


Day-Ahead Electricity Price Forecasting for Sustainable Electricity Markets: A Multi-Objective Optimization Approach Combining Improved NSGA-II and RBF Neural Networks


Abstract
1. Introduction
- During the optimization process, a vast quantity of parameters need to be continuously adjusted, which increases the tediousness of parameter adjustment during the network training process, resulting in an increase in the number of network iterations and a slower convergence speed.
- The genetic algorithm employs a stochastic approach to explore all potential solution sets of the problem. It assesses the quality of solutions solely according to the fitness value. This results in a relatively sluggish convergence rate of the algorithm and makes the population more susceptible to the premature convergence phenomenon.
- In view of the features such as nonlinearity, high-frequency dynamics, and multivariate dependence of electricity price data, a hybrid prediction framework that integrates the improved NSGA-II algorithm and the RBF neural network is proposed. Through dynamic crowding degree calculation, adaptive crossover/mutation probabilities, and an enhanced elite retention strategy, it effectively solves the problems of premature convergence and insufficient diversity of traditional multi-objective optimization algorithms.
- Combined with the maximum information coefficient (MIC) and key influencing factors, the multivariate feature engineering screening can significantly reduce noise interference and improve the effectiveness of model input.
- A multi-objective optimization mechanism that takes into account both prediction accuracy and model complexity is designed. By optimizing the count of hidden layer nodes and parameters of RBF through NSGA-II, the risk of overfitting is reduced, prediction performance is ensured, and the model is lightened.
2. Analysis of the Dynamic Characteristics of Electricity Prices and Multivariate Feature Engineering
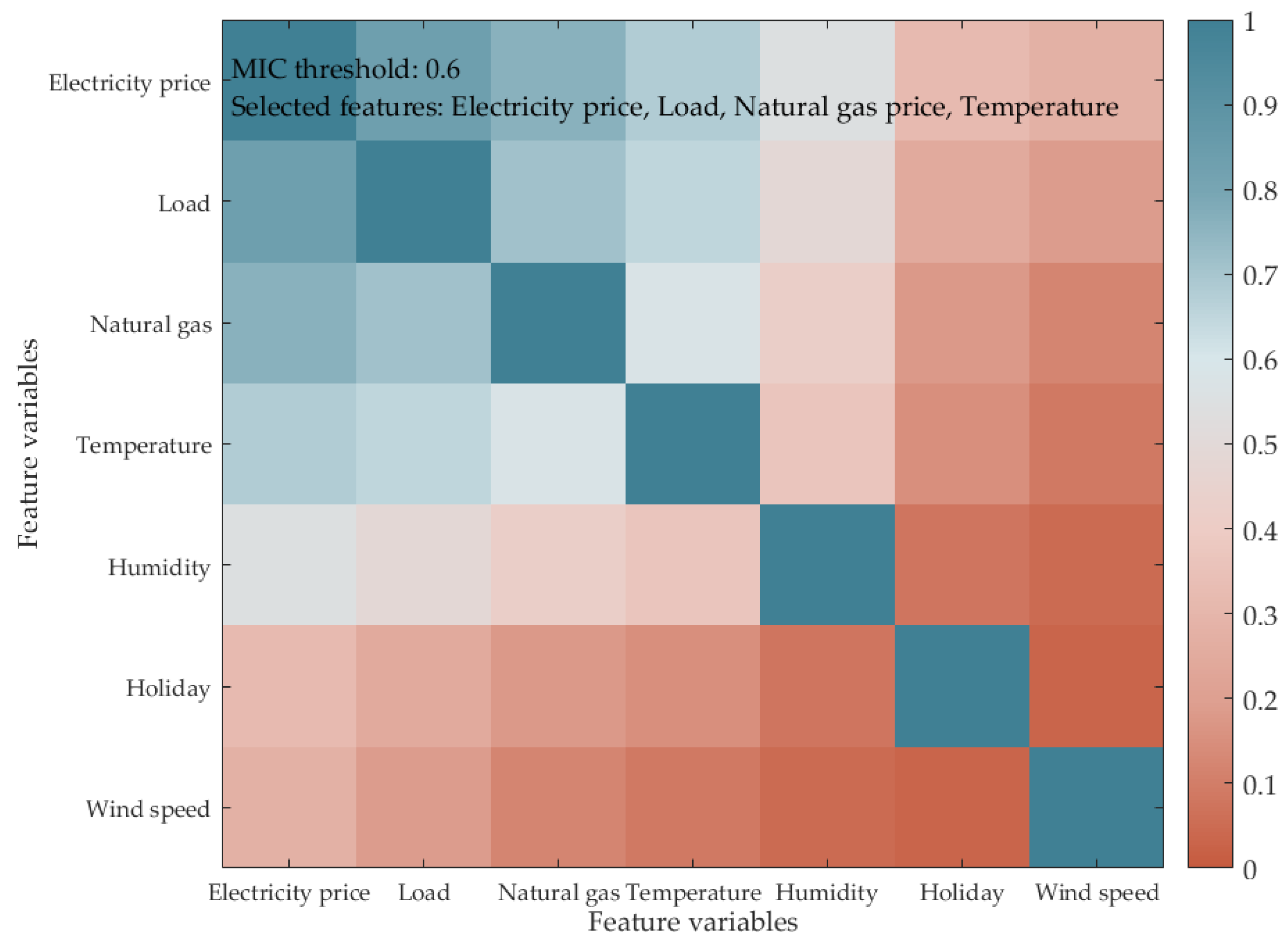
2.1. Feature Selection Approach Relying on the MIC
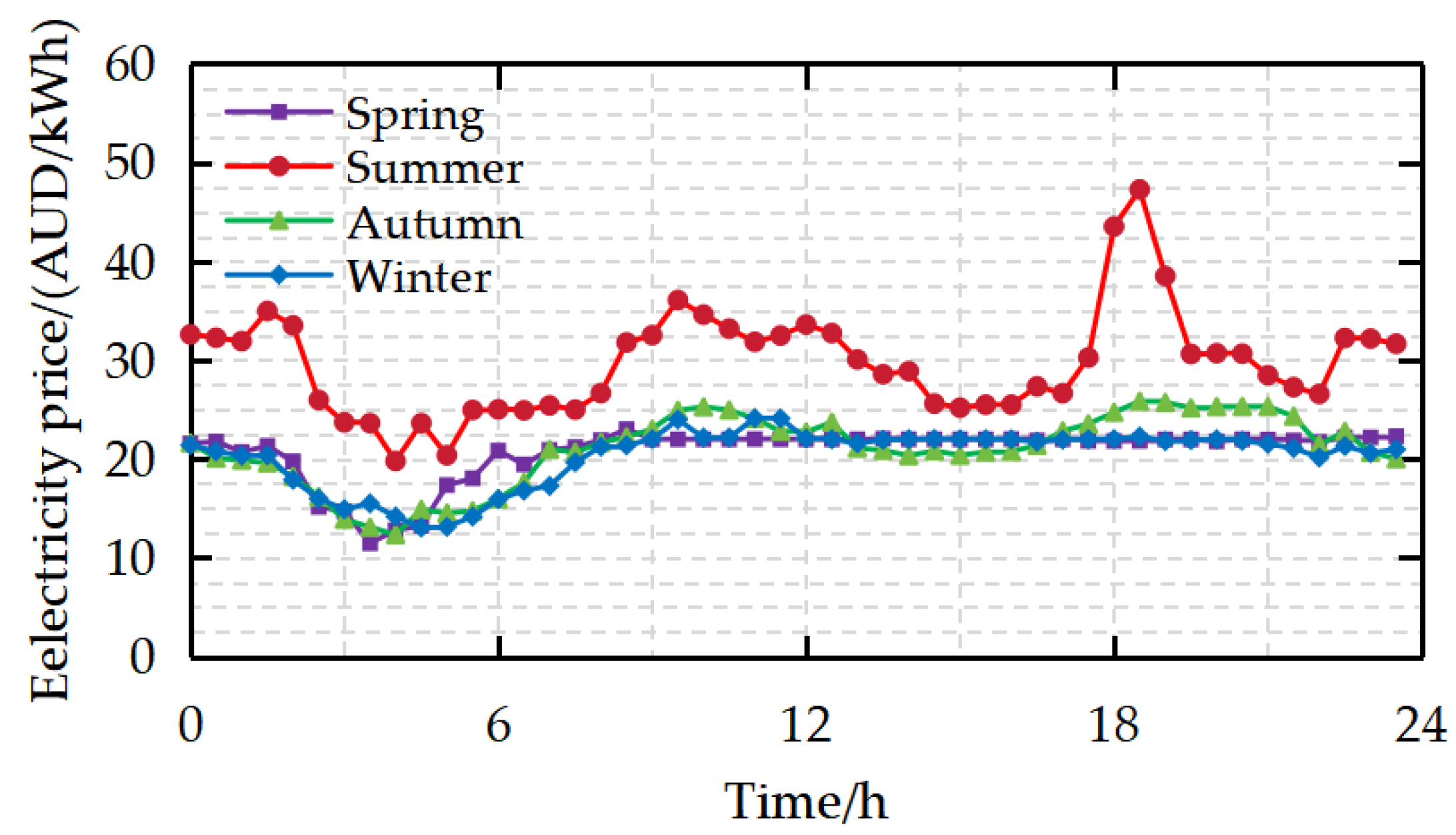
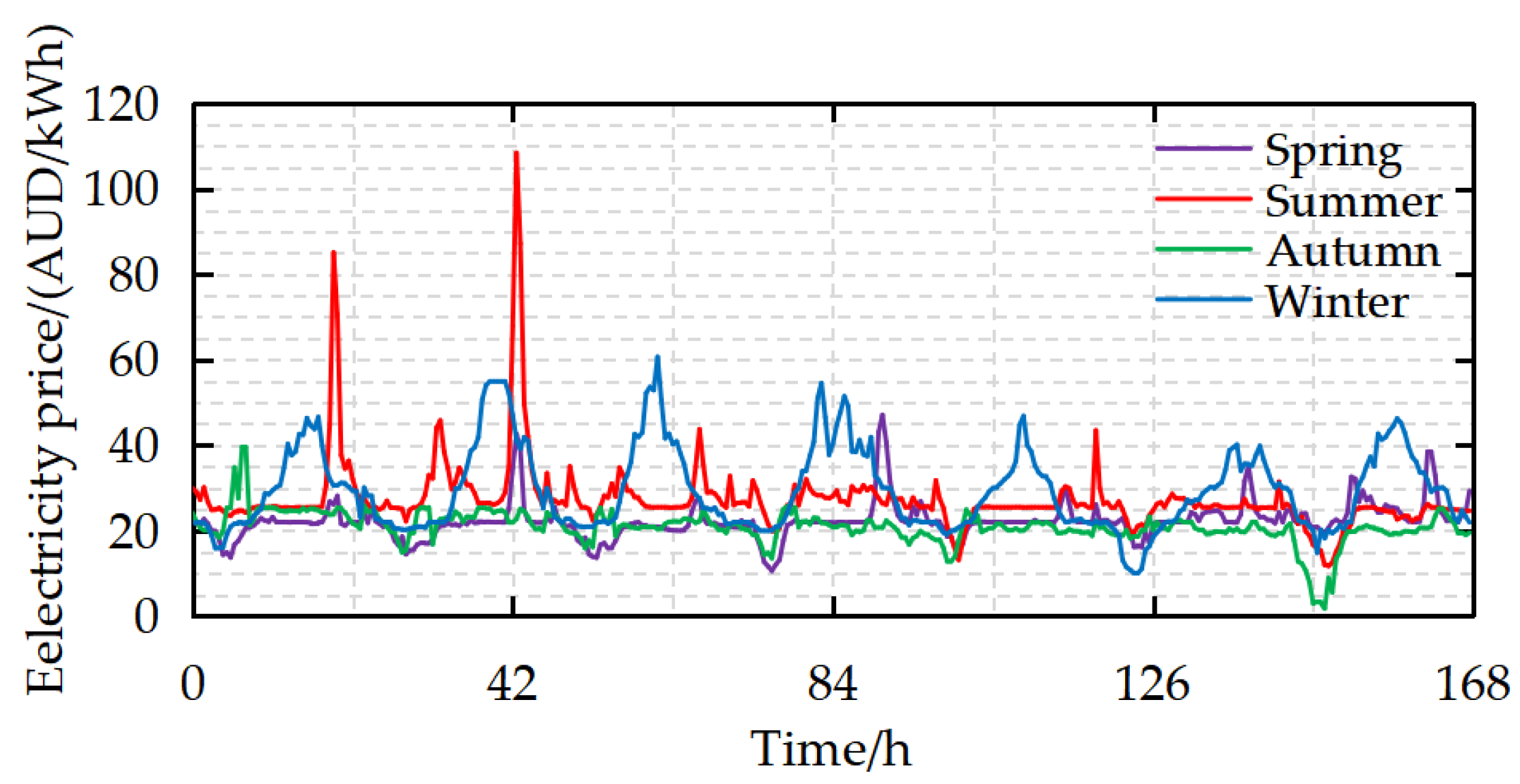
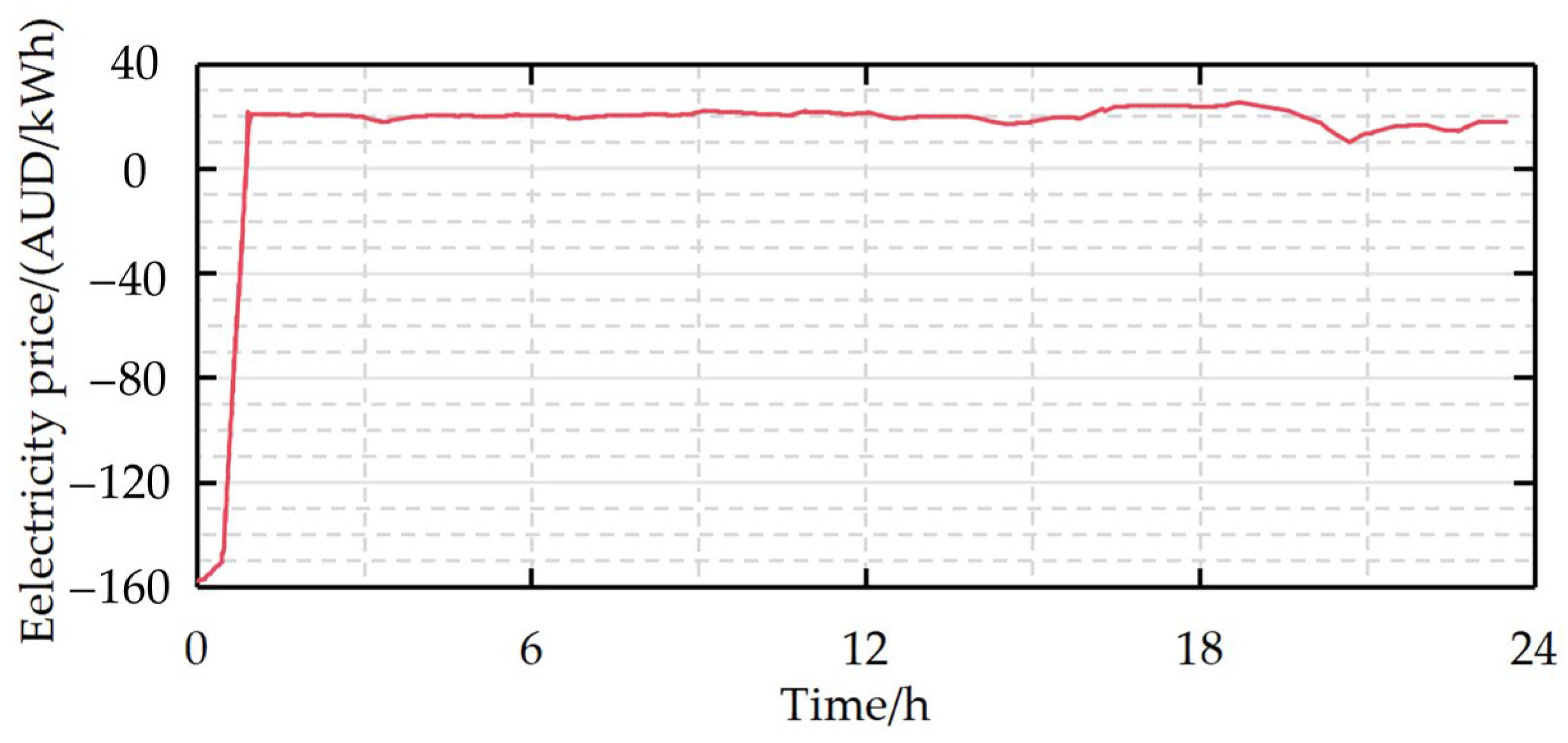
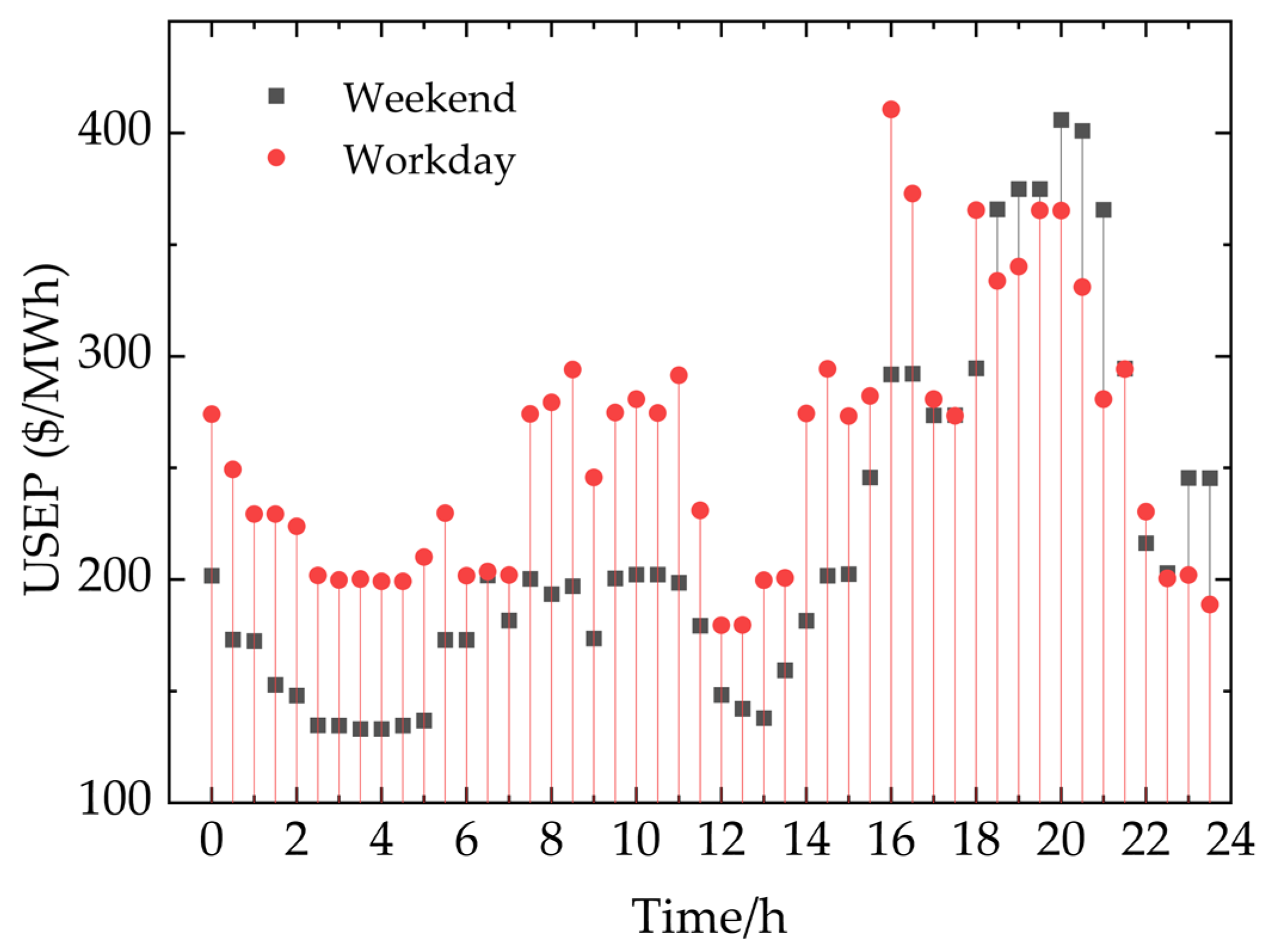
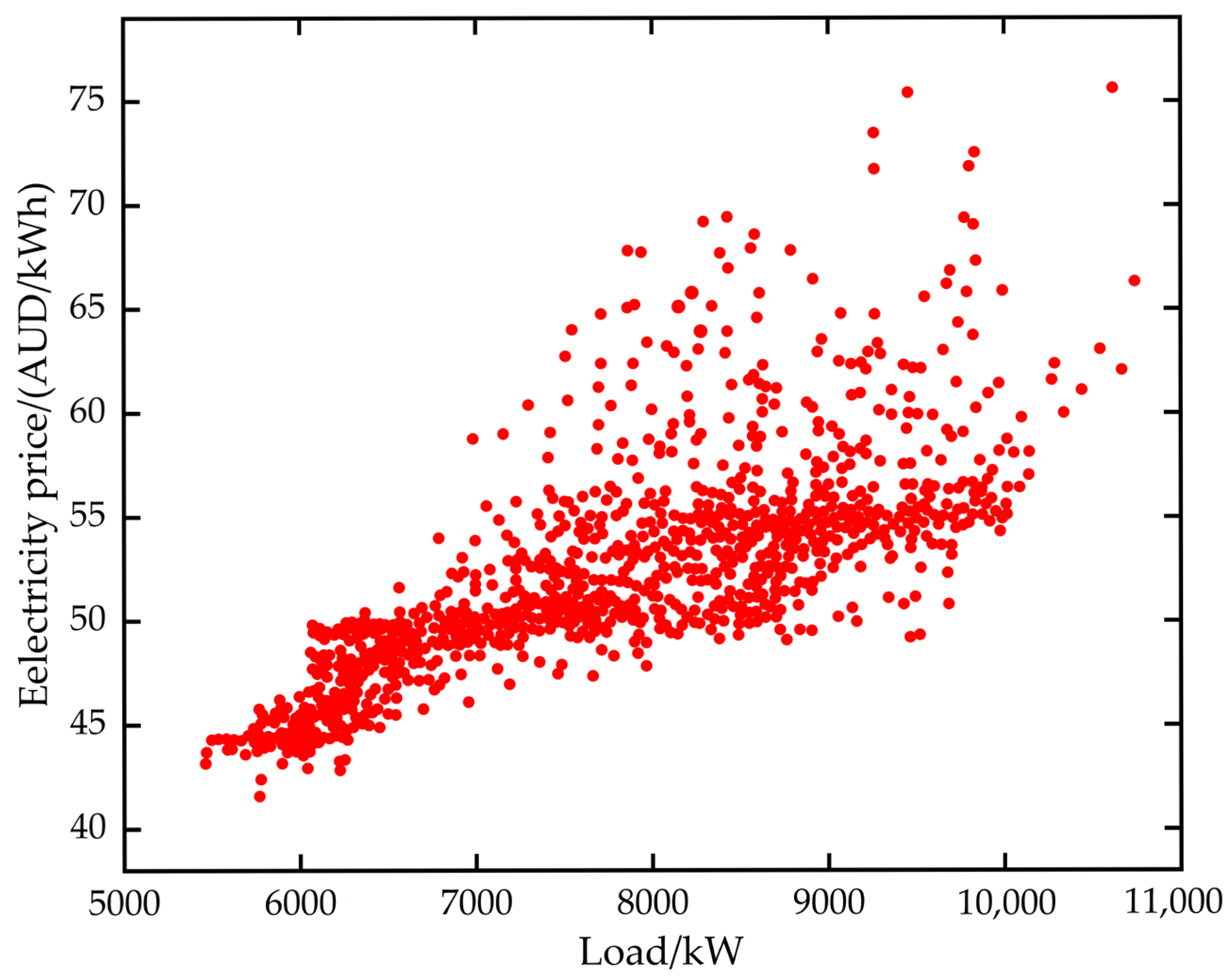
2.2. Analysis of the Nonlinear Characteristics of Electricity Price Data
2.3. Sorting of Multivariate Nonlinear Correlations and Screening of Key Factors
3. Theoretical Basis and Improvement of Multi-Objective Optimization Method
3.1. Theoretical Foundation of RBF
3.2. Limitations of Standard NSGA-II
- When the basic NSGA-II algorithm selects excellent population individuals, it places its dependence on two factors: the Pareto rank and the crowding distance. As the number of iterative steps grows, in the situation where the Pareto ranks of individuals are identical, the degree of crowding takes precedence in the process of individual selection. This algorithm uses a fixed crowding distance-based individual sorting method, which cannot scientifically reflect the distribution of the solution set. When a group of individuals with low crowding distances appears, eliminating such individuals may lead to the elimination of most individuals and change the crowding distances of other individuals. However, the fixed crowding distance sorting method ignores this dynamic change.
- The elitist selection tactic of the fundamental NSGA-II algorithm integrates the non-dominated sorting of both the parent and offspring populations. It engages in competition to produce the subsequent generation and preserves some parent individuals, in part, to enhance the diversity of the population. However, it has obvious defects. It is easy to make the algorithm converge prematurely to a local optimal solution, and it also leads to a decrease in the overall convergence performance.
- The fundamental NSGA-II algorithm assigns fixed values to the genetic operator probabilities. Typically, the crossover probability lies within the range of [0.9, 0.97], while the mutation probability ranges from [0.0001, 0.1]. These values exert a substantial influence on the solution outcome and the convergence of the algorithm. If the crossover probability is too high, it is easy to destroy the population pattern and the structure of excellent individuals in the algorithm. If it is too low, the search for the optimal solution will slow down or even stagnate. Should the mutation probability be exceedingly low, the generation of novel individuals becomes arduous, thereby diminishing the diversity of the population. If the value is overly large, the algorithm will degenerate into a random search. For diverse optimization problems, a substantial number of experiments are necessary to ascertain the crossover and mutation probabilities. Generally speaking, it is quite challenging to identify the optimal values. Therefore, the fixed crossover and mutation probabilities are obvious defects of this algorithm, which may easily lead to the degradation of the algorithm.
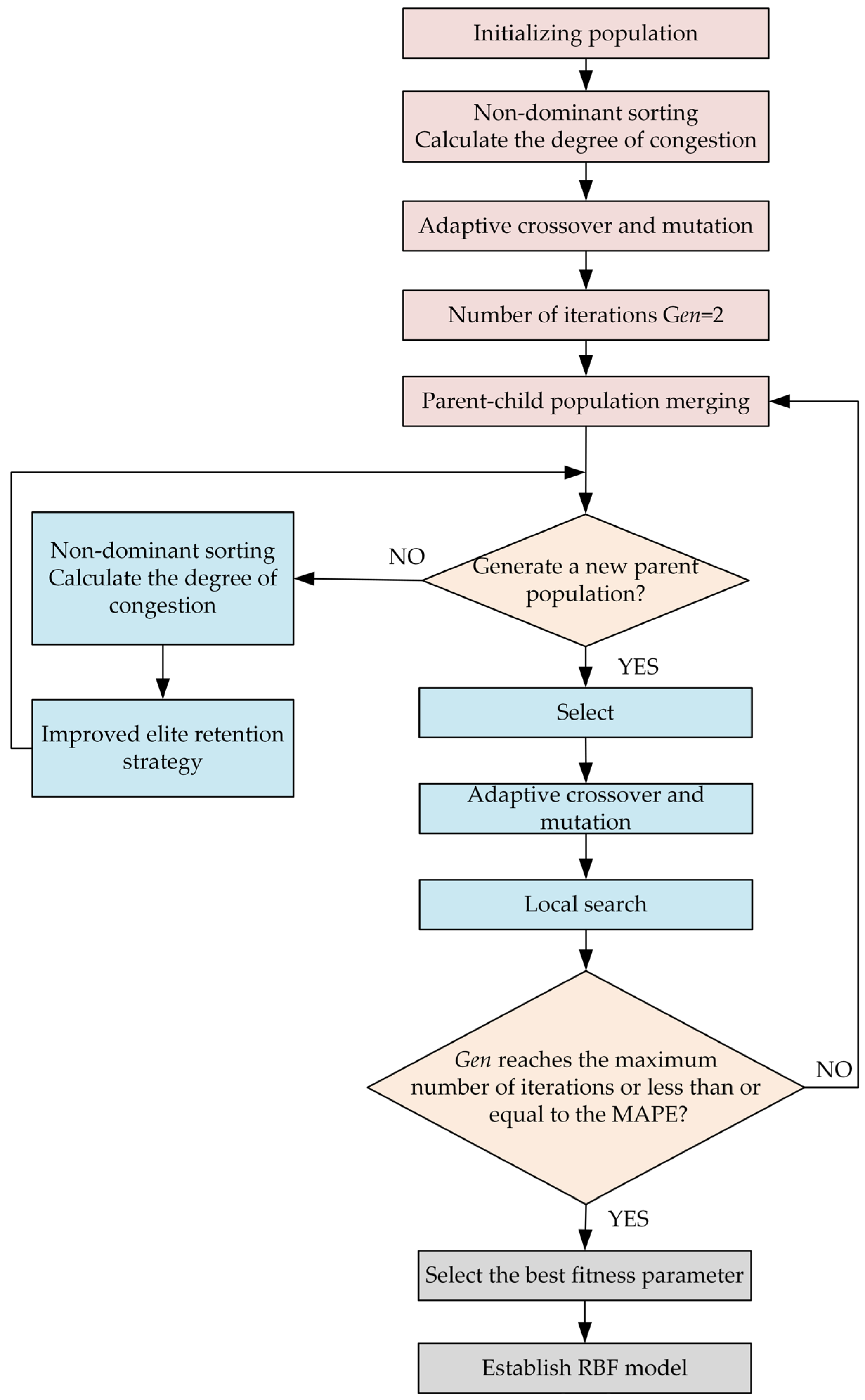
3.3. Proposed Improvements and Mechanisms
- Improvement of the crowding distance calculation
- 2.
- Improved elitist retention strategy
- 3.
- Improved strategy for adaptive crossover and mutation probabilities
- 4.
- Introduction of local search operation
4. The Day-Ahead Electricity Price Prediction Model Based on RBF and the Improved NSGA-II
4.1. The Design of Optimizing the Structure of the RBF Network with the NSGA-II
4.1.1. Optimization Design of RBF Neural Network Structure
4.1.2. Optimal Parameter Configuration
4.1.3. Multi-Objective Optimization Process
4.1.4. Algorithm Pseudocode
| Algorithm 1: Improved NSGA-II-RBF Optimization |
| Input: training data Dtrain, test data Dtest, population size N, max iterations Tmax Output: Pareto-optimal RBF models 1 Initialize: Generate initial population P0 with RBF parameters (centers ci, widths , weights wi) using K-means clustering. Set iteration t ← 0. 2 While t ≤ Tmax do: 3 Fitness evaluation: For each individual i ∈ Pt: Train RBF model Mi on Dtrain. Compute MAPE (Equation (16)) and complexity F (hidden nodes) using Dtest. Assign Fitnessi = (MAPEi, Fi). 4 Non-dominated sorting: Rank individuals into Pareto fronts , ,… using fast non-dominated sorting. 5 Dynamic crowding distance calculation: For each front : Compute pairwise Euclidean distances (Equation (5)). Update the crowding distance di using Equation (6) (incorporating local density and global distribution). 6 Elite selection: Merge parent Pt and offspring . Select top N individuals from Rt by prioritizing: Lower Pareto rank. Higher dynamic crowding distance (to preserve diversity) 7 Genetic operations: Adaptive crossover: For each pair (i,j): Compute crossover probability pc (Equation (8)) based on fitness. Perform simulated binary crossover if rand () < pc. Adaptive mutation: For each individual i: Compute mutation probability pm (Equation (9)). Apply polynomial mutation if rand() pm. 8 Local search: For the top 5% elite individuals: Perturb parameters within a neighborhood. Retain improved solutions to refine the Pareto front. 9 t ← t + 1. 10 Return Pareto-optimal RBF models from final population PTmax. |
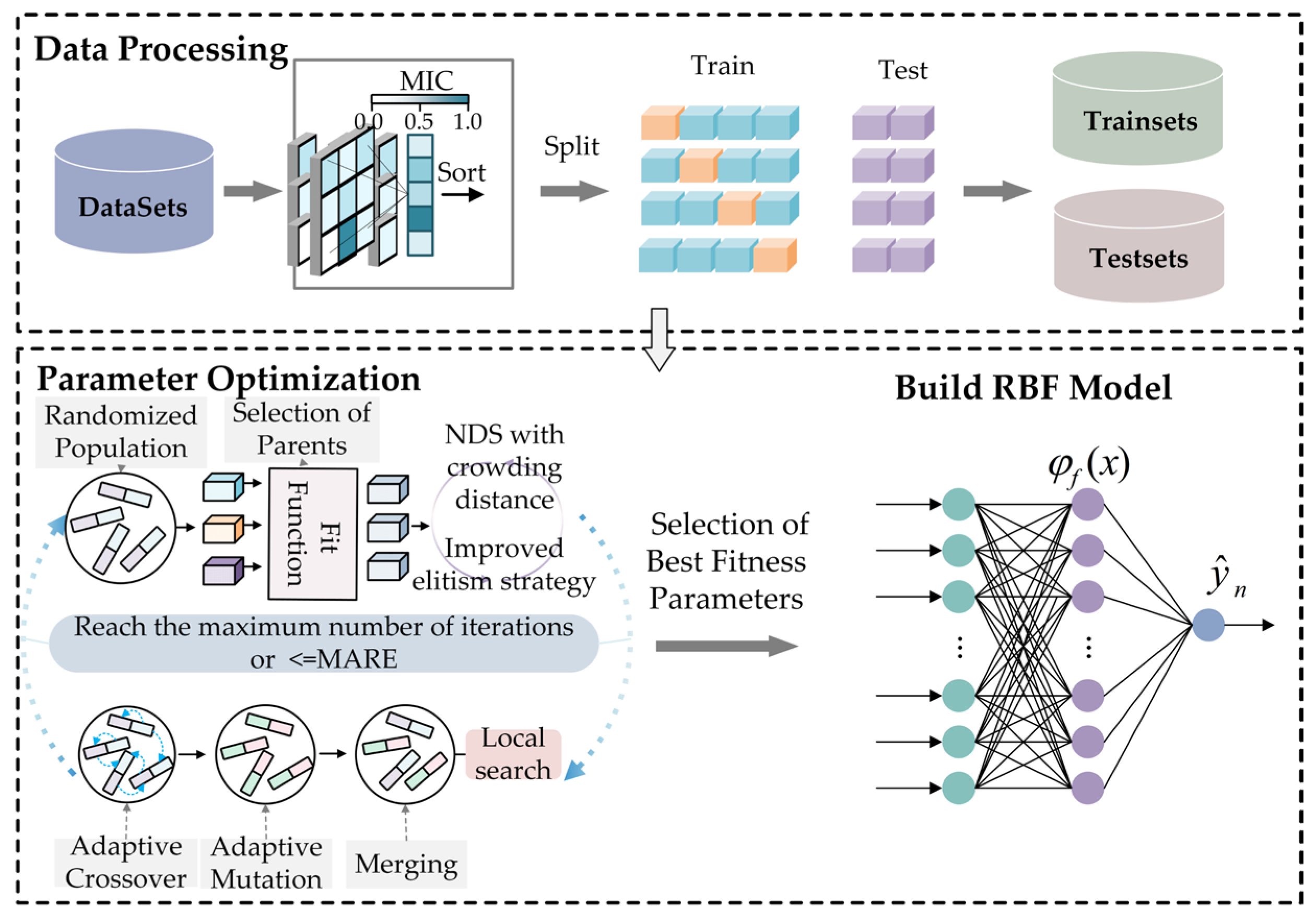
4.2. Prediction Model Framework and Implementation Steps
- Obtain historical electricity price data and data from multiple influencing factors, and use the MIC method to conduct a feature correlation analysis of the influencing factors.
- Input the historical electricity price data and influencing factor data, and preprocess all the data.
- Formulate a multi-objective optimization function. In this function, the objective function for prediction precision is the MAPE, and the objective function for model intricacy is the number of nodes within the hidden layer of the RBF neural network model. The calculation formula for the MAPE is as follows:
- 4.
- Through feature extraction, use the NSGA-II algorithm to optimize the structure of the RBF neural network and train the model.
- 5.
- Generate and present the prognoses regarding the day-ahead electricity price.
5. Comparative Analysis of Simulation Experiment and Model Performance
5.1. Dataset Construction and Preprocessing Method
5.1.1. Data Collection and Seasonal Division of Singapore Electricity Market
5.1.2. Data Normalization
5.2. Error Evaluation Index
5.3. Analysis of Prediction Results and Algorithm Performance
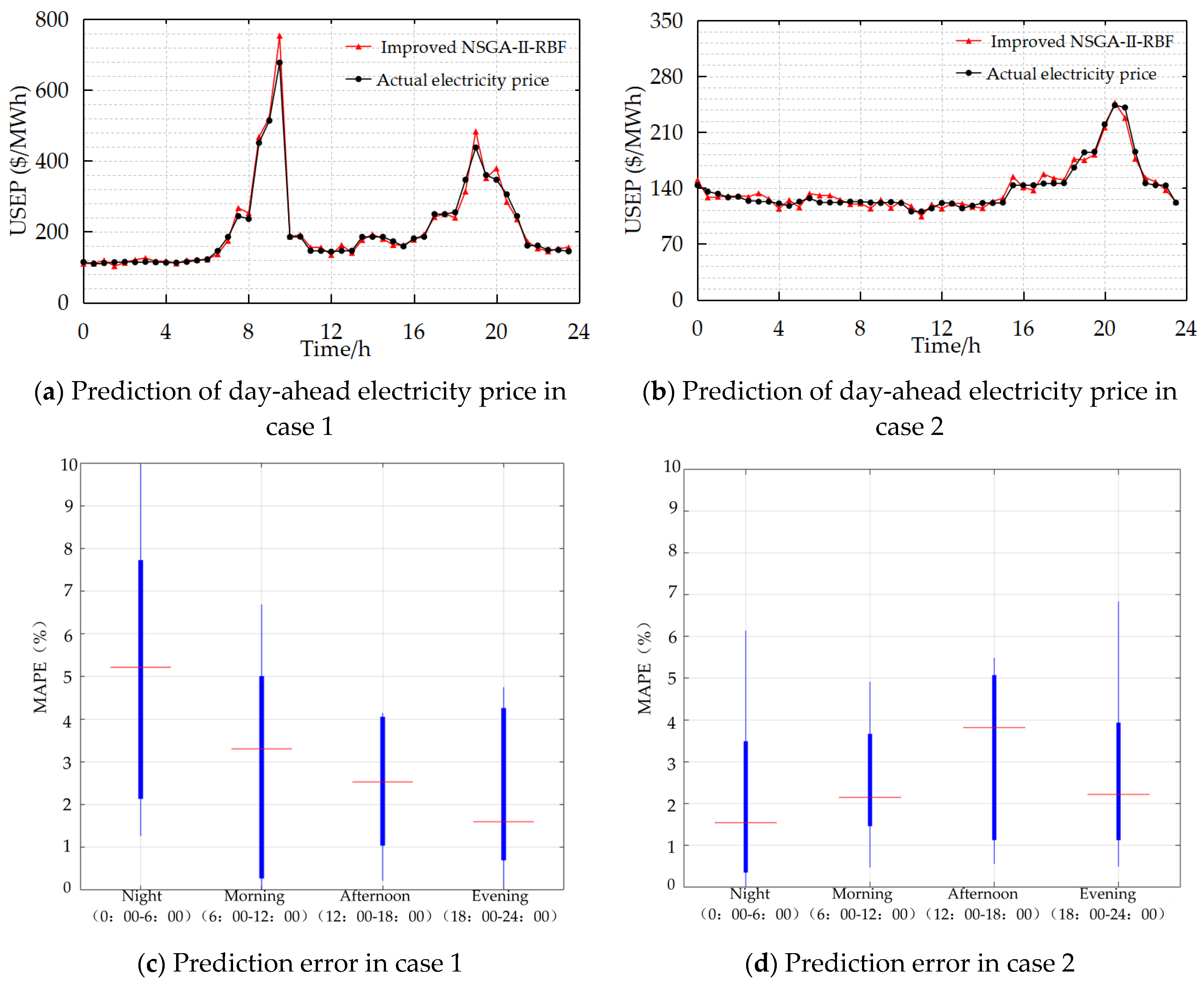
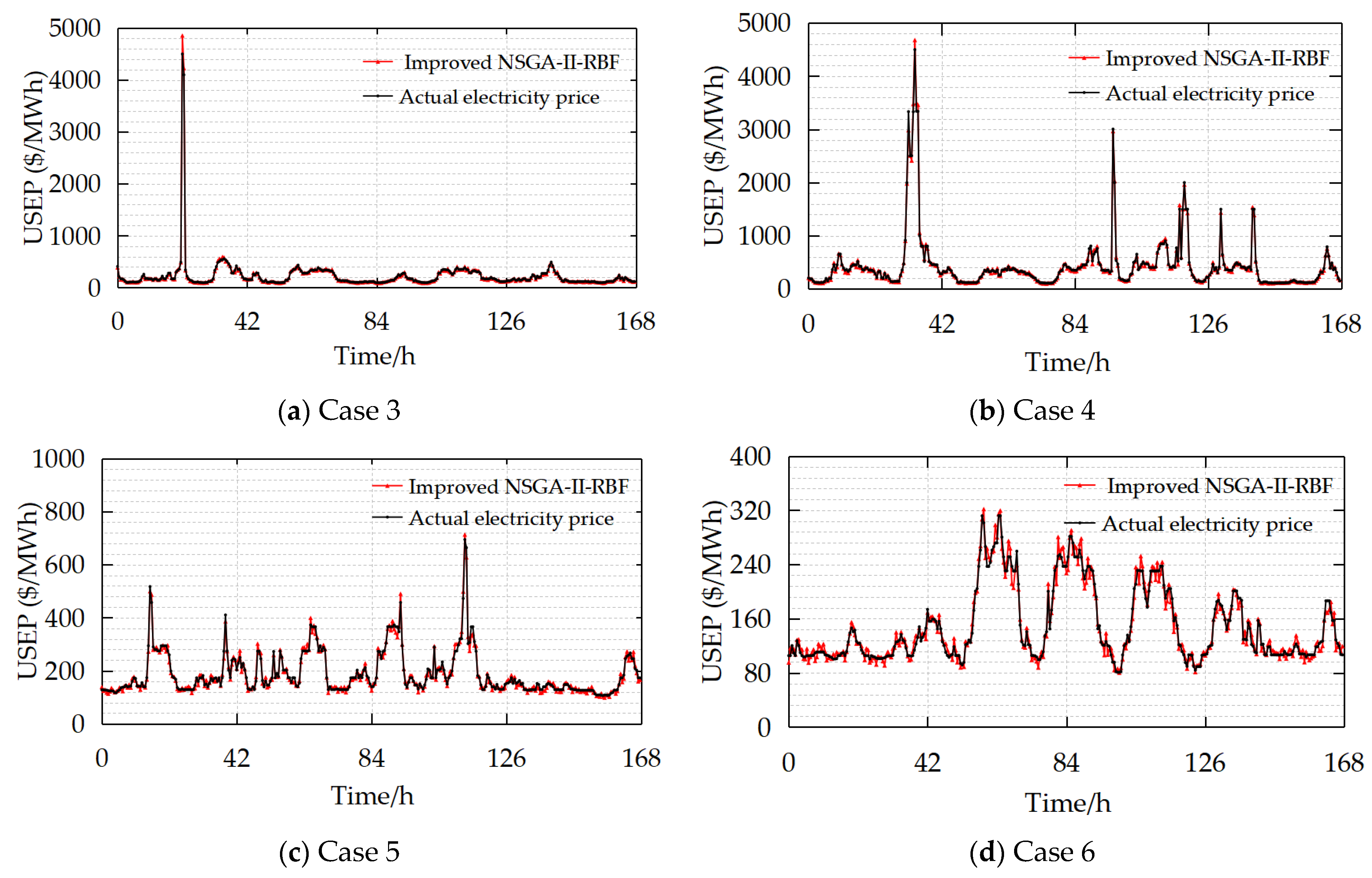
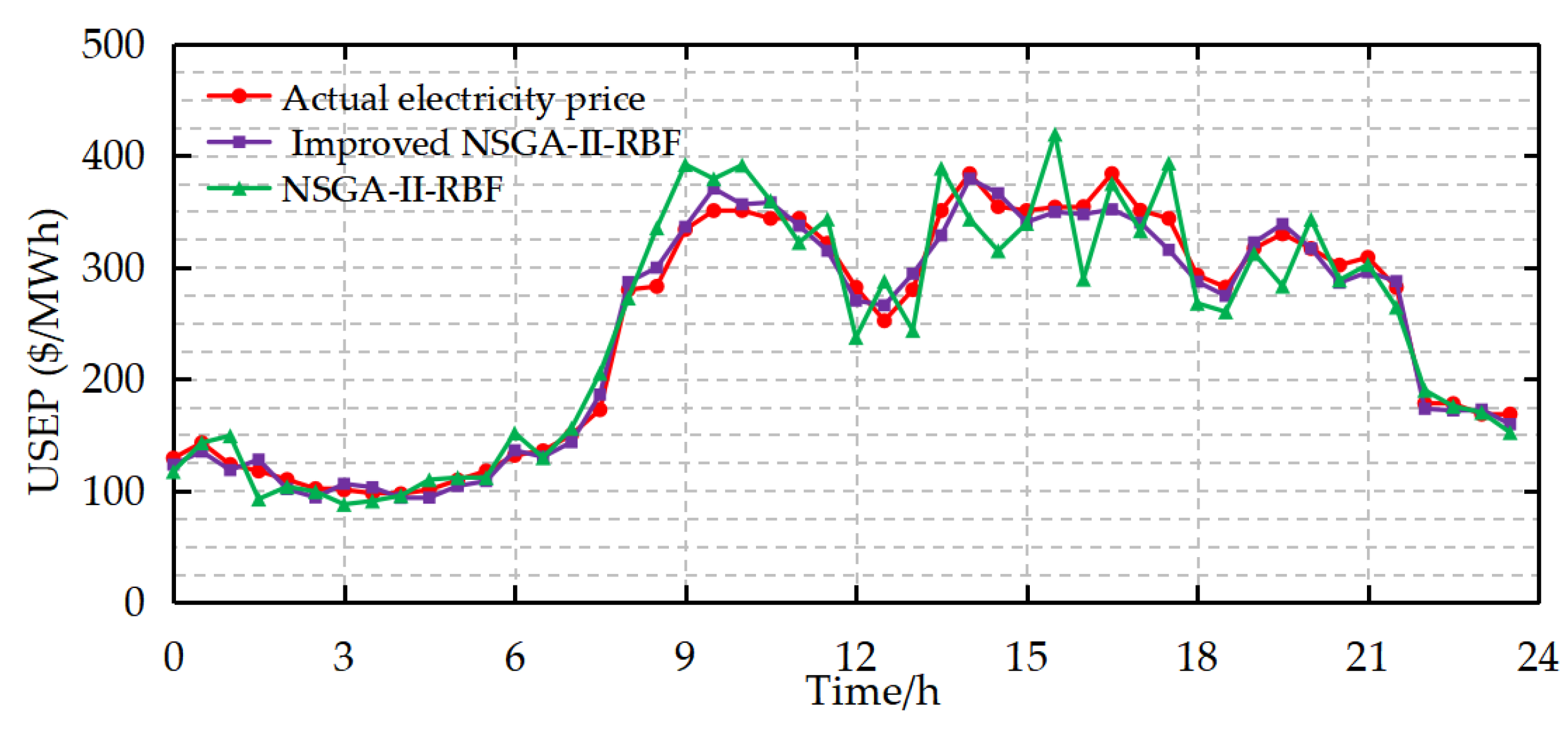
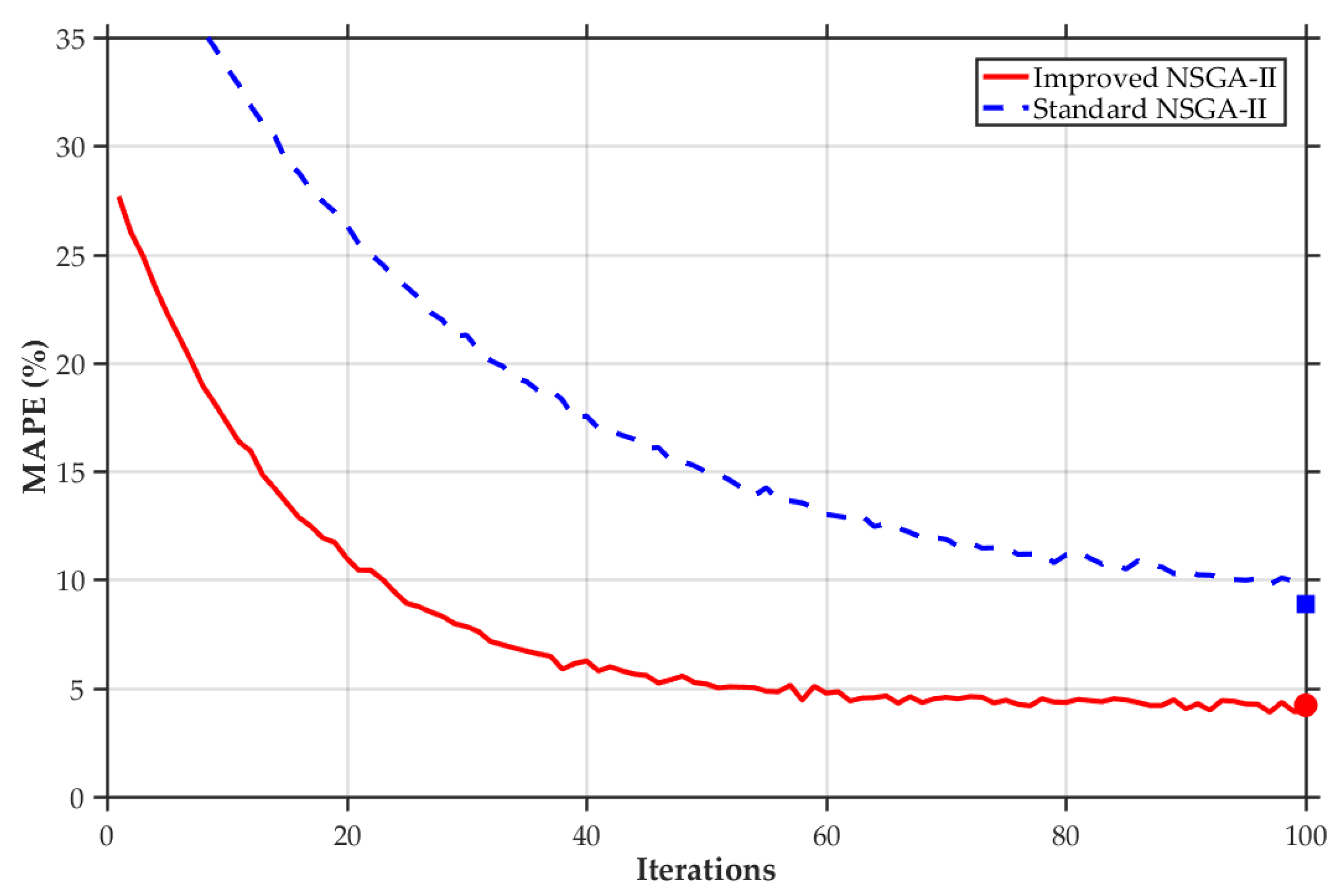
5.3.1. Analysis on the Comparison Between the Model Prior to and Subsequent to the Enhancement of NSGA-II
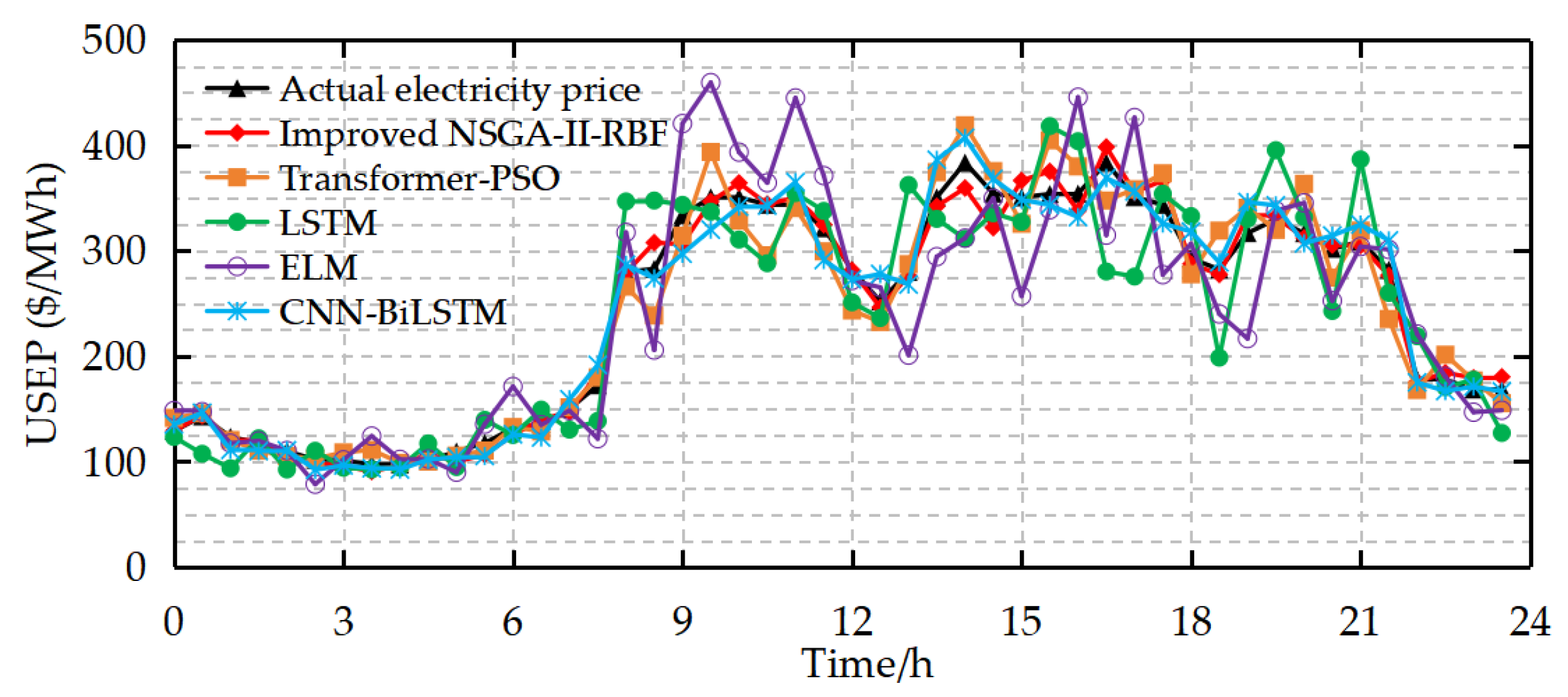
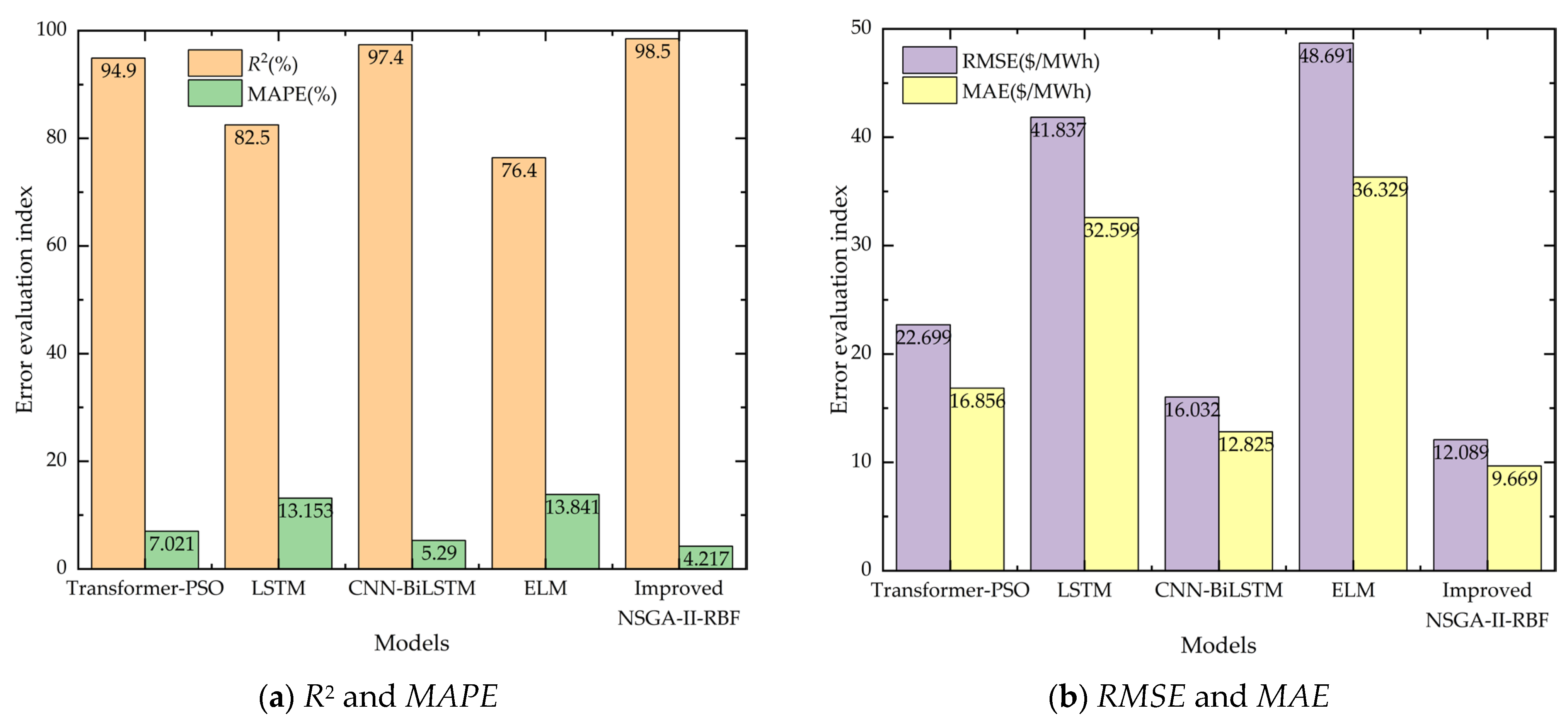
5.3.2. Comparative Analysis of Different Models
6. Conclusions
- The MIC-based feature selection method successfully identifies critical factors, such as international gas prices, electricity load, and temperature. By integrating these features with historical price data, the model optimizes input data quality and significantly improves prediction accuracy.
- The improved NSGA-II algorithm outperforms traditional optimization methods in RBF network training. Through dynamic crowding degree calculation, adaptive crossover and mutation probabilities, and enhanced elitist retention strategies, it maintains population diversity, accelerates convergence, and avoids local optima to find optimal network parameters.
- The proposed model overcomes limitations of conventional methods in handling nonlinearity, high-frequency dynamics, and multivariate dependencies. It provides a reliable prediction tool for sustainable market operations, enabling stakeholders to formulate optimal strategies, reduce renewable energy curtailment, and promote grid sustainability.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, J.; Wang, J.; Cardinal, J. Evolution and reform of UK electricity market. Renew. Sustain. Energy Rev. 2022, 161, 112317. [Google Scholar] [CrossRef]
- Hu, J.; Harmsen, R.; Crijns-Graus, W.; Worrell, E.; van den Broek, M. Identifying barriers to large-scale integration of variable renewable electricity into the electricity market: A literature review of market design. Renew. Sustain. Energy Rev. 2018, 81, 2181–2195. [Google Scholar] [CrossRef]
- Zhang, B.; Tian, H.; Berry, A.; Huang, H.; Roussac, A.C. Experimental comparison of two main paradigms for day-ahead average carbon intensity forecasting in power grids: A case study in Australia. Sustainability 2024, 16, 8580. [Google Scholar] [CrossRef]
- Ibebuchi, C.C. Day-Ahead Energy Price Forecasting with Machine Learning: Role of Endogenous Predictors. Forecasting 2025, 7, 18. [Google Scholar] [CrossRef]
- Lago, J.; Marcjasz, G.; De Schutter, B.; Weron, R. Forecasting day-ahead electricity prices: A review of state-of-the-art algorithms, best practices and an open-access benchmark. Appl. Energy 2021, 293, 116983. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Xue, F.; Li, X.; Li, H.; Wang, W.; Zhong, Y.; Zhao, J.; Zhang, Y. Optimization control strategy for photovoltaic/hydrogen system efficiency considering the startup process of alkaline electrolyzers. Int. J. Hydrogen Energy 2025, 106, 65–79. [Google Scholar] [CrossRef]
- Klyuev, R.V.; Morgoev, I.D.; Morgoeva, A.D.; Gavrina, O.A.; Martyushev, N.V.; Efremenkov, E.A.; Mengxu, Q. Methods of forecasting electric energy consumption: A literature review. Energies 2022, 15, 8919. [Google Scholar] [CrossRef]
- Karabiber, O.A.; Xydis, G. Electricity price forecasting in the Danish day-ahead market using the TBATS, ANN and ARIMA methods. Energies 2019, 12, 928. [Google Scholar] [CrossRef]
- Ioannidis, F.; Kosmidou, K.; Savva, C.; Theodossiou, P. Electricity pricing using a periodic GARCH model with conditional skewness and kurtosis components. Energy Econ. 2021, 95, 105110. [Google Scholar] [CrossRef]
- Gonzalez, J.P.; Roque, A.M.S.M.S.; Perez, E.A. Forecasting functional time series with a new Hilbertian ARMAX model: Application to electricity price forecasting. IEEE Trans. Power Syst. 2018, 33, 545–556. [Google Scholar] [CrossRef]
- Alsuwaylimi, A.A. Comparison of ARIMA, ANN and hybrid (ARIMA–ANN) models for time series forecasting. Inf. Sci. Lett. 2023, 12, 1003–1016. [Google Scholar]
- Blfgeh, A.; Alkhudhayr, H. A Machine Learning-Based Sustainable Energy Management of Wind Farms Using Bayesian Recurrent Neural Network. Sustainability 2024, 16, 8426. [Google Scholar] [CrossRef]
- Aksan, F.; Li, Y.; Suresh, V.; Janik, P. CNN-LSTM vs. LSTM-CNN to predict power flow direction: A case study of the high-voltage subnet of northeast Germany. Sensors 2023, 23, 901. [Google Scholar] [CrossRef] [PubMed]
- Xuan, H.; Maestrini, L.; Chen, F.; Grazian, C. Stochastic variational inference for GARCH models. Stat. Comput. 2024, 34, 45. [Google Scholar] [CrossRef]
- Keles, D.; Scelle, J.; Paraschiv, F.; Fichtner, W. Extended forecast methods for day-ahead electricity spot prices applying artificial neural networks. Appl. Energy 2016, 162, 218–230. [Google Scholar] [CrossRef]
- Abisoye, B.O.; Sun, Y.; Zenghui, W. Survey of Artificial Intelligence Methods for Renewable Energy Forecasting: Methodologies and Insights. Renew. Energy Focus 2024, 48, 100529. [Google Scholar] [CrossRef]
- Bian, K.; Priyadarshi, R. Machine Learning Optimization Techniques: A Survey, Classification, Challenges, and Future Re-search Issues. Arch. Comput. Methods Eng. 2024, 31, 4209–4233. [Google Scholar] [CrossRef]
- Loizidis, S.; Kyprianou, A.; Georghiou, G.E. Electricity market price forecasting using ELM and bootstrap analysis: A case study of the German and Finnish day-ahead markets. Appl. Energy 2024, 363, 123058. [Google Scholar] [CrossRef]
- Shejul, K.; Harikrishnan, R.; Gupta, H. The improved integrated exponential smoothing based CNN-LSTM algorithm to forecast the day-ahead electricity price. MethodsX 2024, 13, 102923. [Google Scholar] [CrossRef]
- Xiong, X.; Qing, G. A hybrid day-ahead electricity price forecasting framework based on time series. Energy 2023, 264, 126099. [Google Scholar] [CrossRef]
- Sridharan, V.; Tuo, M.; Li, X. Wholesale electricity price forecasting using integrated long-term recurrent convolutional network model. Energies 2022, 15, 7606. [Google Scholar] [CrossRef]
- Zhang, T.; Tang, Z.; Wu, J.; Du, X.; Chen, K. Short term electricity price forecasting using a new hybrid model based on two-layer decomposition technique and ensemble learning. Electr. Power Syst. Res. 2022, 205, 107762. [Google Scholar] [CrossRef]
- Jiang, P.; Nie, Y.; Wang, J.; Huang, X. Multivariable short-term electricity price forecasting using artificial intelligence and multi-input multi-output scheme. Energy Econ. 2023, 117, 106471. [Google Scholar] [CrossRef]
- Ghimire, S.; Deo, R.C.; Casillas-Pérez, D.; Salcedo-Sanz, S. Two-step deep learning framework with error compensation technique for short-term, half-hourly electricity price forecasting. Appl. Energy 2024, 353, 122059. [Google Scholar] [CrossRef]
- Sai, W.; Pan, Z.; Liu, S.; Jiao, Z.; Zhong, Z.; Miao, B.; Chan, S.H. Event-driven forecasting of wholesale electricity price and frequency regulation price using machine learning algorithms. Appl. Energy 2023, 352, 121989. [Google Scholar] [CrossRef]
- Fraunholz, C.; Kraft, E.; Keles, D.; Fichtner, W. Advanced price forecasting in agent-based electricity market simulation. Appl. Energy 2021, 290, 116688. [Google Scholar] [CrossRef]
- Laitsos, V.; Vontzos, G.; Bargiotas, D.; Daskalopulu, A.; Tsoukalas, L.H. Data-driven techniques for short-term electricity price forecasting through novel deep learning approaches with attention mechanisms. Energies 2024, 17, 1625. [Google Scholar] [CrossRef]
- Wu, H.; Liang, Y.; Heng, J.-N.; Ma, C.-X.; Gao, X.-Z. MSV-net: Multi-scale visual-inspired network for short-term electricity price forecasting. Energy 2024, 291, 130350. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, J.; Zhang, C.; Qiao, N.; Zhang, J.; Li, Q. Research on short-term electricity price prediction in power market based on BP neural network. In Proceedings of the 2022 9th International Forum on Electrical Engineering and Automation (IFEEA), IEEE, Zhuhai, China, 4–6 November 2022; pp. 1198–1201. [Google Scholar]
- Bashir, T.; Haoyong, C.; Tahir, M.F.; Liqiang, Z. Short term electricity load forecasting using hybrid prophet-LSTM model optimized by BPNN. Energy Rep. 2022, 8, 1678–1686. [Google Scholar] [CrossRef]
- Hadjout, D.; Torres, J.; Troncoso, A.; Sebaa, A.; Martínez-Álvarez, F. Electricity consumption forecasting based on ensemble deep learning with application to the Algerian market. Energy 2022, 243, 123060. [Google Scholar] [CrossRef]
- Geng, G.; He, Y.; Zhang, J.; Qin, T.; Yang, B. Short-term power load forecasting based on PSO-optimized VMD-TCN-attention mechanism. Energies 2023, 16, 4616. [Google Scholar] [CrossRef]
- Jia, W.; Zhao, D.; Shen, T.; Su, C.; Hu, C.; Zhao, Y. A new optimized GA-RBF neural network algorithm. Comput. Intell. Neurosci. 2014, 2014, 982045. [Google Scholar] [CrossRef] [PubMed]
- Tao, J.; Yu, Z.; Zhang, R.; Gao, F. RBF neural network modeling approach using PCA based LM–GA optimization for coke furnace system. Appl. Soft Comput. 2021, 111, 107691. [Google Scholar] [CrossRef]
- Zhang, Y.; Shang, P. KM-MIC: An improved maximum information coefficient based on K-Medoids clustering. Commun. Nonlinear Sci. Numer. Simul. 2022, 111, 106418. [Google Scholar] [CrossRef]
- Zhao, W.; Zhou, L.; Han, C. A Hybrid Optimization Approach Combining Rolling Horizon with Deep-Learning-Embedded NSGA-II Algorithm for High-Speed Railway Train Rescheduling Under Interruption Conditions. Sustainability 2025, 17, 2375. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Nonlinear Processing Ability | Parameter Adaptability | Computational Efficiency | Multi-Objective Optimization |
|---|---|---|---|---|
| ARIMA | low | no | high | no |
| LSTM | middle | Low (fixed hyperparameter) | middle | no |
| CNN-BiLSTM | middle | Chinese (manual parameter adjustment) | low | no |
| Transformer-PSO | high | Central (dynamic weighting) | low | portion |
| Improved NSGA-II-RBF | high | High (dynamic optimization) | high | yes |
| Parameter Category | Parameter Name | Numerical Value | Explanation |
|---|---|---|---|
| Population parameters | Population size | 200 | Ensure diversity and avoid premature convergence. |
| Genetic manipulation | Cross probability () | Adaptive range: 0.5–0.9 | The initial value is 0.9, which is dynamically adjusted according to individual fitness. |
| Mutation probability () | Adaptive range: 0.005–0.1 | The initial value is 0.1, which is dynamically adjusted according to individual fitness. | |
| Terminal condition | Maximum number of iterations | 100 | According to the complexity adjustment of the problem, it is necessary to balance the calculation time and convergence effect. |
| Case | Characteristic Date | Training Data (Date) | Test Data (Date) |
|---|---|---|---|
| 1 | A typical Monday in summer | Monday, 29 May 2023–Monday, 17 July 2023 | Monday, 24 July 2023 |
| 2 | A typical Sunday in summer | 28 May 2023 (Sunday)–16 July 2023 (Sunday) | 23 July 2023 (Sunday) |
| 3 | A typical day of the weekly electricity price in spring | 23 January 2023 (Monday)–19 March 2023 (Sunday) | Monday, 20 March 2023–Sunday, 26 March 2023. |
| 4 | Typical days of the weekly electricity price in summer | Monday, 1 May 2023–Sunday, 25 June 2023 | 26 June 2023 (Monday)–2 July 2023 (Sunday) |
| 5 | A typical day of the weekly electricity price in autumn | Monday, 31 July 2023–Sunday, 24 September 2023 | Monday, 25 September 2023–Sunday, 1 October 2023. |
| 6 | Typical days of the weekly electricity price in winter | Monday, 30 October 2023–Sunday, 24 December 2023 | Monday, 25 December 2023–Sunday, 31 December 2023 |
| Prediction Model | F | MAE ($/MWh) | RMSE ($/MWh) | MAPE | R2 | Avg. Iteration Time (s) |
|---|---|---|---|---|---|---|
| NSGA-II-RBF | 15 | 22.264 | 28.469 | 8.861% | 0.919 | 12.3 |
| Improved NSGA-II-RBF | 9 | 9.669 | 12.089 | 4.217% | 0.985 | 9.8 |
| Compare Models | MAE | RMSE | MAPE |
|---|---|---|---|
| LSTM | 0.003 | 0.002 | 0.001 |
| Transformer-PSO | 0.012 | 0.008 | 0.004 |
| CNN-BiLSTM | 0.007 | 0.006 | 0.003 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Liu, Z.; Zhang, G.; Sun, Y.; Qiu, S.; Song, S.; Wang, D. Day-Ahead Electricity Price Forecasting for Sustainable Electricity Markets: A Multi-Objective Optimization Approach Combining Improved NSGA-II and RBF Neural Networks. Sustainability 2025, 17, 4551. https://doi.org/10.3390/su17104551
Li C, Liu Z, Zhang G, Sun Y, Qiu S, Song S, Wang D. Day-Ahead Electricity Price Forecasting for Sustainable Electricity Markets: A Multi-Objective Optimization Approach Combining Improved NSGA-II and RBF Neural Networks. Sustainability. 2025; 17(10):4551. https://doi.org/10.3390/su17104551
Chicago/Turabian StyleLi, Chunlong, Zhenghan Liu, Guifan Zhang, Yumiao Sun, Shuang Qiu, Shiwei Song, and Donglai Wang. 2025. "Day-Ahead Electricity Price Forecasting for Sustainable Electricity Markets: A Multi-Objective Optimization Approach Combining Improved NSGA-II and RBF Neural Networks" Sustainability 17, no. 10: 4551. https://doi.org/10.3390/su17104551
APA StyleLi, C., Liu, Z., Zhang, G., Sun, Y., Qiu, S., Song, S., & Wang, D. (2025). Day-Ahead Electricity Price Forecasting for Sustainable Electricity Markets: A Multi-Objective Optimization Approach Combining Improved NSGA-II and RBF Neural Networks. Sustainability, 17(10), 4551. https://doi.org/10.3390/su17104551