
Developing a Novel Audit Risk Metric Through Sentiment Analysis


Abstract
1. Introduction
2. Related Previous Studies and Research Questions Development
2.1. Related Previous Studies
2.2. Research Questions Development
- (1)
- How can sentiment analysis techniques be applied to audit reports to develop a novel audit risk metric that captures qualitative dimensions of audit risk?
- (2)
- What are the advantages of the Audit Risk Sentiment Value (ARSV) over traditional audit risk proxies, such as audit fees, audit hours, and discretionary accruals?
- (3)
- How does incorporating qualitative data into audit risk measurement enhance the interpretability and usefulness of audit reports for diverse stakeholders, including non-expert users?
- (4)
- What implications does adopting sentiment-based audit risk measures have for aligning audit practices with sustainability and transparency goals?
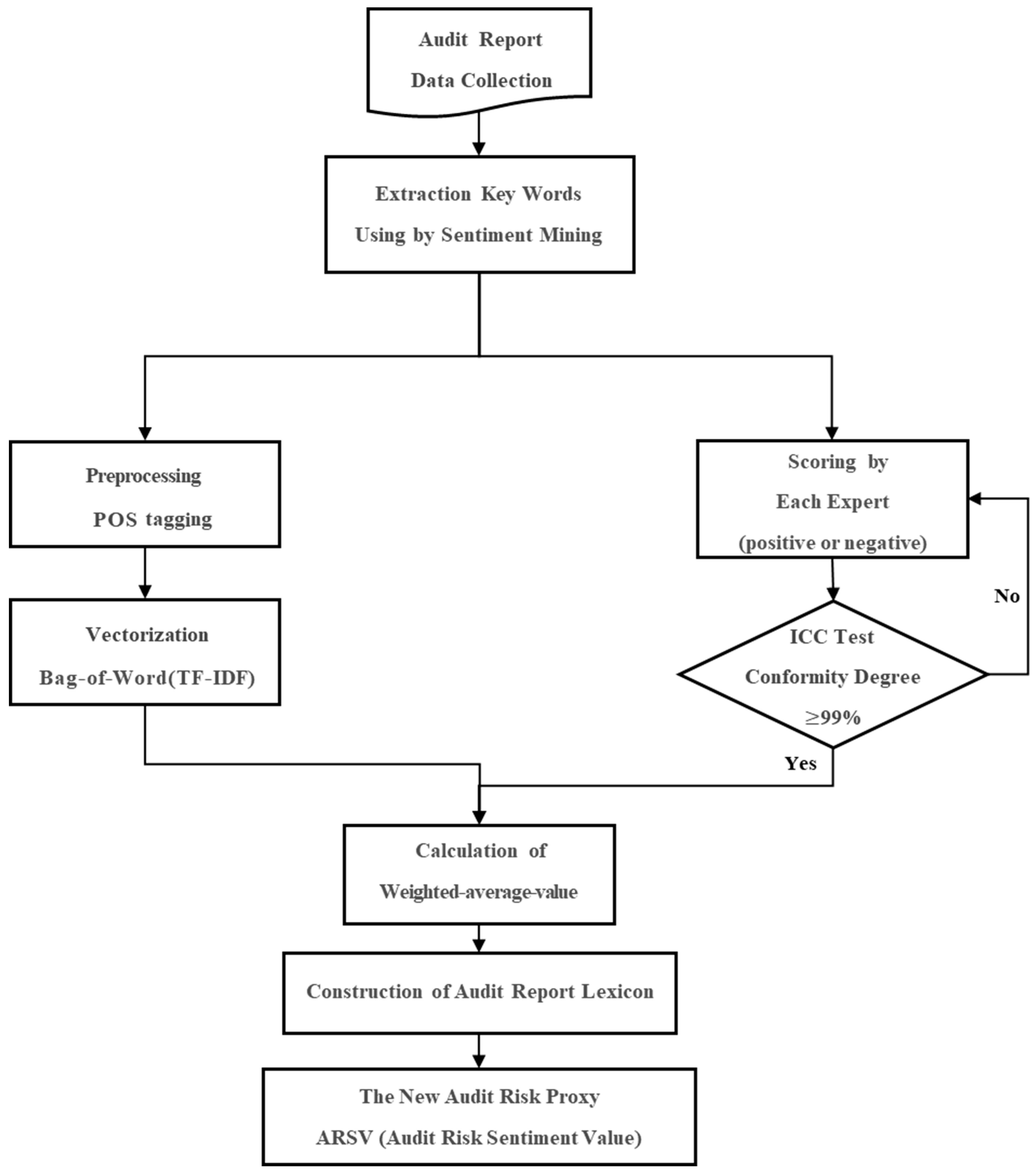
3. Research Design of Analyzing Texts in the Audit Report
3.1. Data Processing
3.2. Keyword Extraction from the Audit Report
4. Development of a New Audit Risk Proxy
4.1. Quantification of Audit Report Text Data Using Sentiment Mining
4.2. Establishment of the Audit Report Lexicon
5. Research Design of Empirical Test
5.1. Comparing the New Audit Risk Proxy with Existing Audit Risk Measures by Vuong Test Using a Dummy Variable of Explanatory Language as a Dependent Variable
5.2. Robustness Check: Vuong Test Comparison of Audit Risk Proxies with Continuous Explanatory Language
6. Research Results
Comparing the New Audit Risk Proxy with Existing Audit Risk Measures by Vuong Test
7. Discussions
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- DeFond, M.; Zhang, J. A review of archival auditing research. J. Account. Econ. 2014, 58, 275–326. [Google Scholar] [CrossRef]
- Choi, S.U.; Na, H.J.; Lee, K.C. Does explanatory language convey the auditor’s perceived audit risk? A study using a novel big data analysis metric. Manag. Audit. J. 2023, 38, 783–812. [Google Scholar] [CrossRef]
- Hope, O.-K.; Hu, D.; Lu, H. The benefits of specific risk-factor disclosures. Rev. Account. Stud. 2017, 22, 809–839. [Google Scholar] [CrossRef]
- Choi, S.U.; Lee, K.C.; Na, H.J. Exploring the deep neural network model’s potential to estimate abnormal audit fees. Manag. Decis. 2022, 60, 3304–3323. [Google Scholar] [CrossRef]
- Chopra, S.S.; Senadheera, S.S.; Dissanayake, P.D.; Withana, P.A.; Chib, R.; Rhee, J.H.; Ok, Y.S. Navigating the challenges of environmental, social, and governance (ESG) reporting: The path to broader sustainable development. Sustainability 2024, 16, 606. [Google Scholar] [CrossRef]
- Loughran, T.; McDonald, B. When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks. J. Financ. 2011, 66, 35–65. [Google Scholar] [CrossRef]
- Li, F. The information content of forward-looking statements in corporate filings—A naïve Bayesian machine learning approach. J. Account. Res. 2010, 48, 1049–1102. [Google Scholar] [CrossRef]
- Christensen, B.E.; Glover, S.M.; Wolfe, C.J. Do critical audit matter disclosures improve the informational value of audit reports? Account. Rev. 2018, 93, 59–79. [Google Scholar]
- Willett, P. The Porter stemming algorithm: Then and now. Program 2006, 40, 219–223. [Google Scholar] [CrossRef]
- Chiche, A.; Yitagesu, B. Part of speech tagging: A systematic review of deep learning and machine learning approaches. J. Big Data 2022, 9, 10. [Google Scholar] [CrossRef]
- Addiga, A.; Bagui, S. Sentiment analysis on Twitter data using term frequency-inverse document frequency. J. Comput. Commun. 2022, 10, 117–128. [Google Scholar] [CrossRef]
- Akuma, S.; Lubem, T.; Adom, I.T. Comparing Bag of Words and TF-IDF with different models for hate speech detection from live tweets. Int. J. Inf. Technol. 2022, 14, 3629–3635. [Google Scholar] [CrossRef]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar] [CrossRef]
- Jain, S.; Jain, S.K.; Vasal, S. An Effective TF-IDF Model to Improve the Text Classification Performance. In Proceedings of the 2024 IEEE 13th International Conference on Communication Systems and Network Technologies (CSNT), Jabalpur, India, 6–7 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–4. [Google Scholar] [CrossRef]
- Demartini, C.; Trucco, S. Does intellectual capital disclosure matter for audit risk? Evidence from the UK and Italy. Sustainability 2016, 8, 867. [Google Scholar] [CrossRef]
- Kim, J.; Kim, M.; Yoon, Y.; No, W.G.; Vasarhelyi, M.A. Assessing audit effort in response to exogenous shocks: Evidence from Korea on the impact of enhanced audit standards and COVID-19. Int. J. Audit. 2024, 28, 695–716. [Google Scholar] [CrossRef]
- Duramany-Lakkoh, E.K. An Assessment of the Relationship between Audit Tenure and Audit Quality using a Modified Jones Model. Eur. J. Account. Audit. Financ. Res. 2022, 10, 14–35. [Google Scholar] [CrossRef]
- Linsley, P.M.; Shrives, P.J. Risk reporting: A study of risk disclosures in the annual reports of UK companies. Br. Account. Rev. 2006, 38, 387–404. [Google Scholar] [CrossRef]
- Velte, P.; Issa, J. The impact of key audit matter (KAM) disclosure in audit reports on stakeholders’ reactions: A literature review. Probl. Perspect. Manag. 2019, 17, 323–334. [Google Scholar] [CrossRef]
- Mcchlery, S.; Hussainey, K. Risk disclosure behaviour: Evidence from the UK extractive industry. J. Appl. Account. Res. 2021, 22, 194–210. [Google Scholar] [CrossRef]
- Davidson, R.A.; Neu, D. A note on the association between audit firm size and audit quality. Contemp. Account. Res. 1993, 9, 479–488. [Google Scholar] [CrossRef]
- Broye, G.; Weill, L. Does leverage influence auditor choice? A cross-country analysis. Appl. Financ. Econ. 2008, 18, 715–731. [Google Scholar] [CrossRef]
- Bae, G.S.; Choi, S.U.; Lamoreaux, P.T. Auditors’ fee premiums and low-quality internal controls. Contemp. Account. Res. 2021, 38, 153–179. [Google Scholar] [CrossRef]
- Swandewi, N.; Badera, I.D.N. The effect of audit opinion, audit delay, and return on assets on auditor switching. Am. J. Humanit. Soc. Sci. Res. 2021, 5, 593–600. [Google Scholar]
- Kannan, Y.H.; Skantz, T.R. The impact of CEO and CFO equity incentives on audit scope and perceived risks as revealed through audit fees. Audit. A J. Pract. Theory 2014, 33, 111–139. [Google Scholar] [CrossRef]
- Johnstone, K.M. Client-acceptance decisions: Simultaneous effects of client business risk, audit risk, auditor business risk, and risk adaptation. Audit. A J. Pract. Theory 2000, 19, 1–25. [Google Scholar] [CrossRef]
- Visvanathan, G. Intangible assets on the balance sheet and audit fees. Int. J. Discl. Gov. 2017, 14, 185–202. [Google Scholar] [CrossRef]
- An, R.; Li, W.; Wang, D.; Wang, Y.; Yu, L. Do key audit matters affect operating activities? Evidence from inventory management. Abacus 2023, 59, 300–339. [Google Scholar] [CrossRef]
- Pittman, J.; Stein, S.E.; Valentine, D.F. The importance of audit partners’ risk tolerance to audit quality. Contemp. Account. Res. 2023, 40, 2512–2546. [Google Scholar] [CrossRef]
- Guo, F.; Lin, C.; Masli, A.; Wilkins, M.S. Auditor responses to shareholder activism. Contemp. Account. Res. 2021, 38, 63–95. [Google Scholar] [CrossRef]
- Dang, V.C.; Nguyen, Q.K. Internal corporate governance and stock price crash risk: Evidence from Vietnam. J. Sustain. Financ. Invest. 2024, 14, 24–41. [Google Scholar] [CrossRef]
- Martani, D.; Rahmah, N.A.; Fitriany, F.; Anggraita, V. Impact of audit tenure and audit rotation on the audit quality: Big 4 vs non big 4. Cogent Econ. Financ. 2021, 9, 1901395. [Google Scholar] [CrossRef]
- Baatwah, S.R. Key audit matters and big4 auditors in Oman: A quantile approach analysis. J. Financ. Report. Account. 2023, 21, 1124–1148. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Criteria | N | |||||
|---|---|---|---|---|---|---|
| Initial firm-years listed in KOSPI market from 2018 to 2023 | 4242 | |||||
| Excluding: Financial industries (initial word of KIS-code started from ’K’) | (278) | |||||
| Excluding: Non-December fiscal year-end | (62) | |||||
| Excluding: Unavailable financial data required from the database | (107) | |||||
| Final observations | 3795 | |||||
| Observations by year | ||||||
| Year | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 |
| N | 656 | 615 | 618 | 644 | 657 | 665 |
| Variable | Word | TF-IDF Frequency | Scoring Value | ARSV |
|---|---|---|---|---|
| English (Translated) | ||||
| Positive Words | unqualified | 0.01 | 3 | 0.03 |
| financing | 0 | 3 | 0 | |
| terminate | 0.32 | 3 | 0.96 | |
| improvement | 0.21 | 2 | 0.42 | |
| revenue | 0.65 | 2 | 1.3 | |
| current assets | 0 | 2 | 0 | |
| receivable | 0 | 2 | 0 | |
| retained | 0.12 | 2 | 0.24 | |
| pushing | 0.51 | 2 | 1.02 | |
| land | 0.23 | 1 | 0.23 | |
| common stock | 0.43 | 1 | 0.43 | |
| negotiation | 0.02 | 1 | 0.02 | |
| … | … | … | ||
| Negative Words | uncertainty | 0 | −3 | 0 |
| litigation | 0 | −3 | 0 | |
| loss | 0 | −3 | 0 | |
| aggravated | 0.03 | −3 | −0.09 | |
| restatement | 0.32 | −3 | −0.96 | |
| expense | 0 | −2 | 0 | |
| exposure | 0.16 | −2 | −0.32 | |
| govern | 0.23 | −2 | −0.46 | |
| delay | 0.21 | −2 | −0.42 | |
| reason | 0.71 | −1 | −0.71 | |
| calculation | 0.22 | −1 | −0.22 | |
| symptom | 0.31 | −1 | −0.31 | |
| accrual | 0.23 | −1 | −0.23 | |
| … | … | … |
| Variable | Definition |
|---|---|
| SIZE | the natural log of total assets; |
| LEV | debt to equity ratio (= total debt/total assets); |
| GRW | revenue growth rate (= revenue of period t − revenue of period t − 1)/revenue of period t − 1; |
| ROA | return on total assets (= net income/total assets); |
| CFO | operation cash flow ratio (= operation cash flow/total assets); |
| RISK | market risk (= standard deviation of recent five years’ return on sales); |
| PPER | tangible assets ratio (= tangible assets scaled by total assets); |
| INVREC | sum of inventory and receivables scaled by total assets; |
| LOSS | dummy variable equal to 1 if the firm’s net loss, otherwise 0; |
| LARGEST | the largest shareholder ownership; |
| FOREIGN | the foreign shareholder ownership; |
| BIG4 | dummy variable equal to 1 for BIG4 client, otherwise 0. |
| KAM | dummy variable equal to 1 for including Key Audit Matter, otherwise 0. |
| Dependent Variable: EXL_Dummy | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Variable | Audit Risk = ARSV | Audit Risk = LNFEE | Audit Risk = LNHOUR | Audit Risk = |MJDA| | ||||||||
| Coefficient | Wald χ2 | Coefficient | Wald χ2 | Coefficient | Wald χ2 | Coefficient | Wald χ2 | |||||
| Intercept | −1.327 | 0.030 | −4.687 | 1.632 | −1.787 | 0.244 | −0.543 | 0.114 | ||||
| Audit Risk | −452.232 | 298.960 | *** | 0.805 | 23.846 | *** | 0.670 | 11.776 | *** | 6.828 | 22.897 | *** |
| SIZE | −0.291 | 9.428 | *** | −0.502 | 24.807 | *** | −0.434 | 16.253 | *** | −0.119 | 2.033 | |
| LEV | 2.060 | 15.102 | *** | 2.510 | 36.784 | *** | 2.686 | 42.826 | *** | 3.379 | 55.775 | *** |
| GRW | 0.166 | 0.415 | 0.250 | 1.793 | 0.234 | 1.583 | 0.346 | 2.902 | * | |||
| ROA | 0.368 | 0.067 | −0.114 | 0.010 | −0.216 | 0.037 | 1.402 | 1.337 | ||||
| CFO | −0.727 | 0.251 | −1.462 | 1.582 | −1.503 | 1.680 | −0.478 | 0.154 | ||||
| RISK | 3.022 | 5.624 | ** | 3.286 | 11.184 | *** | 3.497 | 12.806 | *** | 3.315 | 7.918 | *** |
| INVREC | −0.360 | 0.197 | −1.332 | 4.558 | ** | −1.379 | 4.957 | ** | −0.151 | 0.049 | ||
| PPER | 0.108 | 0.037 | −0.749 | 2.842 | * | −0.739 | 2.780 | * | −0.410 | 0.673 | ||
| LOSS | 0.198 | 0.549 | 0.276 | 1.860 | 0.279 | 1.938 | 0.364 | 2.677 | ||||
| LARGEST | −57.329 | 1.021 | −14.255 | 0.107 | −31.831 | 0.547 | −83.725 | 3.043 | * | |||
| FORN | 62.076 | 0.388 | −78.294 | 0.918 | −75.396 | 0.841 | −65.162 | 0.494 | ||||
| BIG4 | −0.541 | 7.213 | *** | −0.735 | 20.526 | *** | −0.764 | 20.082 | *** | −0.703 | 17.293 | *** |
| KAM | 8.748 | 45.470 | *** | 9.293 | 56.716 | *** | 9.335 | 56.290 | *** | 19.633 | 0.004 | |
| Fixed Effect | Included | Included | Included | Included | ||||||||
| pseudo R2 | 0.786 | 0.608 | 0.604 | 0.578 | ||||||||
| −2 Log L | 974.066 | 1583.733 | 1595.956 | 1275.020 | ||||||||
| HL Chisq | 0.182 | 0.072 | 0.021 | 0.043 | ||||||||
| N_obs | 3795 | 3795 | 3795 | 3795 | ||||||||
| Vuong Test | ||||||||||||
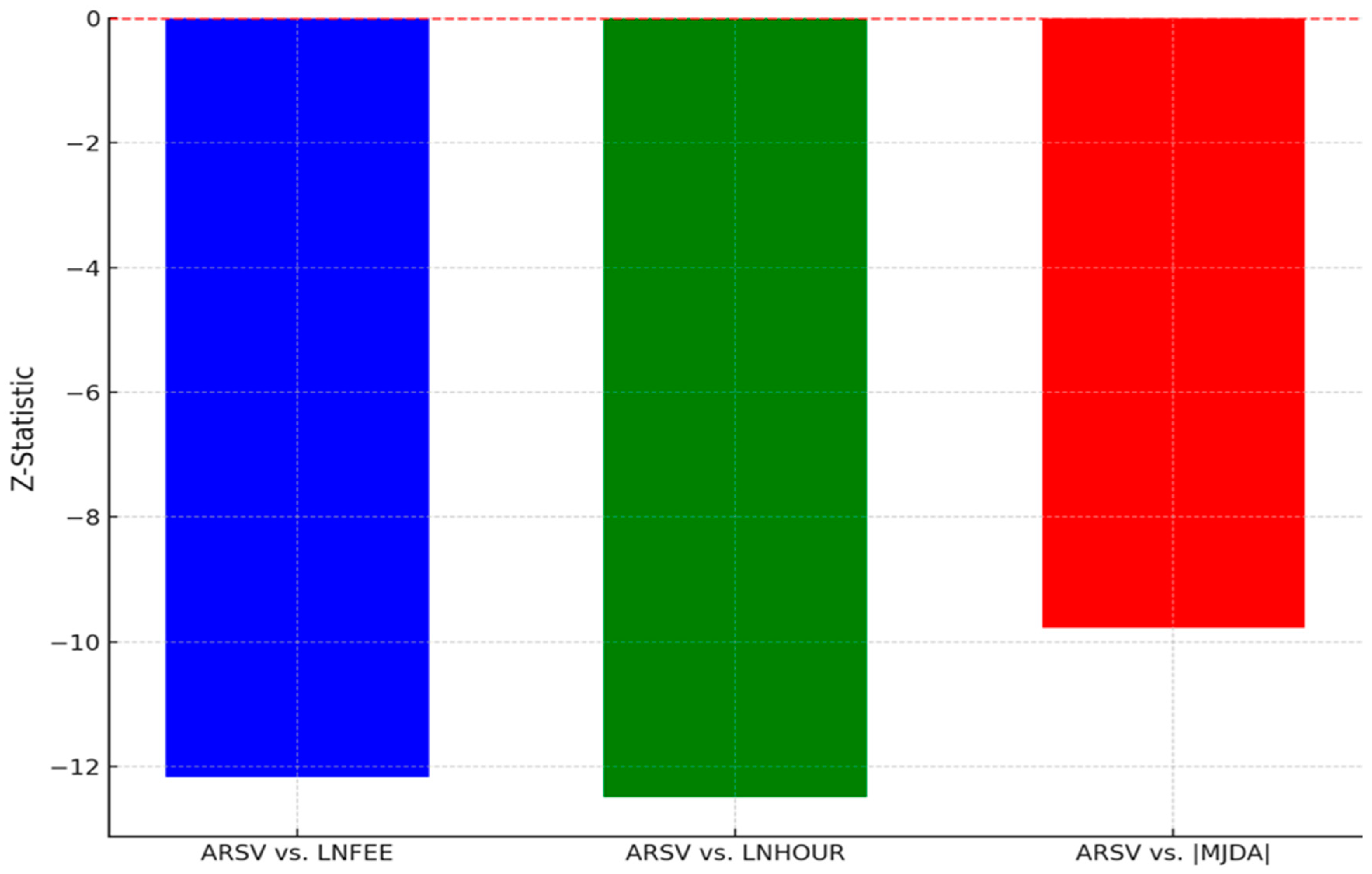
| vs. ARSV | Z | Preferred Model | Z | Preferred Model | Z | Preferred Model | ||||||
| −12.168 *** | ARSV | −12.492 *** | ARSV | −9.775 *** | ARSV | |||||||
| Dependent Variable: EXL_Number | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Variable | Audit Risk = ARSV | Audit Risk = LNFEE | Audit Risk = LNHOUR | Audit Risk = |MJDA| | ||||||||
| Coefficient | t-Value | Coefficient | t-Value | Coefficient | t-Value | Coefficient | t-Value | |||||
| Intercept | 0.194 | 1.597 | −0.019 | −0.129 | 0.327 | 2.277 | ** | 0.104 | 0.850 | |||
| Audit Risk | −33.707 | −31.472 | *** | 0.099 | 7.095 | *** | 0.080 | 5.013 | *** | 0.969 | 6.854 | *** |
| SIZE | −0.007 | −1.422 | −0.053 | −6.290 | *** | −0.043 | −4.851 | *** | −0.003 | −0.548 | ||
| LEV | 0.164 | 5.399 | *** | 0.266 | 7.509 | *** | 0.285 | 8.053 | *** | 0.326 | 8.472 | *** |
| GRW | 0.007 | 0.499 | 0.008 | 0.495 | 0.006 | 0.395 | 0.016 | 0.797 | ||||
| ROA | −0.084 | −0.930 | −0.183 | −1.739 | * | −0.200 | −1.893 | * | −0.123 | −1.020 | ||
| CFO | 0.002 | 0.018 | −0.115 | −1.171 | −0.110 | −1.115 | 0.017 | 0.154 | ||||
| RISK | 0.341 | 4.333 | *** | 0.486 | 5.321 | *** | 0.514 | 5.610 | *** | 0.495 | 4.565 | *** |
| INVREC | −0.073 | −1.623 | −0.175 | −3.335 | *** | −0.171 | −3.244 | *** | −0.047 | −0.821 | ||
| PPER | −0.050 | −1.624 | −0.107 | −2.977 | *** | −0.110 | −3.043 | *** | −0.085 | −2.120 | ** | |
| LOSS | 0.018 | 1.186 | 0.026 | 1.431 | 0.027 | 1.469 | 0.033 | 1.631 | ||||
| LARGEST | −8.032 | −2.590 | *** | −4.986 | −1.364 | −6.852 | −1.874 | * | −11.040 | −2.720 | *** | |
| FORN | 6.937 | 1.446 | −1.565 | −0.280 | 0.772 | 0.138 | 3.007 | 0.488 | ||||
| BIG4 | −0.034 | −3.001 | *** | −0.068 | −4.963 | *** | −0.072 | −5.049 | *** | −0.059 | −4.023 | *** |
| KAM | 0.495 | 26.043 | *** | 0.703 | 34.069 | *** | 0.707 | 34.153 | *** | 0.700 | 29.221 | *** |
| Fixed Effect | Included | Included | Included | Included | ||||||||
| F-Value | 62.454 *** | 35.939 *** | 35.229 *** | 49.857 *** | ||||||||
| Adj_R2 | 0.599 | 0.460 | 0.455 | 0.446 | ||||||||
| N_obs | 3795 | 3795 | 3795 | 3795 | ||||||||
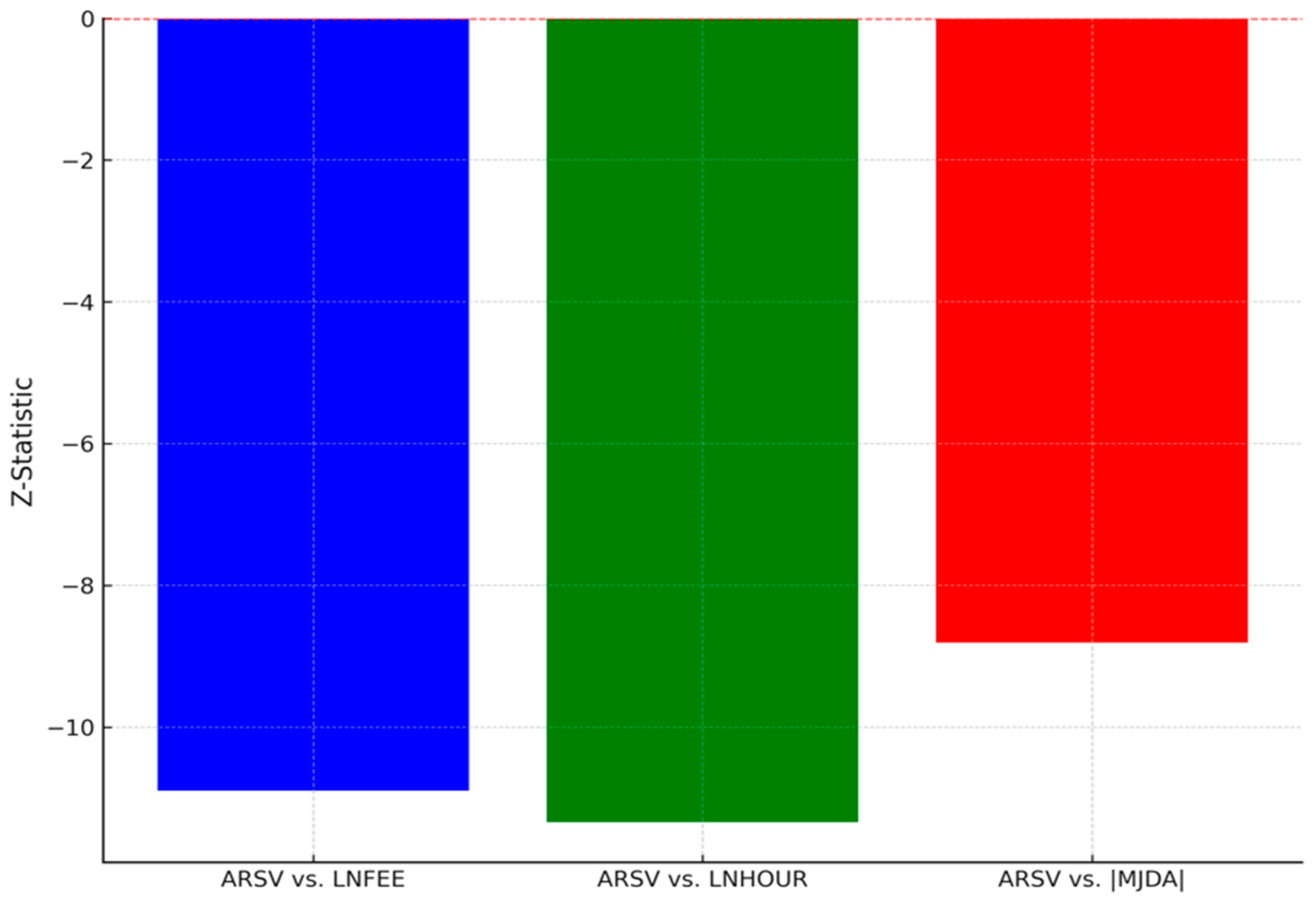
| Vuong Test | ||||||||||||
| vs. ARSEV | Z | Preferred Model | Z | Preferred Model | Z | Preferred Model | ||||||
| −10.889 *** | ARSEV | −11.333 *** | ARSEV | −8.801 *** | ARSEV | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Sun, F.; Kim, M.G.; Na, H.J. Developing a Novel Audit Risk Metric Through Sentiment Analysis. Sustainability 2025, 17, 2460. https://doi.org/10.3390/su17062460
Wang X, Sun F, Kim MG, Na HJ. Developing a Novel Audit Risk Metric Through Sentiment Analysis. Sustainability. 2025; 17(6):2460. https://doi.org/10.3390/su17062460
Chicago/Turabian StyleWang, Xiao, Feng Sun, Min Gyeong Kim, and Hyung Jong Na. 2025. "Developing a Novel Audit Risk Metric Through Sentiment Analysis" Sustainability 17, no. 6: 2460. https://doi.org/10.3390/su17062460
APA StyleWang, X., Sun, F., Kim, M. G., & Na, H. J. (2025). Developing a Novel Audit Risk Metric Through Sentiment Analysis. Sustainability, 17(6), 2460. https://doi.org/10.3390/su17062460