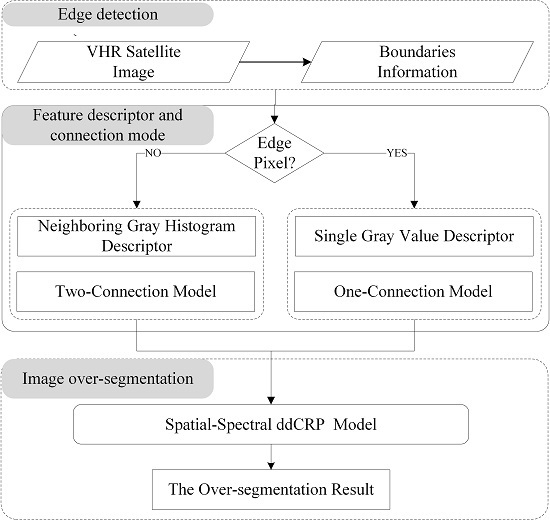
After the ddCRP is introduced in the first subsection, we systematically the characteristics of its three components, i.e., distance dependent term, likelihood term, and connection mode.
2.1. ddCRP
The CRP is a classical representation of the Dirichlet Process (DP) mixture model, which is an intuitional way to obtain a distribution over infinite partitions of the integers. Under the metaphor of the CRP, the random process is described, as follows. Customers enter a Chinese restaurant one by one for dinner. When a customer enters the restaurant, he or she chooses a table, which has been occupied by other customers who entered previously with a probability proportional to the number of customers already sitting at the table. Otherwise, one takes a seat at a new table with a probability proportional to a scale parameter
. The random process is given by
where
represents the index of table chosen by the
customer;
denotes the table assignments of
N customers with the exception of
customer;
is the number of tables already occupied by some customers; and,
denotes the number of customers sitting at table
.
After all of the customers have taken their seats, a random partition has been realized. Customers sitting at the same table belong to a same cluster. This specific clustering property indicates a powerful probabilistic clustering method. The most important advantage of this algorithm is that the number of partitions does not need to be assigned in advance. The reason is that the CRP treats the number of clusters as a random variable that can be inferred from the observations by marginalizing out the random measure function.
Please note that, although the customers are described as entering the restaurant one by one in order, any permutation of their ordering has the same joint probability distribution of the original sequence. This is the exchangeability property of CRP mixture model. In practice, exchangeability is not a reasonable assumption for many realistic applications. As for image over-segmentation, it is necessary to identify the spatially contiguous segments where the same label is allocated to the neighbor pixels with homogeneous spectra. Therefore, the traditional CRP model is not suitable for image over-segmentation. To introduce the dependency among random variables, Blei et al. proposed the distance dependent Chinese restaurant process (ddCRP) in [
37]. The partition, formed by assigning the customers to tables in the CRP, is replaced with the relationship between one customer and other customers in the ddCRP. Under the similar metaphor of the CRP, the ddCRP model states that each customer selects another customer to sit with, who has already entered the restaurant. Given the relationship among customers, it is easy to infer which customers will sit at the same table. Therefore, the tables are a byproduct of the customer assignments. Let
denote the decay function,
the distance measure between two observations
and
,
the scaling parameter, and
the customer assignment of
customer, i.e.,
customer choose to sit with
customer. The random process is to allocate customer assignments according to
where the distance measure
is used to evaluate the difference between the two observations
i and
j, and the decay function
mediates how the distance affects the probability of connecting the two customers together. The farther the distance between the two data points, the smaller their probability of connecting with each other. The traditional CRP is a particular case of ddCRP when the decay function is assumed to be a constant, i.e.,
.
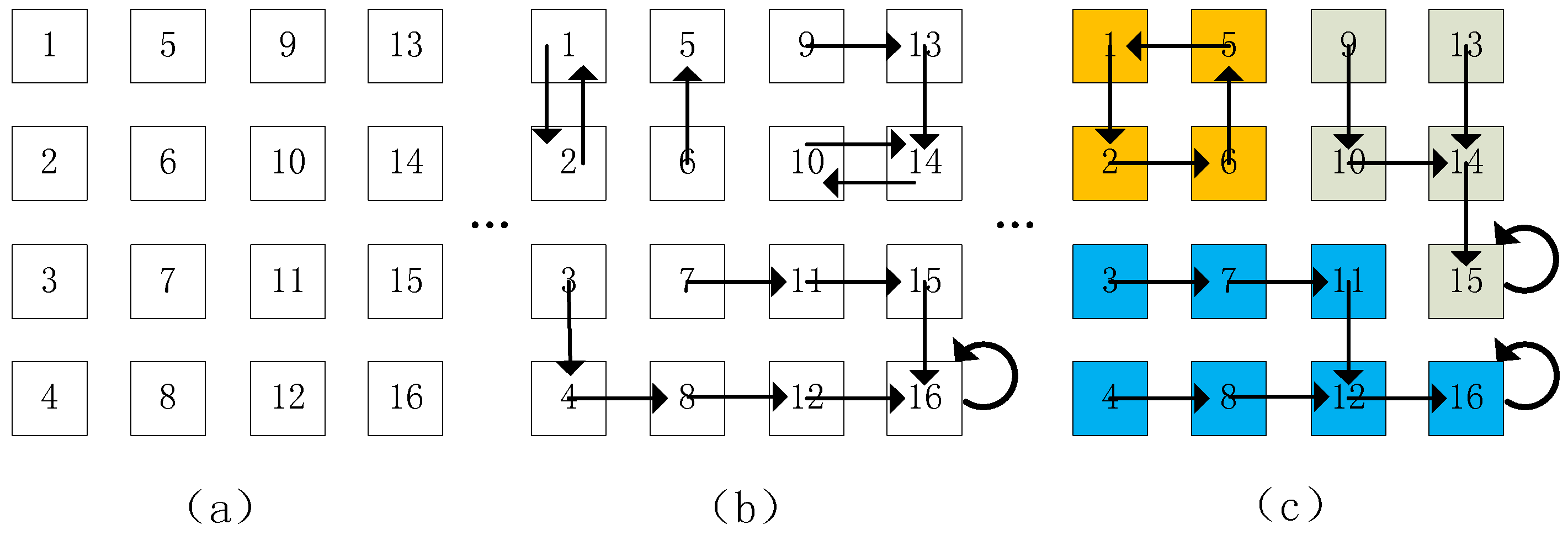
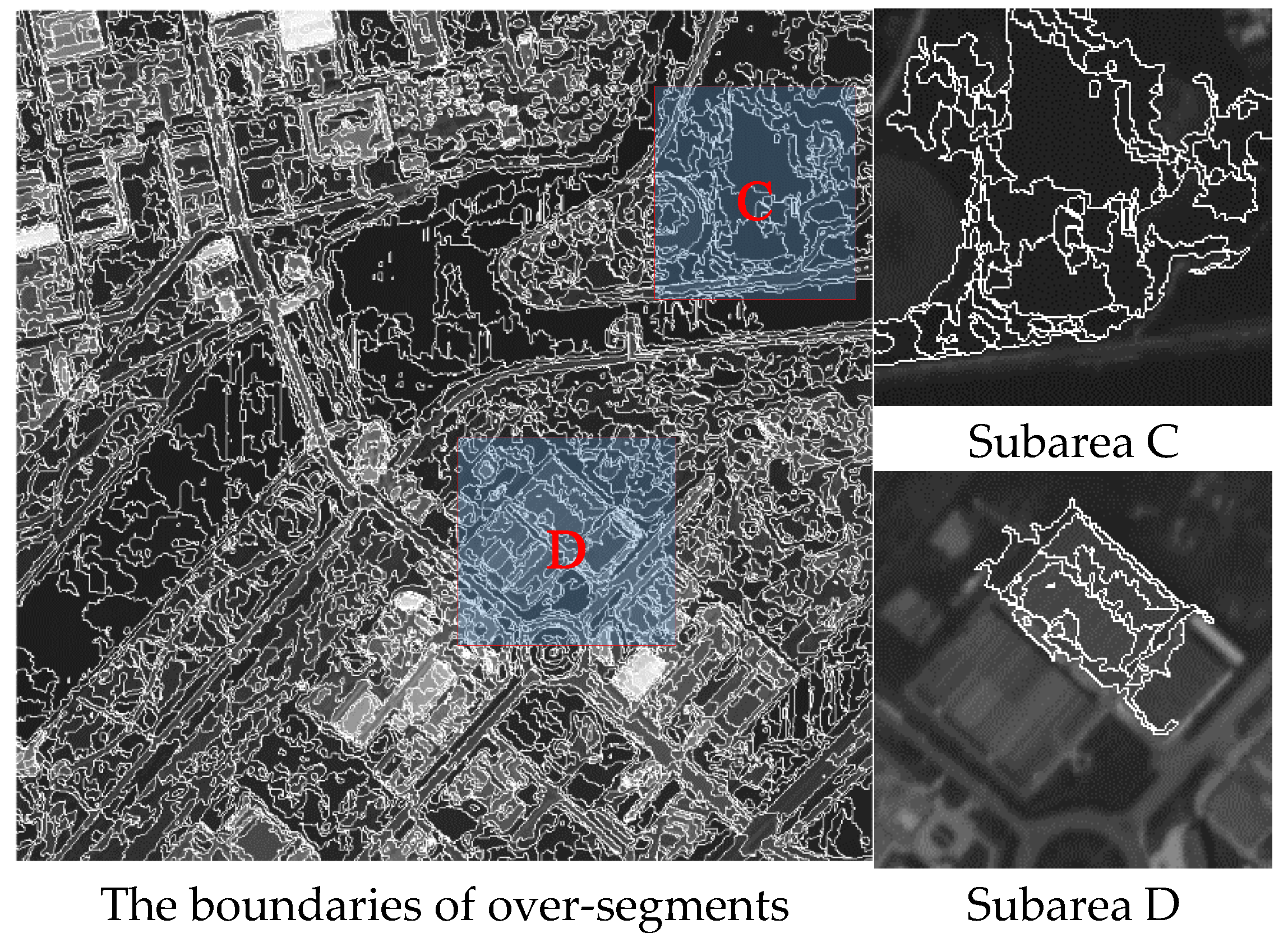
To bridge the gap of terminologies between feature clustering and image over-segmentation,
Figure 1 is employed to construct the analogy between the metaphor of ddCRP and image over-segmentation. An image with 16 pixels is shown in
Figure 1a, where each numbered square denotes a pixel. The image is a restaurant, which accommodates 16 customers under the metaphor of the ddCRP.
Figure 1b shows a middle state during the random process of customer assignments, where each arrow indicates a customer choose to sit with another customer. All of customers, who chose to sit with, naturally form a cluster. In other words, they sit at a same table in the ddCRP. This is illustrated in
Figure 1c, where the pixels with a same color belong to a cluster. Under the terminology of image over-segmentation, a segment also consists of all of the pixels with a same color, where every two pixels within a segment can reach to each other along the inferred customer assignments in the ddCRP. Therefore, the inferred customer assignments are the key to derive the results of image over-segmentation.
Given an image with
N pixels
, the image over-segmentation is to partition pixels into multiple regions with label
. In the ddCRP, the label
is a by-product of customer assignment
, whose posterior is given by
. The customer assignment, e.g.,
, is assumed to be dependent on the distance between two pixels, e.g.,
and is independent of other customer assignments. Therefore, the posterior of customer assignment is proportional to
where the likelihood of image pixels is given by
. It is difficult to compute the posterior because the ddCRP places a prior over a huge number of customer assignments. A simple Gibbs sampling method can be used to approximate the posterior by inferring its conditional probability
where
represent the customer assignments of all of the pixels with exception of
pixel, and
denotes the pixels associate with
segment derived from
;
is a prior of the parameter
, which is utilized to generate observations using a probability
. In this paper, the prior
and the probability distribution
are assumed to be Dirichlet process [
36] and multinomial distribution, respectively. The parameter
can be marginalized out, since they are conjugated. As a family of stochastic processes, the Dirichlet process can be seen as the infinite-dimensional generalization of the Dirichlet distribution.
As the shown in Equation (4), there are three possible situations to generate a new assignment . In situation 1, the assignment points to another pixel but do not make any change in the over-segmentation result. The situation 2 means that two different segments are merged into a new segment due to the customer assignment . For situation 3, the assignment points to itself in a probability proportional to .
In the following, we analyze the characteristics of the three components in the ddCRP, i.e., the distance dependent term , the likelihood of the image , and the connection mode among the pixels.
2.2. Distance Dependent Term
As for image over-segmentation, the dependence between the pixels can be naturally embedded into the ddCRP by the use of a spatial distance measure and a decay function, for example, the Euclidean distance between pixels
where
is pixel’s location in an image. The decay function is used to mediate the effects of distance between pixels on the sampling probability. The decay function should satisfy the following nonrestrictive assumptions; it should (1) be nonincreasing and (2) take nonnegative finite values, and (3)
. There are several types of decay functions [
37], such as the window decay function, the exponential decay function and the logistic decay function. If the distance satisfies the preference, the decay function returns a larger value; otherwise, it returned a smaller value.
Since over-segments consist of a set of pixels that are spatially adjacent and spectrally homogeneous, only the neighboring pixels are considered in this paper, i.e., pixels
and
with spatial distance
. As shown in
Figure 1, the possible assignments of the 11th pixel consist of 7th, 10th, 12th, and 15th pixels. Therefore, the information on neighboring spatial locations has been introduced by this setting. In order to take spectral information between neighboring pixels into account in this model, the spectral difference between neighboring pixels is also introduced in the ddCRP. Spectral distance can be represented by the difference
, where
is the DN value of
i-th pixel. So, the spectral difference and the spatial distance are combined to the final distance measure,
. The ddCRP model with spatial and spectral distance abbreviated to spatial-spectral ddCRP model. In our previse work [
42], empirical experiments showed that the spatial-spectral ddCRP model exhibits a promising performance.
2.3. Likelihood Term
Let the prior and probability distribution are the Dirichlet distribution and the multinomial distribution, respectively. Given customer assignments
, the likelihood of
kth segment is
where
denotes the parameter of the base distribution
, which is initialized while using a uniform distribution. The
represents the gamma function. Each visual word is denoted by
. In this paper, the visual word is a digital number (DN) value of panchromatic images.
denotes the number of pixels belonging to the
segment. As shown in Equation (2),
kth and
lth over-segments could be merged into a new one in a probability proportional to the production of distance dependent term and the likelihood ratio
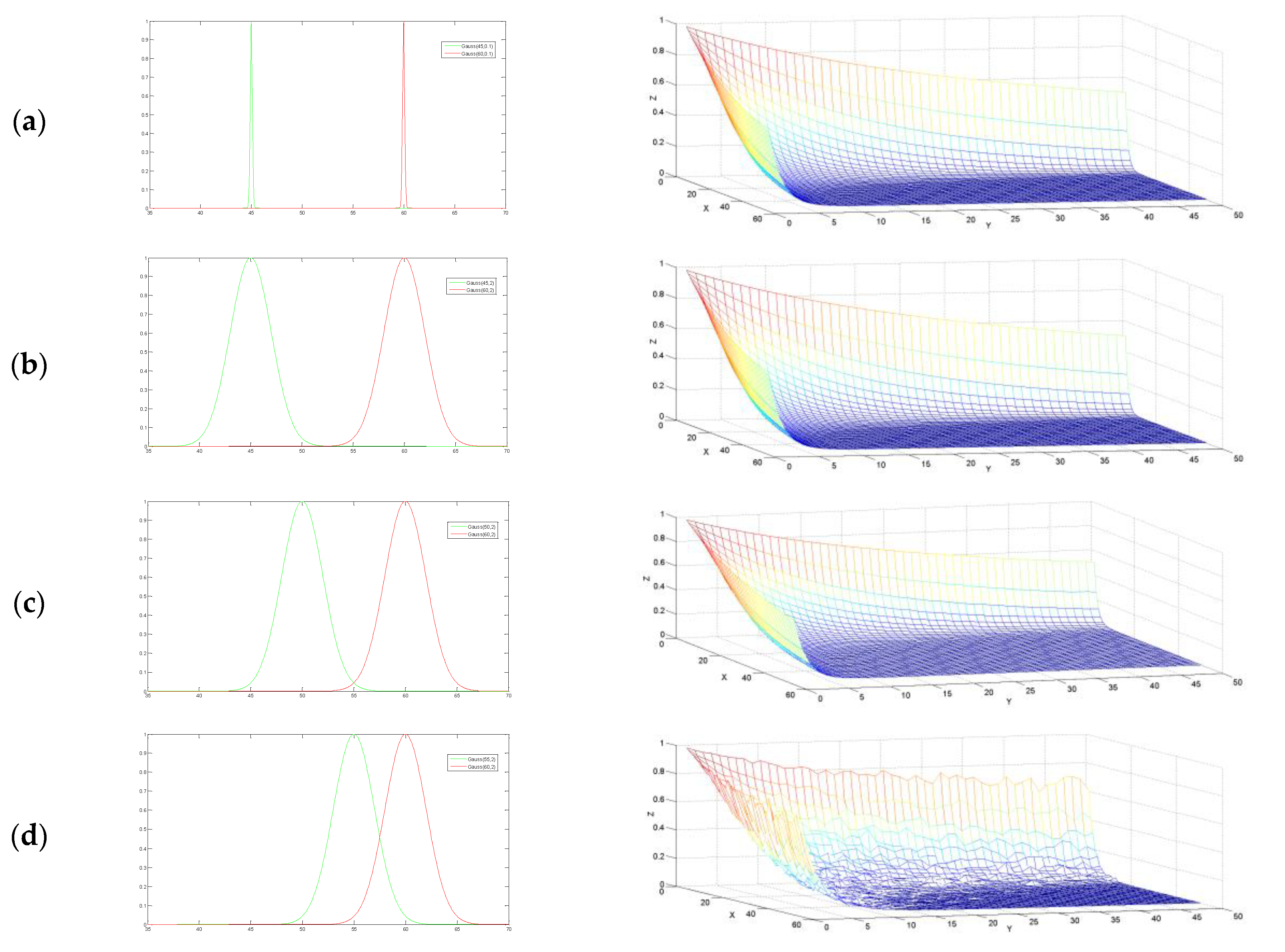
. For the sake of simplifying description, the likelihood ratio is called the merging probability of two over-segments in the following. To reveal the characteristics of the merging probability, we performed five simulated experiments, where a paired of Gaussian distributions are utilized to simulate DN values of pixels within
kth and
lth over-segments.
Table 1 lists parameters of Gaussian distributions, i.e., mean
and variance
, used in the five experiments. For each experiment, two subfigures are drawn on each row of
Figure 2, where the left subfigure shows the paired of Gaussian distributions, and the right one is the distribution of the merging probability over the numbers of pixels within the paired over-segments. Within the right subfigure, the
z-axis is the merging probability and
x-,
y-axis is the number of simulated pixels within the two over-segments, respectively.
It can be seen from
Figure 2 that the distributions of the merging probability exhibit a similar pattern in the first four experiments, i.e., from (a) to (d). The merging probability is always less than 1. That is to say the two over-segments incline to remain to be separated, since they are not similar in terms of the rather large difference between the two mean DN values. Therefore, during the inferring process in the ddCRP, the customer assignment is allocated with a lower probability. In other words, any paired of pixels from the two over-segments would connect with each other with a lower probability.
Furthermore, for a given number of pixels within one segment, the merging probability decreases with the increase of number of pixels within the other segment. The underlining reason is that the dissimilarity between the two over-segments can be furthermore verified with more and more observations. In other words, a reliable state of customer assignments would be expected only when the number of pixels within each segment is up to some level. As shown in
Figure 2a–d, the merging probability would be lower than 0.1 and become stable when the number of pixels is larger than about eight. This observation motivate us to use a number of pixels instead of individual pixel as a descriptor of each pixel in the improved model in
Section 3.
As shown in
Figure 2d, explicit local fluctuations occur in the distribution of merging probability since the two segments become more similar in terms of mean DN values. It can be seen from
Figure 2e that the merging probability of experiment (e) looks very different from the other four experiments. The merging probability is significantly larger than 1 for most cases. This results show that the two over-segments would incline to be merged when they are similar in terms of mean DN values. This argument could also be verified furthermore when the number of pixels become more and more. It can be seen from
Figure 2 that, if two segments are generated from dissimilar distributions, the merging probability will be less than 1, otherwise larger than 1. This suggests that it would be a good choice to let the parameter
equal to 1 in the ddCRP.
2.4. Connection Mode
In the ddCRP, the customer assignment is always allocated from some candidates that satisfy pre-specified constraints, which is called the connection mode in this paper. As shown in
Figure 3a, the assignment of the 11th pixel is connected with one of its nearest neighbors (i.e., 7th, 10th, 12th, and 15th pixels) or itself according to the Gibbs sampling formula Equation (4). This setting implies a competition among the candidates and decreases the connecting probability of each candidate to some extent. Actually, it may be unnecessary to compare the connection relationship between pixels and other neighboring pixels. As shown in
Figure 3b,c, each pixel might point to multiple pixels, i.e., multiple arrows. To discriminate different cases, one arrow that a pixel points to another pixel, is termed as “one-connection mode” (CM1), two arrows “two-connection mode” (CM2), and four arrows “four-connection mode” (CM4), respectively. Under the metaphor of CRP, the number of arrows indicates how many customers one could select to sit with during the inferring process.
Figure 4 shows the results of over-segmentation over three kinds of geographic scenes, i.e., Suburban (S), Farmland (F), and Urban (U) areas, using the three type of connection modes. The suburban area contains sparse buildings, roads, and fields. The area of farmland consists of cultivated lands with similar shapes and slightly different spectra. In contrast, the urban area displays a large spectral variation, contains many buildings and roads, and has a complex structure. The images come from panchromatic TIANHUI satellites, which have a size of 200 × 200 pixels and a resolution of approximately 2 m.
Four metrics are employed to quantitatively evaluate the quality of image over-segmentations, i.e., the boundary recall (BR) [
43], the achievable segmentation accuracy (ASA) [
44], the under-segmentation error (UE) [
45], and the degree of landscape fragmentation (LF) [
42]. The BR is to measure how many percentage of real object boundaries have been discovered by an over-segmentation method. Based on the overlap between segments and real object regions, the ASA and UE is the percentage of pixels within or out of object regions, respectively. The last metric is to measure the degree of fragmentation for an over-segmentation result.
It can be seen from
Table 2 that the CM1 is the best connection mode in terms of both BR and ASA for all of the three scenes. In contrast, the CM4 is the best one in terms of LF for all of the three scenes. The CM2 is in the middle among the three connection modes for all of the experiments with the exception of the UE of urban area. Please note that the metrics of both BR and ASA could increase with the number of segments. This also can reflected by the measurement of LF. The FL under CM1 is the highest among the three connection mode for all of three scenes. It also can be seen from
Figure 4 that, under the CM1, there exist many segments of very small size, even many isolated points. In contrast, the size of segments is rather large under the CM4 and there explicitly exist under-segmented results. For example, many long and narrow objects, e.g., roads, are often incorrectly merged into larger regions under the CM4. To make full use of characteristics of different connection modes, both CM1 and CM2 will be utilized in our proposed method in
Section 3.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}