1. Introduction
Image classification for very high-resolution remote sensing images (VHRRSI) is an important aspect of efficient and effective earth observation information extraction. Assigning labels to each pixel of a VHRRSI, which is called per-pixel or pixel-wise classification, is of great importance and considered to be the basis for land mapping, image understanding, contour detection, object extraction, and so on [
1,
2,
3,
4].
For image classification, feature extraction is the key to achieving high-quality classification results. In 2006, Hinton [
5] noted that a deep neural network could learn more meaningful and profound features than the existing techniques, thereby enhancing the network performance. Since then, the application of deep learning to various fields has been tested widely, with largely positive results [
6,
7,
8]. In particular, deep networks have been successfully employed for feature extraction of remote sensing images in many studies [
9,
10,
11,
12,
13,
14,
15], outperforming other conventional methods. At present, finer-resolution acquired remote sensing images yield improved ground-object perception [
16]. However, the inter-class and intra-class variation make it difficult for land object classification [
17].
The attention mechanism is a technique that simulates the process employed by humans to understand and perceive images. The objective of this approach is to direct all focus, processing power, and resources to the most valuable and informative feature areas [
18,
19]. Hence, sensitivity to features containing important information is heightened, useful information is highlighted, and unnecessary information and noise are suppressed to better facilitate data mining. The attention mechanism has been applied in many different fields, such as image recognition [
20,
21], object detection [
22], positioning [
23], and multimodal reasoning and matching [
24].
In remote sensing, the most common attention mechanism uses saliency-guided sampling for graphical feature extraction. For example, Zhang et al. [
25] previously employed a context-aware saliency strategy to extract salient and unsalient areas from images, and then used an unsupervised sparse auto-encoder for feature extraction to acquire useful graphical information. Similarly, Hu et al. [
26] tested two kinds of saliency-guided sampling methods, a salient region-based method and a keypoint-based method on a University of California (UC)-Merced dataset and an RS19 dataset. The aim was to achieve optical, high-spatial-resolution, remote-sensing image scene classification. Chen et al. [
27] used JUDD, a visual saliency model, to acquire saliency maps from unlabeled remote sensing data. Those researchers then trained a neural network using a sparse filtering model and used it for remote sensing classification. It is notable that the methods mentioned above all follow the same classification workflow: area selection and extraction, feature extraction training, and classifier training. Therefore, the attention mechanism and the feature extraction and classification by the neural network are relatively independent. Thus, the network classification results do not influence the image focus points or the information to be highlighted or suppressed.
To unify the application processes of the attention mechanism and the feature extraction and classification by the neural network, some state-of-the-art methods to adaptively develop attention-aware features through network training have been proposed. For example, Hu et al. [
28] previously proposed a mechanism for constant feature extraction calibration through network training; this approach enables the network to amplify the meaningful feature channels and to suppress useless feature channels from global information. In addition, Yang et al. [
29] used an attention mechanism to extract additional valuable information on the transition layer; this information was then passed to the next feature extraction block for subsequent feature exploitation. Kim et al. [
30] employed a joint residual attention model that utilized the attention mechanism to select the most helpful visual information so as to achieve enhanced language feature selection and information extraction to solve visual question-answering problems. In the above methods, an attention mask branch and a feature extraction trunk branch are used to enhance the informative feature sensitivity and to suppress unnecessary information through element-wise multiplication. However, as noted in previous studies, many networks use global information (i.e., global average pooling) when adopting the attention mechanism to model the relations and dependency among different channels. The attention weight acquired by that process is then used for feature recalibrations. However, for VHRRSI pixel-wise classification, the assignment of different priorities to different locations in the same channel (rather than different channels) is more preferable, provided that the location is of interest to the network training and constitutes an informative area. This approach is discussed in more detail in this paper.
When the attention mechanism is used, every pixel location has an independent weight of focus to highlight discriminative and effective features, and to weaken information detrimental to classification, such as background information and noise. Previously, Chen et al. [
31] and Wang et al. [
20] applied the soft attention mechanism. In that technique, soft mask branches are used to generate weight maps with the same input data size for feature recalibration, and then assigned different priorities to different positions. This approach simulates the biological process that causes human visual systems to be instantly attracted to a small amount of important information in a complex image. Kong and Fowlkes [
32] subsequently constructed a plug-in attentional gating unit that applies a pixel-wise mask to the feature maps. This perforated convolution yields perfect results, but the mask is binary. In addition, Fu et al. [
33] proposed a dual attention network using a pixel-wise self-attention matrix to capture the spatial and channel dependencies. Their mask attention mechanism exhibits good performance. However, the attention masks are determined using the Gumbel-Max trick or through self-transpose multiplication, and not directly from network feature learning, which would be more complex.
Contrary to its application in previous studies, the attention mechanism is not limited to the use of masks to calibrate features in trunk branches. Theoretically, the neurons on a certain area of the visual cortex are influenced by the activities of the neurons on other areas, as transferred via feedback [
34]. This is because humans acquire an improved understanding of the target information when they reconsider or review images. Therefore, we can return high-level semantic features to low-level feature learning through feedback, so as to relearn feature-based weights and to obtain more noteworthy and relevant information. This process differs from those of networks such as the residual neural network (ResNet) [
14] and DenseNet [
35], in which feedforward only is used for hierarchically high-level feature extractions. The attention mechanism has been proven useful in various fields, such as computer vision, but has seldom been used in VHRRSI pixel-wise classification.
When observing a remote sensing image, humans automatically observe the spatial structures of the different areas, from the local areas to the global image (or conversely), so as to focus on the most effective areas and ignore unimportant information. This mechanism verifies the importance of the receptive field on different scales. Generally, multi-scale strategies can be classified into two kinds: feature concatenation on different scales by skipping layers for the final classification [
36,
37,
38], and the simultaneous convolution with multi-scale kernels on the input data [
13,
39,
40]. For instance, Bansal et al. [
41] previously created a hypercolumn descriptor using convolutional features (pixels) from different layers; this descriptor was then fed into a multi-layer perceptron (MLP) for pixel-wise classification. However, features on different scales are concatenated and independent in feature extraction.
In this study, for improved feature extraction and higher-accuracy VHRRSI pixel-wise classification, we propose a novel attention mechanism involving a neural network for multi-scale spatial and spectral information. The multi-scale strategy and attention mask technique are combined and the features are recalibrated by constructing attention masks on different scales. Motivated by previous research [
29], we attempt to merge two kinds of attention mechanism (soft and feedback) using mask and trunk branches, with high-level feature feedback being assigned to the trunk branch. For hierarchical feature extraction in the shallow layers, the attention mask is constructed using a kernel with a small receptive field to fit the characteristics of the low-level features, such as details and boundaries. For the deep layers, the attention mask is constructed on a large scale; this concentrates focus on the more abstract, robust, and discriminative high-level features. The feature extraction that results on the large and small scales are closely related, fitting the characteristics of hierarchical feature extraction.
The network itself is a stack of multiple attention modules, and two kinds of convolutional neural network (CNN)-based attention mechanisms are unified in every module. First, the network employs an element-wise soft attention mechanism combined with multi-scale convolution to construct attention masks of different receptive fields. The network designs the attention mask of every module by increasing the receptive field order using a convolutional kernel of the same scale and hierarchically promotes the informative feature sensitivity in local spatial structures of different scales by stacking attention masks. When the trunk branch of every module performs feature extraction, high-level features are used to update the low-level feature learning to better re-weight the focus and to facilitate feature extraction and image classification.
The major contributions of this article are as follows: the attention mechanism is applied to the VHRRSI pixel-wise classification, with the mask branch and trunk brunch mechanisms being combined for feature learning. Hence, the efficiency of the VHRRS image classification is improved. The network realizes the soft attention mechanism and achieves end-to-end and pixel-to-pixel feature recalibration, thereby assigning diverse priorities to different locations on the feature maps. This supports the network in highlighting the most discriminative and useful features and by suppressing useless feature learning and extraction in accordance with the classification requirements.
Based on the concept of feedback attention, the network returns the high-level features to the shallow layers. In addition to enhancing the information flow through feature reuse, this concept also allows high-level visual information to re-weight and re-update the lower-layer feature extraction. Hence, key points are captured and the network training becomes more target-oriented. The network sensitivity to informative features is increased by this top-down strategy.
The network combines the multi-scale strategy with the attention mechanism. Spatial and spectral information are used jointly and the network concentrates on different valuable and effective features under different local spatial structures in accordance with the attention mask scales utilized in the stacked attention modules. Additionally, the added internal companion supervision measures the effectiveness of different-scale attention modules, enhancing the effectiveness and richness of the features extracted by the network.
The remainder of this paper is organized as follows:
Section 2 presents the proposed method and introduces the network design and structure;
Section 3 describes the experimental setup, data preparation, and strategy, and presents the experimental results;
Section 4 discusses the influence of the training data volume and training time; and
Section 5 summarizes the entire article.
2. Proposed Method
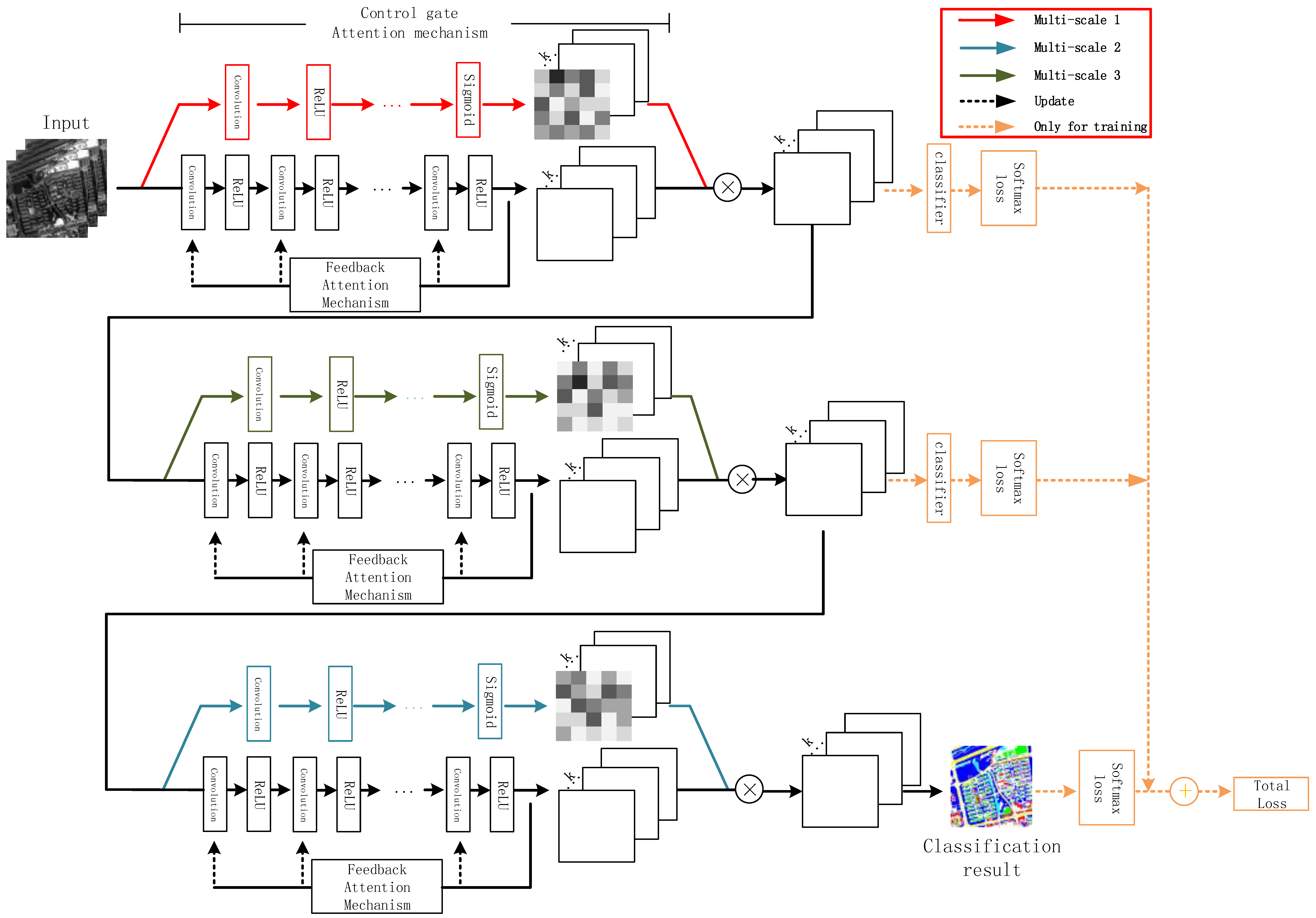
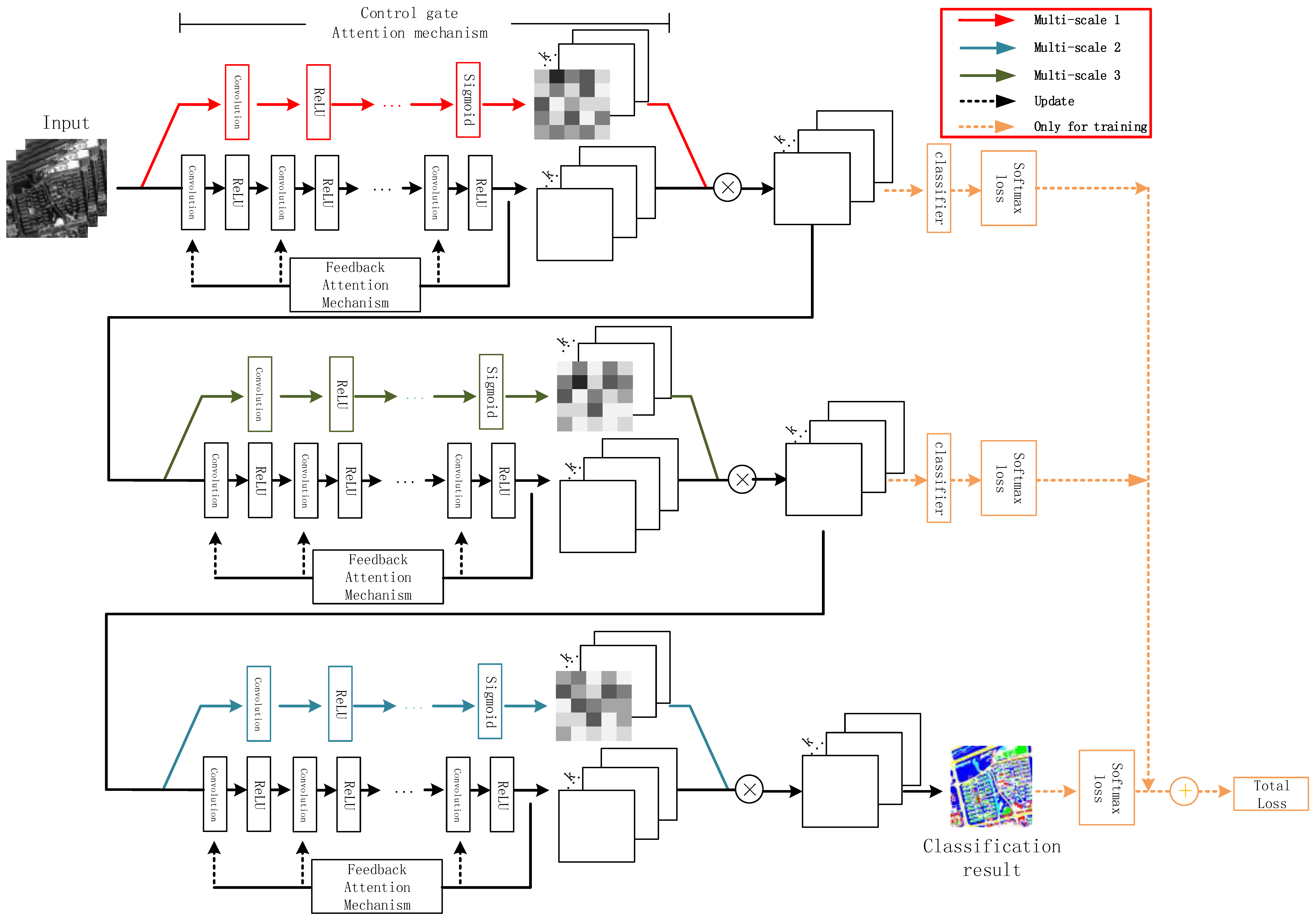
This section first introduces the mechanisms utilized in the framework and then presents the network construction. A flowchart of the attention-mechanism-based method is presented in
Figure 1. The entire network is composed of several attention blocks. In each block, the soft attention mechanism and feedback attention mechanism form the control gate mask and trunk branches, respectively, and the point-wise multiplication of these two branches enables the fusion of these two attention mechanisms. Each block employs a control gate with a specified scale, and the stacking of the blocks allows the network to fuse the multi-scale information. The internal classifiers and softmax loss exist only for network training and are removed when the network is ready for image classification. The method is explained in detail below.
2.1. Feedback Attention Mechanism
Deep learning networks, such as the VGG neural network [
12], ResNet [
14], and DenseNet [
35], all employ a feedforward approach to feature learning, in which high-level features are learned from low-level features. This hierarchical learning approach simulates the hierarchical structure of the images, in which points form lines, lines form graphs, graphs form parts, and parts form objects [
25]. It has also been observed that humans can capture information on a target faster and with more precision when they re-consider the target with additional attention. Inspired by CliqueNet [
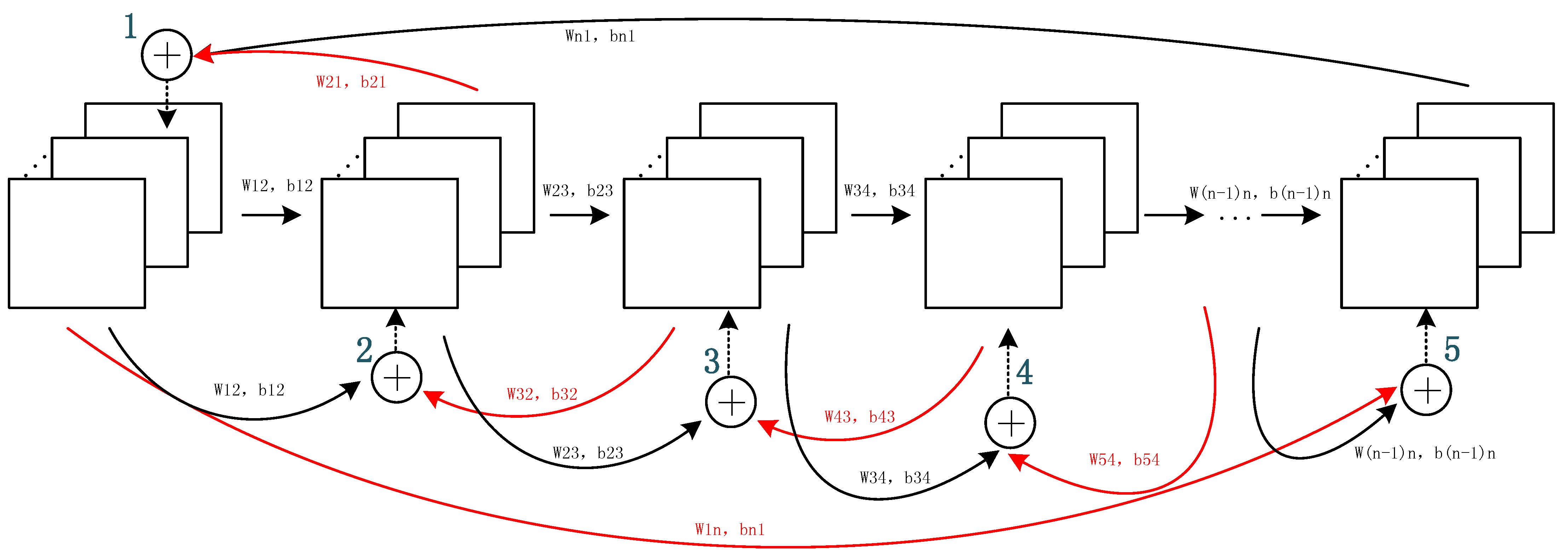
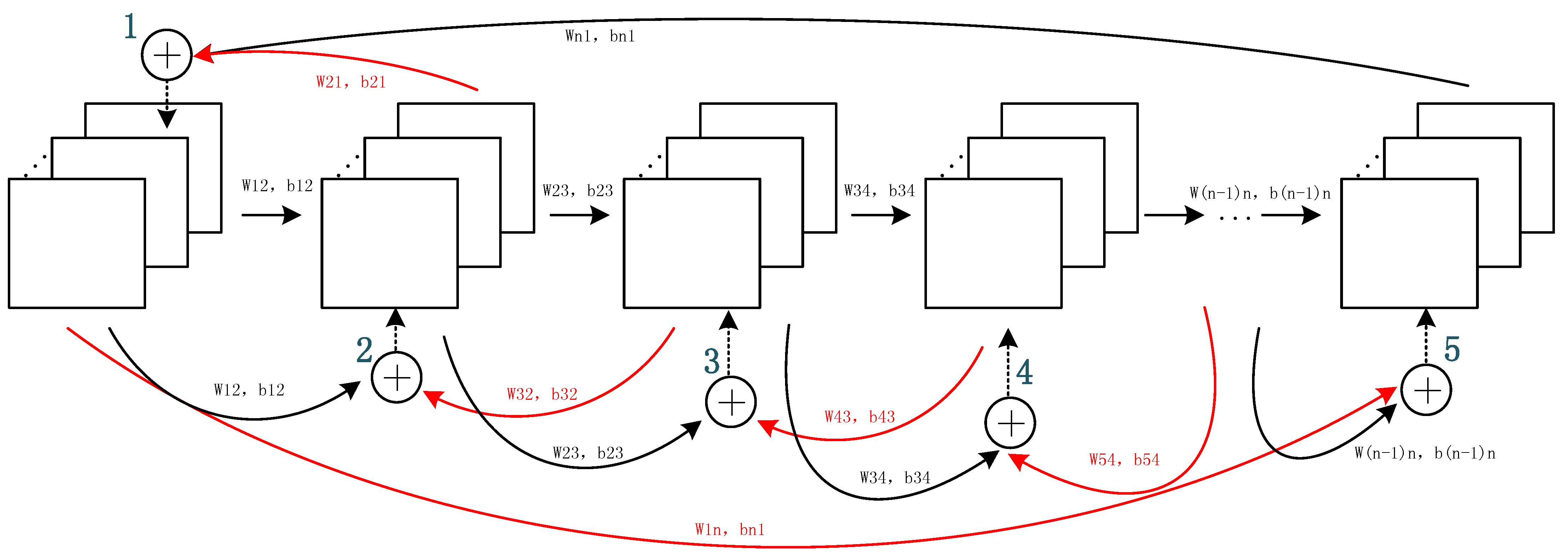
29], we believe that the introduction of the feedback attention mechanism as a form of additional attention on high-level features can simulate this biological phenomenon, by assisting low-level feature learning for improved target-oriented feature extraction. In our design, the feedback attention mechanism comprises two parts: the feedforward and feedback stages. The feedforward stage learns high-level features from the low-level features acquired from the image details so as to acquire abstract and discriminative features. The feedback stage follows, in which high-level features are returned to aid lower-level feature learning. The convolutional network with the feedback attention mechanism is illustrated in
Figure 2.
The feedforward process is a CNN without the classification layer. The CNN is an improved MLP, which is generated by several blocks stacked together, each of which is used for feature extraction and comprises convolution, pooling, and non-linear transformation.
The convolutional layer uses a sliding window as a kernel to move across the image and to calculate the point-to-point inner product in the corresponding area, such that each pixel in the features corresponds to a continuous area in the input data. This locally connected approach simulates the biological mechanism, in which a certain area in the visual cortex corresponds to some local area when information is transmitted to the human brain [
42]. The kernel remains unchanged during sliding; hence, it performs image processing in a share weight manner for different locations. Share weights reduce the parameter amount between each pair of hidden layers and enable each kernel to locate similar features in the images at the same time. A greater number of kernels indicates more abundant feature representations, stronger feature mining ability, and more comprehensive extracted features.
The operation in the convolutional layer is a linear transformation that can handle the linearly separable problems. However, the features of a VHRRSI are complex, and cannot always be linearly simulated. Therefore, the introduction of non-linear layers is necessary to increase the network complexity and expression ability. In a CNN, such layers are called activation functions. Common activation functions include the rectified linear unit (ReLU), sigmoid, and tanh. Each function has its own advantages. In particular, the ReLU function,
, assigns a 0 value to negative elements and maintains positive values. It reduces the training time [
11], alleviates the gradient vanishing problem to some degree [
43], and is a very widely used non-linear function.
The operation in the pooling layer is a statistical aggregation. This operation selects values to represent the corresponding and non-overlapping areas in the image, so as to reduce the feature map dimensions. Pooling increases the receptive fields and scale invariance of the features, reduces redundancy and computation, and retains the most representative features to help extract the hierarchical features. However, the pooling layer causes a loss of location information while increasing the receptive field. Moreover, the dimension reductions cause continuous changes in the feature map sizes, making it difficult to realize direct end-to-end and pixel-to-pixel image pixel-wise classification without up-sampling; this aspect increases the classification complexity. For this reason, dilated convolution [
44] is used to replace pooling in order to increase the receptive fields, while also maintaining the spatial location information, keeping the feature maps of the same size as the input data, and realizing pixel-wise classification.
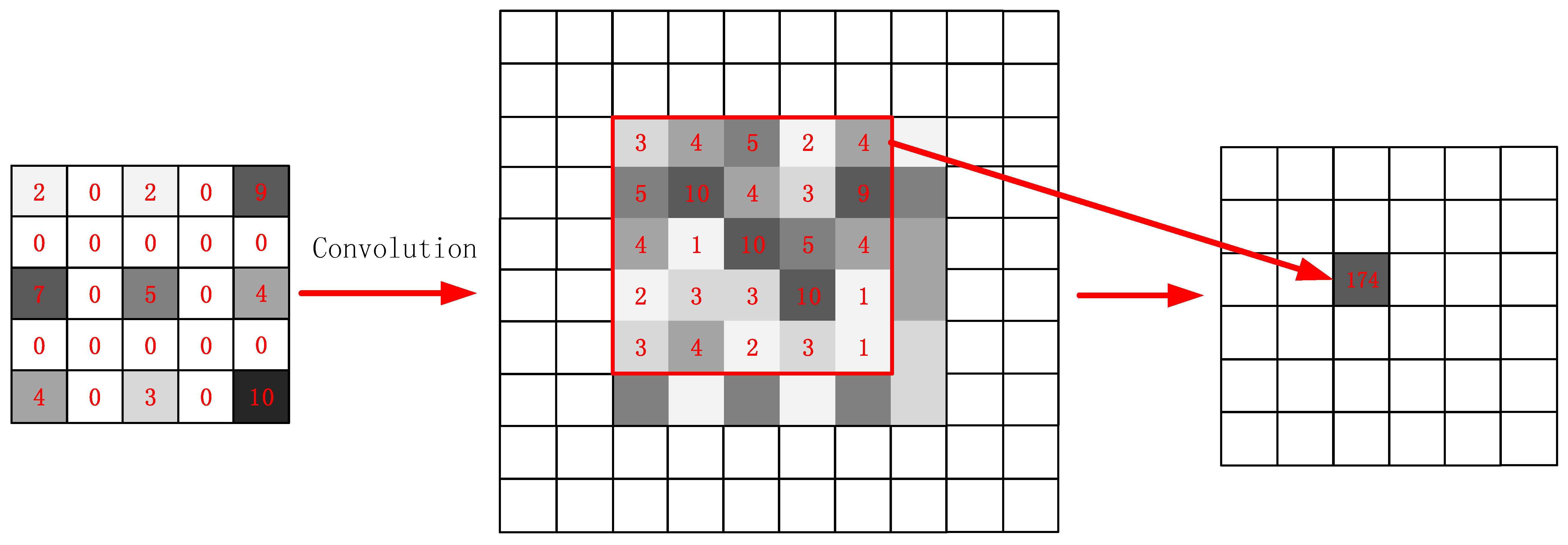
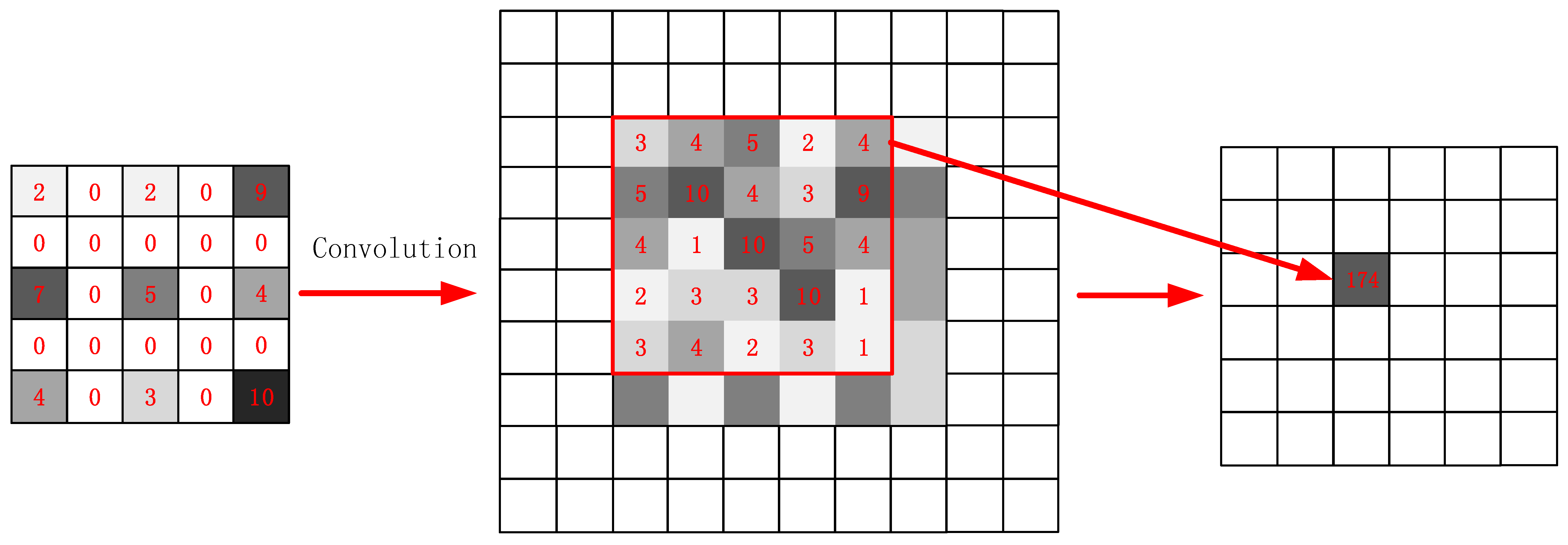
The dilated convolution flowchart is shown in
Figure 3. Note that the kernel does not calculate the inner product in the continuous area on the feature map. The original kernel is expanded according to a skipping interval depending on the dilation size. The interval is filled with 0 values, meaning that the feature points at those locations on the kernel are not considered in the computation. The convolution is conducted between the expanded kernel and the feature map areas of the corresponding size; sample values are given in the flowchart to aid understanding. As the kernel expands, the area in the previous layers mapped by the nodes in the next hidden layer also expands, and the receptive field consequently expands. Through a padding operation, dilated convolution ensures that the generated feature maps are always the same size as the input data. This approach allows for the easy production of the final pixel-to-pixel, pixel-wise classification results.
The feedforward process is described in the following formula:
where
indicates the convolution operation;
represents the
feature maps with size
generated by layer
; and
is the set of various kernels used on the feature maps in layer
. Further,
, where
, indicating that the kernel size is
and its depth
is equal to the third dimension of feature maps
from layer
;
is the bias corresponding to
; and
is the activation function.
The aforementioned process is a hierarchical feature extraction that proceeds gradually from a low to high level. However, the features extracted at the high level do not provide additional assistance to the feature learning from the lower level. Therefore, in the proposed method, we add a feedback stage after the feedforward stage. This stage uses the features acquired in the high level to help re-weight the focus of the lower layer such that it assigns attention to the correct focus more quickly and effectively. The unrelated neuron activities that decrease the classification accuracy, including factors such as background information and noise, are simultaneously suppressed.
The feedback stage is also a CNN network (
Figure 2). However, in this stage, the layers related to the feedforward stage are re-updated. All levels are re-updated by features acquired from one layer higher in the feedforward stage and one previous lower layer re-updated in the feedback stage. Apart from the first and last layers in the feedforward stages, all other stages are re-updated according to the following rule:
where
and
are the local weight and bias from the hidden layer
to layer
, respectively;
and
are the parameters bringing the higher-layer features from layer
to layer
; and
is the non-linear activation function.
Feature maps from layer are acquired by performing a convolutional non-linear transformation on the features from layers and . In the feedback stage, the computation on the features from the higher and lower layer is performed element-wise, such that the dimensions of the kernels used for feature extraction and learning in all layers must remain the same in the feedforward process, along with the sizes of the generated feature maps. The last layer of the feedforward stage serves as the lower layer of the first layer in the feedback stage. Therefore, for the last layer of the feedback stage, the first layer can be considered as its higher layer.
In the feedback mechanism, parameters and are shared in the feedforward and feedback stages. Through the feedback of the higher layer and the feature combination with the low layer, feature reuse is realized to some degree. Under this condition, we can maximize the information flow. Meanwhile, because of the feature reuse, we can minimize the number of feature maps extracted from each layer to prevent information redundancy and the massive computational burden caused by high-dimensional kernels.
2.2. Control Gate Attention Mechanism
In addition to the aforementioned attention mechanism that returns the features from the higher layer to the lower layer to re-update the weight, we can also use the “control gate” to simulate the human focus mechanism. The human visual system is instantly attracted to important visual targets. This behavior indicates that the human visual system does not assign the same priority to different positions, but instead gives distinct priority to certain task-specific areas and features. In some studies, the priority assigned to certain pixels has been improved by increasing their weights. For instance, Pinheiro [
45] aggregated the predicted pixel-wise labels to the image level and placed greater weights on pixels having corresponding image-level labels that matched the given image labels. However, transference of the pixel-level labels to the image-level labels seems a little complex. Therefore, in this study, we adopt an alternative method to adjust the priority, which is called the control gate approach.
A control gate allows for the focus and related resources to be assigned to the most intrinsic, discriminative, and informative areas. We use the control gate as a mask mechanism and utilize it for feature recalibration, selectively enlarging the valuable areas and suppressing useless features, such as noise and background. Unlike Hu et al. [
28] and Yang et al. [
29], who used global pooling to enlarge the valuable channels, our control gate performs pixel-to-pixel modeling on masks that are the same sizes as the original feature maps. The positions in the masks represent the weights or propriety values of the corresponding pixels on the original maps. The priorities of the pixels on the original feature maps can differ, indicating that each pixel may play a different role according to different classification objectives. These kinds of masks are more suitable for pixel-wise classification than global pooling.
The control gate is also a feedforward fully convolutional neural network that maintains the size of the acquired mask. The generated mask indicates the calibrated importance of every position on the feature maps; therefore, the control gate of the proposed method is designed as a soft attention mechanism, wherein the value of every pixel on the mask varies from 0 to 1 [
27]. Therefore, the convolutional network of the control gate is also stacked using elements such as convolution and non-linear transformation. However, different from the feedback attention mechanism, we replaced the previously used ReLU non-linear transformation with the sigmoid activation function in the last layer of the control gate to ensure that the mask outputs are between 0 and 1. The sigmoid function is expressed as
In this mechanism, the masks help recalibrate and select the most intrinsic and discriminative features toward the classification objective in the feedforward process, and also prevent the updating of the parameters with incorrect gradients during backpropagation [
20]. Therefore, the use of such a control gate mechanism renders our network more expressive and robust.
2.3. Structure of the Proposed Method
As the attention mechanism can be beneficial for pixel-wise classification, in this study, we build a multi-scale deep neural network that fuses two different attention mechanisms: soft and feedback.
2.3.1. Fusion of Two Attention Mechanisms
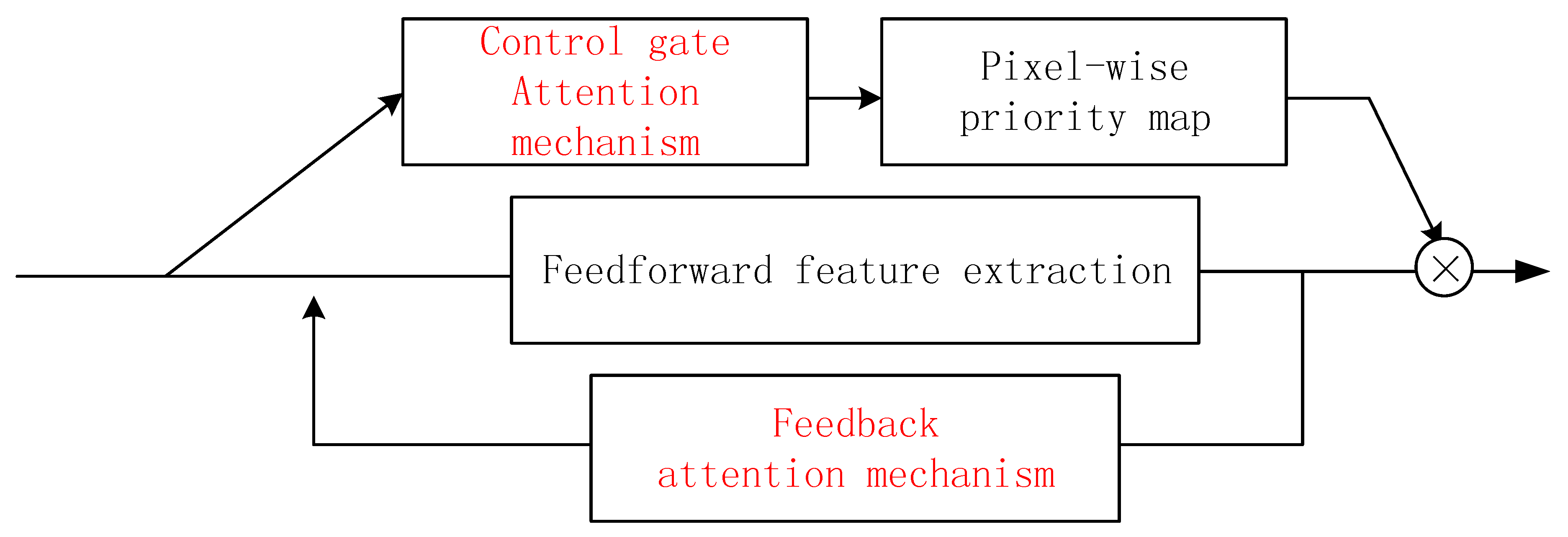
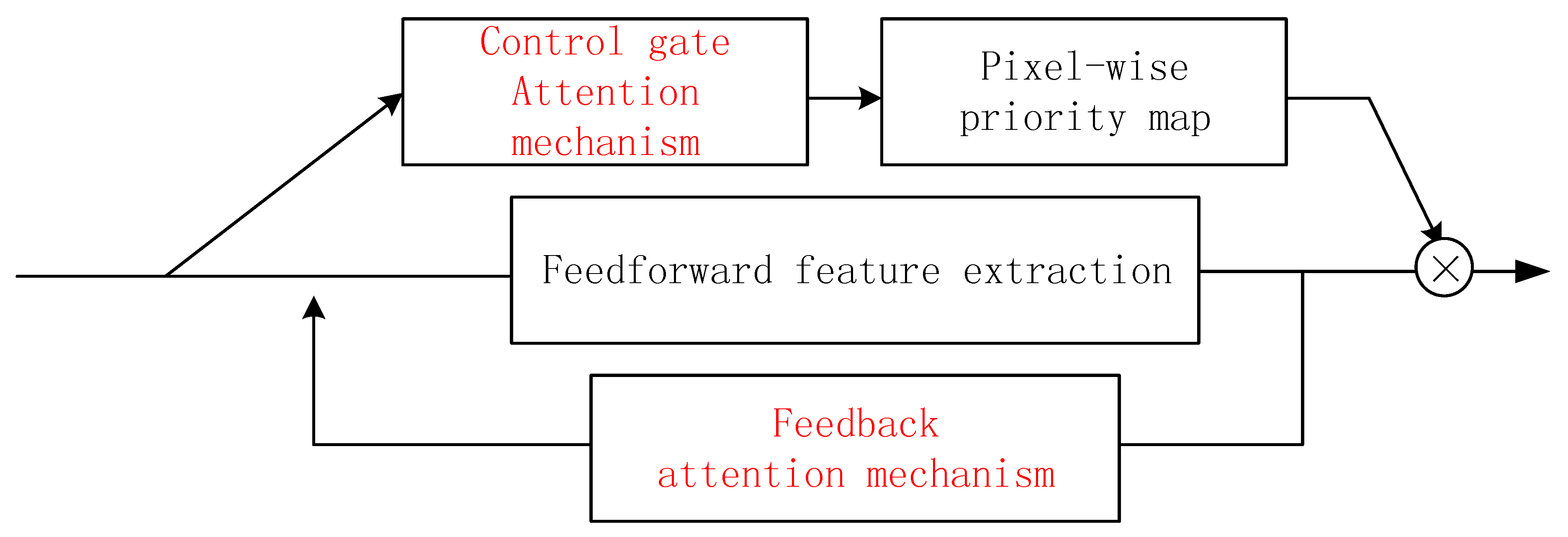
The two attention mechanisms have different objectives; hence, we take these two mechanisms as different components to form the framework. The fusion of the two mechanisms is shown in
Figure 4.
The feedback attention mechanism is designed to form the trunk branch, so as to handle attention-aware feature learning. The trunk branch has two stages; in the first, the higher-layer features are learned from the low level in a bottom-up manner to implement hierarchical feature learning. In the feedback stage, all the layers are re-updated with one layer higher and one layer lower information using the top-down strategy. Hence, both shallower and deeper information are fused to help re-weight the focus and train the network in a more task-oriented manner. In short, the trunk branch implements a feature re-use and focus re-weighting process.
The control gate is not utilized for feature extraction, but rather to learn the weights corresponding to the features’ importance in the feature extraction process. Therefore, the control gate serves as a mask branch to assist the feedback-attention-based trunk branch, rather than the main stream.
In many previous studies, such as that by Wang et al. [
20], down- and up-sampling were used to reduce and restore the mask dimensions when constructing mask branches. This approach enlarges the receptive field while generating masks of the same size as the input data. However, this method inevitably yields information loss. Therefore, in the proposed method, we use dilated convolution to replace the pooling for receptive field enlargement when constructing the convolution networks for the trunk and mask branches. The sizes of the generated feature maps and the mask maps remain unchanged from the original input data, which is convenient for the soft attention mechanism and the pixel-to-pixel and end-to-end pixel-wise classification.
The feature maps and mask maps from the trunk and mask branches, respectively, are fused by implementing element-wise multiplication on the corresponding positions. Hence, the extracted features are recalibrated according to their weights, such that different priorities are assigned to pixels at different locations and on different channels. As a result, more goal-oriented, effective, and discriminative features of ground objects are acquired for pixel-wise classification.
2.3.2. Stacking of Multi-Scale Attention-Mechanism-Containing Modules
A deep network constantly receives feature maps from different layers, and these maps represent different and hierarchical features; hence, different attention mask branches are required to acquire different focuses and to combine them to handle complex ground conditions. Therefore, the trunk and attention branches are fused into a module, and multiple module stacking is used to model the requirements for different focuses. The recalibrated feature maps from the previous module are input to the next module as input data for the next feature learning and recalibration. The constantly added attention modules enable us to acquire different kinds of attention focuses and, therefore, increase the expressive capacity of the network [
20].
In accordance with the characteristics of the deep network, increasing the network layer depth causes the feature maps extracted by the network to change hierarchically. Therefore, when the network is stacked using several modules, the shallow modules extract features with a greater focus on detailed information such as boundaries and locations, while the features from the higher modules are more abstract, discriminative, and target-oriented. The control gates must be adjusted according to the feature map type because the characteristics of the extracted features differ. Therefore, the control gate spatiality can be adjusted so that it fits the characteristics of the hierarchical features. From shallow to deep, different modules are equipped with masks using different convolution kernels of varying sizes, which focus on different local spatial structures. Kernels with a size of 1 × 1 focus on the pixels themselves and the relationships among the bands; therefore, they are better suited to processing details-focused feature maps. In contrast, kernels of larger sizes generate larger receptive fields, and the focus is on the surrounding spatial structures. More global information is considered; therefore, these kernels are more suitable for handling the abstract features generated by higher modules. Additionally, the receptive fields of feature maps generated by deeper layers are bigger, which correspond to an improved matching. Another benefit of using kernels of different sizes is that spatial and spectral joint features can be utilized because small kernels place greater focus on spectral information, whereas larger kernels concentrate on spectral and spatial information. Ground-object classification can be difficult if we rely solely on spectral information for classification because of the uncontrolled field conditions for ground objects with similar spectra. However, if we rely solely on spatial information, the intrinsic information provided by the spectral information may be ignored.
Module stacking continuously increases the network length. Although increased depth is a research trend in the field of neural networks, problems such as gradient vanishing and training difficulty render the network capability disproportionate to the network depth. Huang et al. [
35] believe that shorter connections between the input and output layers can lower the risks associated with a deeper network. Motivated by past research [
40,
46,
47], in this study, we construct supervised learning by implementing additional supervisions for each module and then by combining their loss with that of the top classifier. In this manner, gradients can be propagated to shallow layers more efficiently during backpropagation, which is more convenient for network training and optimization. Meanwhile, when classification results generated by different-scale modules are improved in the direction of the ground truth, internal classifiers enhance the hidden-layer transparency and the features are extracted in the target-oriented direction. This approach reduces the feature redundancy and improves the feature extraction efficiency.
The outputs of the internal classifiers and the final top classifier are all pixel-to-pixel classification results of multiple categories. The difference between the output results and ground truth results is called Loss. We define the Loss function for each classifier as
The classifier generates a pixel-wise classification result with size
. Here,
is the class of the pixel at location
in the classification result. Every pixel can be classified into one of
types. Further,
is the network parameter and
is the probability of the pixel at location
on the original image being classified as type
. Finally,
is the indicative function: if the equation in brackets is true, the function returns 1; otherwise, it returns 0. Therefore, the overall cost function of the network is as follows:
where
indicates that, in the pixel-wise classification, the total Loss generated by the network comprises the Loss from different scale modules and the Loss from the top of the network.
is the total number of modules. With supervision on all modules, the network performs training in a more robust and effective manner and, consequently, achieves superior classification results. The acquired
is used in the backpropagation to update the network parameters.
Therefore, the overall training workflow is as follows: the image data are input to the network, after which they pass through the modules in sequence. Each module uses the control gate with different scales to observe, acquire, and highlight the attention-aware features of the feature maps. In each module, the input data are processed in the trunk and mask branches. When the feature and mask maps are generated, the mask maps are utilized to recalibrate the feature maps through element-wise multiplication. Hence, different priorities are assigned to the different areas of the input data, and consequently, useful features are highlighted while unnecessary features such as noise and background are suppressed. Then, internal classifiers are used to conduct pixel-wise classifications of the feature maps generated by the previous modules, and the results and ground truth are compared to calculate Loss. The features for internal classifiers are also inputted into the module of the next scale for consequent feature extraction. The final classification result fused with the loss functions from previous modules is utilized to update the network iteratively.
4. Discussion
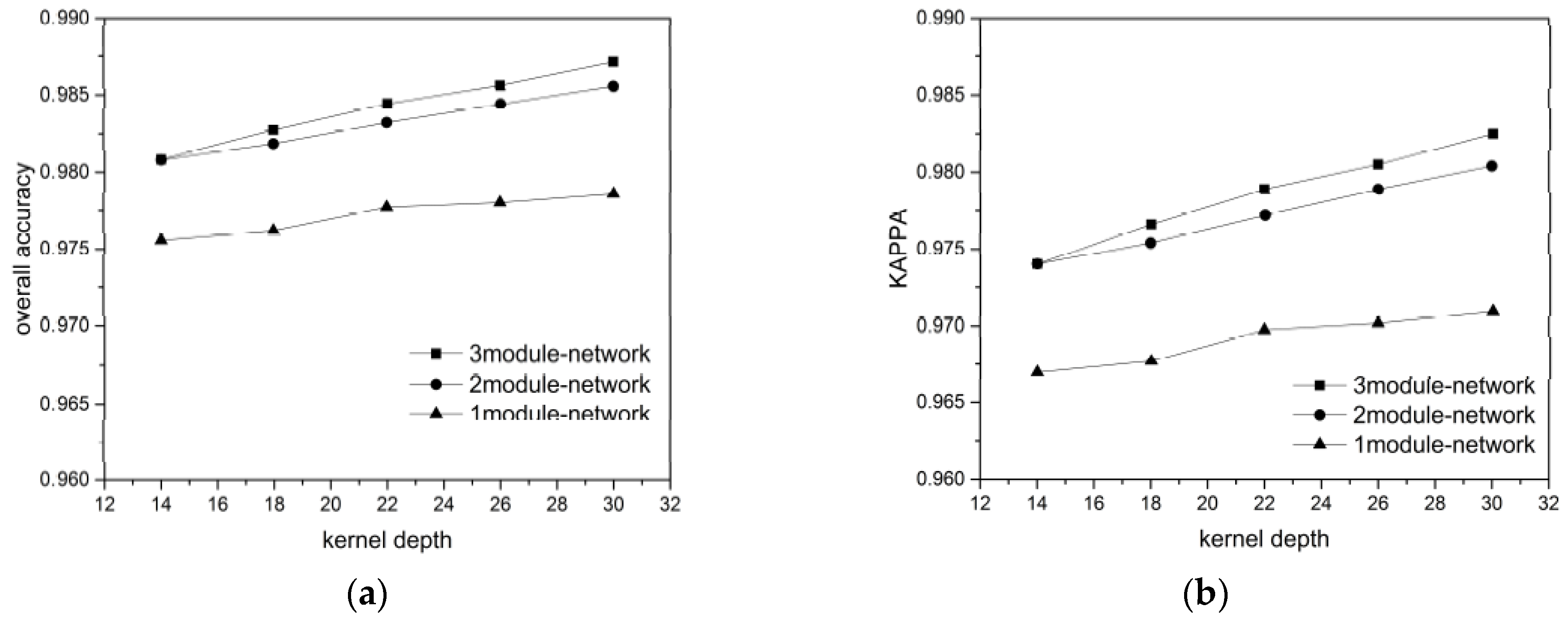
4.1. Influence of Training Data Volume
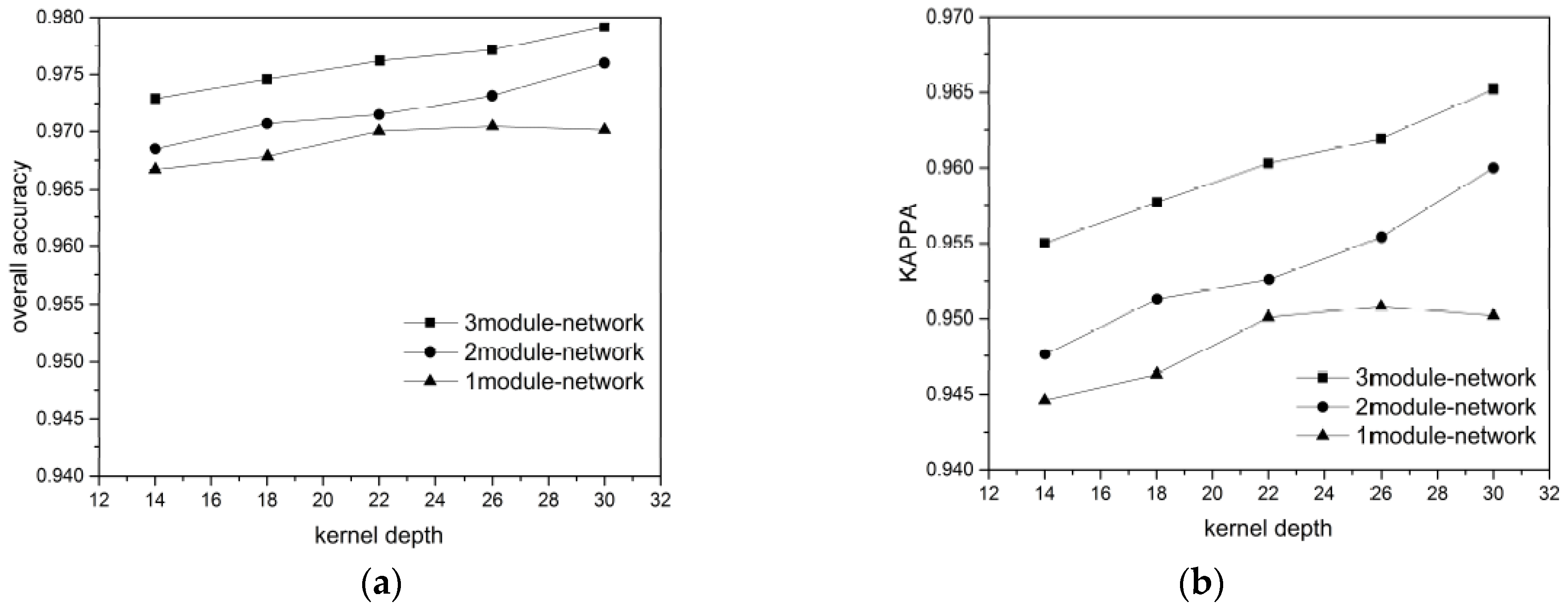
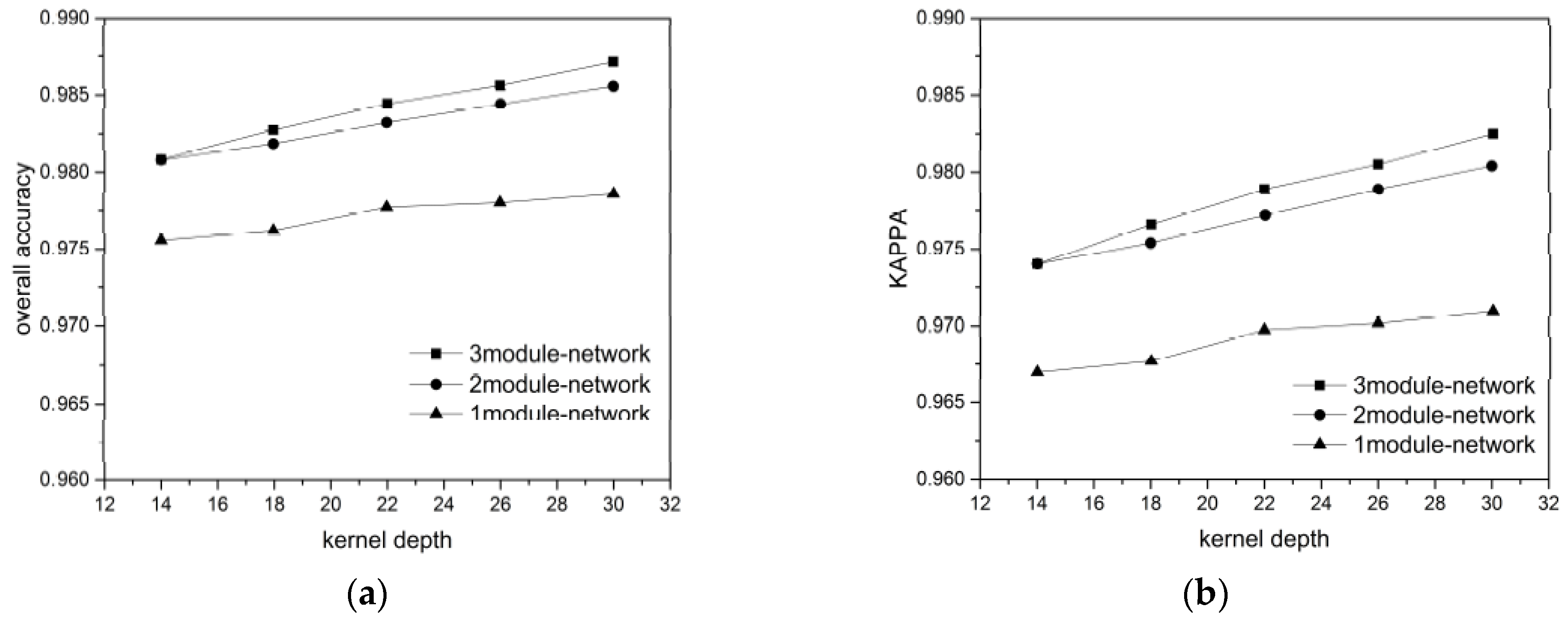
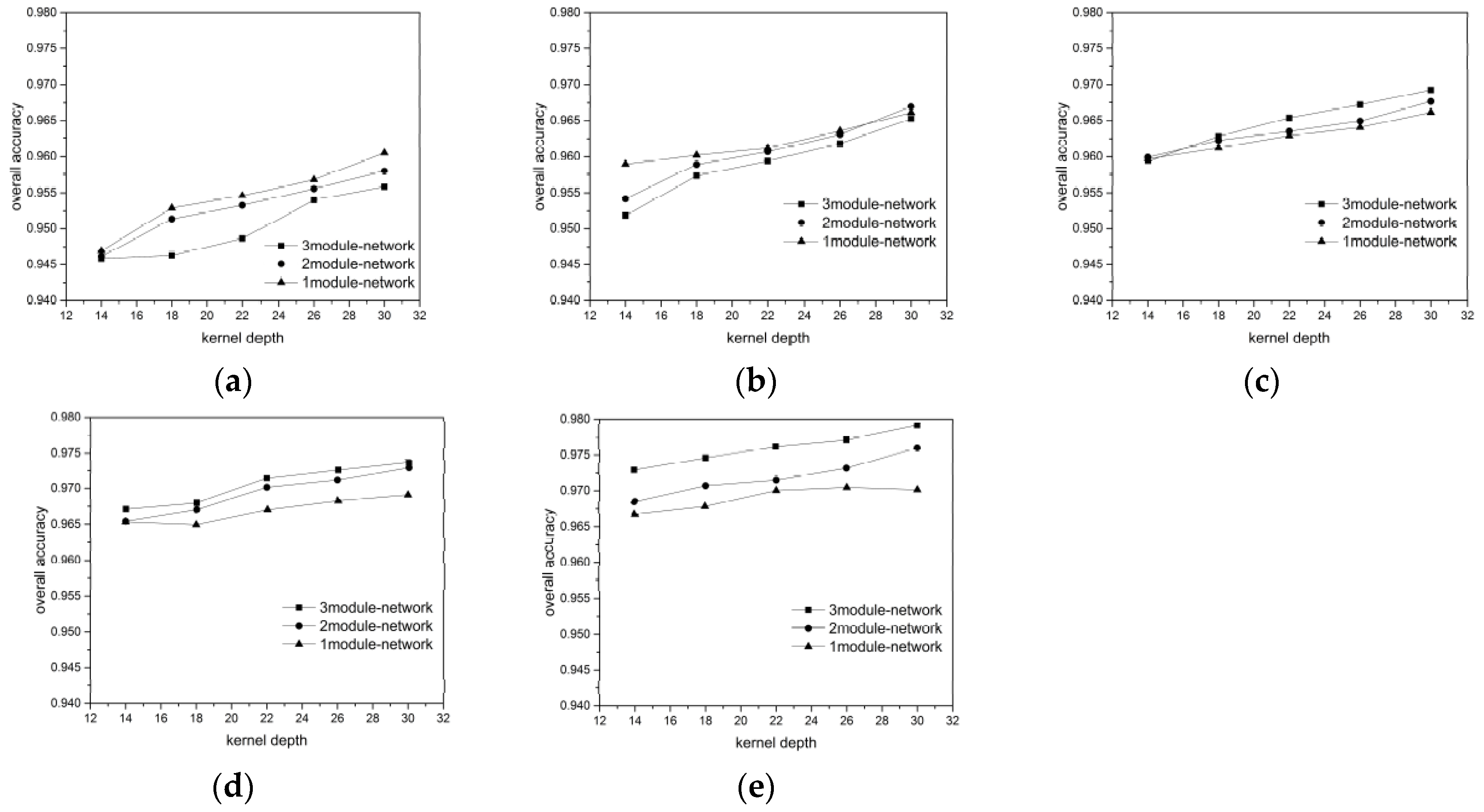
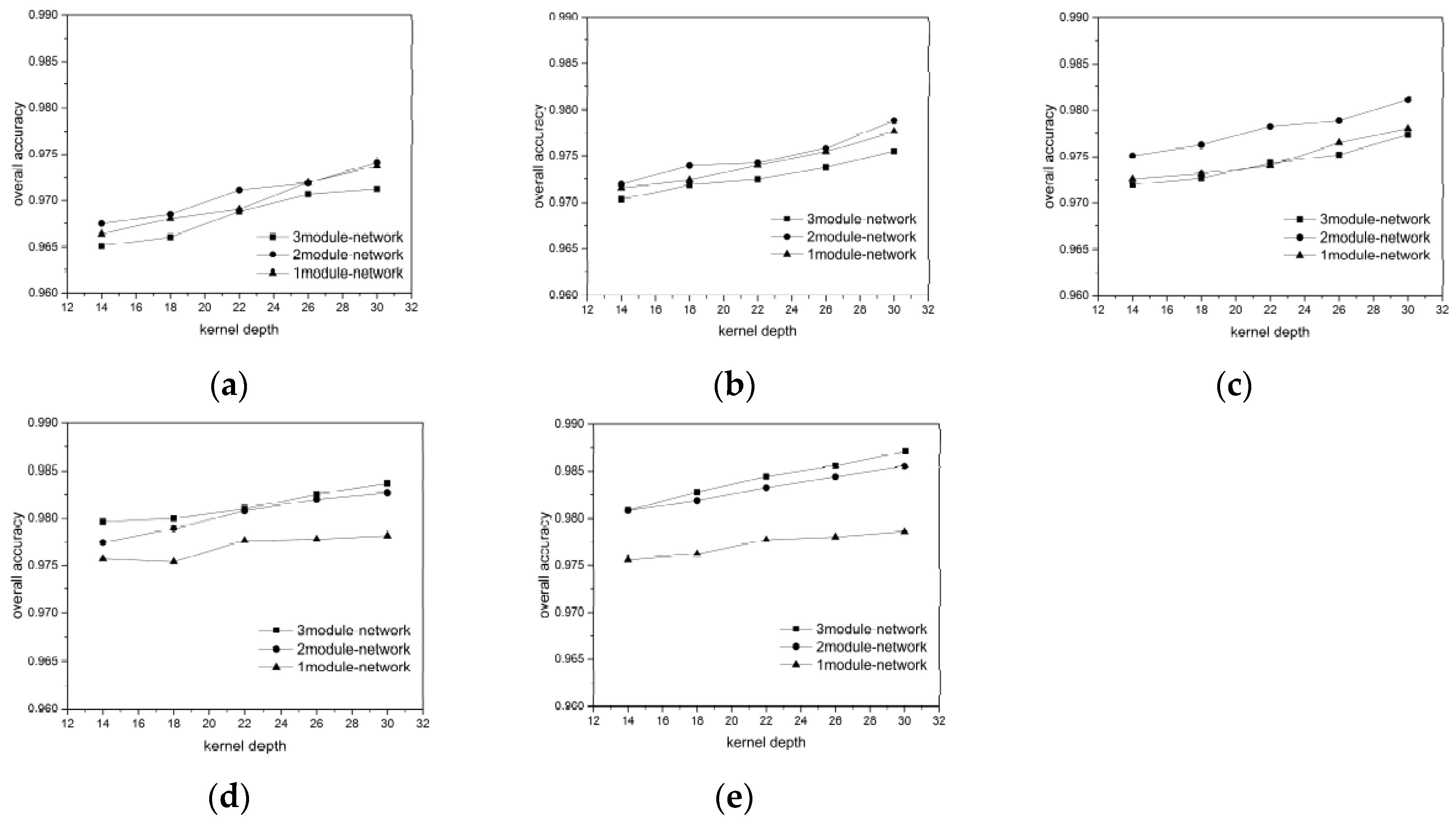
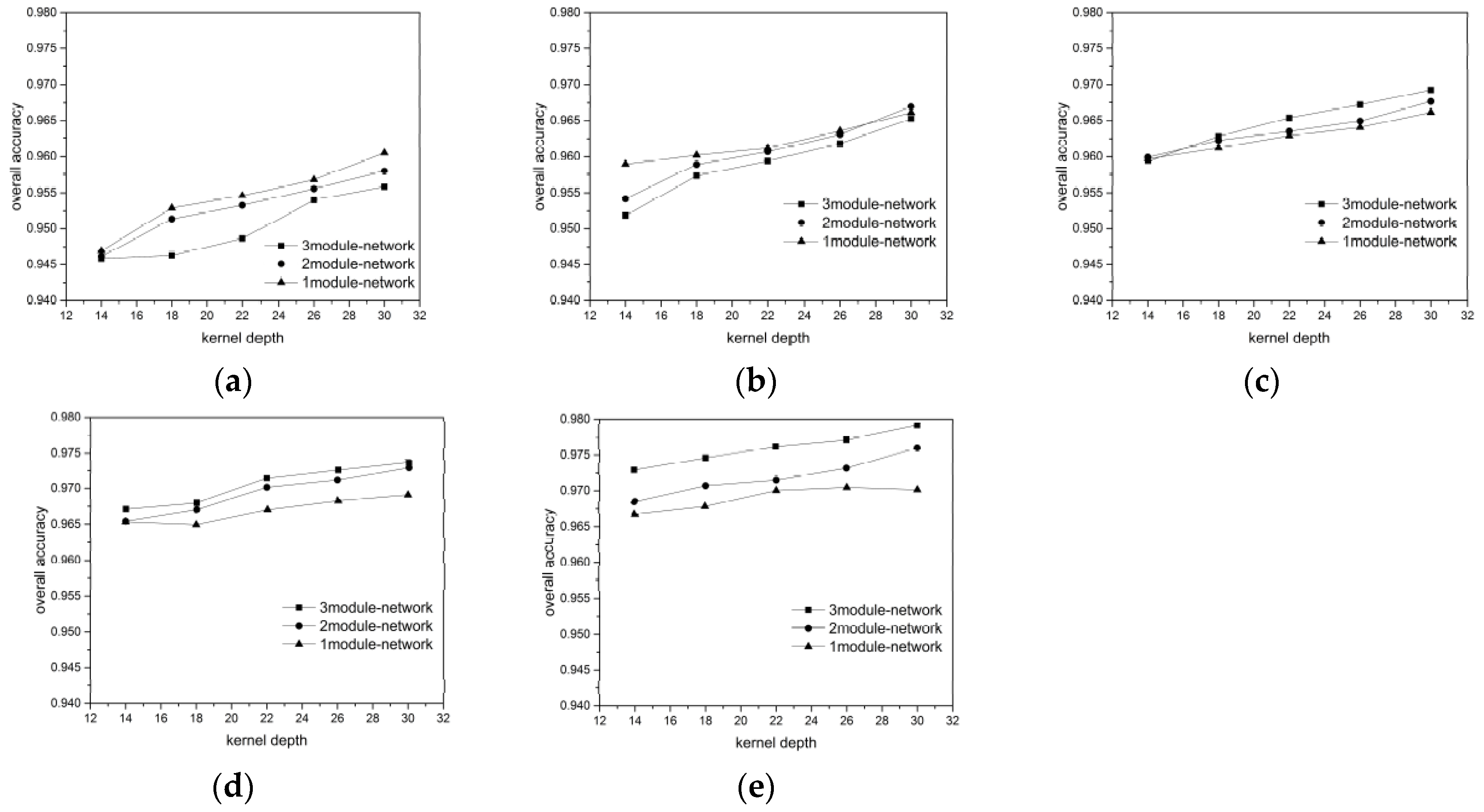
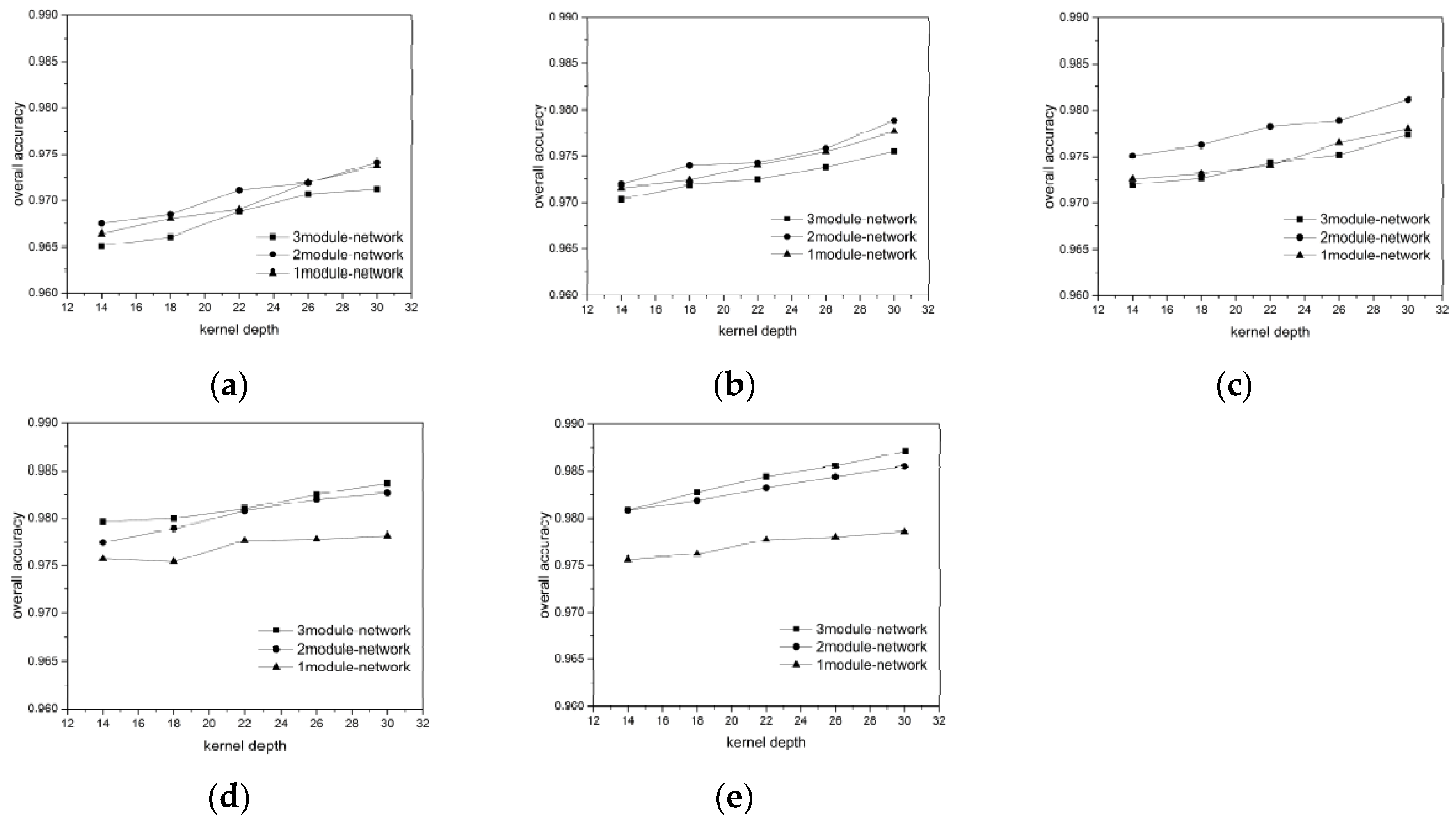
For each ground object category, we randomly chose 300, 400, 500, 600, and 700 labeled pixels as the training + validation data (ratio 7:3) to verify the influence of the training data volume on the network performance. The results are showing in
Figure 11 and
Figure 12, for the BJ02 and GF02 images, respectively.
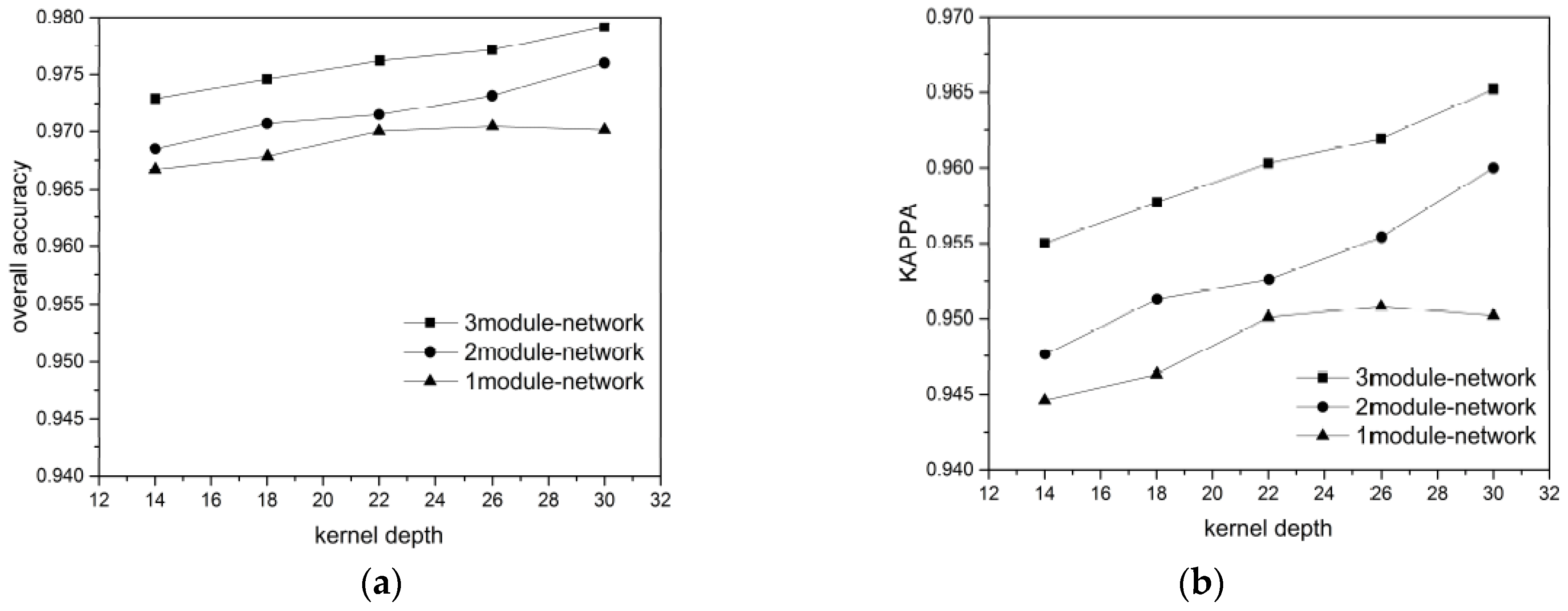
Considering the BJ02 and GF02 results, we found that the influence of the network depth on the network performance was affected by the training data volume. In our experiment, a longer network did not guarantee a superior classification result. For instance, when the 300 or 400 pixels/category training data were used for the BJ02 images, the network depth was inversely proportional to the classification accuracy. When the training data volume was small, the shallow networks achieved superior accuracy, with the shortest one achieving 96.1% OA and the longest one achieving only 95.6% OA. For GF02, when the training data volume was less than 500 pixels/category, the longest network exhibited the weakest performance. However, when the training data volume was small, the network length was not inversely proportional to the classification accuracy, unlike that for the BJ02 images. The 1-module networks exhibited only slightly poorer performance than the 2-module networks.
When the training data volume was 700 pixels/category, a deeper network corresponded to superior performance. This was because the number of parameters to be trained in the deep networks was greater than that in the shallow networks. When the labeled pixels were few, they became a burden for network training. Although we used a feedback attention or internal classifier mechanism to assist gradient propagation and to suppress the influence of overfitting, when the training data volume was small, the complexity of the deep networks induced more problems than encountered for the shallow networks. Nonetheless, when the training data volume was small, an increase in the number of convolutional kernels brought the deep network accuracy increasingly closer to that of the shallow networks. This indicates that the combined effect of the network depth and the number of convolutional kernels can assist the network in better extracting features for classification.
As the training data volume increased, the benefits of the deep networks emerged. The networks with larger numbers of modules could extract a greater number of hierarchical features using the added convolutional layers. The shallow layers extracted features with a greater focus on the ground-object details, such as their locations and boundaries, whereas the deeper layers extracted features that were more abstract, discriminative, and target-oriented. Therefore, the hierarchical features strengthened the expressive ability of the networks. Additionally, in our network design, one module comprised a mask branch and a trunk branch and different modules utilized different masks to focus on the features of the local spatial structures on different scales. Each module corresponded to a kind of attention. The mix of multiple attention types helped the networks handle more complex situations regarding ground objects. Therefore, for the BJ02 experiments, when the number of convolutional kernels was 30, the 3-module network could achieve an OA of approximately 98%, while the classification accuracy of the 1-module network was less than 97%. For the GF02 images, the networks stacked with 3 modules could achieve an OA exceeding 98.7% and a Kappa higher than 98.3%.
In addition, we found that the influences of the number of the convolutional kernels on the network performance differed with the training data. Taking the BJ02 results as an example, when the training data volume was small, the network classification accuracy increased rapidly and became more noticeable. However, as the training data volume increased, the classification accuracy increase became slower. When the network had just one module, the accuracy tended to remain stable even when the number of convolutional kernels increased. This may have been because the network required a larger number of feature detectors to identify the most discriminative features for ground object classification when there were fewer training samples. However, with an increase in the training data volume, the features most common and inherent to each category could be acquired even with fewer convolutional kernels by using a greater training data volume to train the network. Therefore, the benefits of the convolutional kernels were occluded and became less significant. Nonetheless, for the largest training data volume, the classification accuracy increased from 97.2% to 97.9% in the 3-module network when 14 and 30 kernels were used.
Furthermore, regarding the experimental results, when the training data volume decreased drastically, the network accuracy dropped gradually. This outcome demonstrated the network robustness and indicated that the networks could handle conditions involving a small volume of training data, which is very helpful for the remote sensing field.
4.2. Influence of Training Time
Comparison of the training times of the proposed method and the state-of-the-art methods mentioned in
Section 3.2.3 revealed some limitations to our proposed method. Considerable feature reuse and feature fusion are involved in the network training; hence, a large amount of floating point arithmetic appears in the feed forward and backpropagation, and the kernels with different scales (especially 5 × 5 kernels) consume an extremely large amount of time for operations such as convolution. Therefore, with the Quadro K620 graphics card and a training data volume of 700 pixels/category, training a network with 3 modules and 30 kernels/convolution consumes 3.5 h. This training time is closer to that for the contextual deep CNN and DenseNet tested in
Section 3.2.3. However, URDNN, DNN, and SCAE + SVM have considerably shorter training times, at less than 1 h. Training using SENet consumes approximately 2.5 h. Although the training time differs for each method, the classification times after training are all less than 1 s, which is acceptable. Therefore, decreasing the network complexity and improving its training efficiency will be our next research aim.
5. Conclusions
This paper has proposed a novel deep neural network fused with an attention mechanism to perform VHRRS image pixel-wise classification. The proposed network simulates the manner in which human beings comprehend images, emphasizing helpful information while suppressing unnecessary information, and thereby promoting sensibility toward informative features and providing convenience for superior information mining and image pixel-wise classification. The network is designed to have a “trunk branch” + “mask branch” structure. The feedback attention mechanism is implemented in the trunk branch, which applies feature reuse to return higher-level features to a lower level to re-assess the objective and re-weight the focus. In the mask branch, the neural network assigns a different priority to each pixel location by assigning different weights. Hence, attention is emphasized or suppressed and the neural network is aided in achieving end-to-end, pixel-to-pixel, pixel-wise classification. Furthermore, the proposed method adopts various masks with different scales to discern ground-object features on different scales. Through a 1 × 1 convolution mask, spectral information and the relationship among bands is found, while masks with larger scales help incorporate the surroundings and extract features from different local spatial structures. The internal classifiers enhance the effectiveness of the features extracted by hidden layers, thereby decreasing the feature redundancy.
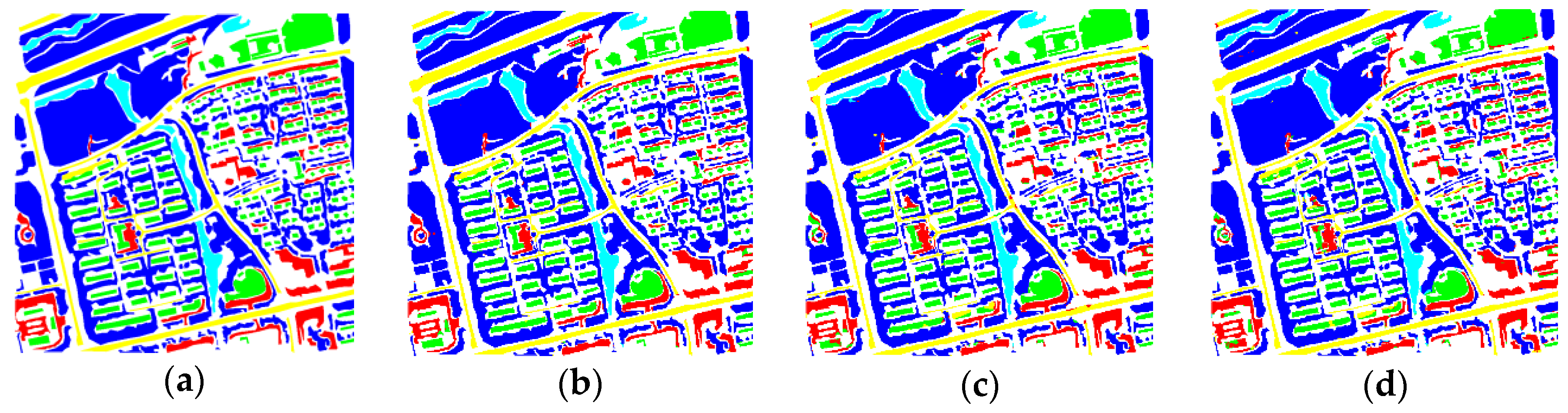
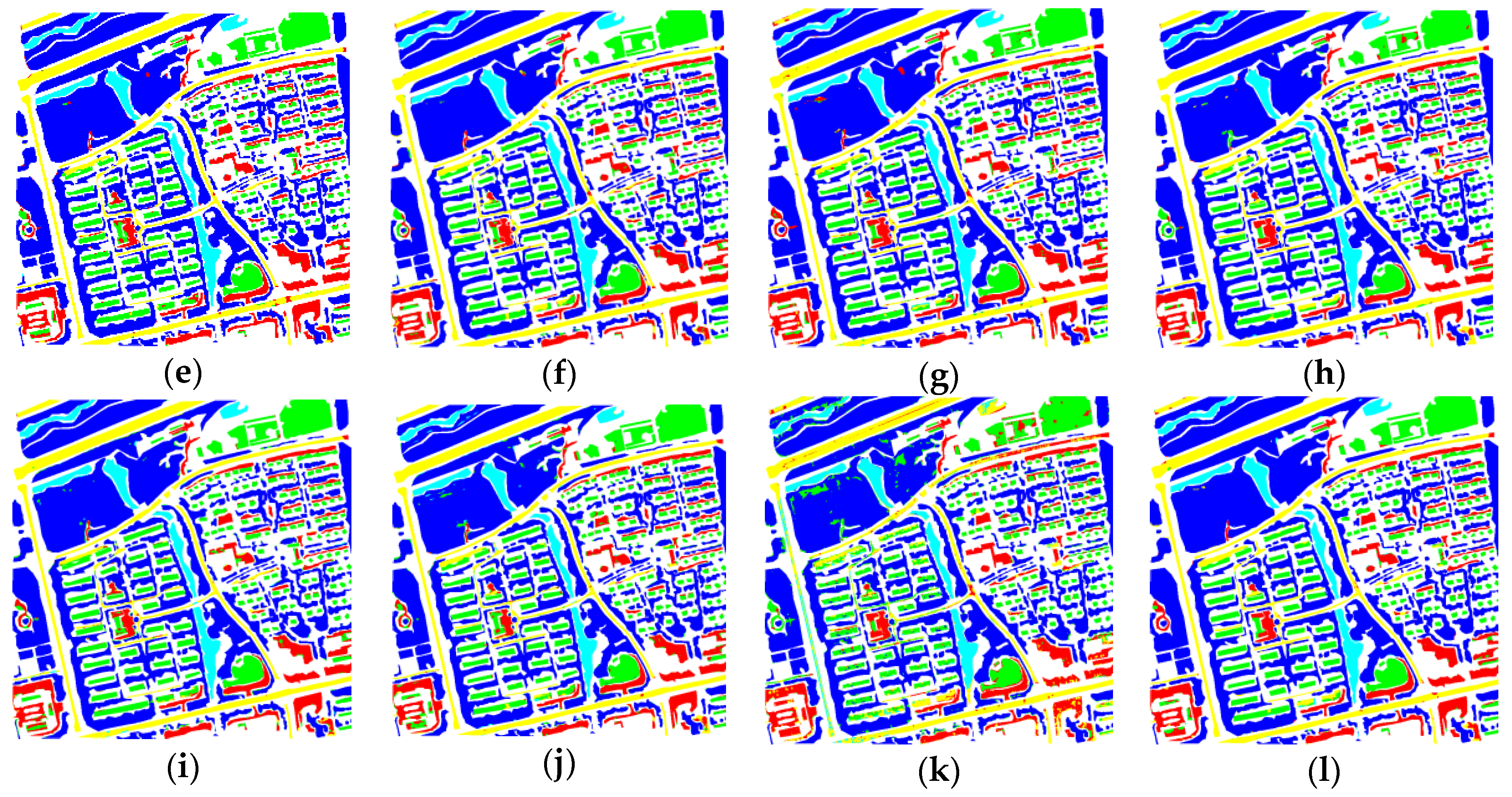
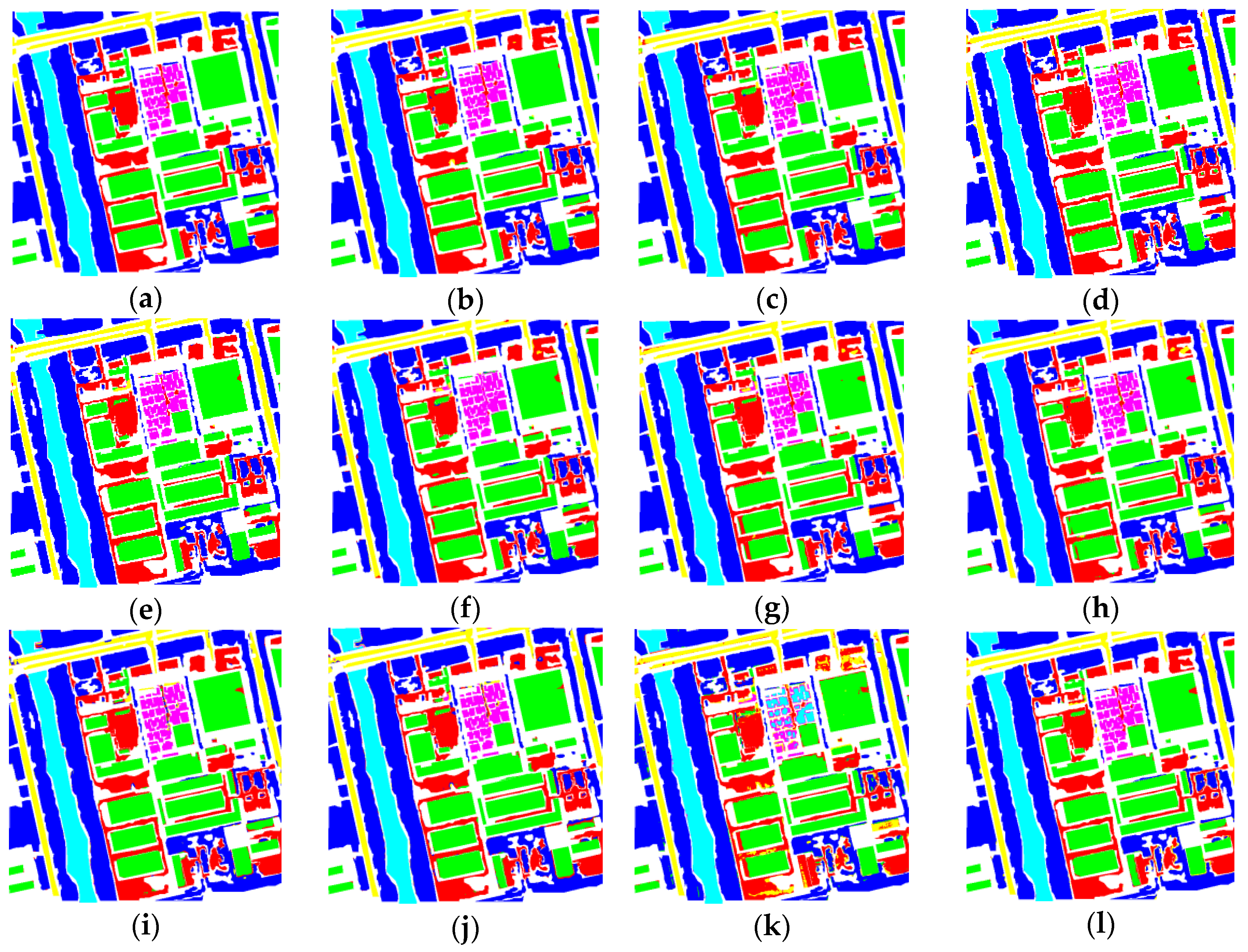
We conducted detailed experiments on our proposed method using BJ02 and GF02 images. The proposed method achieved satisfactory accuracy for these images, with OA = 97.9%, Kappa = 96.5% and OA = 98.7%, Kappa = 98.3%, respectively. The experiments verified that the network structures have apparent influences on the network behavior. First, to a certain extent, an increase in the number of convolutional kernels can increase the network’s classification capability, because more feature maps help the network to cover additional kinds of features. However, in this work, we could still achieve satisfactory results by utilizing feature re-use, even though we adopted fewer kernels compared with other methods. Second, a deeper network is not always superior. In this work, when a small volume of labeled training data was utilized, the deeper network possessed more parameters to be trained. In such a case, training problems had a tendency to arise, which rendered the classification capability inversely proportional to the length of the network. However, when a greater volume of training data was used, networks with more modules usually yielded better results, exhibiting a relationship with the network length.
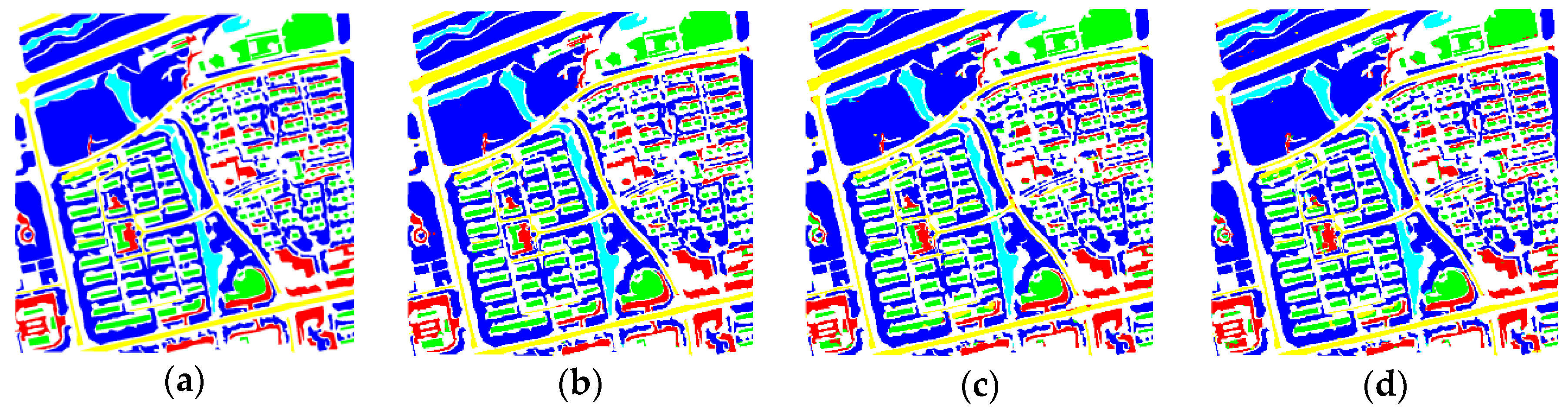
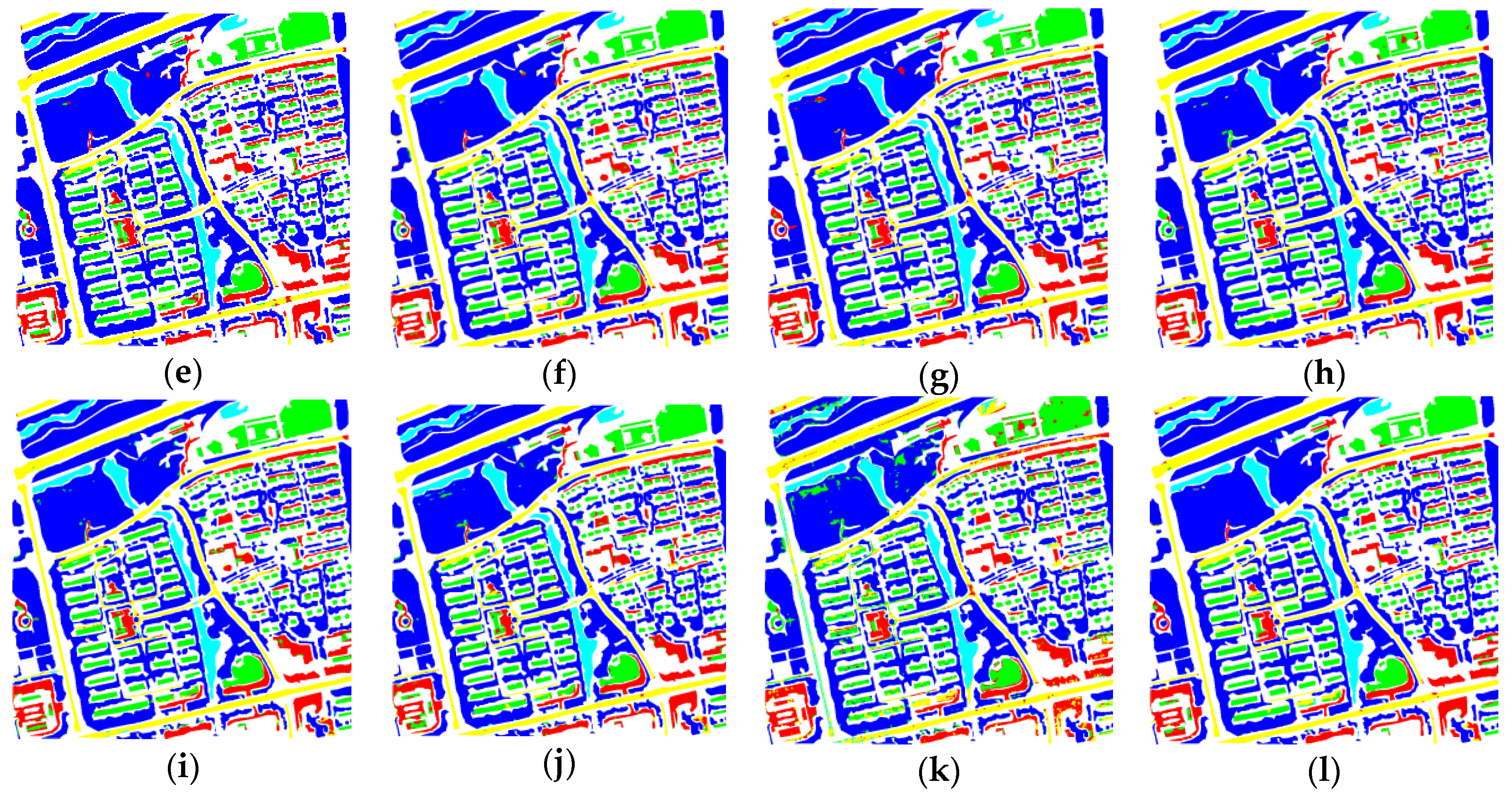
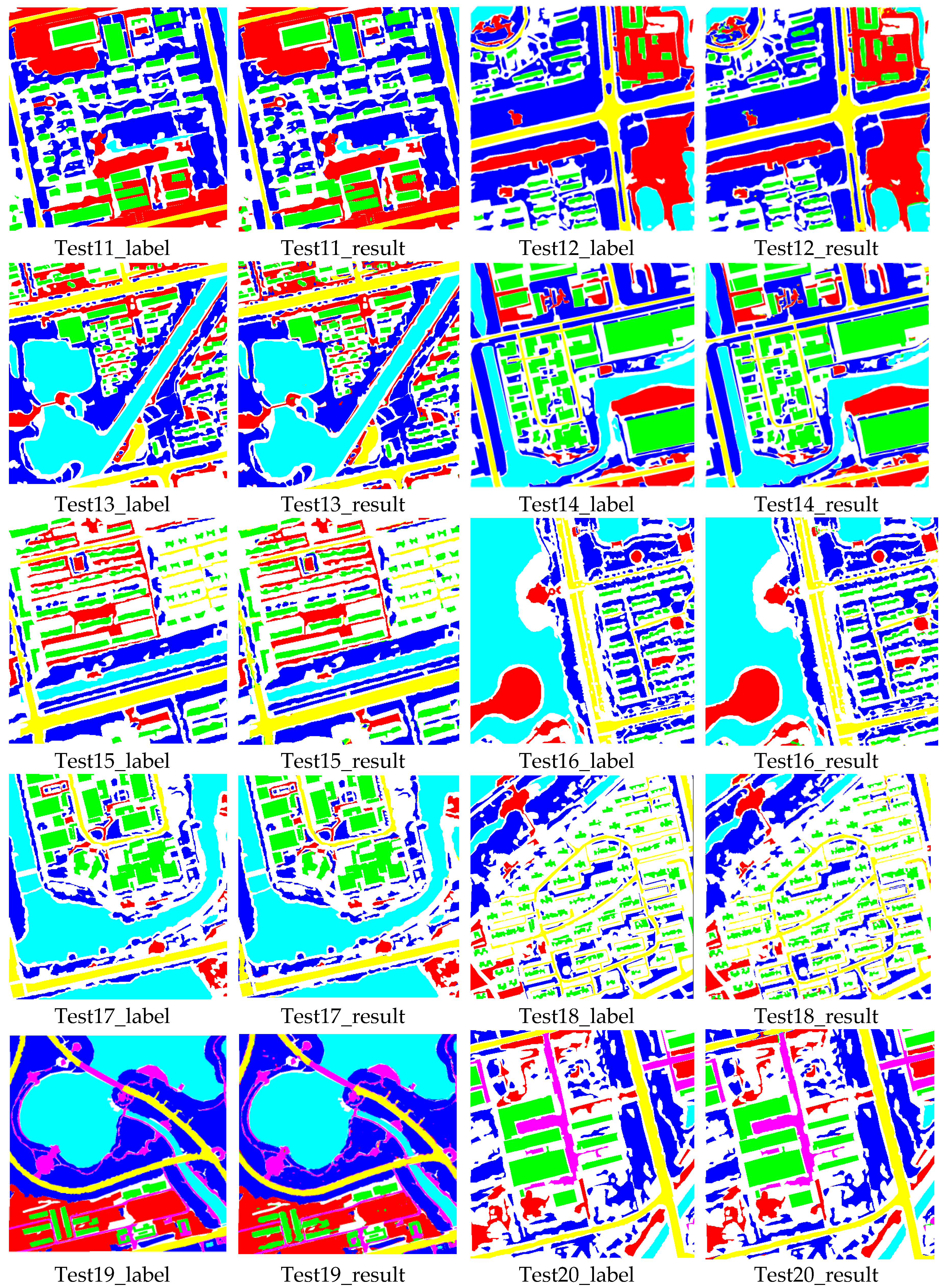
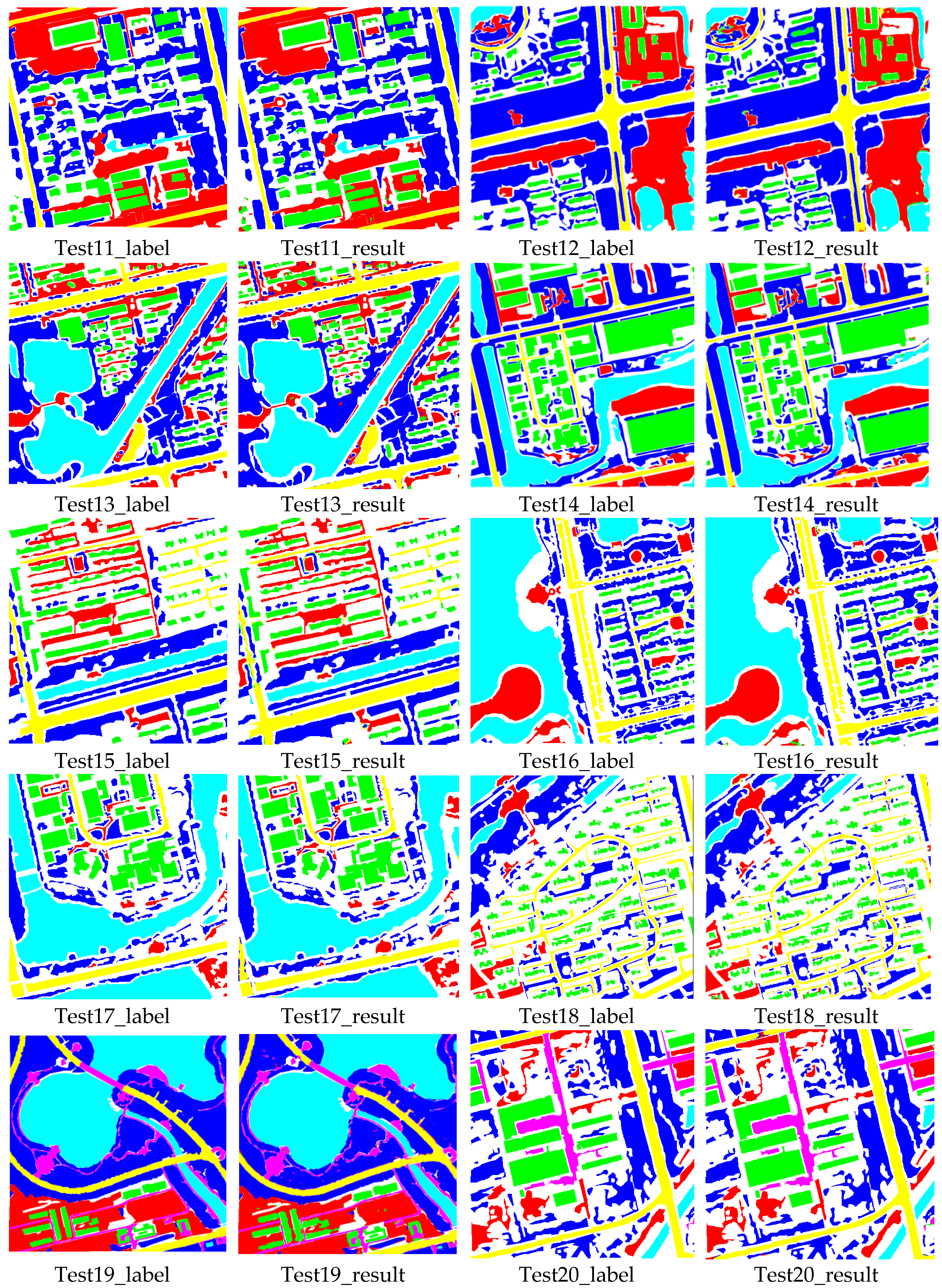
In the experiments, we also investigated the influence of the network components on the proposed method, and performed comparisons with some state-of-the-art methods, including methods with attention mechanisms and other popular methods. Furthermore, we applied the proposed method to additional images from the Quickbird, Geoeye, GF02, BJ02, etc., satellites, to verify the effectiveness and practicality of our method. In terms of accuracy and visual effects, the proposed method achieved competitive results. It not only yielded a higher accuracy, but also exhibited reduced confusion among some ground objects (such as buildings, bare land, and roads) compared with the other methods, and exhibited superior performance with regards to the edge preservation and interior integrity of ground objects.
To some degree, this work proved the effectiveness of this novel neural network for VHRRSI pixel-wise classification. In the near future, we plan to perform further research to adapt this method to fit more specific and complex applications such as object identification, so as to increase its feasibility for practical, real-world use.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}