CNN-Based Land Cover Classification Combining Stratified Segmentation and Fusion of Point Cloud and Very High-Spatial Resolution Remote Sensing Image Data



Abstract
1. Introduction
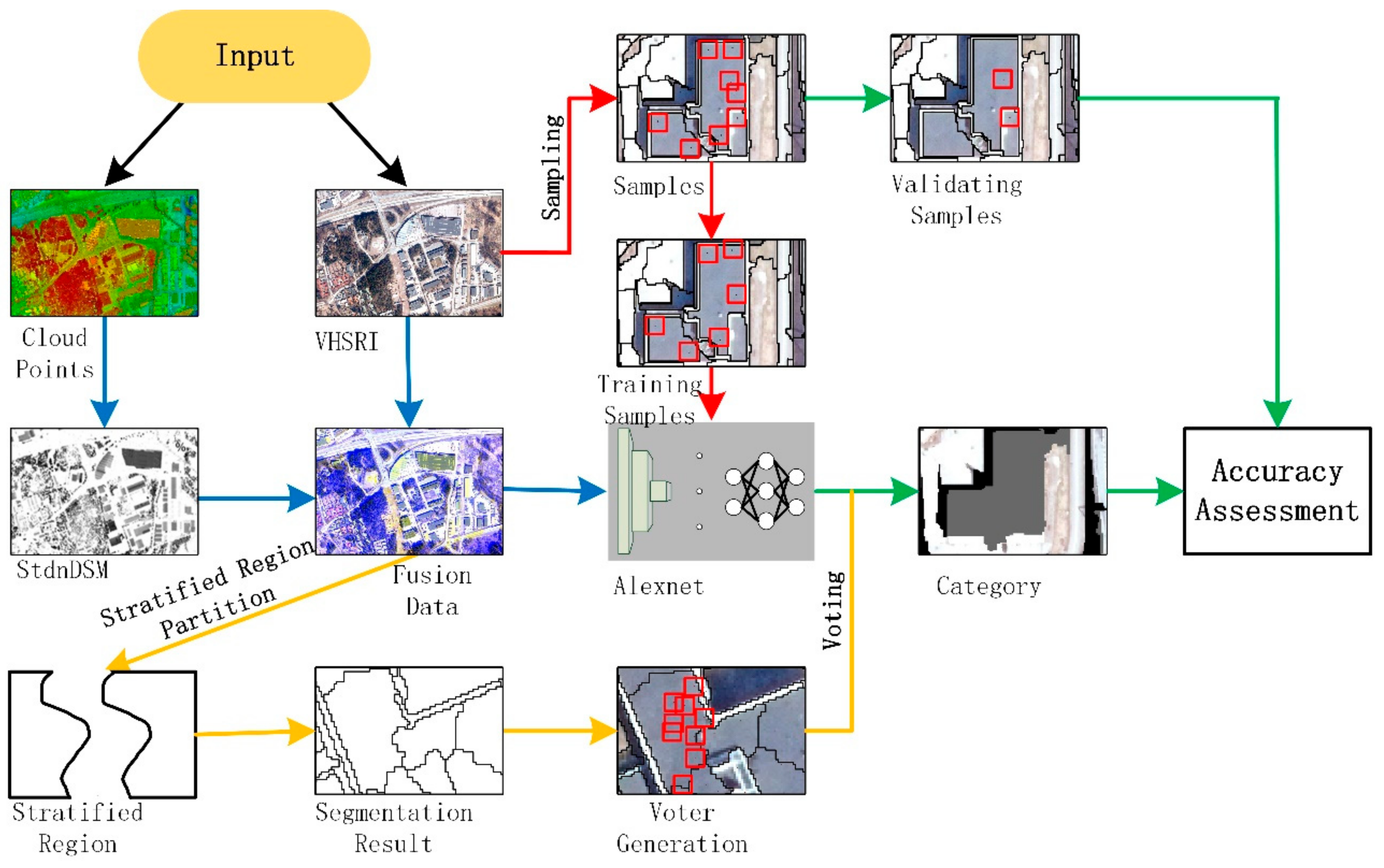
2. Materials and Methods
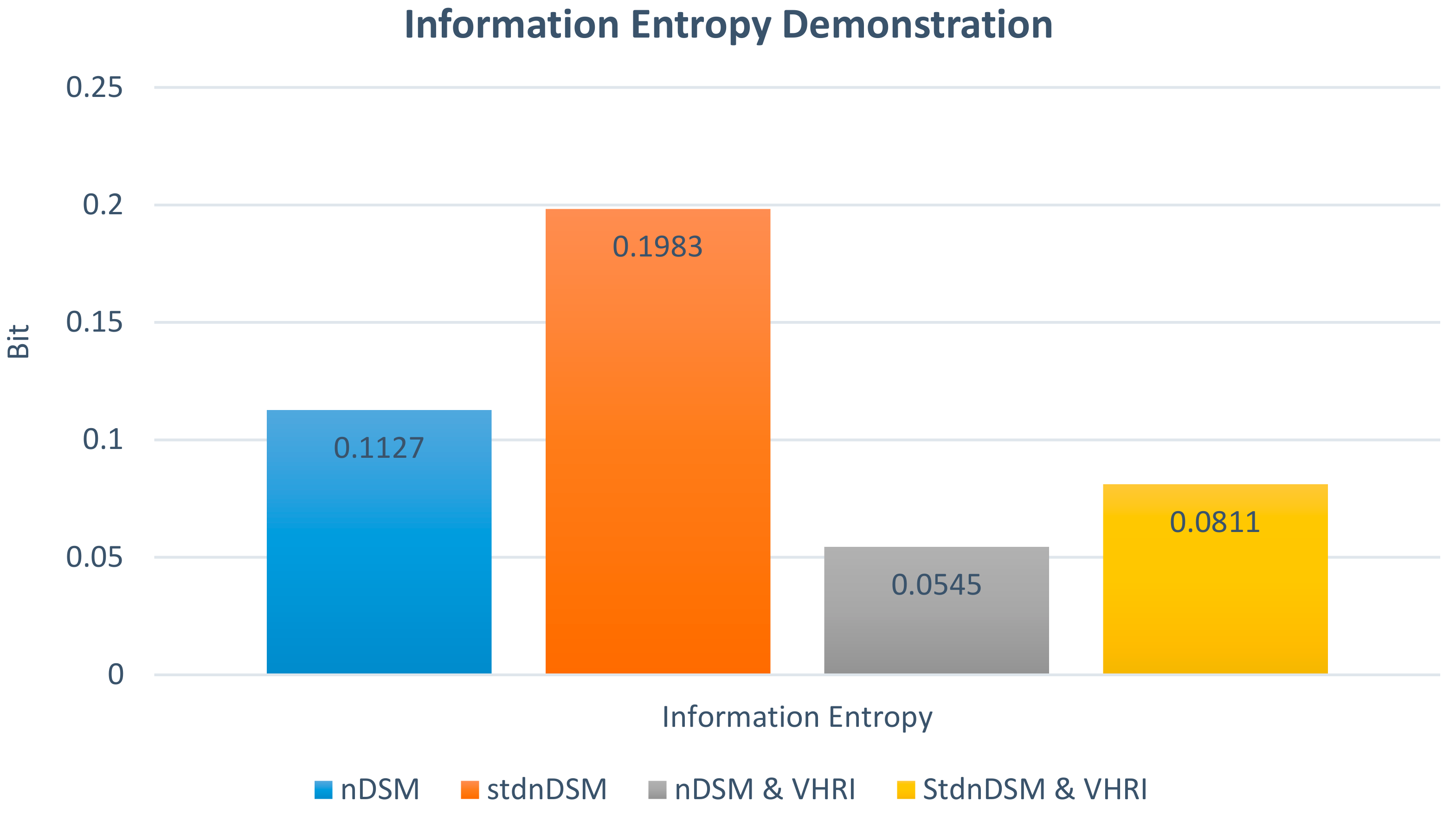
2.1. StdnDSM for Point Cloud Data Fusion
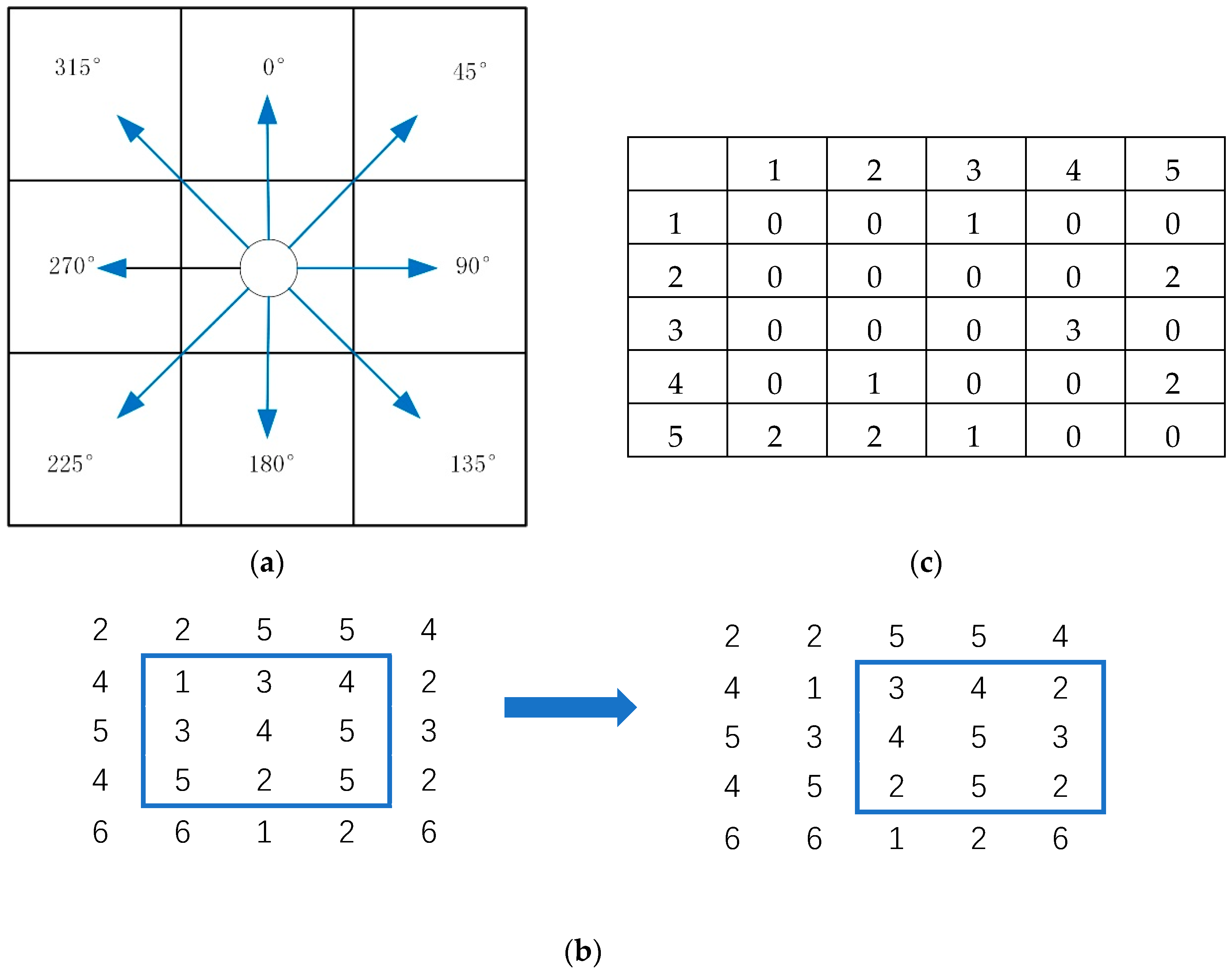
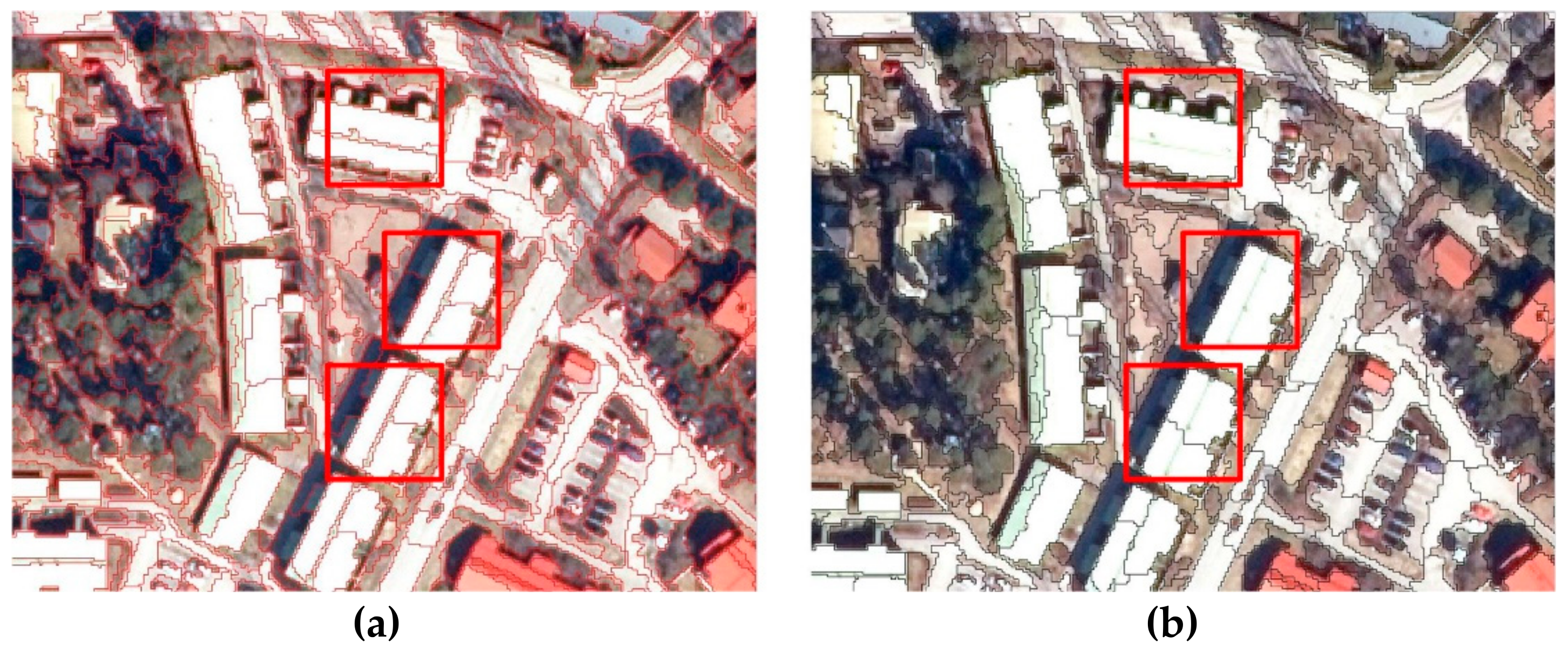
2.2. Stratified Segmentation
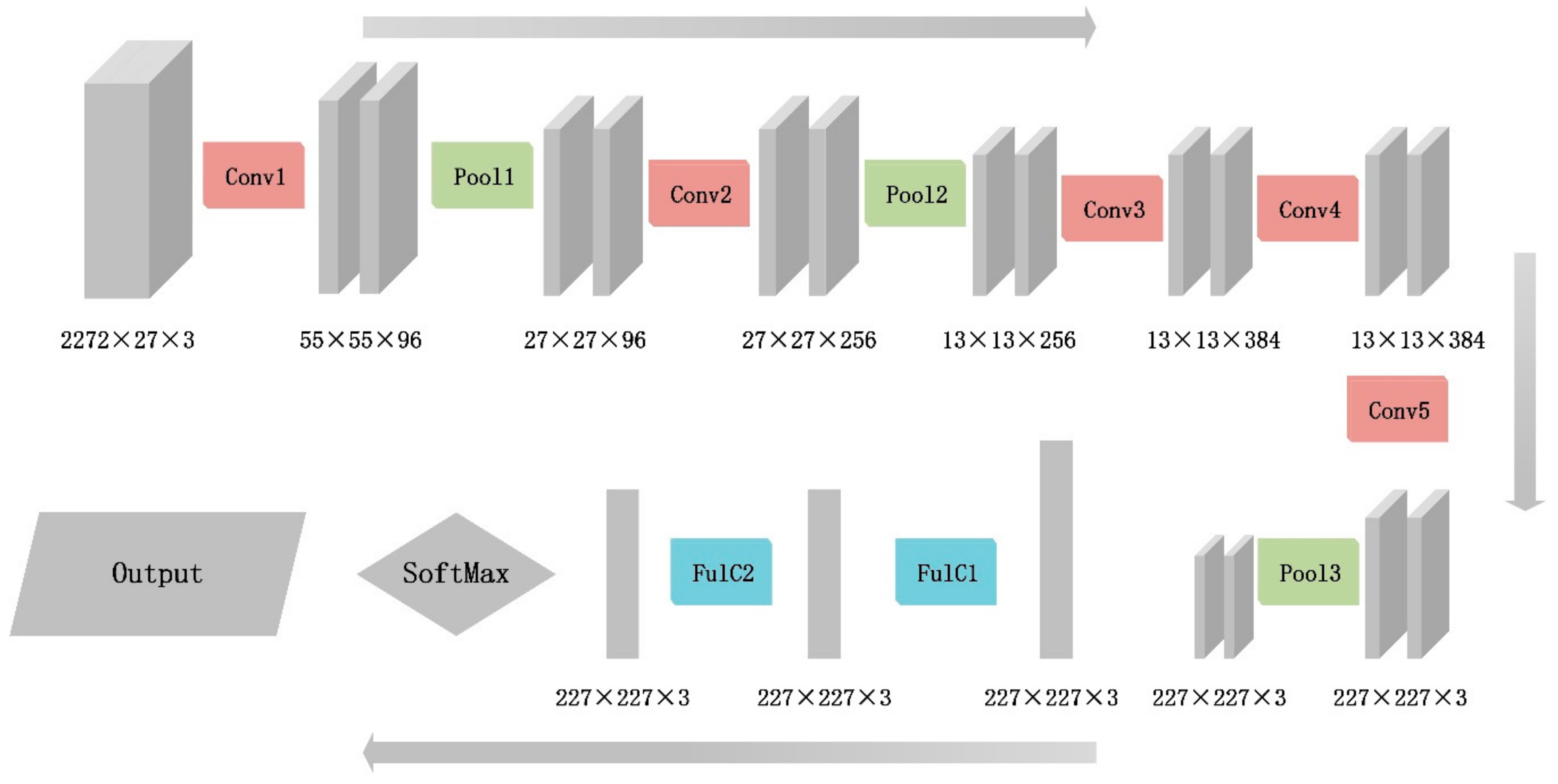
2.3. Convolutional Neural Network and Alexnet
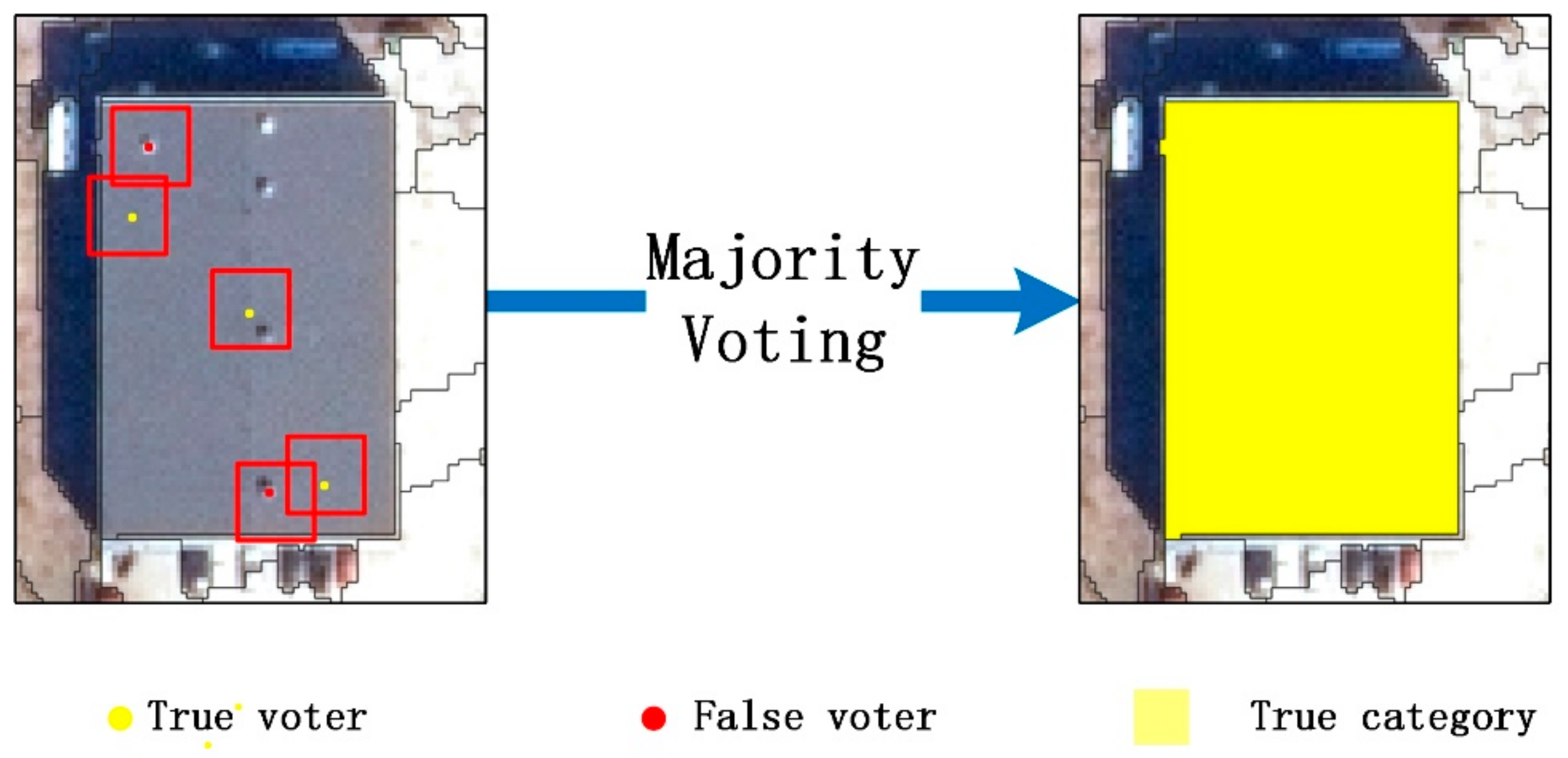
2.4. Region-Based Majority Voting
2.5. Accuracy Assessment Methods
2.6. Experiment Description
2.6.1. Image Description and Data Fusion
2.6.2. Sampling for Training and Testing
2.6.3. Stratified MRS
2.6.4. CNN Training and Classification
3. Results
3.1. Efficiency
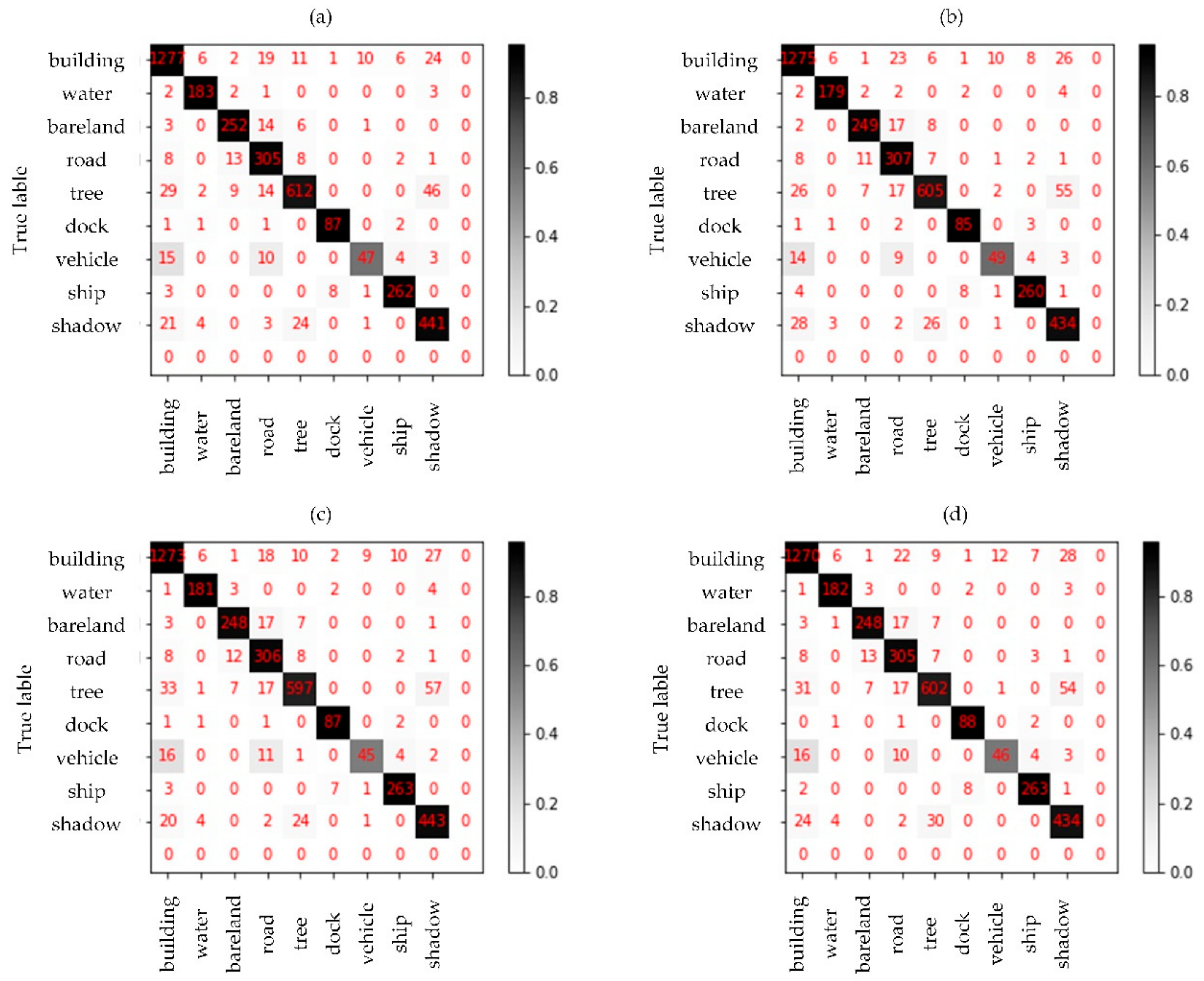
3.2. Classification Results and Accuracy
4. Discussion
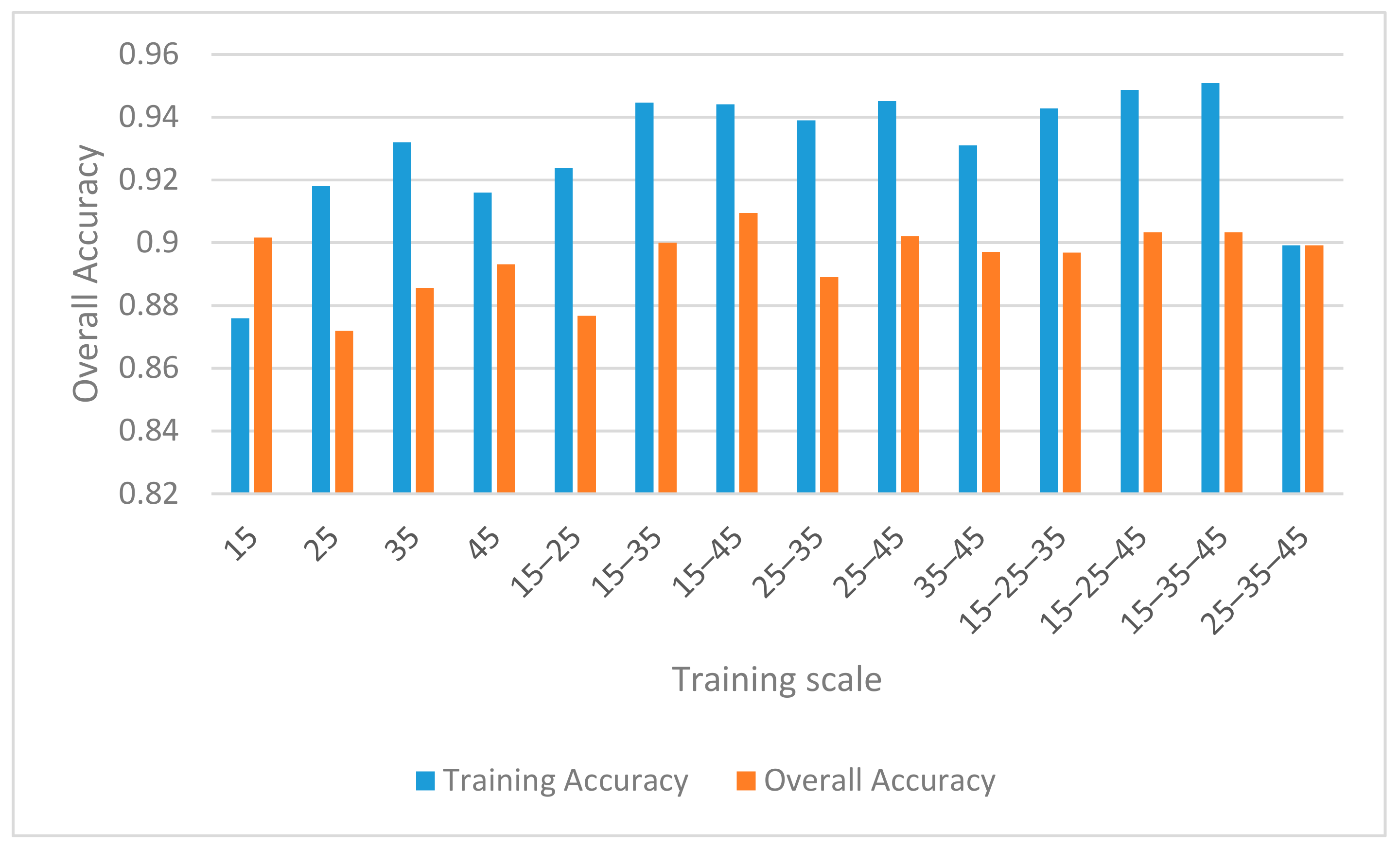
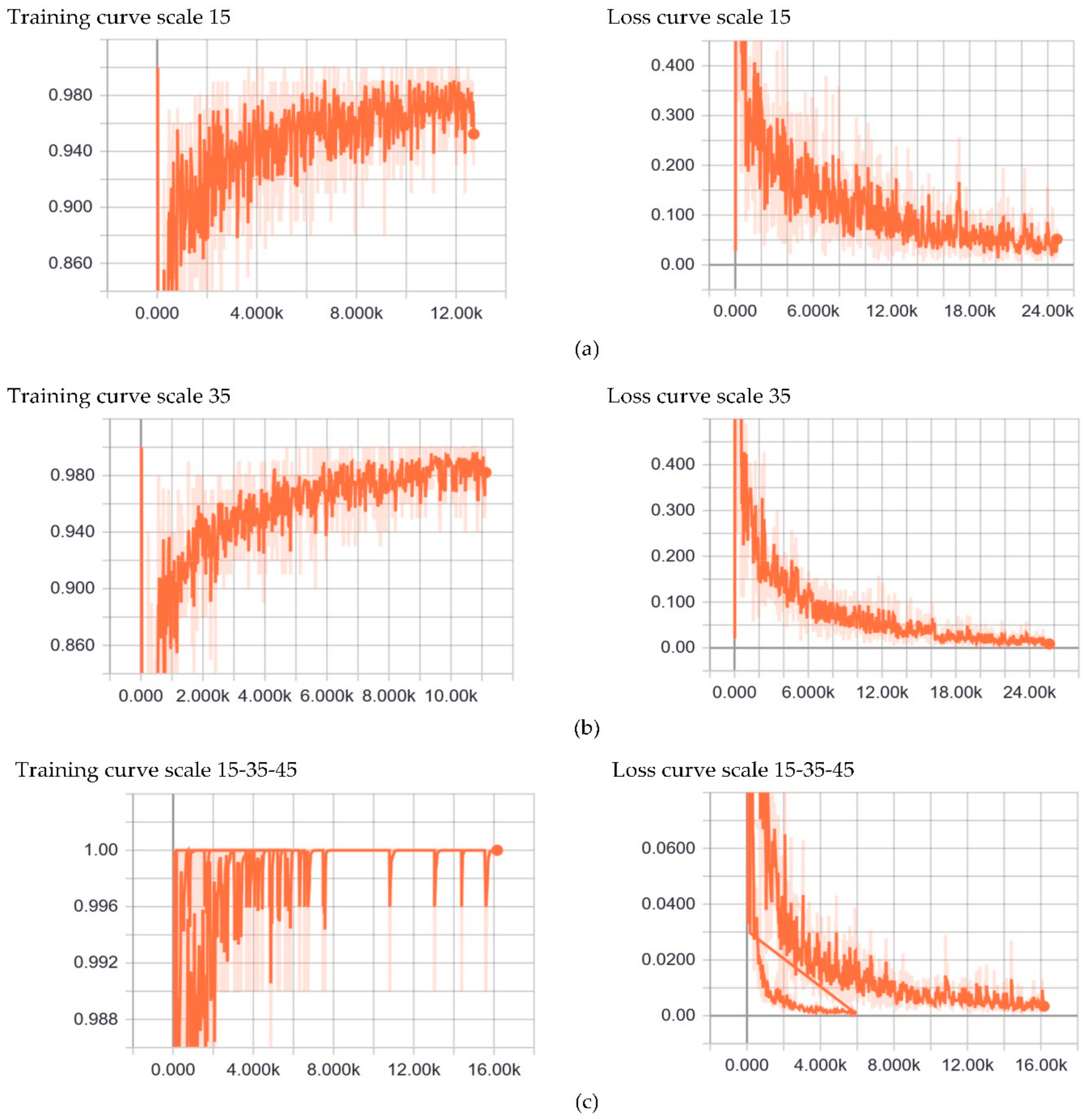
4.1. Influences of Sampling Strategy and CNN Parameters
4.1.1. Sampling Strategy
4.1.2. CNN Parameters Setting
4.2. Pros and Cons of Point Cloud added Fusion Data and Stratified MRS
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Minar, M.R.; Naher, J. Recent Advances in Deep Learning: An Overview. arXiv 2018, arXiv:1807.08169. [Google Scholar]
- Vanderhoof, M.K.; Lane, C.R. The potential role of very high-resolution imagery to characterise lake, wetland and stream systems across the Prairie Pothole Region, United States. Int. J. Remote Sens. 2019, 40, 5768–5798. [Google Scholar] [CrossRef]
- Ming, D.; Zhou, T.; Wang, M.; Tan, T. Land cover classification using random forest with genetic algorithm-based parameter optimization. J. Appl. Remote Sens. 2016, 10, 35021. [Google Scholar] [CrossRef]
- Ming, D.; Li, J.; Wang, J.; Zhang, M. Scale parameter selection by spatial statistics for GeOBIA: Using mean-shift based multi-scale segmentation as an example. ISPRS J. Photogramm. Remote Sens. 2015, 106, 28–41. [Google Scholar] [CrossRef]
- Chen, Y.; Ming, D.; Zhao, L.; Lv, B.; Zhou, K.; Qing, Y. Review on High Spatial Resolution Remote Sensing Image Segmentation Evaluation. Photogramm. Eng. Remote Sens. 2018, 84, 629–646. [Google Scholar] [CrossRef]
- Lv, Z.Y.; Shi, W.Z.; Benediktsson, J.A.; Ning, X.J. Novel Object-Based Filter for Improving Land-Cover Classification of Aerial Imagery with Very High Spatial Resolution. Remote Sens. 2016, 8, 1023. [Google Scholar] [CrossRef]
- Cui, G.; Lv, Z.; Li, G.; Benediktsson, J.A.; Lu, Y. Refining Land Cover Classification Maps Based on Dual-Adaptive Majority Voting Strategy for Very High Resolution Remote Sensing Images. Remote Sens. 2018, 10, 1238. [Google Scholar] [CrossRef]
- Lv, X.W.; Ming, D.; Chen, Y.Y.; Wang, M. Very high resolution remote sensing image classification with SEEDS-CNN and scale effect analysis for superpixel CNN classification. Int. J. Remote Sens. 2019, 40, 506–531. [Google Scholar] [CrossRef]
- Shao, Z.; Fu, H.; Li, D.; Altan, O.; Cheng, T. Remote sensing monitoring of multi-scale watersheds impermeability for urban hydrological evaluation. Remote Sens. Environ. 2019, 232, 111338. [Google Scholar] [CrossRef]
- Hay, G.J.; Blaschke, T. Special Issue: Geographic Object-Based Image Analysis (GEOBIA) Foreword. Photogramm. Eng. Remote Sens. 2010, 76, 121–122. [Google Scholar]
- Chen, Y.; Ming, D.; Lv, X. Superpixel Based Land Cover Classification of VHR Satellite Image Combining Multi-Scale CNN and Scale Parameter Estimation. Earth Sci. Inform. 2019. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Lu, T.; Zhou, K.; Wang, M.; Bao, H. A New Method for Region-Based Majority Voting CNNs for Very High Resolution Image Classification. Remote Sens. 2018, 10, 1946. [Google Scholar] [CrossRef]
- Zhou, W.; Ming, D.; Xu, L.; Bao, H.; Wang, M. Stratified Object-Oriented Image Classification Based on Remote Sensing Image Scene Division. J. Spectrosc. 2018, 2018, 1–11. [Google Scholar] [CrossRef]
- Xu, L.; Ming, D.P.; Zhou, W.; Bao, H.Q.; Chen, Y.Y.; Ling, X. Farmland Extraction from High Spatial Resolution Remote Sensing Images Based on Stratified Scale Pre-Estimation. Remote Sens. 2019, 11, 108. [Google Scholar] [CrossRef]
- Ming, D.; Zhang, X.; Zhou, W.; Wang, M. Cropland Extraction Based on OBIA and Adaptive Scale Pre-estimation. Photogramm. Eng. Remote Sens. 2016, 82, 635–644. [Google Scholar] [CrossRef]
- Shao, Z.; Pan, Y.; Diao, C.; Cai, J. Cloud Detection in Remote Sensing Images Based on Multiscale Features-Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4062–4076. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Tiede, D.; Wendt, L.; Sudmanns, L.; Lang, S. Convolutional Neural Network (CNN) for Dwelling Extraction in Refugee/IDP Camps. In Proceedings of the 39th EARSeL Symposium Digital I Earth I Observation, Salzburg, Austria, 1–4 July 2019. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Rezaee, M.; Mahdianpari, M.; Zhang, Y.; Salehi, B. Deep Convolutional Neural Network for Complex Wetland Classification Using Optical Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3030–3039. [Google Scholar] [CrossRef]
- Khamparia, A.; Singh, K.M. A systematic review on deep learning architectures and applications. Expert Syst. 2019, 36, e12400. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.; Zhang, L.P.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Scott, G.J.; England, M.R.; Starms, W.A.; Marcum, R.A.; Davis, C.H. Training Deep Convolutional Neural Networks for Land–Cover Classification of High-Resolution Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 549–553. [Google Scholar] [CrossRef]
- Ming, D.; Zhou, W.; Xu, L.; Wang, M.; Ma, Y. Coupling Relationship among Scale Parameter, Segmentation Accuracy, and Classification Accuracy in GeOBIA. Photogramm. Eng. Remote Sens. 2018, 84, 681–693. [Google Scholar] [CrossRef]
- Han, S.; Liu, X.; Mao, H.; Pu, J.; Pedram, A.; Horowitz, M.; Dally, B. Deep compression and EIE: Efficient inference engine on compressed deep neural network. In Proceedings of the 2016 IEEE Hot Chips 28 Symposium (HCS), Cupertino, CA, USA, 21–23 August 2016; pp. 1–6. [Google Scholar]
- Hong, Z.; Ming, D.; Zhou, K.; Guo, Y.; Lu, T. Road Extraction From a High Spatial Resolution Remote Sensing Image Based on Richer Convolutional Features. IEEE Access 2018, 6, 46988–47000. [Google Scholar] [CrossRef]
- Lu, T.; Ming, D.; Lin, X.; Hong, Z.; Bai, X.; Fang, J. Detecting Building Edges from High Spatial Resolution Remote Sensing Imagery Using Richer Convolution Features Network. Remote Sens. 2018, 10, 1496. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very Deep Convolutional Neural Networks for Complex Land Cover Mapping Using Multispectral Remote Sensing Imagery. Remote Sens. 2018, 10, 1119. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Ni, H.; Lin, X.; Ning, X.; Zhang, J. Edge Detection and Feature Line Tracing in 3D-Point Clouds by Analyzing Geometric Properties of Neighborhoods. Remote Sens. 2016, 8, 710. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.B.T.; Meena, S.R. Potential of Convolutional Neural Networks for Earthquake-triggered Mass Movement Detection Using Optical and SAR Data. In Proceedings of the Living Planet Symposium, MiCo—Milano Congressi, Milan, Italy, 13–17 May 2019. [Google Scholar]
- Xu, X.; Li, W.; Ran, Q.; Du, Q.; Gao, L.; Zhang, B. Multisource Remote Sensing Data Classification Based on Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 937–949. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of Different Machine Learning Methods and Deep-Learning Convolutional Neural Networks for Landslide Detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef]
- Serifoglu, C.; Gungor, O.; Yilmaz, V. Performance evaluation of different ground filtering algorithms for uav-based point clouds. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 245–251. [Google Scholar] [CrossRef]
- Bittner, K.; Adam, F.; Cui, S.; Korner, M.; Reinartz, P. Building Footprint Extraction From VHR Remote Sensing Images Combined With Normalized DSMs Using Fused Fully Convolutional Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2615–2629. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S.; Wang, Q. Hierarchical semantic cognition for urban functional zones with VHR satellite images and POI data. ISPRS J. Photogramm. Remote Sens. 2017, 132, 170–184. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, X.; Gao, S.; Gong, L.; Kang, C.G.; Zhi, Y.; Chi, G.H.; Shi, L. Social Sensing: A New Approach to Understanding Our Socioeconomic Environments. Ann. Assoc. Am. Geogr. 2015, 105, 512–530. [Google Scholar] [CrossRef]
- Yilmaz, V.; Gungor, O.; Yılmaz, V. Determining the optimum image fusion method for better interpretation of the surface of the Earth. Nor. Geogr. Tidsskr. Nor. J. Geogr. 2016, 70, 1–13. [Google Scholar] [CrossRef]
- Saralıoğlu, E.; Görmüş, E.T.; Güngör, O. Mineral exploration with hyperspectral image fusion. In Proceedings of the 2016 24th Signal Processing and Communication Application Conference (SIU), Zonguldak, Turkey, 16–19 May 2016; pp. 1281–1284. [Google Scholar]
- Nahhas, F.H.; Shafri, H.Z.; Sameen, M.I.; Pradhan, B. Deep Learning Approach for Building Detection Using LiDAR–Orthophoto Fusion. J. Sens. 2018, 2018, 1–12. [Google Scholar] [CrossRef]
- Yilmaz, V.; Yilmaz, C.S.; Gungor, O. Genetic algorithm-based synthetic variable ratio image fusion. Geocarto Int. 2019, 1–18. [Google Scholar] [CrossRef]
- Pan, X.; Gao, L.; Marinoni, A.; Zhang, B.; Yang, F.; Gamba, P. Semantic Labeling of High Resolution Aerial Imagery and LiDAR Data with Fine Segmentation Network. Remote Sens. 2018, 10, 743. [Google Scholar] [CrossRef]
- Kobler, A.; Ogrinc, P. REIN Algorithm and the Influence of Point Ccloud Density on NDSM and DEM Precision in a Submediterranean Forest. In Proceedings of the SPRS Workshop on Laser Scanning 2007 and SilviLaser 2007, Espoo, Finland, 12–14 September 2007. [Google Scholar]
- Marceau, D.; Howarth, P.; Dubois, J.; Gratton, D. Evaluation Of The Grey-level Co-occurrence Matrix Method For Land-cover Classification Using Spot Imagery. IEEE Trans. Geosci. Remote Sens. 1990, 28, 513–519. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Mancybern. 1973, 3, 610–621. [Google Scholar] [CrossRef]
- Puissant, A.; Hirsch, J.; Weber, C. The utility of texture analysis to improve per-pixel classification for high to very high spatial resolution imagery. Int. J. Remote Sens. 2005, 26, 733–745. [Google Scholar] [CrossRef]
- Baatz, M.; Schäpe, A. Multiresolution Segmentationan Optimization Approach for High Quality Multi-Scale Image Segmentation. Angew. Geogr. Inf. 2000, 12, 12–23. [Google Scholar]
- Zarandy, A.; Rekeczky, C.; Szolgay, P.; Chua, L.O.; Akos, Z. Overview of CNN research: 25 years history and the current trends. In Proceedings of the 2015 IEEE International Symposium on Circuits and Systems (ISCAS), Lisbon, Portugal, 24–27 May 2015; pp. 401–404. [Google Scholar]
- Seising, R. 60 years “A Mathematical Theory of Communication”-Towards a “Fuzzy Information Theory”. In Proceedings of the Joint 2009 International Fuzzy Systems Association World Congress and 2009 European Society of Fuzzy Logic and Technology Conference 2009, Lisbon, Portugal, 20–24 July 2009; pp. 1332–1337. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual Class | ||||
|---|---|---|---|---|
| Predicted Class | ||||
| Correlation Matrix | ||||
|---|---|---|---|---|
| Layer | R | G | B | nDSM |
| R | 1 | 0.0794 | 0.17983 | 0.11541 |
| G | 0.0794 | 1 | 0.9668 | 0.93594 |
| B | 0.17983 | 0.9668 | 1 | 0.97563 |
| nDSM | 0.11541 | 0.93594 | 0.97563 | 1 |
| Category | Bare Land | Building | Dock | Road | Shadow | Ship | Tree | Vehicle | Water |
|---|---|---|---|---|---|---|---|---|---|
| Amount | 1594 | 6871 | 882 | 2659 | 2941 | 2344 | 6147 | 659 | 903 |
| Regions | Region 1 | Region 2 | Region 3 | Region 4 | |
|---|---|---|---|---|---|
| Parameters | |||||
| Scale Parameter | 20 | 20 | 20 | 20 | |
| Shape | 0.7 | 0.3 | 0.5 | 0.4 | |
| Compactness | 0.3 | 0.7 | 0.5 | 0.6 | |
| Band Ratio | 1:1:1:7 | 1:1:1:7 | 1:1:1:7 | 1:1:1:1 | |
| Segmentation Methods | Polygon Amount | Voters Amount |
|---|---|---|
| Stratified MRS of Fusion Data | 94,144 | 278,836 |
| Unstratified MRS of Fusion Data | 106,985 | 297,227 |
| Unstratified MRS of VHSRI | 202,364 | 340,978 |
| Scale | Training Accuracy | Overall Accuracy |
|---|---|---|
| 15 | 0.876 | 0.9016 |
| 25 | 0.918 | 0.8719 |
| 35 | 0.932 | 0.8856 |
| 45 | 0.916 | 0.8932 |
| 15–25 | 0.9238 | 0.8767 |
| 15–35 | 0.9446 | 0.9 |
| 15–45 | 0.9441 | 0.9095 |
| 25–35 | 0.939 | 0.889 |
| 25–45 | 0.9451 | 0.9021 |
| 35–45 | 0.931 | 0.8971 |
| 15–25–35 | 0.9428 | 0.8969 |
| 15–25–45 | 0.9487 | 0.9034 |
| 15–35–45 | 0.9508 | 0.9034 |
| 25–35–45 | 0.8992 | 0.8992 |
| Categories | Accuracy by Synchronous Sampling | Accuracy by Asynchronous Sampling |
|---|---|---|
| Bare Land | 90.65% | 92.43% |
| Building | 93.97% | 93.41% |
| Dock | 90.63% | 92.53% |
| Road | 86.4% | 88.92% |
| Shadow | 85.3% | 89.67% |
| Ship | 94.93% | 94.56% |
| Tree | 92.59% | 93.5% |
| Vehicle | 79.66% | 85.79% |
| Water | 93.37% | 95.62% |
| Overall | 90.95% | 91.53% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, K.; Ming, D.; Lv, X.; Fang, J.; Wang, M. CNN-Based Land Cover Classification Combining Stratified Segmentation and Fusion of Point Cloud and Very High-Spatial Resolution Remote Sensing Image Data. Remote Sens. 2019, 11, 2065. https://doi.org/10.3390/rs11172065
Zhou K, Ming D, Lv X, Fang J, Wang M. CNN-Based Land Cover Classification Combining Stratified Segmentation and Fusion of Point Cloud and Very High-Spatial Resolution Remote Sensing Image Data. Remote Sensing. 2019; 11(17):2065. https://doi.org/10.3390/rs11172065
Chicago/Turabian StyleZhou, Keqi, Dongping Ming, Xianwei Lv, Ju Fang, and Min Wang. 2019. "CNN-Based Land Cover Classification Combining Stratified Segmentation and Fusion of Point Cloud and Very High-Spatial Resolution Remote Sensing Image Data" Remote Sensing 11, no. 17: 2065. https://doi.org/10.3390/rs11172065
APA StyleZhou, K., Ming, D., Lv, X., Fang, J., & Wang, M. (2019). CNN-Based Land Cover Classification Combining Stratified Segmentation and Fusion of Point Cloud and Very High-Spatial Resolution Remote Sensing Image Data. Remote Sensing, 11(17), 2065. https://doi.org/10.3390/rs11172065