Abstract
As most of the forest fires in South Korea are related to human activity, socio-economic factors are critical in estimating their probability. To estimate and analyze how human activity is influencing forest fire probability, this study considered not only environmental factors such as precipitation, elevation, topographic wetness index, and forest type, but also socio-economic factors such as population density and distance from urban area. The machine learning Maximum Entropy (Maxent) and Random Forest models were used to predict and analyze the spatial distribution of forest fire probability in South Korea. The model performance was evaluated using the receiver operating characteristic (ROC) curve method, and models’ outputs were compared based on the area under the ROC curve (AUC). In addition, a multi-temporal analysis was conducted to determine the relationships between forest fire probability and socio-economic or environmental changes from the 1980s to the 2000s. The analysis revealed that the spatial distribution was concentrated in or around cities, and the probability had a strong correlation with variables related to human activity and accessibility over the decades. The AUC values for validation were higher in the Random Forest result compared to the Maxent result throughout the decades. Our findings can be useful for developing preventive measures for forest fire risk reduction considering socio-economic development and environmental conditions.
1. Introduction
Analysis of forest fire probability is important in disaster risk reduction (DRR) because it provides means for preventing and managing forest fires. The most direct cause of forest fires that occur in South Korea, where approximately 65% of the land is covered by forest, is human activity [1,2,3]. Most of these forest fires, caused by human negligence, waste incineration, stubble burning, and discarded cigarettes, are considered to be accidental. While human activity directly causes most forest fires in South Korea, climatic, meteorological and environmental conditions cannot be disregarded, as they contribute to the ignition, combustion, and spread of accidental forest fires [4,5]. According to the Korea Forest Service (KFS), approximately 57% of the forest fires occurred between March and May during the period 1974–2017, and an average of 37% of the forest fires are reported to have resulted from human negligence, followed by stubble burning (17%), waste incineration (14%) and discarded cigarettes (5%) [6,7]. Therefore, cautionary periods are generally announced in Korea for the spring and fall, when relatively low humidity and high temperatures prevail, to enhance forest fire prevention [6,7].
Since the Korean War, which lasted from 1950 to 1953, South Korea has experienced rapid economic growth, especially since the 1970s, a phenomenon known as the “Miracle on the Han River” [8]. Along with the socio-economic development, which can be explained by the growth in the gross domestic product (GDP) and GDP per capita, the urban population has increased as urban space has expanded, particularly during the 1990s (Figure 1) [9]. As most forest fires are caused by human activity, increased forest fire occurrence can be a consequence of a higher urbanization rate. Therefore, it was necessary for this study to include socio-economic factors, as well as environmental factors, in developing an effective forest fire probability model.
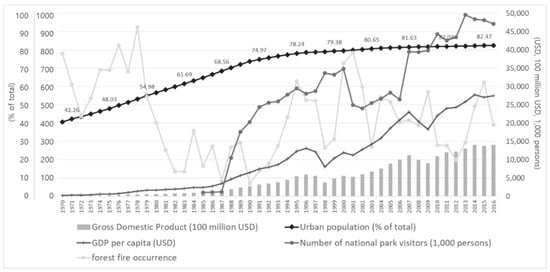
Figure 1.
Socio-economic development of South Korea as described by urban population, GDP, GDP per capita and number of national park visitors. Data is from the Korean Statistical Information Service (KOSIS) and the Korea Forest Service (KFS) [6,7].
Socio-economic variables are among the main factors contributing to the occurrence of forest fires in South Korea, but modeling these factors spatially and temporally has often been considered unimportant and challenging [10,11,12]. However, there are numerous studies worldwide that have included both environmental and socio-economic factors, focusing on the spatial pattern of human-caused fires in various statistical methods, including Generalized Linear Models (GLMs) and Generalized Linear Mixed Models (GLMMs), to predict forest fires [1,13,14,15,16,17,18]. Their study periods vary among daily, seasonally, and larger periods of time.
Machine learning tools have also been used to predict the probability of wildfire occurrence considering both factors using models such as Maximum Entropy (Maxent) and Random Forest [19,20,21]. Machine learning algorithms, which can be referred to as nonparametric models, use iterative training with a random data subset [22]. Maxent is known as a non-linear regression model and was originally designed to predict the spatial distribution of species using point locations and layers [23,24]. It has been applied to fire ignition probability in several studies, because fire ignition distribution can be considered a form of species distribution, and has obtained fairly good results [19,20,21,25,26]. Random Forest is also a nonparametric model and is based on ensemble techniques for classification and regression trees [27,28,29,30]. The model has been applied to estimate fire probability and maps in several studies, and achieved good accuracy [20,29,30,31].
In this study, multiple socio-economic factors that could influence forest fires are included in the analysis to predict and analyze the spatial distribution of forest fire probability in South Korea. The aim of this study are as follows: (1) to predict and analyze the spatial distribution using both Maxent and Random Forest models based on a multi-temporal analysis; (2) to compare the results of the models; and (3) to determine the relationships between forest fire probability and socio-economic or environmental changes from the 1980s to the 2000s.
2. Materials and Methods
2.1. Study Site
South Korea, specifically the southern part of the Korean Peninsula, with a total land area estimated at 99,720 km2, is the study area (Figure 2). South Korea reforested its degraded and devastated forest landscape over a short period of time following the Korean War [32,33]. Currently, following the country’s enormous reforestation efforts, which have been carried out since the 1970s, 65% of the land is covered by dense forest, of which 37% is coniferous, 32% is deciduous, and 27% is mixed [2]. Thus, forest fires are likely to occur on a large scale because the land is primarily covered by coniferous forest, known to be susceptible and prone to fires [34,35,36]. From 2008 to 2017, an average of 421 forest fires occurred per year, resulting in an average loss of 5989 ha of forest per fire and 6,326,285 ha of forest in total [6,7,37].
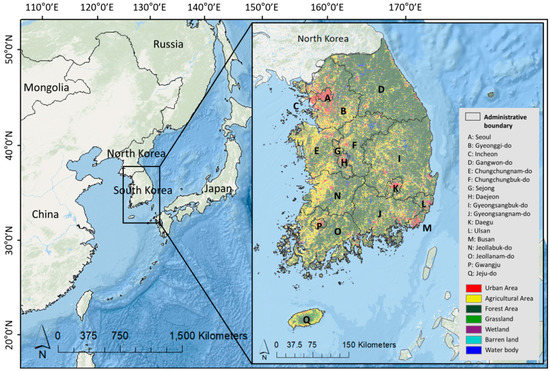
Figure 2.
Study area and its land cover map (2007) from the Ministry of Environment of the Republic of Korea.
South Korea has a temperate climate with four distinct seasons that are greatly influenced by prevailing winds [38]. Temperature and humidity are high during the summer due to the heavy rainfall, whereas temperature and humidity are low during the winter [39,40]. The mean annual temperature of South Korea is 10 °C to 15 °C, while the average August temperature is from 23 °C to 26 °C and the average January temperature is −6 °C to −3 °C. About 50–60% of rainfall is concentrated in summer and the average annual precipitation is around 1200 mm. The average humidity of July and August is between 70% and 85%, while that of March and April is between 50% and 70% [41]. Spring and fall are transitional periods, when the temperatures are mild, with less rainfall [42]. However, as the temperature increases with the low humidity during the spring, the forest fire probability also increases [43].
2.2. Forest Fire Occurrence Data
The KFS offers locational forest fire occurrence data based on field survey [6,7]. This includes the area, extent, cause, date, and geographical location of forest fires. From the 1980s to the 2000s, there was an increase in the number of forest fire occurrences (Figure 3). The total fire occurrences were 1291, 3279, and 5196, during the 1980s, 1990s, and 2000s, respectively (Figure 4).
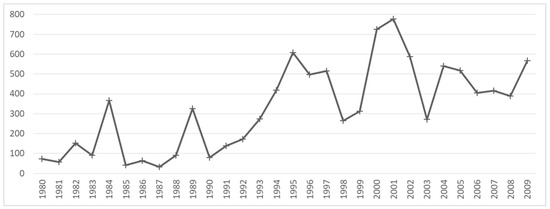
Figure 3.
Number of annual forest fire occurrences from 1980 to 2009 based on the point location data. Data from the KFS.
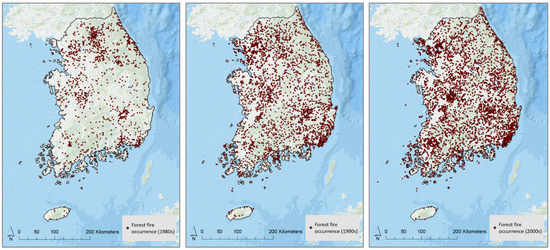
Figure 4.
Location of forest fire occurrences during the 1980s, 1990s, and 2000s.
In the analysis using Maxent, we used only the original location data provided by the KFS, because the Maxent model does not need absence data for the analysis. Whereas, in the analysis using Random Forest, we created absence data as random points, and these were combined with the original location data, as needed for the analysis [29]. The absence points are randomly distributed individual points in free-fire sites in this study.
The fire locations dataset is commonly partitioned into two subsets: training and validation. Considering the literature information regarding these subsets, we found that 70% of the whole fire data is common enough for model training, and the rest of it is often separated to investigate the accuracy of the models’ predictions [44]. In the case of non-fire locations (i.e., absence points), they were also randomly split into a ratio of 70/30 for calibration of RF model and for validation purpose [29,45].
2.3. Socio-Economic and Environmental Factors
Previous researchers have used several different factors to model the forest fire susceptibility [1,12,13,14,15,16,17,18,19,20,21,25,26,28,29,31,44,45,46]. To analyze the socio-economic and environmental impact on forest fire probability, several variables like slope, elevation, aspect, population density, and distance to roads that are highly correlated with forest fire occurrence were selected based on the literature review to be included in the model [1,12,13,14,15,16,17,18,19,20,21,28,29,31,47,48] (Table 1, Figure 5). Environmental data included forest type (forestype), elevation (elev), topographic wetness index (TWI), precipitation during spring (prcp-spr), average SPI-6 during spring (SPI-spr), and fire weather index (FWI). A forest type map, provided by the KFS in a vector format, was classified into four categories: coniferous, deciduous, mixed forest, and non-forest. The coniferous includes artificial coniferous forest, Larix kaempferi, Pinus densiflora artificial forest, Pinus densiflora, Pinus koraiensis, and Pinus rigida, while the deciduous includes artificial boreal forest, boreal forest, Castanea crenata, and Quercus. Elevation was extracted from a digital elevation model (DEM) at 30-km spatial resolution provided by the Ministry of Land, Infrastructure and Transport (MOLIT). TWI, which can be calculated to determine the aspect of steady-state soil wetness, was calculated using the relevant equation [49]. For meteorological data, we gathered the observed data of the Automated Synoptic Observing System from the Korea Meteorological Administration and interpolated using the inverse distance weighted (IDW) method. To relate the geographical features to precipitation, the precipitation lapse rate reflecting elevation was applied to the dataset [50,51]. The 6-month Standardized Precipitation Index (SPI-6), which is widely used to detect meteorological drought with monthly precipitation data, was calculated using the R package ‘SPIGA’ [52,53]. This index measures rainfall conditions over a 6-month period, and it can reflect the amount of antecedent precipitation that also has a correlation with fire occurrence [54]. Meteorological variables during the spring were considered in the study because forest fires in South Korea historically occur primarily during the spring; high precipitation during the summer affects the annual average and makes the probability analysis more challenging [6,7]. The spring in this study was defined as the months of March, April, and May [55]. Also, the fire weather index (FWI) was calculated using the R package ‘fwi.fbp’ with the observed data and interpolated using the IDW method [56].

Table 1.
Input variables used to estimate forest fire probability.
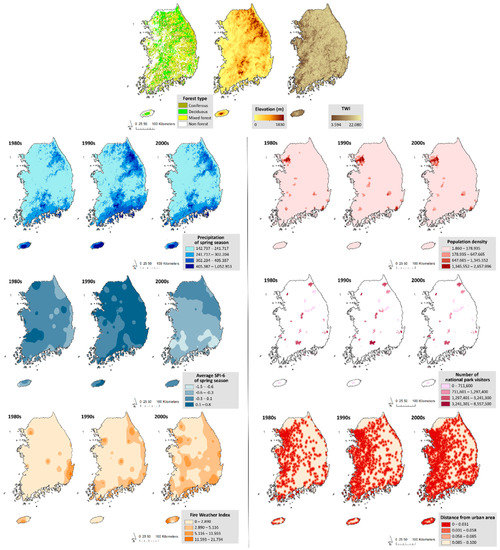
Figure 5.
Maps of environmental and socio-economic input variables for the 1980s, 1990s, and 2000s.
The socio-economic variables included the population density (pop), number of national park visitors (visitors), and distance from urban area (urban). The primary data of socio-economic variables, predominantly statistical data, were transformed into spatial data using ArcMap 10.4.1. The population data was given as statistical but non-spatial data, and the administrative boundaries were given as polygon data at the municipal level. The population was spatially joined to the polygon data, and the population density was then calculated within the boundaries. The number of national park visitors was also given as statistical data and was spatially joined to the national park boundaries. The rest of the area in this study was interpolated using the IDW method. Distance from the given area to an urban area was calculated using the Euclidean distance. We used the land cover map derived from the Landsat 1, 2 MSS, 5 TM, and 7 ETM provided by BIZ-GIS to calculate the distance between a certain grid point and an urban area [57]. For this study, all the input variables were set to a spatial resolution of 1 km in an ASCII grid format for the Maxent, and into a point format for the Random Forest. In addition, as the study aims to have a higher resolution map of forest fire probability than that of previous studies, we resampled both datasets with coarser resolution and those with higher resolution at 1 km, because we thought that downscaling would not change the properties of the coarser data, but would allow us to keep all details in the high-resolution data.
2.4. Maximum Entropy Model (Maxent)
Maxent is a machine learning tool primarily used for the current and potential prediction of the spatial distribution of species by evaluating the contrasts between point locations and layers. Maxent uses presence-only data to estimate the probability distribution or habitat suitability of species based on the theory of maximum entropy. The model predicts the distribution subject based on input constraints and input variables, which can be continuous or categorical [22,58,59].
Maxent generates a probability of presence varying from 0 to 1 and the response curves for each variable through model training. In addition, the results of the model run include the area under the receiver operating characteristic curve (AUC). AUC values are frequently used as a measure of model performance and accuracy. The range of an AUC value is from 0.0 to 1.0, and a value of 0.5 indicates that the model performance is no better than random, while values nearer 1.0 indicate better model performance. A model generating fair or good predictions has an AUC value greater than 0.7 [60,61].
Moreover, Maxent is known to be highly accurate with regard to statistical value [22,23,24,25,62,63,64]. It has obtained fairly good results in predicting forest fires in several studies because fire occurrence can be considered as a species distribution [18,19,20,24,25]. In this study, Maxent version 3.4.1 was used to estimate forest fire probability in South Korea at a 1-km spatial resolution. The output format was set as logistic to obtain the probability value between 0 and 1, 30% of the forest fire location points were randomly used, the maximum iterations were set to 5000, and 10 simulation runs were conducted with Bootstrap to reduce the probabilistic uncertainty.
2.5. Random Forest Model
Random Forest is an algorithm based on ensemble techniques for classification and regression trees [29,30,31]. The model generates decision trees on several randomly selected bootstrap samples to get prediction from each tree and selects a subset of explanatory variables at every node. The final outcome of the model is the average of the results of all the trees [65]. When running the Random Forest model, it is necessary to define the number of variables to be used in each tree-building process (mtry) and the number of trees to be grown in the forest (ntree). The model is known to be having low bias and low variance because the result is averaged over a large number of trees.
The Random Forest model leaves about one-third of the samples for validation, and obtains an unbiased estimate of the generalization error. The proportion of mis-classifications (%) over all out-of-bag elements is called the out-of-bag (OOB) error. The OOB error can evaluate the model performance without a separate test set [66,67].
The aim of the Random Forest model is to identify a suitable model to analyze the relationship between independent variables and a dependent variable in the calibration phase to determine the weight value for each factor, provided with variable importance [68]. In this study, the R packages ‘randomForest’ and ‘sdm’ were used [69,70]. The forest fire occurrence data was used as dependent variable, and forest type, elevation, topographic wetness index, precipitation during spring, SPI-6 during spring, fire weather index, population density, number of national park visitors and distance from urban area are used as independent variables.
2.6. Model Performance
The investigation of the model performance is necessary for the modeling process. For this purpose, we used validation data sets which were not used in the model training step. In this study, the predictive performance of the models was evaluated by applying the most common threshold-independent method, the receiver operating characteristic (ROC) curve [71]. The ROC curve is drawn by plotting all combinations of sensitivities on the vertical axis and the proportions of false negatives (1-specificity) on the horizontal axis. The area under the ROC curve (AUC) has been considered to be a quantitative performance metric [29,45,46]. An AUC value = 1 indicates a perfect prediction, whereas an AUC < 0.5 demonstrates a weak performance [72]. Model performance based on the AUC metric can be classified as follows: 50–60% (poor), 60–70% (moderate), 70–80% (good), 80–90% (very good), and 90–100% (excellent) [73]. Sensitivity is obtained based on the fraction of fire occurrences (i.e., positive points) that are correctly predicted, while “1-specificity” is the fraction of incorrectly predicted cases that did not occur [74].
3. Results
3.1. Maxent Results
For the Maxent analysis, the average forest fire probability was 0.421, 0.464, and 0.461 during the 1980s, 1990s, and 2000s, respectively. The analysis revealed that the average forest fire probability increased until the 1990s and then slightly decreased during the 2000s.
With regard to the spatial distribution, the probability of forest fires was higher in urban areas and the eastern coastal area, where the population has accessibility to low-elevation forests (Figure 6). The probability has been concentrated in South Korea’s largest cities, Seoul, Busan, Daejeon, and Gwangju, over the decades.
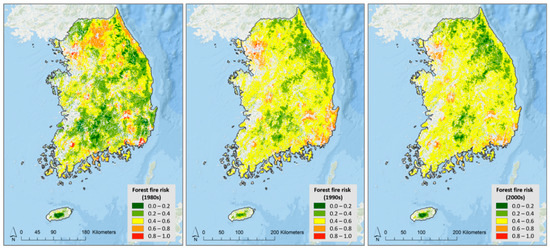
Figure 6.
Forest fire probability during the 1980s, 1990s, and 2000s (Maxent analysis).
The Maxent results show the percent contribution of each input variable to forest fire probability. The output was significant for the variable pop during all decades (Table 2). Elev also had high a percent contribution across all time periods. Other than these variables, urban accounted for a significant percentage during the 1980s and the 1990s, and TWI during the 2000s. Additionally, the percent contribution of climate variables like prcp-spr, SPI-spr, and FWI indicated either a decreasing trend or insignificant importance over time.
Table 2.
Percent contribution of each input variable to forest fire probability during the 1980s, 1990s, and 2000s (Maxent Analysis).
Maxent produced response curves that showed how the predicted forest fire probability changes across each variable. The red curves show the average response of the replicates. Each variable showed a similar correlation with forest fire probability (Figure 7). Maxent predicted a significant negative correlation between elev and forest fire probability. TWI, which is related to soil moisture, also showed a strong negative correlation in both analyses and across all decades. Additionally, forestype was a variable with only intermediate importance, based on its percent contribution, and there was little difference, less than 10%, between the categories of forestype. However, the probability was the highest in coniferous forest during the entire period.
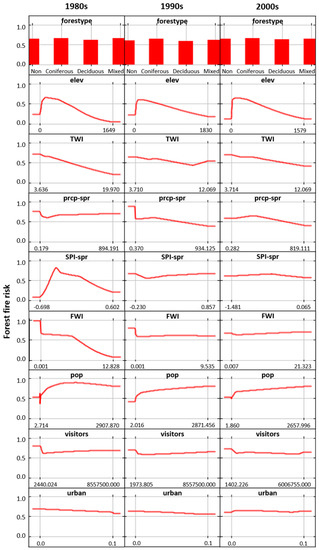
Figure 7.
Response curves illustrating the relationship between forest fire probability and the input variables during the 1980s, 1990s, and 2000s (Maxent analysis).
Prcp-spr generally showed a negative correlation. On the other hand, SPI-spr exhibited inconsistent results as it showed both a negative and a positive correlation. FWI showed a negative correlation during the 1980s but it showed a positive correlation during the 2000s. Taken together, the analysis supports the conjecture that less rainfall can affect the occurrence of forest fires.
Pop showed a positive correlation during the entire period of the Maxent analysis. This indicates that if the population density is higher, forest fire probability increases. However, the visitors did not have a significant correlation with the probability. In addition, the forest fire probability slightly decreased as the distance from urban area (urban) increased.
3.2. Random Forest Results
For the Random Forest analysis, the average forest fire probabilities, which are the average raster values for the study area, were 0.617, 0.628, and 0.618 during the 1980s, 1990s, and 2000s, respectively. The analysis also revealed that the average forest fire probability increased until the 1990s and then decreased during the 2000s.
With regard to spatial distribution, there are some differences over time, but there is a high forest fire probability in and around urban areas and the eastern coastal area in Random Forest analysis (Figure 8). Over the decades, forest fire probability has been concentrated in South Korea’s largest cities, Seoul, Busan, Daejeon, and Gwangju.
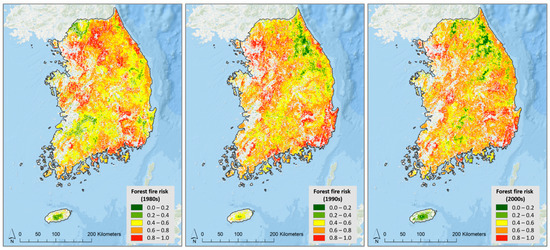
Figure 8.
Forest fire probability during the 1980s, 1990s, and 2000s (Random Forest analysis).
The Random Forests results show the importance of each input variable to forest fire probability. The results indicate the significance of pop and elev across all decades (Table 3). Other than these variables, SPI-spr accounted for a significant percentage during the 1980s and the 2000s, and urban during the 2000s.
Table 3.
Variable importance of each input variable to forest fire probability during the 1980s, 1990s, and 2000s (Random Forest analysis).
3.3. Comparison and Validation of the Models
Both the Maxent and Random Forest results showed that the spatial distribution of forest fires in South Korea is concentrated around cities and eastern coastal area. The trend of concentration of probability increased over the decades. Although the results from the Random Forest showed higher average probability compared to those from the Maxent, there were similarities on the overall spatial distribution of forest fire. In addition, the average probability was the highest during the 1990s in both analyses.
In terms of variable importance, both the Maxent and Random Forest results showed a high contribution of pop and elev to the forest fire probability. In particular, pop was the most important variable in both the Maxent and Random Forest analyses and across all decades. The contribution of pop was the highest during the 1990s in both analyses. Elev also contributed as one of the significant variables across all decades in both analyses. The Maxent result showed little significance for the climate variables, particularly those related to precipitation, whereas the Random forest had considerable significance on SPI-spr.
In this study, AUC values were used to measure the model performance and accuracy. The results showed relatively high statistical accuracy, considering that forest fire occurrence in South Korea is primarily a result of human activities and that it was simulated at a 1-km spatial resolution on a national level. The AUC values of fire probability were 0.753, 0.652, and 0.636 during the 1980s, 1990s, and 2000s, respectively, for Maxent, whereas for Random Forest they were 0.909, 0.898, and 0.906, respectively. Therefore, the Random Forest model performs better than the Maxent model in terms of accuracy in estimating South Korean forest fire probability.
4. Discussion
4.1. Impact of Socio-Economic and Environmental Drivers on Forest Fires
As South Korea has grown rapidly, urban sprawl and the concentration of urban population has increased significantly alongside the country’s socio-economic development from the 1980s to the 2000s, particularly during the 1990s [75]. During this period of rapid development, there has been an increasing trend in the occurrence of forest fires. In this study, we attempted to determine the relationship between socio-economic development and forest fire probability in South Korea.
As most of the forest fires in South Korea are reported to be a result of human activity, population density and forest elevation can help explain the results of the study. A higher population concentration and lower forest elevation can signify a higher presence of human activity [76]. These variables are considered to be relevant to human activity because population density leads to an increase in human activity and forests at higher elevations are less accessible.
This study confirmed that forest fire probability has a strong correlation with human-related variables like population density, especially during the 1990s, and elevation. From both the Maxent and Random Forest results, the percent contribution or variable importance of population density and elevation consistently had significant importance throughout the entire study period. However, the percent contribution and importance of the population density was the highest during the 1990s when there was a significant urban sprawl. In terms of the spatial distribution of forest fires in South Korea, it was found that forest fires were mostly in urban areas and in the eastern coastal area in both analyses.
In line with this, the distance from urban area had a fairly high significance with regard to fire probability. The significance has decreased over the decades in both analyses, and we conjecture this to be caused by the sudden urbanization throughout the country that contributed to decreasing importance of distance from urban area over time.
Among the environmental variables, TWI also showed a distinct contribution in both analyses across all decades and a negative correlation to the probability for the Maxent result. As TWI is an indicator measuring the availability of long-term soil moisture, it is assumed that the forest fire probability will be higher in dry soil conditions. Also, for the Maxent analysis, precipitation during spring generally was negatively correlated with the probability.
There is a less than 10% difference between forest types in the Maxent analysis, but most of the cases show that coniferous forest has a slightly larger correlation to fire probability. This can be inferred because the Japanese red pine (Pinus densiflora), a coniferous tree with good burning characteristics, is the dominant tree species in South Korea. Hence, as the dominant species is coniferous, the forest has been susceptible to fire and the amount of available fuel is high during the spring [77,78,79].
4.2. Machine Learning Models with Regard to Spatial Distribution and Accuracy
In terms of spatial distribution, the forest fire probability is more concentrated in or around urban areas over time in both the Maxent and Random Forest analyses. This reflects a lower range of spatial variability in fire probability but indicates that fires occur more frequently near cities.
The South Korean forest fires, which are mostly caused by human activity, show lower spatial autocorrelation compared to other disasters or natural forest fires [80]. This has reduced the prediction accuracy of models, but we presented statistically significant results by applying machine learning models to forest fire prediction. The AUC value decreased over the decades in the Maxent analysis. This is due to the fact that the samples become larger over the decades, and this can violate the assumption of independent observations due to spatial autocorrelation [18,81]. However, for Random Forest analysis, the AUC value was highest during the 1980s and the lowest during the 1990s. The value has not decreased over the decades, despite the larger samples. This shows that the Random Forest model has a higher capability of dealing with spatial autocorrelation issues with larger samples [82,83].
The overall spatial distributions of the two model results and the importance of the main variables were similar. However, the Random Forest was superior in obtaining higher AUC values, while the forest fire probability was obtaining overall higher or overestimated probability compared to the Maxent result. In the case of the Maxent result, the AUC values were relatively low, but the fire probability was estimated adequately and provided response analysis of each variable. By using both the Maxent model and the Random Forest model, it is possible to resolve the issues regarding the overestimation and the prediction accuracy, and to obtain the spatial distribution of forest fire and to verify the impact of socio-economic drivers to forest fires.
4.3. Limitations and Uncertainty
The forest fire occurrence data used in this study was based on field surveys from the Korea Forest Service. The agency uses the field data to document forest fire occurrence, but understanding the potential uncertainty and data reliability is necessary. Fire detection with satellite imagery is considered one option based on scientific studies. A comparison between field data and satellite-derived data and understanding errors are suggested in a future study.
Most of the socio-economic source data used in this study are not created for the purpose of performing spatial analysis. However, the data had to be used as variables in order to demonstrate the relationships between forest fire probability and socio-economic changes, thus they are transformed into grid maps. This may create data uncertainty, which can lead to model uncertainty.
Due to the absence of some data, some of the variables are interpolated. Interpolation is useful to fill in the gaps when looking for values missing but it can also affect the accuracy of models due to the uncertainty created in making predictions. In this study, the observed climate data was interpolated to make grid maps to get prcp-spr, SPI-spr and FWI. From the Maxent result, SPI-spr and FWI showed an inconsistent correlation with fire probability. This may be due to the uncertainty from interpolation. Not only climate data, but also socio-economic data was interpolated. In terms of including the number of visitors to national parks, this was to provide human access to the forest area. The number of visitors to national parks was used as the best alternative plan because there were no existing data counting visitors to all forest areas. It was possible to approximately estimate the number of people visiting the forest areas from the 1980s by interpolating. As a result, the number of national park visitors showed an insignificant correlation with fire probability. This might be explained by the fact that the source data was limited only to the number of visitors to national parks.
To make comparisons among the decades, only the variables that were available or were created since the 1980s could be used. Available datasets have increased since then, but they couldn’t have been used for comparisons of whole periods. For example, road density from a node and link dataset can be used to represent urbanization, but unfortunately, this was only available from 2008. Thus, distance from urban area was used instead to explain the effect of human accessibility to fire occurrence.
As society becomes more complex, future studies need to incorporate more advanced socio-economic variables and different model approaches in order to gain new insights and further reduce uncertainties. For instance, south-facing slopes in forests present ideal conditions for the fire outbreaks due to the low humidity and soil moisture that result from an abundance of sunlight. These conditions also encourage the growth of pine trees, which, in turn, leads to a larger accumulation of fuel for a given fire [48]. More than 50% of the forest fires studied occurred on south-facing slopes according to the ‘2011 Forest Disaster White Paper’ published by the National Institute of Forest Science, which included an investigation of forest fire characteristics from 2007 to 2011 [84]. However, this aspect was not considered among the input variables in this study, because the model was simulated at a spatial resolution of 1 km—a large area in which to define only one aspect in a grid. Thus, this aspect should be included in a future study with downscaled model output.
4.4. Towards Forest Fire Risk Reduction
This study is meaningful as it considers both socio-economic and environmental variables in the model and shows the linkage between socio-economic development and forest fire probability. For both analyses, the average forest fire probability was highest during the 1990s, exceeding even the 2000s, despite ongoing socio-economic development. We assume that this is a result of increased and more advanced forest management during the 2000s. The KFS established and implemented the Basic Plan for the Prevention of Forest Fires (2006–2010) after a large-scale forest fire in 2000 and continued to expand the budget to prevent forest fires across the country [85].
The results indicate that effectively managing human activity is significant in preventing forest fire occurrence and that socio-economic factors are increasingly being considered in causing and preventing forest fires. Additionally, through analyses of forest fire probability and the identification of key input variables, potential forest fire occurrences can be decreased, and sustainable forest management can be achieved [80,86,87]. Probability maps can be utilized to reduce disaster risk in fire-prone areas; there are several measures that can be used to sustainably manage forests more effectively including controlling forest density to mitigate water competition and fire spreading, increasing species diversity to diversify burn severity, selecting tree species to mitigate climate change and potential fire risk, establishing fire safety standards and preventive measures in populated areas, and monitoring fire-prone areas to quickly respond to forest fire occurrences [88,89,90,91,92,93,94,95]. Because forest fires are preventable disasters, to some extent, we suggest that it is critical to implement preventive and precautionary measures in a timely fashion, especially measures related to human activity in forests close to urban areas.
5. Conclusions
South Korea has rapidly urbanized, and has experienced an increasing trend in forest fire occurrence. By modeling forest fire probability for three separate periods using a machine learning algorithm like Maxent and Random Forest, this study simulated the forest fire probability and identified the impact of socio-economic changes, such as urban sprawl, on fire probability.
In terms of average forest fire probability, the probability was highest during the 1990s and the probability of forest fires was high in urban areas and the eastern coastal area in both analyses. The variables with the highest percent contribution were pop and elev across all decades. In particular, population density was found to be the most significant and positively correlated variable for fire occurrence in this study, particularly during the 1990s.
The results showed relatively high statistical accuracy, given that forest fires in South Korea primarily result from human activity that is fairly unpredictable, and that a 1-km spatial resolution was used for the analysis. The accuracy of the model was higher in the Random Forest result compared to that of the Maxent, but the average forest fire probability was overestimated in the Random Forest model.
This study shows that over the decades, the spatial distribution of fire probability has become more and more concentrated in or around cities, and that the forest fire probability has a strong correlation with human-related variables over time. This indicates that it is important to implement preventative and preparedness measures in forest fire management to reduce the occurrence and impact of forest fires in South Korea.
Author Contributions
Conceptualization, S.J.K. and C.-H.L.; Methodology, S.J.K. and O.R.; Validation, S.J.K. and O.R.; Formal Analysis, S.J.K.; Investigation, S.J.K.; Resources, S.J.K., C.-H.L. and G.S.K.; Data Curation, S.J.K., G.S.K. and J.L.; Writing—Original Draft Preparation, S.J.K.; Writing—Review & Editing, C.-H.L., G.S.K., J.L., T.G. and O.R.; Visualization, S.J.K.; Supervision, W.-K.L. and Y.S.; Project Administration, W.-K.L.; Funding Acquisition, W.-K.L.
Funding
This research was funded by the Ministry of Environment (MOE) of the Republic of Korea (Project Number: 2014001310008).
Acknowledgments
This study was jointly completed by the request of the UNDP Seoul Policy Centre. This study was supported by the “Climate Change Correspondence Program (Project Number: 2014001310008)” of the Ministry of Environment (MOE) of the Republic of Korea. This work was funded through the framework of the Leibniz Competition (SAW-2016-PIK-1) and by the German Federal Ministry of Education and Research through the funding line “Economics of Climate Change”.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kwak, H.; Lee, W.K.; Saborowski, J.; Lee, S.Y.; Won, M.S.; Koo, K.S.; Lee, M.B.; Kim, S.N. Estimating the spatial pattern of human-caused forest fires using a generalized linear mixed model with spatial autocorrelation in South Korea. Int. J. Geogr. Inf. Sci. 2012, 26, 1589–1602. [Google Scholar] [CrossRef]
- Korea Forest Service. 2016 Forest Basic Statistics; Korea Forest Service: Daejeon, Korea, 2016. (In Korean)
- Lee, S.Y.; Chae, H.M.; Park, G.S.; Ohga, S. The potential impact of climate change on people-caused forest fire occurrence in South Korea. J. Fac. Agric. Kyushu Univ. 2012, 57, 17–25. [Google Scholar]
- Brown, A.A.; Davis, K.P. Forest Fire: Control and Use; McGraw-Hill: New York, NY, USA, 1973. [Google Scholar]
- Park, J.K.; Jung, W.S.; Kim, E.B.; Jeong, H.J. Study on Analysis of Meteorological Phenomenon effecting on Forest Fire. Proc. Korean Soc. Hazard Mitig. Conf. 2014, 19, 376. (In Korean) [Google Scholar]
- Korea Forest Service. 2016 Statistical Yearbook of Forest Fire; No. 11-1400000-000424-10; Korea Forest Service: Daejeon, Korea, 2017. (In Korean)
- Korea Forest Service. 2017 Statistical Yearbook of Forest Fire; No. 11-1400000-000424-10; Korea Forest Service: Daejeon, Korea, 2018. (In Korean)
- Bridges, B. The Seoul Olympics: Economic miracle meets the world. Int. J. Hist. Sport 2008, 25, 1939–1952. [Google Scholar] [CrossRef]
- Rii, H.U.; Ahn, J.S. Urbanization and its impact on Seoul, Korea. Urbanization. In East Asian and Habitat II; Chung-hua Institution for Economic Research: Taipei, Taiwan, 2002; pp. 83–100. [Google Scholar]
- Romero-Calcerrada, R.; Barrio-Parra, F.; Millington, J.D.A.; Novillo, C.J. Spatial modelling of socioeconomic data to understand patterns of human-caused wildfire ignition risk in the SW of Madrid (central Spain). Ecol. Modell. 2010, 221, 34–45. [Google Scholar] [CrossRef]
- Vilar, L.; Woolford, D.G.; Martell, D.L.; Martín, M.P. A model for predicting human-caused wildfire occurrence in the region of Madrid, Spain. Int. J. Wildland Fire 2010, 19, 325–337. [Google Scholar] [CrossRef]
- Forkel, M.; Dorigo, W.; Lasslop, G.; Teubner, I.; Chuvieco, E.; Thonicke, K. A data-driven approach to identify controls on global fire activity from satellite and climate observations (SOFIA V1). Geosci. Model Dev. 2017, 10, 4443–4476. [Google Scholar] [CrossRef]
- Aragao, L.E.O.C.; Malhi, Y.; Barbier, N.; Lima, A.; Shimabukuro, Y.; Anderson, L.; Saatchi, S. Interactions between rainfall, deforestation and fires during recent years in the Brazilian Amazonia. Philos. Trans. R. Soc. B 2008, 363, 1779–1785. [Google Scholar] [CrossRef]
- Syphard, A.D.; Radeloff, V.C.; Keuler, N.S.; Taylor, R.S.; Hawbaker, T.J.; Stewart, S.I.; Clayton, M.K. Predicting spatial patterns of fire on a southern California landscape. Int. J. Wildland Fire 2008, 17, 602–613. [Google Scholar] [CrossRef]
- Martínez, J.; Vega-Garcia, C.; Chuvieco, E. Human-caused wildfire risk rating for prevention planning in Spain. J. Environ. Manag. 2009, 90, 1241–1252. [Google Scholar] [CrossRef]
- Plucinski, M.P. The timing of vegetation fire occurrence in a human landscape. Fire Saf. J. 2014, 67, 42–52. [Google Scholar] [CrossRef]
- Costafreda-Aumedes, S.; Cosmas, C.; Vega-Garcia, C. Human-caused fire occurrence modelling in perspective: A review. Int. J. Wildland Fire 2017, 26, 983–998. [Google Scholar] [CrossRef]
- Costafreda-Aumedes, S.; Vega-Garcia, C.; Cosmas, C. Improving fire season definition by optimized temporal modelling of daily human-caused ignitions. J. Environ. Manag. 2018, 217, 90–99. [Google Scholar] [CrossRef] [PubMed]
- Bar Massada, A.B.; Syphard, A.D.; Stewart, S.I.; Radeloff, V.C. Wildfire ignition-distribution modelling: A comparative study in the Huron–Manistee National Forest, Michigan, USA. Int. J. Wildland Fire 2013, 22, 174–183. [Google Scholar] [CrossRef]
- Oliveira, S.; Oehler, F.; San-Miguel-Ayanz, J.; Camia, A.; Pereira, J.M. Modeling spatial patterns of fire occurrence in Mediterranean Europe using Multiple Regression and Random Forest. For. Ecol. Manag. 2012, 275, 117–129. [Google Scholar] [CrossRef]
- Vilar, L.; Gómez, I.; Martínez-Vega, J.; Echavarría, P.; Riaño, D.; Martín, M.P. Multitemporal modelling of socio-economic wildfire drivers in Central Spain between the 1980s and the 2000s: Comparing generalized linear models to machine learning algorithms. PLoS ONE 2016, 11, e0161344. [Google Scholar] [CrossRef] [PubMed]
- Hastie, T.; Tibshirani, R.; Friedman, J. Overview of supervised learning. In The Elements of Statistical Learning; Springer: New York, NY, USA, 2009; pp. 9–41. ISBN 978-0-387-84858-7. [Google Scholar]
- Elith, J.; Graham, C.H.; Anderson, R.P.; Dudík, M.; Ferrier, S.; Guisan, A.; Hijmans, R.J.; Huettmann, F.; Leathwick, J.R.; Lehmann, A.; et al. Novel methods improve prediction of species’ distributions from occurrence data. Ecography 2006, 29, 129–151. [Google Scholar] [CrossRef]
- Phillips, S.J.; Anderson, R.P.; Schapire, R.E. Maximum entropy modeling of species geographic distributions. Ecol. Model. 2006, 190, 231–259. [Google Scholar] [CrossRef]
- Parisien, M.A.; Moritz, M.A. Environmental controls on the distribution of wildfire at multiple spatial scales. Ecol. Monogr. 2009, 79, 127–154. [Google Scholar] [CrossRef]
- Renard, Q.; Pélissier, R.; Ramesh, B.R.; Kodandapani, N. Environmental susceptibility model for predicting forest fire occurrence in the Western Ghats of India. Int. J. Wildland Fire 2012, 21, 368–379. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Archibald, S.; Roy, D.P.; van Wilgen, B.W.; Scholes, R.J. What limits fire? An examination of drivers of burnt area in Southern Africa. Glob. Chang. Biol. 2009, 15, 612–630. [Google Scholar] [CrossRef]
- Arpaci, A.; Malowerschnig, B.; Sass, O.; Vacik, H. Using multi variate data mining techniques for estimating fire susceptibility of Tyrolean forests. Appl. Geogr. 2014, 53, 258–270. [Google Scholar] [CrossRef]
- Rahmati, O.; Pourghasemi, H.R.; Melesse, A.M. Application of GIS-based data driven random forest and maximum entropy models for groundwater potential mapping: A case study at Mehran Region, Iran. Catena 2016, 137, 360–372. [Google Scholar] [CrossRef]
- Aldersley, A.; Murray, S.J.; Cornell, S.E. Global and regional analysis of climate and human drivers of wildfire. Sci. Total Environ. 2011, 409, 3472–3481. [Google Scholar] [CrossRef] [PubMed]
- Kim, G.S.; Lim, C.H.; Kim, S.J.; Lee, J.; Son, Y.; Lee, W.K. Effect of national-scale afforestation on forest water supply and soil loss in South Korea, 1971–2010. Sustainability 2017, 9, 1017. [Google Scholar] [CrossRef]
- Lee, J.; Lim, C.H.; Kim, G.S.; Markandya, A.; Chowdhury, S.; Kim, S.J.; Son, Y. Economic viability of the national-scale forestation program: The case of success in the Republic of Korea. Ecosyst. Serv. 2018, 29, 40–46. [Google Scholar] [CrossRef]
- Lee, H.W.; Tak, S.H.; Lee, S.H. Numerical experiment on the variation of atmospheric circulation because of wild fire. J. Environ. Sci. Int. 2013, 22, 173–185. [Google Scholar] [CrossRef]
- Campbell, J.L.; Harmon, M.E.; Mitchell, S.R. Can fuel-reduction treatments really increase forest carbon storage in the western US by reducing future fire emissions? Front. Ecol. Environ. 2012, 10, 83–90. [Google Scholar] [CrossRef]
- Moreira, F.; Vaz, P.; Catry, F.; Silva, J.S. Regional variations in wildfire susceptibility of land-cover types in Portugal: Implications for landscape management to minimize fire hazard. Int. J. Wildland Fire 2009, 18, 563–574. [Google Scholar] [CrossRef]
- Korea Forest Service. 2017 47th Forestry Statistical Yearbook; No. 11-1400000-000001-10; Korea Forest Service: Daejeon, Korea, 2017. (In Korean)
- Kim, Y.H.; Baik, J.J. Daily maximum urban heat island intensity in large cities of Korea. Theor. Appl. Climatol. 2004, 79, 151–164. [Google Scholar] [CrossRef]
- Kim, S.J.; Lim, C.H.; Lim, Y.J.; Moon, J.; Song, C.; Lee, W.K. Analyzing Climate Zones Using Hydro-Meteorological Observation Data in Andong Dam Watershed, South Korea. J. Clim. Chang. Res. 2016, 7, 269–282. (In Korean) [Google Scholar] [CrossRef]
- Kim, S.J.; Kim, M.; Lim, C.H.; Lee, W.K.; Kim, B.J. Applicability Analysis of FAO56 Penman-Monteith Methodology for Estimating Potential Evapotranspiration in Andong Dam Watershed Using Limited Meteorological Data. J. Clim. Chang. Res. 2017, 8, 125–143. (In Korean) [Google Scholar] [CrossRef]
- NIMS. Climate Change Over 100 Years on the Korean Peninsula; No. 11-1360620-000132-01; National Institute of Meteorological Science (NIMS): Seogwipo, Korea, 2018. (In Korean)
- Kolbek, J.; Srutek, M.; Box, E.E. (Eds.) Forest Vegetation of Northeast Asia; Springer Science & Business Media: Berlin, Germany, 2013; Volume 28, ISBN 978-94-017-0143-3. [Google Scholar]
- McKenzie, D.; Gedalof, Z.E.; Peterson, D.L.; Mote, P. Climatic change, wildfire, and conservation. Conserv. Biol. 2004, 18, 890–902. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Aretano, R.; Semeraro, T. Investigation of general indicators influencing on forest fire and its susceptibility modeling using different data mining techniques. Ecol. Indic. 2016, 64, 72–84. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Rossi, M. Forest fire susceptibility mapping in the Minudasht forests, Golestan province, Iran. Environ. Earth Sci. 2015, 73, 1515–1533. [Google Scholar] [CrossRef]
- Adeney, J.M.; Christensen, N.L., Jr.; Pimm, S.L. Reserves protect against deforestation fires in the Amazon. PLoS ONE 2009, 4, e5014. [Google Scholar] [CrossRef] [PubMed]
- Lee, B.; Ryu, G.; Kim, S.; Kim, K. Development of forest fire occurrence probability model using logistic regression. J. Korean For. Soc. 2012, 101, 1–6. (In Korean) [Google Scholar]
- Ruffault, J.; Mouillot, F. Contribution of human and biophysical factors to the spatial distribution of forest fire ignitions and large wildfires in a French Mediterranean region. Int. J. Wildland Fire 2017, 26, 498–508. [Google Scholar] [CrossRef]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Nalder, I.A.; Wein, R.W. Spatial interpolation of climatic normals: Test of a new method in the Canadian boreal forest. Agric. For. Meteorol. 1998, 92, 211–225. [Google Scholar] [CrossRef]
- Yun, J.I.; Choi, J.Y.; Yoon, Y.K.; Chung, U. A spatial interpolation model for daily minimum temperature over mountainous regions. Korean J. Agric. For. Meteorol. 2000, 2, 175–182. (In Korean) [Google Scholar]
- McKee, T.B.; Doesken, N.J.; Kleist, J. The relationship of drought frequency and duration to time scales. In Proceedings of the 8th Conference on Applied Climatology, Anaheim, CA, USA, 17–22 January 1993; American Meteorological Society: Boston, MA, USA, 1993; Volume 17, No. 22. pp. 179–183. [Google Scholar]
- Ayala-Bizarro, I.; Zúñiga-Mendoza, J. SPIGA: Compute SPI Index Using the Methods Genetic Algorithm and Maximum Likelihood. R package version 1.0.0. 2016. Available online: https://CRAN.R-project.org/package=SPIGA (accessed on 25 September 2018).
- Roy, D.P.; Kumar, S.S. Multi-year MODIS active fire type classification over the Brazilian Tropical Moist Forest Biome. Int. J. Digit. Earth 2017, 10, 54–84. [Google Scholar] [CrossRef]
- Hirose, K.; Kim, C.K.; Kim, C.S.; Chang, B.W.; Igarashi, Y.; Aoyama, M. Wet and dry deposition patterns of plutonium in Daejeon, Korea. Sci. Total Environ. 2009, 332, 243–252. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Cantin, A.; Parisien, M.A.; Wotton, M.; Anderson, K.; Flannigan, M. fwi.fbp: Fire Weather Index System and Fire Behaviour Prediction System Calculations. R package version 1.7. 2016. Available online: https://CRAN.R-project.org/package=fwi.fbp (accessed on 26 October 2018).
- Danielsson, P.E. Euclidean distance mapping. Comput. Graph. Image Process. 1980, 14, 227–248. [Google Scholar] [CrossRef]
- Syphard, A.D.; Keeley, J.E. Location, timing and extent of wildfire vary by cause of ignition. Int. J. Wildland Fire 2015, 24, 37–47. [Google Scholar] [CrossRef]
- West, A.M.; Kumar, S.; Jarnevich, C.S. Regional modeling of large wildfires under current and potential future climates in Colorado and Wyoming, USA. Clim. Change 2016, 134, 565–577. [Google Scholar] [CrossRef]
- Swets, J.A. Measuring the accuracy of diagnostic systems. Science 1988, 240, 1285–1293. [Google Scholar] [CrossRef]
- Proosdij, A.S.; Sosef, M.S.; Wieringa, J.J.; Raes, N. Minimum required number of specimen records to develop accurate species distribution models. Ecography 2016, 39, 542–552. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620. [Google Scholar] [CrossRef]
- Deblauwe, V.; Barbier, N.; Couteron, P.; Lejeune, O.; Bogaert, J. The global biogeography of semi-arid periodic vegetation patterns. Glob. Ecol. Biogeogr. 2008, 17, 715–723. [Google Scholar] [CrossRef]
- Lim, C.H.; Yoo, S.; Choi, Y.; Jeon, S.W.; Son, Y.; Lee, W.K. Assessing Climate Change Impact on Forest Habitat Suitability and Diversity in the Korean Peninsula. Forest 2018, 9, 259. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C., Jr.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef] [PubMed]
- Prasad, A.M.; Iverson, L.R.; Liaw, A. Newer classification and regression tree techniques: Bagging and random forests for ecological prediction. Ecosystems 2006, 9, 181–199. [Google Scholar] [CrossRef]
- Wiesmeier, M.; Barthold, F.; Blank, B.; Kögel-Knabner, I. Digital mapping of soil organic matter stocks using Random Forest modeling in a semi-arid steppe ecosystem. Plant Soil. 2011, 340, 7–24. [Google Scholar] [CrossRef]
- Calle, M.L.; Urrea, V. Letter to the editor: Stability of random forest importance measures. Brief. Bioinf. 2010, 12, 86–89. [Google Scholar] [CrossRef] [PubMed]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Naimi, B.; Araujo, M.B. sdm: A reproducible and extensible R platform for species distribution modelling. Ecography 2016, 39, 368–375. [Google Scholar] [CrossRef]
- Tien Bui, D.; Le, K.T.T.; Nguyen, V.C.; Le, H.D.; Revhaug, I. Tropical forest fire susceptibility mapping at the Cat Ba national park area, Hai Phong City, Vietnam, using GIS-Based kernel logistic regression. Remote Sens. 2016, 8, 347. [Google Scholar] [CrossRef]
- Frattini, P.; Costa, G.; Carrara, A. Techiniques for evaluating performance of landslide susceptibility models. Eng. Geol. 2010, 111, 62–72. [Google Scholar] [CrossRef]
- Yesilnacar, E.K. The Application of Computational Intelligence to Landslide Susceptibility Mapping in Turkey. Ph.D. Thesis, Department of Geomatics, University of Melbourne, Melbourne, Australia, 2005. [Google Scholar]
- Tien Bui, D.; Bui, Q.P.; Pradhan, B.; Nampak, H.; Trinh, P.T. A hybrid artificial intelligence approach using GI-based neural-fuzzy inference system and particle swarm optimization for forest fire susceptibility modeling at a tropical area. Agric. For. Meteorol. 2017, 233, 32–44. [Google Scholar] [CrossRef]
- Ho-Sang, S. Characteristics of Urban Sprawl in Seoul Metropolitan Region: An Integration of Remote Sensing and GIS Approach. Korea Spat. Plan. Rev. 2004, 40, 53–69. (In Korean) [Google Scholar]
- Small, C.; Nicholls, R.J. A global analysis of human settlement in coastal zones. J. Coast. Res. 2003, 584–599. [Google Scholar] [CrossRef]
- Lee, S.W.; Lee, M.B.; Lee, Y.G.; Won, M.S.; Kim, J.J.; Hong, S.K. Relationship between landscape structure and burn severity at the landscape and class levels in Samchuck, South Korea. For. Ecol. Manag. 2009, 258, 1594–1604. [Google Scholar] [CrossRef]
- Lee, H.J.; Kim, E.J.; Lee, S.W. Examining Spatial Variation in the Effects of Japanese Red Pine (Pinus densiflora) on Burn Severity Using Geographically Weighted Regression. Sustainability 2017, 9, 804. [Google Scholar] [CrossRef]
- Lee, H.J.; Choi, Y.E.; Lee, S.W. Complex Relationships of the Effects of Topographic Characteristics and Susceptible Tree Cover on Burn Severity. Sustainability 2018, 10, 295. [Google Scholar] [CrossRef]
- Lim, C.H.; Kim, Y.S.; Won, M.; Kim, S.J.; Lee, W.K. Can satellite-based data substitute for surveyed data to predict the spatial probability of forest fire? A geostatistical approach to forest fire in the Republic of Korea. Geomat. Nat. Haz. Risk 2018, in press. [Google Scholar]
- Heckmann, T.; Gegg, K.; Gegg, A.; Becht, M. Sample size matters: Investigating the effect of sample size on a logistic regression susceptibility model for debris flows. Nat. Hazards Earth Syst. Sci. 2014, 14, 259–278. [Google Scholar] [CrossRef]
- Hernandez, P.A.; Franke, I.; Herzog, S.K.; Pacheco, V.; Paniagua, L.; Quintana, H.L.; Soto, A.; Swenson, J.J.; Tovar, C.; Valqui, T.H.; et al. Predicting distribution in poor-studied landscapes. Biodivers. Conserv. 2008, 17, 1353–1366. [Google Scholar] [CrossRef]
- Williams, J.N.; Seo, C.; Thorne, J.; Nelson, J.K.; Erwin, S.; O’Brien, J.M.; Schwartz, M.W. Using species distribution models to predict new occurrences for rare plants. Divers. Distrib. 2009, 15, 565–576. [Google Scholar] [CrossRef]
- Kim, K.; Koo, K.; Youn, H.J.; Lee, C.; Won, M.; Lee, B.D.; Woo, C.S.; Kim, S.; Lee, M.B. 2011 Forest Disaster White Paper; No. 11-1400377-000524-01; National Institute of Forest Science (NIFOS): Daejeon, Korea, 2012. (In Korean)
- Korea Forest Service. 2006 Comprehensive Measures to Prevent Forest Fires. 1st Year of Basic Plan for Prevention of Forest Fire; Korea Forest Service: Daejeon, Korea, 2006. (In Korean)
- Iliadis, L.S. A decision support system applying an integrated fuzzy model for long-term forest fire risk estimation. Environ. Model. Softw. 2005, 20, 613–621. [Google Scholar] [CrossRef]
- Miller, C.; Ager, A.A. A review of recent advances in risk analysis for wildfire management. Int. J. Wildland Fire 2013, 22, 1–14. [Google Scholar] [CrossRef]
- Chou, Y.H.; Minnich, R.A.; Chase, R.A. Mapping probability of fire occurrence in San Jacinto Mountains, California, USA. Environ. Manag. 1993, 17, 129–140. [Google Scholar] [CrossRef]
- Hirsch, K.; Kafka, V.; Tymstra, C.; McAlpine, R.; Hawkes, B.; Stegehuis, H.; Peck, K. Fire-smart forest management: A pragmatic approach to sustainable forest management in fire-dominated ecosystems. Forest Chron. 2001, 77, 357–363. [Google Scholar] [CrossRef]
- Millington, J.D. Wildfire risk mapping: Considering environmental change in space and time. J. Mediterr. Ecol. 2005, 6, 33. [Google Scholar]
- Ritchie, M.W.; Skinner, C.N.; Hamilton, T.A. Probability of tree survival after wildfire in an interior pine forest of northern California: Effects of thinning and prescribed fire. For. Ecol. Manag. 2007, 247, 200–208. [Google Scholar] [CrossRef]
- Hughes, R.; Mercer, D. Planning to reduce risk: The wildfire management overlay in Victoria, Australia. Geograph. Res. 2009, 47, 124–141. [Google Scholar] [CrossRef]
- Gill, A.M.; Stephens, S.L. Scientific and social challenges for the management of fire-prone wildland–urban interfaces. Environ. Res. Lett. 2009, 4, 034014. [Google Scholar] [CrossRef]
- Keane, R.E.; Drury, S.A.; Karau, E.C.; Hessburg, P.F.; Reynolds, K.M. A method for mapping fire hazard and risk across multiple scales and its application in fire management. Ecol. Model. 2010, 221, 2–18. [Google Scholar] [CrossRef]
- San-Miguel-Ayanz, J.; Moreno, J.M.; Camia, A. Analysis of large fires in European Mediterranean landscapes: Lessons learned and perspectives. For. Ecol. Manag. 2013, 294, 11–22. [Google Scholar] [CrossRef]








© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).