1. Introduction
The spatiotemporal prediction of air pollution has long been a major topic in environmental science and atmospheric chemistry research [
1]. With rapid urbanization and industrial development, air pollution issues have become increasingly severe, posing serious threats to human health and ecological environments [
2]. Therefore, accurately forecasting future air quality levels in specific regions through indicators such as particulate matter (PM2.5), inhalable particles (PM10), and the comprehensive Air Quality Index (AQI), which reflects the pollution status of an area, holds significant value for government authorities to implement targeted measures and raise public environmental awareness [
3].
Traditional air quality prediction methods primarily include numerical and statistical approaches. Numerical methods are based on physical descriptions of atmospheric chemical processes and meteorological circulations, employing numerical simulations and differential equation solvers to predict future pollutant concentrations. For instance, Ghude et al. [
4] proposed a coupled regional meteorology–atmospheric chemistry online model (WRF-Chem) that describes the feedback between atmospheric aerosols and meteorology through mathematical formulations, enabling the prediction of future PM2.5 levels using various ecosystem emission data. Statistical methods, on the other hand, establish models that characterize the correlations between historical data and air pollutant concentrations for regression-based predictions. Ni et al. [
5] used multi-source meteorological data for correlation analysis to determine the relationships among different indicators and applied an Autoregressive Integrated Moving Average (ARIMA) time series model for PM2.5 time series forecasting. Wang et al. [
6] utilized two classic machine learning techniques, Random Forest (RF) and Support Vector Machines (SVMs), to achieve hybrid predictions of daily PM10 and SO
2 concentrations. Although these traditional methods have practical applications, they generally assume known emission sources and atmospheric circulation conditions and struggle to handle complex non-linear problems, limiting their prediction accuracy and spatiotemporal resolution [
7].
In recent years, deep learning techniques have gained widespread application in spatiotemporal data analysis, demonstrating powerful modeling and prediction capabilities. An increasing number of studies have attempted to apply deep learning techniques to spatiotemporal air pollution prediction problems. For example, Chen et al. [
8] proposed an air quality prediction model integrating dual long short-term memory (LSTM) networks with a sequence-to-sequence approach, outperforming various classic machine learning models, including Support Vector Regression (SVR), Ridge Regression, and XGBoost. Gurumoorthy et al. [
9] introduced an air quality prediction method using reinforced swarm optimization (RSO) and Bidirectional Gated Recurrent Units (Bi-GRU). Although these methods achieved high prediction accuracy, they were limited to predicting one-dimensional time series data from single monitoring stations. To address this limitation, some studies have attempted to fuse Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) to construct ConvLSTM hybrid models for the simultaneous extraction of spatial and temporal features [
10,
11,
12]. Building upon this model, Liu et al. [
13] incorporated an attention mechanism into ConvLSTM, enabling global PM2.5 prediction using monitoring station data. Additionally, other studies have explored incorporating auxiliary information, such as remote sensing imagery [
14,
15] and environmental images [
16,
17], into deep learning models to further improve prediction accuracy.
Despite the progress made by deep learning models in regional air quality prediction, challenges remain regarding the effective capture of complex spatiotemporal correlations between meteorological conditions and air pollutant concentrations. A critical gap in the existing research is the difficulty in simultaneously addressing spatial heterogeneity and temporal continuity in air quality data. Most current models either focus predominantly on temporal patterns using recurrent architectures or prioritize spatial relationships using convolutional approaches but rarely integrate both dimensions optimally. Additionally, the majority of existing models fail to fully leverage the spatial relationships between monitoring stations, particularly in regions with sparse monitoring networks. These limitations result in prediction inaccuracies, especially for medium-to-long-term forecasting and in areas with complex terrain or meteorological conditions.
The spatiotemporal air quality prediction task is akin to video prediction, requiring the extraction of temporal and spatial dynamic patterns from continuous time series data. In air quality prediction, the focus is on the diffusion and evolution trends of pollutant concentrations across spatial and temporal dimensions. In the field of computer vision (CV), the Swin Transformer has recently demonstrated outstanding performance in various vision tasks by effectively integrating local spatial information and global contexts through its innovative shifted window attention mechanism, which computes self-attention within local windows [
18,
19]. Inspired by this, this study proposes a novel spatiotemporal air quality prediction method that integrates Kriging interpolation with a SwinLSTM model. First, Kriging interpolates the collected one-dimensional station data onto a two-dimensional spatial plane. Then, a prediction network integrating Swin Transformer and LSTM modules is constructed to capture more comprehensive spatiotemporal dependencies in the air quality prediction task.
The main contributions of this paper are summarized as follows:
(1) The Kriging interpolation is introduced to the deep learning-based air quality prediction task, interpolating sparse monitoring station data over the entire spatial region, providing spatial distribution input for the deep learning model, and compensating for the shortcomings of single-model spatiotemporal modeling.
(2) Swin Transformer is integrated into the LSTM module, proposing a novel SwinLSTM structure that addresses the limited capability of convolutional structures in extracting spatial distribution features of air quality-related indicators, significantly improving prediction accuracy.
(3) A novel end-to-end spatiotemporal air quality prediction architecture is designed that divides the interpolated meteorological spatial dimension indicators into patches for encoding. The SwinLSTM Cell inherits features from the previous moment and propagates the current moment’s features to the next moment, finally decoding the corresponding air quality spatial distribution prediction results and providing an end-to-end solution for this task.
The remainder of this paper is organized as follows: In
Section 2, the Kriging interpolation algorithm, LSTM structure, and Swin Transformer structure relevant to the current research are presented. In
Section 3, the proposed SwinLSTM and its application to the air quality prediction task are described in detail. In
Section 4, prediction experiments with multiple indicators and time horizons are conducted using three years of meteorological data from China’s Dongting Lake region to demonstrate the effectiveness of the model.
Section 5 presents the paper’s conclusion and future work.
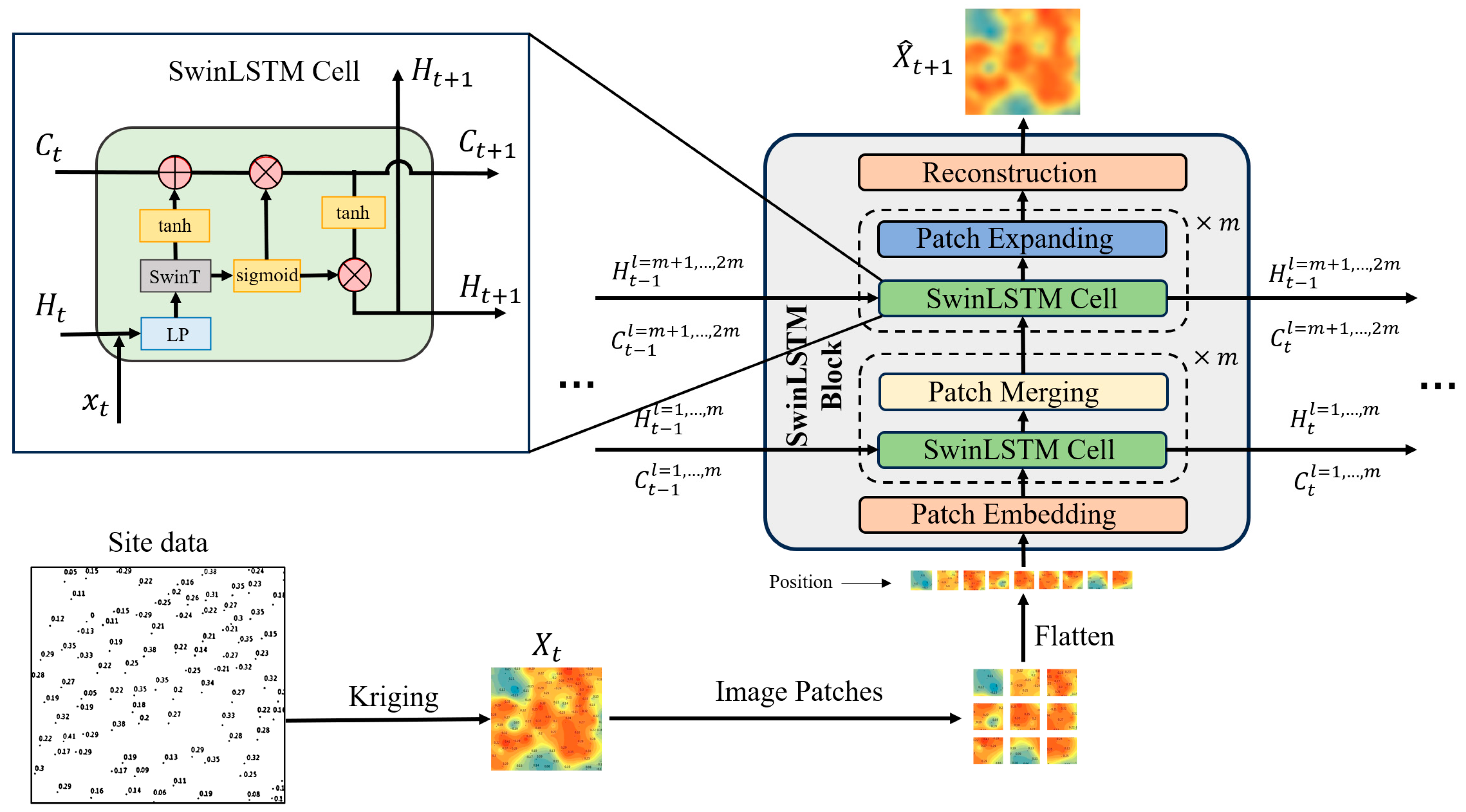
3. Main Method
The overall architecture of the proposed air quality spatiotemporal prediction algorithm is illustrated in
Figure 3. Initially, based on the location information of monitoring stations, a two-dimensional meteorological data distribution image
for each time step
t was obtained through Kriging interpolation. For the variogram modeling in this study, a spherical model was selected after comparing the fitness with exponential and Gaussian alternatives, as it best captured the spatial correlation structure of the air quality data in our study region while maintaining computational efficiency. Subsequently, the image was segmented into non-overlapping patches. After applying cosine positional encoding [
28] to each patch, they were input into the SwinLSTM Block for spatial feature extraction. Combining the hidden state
and cell state
extracted from the previous time step, the block generated the current hidden state
and cell state
.
was duplicated, with one copy used as a feature for predicting the meteorological data distribution
at the next time step, while the other was transmitted to the SwinLSTM Block of the subsequent time step along with
to maintain and update temporal information. The specific details of the model will be elaborated in the following sections.
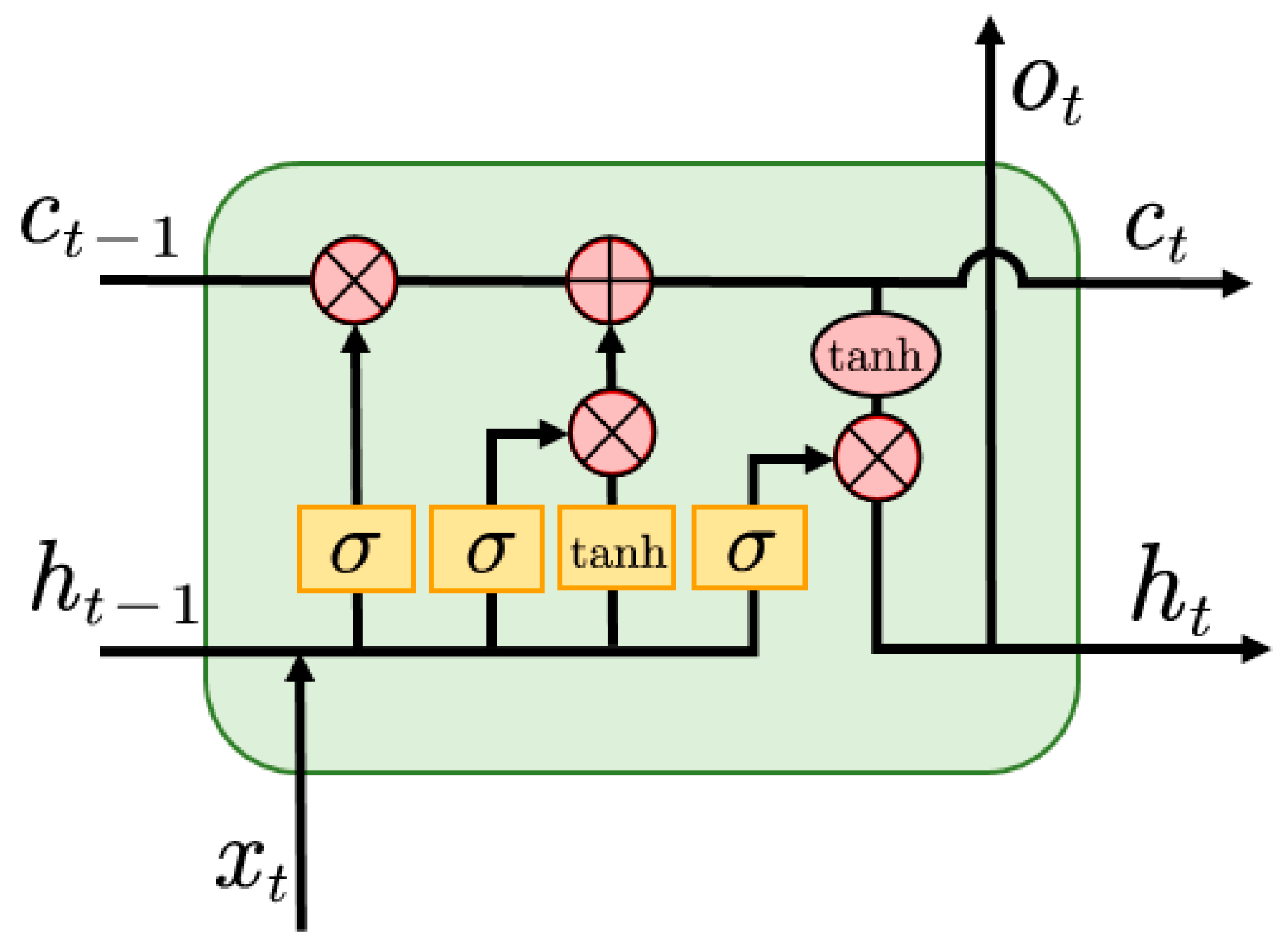
3.1. SwinLSTM Cell
The SwinLSTM Cell, serving as the core spatiotemporal feature extraction module in this model, inherits its concept from the LSTM structure introduced in
Section 2.2 and is inspired by ConvLSTM [
28].
In SwinLSTM, the hidden state
inherited from the previous time step was first concatenated with the current two-dimensional meteorological data. This combined feature was then input into the Swin Transformer module, as shown in
Figure 2, to extract spatial features
, expressed as follows:
where
denotes the linear projection layer and
represents the Swin Transformer feature extraction module.
Subsequently,
was mapped to the cell state
and the updated hidden state
of the next time step through the forget gate and output gate structures, respectively:
where
represents the Hadamard product.
3.2. SwinLSTM Block
SwinLSTM Cell is merely a basic structural unit capable of temporal feature transmission. To achieve dynamic spatiotemporal modeling and the prediction of two-dimensional meteorological data distributions, this study designed a SwinLSTM Block comprising multiple SwinLSTM Cells. In addition to the fundamental SwinLSTM Cell, the use of Block incorporates several key modules for processing the data and features input.
Specifically, after the input of two-dimensional meteorological data,
was segmented into multiple non-overlapping patches, and the iRPE [
29] method was first employed to perform positional encoding on these patches. This introduced relative positional and contextual information to each patch, ensuring that their relative relationships and overall structure were not lost during the partitioning process. Following iRPE encoding, the patches were mapped to a high-dimensional feature space by a Patch Embedding layer with a 1 × 1 convolution kernel. Given that the input and output formats of this meteorological spatiotemporal prediction task remained consistent, this study adopted the encoder–decoder paradigm inspired by the classic U-Net [
30] architecture. The features first underwent m downsampling operations, with each downsampling including a SwinLSTM Cell for spatiotemporal feature extraction and a Patch Merging module that combined features of adjacent patches to achieve spatial downsampling. This path corresponded to the hierarchical extraction of spatiotemporal features, capturing representations from fine to coarse granularity. After obtaining the final bottom-level feature representation through downsampling,
upsampling operations followed. Each upsampling operation consisted of a SwinLSTM Cell and a Patch Expansion module. The SwinLSTM Cell is responsible for generating new spatiotemporal feature representations, while the Patch Expansion module expands features in the spatial dimension. This process restored feature resolution gradually, transitioning from abstract semantic features to concrete pixel-level predictions. Finally, after m upsampling operations, the features were mapped back to two-dimensional space through a 1 × 1 convolution layer, outputting the predicted meteorological distribution map
.
3.3. Loss Function
To simultaneously capture the disparities between predicted and actual meteorological spatiotemporal results, this study proposes a comprehensive loss function to guide model training. This loss function comprises two components: pixel-level regression loss and spatiotemporal gradient loss.
The pixel-level regression loss aims to minimize pixel value differences between predicted and actual values, utilizing a smooth L1 loss function, which is calculated as follows:
where
T denotes the total prediction time length,
M and
N represent the horizontal and vertical coordinate ranges of the Kriging-interpolated two-dimensional meteorological distribution, respectively.
and
indicate the predicted and actual values at time
t, row
i, and column
j.
is the smooth L1 loss function, which, compared to traditional norm losses, facilitates stable gradient updates. It is specifically calculated as follows:
Furthermore, this study introduces spatiotemporal gradient loss, defined as follows:
where
,
, and
represent gradient calculations in temporal, horizontal, and vertical spatial dimensions, respectively. This loss term penalizes the gradient differences between predicted and actual values in both time and space, facilitating the model’s learning of spatiotemporal evolution patterns.
By linearly combining the aforementioned loss terms, the comprehensive loss function is derived as follows:
where
and
are hyperparameters balancing the two loss terms.
During model training, minimizing this comprehensive loss function yields SwinLSTM with robust spatiotemporal modeling capabilities. The resulting predictions not only closely approximate actual values at the pixel level but also align well with real data in terms of the spatiotemporal evolution structure.
4. Experiments
The model code was developed in a PC environment using Python 3.9 and PyTorch 2.0.1+cu118 deep learning framework, compiled on the Jupyter interactive platform. The hardware configuration included a 13th Gen Intel(R) Core(TM) i5-13600K CPU and an NVIDIA GeForce RTX 3060 GPU.
4.1. Dataset Collection and Preprocessing
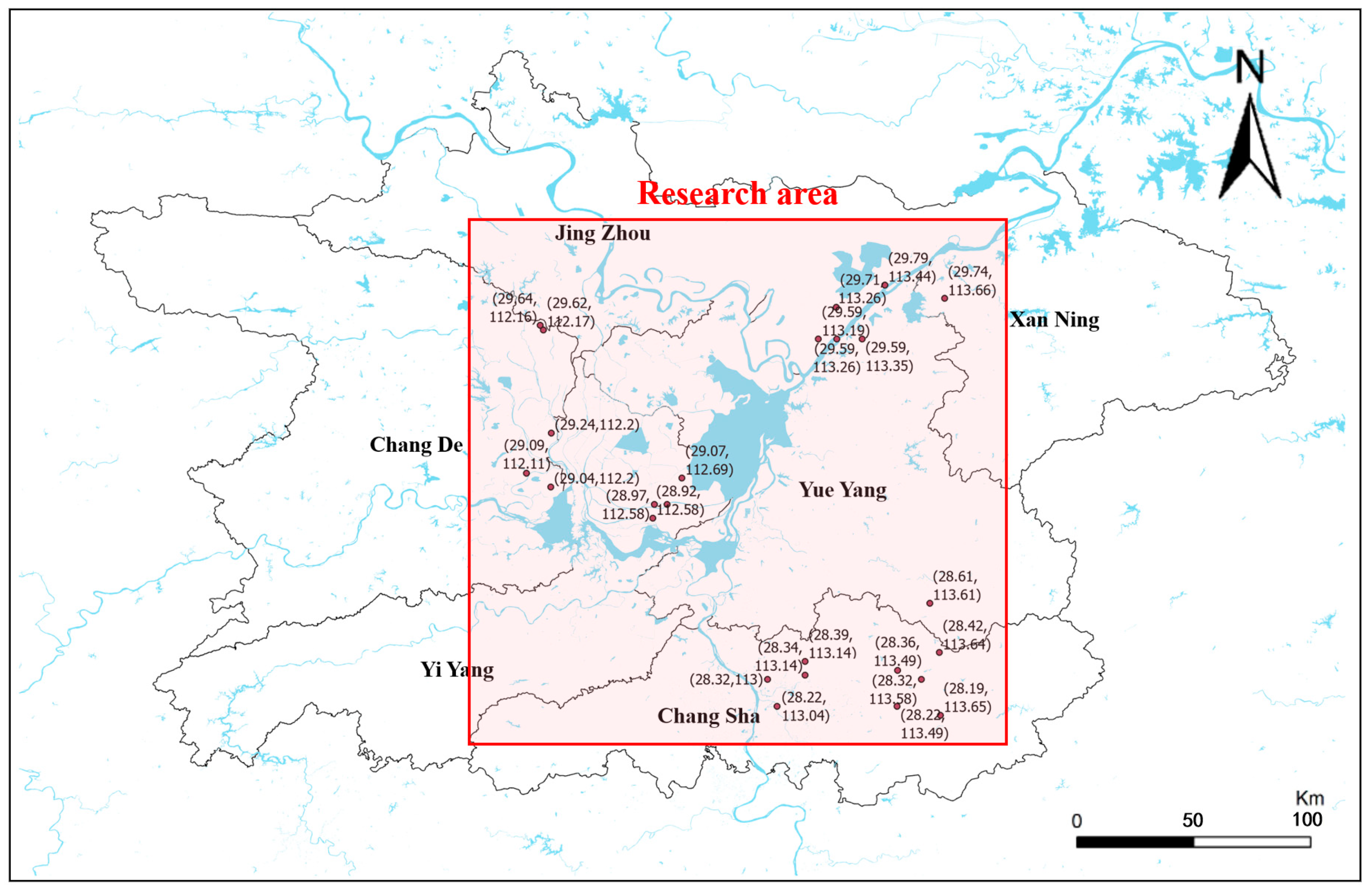
To validate the effectiveness of the proposed research framework, this study collected air quality data from 29 monitoring stations across four cities surrounding China’s Dongting Lake, including Changsha, Yueyang, Changde, and Yiyang, over a three-year period from 1 January 2020 to 31 December 2022. Each monitoring station recorded local air quality indicators at hourly intervals, including the PM2.5, PM10, SO
2 concentration, NO
2 concentration, O
3 concentration, CO concentration, and AQI index. The distribution of the 29 monitoring stations is illustrated in
Figure 4, where brown dots represent individual monitoring stations, and blue areas indicate water systems or reservoirs. The meteorological research and prediction area covers the region from 111.60° E to 113.90° E longitude and from 28.00° N to 30.00° N latitude, as indicated by the red area in the figure.
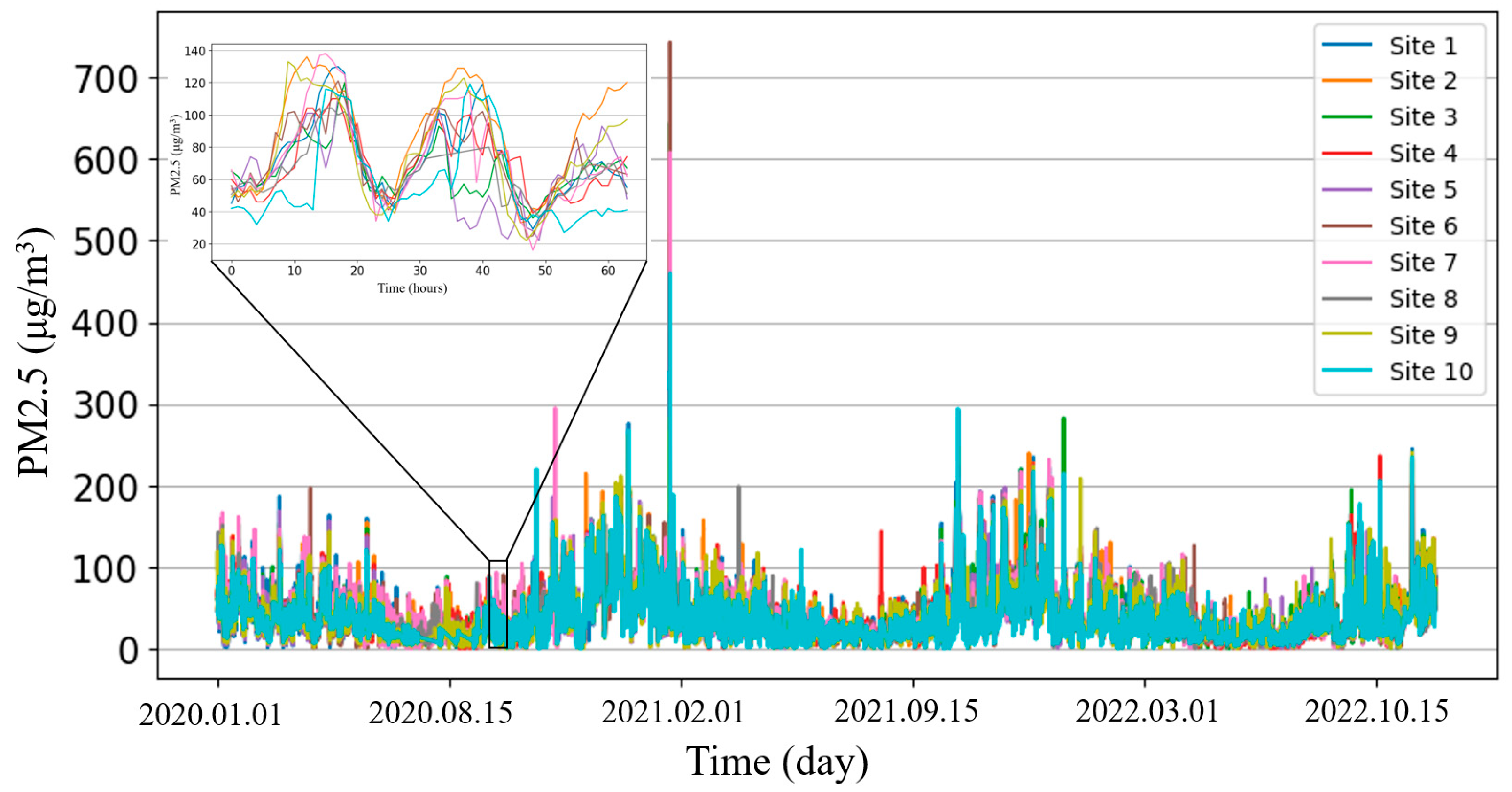
Following data collection, preprocessing was conducted, including the imputation of missing values caused by station malfunctions. The resulting PM2.5 value variation curves collected from multiple stations over the three-year period are shown in
Figure 5. Notably, from a long-term macroscopic perspective, PM2.5 variations exhibit an annual cyclical pattern, with higher levels in winter and lower levels in summer. Microscopically, PM2.5 values also demonstrate a daily pattern, with higher levels during the day and lower levels at night. Additionally, it was observed that PM2.5 values from some stations were significantly higher than the group average during certain periods. To mitigate the influence of outliers in the dataset, this experiment employed robust standardization processing. Data scaling based on quartiles was applied to stabilize the data distribution, facilitating the unification of data across different scale ranges while avoiding the impact of extreme values on model training, i.e.:
where
represents the collected raw value,
denotes the standardized value,
represents the mean of the specific air quality indicator,
represents the first quartile, and
represents the third quartile.
4.2. Data Partitioning and Parameter Settings
For the PM2.5 spatiotemporal prediction task, a rolling window modeling approach was adopted. Specifically, for the temporal dimension T, the time series was divided into overlapping sample windows, each containing Δt time steps. The first time steps (a) served as the input feature set , while the subsequent time steps (b) were used as the prediction target . It should be noted that each time step comprised multi-dimensional input features, including not only the air quality indicators to be predicted but also meteorological conditions (temperature, humidity, and wind speed) as auxiliary features, which were aligned with the features before being input into the model. The dataset was then split into training and testing sets. To satisfy the principle of lagged prediction in the time series models, data from 1 January 2020 to 31 December 2021 (two years) were selected as the training set, while data from 1 January 2022 to 31 December 2022 (one year) were used as the testing set.
In the spatial dimension, Kriging interpolation was applied to the original observational data using monitoring station location information, resulting in 64 × 64 two-dimensional air quality concentration distribution images. Through the aforementioned dataset construction method, the input was defined as a combination of meteorological features and air quality indicators with a feature set step length (a) of 48 h (past two days). The output labels were set as the prediction results for PM2.5 and PM10 indicators at 1, 6, and 24 h ahead to validate the model’s performance across different prediction time spans.
Regarding the model parameters, the number of backbone feature upsampling and downsampling layers m was set to two. The Swin Transformer’s patch size was set to six pixels, with a window size of four patches, an embedding dimension of 64, and four attention heads. For the training configuration, the AdamW optimizer, most compatible with transformer architectures, was employed with a base learning rate of 1 × 10−4. An exponential decay learning rate strategy based on training steps was adopted, with a decay rate of 0.999 and a step size of one. The total number of training iterations was set to 1000.
4.3. Evaluating Indicator
As air quality spatiotemporal prediction is a regression task, this study implemented three different evaluation metrics: mean absolute error (MAE), Root Mean Square Error (RMSE), and R-squared (
R2). The calculation formulas for these metrics are shown in Equations (25), (26), and (27), respectively.
where
represents the sample size,
is the true value of the
i-th sample,
is the corresponding predicted value, and
is the mean of all true values. The
value ranges from 0 to 1, with values closer to 1 indicating better model predictions and values closer to 0 suggesting poorer predictive performance.
4.4. Result Analysis
Figure 6 presents the experimental results of the proposed SwinLSTM model for the 24 h prediction task compared with the currently mainstream ConvLSTM algorithm.
The results show that the PM2.5 indicator of distribution predicted by the SwinLSTM model more closely aligns with the actual values. This is evident from the mean absolute error percentage (MAEP), where for short-term prediction (t = 1 h), SwinLSTM and ConvLSTM yield errors of 0.60% and 0.95%, respectively. While SwinLSTM leads in terms of accuracy, the difference is not substantial. However, when extending the prediction time step to 24 h, SwinLSTM maintains a high prediction accuracy with an error percentage below 0.9%, while ConvLSTM’s error percentage increases to 2.37%. This demonstrates that the proposed model can better capture spatiotemporal dependencies, thereby improving prediction accuracy.
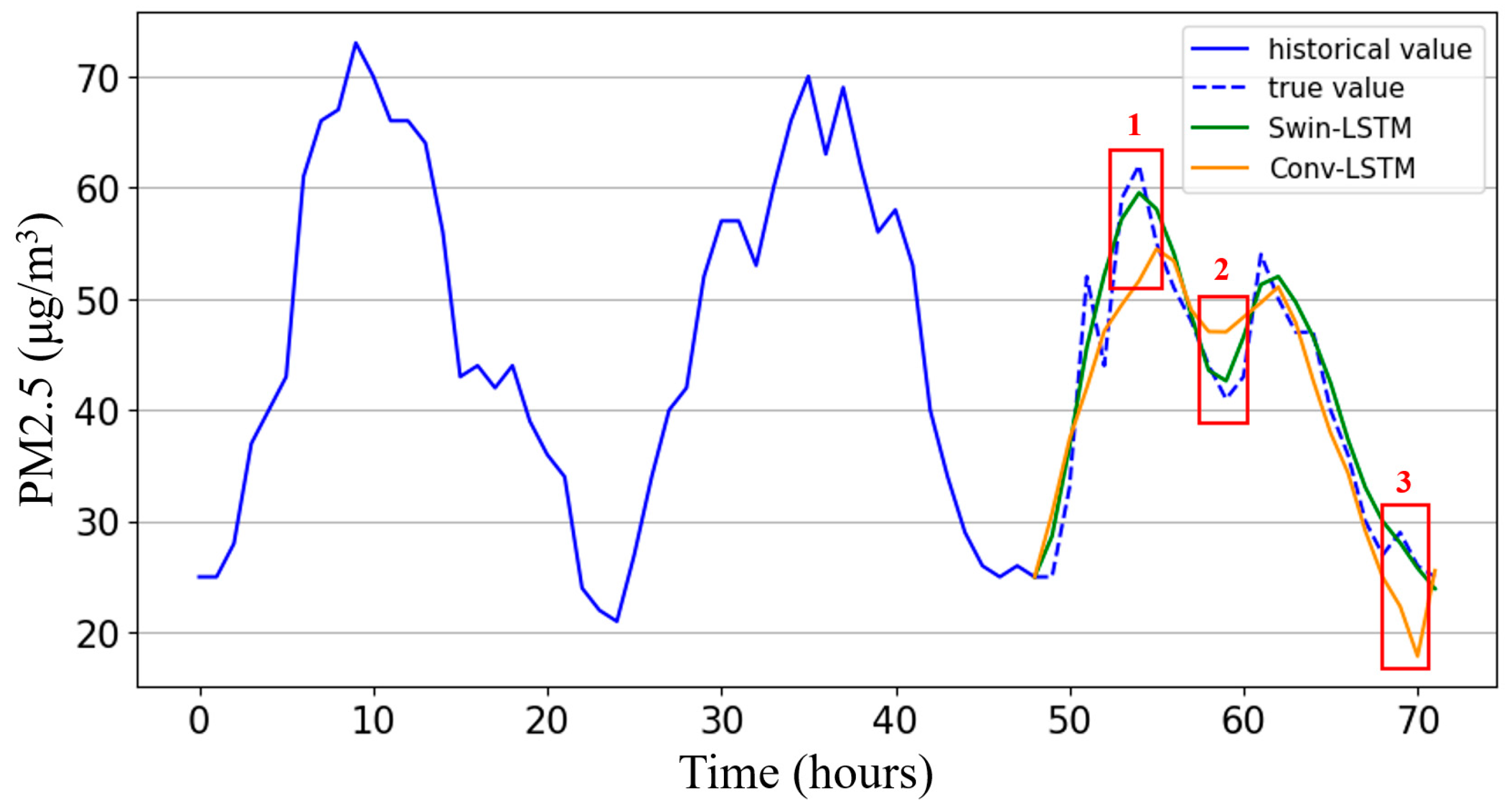
To evaluate the model’s air quality prediction accuracy at fixed locations, samples were taken from the final output PM2.5 indicator spatial distribution map at different times for a single station location. A comparison between the proposed SwinLSTM model and the ConvLSTM model is shown in
Figure 7, using Station 1 as a benchmark, with the red box highlighting typical comparison areas.
The SwinLSTM model’s predictions more closely follow the trend of actual observed values, especially when judging daily PM2.5 concentration peaks and troughs. ConvLSTM typically exhibits larger errors at these extreme values, while SwinLSTM maintains higher accuracy. This comprehensively demonstrates that the proposed model, by combining multi-head self-attention mechanisms with LSTM, achieves efficient feature fusion, resulting in more powerful spatial modeling capabilities and the better capture of dynamic patterns in the temporal dimension.
Table 1 presents comparative results of the SwinLSTM model for PM10 indicators across three different prediction time steps, alongside quantitative comparisons with previously proposed models.
It is evident that the method of first using RNN time series models for single-dimension predictions at each monitoring station, followed by Kriging interpolation to extend predictions to the entire Dongting Lake area, is notably inferior to the approach used in this study. The latter uses Kriging interpolation first, followed by full-area prediction based on two-dimensional meteorological distribution maps. Furthermore, the proposed SwinLSTM exhibited the best performance across all prediction time steps. Compared to ConvLSTM, it showed a 2.75% improvement in the value for 3 h predictions and a 6.47% improvement for 24 h predictions.
4.5. Discussion
The superior performance of the SwinLSTM model can be attributed to several key innovations that address limitations in existing methodologies. Unlike traditional LSTM or GRU models that only capture temporal patterns at individual stations, this study’s approach integrates spatial interpolation with advanced spatiotemporal modeling. The performance gap is particularly evident in medium- to long-term forecasting, where the model maintains high accuracy while pure time series approaches deteriorate rapidly. This improvement stems from SwinLSTM’s ability to model the complex diffusion patterns of pollutants across space. Second, compared to CNN-based architecture like ConvLSTM, the SwinLSTM model demonstrates superior feature extraction capabilities. The shifted window attention mechanism enables both local detail preservation and global context integration, overcoming the fixed receptive field constraints of conventional convolutions. This is particularly important for capturing distant correlations in air quality patterns that may be influenced by regional meteorological phenomena. Third, the hierarchical feature representation in Swin Transformer components allows the model to detect multiscale spatiotemporal dependencies that single-scale models often miss. This is reflected in the 6.47% improvement in R2 value for 24 h predictions compared to ConvLSTM, highlighting SwinLSTM’s enhanced capability to maintain prediction accuracy over longer horizons.
The superior long-term prediction capability of SwinLSTM suggests that attention mechanisms more effectively capture persistent spatiotemporal dependencies compared to convolutional approaches. This has significant implications for air quality management, as more accurate 24 h forecasts provide authorities with a crucial lead time for implementing mitigation measures. The model’s ability to capture peak pollution events more accurately than comparison models indicates that the hierarchical representation learning in Swin Transformer components successfully models the complex, non-linear relationships that drive extreme pollution episodes. This capability is particularly valuable for public health applications, as high-concentration episodes pose the greatest health risks.
The performance variations observed also provide guidance for model deployment strategies. For instance, the model could be dynamically configured to emphasize different aspects of its architecture based on the prediction horizon—potentially emphasizing the LSTM components for short-term predictions and the Swin Transformer components for longer-term forecasts. These insights not only validate the theoretical advantages of the proposed SwinLSTM architecture but also offer practical guidance for both model refinement and operational implementation in air quality management systems.
5. Conclusions
This research addresses the crucial environmental monitoring issue of regional air quality spatiotemporal prediction by proposing an innovative deep learning-based method. This method first uses Kriging interpolation to extend multi-dimensional meteorological and pollutant indicators recorded at monitoring stations to two-dimensional distribution images of the entire region. It then employs the proposed SwinLSTM model to predict future regional air quality in both spatial and temporal dimensions.
The experimental results from the Dongting Lake area in China demonstrate that the proposed SwinLSTM model not only achieves excellent results in short-term PM2.5 and PM10 prediction tasks, significantly outperforming the current mainstream ConvLSTM model but also shows more pronounced advantages in medium- to long-term prediction tasks. This proves that the proposed model can better capture the spatiotemporal correlations and evolution patterns of regional air quality.
Despite the promising results, several limitations of this study should be acknowledged. Data availability constraints restricted the analysis to a three-year period and specific pollutants; a longer time series and additional pollutants could enhance the model’s robustness. The model’s performance is dependent on the specific geographical and meteorological conditions of the Dongting Lake region, potentially limiting direct transferability to regions with substantially different characteristics without retraining or adaptation. The computational resources required for the SwinLSTM architecture may present implementation challenges for real-time prediction systems with limited processing capabilities.
Future work will explore more comprehensive and efficient spatiotemporal feature fusion methods, such as considering geographical factors like terrain, lakes, and altitude, to enable the model to better capture geographical conditions affecting air quality dispersion. Cross-attention mechanisms for multimodal fusion will be used to model spatiotemporal features. Additionally, the incorporation of forecast data from numerical weather models into input features will be attempted to further improve prediction fidelity. Furthermore, empirical studies on meteorological predictions will be conducted over larger regional scales, and predictions for more meteorological indicators will be made. This will provide technical support for formulating more comprehensive environmental control policies, demonstrating important theoretical value and practical significance across a wider range of fields.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}