Investigating Online Destination Images Using a Topic-Based Sentiment Analysis Approach

Abstract
1. Introduction
2. Related Work
2.1. Sentiment Analysis
2.2. Studies on Tourist Reviews Using Text Mining Techniques
3. Methodology
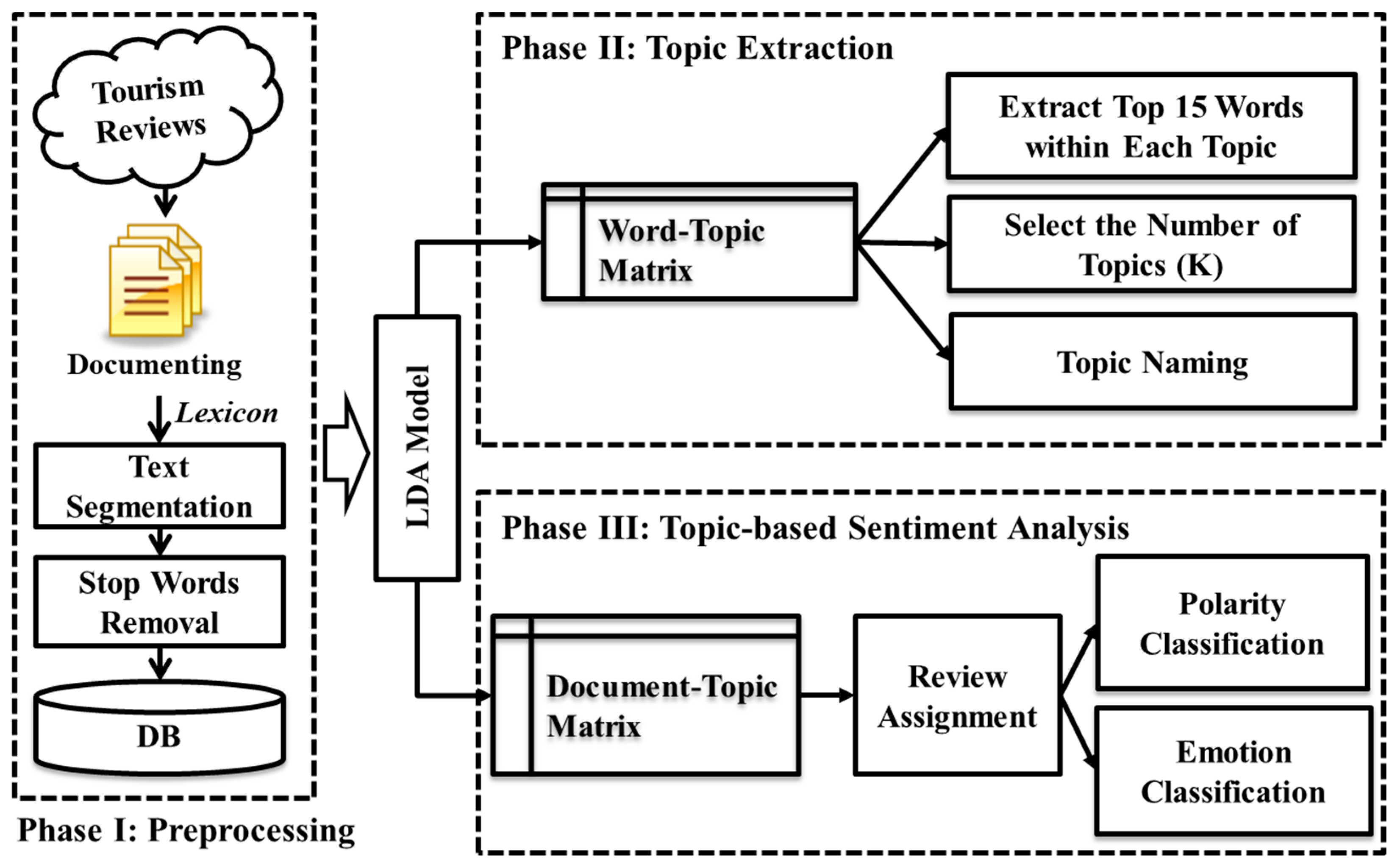
3.1. Research Framework
3.2. Data Collection
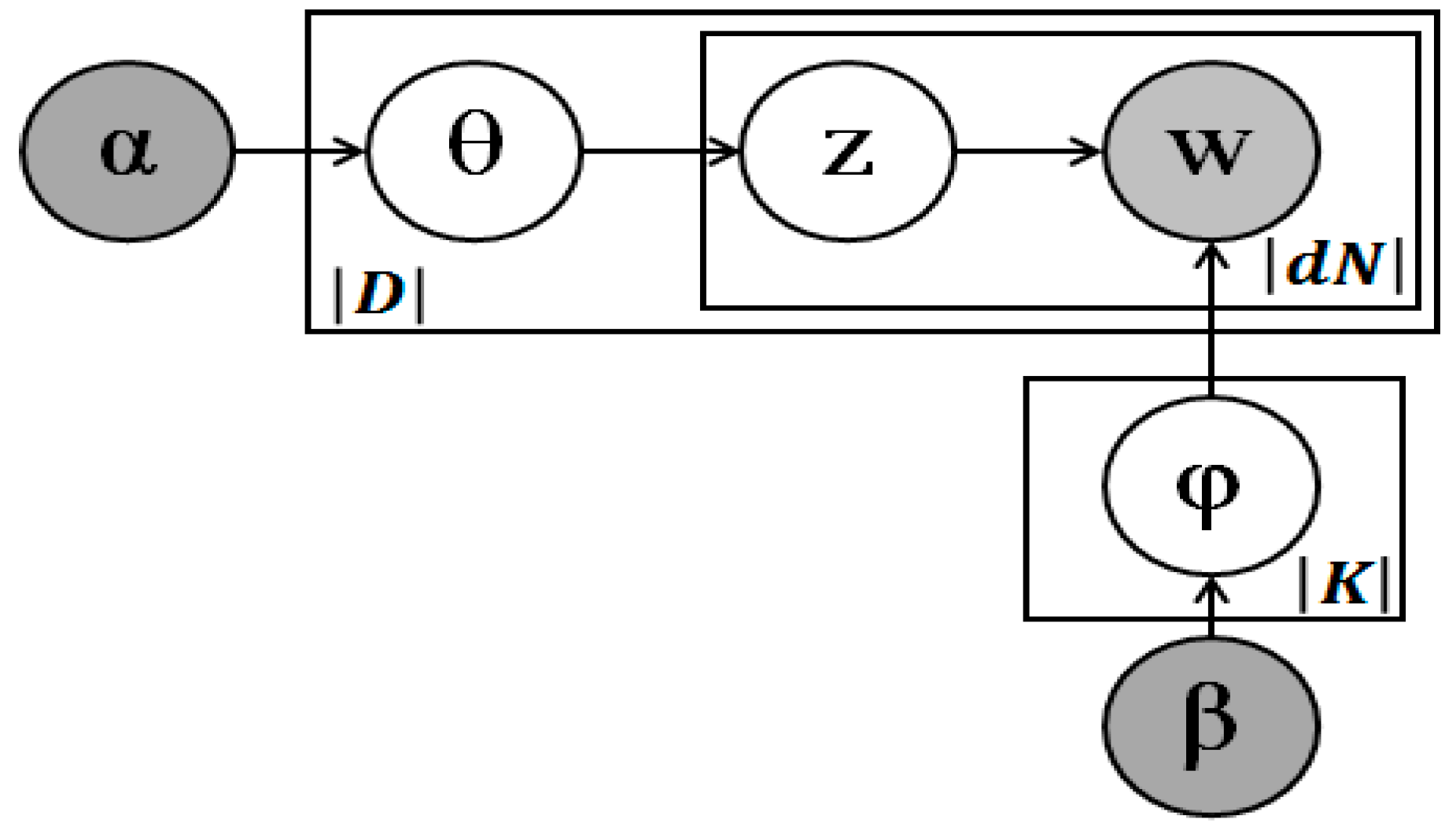
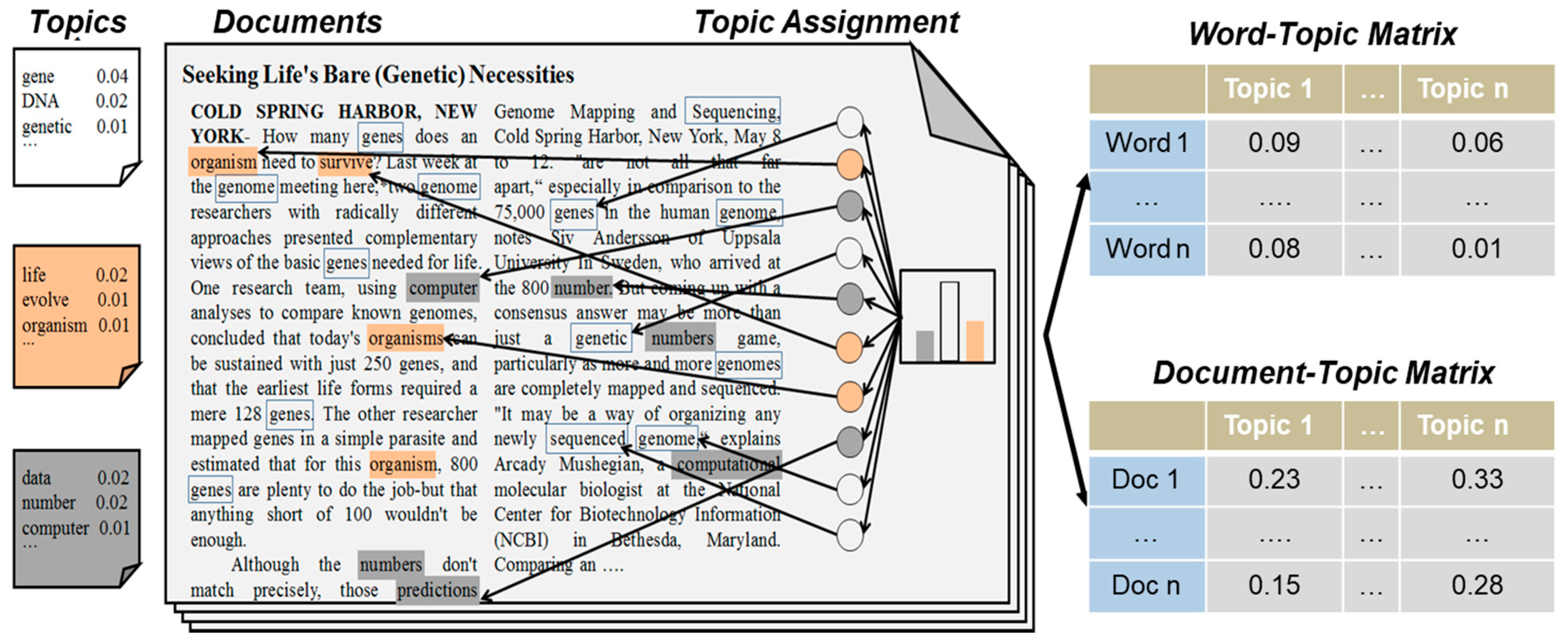
3.3. Topic Extraction
- Choose the topic distribution
- For each word
- -
- Choose a topic
- -
- Choose a word from , a multinomial probability conditioned on topic .
3.4. Topic-Based Sentiment Analysis
4. Results
4.1. Topic Extraction
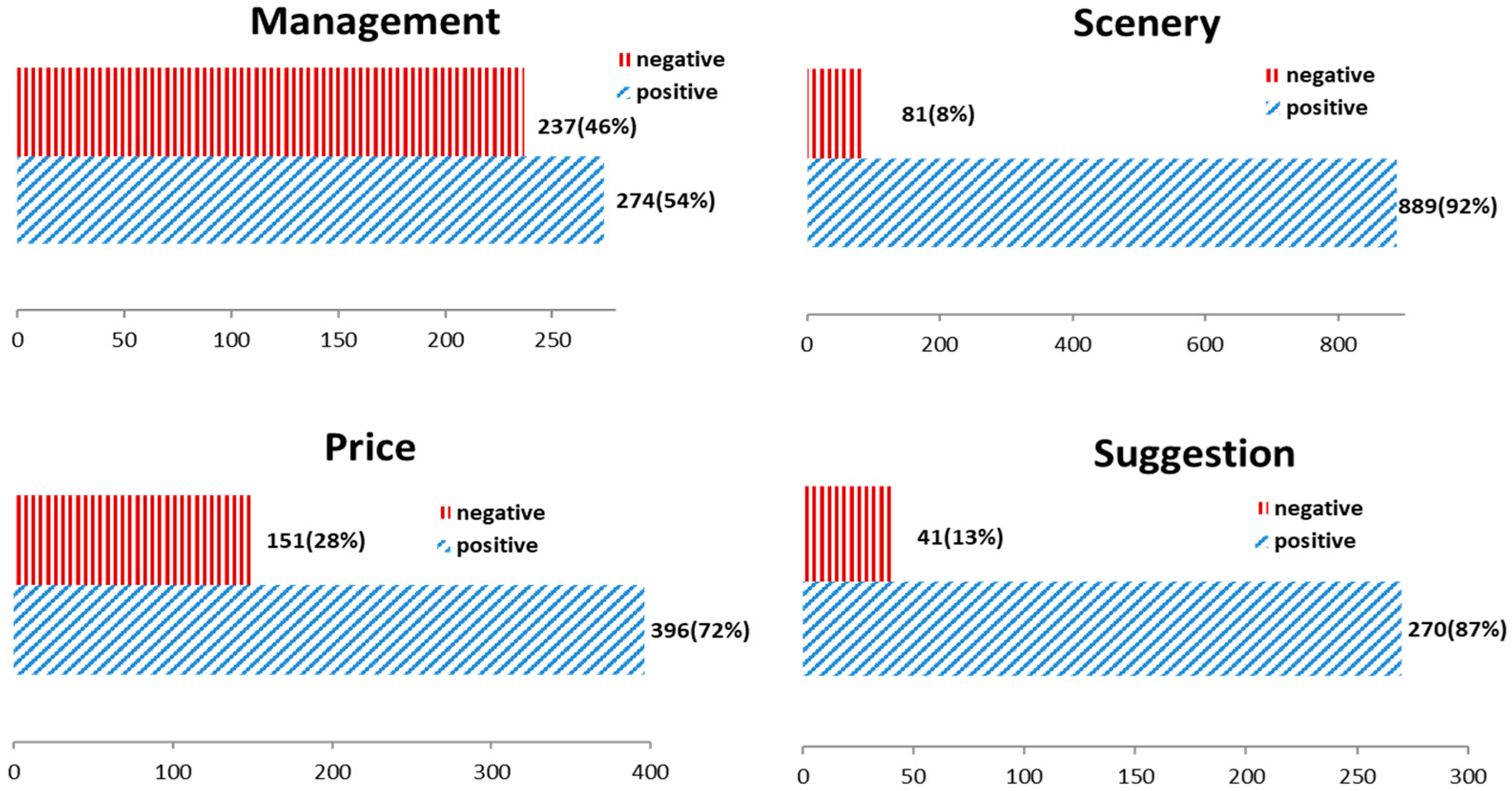
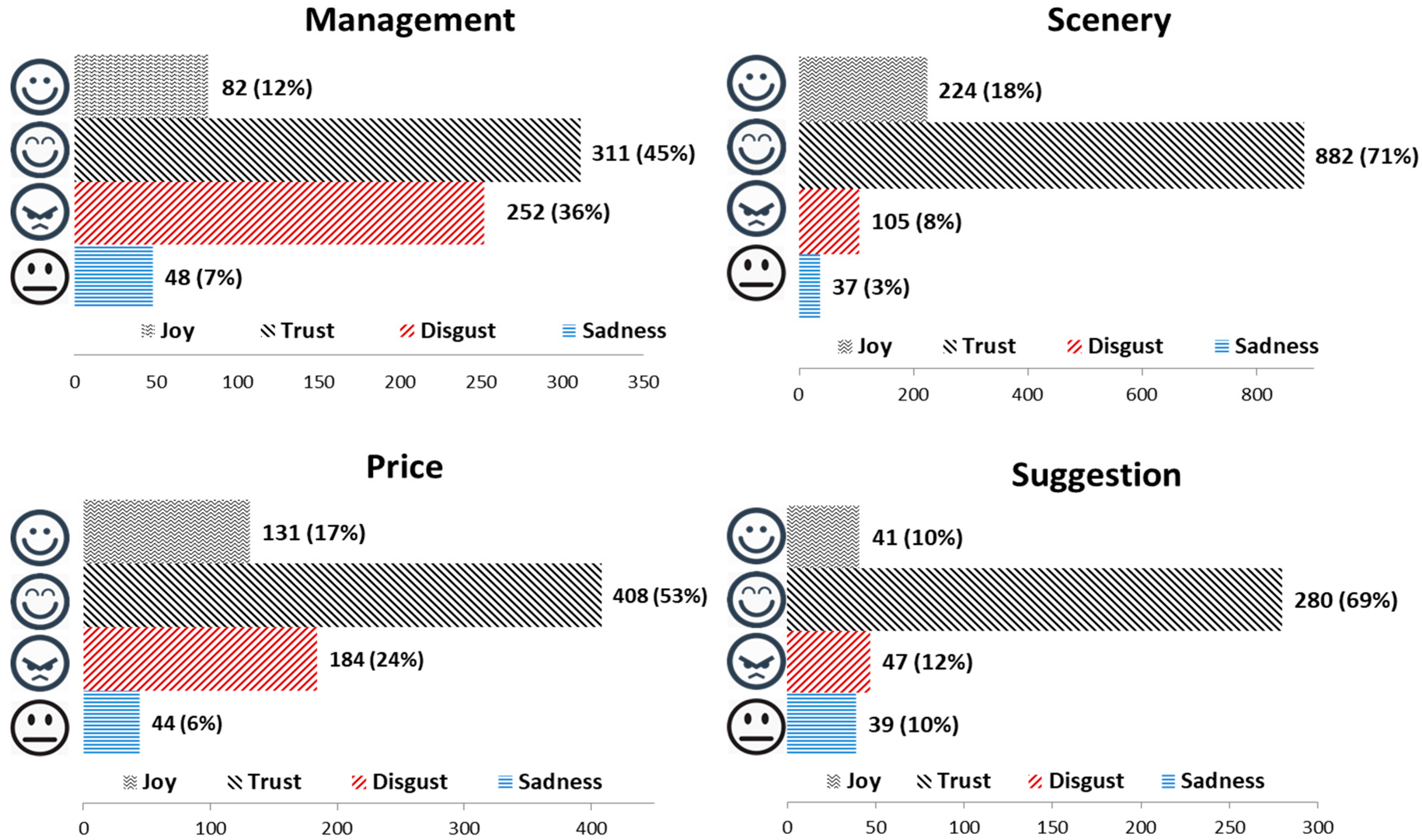
4.2. Topic-Based Sentiment Analysis
5. Discussion and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chevalier, J.A.; Mayzlin, D. The Effect of Word of Mouth on Sales: Online Book Reviews. J. Mark. Res. 2006, 43, 345–354. [Google Scholar] [CrossRef]
- Duan, W.; Gu, B.; Whinston, A.B. The dynamics of online word-of-mouth and product sales—An empirical investigation of the movie industry. J. Retail. 2008, 84, 233–242. [Google Scholar] [CrossRef]
- Hu, N.; Bose, I.; Gao, Y.; Liu, L. Manipulation in digital word-of-mouth: A reality check for book reviews. Decis. Support Syst. 2011, 50, 627–635. [Google Scholar] [CrossRef]
- Ye, Q.; Law, R.; Gu, B. The impact of online user reviews on hotel room sales. Int. J. Hosp. Manag. 2009, 28, 180–182. [Google Scholar] [CrossRef]
- Spool, J.M. The Magic Behind Amazon’s 2.7 Billion Dollar Question. Available online: https://articles.uie.com/magicbehindamazon/ (accessed on 5 June 2017).
- Xiang, Z.; Gretzel, U. Role of social media in online travel information search. Tour. Manag. 2010, 31, 179–188. [Google Scholar] [CrossRef]
- Sun, M.; Ryan, C.; Pan, S. Using Chinese Travel Blogs to Examine Perceived Destination Image: The Case of New Zealand. J. Travel Res. 2015, 54, 543–555. [Google Scholar] [CrossRef]
- Mak, A.H.N. Online destination image: Comparing national tourism organisation’s and tourists’ perspectives. Tour. Manag. 2017, 60, 280–297. [Google Scholar] [CrossRef]
- Crompton, J.L. An Assessment of the Image of Mexico as a Vacation Destination and the Influence of Geographical Location Upon That Image. J. Travel Res. 1979, 17, 18–23. [Google Scholar] [CrossRef]
- Lin, C.; He, Y. Joint sentiment/topic model for sentiment analysis. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 375–384. [Google Scholar]
- Xianghua, F.; Guo, L.; Yanyan, G.; Zhiqiang, W. Multi-aspect sentiment analysis for Chinese online social reviews based on topic modeling and HowNet lexicon. Knowl.-Based Syst. 2013, 37, 186–195. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Shirai, K.; Velcin, J. Sentiment analysis on social media for stock movement prediction. Expert Syst. Appl. 2014, 42, 9603–9611. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’04, Seattle, WA, USA, 22–25 August 2004; Volume 4, p. 168. [Google Scholar]
- Marrese-Taylor, E.; Velásquez, J.D.; Bravo-Marquez, F. A novel deterministic approach for aspect-based opinion mining in tourism products reviews. Expert Syst. Appl. 2014, 41, 7764–7775. [Google Scholar] [CrossRef]
- Xiang, Z.; Du, Q.; Ma, Y.; Fan, W. A comparative analysis of major online review platforms: Implications for social media analytics in hospitality and tourism. Tour. Manag. 2017, 58, 51–65. [Google Scholar] [CrossRef]
- Guo, Y.; Barnes, S.J.; Jia, Q. Mining meaning from online ratings and reviews: Tourist satisfaction analysis using latent dirichlet allocation. Tour. Manag. 2017, 59, 467–483. [Google Scholar] [CrossRef]
- Pearce, P.L.; Wu, M.-Y. Entertaining International Tourists: An Empirical Study of an Iconic Site in China. J. Hosp. Tour. Res. 2015, XX, 1–21. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions, 1st ed.; Cambridge University Press: New York, NY, USA, 2015. [Google Scholar]
- Rozin, P.; Royzman, E.B. Negativity Bias, Negativity Dominance, and Contagion Paul. Personal. Soc. Psychol. Rev. 2001, 5, 296–320. [Google Scholar] [CrossRef]
- Baumeister, R.F.; Bratslavsky, E.; Finkenauer, C.; Vohs, K.D. Bad is stronger than good. Rev. Gen. Psychol. 2001, 5, 323–370. [Google Scholar] [CrossRef]
- Blei, D.M.; Edu, B.B.; Ng, A.Y.; Edu, A.S.; Jordan, M.I.; Edu, J.B. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Li, N.; Wu, D. Using text mining and sentiment analysis for online forums hotspot detection and forecast. Decis. Support Syst. 2010, 48, 354–368. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up?: Sentiment classification using machine learning techniques. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing, Stroudsburg, PA, USA, 6–7 July 2002; pp. 79–86. [Google Scholar]
- Liu, B. Sentiment Analysis and Opinion Mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef]
- Moraes, R.; Valiati, J.F.; Gavião Neto, W.P. Document-level sentiment classification: An empirical comparison between SVM and ANN. Expert Syst. Appl. 2013, 40, 621–633. [Google Scholar] [CrossRef]
- Tan, S.; Zhang, J. An empirical study of sentiment analysis for chinese documents. Expert Syst. Appl. 2008, 34, 2622–2629. [Google Scholar] [CrossRef]
- Mehrabian, A.; Russell, J.A. An Approach to Environmental Psychology; MIT Press: Cambridge, CA, USA, 1974; Volume 315. [Google Scholar]
- Plutchik, R. Emotion: A Psychoevolutionary Synthesis; Harper and Row: Manhattan, NY, USA, 1980. [Google Scholar]
- Mishne, G. Experiments with mood classification in blog posts. In Proceedings of the ACM SIGIR Workshop on Stylistic Analysis of Text for Information Access, Salvador, Brazil, 15-19 August 2005; pp. 321–327. [Google Scholar]
- Yang, C.; Lin, K.; Chen, H.-H. Emotion Classification Using Web Blog Corpora. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence, Fremont, CA, USA, 2–5 November 2007. [Google Scholar]
- Lin, K.H.Y.; Yang, C.; Chen, H.H. Emotion classification of online news articles from the reader’s perspective. In Proceedings of the 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, WI-IAT’08, Sydney, Australia, 9–12 December 2008; pp. 220–226. [Google Scholar]
- Tokuhisa, R.; Matsumoto, Y. Emotion Classification Using Massive Examples Extracted from the Web. In Proceedings of the 22nd International Conference on Computational Linguistics, Manchester, UK, 18–22 August 2008; pp. 881–888. [Google Scholar]
- Chaumartin, F.-R. UPAR7: A knowledge-based system for headline sentiment tagging. In Proceedings of the 4th International Workshop on Semantic Evaluations, Prague, Czech Republic, 23–24 June 2007; pp. 422–425. [Google Scholar]
- Al Masum, S.M.; Prendinger, H.; Ishizuka, M. Emotion Sensitive News Agent: An Approach Towards User Centric Emotion Sensing from the News. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence, Fremont, CA, USA, 2–5 November 2007; pp. 614–620. [Google Scholar]
- Li, W.; Xu, H. Text-based emotion classification using emotion cause extraction. Expert Syst. Appl. 2014, 41, 1742–1749. [Google Scholar] [CrossRef]
- Zhang, Z.; Ye, Q.; Zhang, Z.; Li, Y. Sentiment classification of Internet restaurant reviews written in Cantonese. Expert Syst. Appl. 2011, 38, 7674–7682. [Google Scholar]
- Kang, H.; Yoo, S.J.; Han, D. Senti-lexicon and improved Naïve Bayes algorithms for sentiment analysis of restaurant reviews. Expert Syst. Appl. 2012, 39, 6000–6010. [Google Scholar] [CrossRef]
- Choi, S.; Lehto, X.Y.; Morrison, A.M. Destination image representation on the web: Content analysis of Macau travel related websites. Tour. Manag. 2007, 28, 118–129. [Google Scholar] [CrossRef]
- Levy, S.E.; Duan, W.; Boo, S. An Analysis of One-Star Online Reviews and Responses in the Washington, D.C., Lodging Market. Cornell Hosp. Q. 2013, 54, 49–63. [Google Scholar] [CrossRef]
- Ariyasriwatana, W.; Quiroga, L.M. A thousand ways to say “Delicious!” Categorizing expressions of deliciousness from restaurant reviews on the social network site Yelp. Appetite 2016, 104, 18–32. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Park, S. What makes a useful online review? Implication for travel product websites. Tour. Manag. 2015, 47, 140–151. [Google Scholar] [CrossRef]
- Bucur, C. Using Opinion Mining Techniques in Tourism. Procedia Econ. Financ. 2015, 23, 1666–1673. [Google Scholar] [CrossRef]
- Hu, Y.-H.; Chen, Y.-L.; Chou, H.-L. Opinion mining from online hotel reviews—A text summarization approach. Inf. Process. Manag. 2017, 53, 436–449. [Google Scholar] [CrossRef]
- Hu, Y.H.; Chen, K. Predicting hotel review helpfulness: The impact of review visibility, and interaction between hotel stars and review ratings. Int. J. Inf. Manag. 2016, 36, 929–944. [Google Scholar] [CrossRef]
- Farhadloo, M.; Patterson, R.A.; Rolland, E. Modeling Customer Satisfaction from Unstructured Data Using A Bayesian Approach. Decis. Support Syst. 2016, 90, 1–11. [Google Scholar] [CrossRef]
- Cenni, I.; Goethals, P. Negative hotel reviews on TripAdvisor: A cross-linguistic analysis. Discourse Context Media 2017, 16, 22–30. [Google Scholar] [CrossRef]
- Rosenberg, S.D.; Schnurr, P.P.; Oxman, T.E. Content Analysis: A Comparison of Manual and Computerized Systems. J. Personal. Assess. 1990, 54, 298–310. [Google Scholar]
- Dong, Z.; Dong, Q. HowNet—A hybrid language and knowledge resource. In Proceedings of the 2003 International Conference on Natural Language Processing and Knowledge Engineering, NLP-KE 2003, Beijing, China, 26–29 October 2003; pp. 820–824. [Google Scholar]
- Blei, D.M. Introduction to Probabilistic Topic Modeling. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Maskeri, G.; Sarkar, S.; Heafield, K. Mining business topics in source code using latent dirichlet allocation. In Proceedings of the 1st India Software Engineering Conference—ISEC’08, Hyderabad, India, 19–22 February 2008; p. 113. [Google Scholar]
- Shi, Z.; Lee, G.; Whinston, A.B. Toward A Better Measure of Business Proximity: Topic Modeling for Industry Intelligence. MIS Q. 2016, 40, 1035–1056. [Google Scholar] [CrossRef]
- Alam, M.H.; Ryu, W.J.; Lee, S.K. Joint multi-grain topic sentiment: Modeling semantic aspects for online reviews. Inf. Sci. 2016, 339, 206–223. [Google Scholar] [CrossRef]
- Hindle, A.; Ernst, N.A.; Godfrey, M.W.; Mylopoulos, J. Automated Topic Naming to Support Cross-project Analysis of Software Maintenance Activities. In Proceedings of the 8th Working Conference on Mining Software Repositories, Honolulu, HI, USA, 21–22 May 2011; pp. 163–172. [Google Scholar]
- Xu, L.; Lin, H.; Pan, Y.; Ren, H.; Chen, J. Constructing the Affective Lexicon Ontology. J. China Soc. Sci. Tech. Inf. 2008, 27, 180–185. [Google Scholar]
- Liu, S.M.; Chen, J.-H. A multi-label classification based approach for sentiment classification. Expert Syst. Appl. 2015, 42, 1083–1093. [Google Scholar] [CrossRef]
- Gao, K.; Su, S.; Wang, J.S. A sentiment analysis hybrid approach for microblogging and E-commerce corpus. In Proceedings of the 2015 7th International Conference on Modelling, Identification and Control (ICMIC), Sousse, Tunisia, 18–20 December 2015; pp. 3–8. [Google Scholar]
- Beerli, A.; Martin, J.D. Factors influencing destination image. Ann. Tour. Res. 2004, 31, 657–681. [Google Scholar] [CrossRef]
- Chi, C.G.Q.; Qu, H. Examining the structural relationships of destination image, tourist satisfaction and destination loyalty: An integrated approach. Tour. Manag. 2008, 29, 624–636. [Google Scholar] [CrossRef]
- Westbrook, R.A.; Oliver, R. The Dimensionality of Consumption Emotion Pattems and Consumer Satisfaction. J. Consum. Res. 1991, 18, 84–91. [Google Scholar] [CrossRef]
- Jin, Q.; Liu, N.N.; Bay, C.W.; Kong, H.; Zhao, K. Transferring Topical Knowledge from Auxiliary Long Texts for Short Text Clustering. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Scotland, UK, 24–28 October 2011; pp. 775–784. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Concept | Study | Data 1 | Method 2 |
|---|---|---|---|---|
| Content analysis | Refers to the process that quantifies or qualifies the unstructured text data. | Choi et al. (2007) [38] | 81 sites | Identifies the words frequently used in each of five sub-categories of websites. |
| Levy et al. (2013) [39] | T | Extracts hotel complaints using one-star reviews | ||
| Ariyasriwatana and Quiroga (2016) [40] | Y | Explores expressions of deliciousness | ||
| Liu and Park (2015) [41] | Y | Examines the effect of review content features on helpfulness | ||
| Document-based sentiment analysis | Refers to the process that analyzes sentiments or emotions at the document level. | Zhang et al. (2011) [36] | - | Performs a polarity classification using SVM and NB |
| Kang et al. (2012) [37] | - | Proposes a polarity classification approach based on senti-lexicon and NB | ||
| Hu et al. (2017) [43] | T | Identifies the most informative sentences using a multi-text summarization technique | ||
| Bucur (2015) [42] | T | Performs polarity classifications based on a lexicon | ||
| Hu and Chen (2016) [44] | T | Uses review sentiment features to predict helpfulness. | ||
| Topic-based sentiment analysis | Refers to the process of topic extraction and analyzing sentiments and emotions at the topic level | Pearce and Wu (2015) [17] | T | Extracts tourism topics of attraction by a thematic and semantic analysis |
| Marrese-Taylor et al. (2014) [14] | T | Proposes a deterministic rule for word and sentiment orientation | ||
| Farhadloo et al. (2016) [45] | T | Extracts topics using a Bayesian approach | ||
| Xiang et al. (2017) [15] | T, E, Y | Extracts topics on three platforms using an LDA model | ||
| Cenni and Goethals (2017) [46] | T | Examines the divergence over topics written in different languages using a Cross-linguistic analysis approach | ||
| Guo et al. (2017) [16] | T | Extracts hotel topics using an LDA model |
| Reviews | Number of Reviews | Mean | Maximum | Minimum |
|---|---|---|---|---|
| Positive reviews | 1000 | 87 | 1055 | 6 |
| Negative reviews | 1000 | 85 | 687 | 15 |
| Total reviews | 2000 | 86 | 1055 | 6 |
| Topic Naming Method | Study |
|---|---|
| Topics are named manually by summarizing the meaning of frequent words or assigning a topic from the predefined topics | Maskeri et al. (2008) [50]; Xianghua et al. (2013) [11]; Shi et al. (2016) [51]; Alam et al. (2016) [52]; Xiang et al. (2017) [15]; Guo et al. (2017) [16] |
| Topics are named automatically based on supervised learning and a user-defined word-list | Hindle et al. (2011) [53] |
| Top 15 Words and Corresponding Weights 1 | |||||
|---|---|---|---|---|---|
| Topic 1. Management 0.2177 | |||||
| attraction | 0.0445 | time | 0.0212 | suggest | 0.0190 |
| hour | 0.0174 | tourist | 0.0153 | hotel | 0.0120 |
| queue | 0.0115 | guide | 0.0114 | cableway | 0.0114 |
| service | 0.0106 | cable car | 0.0101 | visit | 0.0095 |
| charged | 0.0081 | beauty | 0.0078 | management | 0.0077 |
| Topic 2. Scenery 0.1688 | |||||
| landscape | 0.0321 | worth | 0.0296 | rape flower | 0.0136 |
| beautiful | 0.0129 | season | 0.0108 | park | 0.0084 |
| all the way | 0.0079 | best | 0.0077 | esthetical | 0.0074 |
| rental car | 0.0073 | lakeside | 0.0065 | feel | 0.0065 |
| sunrise | 0.0063 | photograph | 0.0061 | cattle | 0.0057 |
| Topic 3. Price and Scenery 0.2873 | |||||
| local | 0.0415 | scenery | 0.0412 | good | 0.0348 |
| ticket | 0.0333 | feel | 0.0280 | special | 0.0167 |
| night | 0.0105 | just so so | 0.0132 | very beautiful | 0.0134 |
| like | 0.0105 | cost-effective | 0.0094 | commercialized | 0.0092 |
| really | 0.0088 | bad | 0.0085 | a visit | 0.0081 |
| Top 15 Words and Corresponding Weights 1 | ||||||
|---|---|---|---|---|---|---|
| Topic 1. Management 0.2823 | ||||||
| attraction | 0.0583 | ticket | 0.0416 | hour | 0.0228 | |
| tourist | 0.0201 | just so so | 0.0162 | hotel | 0.0157 | |
| queue | 0.0151 | cableway | 0.0150 | service | 0.0139 | |
| cable car | 0.0133 | really | 0.0110 | bad | 0.0106 | |
| management | 0.0101 | top of mountain | 0.0098 | only | 0.0088 | |
| Topic 2. Scenery 0.1345 | ||||||
| beautiful | 0.0169 | season | 0.0137 | beauty | 0.0109 | |
| best | 0.0105 | all the way | 0.0103 | esthetical | 0.0097 | |
| feel | 0.0085 | sightseeing | 0.0079 | cattle | 0.0074 | |
| clouds | 0.0069 | experience | 0.0068 | back | 0.0066 | |
| lake | 0.0063 | km | 0.0061 | blue sky | 0.0061 | |
| Topic 3. Price 0.2412 | ||||||
| local | 0.0548 | feel | 0.0371 | guide | 0.0158 | |
| night | 0.0139 | like | 0.0139 | visit | 0.0131 | |
| recommend | 0.0126 | commercialized | 0.0121 | charged | 0.0112 | |
| park | 0.0109 | disappointed | 0.0102 | feature | 0.0097 | |
| weather | 0.0089 | cheap | 0.0088 | lodge | 0.0081 | |
| Topic 4. Suggestion 0.3818 | ||||||
| scenery | 0.0568 | good | 0.0480 | worth | 0.0443 | |
| landscape | 0.0435 | time | 0.0307 | suggest | 0.0275 | |
| special | 0.0230 | beautiful | 0.0185 | rape flower | 0.0185 | |
| friends | 0.0138 | cost-effective | 0.0130 | price | 0.0128 | |
| a visit | 0.0112 | be fit for | 0.0102 | choose | 0.0100 | |
| Top 15 Words and Corresponding Weights 1 | |||||
|---|---|---|---|---|---|
| Topic 1. Management 0.2781 | |||||
| time | 0.0353 | suggest | 0.0316 | ticket | 0.0303 |
| hour | 0.0290 | hotel | 0.0200 | queue | 0.0192 |
| cableway | 0.0190 | friends | 0.0165 | cable car | 0.0130 |
| top of mountain | 0.0125 | schedule | 0.0107 | downhill | 0.0107 |
| several | 0.0104 | mood | 0.0102 | sunrise | 0.0098 |
| Topic 2. Scenery 0.1673 | |||||
| beautiful | 0.0210 | season | 0.0353 | beauty | 0.0136 |
| all the way | 0.0128 | best | 0.0126 | rental car | 0.0118 |
| lakeside | 0.0106 | feel | 0.0106 | cattle | 0.0092 |
| clouds | 0.0086 | experience | 0.0084 | on the way | 0.0082 |
| natives | 0.0078 | lake | 0.0078 | km | 0.0076 |
| Topic 3. Price and Management 0.2709 | |||||
| attraction | 0.0747 | tourist | 0.0257 | ticket | 0.0226 |
| guide | 0.0192 | service | 0.0178 | visit | 0.0159 |
| bad | 0.0135 | charged | 0.0135 | management | 0.0122 |
| only | 0.0112 | two | 0.0106 | dine | 0.0087 |
| drive | 0.0085 | staff | 0.0083 | too bad | 0.0083 |
| Topic 4. Suggestion 0.3265 | |||||
| good | 0.0587 | feel | 0.0473 | special | 0.0281 |
| rape flower | 0.0226 | just so so | 0.0220 | night | 0.0177 |
| cost- effective | 0.0159 | recommend | 0.0161 | like | 0.0177 |
| commercialized | 0.0155 | really | 0.0149 | price | 0.0126 |
| be fit for | 0.0124 | feature | 0.0124 | choose | 0.0122 |
| Topic 5. Scenery 0.3921 | |||||
| local | 0.0713 | scenery | 0.0709 | worth | 0.0553 |
| landscape | 0.0542 | very beautiful | 0.0231 | park | 0.0141 |
| a visit | 0.0139 | disappointed | 0.0133 | esthetical | 0.0125 |
| beautiful | 0.0123 | weather | 0.0116 | photograph | 0.0104 |
| sightseeing | 0.0102 | been | 0.0100 | pity | 0.0091 |
| Topic Number K | 3 | 4 | 5 |
|---|---|---|---|
| Average KL distance between topics | 7.6899 | 7.7199 | 7.2895 |
| Topic | Extracted Words | Distinctive Words | Topic Naming |
|---|---|---|---|
| Topic 1 | attraction, ticket, hour, tourist, just so so, hotel, queue, cableway, service, cable car, really, bad, management, top of mountain, only | queue, cableway, hour, service, cable car, management | management |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, G.; Hong, T. Investigating Online Destination Images Using a Topic-Based Sentiment Analysis Approach. Sustainability 2017, 9, 1765. https://doi.org/10.3390/su9101765
Ren G, Hong T. Investigating Online Destination Images Using a Topic-Based Sentiment Analysis Approach. Sustainability. 2017; 9(10):1765. https://doi.org/10.3390/su9101765
Chicago/Turabian StyleRen, Gang, and Taeho Hong. 2017. "Investigating Online Destination Images Using a Topic-Based Sentiment Analysis Approach" Sustainability 9, no. 10: 1765. https://doi.org/10.3390/su9101765
APA StyleRen, G., & Hong, T. (2017). Investigating Online Destination Images Using a Topic-Based Sentiment Analysis Approach. Sustainability, 9(10), 1765. https://doi.org/10.3390/su9101765