Adversarial Reconstruction-Classification Networks for PolSAR Image Classification



Abstract
1. Introduction
2. Feature Extraction of PolSAR Images
2.1. Coherency Matrix
2.2. Cloude-Pottier Decomposition
3. Related Work
3.1. Sliding Window Fully Convolutional Networks
3.2. Deep Reconstruction-Classification Networks
3.3. Semantic Segmentation Using Adversarial Networks
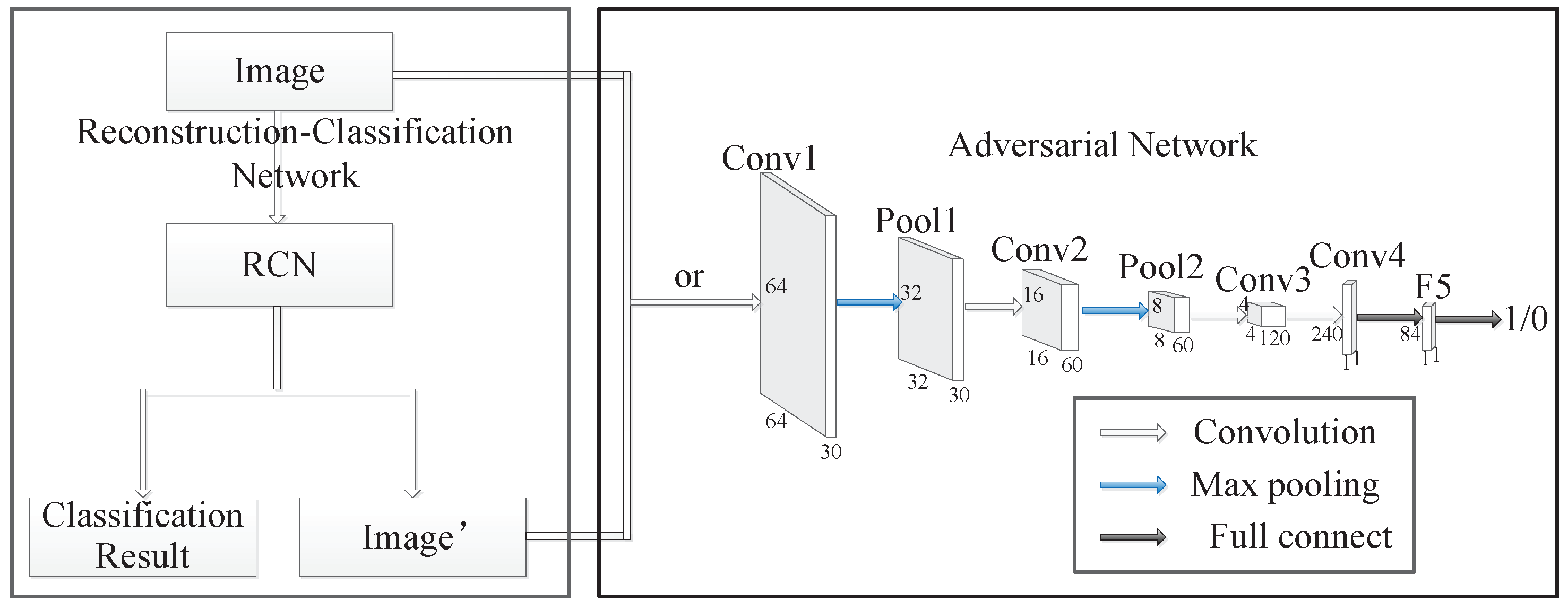
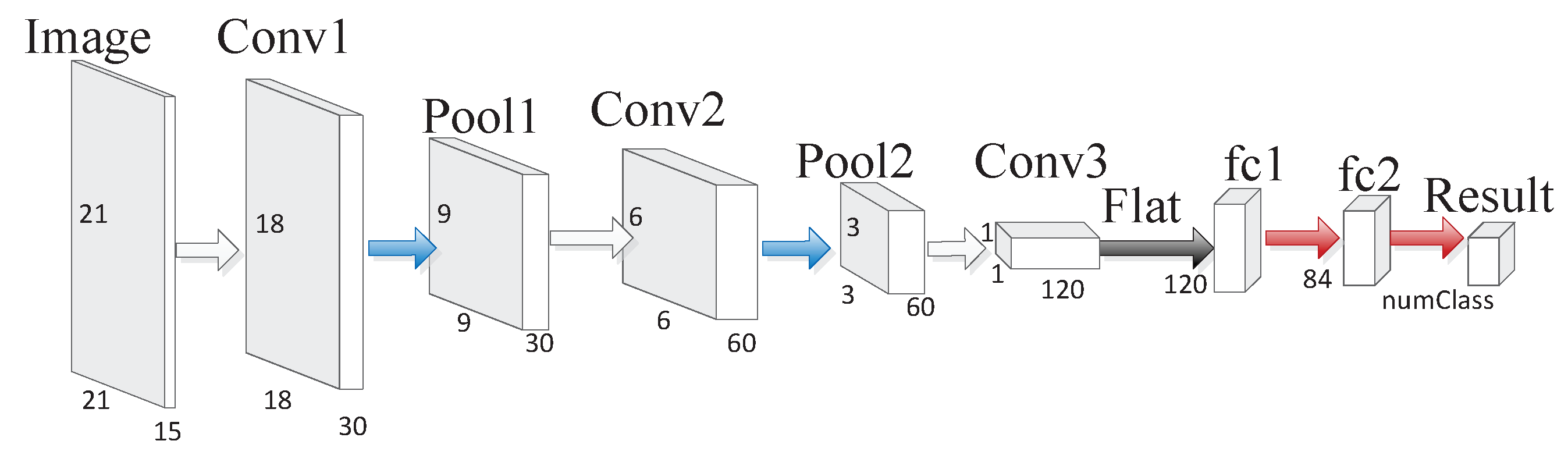
4. Methodology
4.1. Reconstruction-Classification Networks
4.2. Adversarial Reconstruction-Classification Networks
4.2.1. Adversarial Training for RCN
4.2.2. Training the Adversarial Model
4.2.3. Training the RCN Model
| Algorithm 1 The adversarial reconstruction-classificati networks (ARCN) learning algorithm. |
| Input: Labeled samples: ; Unlabeled samples ; Learning rate: ; |
|
| Output: ARCN learnt parameters: = . |
5. Experimental Results
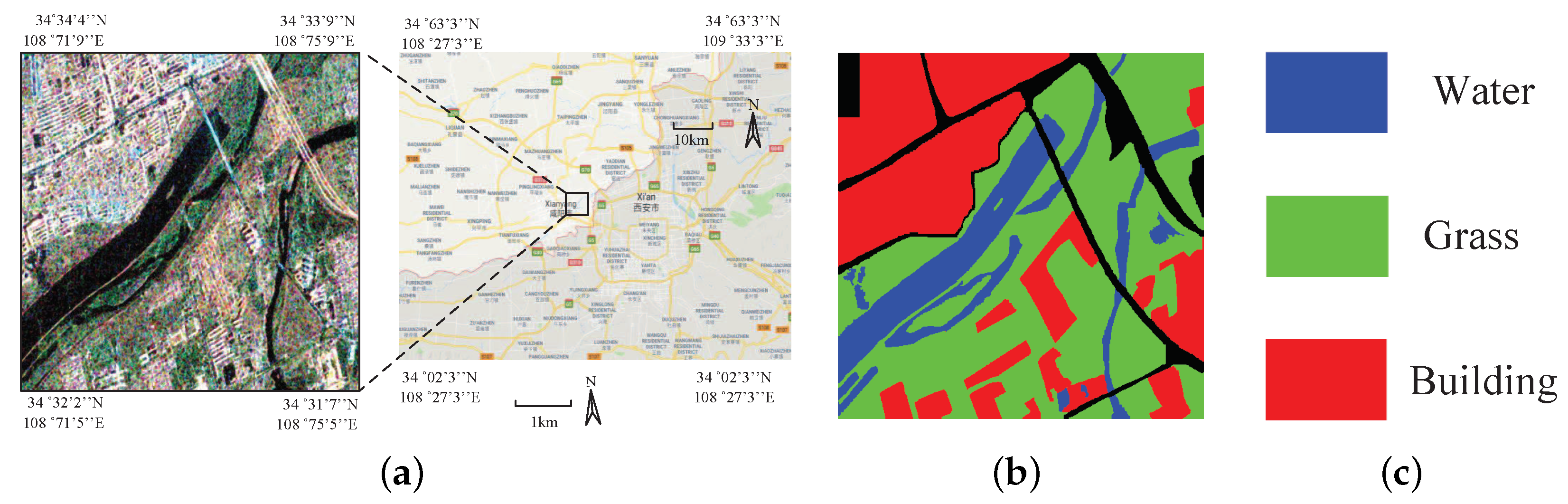
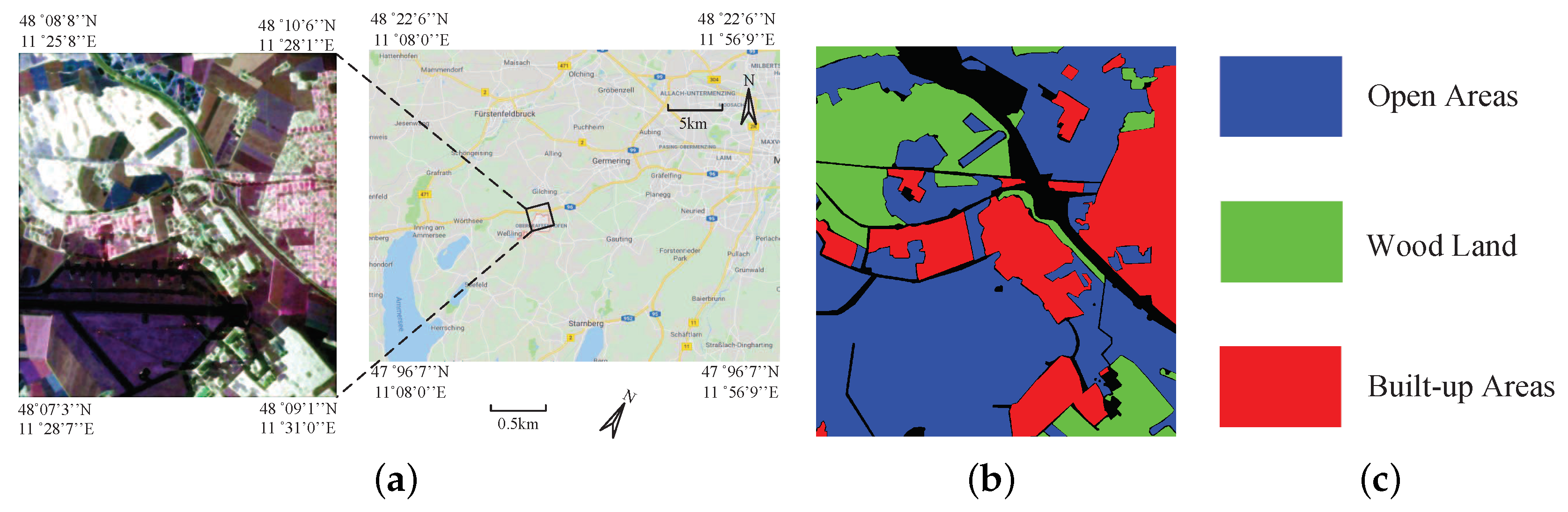
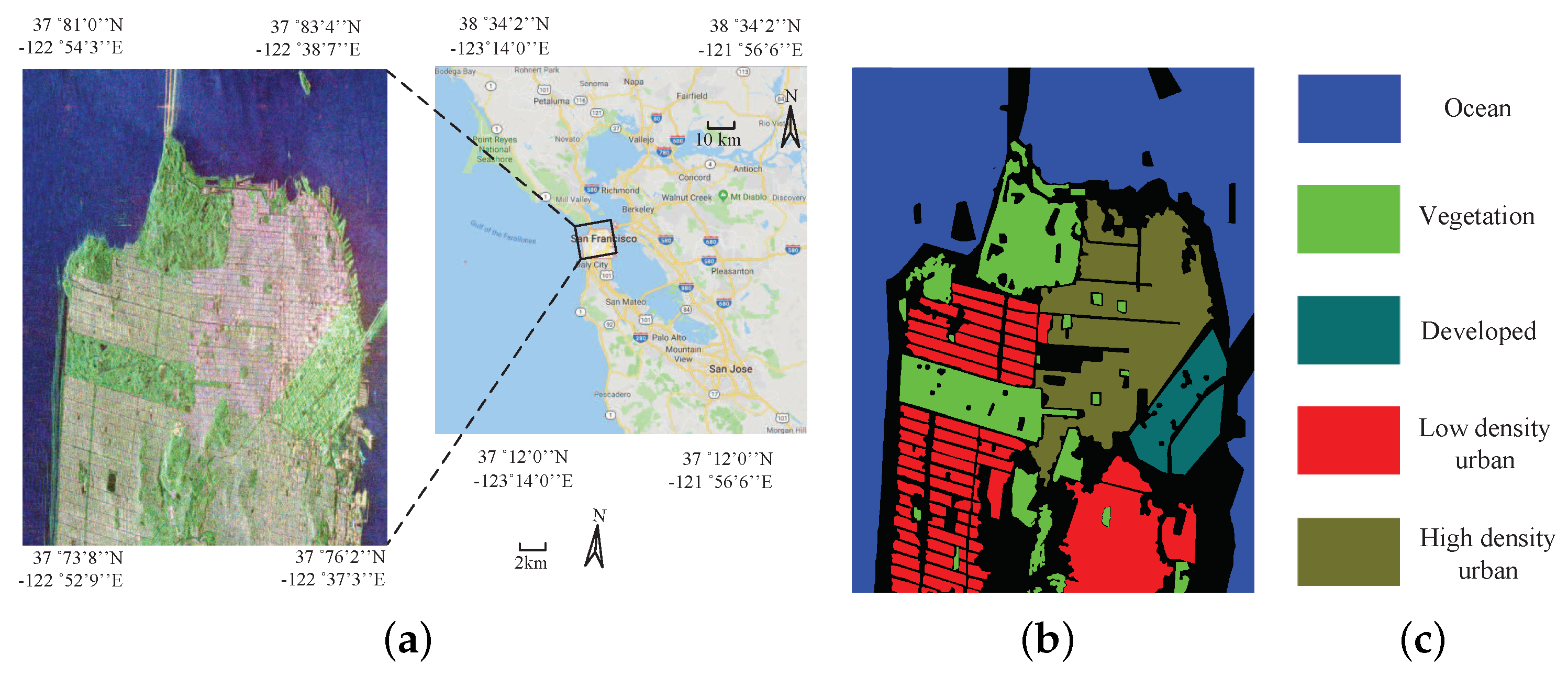
5.1. Description of Experimental PolSAR Images
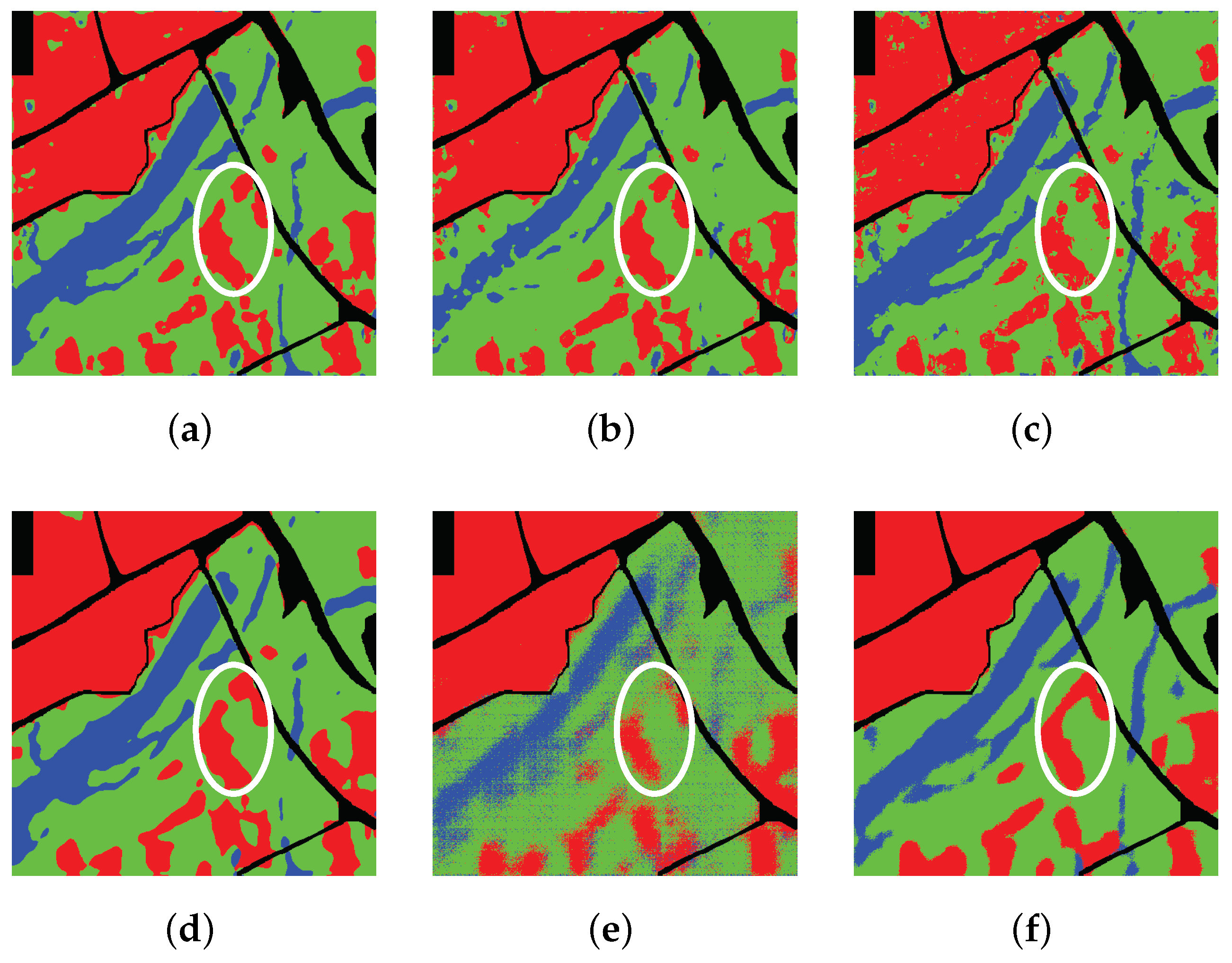
5.1.1. Xi’an
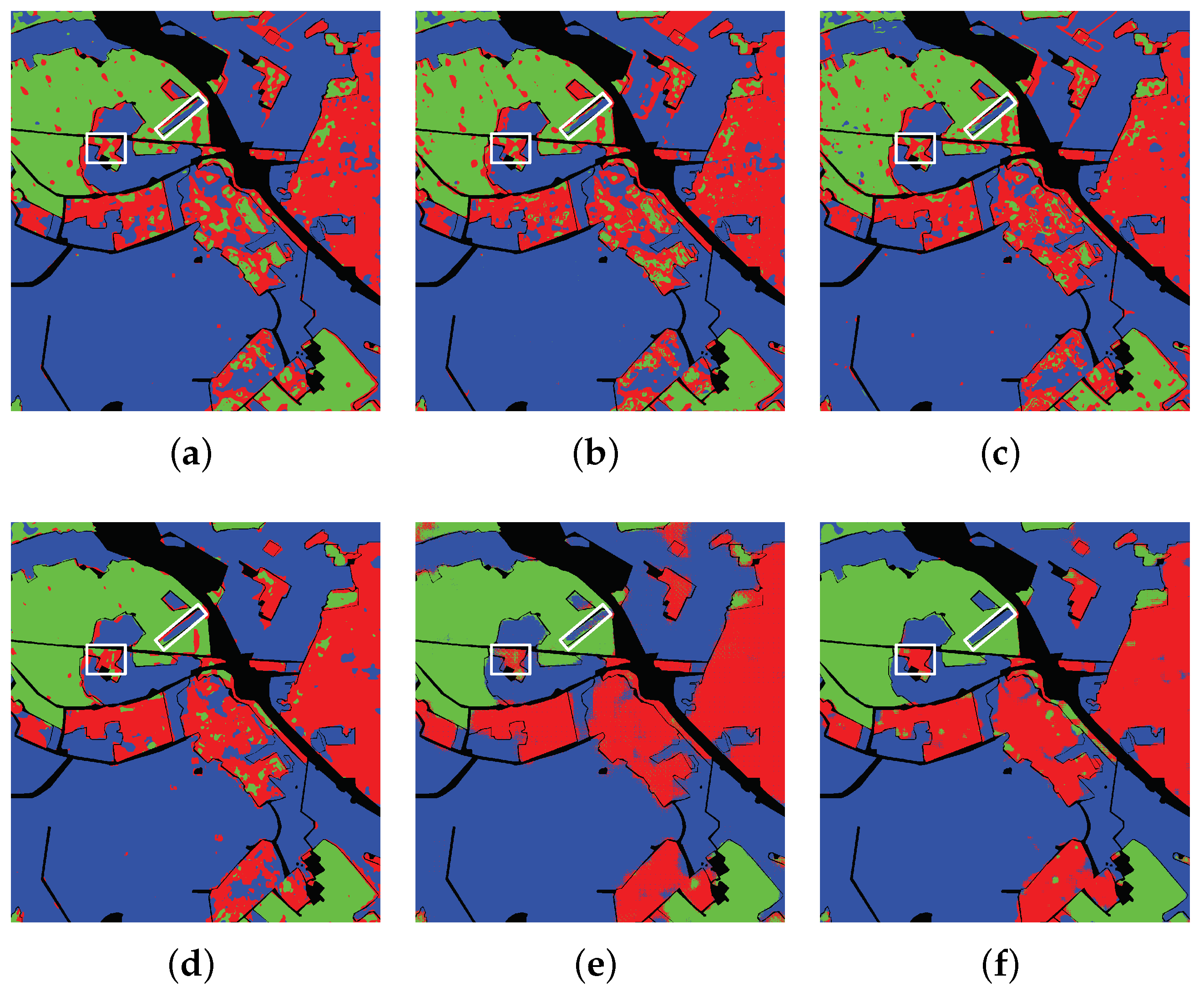
5.1.2. Oberpfaffenhofen
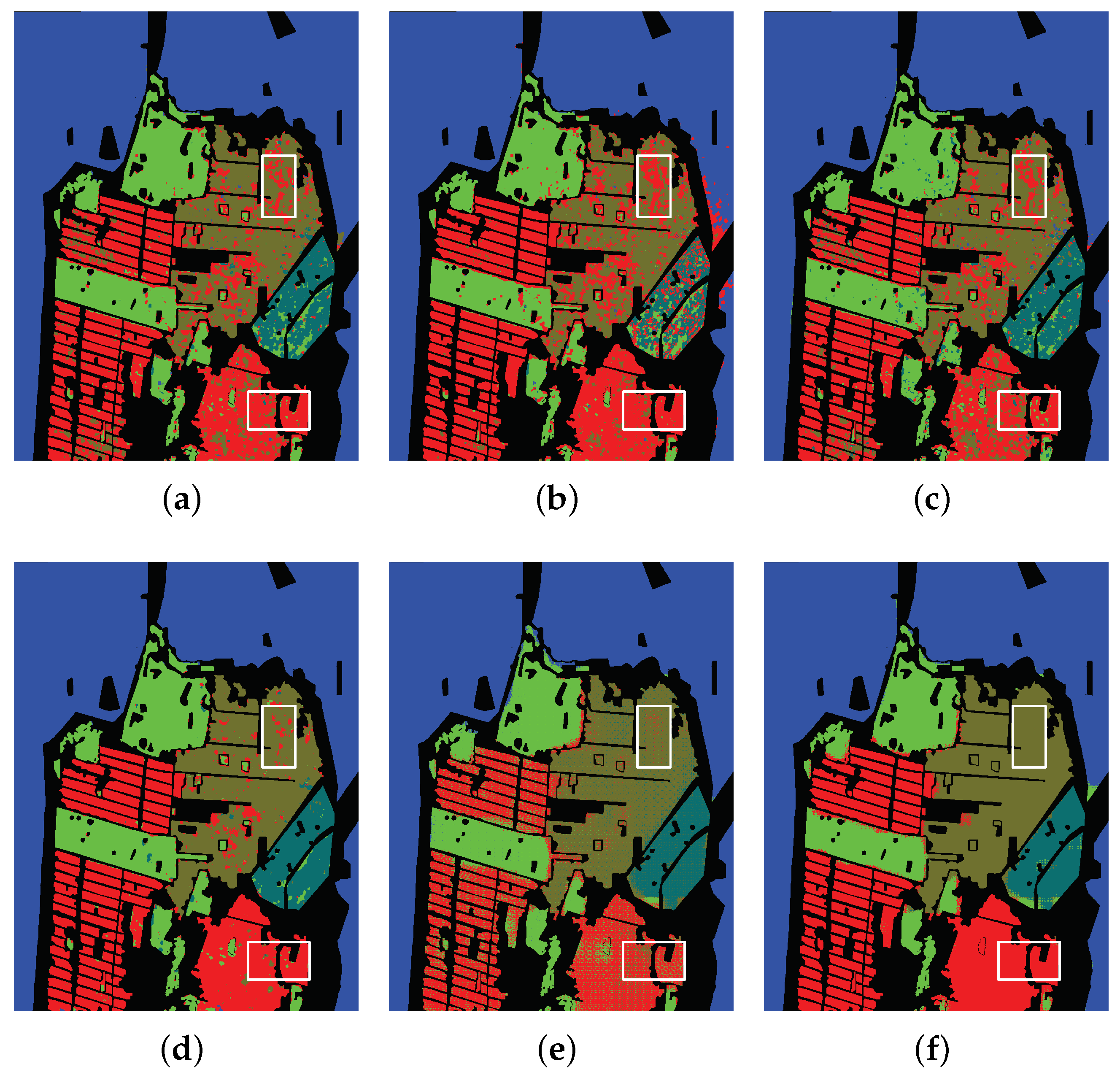
5.1.3. San Francisco
5.2. Parameter Setting
5.3. Classification Performance
5.3.1. Xi’an Data Set
5.3.2. Oberpfaffenhofen Data Set
5.3.3. San Francisco Data Set
6. Discussion
6.1. Accuracy
6.2. Execution Time
6.3. Memory Consumption
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PolSAR | Polarimetric synthetic aperture radar |
| FCN | Fully convolutional network |
| SFCN | Sliding window fully convolutional network |
| RCN | Reconstruction-classification networks |
| ARCN | Adversarial reconstruction-classification networks |
| KNN | K-nearest neighbor |
| SVM | Support vector machine |
| SAE | Stacked auto-encoder |
| CNN | Convolutional neural network |
| DRCN | Deep reconstruction-classification network |
| GAN | Generative adversarial network |
| CRF | Conditional random field |
| SRC | Sparse representation classifier |
| OA | Overall accuracy |
| RBF | Radial basis function |
References
- Chen, W.; Gou, S.; Wang, X.; Li, X.; Jiao, L. Classification of PolSAR Images Using Multilayer Autoencoders and a Self-Paced Learning Approach. Remote Sens. 2018, 10, 110. [Google Scholar] [CrossRef]
- Zhang, F.; Ni, J.; Yin, Q.; Li, W.; Li, Z.; Liu, Y.; Hong, W. Nearest-Regularized Subspace Classification for PolSAR Imagery Using Polarimetric Feature Vector and Spatial Information. Remote Sens. 2017, 9, 1114. [Google Scholar] [CrossRef]
- Hou, B.; Chen, C.; Liu, X.; Jiao, L. Multilevel distribution coding model-based dictionary learning for PolSAR image classification. IEEE J. Sel. Top. Appl. Earth Obs. 2015, 8, 5262–5280. [Google Scholar]
- Cheng, J.; Ji, Y.; Liu, H. Segmentation-based PolSAR image classification using visual features: RHLBP and color features. Remote Sens. 2015, 7, 6079–6106. [Google Scholar] [CrossRef]
- Tao, C.; Chen, S.; Li, Y.; Xiao, S. PolSAR land cover classification based on roll-invariant and selected hidden polarimetric features in the rotation domain. Remote Sens. 2017, 9, 660. [Google Scholar]
- Zhang, L.; Sun, L.; Zou, B.; Moon, W.M. Fully Polarimetric SAR Image Classification via Sparse Representation and Polarimetric Features. IEEE J. Sel. Top. Appl. Earth Obs. 2015, 8, 3923–3932. [Google Scholar] [CrossRef]
- Krogager, E. New decomposition of the radar target scattering matrix. Electron. Lett. 1990, 26, 1525–1527. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. An entropy based classification scheme for land applications of polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar] [CrossRef]
- Xu, Q.; Chen, Q.; Yang, S.; Liu, X. Superpixel-based classification using K distribution and spatial context for polarimetric SAR images. Remote Sens. 2016, 8, 619. [Google Scholar] [CrossRef]
- Huynen, J.R. Phenomenological theory of radar targets. Electromagn. Scatt. 1978, 653–712. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S.L. A three-component scattering model for polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef]
- Van Zyl, J.J.; Arii, M.; Kim, Y. Model-based decomposition of polarimetric SAR covariance matrices constrained for nonnegative eigenvalues. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3452–3459. [Google Scholar] [CrossRef]
- Yamaguchi, Y.; Moriyama, T.; Ishido, M.; Yamada, H. Four-component scattering model for polarimetric SAR image decomposition. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1699–1706. [Google Scholar] [CrossRef]
- Kong, J.A.; Swartz, A.A.; Yueh, H.A.; Novak, L.M.; Shin, R.T. Identification of terrain cover using the optimum polarimetric classifier. J. Electromagn. Waves Appl. 1988, 2, 171–194. [Google Scholar]
- Lee, J.-S.; Grunes, M.R.; Kwok, R. Classification of multi-look polarimetric SAR imagery based on complex Wishart distribution. Int. J. Remote Sens. 1994, 15, 2299–2311. [Google Scholar] [CrossRef]
- Lee, J.-S.; Grunes, M.R.; Ainsworth, T.L.; Du, L.-J.; Schuler, D.-L.; Cloude, S.R. Unsupervised classification using polarimetric decomposition and the complex Wishart classifier. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2249–2258. [Google Scholar]
- Schneider, R.Z.; Papathanassiou, K.P.; Hajnsek, I.; Moreira, A. Polarimetric and interferometric characterization of coherent scatterers in urban areas. IEEE Trans. Geosci. Remote Sens. 2006, 44, 971–984. [Google Scholar] [CrossRef]
- Shimoni, M.; Borghys, D.; Heremans, R.; Perneel, C.; Acheroy, M. Fusion of PolSAR and PolInSAR data for land cover classification. Int. J. Appl. Earth Obs. 2009, 11, 169–180. [Google Scholar] [CrossRef]
- Garestier, F.; Dubois-Fernandez, P.; Dupuis, X.; Paillou, P.; Hajnsek, I. PolInSAR analysis of X-band data over vegetated and urban areas. IEEE Trans. Geosci. Remote Sens. 2006, 44, 356–364. [Google Scholar] [CrossRef]
- Biondi, F. Multi-chromatic analysis polarimetric interferometric synthetic aperture radar (MCA-PolInSAR) for urban classification. Int. J. Remote Sens. 2018, 1–30. [Google Scholar] [CrossRef]
- Chen, S.; Wang, X.; Sato, M. PolInSAR complex coherence estimation based on covariance matrix similarity test. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4699–4710. [Google Scholar] [CrossRef]
- Liu, F.; Jiao, L.; Hou, B.; Yang, S. POL-SAR Image classification based on Wishart DBN and local spatia information. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3292–3308. [Google Scholar] [CrossRef]
- Chen, Y.; Jiao, L.; Li, Y.; Zhao, J. Multilayer Projective Dictionary Pair Learning and Sparse Autoencoder for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6683–6694. [Google Scholar] [CrossRef]
- Richardson, A.; Goodenough, D.G.; Chen, H.; Moa, B.; Hobart, G.; Myrvold, W. Unsupervised nonparametric classification of polarimetric SAR data using the K-nearest neighbor graph. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Honolulu, HI, USA, 25–30 July 2010; pp. 1867–1870. [Google Scholar]
- Zhang, L.; Zou, B.; Zhang, J.; Zhang, Y. Classification of polarimetric SAR image based on support vector machine using multiple-component scattering model and texture features. EURASIP J. Adv. Signal Process. 2010, 2010. [Google Scholar] [CrossRef]
- Lardeux, C.; Frison, P.L.; Tison, C.C.; Souyris, J.C.; Stoll, B.; Fruneau, B.; Rudant, J.P. Support vector machine for multifrequency SAR polarimetric data classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 4143–4152. [Google Scholar] [CrossRef]
- Fukuda, S.; Hirosawa, H. Support vector machine classification of land cover: application to polarimetric SAR data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Sydney, Australia, 9–13 July 2001; pp. 187–189. [Google Scholar]
- Yueh, H.A.; Swartz, A.A.; Kong, J.A.; Shin, R.T.; Novak, L.M. Bayes classification of terrain cover using normalized polarimetric data. J. Geophys. Res. 1988, 93, 15261–15267. [Google Scholar] [CrossRef]
- Chen, Y.; Jiao, L.; Li, Y.; Li, L.; Zhang, D.; Ren, B.; Marturi, N. A Novel Semicoupled Projective Dictionary Pair Learning Method for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2018. [Google Scholar] [CrossRef]
- Chen, K.-S.; Huang, W.; Tsay, D.; Amar, F. Classification of multifrequency polarimetric SAR imagery using a dynamic learning neural network. IEEE Trans. Geosci. Remote Sens. 1996, 34, 814–820. [Google Scholar] [CrossRef]
- Hellmann, M.; Jager, G.; Kratzschmar, E.; Habermeyer, M. Classification of full polarimetric SAR-data using artificial neural networks and fuzzy algorithms. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Hamburg, Gemany, 28 June–2 July 1999; pp. 1995–1997. [Google Scholar]
- Chen, C.; Chen, K.; Lee, J. The use of fully polarimetric information for the fuzzy neural classification of SAR images. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2089–2100. [Google Scholar] [CrossRef]
- Hou, B.; Kou, H.; Jiao, L. Classification of Polarimetric SAR Images Using Multilayer Autoencoders and Superpixels. IEEE J. Sel. Top. Appl. Earth Obs. 2016, 9, 3072–3081. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 1–13. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Conference on Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhu, X.; Tuia, D.; Mou, L.; Xia, G.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.; Xu, F.; Jin, Y. Polarimetric SAR image classification using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Xie, W.; Jiao, L.; Hou, B.; Ma, W.; Zhao, J.; Zhang, S.; Liu, F. POLSAR image classification via Wishart-AE model or Wishart-CAE model. IEEE J. Sel. Top. Appl. Earth Obs. 2017, 10, 3604–3615. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Liu, G.; Jiao, L. A Novel Deep Fully Convolutional Network for PolSAR Image Classification. Remote Sens. 2018, 10, 1984. [Google Scholar] [CrossRef]
- Ghifary, M.; Kleijn, W.B.; Zhang, M.; Balduzzi, D.; Li, W. Deep reconstruction-classification networks for unsupervised domain adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 597–613. [Google Scholar]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic segmentation using adversarial networks. arXiv, 2016; arXiv:1611.08408. [Google Scholar]
- Cloude, S.R.; Pottier, E. A review of target decomposition theorems in radar polarimetry. IEEE Trans. Geosci. Remote Sens. 1996, 34, 498–518. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Conference on Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Lee, J.-S.; Grunes, M.R.; De Grandi, G. Polarimetric SAR speckle filtering and its implication for classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2363–2373. [Google Scholar]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Projective dictionary pair learning for pattern classification. In Proceedings of the Conference on Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 793–801. [Google Scholar]
- Ding, J.; Chen, B.; Liu, H.; Huang, M. Convolutional neural network with data augmentation for SAR target recognition. IEEE Geosci. Remote Sens. Lett. 2016, 13, 364–368. [Google Scholar] [CrossRef]
- Cohen, P. A coefficient of agreement for nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Ren, B.; Hou, B.; Zhao, J.; Jiao, L. Unsupervised classification of polarimetirc SAR image via improved manifold regularized low-rank representation with multiple features. JIEEE J. Sel. Top. Appl. Earth Obs. 2017, 10, 580–595. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Water | Grass | Building | OA | Kappa |
|---|---|---|---|---|---|
| SVM | 0.8167 | 0.9075 | 0.9012 | 0.8916 | 0.8199 |
| SRC | 0.5754 | 0.9169 | 0.9031 | 0.8607 | 0.7624 |
| SAE | 0.8861 | 0.8736 | 0.8957 | 0.8833 | 0.8086 |
| CNN | 0.8159 | 0.8990 | 0.9382 | 0.9004 | 0.8352 |
| SFCN | 0.5833 | 0.8437 | 0.8957 | 0.8229 | 0.7059 |
| ARCN | 0.8074 | 0.9527 | 0.9540 | 0.9313 | 0.8856 |
| Methods | Built-up Areas | Wood Land | Open Areas | OA | Kappa |
|---|---|---|---|---|---|
| SVM | 0.6978 | 0.8665 | 0.9682 | 0.8815 | 0.7959 |
| SRC | 0.7237 | 0.8380 | 0.9498 | 0.8721 | 0.7809 |
| SAE | 0.7807 | 0.8284 | 0.9604 | 0.8902 | 0.8119 |
| CNN | 0.8266 | 0.9234 | 0.9677 | 0.9242 | 0.8704 |
| SFCN | 0.9220 | 0.9157 | 0.9588 | 0.9413 | 0.9006 |
| ARCN | 0.9173 | 0.9551 | 0.9837 | 0.9617 | 0.9348 |
| Methods | Ocean | Vegetation | Low Density Urban | High Density Urban | Developed | OA | Kappa |
|---|---|---|---|---|---|---|---|
| SVM | 0.9983 | 0.9146 | 0.8720 | 0.7735 | 0.8163 | 0.9193 | 0.8837 |
| SRC | 0.9890 | 0.8830 | 0.9457 | 0.7093 | 0.5142 | 0.9016 | 0.8576 |
| SAE | 0.9990 | 0.8978 | 0.8334 | 0.7841 | 0.8583 | 0.9135 | 0.8754 |
| CNN | 0.9999 | 0.9611 | 0.9754 | 0.9156 | 0.9514 | 0.9747 | 0.9635 |
| SFCN | 0.9998 | 0.9016 | 0.8273 | 0.9325 | 0.8046 | 0.9340 | 0.9051 |
| ARCN | 0.9977 | 0.8817 | 0.9962 | 0.9873 | 0.9238 | 0.9772 | 0.9672 |
| Methods | Xi’an | Oberpfaffenhofen | San Francisco | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Train | Predict | Total | Train | Predict | Total | Train | Predict | Total | |
| SVM | 0.07 | 5.13 | 5.20 | 0.12 | 62.52 | 62.64 | 0.03 | 44.48 | 44.51 |
| SRC | 0.49 | 0.40 | 0.89 | 0.34 | 2.24 | 2.58 | 0.27 | 2.70 | 2.97 |
| SAE | 7.93 | 0.21 | 8.14 | 8.97 | 0.58 | 9.55 | 5.97 | 1.08 | 7.05 |
| CNN | 41.26 | 3.02 | 44.28 | 33.1 | 18.94 | 52.04 | 35.1 | 30.66 | 65.76 |
| SFCN | 24.89 | 0.11 | 25.00 | 30.49 | 0.73 | 31.22 | 36.38 | 1.29 | 37.67 |
| ARCN | 206.57 | 0.11 | 206.68 | 286.72 | 0.74 | 287.46 | 195.05 | 1.29 | 196.34 |
| Methods | Xi’an | Oberpfaffenhofen | San Francisco |
|---|---|---|---|
| SVM | 0.026 | 0.14 | 0.24 |
| SRC | 0.026 | 0.14 | 0.24 |
| SAE | 0.026 | 0.14 | 0.24 |
| CNN | 11.9 | 66.1 | 110.5 |
| SFCN | 0.076 | 0.55 | 0.85 |
| ARCN | 0.076 | 0.55 | 0.85 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Li, Y.; Jiao, L.; Peng, C.; Zhang, X.; Shang, R. Adversarial Reconstruction-Classification Networks for PolSAR Image Classification. Remote Sens. 2019, 11, 415. https://doi.org/10.3390/rs11040415
Chen Y, Li Y, Jiao L, Peng C, Zhang X, Shang R. Adversarial Reconstruction-Classification Networks for PolSAR Image Classification. Remote Sensing. 2019; 11(4):415. https://doi.org/10.3390/rs11040415
Chicago/Turabian StyleChen, Yanqiao, Yangyang Li, Licheng Jiao, Cheng Peng, Xiangrong Zhang, and Ronghua Shang. 2019. "Adversarial Reconstruction-Classification Networks for PolSAR Image Classification" Remote Sensing 11, no. 4: 415. https://doi.org/10.3390/rs11040415
APA StyleChen, Y., Li, Y., Jiao, L., Peng, C., Zhang, X., & Shang, R. (2019). Adversarial Reconstruction-Classification Networks for PolSAR Image Classification. Remote Sensing, 11(4), 415. https://doi.org/10.3390/rs11040415