
Research on High-Precision Target Detection Technology for Tomato-Picking Robots in Sustainable Agriculture


 ,
,  ,
,
Abstract
1. Introduction
2. Materials and Methods
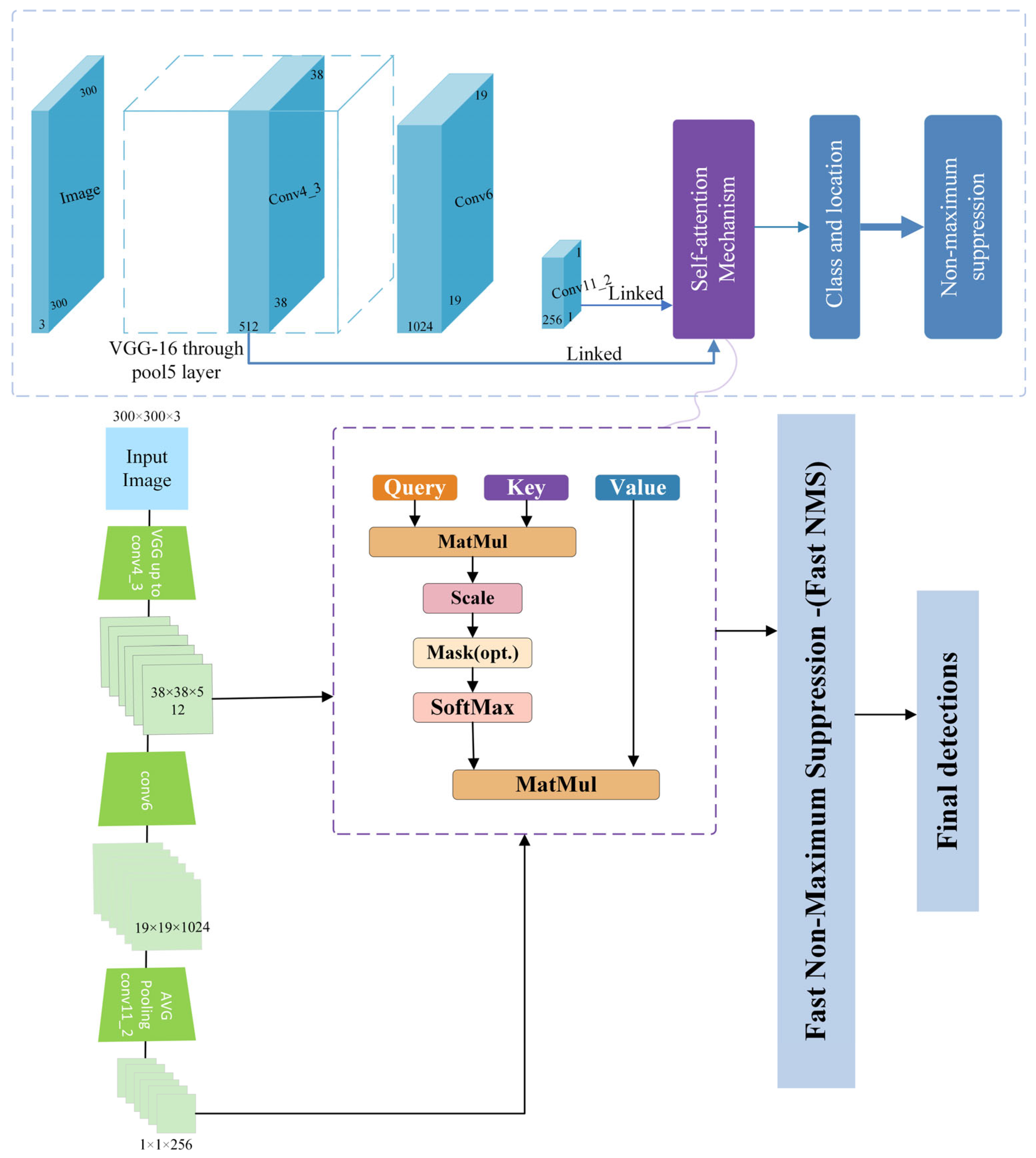
2.1. Modified Deep Learning Model of Single-Shot Multi-Box Detector
2.2. Self-Attention Mechanism
2.3. Generating Detecting Model Based on Deep Learning
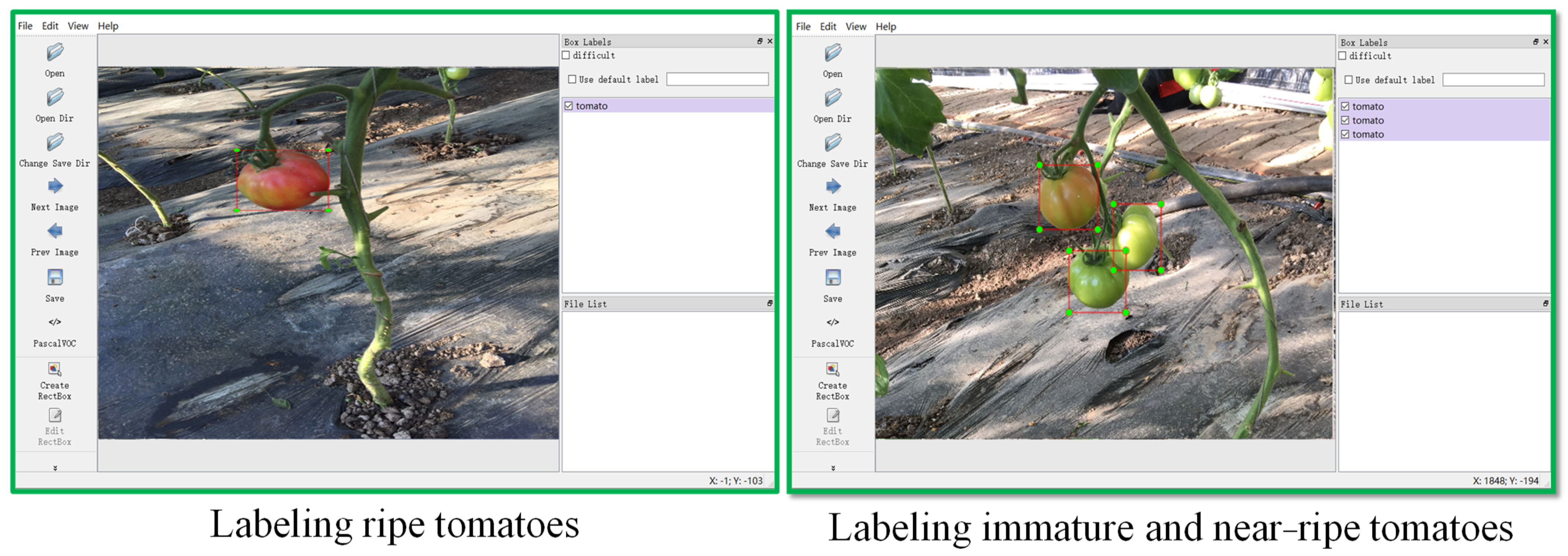
2.4. Experiments and Statistical Analysis
3. Results
4. Discussion
4.1. Overall Judgement on the Modified SSD Model
4.2. The Unique Effects of Modification
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rajendran, V.; Debnath, B.; Mghames, S.; Mandil, W.; Parsa, S.; Parsons, S.; Ghalamzan, E.A. Towards Autonomous Selective Harvesting: A Review of Robot Perception, Robot Design, Motion Planning and Control. J. Field Robot. 2023, 41, 2247–2279. [Google Scholar]
- Groher, T.; Heitkaemper, K.; Walter, A.; Liebisch, F.; Umstaetter, C. Status quo of adoption of precision agriculture enabling technologies in Swiss plant production. Precis. Agric. 2020, 21, 1327–1350. [Google Scholar]
- Wang, Z.; Xun, Y.; Wang, Y.; Yang, Q. Review of smart robots for fruit and vegetable picking in agriculture. Int. J. Agric. Biol. Eng. 2022, 15, 33–54. [Google Scholar]
- de Almeida Machado, T.; Fernandes, H.C.; Megguer, C.A.; Santos, N.T.; Santos, F.L. Quantitative and qualitative loss of tomato fruits during mechanized harvest. Rev. Bras. Eng. Agric. Ambient. 2018, 22, 799–803. [Google Scholar]
- Wang, L.; Zhao, B.; Fan, J.; Hu, X.; Wei, S.; Li, Y.; Zhou, Q.; Wei, C. Development of a tomato harvesting robot used in greenhouse. Int. J. Agric. Biol. Eng. 2017, 10, 140–149. [Google Scholar]
- Liu, J.; Liu, Z. The Vision-Based Target Recognition, Localization, and Control for Harvesting Robots: A Review. Int. J. Precis. Eng. Manuf. 2024, 25, 409–428. [Google Scholar]
- Zhao, Y.; Gong, L.; Huang, Y.; Liu, C. A review of key techniques of vision-based control for harvesting robot. Comput. Electron. Agric. 2016, 127, 311–323. [Google Scholar]
- Feng, Q.; Cheng, W.; Zhou, J.; Wang, X. Design of structured-light vision system for tomato harvesting robot. Int. J. Agric. Biol. Eng. 2014, 7, 19–26. [Google Scholar]
- Yang, G.; Wang, J.; Nie, Z.; Yang, H.; Yu, S. A Lightweight YOLOv8 Tomato Detection Algorithm Combining Feature Enhancement and Attention. Agronomy 2023, 13, 1824. [Google Scholar] [CrossRef]
- Liu, G.; Nouaze, J.C.; Mbouembe, P.L.T.; Kim, J.H. YOLO-Tomato: A Robust Algorithm for Tomato Detection Based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef]
- Dong, W.; Roy, P.; Peng, C.; Isler, V. Ellipse R-CNN: Learning to Infer Elliptical Object from Clustering and Occlusion. IEEE Trans. Image Process. 2021, 30, 2193–2206. [Google Scholar] [CrossRef] [PubMed]
- Mojaravscki, D.; Magalhaes, P.S.G. Comparative Evaluation of Color Correction as Image Preprocessing for Olive Identification under Natural Light Using Cell Phones. Agriengineering 2024, 6, 155–170. [Google Scholar] [CrossRef]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and Localization Methods for Vision-Based Fruit Picking Robots: A Review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef] [PubMed]
- Miao, Z.; Yu, X.; Li, N.; Zhang, Z.; He, C.; Li, Z.; Deng, C.; Sun, T. Efficient tomato harvesting robot based on image processing and deep learning. Precis. Agric. 2023, 24, 254–287. [Google Scholar] [CrossRef]
- Liu, M.; Chen, W.; Cheng, J.; Wang, Y.; Zhao, C. Y-HRNet: Research on multi-category cherry tomato instance segmentation model based on improved YOLOv7 and HRNet fusion. Comput. Electron. Agric. 2024, 227, 109531. [Google Scholar]
- Oikonomou, K.M.; Kansizoglou, I.; Gasteratos, A. A Framework for Active Vision—Based Robot Planning Using Spiking Neural Networks. In Proceedings of the 2022 30th Mediterranean Conference on Control and Automation (Med); Mediterranean Conference On Control And Automation, Vouliagmeni, Greece, 28 June–1 July 2022; IEEE: New York, NY, USA, 2022; pp. 867–871. [Google Scholar]
- Nugroho, D.P.; Widiyanto, S.; Wardani, D.T. Comparison of Deep Learning-Based Object Classification Methods for Detecting Tomato Ripeness. Int. J. Fuzzy Log. Intell. Syst. 2022, 22, 223–232. [Google Scholar] [CrossRef]
- Yuan, T.; Lv, L.; Zhang, F.; Fu, J.; Gao, J.; Zhang, J.; Li, W.; Zhang, C.; Zhang, W. Robust Cherry Tomatoes Detection Algorithm in Greenhouse Scene Based on SSD. Agriculture 2020, 10, 160. [Google Scholar] [CrossRef]
- Magalhaes, S.A.; Castro, L.; Moreira, G.; dos Santos, F.N.; Cunha, M.; Dias, J.; Moreira, A.P. Evaluating the Single-Shot MultiBox Detector and YOLO Deep Learning Models for the Detection of Tomatoes in a Greenhouse. Sensors 2021, 21, 3569. [Google Scholar] [CrossRef]
- Huo, B.; Li, C.; Zhang, J.; Xue, Y.; Lin, Z. SAFF-SSD: Self-Attention Combined Feature Fusion-Based SSD for Small Object Detection in Remote Sensing. Remote Sens. 2023, 15, 3027. [Google Scholar] [CrossRef]
- Suh, H.-S.; Meng, J.; Nguyen, T.; Kumar, V.; Cao, Y.; Seo, J.-S. Algorithm-hardware Co-optimization for Energy-efficient Drone Detection on Resource-constrained FPGA. ACM Trans. Reconfig. Technol. Syst. 2023, 16, 33. [Google Scholar] [CrossRef]
- Chen, Z.G.; Wu, K.H.; Li, Y.B.; Wang, M.J.; Li, W. SSD-MSN: An Improved Multi-Scale Object Detection Network Based on SSD. IEEE Access 2019, 7, 80622–80632. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Y.A.; Gao, T.; Fang, Y.; Chen, T. A Novel SSD-Based Detection Algorithm Suitable for Small Object. Ieice Trans. Inf. Syst. 2023, E106D, 625–634. [Google Scholar]
- Xie, J.; Pang, Y.W.; Nie, J.; Cao, J.; Han, J.G. Latent Feature Pyramid Network for Object Detection. IEEE Trans. Multimed. 2023, 25, 2153–2163. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Brauwers, G.; Frasincar, F. A General Survey on Attention Mechanisms in Deep Learning. IEEE Trans. Knowl. Data Eng. 2023, 35, 3279–3298. [Google Scholar] [CrossRef]
- Ahmed, N. Data-Free/Data-Sparse Softmax Parameter Estimation With Structured Class Geometries. IEEE Signal Process. Lett. 2018, 25, 1408–1412. [Google Scholar] [CrossRef]
- Mu, Y.; Chen, T.-S.; Ninomiya, S.; Guo, W. Intact Detection of Highly Occluded Immature Tomatoes on Plants Using Deep Learning Techniques. Sensors 2020, 20, 2984. [Google Scholar] [CrossRef]
- Lawal, M.O. Tomato detection based on modified YOLOv3 framework. Sci. Rep. 2021, 11, 1447. [Google Scholar] [CrossRef]
- Yin, H.; Chai, Y.; Yang, S.X.; Mittal, G.S. Ripe Tomato Detection for Robotic Vision Harvesting Systems in Greenhouses. Trans. Asabe 2011, 54, 1539–1546. [Google Scholar] [CrossRef]
- de Bruijn, J.; Fuentes, N.; Solar, V.; Valdebenito, A.; Vidal, L.; Melin, P.; Fagundes, F.; Valdes, H. The Effect of Visible Light on the Postharvest Life of Tomatoes (Solanum lycopersicum L.). Horticulturae 2023, 9, 94. [Google Scholar] [CrossRef]
- Bechar, A.; Vigneault, C. Agricultural robots for field operations. Part 2: Operations and systems. Biosyst. Eng. 2017, 153, 110–128. [Google Scholar]
- Wang, G.; Huang, D.; Zhou, D.; Liu, H.; Qu, M.; Ma, Z. Maize (Zea mays L.) seedling detection based on the fusion of a modified deep learning model and a novel Lidar points projecting strategy. Int. J. Agric. Biol. Eng. 2022, 15, 172–180. [Google Scholar]
- Zhao, H.; Li, Z.; Zhang, T. Attention Based Single Shot Multibox Detector. J. Electron. Inf. Technol. 2021, 43, 2096–2104. [Google Scholar]
- Liu, X.; Pan, H.; Li, X. Object detection for rotated and densely arranged objects in aerial images using path aggregated feature pyramid networks. In Proceedings of the 11th International Symposium on Multispectral Image Processing and Pattern Recognition (MIPPR)—Pattern Recognition and Computer Vision, Wuhan, China, 10–12 November 2020. [Google Scholar]
- Hassanzadeh, A. On the Use of Imaging Spectroscopy from Unmanned Aerial Systems (UAS) to Model Yield and Assess Growth Stages of a Broadacre Crop; Rochester Institute of Technology: Rochester, NY, USA, 2022. [Google Scholar]
- Rapado-Rincón, D.; van Henten, E.J.; Kootstra, G. Development and evaluation of automated localisation and reconstruction of all fruits on tomato plants in a greenhouse based on multi-view perception and 3D multi-object tracking. Biosyst. Eng. 2023, 231, 78–91. [Google Scholar] [CrossRef]
- Yao, M.; Min, Z. Summary of Fine-Grained Image Recognition Based on Attention Mechanism. In Proceedings of the 13th International Conference on Graphics and Image Processing (ICGIP), Kunming, China, 18–20 August 2022. [Google Scholar]
- Ramik, D.M.; Sabourin, C.; Moreno, R.; Madani, K. A machine learning based intelligent vision system for autonomous object detection and recognition. Appl. Intell. 2014, 40, 358–375. [Google Scholar]
- Liu, B.; Wei, S.S.; Zhang, F.; Guo, N.W.; Fan, H.Y.; Yao, W. Tomato leaf disease recognition based on multi-task distillation learning. Front. Plant Sci. 2024, 14, 1330527. [Google Scholar]
- Fang, Y.C.; Ma, Z.Y.; Zhang, Z.X.; Zhang, X.Y.; Bai, X. Dynamic Multi-Task Learning with Convolutional Neural Network. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017; pp. 1668–1674. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy Rate/% | Recall Rate/% | Time Consumption per Image/ms | Model Size/MB |
|---|---|---|---|---|
| Modified SSD in this study | 94.77 a | 96.1 a | 29 a | 155 a |
| Classical SSD with Self-attention mechanism | 94.2 a | 96.7 a | 37 b | 197 b |
| Classical SSD | 91.77 b | 95.7 b | 28 a | 153 a |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, K.; Chen, S.; Wang, G.; Qi, J.; Gao, X.; Xiang, M.; Zhou, Z. Research on High-Precision Target Detection Technology for Tomato-Picking Robots in Sustainable Agriculture. Sustainability 2025, 17, 2885. https://doi.org/10.3390/su17072885
Song K, Chen S, Wang G, Qi J, Gao X, Xiang M, Zhou Z. Research on High-Precision Target Detection Technology for Tomato-Picking Robots in Sustainable Agriculture. Sustainability. 2025; 17(7):2885. https://doi.org/10.3390/su17072885
Chicago/Turabian StyleSong, Kexin, Shuyu Chen, Gang Wang, Jiangtao Qi, Xiaomei Gao, Meiqi Xiang, and Zihao Zhou. 2025. "Research on High-Precision Target Detection Technology for Tomato-Picking Robots in Sustainable Agriculture" Sustainability 17, no. 7: 2885. https://doi.org/10.3390/su17072885
APA StyleSong, K., Chen, S., Wang, G., Qi, J., Gao, X., Xiang, M., & Zhou, Z. (2025). Research on High-Precision Target Detection Technology for Tomato-Picking Robots in Sustainable Agriculture. Sustainability, 17(7), 2885. https://doi.org/10.3390/su17072885