Large-Scale Remote Sensing Image Retrieval Based on Semi-Supervised Adversarial Hashing


Abstract

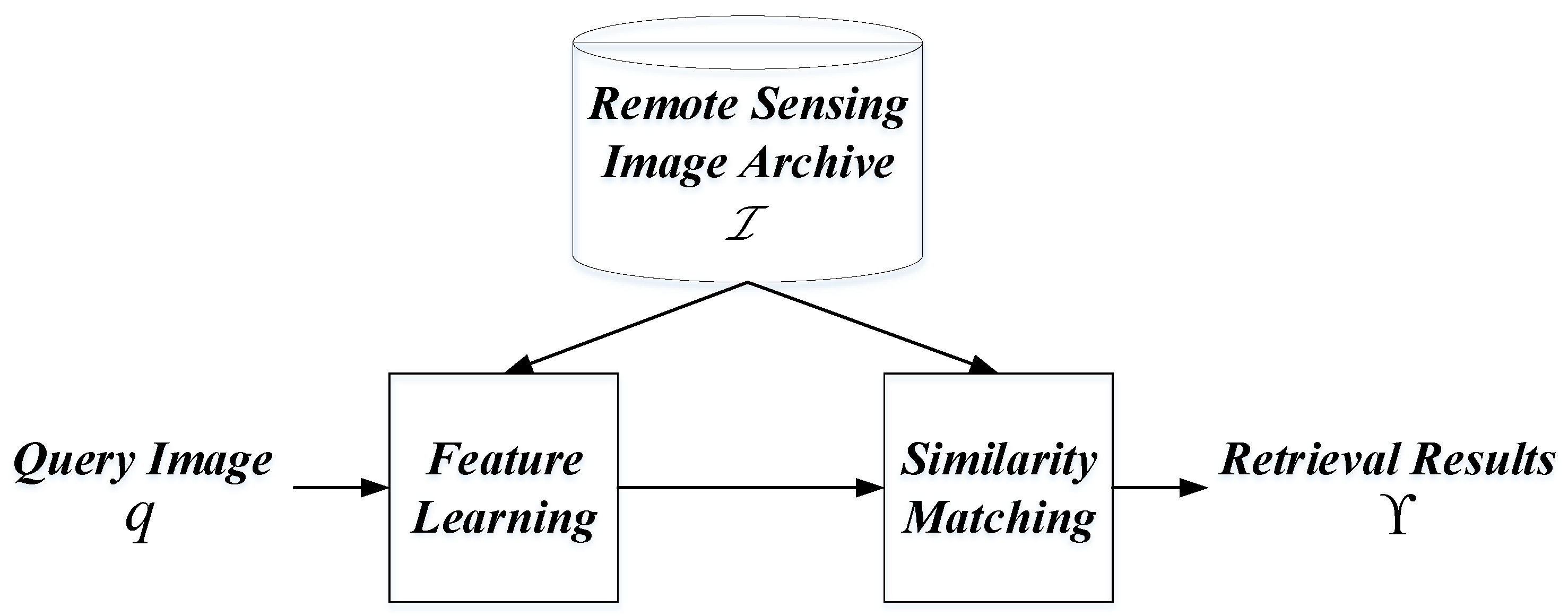
1. Introduction
- To ensure our hashing method is practical, we adopt a two-stage scheme to replace the end-to-end learning framework. Thus, any useful RS feature learning methods can be used to learn effective visual features.
- To get the bit balanced hash codes, we embed our hash learning in the generative adversarial framework. Through the adversarial learning, the prior binary uniform distribution can be imposed on the generated codes. Thus, SDAH can ensure the coding balance intuitively.
- To learn the effective binary code with minimal costs, we expand SDAH to the semi-supervised framework. In addition, the hashing objective function is developed to ensure the binary vectors are not only similarity preserving and low quantization loss but also discriminative.
2. Related Work
2.1. Remote Sensing Image Retrieval
2.2. Learning to Hash
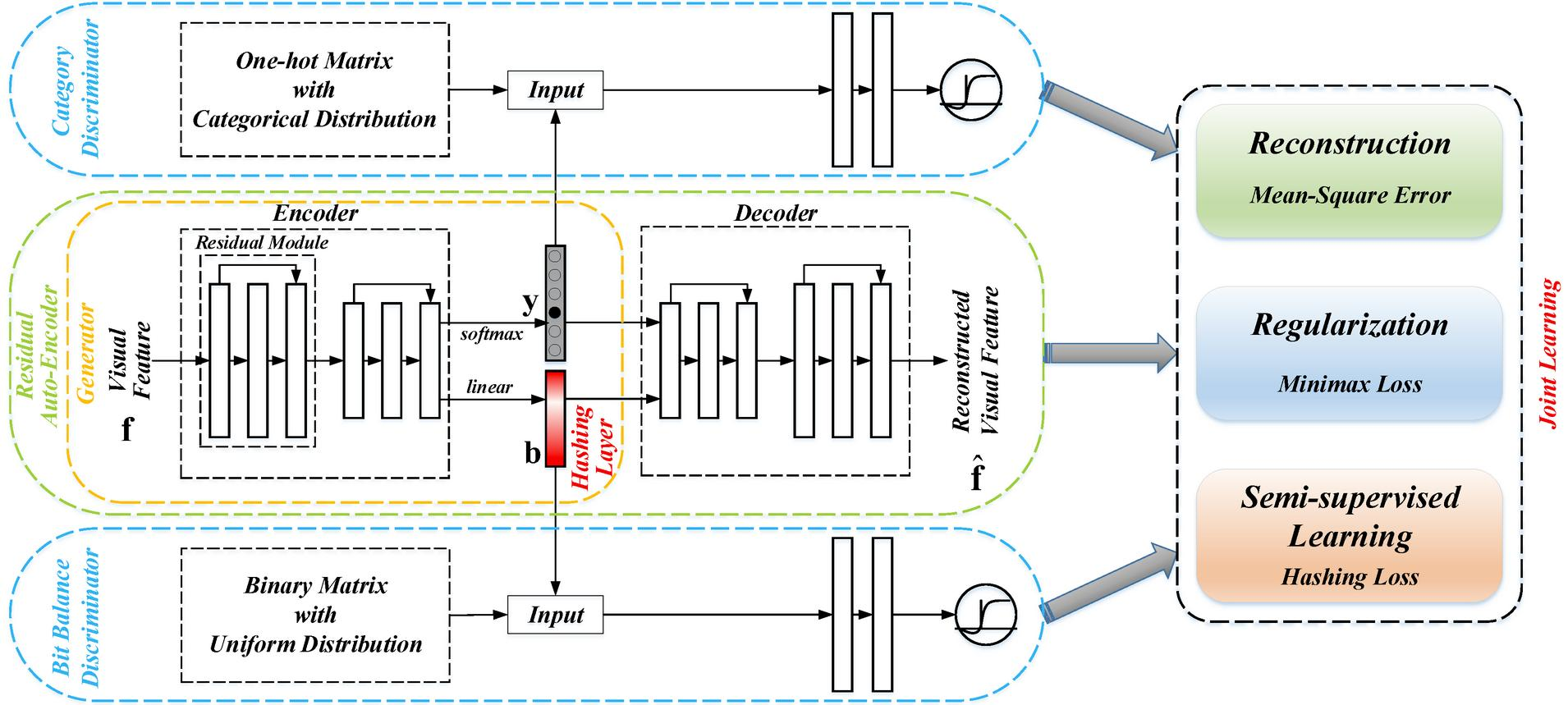
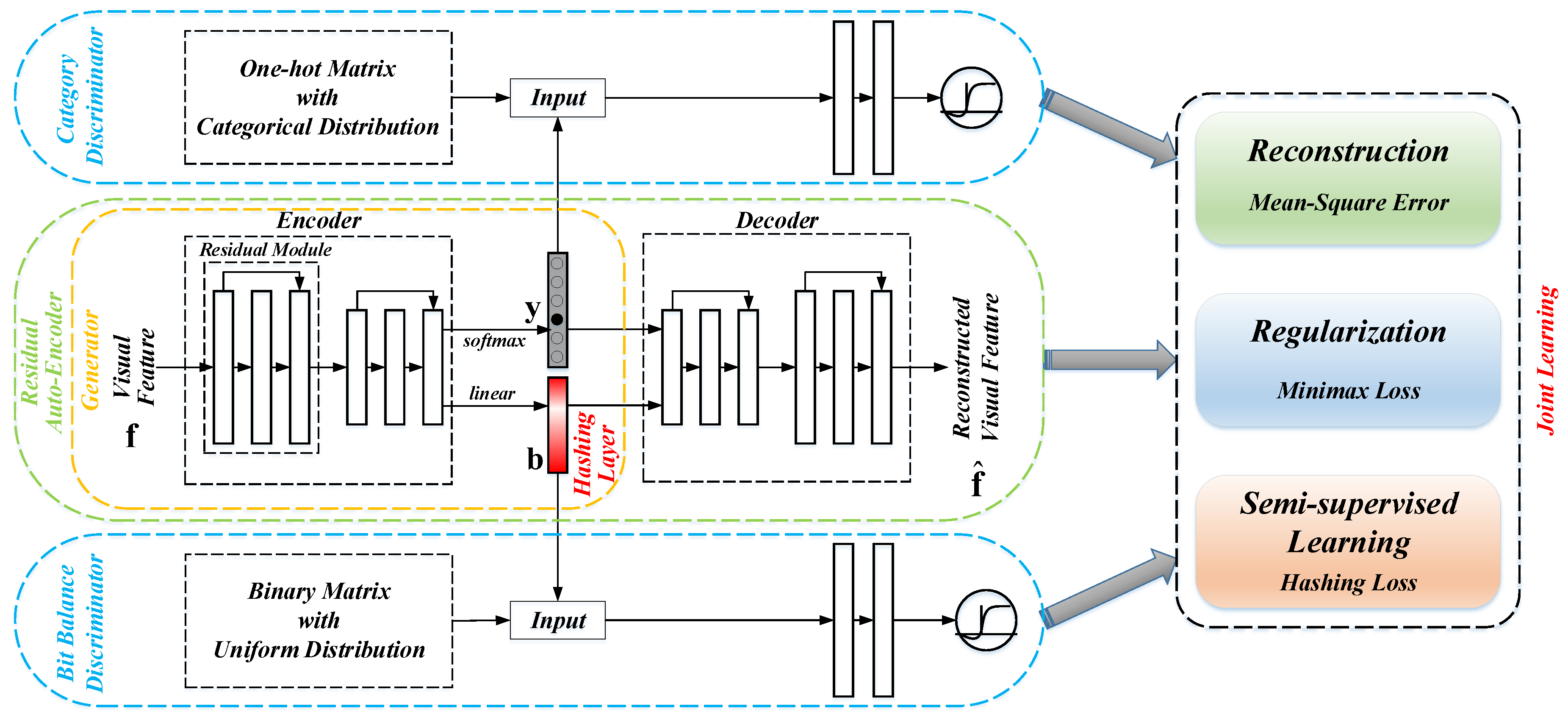
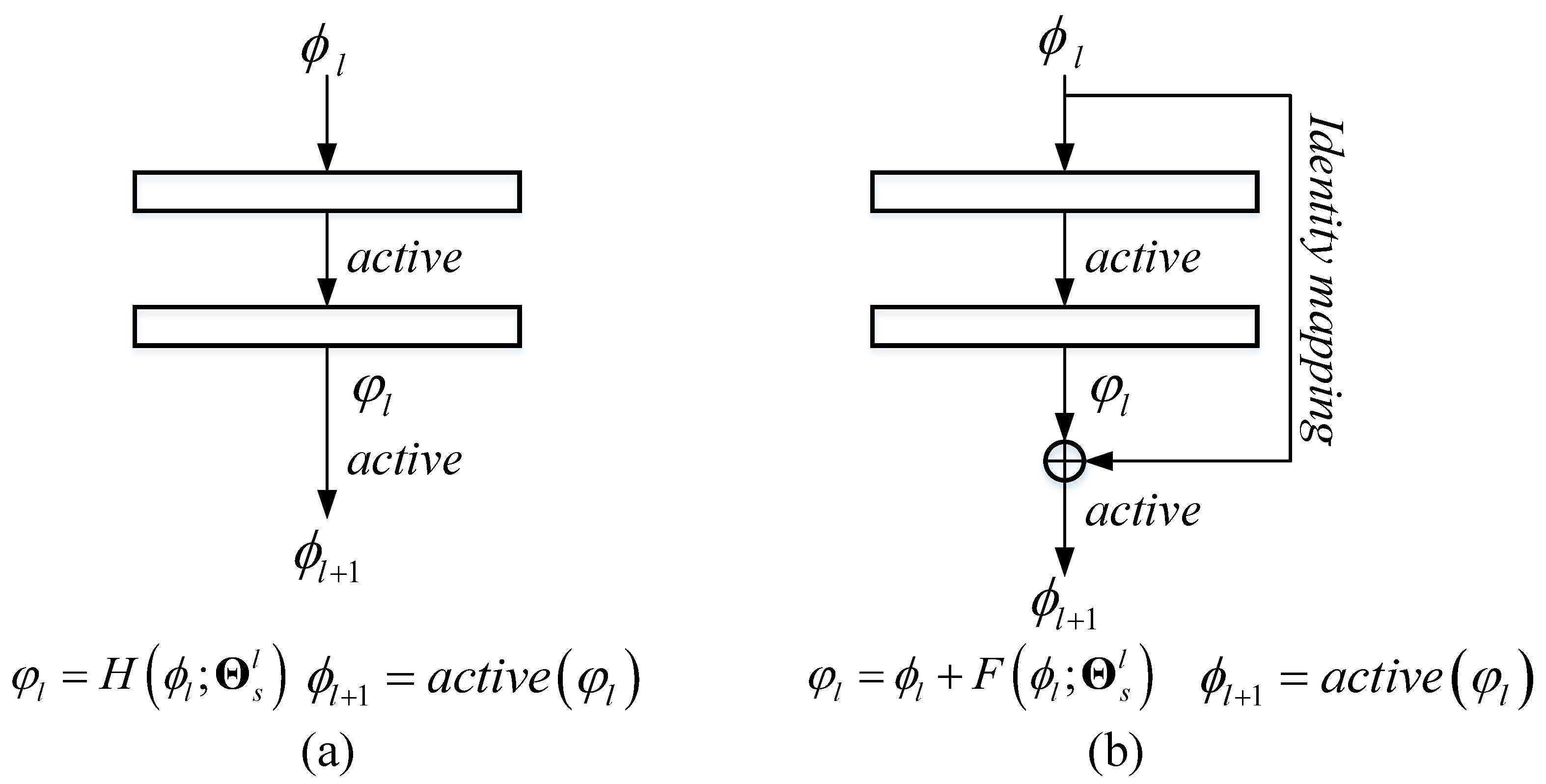
3. Methodology
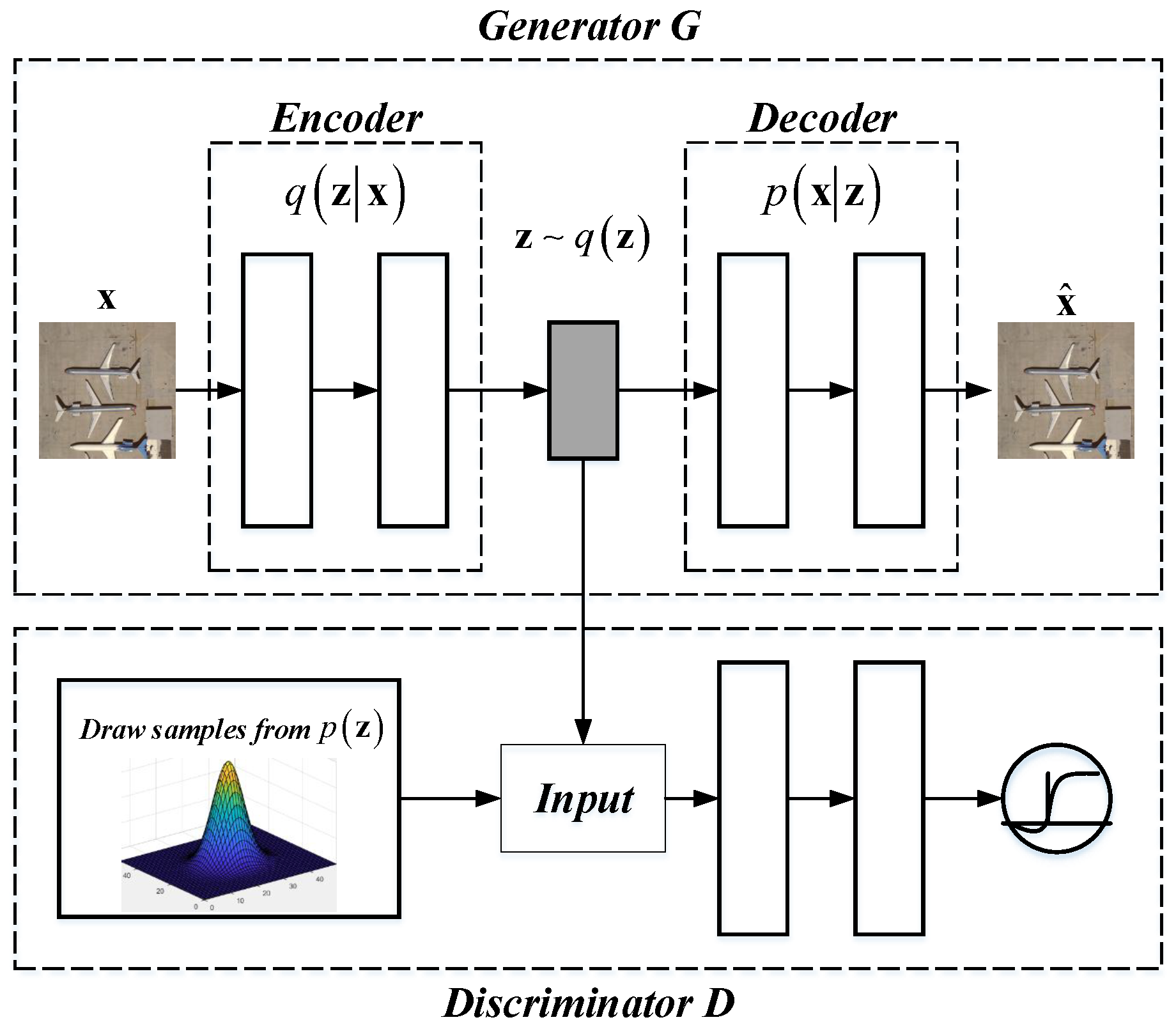
3.1. Adversarial Autoencoder
3.2. Proposed Deep Hashing Network
3.3. Learning Strategy of Proposed Hashing Network
3.3.1. Unsupervised Reconstruction
3.3.2. Adversarial Regularization
3.3.3. Semi-Supervised Learning
3.3.4. Flow of Learning Strategy
4. Dataset Introduction
5. Experiments
5.1. Experimental Settings
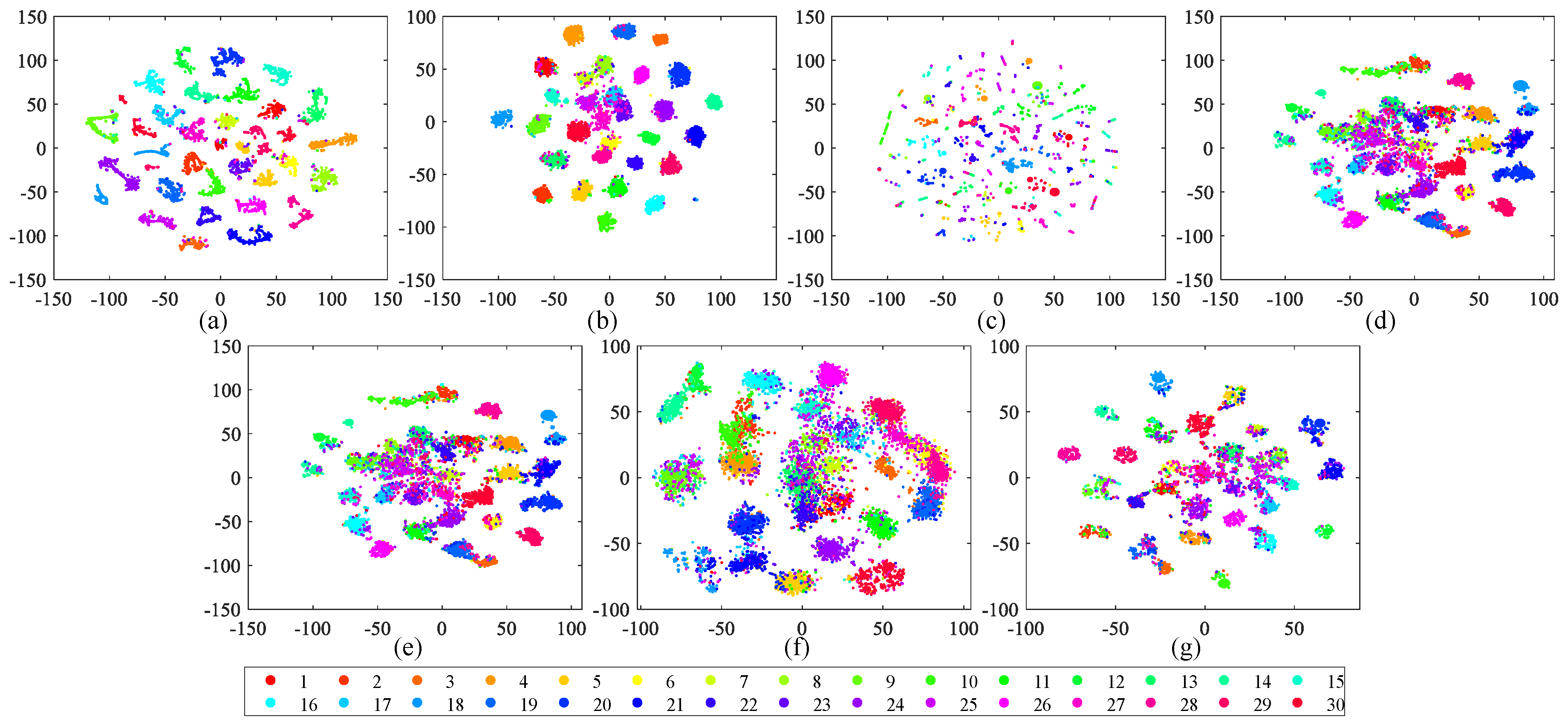
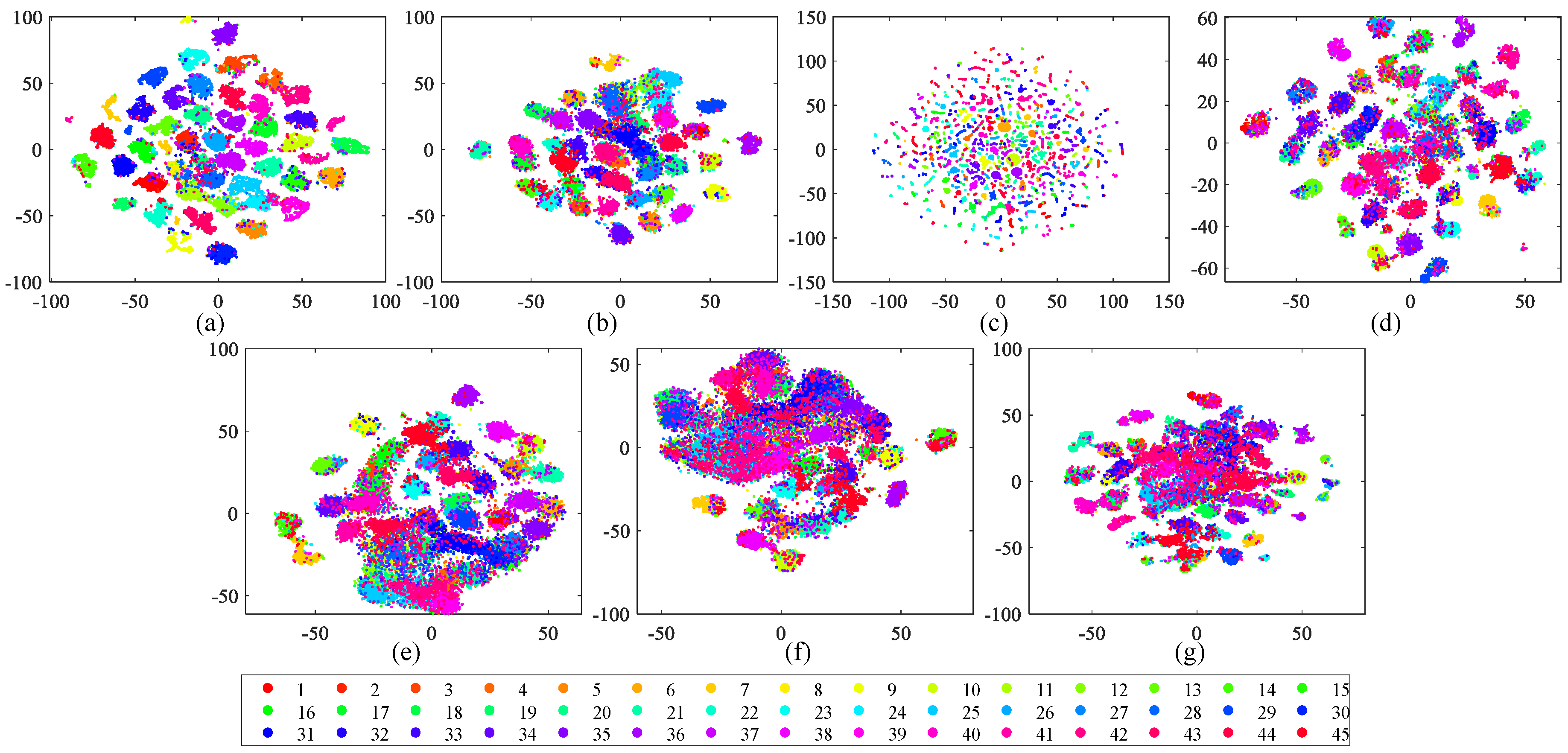
5.2. Retrieval Performance Based on Different Visual Features
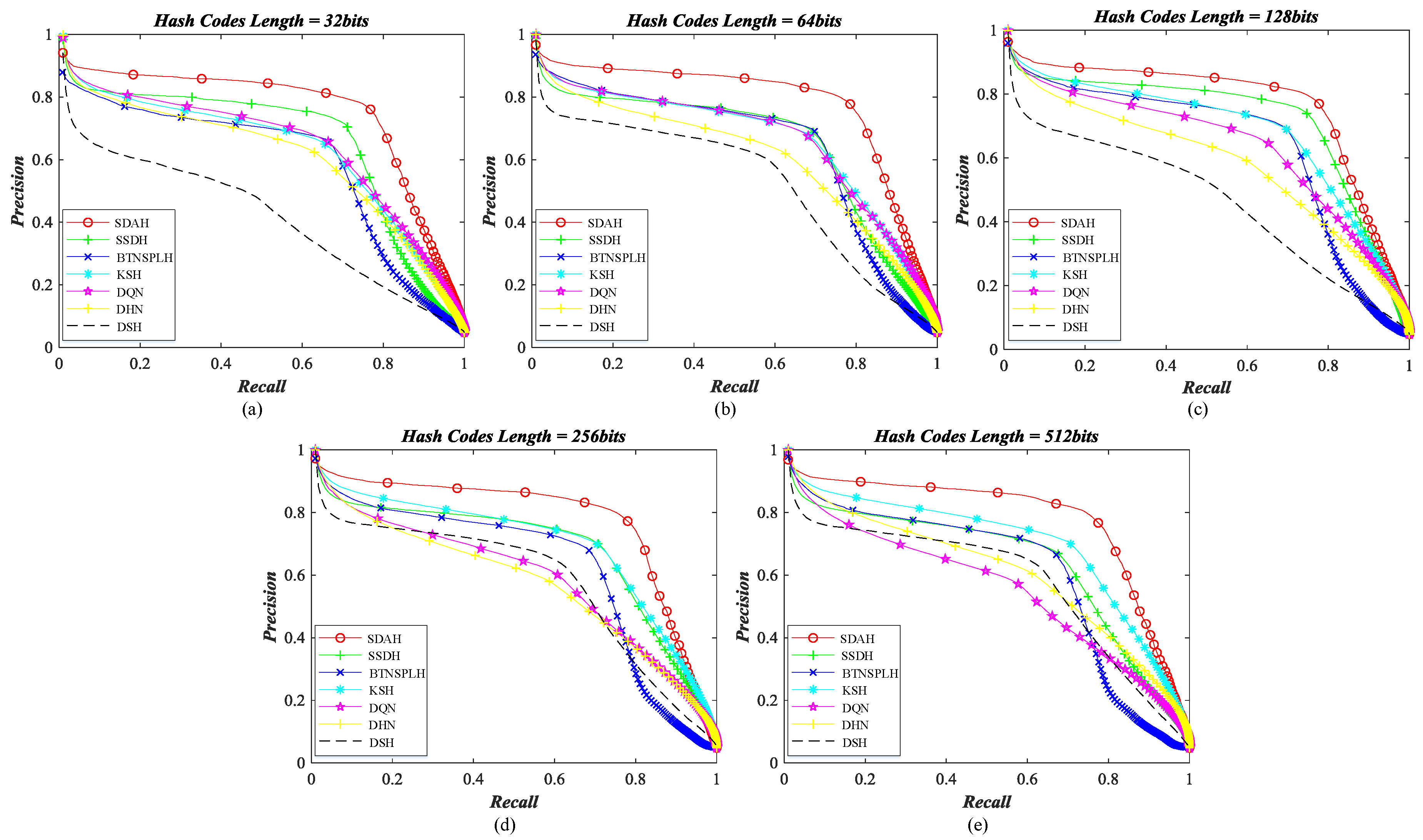
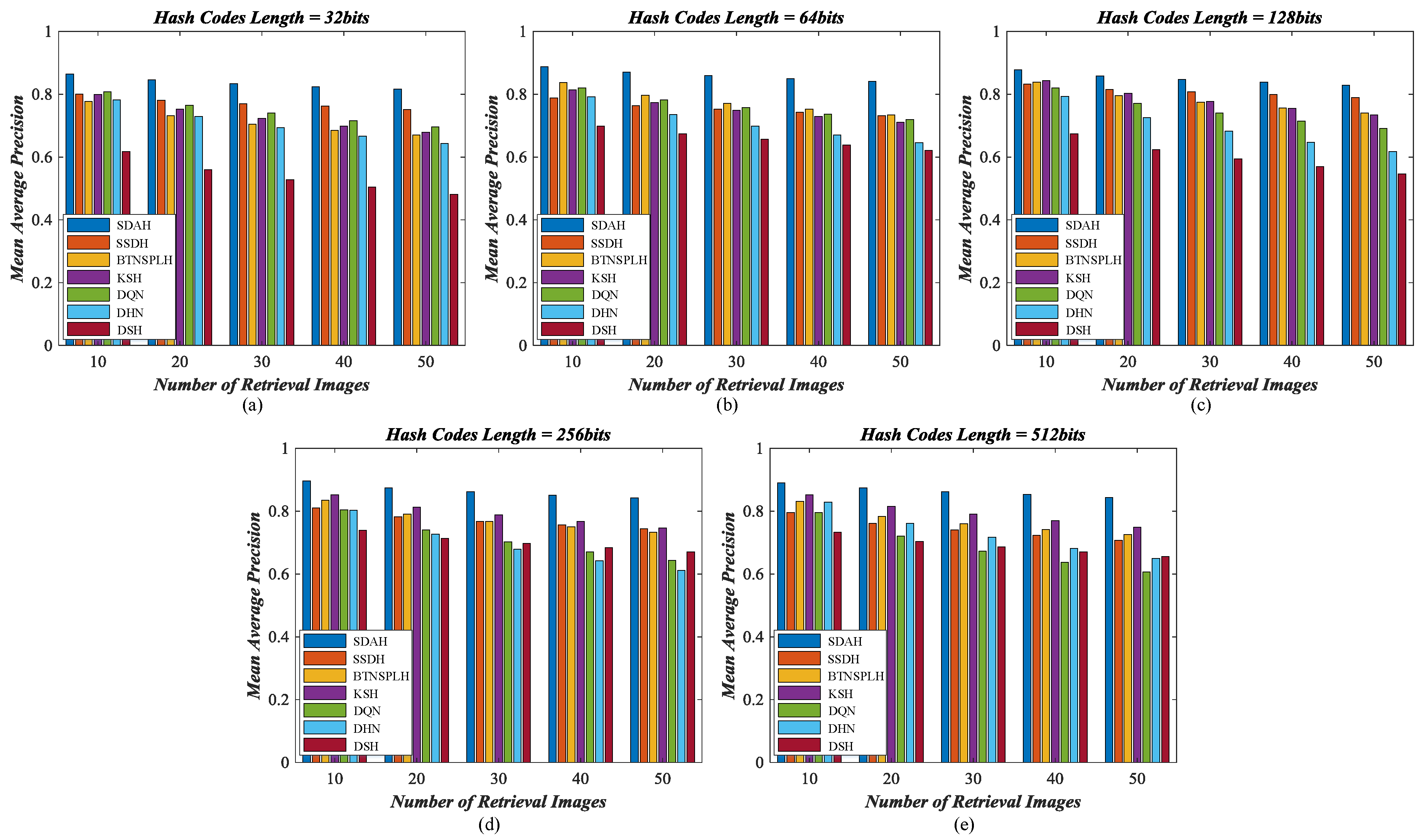
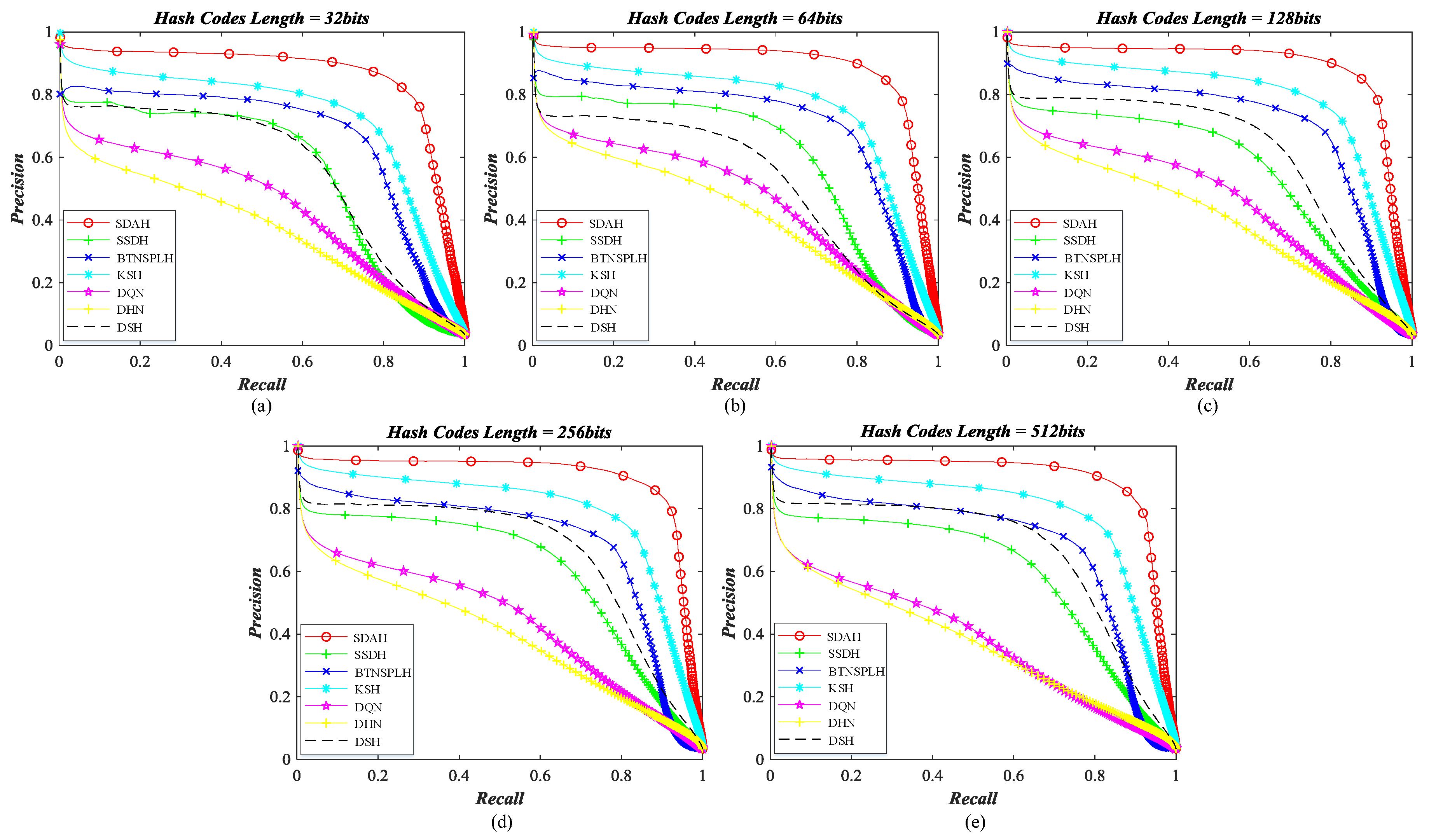
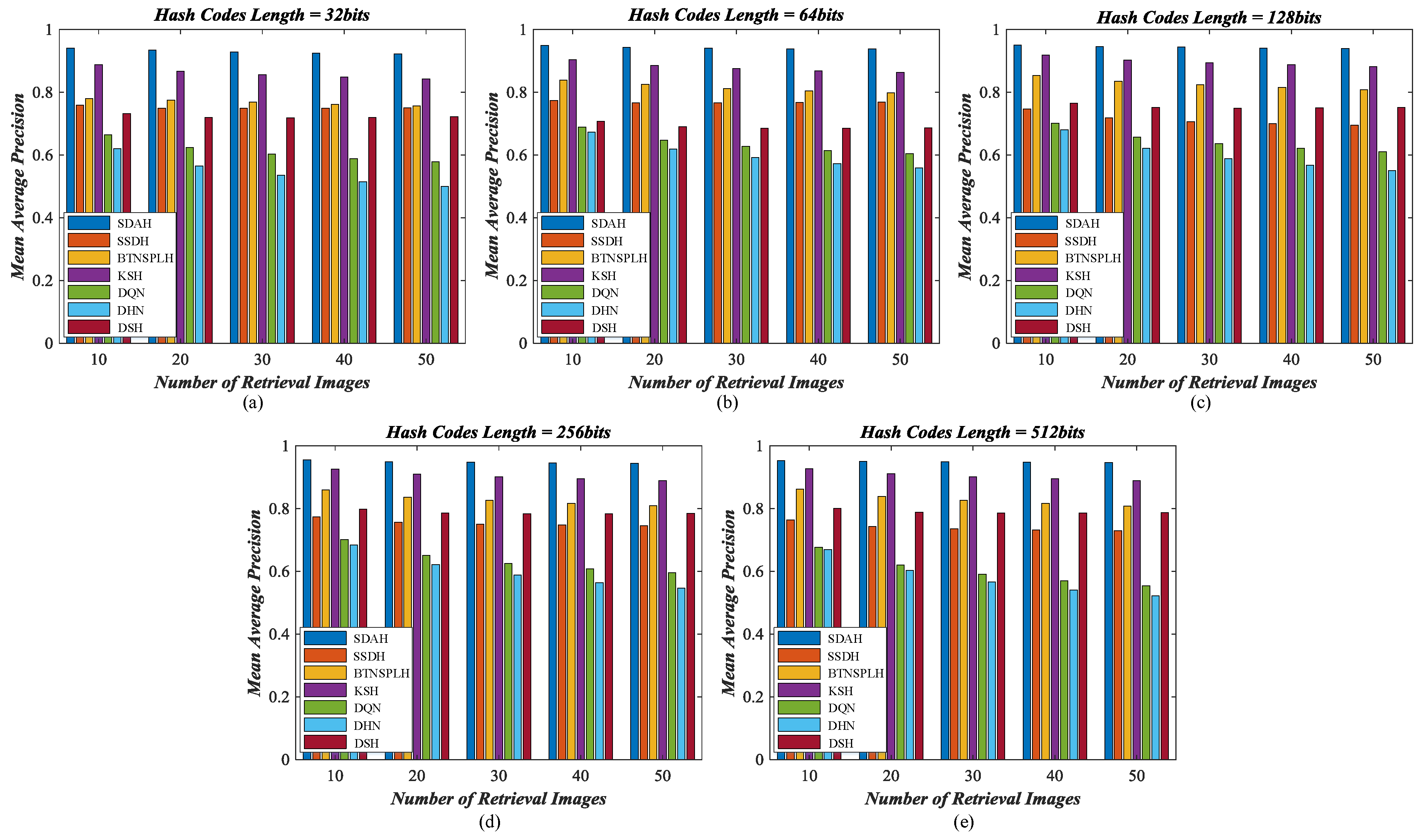
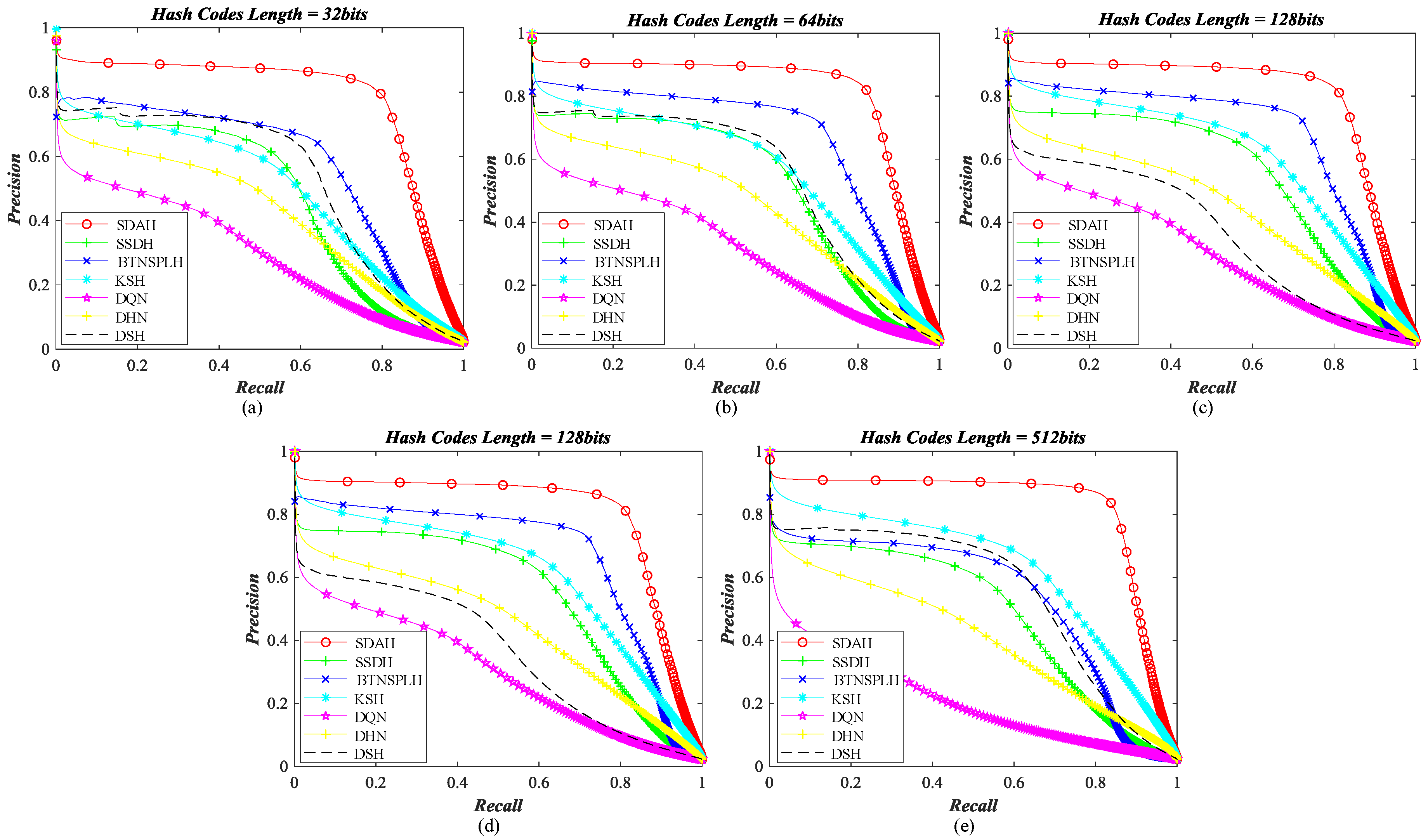
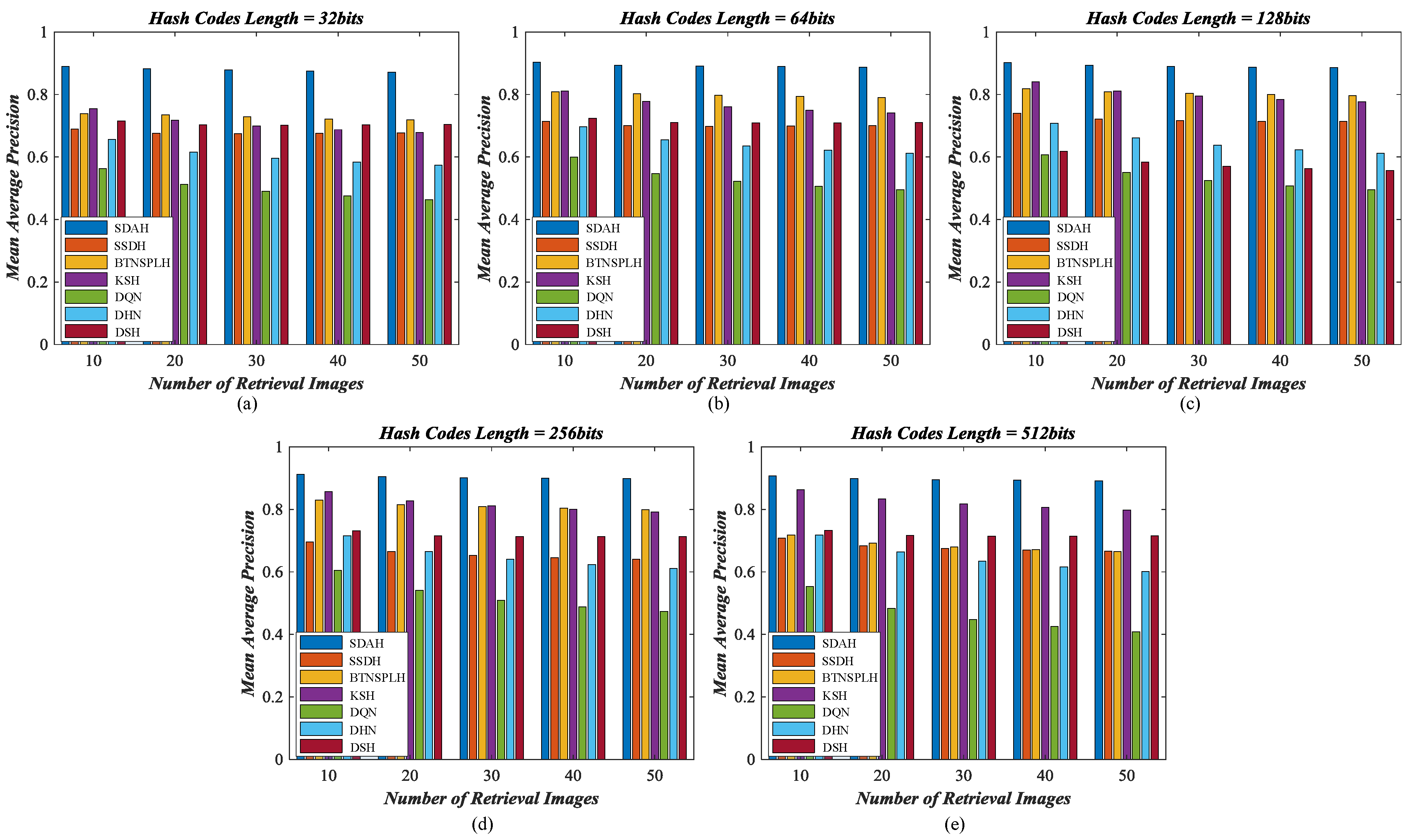
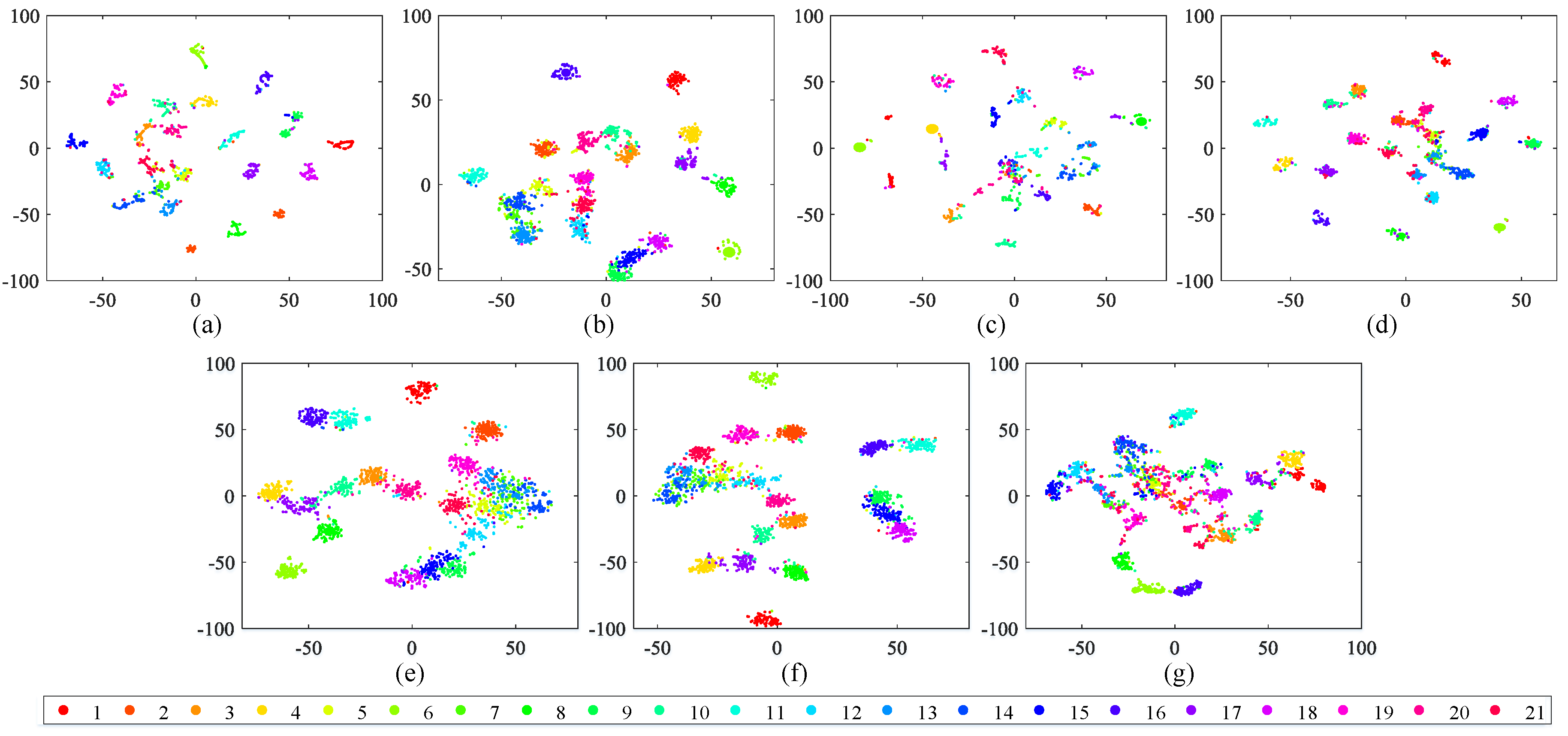
5.3. Retrieval Behavior Compared with Diverse Hashing Methods
- Kernel-based supervised hashing (KSH) [59]. KSH is a classical and successful hash learning method, which aims to map images into the compact binary codes by minimizing/maximizing the hamming distances between similar/dissimilar data pairs. The target hash functions and their algebra relaxation are formulated in the kernel version.
- Bootstrap sequential projection learning based hashing (BTNSPLH) [77]. BTNSPLH develops a nonlinear function for hash learning, which can also explore the latent relationships between images. Meanwhile, a semi-supervised optimization method based on the bootstrap sequential projection learning is proposed to obtain the binary vectors with the lowest errors during the hash coding.
- Semi-supervised deep hashing (SSDH) [78]. SSDH proposes a semi-supervised deep neural network to accomplish the hash leaning in the end-to-end fashion. The developed hashing function minimizes the empirical error on both labeled and unlabeled data, which can preserve the semantic similarities and capture underlying data structures simultaneously.
- Deep quantization network (DQN) based hashing [79]. DQN embeds a hash layer on the top of the normal CNN model to learn the image’s representation and hash codes at the same time. To obtain the useful hash codes, the pairwise cosine loss is developed to remain the similarity relationships between images while the product quantization loss is introduced to reduce the quantization errors.
- Deep hashing network (DHN) [38]. Similar to DQN, another deep neural network with the hashing layer is developed. DHN also develops the specific loss functions to deal with the issues of similarity preserving and quantization loss.
- Deep supervised hashing (DSH) [35]. Based on the usual CNN framework, DSH devises a new hashing network to generate the high discriminative hash codes. Besides preserving the similarity relationships using the supervised information, the designed hash function can also reduce the information loss in the binarization stage by imposing the regularization on the real-valued outputs.
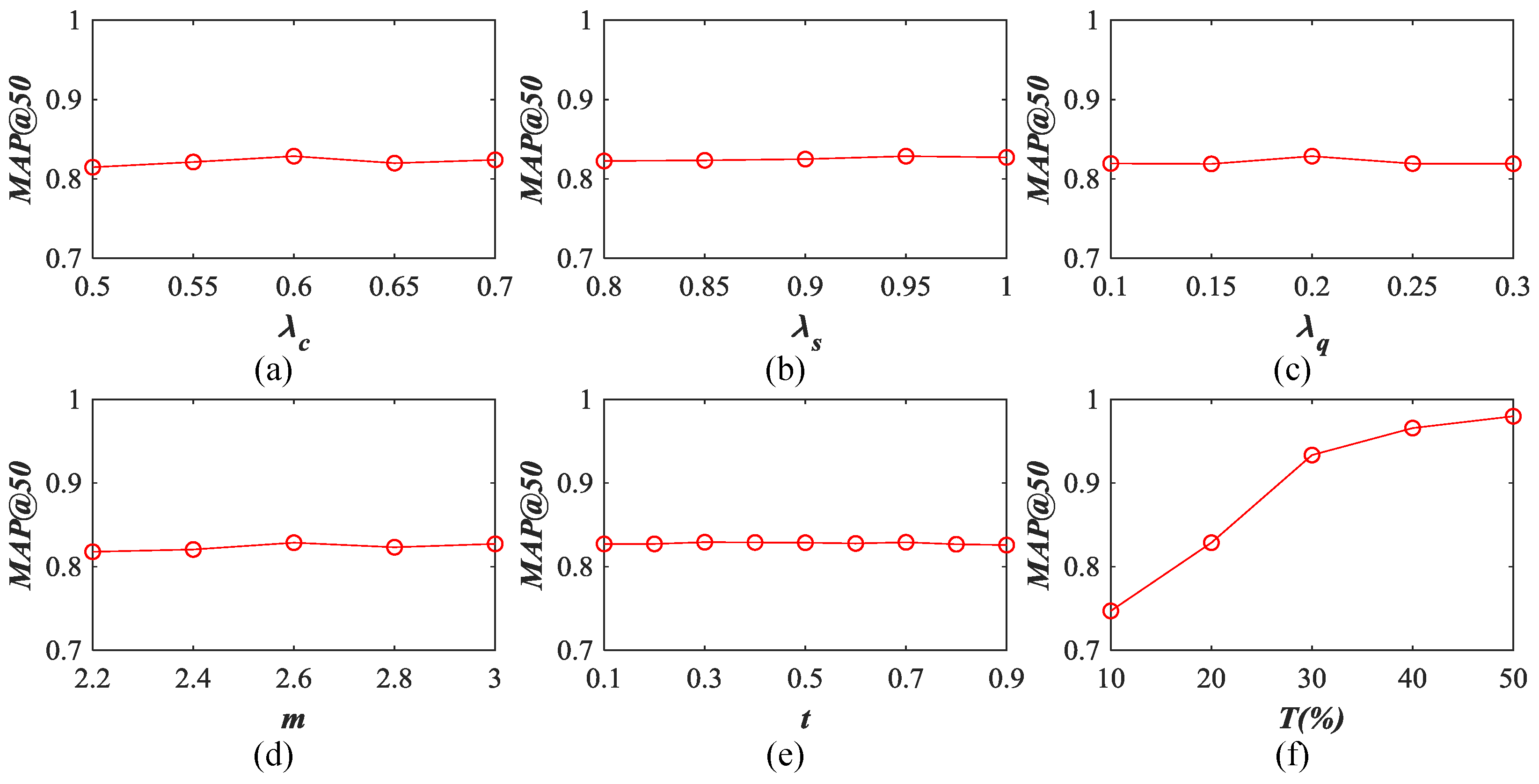
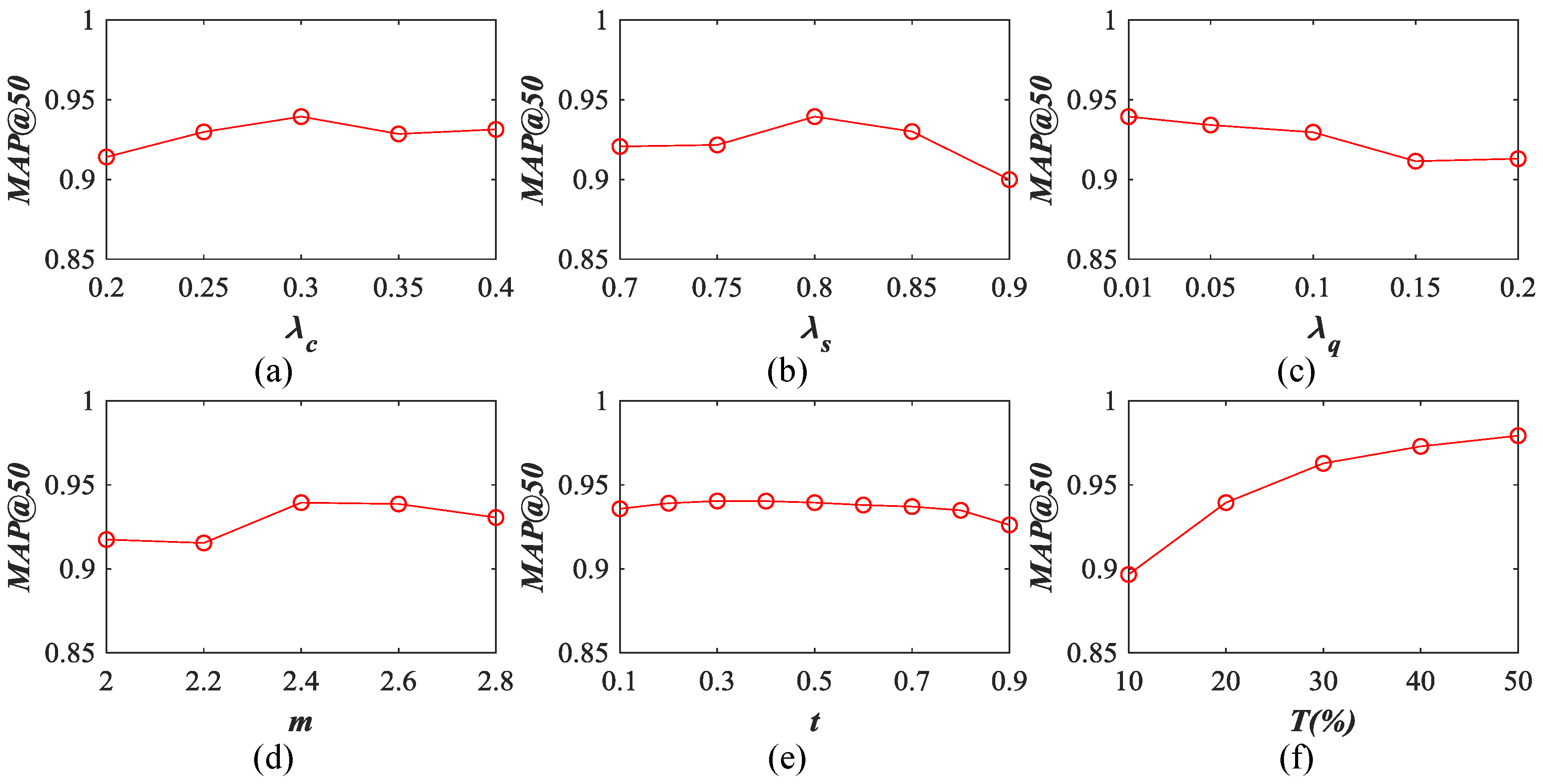
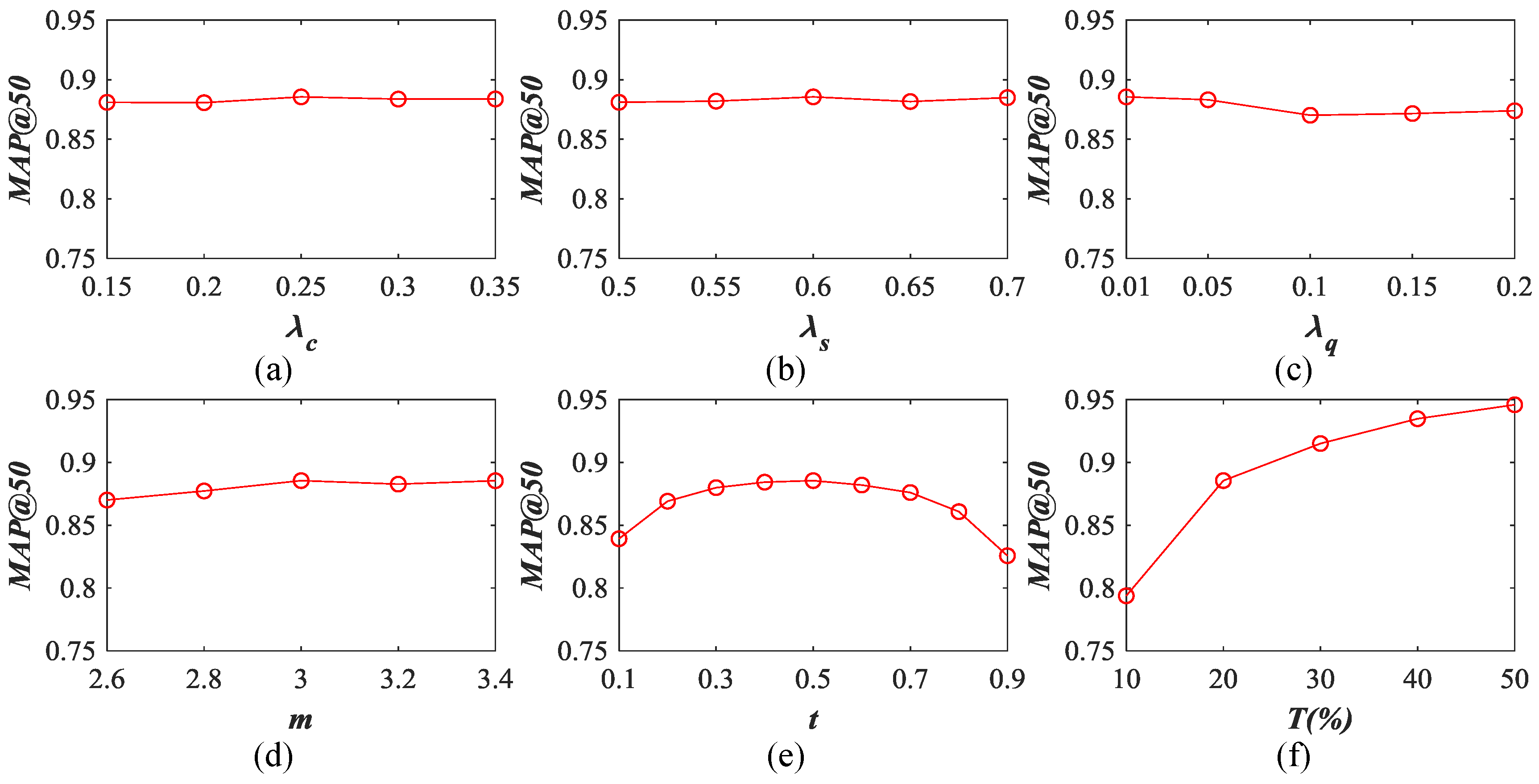
5.4. Influence of Different Parameters
5.5. Computational Cost
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef]
- Quartulli, M.; Olaizola, I.G. A review of EO image information mining. ISPRS J. Photogramm. Remote Sens. 2013, 75, 11–28. [Google Scholar] [CrossRef]
- Shyu, C.R.; Klaric, M.; Scott, G.J.; Barb, A.S.; Davis, C.H.; Palaniappan, K. GeoIRIS: Geospatial information retrieval and indexing system—Content mining, semantics modeling, and complex queries. IEEE Trans. Geosci. Remote Sens. 2007, 45, 839–852. [Google Scholar] [CrossRef] [PubMed]
- Aptoula, E. Remote sensing image retrieval with global morphological texture descriptors. IEEE Trans. Geosci. Remote Sens. 2013, 52, 3023–3034. [Google Scholar] [CrossRef]
- Demir, B.; Bruzzone, L. Hashing-based scalable remote sensing image search and retrieval in large archives. IEEE Trans. Geosci. Remote Sens. 2015, 54, 892–904. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, Y.; Li, Y. A Survey on Deep Learning-Driven Remote Sensing Image Scene Understanding: Scene Classification, Scene Retrieval and Scene-Guided Object Detection. Appl. Sci. 2019, 9, 2110. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, M.L.; Nie, F.P.; Li, X.L. Detecting coherent groups in crowd scenes by multiview clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef]
- Wang, Q.; Qin, Z.Q.; Nie, F.P.; Li, X.L. Spectral embedded adaptive neighbors clustering. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1265–1271. [Google Scholar] [CrossRef]
- Wang, Q.; Wan, J.; Li, X.L. Hierarchical feature selection for random projection. IEEE Trans. Neural Networks and Learning Systems 2018, 30, 1581–1586. [Google Scholar] [CrossRef]
- Wang, Q.; Wan, J.; Nie, F.P.; Liu, B. Robust hierarchical deep learning for vehicular management. IEEE Trans. Veh. Technol. 2018, 68, 4148–4156. [Google Scholar] [CrossRef]
- Wang, J.; Shen, H.T.; Song, J.; Ji, J. Hashing for similarity search: A survey. arXiv 2014, arXiv:1408.2927. [Google Scholar]
- Wang, J.; Zhang, T.; Sebe, N.; Shen, H.T. A survey on learning to hash. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 769–790. [Google Scholar] [CrossRef] [PubMed]
- Muja, M.; Lowe, D.G. Fast approximate nearest neighbors with automatic algorithm configuration. VISAPP 2009, 2, 2. [Google Scholar]
- Muja, M.; Lowe, D.G. Scalable nearest neighbor algorithms for high dimensional data. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2227–2240. [Google Scholar] [CrossRef] [PubMed]
- Indyk, P.; Motwani, R. Approximate nearest neighbors: Towards removing the curse of dimensionality. In Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 24–26 May 1998; pp. 604–613. [Google Scholar]
- Charikar, M.S. Similarity estimation techniques from rounding algorithms. In Proceedings of the Thiry-Fourth Annual ACM Symposium on Theory of Computing, Montreal, QC, Canada, 19–21 May 2002; pp. 380–388. [Google Scholar]
- Andoni, A.; Indyk, P. Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. Commun. ACM 2008, 51, 117. [Google Scholar] [CrossRef]
- Chi, L.; Zhu, X. Hashing techniques: A survey and taxonomy. ACM Comput. Surv. (CSUR) 2017, 50, 11. [Google Scholar] [CrossRef]
- Gionis, A.; Indyk, P.; Motwani, R. Similarity search in high dimensions via hashing. In Proceedings of the 25rd International Conference on Very Large Data, Edinburgh, Scotland, UK, 7–10 September 1999; pp. 518–529. [Google Scholar]
- Datar, M.; Immorlica, N.; Indyk, P.; Mirrokni, V.S. Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the Twentieth Annual Symposium on Computational Geometry, Brooklyn, NY, USA, 8–11 June 2004; pp. 253–262. [Google Scholar]
- Lv, Q.; Josephson, W.; Wang, Z.; Charikar, M.; Li, K. Multi-probe LSH: Efficient indexing for high-dimensional similarity search. In Proceedings of the 33rd International Conference on Very Large Data Bases, Vienna, Austria, 23–27 September 2007; pp. 950–961. [Google Scholar]
- Li, P.; König, C. b-Bit minwise hashing. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 671–680. [Google Scholar]
- Li, P.; Konig, A.; Gui, W. b-Bit minwise hashing for estimating three-way similarities. In Proceedings of the Advances in Neural Information Processing Systems 2010, Vancouver, BC, Canada, 6–11 December 2010; Curran Associates, Inc.: Red Hook, NY, USA, 2010; pp. 1387–1395. [Google Scholar]
- Gan, J.; Feng, J.; Fang, Q.; Ng, W. Locality-sensitive hashing scheme based on dynamic collision counting. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 541–552. [Google Scholar]
- Cao, Y.; Qi, H.; Zhou, W.; Kato, J.; Li, K.; Liu, X.; Gui, J. Binary hashing for approximate nearest neighbor search on big data: A survey. IEEE Access 2017, 6, 2039–2054. [Google Scholar] [CrossRef]
- Weiss, Y.; Torralba, A.; Fergus, R. Spectral hashing. In Proceedings of the Advances in Neural Information Processing Systems 2009, Vancouver, BC, Canada, 7–10 December 2009; Curran Associates, Inc.: Red Hook, NY, USA, 2009; pp. 1753–1760. [Google Scholar]
- Liu, W.; Mu, C.; Kumar, S.; Chang, S.F. Discrete graph hashing. In Proceedings of the Advances in Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 3419–3427. [Google Scholar]
- Shi, X.; Xing, F.; Cai, J.; Zhang, Z.; Xie, Y.; Yang, L. Kernel-based supervised discrete hashing for image retrieval. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 419–433. [Google Scholar]
- Gui, J.; Liu, T.; Sun, Z.; Tao, D.; Tan, T. Fast supervised discrete hashing. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 490–496. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–8 December 2012; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Erin Liong, V.; Lu, J.; Wang, G.; Moulin, P.; Zhou, J. Deep hashing for compact binary codes learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2475–2483. [Google Scholar]
- Lai, H.; Pan, Y.; Liu, Y.; Yan, S. Simultaneous feature learning and hash coding with deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3270–3278. [Google Scholar]
- Zhao, F.; Huang, Y.; Wang, L.; Tan, T. Deep semantic ranking based hashing for multi-label image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1556–1564. [Google Scholar]
- Liu, H.; Wang, R.; Shan, S.; Chen, X. Deep supervised hashing for fast image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2064–2072. [Google Scholar]
- Xia, R.; Pan, Y.; Lai, H.; Liu, C.; Yan, S. Supervised hashing for image retrieval via image representation learning. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Wang, D.; Cui, P.; Ou, M.; Zhu, W. Deep multimodal hashing with orthogonal regularization. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Zhu, H.; Long, M.; Wang, J.; Cao, Y. Deep hashing network for efficient similarity retrieval. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Li, Q.; Sun, Z.; He, R.; Tan, T. Deep supervised discrete hashing. In Proceedings of the Advances in Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 2482–2491. [Google Scholar]
- Li, Y.; Zhang, Y.; Huang, X.; Zhu, H.; Ma, J. Large-scale remote sensing image retrieval by deep hashing neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 56, 950–965. [Google Scholar] [CrossRef]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Datcu, M.; Daschiel, H.; Pelizzari, A.; Quartulli, M.; Galoppo, A.; Colapicchioni, A.; Pastori, M.; Seidel, K.; Marchetti, P.G.; d’Elia, S. Information mining in remote sensing image archives: System concepts. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2923–2936. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Geographic image retrieval using local invariant features. IEEE Trans. Geosci. Remote Sens. 2013, 51, 818–832. [Google Scholar] [CrossRef]
- Xu, S.; Fang, T.; Li, D.; Wang, S. Object classification of aerial images with bag-of-visual words. IEEE Geosci. Remote Sens. Lett. 2009, 7, 366–370. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Tang, X.; Zhang, X.; Liu, F.; Jiao, L. Unsupervised deep feature learning for remote sensing image retrieval. Remote Sens. 2018, 10, 1243. [Google Scholar] [CrossRef]
- Jiao, L.; Tang, X.; Hou, B.; Wang, S. SAR images retrieval based on semantic classification and region-based similarity measure for earth observation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3876–3891. [Google Scholar] [CrossRef]
- Tang, X.; Jiao, L.; Emery, W.J. SAR image content retrieval based on fuzzy similarity and relevance feedback. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1824–1842. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Tao, C.; Zhu, H. Content-based high-resolution remote sensing image retrieval via unsupervised feature learning and collaborative affinity metric fusion. Remote Sens. 2016, 8, 709. [Google Scholar] [CrossRef]
- Ferecatu, M.; Boujemaa, N. Interactive remote-sensing image retrieval using active relevance feedback. IEEE Trans. Geosci. Remote Sens. 2007, 45, 818–826. [Google Scholar] [CrossRef]
- Demir, B.; Bruzzone, L. A novel active learning method in relevance feedback for content-based remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2323–2334. [Google Scholar] [CrossRef]
- Tang, X.; Jiao, L. Fusion similarity-based reranking for SAR image retrieval. IEEE Geosci. Remote Sens. Lett. 2016, 14, 242–246. [Google Scholar] [CrossRef]
- Tang, X.; Jiao, L.; Emery, W.J.; Liu, F.; Zhang, D. Two-stage reranking for remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5798–5817. [Google Scholar] [CrossRef]
- He, J.; Liu, W.; Chang, S.F. Scalable similarity search with optimized kernel hashing. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; pp. 1129–1138. [Google Scholar]
- Heo, J.P.; Lee, Y.; He, J.; Chang, S.F.; Yoon, S.E. Spherical hashing. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2957–2964. [Google Scholar]
- Heo, J.P.; Lee, Y.; He, J.; Chang, S.F.; Yoon, S.E. Spherical hashing: Binary code embedding with hyperspheres. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2304–2316. [Google Scholar] [CrossRef] [PubMed]
- Shen, F.; Shen, C.; Liu, W.; Tao Shen, H. Supervised discrete hashing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 37–45. [Google Scholar]
- Do, T.T.; Doan, A.D.; Nguyen, D.T.; Cheung, N.M. Binary hashing with semidefinite relaxation and augmented lagrangian. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 802–817. [Google Scholar]
- Liu, W.; Wang, J.; Ji, R.; Jiang, Y.G.; Chang, S.F. Supervised hashing with kernels. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2074–2081. [Google Scholar]
- Salakhutdinov, R.; Hinton, G. Semantic hashing. Int. J. Approx. Reason. 2009, 50, 969–978. [Google Scholar] [CrossRef]
- Do, T.T.; Doan, A.D.; Cheung, N.M. Learning to hash with binary deep neural network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 219–234. [Google Scholar]
- Jiang, Q.Y.; Li, W.J. Asymmetric deep supervised hashing. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018. [Google Scholar]
- Li, Y.; Zhang, Y.; Huang, X.; Ma, J. Learning source-invariant deep hashing convolutional neural networks for cross-source remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6521–6536. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Ghasedi Dizaji, K.; Zheng, F.; Sadoughi, N.; Yang, Y.; Deng, C.; Huang, H. Unsupervised deep generative adversarial hashing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3664–3673. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. Learning low dimensional convolutional neural networks for high-resolution remote sensing image retrieval. Remote Sens. 2017, 9, 489. [Google Scholar] [CrossRef]
- Wu, C.; Zhu, J.; Cai, D.; Chen, C.; Bu, J. Semi-supervised nonlinear hashing using bootstrap sequential projection learning. IEEE Trans. Knowl. Data Eng. 2012, 25, 1380–1393. [Google Scholar] [CrossRef]
- Zhang, J.; Peng, Y. SSDH: Semi-supervised deep hashing for large scale image retrieval. IEEE Trans. Circuits Syst. Video Technol. 2017, 29, 212–225. [Google Scholar] [CrossRef]
- Cao, Y.; Long, M.; Wang, J.; Zhu, H.; Wen, Q. Deep quantization network for efficient image retrieval. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene Number | Scene | Volume | Scene Number | Scene | Volume |
|---|---|---|---|---|---|
| 1 | Agricultural | 100 | 12 | Intersection | 100 |
| 2 | Airplane | 100 | 13 | Medium Residential | 100 |
| 3 | Baseball Diamond | 100 | 14 | Mobile Home Park | 100 |
| 4 | Beach | 100 | 15 | Overpass | 100 |
| 5 | Buildings | 100 | 16 | Parking Lot | 100 |
| 6 | Chaparral | 100 | 17 | River | 100 |
| 7 | Dense Residential | 100 | 18 | Runway | 100 |
| 8 | Forest | 100 | 19 | Sparse Residential | 100 |
| 9 | Freeway | 100 | 20 | Storage Tanks | 100 |
| 10 | Golf Course | 100 | 21 | Tennis Court | 100 |
| 11 | Harbor | 100 |
| Scene Number | Scene | Volume | Scene Number | Scene | Volume |
|---|---|---|---|---|---|
| 1 | Airport | 360 | 16 | Mountain | 340 |
| 2 | Bare Land | 310 | 17 | Park | 350 |
| 3 | Baseball Field | 220 | 18 | Parking | 390 |
| 4 | Beach | 400 | 19 | Playground | 370 |
| 5 | Bridge | 360 | 20 | Pond | 420 |
| 6 | Center | 260 | 21 | Port | 380 |
| 7 | Church | 240 | 22 | Railway Station | 260 |
| 8 | Commercial | 350 | 23 | Resort | 290 |
| 9 | Dense Residential | 410 | 24 | River | 410 |
| 10 | Desert | 300 | 25 | School | 300 |
| 11 | Farmland | 370 | 26 | Sparse residential | 300 |
| 12 | Forest | 250 | 27 | Square | 330 |
| 13 | Industrial | 390 | 28 | Stadium | 290 |
| 14 | Meadow | 280 | 29 | Storage tanks | 360 |
| 15 | Medium Residential | 290 | 30 | Viaduct | 420 |
| Scene Number | Scene | Volume | Scene Number | Scene | Volume |
|---|---|---|---|---|---|
| 1 | Airplane | 700 | 24 | Medium Residential | 700 |
| 2 | Airport | 700 | 25 | Mobile Home Park | 700 |
| 3 | Baseball Diamond | 700 | 26 | Mountain | 700 |
| 4 | Basketball Court | 700 | 27 | Overpass | 700 |
| 5 | Beach | 700 | 28 | Palace | 700 |
| 6 | Bridge | 700 | 29 | Parking Lot | 700 |
| 7 | Chaparral | 700 | 30 | Railway | 700 |
| 8 | Church | 700 | 31 | Railway Station | 700 |
| 9 | Circular Farmland | 700 | 32 | Rectangular Farmland | 700 |
| 10 | Cloud | 700 | 33 | River | 700 |
| 11 | Commercial Area | 700 | 34 | Roundabout | 700 |
| 12 | Dense Residential | 700 | 35 | Runway | 700 |
| 13 | Desert | 700 | 36 | Sea Ice | 700 |
| 14 | Forest | 700 | 37 | Ship | 700 |
| 15 | Freeway | 700 | 38 | Snow Berg | 700 |
| 16 | Golf Course | 700 | 39 | Sparse Residential | 700 |
| 17 | Ground Track Field | 700 | 40 | Stadium | 700 |
| 18 | Harbor | 700 | 41 | Storage Tank | 700 |
| 19 | Industrial Area | 700 | 42 | Tennis Court | 700 |
| 20 | Intersection | 700 | 43 | Terrace | 700 |
| 21 | Island | 700 | 44 | Thermal Power Station | 700 |
| 22 | Lake | 700 | 45 | Wetland | 700 |
| 23 | Meadow | 700 |
| Residual Auto-Encoder | Encoder (Generator) | |
| Latent | c, K | |
| Decoder | ||
| Category Discriminator | ||
| Uniform Discriminator | ||
| BOW | AlexFC7 | VGG16FC7 | AlexFineFC7 | VGG16FineFC7 | ||
|---|---|---|---|---|---|---|
| UCM | 0.50 | 0.20 | 0.90 | 0.60 | 0.40 | |
| 0.50 | 0.75 | 0.70 | 0.95 | 0.80 | ||
| 0.65 | 0.05 | 0.05 | 0.20 | 0.10 | ||
| m | 2.60 | 1.40 | 1.00 | 2.60 | 4.00 | |
| AID | 1.00 | 0.45 | 0.50 | 0.30 | 0.35 | |
| 0.85 | 0.95 | 0.85 | 0.80 | 0.70 | ||
| 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | ||
| m | 1.60 | 2.40 | 1.40 | 2.40 | 2.20 | |
| NWPU | 0.90 | 0.95 | 0.80 | 0.25 | 0.90 | |
| 0.10 | 0.55 | 0.45 | 0.60 | 0.10 | ||
| 0.05 | 0.01 | 0.01 | 0.01 | 0.05 | ||
| m | 3.00 | 3.00 | 2.00 | 3.00 | 3.00 |
| BOW | AlexFC7 | VGG16FC7 | AlexFineFC7 | VGG16FineFC7 | |||
|---|---|---|---|---|---|---|---|
| UCM | Baseline | 0.3338 | 0.4815 | 0.4613 | 0.6551 | 0.8027 | |
| Hash codes bits | 32 | 0.4362 | 0.7064 | 0.6414 | 0.8164 | 0.8994 | |
| 64 | 0.4429 | 0.7314 | 0.7001 | 0.8214 | 0.9173 | ||
| 128 | 0.4503 | 0.7319 | 0.7316 | 0.8286 | 0.9225 | ||
| 256 | 0.4734 | 0.7471 | 0.7369 | 0.8319 | 0.9277 | ||
| 512 | 0.4801 | 0.7572 | 0.7503 | 0.8428 | 0.9269 | ||
| AID | Baseline | 0.2783 | 0.4683 | 0.4240 | 0.8276 | 0.9516 | |
| Hash codes bits | 32 | 0.3850 | 0.5975 | 0.6234 | 0.9230 | 0.9623 | |
| 64 | 0.4943 | 0.7228 | 0.6625 | 0.9379 | 0.9673 | ||
| 128 | 0.5018 | 0.7346 | 0.7064 | 0.9394 | 0.9754 | ||
| 256 | 0.5114 | 0.7519 | 0.7284 | 0.9448 | 0.9755 | ||
| 512 | 0.5159 | 0.7641 | 0.7319 | 0.9466 | 0.9779 | ||
| NWPU | Baseline | 0.2284 | 0.4128 | 0.4123 | 0.6981 | 0.9044 | |
| Hash codes bits | 32 | 0.3469 | 0.6020 | 0.6181 | 0.8715 | 0.9324 | |
| 64 | 0.3609 | 0.6557 | 0.6234 | 0.8816 | 0.9572 | ||
| 128 | 0.4048 | 0.6717 | 0.6523 | 0.8856 | 0.9614 | ||
| 256 | 0.4524 | 0.6727 | 0.6708 | 0.8916 | 0.9688 | ||
| 512 | 0.4676 | 0.6823 | 0.6795 | 0.8988 | 0.9710 | ||
| SDAH | SSDH | BTNSPLH | KSH | DQN | DHN | DSH | |
|---|---|---|---|---|---|---|---|
| Agriculture | 0.9487 | 0.9416 | 0.9349 | 0.9304 | 0.9386 | 0.9376 | 0.7457 |
| Airplane | 0.9438 | 0.8373 | 0.8191 | 0.8510 | 0.9245 | 0.9340 | 0.4622 |
| Baseball Diamond | 0.8931 | 0.9313 | 0.9378 | 0.8197 | 0.9050 | 0.8597 | 0.6699 |
| Beach | 0.9497 | 0.9952 | 0.9955 | 0.9607 | 0.9647 | 0.9303 | 0.9383 |
| Buildings | 0.6772 | 0.5353 | 0.7938 | 0.3125 | 0.2699 | 0.3037 | 0.3152 |
| Chaparral | 0.9723 | 0.9654 | 0.9451 | 0.9685 | 0.9611 | 0.9562 | 0.7813 |
| Dense Residential | 0.4796 | 0.3436 | 0.1834 | 0.2533 | 0.1522 | 0.1645 | 0.2382 |
| Forest | 0.9487 | 0.9902 | 0.9700 | 0.9973 | 0.9803 | 0.9442 | 0.8299 |
| Freeway | 0.9642 | 0.8115 | 0.6650 | 0.8253 | 0.7518 | 0.5310 | 0.4530 |
| Golf Course | 0.7673 | 0.6357 | 0.7634 | 0.6226 | 0.6445 | 0.5373 | 0.4514 |
| Harbor | 0.9452 | 0.9233 | 0.7023 | 0.9747 | 0.8725 | 0.7559 | 0.8240 |
| Intersection | 0.7813 | 0.7696 | 0.7787 | 0.5906 | 0.4692 | 0.3567 | 0.5202 |
| Medium-density Residential | 0.8182 | 0.5740 | 0.5877 | 0.7210 | 0.4176 | 0.3805 | 0.3175 |
| Mobile Home Park | 0.7295 | 0.7157 | 0.6530 | 0.5304 | 0.5477 | 0.4064 | 0.4911 |
| Overpass | 0.8070 | 0.8017 | 0.7314 | 0.6044 | 0.5313 | 0.3983 | 0.6388 |
| Parking Lot | 0.9436 | 0.9809 | 0.4928 | 0.9824 | 0.9730 | 0.8294 | 0.7406 |
| River | 0.8102 | 0.7906 | 0.7210 | 0.6256 | 0.5285 | 0.4558 | 0.4457 |
| Runway | 0.9188 | 0.9099 | 0.8665 | 0.9146 | 0.8282 | 0.6644 | 0.8025 |
| Sparse Residential | 0.8842 | 0.8072 | 0.9641 | 0.7247 | 0.6282 | 0.6098 | 0.4173 |
| Storage Tanks | 0.5743 | 0.5643 | 0.2403 | 0.5059 | 0.5387 | 0.4735 | 0.2197 |
| Tennis Courts | 0.6434 | 0.4696 | 0.7879 | 0.6373 | 0.5588 | 0.5184 | 0.1638 |
| Average | 0.8286 | 0.7759 | 0.7397 | 0.7311 | 0.6851 | 0.6166 | 0.5460 |
| SDAH | SSDH | BTNSPLH | KSH | DQN | DHN | DSH | |
|---|---|---|---|---|---|---|---|
| Airport | 0.9661 | 0.5831 | 0.8448 | 0.9403 | 0.3597 | 0.4588 | 0.6298 |
| Bare Land | 0.9873 | 0.7902 | 0.6731 | 0.9842 | 0.3624 | 0.5352 | 0.8339 |
| Baseball Field | 0.9771 | 0.8307 | 0.8910 | 0.9804 | 0.5775 | 0.4645 | 0.8126 |
| Beach | 0.9562 | 0.7687 | 0.9680 | 0.9653 | 0.8312 | 0.7224 | 0.8459 |
| Bridge | 0.9649 | 0.7765 | 0.9339 | 0.9632 | 0.8186 | 0.7168 | 0.8117 |
| Center | 0.9098 | 0.6577 | 0.7360 | 0.5305 | 0.2414 | 0.3002 | 0.7136 |
| Church | 0.9126 | 0.5572 | 0.7094 | 0.8153 | 0.2017 | 0.2519 | 0.6206 |
| Commercial | 0.9379 | 0.4750 | 0.7527 | 0.9271 | 0.3041 | 0.2671 | 0.6330 |
| Dense Residential | 0.9827 | 0.6908 | 0.9288 | 0.9784 | 0.7900 | 0.6719 | 0.7718 |
| Desert | 0.9651 | 0.8194 | 0.5360 | 0.9344 | 0.4661 | 0.5230 | 0.8857 |
| Farmland | 0.9481 | 0.6925 | 0.9402 | 0.9520 | 0.8535 | 0.7893 | 0.6895 |
| Forest | 0.9717 | 0.9183 | 0.8995 | 0.9566 | 0.8876 | 0.8631 | 0.9263 |
| Industrial | 0.9353 | 0.5745 | 0.7946 | 0.9129 | 0.4837 | 0.3854 | 0.6467 |
| Meadow | 0.9707 | 0.9188 | 0.8049 | 0.9691 | 0.8213 | 0.8295 | 0.9186 |
| Medium Residential | 0.9281 | 0.6719 | 0.7780 | 0.8668 | 0.4677 | 0.4404 | 0.6896 |
| Mountain | 0.9686 | 0.7784 | 0.9675 | 0.9600 | 0.8929 | 0.7606 | 0.8622 |
| Park | 0.8884 | 0.5717 | 0.3321 | 0.6658 | 0.1991 | 0.2667 | 0.6503 |
| Parking | 0.9894 | 0.9116 | 0.9436 | 0.9763 | 0.9946 | 0.9459 | 0.9513 |
| Playground | 0.9502 | 0.7330 | 0.9309 | 0.9704 | 0.7496 | 0.6440 | 0.7991 |
| Pond | 0.9254 | 0.6867 | 0.8809 | 0.9693 | 0.7867 | 0.5993 | 0.7784 |
| Port | 0.9648 | 0.7400 | 0.8018 | 0.9642 | 0.5954 | 0.5181 | 0.7700 |
| Railway Station | 0.9087 | 0.5789 | 0.8138 | 0.8120 | 0.4146 | 0.3852 | 0.6367 |
| Resort | 0.8493 | 0.4789 | 0.5710 | 0.4257 | 0.1178 | 0.1069 | 0.5182 |
| River | 0.9646 | 0.6312 | 0.8880 | 0.9628 | 0.6448 | 0.3307 | 0.6979 |
| School | 0.7914 | 0.3656 | 0.6237 | 0.6386 | 0.1042 | 0.1127 | 0.3917 |
| Sparse residential | 0.9828 | 0.8575 | 0.9724 | 0.9798 | 0.9227 | 0.8608 | 0.8533 |
| Square | 0.8582 | 0.3666 | 0.4750 | 0.3565 | 0.1937 | 0.1285 | 0.5231 |
| Stadium | 0.9541 | 0.8922 | 0.9382 | 0.9780 | 0.8740 | 0.7585 | 0.9034 |
| Storage tanks | 0.8767 | 0.7668 | 0.7632 | 0.8741 | 0.8134 | 0.5935 | 0.8577 |
| Viaduct | 0.9958 | 0.8023 | 0.9390 | 0.9846 | 0.9793 | 0.9370 | 0.8550 |
| Average | 0.9394 | 0.6962 | 0.8011 | 0.8732 | 0.5917 | 0.5389 | 0.7493 |
| SDAH | SSDH | BTNSPLH | KSH | DQN | DHN | DSH | |
|---|---|---|---|---|---|---|---|
| Airplane | 0.9264 | 0.8064 | 0.9258 | 0.8801 | 0.6249 | 0.7801 | 0.7700 |
| Airport | 0.8661 | 0.5673 | 0.3985 | 0.6475 | 0.2310 | 0.4976 | 0.2910 |
| Baseball Diamond | 0.9259 | 0.7089 | 0.9470 | 0.8753 | 0.2754 | 0.4615 | 0.5786 |
| Basketball Court | 0.8508 | 0.5391 | 0.9312 | 0.5563 | 0.1251 | 0.3489 | 0.4095 |
| Beach | 0.9381 | 0.7883 | 0.8797 | 0.8549 | 0.4300 | 0.6506 | 0.5875 |
| Bridge | 0.8905 | 0.7999 | 0.9525 | 0.8708 | 0.6461 | 0.7402 | 0.6834 |
| Chaparral | 0.9754 | 0.9689 | 0.9384 | 0.9667 | 0.9391 | 0.9447 | 0.7546 |
| Church | 0.7778 | 0.4859 | 0.6902 | 0.3849 | 0.0706 | 0.2138 | 0.2426 |
| Circular Farmland | 0.9516 | 0.8773 | 0.9125 | 0.9241 | 0.9091 | 0.9270 | 0.7249 |
| Cloud | 0.9723 | 0.9232 | 0.9728 | 0.9711 | 0.9519 | 0.9347 | 0.9370 |
| Commercial Area | 0.7857 | 0.4903 | 0.8125 | 0.4987 | 0.1928 | 0.4174 | 0.3659 |
| Dense Residential | 0.8434 | 0.6357 | 0.8755 | 0.7972 | 0.3967 | 0.4670 | 0.3909 |
| Desert | 0.9383 | 0.8891 | 0.8939 | 0.9001 | 0.8394 | 0.8425 | 0.8296 |
| Forest | 0.9486 | 0.8668 | 0.5751 | 0.9332 | 0.8569 | 0.8289 | 0.6403 |
| Freeway | 0.8778 | 0.5866 | 0.7960 | 0.5119 | 0.3270 | 0.3471 | 0.4567 |
| Golf Course | 0.8735 | 0.7455 | 0.9145 | 0.8255 | 0.6063 | 0.7205 | 0.6424 |
| Ground Track Field | 0.9170 | 0.6986 | 0.9046 | 0.9094 | 0.2855 | 0.4943 | 0.6375 |
| Harbor | 0.9534 | 0.8231 | 0.8851 | 0.8970 | 0.7680 | 0.8096 | 0.6062 |
| Industrial Area | 0.8811 | 0.6543 | 0.5709 | 0.7620 | 0.5537 | 0.6051 | 0.4530 |
| Intersection | 0.8843 | 0.7279 | 0.8414 | 0.8160 | 0.3174 | 0.6676 | 0.6722 |
| Island | 0.9335 | 0.8925 | 0.8758 | 0.9227 | 0.7559 | 0.7886 | 0.8098 |
| Lake | 0.9291 | 0.8056 | 0.8137 | 0.8394 | 0.7151 | 0.7447 | 0.7410 |
| Meadow | 0.9376 | 0.8690 | 0.4655 | 0.8756 | 0.7802 | 0.7495 | 0.7957 |
| Medium Residential | 0.7869 | 0.5356 | 0.6655 | 0.5448 | 0.2460 | 0.3478 | 0.2664 |
| Mobile Home Park | 0.8670 | 0.7240 | 0.9051 | 0.8599 | 0.2915 | 0.5411 | 0.5180 |
| Mountain | 0.9021 | 0.7057 | 0.8992 | 0.8381 | 0.6495 | 0.6674 | 0.2659 |
| Overpass | 0.9403 | 0.7429 | 0.9022 | 0.8205 | 0.4358 | 0.6185 | 0.5801 |
| Palace | 0.6588 | 0.4539 | 0.5326 | 0.2617 | 0.0659 | 0.1053 | 0.2487 |
| Parking Lot | 0.9466 | 0.7914 | 0.8986 | 0.8985 | 0.5695 | 0.7066 | 0.7377 |
| Railway | 0.8916 | 0.6106 | 0.7079 | 0.7709 | 0.4158 | 0.4429 | 0.5240 |
| Railway Station | 0.8418 | 0.6499 | 0.2873 | 0.6035 | 0.1968 | 0.3925 | 0.4480 |
| Rectangular Farmland | 0.8750 | 0.6560 | 0.7838 | 0.8194 | 0.6961 | 0.7155 | 0.3041 |
| River | 0.8336 | 0.5890 | 0.7924 | 0.5617 | 0.3015 | 0.4767 | 0.3939 |
| Roundabout | 0.8343 | 0.7346 | 0.9212 | 0.8879 | 0.6344 | 0.7619 | 0.6350 |
| Runway | 0.8465 | 0.7236 | 0.7872 | 0.7054 | 0.3776 | 0.5210 | 0.6405 |
| Sea Ice | 0.9812 | 0.9467 | 0.9795 | 0.9606 | 0.9085 | 0.9146 | 0.9311 |
| Ship | 0.8679 | 0.5999 | 0.9194 | 0.8160 | 0.2772 | 0.6068 | 0.4182 |
| Snowberg | 0.9553 | 0.8950 | 0.9369 | 0.9447 | 0.9071 | 0.8867 | 0.7867 |
| Sparse Residential | 0.9285 | 0.6838 | 0.3809 | 0.8631 | 0.3858 | 0.6606 | 0.4903 |
| Stadium | 0.8854 | 0.7499 | 0.8782 | 0.8302 | 0.6231 | 0.6526 | 0.7206 |
| Storage Tank | 0.9184 | 0.7841 | 0.8226 | 0.7864 | 0.6635 | 0.7739 | 0.6866 |
| Tennis Court | 0.7918 | 0.4402 | 0.8991 | 0.6653 | 0.0959 | 0.1987 | 0.2357 |
| Terrace | 0.8542 | 0.6699 | 0.7217 | 0.8051 | 0.3727 | 0.5907 | 0.3062 |
| Thermal Power Station | 0.8513 | 0.6147 | 0.8334 | 0.7251 | 0.2971 | 0.5558 | 0.5132 |
| Wetland | 0.8116 | 0.6574 | 0.5818 | 0.5126 | 0.2484 | 0.4064 | 0.3991 |
| Average | 0.8855 | 0.7135 | 0.7958 | 0.7756 | 0.4946 | 0.6117 | 0.5571 |
| Target Image Archive Size | 1000 | 5000 | 10,000 | 15,000 | 20,000 | 25,000 | 31,500 | |
|---|---|---|---|---|---|---|---|---|
| AlexFineFC7 | 31.79 | 152.71 | 306.00 | 454.86 | 563.74 | 765.99 | 949.25 | |
| Hash codes bits | 32 | 0.60 | 1.36 | 2.81 | 3.14 | 3.74 | 5.46 | 6.25 |
| 64 | 0.81 | 2.47 | 4.23 | 6.58 | 7.99 | 11.03 | 13.08 | |
| 128 | 1.28 | 4.76 | 9.68 | 13.97 | 18.09 | 23.43 | 29.56 | |
| 256 | 2.41 | 10.40 | 21.45 | 32.78 | 43.40 | 54.36 | 68.28 | |
| 512 | 4.76 | 22.16 | 45.70 | 64.16 | 79.11 | 106.32 | 132.72 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, X.; Liu, C.; Ma, J.; Zhang, X.; Liu, F.; Jiao, L. Large-Scale Remote Sensing Image Retrieval Based on Semi-Supervised Adversarial Hashing. Remote Sens. 2019, 11, 2055. https://doi.org/10.3390/rs11172055
Tang X, Liu C, Ma J, Zhang X, Liu F, Jiao L. Large-Scale Remote Sensing Image Retrieval Based on Semi-Supervised Adversarial Hashing. Remote Sensing. 2019; 11(17):2055. https://doi.org/10.3390/rs11172055
Chicago/Turabian StyleTang, Xu, Chao Liu, Jingjing Ma, Xiangrong Zhang, Fang Liu, and Licheng Jiao. 2019. "Large-Scale Remote Sensing Image Retrieval Based on Semi-Supervised Adversarial Hashing" Remote Sensing 11, no. 17: 2055. https://doi.org/10.3390/rs11172055
APA StyleTang, X., Liu, C., Ma, J., Zhang, X., Liu, F., & Jiao, L. (2019). Large-Scale Remote Sensing Image Retrieval Based on Semi-Supervised Adversarial Hashing. Remote Sensing, 11(17), 2055. https://doi.org/10.3390/rs11172055