
Comparison of Selected Ensemble Supervised Learning Algorithms Used for Meteorological Normalisation of Particulate Matter (PM10)


Abstract
1. Introduction
2. Materials and Methods
2.1. Research Area
2.2. Data Sources and Computational Methods
3. Result and Discussion
3.1. Evaluating the Accuracy of Machine Learning Algorithms
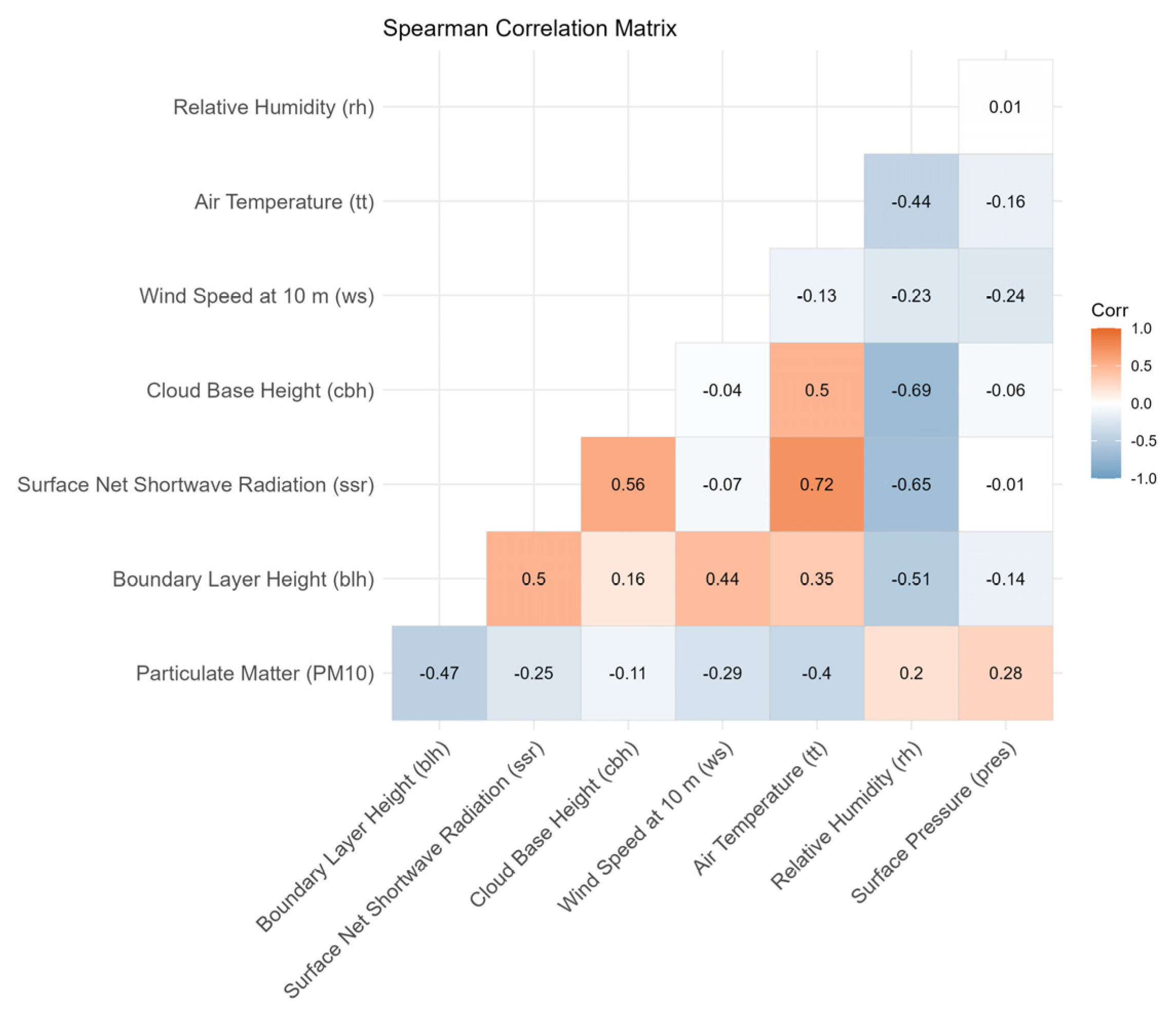
3.2. Importance Variable
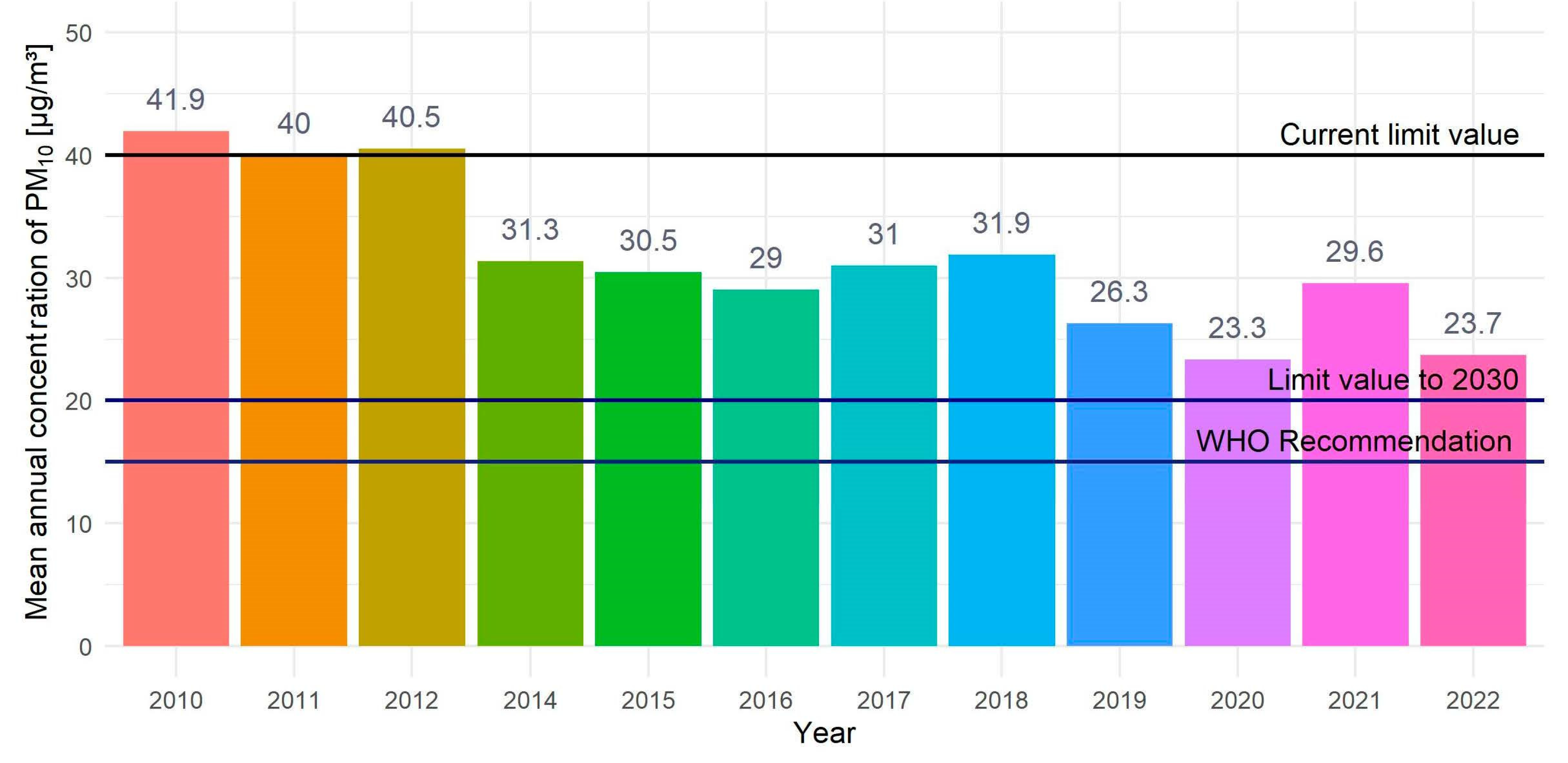
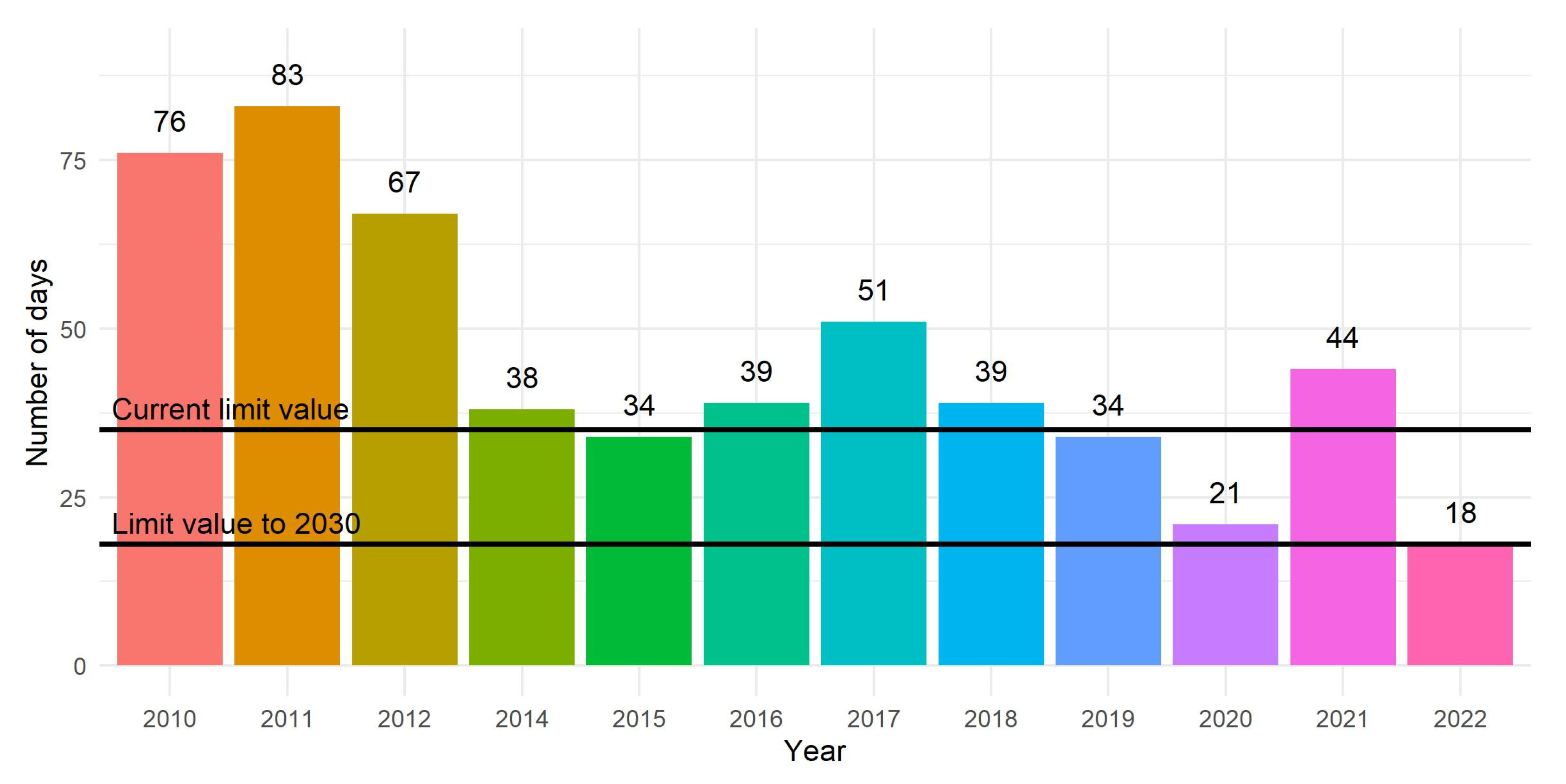
3.3. Comparison of Particulate Matter Trends
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| EU | European Union |
| WHO | World Health Organization |
| PM10 | Particulate matter |
| NOx | Nitrogen oxide |
| NO2 | Nitrogen dioxide |
| SO2 | Sulfur dioxide |
| CO | Carbon monoxide |
| O3 | Ozone |
| RF | Random Forest |
| GBM | Gradient Boosted Regression Model |
| ws | Wind speed |
| wd_cut | Wind direction |
| rh | Relative humidity |
| tt | Air temperature |
| pres | Atmospheric pressure |
| blh | Boundary layer height |
| cbh | Cloud base height |
| ssr | Surface net solar radiation |
| CART | Decision Tree Model |
| Ranger | Random Forest Model |
| Cubist | Cubist Rules Model |
| jday | Day of the year according to the Julian calendar |
| wday | Day of the week |
| hour | Hour of the day |
| FAC2 | Fraction of predictions within a factor of two |
| MB | The mean bias |
| MGE | The mean gross error |
| NMB | The normalised mean bias |
| NMGE | The normalised mean gross error |
| RMSE | The root mean square error |
| r | The Pearson correlation coefficient |
| COE | The coefficient of efficiency |
| IOA | The Index of Agreement based on Willmott |
| R2 | The coefficient of determination |
| EMA | Exploratory Model Analysis |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator | Full Name | Description |
|---|---|---|
| FAC2 | Fraction of predictions within a factor of two | Percentage of predictions within the range of 0.5 to 2 times the observed value. |
| MB | Mean Bias | Average difference between predicted and observed values. |
| MGE | Mean Gross Error | Average absolute difference between predicted and observed values. |
| NMB | Normalised Mean Bias | Mean Bias divided by the sum of observed values, expressed as a percentage. |
| NMGE | Normalised Mean Gross Error | Mean Gross Error divided by the sum of observed values, expressed as a percentage. |
| RMSE | Root Mean Square Error | Error measure that gives greater weight to large deviations. |
| r | Pearson Correlation Coefficient | Measures the strength of the linear relationship between observed and predicted values. |
| COE | Coefficient of Efficiency | Indicates how well the model predictions match observed values. |
| IOA | Index of Agreement | Measures the degree of model agreement with observations. |
References
- Loomis, D.; Grosse, Y.; Lauby-Secretan, B.; El Ghissassi, F.; Bouvard, V.; Benbrahim-Tallaa, L.; Guha, N.; Baan, R.; Mattock, H.; Straif, K. The Carcinogenicity of Outdoor Air Pollution. Lancet Oncol. 2013, 14, 1262–1263. [Google Scholar] [CrossRef]
- Zhang, Y.; Ma, Y.; Feng, F.; Cheng, B.; Wang, H.; Shen, J.; Jiao, H. Association between PM10 and Specific Circulatory System Diseases in China. Sci. Rep. 2021, 11, 12129. [Google Scholar] [CrossRef]
- Combes, A.; Franchineau, G. Fine Particle Environmental Pollution and Cardiovascular Diseases. Metabolism 2019, 100, 153944. [Google Scholar] [CrossRef]
- Caffè, A.; Scarica, V.; Animati, F.M.; Manzato, M.; Bonanni, A.; Montone, R.A. Air Pollution and Coronary Atherosclerosis. Future Cardiol. 2025, 21, 53–66. [Google Scholar] [CrossRef]
- Basith, S.; Manavalan, B.; Shin, T.H.; Park, C.B.; Lee, W.S.; Kim, J.; Lee, G. The Impact of Fine Particulate Matter 2.5 on the Cardiovascular System: A Review of the Invisible Killer. Nanomaterials 2022, 12, 2656. [Google Scholar] [CrossRef]
- International Agency for Research on Cancer. Air Pollution and Cancer; Straif, K., Cohen, A., Samet, J., Eds.; IARC Scientific Publications: Lyon, France, 2013; Volume 161, ISBN 978-92-832-2. [Google Scholar]
- European Environment Agency. Air Quality in Europe 2022; European Environment Agency: Copenhagen, Denmark, 2022. [Google Scholar]
- Cakaj, A.; Lisiak-Zielińska, M.; Khaniabadi, Y.O.; Sicard, P. Premature Deaths Related to Urban Air Pollution in Poland. Atmos. Environ. 2023, 301, 119723. [Google Scholar] [CrossRef]
- Grange, S.K.; Carslaw, D.C. Using Meteorological Normalisation to Detect Interventions in Air Quality Time Series. Sci. Total Environ. 2019, 653, 578–588. [Google Scholar] [CrossRef]
- Grange, S.K.; Carslaw, D.C.; Lewis, A.C.; Boleti, E.; Hueglin, C. Random Forest Meteorological Normalisation Models for Swiss PM 10 Trend Analysis. Atmos. Chem. Phys. 2018, 18, 6223–6239. [Google Scholar] [CrossRef]
- Vu, T.V.; Shi, Z.; Cheng, J.; Zhang, Q.; He, K.; Wang, S.; Harrison, R.M. Assessing the Impact of Clean Air Action on Air Quality Trends in Beijing Using a Machine Learning Technique. Atmos. Chem. Phys. 2019, 19, 11303–11314. [Google Scholar] [CrossRef]
- Ceballos-Santos, S.; González-Pardo, J.; Carslaw, D.C.; Santurtún, A.; Santibáñez, M.; Fernández-Olmo, I. Meteorological Normalisation Using Boosted Regression Trees to Estimate the Impact of COVID-19 Restrictions on Air Quality Levels. Int. J. Environ. Res. Public Health 2021, 18, 13347. [Google Scholar] [CrossRef]
- Lovrić, M.; Antunović, M.; Šunić, I.; Vuković, M.; Kecorius, S.; Kröll, M.; Bešlić, I.; Godec, R.; Pehnec, G.; Geiger, B.C.; et al. Machine Learning and Meteorological Normalization for Assessment of Particulate Matter Changes during the COVID-19 Lockdown in Zagreb, Croatia. Int. J. Environ. Res. Public Health 2022, 19, 6937. [Google Scholar] [CrossRef]
- Munir, S.; Coskuner, G.; Jassim, M.S.; Aina, Y.A.; Ali, A.; Mayfield, M. Changes in Air Quality Associated with Mobility Trends and Meteorological Conditions during COVID-19 Lockdown in Northern England, UK. Atmosphere 2021, 12, 504. [Google Scholar] [CrossRef]
- Petetin, H.; Bowdalo, D.; Soret, A.; Guevara, M.; Jorba, O.; Serradell, K.; Pérez García-Pando, C. Meteorology-Normalized Impact of the COVID-19 Lockdown upon NO2 Pollution in Spain. Atmos. Chem. Phys. 2020, 20, 11119–11141. [Google Scholar] [CrossRef]
- Lv, Y.; Tian, H.; Luo, L.; Liu, S.; Bai, X.; Zhao, H.; Lin, S.; Zhao, S.; Guo, Z.; Xiao, Y.; et al. Meteorology-Normalized Variations of Air Quality during the COVID-19 Lockdown in Three Chinese Megacities. Atmos. Pollut. Res. 2022, 13, 101452. [Google Scholar] [CrossRef]
- Gagliardi, R.V.; Andenna, C. Machine Learning Meteorological Normalization Models for Trend Analysis of Air Quality Time Series. Int. J. Environ. Impacts 2021, 4, 375–387. [Google Scholar] [CrossRef]
- Falocchi, M.; Zardi, D.; Giovannini, L. Meteorological Normalization of NO2 Concentrations in the Province of Bolzano (Italian Alps). Atmos. Environ. 2021, 246, 118048. [Google Scholar] [CrossRef]
- Zheng, H.; Kong, S.; Zhai, S.; Sun, X.; Cheng, Y.; Yao, L.; Song, C.; Zheng, Z.; Shi, Z.; Harrison, R.M. An Intercomparison of Weather Normalization of PM2.5 Concentration Using Traditional Statistical Methods, Machine Learning, and Chemistry Transport Models. NPJ Clim. Atmos. Sci. 2023, 6, 214. [Google Scholar] [CrossRef]
- Ali-Taleshi, M.S.; Riyahi Bakhtiari, A.; Hopke, P.K. Meteorologically Normalized Spatial and Temporal Variations Investigation Using a Machine Learning-Random Forest Model in Criteria Pollutants across Tehran, Iran. Urban Clim. 2024, 53, 101790. [Google Scholar] [CrossRef]
- Kamińska, J.A. A Random Forest Partition Model for Predicting NO2 Concentrations from Traffic Flow and Meteorological Conditions. Sci. Total Environ. 2019, 651, 475–483. [Google Scholar] [CrossRef]
- Kamińska, J.A. The Use of Random Forests in Modelling Short-Term Air Pollution Effects Based on Traffic and Meteorological Conditions: A Case Study in Wrocław. J. Environ. Manag. 2018, 217, 164–174. [Google Scholar] [CrossRef]
- Cole, M.A.; Elliott, R.J.R.; Liu, B. The Impact of the Wuhan COVID-19 Lockdown on Air Pollution and Health: A Machine Learning and Augmented Synthetic Control Approach. Environ. Resour. Econ. 2020, 76, 553–580. [Google Scholar] [CrossRef]
- Mallet, M.D. Meteorological Normalisation of PM10 Using Machine Learning Reveals Distinct Increases of Nearby Source Emissions in the Australian Mining Town of Moranbah. Atmos. Pollut. Res. 2021, 12, 23–35. [Google Scholar] [CrossRef]
- Wu, Q.; Li, T.; Zhang, S.; Fu, J.; Seyler, B.C.; Zhou, Z.; Deng, X.; Wang, B.; Zhan, Y. Evaluation of NOx Emissions before, during, and after the COVID-19 Lockdowns in China: A Comparison of Meteorological Normalization Methods. Atmos. Environ. 2022, 278, 119083. [Google Scholar] [CrossRef]
- Quinlan, J.R. Combining Instance-Based and Model-Based Learning. In Proceedings of the International Conference on Machine Learning 1993, Amherst, MA, USA, 27–29 June 1993; pp. 236–243. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–600. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, H.; Dong, J.; Poslad, S.; Li, R.; Zhang, X.; Rui, X. A Framework to Predict High-Resolution Spatiotemporal PM2.5 Distributions Using a Deep-Learning Model: A Case Study of Shijiazhuang, China. Remote Sens. 2020, 12, 2825. [Google Scholar] [CrossRef]
- Xu, Y.; Ho, H.C.; Wong, M.S.; Deng, C.; Shi, Y.; Chan, T.C.; Knudby, A. Evaluation of Machine Learning Techniques with Multiple Remote Sensing Datasets in Estimating Monthly Concentrations of Ground-Level PM2.5. Environ. Pollut. 2018, 242, 1417–1426. [Google Scholar] [CrossRef]
- Walsh, K.J.; Milligan, M.; Woodman, M.; Sherwell, J. Data Mining to Characterize Ozone Behavior in Baltimore and Washington, DC. Atmos. Environ. 2008, 42, 4280–4292. [Google Scholar] [CrossRef]
- Magesh, S.; Geng, K. A Machine Learning Interpretation of the Correlation between Poverty and Air Pollution in the Contiguous United States. Sci. Rep. 2025, 15, 2407. [Google Scholar] [CrossRef]
- Méndez, M.; Merayo, M.G.; Núñez, M. Machine Learning Algorithms to Forecast Air Quality: A Survey. Artif. Intell. Rev. 2023, 56, 10031–10066. [Google Scholar] [CrossRef]
- Tian, H.; Huang, L.; Hu, S.; Wu, W. A Modified Machine Learning Algorithm for Multi-Collinearity Environmental Data. Environ. Ecol. Stat. 2024, 31, 1063–1083. [Google Scholar] [CrossRef]
- Mampitiya, L.; Rathnayake, N.; Hoshino, Y.; Rathnayake, U. Performance of Machine Learning Models to Forecast PM10 Levels. MethodsX 2024, 12, 102557. [Google Scholar] [CrossRef]
- European Parliament; The Council of the European Union. Directive (EU) 2024/2881 of the European Parliament and of the Council of 23 October 2024 on Ambient Air Quality and Cleaner Air for Europe. Off. J. Eur. Union 2024, L 2881, 1–30. [Google Scholar]
- Chief Inspectorate of Environmental Protection (GIOS). Air Quality Monitoring Archive; Chief Inspectorate of Environmental Protection (GIOS): Warsaw, Poland, 2025. [Google Scholar]
- Institute of Meteorology; (IMGW-PIB), W.M. Public Data Portal 2025. Available online: https://danepubliczne.imgw.pl/ (accessed on 20 May 2024).
- Hersbach, H.; Bell, B.; Berrisford, P.; Biavati, G.; Horányi, A.; Muñoz Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Rozum, I.; et al. ERA5 Hourly Data on Single Levels from 1979 to Present; European Centre for Medium-Range Weather Forecasts: Reading, UK, 2023. [Google Scholar]
- Rokach, L.; Maimon, O. Decision Trees. In Data Mining and Knowledge Discovery Handbook; Rokach, L., Maimon, O., Eds.; Springer: Boston, MA, USA, 2005; pp. 165–192. ISBN 038725465X. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Wright, M.N.; Ziegler, A. Ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef]
- Kuhn, M.; Wickham, H. Tidymodels: A Collection of Packages for Modeling and Machine Learning Using Tidyverse Principles. Available online: https://www.tidymodels.org (accessed on 20 May 2024).
- Carslaw, D.C.; Ropkins, K. Openair—An r Package for Air Quality Data Analysis. Environ. Model. Softw. 2012, 27–28, 52–61. [Google Scholar] [CrossRef]
- Biecek, P.; Burzykowski, T. Explanatory Model Analysis; Chapman and Hall/CRC: New York, NY, USA, 2021; ISBN 9780367135591. [Google Scholar]
- Kunsch, H.R. Annals of Statistics. Jackknife Bootstrap Gen. Station. Obs. 1989, 17, 1217–1241. [Google Scholar]
- Wang, X.; Yu, Q. Unbiasedness of the Theil–Sen Estimator. J. Nonparametr. Stat. 2005, 17, 685–695. [Google Scholar] [CrossRef]
- Rzeszutek, M. Parameterization and Evaluation of the CALMET/CALPUFF Model System in near-Field and Complex Terrain—Terrain Data, Grid Resolution and Terrain Adjustment Method. Sci. Total Environ. 2019, 689, 31–46. [Google Scholar] [CrossRef]
- Rzeszutek, M.; Szulecka, A. Assessment of the AERMOD Dispersion Model in Complex Terrain with Different Types of Digital Elevation Data. IOP Conf. Ser. Earth Environ. Sci. 2021, 642, 012014. [Google Scholar] [CrossRef]
- Rood, A.S. Performance Evaluation of AERMOD, CALPUFF, and Legacy Air Dispersion Models Using the Winter Validation Tracer Study Dataset. Atmos. Environ. 2014, 89, 707–720. [Google Scholar] [CrossRef]
- Carruthers, D.J.; Seaton, M.D.; McHugh, C.A.; Sheng, X.; Solazzo, E.; Vanvyve, E. Comparison of the Complex Terrain Algorithms Incorporated into Two Commonly Used Local-Scale Air Pollution Dispersion Models (ADMS and AERMOD) Using a Hybrid Model. J. Air Waste Manag. Assoc. 2011, 61, 1227–1235. [Google Scholar] [CrossRef]
- Thepanondh, S.; Jittra, N.; Pinthong, N. Performance Evaluation of AERMOD and CALPUFF Air Dispersion Models in Industrial Complex Area. Air Soil Water Res. 2015, 8, 87–95. [Google Scholar] [CrossRef]
- Biecek, P. DALEX: Explainers for Complex Predictive Models in R. J. Mach. Learn. Res. 2018, 19, 1–5. [Google Scholar]
- Szulecka, A.; Oleniacz, R.; Rzeszutek, M. Functionality of Openair Package in Air Pollution Assessment and Modeling—A Case Study of Krakow. Environ. Prot. Nat. Resour. 2017, 28, 22–27. [Google Scholar] [CrossRef]
- Oleniacz, R.; Bogacki, M.; Szulecka, A.; Rzeszutek, M.; Mazur, M. Assessing the Impact of Wind Speed and Mixing-Layer Height on Air Quality in Krakow (Poland) in the Years 2014–2015. J. Civ. Eng. Environ. Archit. 2016, XXXIII, 315–342. [Google Scholar] [CrossRef]
- Foskinis, R.; Gini, M.I.; Kokkalis, P.; Diapouli, E.; Vratolis, S.; Granakis, K.; Zografou, O.; Komppula, M.; Vakkari, V.; Nenes, A.; et al. On the Relation between the Planetary Boundary Layer Height and in Situ Surface Observations of Atmospheric Aerosol Pollutants during Spring in an Urban Area. Atmos. Res. 2024, 308, 107543. [Google Scholar] [CrossRef]
- Du, C.; Liu, S.; Yu, X.; Li, X.; Chen, C.; Peng, Y.; Dong, Y.; Dong, Z.; Wang, F. Urban Boundary Layer Height Characteristics and Relationship with Particulate Matter Mass Concentrations in Xi’an, Central China. Aerosol Air Qual. Res. 2013, 13, 1598–1607. [Google Scholar] [CrossRef]
- Bogacki, M.; Oleniacz, R.; Rzeszutek, M.; Paulina, B.; Szulecka, A. Assessing the Impact of Road Traffic Reorganization on Air Quality: A Street Canyon Case Study. Atmosphere 2020, 11, 695. [Google Scholar] [CrossRef]
- Bogacki, M.; Mazur, M.; Oleniacz, R.; Rzeszutek, M.; Szulecka, A. Re-Entrained Road Dust PM10 Emission from Selected Streets of Krakow and Its Impact on Air Quality. E3S Web Conf. 2018, 28, 01003. [Google Scholar] [CrossRef]
- Rzeszutek, M.; Bogacki, M.; Paulina, B.; Szulecka, A. Improvement Assessment of the OSPM Model Performance by Considering the Secondary Road Dust Emissions. Transp. Res. Part D Transp. Environ. 2019, 68, 137–149. [Google Scholar] [CrossRef]
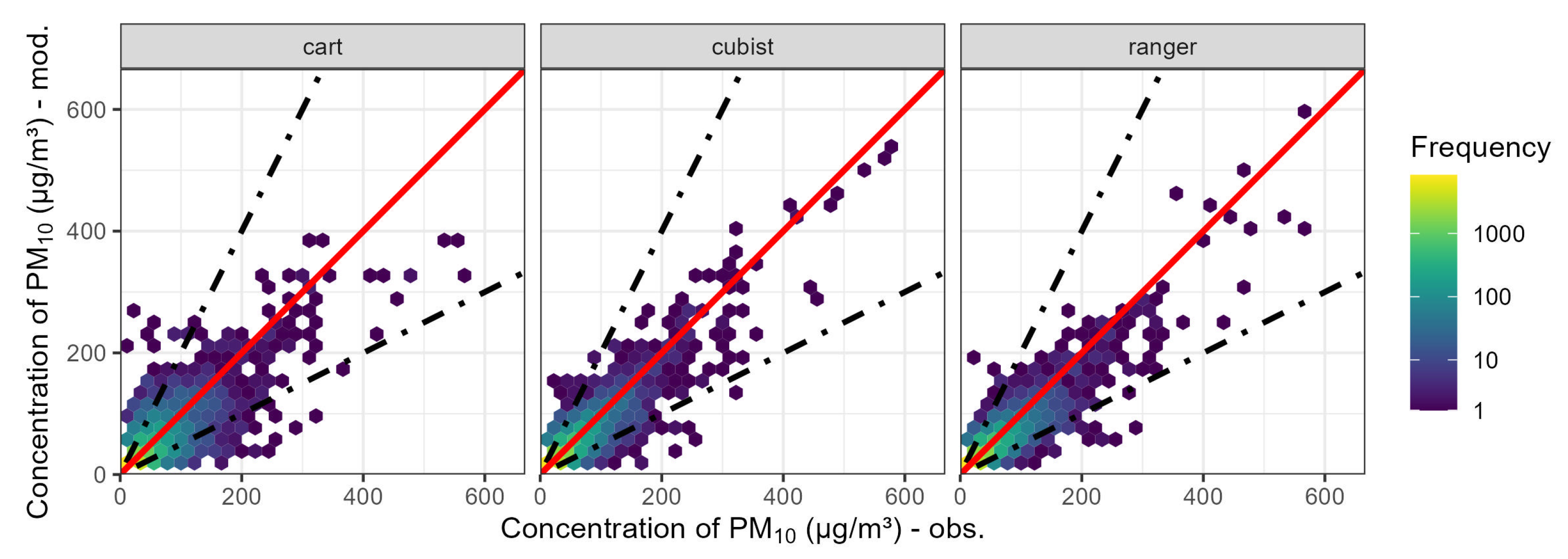
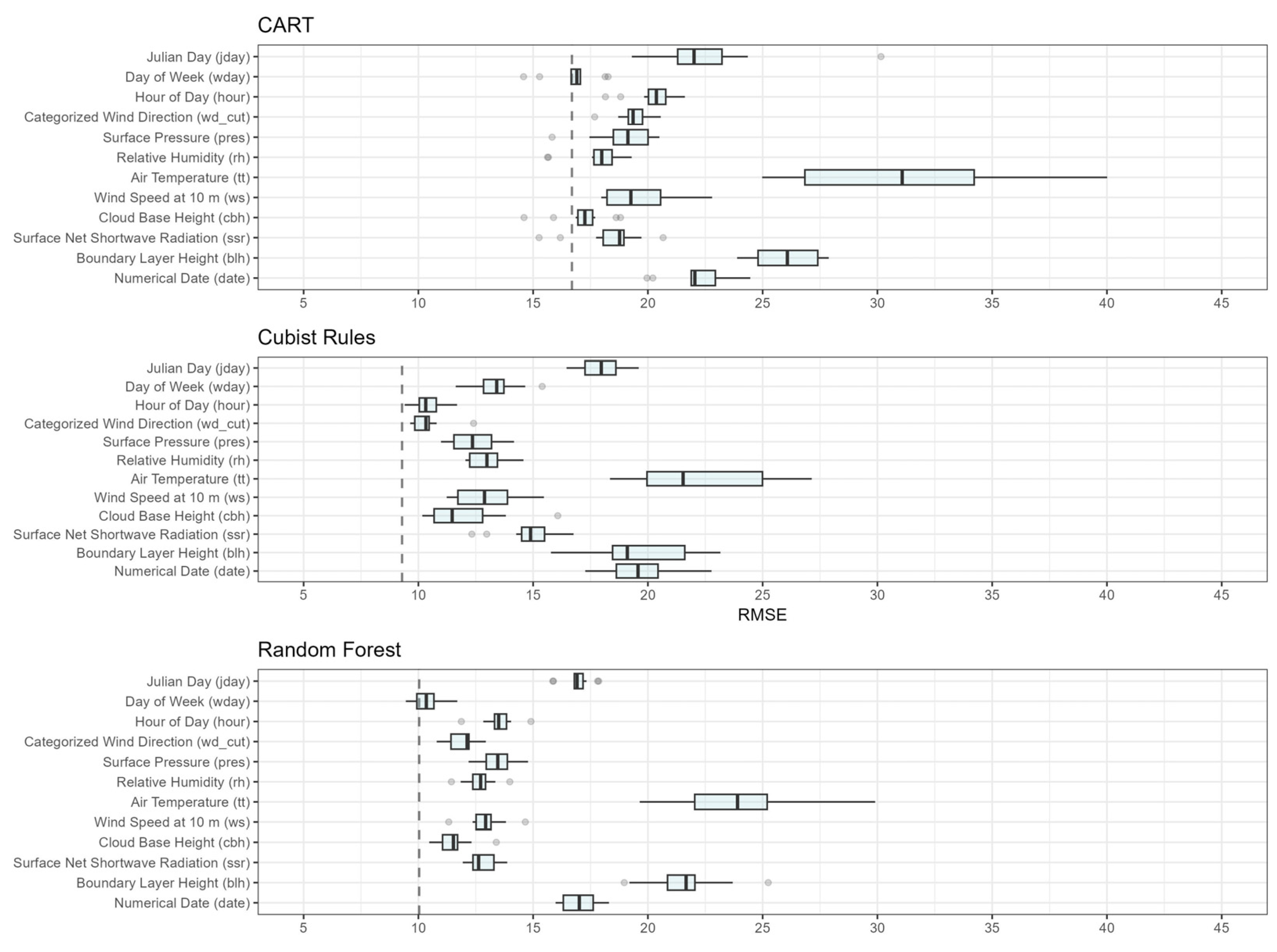
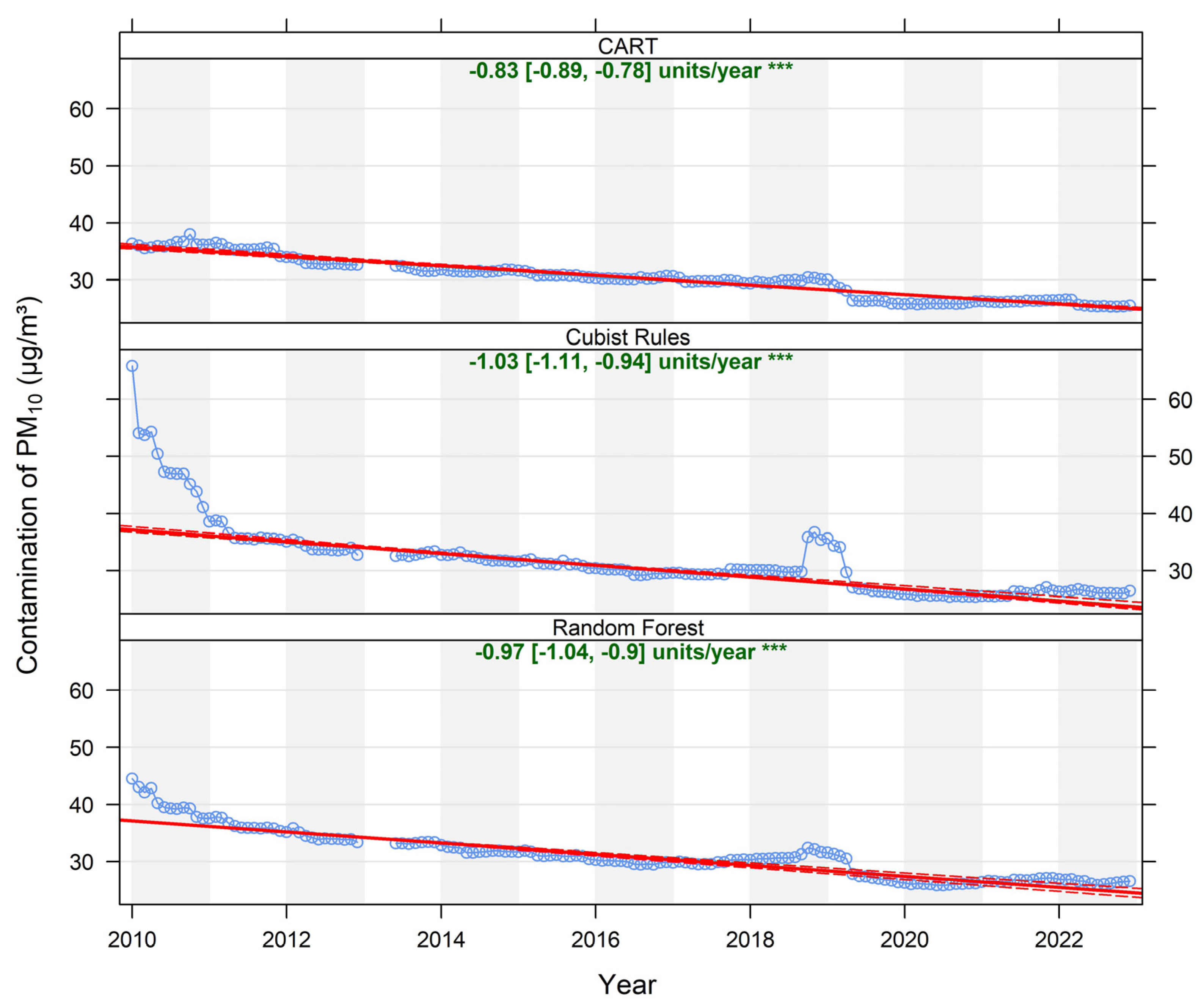
| Model | FAC2 | MB | MGE | NMB | NMGE | RMSE | r | COE | IOA |
|---|---|---|---|---|---|---|---|---|---|
| Cart | 0.82 | −0.14 | 11.94 | −0.001 | 0.39 | 19.96 | 0.75 | 0.33 | 0.66 |
| Cubist | 0.90 | −0.11 | 8.52 | −0.040 | 0.28 | 14.06 | 0.88 | 0.52 | 0.76 |
| Ranger | 0.91 | 0.11 | 8.46 | 0.004 | 0.28 | 14.09 | 0.89 | 0.52 | 0.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gora, K.; Rzeszutek, M. Comparison of Selected Ensemble Supervised Learning Algorithms Used for Meteorological Normalisation of Particulate Matter (PM10). Sustainability 2025, 17, 5274. https://doi.org/10.3390/su17125274
Gora K, Rzeszutek M. Comparison of Selected Ensemble Supervised Learning Algorithms Used for Meteorological Normalisation of Particulate Matter (PM10). Sustainability. 2025; 17(12):5274. https://doi.org/10.3390/su17125274
Chicago/Turabian StyleGora, Karolina, and Mateusz Rzeszutek. 2025. "Comparison of Selected Ensemble Supervised Learning Algorithms Used for Meteorological Normalisation of Particulate Matter (PM10)" Sustainability 17, no. 12: 5274. https://doi.org/10.3390/su17125274
APA StyleGora, K., & Rzeszutek, M. (2025). Comparison of Selected Ensemble Supervised Learning Algorithms Used for Meteorological Normalisation of Particulate Matter (PM10). Sustainability, 17(12), 5274. https://doi.org/10.3390/su17125274