1. Introduction
Today, remote sensing (RS) data from different sensors and platforms have become increasingly available for estimating forest characteristics at the scale of plots, stands, landscapes, and entire countries or regions, e.g., [
1]. For practitioners this development is welcome, but it also poses several challenges with regard to the selection of RS data source for applications. An interesting possibility is to make use of several sources of RS data simultaneously through composite estimation (CE) [
2] or in a sequential manner through data assimilation (DA) [
3].
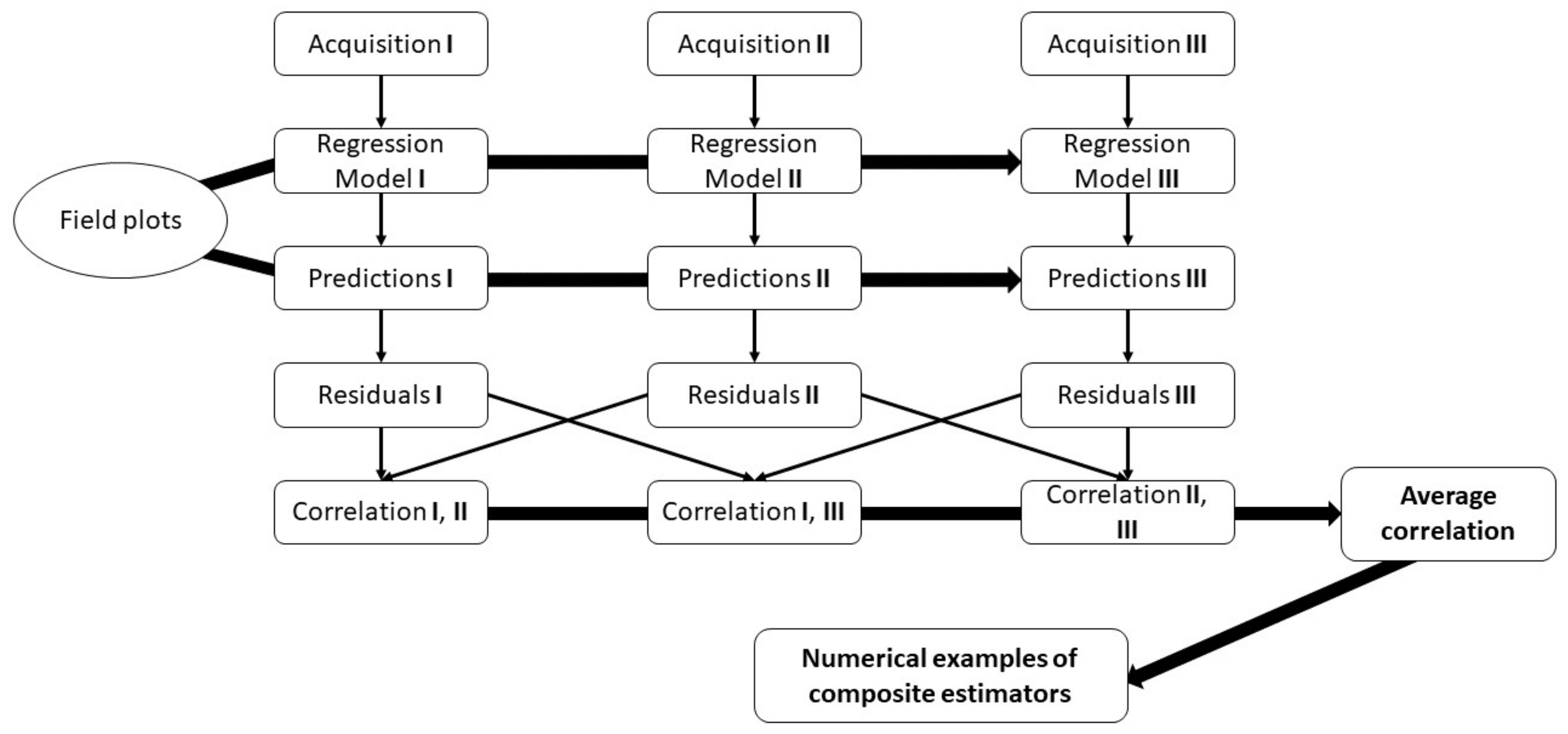
An ordinary CE is constructed as a weighted average of several individual estimates; to minimize the variance of the CE, the weights are set inversely proportional to the variance of the individual estimators, e.g., [
2]. In case estimates are correlated, this must be taken into account in the calculation of weights and in estimating the variance of the CE. CEs are sometimes applied in national forest inventories, e.g., [
4].
DA [
3] can be seen as an extension of ordinary CE for the case when time differences between estimates make it necessary to include a model for updating previous estimates to current time before combining with a new estimate. In case the time difference between estimates is short, the difference (in results) between a CE and a standard DA-based estimator, such as the Kalman filter, e.g., [
3], is minor. However, DA is a more useful concept than ordinary CE at longer time spans between RS data acquisitions and through DA entire time series of RS data of different kinds can be used for improving the precision of an estimate of current state [
5]. Many DA methods exist, e.g., [
3], in which the standard Kalman filter assumes independent estimators (or direct observations) at the different time points and a linear model for updating previous estimates to current time. Similarly to ordinary CE, the Kalman filter estimator of current state is a weighted average of a new and an updated estimate; the weights are assigned to be inversely proportional to the variance of the estimators involved.
Studying recent developments in forestry applications of DA, promising results have been obtained in simulation studies [
5]. However, the empirical results presented by [
6,
7] pointed out problems to fully realize the theoretical potential of DA in practice. In the latter studies, making use of only the last measurement for estimating the current state of key forest characteristics was sometimes almost as good as making use of the entire time series through DA. However, all these studies [
5,
6,
7] assumed the estimates to be uncorrelated between subsequent time periods, as is the practice in standard DA through Kalman filtering [
3,
8,
9]. However, using a certain kind of RS data repeatedly, such as data from airborne laser scanning (ALS), e.g., [
10], it is likely that certain conditions of a given plot or stand will tend to make the estimates always deviate in a certain direction from the true value. Such conditions could be that a plot is located in steep terrain or that it has an unusual stand structure. Focusing on a specific plot (or stand), such systematic deviations cause biased estimates. However, in applications it will not be known for which plots the estimates tend to be systematically too high or too low, and a reasonable model assumption is that the deviation, based on a certain type of RS data, is composed of two terms: a random effect which remains the same over a certain period of time (due to plot conditions), and a random term which is independent of the other random effect and between subsequent acquisitions (i.e., white noise due to variable RS data acquisition conditions).
Many standard applications of CE and DA assume that the estimates (or observations) are independent. When this is not the case, more advanced methods should preferably be applied but this issue is, sometimes, not fully acknowledged, not even in meteorology where DA has been applied for several decades, e.g., [
11], where it is pointed out that treating observations as independent when they are not might lead to substantial loss of DA efficiency.
Although the literature about RS-based assessment of forest characteristics is vast, e.g., [
10,
12,
13,
14], no studies appear to be available where error correlations between subsequent estimates are assessed. For ocular stand level inventories, a study of correlated measurement errors was reported by [
15].
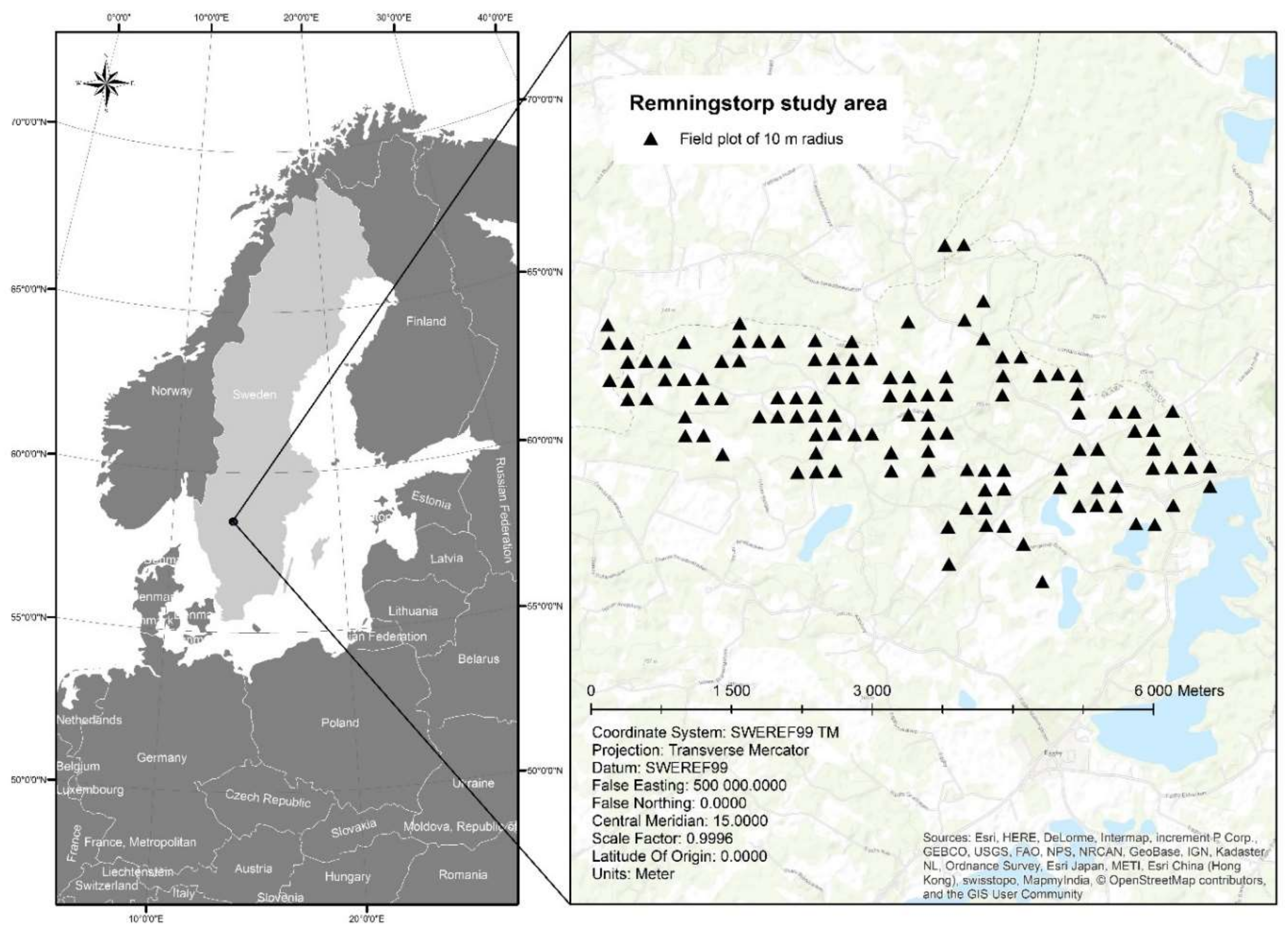
The objective of this study was to estimate the correlation of plot level deviations between estimated and ground truth values, for estimates of forest attributes from different datasets using the same type of RS sensor as well as across estimates using different sensors. The RS data types evaluated were multispectral data from the SPOT-5 satellite, 3D data from airborne laser scanning (ALS), and TerraSAR-X add-on for Digital Elevation Measurement Interferometric Synthetic Aperture Radar (TanDEM-X InSAR) radar data. The forest attributes studied were growing stock volume, basal area weighted mean height (also known as Lorey’s height), and basal area weighted mean diameter. All data were acquired from the Remningstorp test site in southern Sweden. Further, we demonstrate the implication for CE of assuming estimates to be independent in case they are not and we discuss similar implications in DA applications.
As a matter of terminology, we acknowledge the difference between
predicting a random variable (e.g., when a regression model is used for predicting an unknown random quantity) and
estimating a fixed parameter. However, in order to simplify the text, and since the convention to separate between prediction and estimation seems not to be generally adopted, we have chosen to use the term
estimation for both cases [
16].
4. Discussion
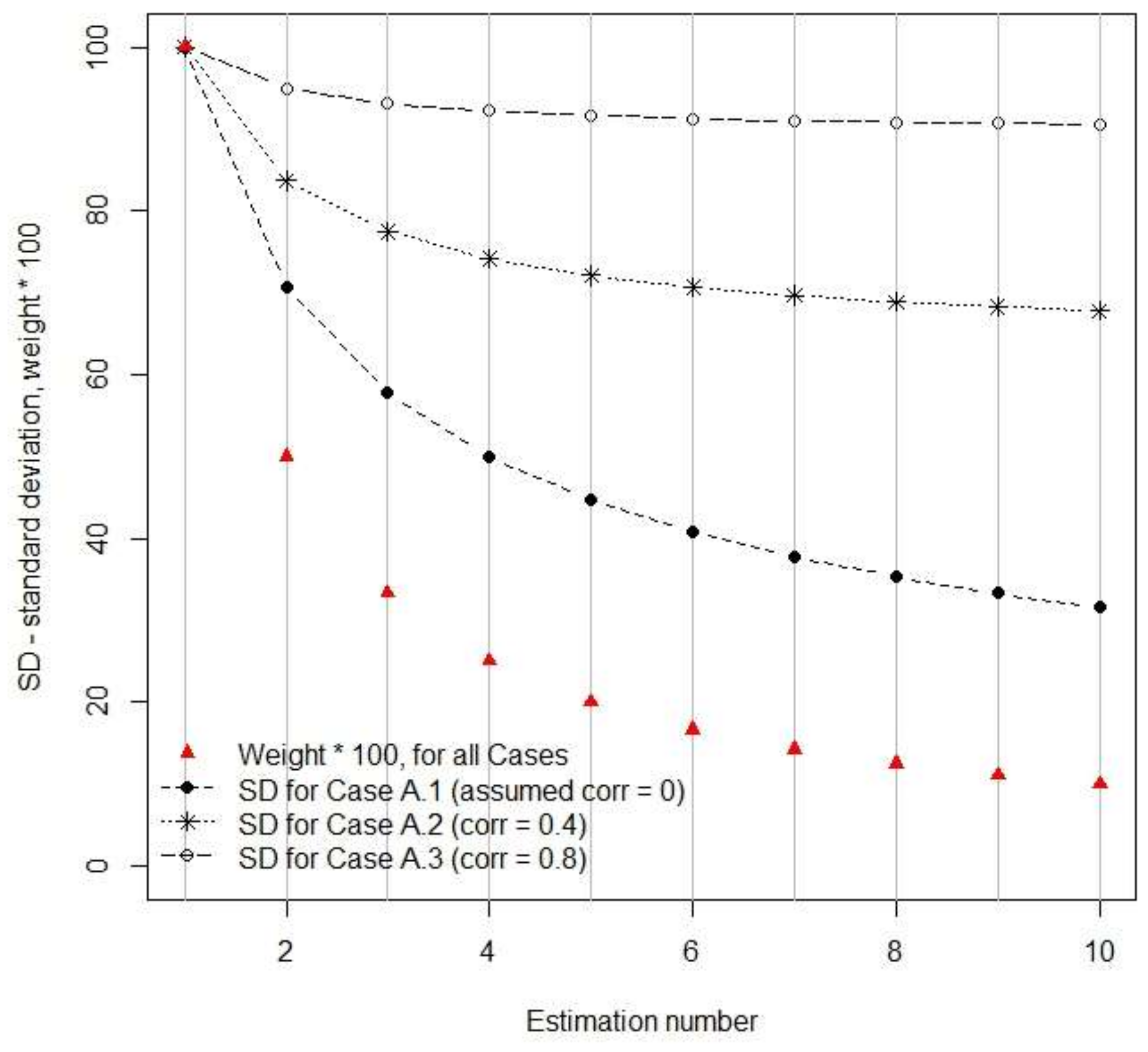
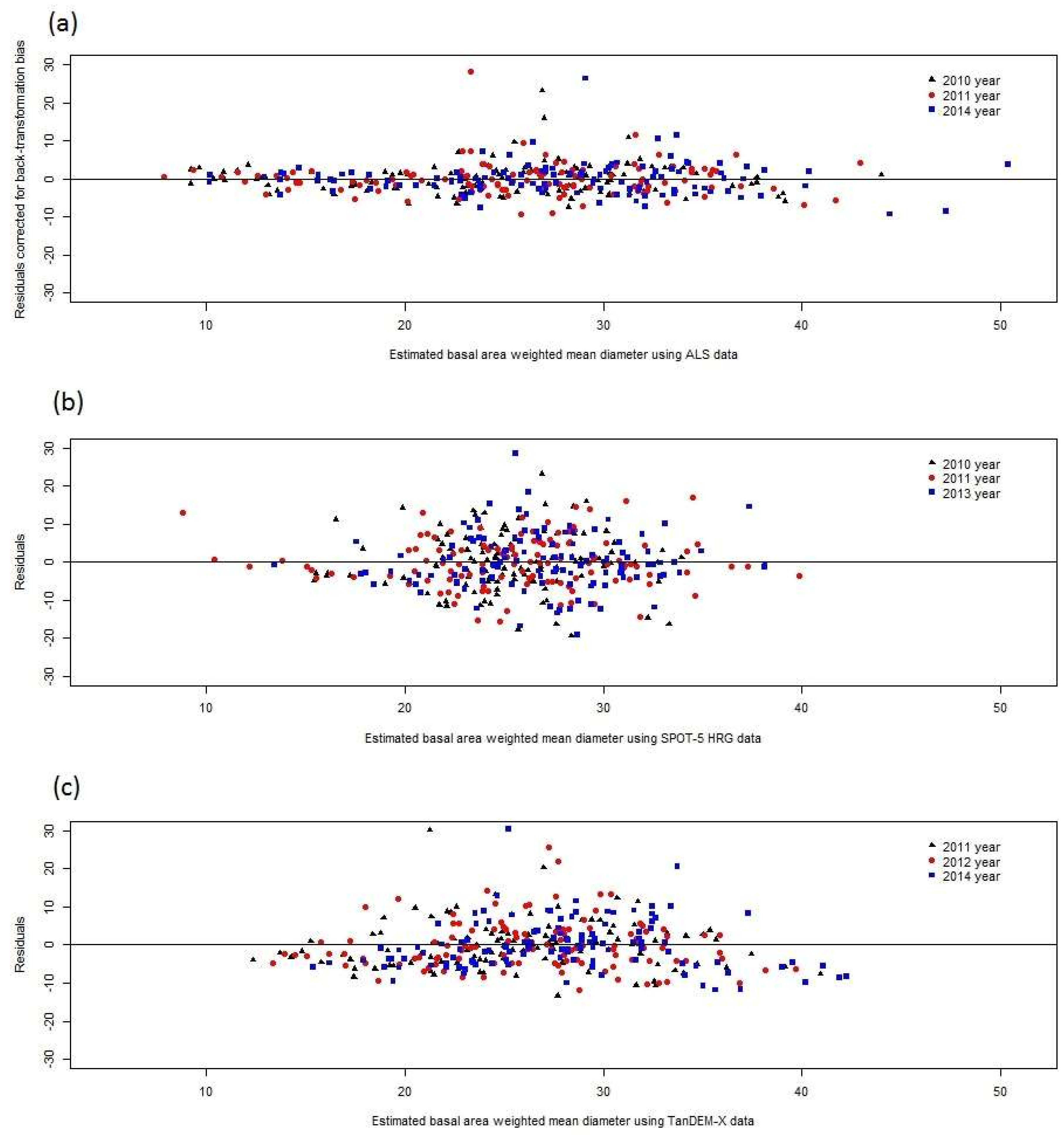
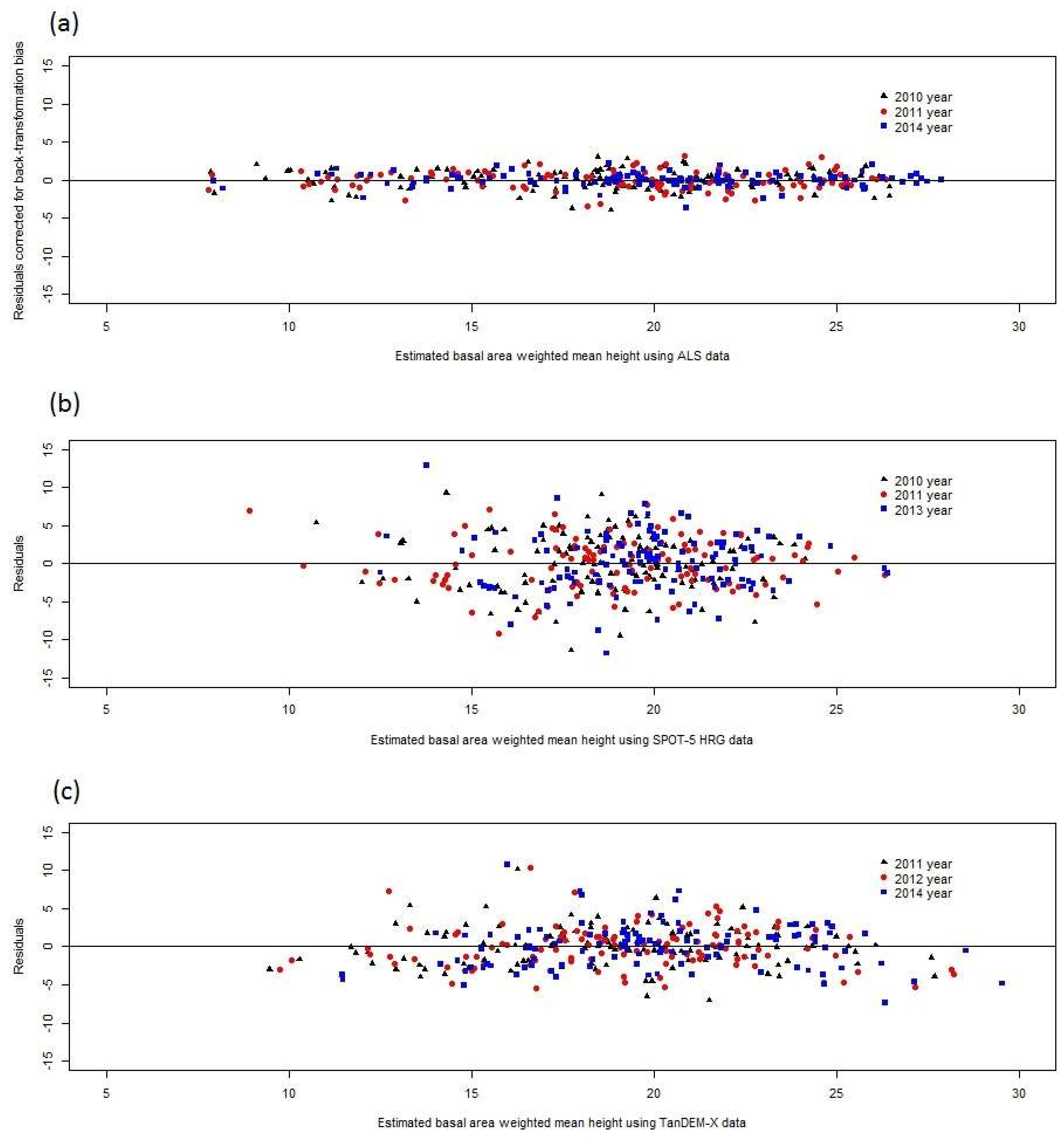
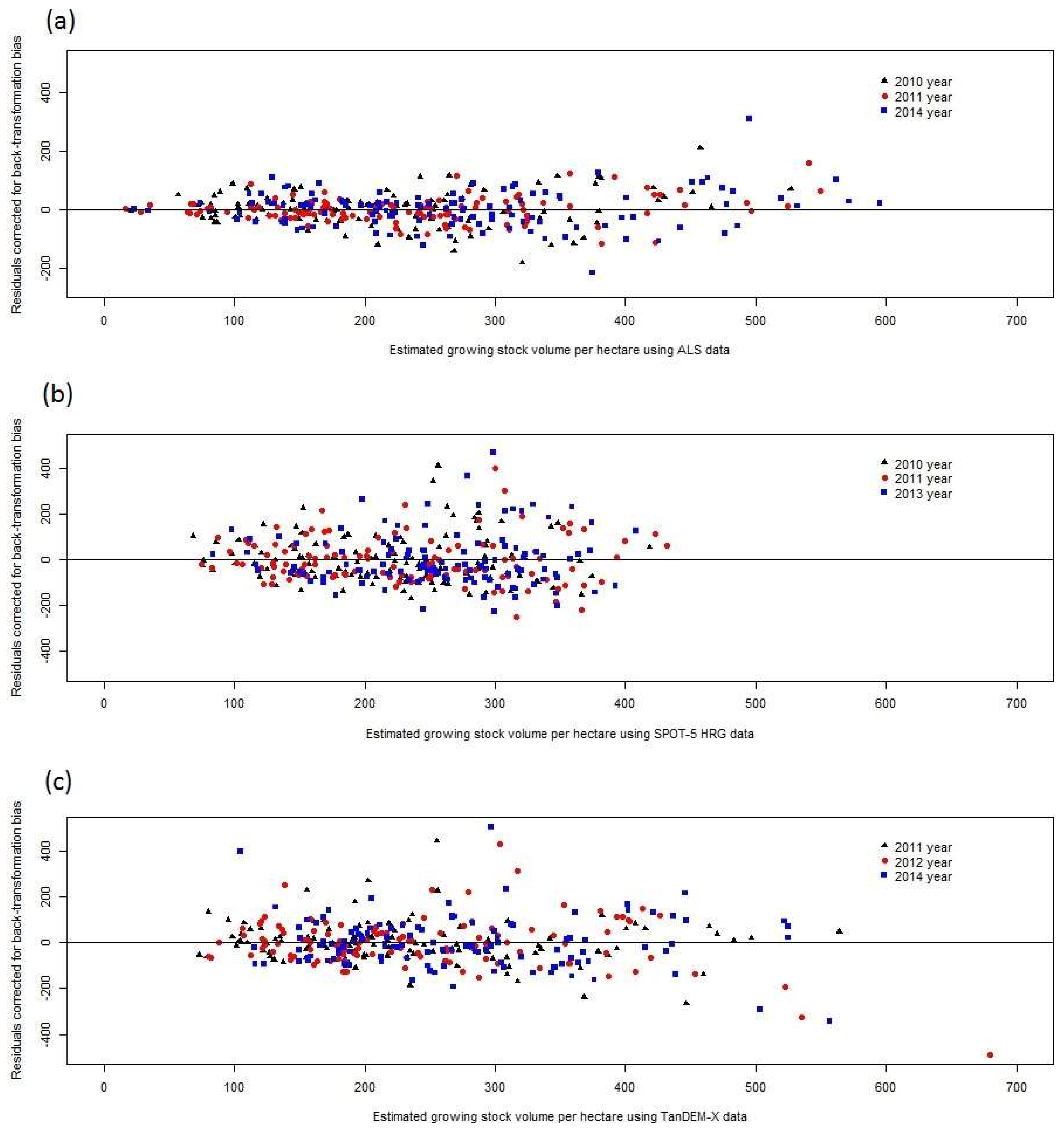
The correlations between residuals of RS-based estimates of forest attributes were found to be strong in the Remningstorp study area. Further studies are needed to show if this is the case in other areas as well, but as will be further discussed below, several factors linked to how RS-based estimates are derived make it plausible that similar results would be obtained also in other areas. Thus, CEs using RS-data-based estimates of growing stock volume, mean diameter, and mean height (i.e., the attributes evaluated in this study) ideally should consider that the estimates are correlated or otherwise the results will be less precise and misleading in terms of reported variances (and thus confidence intervals) of the CEs. However, it should be pointed out that in most cases only minor gains in precision would be obtained through correctly considering residual error correlations in determining the weights of the individual estimates in CE. Perhaps more importantly, considering correlations makes estimated variances of CEs realistic, whereas CE variances otherwise might be severely underestimated.
In the methods section of the article, it was pointed out that there are many similarities between a CE obtained in a sequential manner, as in this study, and data assimilation using standard Kalman filter approaches [
9]. Since the standard Kalman filter assumes uncorrelated estimates most of the conclusions from this study, with regard to CE, would hold for DA as well, although the forecasting step of DA makes direct comparison difficult.
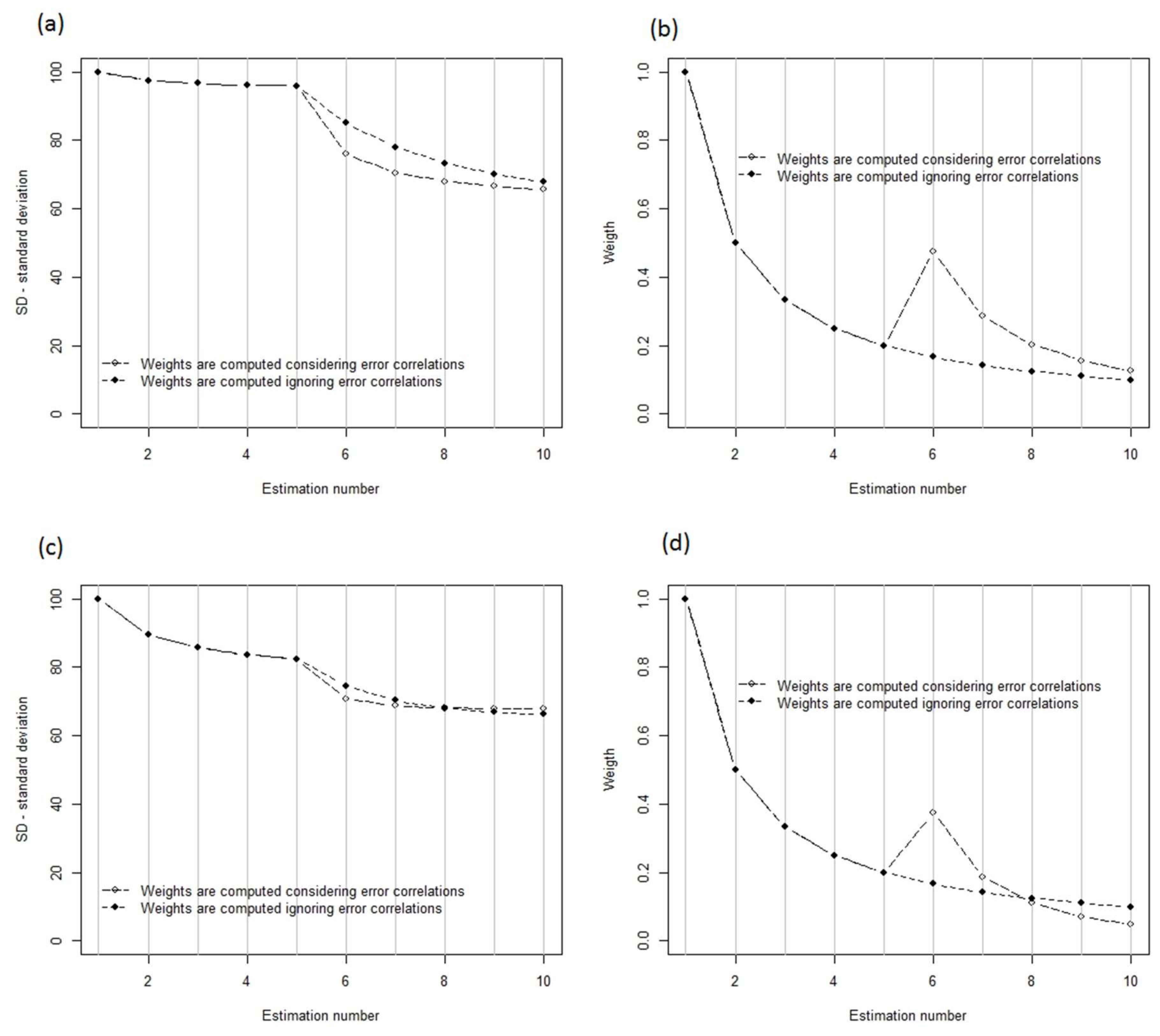
When different types of estimators are mixed in a CE (cases B and C), it was demonstrated that the differences between the estimators, in terms of residual error correlation, must be substantial before the benefit of handling correlations in the computation of weights becomes evident. When the differences, in terms of standard deviation and error correlation, between different RS-data-based estimates were small to moderate (case B) it was found that using slightly incorrect weights did not affect the (true) standard deviation of CE very much. However, with substantial differences between methods (case C) correct handling of error correlations appears to be important. In this case a precise estimate was obtained after a series of correlated, less precise, estimates. The correct solution assigned high weight to the last estimate, and as a result the standard error of the CE was substantially reduced. Ignoring residual error correlation led to a CE with poor, and overestimated, precision.
Strong error correlation might be part of the reason why the empirical studies by [
6,
7] showed that DA was only slightly better than consistently using only the last RS-data-based estimate. The RS data used in these cases were point clouds from digital aerial photos and TanDEM-X InSAR data, respectively. The first type of data was not evaluated in this study, whereas the latter was found to lead to estimates with substantial error correlations.
Error correlation causes problems also in non-forestry applications of DA, but it appears that it is only rather recently that the topic has been highlighted [
11]. In that study, in the context of meteorology, correlated errors obtained from RS data were found to lead to similar problems as the ones identified in this study. In our study all RS data types resulted in moderate to strong error correlations between the regression residuals, across acquisitions using the same sensor. The correlations across RS data types were weaker and this suggests that efficient CE procedures might incorporate estimates from different RS data types, provided the differences in precision are not substantial. However, in doing so the problem observed by [
33] must be avoided, i.e., that estimates and estimated variances can be correlated thus causing CEs of the kind applied in this study to be biased. Further, in general the correlations were weaker for height than for volume and diameter, which suggests that CE would work better for this attribute. However, this study was conducted at the level of single plots but in practical forestry estimating attributes at the level of stands is typically more important. Thus, an important continuation of the current study would be to investigate if the plot level effects remain the same within entire stands or if they vary between plots in stands. In the latter case, the potential problems observed in this study would be less severe.
The reasons for the correlated residuals might be several. In general, plots that give a certain response in terms of RS data from a specific sensor still are variable with regard to the target characteristic. For example, plots with the same growing stock volume may have either dense or sparse canopy cover, or they may be located in either steep or flat terrain, leading to different registered reflectance values in a satellite image. This underlies the well-known effect in regression analysis that the estimates “tend towards the mean”, i.e., that the highest true values tends to be underestimated and the lowest true values overestimated.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



