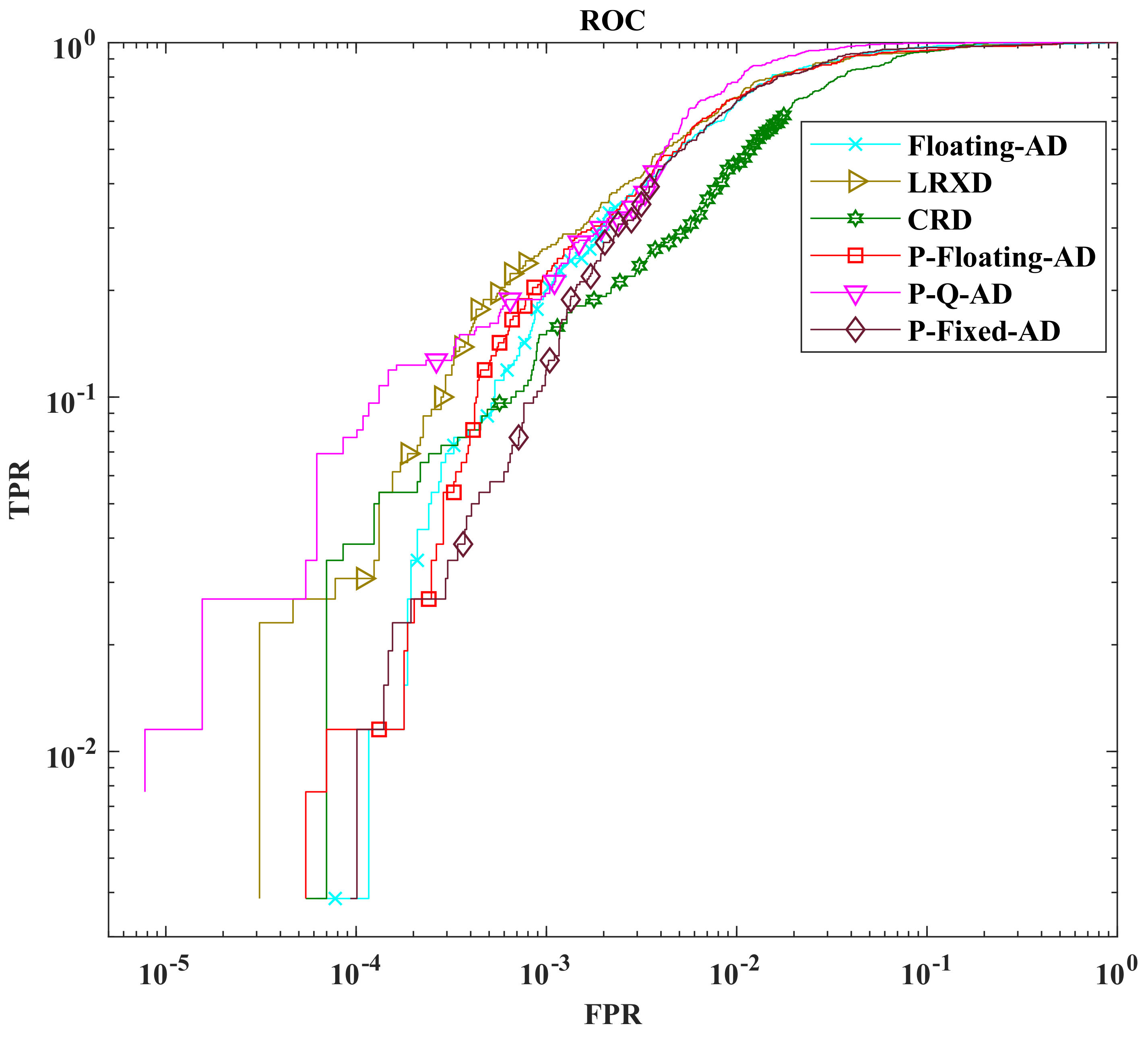
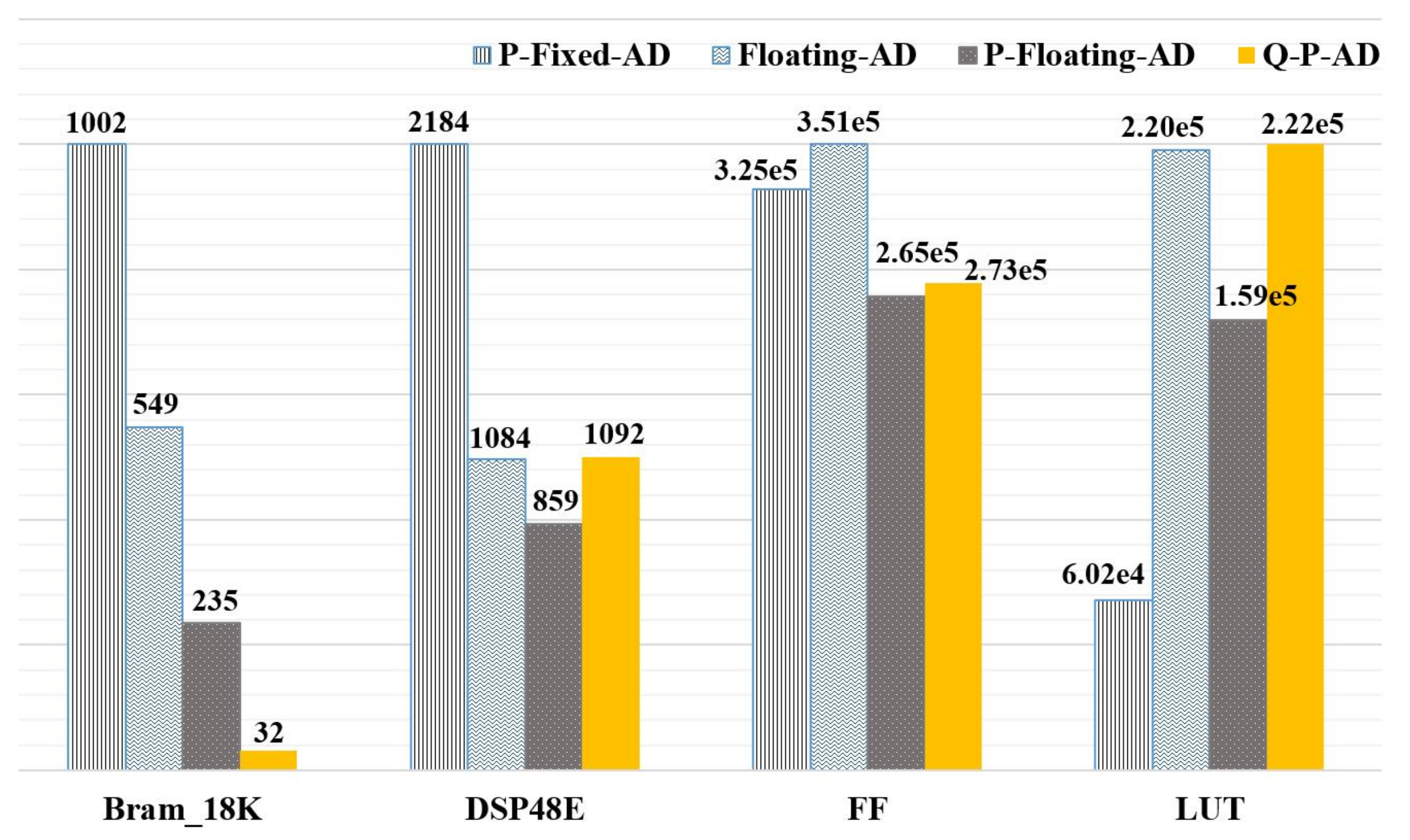
3.1. Basic Analysis for Real-Time Onboard HSI AD
In general, a detector can be designed in two stages: the first one is algorithm design. Improving the throughput of the algorithm in the algorithm design stage is the main work of this paper. The second stage is the hardware implementation in which increasing the chip/device resource utilization and computational performance are general approaches to improve the throughput.
In the algorithm design stage, the throughput is not only related to the neurons number of the network but also depended on the bit-widths of each arithmetic operations. Hence, to improve the detection speed, the redundant neurons and the data bits should be decreased. However, to some extent, the neurons number and the bit-widths may impact the detection accuracy. The speed and accuracy always conflict with each other in a latent relationship. Considering the arithmetic operation can be customized as well as the network, the throughput is not just related to the computation complexity. So, it is difficult to evaluate the throughput for algorithm optimization in the algorithm design stage.
In this section, the AHCF is defined to indicate the throughput in the algorithm design stage. To maximize the detection speed and accuracy, a latent relationship between the objects of throughput and accuracy is built up.
Both objects are related to the factors including neurons number, local window size, leaky value
of the network in Formula (
1), and the bit-widths of the arithmetic units. Actually, the above problem is a constrained multi-objective optimization problem. The solution to this problem can be regarded as a multi-objective programming (MOP) problem which is an NP-hard problem. To define the problem, a series of constraining conditions and the objects functions are proposed in the following
Section 3.2 and
Section 3.3. By solving the MOP with NSGA-II in
Section 3.4, the structure pruning, and the data quantization can be implemented for the network of the HSI AD.
3.3. The Quantified Detection Speed with Network Structure and Arithmetic Units in Hardware
In this section, the factor which determines the throughput of the detection algorithm is analyzed. Then, the relationship between the detection accuracy and this factor is built to optimize the throughput of the detection algorithm. Because different detection algorithms may be realized with different basic operations which cost different hardware resources in FPGA. If an algorithm requires fewer resources, then a higher throughput can be achieved by implementing multi-parallel copies of the algorithm in the FPGA devices.
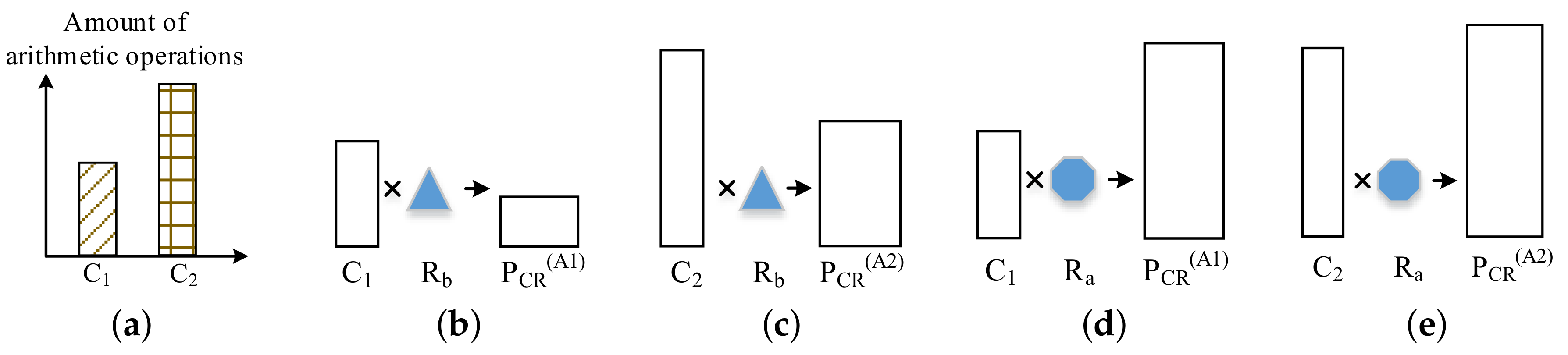
To analyze the factors which affect the throughput during the algorithm design stage, we assume there are two detection Algorithms A1 and A2 with
and
number of arithmetic operations respectively for one PUT detection as shown in
Figure 11a (
<
). Obviously, if the basic arithmetic operators of both algorithms are the same, then algorithm A1 will reach higher throughput than A2 on the same device. However, in the programmable logic, the different basic arithmetic operator may be realized with different type and different amount of hardware resources (
or
in
Figure 11), e.g., lookup table (LUT), digital signal processing (DSP) blocks.
In
Figure 11, the product of the arithmetic operations amount
C and the resources for basic operator
R is defined as algorithm–hardware–cost–factor (AHCF) and marked as
. The
means the resource requirement in theory for the algorithm to detect one PUT with a certain time. This “certain time” is equal to the processing time of one arithmetic operation. In this paper, to simplify the expression, it is defined as the operation cycle.
Assume
, the
of Algorithm A1 and A2 can be expressed as from
Figure 11b–e. In
Figure 11, there are two relationships between the PCR of Algorithm A1 and A2. In general,
where
and
mean
of A1and A2 respectively. However, in some situation, the relationship may be
(when
, in
Figure 11c,d).
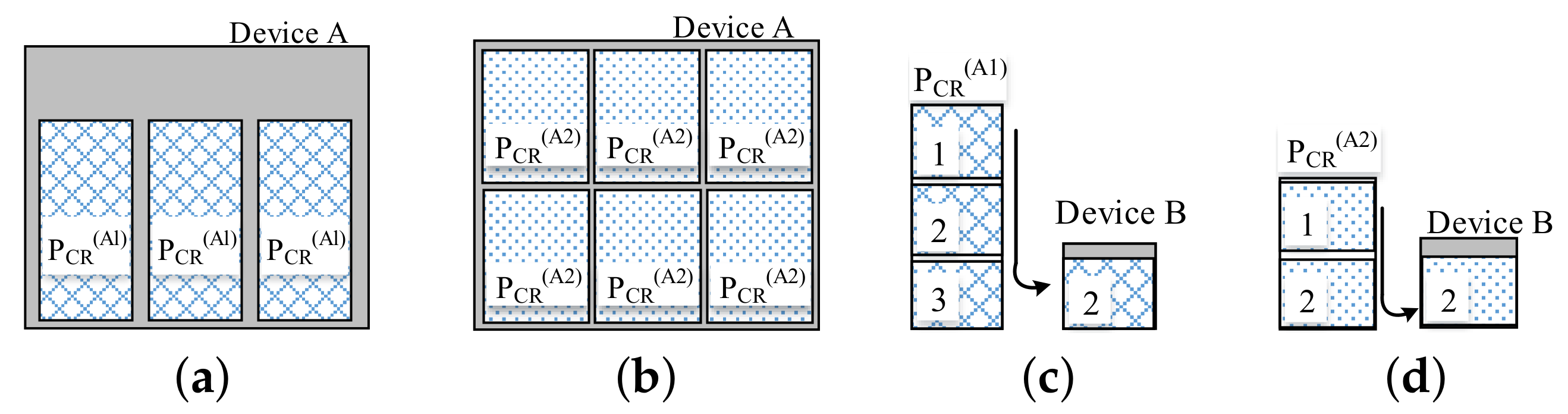
For different
, the detection throughput can be analysis from
Figure 12.
In
Figure 12, the
and
are the AHCFs of Algorithm A1 and A2 respectively. Assume
(even though
). When the available resource of a device is greater than the
(
Figure 6a,b), the algorithm (A1 or A2) with small
can be implemented with more times in the device at the same time and lead to higher detection throughput (six pixels can be detected at the same time in
Figure 12b. However, in
Figure 12a, it is three pixels).
An instance for the theory throughput analysis on A1 and A2 in an FPGA chip with 300,000 LUTs is shown in
Table 1.
In
Table 1, we assume that Algorithm A1 require 5000 times multiply and add operation pairs for one PUT detection. Each operation requires 16 LUTs. The AHCF
is 80,000 LUTs. Therefore, in the FPGA with 300,000 LUTs, three pixels can be detected at the same time. The resources utilization is 80%. For A2, the AHCF
is 45,000 LUTs. We can detect six pixels at the same time with 90% resource utilization. Even though, the device resources utilization in
Figure 12b (A2) is higher than that in
Figure 12a (A1), the algorithm A2 is better than A1, because A2 produce higher throughput (6 > 3) due to
(Even though
).
When the available resource of a device is fewer than
(as in
Figure 12c,d, this situation is common for most of the deep learning applications), the algorithm need be split into several parts to be executed in the device at different time (operation cycles). More operation cycles are required for a bigger
and cause lower throughput (two cycles are required for one PUT in
Figure 12d, but in
Figure 12c it is three cycles). In
Figure 12c (A2) and
Figure 12d (A1), because of the Algorithm A2 produce high throughput (fewer operation cycles requirement) due to
, the Algorithm A2 is better than A1 as well.
In this situation, an instance for the theory throughput analysis on A1 and A2 in an FPGA chip with 30,000 LUTs is shown in
Table 2.
In
Table 2, we assume that for one PUT detection, the Algorithm A1 requires 5000 times multiply-and-add operation pairs, each operation requires 16 LUTs. The AHCF
is 80,000 LUTs. In the FPGA with 30,000 LUTs, at least three operation cycles are required to complete one PUT detection. For A2, the AHCF
is 45,000, at least two operation cycles are required. Therefore, the throughput of A2 is greater than A1. The resources utilizations of A1 and A2 are not in certain relationship.
Therefore, the throughput is related to the value of the , rather than C. The relationship between throughput and is negative. So, in this paper, the is regarded as the feature to indicate the detection algorithm throughput in the algorithm design stage.
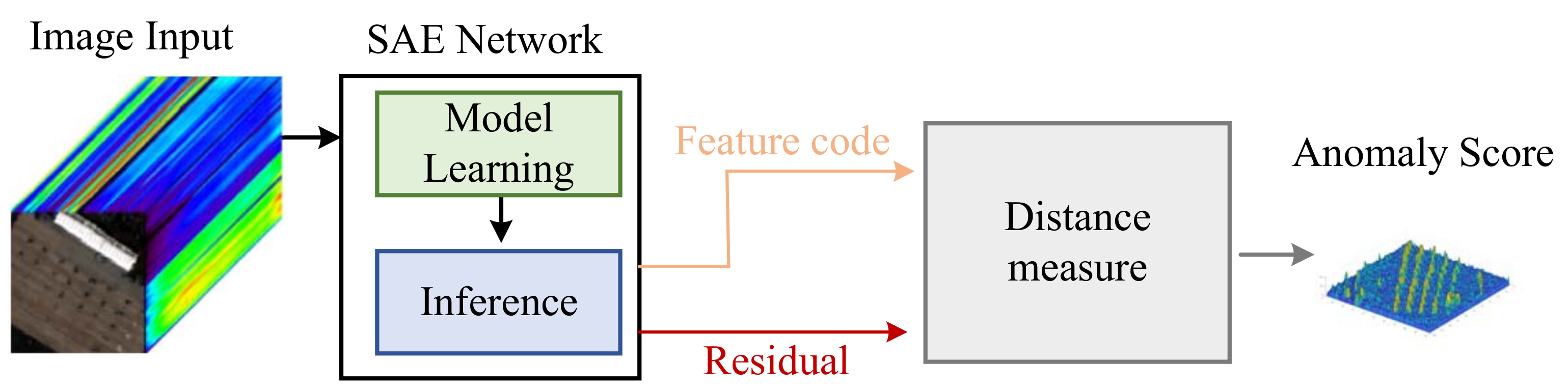
Because of the multiply operation and the add operation are generally appearing in pairs, for the SAE based HSI AD, the multipliers amount is used to represent for the computation operations
C which is approximatively quantified by the number of the neurons and the window size as follow:
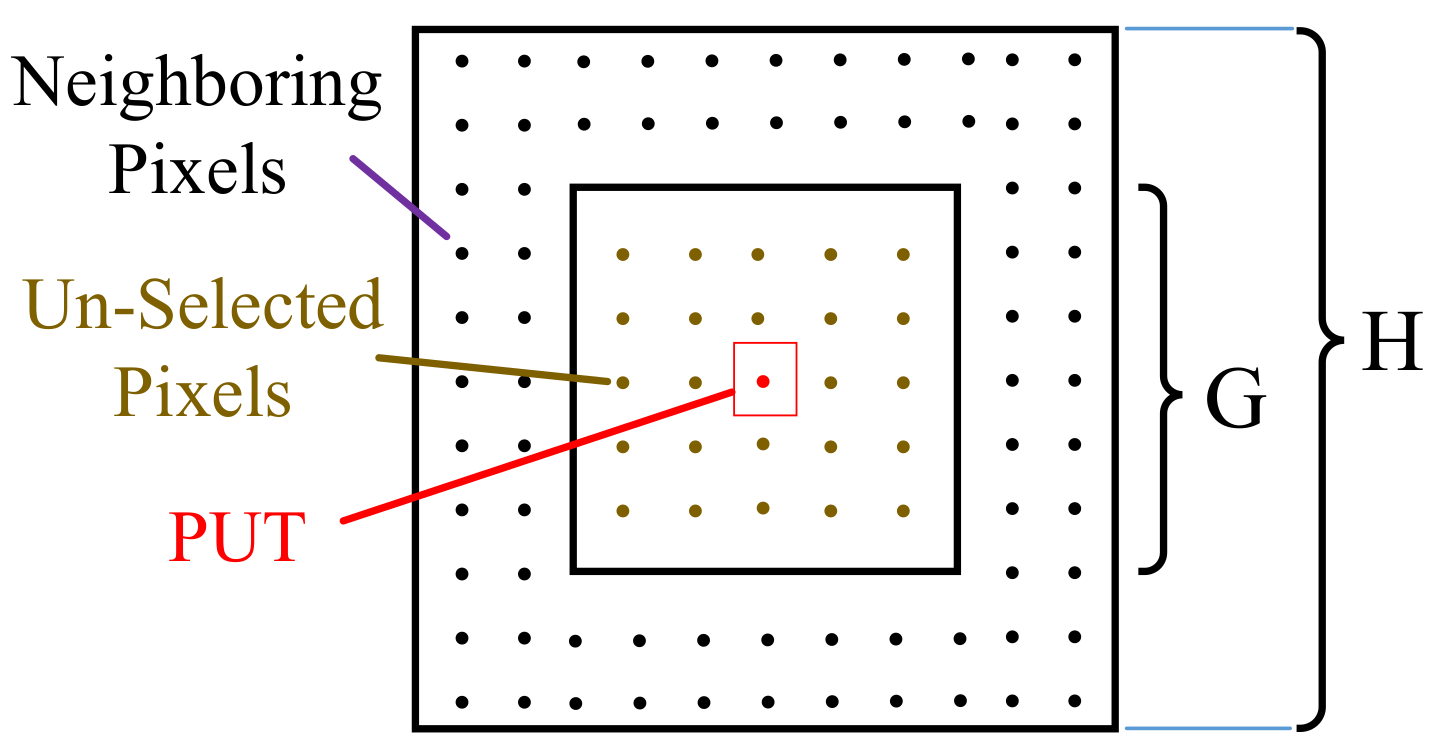
where
H and
G are the local window height and the guard window height respectively, which are shown in
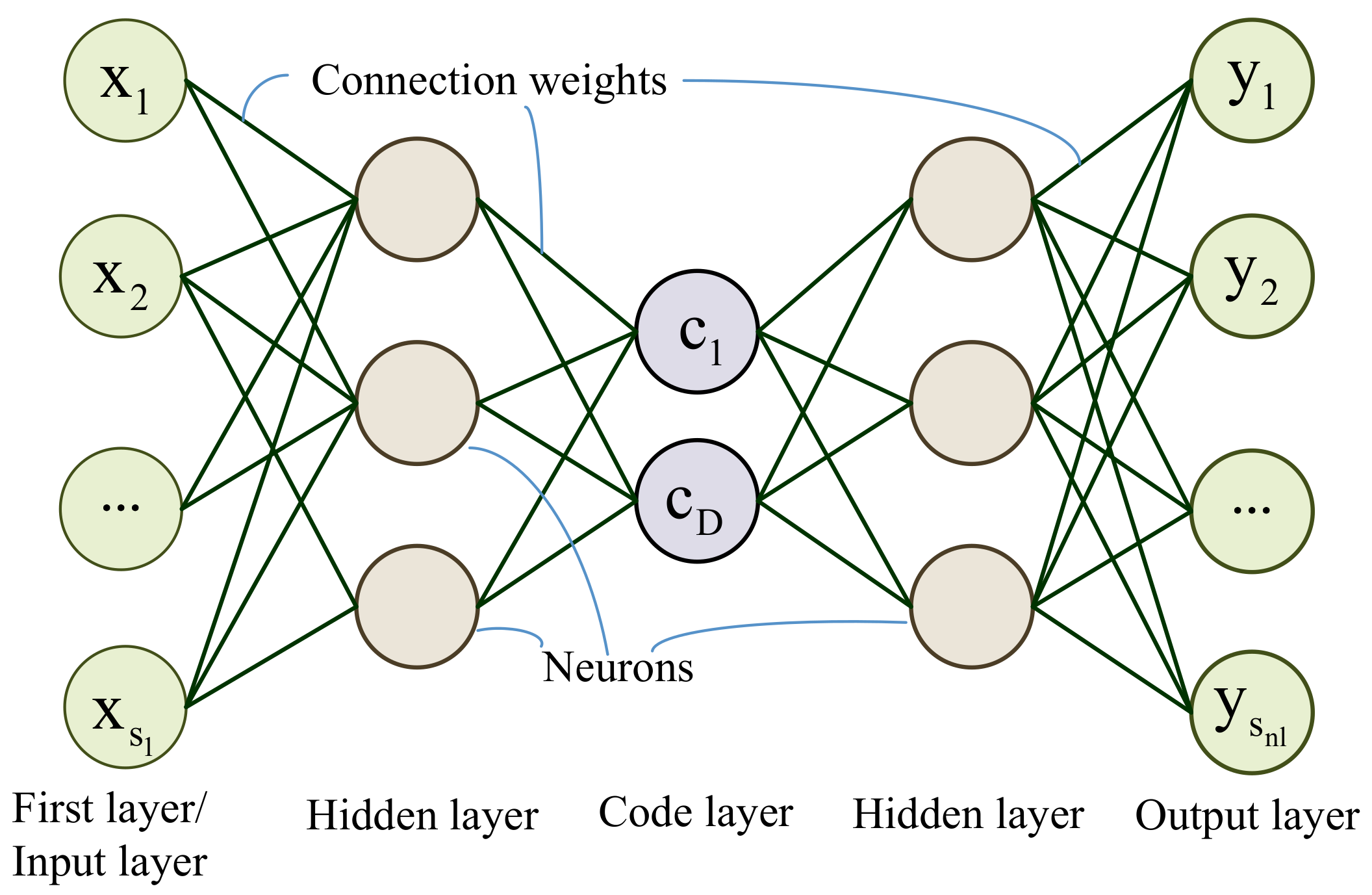
Figure 10. According to previous researches, the layers number
of the network is set as 5 [
23]. Due to the symmetrical structure of the autoencoder network, the neurons number of the first and the last layer are equal to the spectral band number
B. Therefore, only the neuron number of the second (
) and the middle layer (
) are employed as the basic genes. The range of the
and the
are specified as in
Table 3.
The resource consumption per operation depends on the bit-width of the data. In this paper, the resource consumption per operation is defined as function
, where
is the data bit-width of the
l-th layer in the network. However, the function
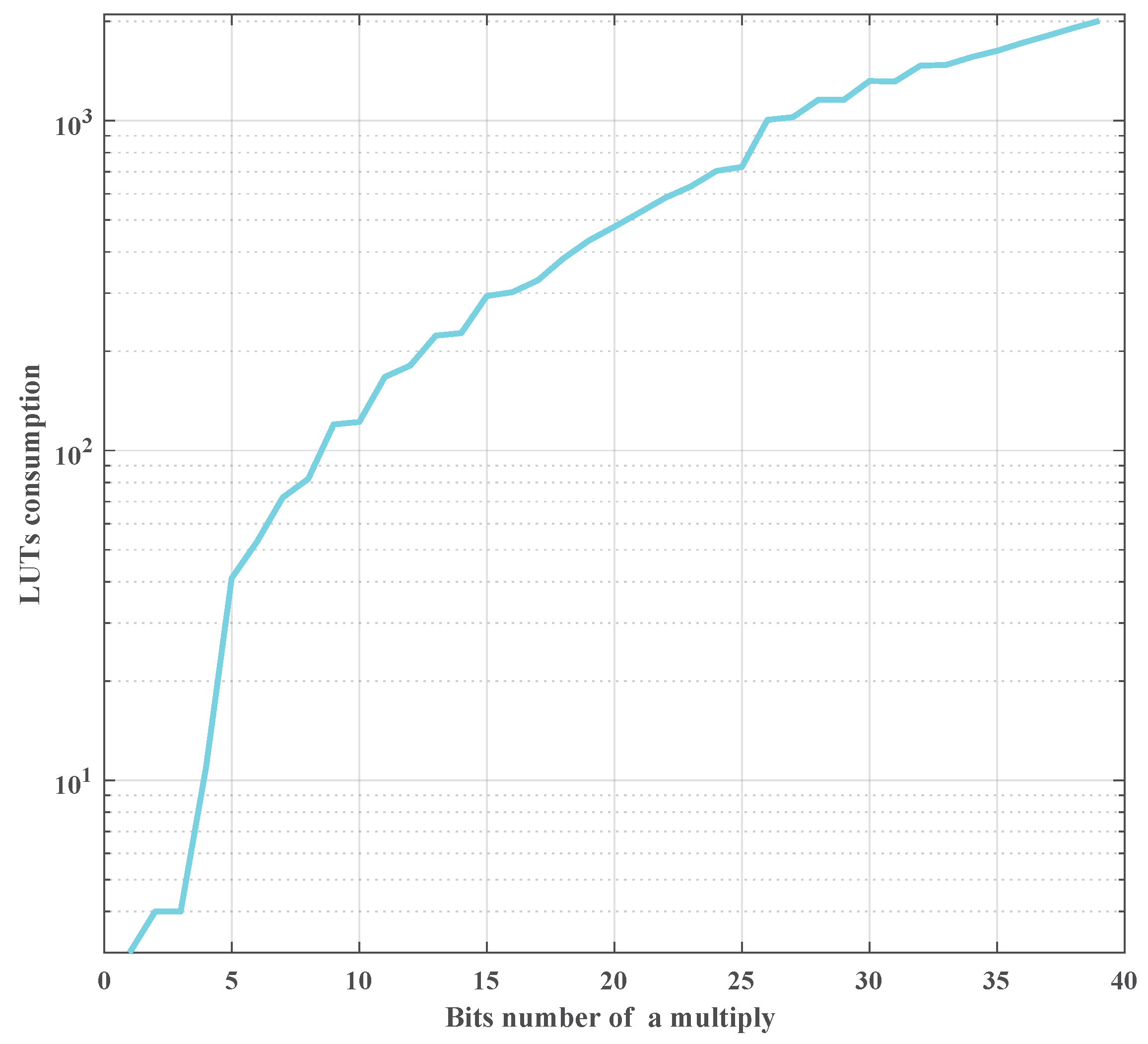
is hard to describe with a fixed explicit formulation directly for different kinds of FPGAs. Fortunately, the FPGA type can be fixed for a certain detection mission. In this work, by implementing different bits-width multipliers in a ZYNQ UltraScale device, the resources consumption versus bit-width multiplier is shown in the
Figure 13.
An arithmetic operation can be implemented by the DSP elements resources or LUT resources. The input bit-width of the DSPs are fixed in FPGA chips, such as 18 bits or 36 bits. Even if a multiplier with less bit-width operand (<18), it still consumes the whole DSP. Moreover, in an FPGA device, DSPs are fewer than the LUTs. The LUTs are programmable logic resources and can be realized an arbitrarily bit-width multiplier. The LUTs consumption is related to the operand bit-width. For a detection mission, just employing DSPs is not enough to realize arithmetic operations. The LUTs should be used as well. DSPs consumption is less sensitive than LUTs consumption on the different bit-width operand. To simplify the relationship between the resources consumption and the operand bit-width, in this paper, only the LUTs amount is used to represent the resources consumption of arithmetic operation as shown in
Figure 13.
In
Figure 13, LUTs are shown in logarithmic coordinates. It can be found that the LUTs consumption and the bit-width are in positive correlation. For example, the LUTs consumption of a 40 bits-width multiplier is about 50 times of a five bits-width multiplier. This figure can be used to replace the function
.
Therefore, the
of the network can be expressed as follow:
where
G,
H,
l,
, and
have the same meaning as that in Formula (
10).
is the data bits number of the outputs of
l-th layer and the weights between
l-th layer and
-th layer.
To determine the minimum without accuracy loss, an error analysis approach was proposed here for the full connection network, which can be extended to other kinds of network easily.
Considering the symmetrical structure of the SAE network in HSI AD, the
is set in symmetry in term of layer number. For a certain data with
bits in the decimal bit, its quantization error is described as follow:
To determine the decimal bits number of the
with
, the output of the
l-th layer (namely,
in Formula (
3a)) can be described as follow:
Depending on Formula (
13), if the quantization error
of
was less than the sum of the last two items (more data bits are required), the quantization error can be ignored. In this paper, to minimize the AHCF (
), a quantization error in a certain degree was acceptable if the total detection accuracy can be kept. Therefore, the decimal bits number of
can be deducted as follows:
Considering the decimal bit analysis and in case of the data overflow, the integer part bit-width (
) of the
can be deducted as follow:
To evaluate the statistic characteristics of Formulas (
12) and (
15), the mean of
with training dataset in floating point precision was employed in Formula (
12) and the maximum of
is used for Formula (
15).
Therefore, the AHCF
reduction problem can be described as follows: in the condition of minimizing the loss of detection accuracy, how to find the smallest
in Formula (
10) by structure pruning and how to reduce the
in conditions as Formulas (
13) and (
15) by quantization.
Therefore, the latent relationship between detection accuracy and the AHCF
can be described as MOP in Formula (
16) to prune the network structure and quantify the data precision. The goal of the optimization is to maximize the detection accuracy and minimize the AHCF
. The MOP is as follow:
where
B is spectral bands number of the input HSI.
H and
G are the local window height and the guard window height.
is the neurons number of a layer.
C is the computational amount as in Formula (
10).
is the area under the curve which is defined in Formula (
9).
is the bits number of the arithmetic units which connected the outputs of
l-th layer and the
-th layer.
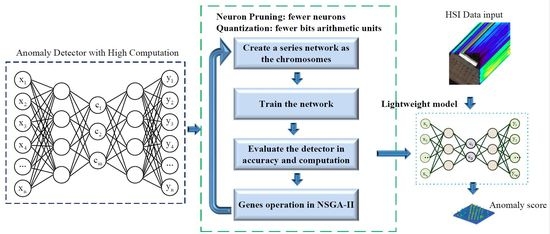
3.4. The Multiobjective Optimization with NSGA-II
Because the problem in Formula (
16) is a non-deterministic polynomial-time hardness (NP-hard) problem, it can not be solved in polynomial time. To solve Formula (
16), a genetic algorithm based on the optimization approach named nondominated sorting genetic algorithm II (NSGA-II) is employed in the proposed P-Q-AD to find the optimal solutions [
42,
43]. The flowchart of the proposed P-Q-AD for onboard HSI AD is shown in
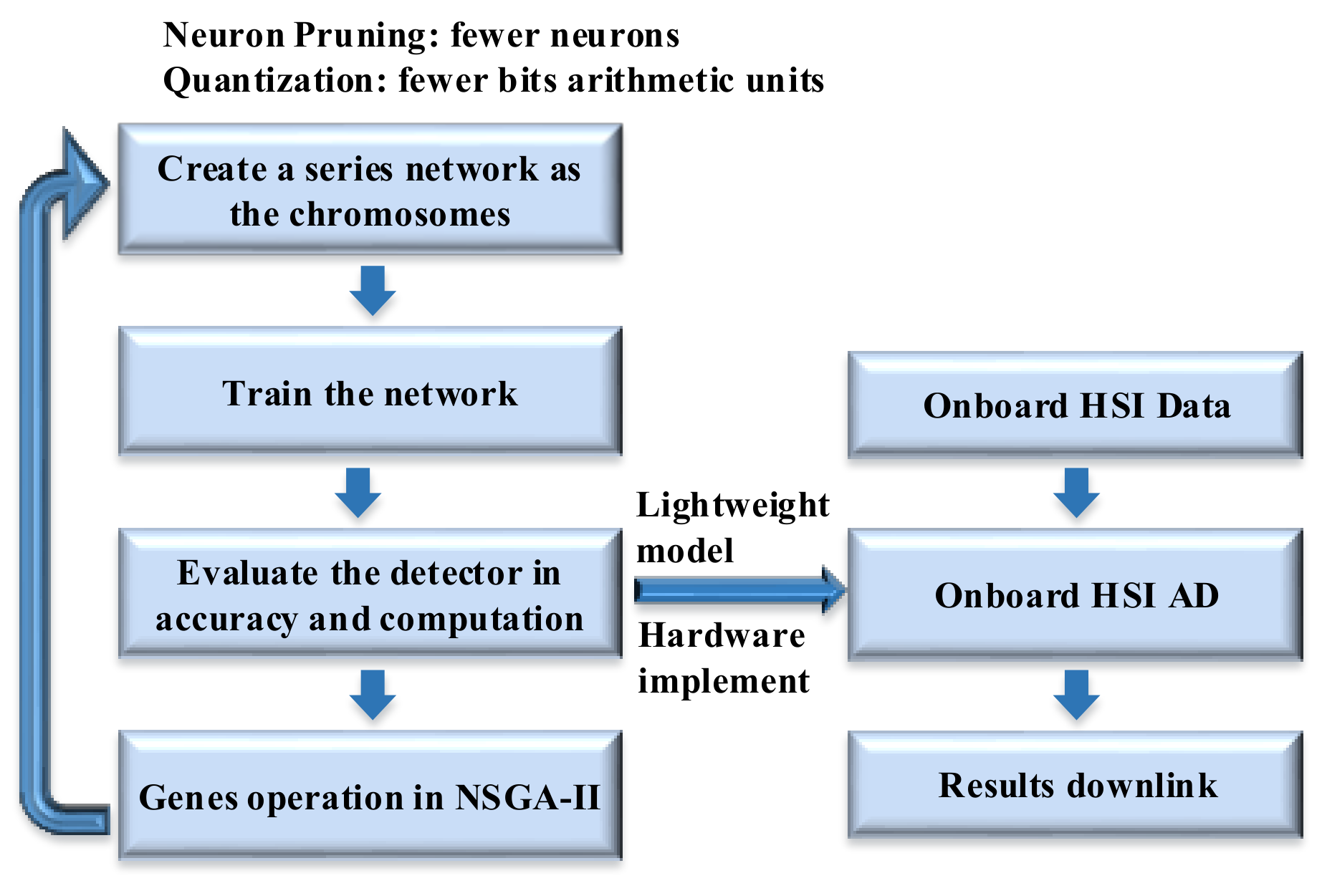
Figure 14.
Firstly, the chromosomes are initialized with a developed series of network models for NSGA-II processing. Then, these network models are trained for HSI AD. The AHCF and detection accuracy are evaluated for the corresponding chromosomes. Finally, the genes are updated and the next generation chromosomes are generated according to the evaluation results. If the generation number reaches the maximum value which is set depending on experience(generally, it is set to 200), a lightweight model is generated for hardware implementation. Otherwise, an offspring chromosome will be produced for the next generation. Therefore, the proposed P-Q-AD can be set up and executed on an onboard platform in real time. In onboard HSI AD mission, the HSI data can be directly fed into the detector along with the data collection of the camera. Only the detection results will be transferred to the ground through the downlink.
The parameters, such as neurons number, data bits number, local window size, leaky value
of the network, determine both of the accuracy and the AHCF for an HSI AD as in formula (
16). Thus, those parameters are employed as basic genes for the NSGA-II. The range of the basic genes is listed in
Table 3. The
is the neurons number of the middle layer and equals to
D. The ranges of the basic genes are set up by experience and listed in
Table 3. Because the NSGA-II will be executed to optimize genes value from the ranges in
Table 3, a wide range is harmless to the optimization results except for a long optimization searching time (not detection time). Therefore, in this paper, the genes ranges are set wider than the value in our experience. It is necessary to note that, generally, the multiply operation is more complex than the shift operation in FPGAs. More resources or more cycles are generally required for the multiply operation. Thus, to speed up the process, the leaky value is limited to a series of discrete value as that
(where
). For most of the imaging spectrometers, the data resolutions are ranged from eight bits to 16 bits [
34]. Therefore, the maximum data bit-width of the input and the output layer is set as 5 and 16 for integer and the decimal bits (
and
) respectively in case of data overflow.
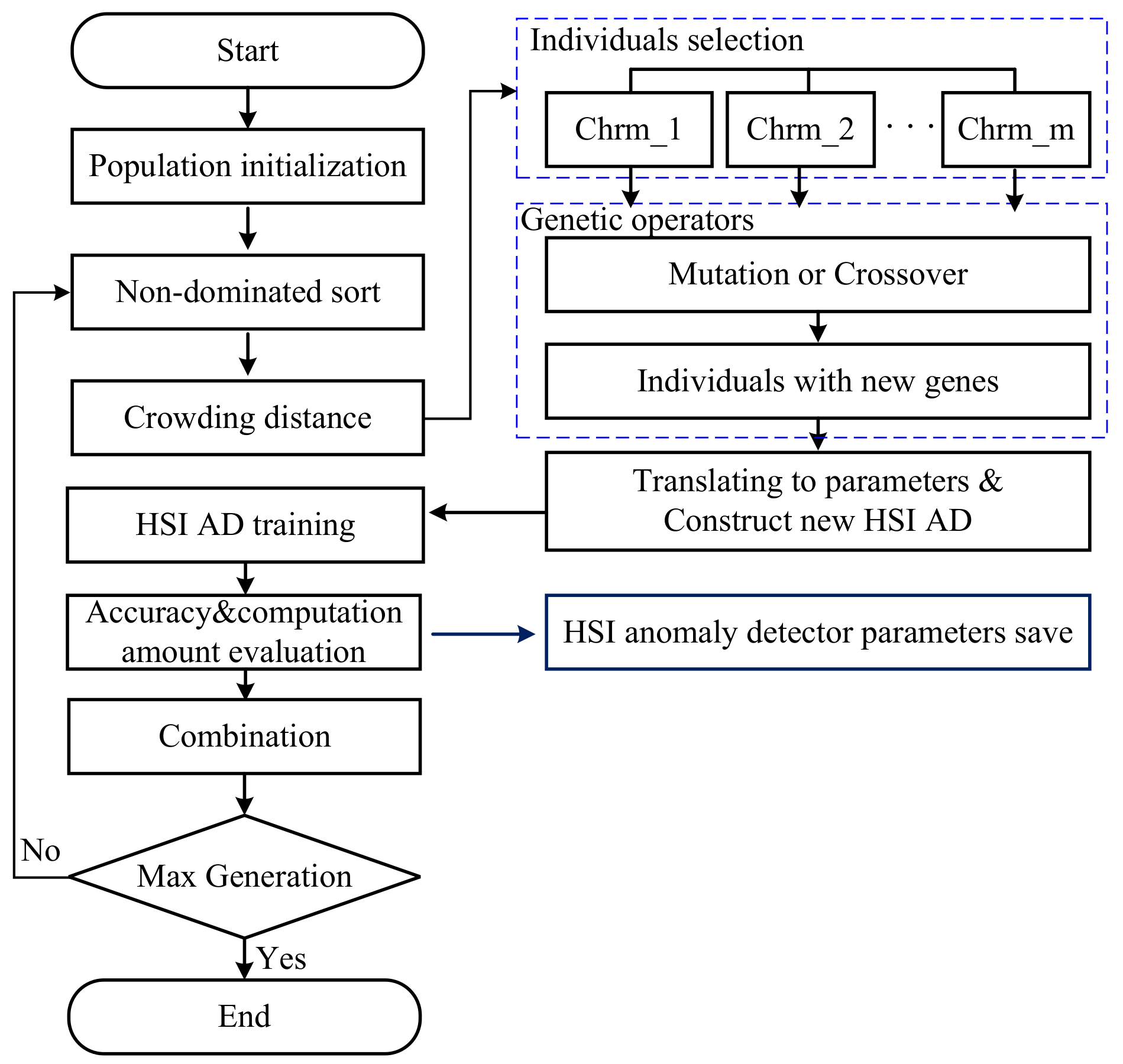
The basic flow of the NSGA-II is shown in
Figure 15. The population is initialized within a specified range as in
Table 3. The accuracy and AHCF
were used as the fitness function results. The chromosome vector was generated which not only contains the basic genes but also the results of the fitness function and the crowding distance information.
As shown in
Figure 15, after the population initialization, a non-dominated sort is executed to rank the individuals depending on the values of the AUC and
. With non-dominated sort, the individuals will be divided into several levels of rank.
To preserve the diversity of the parent chromosome, the crowding distance was calculated for each individual. The crowding distance of an individual was the perimeter of a cuboid which vertices are the nearest neighbor individuals in the same rank. Please refer to [
43] for more details about the calculation. Then, individuals will be selected as parent individuals for genetic operators.
With genetic operators, individuals with new genes are generated by mutation or crossover operations. Then, the genes of those individuals will be translated into the network structure parameters and the data bit-width of HSI ADs. Those new HSI ADs were trained and evaluated to get their fitness function value including accuracy and AHCF. The fitness values and genes were combined as new individuals.
If the generation number reached to the maximum which is set to 200 in this paper, the optimization were stopped. Otherwise, optimization will be continued to generate a new generation from the non-dominated sort stage. More details about NSGA-II can be found in ref. [
42,
43].
With NSGA-II, the network of the HSI AD can be built with structure pruning and quantization. Then, the P-Q-AD can be built up as the formula and structure as the description in
Section 2.2 and reference [
23], the number of neurons and the bit-width of arithmetic operators are determined by the best chromosome with lower
and less detection accuracy loss for onboard detection mission.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}