In this segment of the paper, we plunge into the complex world of machine learning, considering it as a crucial facet within the realm of artificial intelligence (AI). Our exploration commences with an overview of the current state of AI, clarifying its contemporary advancements and direction. We then navigate the discourse towards a comparative analysis of AI, machine learning, deep learning, and generative AI [
14]. Through this comparative lens, we illuminate their distinct features as well as their overlapping facets. This comparison shines a light on their unique characteristics and shared elements, enabling us to appreciate the interconnectedness and individuality of these concepts. This understanding is crucial in realizing the full potential of AI and its multifaceted aspects in current and future applications.
As our discourse unfolds, we underscore the concept of AutoML, an innovative tool that has become central to numerous sectors, including healthcare. By highlighting specific instances, we illustrate the profound transformative influence AutoML has on these industries, enabling efficiency and precision. As we approach the end of this section, we turn our attention to the pressing issue of health inequity. We propose potential pathways through which AutoML, when thoughtfully applied, could serve as a powerful tool in mitigating this pervasive challenge. The overarching objective of this discourse is to inspire a profound comprehension of the complex intersections among AI, AutoML, and health equity, thus deepening our understanding of how these components can synergistically work towards a more equitable future.
1.2.1. Comparative Analysis of AI, Machine Learning, Deep Learning, and Generative AI
In recent years, the disciplines of artificial intelligence (AI), machine learning (ML), and deep learning (DL) have garnered substantial attention, establishing themselves as focal points in the technology sector. These techniques, subsets of AI, are employed to automate processes, predict outcomes, and derive insights from extensive datasets. The preceding six months have witnessed a phenomenal surge in generative AI, most notably marked by OpenAI’s “ChatGPT” [
15]. Despite some shared characteristics, these areas exhibit profound differences. This section will elucidate the principal distinctions among AI, ML, DL, and generative AI.
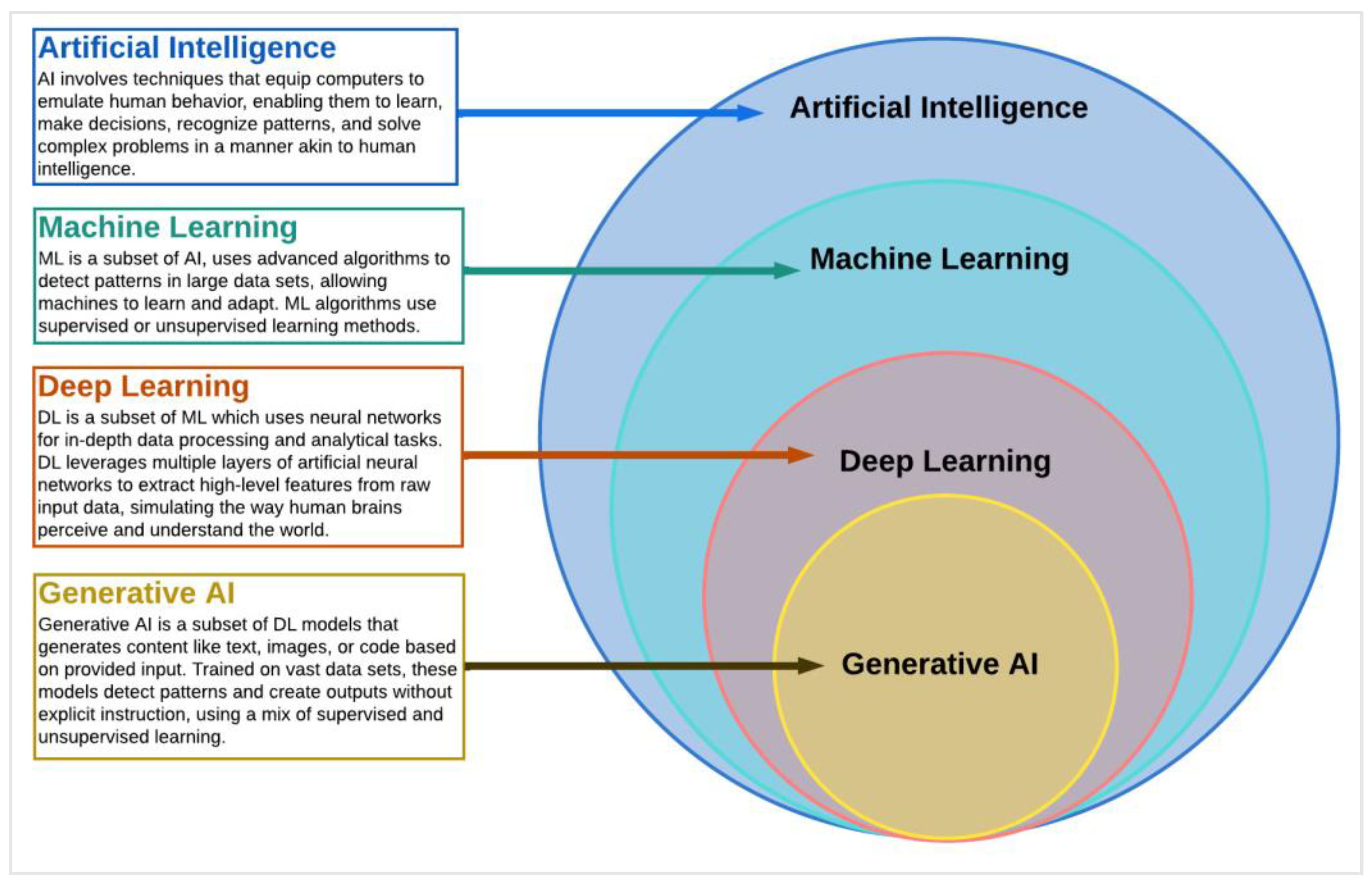
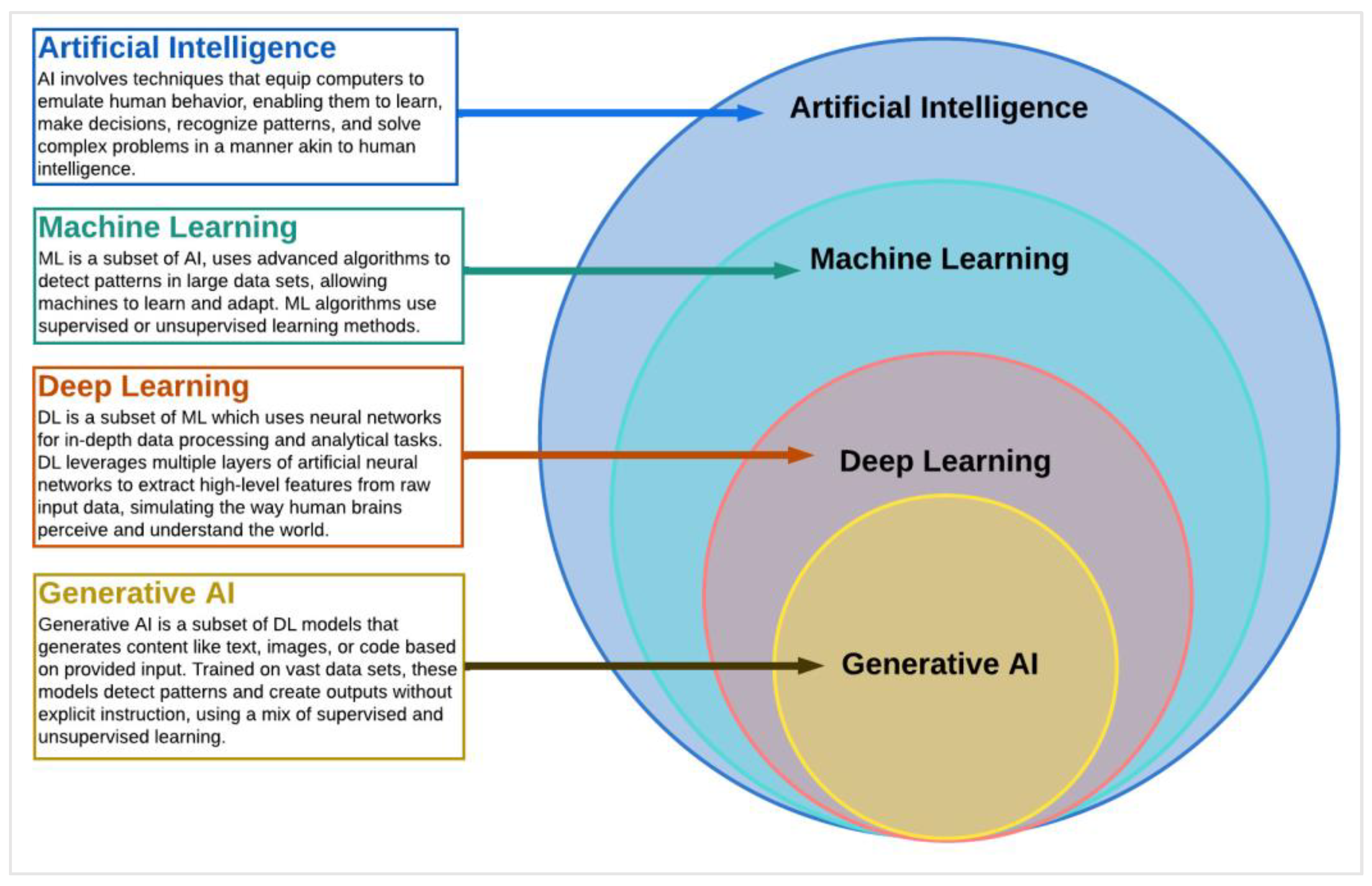
Artificial intelligence (AI), a key pillar of computer science, represents a complex and dynamic field that engages a wide array of techniques to empower machines to exhibit capabilities analogous to human cognition (refer to
Figure 1). It incorporates methods that facilitate computational systems to replicate human-like behavior, ranging from basic task execution to advanced problem solving and decision making.
This field aims at creating systems that can intelligently analyze the environment, learn from experiences, draw inferences, understand complex concepts, and even exhibit creativity, all of which were traditionally considered unique to human intelligence; it is commonly defined as a field that encompasses any technology that imparts human-like cognitive abilities to computers [
17].
The notion of AI achieving human-level cognitive abilities has been popularized through various methodologies, one of the most notable ones being the seminal—albeit somewhat antiquated—Turing Test. This test, proposed by the British mathematician Alan Turing, gauges a machine’s ability to exhibit intelligent behavior that is indistinguishable from that of a human. Modern manifestations of AI, such as Apple’s Siri, exemplify this notion quite vividly. When we interact with Siri and receive a coherent response, it mirrors a human-like conversational ability, indicating how far AI has evolved in mimicking human interaction.
Machine learning (ML), a significant subset of AI (refer to
Figure 1), is primarily concerned with deciphering patterns embedded within datasets. This intricate process not only empowers machines to derive rules for optimal behavior but also equips them to adapt to evolving circumstances in the world. The algorithms involved in this endeavor, while not novel in their inception, have been known and explored for decades and, in some cases, centuries. However, it is the recent breakthroughs in the domain of computer science and parallel computing that have imbued these algorithms with the capability to operate at an unprecedented scale. Now they can handle and analyze voluminous datasets, a feat that was previously unattainable. This transformative advancement has significantly broadened the application and impact of ML, heralding a new era in the field of AI [
18].
Deep learning (DL), a subset of ML (refer to
Figure 1), operates through the utilization of intricate neural networks. In essence, it represents a set of interrelated techniques akin to other methodological groups such as ‘Decision Trees’ or ‘Support Vector Machines’. The recent surge in its popularity can be largely attributed to the significant strides made in parallel computing. This has enabled DL techniques to handle larger datasets and perform more complex computations, thereby resulting in heightened interest and widespread application in the field. Nevertheless, there exists a significant differentiation between ML and DL in terms of the learning methods they employ. ML algorithms typically utilize either supervised or unsupervised learning approaches. In supervised learning, algorithms are trained on labeled datasets, where each input data point is associated with a specific output [
19]. For example, an algorithm can be trained using a collection of labeled images of cats and dogs, enabling it to predict whether a new image contains a cat or a dog. However, unsupervised learning algorithms are employed when input data lack designated outputs, and their purpose is to identify patterns within the data [
19].
In the realm of DL, algorithms primarily leverage a form of supervised learning known as deep neural networks. These networks are composed of multiple layers of interconnected nodes designed to hierarchically process data. Each layer in the network extracts features from the input data, which are then used by subsequent layers to further refine the output. DL algorithms have the capacity to learn from unstructured data, including images, audio, and text, making them versatile across various applications such as image recognition, speech recognition, and natural language processing [
20]. However, a limitation of DL algorithms, as observed in studies, is their lack of interpretability [
21]. Due to their autonomous learning nature, deciphering the decision-making process of deep neural networks can be challenging, posing a significant obstacle in scenarios where end-users or stakeholders require explanations for an algorithm’s decisions. Conversely, ML algorithms often provide superior interpretability, as they are designed to make decisions based on specific rules or criteria. For instance, the logic behind a Decision Tree algorithm, which relies on a series of if–then statements, can be easily articulated and understood [
22]. Moreover, DL algorithms have gained recognition for their remarkable accuracy and performance in tasks involving image recognition and natural language processing. Their ability to discern complex patterns and relationships within data contributes to this superior performance, which may prove challenging for other types of algorithms [
23].
However, it is essential to acknowledge that DL algorithms can be computationally demanding and may require specialized hardware to achieve optimal accuracy and performance [
24]. In contrast, ML algorithms, while potentially lacking the same level of accuracy or performance, generally exhibit higher speed and require fewer computational resources. Despite these differences, ML algorithms remain effective in tasks such as predictive modeling and anomaly detection.
Generative AI represents a subset of sophisticated DL models designed to produce text, images, or code based on textual or visual inputs. Two leading frameworks in the realm of generative AI currently dominate the field:
generative adversarial networks (GANs) and
generative pre-trained transformers (GPTs) [
25].
The concept of GANs, devised by Ian Goodfellow [
26] in 2014, operates on the premise of competition between two neural network sub-models. A generator model is tasked with creating new content, while a discriminator model is charged with classifying this content as real or counterfeit. These models engage in a perpetual learning cycle, consistently enhancing their capabilities until the discriminator is unable to distinguish between the output of the generator and authentic input examples. On the other hand, the GPT framework is employed primarily for generative language modeling.
Generative AI’s main objective is to emulate human interaction. It operates using a synergistic blend of supervised learning (predicting the subsequent word in a sentence based on the preceding words) and unsupervised learning (discerning the structure of language without explicit guidance or labels). Its capabilities are vast, ranging from generating text and code, providing translations across various languages, creating a diverse range of creative content, and engaging in conversational dialogue.
1.2.2. Why Is Generative AI Crucial in Today’s Technological Landscape?
The origin of generative AI can be traced back to the 1950s, when pioneers in computer science began to experiment with Markov Chains algorithms [
27] to generate novel data. Despite its longstanding history, it is only in recent years that we have seen transformative strides in generative AI’s performance and capabilities. This leap in progress has witnessed its application in diverse fields, whether it be generating engaging narratives in text generation [
28], synthesizing melodious compositions in music generation [
29], or crafting visually engaging content in image generation [
30,
31]. However, the recent advancements in AI technology now demand a reassessment of how we interact with our environment. AI has bolstered computing capabilities, enhancing both speed and scalability [
32,
33,
34,
35]. In bioinformatics, it has ushered in a revolution, allowing for rapid, accurate, and cost-effective human genome sequencing [
36,
37,
38,
39].
By taking on routine tasks, AI has propelled workplace efficiency and productivity to unprecedented levels [
40,
41], While these AI tools might not surpass human ingenuity yet, they serve as vital enablers for innovation, design, and engineering, thereby considerably amplifying human creativity and efficiency.
Cutting-edge generative AI technologies, such as GPT-4 and DALL-E 2, are designed around machine learning algorithms that can autonomously produce novel content. GPT-4, OpenAI’s most sophisticated large language model yet, excels in understanding and using context-appropriate words, thereby creating meaningful language that mirrors human communication with striking accuracy. The vast potential of AI cannot be overstated. Its applications span from driving breakthroughs in disease management to boosting workplace performance. The promise that AI holds is profound and its implications far-reaching. While generative AI has yet to fully capture the nuances of human creativity, it has nonetheless emerged as a potent catalyst for innovation in various domains, including design and engineering. This thereby amplifies human inventiveness and productivity.
1.2.3. What Is Automated Machine Learning?
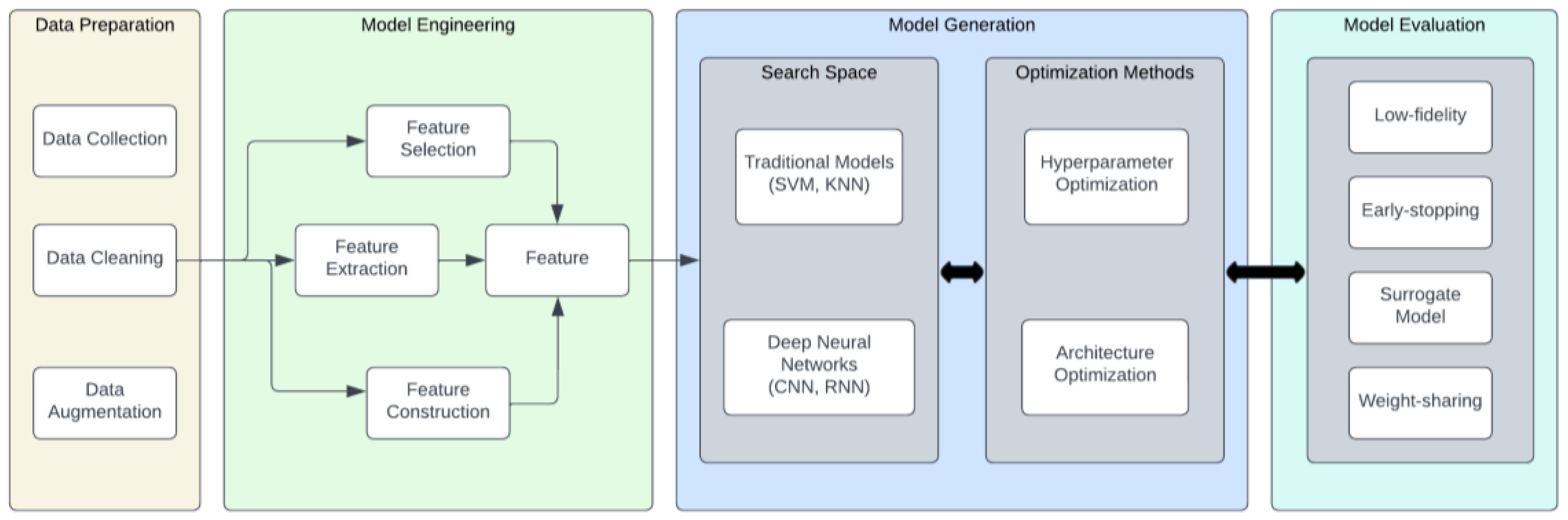
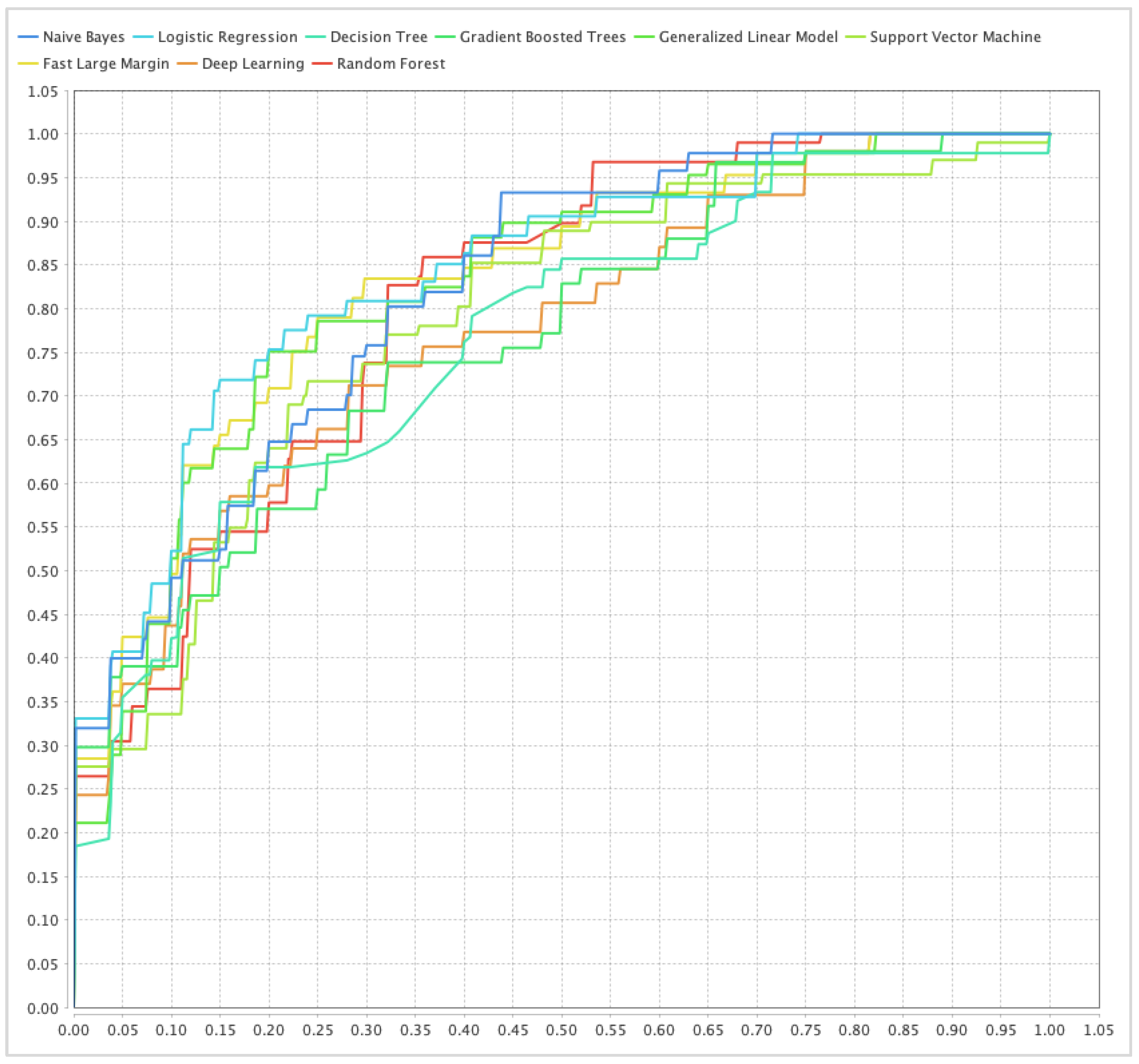
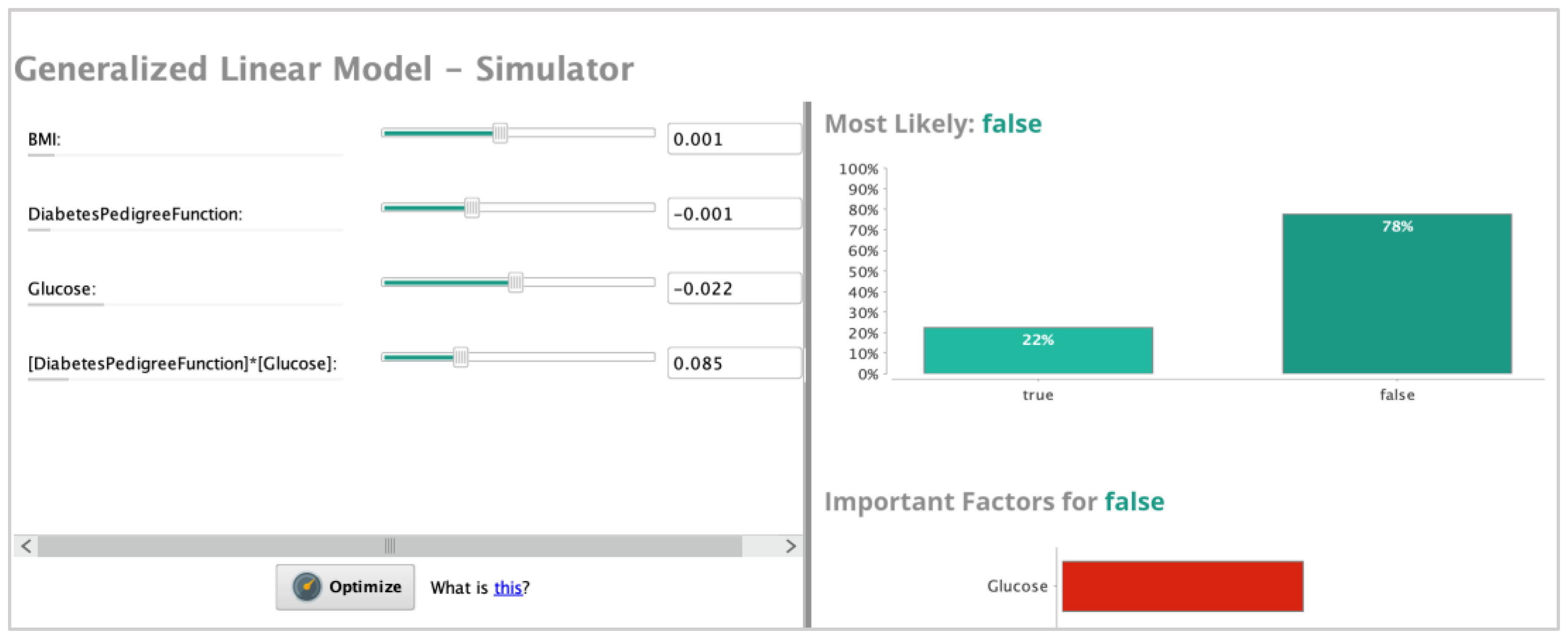
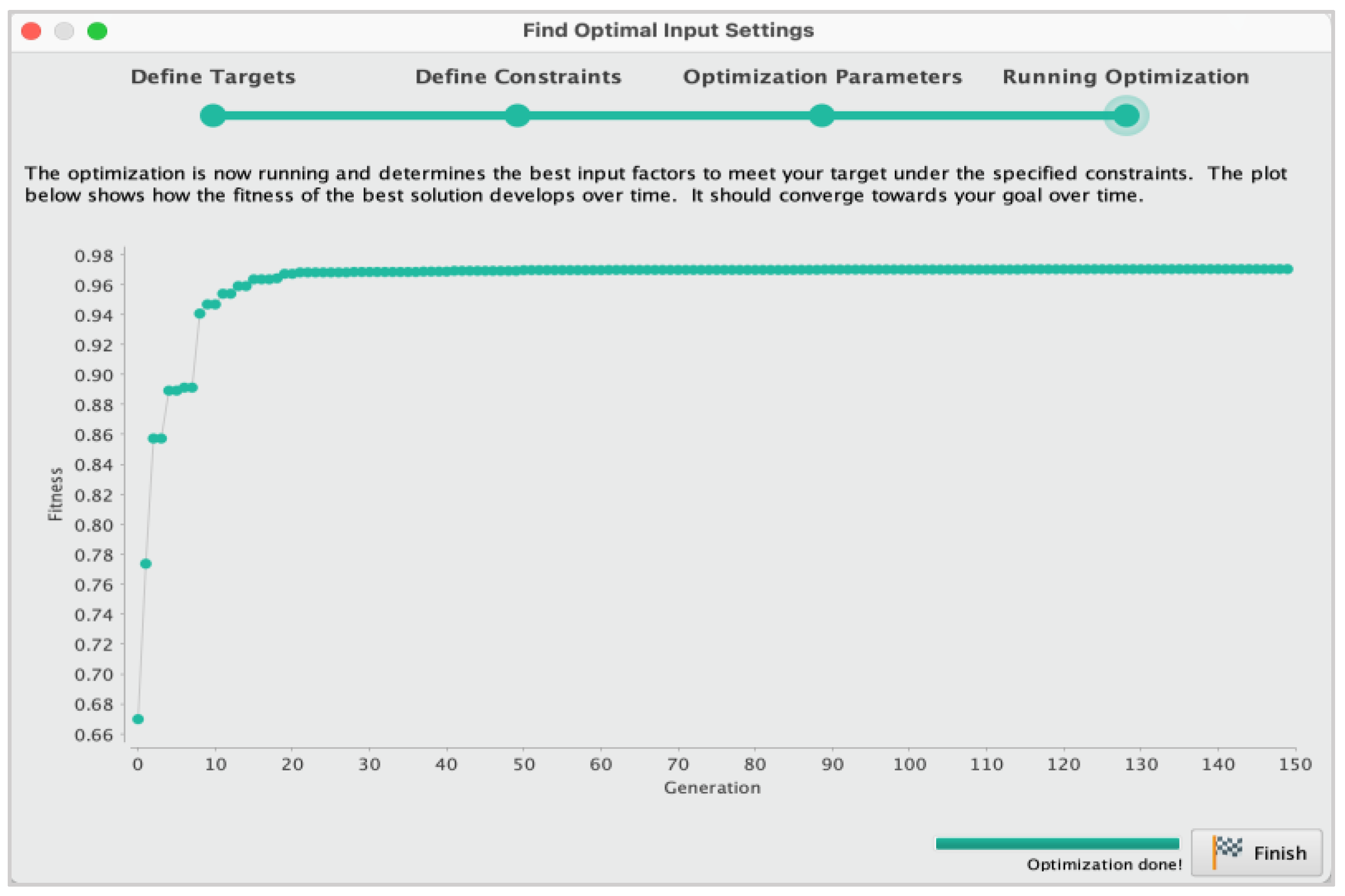
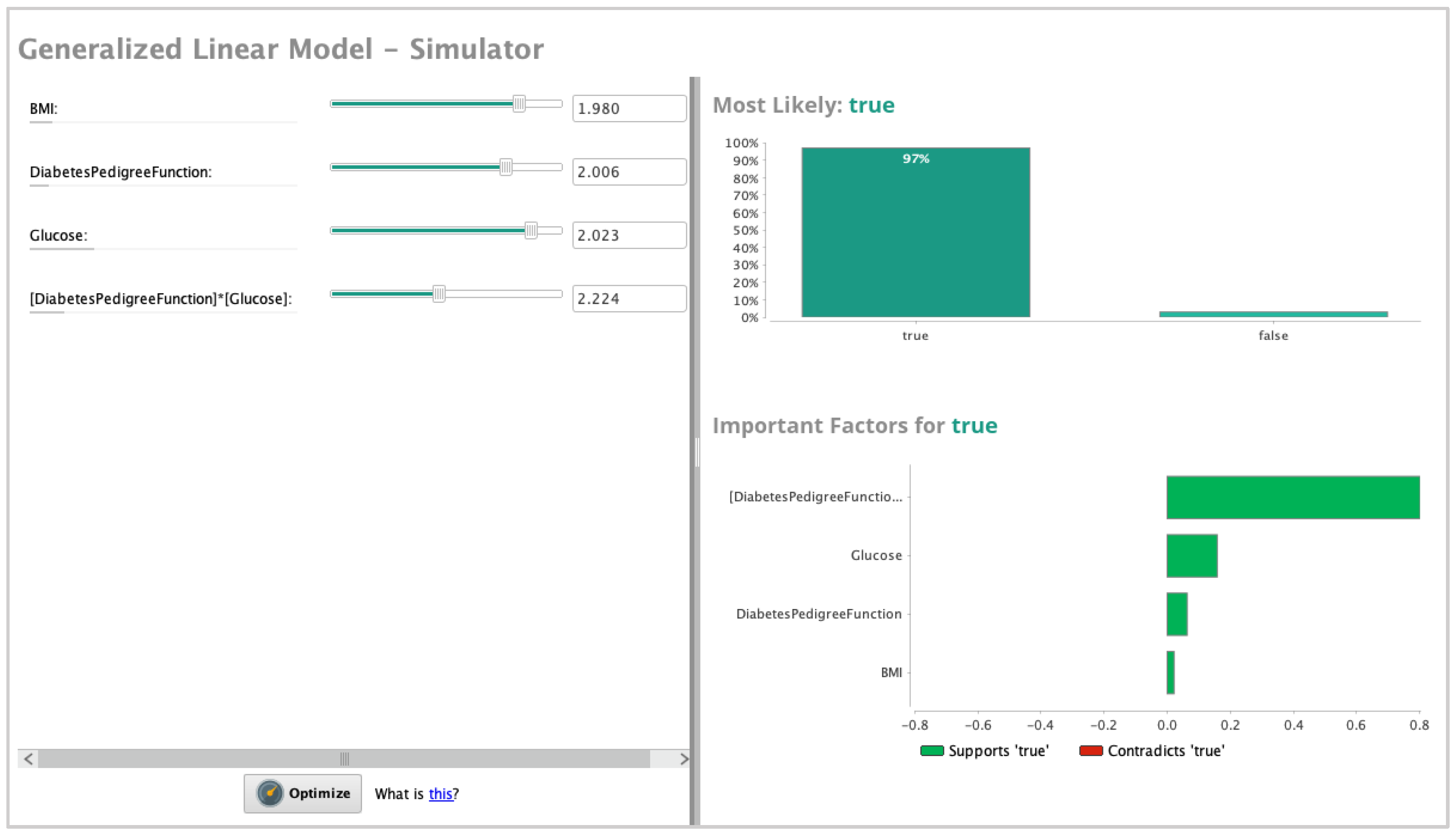
In the landscape of computational intelligence, the relevance and applicability of deep learning models have surged across diverse sectors, successfully addressing complex AI tasks. However, the creation of these intricate models often involves a labor-intensive, trial-and-error process conducted manually by domain experts, a methodology that mandates substantial resource allocation and an extensive time commitment. To circumnavigate these challenges, the paradigm of AutoML has risen to prominence as a solution aiming to streamline and optimize the machine learning pipeline, refer to Figure 2 for an example of machine learning pipeline [
42]. The concept of AutoML, however, is interpreted differently by different sectors of the scientific community. For example, Ref. [
43] theorizes that AutoML is primarily designed to mitigate the demand for data scientists, thereby equipping domain experts with the capacity to construct machine learning applications without a deep reservoir of ML knowledge.
In contrast, Ref. [
44] perceives AutoML as a harmonious blend of automation and machine learning. This definition emphasizes the automated assemblage of an ML pipeline, constrained by a limited computational budget. In a world experiencing an exponential growth in computing power, AutoML has emerged as a focal point for both industrial and academic research. A comprehensive AutoML system exhibits the dynamic amalgamation of a multitude of techniques, resulting in an intuitive, end-to-end ML pipeline system. Several AI-centric companies, including Google, Microsoft Azure, Amazon, H2O.ai, and RapidMiner, have developed and publicly shared systems like Cloud AutoML.
Figure 2 illustrates the structure of an AutoML pipeline, comprising several key processes: (1) Data preparation: this consists of data collection, data cleaning, and data augmentation; for more details, refer to [
45]. (2) Model or feature engineering: this consists of feature selection (Chen and Li, 2022), feature extraction, and feature selection; for more details, refer to [
46]. (3) Model generation: this consists of two parts: a. search space (this includes traditional models such as Support Vector Machine (SVM) (Garcia and Moreno, 2017) and the k-nearest neighbors algorithm (KNN)) and b. optimization methods (these include hyperparameter optimization and architecture optimization); for more details, refer to [
47]. (4) Model evaluation: this consists of low-fidelity (Davis, 2019), early stopping (Nelson and Thompson, 2020), surrogate model (Martinez, 2021), and weight-sharing (Rivera and Santos, 2022); for more details, refer to [
48].





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}