucas-Dias, J. Minimum volume simplex analysis: A fast algorithm to unmix hyperspectral data. In Proceedings of the IEEE Geoscience Remote Sensing Symposium (IGARSS’08), Boston, MA, USA, 8–12 August 2008; Volume 4, pp. 2369–2371. [Google Scholar]
- Bioucas-Dias, J. A variable splitting augmented Lagrangian approach to linear spectral unmixing. In Proceedings of the 1st IEEE WHISPERS, Grenoble, France, 26–28 August 2009. [Google Scholar]
- Liu, L.; Du, B.; Zhang, L. Hyperspectral Unmixing via Double Abundance Characteristics Constraints Based NMF. Remote Sens. 2016, 8, 464. [Google Scholar] [CrossRef]
- Shao, Y.; Lan, J.; Zhang, Y.; Zou, J. Spectral Unmixing of Hyperspectral Remote Sensing Imagery via Preserving the Intrinsic Structure Invariant. Sensors 2018, 18, 3528. [Google Scholar] [CrossRef] [PubMed]
- Jia, K.; Liang, S.; Gu, X.; Baret, F.; Wei, X.; Wang, X. Fractional vegetation cover estimation algorithm for Chinese GF-1 wide field view data. Remote Sens. Environ. 2016, 177, 184–191. [Google Scholar] [CrossRef]
- Paura, P.; Piper, J.; Plemmons, R.J. Nonnegative matrix factorization for spectral data analysis. In Linear Algebra and Its Applications; THOMSON: Luton, UK, 2006; Volume 416, pp. 29–47. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MDWSU | FDNS | L1/2-NMF | MVC-NMF | VCA-FCLS | |
|---|---|---|---|---|---|
| Rice | 0.1654 | 0.2354 | 0.4597 | 0.2380 | 0.2056 |
| Corn | 0.1921 | 0.1975 | 0.5632 | 0.2076 | 0.3421 |
| Weed | 0.2072 | 0.2236 | 0.3216 | 0.3154 | 0.1768 |
| AVERAGE | 0.1882 | 0.2188 | 0.4481 | 0.2536 | 0.2418 |
| MDWSU | FDNS | Hierarchical MEMSA | L1/2-NMF | MVC-NMF | VCA-FCLS |
|---|---|---|---|---|---|
| 0.0075 | 0.0088 | 0.0087 | 0.0106 | 0.0097 | 0.0118 |
| MDWSU | FDNS | L1/2-NMF | MVC-NMF | VCA-FCLS | |
|---|---|---|---|---|---|
| Water | 0.1135 | 0.2142 | 0.3278 | 0.3876 | 0.5310 |
| Tree | 0.1218 | 0.1882. | 0.4571 | 0.4782 | 0.4674 |
| Tidal flat | 0.0712 | 0.2537 | 0.1037 | 0.0958 | 0.0897 |
| AVERAGE | 0.1021 | 0.2187 | 0.2962 | 0.3205 | 0.3627 |
| MDWSU | FDNS | Hierarchical MEMSA | L1/2-NMF | MVC-NMF | VCA-FCLS |
|---|---|---|---|---|---|
| 0.0063 | 0.0078 | 0.0075 | 0.0115 | 0.0124 | 0.0098 |
| MDWSU | FDNS | L1/2-NMF | MVC-NMF | VCA-FCLS | |
|---|---|---|---|---|---|
| Alunite | 0.1356 | 0.1245 | 0.1895 | 0.1965 | 0.1278 |
| Buddingtonite | 0.0967 | 0.0983 | 0.1269 | 0.1157 | 0.2638 |
| Chalcedony | 0.0981 | 0.0991 | 0.1104 | 0.1087 | 0.0931 |
| Dumortierite | 0.0827 | 0.1153 | 0.1371 | 0.0721 | 0.1288 |
| Jarosite | 0.0928 | 0.0986 | 0.1183 | 0.1212 | 0.1372 |
| Kaolinite | 0.0698 | 0.1181 | 0.1081 | 0.1279 | 0.1219 |
| Montmorillonite | 0.0564 | 0.0861 | 0.0937 | 0.0723 | 0.1752 |
| Muscovite | 0.0803 | 0.1035 | 0.0921 | 0.1327 | 0.1935 |
| Nontronite | 0.0741 | 0.0723 | 0.0901 | 0.0927 | 0.2649 |
| Pyrope | 0.1291 | 0.0823 | 0.0779 | 0.1361 | 0.1219 |
| Sphene | 0.0671 | 0.1031 | 0.1316 | 0.1890 | 0.1357 |
| AVERAGE | 0.0893 | 0.1001 | 0.1159 | 0.1240 | 0.1603 |
| MDWSU | FDNS | Hierarchical MEMSA | L1/2-NMF | MVC-NMF | VCA-FCLS |
|---|---|---|---|---|---|
| 0.0052 | 0.0068 | 0.0066 | 0.0073 | 0.0075 | 0.0072 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, Y.; Lan, J. A Spectral Unmixing Method by Maximum Margin Criterion and Derivative Weights to Address Spectral Variability in Hyperspectral Imagery. Remote Sens. 2019, 11, 1045. https://doi.org/10.3390/rs11091045
Shao Y, Lan J. A Spectral Unmixing Method by Maximum Margin Criterion and Derivative Weights to Address Spectral Variability in Hyperspectral Imagery. Remote Sensing. 2019; 11(9):1045. https://doi.org/10.3390/rs11091045
Chicago/Turabian StyleShao, Yang, and Jinhui Lan. 2019. "A Spectral Unmixing Method by Maximum Margin Criterion and Derivative Weights to Address Spectral Variability in Hyperspectral Imagery" Remote Sensing 11, no. 9: 1045. https://doi.org/10.3390/rs11091045
APA StyleShao, Y., & Lan, J. (2019). A Spectral Unmixing Method by Maximum Margin Criterion and Derivative Weights to Address Spectral Variability in Hyperspectral Imagery. Remote Sensing, 11(9), 1045. https://doi.org/10.3390/rs11091045