A Multiple-Feature Reuse Network to Extract Buildings from Remote Sensing Imagery




Abstract
1. Introduction
- We use fully convolutional DenseNets to extract buildings from remote sensing imagery. We demonstrate that dense connectivity improves the accuracy of common CNN models when extracting buildings from remote sensing imagery.
- We propose a full dense connectivity decoder that preserves the connections in all layers while reducing the required computation.
- We apply a compression approach to regulate and aggregate information from skip connections before entering the decoder.
- We supply a new CNN-based model called a multiple-feature reuse network (MFRN) for extracting buildings from remote sensing imagery that can make use of hierarchical image features.
2. Related Works
2.1. CNNs
2.2. Decoder and Encoder Architectures
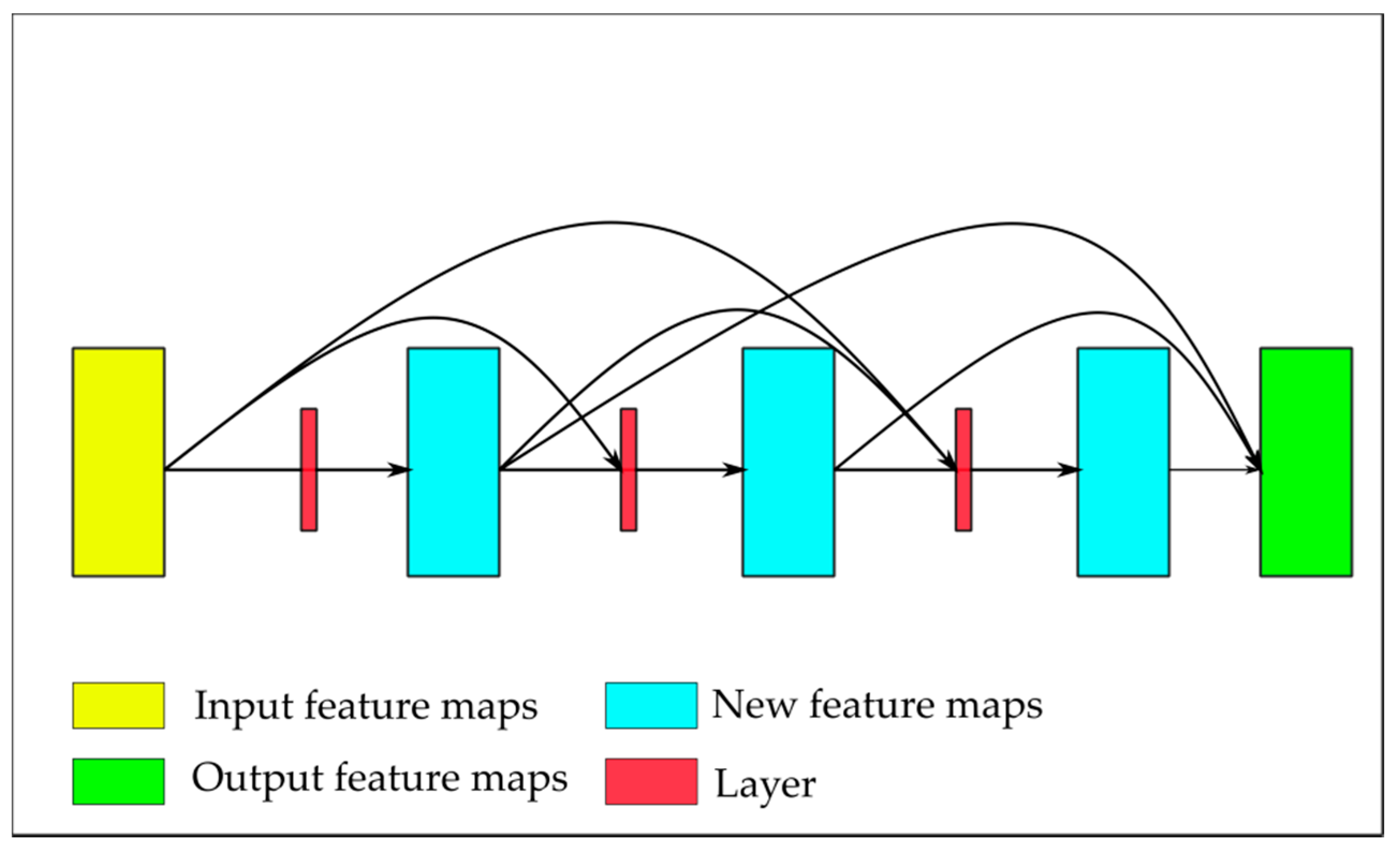
2.3. Skip Connections
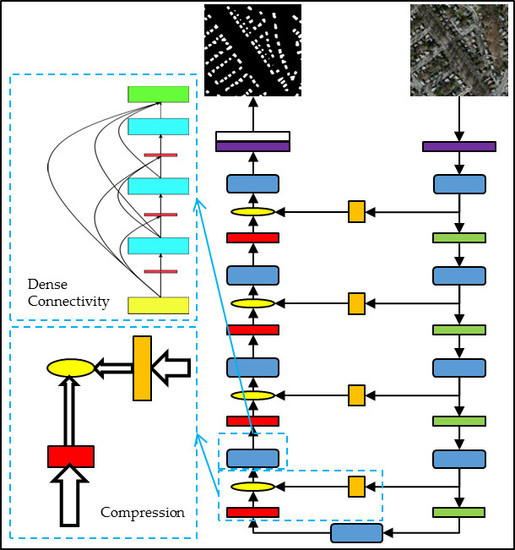
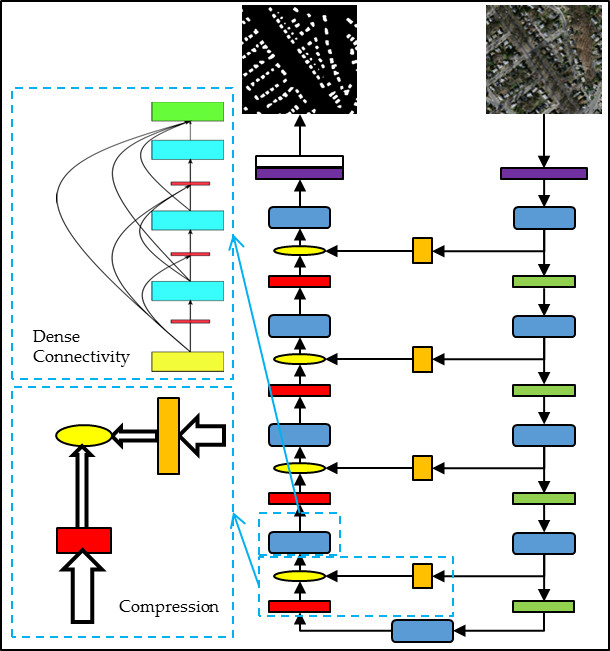
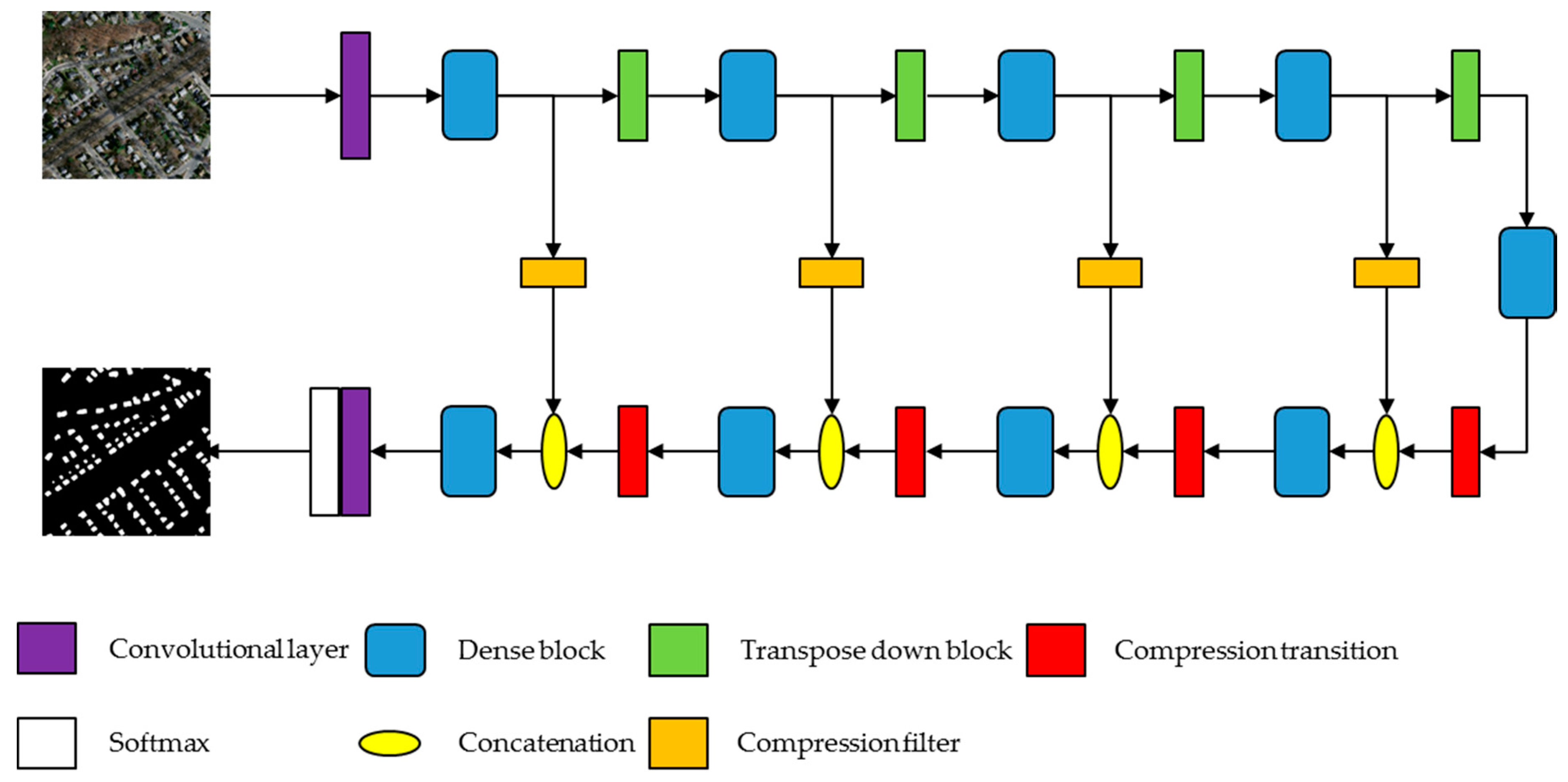
3. Method
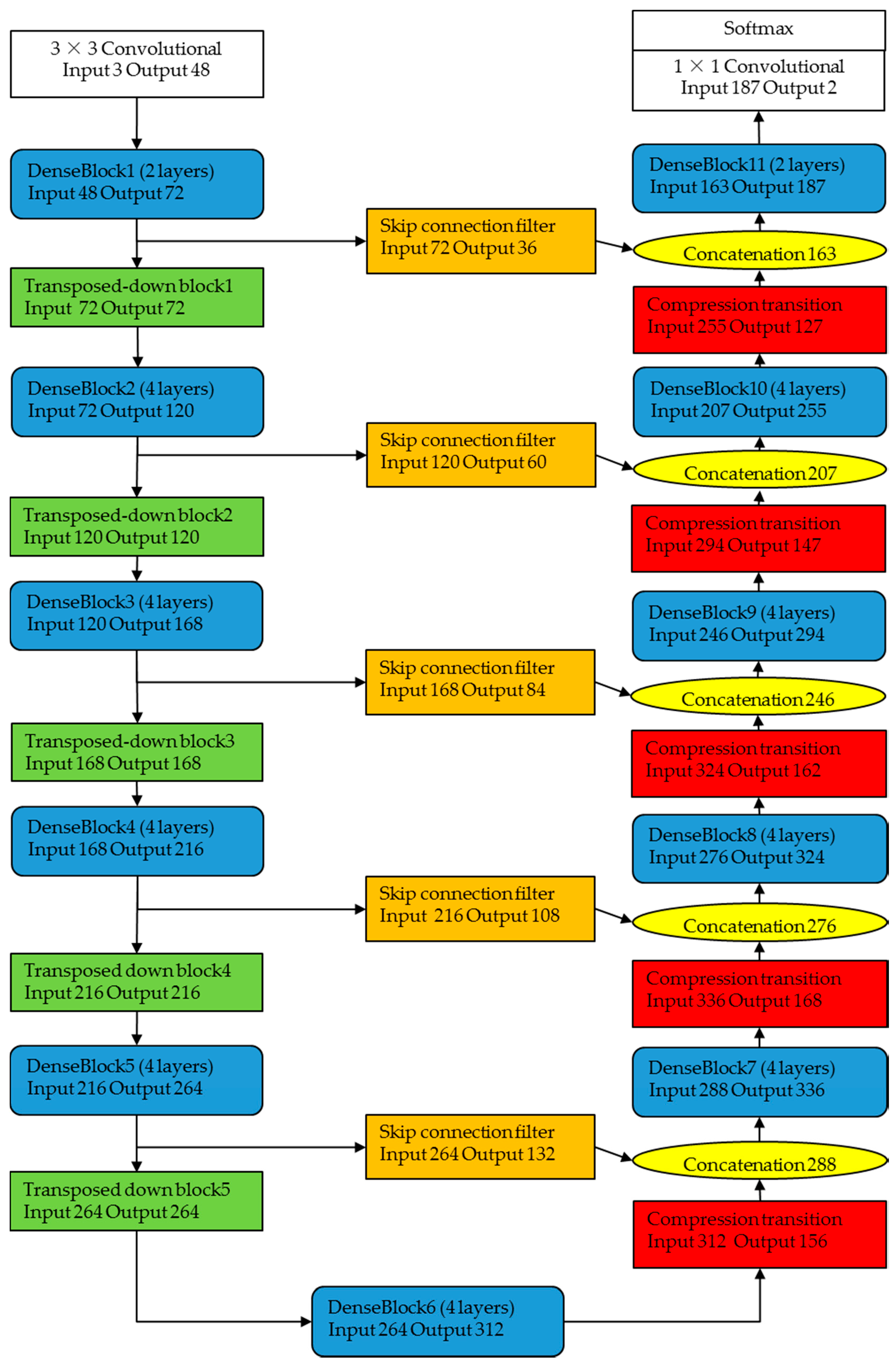
3.1. Overview of the Proposed Method
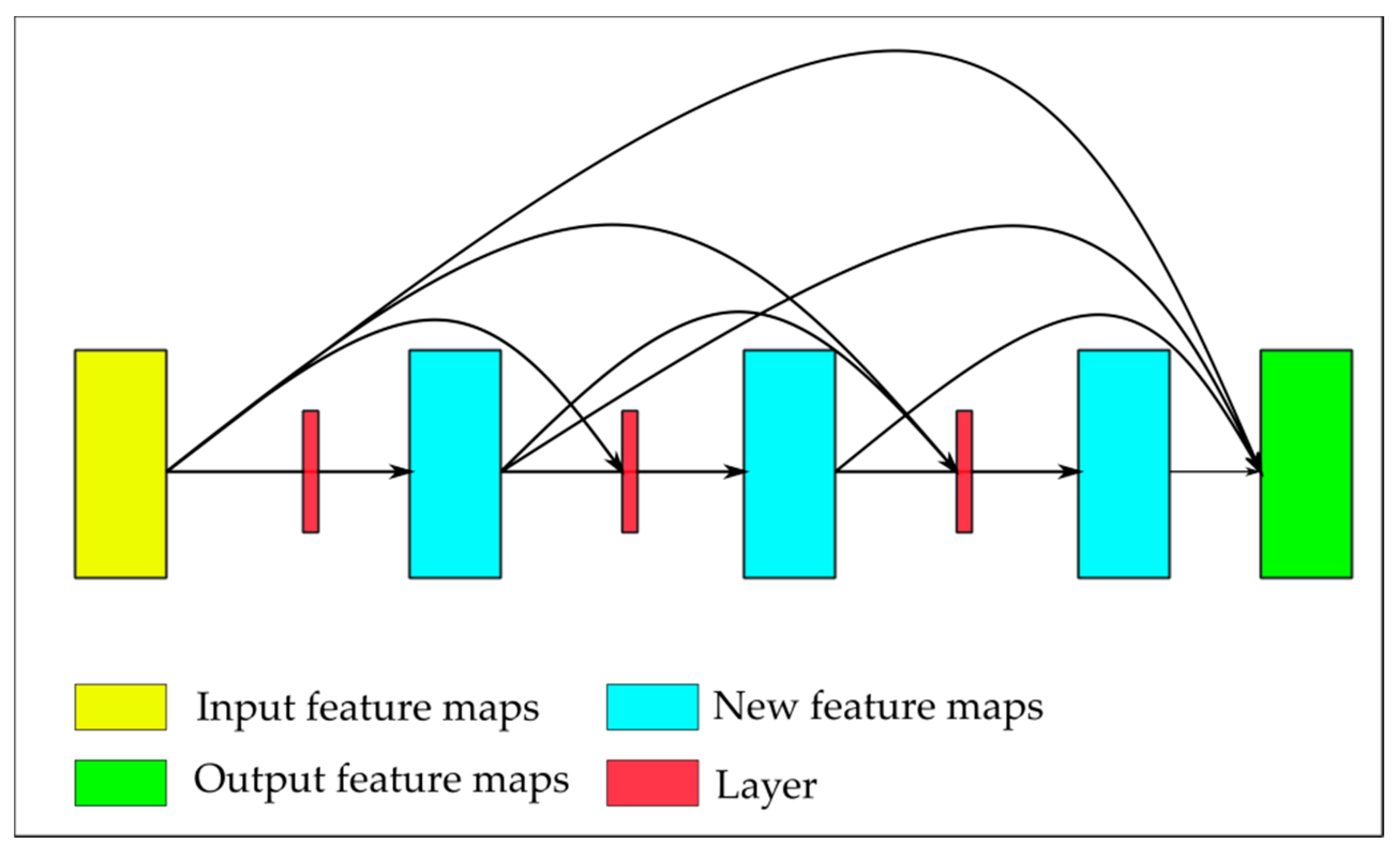
3.2. Dense Block
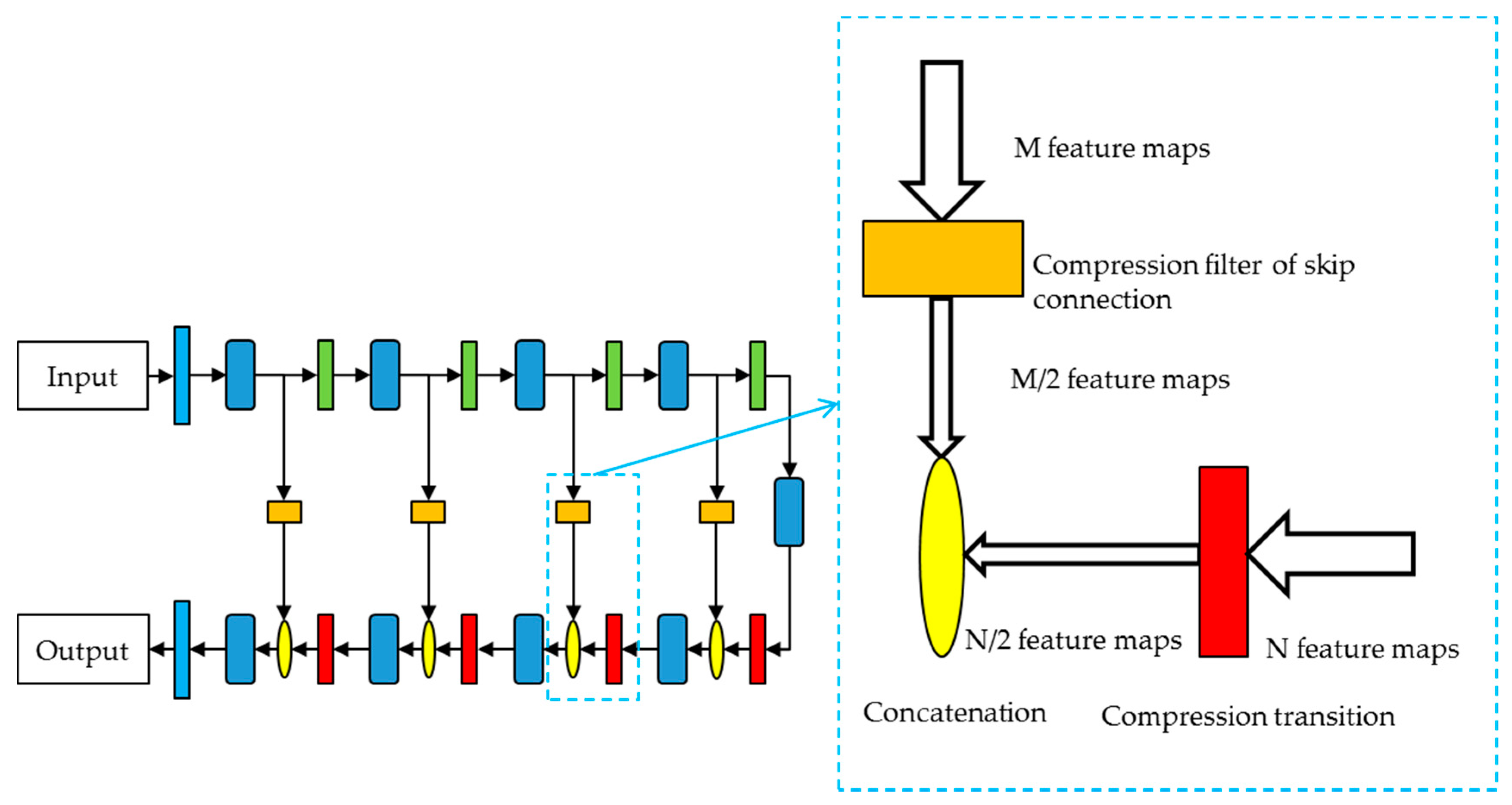
3.3. Decoder with Compression Transition
3.4. Skip Connection Filter
3.5. Implementation Details
3.6. Post Processing
4. Experiment
4.1. Datasets
4.2. Training
4.3. Metrics
4.4. Results and Analysis
4.4.1. Comparison between MFRN and Other Models
4.4.2. Comparison between MFRNs with Different Parameters and Structures
5. Discussion
5.1. Model Size
5.2. Reuse of Multiple Features
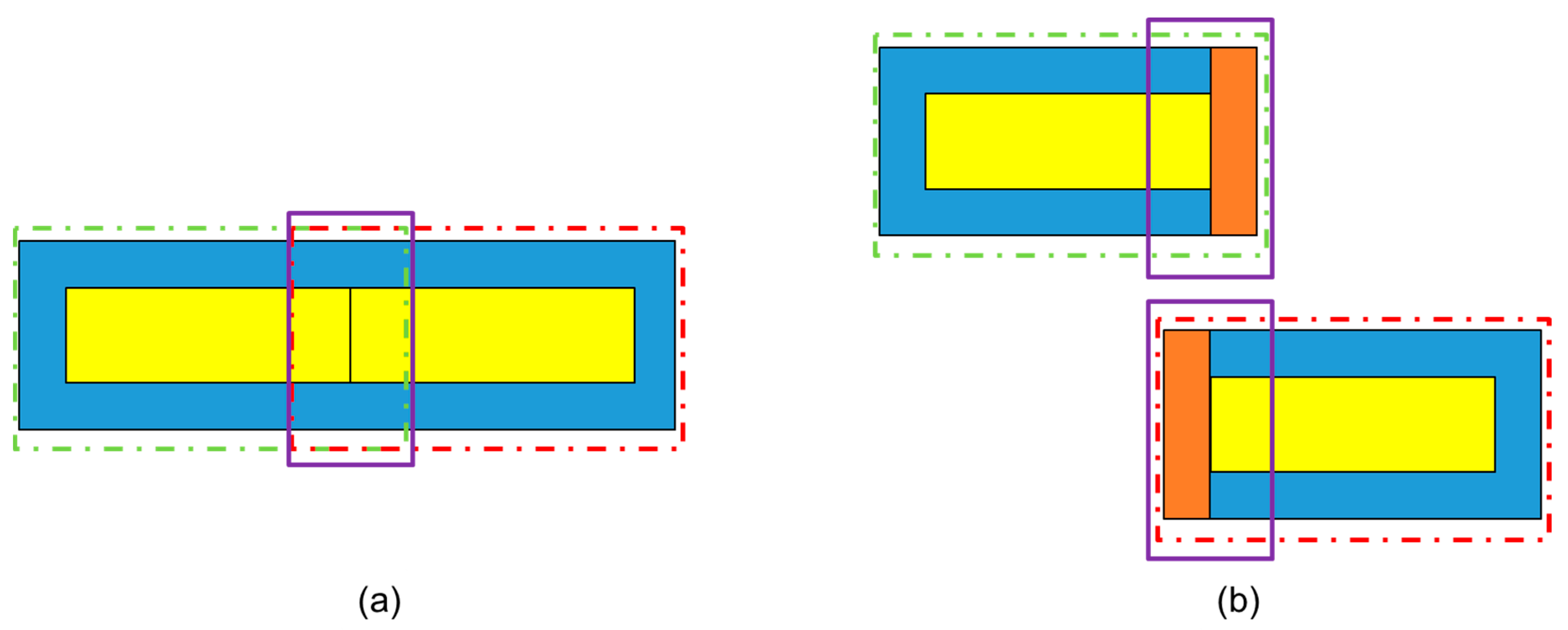
5.3. Overlapped Sliding Cutting
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Tong, X.; Hong, Z.; Liu, S.; Zhang, X.; Xie, H.; Li, Z.; Yang, S.; Wang, W.; Bao, F. Building-damage detection using pre-and post-seismic high-resolution satellite stereo imagery: A case study of the May 2008 wenchuan earthquake. ISPRS J. Photogramm. Remote Sens. 2012, 68, 13–27. [Google Scholar] [CrossRef]
- Moya, L.; Marval Perez, L.R.; Mas, E.; Adriano, B.; Koshimura, S.; Yamazaki, F. Novel unsupervised classification of collapsed buildings using satellite imagery, hazard scenarios and fragility functions. Remote Sens. 2018, 10, 296. [Google Scholar] [CrossRef]
- Huang, X.; Wen, D.; Li, J.; Qin, R. Multi-level monitoring of subtle urban changes for the megacities of china using high-resolution multi-view satellite imagery. Remote Sens. Environ. 2017, 196, 56–75. [Google Scholar] [CrossRef]
- Pang, S.; Hu, X.; Wang, Z.; Lu, Y. Object-based analysis of airborne lidar data for building change detection. Remote Sens. 2014, 6, 10733–10749. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.E.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. In Advances in Neural Information Processing Systems; Touretzky, D.S., Mozer, M.C., Hasselmo, M.E., Eds.; MIT Press: Cambridge, MA, USA, 1990; pp. 396–404. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the ECCV 2014: Computer Vision–ECCV 2014 European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Berlin, Germany, 2014. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Proceedings of the European Conference on Computer Vision, Berlin, Germany, 5–11 September 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin, Germany, 2010; pp. 210–223. [Google Scholar]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Dalla Mura, M. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv, 2016. Available online: https://arxiv.org/abs/1606.02585 (accessed on 22 August 2018)arXiv:1606.02585.
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv, 2015. Available online: https://arxiv.org/abs/1511.07122 (accessed on 22 August 2018)arXiv:1511.07122.
- Hamaguchi, R.; Fujita, A.; Nemoto, K.; Imaizumi, T.; Hikosaka, S. Effective use of dilated convolutions for segmenting small object instances in remote sensing imagery. arXiv, 2017. Available online: https://arxiv.org/abs/1709.00179 (accessed on 22 August 2018)arXiv:1709.00179.
- Yuan, J. Automatic building extraction in aerial scenes using convolutional networks. arXiv, 2016. Available online: https://arxiv.org/abs/1602.06564 (accessed on 22 August 2018)arXiv:1602.06564.
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. High-resolution semantic labeling with convolutional neural networks. arXiv, 2016. Available online: https://arxiv.org/abs/1611.01962 (accessed on 22 August 2018)arXiv:1611.01962.
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation. arXiv, 2016. Available online: https://arxiv.org/abs/1611.09326 (accessed on 22 August 2018)arXiv:1611.09326.
- Huang, G.; Liu, Z.; Weinberger, K.Q.; van der Maaten, L. Densely connected convolutional networks. arXiv, 2016. Available online: https://arxiv.org/abs/1608.06993 (accessed on 22 August 2018)arXiv:1608.06993.
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; Arbib, M.A., Ed.; MIT Press: Cambridge, MA, USA, 1998; pp. 255–258. ISBN 0-262-51102-9. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J. Spectral–spatial classification of hyperspectral imagery based on partitional clustering techniques. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2973–2987. [Google Scholar] [CrossRef]
- Gao, Y.; Marpu, P.; Niemeyer, I.; Runfola, D.M.; Giner, N.M. Object-based classification with features extracted by a semi-automatic feature extraction algorithm—Seath. Geocarto Int. 2011, 26, 211–226. [Google Scholar] [CrossRef]
- Senthilnath, J.; Kumar, D.; Benediktsson, J.A.; Zhang, X. A novel hierarchical clustering technique based on splitting and merging. Int. J. Image Data Fusion 2016, 7, 19–41. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the MICCAI 2015: Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv, 2015. Available online: https://arxiv.org/abs/1511.00561 (accessed on 22 August 2018)arXiv:1511.00561. [CrossRef] [PubMed]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2017, 140, 20–32. [Google Scholar] [CrossRef]
- Li, Y.; He, B.; Long, T.; Bai, X. Evaluation the performance of fully convolutional networks for building extraction compared with shallow models. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Islam, M.A.; Rochan, M.; Bruce, N.D.; Wang, Y. Gated feedback refinement network for dense image labeling. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2017. [Google Scholar] [CrossRef]
- Wu, G.; Shao, X.; Guo, Z.; Chen, Q.; Yuan, W.; Shi, X.; Xu, Y.; Shibasaki, R. Automatic building segmentation of aerial imagery using multi-constraint fully convolutional networks. Remote Sens. 2018, 10, 407. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv, 2015. Available online: https://arxiv.org/abs/1502.03167 (accessed on 22 August 2018)arXiv:1502.03167.
- Bridle, J.S. Probabilistic Interpretation of Feedforward Classification Network Outputs, with Relationships to Statistical Pattern Recognition; Springer: Berlin, Germany, 1990; pp. 227–236. ISBN 978-3-642-76153-9. [Google Scholar]
- Chollet, F.; Keras. GitHub Repository. Available online: https://github.com/fchollet/keras (accessed on 22 August 2018).
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014. Available online: https://arxiv.org/abs/1412.6980 (accessed on 22 August 2018)arXiv:1412.6980.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer in the Dense Block |
|---|
| BatchNormalization |
| ReLU |
| 3 × 3 Convolution |
| Dropout |
| Metric | Parameters | Time for Each Batch | Overall Accuracy | F1 |
|---|---|---|---|---|
| FCN8 | 134.27 million | 851 ms | 93.27% | 81.38% |
| U-Net | 7.7 million | 790 ms | 93.63% | 81.93% |
| FC-DenseNet56 | 3.49 million | 775 ms | 93.84% | 83.54% |
| MFRN with compression factor 0.3 | 1.57 million | 752 ms | 93.88% | 82.38% |
| MFRN with compression factor 0.4 | 2.07 million | 746 ms | 94.36% | 84.45% |
| MFRN with compression factor 0.5 | 2.81 million | 792 ms | 94.51% | 85.01% |
| MFRN with no filters | 2.70 million | 780 ms | 94.20% | 83.29% |
| Short MFRN with compression factor 0.5 | 1.87 million | 785 ms | 93.68% | 82.06% |
| 95% Confidence Interval for Mean | ||||||
|---|---|---|---|---|---|---|
| N | Mean | Std. Deviation | Std. Error | Lower Bound | Upper Bound | |
| 0.3 | 10 | 0.821610 | 0.0093475 | 0.0029560 | 0.814923 | 0.828297 |
| 0.4 | 10 | 0.838430 | 0.0110515 | 0.0034948 | 0.830524 | 0.846336 |
| 0.5 | 10 | 0.842170 | 0.0138517 | 0.0043803 | 0.832261 | 0.852079 |
| Total | 30 | 0.834070 | 0.0143972 | 0.0026286 | 0.828694 | 0.839446 |
| Sum of Squares | df | Mean Square | F | sig | |
|---|---|---|---|---|---|
| Between Groups | 0.002 | 2 | 0.001 | 8.964 | 0.001 |
| Within Groups | 0.004 | 27 | 0.000 | ||
| Total | 0.006 | 29 |
| (I) Compression Factor | (J) Compression Factor | 95% Confidence Interval | ||||
|---|---|---|---|---|---|---|
| Mean Difference (I-J) | Std. Error | Sig. | Lower Bound | Upper Bound | ||
| 0.3 | 0.4 | −0.0168200 * | 0.0051729 | 0.003 | −0.027434 | −0.006206 |
| 0.5 | −0.0205600 * | 0.0051729 | 0.000 | −0.031174 | −0.009946 | |
| 0.4 | 0.3 | 0.0168200 * | 0.0051729 | 0.003 | 0.006206 | 0.027434 |
| 0.5 | −0.0037400 | 0.0051729 | 0.476 | −0.014354 | 0.006874 | |
| 0.5 | 0.3 | 0.0205600 * | 0.0051729 | 0.000 | 0.009946 | 0.031174 |
| 0.4 | 0.0037400 | 0.0051729 | 0.476 | −0.006874 | 0.014354 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Liang, J.; Weng, M.; Zhu, H. A Multiple-Feature Reuse Network to Extract Buildings from Remote Sensing Imagery. Remote Sens. 2018, 10, 1350. https://doi.org/10.3390/rs10091350
Li L, Liang J, Weng M, Zhu H. A Multiple-Feature Reuse Network to Extract Buildings from Remote Sensing Imagery. Remote Sensing. 2018; 10(9):1350. https://doi.org/10.3390/rs10091350
Chicago/Turabian StyleLi, Lin, Jian Liang, Min Weng, and Haihong Zhu. 2018. "A Multiple-Feature Reuse Network to Extract Buildings from Remote Sensing Imagery" Remote Sensing 10, no. 9: 1350. https://doi.org/10.3390/rs10091350
APA StyleLi, L., Liang, J., Weng, M., & Zhu, H. (2018). A Multiple-Feature Reuse Network to Extract Buildings from Remote Sensing Imagery. Remote Sensing, 10(9), 1350. https://doi.org/10.3390/rs10091350