1. Introduction
Landslides are natural geological disasters that can cover large areas, cause serious harm and have complex conditions; notably, they are a manifestation of geomorphological evolution [
1]. Located in the eastern part of Asia, China has complex geological structures and is a country of extensive human activities that has suffered from landslides for a long time [
2,
3,
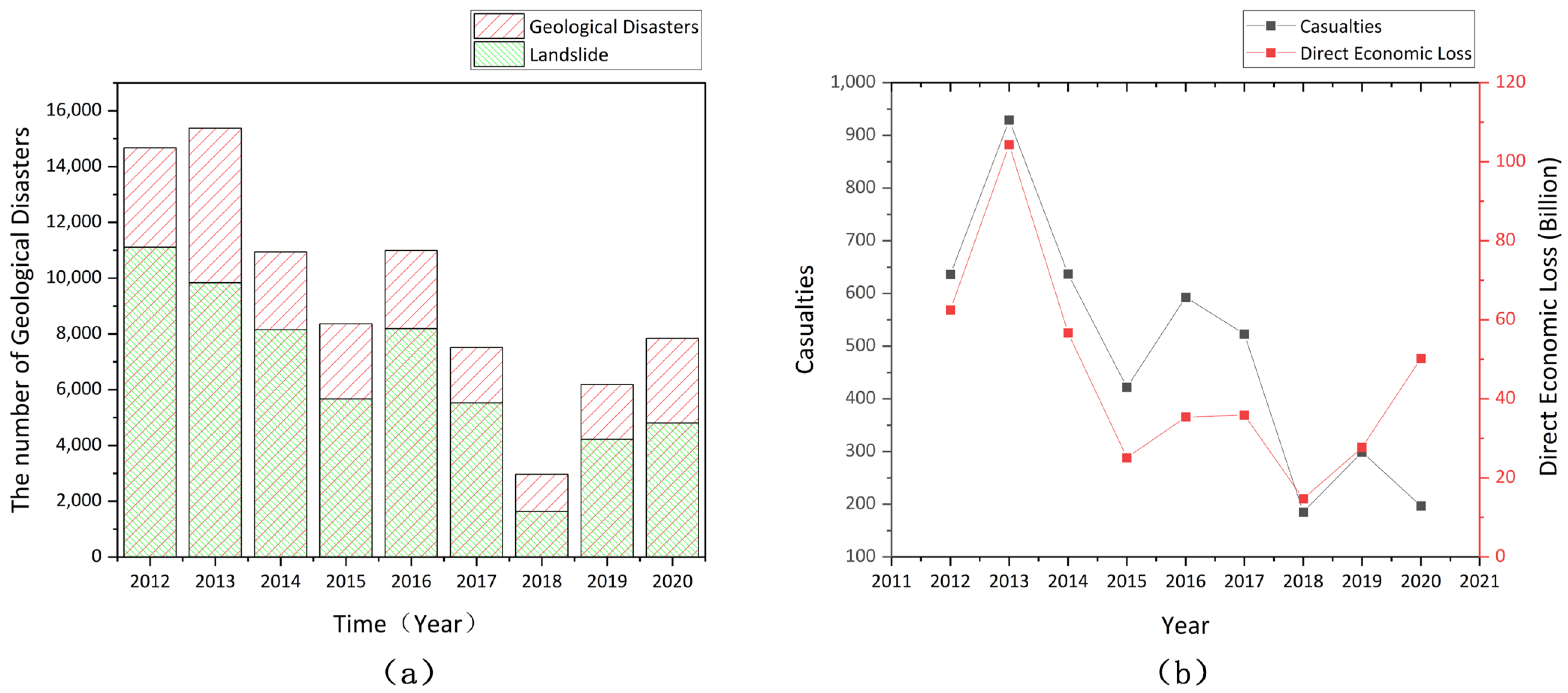
4]. According to data from the National Bureau of Statistics and the National Geological Disaster Bulletin, in the past ten years, from 2012 to 2020, a total of 84,846 geological disasters (landslides, collapses, mudslides, ground subsidence, etc.), including 59,140 landslides, which account for 69.7% of all geological disasters, occurred in China. To date, there have been a total of 4421 casualties from geological disasters, resulting in a direct economic loss of RMB 41.26 billion [
5], as shown in
Figure 1. Scholars have conducted qualitative, semiquantitative, semiqualitative and qualitative research on landslide susceptibility mapping (LSM) and have developed many applicable models. However, relatively little research has been conducted on landslide factors, especially with the gradual deepening of the understanding of landslide phenomena, and it has become necessary to add land use (LU) factors to LSM studies. The accuracy of LU factors is extremely dependent on the quality of remote sensing (RS) images, the choice of classifier, and the subjective judgment of the operator. Thus, LU factors can be unstable, which leads to unstable land use change (LUC) factors. Therefore, this paper focuses on the influence of the band math (band) factor, which is relatively stable and not subjectively influenced by the operator, on LSM.
Scholars around the world use qualitative or quantitative methods for LSM analysis. Qualitative methods rely on expert opinions and are highly subjective, while quantitative methods focus on the relationship between various factors and landslide occurrence [
6,
7]. With the development of geographic information systems (GISs) and RS technologies in recent years, as well as the continuous innovation and optimization of computer software and hardware, machine learning algorithms (MLAs) have been widely used in LSM and use different MLA models, such as logistic regression (LR) [
8,
9,
10], artificial neural network (ANN) [
11,
12,
13], support vector machine (SVM) [
14,
15,
16,
17,
18], Bayesian algorithm [
19,
20,
21], random forest (RF) [
22,
23], extreme gradient boosting (XGBoost) [
24,
25], k-fold cross-validation (CV) [
26,
27] and ensemble learning [
28] models. With the growth of deep learning, convolutional neural networks (CNNs) have also been applied to LSM and provide good predictive ability [
29,
30,
31,
32]. Although the above models have displayed good applicability in the field of LSM, there is no single model that works best in all scenarios, so the performance of each model needs to be compared in different situations [
33]. The application of various models in LSM is relatively mature, but research on landslide factors is relatively rare.
In recent years, with the gradual deepening of the understanding of the mechanisms of landslide occurrence, scholars have gradually given more attention to LSM factors and, in particular, have obtained a more profound understanding of the crucial role of human engineering activities in the occurrence of landslides [
34,
35,
36]; thus, LU factors have received some attention from researchers [
37,
38,
39,
40]. Notably, the time factor was added to the LU factor obtain the LUC factor, which has been gradually recognized by scholars and used in LSM. Soma and Kubota et al. [
41,
42,
43] used the LUC factor for LSM in multiple studies and believed that it is an important factor in LSM. Meneses et al. [
44] evaluated the impacts of LU and LUC factors on landslide susceptibility zonation (LSZ) in a road network in the Zêzere watershed in Portugal. Chen et al. [
45] selected Zhushan town, Xuan’en, as the study area and discussed the influence of LU and LUC factors on LSM. Although the importance of LU/LUC factors in LSM has been gradually recognized, the LU/LUC factors obtained from field geological surveys are characterized by poor timeliness. Moreover, it is difficult to obtain high classification accuracy using a traditional RS classification algorithm based on statistics when the ground environment is complex [
46], and the LU/LUC factors obtained by using various classifiers through RS images rely heavily on operator experience, professional knowledge and subjective judgment and often lack accuracy. With the rapid development of RS technologies, various indices have been obtained through the band math of RS image data and used by scholars in LSM research. Ma et al. [
47] used QuickBird RS images along the Yalu River estuary to combine principal component analysis (PCA), the maximum likelihood method and band math, introduced the concept of stratification and proposed a high-resolution land use RS classification method. Hassan [
48] used the normalized difference vegetation index (NDVI), normalized difference water index (NDWI) and normalized difference building index (NDBI) to represent vegetation, water bodies and built-up land categories, respectively, and applied unsupervised classification results to show that the spectral features of the three land categories were easier to distinguish in the obtained images than in the original images (in Arabic). Jawak et al. [
49] used the mean values of different spectral bands and spectral metrics such as the NDVI, NDWI and NDBI for classification to determine the difference thresholds between different LU/LUC categories. Yang [
50] used the ENVI as a platform, applied the band math tool to obtain the NDVI with outliers removed and established a mixed-pixel decomposition model based on the principle of pixel dichotomy to estimate and optimize vegetation coverage. RS images provide various indices through band math and spectral features, and they can be used to simplify manual and tedious operations and reduce the influence of operator subjectivity on LU/LUC division to a considerable extent.
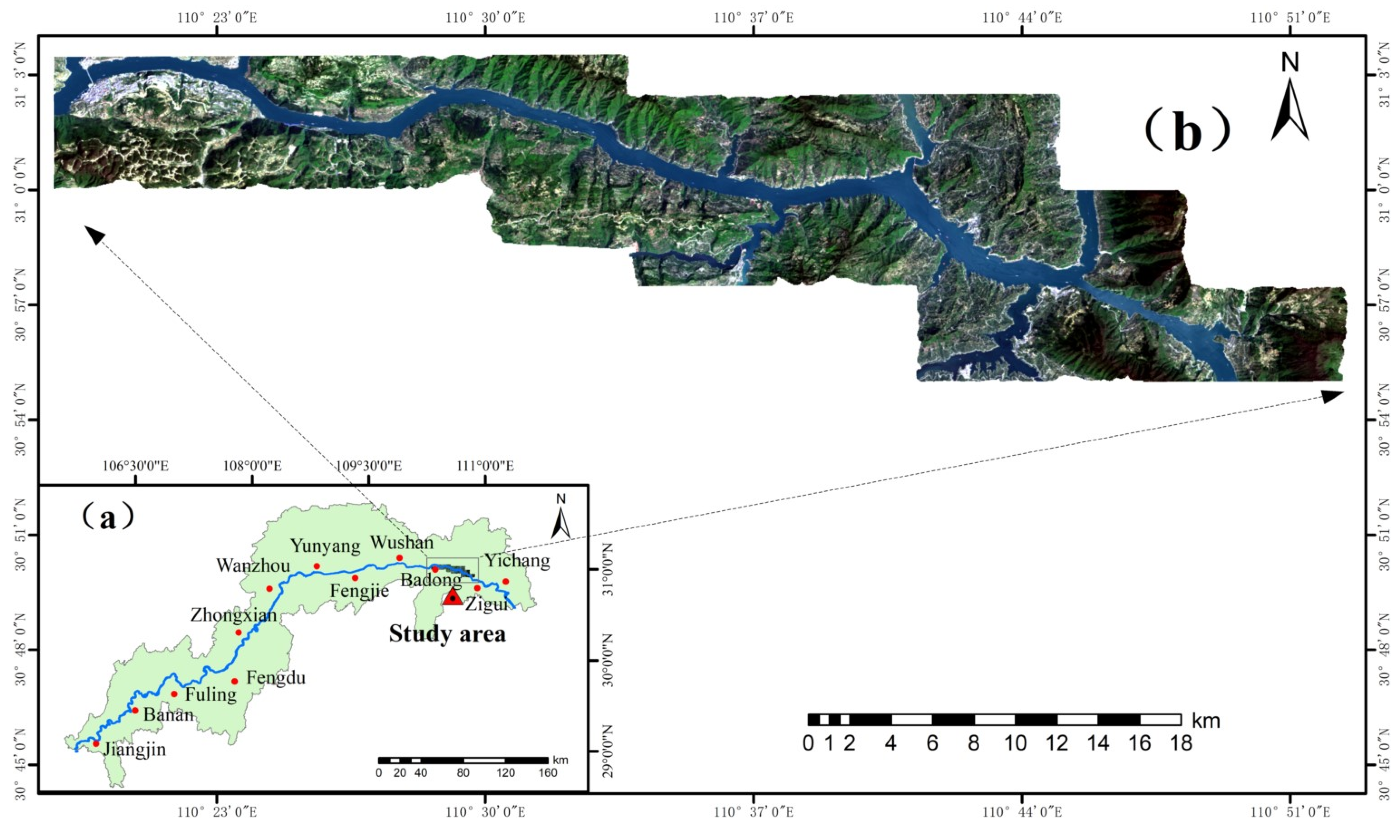
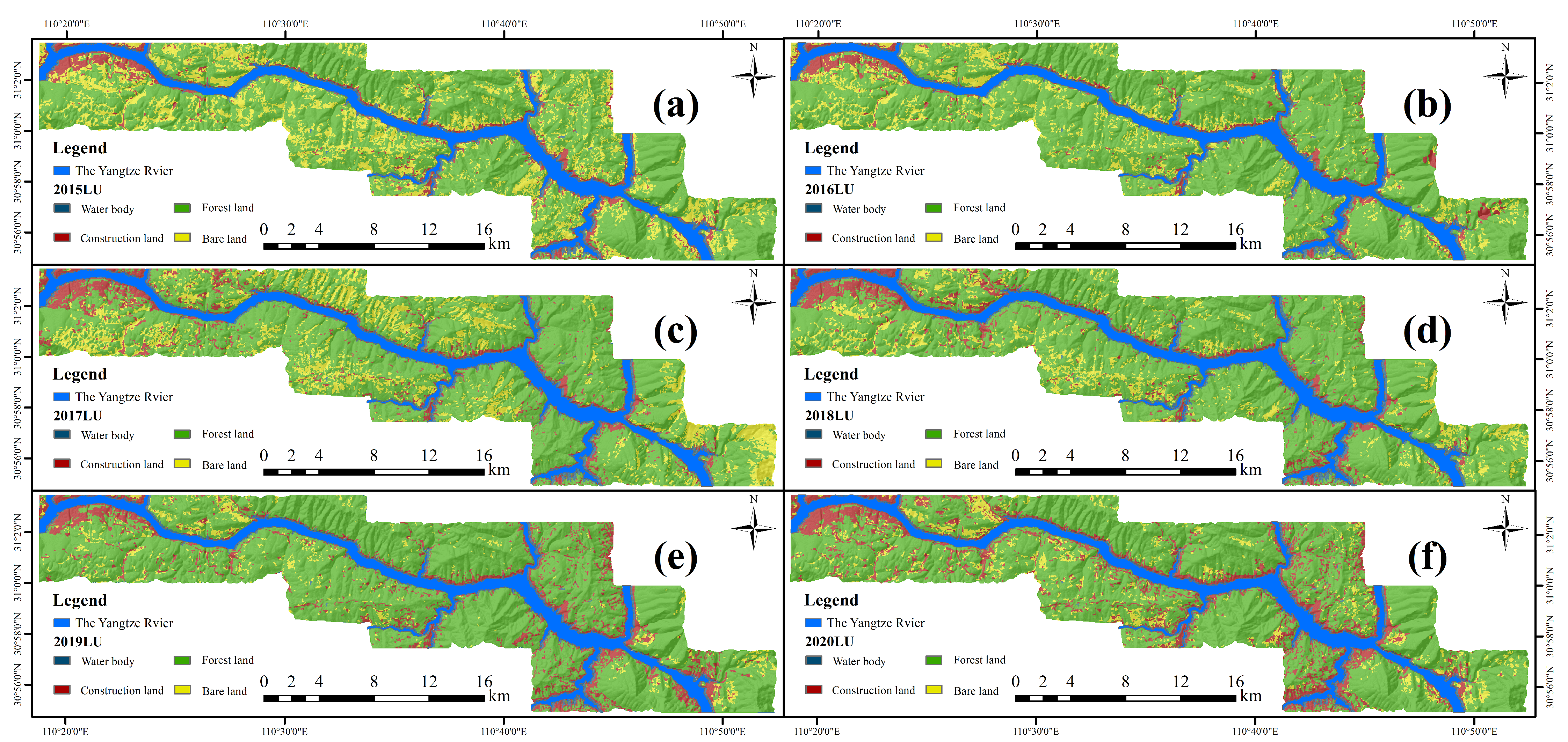
In this paper, the Zigui to Badong section of Three Gorges Reservoir was selected as the study area, and Landsat 8 data from 2015 to 2020 were used. The Landsat 8 satellites were launched in 2013, and compared with other Landsat satellites, the RS images obtained with the Landsat 8 satellites provide better image quality. The years 2015–2020 were relatively late in the Landsat series, which is of guiding significance for the prediction of future landslides. The LU, LUC and band factors were obtained by manipulation of Landsat 8 images. Then, the LU, LUC and band factors were combined with six commonly used factors (altitude, slope, slope aspect, rainfall, terrain wetness index (TWI) and lithology), and the resulting factor combinations were established using three models (ANN, SVM and CNN) for LSM. The receiver operating characteristic (ROC) curve, specific category accuracy and five statistical methods were used to evaluate and analyze the results. Finally, a simple ranking method was used to comprehensively evaluate the prediction performance, and an additional four sets of experiments were conducted with the ANN model to evaluate the LSM results of three different factor combinations to improve the scientific basis, accuracy and timeliness of LSM.
5. Discussion
5.1. Analysis of ANN, SVM and CNN Results
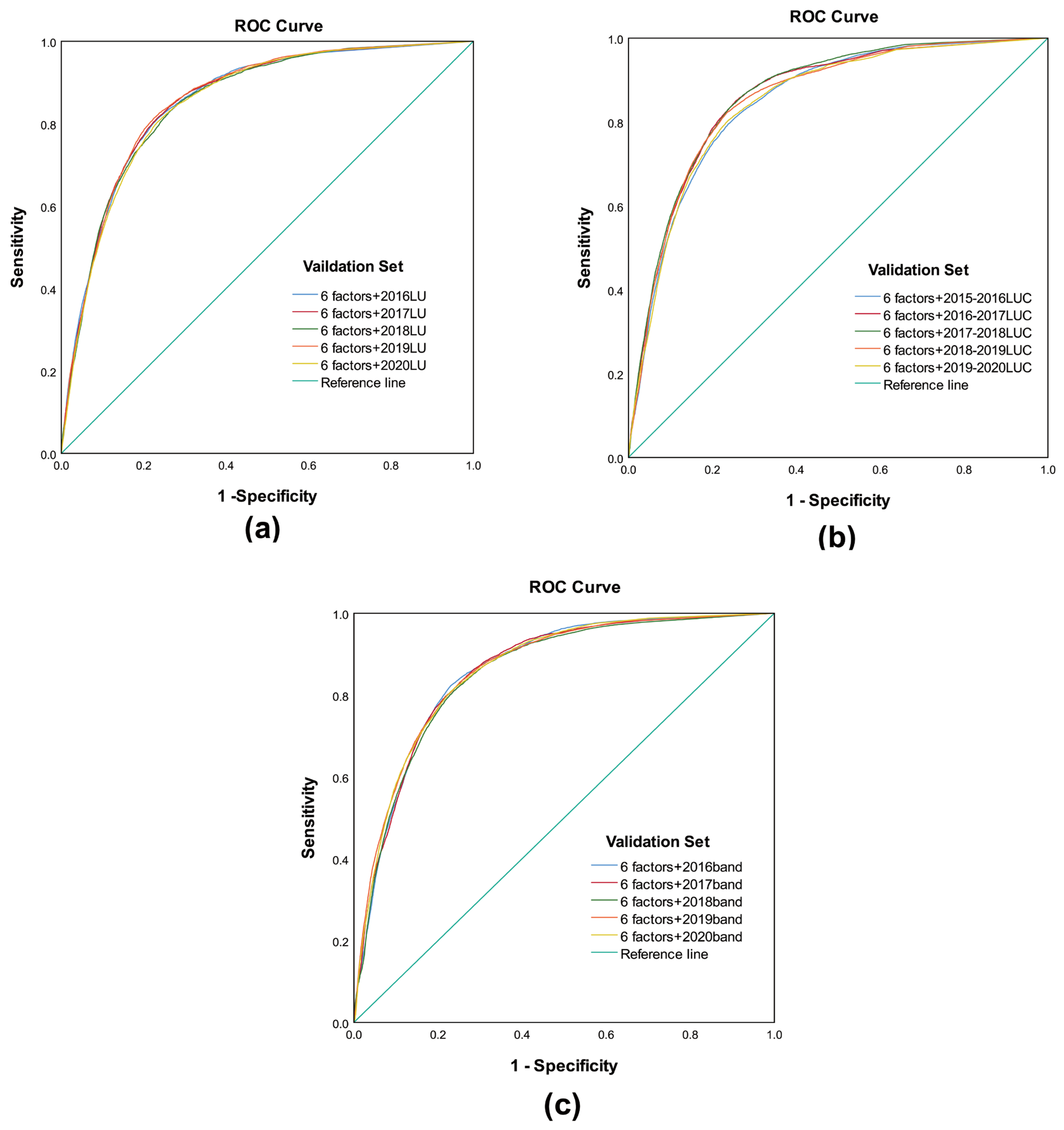
To verify the extent to which the band factor plays an important role in LSM, two other commonly used models, an SVM and a CNN, were selected for comparison. The LSM results of these two models were analyzed using the ROC curve, the specific category accuracy of very high susceptibility areas and five statistical methods.
The AUC values of the three models based on the three factor combinations are shown in
Table 11.
Table 11 shows that for the SVM model, the highest AUC values from 2016–2020 (except in 2017) were all obtained for BMFC; among them, the highest AUC value was obtained for BMFC in 2018 (0.854). For the CNN model, the highest AUC values from 2016–2020 were all associated with BMFC, and the highest AUC value was obtained for BMFC in 2020 (0.833).
The specific category accuracies of very high susceptibility areas for the three models based on the three factor combinations are shown in
Table 12.
Table 12 shows that for the SVM model, the highest specific category accuracy value of very high susceptibility areas was obtained for LUFC in 2018 (15.58%), and the highest values in other years were obtained for LUCFC (14.22%) in 2016, BMFC (13.98%) in 2017, LUFC (15.16%) in 2019 and LUFC (14.82%) in 2020. For the CNN model, the highest specific category accuracy value of very high susceptibility areas was obtained for BMFC in 2017 (15.95%), and the highest values in other years were obtained for LUFC in 2016 (14.44%), BMFC in 2018 (12.23%), LUFC in 2019 (11.82%) and LUFC in 2020 (12.49%).
Statistical analyses of the results of the SVM and CNN models based on the three factor combinations were performed, and the results are shown in
Table 13.
Table 13 shows that for the SVM model, the highest OA value was obtained for LUCFC in 2017 (83.69%), the highest precision was obtained for BMFC in 2018 (0.0846), the highest recall was obtained for BMFC in 2018 (0.7113), the highest F-measure value was obtained for BMFC in 2018 (0.1512) and the highest MCC was obtained for BMFC in 2018 (0.2413). For the CNN model, the highest OA value was obtained for BMFC in 2017 (86.06%), the highest precision was obtained for BMFC in 2017 (0.0783), the highest recall was obtained for BMFC in 2016 (0.7553), the highest F-measure was obtained for BMFC in 2020 (0.1374) and the highest MCC was obtained for BMFC in 2020 (0.2229).
For the ANN model, the highest AUC values (except in 2018) were all obtained for BMFC, the highest specific category accuracy values of very high susceptibility areas were all obtained for BMFC (except in 2016), and the OA, precision, F-measure and MCC values of the LUCFC in the analysis of the five statistical methods were the highest among those shown. For the SVM model, the highest AUC values were all obtained for BMFC (except in 2017), and the specific category accuracy values of very high susceptibility areas based on LUFC, LUCFC and BMFC were highest between 2016 and 2020. Among the five statistical methods, all the highest values were associated with the BMFC, except for the highest OA value, which corresponded to the LUCFC. For the CNN model, the highest AUC values between 2016 and 2020 were all obtained for BMFC, the highest specific category accuracy values of very high susceptibility areas in 2017 and 2018 were obtained for BMFC, and the highest five statistical methods were all obtained for BMFC. In general, LUFC, LUCFC and BMFC from 2016–2020 had advantages and disadvantages with respect to the AUC values, specific category accuracy values of very high susceptibility areas and the five statistical methods based on the three models. However, generally, the results for BMFC were better than those for LUFC and LUCFC, indicating that the band factor had a better impact on LSM than did the LU and LUC factors.
5.2. Simple Quantitative Ranking Analysis
To more intuitively reflect the importance of the three factors, namely, LU, LUC and band, in LSM, a simple ranking method was used to score different factor combinations. The higher the score was, the better the prediction performance. In this study, the scoring principles were as follows. The scores obtained for the AUC value, specific category accuracy value of very high susceptibility areas and the five statistical methods (OA, precision, recall, F-measure and MCC) for LUFC, LUCFC and BMFC, in order from highest to lowest, were ranked as 3 points, 2 points and 1 point, respectively. The scores of the AUC value, the specific category accuracy value of very high susceptibility areas and the average of the five statistical methods were added together, with the highest scores indicating the best performance.
The scores of the three factor combinations based on the three models are shown in
Table 14.
Table 14 shows that for the ANN model, the highest AUC score was obtained for BMFC (15 points), the highest specific category accuracy score of very high susceptibility areas was obtained for BMFC (14 points) and the highest average score of the five statistical methods was obtained for LUFC (11 points). The highest overall score of the three was obtained for BMFC (37.2 points). For the SVM model, the highest AUC score was obtained for BMFC (13 points), the highest score for the specific category accuracy of very high susceptibility areas was obtained for BMFC (13 points) and the highest average scores for the five statistical methods were obtained for LUFC and LUCFC (11.6 points). The highest comprehensive score among the three cases was obtained for BMFC (32.8 points). For the CNN model, the highest AUC value (15 points), the highest specific category accuracy of very high susceptibility areas (12 points), and the highest average value of the five statistical methods (12.2 points) were all obtained for BMFC. Moreover, the highest composite score of the three was obtained for BMFC (39.2 points). In summary, BMFC yielded the highest scores for all three models. The LUFC and LUCFC results varied for the three models, and the values were all lower than those for BMFC, which indicates that the band factor was more important than the LUC and LU factors in the three models.
Notably, the band factor from 2016–2020 was obtained using the PCA algorithm by outputting the first principal component of the NDVI/NDBI/NDW bands, that is, the maximum amount of information. The PCA table for the bands from 2016–2020 is shown in
Table 15.
Table 15 shows that the information content values of the first principal component of the PCA output fusion band from 2016–2020 were 85.95, 98.81, 79.63, 91.41 and 87.68%. The smallest amount of information was conveyed by this component in 2018 (79.63%), and according to the results in
Table 11,
Table 12 and
Table 13. In some of the evaluation methods used for the ANN model, BMFC yielded better results than LUFC and LUCFC. For the SVM model, the highest AUC and the highest values of precision, recall, the F-measure and the MCC among the five statistical methods were all obtained for BMFC. For the CNN model, the highest AUC, the highest specific category accuracy of very high susceptibility areas, and the highest values of precision, recall, the F-measure and the MCC among the five statistical methods were all obtained for BMFC. In summary, even in 2018, when information provided by the first principal component in PCA was the most limited, the LSM results based on BMFC were the best for the three different models.
A simple ranking of the scores for LUFC, LUCFC and BMFC revealed that the highest scores were obtained for BMFC in all three models, and the highest predictive ability for BMFC was obtained for the CNN model, followed by the ANN model and then the SVM model. Although the CNN model displayed good prediction ability for BMFC, it yielded the worst results for LUCFC with a temporal dimension, and LUCFC did not provide advantages in the three models; notably, the prediction ability for LUCFC was lower than that for LUFC. The reason for this result may have been that the LUC in this study was only obtained by detecting changes in the data at an interval of one year, and there was no shorter time interval. Thus, the temporality of LUC was not reflected well.
5.3. Stability Analysis
To confirm the stability of the band factor, four groups of experiments were performed using the ANN model. The ROC curve analysis results in 2016 are used as an example, and the AUC values of the three factor combinations of the five groups of ANNs are shown in
Table 16. The stability results are shown in
Figure 17.
Figure 17 shows that the AUC value for BMFC was lower than those for LUFC and LUCFC only in the third set of ANN experiments. The standard deviations of the three factor combinations were 0.025 for LUFC, 0.022 for LUCFC and 0 for BMFC. In LSM, the stability of BMFC was better than that of LUFC and LUCFC, indicating that the stability of the band factor was better than that of the LU and LUC factors.
Research has shown that LU is only considered a dynamic factor when it changes over decades or even centuries, and it is considered to be a static factor in a short period [
88]. Intuitively, the experiments in this paper confirm that there is no significant difference between the results of LUC and LU factors in LSM. Second, due to the variable quality of RS images, the LU data obtained by manual classification and the LUC data obtained by detecting changes in LU data over time are often incorrectly classified. Moreover, the setting of image data parameters, the selection of image processing software and the limitations of modeling methods all influence the image classification accuracy [
89], which in turn affects the results of LSM. Considering these problems, the first principal component (band) of the NDVI/NDWI/NDBI-based results obtained by using the PCA algorithm was added for classification in this study. LU, LUC and band factors were introduced into different models as independent variables for LSM analysis to verify the applicability of the three factors.
6. Conclusions
In this paper, the Zigui to Badong section was used as the study area, and the LUFC, LUCFC and BMFC were analyzed using three models. The ROC curve, specific category accuracy and five statistical methods (OA, precision, recall, F-measure and MCC) were used to evaluate the results of LSM. The predictive performance of each model was evaluated with a simple ranking method. The results showed that in general, the results of BMFC for the ANN model were better than those of LUFC and LUCFC, indicating that the band factor was more important than the LU and LUC factors in the three models. The simple ranking method verified that the score of BMFC for the three different models was higher than the scores of LUFC and LUCFC, indicating that the predictive ability of the band factor in the three different models was greater than that of the LU and LUC factors. Second, for the ROC curve analysis results (AUC values) for 2016 based on five groups of ANN experiments, as an example, the standard deviation of each factor combination was calculated, and the stability of BMFC was better than that of LUFC and LUCFC, indicating that the stability of the band factor was better than that of the LU and LUC factors. Therefore, compared with the LU/LUC factors, with variations in accuracy, the band factor is better in principle and more stable.
Most existing landslide prediction models rely on human labor, which is limited by timeliness and accuracy, while machine learning methods can be used to accurately predict landslides in real time. According to the experimental results presented in this paper, especially the LSM results of the three different models, BMFC yielded better results than LUFC and LUCFC; that is, the band factor was better than the LU and LUC factors and can replace them to a certain extent. Moreover, since the LU and LUC factors are influenced by the subjectivity of the operator and are unstable, the corresponding prediction of landslides has some limitations. The stability factor band, obtained by introducing band math, not only results in better landslide predictions compared with those using the LU and LUC factors but also greatly saves time and labor and machine costs, providing theoretical support for automated landslide monitoring and the real-time evaluation of landslides.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





