Supervised Classification High-Resolution Remote-Sensing Image Based on Interval Type-2 Fuzzy Membership Function


Abstract
:
1. Introduction
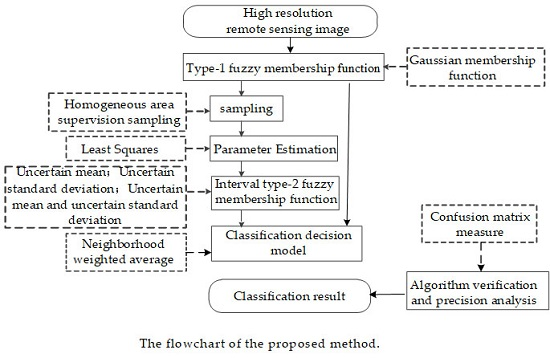
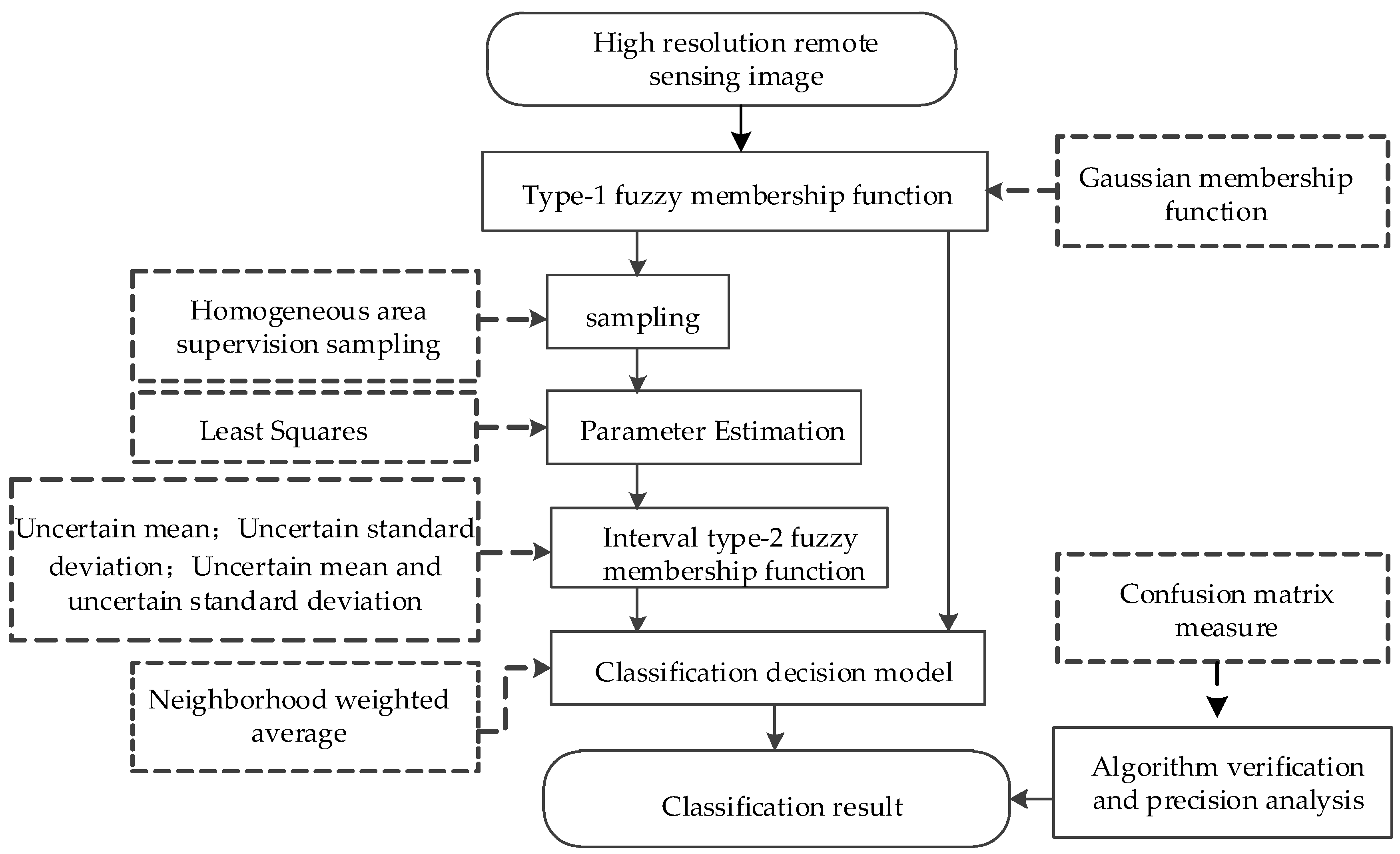
2. Algorithm Descriptions
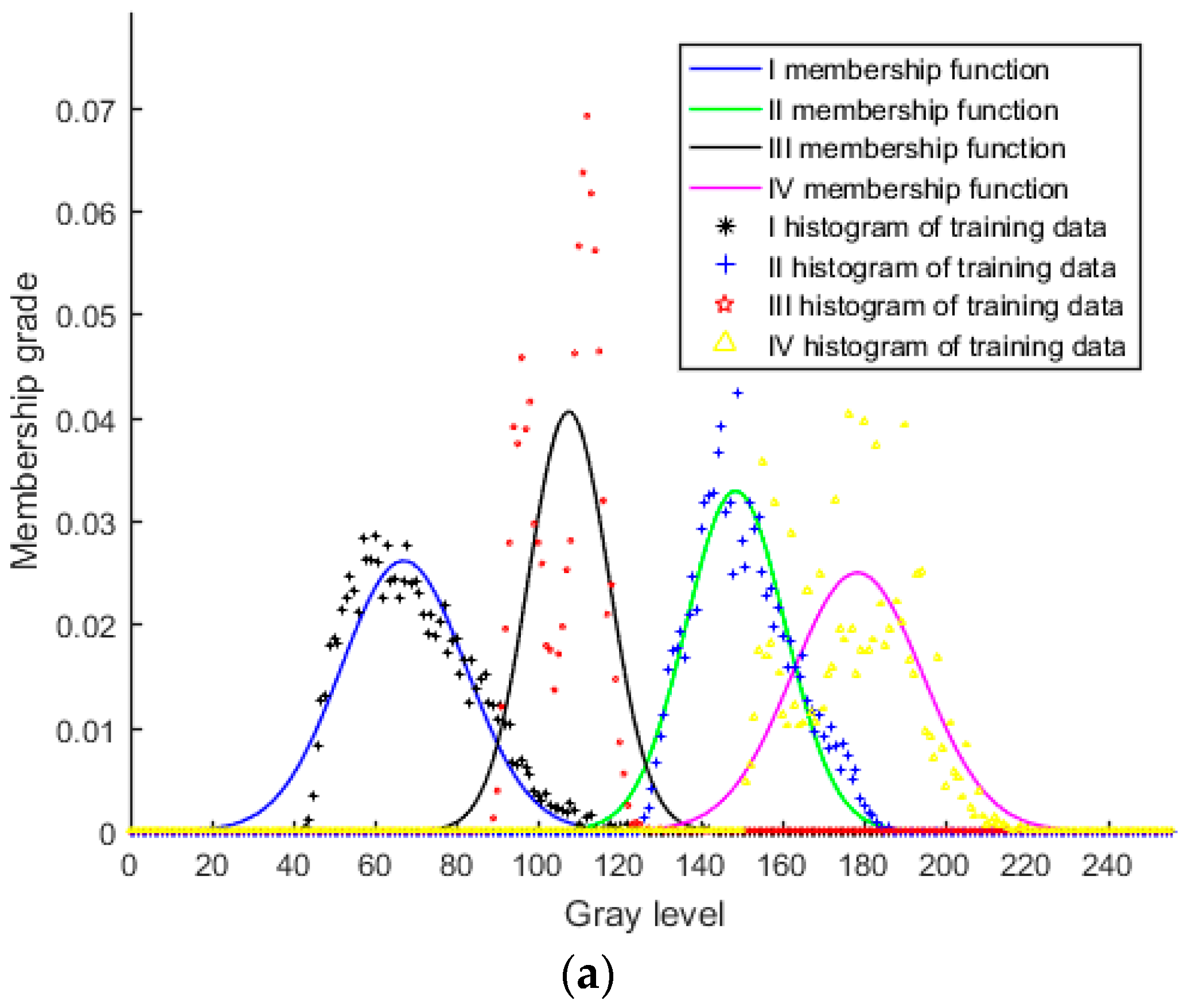
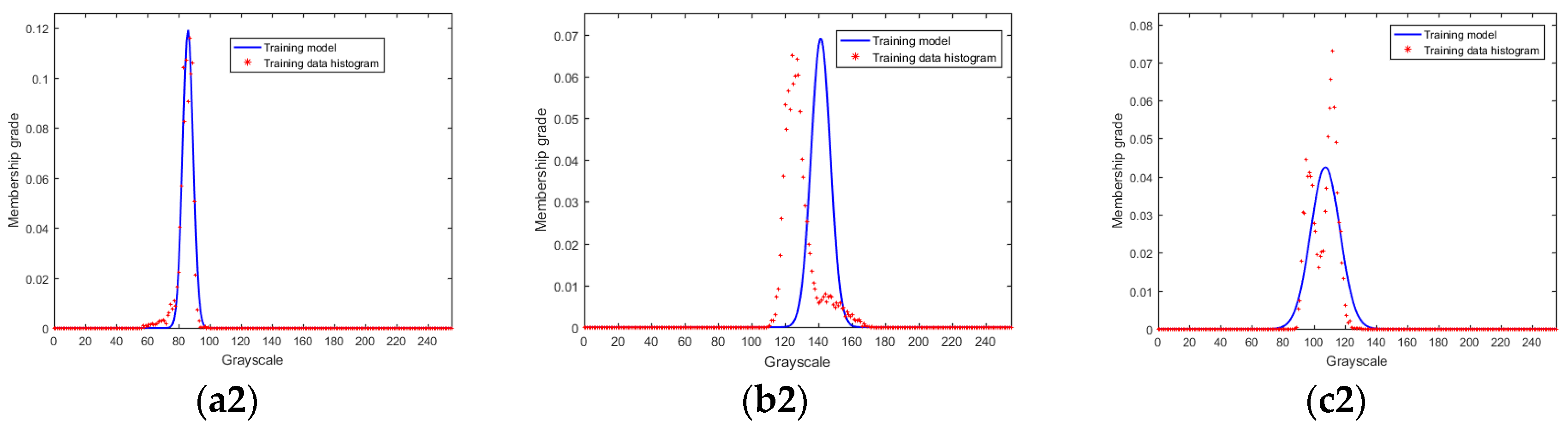
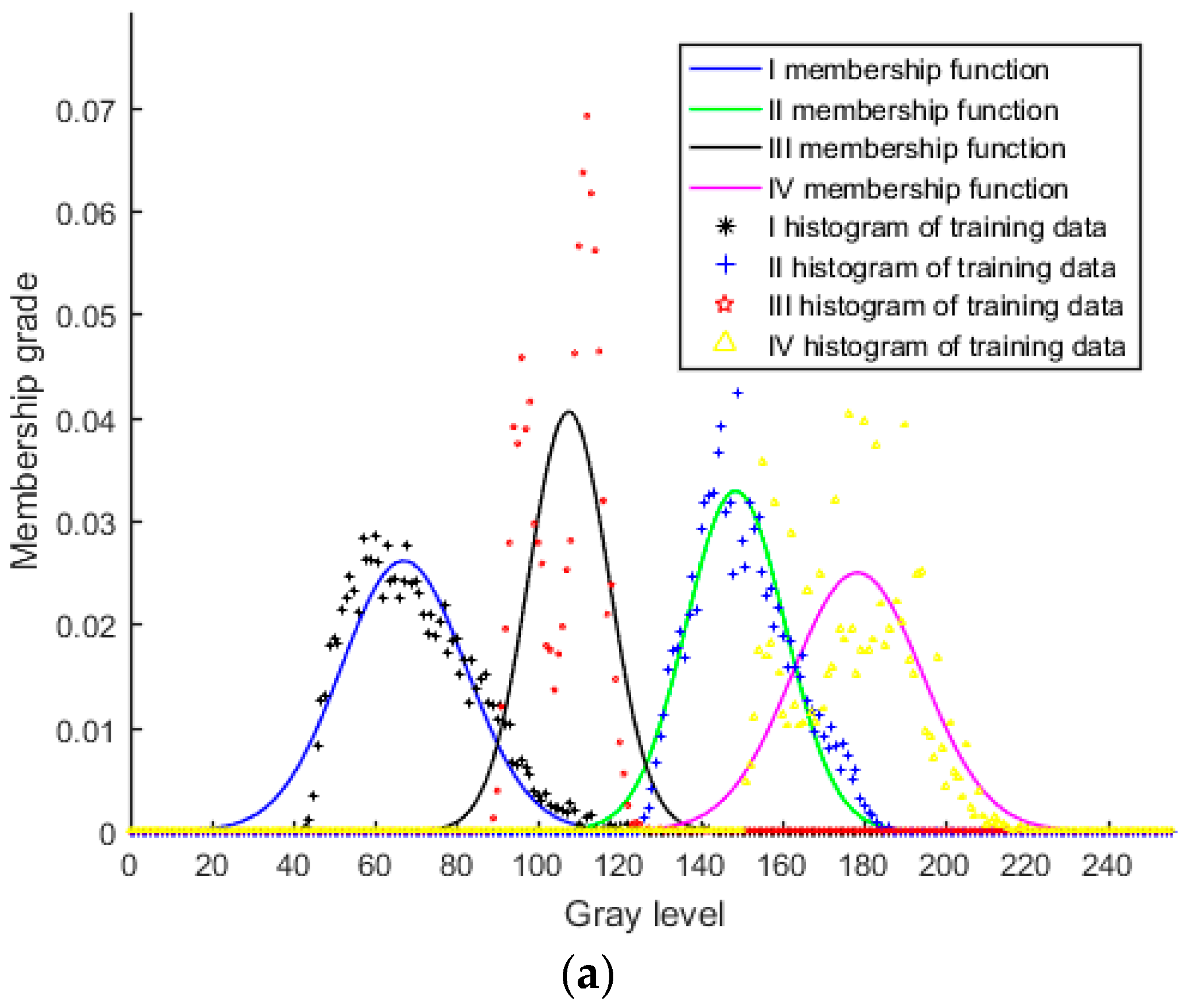
2.1. Type-1 Fuzzy Membership Function Model for Homogeneous Region
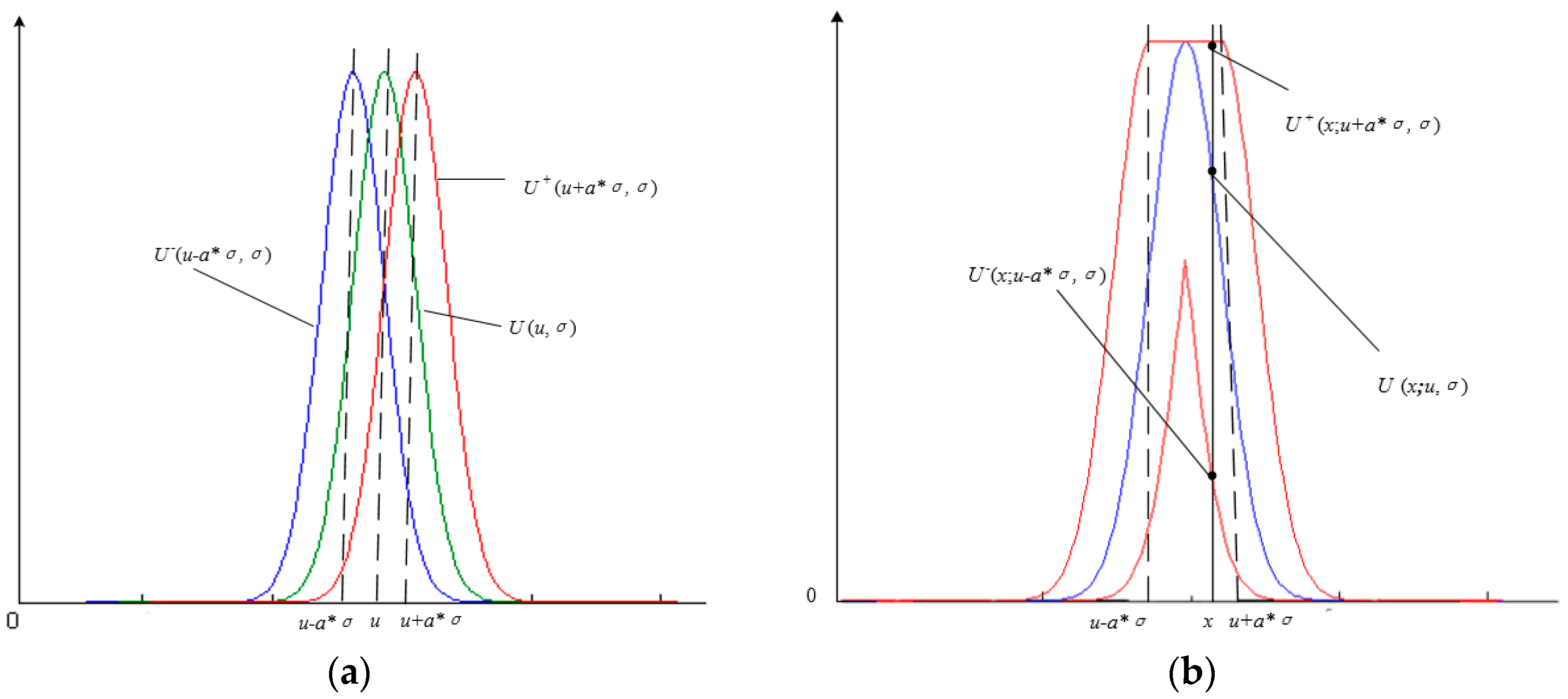
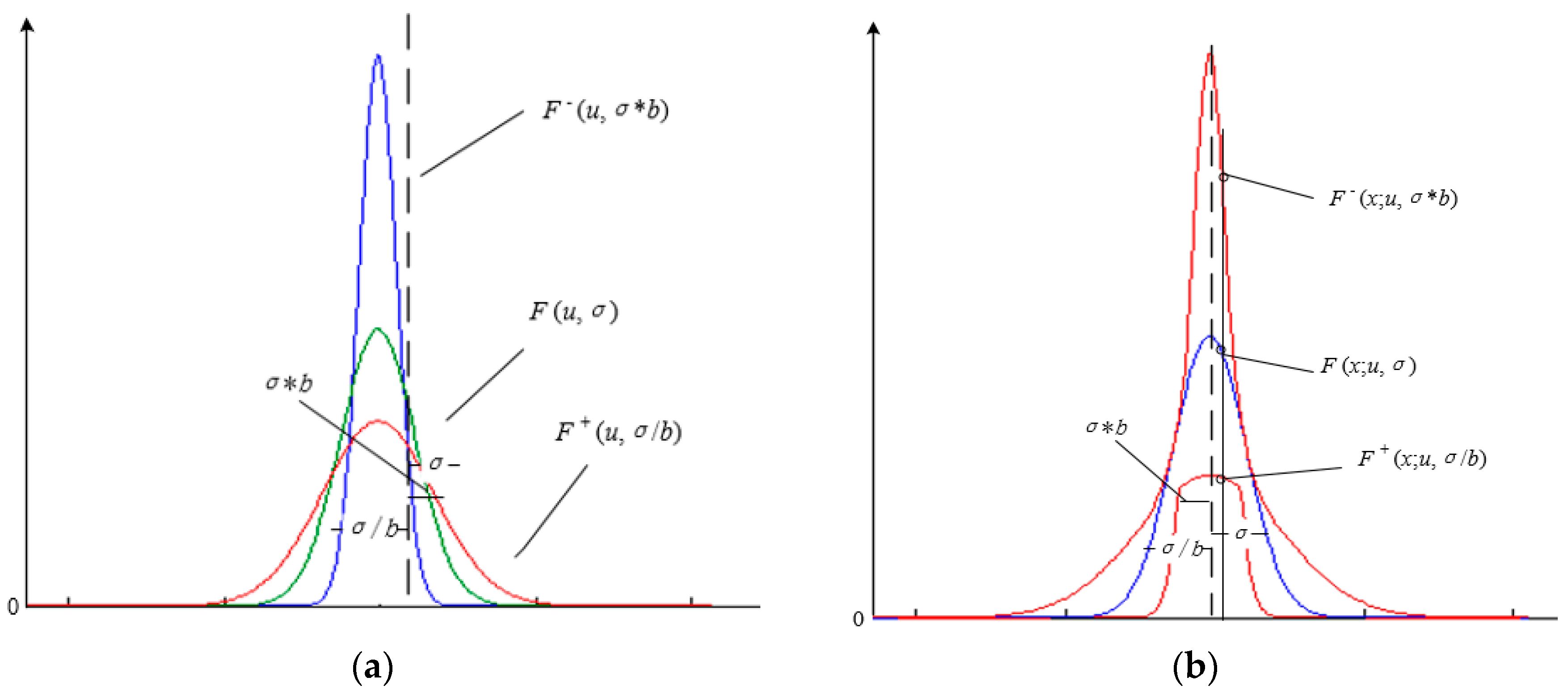
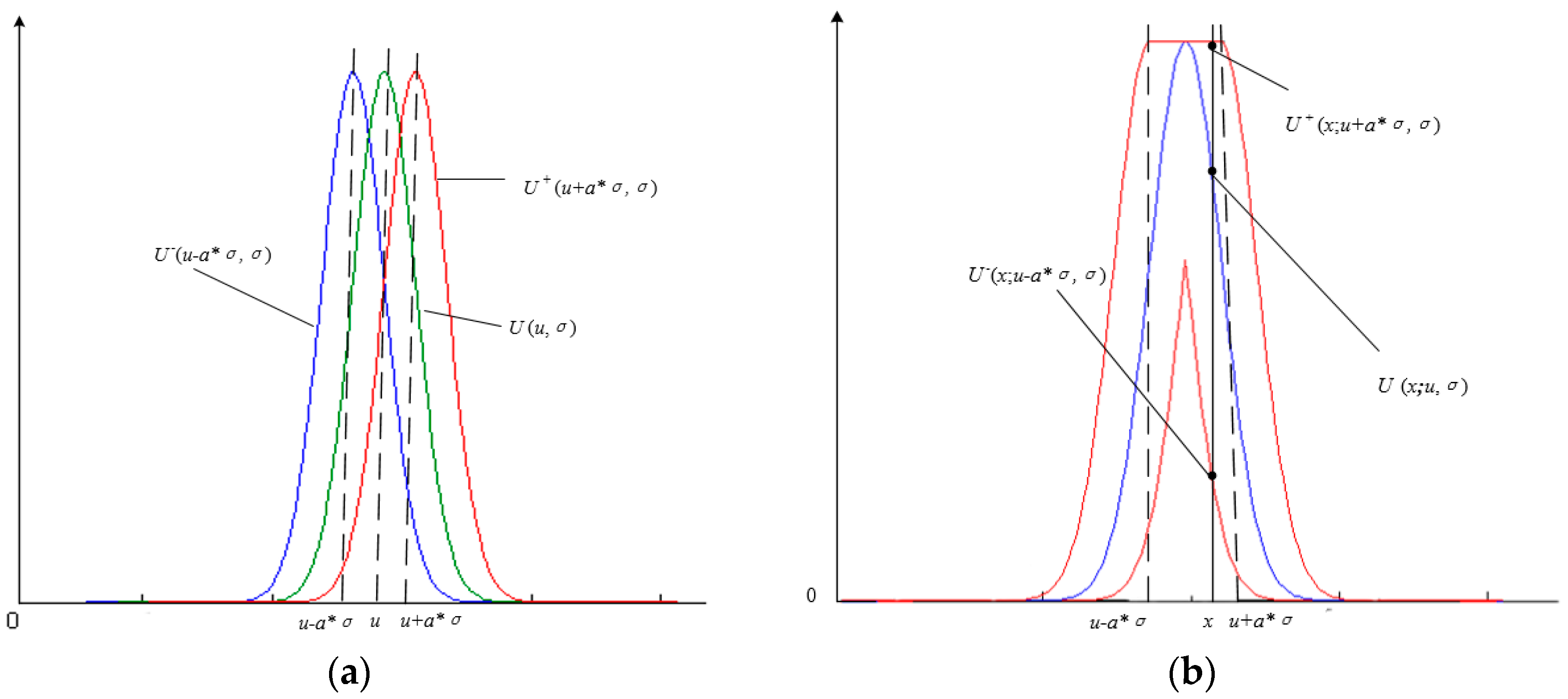
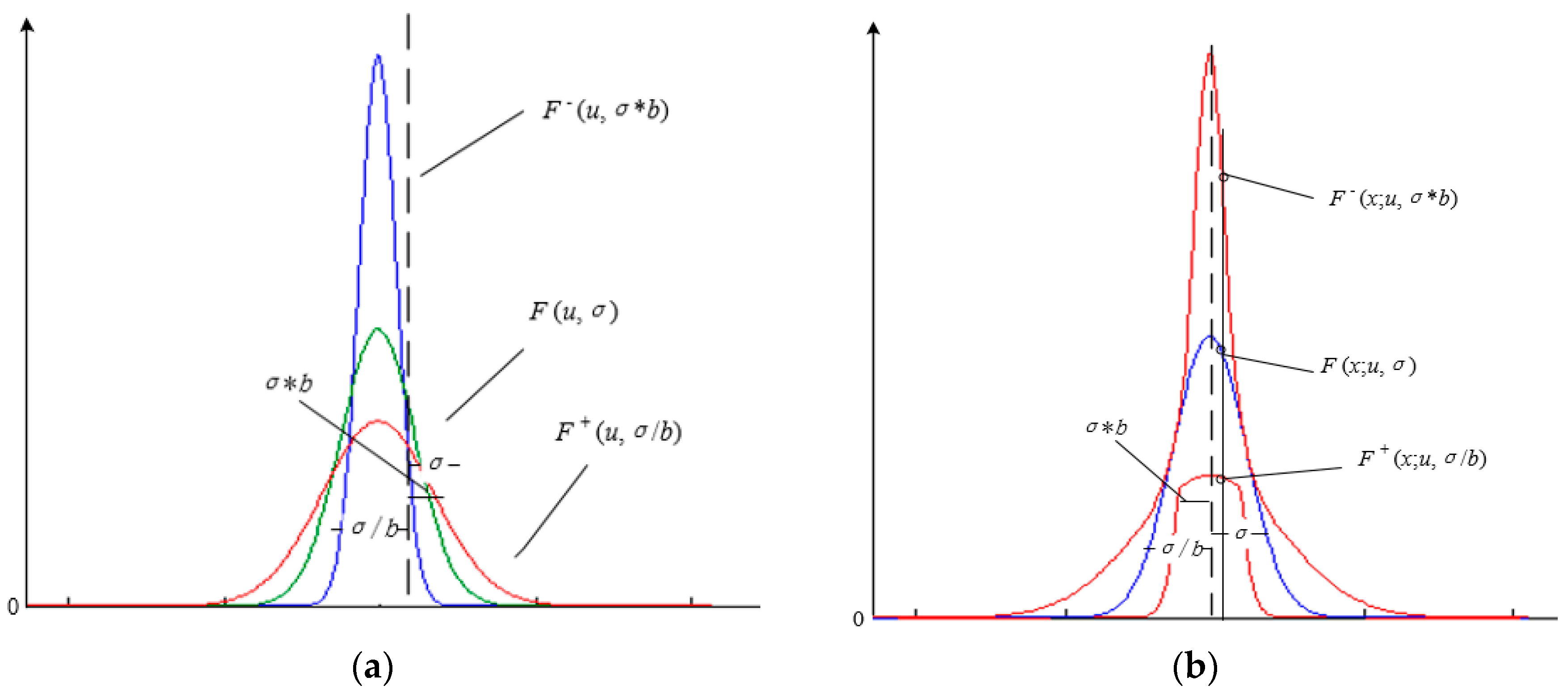
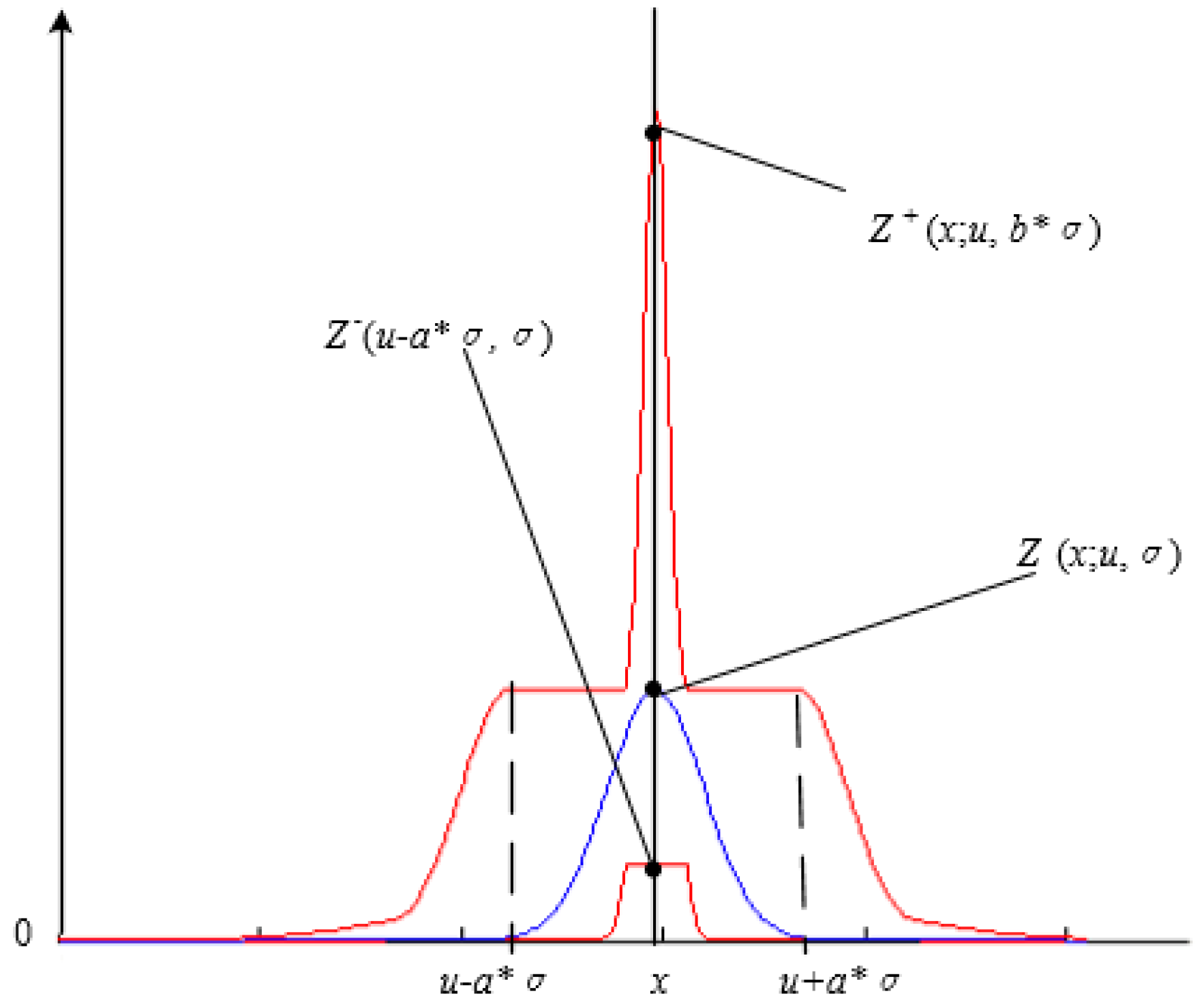
2.2. Interval Type-2 Fuzzy Membership Function Model for a Homogenous Region
- (1)
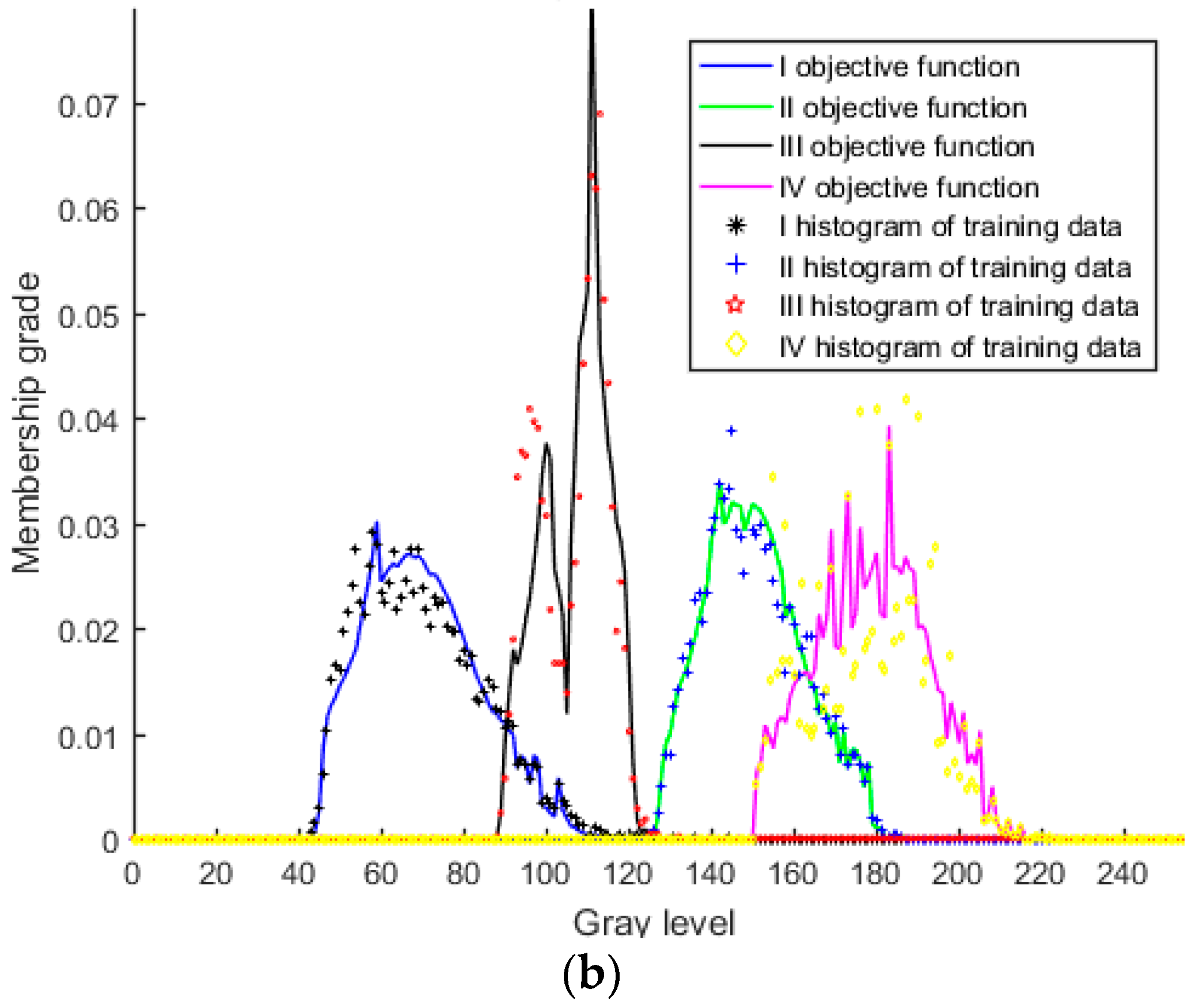
- Supervise sample each region to be classified, and then solve the parameters α, μ, and σ by fitting the least square histogram.
- (2)
- Add adjustment factors a and b, in accordance with prior knowledge, and then according to Equations (12) and (13), construct the interval type-2 fuzzy membership function model with uncertain mean, the interval type-2 fuzzy membership function model with uncertain standard deviation, or the interval type-2 fuzzy membership function model with uncertain mean and uncertain standard deviation.
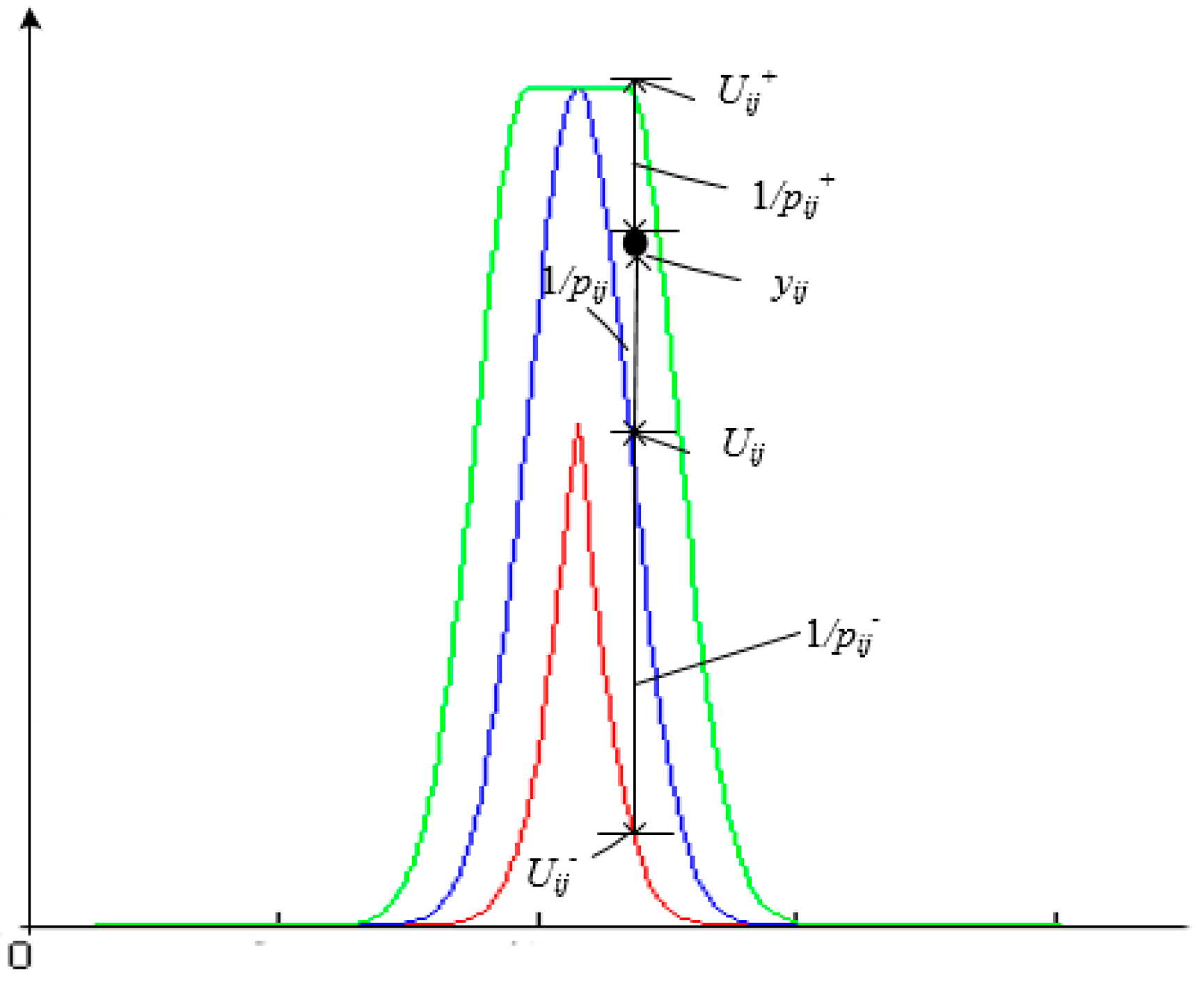
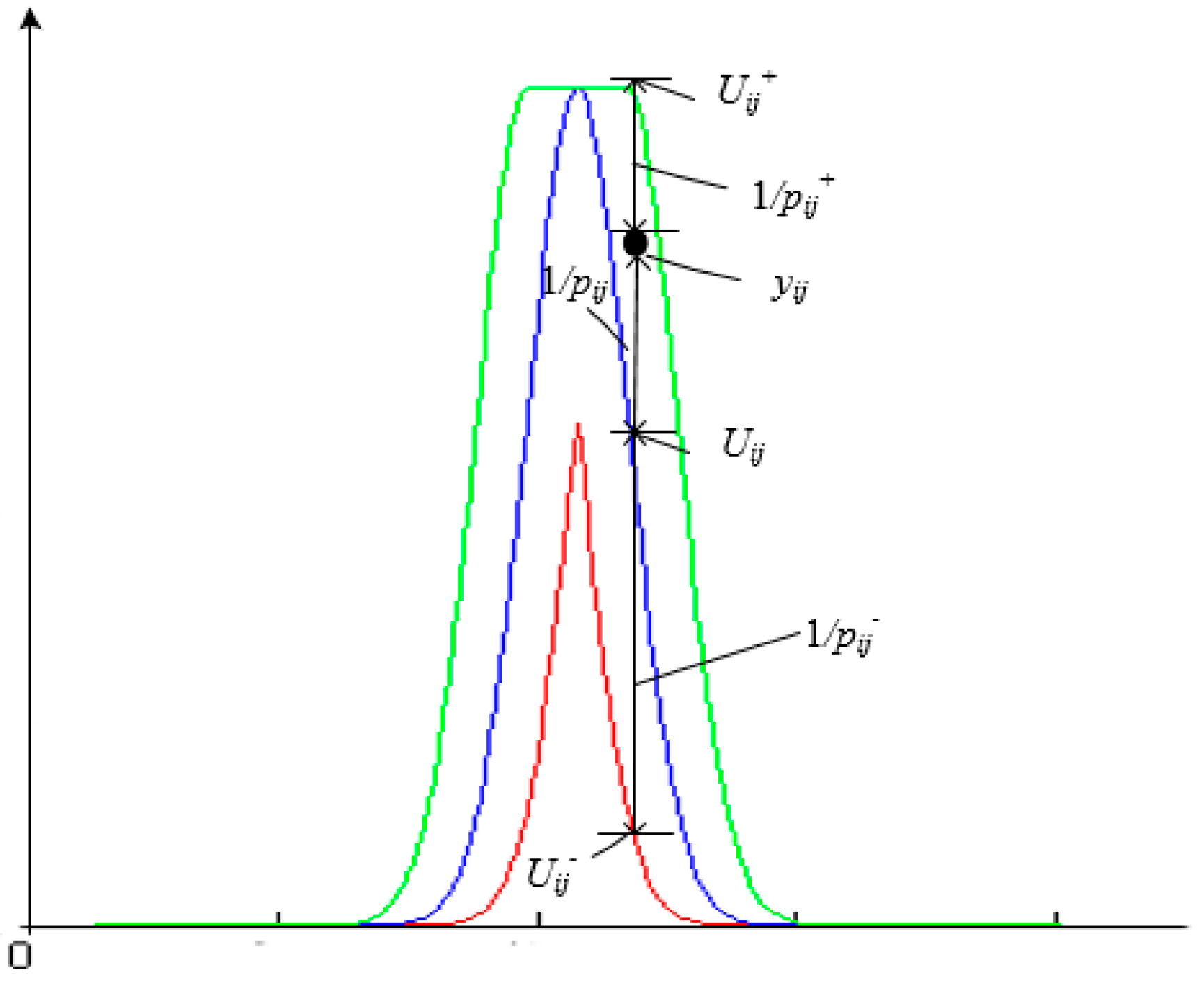
2.3. Classification Decision Model
3. Experiments and Results
3.1. Experimental Results and Analysis of Synthetic High-Resolution Remote-Sensing Images
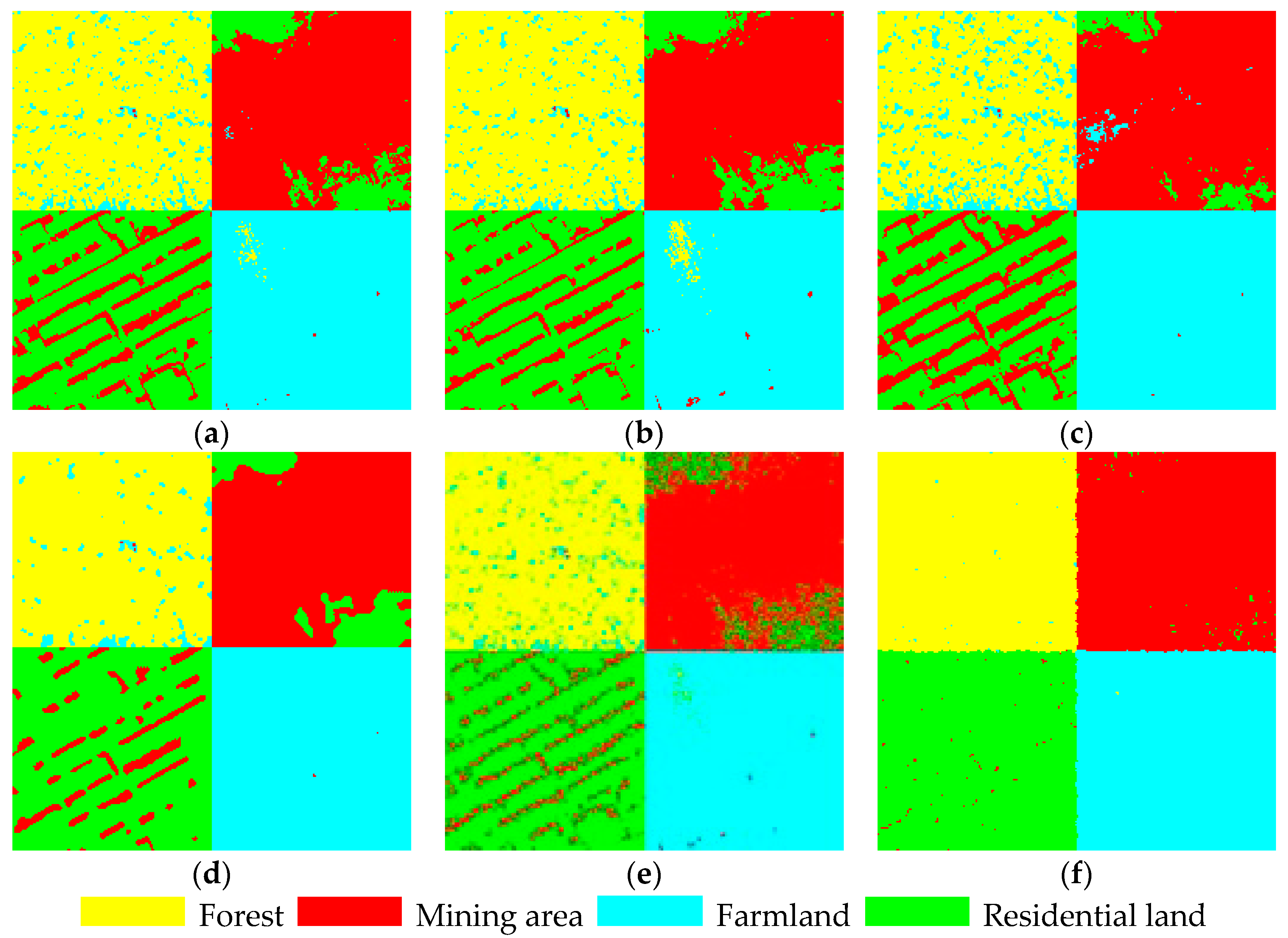
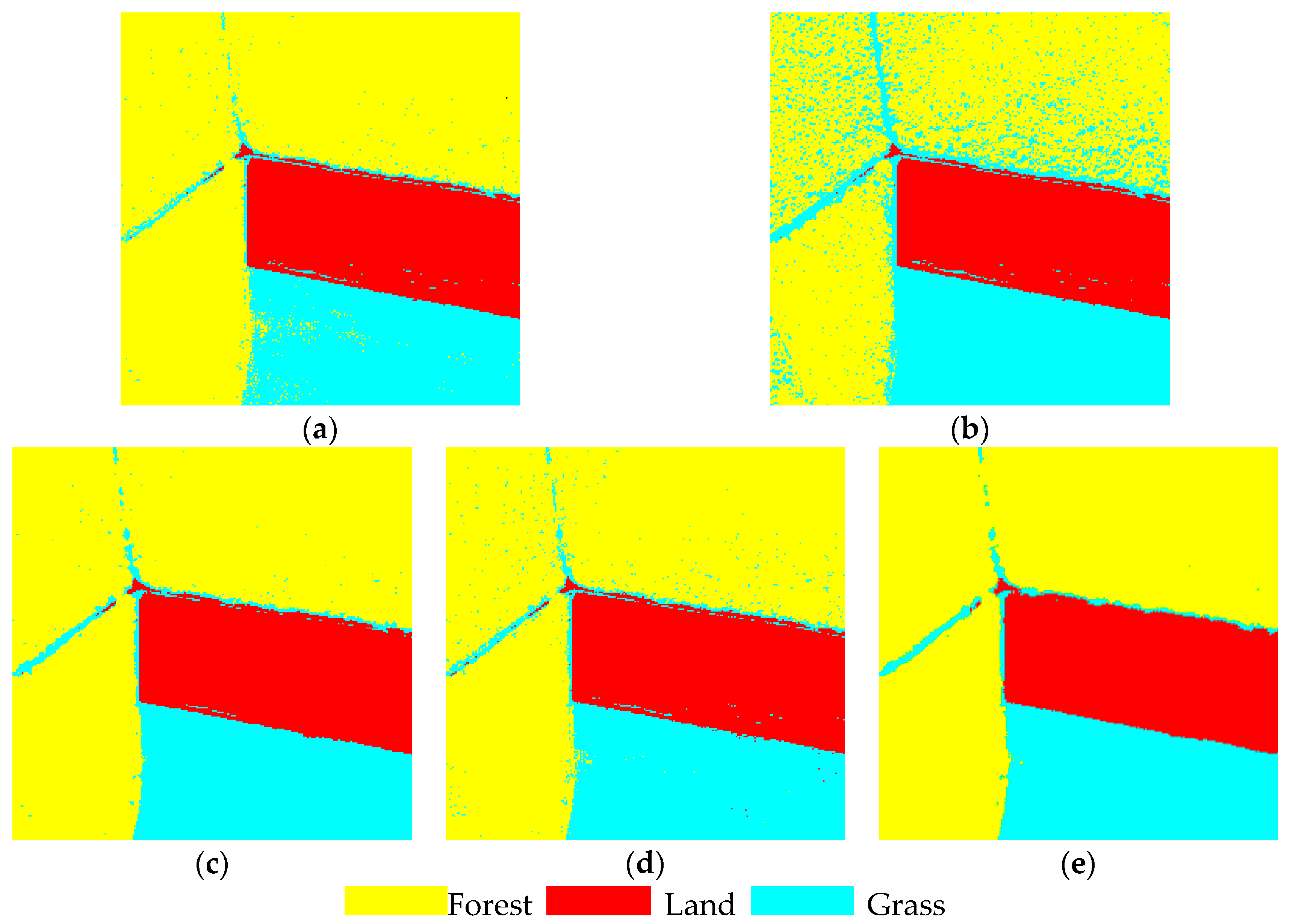
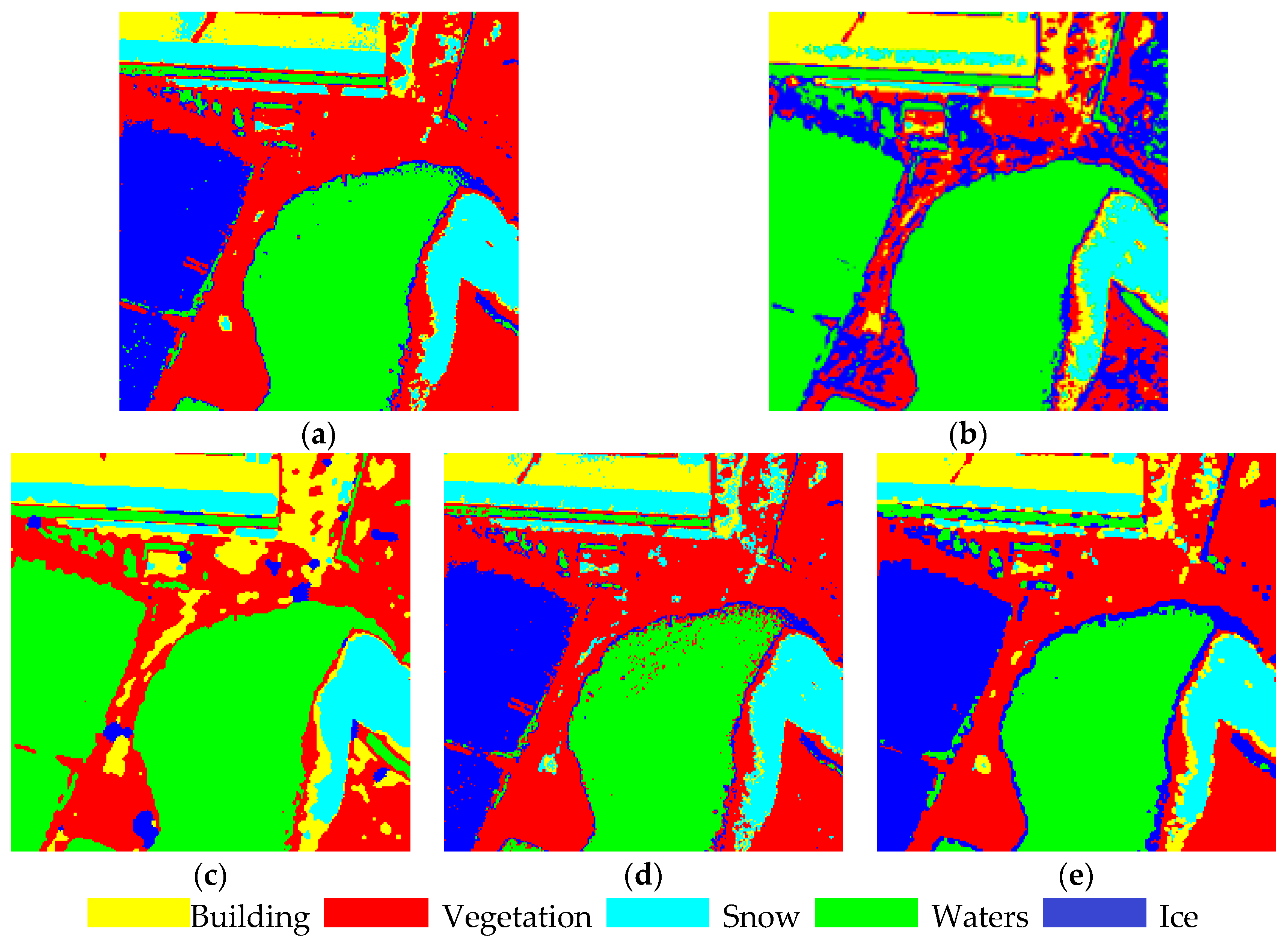
3.2. Experimental Results and Analysis of Real High-Resolution Remote-Sensing Images
- (1)
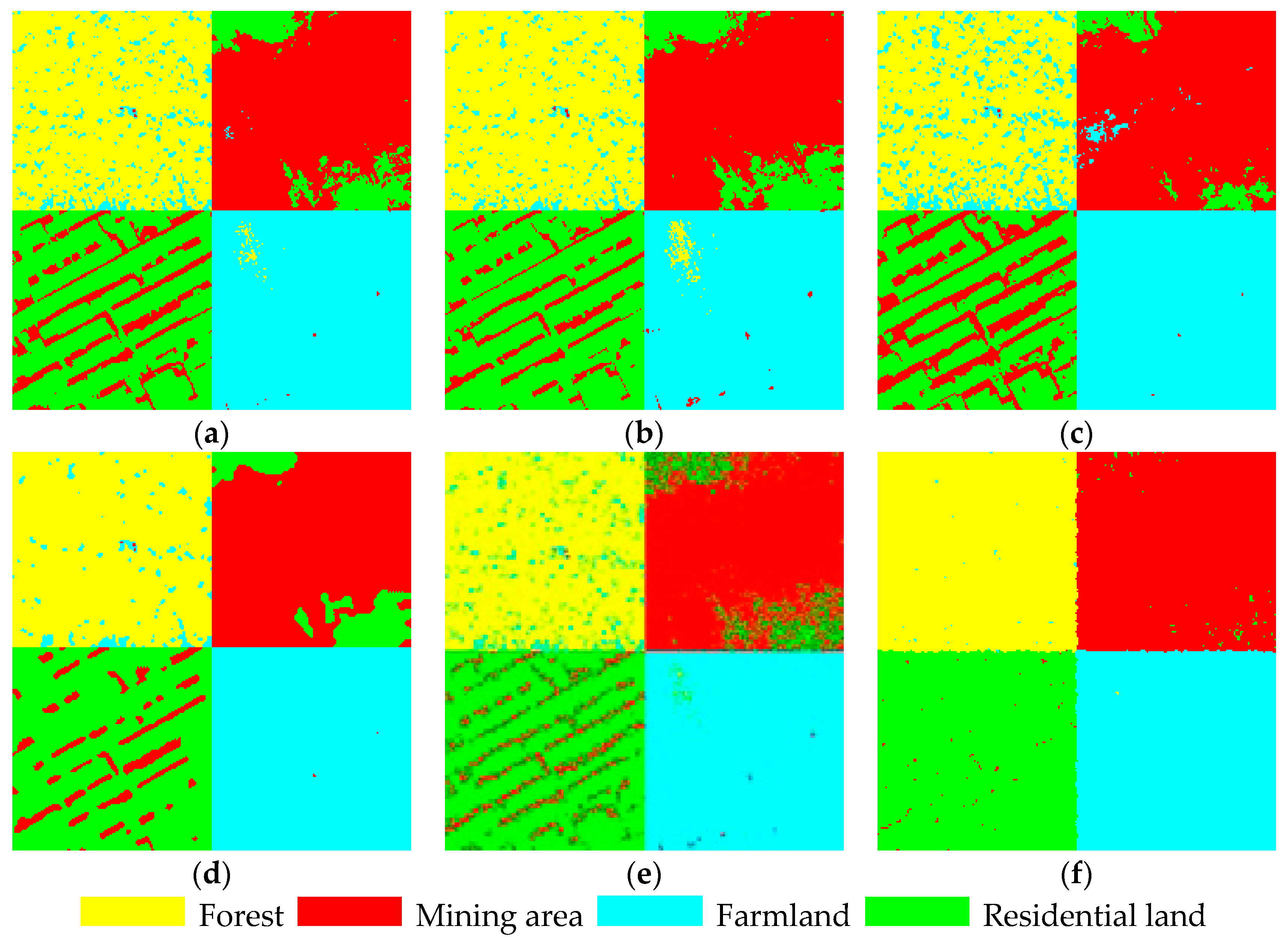
- When the ground object to be classified complies with the standard Gaussian distribution and the grayscale of the heterogeneous region overlaps a little, the classification accuracy of the maximum likelihood method, the FCM method, and the weighted average is similar without considering the spatial relations. The HMRF-FCM method and the proposed neighborhood weighted average method can further improve the classification accuracy.
- (2)
- When the histogram of homogenous regions presents a continuous asymmetric unimodal, continuous multimodel, or irregular distribution feature, the weighted average method proposed in this paper can accurately fit the feature.
- (3)
- The classification decision model integrated with spatial relations that is proposed in this paper can effectively deal with the salt-and-pepper noise in the image and deal with the grayscale overlapping in different regions to some extent.
- (4)
- The time cost of the proposed method is relatively small for a large map sheet. For example, when the map sheet size increases by four times, the computation time will increase from the original 1 s to 13 s. Therefore, the method that is proposed in this paper can be applied to the data processing of large-scale remote-sensing images.
- (5)
- Although the accuracy evaluation of training data can reflect the classification quality of different classification methods, it can not precisely reflect the classification accuracy of the whole image.
- (6)
- When compared with the traditional methods, the proposed method can improve the classification accuracy and is suitable for the classification of high-resolution remote-sensing images.
4. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Fu, S.; Ruan, Q.; Wang, W. A feature-dependent fuzzy bidirectional flow for adaptive image sharpening. Neurocomputing 2007, 70, 883–895. [Google Scholar] [CrossRef]
- Bloch, I. Information combination operators for data fusion: A comparative review with classification. IEEE Trans. Syst. Man Cybern. Part A 1996, 26, 52–67. [Google Scholar] [CrossRef]
- Ahmed, M.N.; Yamany, S.M.; Aly, A.; Farag, N.M. Bias field estimation and adaptive segmentation of MRI data using a modified fuzzy C-means algorithm. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999; Volume 1, pp. 1250–1255. [Google Scholar]
- Chen, S.; Zhang, D. Robust image segmentation using FCM with spatial constraints based on new kernel-induced distance measure. IEEE Trans. Syst. Man Cybern. Part B 2004, 34, 1907–1916. [Google Scholar] [CrossRef]
- Cai, W.; Chen, S.; Zhang, D. Fast and robust fuzzy c-means clustering algorithms incorporating local information for image segmentation. Pattern Recognit. 2007, 40, 825–838. [Google Scholar] [CrossRef]
- Zhao, X.; Li, Y.; Zhao, Q. Hidden markov Gaussian random field based fuzzy clustering algorithm for high-resolution remote sensing image segmentation. Acta Electron. Sin. 2016, 44, 679–686. (In Chinese) [Google Scholar] [CrossRef]
- Huang, N.; Jia, Z.; Yu, Y. Image segmentation based on combination of improved FCM and local information. Comput. Appl. Softw. 2011, 28, 97–100. (In Chinese) [Google Scholar]
- Zhao, X.; Li, Y.; Zhao, Q. Image segmentation by fuzzy clustering algorithm combining hidden Markov random field and Gaussian regression model. J. Electron. Inf. Technol. 2014, 36, 2730–2736. (In Chinese) [Google Scholar] [CrossRef]
- Chatzis, S.; Varvarigon, T.A. A fuzzy clustering approach toward hidden Markov random field models for enhanced spatially constrained image segmentation. IEEE Trans. Fuzzy Syst. 2008, 16, 1351–1361. [Google Scholar] [CrossRef]
- Zhao, X.; Li, Y.; Zhao, Q. A fuzzy clustering image segmentation algorithm with double neighborhood system combined with Markov Gaussian model. J. Comput.-Aided Des. Comput. Graph. 2016, 28, 615–623. (In Chinese) [Google Scholar]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning-1. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Liang, Q.; Mendel, J.M. Interval type-2 fuzzy logic systems: Theory and design. IEEE Trans. Fuzzy Syst. 2000, 8, 535–549. [Google Scholar] [CrossRef]
- John, R.I.; Innocent, P.R.; Barnes, M.R. Neuro-fuzzy clustering of radiographict tibia image data using type-2 fuzzy sets. Inf. Sci. 2000, 125, 65–82. [Google Scholar] [CrossRef]
- Liang, Q.; Mendel, J.M. MPEG VBR video traffic modeling and classification using fuzzy technique. IEEE Trans. Fuzzy Syst. 2001, 9, 183–193. [Google Scholar] [CrossRef]
- Karnik, N.N.; Mendel, J.M.; Liang, Q. Type-2 fuzzy logic systems. IEEE Trans. Fuzzy Syst. 1999, 7, 643–658. [Google Scholar] [CrossRef]
- Melin, P.; Urias, J.; Solano, D.; Soto, M.; Lopez, M.; Castillo, O. Voice recognition with neural networks, type-2 fuzzy logic and genetic algorithms. J. Eng. Lett. 2006, 13, 108–116. [Google Scholar]
- Zhang, W.B.; Hu, H.Z.; Liu, W.J. Rules extraction of interval type-2 fuzzy logic system based on fuzzy c-means clustering. In Proceedings of the 4th International Conference on Fuzzy Systems and Knowledge Discovery, Haikou, China, 24–27 August 2007; Volume 2, pp. 256–260. [Google Scholar]
- Kaur, P.; Lamba, I.M.S.; Gosain, A. Kernelized type-2 fuzzy c-means clustering algorithm in segmentation of noisy medical images. In Proceedings of the IEEE Recent Advances in Intelligent Computational Systems (RAICS), Trivandrum, India, 22–24 September 2011; pp. 493–498. [Google Scholar]
- Melin, P.; Castillo, O. A review on the applications of type-2 fuzzy logic in classification and pattern recognition. Expert Syst. Appl. 2013, 40, 5413–5423. [Google Scholar] [CrossRef]
- Tizhoosh, H.R. Image thresholding using type II fuzzy sets. Pattern Recognit. 2005, 38, 2363–2372. [Google Scholar] [CrossRef]
- Bustince, H.; Barrenechea, E.; Pagola, M.; Fernandez, J.; Sanz, J. Comment on: Image thresholding using type II fuzzy sets importance of this method. Pattern Recognit. 2010, 43, 3188–3192. [Google Scholar] [CrossRef]
- Hwang, C.; Rhee, F.C. Uncertain fuzzy clustering: Interval type-2 fuzzy approach to c -means. IEEE Trans. Fuzzy Syst. 2007, 5, 107–120. [Google Scholar] [CrossRef]
- Yu, L.; Xiao, J.; Zheng, G. Robust interval type-2 possibilistic c-means clustering and its application for fuzzy modeling. In Proceedings of the 6th International Conference on Fuzzy Systems and Knowledge Discovery, Tianjin, China, 14–16 August 2009; Volume 4, pp. 360–365. [Google Scholar]
- Askari, G.; Xu, A.G.; Li, Y.; Alavipanah, S.K. Automatic determination of number of homogenous regions in SAR images utilizing splitting and merging based on a reversible jump MCMC algorithm. J. Indian Soc. Remote Sens. 2013, 41, 509–521. [Google Scholar] [CrossRef]
- Chakravarty, S.; Dash, P.K. A PSO based integrated functional link net and interval type-2 fuzzy logic system for predicting stock market indices. Appl. Soft Comput. 2012, 12, 931–941. [Google Scholar] [CrossRef]
- Azad, A.Z.K.; Khanesar, M.A.; Teshnehlab, M. Type-2 fuzzy neural networks for sliding mode fuzzy control of nonlinear dynamical systems with adaptive learning rate. In Proceedings of the 3rd IEEE International Conference on Computer, Control and Communication (IC4), Karachi, Pakistan, 25–26 September 2013; pp. 1–6. [Google Scholar]
- Zeng, J.; Liu, Z.Q. Type-2 Fuzzy Graphical Models for Pattern Recognition; Springer: Heidelberg/Berlin, Germany; Tsinghua University Press: Beijing, China, 2015; pp. 97–112. [Google Scholar]
- Pinheiro, H.N.B.; Ren, T.I.; Cavalcanti, G.D.C.; Jyh, T.I.; Sijbers, J. Type-2 fuzzy GMMs for robust text-independent speaker verification in noisy environments. In Proceedings of the 22nd International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 4531–4536. [Google Scholar]
- Tsang, I.R.; Gabriel, D.; Pinheiro, H.N.B.; Cavalcanti, G.D.C. Speaker verification using type-2 fuzzy gaussian mixture models. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Seoul, Korea, 14–17 October 2012; Volume 41, pp. 2336–2340. [Google Scholar]
- MohammadZadeh, A.; Kaynak, O.; Teshnehlab, M. Two-mode indirect adaptive control approach for the synchronization of uncertain chaotic systems by the use of a hierarchical interval type-2 fuzzy neural network. IEEE Trans. Fuzzy Syst. 2014, 22, 1301–1312. [Google Scholar] [CrossRef]
- Khanesar, M.A.; Kayacan, K. Levenberg-marquardt training method for type-2 fuzzy neural networks and its stability analysis. In Proceedings of the IEEE International Conference on Fuzzy Systems, Istanbul, Turkey, 2–5 August 2015; pp. 1–7. [Google Scholar]
- Aliev, R.A.; Pedrycz, W.; Guirimov, B.G.; Aliev, R.R; Llhan, U. Type-2 fuzzy neural networks with fuzzy clustering and differential evolution optimization. Inf. Sci. 2011, 181, 1591–1608. [Google Scholar] [CrossRef]
- Kaur, P.; Soni, A.K.; Gosain, A. A robust kernelized intuitionistic fuzzy c-means clustering algorithm in segmentation of noisy medical images. Pattern Recognit. Lett. 2013, 34, 163–175. [Google Scholar] [CrossRef]
- Tan, W.W.; Foo, C.L.; Chua, T.W. Type-2 fuzzy system for ECG arrhythmic classification. In Proceedings of the IEEE International Fuzzy Systems Conference, London, UK, 23–26 July 2007; Volume 24, pp. 1–6. [Google Scholar]
- Zarandi, M.H.F.; Torshizi, A.D. A new validation criteria for type-2 fuzzy c-means and possibilistic c-means. In Proceedings of the Annual Meeting of the North American Fuzzy Information Processing Society(NAFIPS), Berkeley, CA, USA, 6–8 August 2012; pp. 1–6. [Google Scholar]
- Bouwmans, T.; Baf, F.E. Modeling of dynamic backgrounds by type-2 fuzzy gaussians mixture models. Stud. Comput. Intell. 2009, 1, 265–277. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Principle | Application |
|---|---|---|
| Interval type-2 fuzzy model based on information entropy [20,21] | Based on the information entropy in information theory, construct the interval type-2 fuzzy information entropy model by defining the fuzzy conditions of information entropy | Image segmentation/classification edge detection |
| Interval type-2 fuzzy model based on FCM [22,23,24] | Under the framework of FCM, construct the interval type-2 FCM model by fuzzy exponential factorization, fuzzy membership function or fuzzy clustering center | Fuzzy clustering |
| Interval type-2 fuzzy neural network model [25,26] | Neural network model operated in accordance with Zadeh Extension Theorem, with interval type-2 fuzzy signal, interval type-2 fuzzy membership function or interval type-2 fuzzy logic activation function | Fuzzy control Time sequence decision |
| Interval type-2 Gaussian mixture model [27,28,29] | Mean or standard deviation in fuzzy Gaussian mixture model | Segmentation/Classification Object identification |
| Method | Accuracy Indicator | Homogenous Region | |||
|---|---|---|---|---|---|
| I | II | III | IV | ||
| Type-1 fuzzy model | User accuracy | 0.998 | 0.796 | 0.901 | 0.833 |
| Product precision | 0.892 | 0.841 | 0.997 | 0.786 | |
| Total accuracy = 0.879; Kappa = 0.839 | |||||
| Maximum likelihood | User accuracy | 0.981 | 0.822 | 0.919 | 0.800 |
| Product precision | 0.913 | 0.791 | 0.978 | 0.834 | |
| Total accuracy = 0.879; Kappa = 0.839 | |||||
| FCM | User accuracy | 0.843 | 0.747 | 0.895 | 1.000 |
| Product precision | 1.000 | 0.905 | 0.695 | 0.827 | |
| Total accuracy = 0.857; Kappa = 0.809 | |||||
| HMRF-FCM | User accuracy | 1.000 | 0.903 | 0.932 | 0.781 |
| Product precision | 0.927 | 0.743 | 1.000 | 0.920 | |
| Total accuracy = 0.898; Kappa = 0.863 | |||||
| Weighted average | User accuracy | 0.995 | 0.878 | 0.936 | 0.874 |
| Product precision | 0.932 | 0.873 | 0.994 | 0.881 | |
| Total accuracy = 0.920; Kappa = 0.889 | |||||
| Neighborhood weighted average | User accuracy | 0.997 | 0.993 | 0.994 | 0.991 |
| Product precision | 0.995 | 0.991 | 0.999 | 0.991 | |
| Total accuracy = 0.994; Kappa = 0.992 | |||||
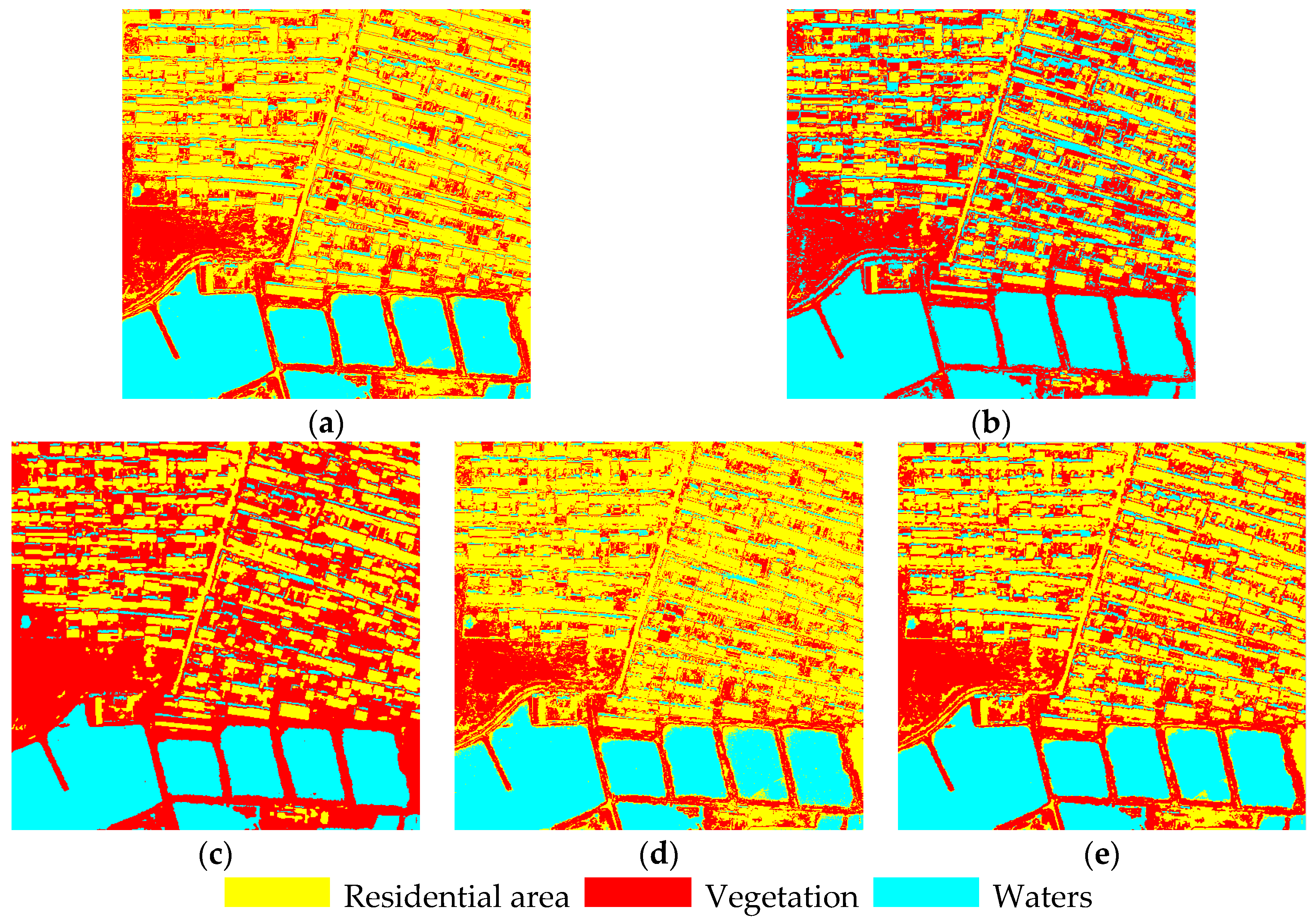
| Images (Figure 10) | Accuracy Indicator | Method | ||||
|---|---|---|---|---|---|---|
| Maximum Likelihood | FCM | HMRF-FCM | Weighted Average | Neighborhood Weighted | ||
| (a) | Total accuracy | 0.878 | 0.899 | 0.691 | 0.812 | 0.907 |
| Kappa | 0.837 | 0.871 | 0.505 | 0.879 | 0.881 | |
| Tims (s) | 1.13 | 156.32 | 4.64 | 1.36 | 1.28 | |
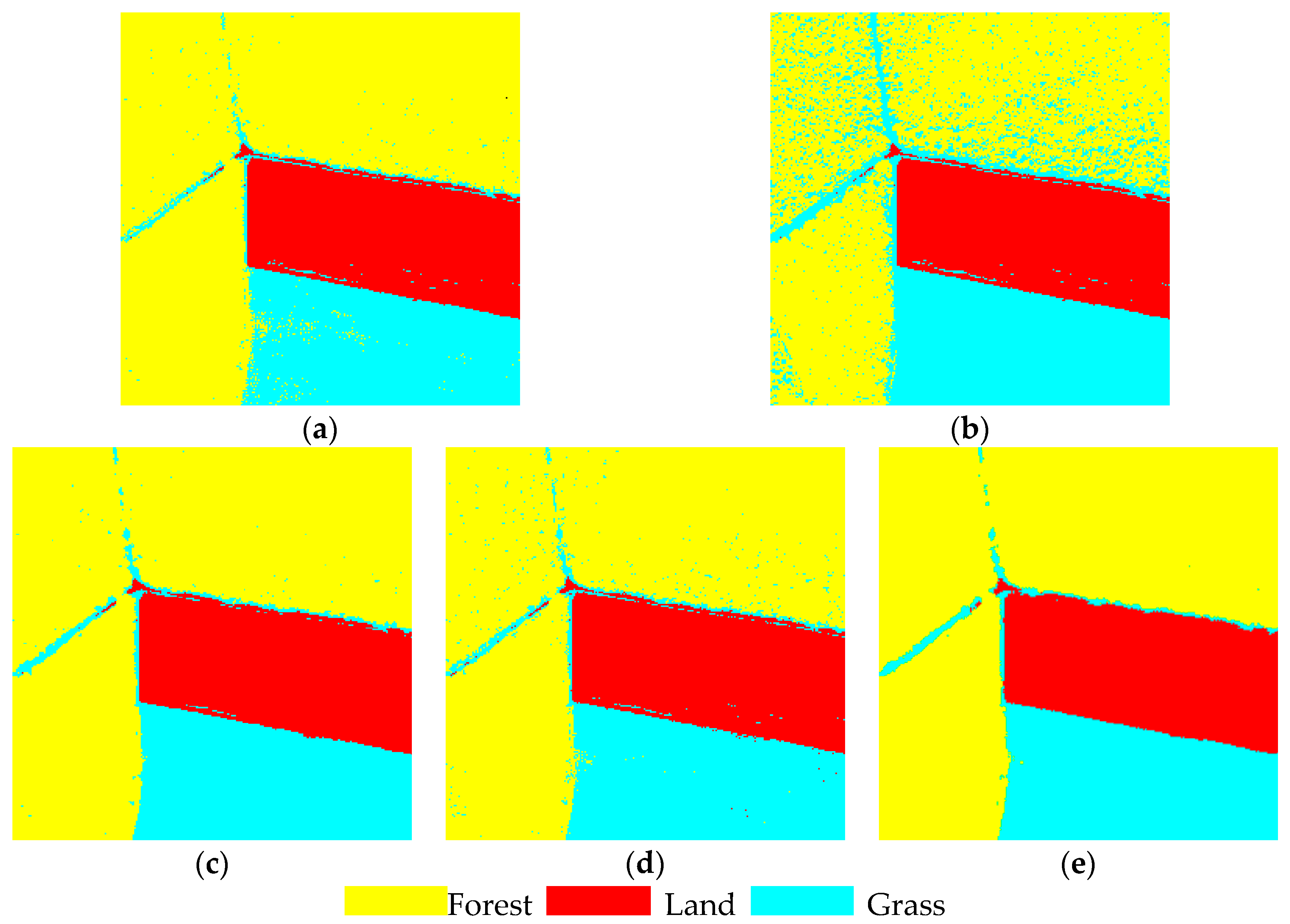
| (b) | Total accuracy | 0.899 | 0.691 | 0.812 | 0.907 | 0.912 |
| Kappa | 0.871 | 0.505 | 0.879 | 0.881 | 0.887 | |
| Tims (s) | 12.7 | 4126 | 132.7 | 13.20 | 13.15 | |
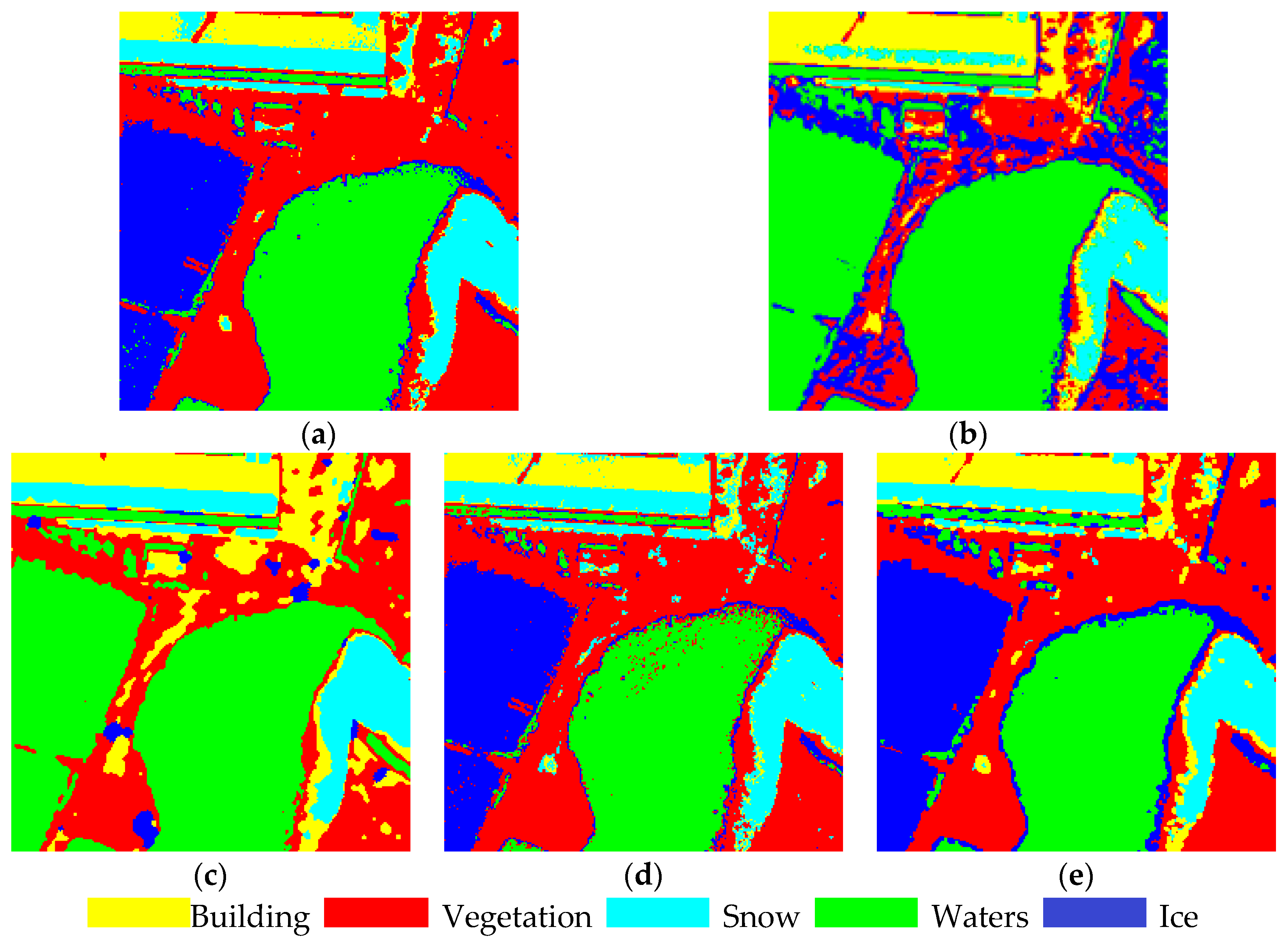
| (c) | Total accuracy | 0.737 | 0.708 | 0.684 | 0.728 | 0.914 |
| Kappa | 0.665 | 0.643 | 0.614 | 0.652 | 0.865 | |
| Tims (s) | 1.38 | 192.27 | 5.35 | 1.72 | 1.68 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Xu, A.; Li, X. Supervised Classification High-Resolution Remote-Sensing Image Based on Interval Type-2 Fuzzy Membership Function. Remote Sens. 2018, 10, 710. https://doi.org/10.3390/rs10050710
Wang C, Xu A, Li X. Supervised Classification High-Resolution Remote-Sensing Image Based on Interval Type-2 Fuzzy Membership Function. Remote Sensing. 2018; 10(5):710. https://doi.org/10.3390/rs10050710
Chicago/Turabian StyleWang, Chunyan, Aigong Xu, and Xiaoli Li. 2018. "Supervised Classification High-Resolution Remote-Sensing Image Based on Interval Type-2 Fuzzy Membership Function" Remote Sensing 10, no. 5: 710. https://doi.org/10.3390/rs10050710
APA StyleWang, C., Xu, A., & Li, X. (2018). Supervised Classification High-Resolution Remote-Sensing Image Based on Interval Type-2 Fuzzy Membership Function. Remote Sensing, 10(5), 710. https://doi.org/10.3390/rs10050710