Improving Ecotope Segmentation by Combining Topographic and Spectral Data

 ,
,
Abstract

1. Introduction
1.1. Context
1.2. Remote Sensing for Ecotope Mapping
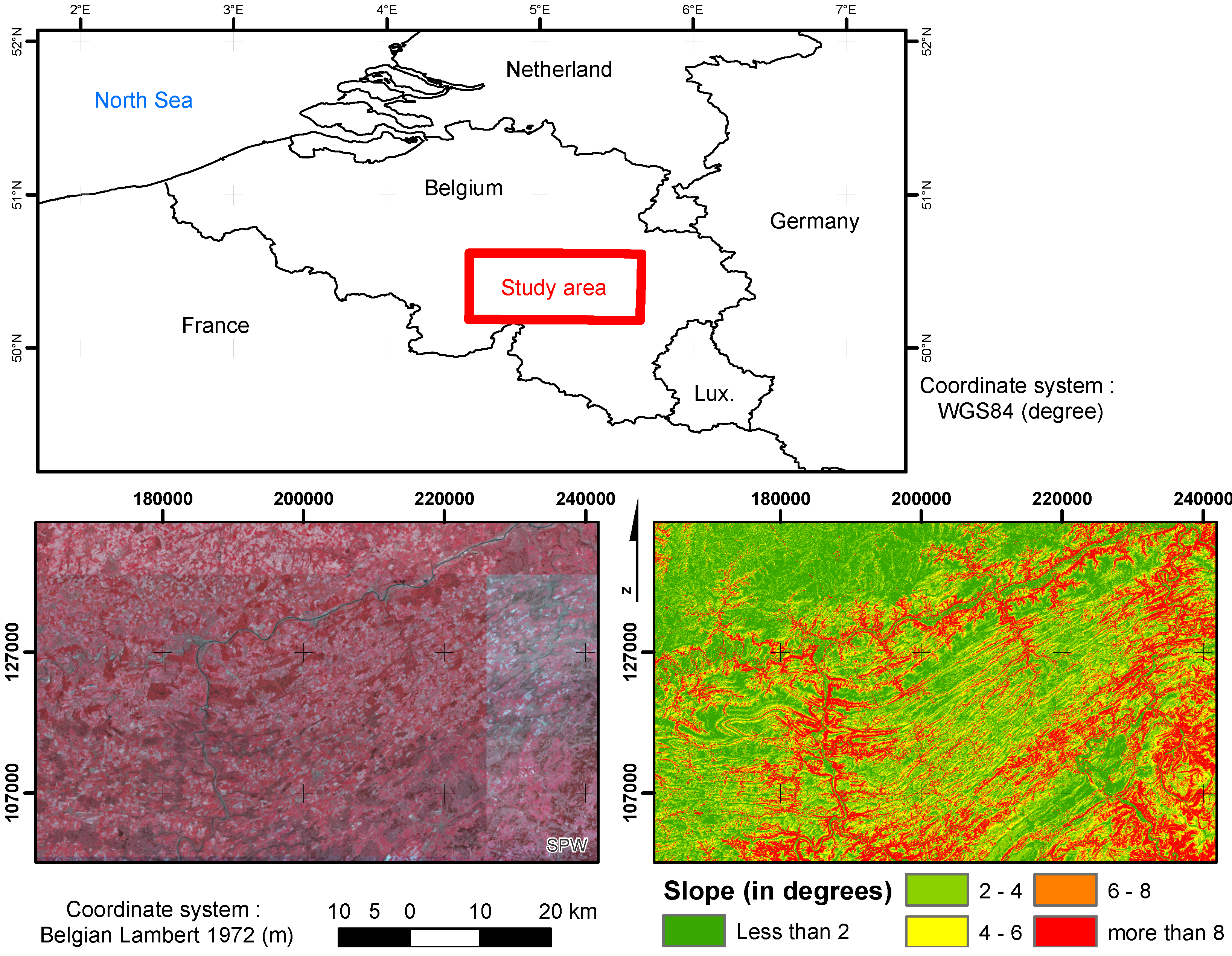
2. Data and Study Area
3. Method
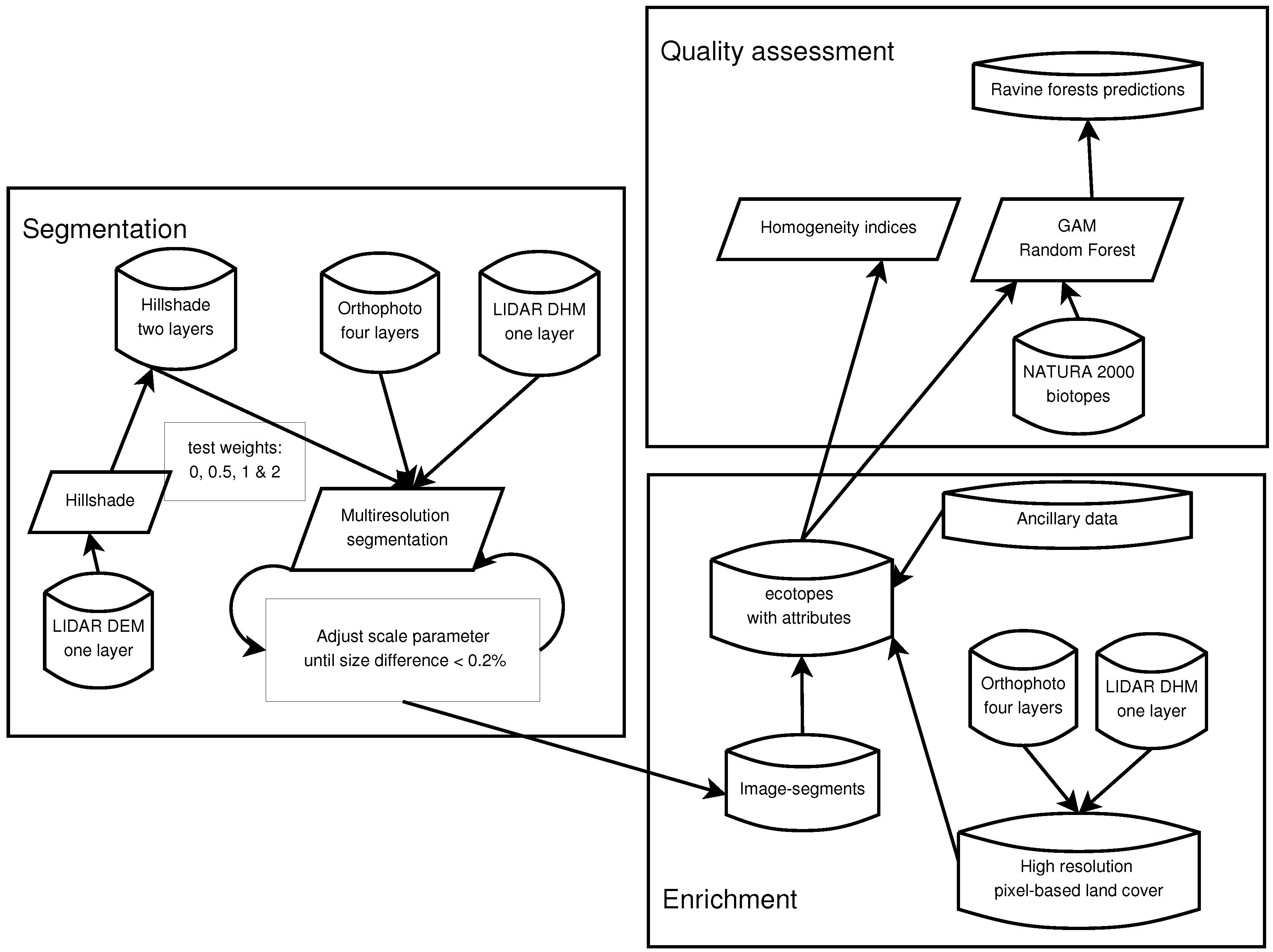
3.1. Automated Ecotope Delineation
3.2. Quality Assessment
3.2.1. High Resolution Pixel-Based Land Cover
3.2.2. Homogeneity Measures
3.2.3. Biotope Models
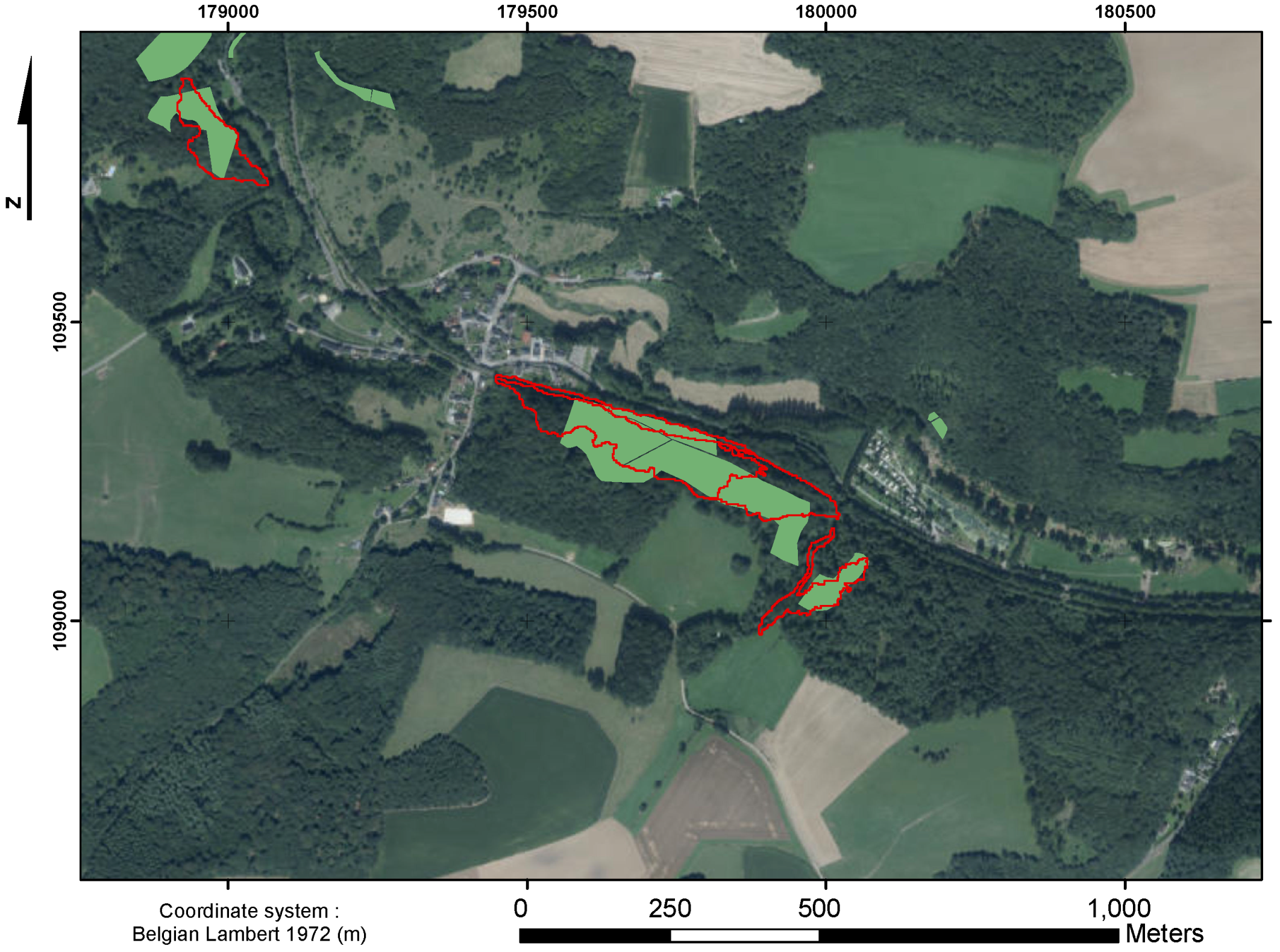
4. Results
5. Discussion
5.1. Consistency of the Polygons
5.2. Usefulness of Biotope Models
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Dataset
Abbreviations
| AUC | Area Under the curve |
| DEM | Digital Elevation Model |
| DHM | Digital Height Model |
| GAM | Generalized Additive Model |
| GEOBIA | Geographic Object-Based Image Analysis |
| PA | Producer’s accuracy |
| OA | Overall accuracy |
| RF | Random Forest |
| STD | Standard Deviation |
| UA | User’s accuracy |
References
- Mittermeier, R.A.; Turner, W.R.; Larsen, F.W.; Brooks, T.M.; Gascon, C. Global Biodiversity Conservation: The Critical Role of Hotspots. In Biodiversity Hotspots: Distribution and Protection of Conservation Priority Areas; Zachos, F.E., Habel, J.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 3–22. [Google Scholar]
- Myers, N.; Mittermeier, R.A.; Mittermeier, C.G.; da Fonseca, G.A.B.; Kent, J. Biodiversity hotspots for conservation priorities. Nature 2000, 403, 853–858. [Google Scholar] [CrossRef] [PubMed]
- Ostermann, O.P. The need for management of nature conservation sites designated under Natura 2000. J. Appl. Ecol. 1998, 35, 968–973. [Google Scholar] [CrossRef]
- Loidi, J. Preserving biodiversity in the European Union: The Habitats Directive and its application in Spain. Plant Biosyst. 1999, 133, 99–106. [Google Scholar] [CrossRef]
- Wells, M.; Timmer, F.; Carr, A. Understanding Drivers and Setting Targets for Biodiversity in Urban Green Design. In Green Design: From Theory to Practice; Yeang, K., Spector, A., Eds.; Black Dog Publishing: London, UK, 2011. [Google Scholar]
- Donald, P.F.; Evans, A.D. Habitat connectivity and matrix restoration: The wider implications of agri-environment schemes. J. Appl. Ecol. 2006, 43, 209–218. [Google Scholar] [CrossRef]
- Bryn, A. Recent forest limit changes in south-east Norway: Effects of climate change or regrowth after abandoned utilisation? Norsk Geogr. Tidsskr.-Nor. J. Geogr. 2008, 62, 251–270. [Google Scholar] [CrossRef]
- Bunce, R.; Metzger, M.; Jongman, R.; Brandt, J.; De Blust, G.; Elena-Rossello, R.; Groom, G.B.; Halada, L.; Hofer, G.; Howard, D.; et al. A standardized procedure for surveillance and monitoring European habitats and provision of spatial data. Landsc. Ecol. 2008, 23, 11–25. [Google Scholar] [CrossRef]
- Pokharel, B.; Dech, J.P. An ecological land classification approach to modeling the production of forest biomass. For. Chron. 2011, 87, 23–32. [Google Scholar] [CrossRef]
- Maes, J.; Egoh, B.; Willemen, L.; Liquete, C.; Vihervaara, P.; Schägner, J.P.; Grizzetti, B.; Drakou, E.G.; La Notte, A.; Zulian, G.; et al. Mapping ecosystem services for policy support and decision making in the European Union. Ecosyst. Serv. 2012, 1, 31–39. [Google Scholar] [CrossRef]
- Egoh, B.; Drakou, E.G.; Dunbar, M.B.; Maes, J.; Willemen, L. Indicators for Mapping Ecosystem Services: A Review; European Commission, Joint Research Centre (JRC): Ispra, Italy, 2012. [Google Scholar]
- Spanhove, T.; Borre, J.V.; Delalieux, S.; Haest, B.; Paelinckx, D. Can remote sensing estimate fine-scale quality indicators of natural habitats? Ecol. Indic. 2012, 18, 403–412. [Google Scholar] [CrossRef]
- Borre, J.V.; Paelinckx, D.; Mücher, C.A.; Kooistra, L.; Haest, B.; De Blust, G.; Schmidt, A.M. Integrating remote sensing in Natura 2000 habitat monitoring: Prospects on the way forward. J. Nat. Conserv. 2011, 19, 116–125. [Google Scholar] [CrossRef]
- Guisan, A.; Zimmermann, N.E. Predictive habitat distribution models in ecology. Ecol. Model. 2000, 135, 147–186. [Google Scholar] [CrossRef]
- Osborne, P.E.; Alonso, J.; Bryant, R. Modelling landscape-scale habitat use using GIS and remote sensing: A case study with great bustards. J. Appl. Ecol. 2001, 38, 458–471. [Google Scholar] [CrossRef]
- Delangre, J.; Radoux, J.; Dufrêne, M. Landscape delineation strategy and size of mapping units impact the performance of habitat suitability models. Ecol. Inform. 2017, 47, 55–60. [Google Scholar] [CrossRef]
- Ellis, E.C.; Wang, H.; Xiao, H.S.; Peng, K.; Liu, X.P.; Li, S.C.; Ouyang, H.; Cheng, X.; Yang, L.Z. Measuring long-term ecological changes in densely populated landscapes using current and historical high resolution imagery. Remote Sens. Environ. 2006, 100, 457–473. [Google Scholar] [CrossRef]
- Gerçek, D. A Conceptual Model for Delineating Land Management Units (LMUs) Using Geographical Object-Based Image Analysis. ISPRS Int. J. Geo-Inf. 2017, 6, 170. [Google Scholar] [CrossRef]
- Chan, J.C.W.; Paelinckx, D. Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Haber, W. Basic concepts of landscape ecology and their application in land management. Physiol. Ecol. Jpn. 1990, 27, 131–146. [Google Scholar]
- Haber, W. Using landscape ecology in planning and management. In Changing Landscapes: An Ecological Perspective; Springer: Berlin, Germany, 1990; pp. 217–232. [Google Scholar]
- Hong, S.K.; Kim, S.; Cho, K.H.; Kim, J.E.; Kang, S.; Lee, D. Ecotope mapping for landscape ecological assessment of habitat and ecosystem. Ecol. Res. 2004, 19, 131–139. [Google Scholar] [CrossRef]
- Shen, L.; Wu, L.; Dai, Y.; Qiao, W.; Wang, Y. Topic modelling for object-based unsupervised classification of VHR panchromatic satellite images based on multiscale image segmentation. Remote Sens. 2017, 9, 840. [Google Scholar] [CrossRef]
- Nemmaoui, A.; Aguilar, M.; Aguilar, F.; Novelli, A.; García Lorca, A. Greenhouse crop identification from multi-temporal multi-sensor satellite imagery using object-based approach: A case study from Almería (Spain). Remote Sens. 2018, 10, 1751. [Google Scholar] [CrossRef]
- Ruan, R.; Ren, L. Urban ecotope mapping using QuickBird imagery. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007; pp. 2963–2966. [Google Scholar]
- Geerling, G.; Vreeken-Buijs, M.; Jesse, P.; Ragas, A.; Smits, A. Mapping river floodplain ecotopes by segmentation of spectral (CASI) and structural (LiDAR) remote sensing data. River Res. Appl. 2009, 25, 795–813. [Google Scholar] [CrossRef]
- Janowski, L.; Trzcinska, K.; Tegowski, J.; Kruss, A.; Rucinska-Zjadacz, M.; Pocwiardowski, P. Nearshore Benthic Habitat Mapping Based on Multi-Frequency, Multibeam Echosounder Data Using a Combined Object-Based Approach: A Case Study from the Rowy Site in the Southern Baltic Sea. Remote Sens. 2018, 10, 1983. [Google Scholar] [CrossRef]
- Guilbert, E.; Moulin, B. Towards a common framework for the identification of landforms on terrain models. ISPRS Int. J. Geo-Inf. 2017, 6, 12. [Google Scholar] [CrossRef]
- Gerçek, D.; Toprak, V.; Strobl, J. Object-based classification of landforms based on their local geometry and geomorphometric context. Int. J. Geogr. Inf. Sci. 2011, 25, 1011–1023. [Google Scholar] [CrossRef]
- Drăguţ, L.; Eisank, C. Automated object-based classification of topography from SRTM data. Geomorphology 2012, 141, 21–33. [Google Scholar] [CrossRef] [PubMed]
- Gessler, P.; Chadwick, O.; Chamran, F.; Althouse, L.; Holmes, K. Modeling soil–landscape and ecosystem properties using terrain attributes. Soil Sci. Soc. Am. J. 2000, 64, 2046–2056. [Google Scholar] [CrossRef]
- Kravchenko, A.N.; Bullock, D.G. Correlation of corn and soybean grain yield with topography and soil properties. Agron. J. 2000, 92, 75–83. [Google Scholar] [CrossRef]
- Sternberg, M.; Shoshany, M. Influence of slope aspect on Mediterranean woody formations: Comparison of a semiarid and an arid site in Israel. Ecol. Res. 2001, 16, 335–345. [Google Scholar] [CrossRef]
- Baatz, M.; Schäpe, A. Multiresolution Segmentation—An optimization approach for high quality multi-scale image segmentation. In Angewandte Geographische Informationsverarbeitung XII; Strobl, J., Blaschke, T., Griesebner, G., Eds.; Wichmann-Verlag: Heidelberg, Germany, 2000; pp. 12–23. [Google Scholar]
- Radoux, J.; Bogaert, P. Accounting for the area of polygon sampling units for the prediction of primary accuracy assessment indices. Remote Sens. Environ. 2014, 142, 9–19. [Google Scholar] [CrossRef]
- OpenStreetMap Contributors. Planet Dump. 2017. Available online: https://www.openstreetmap.org (accessed on 24 September 2018).
- Hijmans, R.; Cameron, S.; Parra, J.; Jones, P.; Jarvis, A. Very high resolution interpolated climate surfaces for global land areas. Int. J. Climatol. 2005, 25, 1965–1978. [Google Scholar] [CrossRef]
- Radoux, J.; Bogaert, P. Good Practices for Object-Based Accuracy Assessment. Remote Sens. 2017, 9, 646. [Google Scholar] [CrossRef]
- Drăguţ, L.; Tiede, D.; Levick, S.R. ESP: A tool to estimate scale parameter for multiresolution image segmentation of remotely sensed data. Int. J. Geogr. Inf. Sci. 2010, 24, 859–871. [Google Scholar] [CrossRef]
- Radoux, J.; Defourny, P. Quality assessment of segmentation results devoted to object-based classification. In Object-Based Image Analysis; Springer: Berlin, Germany, 2008; pp. 257–271. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0 (No Topographic Layers) | 0.5 | 1 | 2 | Grid | |
|---|---|---|---|---|---|
| Slope variance | 4.21 | 4.00 | 3.90 | 3.83 | 4.82 |
| Aspect purity | 94.4 | 94.4 | 94.5 | 94.5 | 94.3 |
| Soil depth purity | 82.8 | 82.8 | 84.0 | 83.1 | 79.9 |
| Soil drainage purity | 80.1 | 80.9 | 81.3 | 81.7 | 80.4 |
| Land cover purity | 75.9 | 76.5 | 76.6 | 76.4 | 72.2 |
| 0 (No Topographic Layers) | 0.5 | 1 | 2 | Grid | |
|---|---|---|---|---|---|
| Slope variance | 10.6 | 8.1 | 7.1 | 6.2 | 11.6 |
| Aspect purity | 93.7 | 95.2 | 95.9 | 96.4 | 93.7 |
| Soil depth purity | 80.2 | 81.9 | 82.7 | 83.5 | 75.6 |
| Soil drainage purity | 79.7 | 81.8 | 82.4 | 82.5 | 78.3 |
| Land cover purity | 69.4 | 75.0 | 75.4 | 76.4 | 64.8 |
| Mean area (m2) | 20,466 | 17,379 | 16,432 | 15,577 | 19,016 |
| 0 | 0.5 | 1 | 2 | |
|---|---|---|---|---|
| Matches | 17 | 60 | 87 | 109 |
| RF | 99.7 | 99.8 | 99.8 | 99.7 |
| RF OA | 93.2 | 94.7 | 95.5 | 92.7 |
| RF AUC | 79.6 | 97.1 | 96.8 | 94.3 |
| RF PA | 77.9 | 97.0 | 95.3 | 92.7 |
| RF UA | 8.90 | 18.9 | 25.3 | 16.1 |
| GAM | 99.8 | 99.8 | 99.9 | 99.8 |
| GAM OA | 96.1 | 95.7 | 97.3 | 95.2 |
| GAM AUC | 81.4 | 95.6 | 97.6 | 95.2 |
| GAM PA | 77.2 | 93.1 | 97.0 | 92.7 |
| GAM UA | 15.0 | 21.9 | 37.2 | 22.5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Radoux, J.; Bourdouxhe, A.; Coos, W.; Dufrêne, M.; Defourny, P. Improving Ecotope Segmentation by Combining Topographic and Spectral Data. Remote Sens. 2019, 11, 354. https://doi.org/10.3390/rs11030354
Radoux J, Bourdouxhe A, Coos W, Dufrêne M, Defourny P. Improving Ecotope Segmentation by Combining Topographic and Spectral Data. Remote Sensing. 2019; 11(3):354. https://doi.org/10.3390/rs11030354
Chicago/Turabian StyleRadoux, Julien, Axel Bourdouxhe, William Coos, Marc Dufrêne, and Pierre Defourny. 2019. "Improving Ecotope Segmentation by Combining Topographic and Spectral Data" Remote Sensing 11, no. 3: 354. https://doi.org/10.3390/rs11030354
APA StyleRadoux, J., Bourdouxhe, A., Coos, W., Dufrêne, M., & Defourny, P. (2019). Improving Ecotope Segmentation by Combining Topographic and Spectral Data. Remote Sensing, 11(3), 354. https://doi.org/10.3390/rs11030354