Ensemble-Based Cascaded Constrained Energy Minimization for Hyperspectral Target Detection




Abstract
:1. Introduction
- Cascaded Detection
- Random Averaging
- Multi-scale Scanning
2. Methodology
2.1. CEM Detector
2.2. Regularized CEM
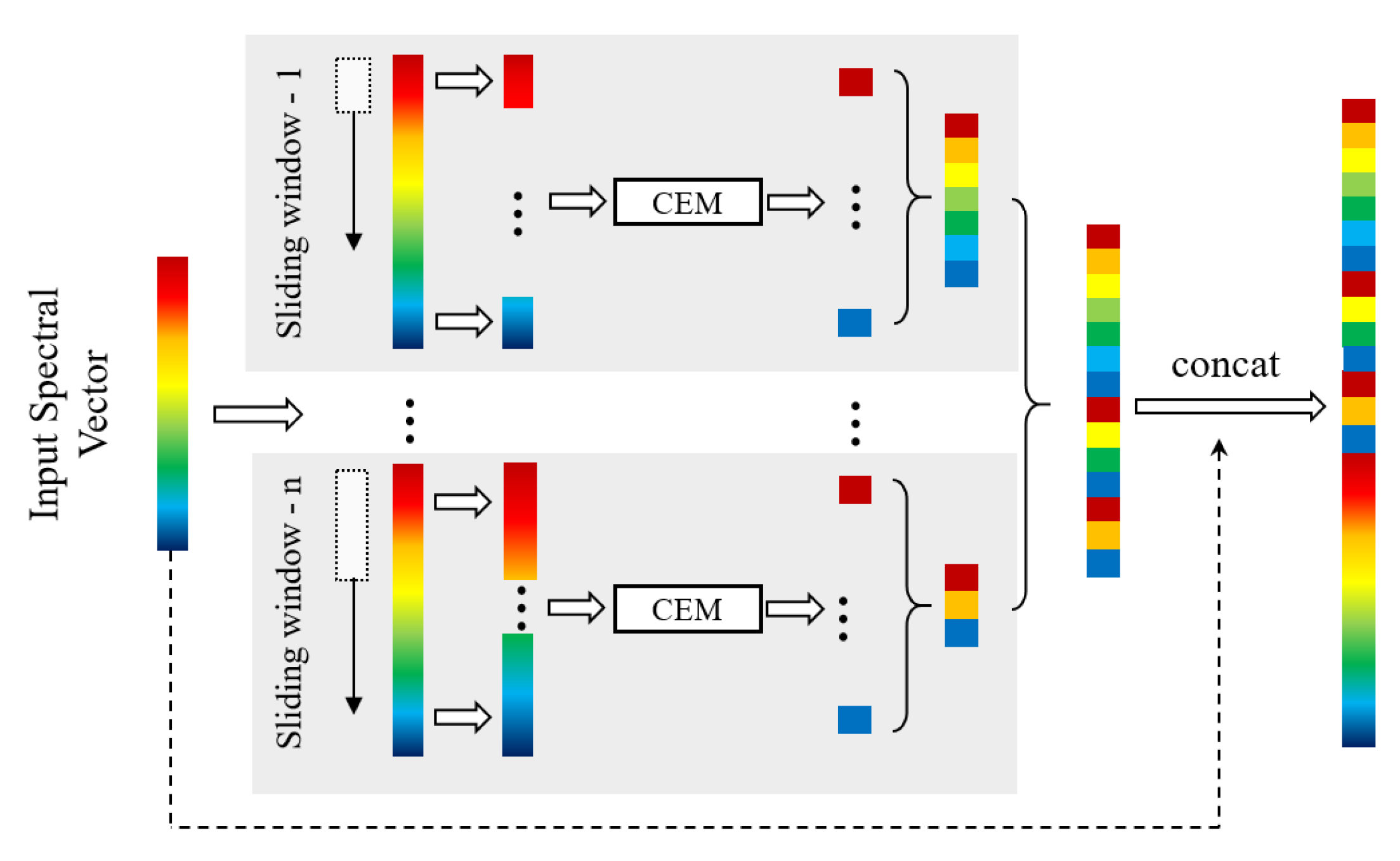
2.3. Ensemble based Cascaded CEM Detector
2.3.1. Multi-Scale Scanning
2.3.2. Cascaded Detection
3. Experiments, Results and Discussion
3.1. Data Used
3.1.1. Synthetic Data
3.1.2. AVIRIS San Diego Data
3.1.3. AVIRIS Cuprite Data
3.2. Experimental Setup and Evaluation Metrics
- In the multi-scale scanning stage, we set the number of windows to and the window size to , where D is the number of bands.
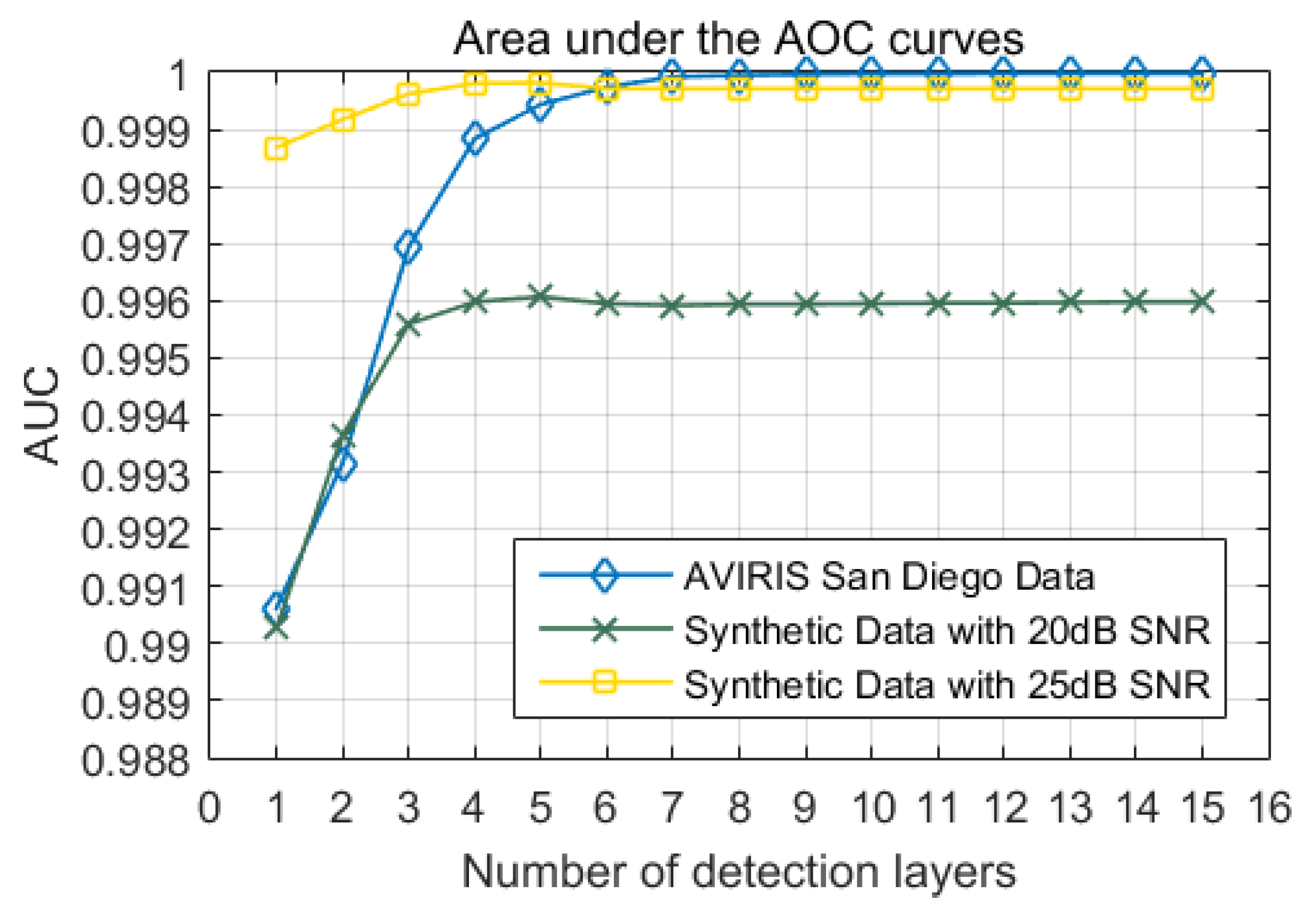
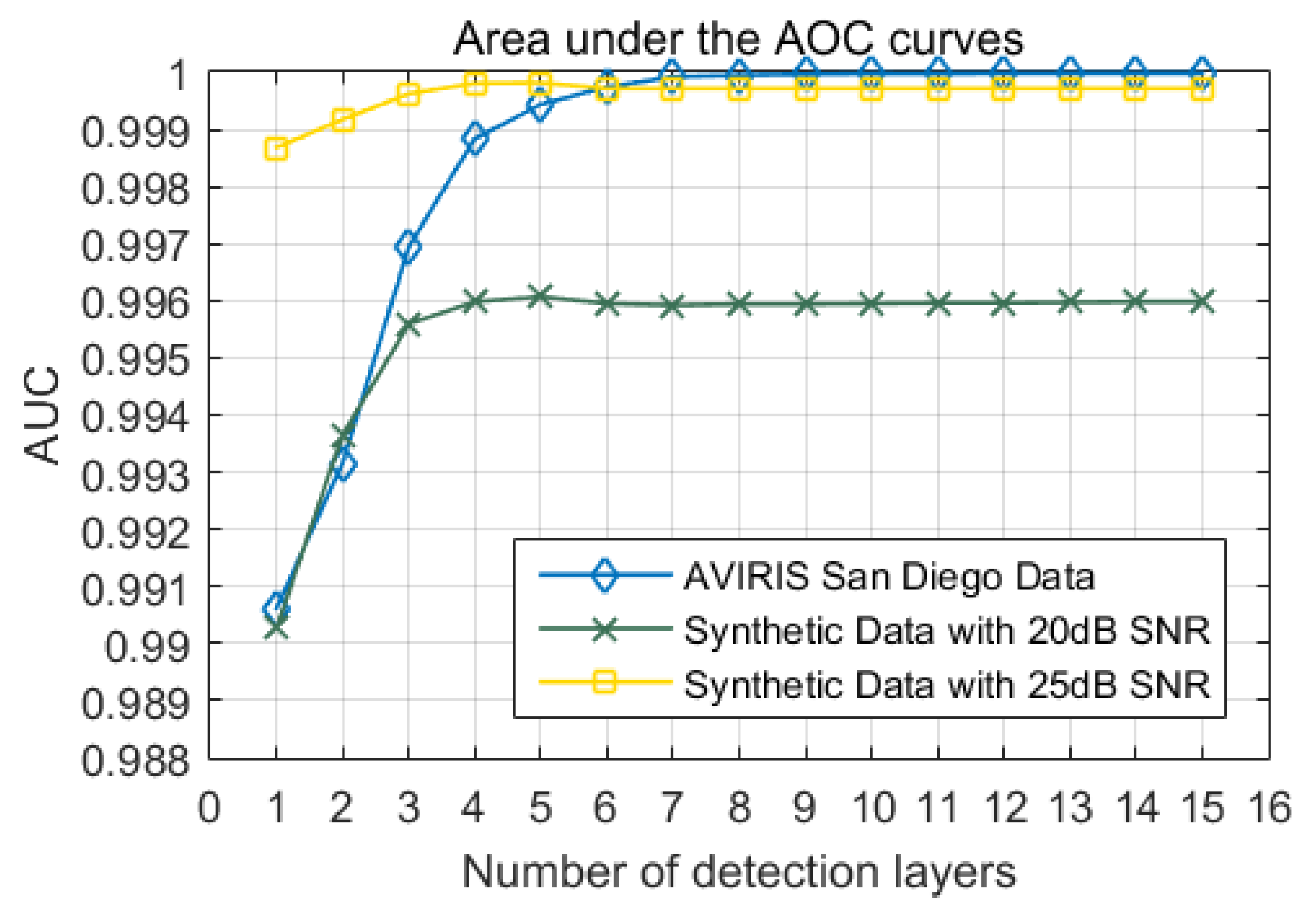
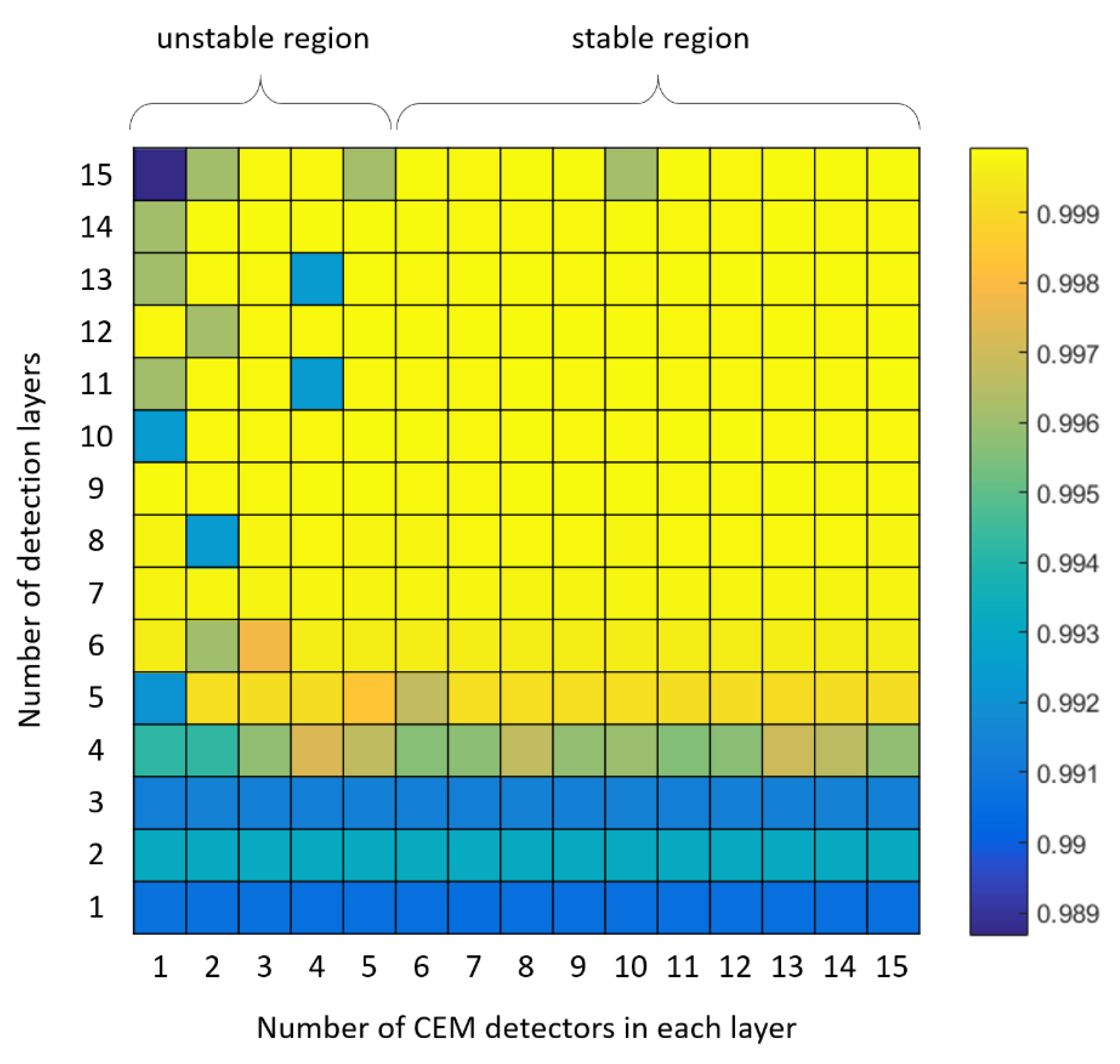
- In the cascaded detection stage, we set the number of detection layers to and the number of CEMs per layer to .
3.3. Detection Results on Synthetic Data
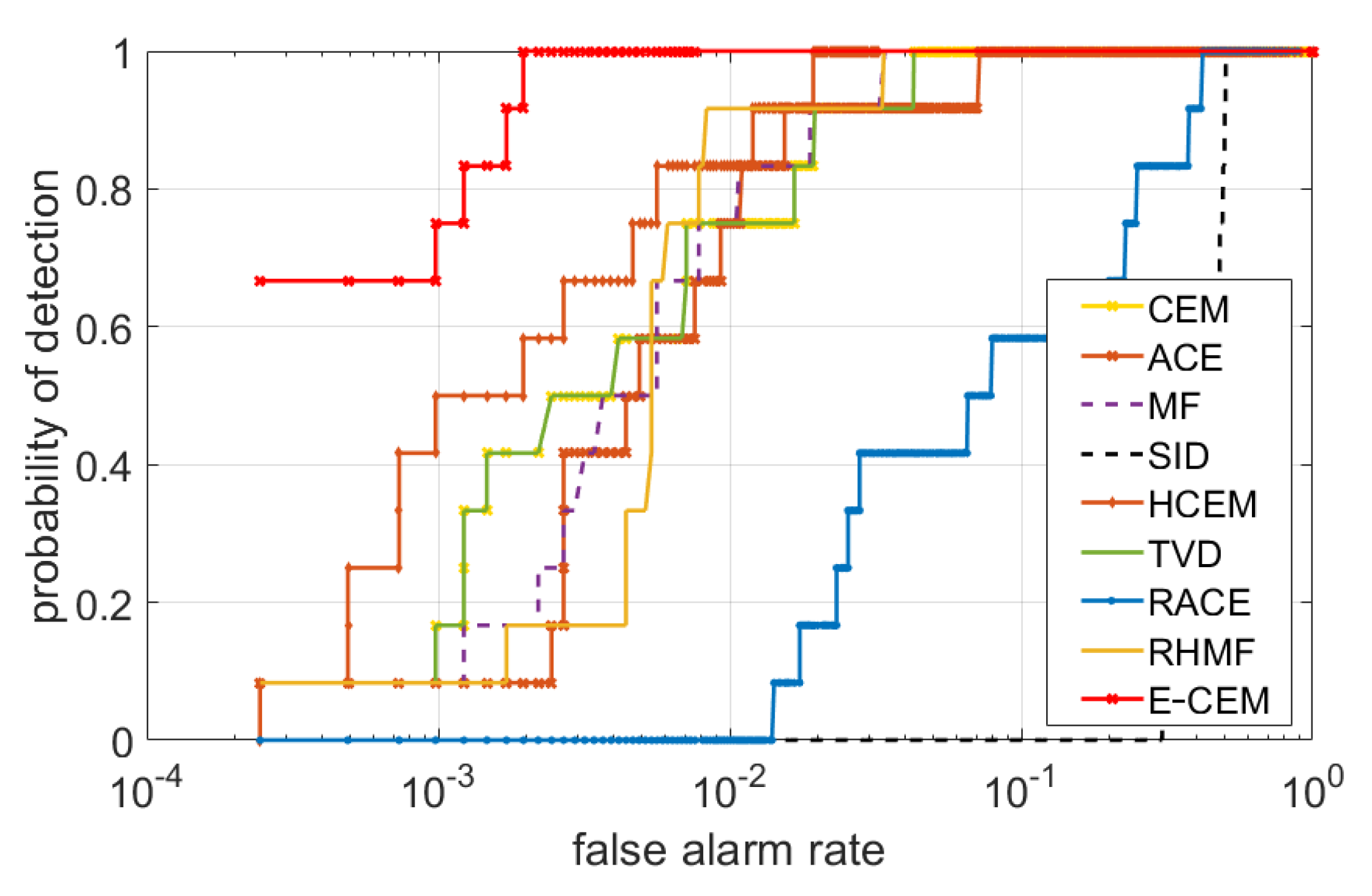
3.4. Detection Results on AVIRIS San Diego Data
3.5. Detection Results on AVIRIS Cuprite Data
3.6. Parameters Analysis
- How important is cascaded detection
- How important is multi-scale scanning
- How important is random averaging
- Analysis on the regularization parameter
3.7. Speed Performance
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- DiPietro, R.S.; Truslow, E.; Manolakis, D.G.; Golowich, S.E.; Lockwood, R.B. False-alarm characterization in hyperspectral gas-detection applications. Imaging Spectrom. XVII 2012, 8515, 85150I. [Google Scholar]
- Farrand, W.H.; Harsanyi, J.C. Mapping the distribution of mine tailings in the Coeur d’Alene River Valley, Idaho, through the use of a constrained energy minimization technique. Remote Sens. Environ. 1997, 59, 64–76. [Google Scholar] [CrossRef]
- Tiwari, K.; Arora, M.; Singh, D. An assessment of independent component analysis for detection of military targets from hyperspectral images. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 730–740. [Google Scholar] [CrossRef]
- Winter, E.M.; Miller, M.A.; Simi, C.G.; Hill, A.B.; Williams, T.J.; Hampton, D.; Wood, M.; Zadnick, J.; Sviland, M.D. Mine detection experiments using hyperspectral sensors. In Proceedings of the Defense and Security, 2004, Orlando, FL, USA, 21 Sptember 2004; Volume 5415, pp. 1035–1042. [Google Scholar]
- Lin, C.; Chen, S.Y.; Chen, C.C.; Tai, C.H. Detecting newly grown tree leaves from unmanned-aerial-vehicle images using hyperspectral target detection techniques. ISPRS J. Photogramm. Remote Sens. 2018, 142, 174–189. [Google Scholar] [CrossRef]
- Rahimzadegan, M.; Sadeghi, B.; Masoumi, M.; Ghalehjoghi, S.T. Application of target detection algorithms to identification of iron oxides using ASTER images: A case study in the North of Semnan province, Iran. Arab. J. Geosci. 2015, 8, 7321–7331. [Google Scholar] [CrossRef]
- Eismann, M.T.; Stocker, A.D.; Nasrabadi, N.M. Automated hyperspectral cueing for civilian search and rescue. Proc. IEEE 2009, 97, 1031–1055. [Google Scholar] [CrossRef]
- Kruse, F.A.; Lefkoff, A.; Boardman, J.; Heidebrecht, K.; Shapiro, A.; Barloon, P.; Goetz, A. The spectral image processing system (SIPS)—interactive visualization and analysis of imaging spectrometer data. Remote Sens. Environ. 1993, 44, 145–163. [Google Scholar] [CrossRef]
- Chang, C.I. An information-theoretic approach to spectral variability, similarity, and discrimination for hyperspectral image analysis. IEEE Trans. Inf. Theory 2000, 46, 1927–1932. [Google Scholar] [CrossRef] [Green Version]
- Manolakis, D.; Marden, D.; Shaw, G.A. Hyperspectral image processing for automatic target detection applications. Lincoln Lab. J. 2003, 14, 79–116. [Google Scholar]
- Manolakis, D.; Lockwood, R.; Cooley, T.; Jacobson, J. Is there a best hyperspectral detection algorithm? SPIE 2009, 7334, 733402. [Google Scholar]
- Scharf, L.L.; Friedlander, B. Matched subspace detectors. IEEE Trans. Signal Process. 1994, 42, 2146–2157. [Google Scholar] [CrossRef]
- Wang, Z.; Xue, J.H. Matched shrunken subspace detectors for hyperspectral target detection. Neurocomputing 2018, 272, 226–236. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Shi, Z.; Tang, W. Robust hyperspectral image target detection using an inequality constraint. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3389–3404. [Google Scholar] [CrossRef]
- Yang, S.; Shi, Z. Hyperspectral image target detection improvement based on total variation. IEEE Trans. Image Process. 2016, 25, 2249–2258. [Google Scholar] [CrossRef] [PubMed]
- Shi, Z.; Yang, S. Robust high-order matched filter for hyperspectral target detection. Electron. Lett. 2010, 46, 1065–1066. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Hierarchical suppression method for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 330–342. [Google Scholar] [CrossRef]
- Harsanyi, J.C.; Chang, C.I. Hyperspectral image classification and dimensionality reduction: An orthogonal subspace projection approach. IEEE Trans. Geosci. Remote Sens. 1994, 32, 779–785. [Google Scholar] [CrossRef]
- Bernabe, S.; Sanchez, S.; Plaza, A.; López, S.; Benediktsson, J.A.; Sarmiento, R. Hyperspectral unmixing on GPUs and multi-core processors: A comparison. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 2013, 6, 1386–1398. [Google Scholar] [CrossRef]
- Kay, S.M. Fundamentals of Statistical Signal Processing; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Manolakis, D.G. Realistic matched filter performance prediction for hyperspectral target detection. Opt. Eng. 2005, 44, 116401. [Google Scholar] [CrossRef]
- Schweizer, S.M.; Moura, J.M. Efficient detection in hyperspectral imagery. IEEE Trans. Image Process. 2001, 10, 584–597. [Google Scholar] [CrossRef]
- Schweizer, S.M.; Moura, J.M. Hyperspectral imagery: Clutter adaptation in anomaly detection. IEEE Trans. Inf. Theory 2000, 46, 1855–1871. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Sparse representation for target detection in hyperspectral imagery. IEEE J. Sel. Top. Signal Process. 2011, 5, 629–640. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Simultaneous joint sparsity model for target detection in hyperspectral imagery. IEEE Geosci. Remote Sens. Lett. 2011, 8, 676–680. [Google Scholar] [CrossRef]
- Banerjee, A.; Burlina, P.; Meth, R. Fast hyperspectral anomaly detection via SVDD. In Proceedings of the 2007 IEEE International Conference on Image Processing, San Antonio, TX, USA, 16–19 September 2007; p. IV-101. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Zhou, M.; Jing, M.; Liu, D.; Xia, Z.; Zou, Z.; Shi, Z. Multi-resolution Networks for Ship Detection in Infrared Remote Sensing Images. Infrared Phys. Technol. 2018, 92, 183–189. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Random access memories A new paradigm for target detection in high resolution aerial remote sensing images. IEEE Trans. Image Process. 2018, 27, 1100–1111. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Ship detection in spaceborne optical image with SVD networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5832–5845. [Google Scholar] [CrossRef]
- Lin, H.; Shi, Z.; Zou, Z. Maritime Semantic Labeling of Optical Remote Sensing Images with Multi-Scale Fully Convolutional Network. Remote Sens. 2017, 9, 480. [Google Scholar] [CrossRef]
- Shi, T.; Xu, Q.; Zou, Z.; Shi, Z. Automatic Raft Labeling for Remote Sensing Images via Dual-Scale Homogeneous Convolutional Neural Network. Remote Sens. 2018, 10, 1130. [Google Scholar] [CrossRef]
- Shi, Z.; Zou, Z. Can a Machine Generate Humanlike Language Descriptions for a Remote Sensing Image? IEEE Trans. Geosci. Remote Sens. 2017, 55, 3623–3634. [Google Scholar] [CrossRef]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring models and data for remote sensing image caption generation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2183–2195. [Google Scholar] [CrossRef]
- Wang, T.; Du, B.; Zhang, L. An automatic robust iteratively reweighted unstructured detector for hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sen. 2014, 7, 2367–2382. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; Chapman and Hall/CRC: Boca Raton, FL, USA, 2012. [Google Scholar]
- Freund, Y.; Schapire, R.; Abe, N. A short introduction to boosting. J. Jpn. Soc. Artif. Intell. 1999, 14, 1612. [Google Scholar]
- Ho, T.K. Random decision forests. Document analysis and recognition, 1995. In Proceedings of the third international conference on, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Barandiaran, I. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Annal. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z.; Wu, J.; Wang, H. Quadratic constrained energy minimization for hyperspectral target detection. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 31 July 2015; pp. 4979–4982. [Google Scholar]
- Zhou, Z.H.; Feng, J. Deep forest: Towards an alternative to deep neural networks. arXiv 2017, arXiv:1702.08835. [Google Scholar]
- Zhou, Z.H. Ensemble learning. In Encyclopedia of Biometrics; Springer: Berlin, Germany, 2015; pp. 411–416. [Google Scholar]
- Clark, R.N.; Swayze, G.A.; Gallagher, A.J.; King, T.V.; Calvin, W.M. The US Geological Survey, Digital Spectral Library: Version 1 (0.2 to 3.0 um); Technical Report; Geological Survey (US): Reston, VI, USA, 1993.
- Chang, Y.C.C.; Ren, H.; Chang, C.I.; Rand, R.S. How to design synthetic images to validate and evaluate hyperspectral imaging algorithms. Proc. SPIE 2008, 6966, 69661P. [Google Scholar]
- Green, R.O.; Eastwood, M.L.; Sarture, C.M.; Chrien, T.G.; Aronsson, M.; Chippendale, B.J.; Faust, J.A.; Pavri, B.E.; Chovit, C.J.; Solis, M.; et al. Imaging spectroscopy and the airborne visible/infrared imaging spectrometer (AVIRIS). Remote Sens. Environ. 1998, 65, 227–248. [Google Scholar] [CrossRef]
- AVIRIS Cuprite Data. Available online: https://aviris.jpl.nasa.gov/data/free_data.html (accessed on 7 February 2019).
- Clark, R.N.; Swayze, G.A.; Livo, K.E.; Kokaly, R.F.; Sutley, S.J.; Dalton, J.B.; McDougal, R.R.; Gent, C.A. Imaging spectroscopy: Earth and planetary remote sensing with the USGS Tetracorder and expert systems. J. Geophys. Res. Planets 2003, 108. [Google Scholar] [CrossRef]
- Iordache, M.D.; Bioucas-Dias, J.M.; Plaza, A. Sparse unmixing of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2014–2039. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Noise of 20 dB SNR | Noise of 25 dB SNR | ||
|---|---|---|---|---|
| Mean | Standard Deviation | Mean | Standard Deviation | |
| CEM [2] | 0.97957 | 5.29 | 0.99733 | 1.13 |
| ACE [10] | 0.96998 | 4.47 | 0.99653 | 2.19 |
| MF [11] | 0.97549 | 4.04 | 0.9892 | 1.33 |
| SID [9] | 0.55201 | 3.86 | 0.88742 | 1.70 |
| HCEM [17] | 0.99221 | 6.81 | 0.99801 | 5.24 |
| TVD [15] | 0.96270 | 8.63 | 0.97745 | 3.62 |
| RACE [37] | 0.98732 | 2.14 | 0.99335 | 9.47 |
| RHMF [16] | 0.98884 | 8.32 | 0.99773 | 1.68 |
| E-CEM (ours) | 0.99941 | 2.47 | 0.99995 | 3.13 |
| Method | San Diego Data | ||
|---|---|---|---|
| w/o Noise | 20 dB SNR | 25 dB SNR | |
| CEM [2] | 0.99047 | 0.98398 | 0.98573 |
| ACE [10] | 0.97882 | 0.97841 | 0.97894 |
| MF [11] | 0.99078 | 0.98396 | 0.98584 |
| SID [9] | 0.81225 | 0.81659 | 0.81507 |
| HCEM [17] | 0.99571 | 0.97173 | 0.97977 |
| TVD [15] | 0.99046 | 0.98398 | 0.98573 |
| RACE [37] | 0.97882 | 0.97842 | 0.97894 |
| RHMF [16] | 0.98982 | 0.98284 | 0.98543 |
| E-CEM (ours) | 0.99988 | 0.98540 | 0.99356 |
| n | Window Wize | AUC |
|---|---|---|
| 1 | (no sliding window) | 0.9916 |
| 2 | 0.9923 | |
| 4 | 0.9999 | |
| 6 | 0.9999 | |
| 8 | 0.9999 |
| t | Noise of 20 dB SNR | Noise of 25 dB SNR | ||
|---|---|---|---|---|
| = constant(t) | = random (0,t) | = constant (t) | = random(0,t) | |
| 0.01 | 0.91310 | 0.99800 | 0.99990 | 0.99997 |
| 0.02 | 0.99520 | 0.99886 | 0.99982 | 0.99994 |
| 0.05 | 0.99669 | 0.99941 | 0.99857 | 0.99995 |
| 0.08 | 0.99051 | 0.99949 | 0.99494 | 0.99996 |
| 0.10 | 0.98198 | 0.99794 | 0.98939 | 0.99980 |
| Method | Synthetic Data | San Diego Data | Cuprite Data |
|---|---|---|---|
| CEM [2] | 0.04 | 0.11 | 0.08 |
| ACE [10] | 0.04 | 0.17 | 0.20 |
| MF [11] | 0.02 | 0.08 | 0.07 |
| SID [9] | 0.07 | 0.53 | 0.94 |
| HCEM [17] | 5.18 | 5.89 | 7.08 |
| TVD [15] | 2.07 | 6.38 | 2.21 |
| RACE [37] | 0.51 | 1.16 | 1.24 |
| RHMF [16] | 4.82 | 43.77 | 21.08 |
| E-CEM (ours) | 2.58 | 13.02 | 15.35 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, R.; Shi, Z.; Zou, Z.; Zhang, Z. Ensemble-Based Cascaded Constrained Energy Minimization for Hyperspectral Target Detection. Remote Sens. 2019, 11, 1310. https://doi.org/10.3390/rs11111310
Zhao R, Shi Z, Zou Z, Zhang Z. Ensemble-Based Cascaded Constrained Energy Minimization for Hyperspectral Target Detection. Remote Sensing. 2019; 11(11):1310. https://doi.org/10.3390/rs11111310
Chicago/Turabian StyleZhao, Rui, Zhenwei Shi, Zhengxia Zou, and Zhou Zhang. 2019. "Ensemble-Based Cascaded Constrained Energy Minimization for Hyperspectral Target Detection" Remote Sensing 11, no. 11: 1310. https://doi.org/10.3390/rs11111310
APA StyleZhao, R., Shi, Z., Zou, Z., & Zhang, Z. (2019). Ensemble-Based Cascaded Constrained Energy Minimization for Hyperspectral Target Detection. Remote Sensing, 11(11), 1310. https://doi.org/10.3390/rs11111310