1. Introduction
As the concept of sustainable development and enhanced ecological protection gains increasing acceptance, the use of new energy vehicles (NEVs) in daily travel has become a crucial approach for promoting societal and environmental progress. NEVs are defined as vehicles that utilize alternative energy sources other than conventional fossil fuels, including battery electric vehicles, hybrid electric vehicles, fuel cell vehicles, and other types powered by clean energy technologies [
1]. As the penetration rate of NEVs continues to rise, the frequency of NEV-related accidents has also shown a corresponding increase. Consequently, the safety performance of NEVs has attracted growing attention from researchers and industry professionals alike [
2]. Due to the significant differences in operating modes compared to traditional fuel vehicles, accidents involving NEVs tend to have more severe consequences, primarily in the following aspects: First, In most operational scenarios, NEVs rely primarily on electric motors for propulsion, which leads to substantially lower vehicle noise levels compared to traditional internal combustion engine (ICE) vehicles [
3]. This notable difference in acoustic signatures can potentially introduce safety hazards for drivers as well as other road users, who may be less aware of the presence of quieter NEVs [
4]. Second, NEV batteries are more prone to catching fire after collisions or rollovers compared to fuel vehicles, leading to more severe traffic accidents [
5]. Additionally, the high starting torque of NEV motors and rapid acceleration increase the risk of accidents [
6]. Finally, some NEVs adopt a single-pedal mode [
7], which can lead to driver errors in emergencies. Traffic accident severity is the key information to allocate the rescue resources required by traffic management authorities. Therefore, predicting the severity of traffic accidents is crucial for aiding traffic authorities in conducting emergency rescue operations and minimizing casualties and property losses.
In recent years, considerable research has been conducted both domestically and internationally on the prediction of traffic accident severity. These studies generally focus on two key aspects: the identification of contributing factors (causal analysis) and the development of predictive models. Causal analysis aims to determine the factors that significantly influence accident severity by utilizing data from established accident databases. These datasets typically contain information on crash characteristics, human factors, vehicle types, and environmental conditions. For instance, George analyzed the influence of various vehicle categories on the severity of accidents, including passenger cars, mopeds, motorcycles, buses, and trucks. The findings of this research indicated that good weather conditions and nighttime crashes are often associated with increased severity [
8]. Ditcharoen highlighted vehicle speed as the most critical factor affecting crash severity, followed by driver-related variables. Other relevant factors included vehicle type, weather conditions, alcohol impairment, and driver fatigue [
9]. Azhar conducted a study using 2014 crash data involving heavy vehicles in Malaysia and applied Classification and Regression Tree (CART) and Random Forest (RF) algorithms to classify and predict injury severity among heavy vehicle drivers. The results identified collision type, driver error, number of vehicles involved, driver age, lighting conditions, and vehicle type as key predictors of injury outcomes [
10]. Wang, applying the Apriori algorithm based on association rules, identified several critical factors influencing accident severity for vulnerable road users. These included regional zoning, the density of restaurants and shopping POIs (Points of Interest), life-service POI density, accident causes, and modes of transport [
11]. Moreover, common methodologies employed in the causal analysis of accident severity include factor analysis, analysis of variance (ANOVA), the Apriori algorithm, Logit-based models, and so on. Li employed factor analysis to rank the importance of characteristics affecting traffic accidents and identified key influencing factors [
12]. Sun conducted qualitative studies on influencing features through variance analysis, identifying significant factors [
13]. Refs. [
14,
15,
16] utilized the Apriori algorithm to mine 10 strong association rules related to traffic accident factors and analyzed these rules in depth. Alkheder combined decision trees, Bayesian networks, and support vector machines to comprehensively analyze risk factors related to traffic accident severity [
17]. Eboli and Theofilatos used the Logit model to reveal the impact of vehicle type, speeding, and traffic flow on collision severity [
18,
19]. However, the studies mentioned above primarily focus on traditional internal combustion engine vehicles, with limited research conducted on causal analysis of accidents involving new energy vehicles (NEVs). Additionally, these studies often fail to comprehensively consider the combined impact of the human–vehicle–road–environment system on traffic accident severity.
Accident severity prediction is built upon causal analysis, utilizing algorithms such as machine learning or neural networks to establish relationships between accident data and severity levels, enabling the prediction of accident outcomes. Zhang developed the FA-RF model to predict accident severity and proposed real-time communication rules based on social robots [
20]. Yang proposed a multi-task DNN framework to predict the severity of injuries, fatalities, and property damage [
21]. Ospina constructed a hybrid algorithm combining genetic algorithms and simulated annealing to detect the severity of motorcycle accidents [
22]. Wang developed a data-driven model based on vehicle kinematic features to achieve precise and near-real-time predictions of occupant injury severity [
23]. Erzurum explored the applicability of single-class classification models in traffic accident prediction [
24]. Hossain combined random forests and classification and regression tree models to predict highway traffic accidents, considering the spatial heterogeneity of accidents. Their results showed significant differences in risk factors across different road sections [
25]. Liu summarized traffic flow parameters into stability coefficients to reduce input variables and used support vector machines, random forests, and logistic regression to conduct real-time accident risk predictions, improving prediction accuracy [
26]. Guo incorporated user risk-driving behavior data from Amap navigation, applied the SMOTE algorithm to generate accident samples, and used logistic regression to predict accident risks, achieving promising results [
27]. Yang extracted eight key accident features and four additional factors of lesser importance based on the random forest algorithm, achieving high-accuracy predictions of accident severity [
28]. Alhaek proposed a deep learning-based approach to predict accident severity, by leveraging Convolutional Neural Networks (CNN) to extract spatial features from high-dimensional data and applying Bidirectional Long Short-Term Memory (BiLSTM) networks to capture the temporal dependencies among various influencing factors [
29]. However, the studies discussed above do not consider the influence of uncertainty in accident characteristics on the accuracy of severity predictions, which limits the reliability of the results.
The shortcomings of these studies can be primarily attributed to two key factors: First, the widespread adoption of NEVs is relatively recent, resulting in insufficient traffic accident data. Second, NEV-specific technologies, such as battery and motor systems, increase the complexity of accident analysis. Existing accident prediction models do not fully account for the characteristics of NEVs, leading to some bias in accident severity predictions. With the implementation of national standards for NEVs, a solid foundation has been laid for studying the severity of NEV accidents. The “Technical Specification of Remote Services and Management System for Electric Vehicles—Part 3: Communication Protocol and Data Format” (GB/T32960.3—2016) [
30] mandates the establishment of a three-tier monitoring platform (national, government, and enterprise levels) for NEVs to enable real-time data collection and transmission. This has, to some extent, supplemented the datasets needed for analyzing accident severity.
However, in real-world driving environments, the occurrence probabilities of accidents with different severity levels (e.g., minor, serious, and fatal) vary significantly. This leads to a highly imbalanced class distribution in accident-related datasets collected based on such standard. Such imbalance tends to cause predictive models to overfit on high-frequency minor accident samples while significantly reducing their ability to detect rare but high-risk fatal events. This severely limits the model’s generalization ability and practical value. Furthermore, the complex feature coupling and uncertainty among vehicle operating parameters (e.g., speed, road type, driving environment) further obscure the relationship between accident severity and key features, reducing both the discriminative accuracy and robustness of the model. The combined challenges of data imbalance and feature uncertainty significantly constrain the accuracy and reliability of accident severity prediction.
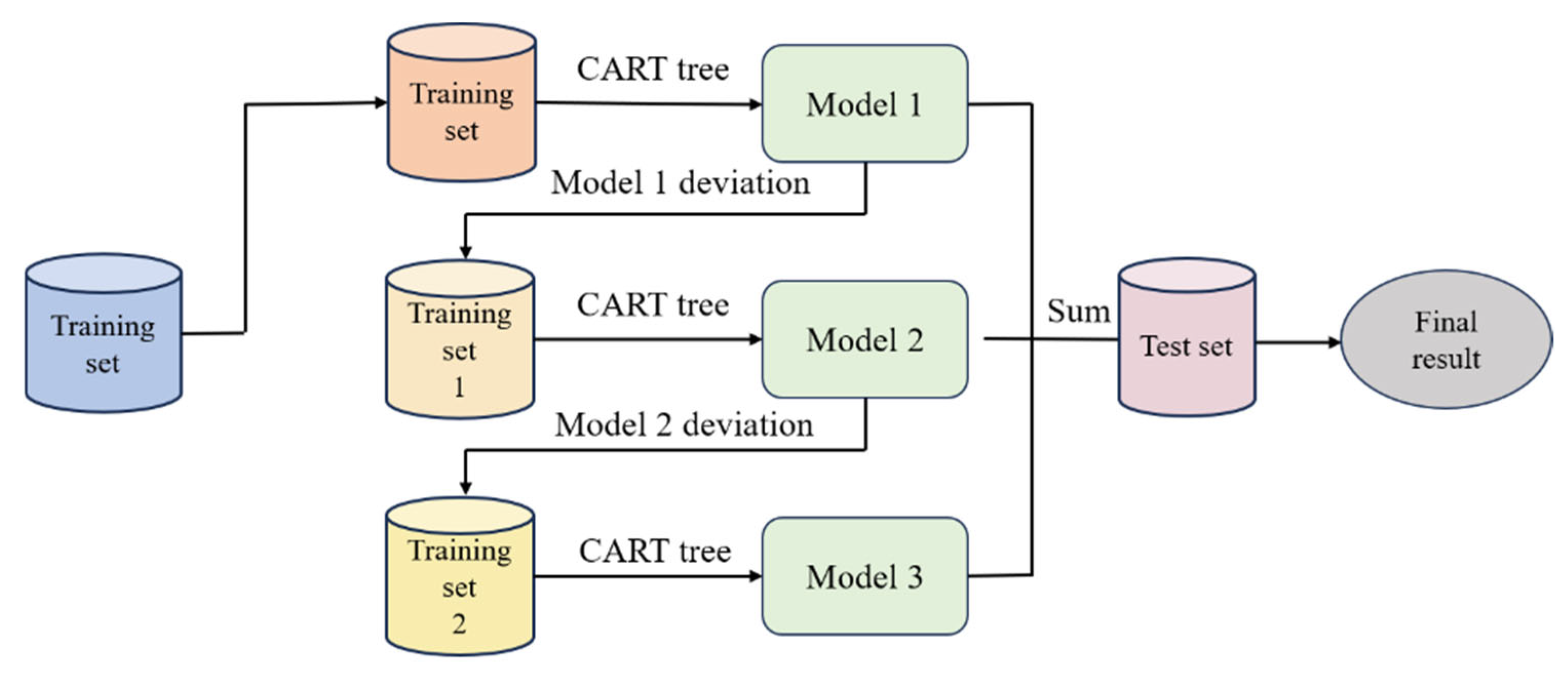
Therefore, to address the challenges of data imbalance and feature coupling uncertainty, this paper proposes a severity prediction method for the NEV accidents based on Cost-sensitive Fuzzy XGBoost (CFXGBoost), which integrates fuzzy neural networks and the XGBoost algorithm to achieve accurate accident severity prediction. The main contributions of this paper are as follows:
- (1)
Based on the traffic accident data from various provinces, 20 feature parameters strongly related to traffic accident severity were extracted using chi-square filtering and wrapper methods.
- (2)
A Cost-sensitive Fuzzy XGBoost method is proposed, which integrates a fuzzy neural network with the XGBoost algorithm to accurately model highly coupled and uncertain accident features. A cost-sensitive mechanism is employed to construct loss functions tailored to different levels of accident severity. This approach significantly enhances the accuracy and robustness of predicting uncertain accident severity.
The structure of this paper is as follows:
Section 2 analyzes accident causes and conducts feature selection;
Section 3 introduces the proposed Cost-sensitive Fuzzy XGBoost algorithm;
Section 4 presents experimental validation and results analysis; and
Section 5 provides conclusions.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




