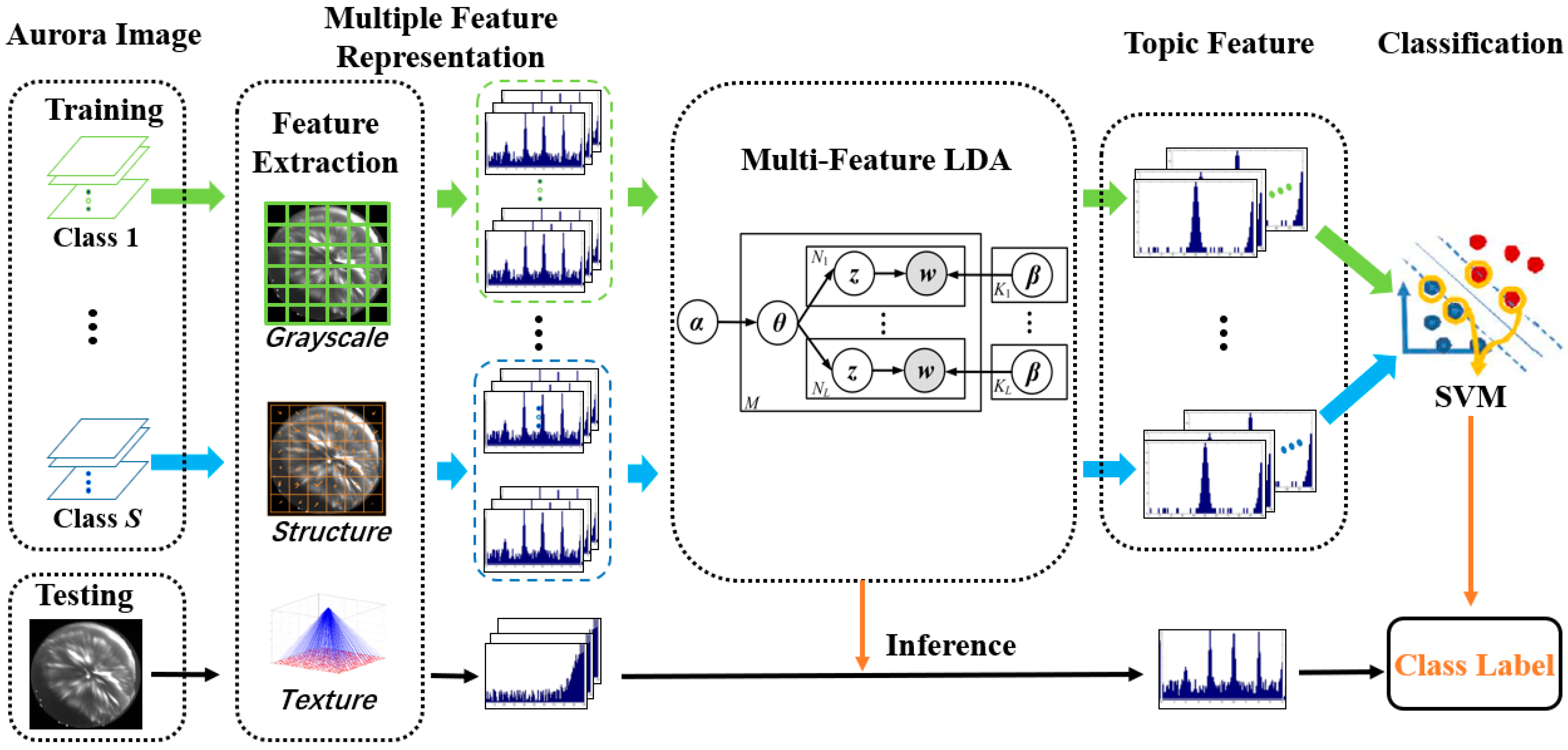
3.2. Multiple Feature Representation
Considering that aurora images have more unique characteristics than other images, using multiple features is a more effective way to describe the images. In the proposed approach, different types of features were extracted, i.e., the local grayscale feature, the local structural feature, and the global textural feature.
(1) Local grayscale feature. Although the aurora images are gray scale with only one spectral band, there is a big difference in the grayscale distribution between different types of auroral images. Firstly in this step, certain numbers of local patches were evenly sampled from the aurora images. There are several methods that can be used to extract the local grayscale feature, such as the histogram statistics method and the mean and standard deviation (MeanStd) method. In the proposed approach, the MeanStd method was selected, which computes the mean and standard deviation of the patches. Due to the advantages of noise suppression and the low feature dimension, it is a simple and convenient method for the subsequent analysis.
(2) Local structural feature. Similarly, certain numbers of local patches were evenly sampled from the aurora images. The methods of structural feature extraction include methods based on mathematical morphology, the pixel shape index, the histogram of oriented gradient (HOG) operator [
29], and SIFT [
30]. SIFT was applied in the proposed approach to extract a 128-dimension structural feature for each patch. Usually, when using SIFT to extract the structural feature from an image, it is necessary to select the first principal component obtained by the classical principal component transformation as the basis image. However, in the proposed approach, this step was omitted since the aurora images were grayscale images.
(3) Global textural feature. Unlike the above two features, the texture feature is a global feature, so there is no need to sample the aurora images. SITI [
19] is utilized to construct a 350-dimensional 1-D histogram. The default parameters were used in our experiments, i.e., the number of bins of the histogram was set to 50, and the minimum and maximum sizes of the shapes were set to 3 and 10,000, respectively.
After extracting the three types of features of the aurora images, it is necessary to combine them in an appropriate way to represent the aurora images. By the use of the proposed method, the different types of features were converted into a unified form (1-D histogram). For local continuous features such as MeanStd and SIFT, the features of all the local patches were quantified into V bins by a vector quantization method such as the k-means clustering algorithm, and then all the local discrete features were aggregated into a global 1-D histogram with V bins by a counting operator. The summation of this histogram over the bins should be the number of local patches. For local discrete features, the histogram of features could be used directly to describe the aurora images. For global continuous features such as SITI, all the features could be stretched into a 1-D histogram with a certain scale. Through the above operation, each aurora image could be represented by multiple 1-D histograms, where the number of 1-D histograms was equal to the number of feature types. Through this strategy, the proposed AI-MFLDA method could fuse more kinds of features, whether local or global, discrete or continuous.
3.3. Proposed AI-MFLDA
In order to describe the aurora images more effectively, a multi-feature topic model was proposed to combine the different types of features. It is worth noting that if a single type of probability function was used to generate only one set of latent topic variables for modeling all the sets of visual words corresponding to the different type of features, the performance would be weakened. The proposed AI-MFLDA method used a new idea to overcome this problem.
For AI-MFLDA, different topic spaces were generated for the different types of features by the same Dirichlet priors, and then each aurora image was represented by the different probability distributions of the latent topic variables called “topic features”. The weights of the different topic variables of each aurora image were then optimized by maximizing the likelihood function of the images. Because a few latent topic variables can describe the distribution of multiple corresponding visual words, the proposed AI-MFLDA was able to reduce the dimension of the features.
As in the LDA model introduced in
Section 2,
,
, and
respectively represented the index of the aurora image, the index of the visual words, and the index of the topics. The index of the types of visual words is denoted as
. For the proposed AI-MFLDA, the index of the types of features is denoted as
, the number of features is denoted as
, and the number of topics corresponding to the
-th type of feature is denoted as
. Moreover,
represents the number of types of visual words, and we use
to denote the number of visual words corresponding to the
-th type of feature in the
-th aurora image. For an aurora image dataset
, each aurora image
in
can be represented by
visual words corresponding to multiple features. For the
-th feature,
is used to denote the visual words of the
-th image and
. By counting the
with the same values, the
visual words are transformed into a 1-D histogram
, where
, and
represents the number of the
-th type of visual word corresponding to the
-th type of feature.
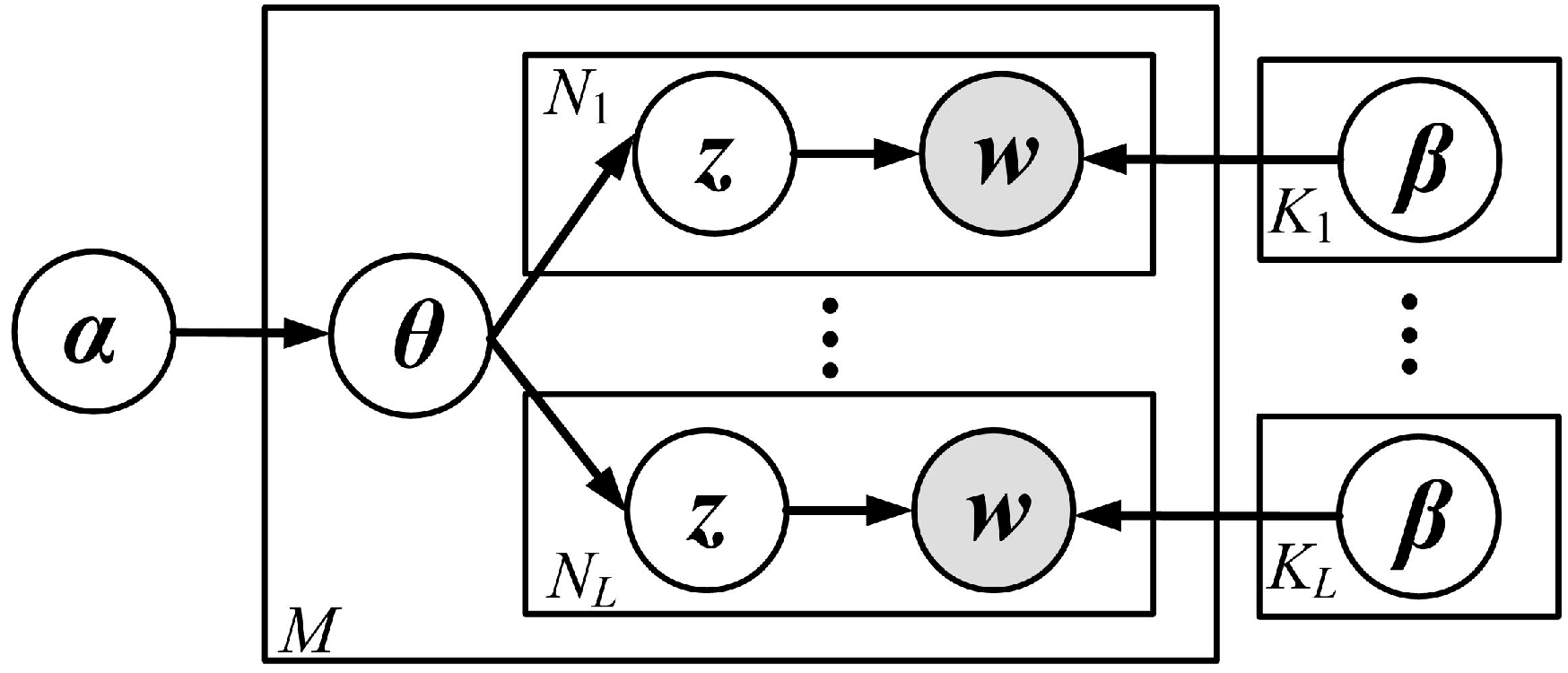
Figure 5 shows a graphical representation of the proposed AI-MFLDA. In the figure,
w denotes the visual words of the aurora images,
z denotes the latent topic variables,
θ denotes the parameters of the probability distribution of
z, and
and
denote the parameters of AI-MFLDA. We used the same latent variables
θ to generate a set of latent topic variables
z for each set of visual words corresponding to each type of feature. The probability of the
L sets of topic variables
z belonging to the aurora image was then adaptively tuned during the maximum likelihood estimation (MLE), which improved the fusion of the multiple features. As a probability generation model, the generative procedure of the proposed AI-MFLDA method was as follows:
For each aurora image :
(1) Choose a Dirichlet variable ;
(2) For each visual word of the aurora image, choose a latent topic variable and choose a visual word corresponding to the -th type of feature from , a categorical probability distribution conditional on the topic variable .
It was found in the above procedure that a latent topic z described a certain probability distribution of all the visual words. It was therefore feasible to use only a small number of topics to describe the aurora image, rather than the visual words, which reduced the feature dimension of the aurora image classification.
The likelihood function of the
i-th aurora image is written as Equation (5). The parameters
and
can be estimated by MLE. Similar to LDA, the estimation of Equation (5) is intractable, and an approximate inference method should be adopted to estimate Equation (5).
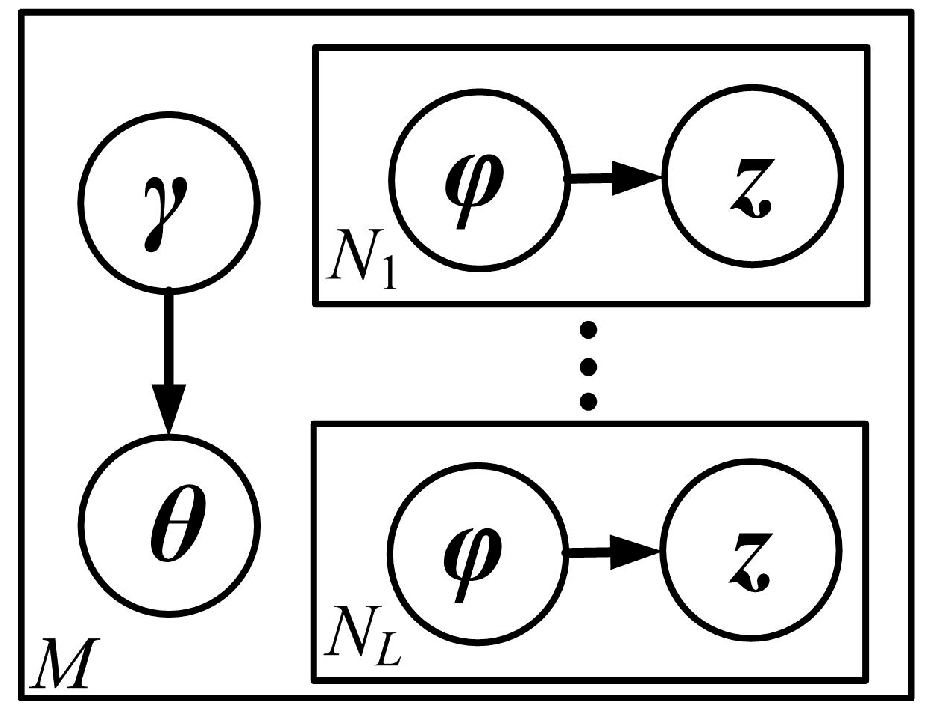
In the proposed approach, an approximate inference algorithm based on variational approximation [
16] is used to estimate Equation (5). By dropping the nodes
w and the edges between
θ and
z, and adding the variational parameters
and
, a family of variational distribution (as shown in
Figure 6), which is then utilized to approximate the likelihood function, can be obtained.
For each aurora image
, the variational distribution is written as:
The log likelihood of each aurora image
can be bounded using Jensen’s inequality as follows:
The right term in Equation (7) is the lower bound of the log likelihood, which can be rewritten as Equation (8):
In Equation (8), the five terms can be rewritten as Equations (9)–(13).
is the first derivative of the log gamma function.
For each aurora image, the variational class variable
can be updated using Equation (14), which is obtained by maximization of the lower bound of the log likelihood Equation (8) with respect to
. The constraint
should also be added to the maximization. In Equation (14),
is the probability of the word
generated by the
-th topic corresponding to the
-th type of feature.
By maximization of the lower bound of the log likelihood Equation (8) with respect to , the update function of the variational Dirichlet variable can be obtained as Equation (15). Each aurora image can acquire a group of , which are viewed as the topic features for the aurora image classification.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}