1. Introduction
As one of the most significant remote sensing techniques, Hyperspectral Images (HSIs) captured by modern remote sensors have been successfully applied in real-world tasks, such as target detection, and crop yield estimation, etc. [
1,
2,
3]. Typically, each pixel in HSIs consists of hundreds of spectral bands/features, which means that HSIs can provide more abundant information about remote sensing objects than multispectral and typical color images with few bands/features, thus HSI classification has attracted much attention in the last several decades. Although many classification models have been introduced, such as Support Vector Machine (SVM), Deep Learning (DL), and Representation based Classification [
4,
5,
6,
7], etc., the curse of dimensionality problem stemming from the high-dimensional features/bands could largely compromise the performance of various classification algorithms, especially when there are only small number of labeled training data. Therefore, many Dimensionality Reduction (DR) methods have been introduced to preprocess the HSI data so that the noisy and redundant features can be removed and the discriminative features can be extracted in low-dimensional subspace. To some extent, DR has become fundamental for HSI data analysis [
8,
9,
10,
11,
12].
Generally speaking, all DR models for HSIs can be divided into two categories: bands selection and feature extraction [
8,
12]. The former focuses on choosing representative subset from original spectral bands with physical meanings by some criteria, while the latter tries to learn new features by transforming observed high-dimensional spectral bands/features to the low-dimensional features with discriminative and structural information. As stated in [
8], discovering optimal bands from enormous numbers of possible band combinations by feature selection methods is typically suboptimal, thus in this paper we only focus on feature extraction based DR methods for HSIs instead of feature selection.
The past decades have witnessed that various feature extraction algorithms have been introduced for HSI data analysis. There are roughly two major classes of DR techniques for feature extraction, the linear and nonlinear DR models. Principal Components Analysis (PCA) may be the most classic linear DR method, which tries to linearly project observed data into the low-dimensional subspace where the data variance is maximized. To further extend PCA into the Bayesian framework, Probabilistic PCA (PPCA) [
13] was also proposed. Other PCA extensions include Kernel PCA (KPCA), Robust PCA, Sparse PCA, and Tensor PCA, etc. [
14,
15,
16,
17,
18]. However, the linear assumption in PCA indicates that PCA and its extensions could fail when there are nonlinear structures embedded into the high-dimensional observations. Thus, many nonlinear DR models have been developed, among which DR models based on manifold learning could be representative because they could be able to capture the intrinsic nonlinear structures (e.g., multiple clusters, subspace structure and manifolds) in observed data with high dimensionality [
12,
19,
20].
Most manifold learning based DR techniques try to model the local geometric structures of data based on graph theory [
19,
21]. The performance of these manifold learning based methods mainly depends on the following two aspects: (i) the design of the similarity graphs, and (ii) the embedding of new test data—the out-of-sample problem. For the first factor, different methods have distinct ideas to construct similarity graph matrices, such as Local Linear Embedding (LLE), Laplace Eigenmap (LE), Neighborhood Preserving Embedding (NPE), and Locality Preserving Projection (LPP) [
19,
22], etc. In [
19], a general Graph Embedding (GE) framework was introduced to unify these existing manifold learning algorithms where various methods to construct different similarity graph matrices were compared. Lunga et al. [
20] also reviewed typical manifold learning based DR methods for HSI classification. Recently, the representation based approaches have also been introduced to manifold learning framework to constitute the similarity graphs [
12]. For example, Sparse Representation (SR), Collaborative Representation (CR) and Low Rank Representation (LRR) [
7] were utilized to construct the sparse graph (
graph), collaborative graph (
graph) and low-rank graph, giving rise to Sparsity Preserving Projection (SPP) [
23], Collaborative Representation based Projection(CRP) [
24] and Low Rank Preserving Projections (LRPP) [
25], respectively. For the second aspect, in order to address the out-of-sample problem encountered by many manifold learning models, extra mappings that project new samples to low-dimensional manifold subspace were added into existing manifold learning algorithms, where linear mapping was typically utilized like LPP and NPE [
19].
The aforementioned techniques are unsupervised DR models, which means that extra labels cannot be utilized even if they are available in HSIs data where we are typically given some labels. By making use of these label information, the unsupervised DR methods can be extended to the supervised settings, which could improve the discriminating power of DR models. Linear Discriminant Analysis (LDA) can be representative in the line. Compared to its linear counterpart PCA, LDA performs DR by maximizing the between-class scatter and minimizing the within-class scatter simultaneously, leading to more discriminative dimensionality-reduced features than PCA. However, LDA and its extensions including Generalized Discriminant Analysis (GDA) suffer from the limitation of extracting maximum
features with
C being the number of label classes [
8] and the Small-Sample-Size (SSS) problem. Nonparametric Weighted Feature Extraction (NWFE) and its kernel extension Kernel NWFE address these issues by using the weighted means to evaluate the nonparametric scatter matrices, resulting in more than
features being learned [
8]. Other LDA extensions include Regularized LDA (RLDA) [
26] and Modified FLDA (MFLDA) [
27].
PCA was also extended to supervised versions to handle the extra labels such as Supervised PPCA (SPPCA) [
16]. However, these methods are most likely incapable of discovering complex nonlinear geometric structure in numerous HSIs spectral features, which could deteriorate the performance of DR models. Therefore, many supervised manifold learning models which are capable of capturing the local geometric structure of neighboring pixels have been developed, such as Supervised LPP (SLPP) [
19], Local Fisher Discriminant Analysis (LFDA) [
28] and local graph discriminant embedding (LGDE) [
29]. The most easy way to realize supervised manifold learning models is to construct the similarity graph matrices based on neighboring samples belonging to the same class. Alternatively, representation based models have been extended into the supervised settings, such as Sparse Graph-based Discriminate Analysis (SGDA) [
30], Weighted Sparse Graph-based Discriminate Analysis (WSGDA) [
31], Collaborative Graph-based Discriminate Analysis (CGDA) [
32], Laplacian regularized CGDA (LapCGDA) [
7], Discriminant Analysis with Graph Learning (DAGL) [
33] and Sparse and Low-Rank Graph-based Discriminant Analysis (SLGDA) [
34], etc.
To further add nonlinearity to the supervised manifold models, kernel tricks are also utilized, resulting into Kernel LFDA (KLFDA) [
28], Kernel CGDA (KCGDA) [
32] and Kernel LapCGDA (KLapCGDA) [
7], etc. A recent survey in [
12] termed these kind of techniques Graph-Embedding Discriminant Analysis, where the basic idea behind these models is to construct various discriminative intrinsic graphs with different criterions, such as
and
graphs employed in SGDA and CGDA, respectively. Although their models have demonstrated the effectiveness for extracting discriminative HSI features in terms of classification accuracy, their performance could become unsatisfactory because of the lack of considering spatial information.
Recently, some researchers have shown that spatial information in HSIs could be efficiently utilized to boost the DR models, leading to the joint spectral-spatial DR techniques where most of these kinds of models can be roughly divided into two classes as stated in [
35]:
- (i)
Spectral-Spatial information can be used as a preprocessing. For example, Gaussian weighted local mean operator was employed to extract spectral-spatial feature in Composite Kernels Discriminant Analysis (CKDA) [
36]. A robust spectral-spatial distance rather than simple spectral distance was adopted in Robust Spatial LLE (RSLLE) [
37]. A local graph-based fusion (LGF) [
38] method was proposed to conduct DR by simultaneously considering the spectral information and the spatial information extracted by morphological profiles (MPs). Recently, Tensor PCA (TPCA) [
18], deep learning based models [
5], superpixels [
29,
39] and propagation filter [
40] techniques were also successfully utilized to extract the spectral-spatial features.
- (ii)
Spectral-spatial information can be used as a spatial constraint/regularization. For instance, the authors of [
41] proposed a Spatial and Spectral Regularized Local Discriminant Embedding (SSRLDE) where the local similarity information was encoded by a spectral-domain regularized local preserving scatter matrix and a spatial-domain local pixel neighborhood preserving scatter matrix. Spectral-Spatial LDA (SSLDA) [
42] made use of a local scatter matrix constructed from a small neighborhood as a regularizer which makes the samples approximate the local mean in the low-dimensional feature space among the small neighborhood. The Spectral-Spatial Shared Linear Regression (SSSLR) [
35] made use of a convex set to describe the spatial structure and a shared structure learning model to learn a more discriminant linear projection matrix for classification. Spatial-spectral hypergraph was used in Spatial-Spectral Hypergraph Discriminant Analysis (SSHGDA) [
43] to construct complex intraclass and interclass scatter matrices to describe the local geometric similarity of HSI data. Superpixel-level graphs and local reconstruction graphs were constructed to be the spatial regularization in Spatial Regularized LGDE (SLGDE) [
29] and Local Geometric Structure Fisher Analysis (LGSFA) [
44], respectively. Recently, He et al. [
45] reviewed many state-of-the-art spectral-spatial feature extraction and classification methods, which demonstrates that spatial information could be beneficial to HSI feature extraction and classification.
In this paper, we focus on the Graph-Embedding Discriminant Analysis framework because of its outstanding performance and low complexity. Although some progress has been made based on this framework, such as SGDA, CGDA, LapCGDA, and SLGDA, etc., the performance of these models could be further improved by efficiently incorporating the spatial information into the framework. Motivated by recently introduced Joint CR (JCR) [
46] and Spatial-aware CR (SaCR) [
10] algorithms, in this paper, we propose the Spatial-aware Collaborative Graph-based Discriminate Analysis (SaCGDA) where spatial-spectral features are firstly preprocessed by the average filtering in JCR and then the spatial information is encoded as a spatial regularization item in CR to construct the spectral-spatial similarity graph in an easy and efficient way. To further improve the performance of the model, inspired by LapCGDA, the spectral Laplacian regularization item is also introduced into SaCGDA, giving rise to the Laplacian regularized SaCGDA (LapSaCGDA) which makes use of the spectral-spatial information more effectively.
The rest of the paper is organized as follows. In
Section 2, we briefly review the related works, including the Collaborative Representation(CR) and the Graph-Embedding Discriminant Analysis framework. The proposed SaCGDA and LapSaCGDA will be introduced in
Section 3. Then, three HSI datasets are used to evaluate the effectiveness of the newly proposed algorithms in
Section 4. Finally, the concluding remarks and comments will be given in
Section 5.
2. Related Works
In this section, we will review some related works, including the typical CR models and its variants JCR and SaCR, plus the Graph-Embedding Discriminant Analysis framework.
For the sake of consistency, we make use of the following notations throughout this paper:
are observed (inputs) data with each sample
in a high-dimensional space
;
are observed (outputs or labels) data with each point
being discrete class label in
, where
C is the number of the classes;
are the dimensionality-reduced variables/features in a low-dimensional space
(
) with each
corresponding to
and/or
. For the sake of convenience, we further denote
X as an
matrix,
an
vector and
Z an
matrix, so the training data can be defined as
. Let
be the number of training data from
l-th class and
. Similar to LDA, the goal of discriminant analysis based DR models is to find the low-dimensional projection
Z with typical linear mapping
where the transformation matrix
linearly projects each sample
to the low-dimensional subspace.
2.1. Collaborative Representation (CR)
The representation based models such as Sparse Representation (SR), Collaborative Representation (CR) and Low-Rank Representation(LRR) have been successfully applied in many tasks [
7]. Compared to the computationally expensive SR, CR can provide comparative classification performance with very efficient closed-form solution to learn the model parameters. Given a test sample
, all the training data are employed to represent it by
where the the regularization parameter
balances the trade-off between the reconstruction residual and the regularization of the representation coefficients. Typically,
norm is used with
. However, other regularization methods can also be adopted [
47,
48]. For example,
instead of
norm brings the sparsity of the coefficient, resulting in SR. A locality regularization [
49]
provides different freedom to training data according to the Euclidean distances from
, where each diagonal entry in the diagonal matrix
is defined by
For classic CR model, be solving the the least-squares problem, the optimal representation coefficients
can be easily obtained with closed-form solution
and then the class label of test sample
can be predicted according to the minimum residual
where
and
are the subsets of
X and
corresponding to specific class label
l, respectively.
As we have mentioned that spatial information is significant for HSI data analysis. Two simple but efficient CR models have been recently developed. The first one termed by Joint CR (JCR) makes use of the spatial information as a preprocessing based on the fact that the neighboring pixels usually share similar spectral characteristics with high probability. Thus, the spatial correlation across neighboring pixels could be indirectly incorporated by a joint model, where each training and testing sample is represented by spatially averaging its neighboring pixels that is similar with the convolution operation in Convolution Neural Network (CNN). Another model called joint Spatial-aware CR (JSaCR) further utilizes the spatial information as a spatial constraint in a very easy and effective way
where
and each element in
are the average spectral features for the test sample
and each training point
centered in a small window with
m neighbors, respectively,
is similarly defined by
, each element in
is associated with each training sample, which encourages that representation coefficients
are spatially coherent w.r.t. the training data,
is a square diagonal matrix with the elements of vector
on the main diagonal. To further explain the spatial constraint in the third term in Equation (
6), let us firstly denote the pixel coordinate of the testing sample
and each training pixel
by
and
, respectively. The spatial relationship between them can be simply measured by smooth parameter
t
where
represents the Euclidean distance with smooth parameter
t adjusting the distance decay speed for the spatial constraint. Actually, the normalized element
is obtained by dividing
from
. A large value of
t implicitly means that pixels that are spatially far away from the test sample will be penalized by assigning coefficients close to 0. As can be seen from the JSaCR formulation, the locality constraint (second term) and spatial constraint (third term) are controlled by the regularization parameters
and
, respectively.
2.2. Graph-Embedding Discriminant Analysis
Graph-Embedding Discriminant Analysis [
12] seeks to learn the projection matrix
P based on the linear model assumption
by preserving the similarities of samples in the original observation space. Many manifold learning models and discriminant analysis based methods can be unified into this framework, such as LPP, NPE, LDA and recently proposed SGDA, CGDA, etc.
Typically, a general Graph-Embedding Discriminant Analysis model can be formulated by finding a low-dimensional subspace where the local neighborhood relationships in the high-dimensional observations can be retained. Based on typical linear mapping
, the objective function of Graph-Embedding Discriminant Analysis is
where the similarity graph matrix
W is built on pairwise distances between observed samples to represent local geometry with each
being the similarity/affinity between samples
and
,
is the Laplacian matrix of graph
G,
T is the diagonal matrix with
nth diagonal element being
and
is a sample scale normalization constraint or some Laplacian matrix of penalty
. By simply re-formulating the objective function as
The optimal projection matrix
P can be obtained by solving a generalized eigenvalue decomposition problem
where
is constructed by the
d eigenvectors corresponding to the
d smallest nonzero eigenvalues. As can be seen from the formulations, the performance of Graph-Embedding Discriminant Analysis algorithms largely depends on the construction methods of the similarity/affinity matrix.
Let’s firstly take the unsupervised LPP model as the classic example where the similarity between two samples
and
is typically measured by the heat kernel if they are the neighbors
with a pre-specified parameter
r.
Compared to unsupervised LPP, supervised discriminant analysis models like LDA, SGDA and CGDA construct the similarity matrix in the supervised manner, which could provide better discriminant ability. For example,
W in LDA, SGDA or CGDA is typically expressed by a block-diagonal matrix
where each
is the within-class similarity matrix of size
based on
training samples only from the
l-th class. Different strategies have been applied to construct the within-class similarity matrix. As can be seen from Equation (
13)
,
,
and
norms are adopted in SGDA, CGDA, SLGDA and LapCGDA, respectively, using the representation based algorithms to construct the similarity matrix
with each
being the number of training data only from
l-th class:
where
is a training sample from
l-th class,
denotes all training samples from
l-th class but excluding
,
in SLGDA indicates the nuclear norm, and
in LapCGDA is the Laplacian matrix constructed by Equation (
11).
Although these models have demonstrated their effectiveness, their performance could be unsatisfactory because the spatial information in HSIs is not utilized. Compared to the spatial constraints like local reconstruction points, superpixel and hypergraph based spatial regularization models in LGSFA [
44], SLGDE [
29] and SSHGDA [
43], the simple spatial prior in JSaCR has been proven to be fast and efficient. Therefore, in this paper, we introduce the spatial prior into CGDA model because of its outstanding performance and low complexity.
3. Laplacian Regularized Spatial-Aware CGDA
In this section, motivated by JSaCR and LapCGDA, we propose Laplacian regularized Spatial-Aware CGDA (LapSaCGDA) by simultaneously introducing spatial prior and spectral manifold regularization into CGDA which will significantly increase the discriminant ability of the learnt similarity/affinity matrix and then boost the performance of the DR model.
Firstly, based on the fact that the average filtering in JCR could smooth the random noises in HSI data, we similarly preprocess all the HSI data, which leads to the new notations such as and , meaning a training sample and all training data after the preprocessing, respectively.
Then, based on the JSaCR model in Equation (
6), it is straightforward to make use of JSaCR instead of typical CR in CGDA to construct the within-class similarity matrix
for
labeled samples belonging to
l-th class by
where
is a preprocessed training sample from
l-th class,
are all preprocessed training samples from
l-th class but excluding
,
and
are similarly defined by
and
with the pixel coordinate
for samples in
l-th class
, respectively.
It is easy to obtain the closed-form solution for the optimization problem in Equation (
17) by
As stated in JSaCR, the locality prior (second term) and spatial prior (third term) in Equation (
17) can be efficient to extract the spectral-spatial structure in HSI data. However, the simple locality prior w.r.t. the second term in Equation (
17) could be inefficient to exploit the intrinsic geometric information compared to manifold priors like the Laplacian regularization used in LapCGDA. Hence, we further propose the Laplacian regularized Spatial-Aware CGDA (LapSaCGDA) by introducing the Laplacian regularization into SaCGDA. In order to compare the two spectral priors, we simply add the spectral Laplacian constraint into SaCGDA as the third regularization instead of replacing the spectral locality constraint in SaCGDA with the spectral Laplacian constraint.
Similar to SaCGDA, the within-class similarity matrix
of LapSaCGDA can be constructed by solving the following optimization problem:
where
with a pre-specified parameter
r.
Mathematically, the closed-form solution for this optimization can be obtained by
It is worth noting that LapSaCGDA could reduce to SaCGDA when , to LapCGDA when or to CGDA when and , thus the proposed LapSaCGDA model is very general and can unify the three models with different regularization parameters’ configurations.
After obtaining all the within-class similarity matrix
by SaCGDA or LapSaCGDA, the block-diagonal similarity matrix
can be simply constructed like Equation (
12). Finally, based on the Graph-Embedding Discriminant Analysis framework, it is easy to evaluate the optimal projection matrix
P by solving the eigenvalue decomposition in Equation (
10).
The complete LapSaCGDA algorithm is outlined in Algorithm 1.
| Algorithm 1 LapSaCGDA for HSIs Dimensionality Reduction and Classification |
- Input:
High-dimensional training samples , training ground truth , pre-fixed latent dimensionality d, and testing pixels , testing ground truth , a pre-specified regularization parameters . - Output:
s = {, P}.
- 1:
Preprocess all the training and testing data by average filtering; - 2:
Evaluate the similarity matrix W by solving Equation ( 20); - 3:
Evaluate the optimal projection matrix P by solving the eigenvalue decomposition in Equation ( 10); - 4:
Evaluate low-dimensional features for all the training and testing data by ; - 5:
Perform KNN and/or SVM in low-dimensional feature space and return classification accuracy ; - 6:
returns
|
As for the model complexity, Algorithm 1 tells us that, compared to other contrastive models like CGDA and LapCGDA, the proposed SaCGDA and LapSaCGDA do not increase the complexity except the average filtering preprocessing step, which could be conducted before the algorithm starts.
4. Experiments
In this section, we will validate the effectiveness of the proposed SaCGDA and LapSaCGDA for HSI feature reduction and classification. The novel model is compared to the classic supervised DR models NWFE [
8], SPPCA [
16], plus recently developed DR techniques LapCGDA [
7], SLGDA [
34], and LGSFA [
44] based on the Graph-Embedding Discriminant Analysis framework in three typical HSI datasets in terms of classification accuracy. In addition, the classic SVM is also applied in the original high-dimensional spectral feature space for comparison. Since all the HSIs datasets are initially preprocessed by the average filtering, the original spectral features can be regarded as the spectral-spatial features as well.
For a fair comparison, firstly all the data will be preprocessed by average filtering with a spatial window, and then K-Nearest Neighbors (KNN) with Euclidean distance and SVM with Radial Basis Function (RBF) kernel are chosen as the classifiers in the dimensionality-reduced space for verifying all the DR models in terms of the classification Overall Accuracy (OA), the classification Average Accuracy (AA) and the Kappa Coefficient (KC) as well as the True Positive Rate (TPR) and False Positive Rates (FPR). The parameter K in KNN is set to be 5, and the optimal parameters of kernel in SVM are selected by the tenfold cross-validation with a given set . The regularization parameters such as in LapCGDA, SLGDA, and the proposed SaCGDA and LapSaCGDA will be chosen by the grid search with a given set firstly. Then, as the optimal projection dimensionality for each DR model has to be pre-specified before model optimization, for each piece of HSI data, where the same training and testing data are randomly picked, we compare and choose the best dimensionality of each DR model in the range of 1–30 in terms of the classification accuracy based on KNN in the projected low-dimensional feature space. Finally, with the selected optimal dimensionality for each piece of HSI data and each DR algorithm, we further compare all the DR techniques as the number of training data increases. Classification maps are also compared when limited training data are available. All the experiments are repeated ten times and the averaged results are reported with standard deviation (STD).
4.1. Data Description
Three HSIs datasets including Pavia University scene, Salinas scene and Indian Pines scene from [
50] are employed in our experiments.
The Pavia University scene (PaviaU) is captured by the sensor known as the Reflective Optics System Imaging Spectrometer (ROSIS-3) over the Pavia University, Italy in 2002. The number of spectral bands is 103 with the image resolution of
pixels after removing some pixels without information and noise bands. The geometric resolution is
m. The data set contains nine land cover types, and the False Color Composition (FCC) and Ground Truth (GT) are shown in
Figure 1.
The Salinas scene (Salinas) was collected by an Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor over Salinas Valley, California in 1998 with the geometric resolution of
m. The spatial size of this data is
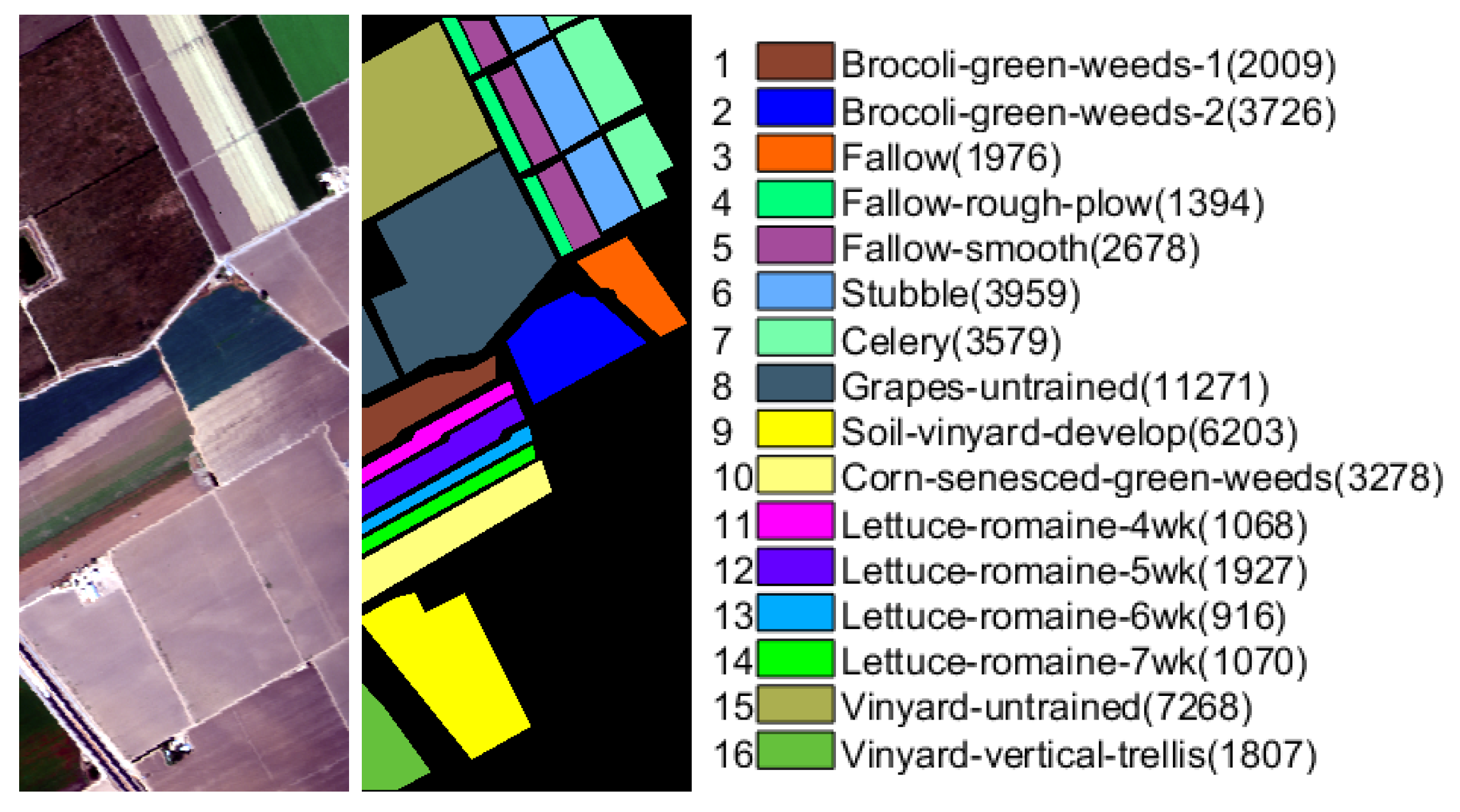
pixels with 224 spectral bands. After removing 20 water absorption and atmospheric effects bands, the number of spectral band becomes 204. Sixteen ground truth classes are labeled in this data set, and the false color composition and ground truth are shown in
Figure 2.
The Indian Pines data (IndianPines) is a scene from Northwest Indiana captured by the AVIRIS sensor in 1992, which consists of
pixels and 200 spectral bands after removing bands with noise and water absorption phenomena. Sixteen ground truth classes are considered in this data set, and the false color composition and ground truth are shown in
Figure 3.
4.2. Experiments on the Pavia University Data
In order to demonstrate the effectiveness of the proposed models, initially, we analyze the parameters’ sensitivity and select optimal parameters for each DR model because the regularization parameters such as in LapCGDA, SLGDA, and the proposed SaCGDA and LapSaCGDA significantly affect the performance of the DR models. In addition, for the proposed SaCGDA and LapSaCGDA, the smooth parameter t in the spatial prior is also optimally searched in the set . In the experiment, 30 samples are randomly picked from each class as training data and the projection dimensionality is fixed to 30 so that the parameters’ sensitivity analysis can be conducted.
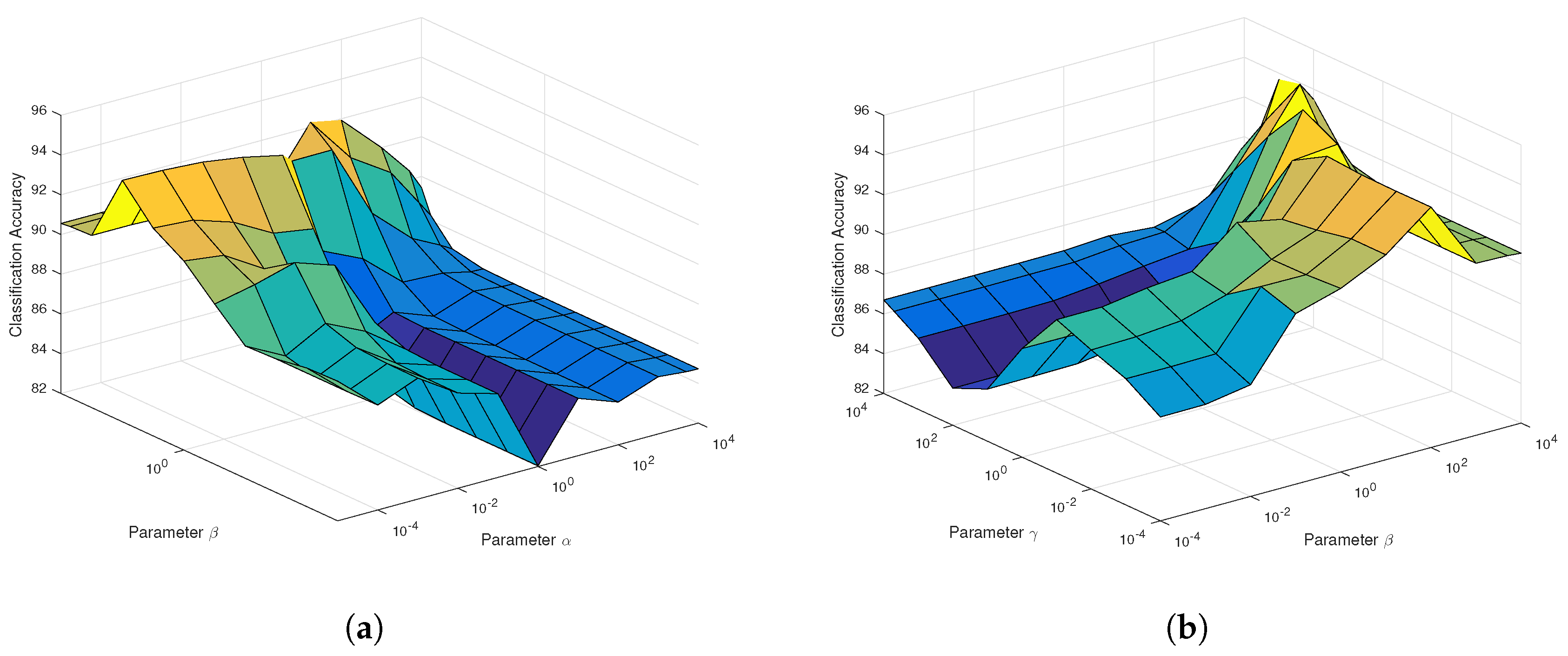
As can be seen from
Figure 4a for SaCGDA, the optimal parameter
w.r.t. the spatial prior significantly affects the OAs compared to the parameter
w.r.t. the spectral locality prior, and the best smooth parameter
t in the spatial prior is 2 in our experiment. Similar results can also be found in the parameters’ sensitivity experiment for LapSaCGDA, which are not completely shown in
Figure 4b because it is difficult to plot the 4D figure w.r.t. three parameters. Here, we simply set the parameter
w.r.t. the spectral locality prior for both SaCGDA and LapSaCGDA because OAs are insensitive to parameter
based on the experimental results of parameters’ sensitivity. The best regularization parameters for LapCGDA, SLGDA, SaCGDA and LapSaCGDA are listed in
Table 1, which will be used in the following experiments. In addition, what can be found from
Figure 4b and
Table 1 is that the best parameter
w.r.t. the spectral manifold prior in LapSaCGDA is larger than the optimal parameter
w.r.t. the spectral locality prior, meaning that the manifold prior has more influence on the DR model than the simple locality prior.
Based on these optimal parameters selected by the grid search, we further choose the best dimensionality of the projection space in terms of the OAs based on KNN and SVM performed in the low-dimensional projection space. The best number of dimensionality of the embedding space will be chosen from the range of 1–30.
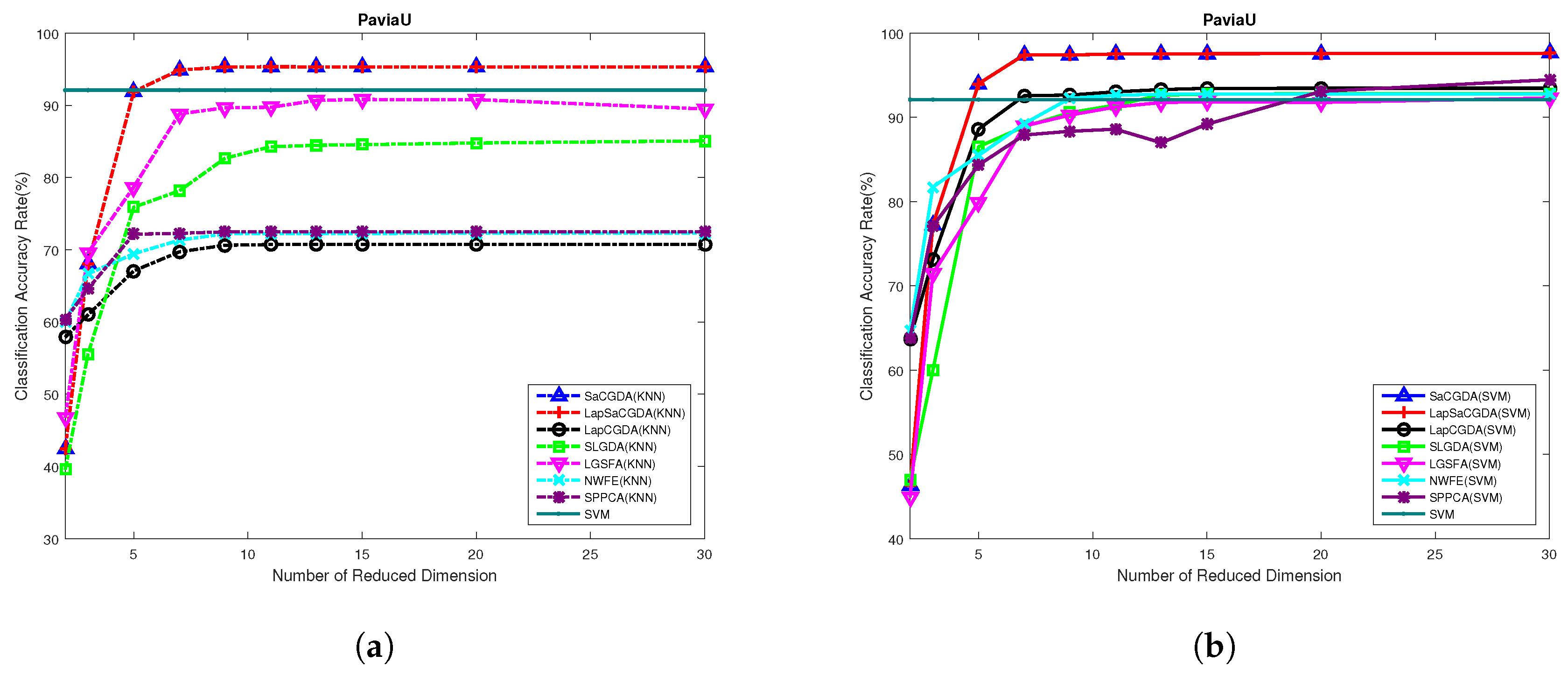
What can be seen from
Figure 5 is that the proposed SaCGDA and LapSaCGDA outperform other DR models in almost all low-dimensional projection spaces, and the optimal number of dimensionality for each DR model in this HSI data is 30. It also should be highlighted that, in the low-dimensional projection space, the OAs based on KNN from the proposed SaCGDA and LapSaCGDA outperform SVM based on original high-dimensional features significantly, meaning the that the learned low-dimensional features are very discriminatory.
Furthermore, we also show the experimental results when different numbers of training data are randomly chosen. In addition, 20–80 samples are randomly chosen from each class, and the remainder are for testing. It can be viewed from
Table 2 that the proposed SaCGDA and LapSaCGDA outperform other state-of-the-art DR techniques and SVM significantly. In addition, based on the fact that LapSaCGDA is superior to SaCGDA in terms of KNN and SVM OAs, we can demonstrate that the spectral Laplacian prior can improve the performance of SaCGDA.
Finally, in order to show the classification results of different methods for each class when limited training data are available, we randomly select 20 samples from each class to compare eight algorithms. The results from different algorithms are objectively and subjectively shown in
Table 3 and
Figure 6, respectively. What can be seen from
Table 3 is that the proposed SaCGDA and LapSaCGDA outperform other models in terms of the AA, OA, KC as well as TPR and FPR in most classes, and LapSaCGDA achieves higher accuracy than SaCGDA, which clearly indicates that the Laplacian regularization in LapSaCGDA is beneficial to the DR model. Accordingly,
Figure 6 subjectively tells us that classification maps from the proposed methods w.r.t. the testing data are more accurate than other contrastive approaches.
4.3. Experiments on the Salinas Data
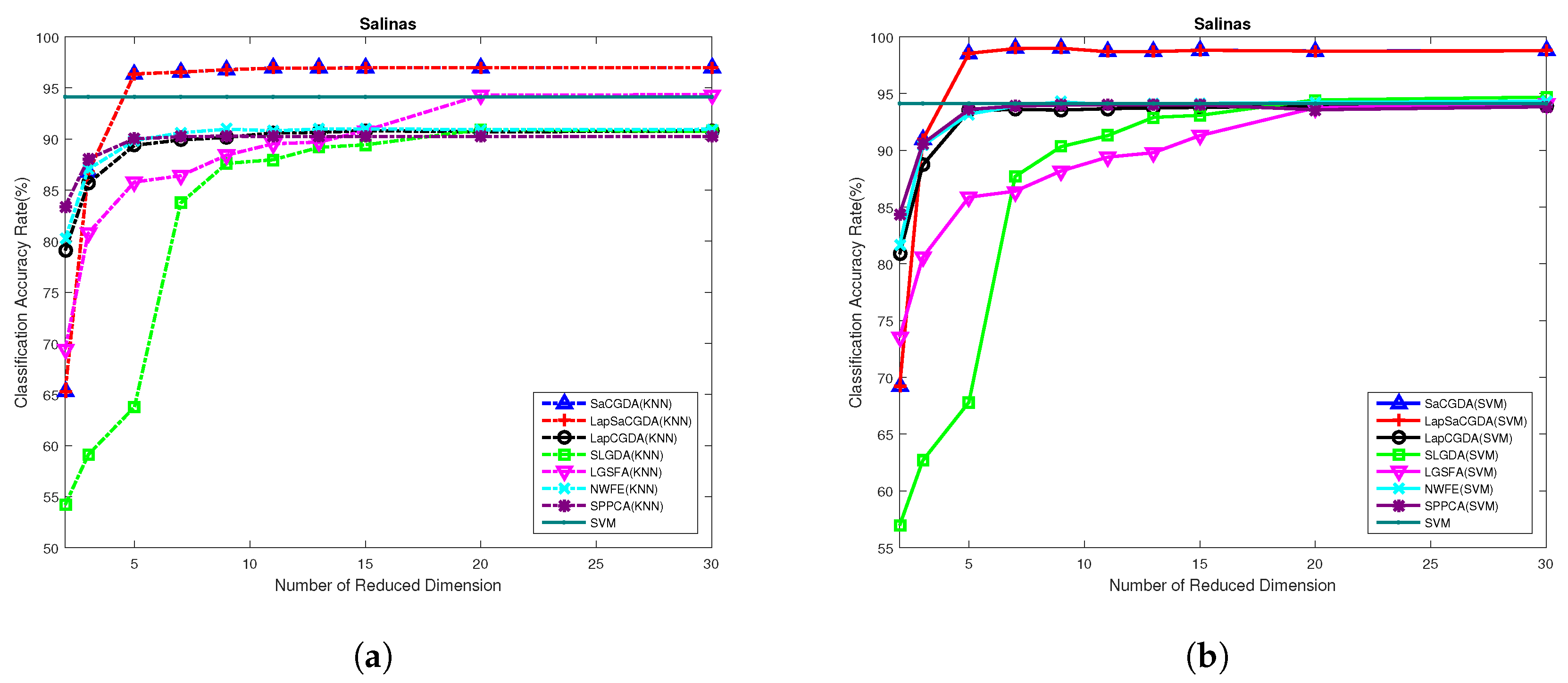
To further verify the proposed models on HSIs data from different HSIs sensors, we utilize Salinas data captured by AVIRIS sensor to demonstrate the effectiveness of the novel methods. Similarly, we firstly select the optimal regularization parameters such as in LapCGDA, SLGDA, and, in addition to the regularization parameters, the smooth parameter t in the spatial prior for the proposed SaCGDA and LapSaCGDA by the grid search. The embedding dimensionality is set 30 and 30 training samples are randomly picked from each class so that the parameter sensitivity can be compared.
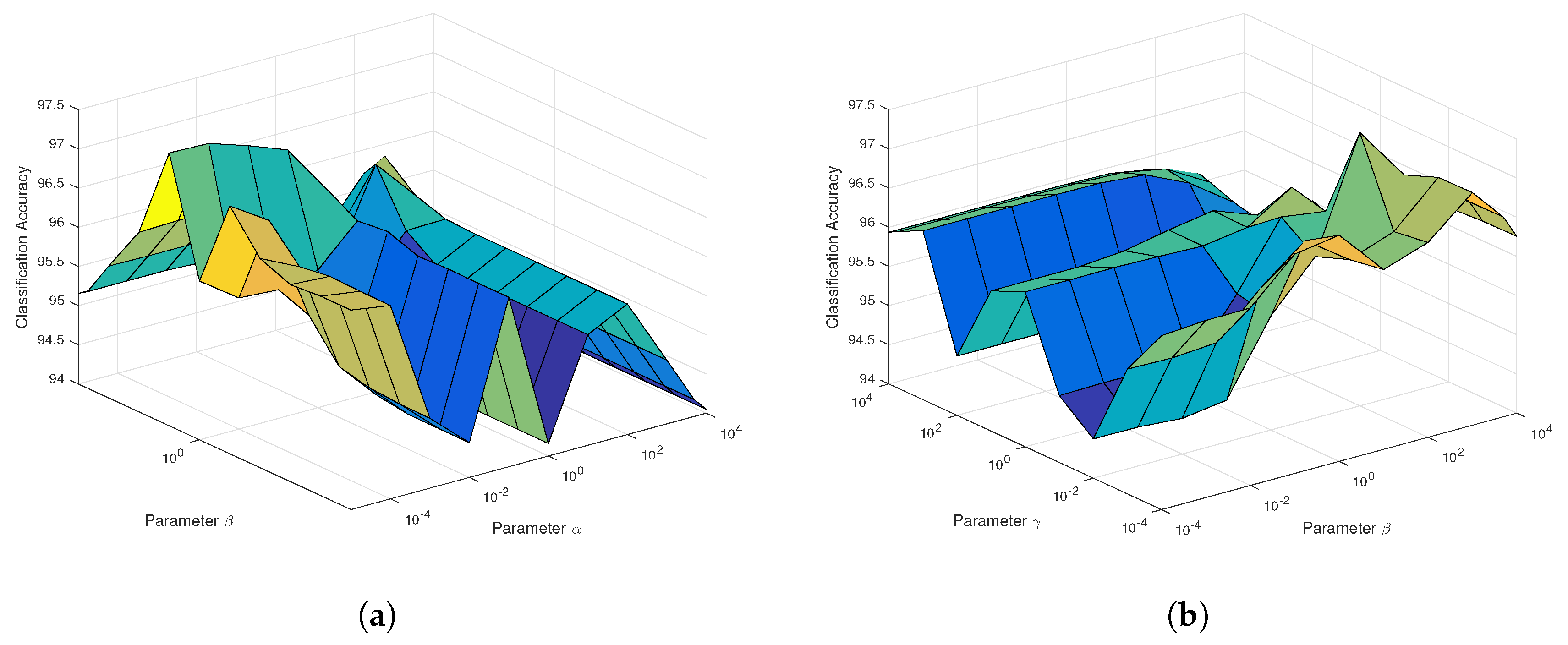
According to
Figure 7a, the regularization parameter
in SaCGDA becomes sensitive to the OA, but the optimal value is still less than 0.001. Thus, we set
for both SaCGDA and LapSaCGDA. In addition, it can be viewed from
Figure 7b that the optimal parameter
w.r.t. the spectral manifold prior in LapSaCGDA is 0.1, which means that this manifold prior affects the DR model largely compared to the parameter
w.r.t. the spectral locality prior. Additionally, for this dataset, the best smooth parameter
t in the spatial prior in SaCGDA and LapSaCGDA is 4 by grid search.
Table 4 displays the best parameters obtained from the parameter sensitivity experiments, which will be used in the following experiments.
Once these optimal parameters are selected by the grid search, we should choose the best dimensionality of the projection space in terms of the OAs based on KNN and SVM performed in the low-dimensional projection space. What can be seen from
Figure 8 is that the proposed SaCGDA and LapSaCGDA outperform other DR models almost in all low-dimensional projection space again, and the optimal number of dimensionality for each DR model in this HSIs data is 30.
Furthermore, based on the optimal projection dimensionality, we also objectively show the experimental results as the amount of training data increases. In addition, 20–80 samples are randomly picked from all the labeled data, and the rest of the samples are for testing. We can conclude from
Table 5 that the proposed SaCGDA and LapSaCGDA achieve the best OAs, especially when only a few pieces of training data are available.
Finally, we select 20 samples from each class to compare all the models in terms of the classification accuracy for each class. As can be viewed from
Table 6, the proposed two models obtain the highest accuracy in almost every class, and LapSaCGDA is slightly superior to SaCGDA due to the Laplacian prior in LapSaCGDA. The classification maps in
Figure 9 give a similar conclusion.
4.4. Experiments on the Indian Pines Data
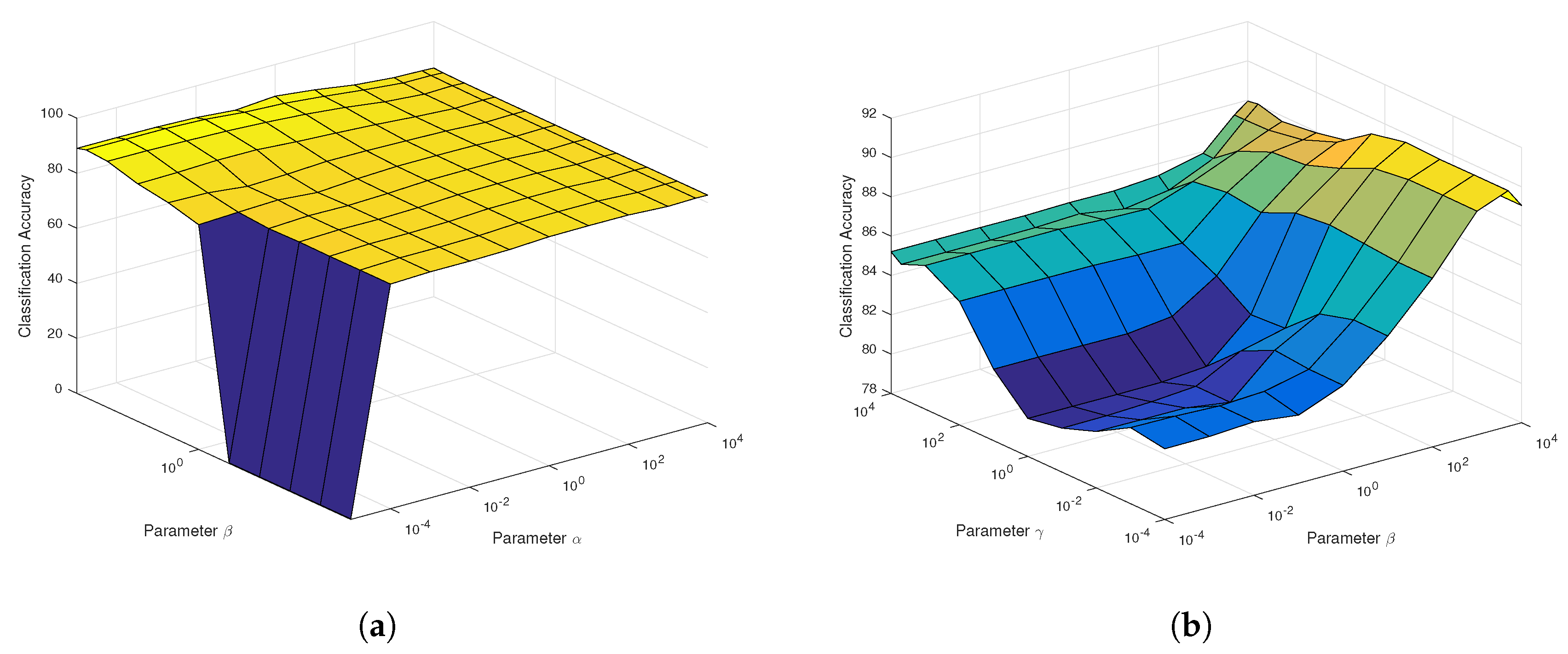
Another challenging HSIs data is the Indian Pines Data, also captured by the AVIRIS sensor. The optimal regularization parameters such as
in the proposed SaCGDA and LapSaCGDA can be observed from the parameters’ sensitivity analysis experiments in
Figure 10, and the best smooth parameter
t in the spatial prior is 2. Thirty training samples are randomly picked from each class in these experiments, and the projecting dimensionality is also fixed to 30 so that the parameter sensitivity analysis can be demonstrated.
What can be viewed from
Figure 10a is that the OAs are not sensitive to the parameter
w.r.t. the spectral locality prior in SaCGDA because the optimal parameter
which dominates the model is so large that other constraints are ignored. For the LapSaCGDA, the best parameter
w.r.t. the manifold prior is also small according to
Figure 10b. The best regularization parameters for LapCGDA, SLGDA, SaCGDA and LapSaCGDA are listed in
Table 7 for the following experiments.
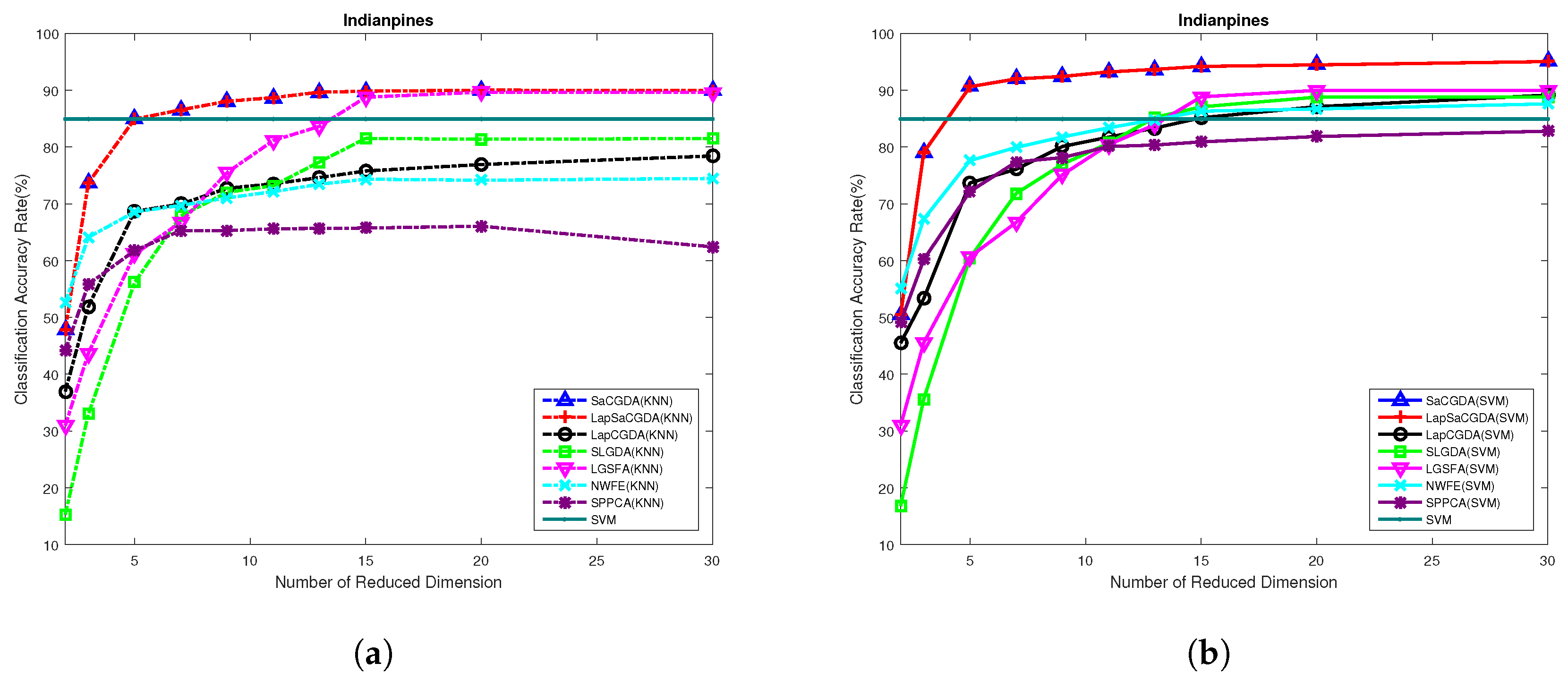
Based on these optimal parameters selected by the grid search, the best dimensionality of the projection space for each DR models can be obtained from
Figure 11 in terms of the OAs based on KNN and SVM performed in the low-dimensional projection space. Once again, the optimal number of dimensionality for almost each DR model in this HSI data is 30, and the proposed SaCGDA and LapSaCGDA are the best among all models although LGSFA shows comparative OAs in high-dimensional embedding space based on KNN.
Moreover, we also show the experimental results when different amounts of training data are selected. In addition, 20–80 samples are randomly picked from all the labeled data, and the other samples become the testing data. For those classes where there are less samples available, no more than
samples out of all data belonging to some classes will be randomly chosen. It can be seen from
Table 8 that LGSFA demonstrates comparative OAs based on KNN compared to the proposed SaCGDA and LapSaCGDA while the two novel models outperform LGSFA and other methods in terms of the SVM classification accuracy. As the spatial prior with large regularization parameter
dominates LapSaCGDA, LapSaCGDA shows the same results compared to SaCGDA because the two spectral constraints in LapSaCGDA are ignored and LapSaCGDA reduces to SaCGDA in this case.
Finally, 20 samples are randomly selected to similarly show the classification accuracy for each class based on SVM. It can be seen from
Table 9 that the proposed SaCGDA and LapSaCGDA are superior to other models when only the spatial prior is utilized, which demonstrates the effectiveness of the spatial prior once again. Accordingly,
Figure 12 shows that the classification maps from the proposed SaCGDA and LapSaCGDA are more accurate than other approaches.
4.5. Discussion
Based on above experimental results, we can provide the following discussions,
- (i)
The proposed SaCGDA significantly outperforms SVM, SPPCA, NWFE, SLGDA, LapCGDA and LGSFA in terms of OA, AA, KC, TPR and FPR in most scenarios, and accordingly the classification maps based on the new model are smoother and more accurate than results from other supervised DR algorithms. These results clearly demonstrate that the introduced spatial constraint is very efficient to model the spatial relationship between pixels.
- (ii)
The Laplacian regularized SaCGDA (LapSaCGDA) could be superior to SaCGDA by further introducing Laplacian constraint into SaCGDA, which makes similar pixels share similar representations. The experimental results verify that LapSaCGDA achieves higher accuracy than SaCGDA in most cases because LapSaCGDA could reveal the intrinsic manifold structures of HSI data more efficiently.
- (iii)
It is also worth pointing out that the SVM classifier always provides better classification results than KNN classifiers. However, if we compare the OAs of KNN based on the proposed two models to OAs of SVM based on other DR techniques like NWFE, SLGDA, LapCGDA and LGSFA, what we can find is that the KNN classification results are better than SVM, which further proves that the proposed two algorithms are more effective to extract discriminative low-dimensional features than other contrastive approaches.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}