Semantic Segmentation on Remotely Sensed Images Using an Enhanced Global Convolutional Network with Channel Attention and Domain Specific Transfer Learning

 ,
, 
Abstract
:
1. Introduction
2. Related Work
2.1. Deep Learning Concepts for Semantic Segmentation
2.2. Modern Deep Learning Architectures For Semantic Segmentation
2.3. Modern Techniques of Deep Learning
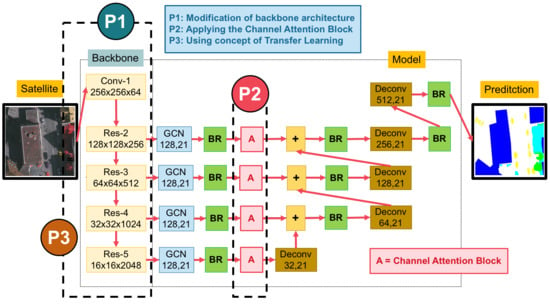
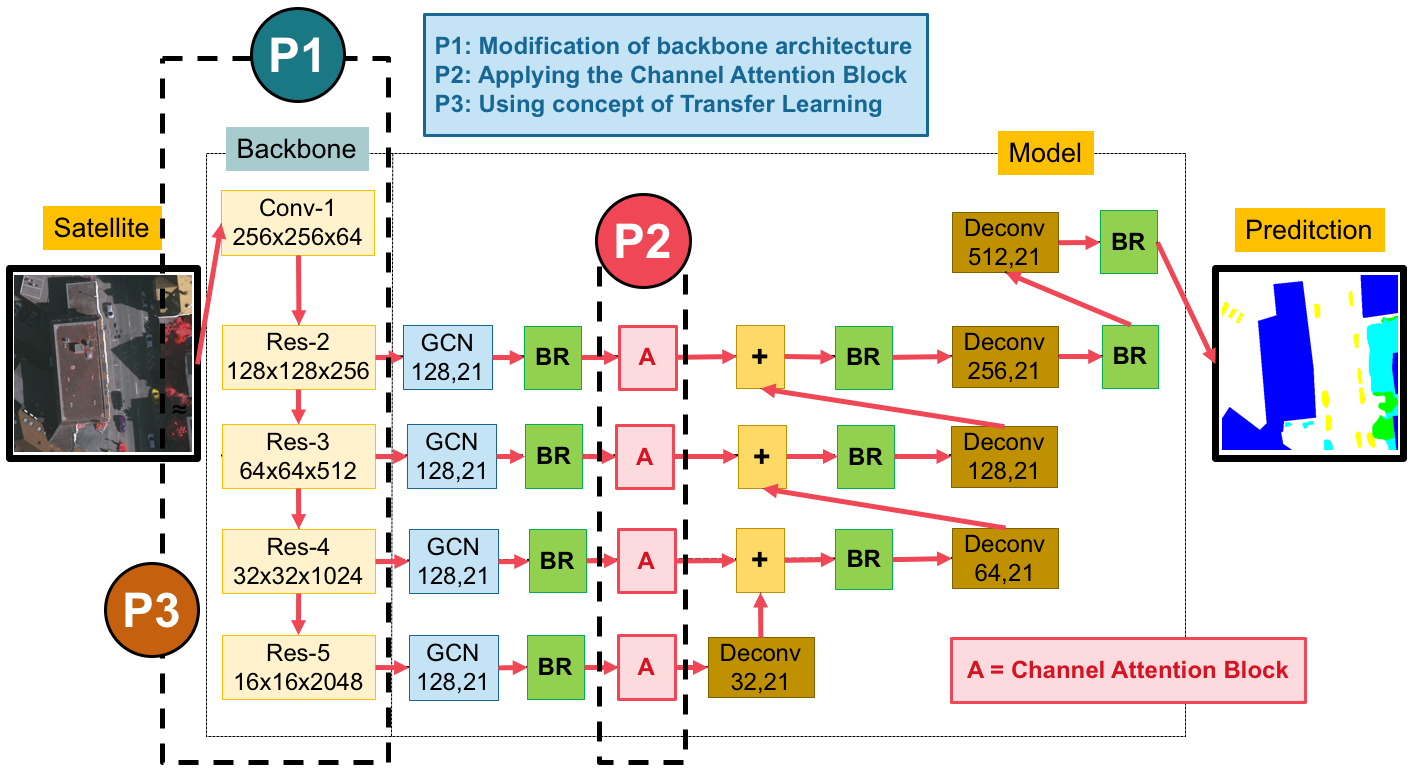
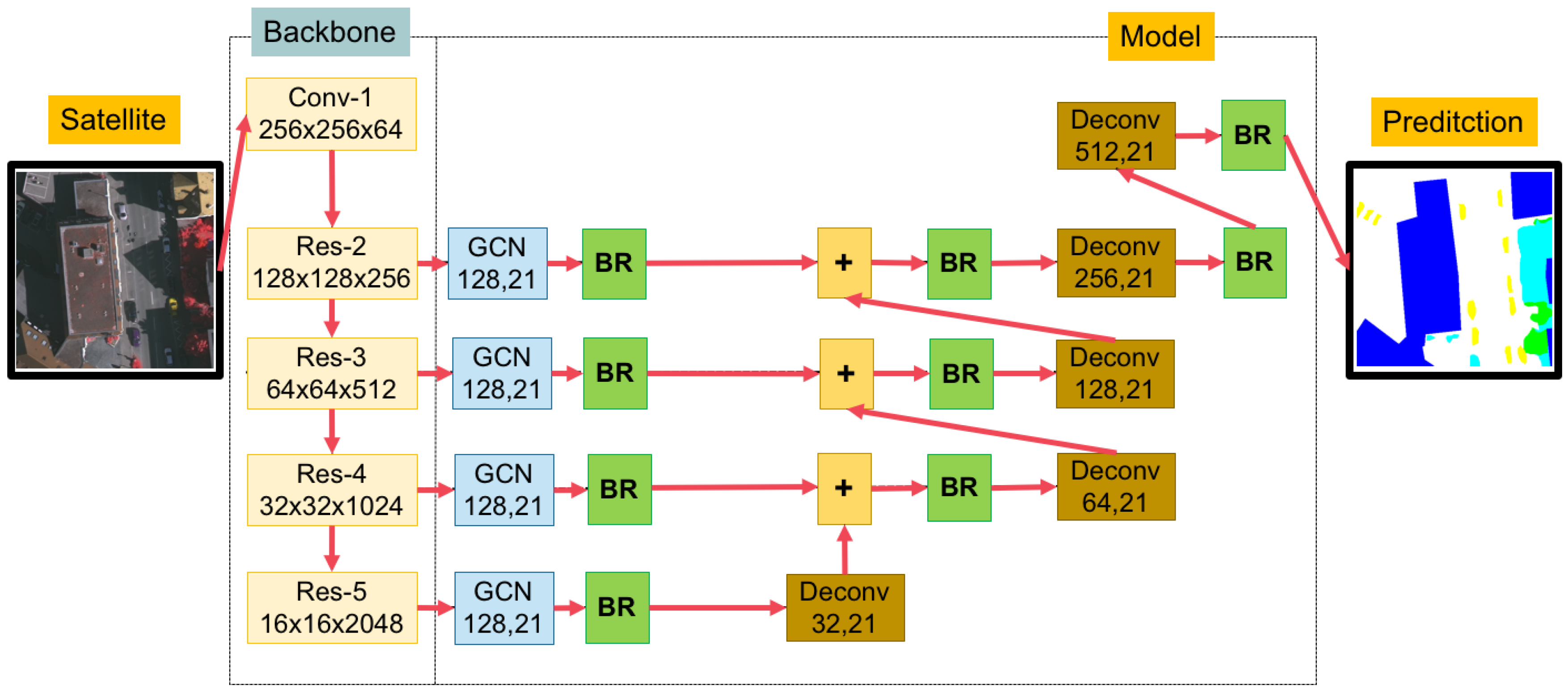
3. The Proposed Method
3.1. Data Preprocessing
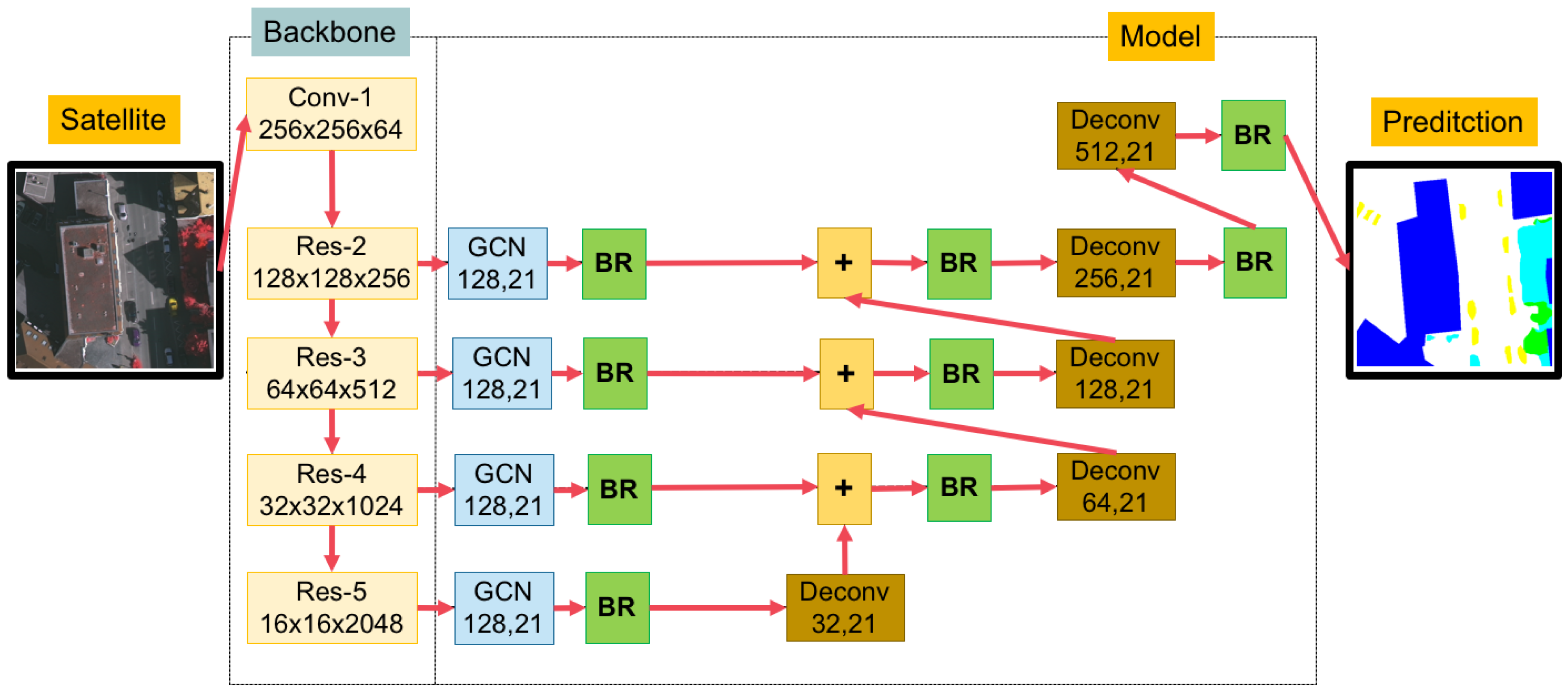
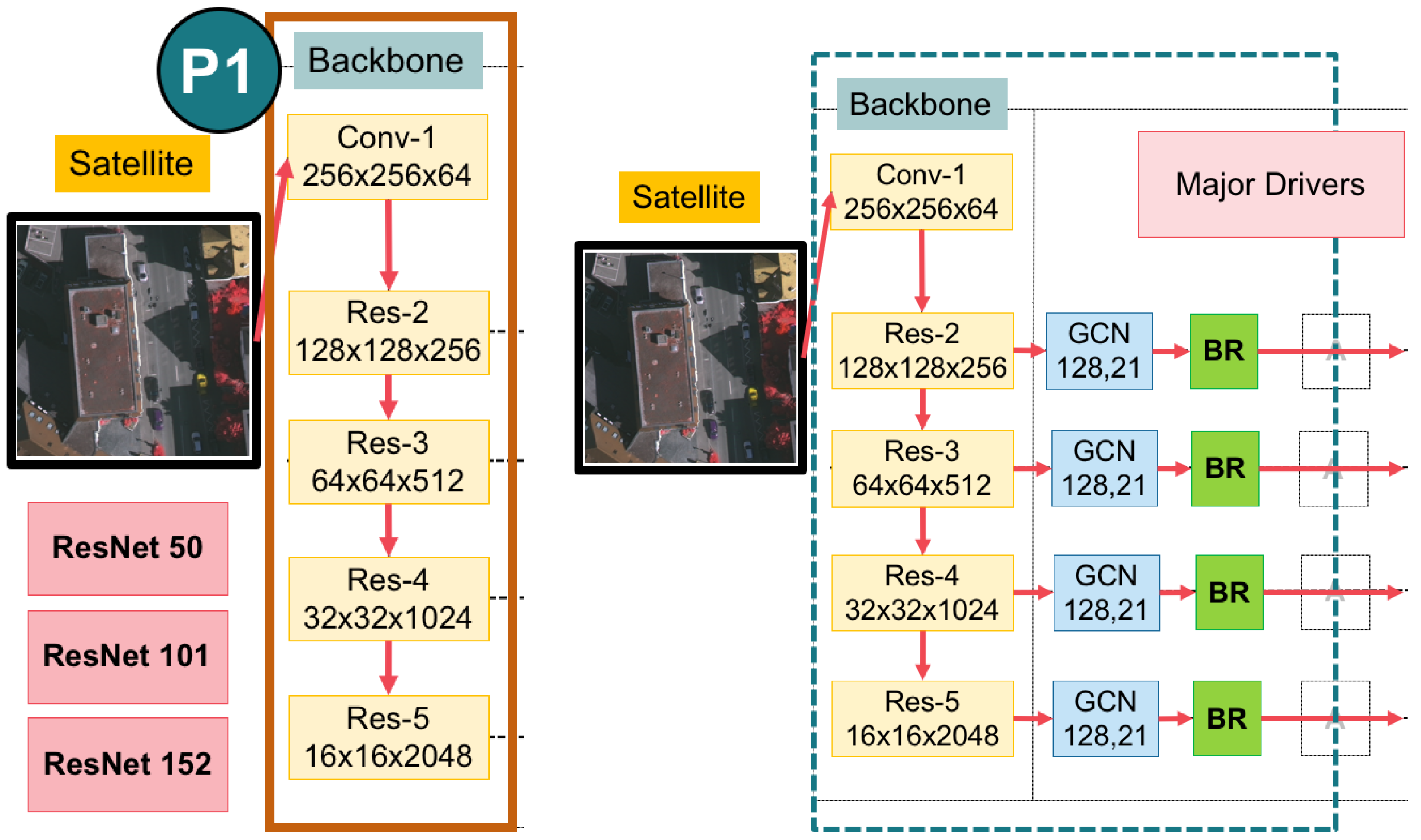
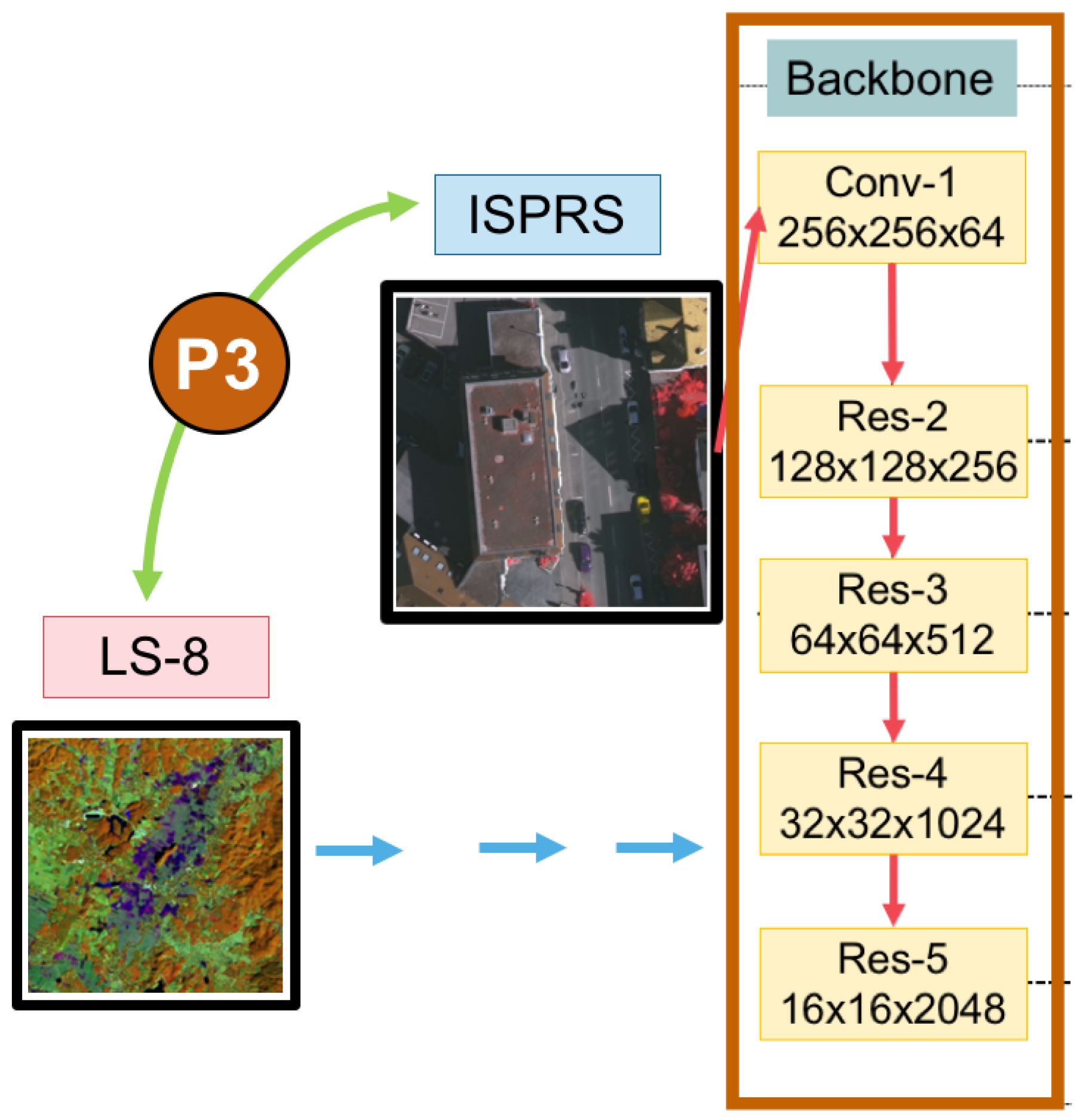
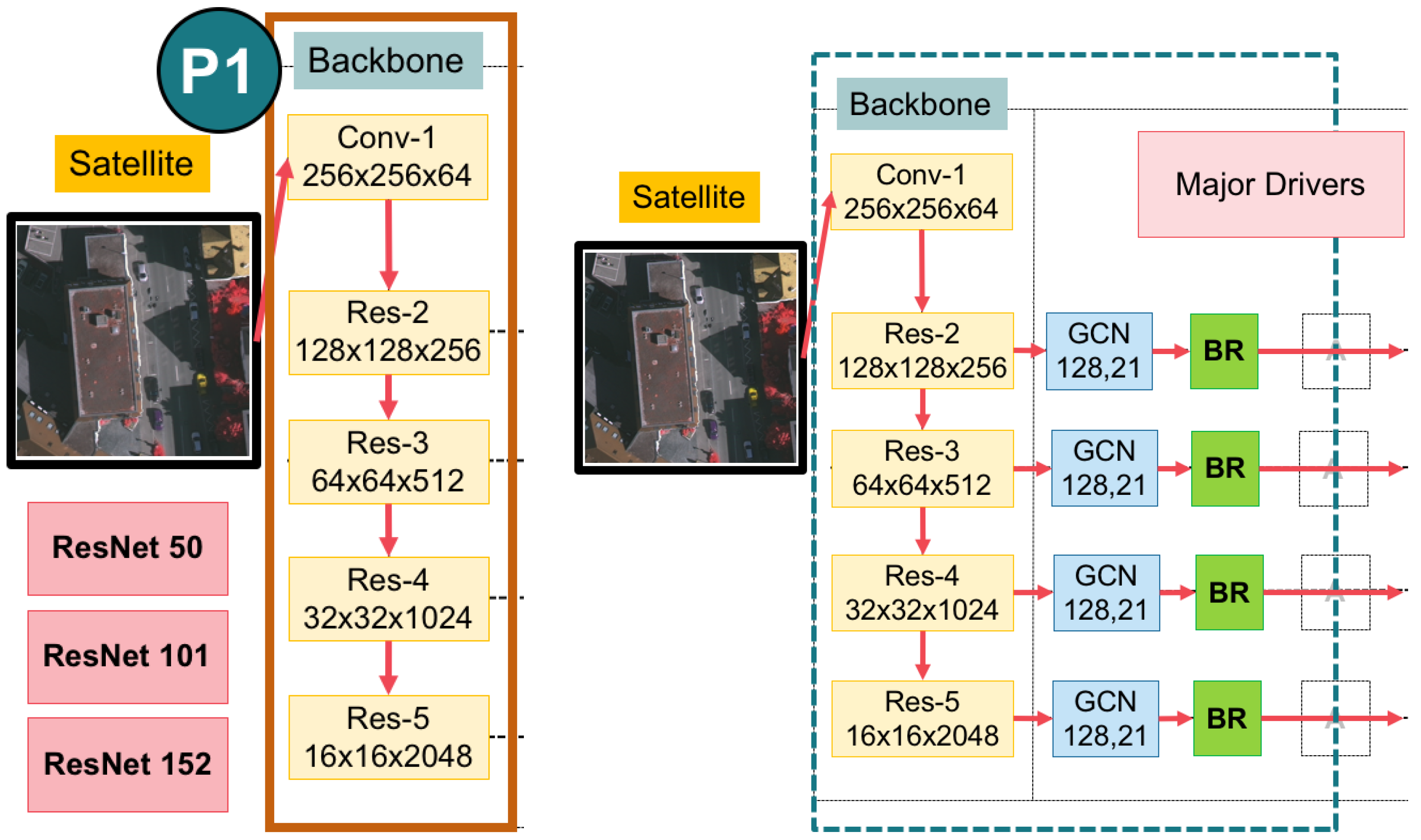
3.2. A Global Convolutional Network (GCN) with Variations of Backbones
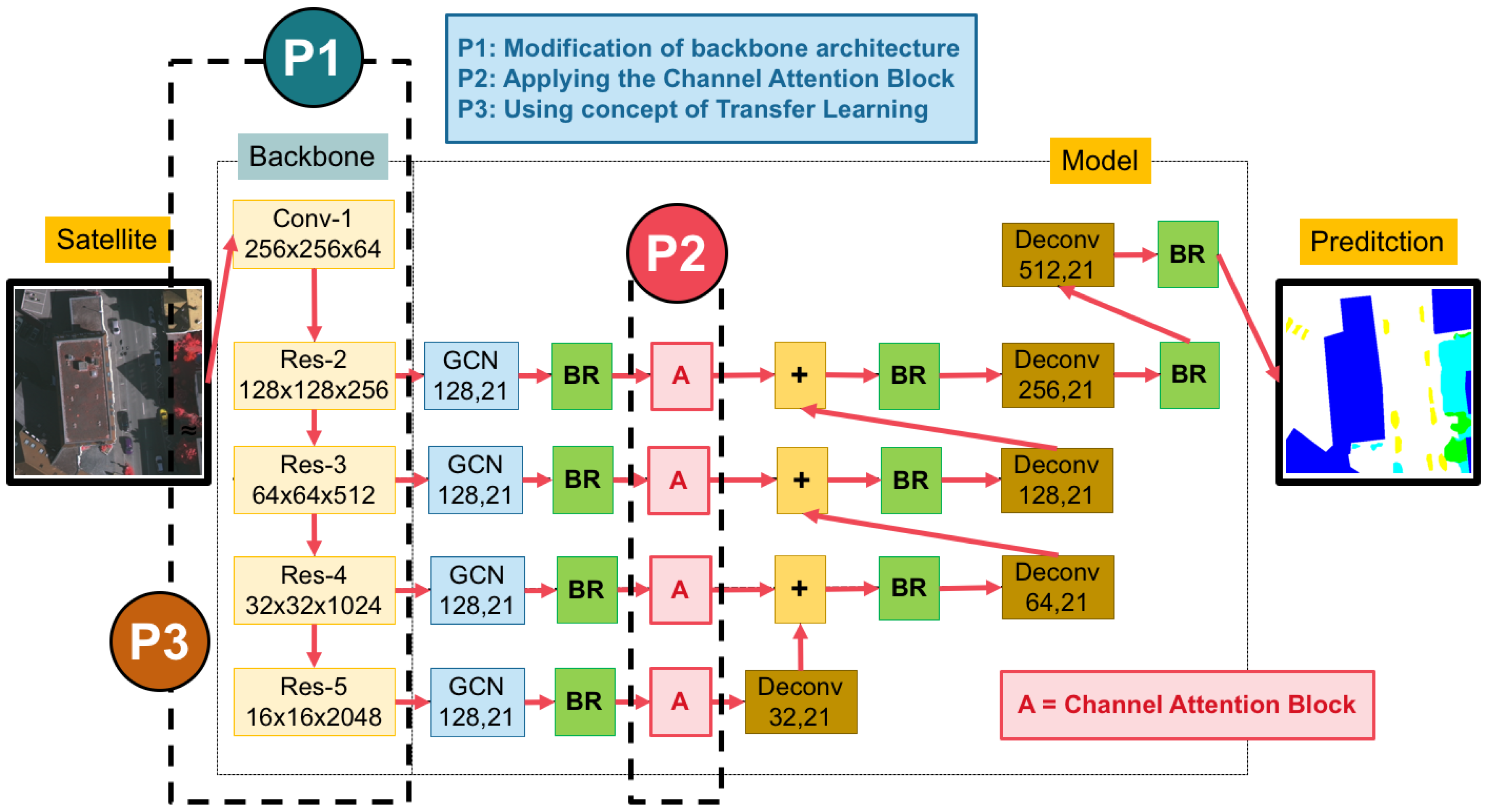
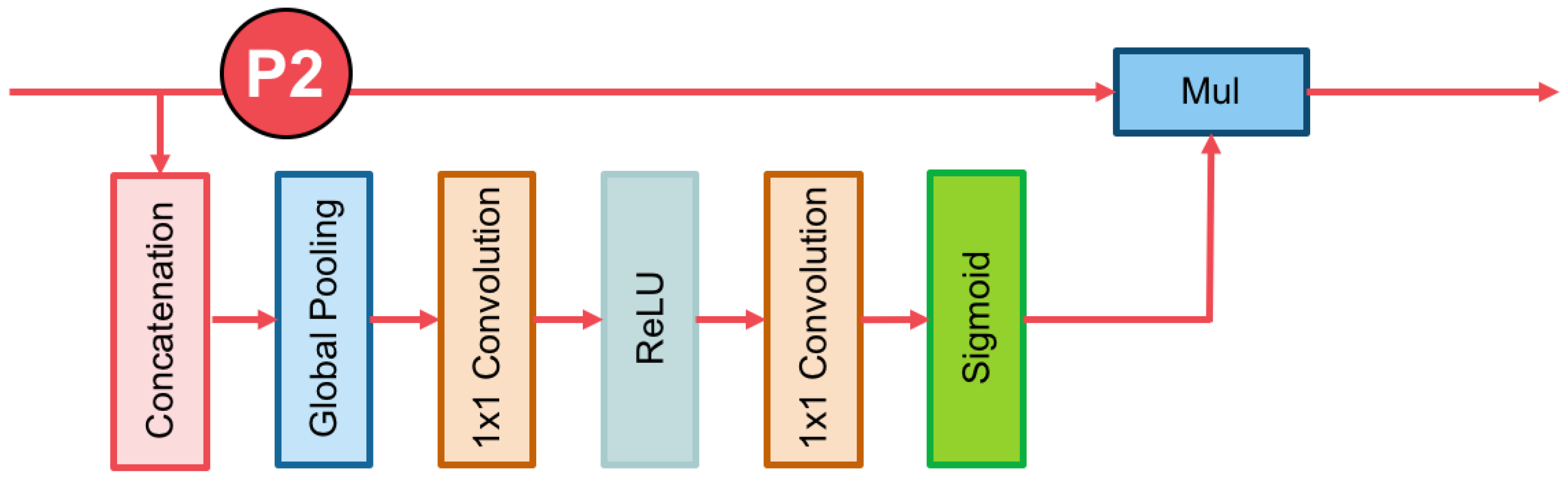
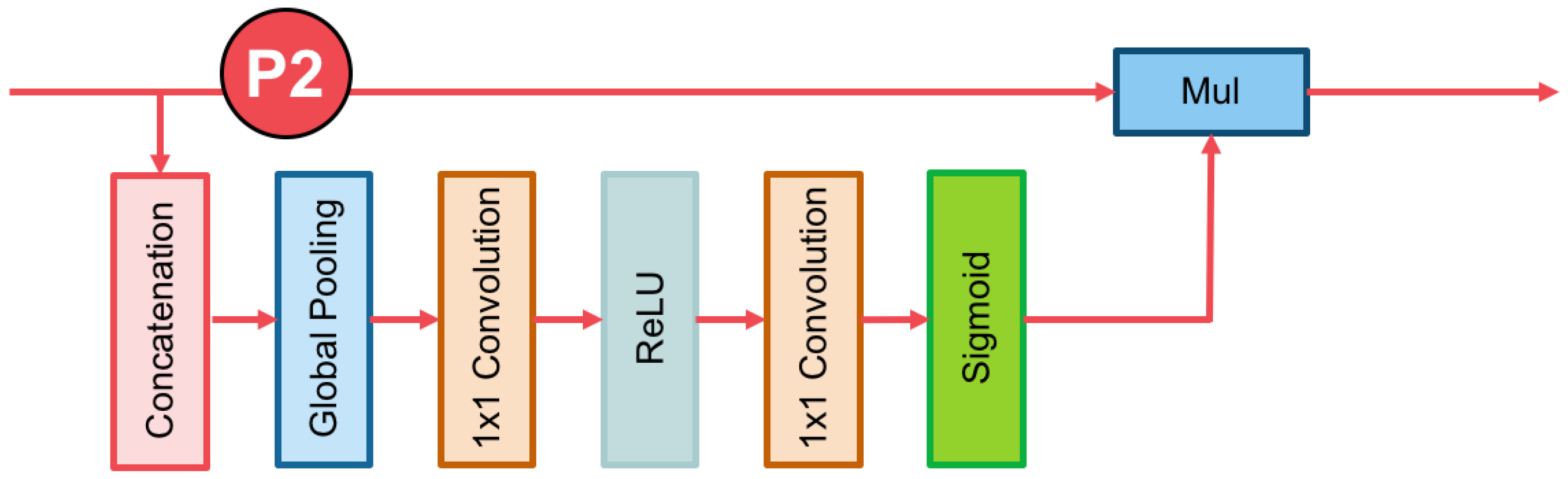
3.3. The Channel Attention Block
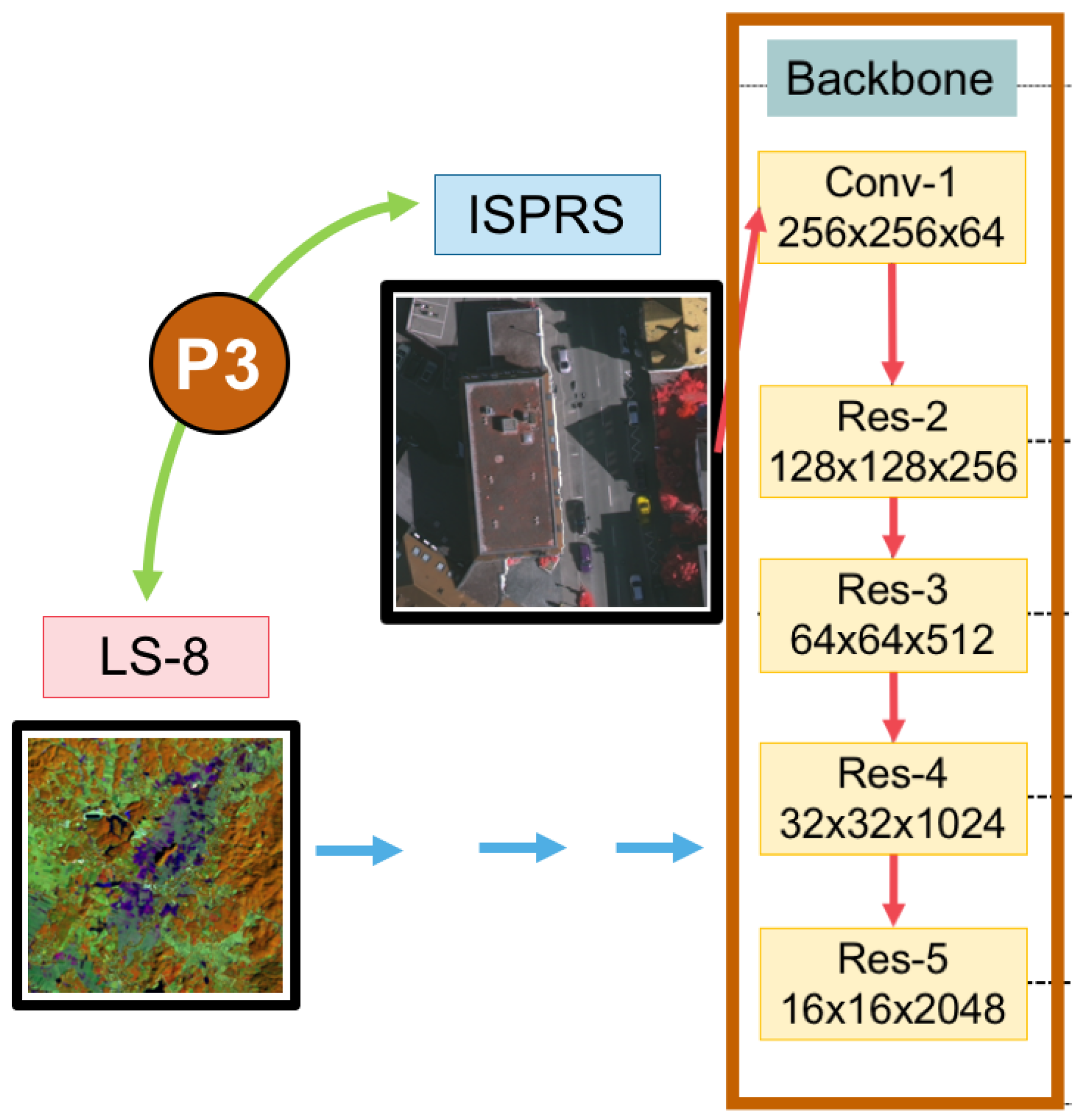
3.4. Domain-Specific Transfer Learning
4. Experimental Datasets and Evaluation
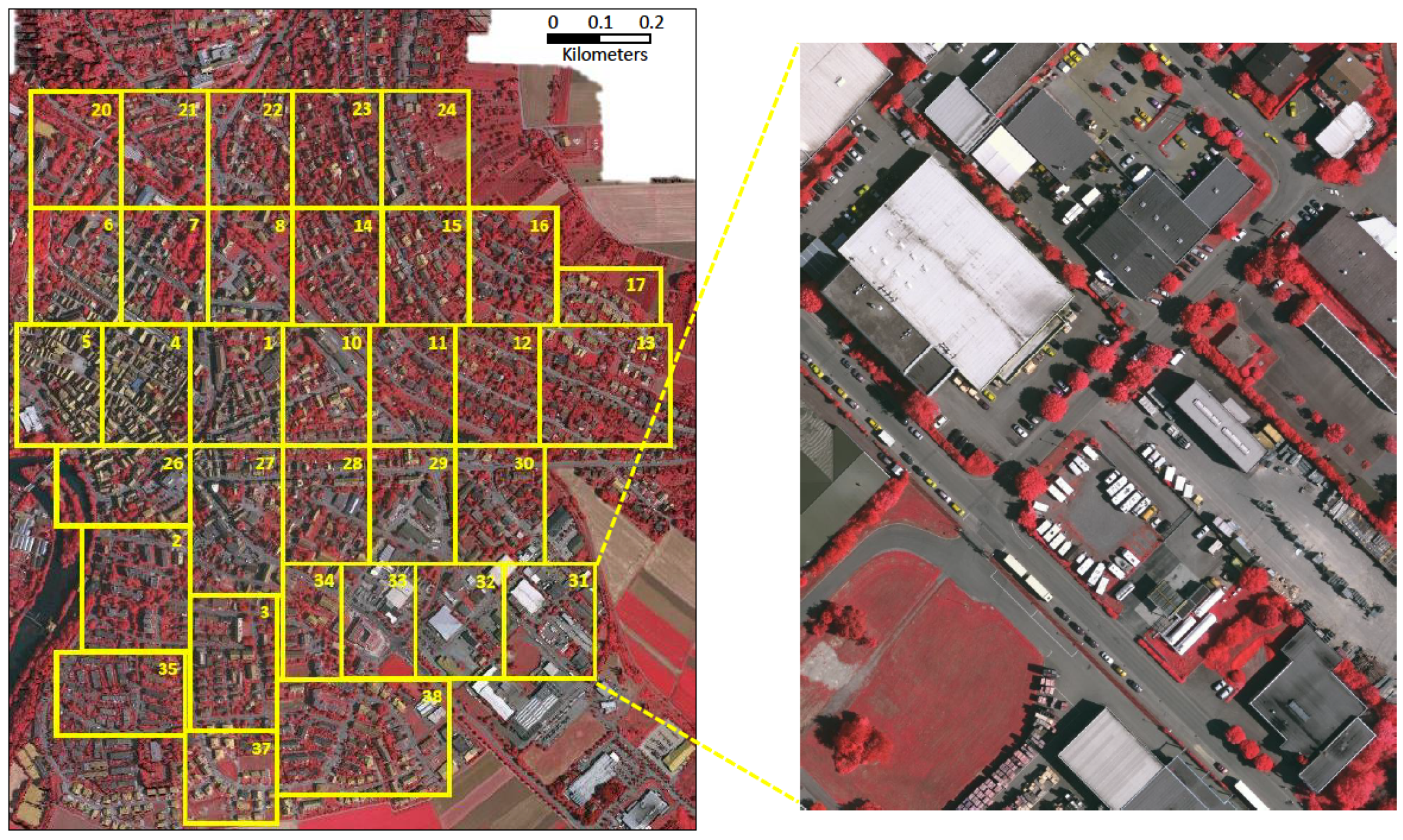
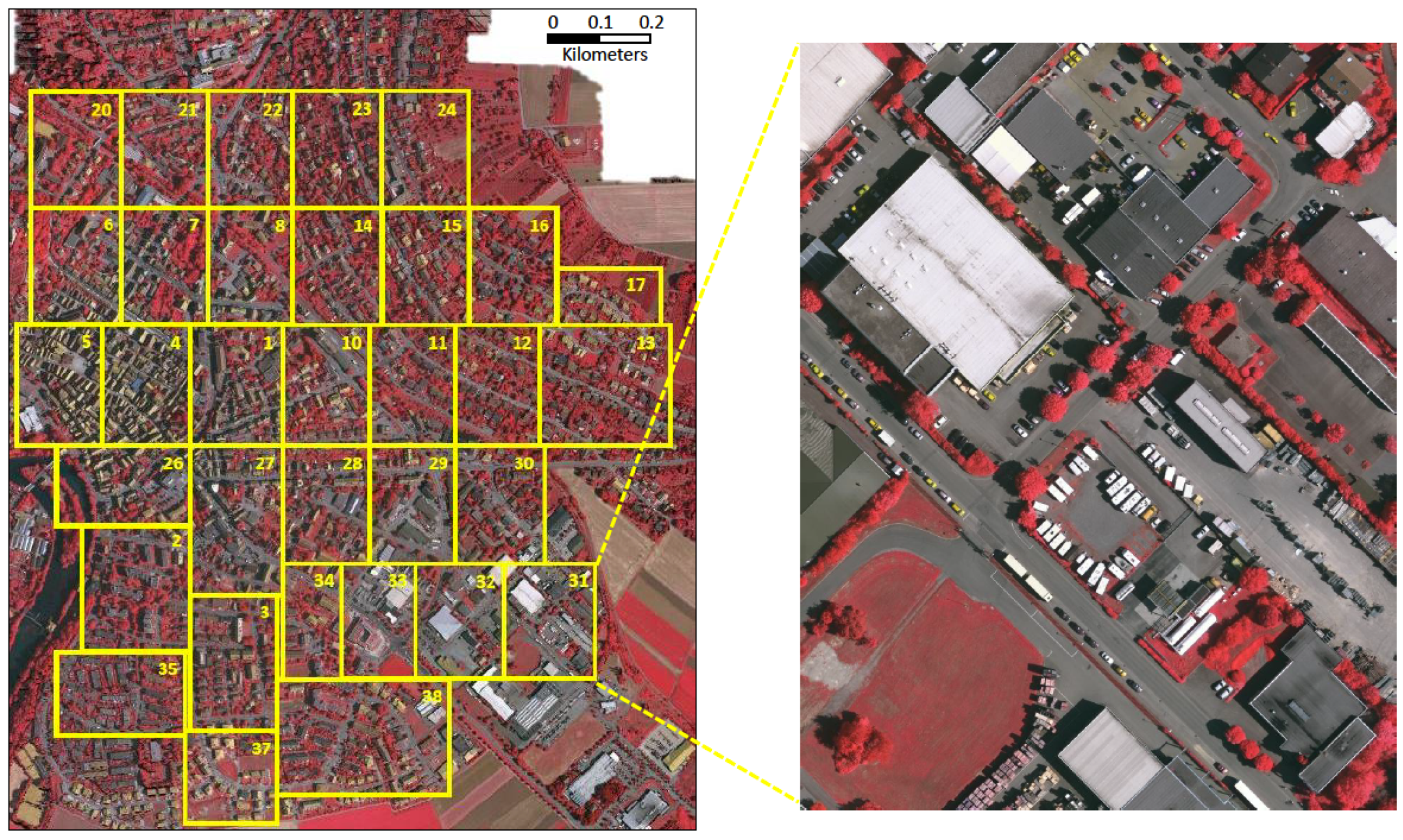
4.1. Landsat-8 Dataset
4.2. ISPRS Vaihingen Dataset
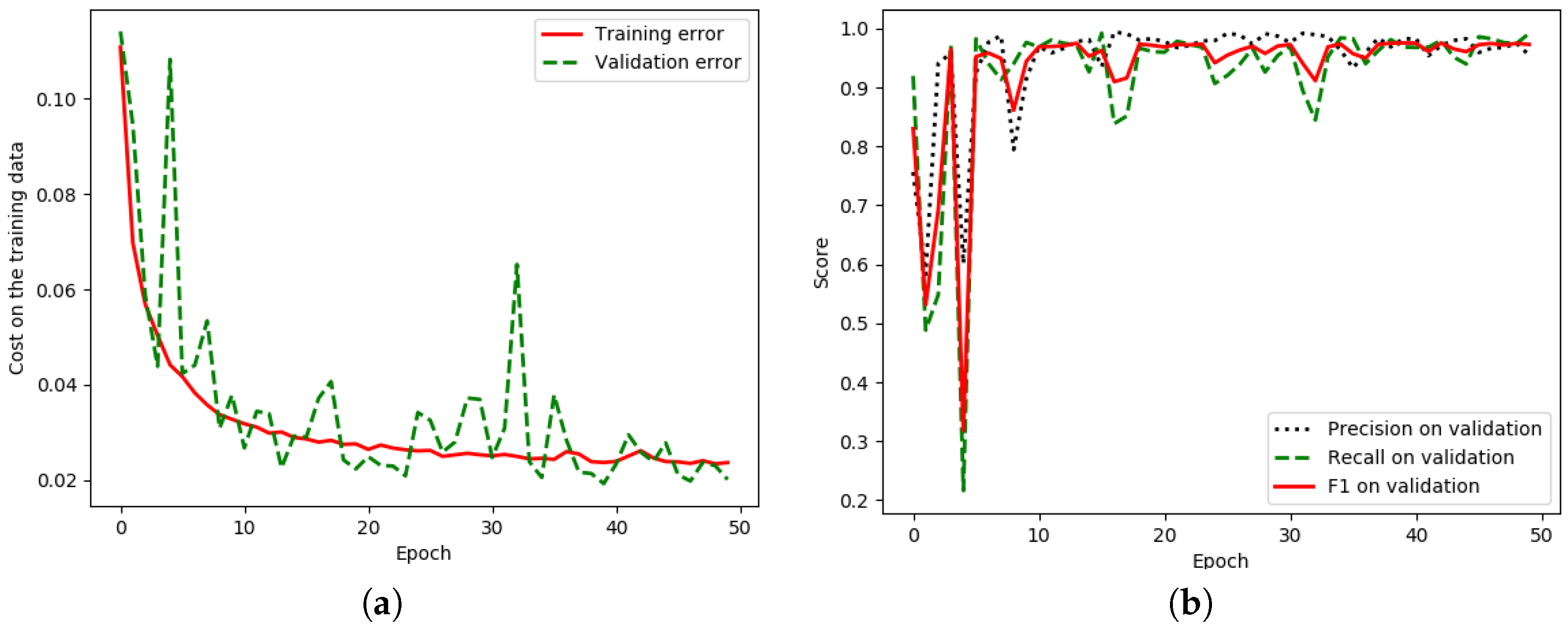
4.3. Evaluation
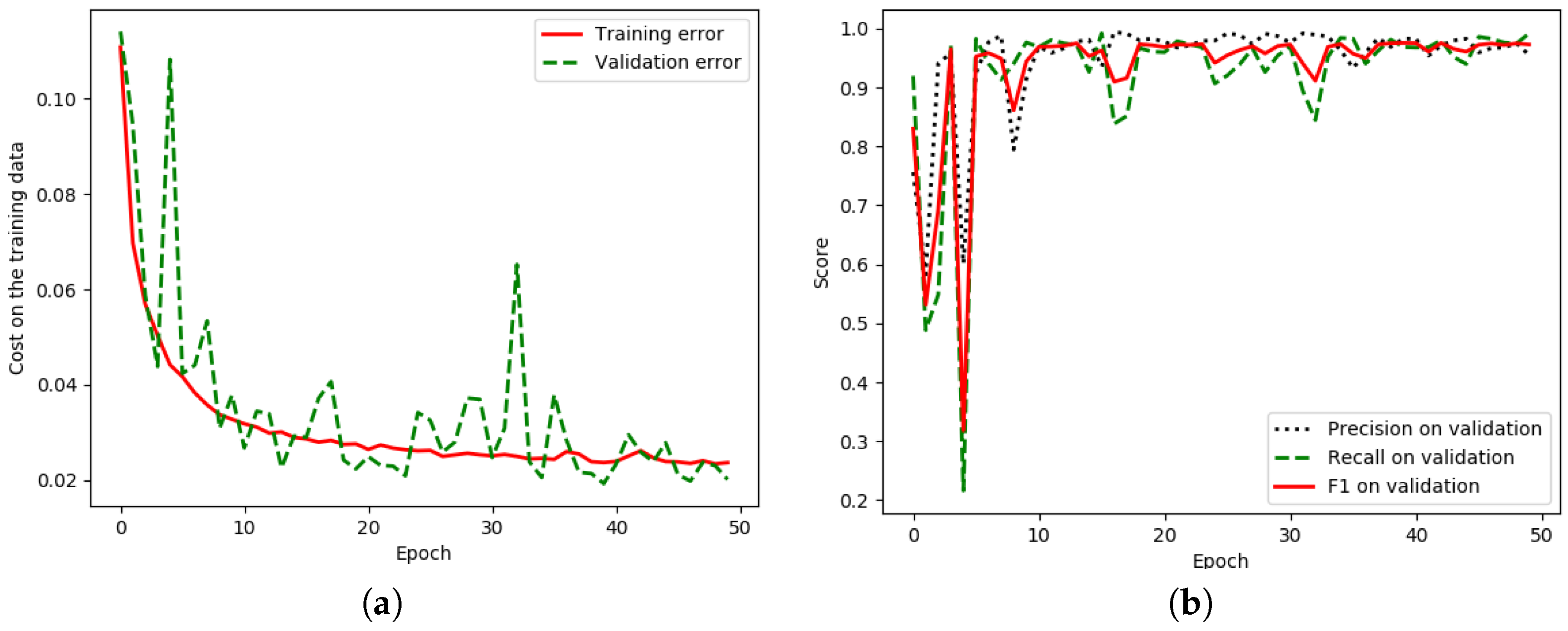
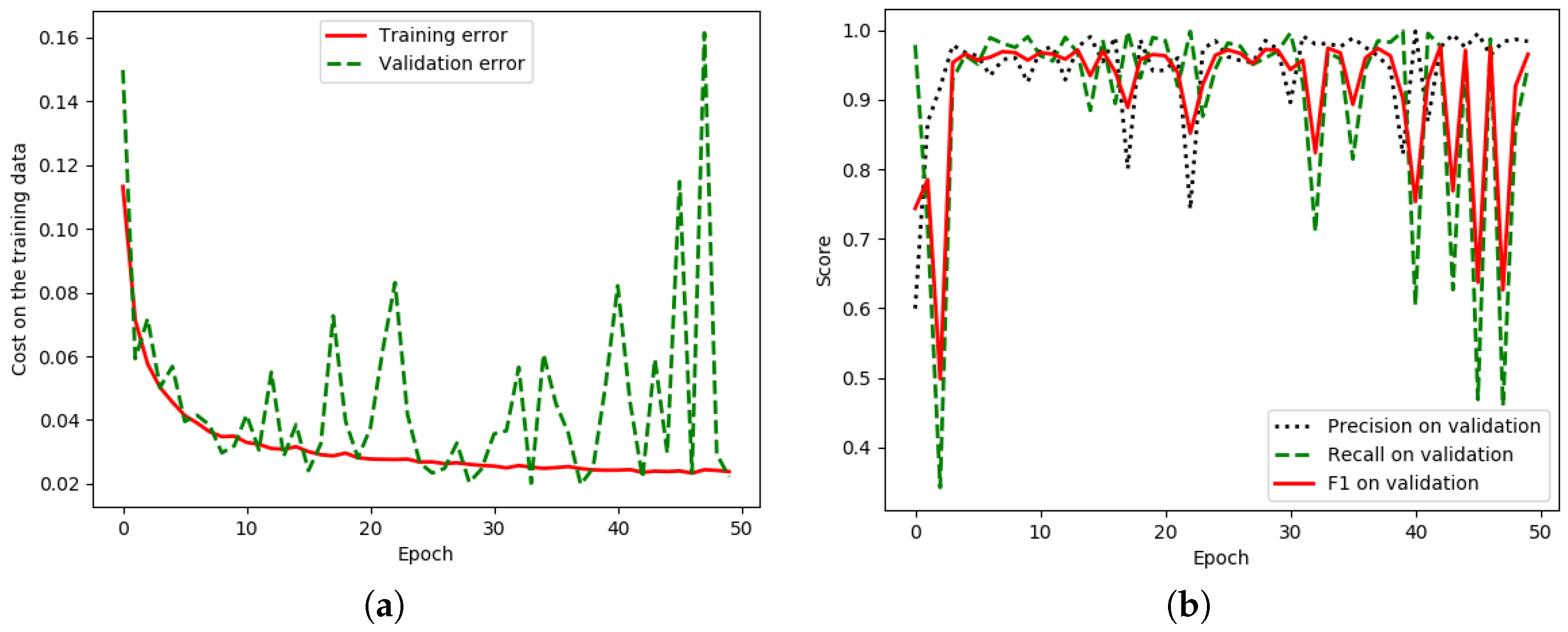
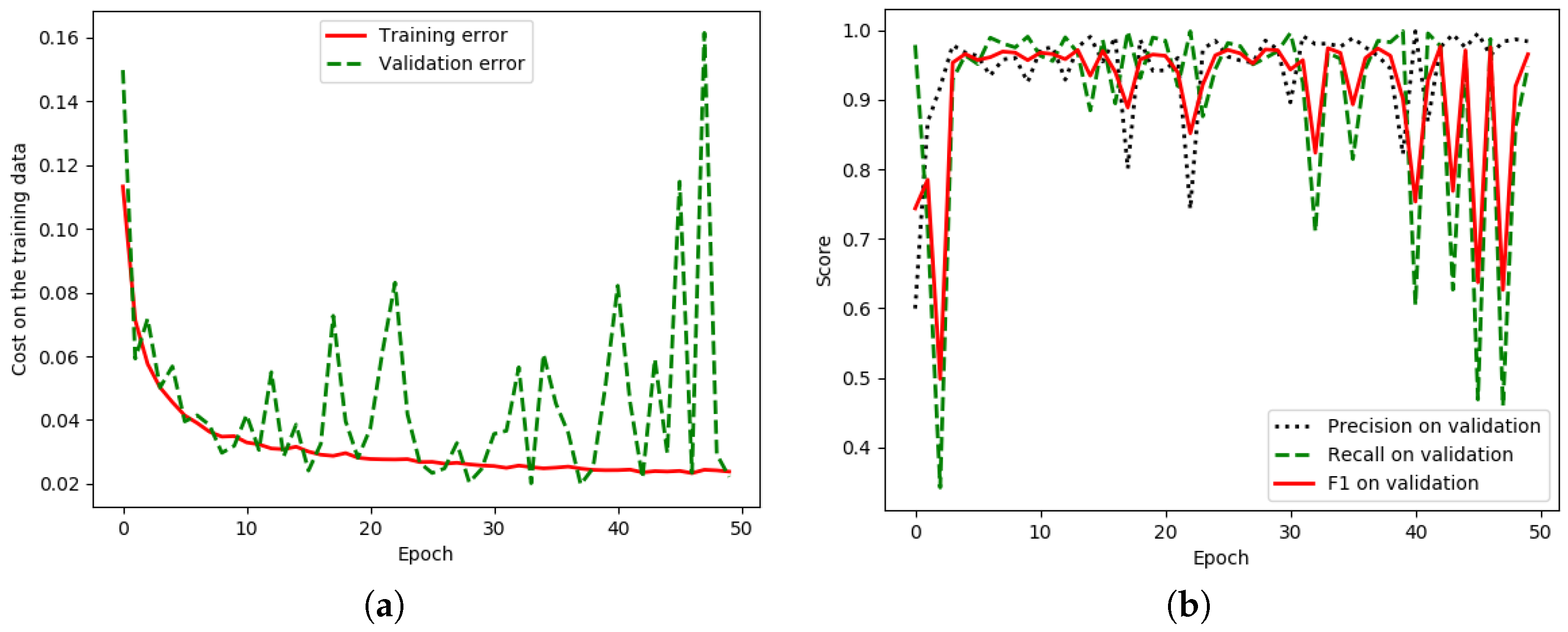
5. Experimental Results and Discussion
5.1. Results of the Landsat-8 Corpus with Discussion
5.1.1. The Effect of an Enhanced GCN on the Landsat-8 Corpus
5.1.2. The Effect of Using Channel Attention on the Landsat-8 Corpus
5.1.3. The Effect of Using Domain-Specific Transfer Learning on Landsat-8 Corpus
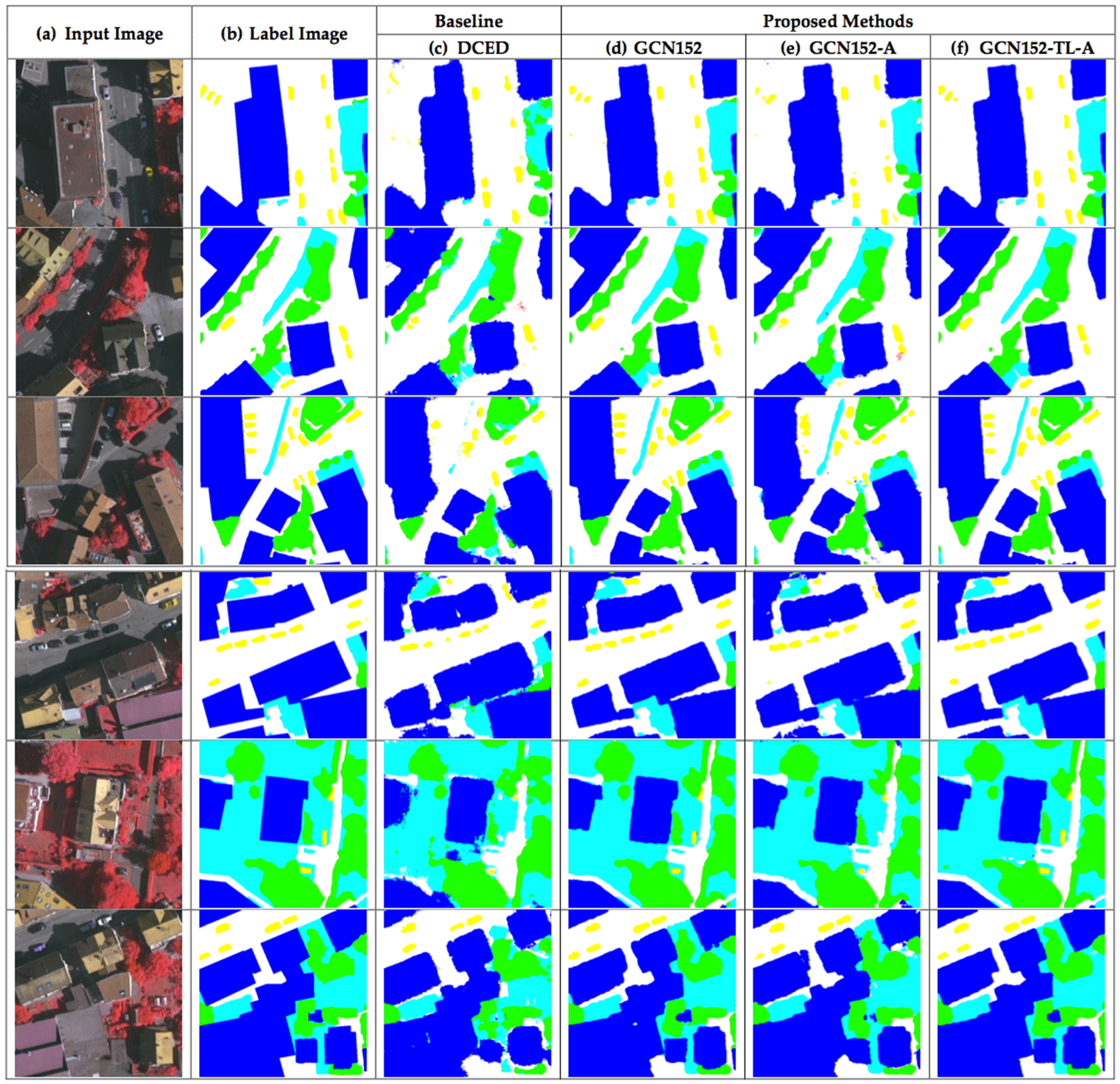
5.2. Results of the ISPRS Vaihingen Challenge Corpus with Discussion
5.2.1. Effect of the Enhanced GCN on the ISPRS Vaihingen Corpus
5.2.2. Effect of Using Channel Attention on ISPRS Vaihingen Corpus
5.2.3. The Effect of Using Domain-Specific Transfer Learning on the ISPRS Vaihingen Corpus
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BR | Boundary Refinement |
| CNN | Convolutional Neural Network |
| DCED | Deep Convolutional Encoder–Decoder |
| GCN | Global Convolutional Network |
| MR | Medium Resolution |
| RGB | Red–Green–Blue |
| LS | Landsat |
| TL | Transfer Learning |
| VHR | Very High Resolution |
References
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Y.; Zhang, Q.; Xiang, S.; Pan, C. Gated convolutional neural network for semantic segmentation in high-resolution images. Remote Sens. 2017, 9, 446. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Vateekul, P.; Jitkajornwanich, K.; Lawawirojwong, S. An Enhanced Deep Convolutional Encoder-Decoder Network for Road Segmentation on Aerial Imagery. In Recent Advances in Information and Communication Technology Series; Springer: Cham, Switzerland, 2017; Volume 566. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. arXiv, 2016; arXiv:1606.00915. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv, 2017; arXiv:1706.05587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Road Segmentation of Remotely-Sensed Images Using Deep Convolutional Neural Networks with Landscape Metrics and Conditional Random Fields. Remote Sens. 2017, 9, 680. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference onComputer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters—Improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1743–1751. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a Discriminative Feature Network for Semantic Segmentation. arXiv, 2018; arXiv:1804.09337. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. arXiv, 2017; arXiv:1709.01507. [Google Scholar]
- Xie, M.; Jean, N.; Burke, M.; Lobell, D.; Ermon, S. Transfer learning from deep features for remote sensing and poverty mapping. arXiv, 2015; arXiv:1510.00098. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks. In Advances in Neural Information Processing Systems 27 (NIPS 2014); Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 3320–3328. [Google Scholar]
- Liu, J.; Wang, Y.; Qiao, Y. Sparse Deep Transfer Learning for Convolutional Neural Network. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; pp. 2245–2251. [Google Scholar]
- International Society for Photogrammetry and Remote Sensing. 2D Semantic Labeling Challenge. Available online: http://www2.isprs.org/commissions/comm3/ wg4/semantic-labeling.html (accessed on 9 September 2018).
- Valada, A.; Vertens, J.; Dhall, A.; Burgard, W. Adapnet: Adaptive semantic segmentation in adverse environmental conditions. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4644–4651. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder–decoder with atrous separable convolution for semantic image segmentation. arXiv, 2018; arXiv:1802.02611. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. arXiv, 2018; arXiv:1808.00897. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Bilinski, P.; Prisacariu, V. Dense Decoder Shortcut Connections for Single-Pass Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6596–6605. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for Semantic Segmentation in Street Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3684–3692. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. arXiv, 2016; arXiv:1611.07709. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. arXiv, 2017; arXiv:1704.08545. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. Segnet: A deep convolutional encoder–decoder architecture for robust semantic pixel-wise labelling. arXiv, 2015; arXiv:1505.07293. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder–decoder architecture for image segmentation. arXiv, 2015; arXiv:1511.00561. [Google Scholar]
- Kendall, A.; Badrinarayanan, V.; Cipolla, R. Bayesian segnet: Model uncertainty in deep convolutional encoder–decoder architectures for scene understanding. arXiv, 2015; arXiv:1511.02680. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Instance-aware semantic segmentation via multi-task network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3150–3158. [Google Scholar]
- Barsi, J.A.; Lee, K.; Kvaran, G.; Markham, B.L.; Pedelty, J.A. The spectral response of the Landsat-8 operational land imager. Remote Sens. 2014, 6, 10232–10251. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Savannah, GA, USA, 2–4 November 2016; Volume 16, pp. 265–283. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; ACM: New York, NY, USA, 2014; pp. 675–678. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Description |
|---|---|
| A | Channel Attention Block |
| GCN | Global Convolutional Network |
| GCN50 | Global Convolutional Network with ResNet50 |
| GCN101 | Global Convolutional Network with ResNet101 |
| GCN152 | Global Convolutional Network with ResNet52 |
| TL | Domain-Specific Transfer Learning |
| Pretrained | Backbone | Model | |||||
|---|---|---|---|---|---|---|---|
| Baseline | - | - | DCED [31,32,33] | 0.6137 | 0.7209 | 0.6495 | 0.5384 |
| - | Res50 | GCN [15] | 0.6678 | 0.7333 | 0.6847 | 0.5734 | |
| - | Res101 | GCN | 0.6899 | 0.8031 | 0.7290 | 0.6154 | |
| Proposed Method | - | Res152 | GCN | 0.7115 | 0.8131 | 0.7563 | 0.6364 |
| - | Res152 | GCN-A | 0.7997 | 0.7937 | 0.7897 | 0.6726 | |
| TL | Res152 | GCN-A | 0.8293 | 0.8476 | 0.8275 | 0.7178 |
| Model | Agriculture | Forest | Misc | Urban | Water | |
|---|---|---|---|---|---|---|
| Baseline | DCED [31,32,33] | 0.9616 | 0.7472 | 0.0976 | 0.7878 | 0.4742 |
| GCN50 [15] | 0.9407 | 0.8258 | 0.1470 | 0.8828 | 0.5426 | |
| GCN101 | 0.9677 | 0.8806 | 0.2561 | 0.7971 | 0.5480 | |
| Proposed Method | GCN152 | 0.9780 | 0.8444 | 0.4256 | 0.7158 | 0.5937 |
| GCN152-A | 0.9502 | 0.9118 | 0.6689 | 0.8675 | 0.6001 | |
| GCN152-TL-A | 0.9781 | 0.8472 | 0.8732 | 0.7988 | 0.6493 |
| Pretrained | Backbone | Model | |||||
|---|---|---|---|---|---|---|---|
| Baseline | - | - | DCED [31,32,33] | 0.7519 | 0.7925 | 0.7693 | 0.8651 |
| - | Res50 | GCN [15] | 0.7636 | 0.7917 | 0.776 | 0.8776 | |
| - | Res101 | GCN | 0.7713 | 0.8059 | 0.7862 | 0.8972 | |
| Proposed Method | - | Res152 | GCN | 0.7736 | 0.8021 | 0.7864 | 0.8977 |
| - | Res152 | GCN-A | 0.7847 | 0.7961 | 0.7902 | 0.9057 | |
| TL | Res152 | GCN-A | 0.7888 | 0.8001 | 0.7942 | 0.9123 |
| Model | IS | Buildings | LV | Tree | Car | |
|---|---|---|---|---|---|---|
| Baseline | DCED [31,32,33] | 0.9590 | 0.9778 | 0.9108 | 0.9805 | 0.6832 |
| GCN50 [15] | 0.9595 | 0.9628 | 0.9403 | 0.9896 | 0.7292 | |
| GCN101 | 0.9652 | 0.9827 | 0.9615 | 0.9797 | 0.7387 | |
| Proposed Method | GCN152 | 0.9543 | 0.9962 | 0.9445 | 0.9754 | 0.7710 |
| GCN152-A | 0.9614 | 0.9865 | 0.9554 | 0.9871 | 0.8181 | |
| GCN152-TL-A | 0.9664 | 0.9700 | 0.9499 | 0.9901 | 0.8567 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Semantic Segmentation on Remotely Sensed Images Using an Enhanced Global Convolutional Network with Channel Attention and Domain Specific Transfer Learning. Remote Sens. 2019, 11, 83. https://doi.org/10.3390/rs11010083
Panboonyuen T, Jitkajornwanich K, Lawawirojwong S, Srestasathiern P, Vateekul P. Semantic Segmentation on Remotely Sensed Images Using an Enhanced Global Convolutional Network with Channel Attention and Domain Specific Transfer Learning. Remote Sensing. 2019; 11(1):83. https://doi.org/10.3390/rs11010083
Chicago/Turabian StylePanboonyuen, Teerapong, Kulsawasd Jitkajornwanich, Siam Lawawirojwong, Panu Srestasathiern, and Peerapon Vateekul. 2019. "Semantic Segmentation on Remotely Sensed Images Using an Enhanced Global Convolutional Network with Channel Attention and Domain Specific Transfer Learning" Remote Sensing 11, no. 1: 83. https://doi.org/10.3390/rs11010083
APA StylePanboonyuen, T., Jitkajornwanich, K., Lawawirojwong, S., Srestasathiern, P., & Vateekul, P. (2019). Semantic Segmentation on Remotely Sensed Images Using an Enhanced Global Convolutional Network with Channel Attention and Domain Specific Transfer Learning. Remote Sensing, 11(1), 83. https://doi.org/10.3390/rs11010083