
Airline Sustainability Modeling: A New Framework with Application of Bayesian Structural Equation Modeling


 ,
,
Abstract
:1. Introduction
- Mainly first moment properties of the raw individual observations are used for statistical methods, which make improvements of analyses much simpler compared to the second moment properties of the sample covariance matrix. Hence, it is easier to use in more complex states.
- Direct impact of the latent variables (construct) is possible which makes obtaining factor score estimates simpler compared to that of the classical regression techniques.
- As it directly models manifest variables with their latent variables through the familiar regression functions, it provides a more direct interpretation and enables the use the common techniques in regression modeling such as residual and outlier analyses in conducting statistical analysis.
2. Literature Review and Research Hypotheses
- H1: Economic performance has a significant impact on financial performance.
- H2: Operational performance has a significant impact on financial performance.
- H3: There is a significant relationship between economic performance and operational performance.
- H4: Cost performance has significant impact on financial performance.
- H5: There is a significant relationship between cost performance and operational performance.
- H6: There is a significant relationship between economic performance and cost performance.
3. Classical-SEM & Bayesian-SEM Theories
4. Materials and Methods
5. Results
6. Discussion
7. Conclusions
- (1)
- Application of the framework which is introduced in Figure 2 in other areas and do comparison study between them.
- (2)
- Comparison study between Classical-SEM (as representative of parametric modeling) and Bayesian-SEM (as a representative semi-parametric modeling) was done, but comparison between these two methods with artificial neural networks (as a representative of non-parametric modeling) could be an interesting topic for future research.
- (3)
- Doing comparison analysis with the leveraging governmental subsidy as the main moderator in the research framework of Figure 2.
Author Contributions
Conflicts of Interest
References
- Schosser, M.; Wittmer, A. Cost and revenue synergies in airline mergers—Examining geographical differences. J. Air Transp. Manag. 2015, 47, 142–153. [Google Scholar] [CrossRef]
- Barbot, C.; Costa, Á.; Sochirca, E. Airlines performance in the new market context: A comparative productivity and efficiency analysis. J. Air Transp. Manag. 2008, 14, 270–274. [Google Scholar] [CrossRef]
- Gudmundsson, S.V. Airline failure and distress prediction: A comparison of quantitative and qualitative models. Transp. Res. Part E Logist. Transp. Rev. 1999, 35, 155–182. [Google Scholar] [CrossRef]
- Cao, Q.; Lv, J.; Zhang, J. Productivity efficiency analysis of the airlines in China after deregulation. J. Air Transp. Manag. 2015, 42, 135–140. [Google Scholar] [CrossRef]
- Hsu, C.I.; Wen, Y.H. Application of grey theory and multiobjective programming towards airline network design. Eur. J. Oper. Res. 2000, 127, 44–68. [Google Scholar] [CrossRef]
- Lee, B.L.; Worthington, A.C. Technical efficiency of mainstream airlines and low-cost carriers: New evidence using bootstrap data envelopment analysis truncated regression. J. Air Transp. Manag. 2014, 38, 15–20. [Google Scholar] [CrossRef]
- Zuidberg, J. Identifying airline cost economies: An econometric analysis of the factors affecting aircraft operating costs. J. Air Transp. Manag. 2014, 40, 86–95. [Google Scholar] [CrossRef]
- Ismail, N.A.; Jenatabadi, H.S. The influence of firm age on the relationships of airline performance, economic situation and internal operation. Transp. Res. Part. A Policy Pract. 2014, 67, 212–224. [Google Scholar] [CrossRef]
- Johnston, A.; Ozment, J. Economies of scale in the US airline industry. Transp. Res. Part E Logist. Transp. Rev. 2013, 51, 95–108. [Google Scholar] [CrossRef]
- Oum, T.H.; Zhang, Y. Utilisation of quasi-fixed inputs and estimation of cost functions: An application to airline costs. J. Transp. Econ. Policy 1991, 121–134. [Google Scholar]
- Hansen, M.M.; Gillen, D.; Djafarian-Tehrani, R. Aviation infrastructure performance and airline cost: A statistical cost estimation approach. Transp. Res. Part E Logist. Transp. Rev. 2001, 37, 1–23. [Google Scholar] [CrossRef]
- Craig, R.; Amernic, J. A privatization success story: Accounting and narrative expression over time. Account. Audit. Account. J. 2008, 21, 1085–1115. [Google Scholar] [CrossRef]
- Halpern, N.; Graham, A. Airport route development: A survey of current practice. Tour. Manag. 2015, 46, 213–221. [Google Scholar] [CrossRef]
- Jenatabadi, H.S.; Ismail, N.A. Application of structural equation modelling for estimating airline performance. J. Air Transp. Manag. 2014, 40, 25–33. [Google Scholar] [CrossRef]
- Bubalo, B.; Gaggero, A.A. Low-cost carrier competition and airline service quality in Europe. Transp. Policy 2015, 43, 23–31. [Google Scholar] [CrossRef]
- Chang, D.S.; Chen, S.H.; Hsu, C.W.; Hu, A.H. Identifying strategic factors of the implantation CSR in the airline industry: The case of Asia-Pacific airlines. Sustainability 2015, 7, 7762–7783. [Google Scholar] [CrossRef]
- Graham, A. Understanding the low cost carrier and airport relationship: A critical analysis of the salient issues. Tour. Manag. 2013, 36, 66–76. [Google Scholar] [CrossRef]
- Navarro, J.L.A.; Martínez, M.E.A.; Trinquecoste, J.F. The effect of the economic crisis on the behaviour of airline ticket prices. A case-study analysis of the New York–Madrid route. J. Air Transp. Manag. 2015, 47, 48–53. [Google Scholar] [CrossRef]
- Kuljanin, J.; Kalić, M. Exploring characteristics of passengers using traditional and low-cost airlines: A case study of Belgrade Airport. J. Air Transp. Manag. 2015, 46, 12–18. [Google Scholar] [CrossRef]
- Hu, Y.; Xiao, J.; Deng, Y.; Xiao, Y.; Wang, S. Domestic air passenger traffic and economic growth in China: Evidence from heterogeneous panel models. J. Air Transp. Manag. 2015, 42, 95–100. [Google Scholar] [CrossRef]
- Zhang, Y. International arrivals to Australia: Determinants and the role of air transport policy. J. Air Transp. Manag. 2015, 44, 21–24. [Google Scholar] [CrossRef]
- Sun, J.Y. Clustered airline flight scheduling: Evidence from airline deregulation in Korea. J. Air Transp. Manag. 2015, 42, 85–94. [Google Scholar] [CrossRef]
- Chung, L.H. Impact of pandemic control over airport economics: Reconciling public health with airport business through a streamlined approach in pandemic control. J. Air Transp. Manag. 2015, 44, 42–53. [Google Scholar] [CrossRef]
- Di Gravio, G.; Mancini, M.; Patriarca, R.; Costantino, F. Overall safety performance of the air traffic management system: Indicators and analysis. J. Air Transp. Manag. 2015, 44, 65–69. [Google Scholar] [CrossRef]
- Augustyniak, W.; López-Torres, L.; Kalinowski, S. Performance of Polish regional airports after accessing the European Union: Does liberalisation impact on airports’ efficiency. J. Air Transp. Manag. 2015, 43, 11–19. [Google Scholar] [CrossRef]
- Mallikarjun, S. Efficiency of US airlines: A strategic operating model. J. Air Transp. Manag. 2015, 43, 46–56. [Google Scholar] [CrossRef]
- Ülkü, T. A comparative efficiency analysis of Spanish and Turkish airports. J. Air Transp. Manag. 2015, 46, 56–68. [Google Scholar] [CrossRef]
- Zou, B.; Kafle, N.; Chang, Y.T.; Park, K. US airport financial reform and its implications for airport efficiency: An exploratory investigation. J. Air Transp. Manag. 2015, 47, 66–78. [Google Scholar] [CrossRef]
- Barros, C.P.; Wanke, P. An analysis of African airlines efficiency with two-stage TOPSIS and neural networks. J. Air Transp. Manag. 2015, 44, 90–102. [Google Scholar] [CrossRef]
- Xiao, Y.; Liu, J.J.; Hu, Y.; Wang, Y.; Lai, K.K.; Wang, S. A neuro-fuzzy combination model based on singular spectrum analysis for air transport demand forecasting. J. Air Transp. Manag. 2014, 39, 1–11. [Google Scholar] [CrossRef]
- Jenatabadi, H.S. Impact of economic performance on organizational capacity and capability: A case study in airline industry. Int. J. Bus. Manag. 2013, 8, 112–120. [Google Scholar]
- Kim, Y.; Yun, S.; Lee, J. Can companies induce sustainable consumption? The impact of knowledge and social embeddedness on airline sustainability programs in the US. Sustainability 2014, 6, 3338–3356. [Google Scholar] [CrossRef]
- Hsu, C.J.; Yen, J.R.; Chang, Y.C.; Woon, H.K. How do the services of low cost carriers affect passengers’ behavioral intentions to revisit a destination? J. Air Transp. Manag. 2016, 52, 111–116. [Google Scholar] [CrossRef]
- Kim, S.L.; Cho, Y.S. Study on Internal Service Quality, Job Satisfaction and Customer Satisfaction in Airline Industry. J. Korea Soc. Comput. Inf. 2016, 21, 113–121. [Google Scholar] [CrossRef]
- Park, E.; Lee, S.; Kwon, S.J.; Del Pobil, A.P. Determinants of behavioral intention to use South Korean airline services: Effects of service quality and corporate social responsibility. Sustainability 2015, 7, 12106–12121. [Google Scholar] [CrossRef]
- Yao, Q.; Xu, M.; Jiang, W.; Zhang, Y. Do marketing and government R&D subsidy support technological innovation? Int. J. Technol. Policy Manag. 2015, 15, 213–225. [Google Scholar]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions and the Bayesian restoration of images. J. Appl. Stat. 1993, 20, 25–62. [Google Scholar] [CrossRef]
- Lee, S.Y. Structural Equation Modeling: A Bayesian Approach 2007, 1st ed.; John Wiley & Sons: West Sussex, UK, 2007; pp. 24–25. [Google Scholar]
- Scheines, R.; Hoijtink, H.; Boomsma, A. Bayesian estimation and testing of structural equation models. Psychometrika 1999, 64, 37–52. [Google Scholar] [CrossRef]
- Lee, S.Y.; Song, X.Y. Evaluation of the Bayesian and maximum likelihood approaches in analyzing structural equation models with small sample sizes. Multivar. Behav. Res. 2004, 39, 653–686. [Google Scholar] [CrossRef] [PubMed]
- Dunson, D.B. Bayesian latent variable models for clustered mixed outcomes. J. R. Stat. Soc. Ser. B Stat. Methodol. 2000, 62, 355–366. [Google Scholar] [CrossRef]
- Caves, D.W.; Christensen, L.R.; Tretheway, M.W. Economies of density versus economies of scale: Why trunk and local service airline costs differ. Rand J. Econ. 1984, 15, 471–489. [Google Scholar] [CrossRef]
- Sickles, R.C. A nonlinear multivariate error components analysis of technology and specific factor productivity growth with an application to the US Airlines. J. Econom. 1985, 27, 61–78. [Google Scholar] [CrossRef]
- Sickles, R.C.; Good, D.; Johnson, R.L. Allocative distortions and the regulatory transition of the US airline industry. J. Econom. 1986, 33, 143–163. [Google Scholar] [CrossRef]
- Borenstein, S. The dominant-firm advantage in multiproduct industries: Evidence from the US airlines. Q. J. Econ. 1991, 106, 1237–1266. [Google Scholar] [CrossRef]
- Banker, R.D.; Johnston, H.H. An empirical study of the business value of the US airlines’ computerized reservations systems. J. Organ. Comp. Electron. Commer. 1995, 5, 255–275. [Google Scholar]
- Duliba, K.A.; Kauffman, R.J.; Lucas, H.C. Appropriating value from computerized reservation system ownership in the airline industry. Organ Sci. 2001, 12, 702–728. [Google Scholar] [CrossRef]
- Ramanathan, R. The long-run behaviour of transport performance in India: A cointegration approach. Transp. Res. Part A Policy Pract. 2001, 35, 309–320. [Google Scholar] [CrossRef]
- Rangarajan, S.; Prasad, V.A. The Indian airline industry—Will the flight be smooth? Emerald Emerg. Mark. Case Stud. 2014, 4, 1–18. [Google Scholar] [CrossRef]
- Liu, C.M. Entry behaviour and financial distress: An empirical analysis of the US domestic airline industry. J. Transp. Econ. Policy 2009, 43, 237–256. [Google Scholar]
- Barros, C.P.; Couto, E. Productivity analysis of European airlines, 2000–2011. J. Air Transp. Manag. 2013, 31, 11–13. [Google Scholar] [CrossRef]
- Moon, J.; Lee, W.S.; Dattilo, J. Determinants of the payout decision in the airline industry. J. Air Transp. Manag. 2015, 42, 282–288. [Google Scholar] [CrossRef]
- Liedtka, S.L.; Church, B.K.; Ray, M.R. Performance variability, ambiguity intolerance, and balanced scorecard-based performance assessments. Behav. Res. Account. 2008, 20, 73–88. [Google Scholar] [CrossRef]
- Carastro, M.J. Nonfinancial Performance Indicators for US Airlines: A Statistical Analysis. Ph.D. Thesis, University of Phoenix, Tempe, AZ, USA, 2010. [Google Scholar]
- Ouellette, P.; Petit, P.; Tessier-Parent, L.P.; Vigeant, S. Introducing regulation in the measurement of efficiency, with an application to the Canadian air carriers industry. Eur. J. Oper. Res. 2010, 200, 216–226. [Google Scholar] [CrossRef]
- Cui, Q.; Li, Y. Airline energy efficiency measures considering carbon abatement: A new strategic framework. Transport. Res. Part D Transport. Environ. 2016, 49, 246–258. [Google Scholar] [CrossRef]
- Button, K.; Neiva, R. Economic efficiency of European air traffic control systems. J. Transp. Econ. Policy 2014, 48, 65–80. [Google Scholar]
- Muthén, B.; Asparouhov, T. Bayesian structural equation modeling: A more flexible representation of substantive theory. Psychol. Methods 2012, 17, 313–335. [Google Scholar] [CrossRef] [PubMed]
- Van de Schoot, R.; Depaoli, S. Bayesian analyses: Where to start and what to report. Eur. Health Psychol. 2014, 16, 75–84. [Google Scholar]
- Stenling, A.; Ivarsson, A.; Johnson, U.; Lindwall, M. Bayesian structural equation modeling in sport and exercise psychology. J. Sport Exerc. Psychol. 2015, 37, 410–420. [Google Scholar] [CrossRef] [PubMed]
- Gelman, A. Bayes, Jeffreys, prior distributions and the philosophy of statistics. Stat. Sci. 2009, 24, 176–178. [Google Scholar] [CrossRef]
- Gelman, A. Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper). Bayesian Anal. 2006, 1, 515–534. [Google Scholar]
- Evans, M.; Jang, G.H. Weak informativity and the information in one prior relative to another. Stat. Sci. 2011, 26, 423–439. [Google Scholar] [CrossRef]
- Flora, D.B.; Curran, P.J. An empirical evaluation of alternative methods of estimation for confirmatory factor analysis with ordinal data. Psychol. Methods 2004, 9, 466–491. [Google Scholar] [CrossRef] [PubMed]
- Ullman, J.B. Structural equation modeling: Reviewing the basics and moving forward. J. Pers. Assess. 2006, 87, 35–50. [Google Scholar] [CrossRef] [PubMed]
- Yanuar, F.; Ibrahim, K.; Jemain, A.A. On the application of structural equation modeling for the construction of a health index. Environ. Health Prev. 2010, 15, 285–291. [Google Scholar] [CrossRef] [PubMed]
- Yanuar, F.; Ibrahim, K.; Jemain, A.A. Bayesian structural equation modeling for the health index. J. Appl. Stat. 2013, 40, 1254–1269. [Google Scholar] [CrossRef]
- Ansari, A.; Jedidi, K.; Dube, L. Heterogeneous factor analysis models: A Bayesian approach. Psychometrika 2002, 67, 49–77. [Google Scholar] [CrossRef]
- Air Transport World (ATW). World Airline Report Electronic Package. 2013. Available online: http://atwonline.com/atw-world-airline-report-electronic-package-2013 (accessed on 1 March 2014).
- Mullen, M.R.; Milne, G.R.; Doney, P.M. An international marketing application of outlier analysis for structural equations: A methodological note. J. Int. Market. 1995, 3, 45–62. [Google Scholar]
- Wan Mohamed Radzi, C.W.J.B.; Salarzadeh Jenatabadi, H.; Hasbullah, M.B. Firm Sustainability Performance Index Modeling. Sustainability 2015, 7, 16196–16212. [Google Scholar] [CrossRef]
- Wang, J.J.; Heinonen, T.H. Aeropolitics in East Asia: An institutional approach to air transport liberalisation. J. Air Transp. Manag. 2015, 42, 176–183. [Google Scholar] [CrossRef]
- Bashir, M.K.; Schilizzi, S. Food security policy assessment in the Punjab, Pakistan: Effectiveness, distortions and their perceptions. Food Secur. 2015, 7, 1071–1089. [Google Scholar] [CrossRef]
- Shor, B.; Bafumi, J.; Keele, L.; Park, D. A Bayesian multilevel modeling approach to time-series cross-sectional data. Polit. Anal. 2007, 15, 165–181. [Google Scholar] [CrossRef]
- Gaggero, A.A.; Piga, C.A. Airline competition in the British Isles. Transp. Res. Part E Logist. Transp. Rev. 2010, 46, 270–279. [Google Scholar] [CrossRef]
- Rose, J.M.; Hensher, D.A.; Greene, W.H.; Washington, S.P. Attribute exclusion strategies in airline choice: Accounting for exogenous information on decision maker processing strategies in models of discrete choice. Transportmetrica 2012, 8, 344–360. [Google Scholar] [CrossRef] [Green Version]
- Bliemer, M.C.; Rose, J.M. Experimental design influences on stated choice outputs: An empirical study in air travel choice. Transp. Res. Part A Policy Pract. 2011, 45, 63–79. [Google Scholar] [CrossRef]
- Bhadra, D. Race to the bottom or swimming upstream: Performance analysis of US airlines. J. Air Transp. Manag. 2009, 15, 227–235. [Google Scholar] [CrossRef]
- Jenatabadi, H.S.; Ismail, N.A. The determination of load factors in the airline industry. Int. Rev. Bus. Res. Pap. 2007, 3, 125–133. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
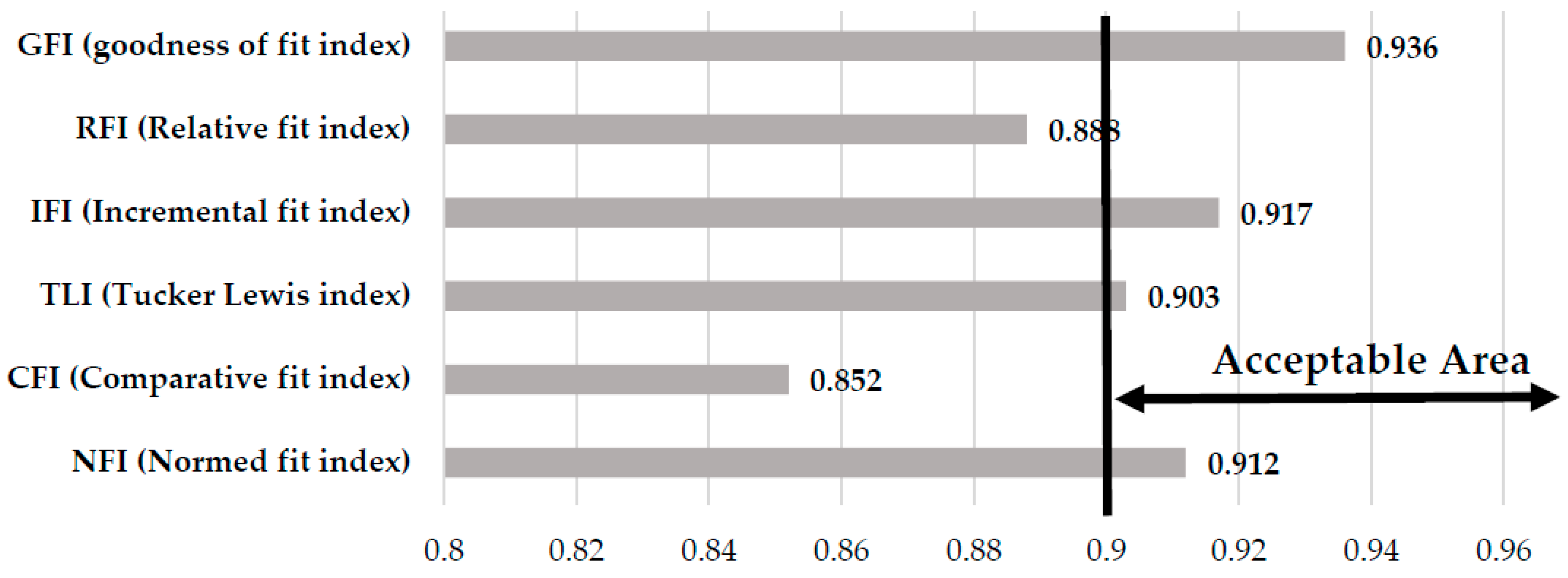{kind=link}
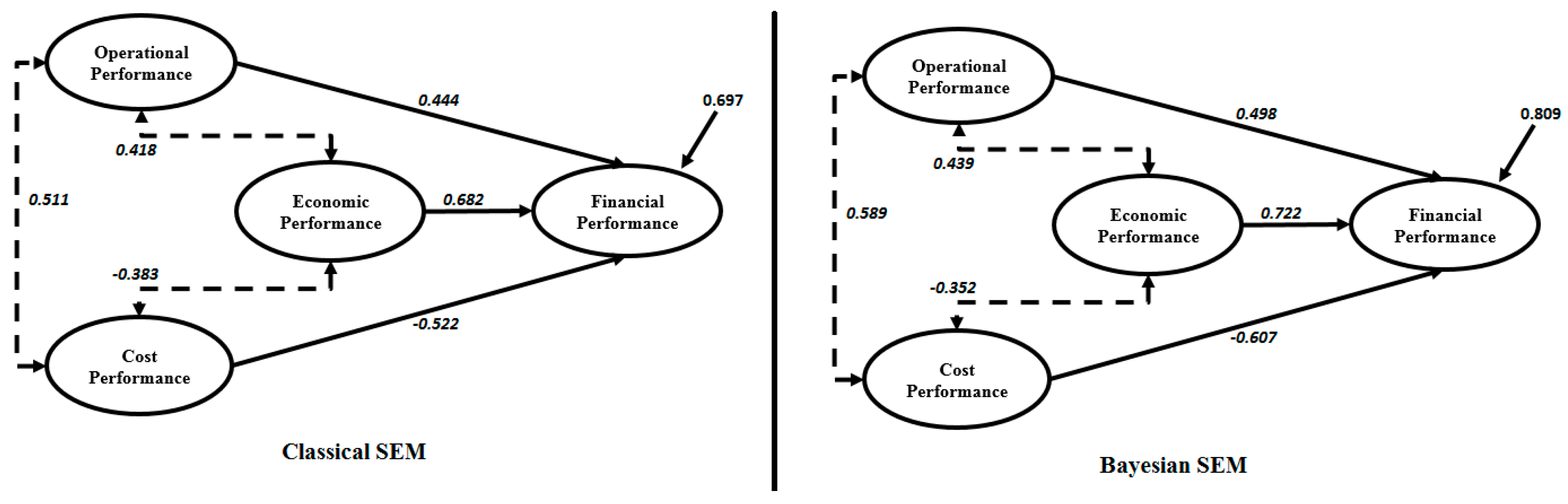{kind=link}
| Observation Number | Mahalanobis D-Squared | p1 | p2 |
|---|---|---|---|
| 9 | 86.25 | 0.0044 | 0.0086 |
| 32 | 69.12 | 0.0068 | 0.0092 |
| 39 | 63.22 | 0.0099 | 0.0112 |
| 86 | 61.59 | 0.0109 | 0.0188 |
| 103 | 45.12 | 0.0182 | 0.0219 |
| 122 | 36.18 | 0.0367 | 0.0286 |
| 209 | 22.19 | 0.0394 | 0.0411 |
| 252 | 20.91 | 0.0421 | 0.0569 |
| 265 | 13.25 | 0.0467 | 0.0758 |
| 271 | 10.37 | 0.0483 | 0.1024 |
| Variable | Skew | C.R. | Kurtosis | C.R. |
|---|---|---|---|---|
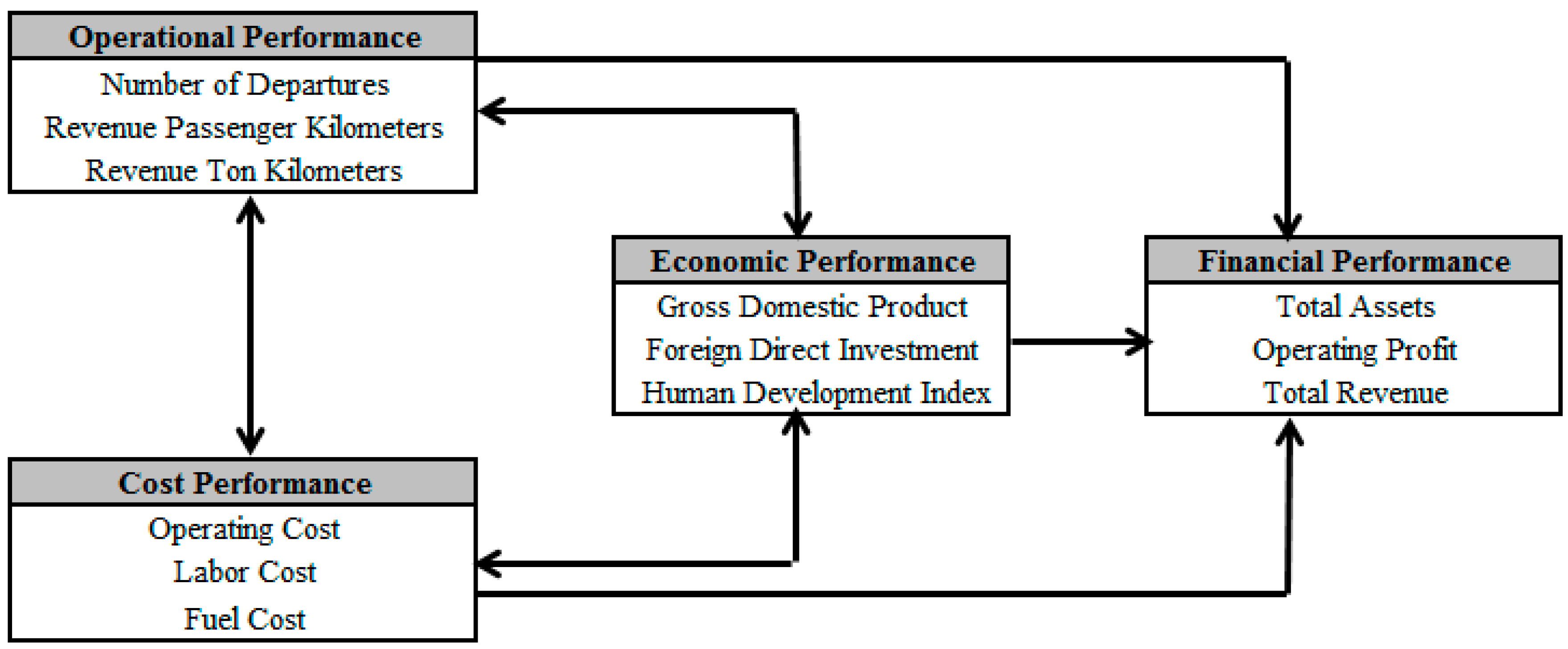
| Number of Departures | 3.063 | 9.549 | 8.640 | 12.775 |
| Revenue Passenger Kilometers | 2.361 | 7.130 | 7.396 | 10.719 |
| Revenue Ton Kilometers | 2.938 | 7.936 | 9.311 | 14.033 |
| Gross Domestic Product | 0.243 | 2.106 | −0.299 | −1.299 |
| Foreign Direct Investment | −0.036 | −0.313 | −0.615 | −2.669 |
| Human Development Index | −0.010 | −0.083 | −0.677 | −2.939 |
| Operating Cost | −0.044 | −0.382 | −0.815 | −3.538 |
| Labor Cost | 0.181 | 1.569 | −1.217 | −5.280 |
| Fuel Cost | 0.687 | 5.959 | 0.471 | 2.046 |
| Total Assets | 0.259 | 2.252 | −0.404 | −1.754 |
| Operating Profit | −0.080 | −0.695 | −0.479 | −2.080 |
| Total Revenue | −0.099 | −0.855 | −0.459 | −1.992 |
| Relation | Estimated Coefficients | |
|---|---|---|
| Classical SEM | Bayesian SEM | |
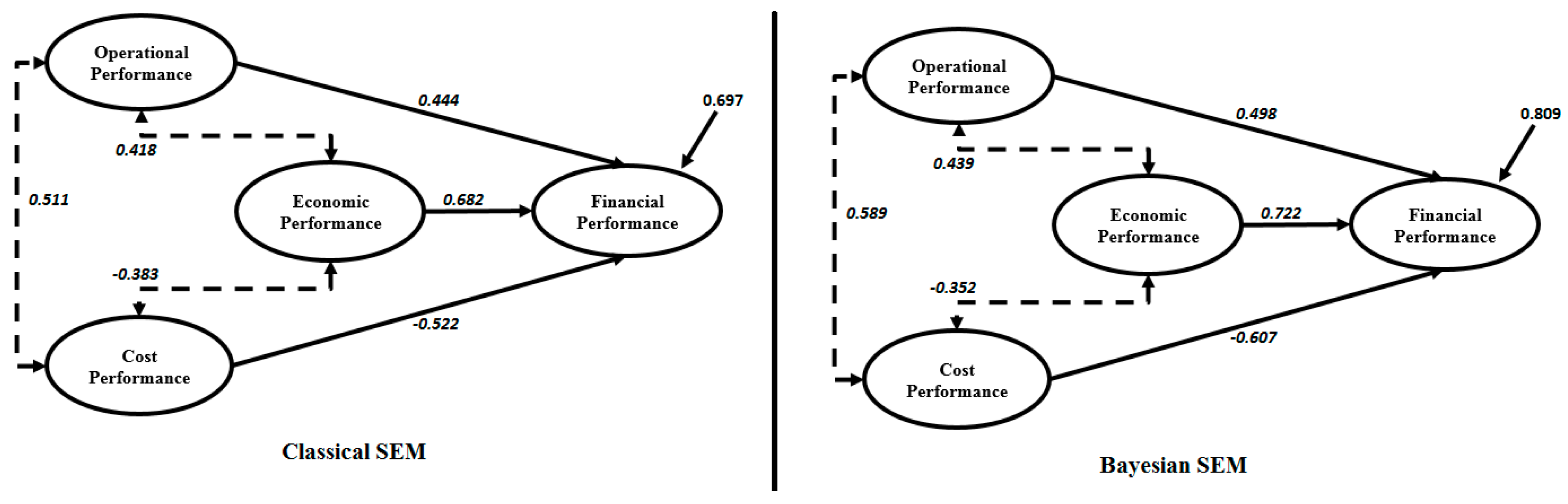
| Economic Performance → Financial Performance | 0.682 * | 0.722 * |
| Operational Performance → Financial Performance | 0.444 * | 0.498 * |
| Cost Performance → Financial Performance | −0.522 * | −0.607 * |
| Economic Performance ↔ Operational Performance | 0.418 * | 0.439 * |
| Economic Performance ↔ Cost Performance | −0.383 * | −0.352 * |
| Operational Performance ↔ Cost Performance | 0.511 * | 0.589 * |
| Factor Loading, [S.E] and (CI) | ||
|---|---|---|
| Measurement Variable | Classical-SEM | Bayesian-SEM |
| Economic Performance | ||
| Foreign Direct Investment | 1 | 1 |
| Gross Domestic Products | 0.666 * [0.078] (0.532, 0.789) | 0.509 * [0.071] (0.421, 0.631) |
| Human Development Index | 0.845 * [0.352] (0.721, 0.936) | 0.812 * [0.342] (0.744, 0.859) |
| Operational Performance | ||
| Number of Departures | 1 | 1 |
| Revenue Passenger Kilometers | 0.688 * [0.138] (0.598, 0.759) | 0.695 * [0.133] (0.613, 0.742) |
| Revenue Ton Kilometers | 0.712 * [0.096] (0.589, 0.796) | 0.716 * [0.091] (0.607, 0.788) |
| Cost Performance | ||
| Operating Cost | 1 | 1 |
| Labor Cost | 0.798 * [0.076] (0.683, 0.843) | 0.799 * [0.074] (0.691, 0.837) |
| Fuel Cost | 0.671 * [0.109] (0.598, 0.711) | 0.684 * [0.102] (0.611, 0.706) |
| Financial Performance | ||
| Total Assets | 1 | 1 |
| Operating Profit | 0.823 * [0.031] (0.729, 0.868) | 0.811 * [0.029] (0.741, 0.855) |
| Total Revenue | 0.745 * [0.056] (0.656, 0.807) | 0.751 * [0.044] (0.631, 0.802) |
| Index | Formula | Bayesian-SEM | Classical-SEM |
|---|---|---|---|
| MAPE | 0.158 | 0.201 | |
| RMSE | 0.185 | 0.199 | |
| MSE | 0.109 | 0.133 | |
| R2 | 0.809 | 0.697 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salarzadeh Jenatabadi, H.; Babashamsi, P.; Khajeheian, D.; Seyyed Amiri, N. Airline Sustainability Modeling: A New Framework with Application of Bayesian Structural Equation Modeling. Sustainability 2016, 8, 1204. https://doi.org/10.3390/su8111204
Salarzadeh Jenatabadi H, Babashamsi P, Khajeheian D, Seyyed Amiri N. Airline Sustainability Modeling: A New Framework with Application of Bayesian Structural Equation Modeling. Sustainability. 2016; 8(11):1204. https://doi.org/10.3390/su8111204
Chicago/Turabian StyleSalarzadeh Jenatabadi, Hashem, Peyman Babashamsi, Datis Khajeheian, and Nader Seyyed Amiri. 2016. "Airline Sustainability Modeling: A New Framework with Application of Bayesian Structural Equation Modeling" Sustainability 8, no. 11: 1204. https://doi.org/10.3390/su8111204
APA StyleSalarzadeh Jenatabadi, H., Babashamsi, P., Khajeheian, D., & Seyyed Amiri, N. (2016). Airline Sustainability Modeling: A New Framework with Application of Bayesian Structural Equation Modeling. Sustainability, 8(11), 1204. https://doi.org/10.3390/su8111204