
Short-Term Load Forecasting Method for Industrial Buildings Based on Signal Decomposition and Composite Prediction Model

Abstract
1. Introduction
2. Theoretical Background
2.1. Data Preprocessing Model
2.1.1. Variational Mode Decomposition (VMD)
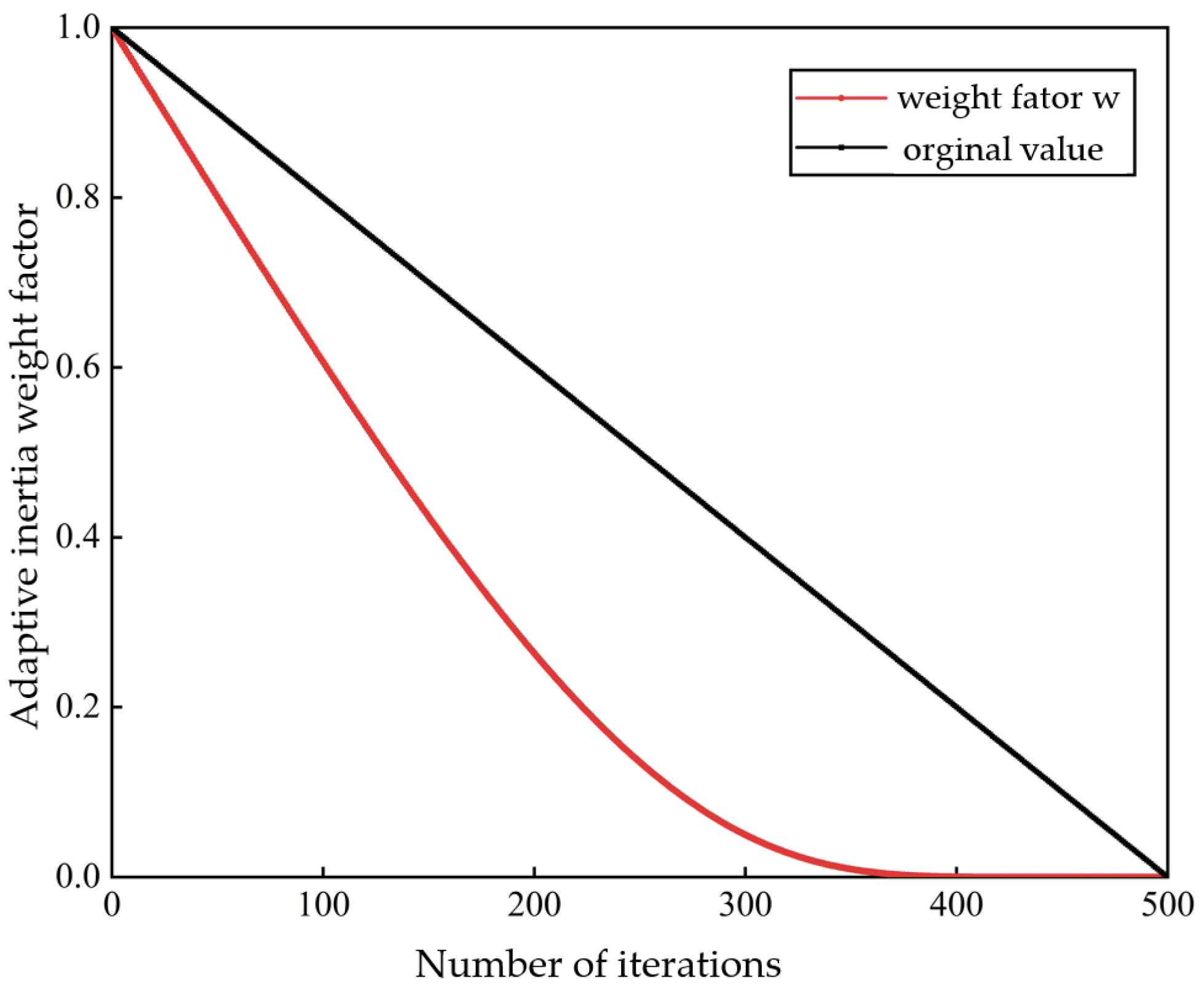
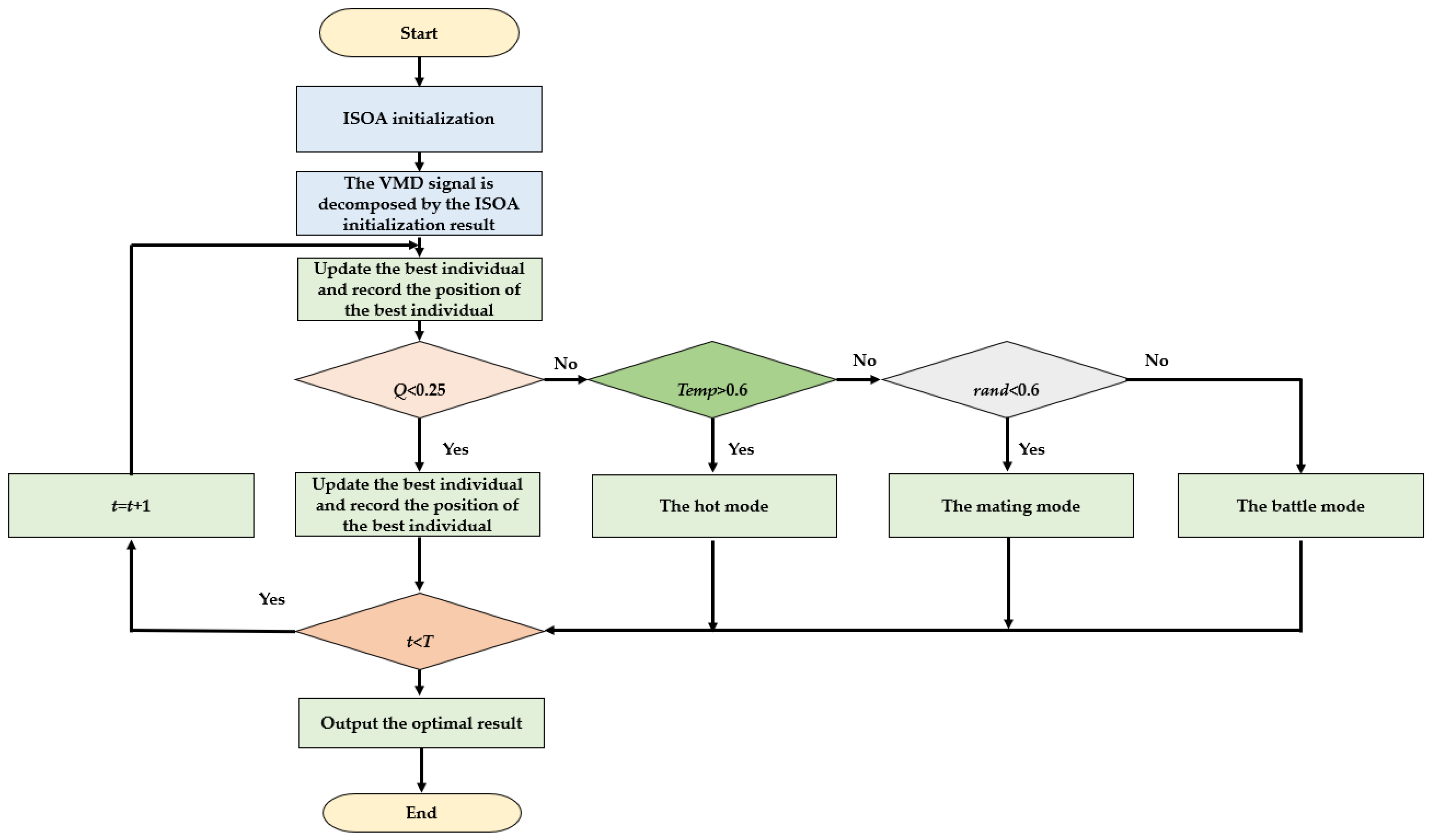
2.1.2. Improved Snake Optimization Algorithm (ISOA)
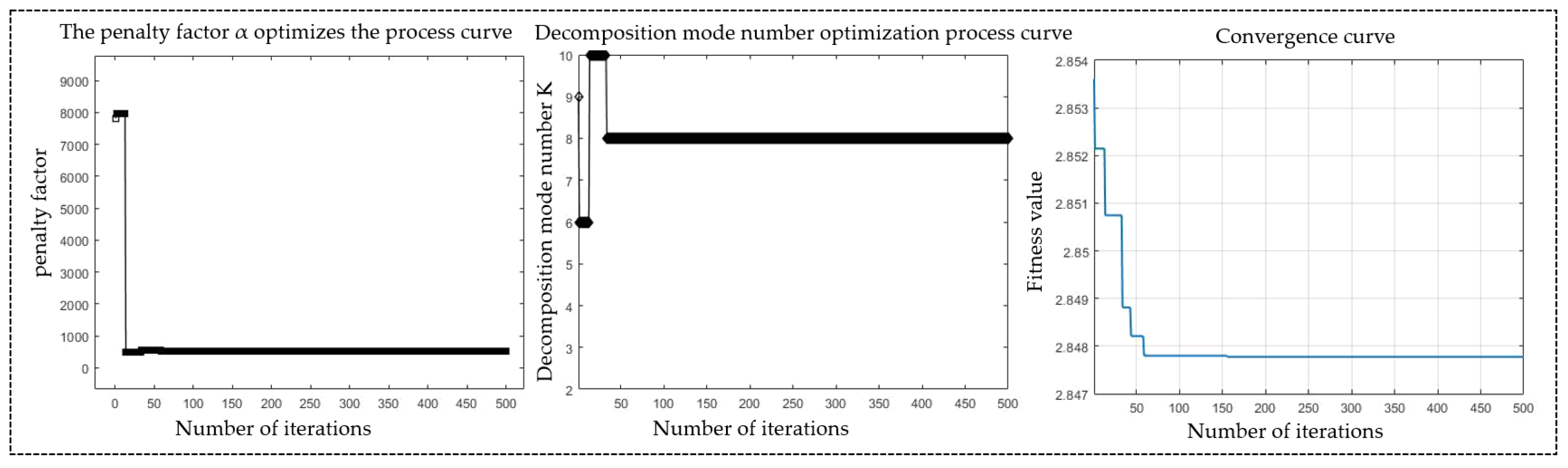
2.1.3. VMD Parameters Optimized Based on ISOA
2.2. Data Prediction Model
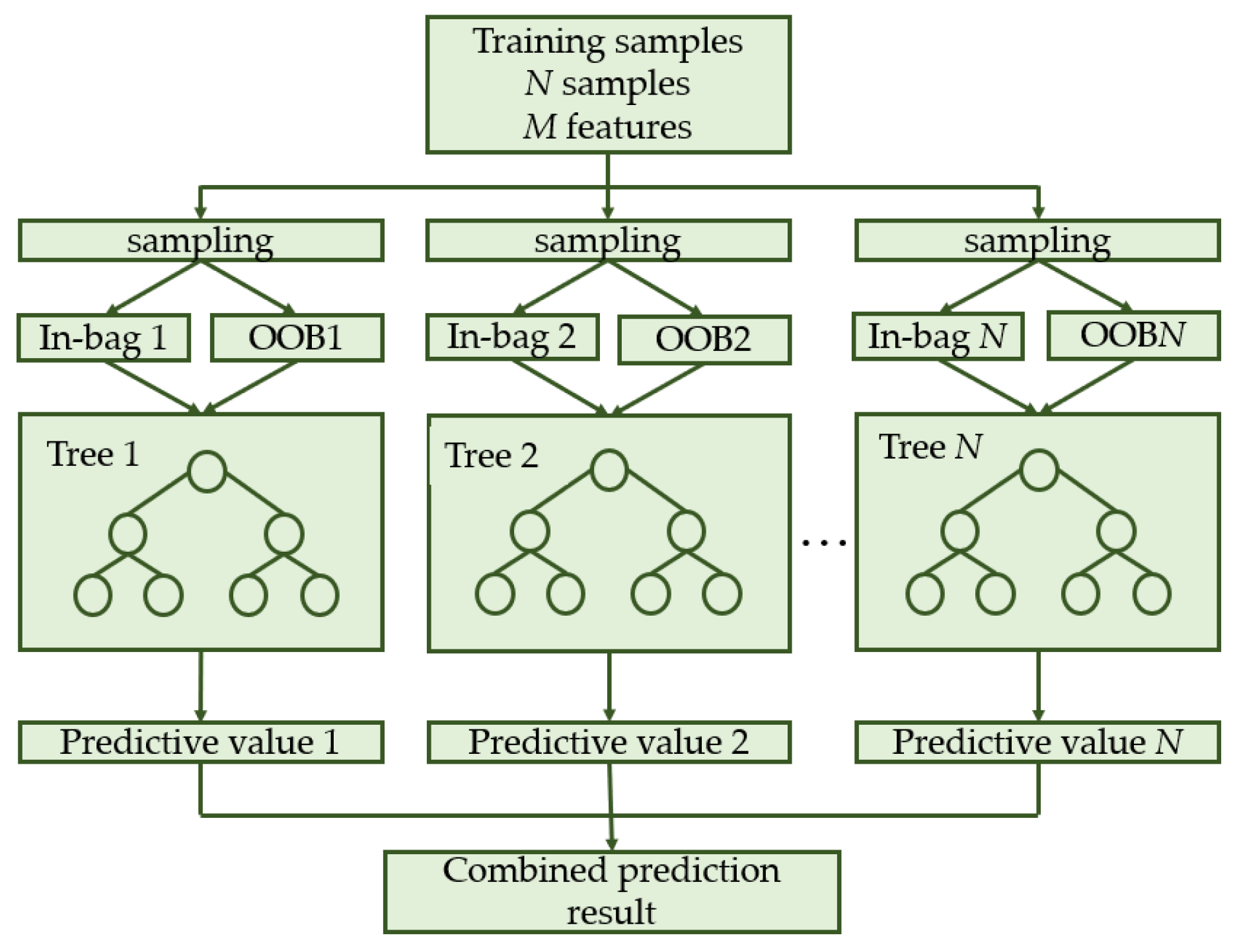
2.2.1. Random Forest (RF)
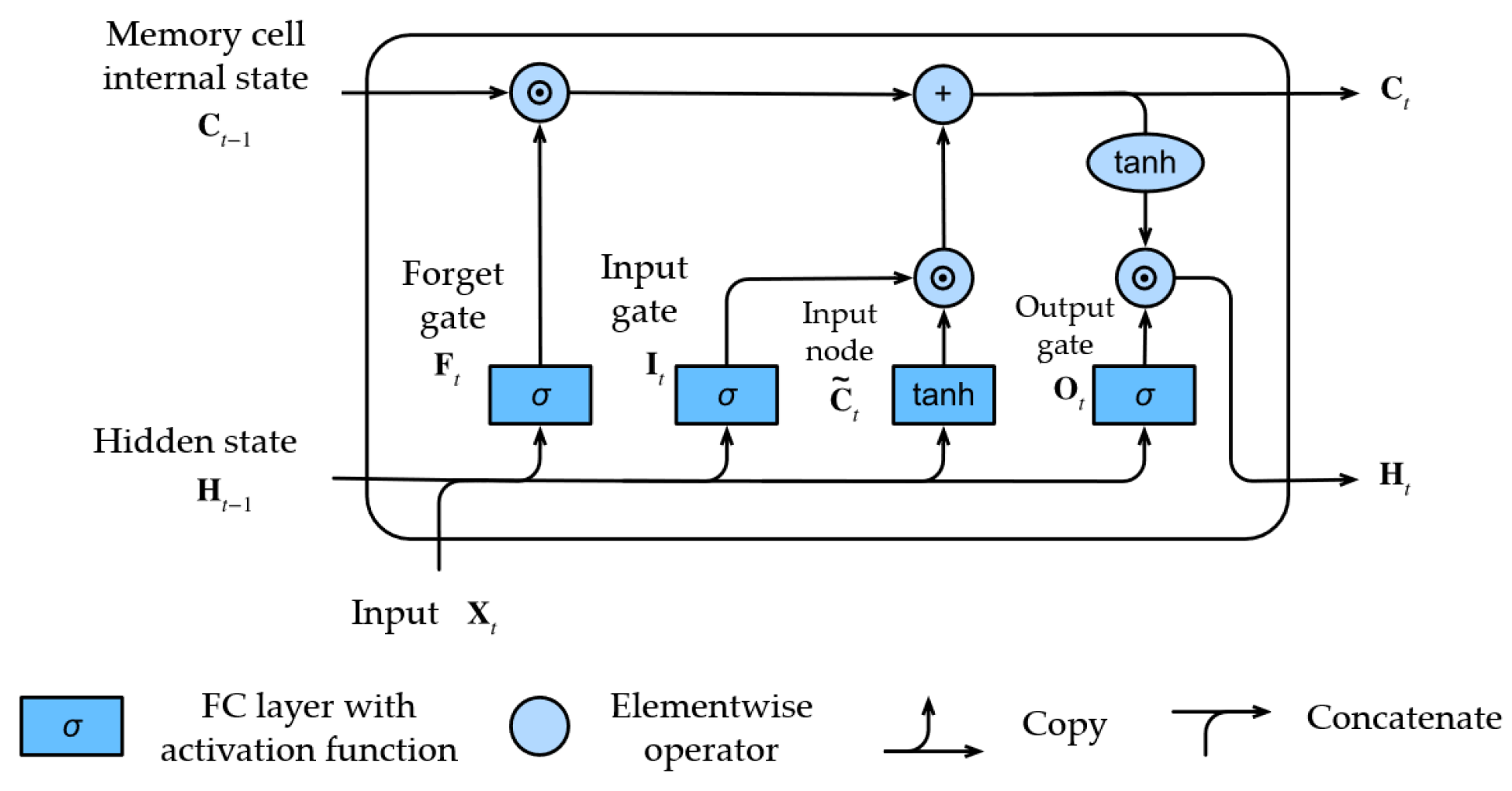
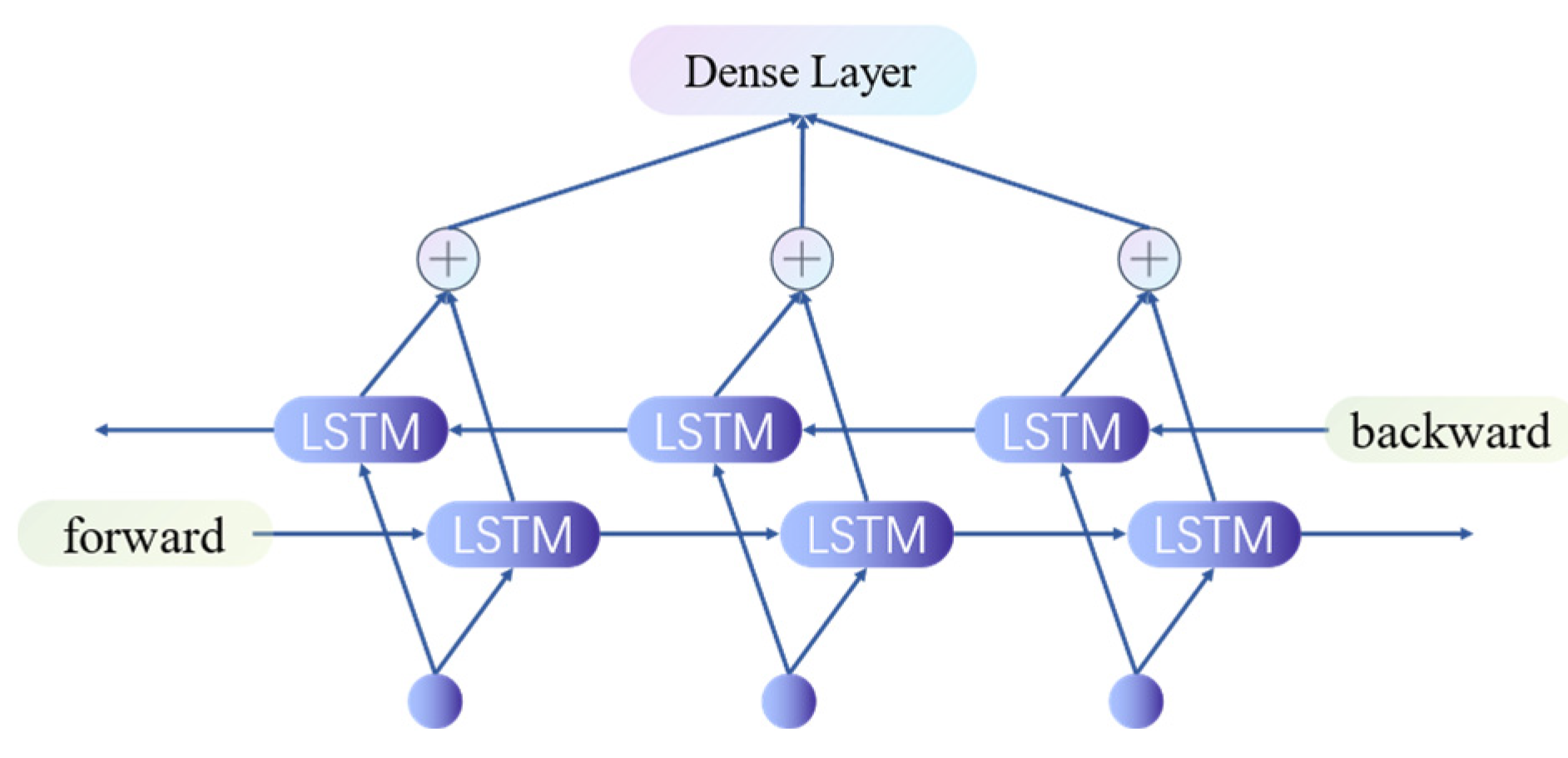
2.2.2. Bidirectional Long Short-Term Memory (BiLSTM)
2.2.3. Attention Mechanism (AM)
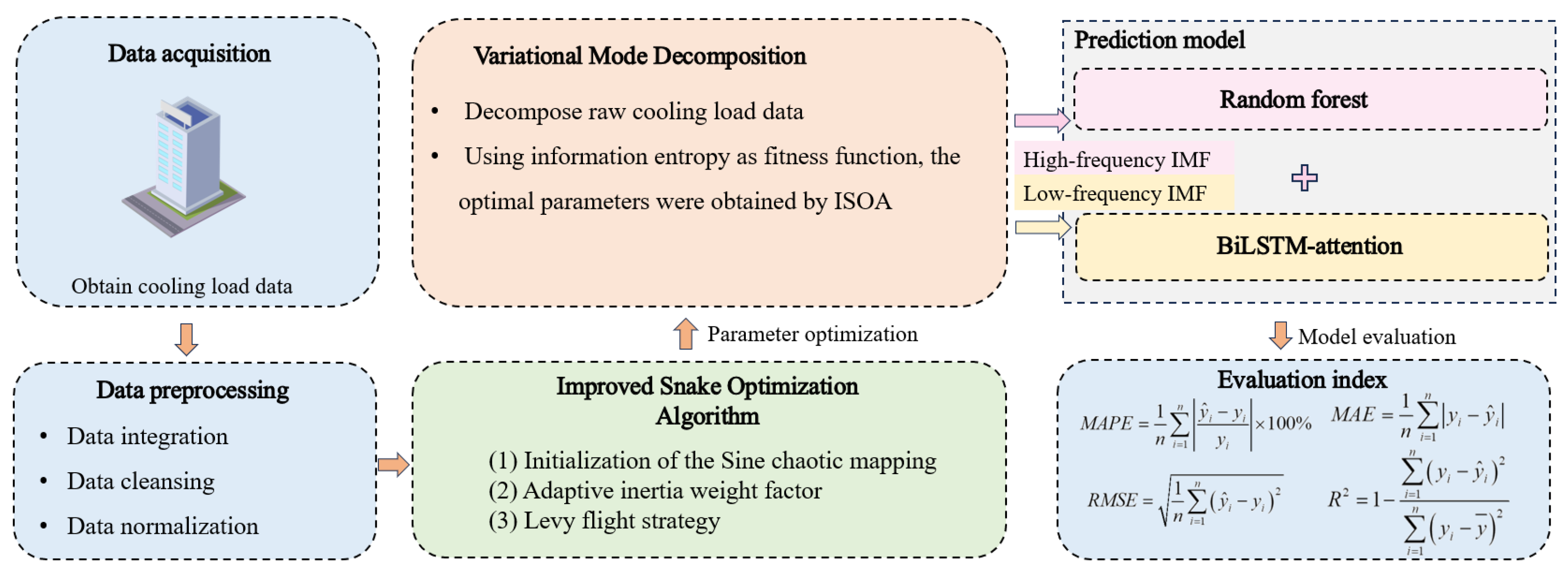
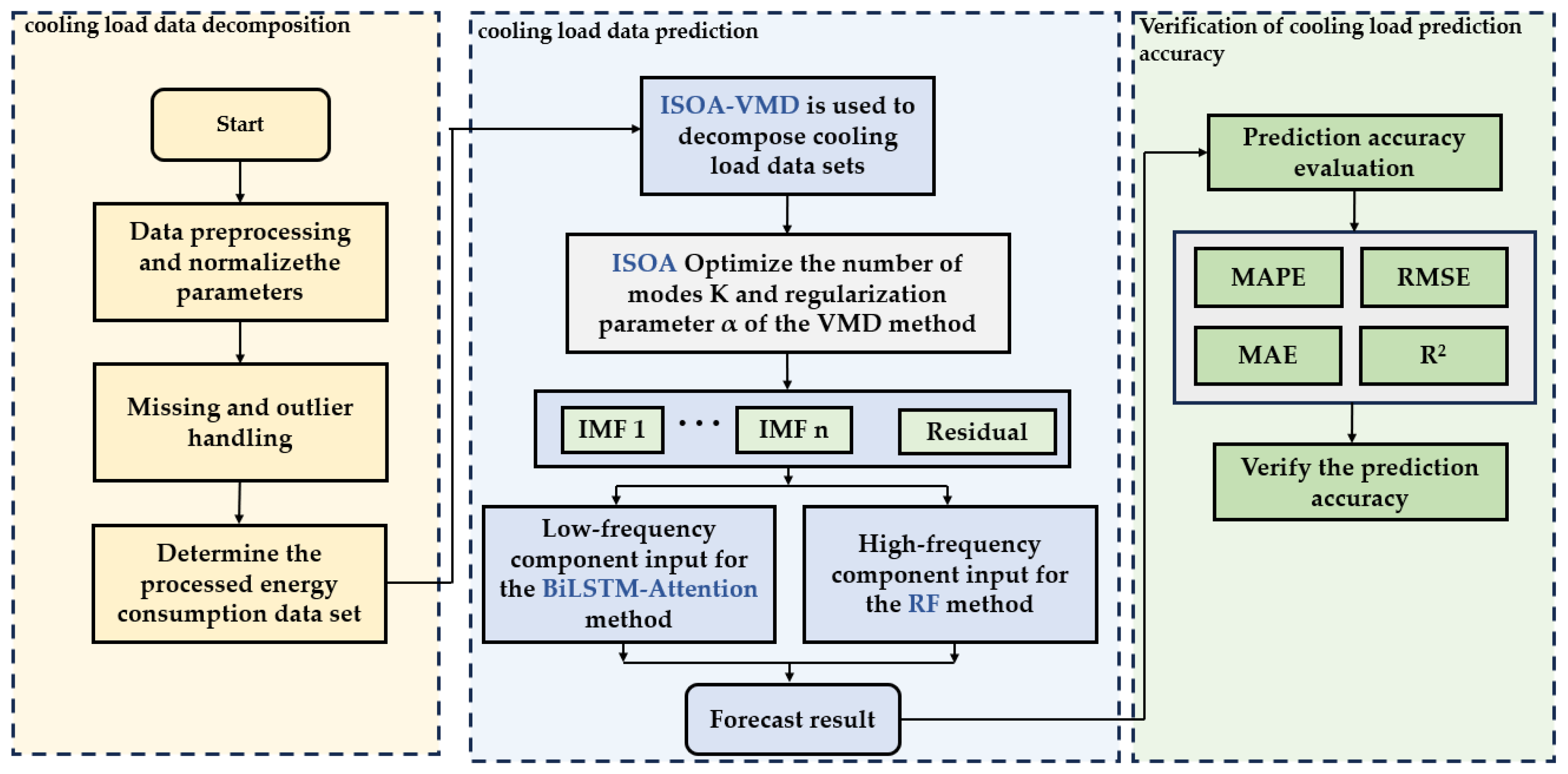
3. Framework of the Proposed Method
4. Experimental Design
4.1. Data
4.2. Evaluation Metrics
4.3. Experimental Settings
5. Results and Discussion
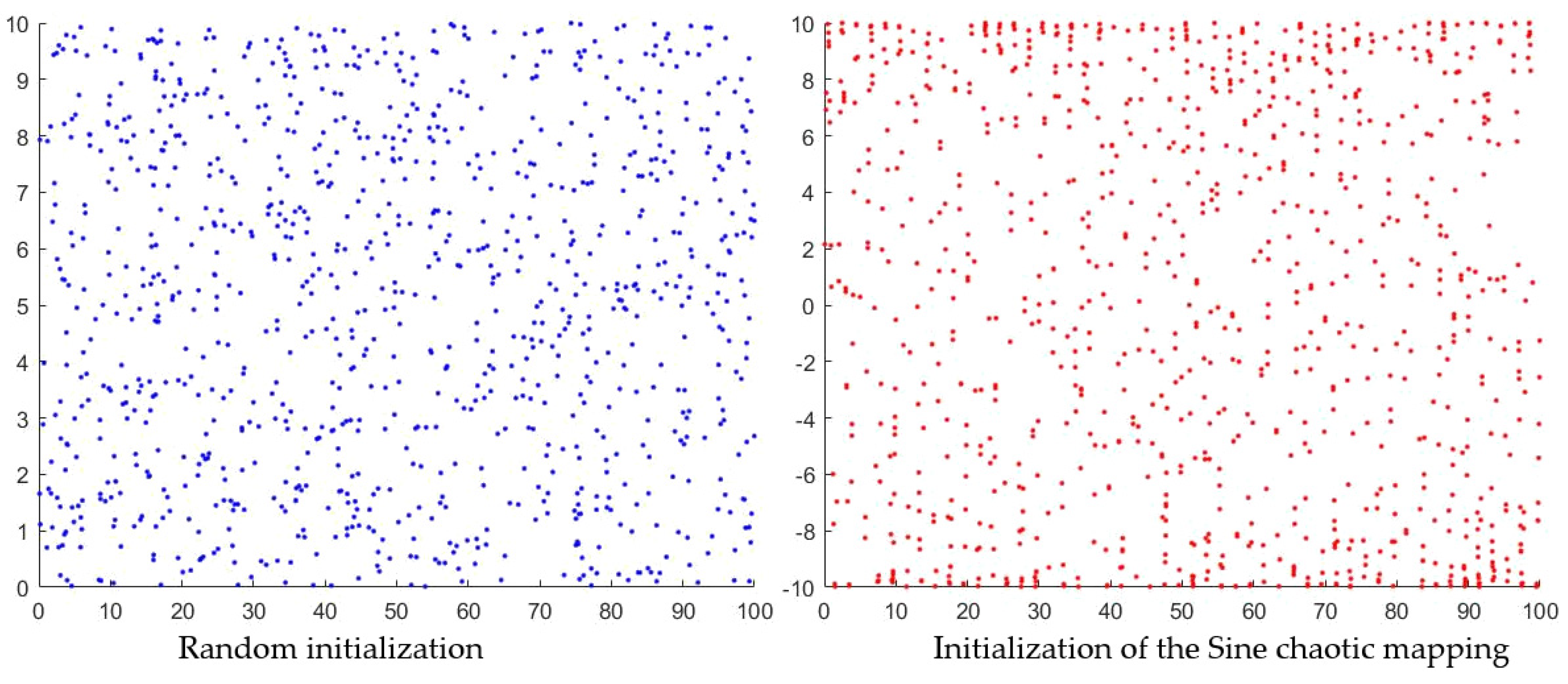
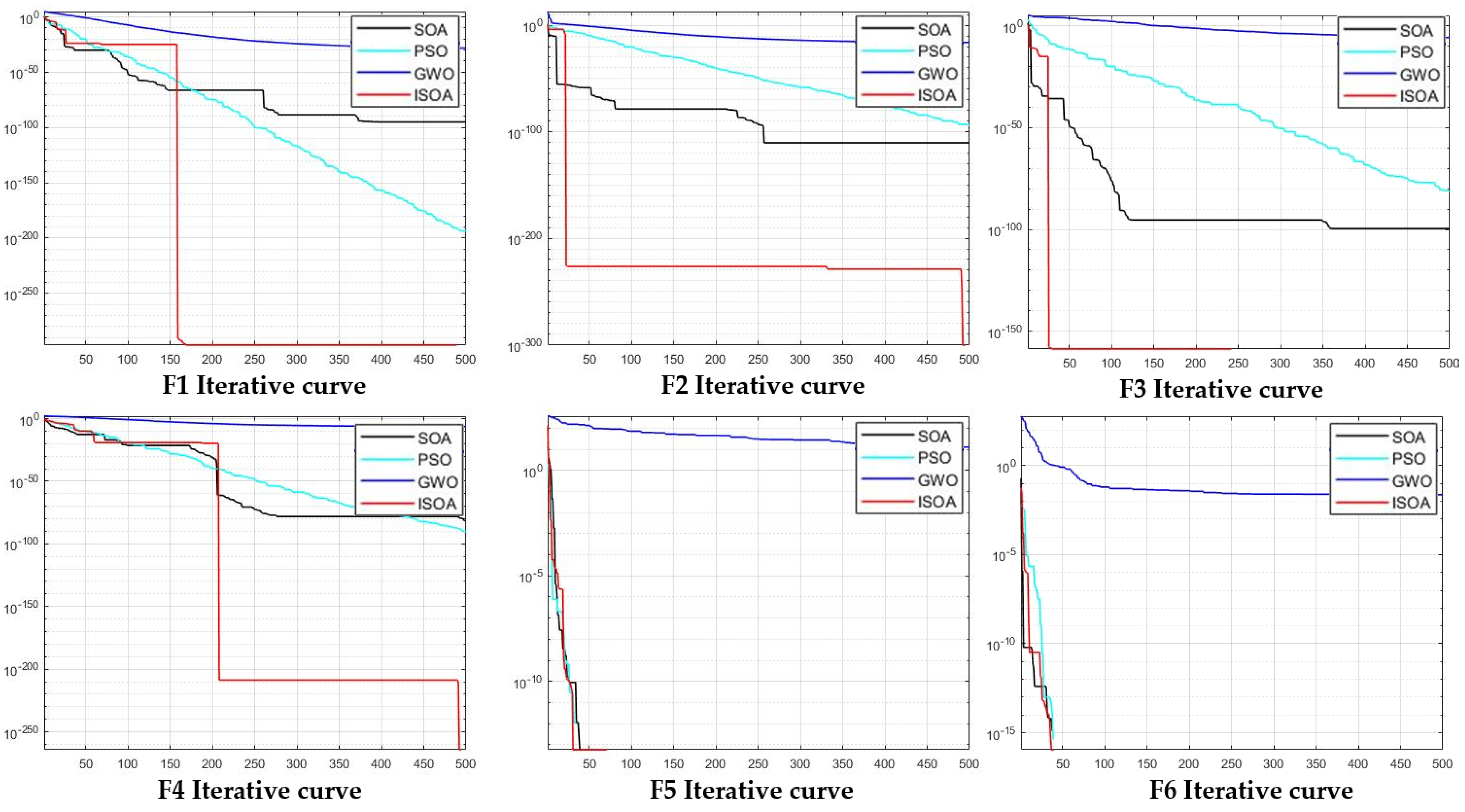
5.1. ISOA Performance Verification
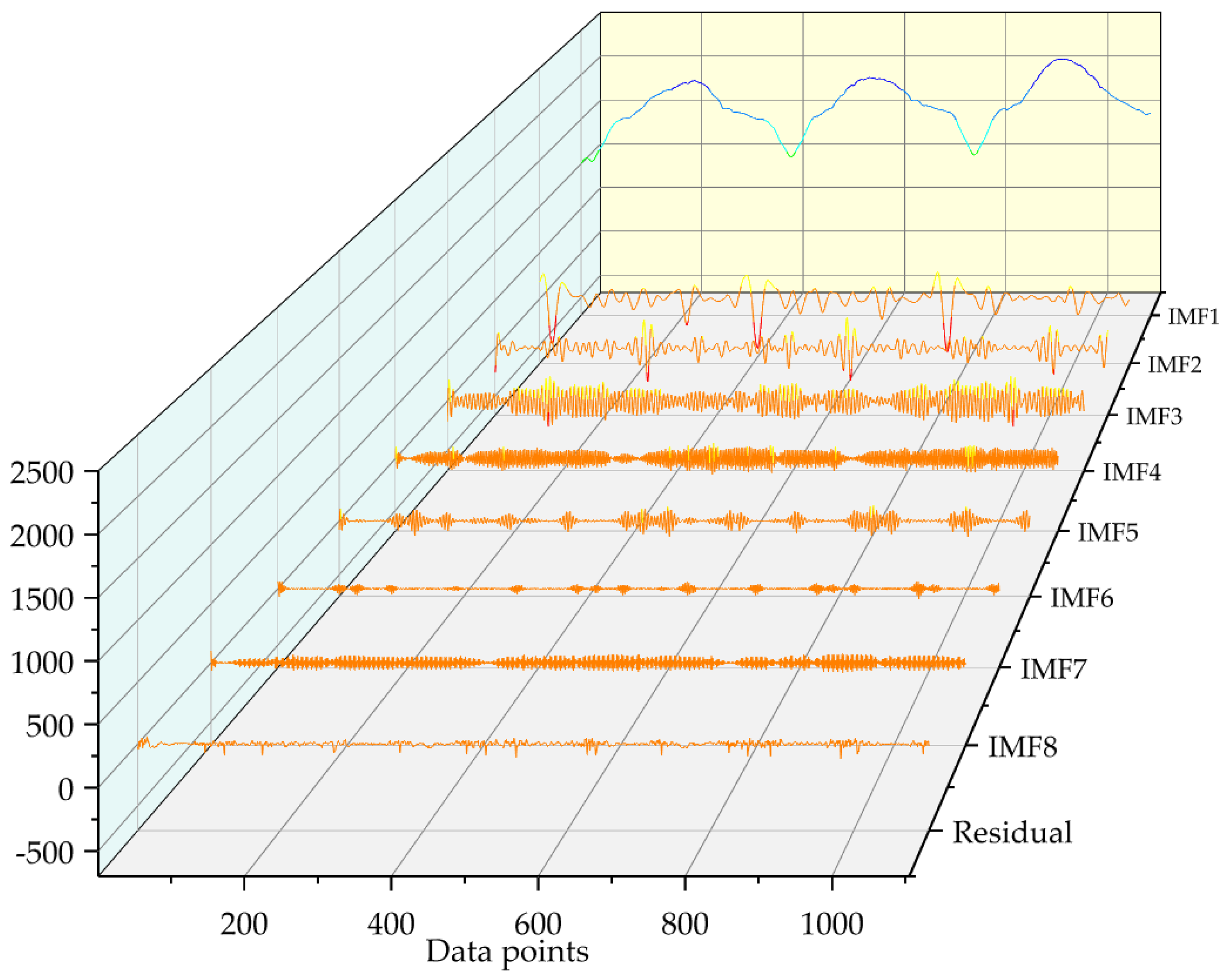
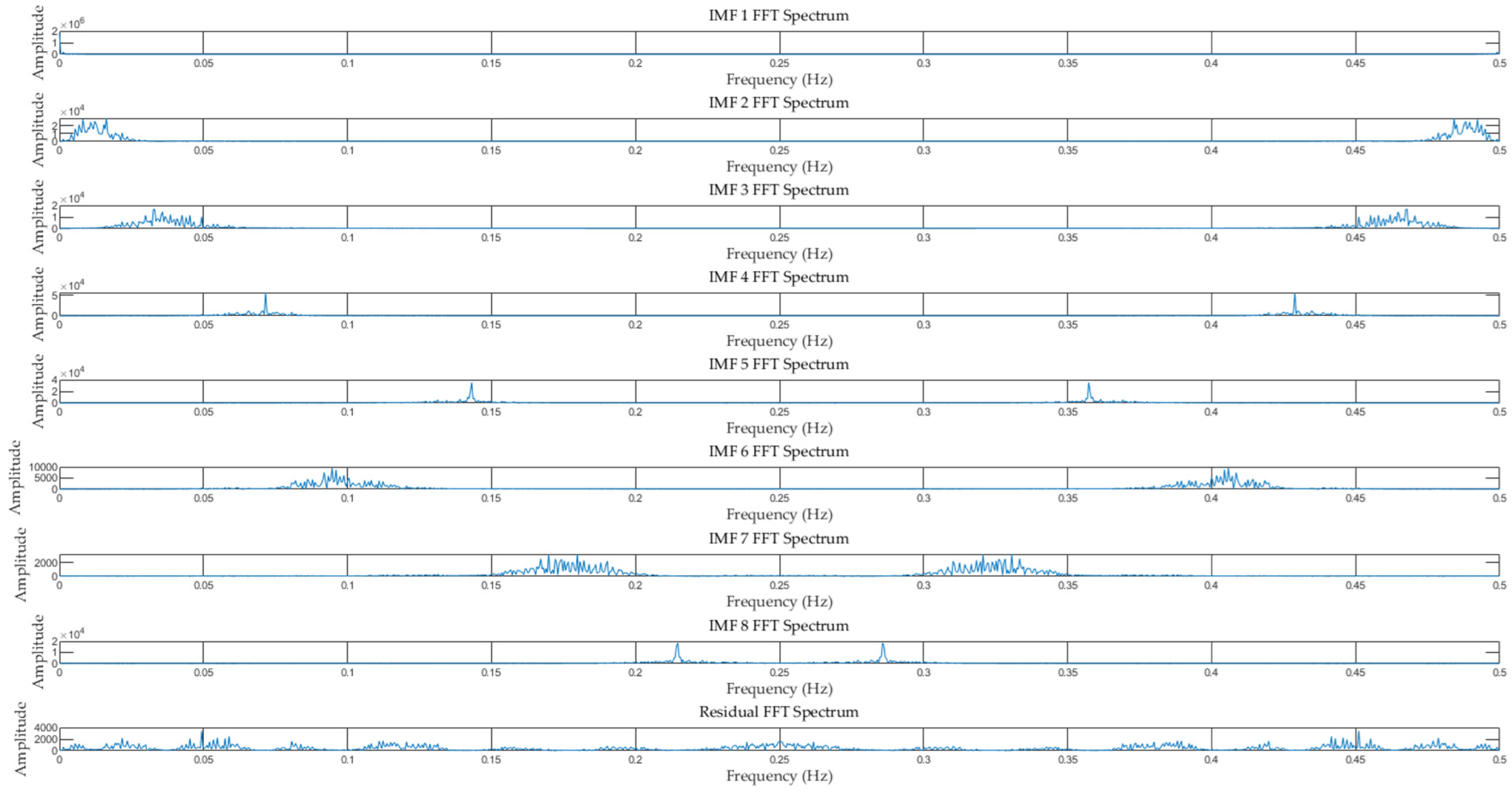
5.2. ISOA-VMD Cooling Load Data Signal Decomposition
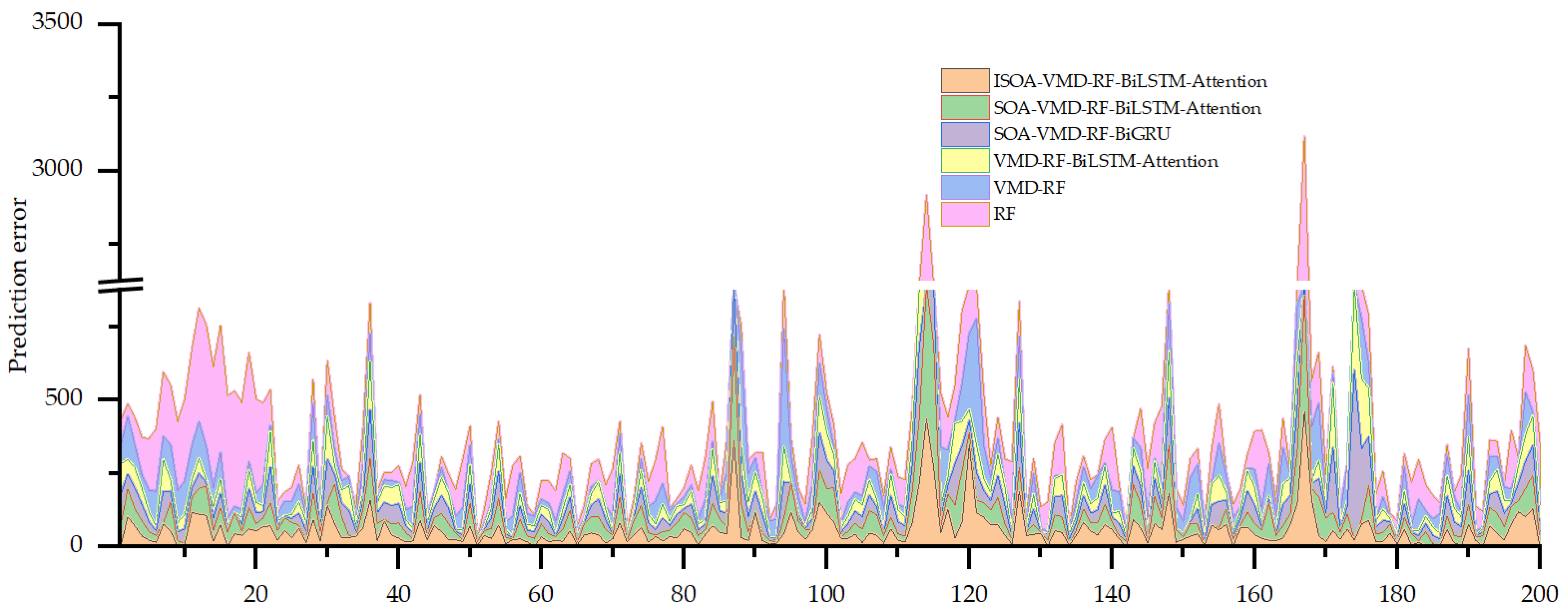
5.3. Performance Validation of the Model
- (1)
- The ISOA–VMD–RF–BiLSTM-attention algorithm outperforms other comparative algorithms in terms of MAE, MAPE, and RMSE for predictions on two industrial building cooling load datasets, while also achieving a higher R2. This indicates good prediction accuracy and stability in the field of cooling load prediction.
- (2)
- The RMSEs of ISO–VMD–RF–BILSTM-attention in two industrial building cooling load data sets were 88.34 and 18.92, compared to 94.99 and 24.77 for SOA–VMD–RF–BiLSTM-attention. Through parameter optimization using the penalty factor for VMD and the number of signal decompositions with envelope entropy as the fitness function, the RMSEs were reduced by approximately 7.1% and 23.6%. This improvement in SOA contributes to enhanced prediction accuracy, especially in complex industrial building scenarios.
5.4. Proof of Concept of the Model
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, N.; Lin, J. The reality and future scenarios of commercial building energy consumption in China. Energy Build. 2008, 40, 2121–2127. [Google Scholar] [CrossRef]
- Kong, M.; Dong, B.; Zhang, R.; O’Neill, Z. HVAC energy savings, thermal comfort and air quality for occupant-centric control through a side-by-side experimental study. Appl. Energy 2022, 306, 117987. [Google Scholar] [CrossRef]
- Zhao, H.; Magoulès, F. A review on the prediction of building energy consumption. Renew. Sustain. Energy Rev. 2012, 16, 3586–3592. [Google Scholar] [CrossRef]
- Gassar, A.A.A.; Cha, S.H. Energy prediction techniques for large-scale buildings towards a sustainable built environment: A review. Energy Build. 2020, 224, 110238. [Google Scholar] [CrossRef]
- Liu, Z.; Quan, Z.; Zhao, Y.; Zhang, W.; Yang, M.; Chang, Z. Mass flow rate prediction of a direct-expansion ice thermal storage system using R134a based on dimensionless correlation and artificial neural network. Energy 2024, 391, 130398. [Google Scholar] [CrossRef]
- Kang, X.; Wang, X.; An, J.; Yan, D. A novel approach of day-ahead cooling load prediction and optimal control for ice-based thermal energy storage (TES) system in commercial buildings. Energy Build. 2022, 275, 112478. [Google Scholar] [CrossRef]
- Wang, Y.; Hou, J.; Zhou, P.; He, Z.; Wei, S.; You, S.; Zhang, H.; Zheng, X. Performance analysis of ice storage tank with smooth-tube and corrugated-tube heat exchangers based on numerical simulation. Appl. Therm. Eng. 2024, 236, 121591. [Google Scholar] [CrossRef]
- Griesbach, M.; König-Haagen, A.; Heberle, F.; Brüggemann, D. Multi-criteria assessment and optimization of ice-energy storage systems in combined heat and cold supply networks of a campus building. Energy Convers. Manage 2023, 287, 117118. [Google Scholar] [CrossRef]
- Mao, Y.; Yu, J.; Zhang, N.; Dong, F.; Wang, M.; Li, X. A hybrid model of commercial building cooling load prediction based on the improved NCHHO-FENN algorithm. J. Build. Eng. 2023, 78, 107660. [Google Scholar] [CrossRef]
- Huang, Y.; Li, C. Accurate heating, ventilation and air conditioning system load prediction for residential buildings using improved ant colony optimization and wavelet neural network. J. Build. Eng. 2021, 35, 101972. [Google Scholar] [CrossRef]
- Pandey, B.; Banerjee, R.; Sharma, A. Coupled EnergyPlus and CFD analysis of PCM for thermal management of buildings. Energy Build. 2021, 231, 110598. [Google Scholar] [CrossRef]
- Cao, J.; Liu, J.; Man, X. A united WRF/TRNSYS method for estimating the heating/cooling load for the thousand-meter scale megatall buildings. Appl. Therm. Eng. 2017, 114, 196–210. [Google Scholar] [CrossRef]
- Vera-García, F.; Rubio-Rubio, J.J.; López-Belchí, A.; Hontoria, E. Modelling and real-data validation of a logistic centre using TRNSYS®: Influences of the envelope, infiltrations and stored goods. Energy Build. 2022, 275, 112474. [Google Scholar] [CrossRef]
- Ahamed, M.S.; Guo, H.; Tanino, K. Modeling heating demands in a Chinese-style solar greenhouse using the transient building energy simulation model TRNSYS. J. Build. Eng. 2020, 29, 101114. [Google Scholar] [CrossRef]
- Mazzeo, D.; Matera, N.; Cornaro, C.; Oliveti, G.; Romagnoni, P.; De Santoli, L. EnergyPlus, IDA ICE and TRNSYS predictive simulation accuracy for building thermal behaviour evaluation by using an experimental campaign in solar test boxes with and without a PCM module. Energy Build. 2020, 212, 109812. [Google Scholar] [CrossRef]
- Mao, Y.; Yu, J.; Zhang, N.; Zhou, M.; Wang, M. Prediction of thermal comfort indoors and cooling loads based on reasonable zoning using the improved HHO with multi-strategy fusion-FENN algorithm. Build. Environ. 2023, 245, 110944. [Google Scholar] [CrossRef]
- Cao, W.; Yu, J.; Chao, M.; Wang, J.; Yang, S.; Zhou, M.; Wang, M. Short-term energy consumption prediction method for educational buildings based on model integration. Energy. 2023, 283, 128580. [Google Scholar] [CrossRef]
- Xie, M.; Qiu, Y.; Liang, Y.; Zhou, Y.; Liu, Z.; Zhang, G. Policies, applications, barriers and future trends of building information modeling technology for building sustainability and informatization in China. Energy Rep. 2022, 8, 7107–7126. [Google Scholar] [CrossRef]
- Zhang, F.; Chan, A.P.C.; Darko, A.; Chen, Z.; Li, D. Integrated applications of building information modeling and artificial intelligence techniques in the AEC/FM industry. Autom. Constr. 2022, 139, 104289. [Google Scholar] [CrossRef]
- Lu, C.; Gu, J.; Lu, W. An improved attention-based deep learning approach for robust cooling load prediction: Public building cases under diverse occupancy schedules. Sustain. Cities Soc. 2023, 96, 104679. [Google Scholar] [CrossRef]
- Abdou, N.; El Mghouchi, Y.; Jraida, K.; Hamdaoui, S.; Hajou, A.; Mouqallid, M. Prediction and optimization of heating and cooling loads for low energy buildings in Morocco: An application of hybrid machine learning methods. J. Build. Eng. 2022, 61, 105332. [Google Scholar] [CrossRef]
- Emhamed, A.A.; Shrivastava, J. Electrical load distribution forecasting utilizing support vector model (SVM). Mat. Today Proc. 2021, 47, 41–46. [Google Scholar] [CrossRef]
- Duan, H.; Yin, X.; Kou, H.; Wang, J.; Zeng, K.; Ma, F. Regression prediction of hydrogen enriched compressed natural gas (HCNG) engine performance based on improved particle swarm optimization back propagation neural network method (IMPSO-BPNN). Fuel 2023, 331, 125872. [Google Scholar] [CrossRef]
- Hu, Y.; Qin, L.; Li, S.; Li, X.; Zhou, R.; Li, Y.; Sheng, W. Adaptive corrected parameters algorithm applied in cooling load prediction based on black-box model: A case study for subway station. Energy Build. 2023, 297, 113429. [Google Scholar] [CrossRef]
- Lei, L.; Shao, S. Prediction model of the large commercial building cooling loads based on rough set and deep extreme learning machine. J. Build. Eng. 2023, 80, 107958. [Google Scholar] [CrossRef]
- Song, C.; Yang, H.; Meng, X.B.; Yang, P.; Cai, J.; Bao, H.; Xu, K. A novel deep-learning framework for short-term prediction of cooling load in public buildings. J. Clean. Prod. 2024, 434, 139796. [Google Scholar] [CrossRef]
- Kavitha, R.J.; Thiagarajan, C.; Priya, P.I.; Anand, A.V.; Al-Ammar, E.A.; Santhamoorthy, M.; Chandramohan, P. Improved Harris Hawks Optimization with Hybrid Deep Learning Based Heating and Cooling Load Prediction on residential buildings. Chemosphere 2022, 309, 136525. [Google Scholar] [CrossRef] [PubMed]
- Dong, F.; Yu, J.; Quan, W.; Xiang, Y.; Li, X.; Sun, F. Short-term building cooling load prediction model based on DwdAdam-ILSTM algorithm: A case study of a commercial building. Energy Build. 2022, 272, 112337. [Google Scholar] [CrossRef]
- Yan, X.; Ji, X.; Meng, Q.; Sun, H.; Lei, Y. A hybrid prediction model of improved bidirectional long short-term memory network for cooling load based on PCANet and attention mechanism. Energy 2024, 292, 130388. [Google Scholar] [CrossRef]
- Guo, J.; Yun, S.; Meng, Y.; He, N.; Ye, D.; Zhao, Z.; Jia, L.; Yang, L. Prediction of heating and cooling loads based on light gradient boosting machine algorithms. Build. Environ. 2023, 236, 110252. [Google Scholar] [CrossRef]
- Gopila, M.; Suresh, G.; Prasad, D. Random decision forest (RDF) and crystal structure algorithm (CryStAl) for uncertainty consideration of RES & load demands with optimal design of hybrid CCHP systems. Energy 2023, 282, 128545. [Google Scholar]
- Karijadi, I.; Chou, S.Y. A hybrid RF-LSTM based on CEEMDAN for improving the accuracy of building energy consumption prediction. Energy Build. 2022, 259, 111908. [Google Scholar] [CrossRef]
- Xu, H.; Liu, Y.; Li, J.; Yu, H.; An, X.; Ma, K.; Liang, Y.; Hu, X.; Zhang, H. Study on the Influence of High and Low Temperature Environment on the Energy Consumption of Battery Electric Vehicles. Energy Rep. 2023, 9, 835–842. [Google Scholar] [CrossRef]
- Pan, J.; Jing, B.; Jiao, X.; Wang, S. Analysis and application of grey wolf optimizer-long short-term memory. IEEE Access 2020, 8, 121460–121468. [Google Scholar] [CrossRef]
- Liu, Z.; Yu, J.; Feng, C.; Su, Y.; Dai, J.; Chen, Y. A hybrid forecasting method for cooling load in large public buildings based on improved long short term memory. J. Build. Eng. 2023, 76, 107238. [Google Scholar] [CrossRef]
- Song, Y.; Xie, H.; Zhu, Z.; Ji, R. Predicting energy consumption of chiller plant using WOA-BiLSTM hybrid prediction model: A case study for a hospital building. Energy Build. 2023, 300, 113642. [Google Scholar] [CrossRef]
- Hashim, F.A.; Hussien, A.G. Snake Optimizer: A novel meta-heuristic optimization algorithm. Knowl. Based Syst. 2022, 242, 108320. [Google Scholar] [CrossRef]
- Fang, M.; Zhang, F.; Yang, Y.; Cai, J.; Bao, H.; Xu, K. The influence of optimization algorithm on the signal prediction accuracy of VMD-LSTM for the pumped storage hydropower unit. J. Energy Storage 2024, 78, 110187. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, H. A novel hybrid model based on GA-VMD, sample entropy reconstruction and BiLSTM for wind speed prediction. Measurement 2023, 222, 113643. [Google Scholar] [CrossRef]
- Sareen, K.; Panigrahi, B.K.; Shikhola, T.; Chawla, A. A robust De-Noising Autoencoder imputation and VMD algorithm based deep learning technique for short-term wind speed prediction ensuring cyber resilience. Energy 2023, 283, 129080. [Google Scholar] [CrossRef]
- Yang, B.; Li, M.; Qin, R.; Luo, E.; Duan, J.; Liu, B.; Wang, Y.; Wang, J.; Jiang, L. Extracted power optimization of hybrid wind-wave energy converters array layout via enhanced snake optimizer. Energy 2024, 293, 130529. [Google Scholar] [CrossRef]
- Yan, C.; Razmjooy, N. Optimal lung cancer detection based on CNN optimized and improved Snake optimization algorithm. Biomed. Signal Process. Control. 2023, 86, 105319. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhang, Z.; He, X.; Luo, E.; Duan, J.; Liu, B.; Wang, Y.; Wang, J.; Jiang, L. Efficient and accurate TEC modeling and prediction approach with random forest and Bi-LSTM for large-scale region. Adv. Space Res. 2024, 73, 650–662. [Google Scholar] [CrossRef]
- Zrira, N.; Kamal-Idrissi, A.; Farssi, R.; Khan, H.A. Time series prediction of sea surface temperature based on BiLSTM model with attention mechanism. J. Sea Res. 2024, 198, 102472. [Google Scholar] [CrossRef]
- Guo, J.; Liu, M.; Luo, P.; Chen, X.; Yu, H.; Wei, X. Attention-based BILSTM for the degradation trend prediction of lithium battery. Energy Rep. 2023, 9, 655–664. [Google Scholar] [CrossRef]
- Shan, L.; Liu, Y.; Tang, M.; Yang, M. CNN-BiLSTM hybrid neural networks with attention mechanism for well log prediction. J. Pet. Sci. Eng. 2021, 205, 108838. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Building Physical Characteristic | Detailed Information |
|---|---|
| Building height | 45 m |
| Building footprint | 28,000 Square meter |
| Building air conditioning coverage | 75% |
| Building insulation system | Polystyrene foam and polyurethane foam |
| Evaluation Index | Formula | Description |
|---|---|---|
| MAPE | Calculates the average of the absolute differences between predicted and actual values, divided by actual values, expressed as a percentage. | |
| RMSE | Measures the square root of the average squared differences between observed and predicted values. | |
| MAE | Computes the average of the absolute differences between observed values and model predictions. | |
| R2 | Indicates the proportion of the variance in the dependent variable that is predictable from the independent variable. |
| Function | Analytic Expression | Dim | Initial Range | Optimal Value |
|---|---|---|---|---|
| 30 | [−100, 100] | 0 | ||
| 30 | [−10, 10] | 0 | ||
| 30 | [−100, 100] | 0 | ||
| 30 | [−100, 100] | 0 | ||
| 30 | [−5.12, 5.12] | 0 | ||
| 30 | [−600, 600] | 0 |
| Algorithm Name | Basic Setup | Parameter Setting |
|---|---|---|
| SOA | , , | |
| PSO | ||
| GWO | , | |
| ISOA | , , |
| Model | MAE | MAPE | RMSE | R2 |
|---|---|---|---|---|
| ISOA-VMD-RF-BiLSIM-attention | 58.71 | 0.042 | 88.34 | 0.938 |
| SOA-VMD-RF-BiLSIM-attention | 59.29 | 0.043 | 94.99 | 0.927 |
| SOA-VMD-RF-BiCRU | 57.38 | 0.046 | 99.21 | 0.921 |
| VMD-RF-BiLSIM-attention | 63.88 | 0.047 | 100.32 | 0.918 |
| VMD-RF | 77.72 | 0.049 | 123.69 | 0.876 |
| RF | 118.38 | 0.062 | 171.052 | 0.763 |
| Model | MAE | MAPE | RMSE | R2 |
|---|---|---|---|---|
| ISOA-VMD-RF-BiLSIM-attention | 12.18 | 0.013 | 18.92 | 0.954 |
| SOA-VMD-RF-BiLSIM-attention | 21.47 | 0.019 | 24.77 | 0.938 |
| SOA-VMD-RF-BiCRU | 28.45 | 0.028 | 34.34 | 0.923 |
| VMD-RF-BiLSIM-attention | 33.54 | 0.031 | 42.72 | 0.922 |
| VMD-RF | 45.37 | 0.043 | 48.21 | 0.921 |
| RF | 67.26 | 0.058 | 63.44 | 0.879 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, W.; Fan, L. Short-Term Load Forecasting Method for Industrial Buildings Based on Signal Decomposition and Composite Prediction Model. Sustainability 2024, 16, 2522. https://doi.org/10.3390/su16062522
Zhao W, Fan L. Short-Term Load Forecasting Method for Industrial Buildings Based on Signal Decomposition and Composite Prediction Model. Sustainability. 2024; 16(6):2522. https://doi.org/10.3390/su16062522
Chicago/Turabian StyleZhao, Wenbo, and Ling Fan. 2024. "Short-Term Load Forecasting Method for Industrial Buildings Based on Signal Decomposition and Composite Prediction Model" Sustainability 16, no. 6: 2522. https://doi.org/10.3390/su16062522
APA StyleZhao, W., & Fan, L. (2024). Short-Term Load Forecasting Method for Industrial Buildings Based on Signal Decomposition and Composite Prediction Model. Sustainability, 16(6), 2522. https://doi.org/10.3390/su16062522