Deriving a Forest Cover Map in Kyrgyzstan Using a Hybrid Fusion Strategy



Abstract
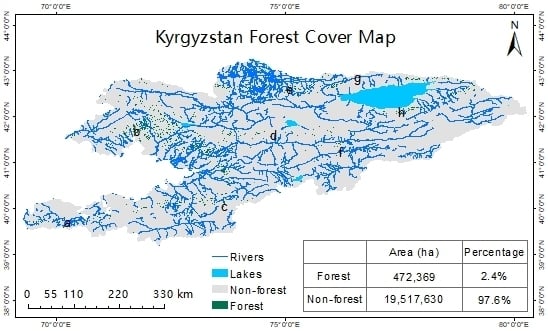
1. Introduction
2. The Study Area and Its Geographical Datasets
2.1. The Study Area
2.2. The Geographical Datasets and Their Preprocessing
2.2.1. The GlobeLand30 Product
2.2.2. The USGS TreeCover2010 Dataset
2.2.3. Landsat Images
2.2.4. The Ancillary Geographical Datasets
3. Methodologies
3.1. Land Cover Product Fusion
3.2. Geographical Feature Fusion
3.3. Classifier Fusion
3.3.1. Preliminaries on Classifiers
3.3.2. Base Classifier
3.3.3. Meta-Classifier
3.3.4. The Two-Layer Structured Classification System
3.4. Selection of Optimal α to Derive Forest Cover Map with High Accuracy
4. Results
5. Discussions and Limitations
5.1. Influence of Auxiliary Geographical Information on Model Accuracy
5.2. Influence of Sample Size on Model Accuracy
5.3. Comparison with Other Forest Cover Products
5.4. Limitations of This Study
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pan, Y.; Birdsey, R.A.; Phillips, O.L.; Jackson, R.B. The structure, distribution, and biomass of the world’s forests. Annu. Rev. Ecol. Evol. Syst. 2013, 44, 593–622. [Google Scholar] [CrossRef]
- Ghosh, S.M.; Behera, M.D. Aboveground biomass estimation using multi-sensor data synergy and machine learning algorithms in a dense tropical forest. Appl. Geogr. 2018, 96, 29–40. [Google Scholar] [CrossRef]
- MacDicken, K.; Jonsson, Ö.; Piña, L.; Marklund, L.; Maulo, S.; Contessa, V.; Adikari, Y.; Garzuglia, M.; Lindquist, E.; Reams, G.; et al. Global Forest Resources Assessment 2015: How Are the World’s Forests Changing? Food and Agriculture Organistation of the United Nations (FAO): Roma, Italy, 2016. [Google Scholar]
- Yin, H.; Khamzina, A.; Pflugmacher, D.; Martius, C. Forest cover mapping in post-Soviet Central Asia using multi-resolution remote sensing imagery. Sci. Rep. 2017, 7, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Sannier, C.; McRoberts, R.E.; Fichet, L.-V.; Makaga, E.M.K. Using the regression estimator with Landsat data to estimate proportion forest cover and net proportion deforestation in Gabon. Remote Sens. Environ. 2014, 151, 138–148. [Google Scholar] [CrossRef]
- Potapov, P.V.; Turubanova, S.A.; Tyukavina, A.; Krylov, A.M.; McCarty, J.L.; Radeloff, V.C.; Hansen, M.C. Eastern Europe’s forest cover dynamics from 1985 to 2012 quantified from the full Landsat archive. Remote Sens. Environ. 2015, 159, 28–43. [Google Scholar] [CrossRef]
- Boyd, D.S.; Danson, F.M.; Danson, F. Satellite remote sensing of forest resources: three decades of research development. Prog. Phys. Geogr. Earth Environ. 2005, 29, 1–26. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Liknes, G.C.; Domke, G.M. Using a remote sensing-based, percent tree cover map to enhance forest inventory estimation. For. Ecol. Manag. 2014, 331, 12–18. [Google Scholar] [CrossRef]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote Sensing Technologies for Enhancing Forest Inventories: A Review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef]
- Healey, S.P.; Cohen, W.B.; Yang, Z.; Brewer, C.K.; Brooks, E.B.; Gorelick, N.; Hernandez, A.J.; Huang, C.; Hughes, M.J.; Kennedy, R.E.; et al. Mapping forest change using stacked generalization: An ensemble approach. Remote Sens. Environ. 2018, 204, 717–728. [Google Scholar] [CrossRef]
- Krawczyk, B.; Woźniak, M.; Herrera, F. On the usefulness of one-class classifier ensembles for decomposition of multi-class problems. Pattern Recognit. 2015, 48, 3969–3982. [Google Scholar] [CrossRef]
- Fernández, A.; Lopez, V.; Galar, M.; Del Jesus, M.J.; Herrera, F.; Hilario, A.F. Analysing the classification of imbalanced data-sets with multiple classes: Binarization techniques and ad-hoc approaches. Knowledge-Based Syst. 2013, 42, 97–110. [Google Scholar] [CrossRef]
- Foody, G.M. Supervised image classification by MLP and RBF neural networks with and without an exhaustively defined set of classes. Int. J. Remote Sens. 2004, 25, 3091–3104. [Google Scholar] [CrossRef]
- Silva, J.; Bacao, F.; Dieng, M.; Foody, G.M.; Caetano, M. Improving specific class mapping from remotely sensed data by cost-sensitive learning. Int. J. Remote Sens. 2017, 38, 3294–3316. [Google Scholar] [CrossRef]
- Clinton, N.; Yu, L.; Gong, P. Geographic stacking: Decision fusion to increase global land cover map accuracy. ISPRS J. Photogramm. Remote Sens. 2015, 103, 57–65. [Google Scholar] [CrossRef]
- Li, G.; Lu, D.; Moran, E.; Hetrick, S. Land-cover classification in a moist tropical region of Brazil with Landsat TM imagery. Int. J. Remote Sens. 2011, 32, 8207–8230. [Google Scholar] [CrossRef] [PubMed]
- Song, X.-P.; Huang, C.; Feng, M.; Sexton, J.O.; Channan, S.; Townshend, J.R. Integrating global land cover products for improved forest cover characterization: An application in North America. Int. J. Digit. Earth 2014, 7, 709–724. [Google Scholar] [CrossRef]
- Masek, J.G.; Huang, C.; Wolfe, R.; Cohen, W.; Hall, F.; Kutler, J.; Nelson, P. North American forest disturbance mapped from a decadal Landsat record. Remote Sens. Environ. 2008, 112, 2914–2926. [Google Scholar] [CrossRef]
- Potapov, P.; Turubanova, S.; Hansen, M.C. Regional-scale boreal forest cover and change mapping using Landsat data composites for European Russia. Remote Sens. Environ. 2011, 115, 548–561. [Google Scholar] [CrossRef]
- Bartholome, E.; Belward, A.S. GLC2000: A new approach to global land cover mapping from Earth observation data. Int. J. Remote Sens. 2005, 26, 1959–1977. [Google Scholar] [CrossRef]
- Friedl, M.A.; Sulla-Menashe, D.; Tan, B.; Schneider, A.; Ramankutty, N.; Sibley, A.; Huang, X. MODIS Collection 5 global land cover: Algorithm refinements and characterization of new datasets. Remote Sens. Environ. 2010, 114, 168–182. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, P.; Yu, L.; Hu, L.; Li, X.; Li, C.; Zhang, H.; Zheng, Y.; Wang, J.; Zhao, Y.; et al. Towards a common validation sample set for global land-cover mapping. Int. J. Remote Sens. 2014, 35, 4795–4814. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Yang, Z.; Dong, J.; Liu, J.; Zhai, J.; Kuang, W.; Zhao, G.; Shen, W.; Zhou, Y.; Qin, Y.; Xiao, X.; et al. Accuracy Assessment and Inter-Comparison of Eight Medium Resolution Forest Products on the Loess Plateau, China. ISPRS Int. J. Geo-Information 2017, 6, 152. [Google Scholar] [CrossRef]
- Feng, M.; Sexton, J.O.; Huang, C.; Anand, A.; Channan, S.; Song, X.P.; Song, D.X.; Kim, D.H.; Noojipady, P.; Townshend, J.R. Earth science data records of global forest cover and change: Assessment of accuracy in 1990, 2000, and 2005 epochs. Remote Sens. Environ. 2016, 184, 73–85. [Google Scholar] [CrossRef]
- Chen, J.; Cao, X.; Peng, S.; Ren, H. Analysis and Applications of GlobeLand30: A Review. ISPRS Int. J. Geo-Information 2017, 6, 230. [Google Scholar] [CrossRef]
- Ridder, R.M. Global Forest Resources Assessment 2010: Options and Recommendations for a Global Remote Sensing Survey of Forests; FAO Resour Assess Programme Work Paper; FAO: Rome, Italy, 2007; Volume 141. [Google Scholar]
- Wan, Z.M. MOD11A2: MODIS/Terra Land Surface Temperature and Emissivity 8-Day L3 Global 1 km Grid SIN V006. NASA EOSDIS Land Processes DAAC, 2015. Available online: https://lpdaac.usgs.gov/products/mod11a2v006/ (accessed on 4 October 2019).
- Jarvis, A.; Reuter, H.I.; Nelson, A.; Guevara, E. Hole-filled seamless SRTM data (Version 4). International Centre for Tropical Agriculture, 2008. Available online: http://srtm.csi.cgiar.org (accessed on 4 October 2019).
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man, Cybern. 1973, 3, 610–621. [Google Scholar] [CrossRef]
- Akosa, J. Predictive Accuracy: A Misleading Performance Measure for Highly Imbalanced Data. In Proceedings of the SAS Global Forum 2017, Orlando, FL, USA, 2–5 April 2017. [Google Scholar]
- Whalen, S.; Pandey, G.; Pandey, G. A Comparative Analysis of Ensemble Classifiers: Case Studies in Genomics. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 807–816. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2012, 12, 2825–2830. [Google Scholar]
- Orozumbekov, A.; Musuraliev, T.; Toktoraliev, B.; Kysanov, A.; Shamshiev, B.; Sultangaziev, O. Forest Rehabilitation in Kyrgyzstan. In Keep Asia Green Volume IV “West and Central Asia”; Lee, D.K., Kleine, M., Eds.; IUFRO Headquarters: Vienna, Austria, 2009; Volume 20-IV, pp. 83–130. [Google Scholar]
- Atamuradov, A.; Karryeva, S. Global Forest Resources Assessment: Turkmenistan Country Report; Food and Agriculture Organistation of the United Nations (FAO): Roma, Italy, 2005. [Google Scholar]
- Didaci, L.; Giacinto, G.; Roli, F.; Marcialis, G.L. A study on the performances of dynamic classifier selection based on local accuracy estimation. Pattern Recognit. 2005, 38, 2188–2191. [Google Scholar] [CrossRef]
- Cadenasso, M.L.; Pickett, S.T.A.; Schwarz, K. Spatial heterogeneity in urban ecosystems: Reconceptualizing land cover and a framework for classification. Front. Ecol. Environ. 2007, 5, 80–88. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forest in the USGS TreeCover2010 with Different Tree Cover Threshold Values | Forest in the GlobeLand30 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | ||
| Area (104 ha) | 89.61 | 71.79 | 58.53 | 47.89 | 27.51 | 16.48 | 12.38 | 6.13 | 0.01 | 155.64 |
| Percentage (%) | 4.48 | 3.59 | 2.93 | 2.39 | 1.38 | 0.82 | 0.62 | 0.31 | 0.0004 | 7.78 |
| Our Product | Forest | Non-Forest | Overall | PA (%) | F1 Score (%) |
|---|---|---|---|---|---|
| Forest | 1642 | 256 | 1898 | 86.51 | 91.78 |
| Non-Forest | 38 | 7987 | 8025 | 99.53 | 98.19 |
| Overall | 1680 | 8243 | 9923 | ||
| UA (%) | 97.74 | 96.89 |
| USGS TreeCover2010 (40%) | Forest | Non-Forest | Overall | PA (%) | F1 Score (%) |
|---|---|---|---|---|---|
| Forest | 1437 | 461 | 1898 | 75.71 | 84.04 |
| Non-Forest | 85 | 7940 | 8025 | 98.94 | 96.67 |
| Overall | 1522 | 8401 | 9923 | ||
| UA (%) | 94.42 | 94.51 |
| GlobeLand30 | Forest | Non-Forest | Overall | PA (%) | F1 Score (%) |
|---|---|---|---|---|---|
| Forest | 1509 | 389 | 1898 | 79.50 | 72.17 |
| Non-Forest | 775 | 7250 | 8025 | 90.34 | 92.57 |
| Overall | 2284 | 7639 | 9923 | ||
| UA (%) | 66.07 | 94.91 |
| Kappa (%) | G (%) | F1 Score (%) | ||
|---|---|---|---|---|
| Base classifiers | DTB | 73.57 | 85.64 | 73.83 |
| EXT | 73.28 | 84.35 | 73.54 | |
| RF | 73.29 | 85.11 | 73.56 | |
| MLP | 69.54 | 81.61 | 69.84 | |
| KNN | 67.87 | 81.53 | 68.18 | |
| Meta classifier | GBM | 73.73 | 86.17 | 74.00 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, T.; Li, Y.; Shi, W.; Zhu, L. Deriving a Forest Cover Map in Kyrgyzstan Using a Hybrid Fusion Strategy. Remote Sens. 2019, 11, 2325. https://doi.org/10.3390/rs11192325
Jia T, Li Y, Shi W, Zhu L. Deriving a Forest Cover Map in Kyrgyzstan Using a Hybrid Fusion Strategy. Remote Sensing. 2019; 11(19):2325. https://doi.org/10.3390/rs11192325
Chicago/Turabian StyleJia, Tao, Yuqian Li, Wenzhong Shi, and Ling Zhu. 2019. "Deriving a Forest Cover Map in Kyrgyzstan Using a Hybrid Fusion Strategy" Remote Sensing 11, no. 19: 2325. https://doi.org/10.3390/rs11192325
APA StyleJia, T., Li, Y., Shi, W., & Zhu, L. (2019). Deriving a Forest Cover Map in Kyrgyzstan Using a Hybrid Fusion Strategy. Remote Sensing, 11(19), 2325. https://doi.org/10.3390/rs11192325