
Beyond Missing Data: A Multi-Scale Graph Fusion Framework for Sustainable Development Insights




Abstract
1. Introduction
- We introduce a novel incomplete multi-view clustering framework that integrates multi-scale measurements and ensemble clustering into the graph construction process, generating robust bipartite similarity graphs.
- We propose a motif-based multi-scale bipartite graph fusion method that effectively integrates information from multiple views, addressing data incompleteness while preserving the underlying structural relationships.
- We demonstrate the effectiveness and robustness of our method through experiments on several benchmark datasets, highlighting its ability to handle incomplete and heterogeneous data in the context of sustainable development research.
2. Materials and Methods
2.1. Preliminaries
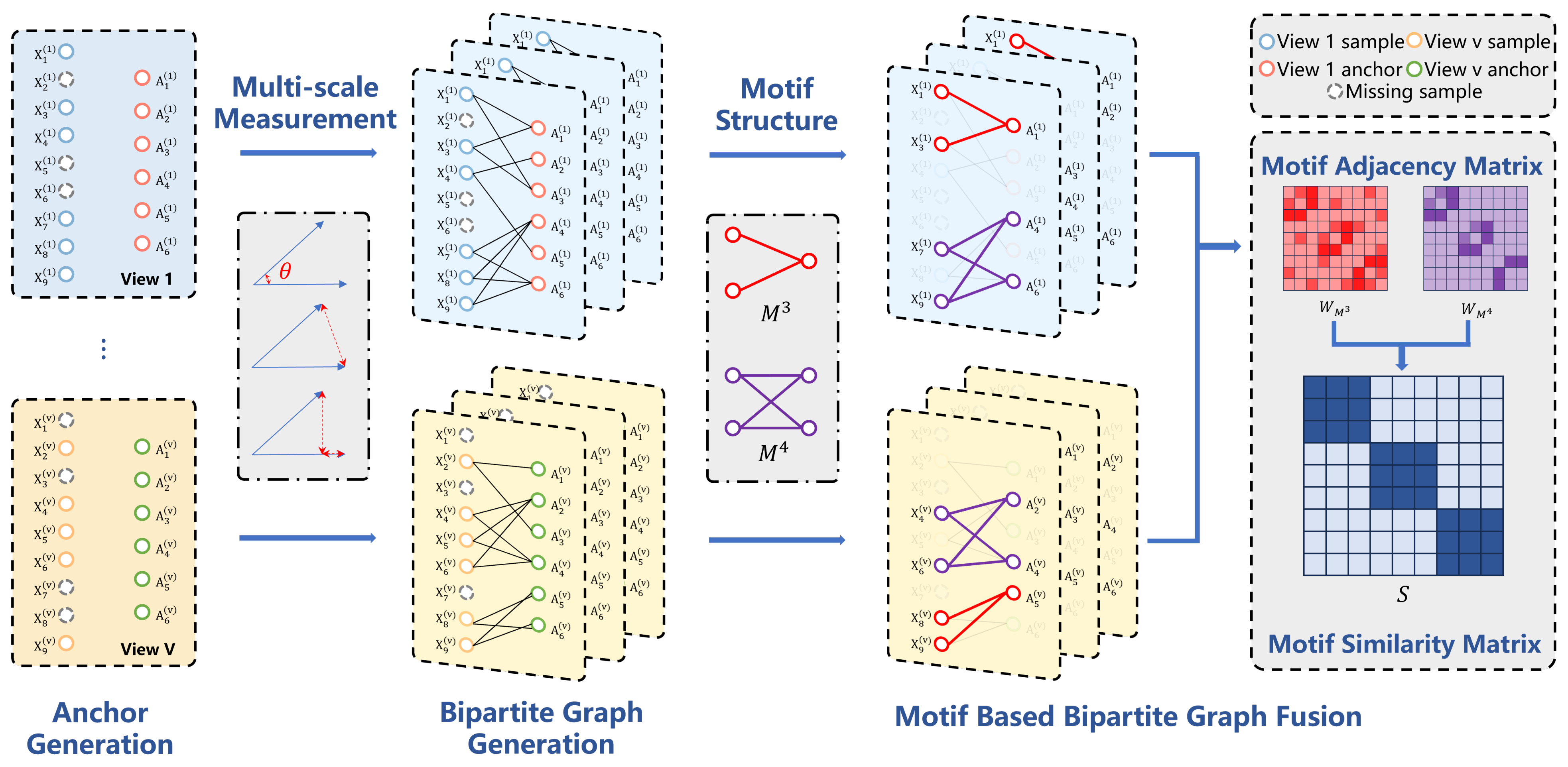
2.2. Multi-Scale Anchor Bipartite Graph
2.3. Motif-Based Bipartite Graph Fusion
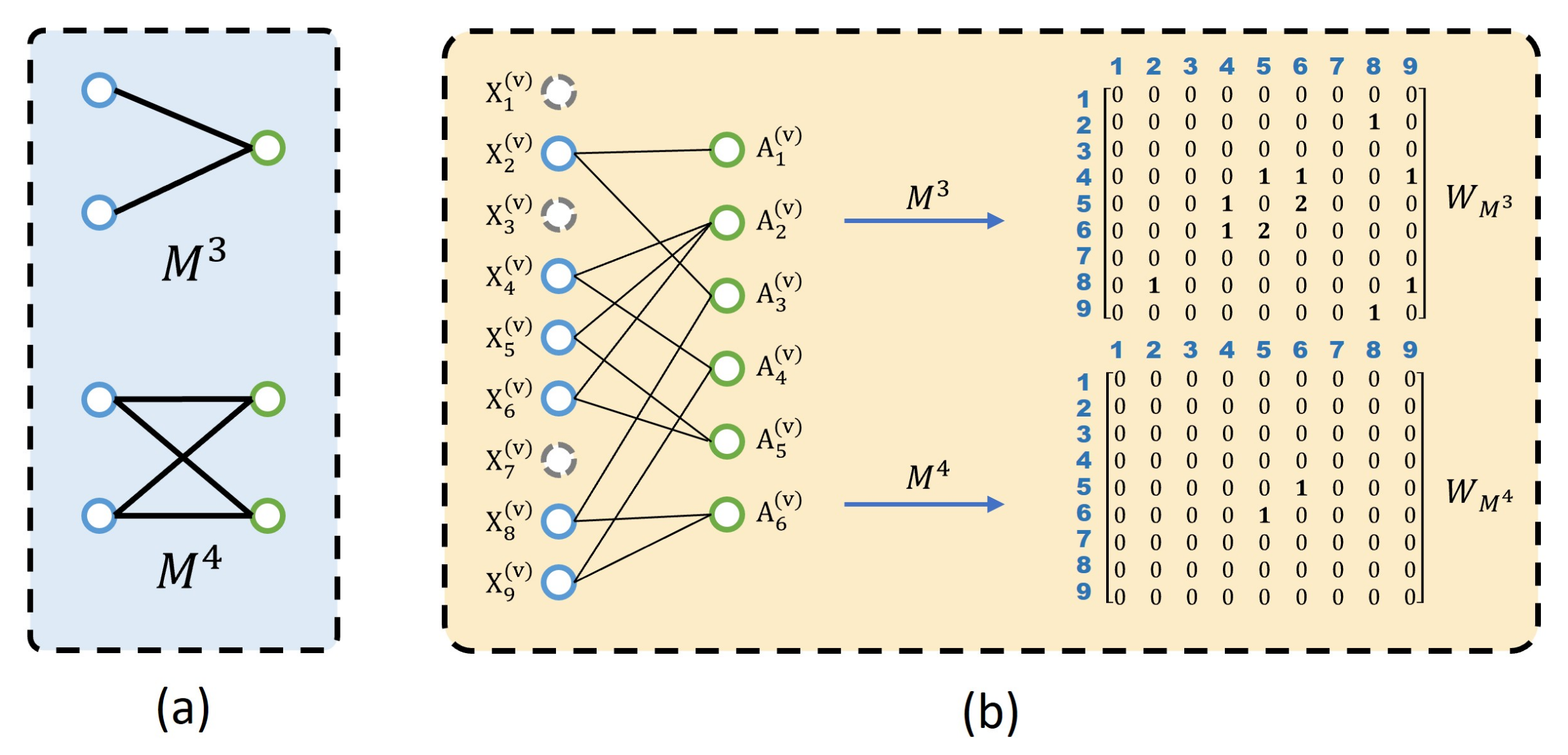
2.3.1. Third-Order Motif ()
2.3.2. Fourth-Order Motif ()
| Algorithm 1 Motif-based multi-scale bipartite graph fusion for incomplete multi-view clustering |
|
2.4. Computational Complexity
- Anchor Selection: The hybrid strategy involves a two-step process: random selection followed by k-means clustering. Selecting candidate anchors randomly from the complete subset has a linear complexity of , where N is the number of samples, p is the number of anchors, V is the number of views, and is the feature dimension of the v-th view. Applying the k-means algorithm to the candidate anchors to obtain p cluster centers incurs a complexity of . The combined complexity for anchor selection is therefore .
- Similarity Graph Construction: For each scale and view, computing distances between samples and anchors, followed by identifying the k-nearest neighbors, incurs a complexity of , where c is the number of scales.
- Motif Extraction: Extracting motifs from bipartite graphs involves identifying higher-order interactions. The complexity for motif extraction is the following:
- –
- For the third-order motif (), the complexity is , where m is the average number of anchors connected to each instance.
- –
- For the fourth-order motif (), the complexity is , where N is the number of instances and p is the number of anchors.
Given that two motif types ( and ) are considered, the total complexity for motif extraction becomes . - Spectral Clustering: The eigenvalue decomposition required for spectral clustering traditionally has a complexity of in the worst case. However, utilizing fast approximate methods can reduce this to , where k is the number of clusters and t is the number of iterations in the algorithm.
3. Experiments
Experimental Settings
4. Results
4.1. Experimental Results and Analysis
4.2. Ablation Study
- w.o. MS (without multi-scale part): This version evaluates the distances between samples using a standard Euclidean metric, without the multi-scale analysis;
- w.o. MF (without motif fusion part): This variant employs the multi-scale analysis but omits the motif fusion component, relying on the similarity matrix to perform spectral clustering;
- w.o. MS and MF (without both components): This version excludes both the multi-scale and motif fusion parts, essentially reducing the method to a basic spectral clustering approach.
- MMBGF_IMC outperforms all variants, demonstrating that both multi-scale analysis and motif fusion contribute significantly to its superior performance;
- Without the multi-scale part (w.o. MS), the method performs noticeably worse, highlighting the importance of capturing hierarchical structures in the data;
- Excluding motif fusion (w.o. MF) also leads to a performance drop, underscoring the role of motif fusion in combining complementary information from different views.

{kind=link}
{kind=link}
{kind=link}
| Methods | meanNMI | meanAcc | meanARI |
|---|---|---|---|
| w.o. MS | 0.5055 | 0.6347 | 0.3705 |
| w.o. MF | 0.4988 | 0.6146 | 0.3624 |
| w.o. MS & MF | 0.4873 | 0.5947 | 0.3634 |
| MMBGF_IMC | 0.5272 | 0.6727 | 0.4103 |
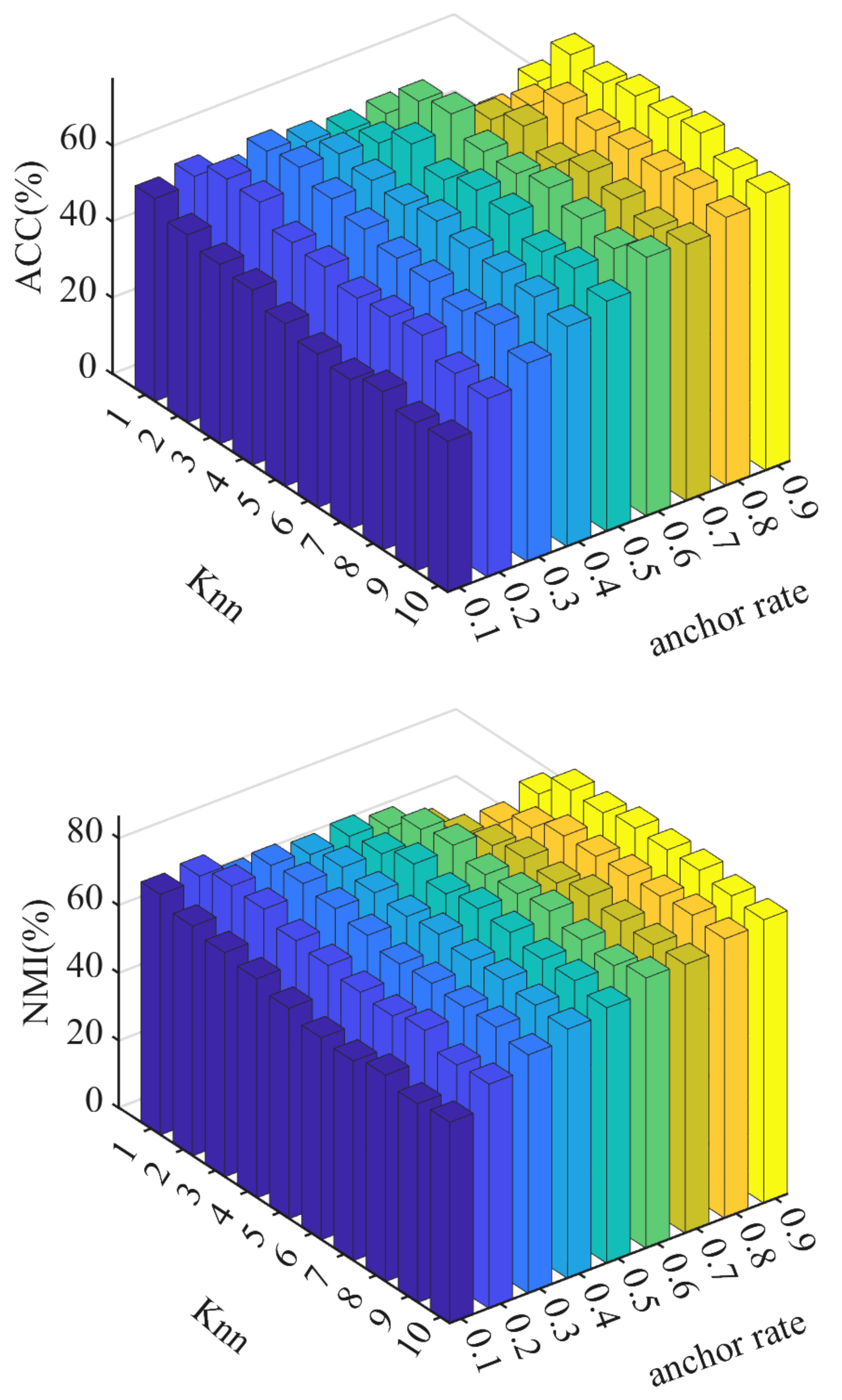
4.3. Parameter Study
- Sensitivity to anchor rate: MMBGF_IMC is more sensitive to changes in the anchor rate than the number of nearest neighbors. As the anchor rate increases, performance improves, particularly in terms of ACC and NMI;
- Effect of Knn: For larger datasets, performance improves with Knn values in the range of 7–10, while for smaller datasets, Knn values in the range of 3–5 yield the best results;
5. Conclusions
5.1. Main Conclusions
5.2. Policy Recommendations
5.3. Limitations
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kharrazi, A.; Qin, H.; Zhang, Y. Urban big data and sustainable development goals: Challenges and opportunities. Sustainability 2016, 8, 1293. [Google Scholar] [CrossRef]
- He, L.; Shen, J.; Zhang, Y. Ecological vulnerability assessment for ecological conservation and environmental management. J. Environ. Manag. 2018, 206, 1115–1125. [Google Scholar] [CrossRef] [PubMed]
- Mariano-Hernández, D.; Hernández-Callejo, L.; Zorita-Lamadrid, A.; Duque-Pérez, O.; García, F.S. A review of strategies for building energy management system: Model predictive control, demand side management, optimization, and fault detect & diagnosis. J. Build. Eng. 2021, 33, 101692. [Google Scholar]
- Datola, G. Implementing urban resilience in urban planning: A comprehensive framework for urban resilience evaluation. Sustain. Cities Soc. 2023, 98, 104821. [Google Scholar] [CrossRef]
- Johnson, D.P.; Ravi, N.; Filippelli, G.; Heintzelman, A. A Novel Hybrid Approach: Integrating Bayesian SPDE and Deep Learning for Enhanced Spatiotemporal Modeling of PM2.5 Concentrations in Urban Airsheds for Sustainable Climate Action and Public Health. Sustainability 2024, 16, 10206. [Google Scholar] [CrossRef]
- Hu, Y.; Cai, H. Multi-View Clustering Through Hypergraphs Integration on Stiefel Manifold. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 01–06. [Google Scholar]
- Li, L.; Zhang, J.; Wang, S.; Liu, X.; Li, K.; Li, K. Multi-view bipartite graph clustering with coupled noisy feature filter. IEEE Trans. Knowl. Data Eng. 2023, 35, 12842–12854. [Google Scholar] [CrossRef]
- Zhao, L.; Zhang, J.; Wang, Q.; Chen, Z. Dual alignment self-supervised incomplete multi-view subspace clustering network. IEEE Signal Process. Lett. 2021, 28, 2122–2126. [Google Scholar] [CrossRef]
- Chen, Z.; Li, Y.; Lou, K.; Zhao, L. Incomplete Multi-View Clustering with Complete View Guidance. IEEE Signal Process. Lett. 2023, 30, 1247–1251. [Google Scholar] [CrossRef]
- Li, Z.; Wu, D.; Nie, F.; Wang, R.; Sun, Z.; Li, X. Multi-View Clustering Based on Invisible Weights. IEEE Signal Process. Lett. 2021, 28, 1051–1055. [Google Scholar] [CrossRef]
- Wang, H.; Yang, Y.; Liu, B. GMC: Graph-based multi-view clustering. IEEE Trans. Knowl. Data Eng. 2019, 32, 1116–1129. [Google Scholar] [CrossRef]
- Li, Z.; Tang, C.; Liu, X.; Zheng, X.; Zhang, W.; Zhu, E. Consensus graph learning for multi-view clustering. IEEE Trans. Multimed. 2021, 24, 2461–2472. [Google Scholar] [CrossRef]
- Wang, H.; Yang, Y.; Liu, B.; Fujita, H. A study of graph-based system for multi-view clustering. Knowl.-Based Syst. 2019, 163, 1009–1019. [Google Scholar] [CrossRef]
- Liu, C.; Wu, S.; Li, R.; Jiang, D.; Wong, H.S. Self-supervised graph completion for incomplete multi-view clustering. IEEE Trans. Knowl. Data Eng. 2023, 35, 9394–9406. [Google Scholar] [CrossRef]
- Cai, X.; Nie, F.; Huang, H.; Kamangar, F. Heterogeneous image feature integration via multi-modal spectral clustering. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1977–1984. [Google Scholar]
- Huang, D.; Wang, C.D.; Lai, J.H. Fast multi-view clustering via ensembles: Towards scalability, superiority, and simplicity. IEEE Trans. Knowl. Data Eng. 2023, 35, 11388–11402. [Google Scholar] [CrossRef]
- Abu Alfeilat, H.A.; Hassanat, A.B.; Lasassmeh, O.; Tarawneh, A.S.; Alhasanat, M.B.; Eyal Salman, H.S.; Prasath, V.S. Effects of distance measure choice on k-nearest neighbor classifier performance: A review. Big Data 2019, 7, 221–248. [Google Scholar] [CrossRef]
- Xia, S.; Xiong, Z.; Luo, Y.; Xu, W.; Zhang, G. Effectiveness of the Euclidean distance in high dimensional spaces. Optik 2015, 126, 5614–5619. [Google Scholar] [CrossRef]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Huang, D.; Wang, C.D.; Wu, J.S.; Lai, J.H.; Kwoh, C.K. Ultra-scalable spectral clustering and ensemble clustering. IEEE Trans. Knowl. Data Eng. 2019, 32, 1212–1226. [Google Scholar] [CrossRef]
- Benson, A.R.; Gleich, D.F.; Leskovec, J. Higher-order organization of complex networks. Science 2016, 353, 163–166. [Google Scholar] [CrossRef]
- Geusebroek, J.M.; Burghouts, G.J.; Smeulders, A.W. The Amsterdam library of object images. Int. J. Comput. Vis. 2005, 61, 103–112. [Google Scholar] [CrossRef]
- Greene, D.; Cunningham, P. Practical Solutions to the Problem of Diagonal Dominance in Kernel Document Clustering. In Proceedings of the 23rd International Conference on Machine learning (ICML’06), Honolulu, HI, USA, 23–29 July 2023; ACM Press: New York, NY, USA, 2006; pp. 377–384. [Google Scholar]
- Samaria, F.S.; Harter, A.C. Parameterisation of a stochastic model for human face identification. In Proceedings of the 1994 IEEE Workshop on Applications of Computer Vision, Sarasota, FL, USA, 5–7 December 1994; IEEE: Piscataway, NJ, USA, 1994; pp. 138–142. [Google Scholar]
- Monadjemi, A.; Thomas, B.T.; Mirmehdi, M. Experiments on high resolution images towards outdoor scene classification. In Proceedings of the Seventh Computer Vision Winter Workshop (CVWW 2002), Bad Aussee, Austria, 6–8 February 2002; Wildenauer, H., Kropatsch, W., Eds.; Vienna University of Technology: Vienna, Austria, 2002; pp. 325–334. [Google Scholar]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Tomancak, P.; Berman, B.P.; Beaton, A.; Weiszmann, R.; Kwan, E.; Hartenstein, V.; Celniker, S.E.; Rubin, G.M. Global analysis of patterns of gene expression during Drosophila embryogenesis. Genome Biol. 2007, 8, R145. [Google Scholar] [CrossRef] [PubMed]
- Amini, M.R.; Usunier, N.; Goutte, C. Learning from multiple partially observed views-an application to multilingual text categorization. Adv. Neural Inf. Process. Syst. 2009, 22, 28–36. [Google Scholar]
- Wen, J.; Zhang, Z.; Xu, Y.; Zhang, B.; Fei, L.; Liu, H. Unified embedding alignment with missing views inferring for incomplete multi-view clustering. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5393–5400. [Google Scholar]
- Wang, S.; Liu, X.; Liu, L.; Tu, W.; Zhu, X.; Liu, J.; Zhou, S.; Zhu, E. Highly-efficient incomplete large-scale multi-view clustering with consensus bipartite graph. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9776–9785. [Google Scholar]
- Zhao, H.; Liu, H.; Fu, Y. Incomplete multi-modal visual data grouping. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 2392–2398. [Google Scholar]
- Sun, L.; Wen, J.; Liu, C.; Fei, L.; Li, L. Balance guided incomplete multi-view spectral clustering. Neural Netw. 2023, 166, 260–272. [Google Scholar] [CrossRef]
- Liang, N.; Yang, Z.; Xie, S. Incomplete multi-view clustering with sample-level auto-weighted graph fusion. IEEE Trans. Knowl. Data Eng. 2022, 35, 6504–6511. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, H.; Wei, Y.; Wang, Z.; Nie, F.; Hu, D. Geometric-inspired graph-based Incomplete Multi-view Clustering. Pattern Recognit. 2024, 147, 110082. [Google Scholar] [CrossRef]
| Dataset | #Clusters | #Instances | #Features |
|---|---|---|---|
| ALOI | 100 | 10,800 | 77/13/64/125 |
| BBC4 | 5 | 685 | 4659/4633/4665/4684 |
| BDGP | 5 | 2500 | 1750/79 |
| ORL | 40 | 400 | 4096/3304/6750 |
| Out-Scene | 8 | 2688 | 512/432/256/48 |
| Reuters | 6 | 18,715 | 10/10 |
| YALE | 15 | 165 | 4096/3304/6750 |
| MeanNMI | MeanACC | MeanARI | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Method/p | 0.1 | 0.3 | 0.5 | 0.7 | 0.9 | 0.1 | 0.3 | 0.5 | 0.7 | 0.9 | 0.1 | 0.3 | 0.5 | 0.7 | 0.9 |
| ALOI | BSV | 0.5108 | 0.5383 | 0.5701 | 0.6096 | 0.6368 | 0.3490 | 0.3685 | 0.3895 | 0.4119 | 0.4329 | 0.0703 | 0.1046 | 0.1546 | 0.2216 | 0.2810 |
| CONCAT | 0.2995 | 0.3176 | 0.3359 | 0.3523 | 0.3711 | 0.1215 | 0.1276 | 0.1336 | 0.1383 | 0.1445 | 0.0183 | 0.0276 | 0.0421 | 0.0582 | 0.0744 | |
| UEAF | 0.5586 | 0.5676 | 0.5756 | 0.5909 | 0.6190 | 0.3469 | 0.3437 | 0.3570 | 0.3880 | 0.4108 | 0.1884 | 0.2085 | 0.2196 | 0.2397 | 0.2749 | |
| CBG | 0.4521 | 0.4526 | 0.4539 | 0.5055 | 0.5561 | 0.2305 | 0.2094 | 0.2269 | 0.2754 | 0.2984 | 0.0379 | 0.0425 | 0.0449 | 0.0637 | 0.0880 | |
| SAGF_IMC | 0.6218 | 0.6441 | 0.6665 | 0.6773 | 0.6785 | 0.5109 | 0.5309 | 0.5520 | 0.5584 | 0.5628 | 0.0803 | 0.1007 | 0.1255 | 0.1472 | 0.1446 | |
| BGIMVC | 0.7303 | 0.7312 | 0.7366 | 0.7361 | 0.7407 | 0.6517 | 0.6513 | 0.6751 | 0.6493 | 0.6795 | 0.2315 | 0.2211 | 0.2039 | 0.2317 | 0.2025 | |
| GIMVC | 0.7124 | 0.7194 | 0.7375 | 0.7447 | 0.7535 | 0.4349 | 0.4461 | 0.4642 | 0.5051 | 0.5089 | 0.2375 | 0.2309 | 0.2746 | 0.3176 | 0.2841 | |
| MMBGF_IMC | 0.7411 | 0.7448 | 0.7552 | 0.7529 | 0.7644 | 0.6825 | 0.6860 | 0.6882 | 0.6889 | 0.6986 | 0.2583 | 0.2442 | 0.2894 | 0.2560 | 0.2955 | |
| BBC4 | BSV | 0.0605 | 0.0678 | 0.0553 | 0.0808 | 0.1052 | 0.3742 | 0.3874 | 0.3674 | 0.3826 | 0.4035 | 0.0104 | 0.0190 | 0.0236 | 0.0133 | 0.0311 |
| CONCAT | 0.0520 | 0.0172 | 0.0598 | 0.1142 | 0.0941 | 0.3615 | 0.3428 | 0.3680 | 0.3775 | 0.3841 | 0.0162 | 0.0043 | 0.0202 | 0.0219 | 0.0484 | |
| UEAF | 0.5729 | 0.5935 | 0.6343 | 0.6151 | 0.5720 | 0.7136 | 0.7422 | 0.7962 | 0.7455 | 0.6863 | 0.5193 | 0.5449 | 0.6176 | 0.5871 | 0.4950 | |
| CBG | 0.4323 | 0.4494 | 0.4925 | 0.5541 | 0.4376 | 0.5012 | 0.5109 | 0.6536 | 0.7616 | 0.5004 | 0.2511 | 0.2626 | 0.3754 | 0.5038 | 0.2879 | |
| SAGF_IMC | 0.4768 | 0.4659 | 0.4760 | 0.4779 | 0.4995 | 0.7032 | 0.6993 | 0.6964 | 0.6949 | 0.6978 | 0.4846 | 0.4682 | 0.4784 | 0.4798 | 0.4950 | |
| BGIMVC | 0.6120 | 0.5907 | 0.6354 | 0.6283 | 0.5937 | 0.8155 | 0.7847 | 0.8222 | 0.8253 | 0.8000 | 0.5958 | 0.5541 | 0.6195 | 0.6126 | 0.5654 | |
| GIMVC | 0.1842 | 0.1873 | 0.1105 | 0.1943 | 0.1544 | 0.4942 | 0.4781 | 0.4223 | 0.4629 | 0.4467 | 0.1880 | 0.1582 | 0.1125 | 0.1861 | 0.1636 | |
| MMBGF_IMC | 0.6470 | 0.6795 | 0.6950 | 0.7014 | 0.7059 | 0.8301 | 0.8590 | 0.8673 | 0.8692 | 0.8692 | 0.6845 | 0.7179 | 0.7330 | 0.7456 | 0.7451 | |
| ORL | BSV | 0.4772 | 0.5390 | 0.5719 | 0.6433 | 0.7154 | 0.3665 | 0.4105 | 0.4540 | 0.4868 | 0.5348 | 0.0562 | 0.0897 | 0.1148 | 0.2225 | 0.3488 |
| CONCAT | 0.4819 | 0.5332 | 0.5872 | 0.6211 | 0.6883 | 0.3603 | 0.3833 | 0.4368 | 0.4435 | 0.4998 | 0.0580 | 0.0950 | 0.1448 | 0.2051 | 0.3072 | |
| UEAF | 0.6859 | 0.7134 | 0.7140 | 0.7154 | 0.7310 | 0.5035 | 0.5198 | 0.5413 | 0.5388 | 0.5528 | 0.3204 | 0.3555 | 0.3595 | 0.3697 | 0.3866 | |
| CBG | 0.8164 | 0.8333 | 0.8506 | 0.8447 | 0.8788 | 0.6518 | 0.6610 | 0.6798 | 0.6663 | 0.7308 | 0.4515 | 0.4868 | 0.5031 | 0.5182 | 0.6312 | |
| SAGF_IMC | 0.6877 | 0.6900 | 0.6938 | 0.6691 | 0.6886 | 0.5163 | 0.5285 | 0.5350 | 0.5118 | 0.5133 | 0.2695 | 0.2710 | 0.2736 | 0.2473 | 0.2651 | |
| BGIMVC | 0.5990 | 0.7173 | 0.7159 | 0.6241 | 0.6447 | 0.3815 | 0.5248 | 0.4978 | 0.4050 | 0.3898 | 0.1871 | 0.3741 | 0.3648 | 0.2123 | 0.2330 | |
| GIMVC | 0.8339 | 0.8451 | 0.8537 | 0.8502 | 0.8618 | 0.6935 | 0.7003 | 0.7155 | 0.7065 | 0.7242 | 0.5579 | 0.5614 | 0.5664 | 0.5791 | 0.6007 | |
| MMBGF_IMC | 0.8535 | 0.8433 | 0.8399 | 0.8504 | 0.8616 | 0.7583 | 0.7383 | 0.7320 | 0.7358 | 0.7588 | 0.6349 | 0.5667 | 0.5778 | 0.6159 | 0.6426 | |
| Out-Scene | BSV | 0.3368 | 0.3423 | 0.3723 | 0.3967 | 0.4201 | 0.4465 | 0.4825 | 0.4889 | 0.5256 | 0.5363 | 0.1762 | 0.2084 | 0.2389 | 0.2796 | 0.3075 |
| CONCAT | 0.1479 | 0.1472 | 0.1482 | 0.1673 | 0.1736 | 0.3026 | 0.3005 | 0.3081 | 0.3218 | 0.3247 | 0.0758 | 0.0790 | 0.0894 | 0.1068 | 0.1153 | |
| UEAF | 0.0599 | 0.0514 | 0.0511 | 0.0517 | 0.0528 | 0.1938 | 0.1914 | 0.1910 | 0.1940 | 0.2028 | 0.0219 | 0.0182 | 0.0195 | 0.0220 | 0.0229 | |
| CBG | 0.3620 | 0.3510 | 0.3837 | 0.3842 | 0.3906 | 0.4810 | 0.5160 | 0.5186 | 0.5116 | 0.5143 | 0.2666 | 0.2662 | 0.2940 | 0.2894 | 0.2964 | |
| SAGF_IMC | 0.4427 | 0.4678 | 0.4567 | 0.4988 | 0.5302 | 0.5374 | 0.4700 | 0.5580 | 0.5735 | 0.5916 | 0.2904 | 0.3445 | 0.3427 | 0.3823 | 0.4190 | |
| BGIMVC | 0.4530 | 0.4566 | 0.4961 | 0.5222 | 0.4689 | 0.5741 | 0.5553 | 0.5688 | 0.6078 | 0.5676 | 0.3589 | 0.3194 | 0.3849 | 0.4298 | 0.3350 | |
| GIMVC | 0.5080 | 0.5316 | 0.5240 | 0.5220 | 0.5264 | 0.6344 | 0.6699 | 0.6365 | 0.6516 | 0.6289 | 0.4035 | 0.4049 | 0.4037 | 0.4586 | 0.4365 | |
| MMBGF_IMC | 0.5262 | 0.5269 | 0.5272 | 0.5303 | 0.5320 | 0.6636 | 0.6762 | 0.6727 | 0.6775 | 0.6797 | 0.4056 | 0.4108 | 0.4103 | 0.4137 | 0.4152 | |
| YALE | BSV | 0.3404 | 0.3824 | 0.4227 | 0.4592 | 0.5454 | 0.3285 | 0.3715 | 0.3988 | 0.4048 | 0.4830 | 0.0599 | 0.0897 | 0.1306 | 0.1811 | 0.2934 |
| CONCAT | 0.3309 | 0.3259 | 0.3977 | 0.4394 | 0.4719 | 0.3236 | 0.3067 | 0.3618 | 0.3964 | 0.4091 | 0.0547 | 0.0612 | 0.1216 | 0.1523 | 0.2114 | |
| UEAF | 0.5782 | 0.5975 | 0.5999 | 0.5924 | 0.5752 | 0.5297 | 0.5267 | 0.5303 | 0.5364 | 0.5182 | 0.3448 | 0.3627 | 0.3682 | 0.3635 | 0.3400 | |
| CBG | 0.6710 | 0.6216 | 0.6044 | 0.6782 | 0.6540 | 0.6182 | 0.5655 | 0.5564 | 0.6200 | 0.6042 | 0.4458 | 0.3861 | 0.3625 | 0.4540 | 0.4258 | |
| SAGF_IMC | 0.5349 | 0.5307 | 0.5541 | 0.5661 | 0.5744 | 0.4806 | 0.4788 | 0.4970 | 0.5097 | 0.5152 | 0.2748 | 0.3120 | 0.2930 | 0.3352 | 0.3388 | |
| BGIMVC | 0.4438 | 0.4649 | 0.4687 | 0.4463 | 0.4583 | 0.3891 | 0.4133 | 0.3885 | 0.3988 | 0.4164 | 0.1543 | 0.2032 | 0.1827 | 0.1746 | 0.1837 | |
| GIMVC | 0.6636 | 0.6261 | 0.6472 | 0.6636 | 0.6620 | 0.6267 | 0.5806 | 0.6042 | 0.6370 | 0.6309 | 0.4397 | 0.3903 | 0.4094 | 0.4715 | 0.4354 | |
| MMBGF_IMC | 0.6687 | 0.6823 | 0.6748 | 0.6727 | 0.6697 | 0.6552 | 0.6806 | 0.6655 | 0.6703 | 0.6636 | 0.4479 | 0.4677 | 0.4621 | 0.4338 | 0.4365 | |
| BDGP | BSV | 0.1631 | 0.1875 | 0.2519 | 0.3012 | 0.3246 | 0.3514 | 0.3634 | 0.4359 | 0.4567 | 0.4949 | 0.0332 | 0.0442 | 0.0919 | 0.1069 | 0.1621 |
| CONCAT | 0.1860 | 0.2132 | 0.2596 | 0.3076 | 0.3612 | 0.3615 | 0.3804 | 0.4084 | 0.4632 | 0.4994 | 0.0414 | 0.0594 | 0.0800 | 0.1179 | 0.1562 | |
| UEAF | 0.4320 | 0.5939 | 0.6739 | 0.7171 | 0.7743 | 0.6998 | 0.8253 | 0.8664 | 0.8892 | 0.9173 | 0.4154 | 0.6183 | 0.6988 | 0.7440 | 0.8047 | |
| CBG | 0.3668 | 0.4762 | 0.5030 | 0.6255 | 0.6825 | 0.5836 | 0.6732 | 0.7040 | 0.8172 | 0.8487 | 0.2441 | 0.3145 | 0.3662 | 0.5848 | 0.6441 | |
| SAGF_IMC | 0.4619 | 0.5189 | 0.7152 | 0.6420 | 0.6683 | 0.6651 | 0.7172 | 0.8844 | 0.7196 | 0.7348 | 0.6651 | 0.7172 | 0.8844 | 0.7196 | 0.7348 | |
| BGIMVC | 0.0251 | 0.0220 | 0.0487 | 0.0785 | 0.0313 | 0.2240 | 0.2220 | 0.2423 | 0.2724 | 0.2304 | 0.0009 | 0.0005 | 0.0035 | 0.0156 | 0.0012 | |
| GIMVC | 0.3734 | 0.5605 | 0.5997 | 0.6049 | 0.6306 | 0.5463 | 0.6886 | 0.6893 | 0.6812 | 0.6739 | 0.2997 | 0.5278 | 0.5529 | 0.5505 | 0.5600 | |
| MMBGF_IMC | 0.4139 | 0.5535 | 0.7138 | 0.7960 | 0.8938 | 0.5161 | 0.7260 | 0.8739 | 0.9251 | 0.9588 | 0.2074 | 0.3903 | 0.7046 | 0.8228 | 0.9004 | |
| Reuters | BSV | 0.0610 | 0.0728 | 0.0892 | 0.1030 | 0.1214 | 0.3380 | 0.3498 | 0.3642 | 0.3873 | 0.3976 | 0.0305 | 0.0361 | 0.0532 | 0.0712 | 0.0987 |
| CONCAT | 0.0550 | 0.0732 | 0.1178 | 0.1446 | 0.1743 | 0.3097 | 0.3297 | 0.3891 | 0.4075 | 0.4383 | 0.0260 | 0.0364 | 0.0783 | 0.1053 | 0.1380 | |
| CBG | 0.0972 | 0.1160 | 0.1333 | 0.1743 | 0.1671 | 0.3683 | 0.3735 | 0.3719 | 0.4258 | 0.4142 | 0.1232 | 0.1319 | 0.1212 | 0.1548 | 0.1676 | |
| GIMVC | 0.2142 | 0.2351 | 0.2457 | 0.2447 | 0.2413 | 0.4342 | 0.4482 | 0.4551 | 0.4543 | 0.4342 | 0.1653 | 0.1598 | 0.1638 | 0.1645 | 0.1582 | |
| MMBGF_IMC | 0.1353 | 0.1626 | 0.2160 | 0.2482 | 0.2948 | 0.4058 | 0.4239 | 0.4642 | 0.4888 | 0.5233 | 0.1192 | 0.1212 | 0.1664 | 0.2054 | 0.2569 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Zhang, H.; Liu, Z.; Zheng, H.; Zhao, L. Beyond Missing Data: A Multi-Scale Graph Fusion Framework for Sustainable Development Insights. Sustainability 2025, 17, 1136. https://doi.org/10.3390/su17031136
Chen Z, Zhang H, Liu Z, Zheng H, Zhao L. Beyond Missing Data: A Multi-Scale Graph Fusion Framework for Sustainable Development Insights. Sustainability. 2025; 17(3):1136. https://doi.org/10.3390/su17031136
Chicago/Turabian StyleChen, Zhikui, Hongwei Zhang, Zhenjiao Liu, Hao Zheng, and Liang Zhao. 2025. "Beyond Missing Data: A Multi-Scale Graph Fusion Framework for Sustainable Development Insights" Sustainability 17, no. 3: 1136. https://doi.org/10.3390/su17031136
APA StyleChen, Z., Zhang, H., Liu, Z., Zheng, H., & Zhao, L. (2025). Beyond Missing Data: A Multi-Scale Graph Fusion Framework for Sustainable Development Insights. Sustainability, 17(3), 1136. https://doi.org/10.3390/su17031136