
Data Preprocessing and Machine Learning Modeling for Rockburst Assessment

Abstract
:1. Introduction
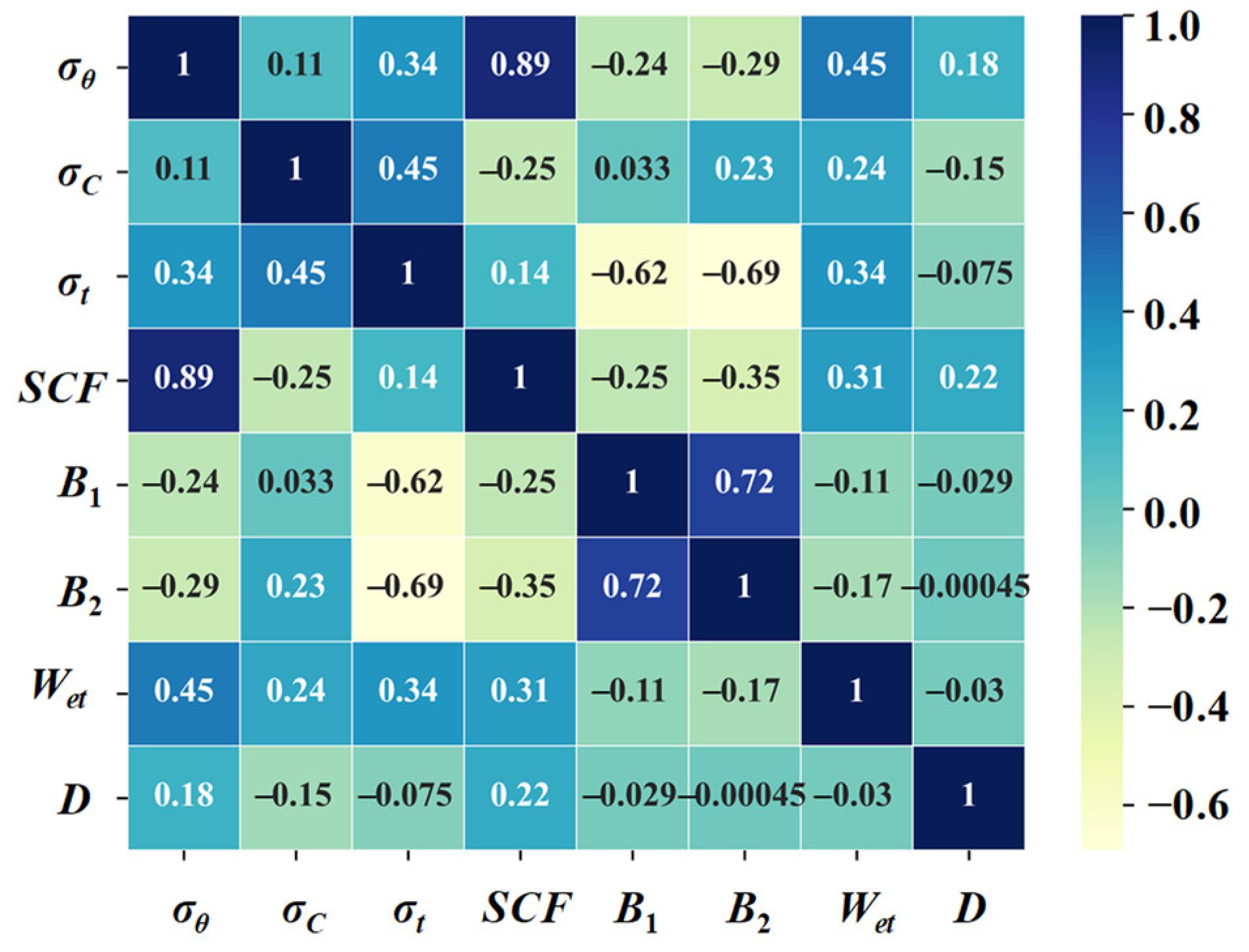
2. Data Compilation and Preprocessing
2.1. Data Sources and Basic Introduction
2.2. Imputation of Missing Value
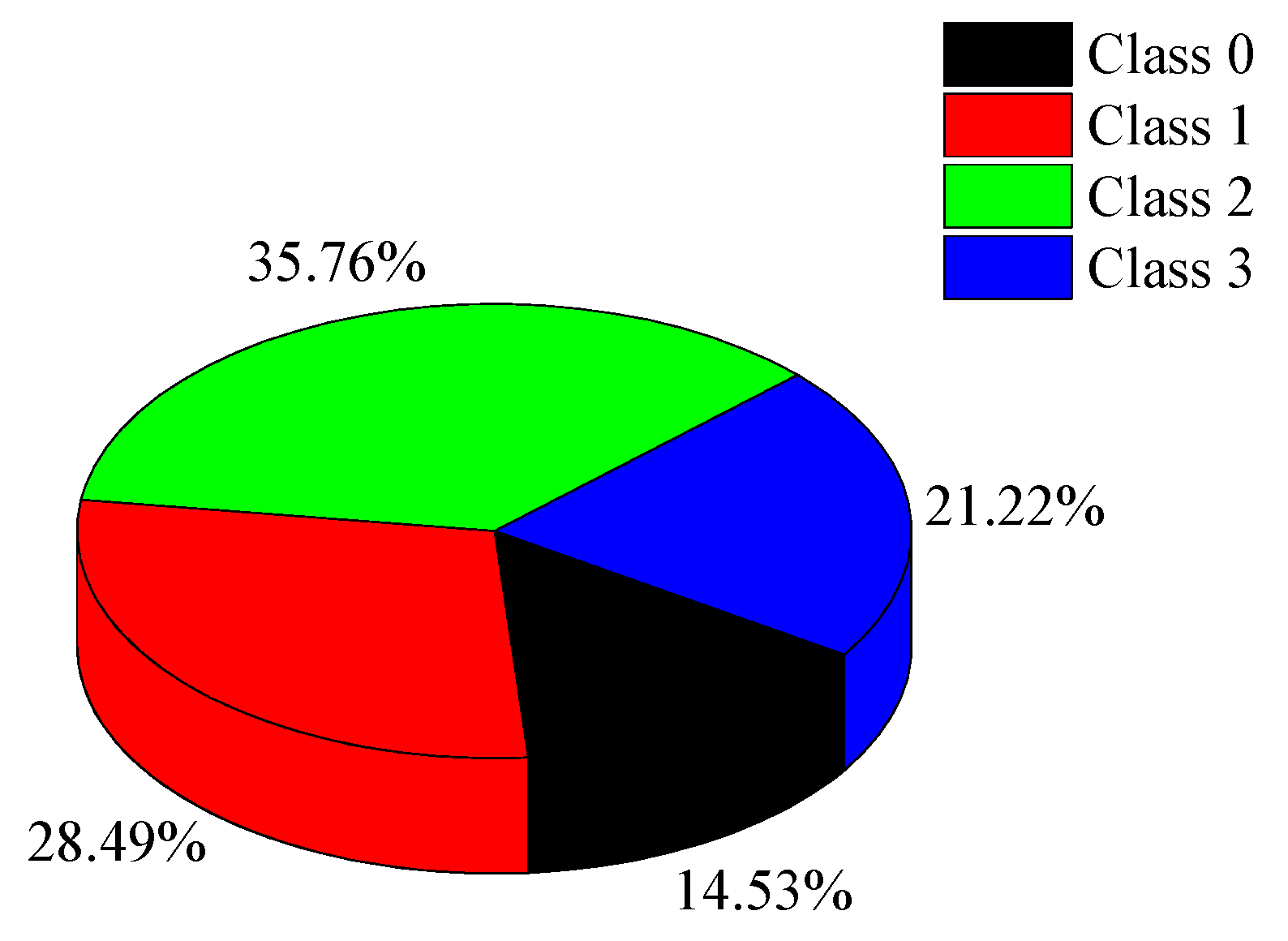
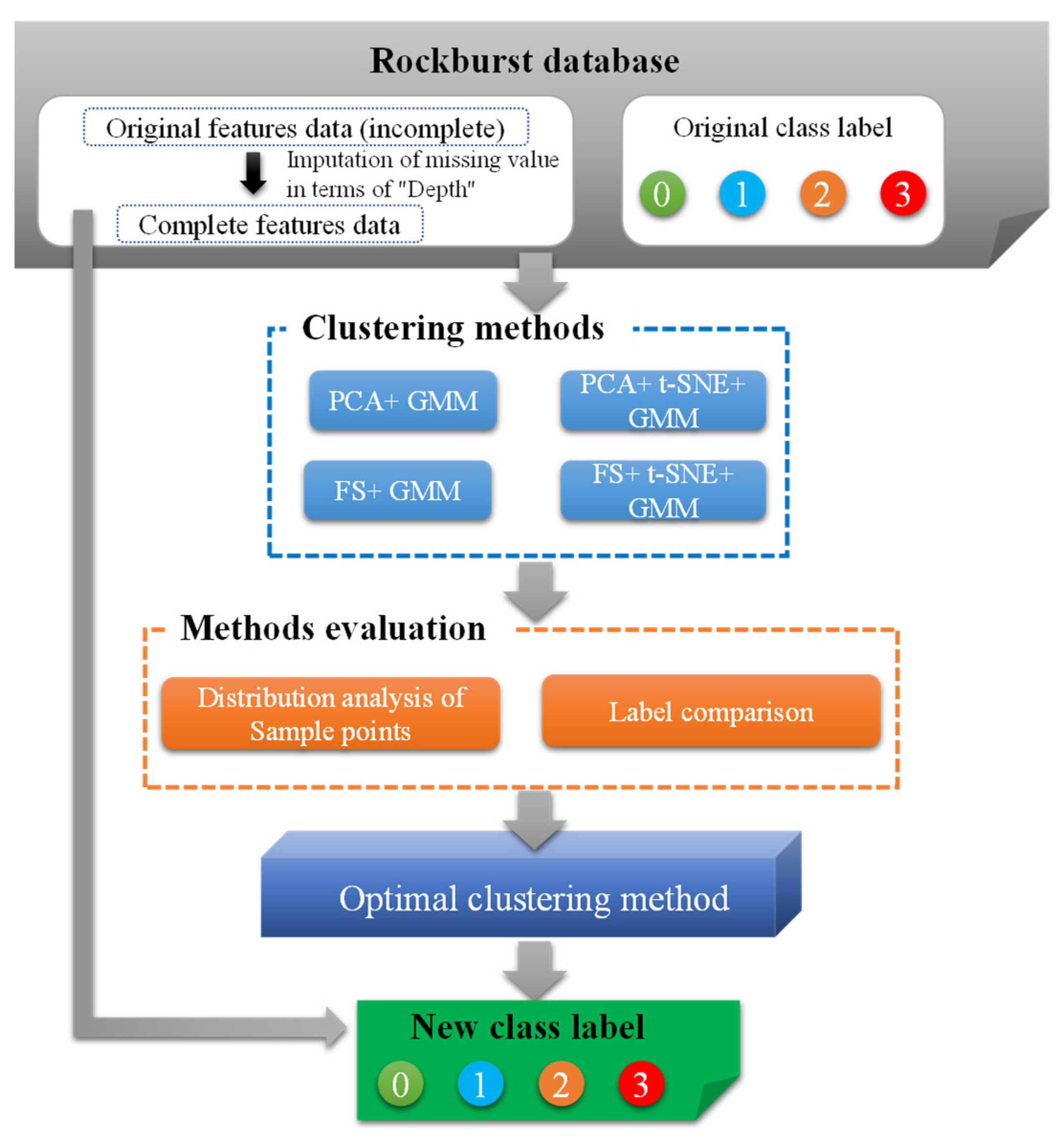
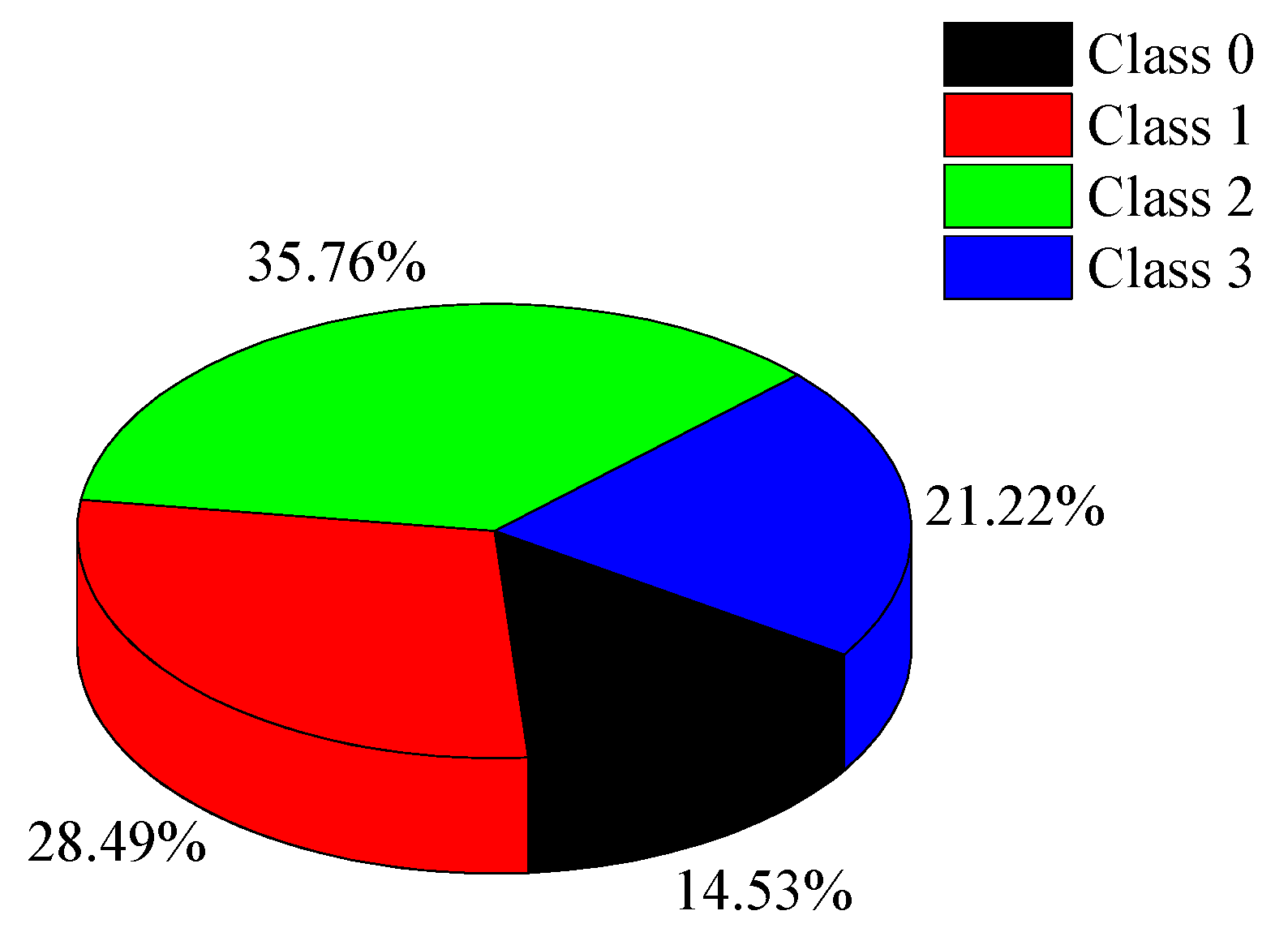
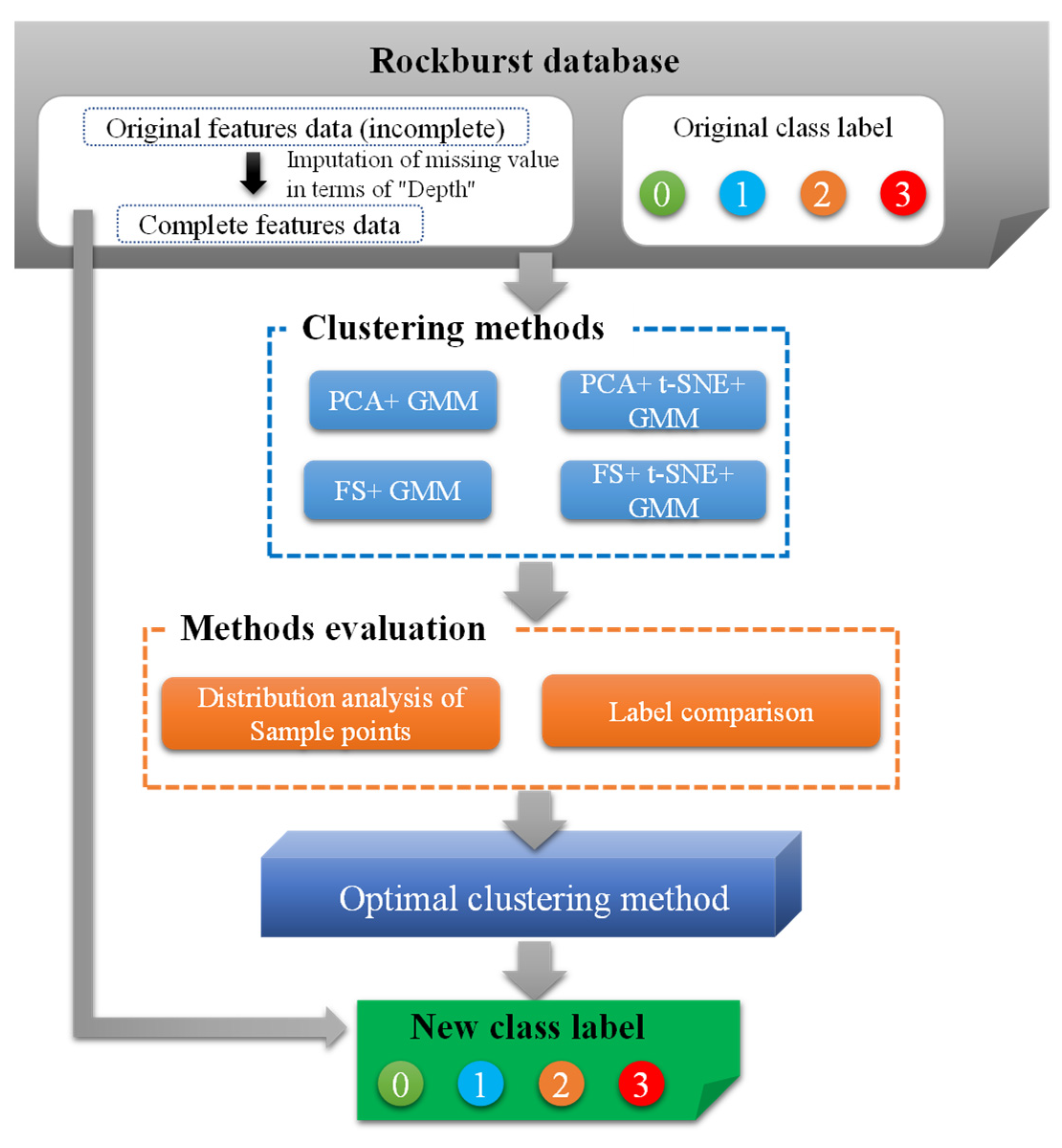
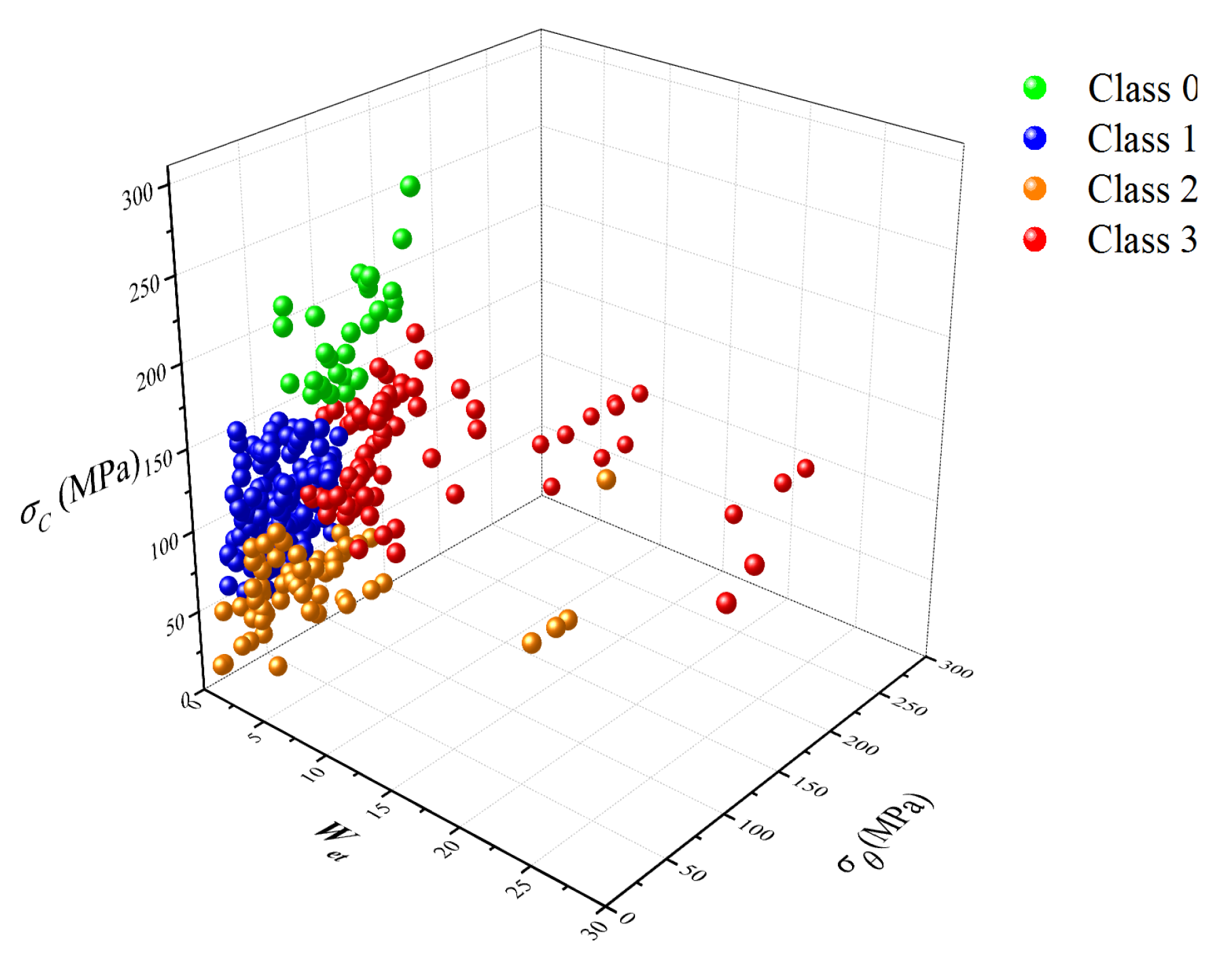
2.3. Relabeling of Original Data
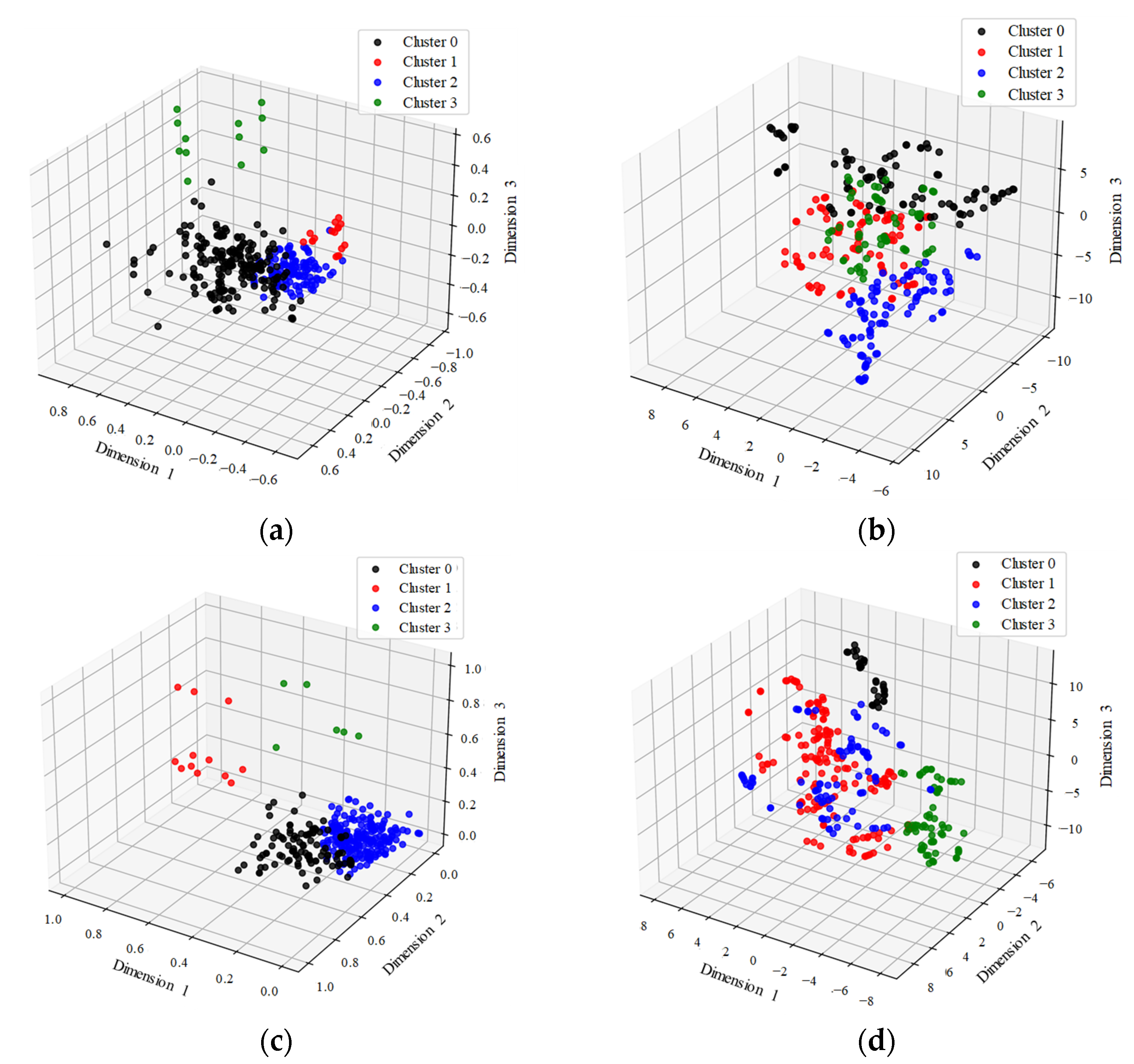
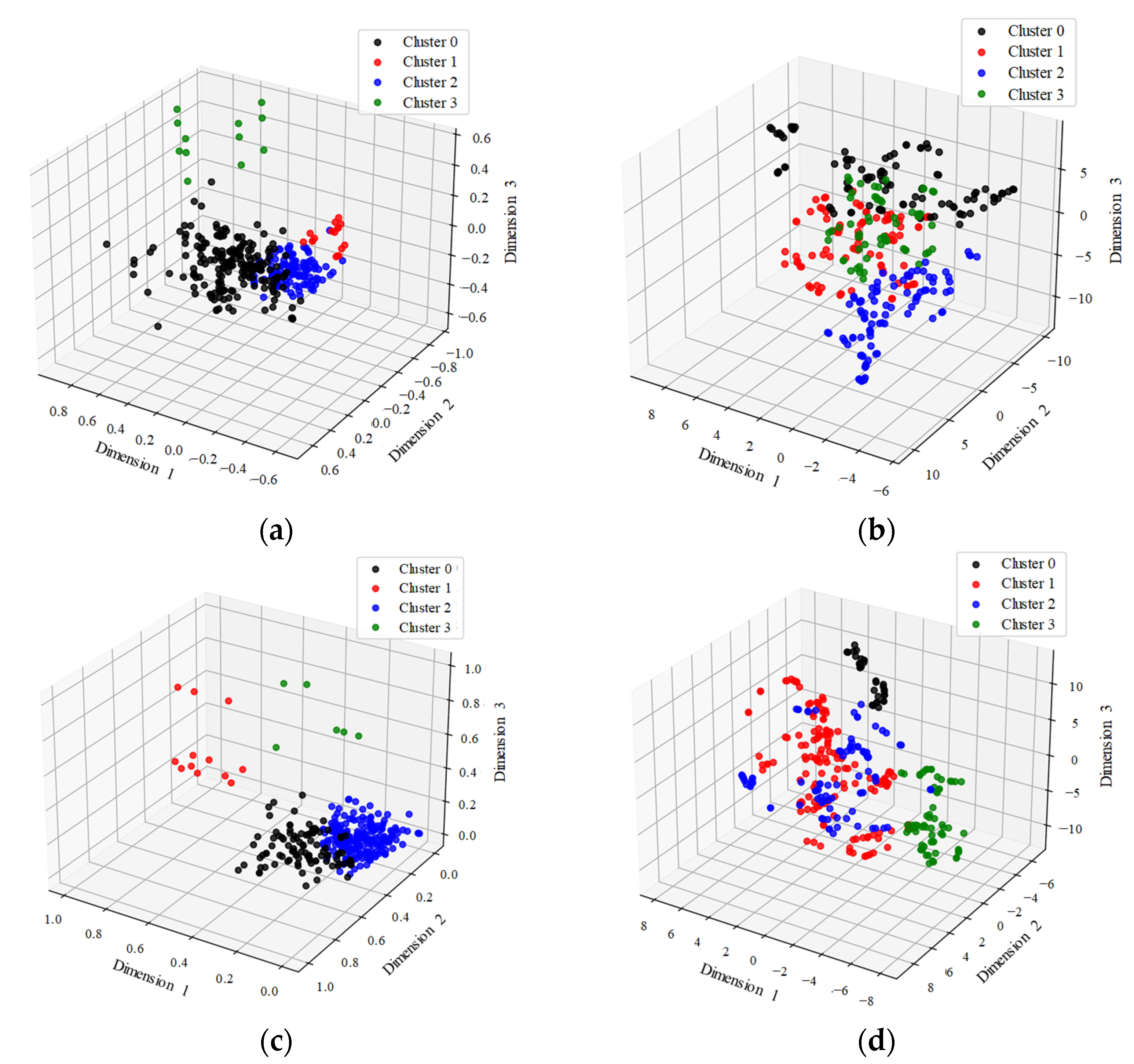
2.3.1. Dimensionality Reduction and the Clustering Method
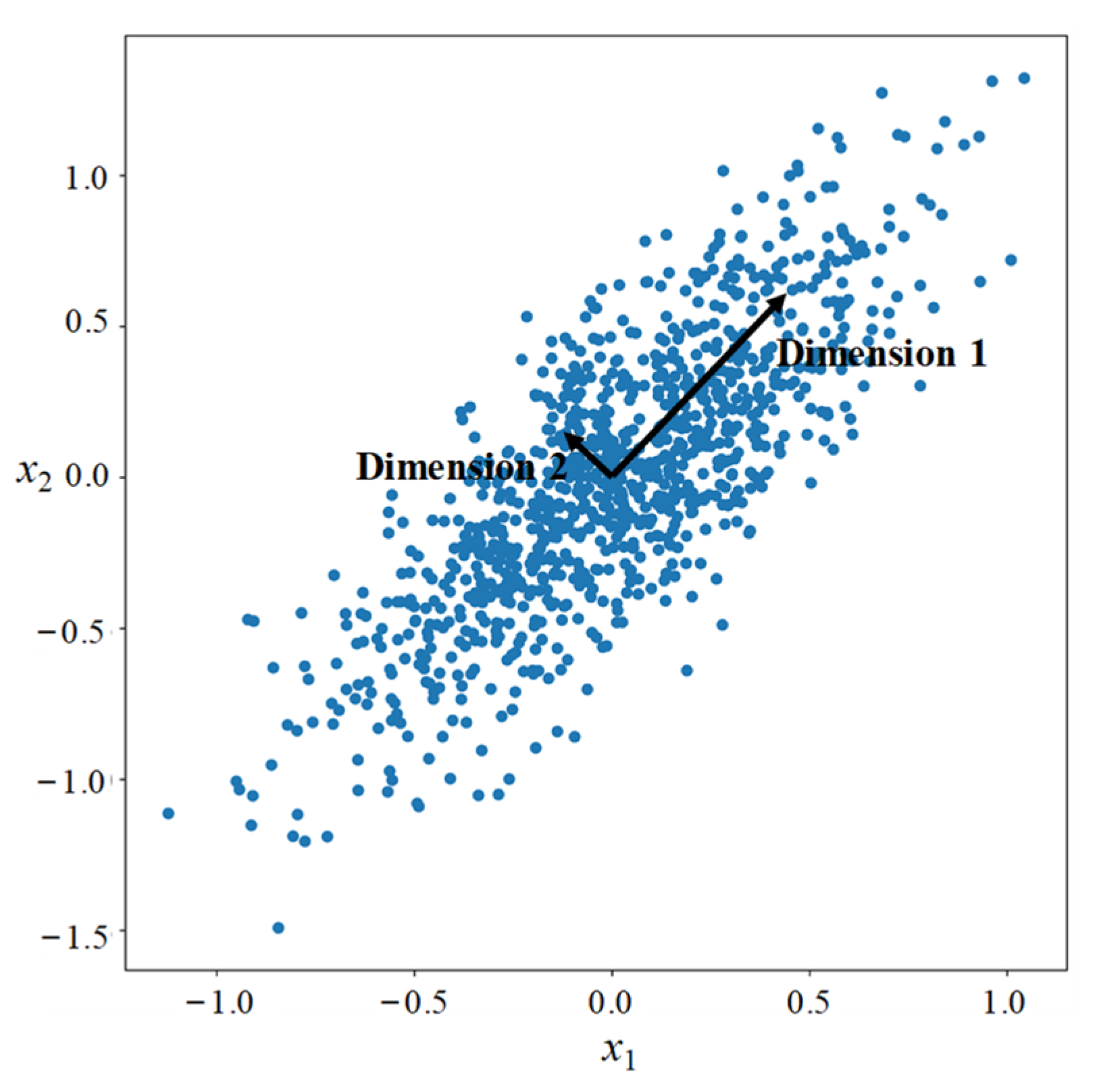
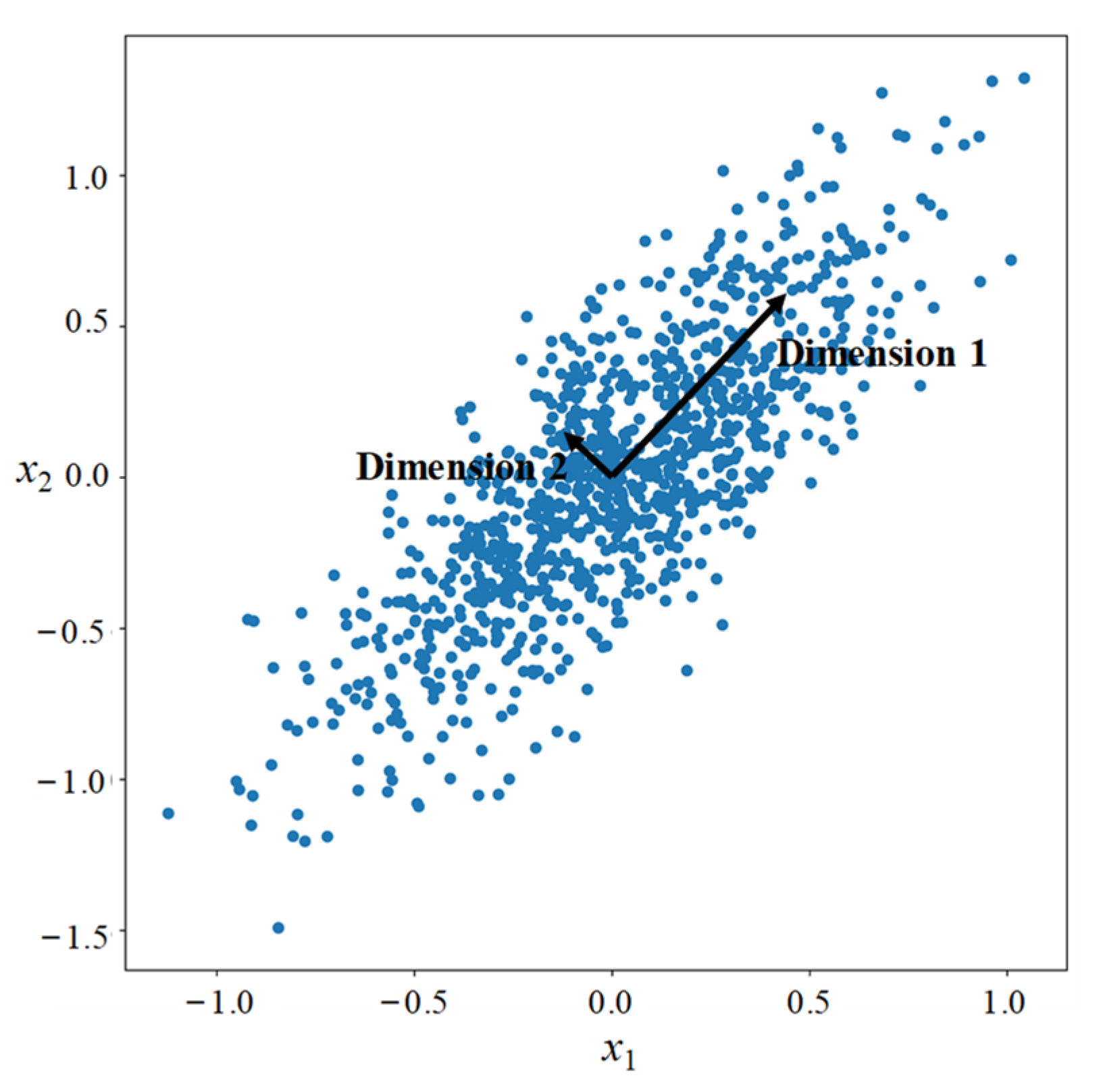
- Principal Component Analysis (PCA)
- 2.
- Feature Selection (FS)
- 3.
- t-distributed Stochastic Neighbor Embedding (t-SNE)
- 4.
- Gaussian Mixture Model (GMM)
| Algorithm 1 EM algorithm in GMM. |
| Step 1 Initialize: Parameters of different Gaussian distributions {μk, σk, αk}, in which μk, σk, αk,k are the mean, variance, probability of kth Gaussian distribution respectively. Step 2 Update the probability rik that the ith sample belongs to kth Gaussian distribution: . Step 3 Update the μk+1: . Step 4 Update the σk+1: . Step 5 Update the αk+1: . Step 6 If , or , or : Store the variables {μk+1, σk+1, αk+1}; Start the next iteration from Step 2. Else if: End the iteration. |
2.3.2. Methods Evaluation
3. Establishment of the Machine Learning Model
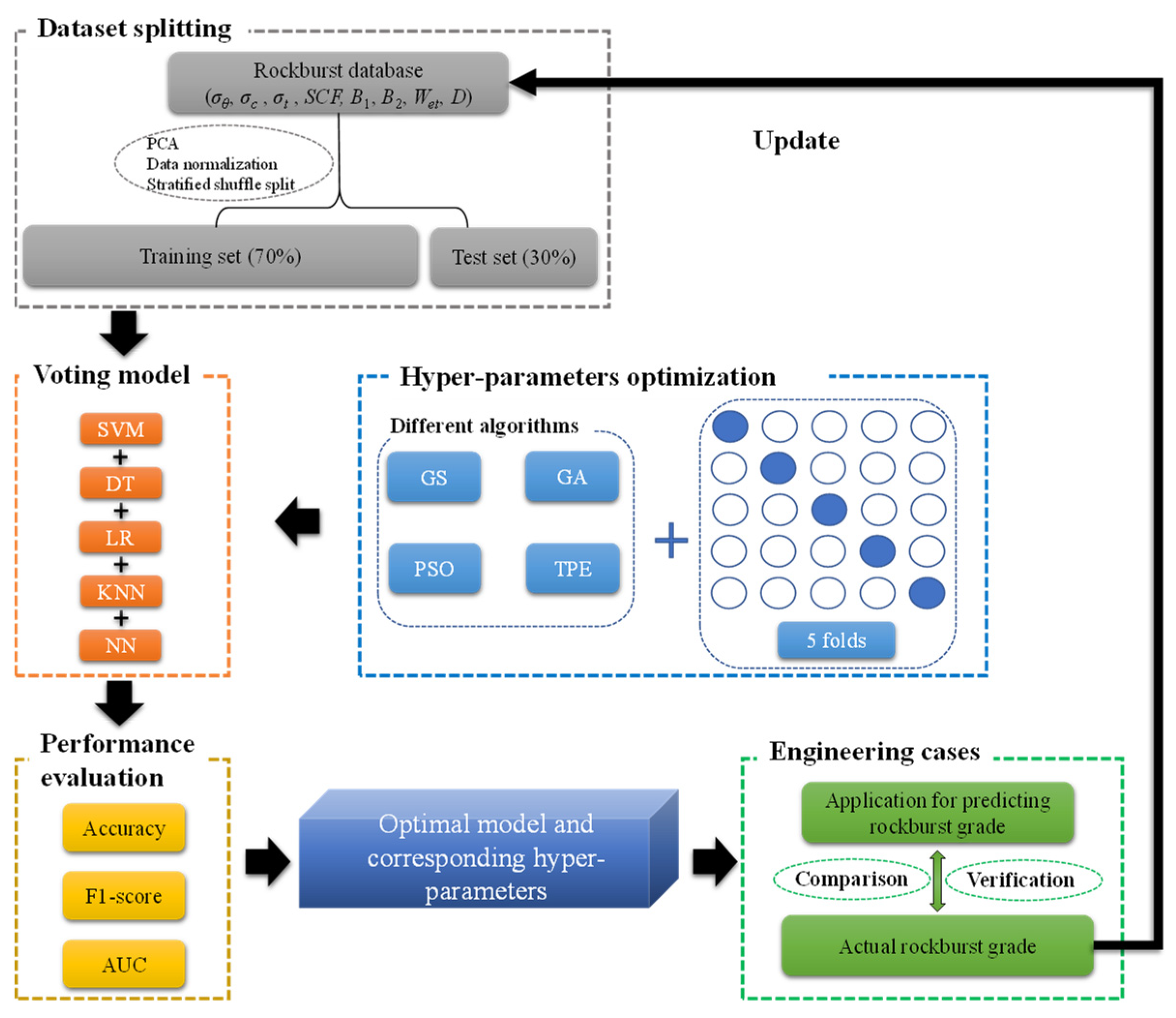
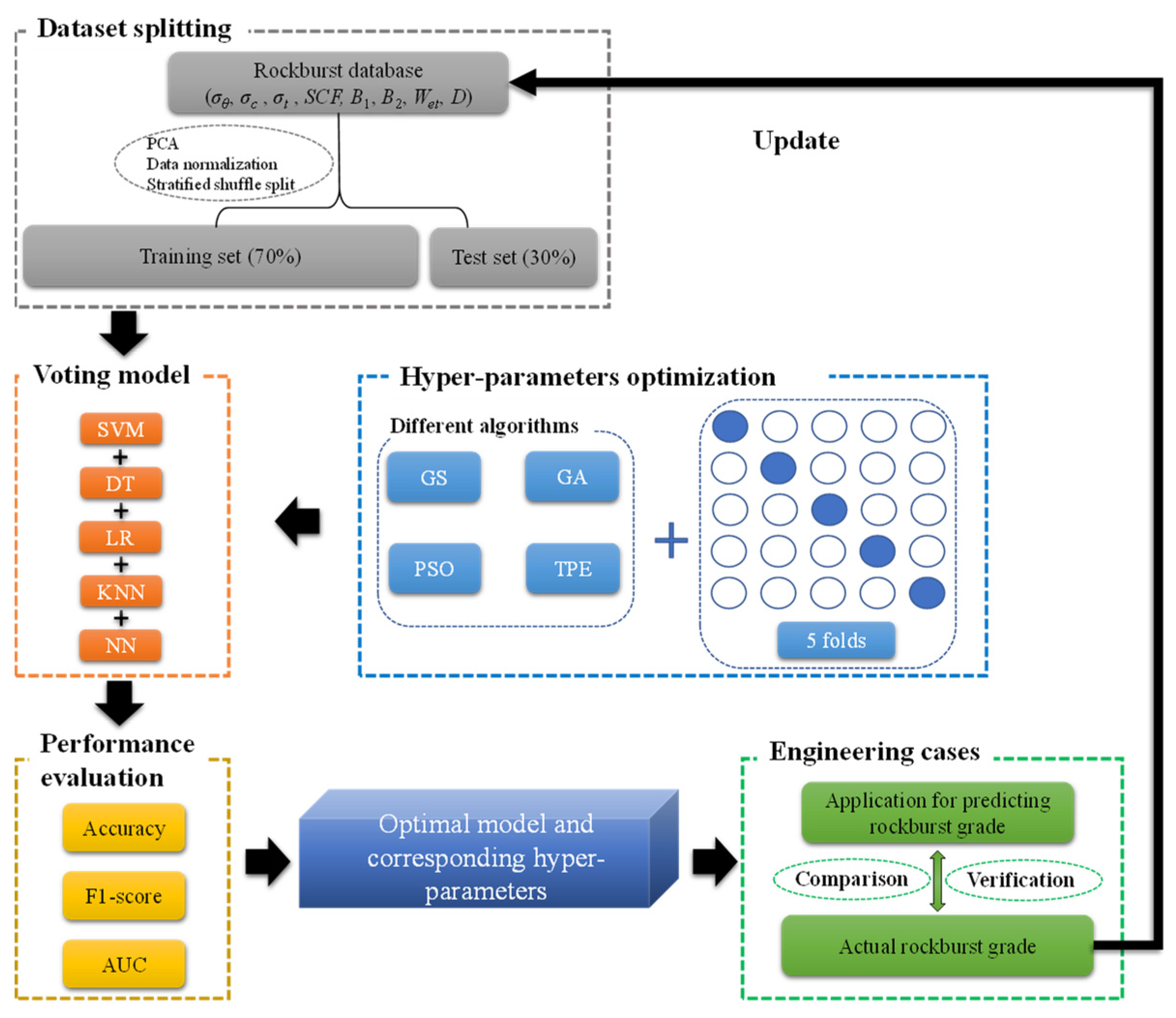
3.1. Dataset Splitting
3.2. Voting Ensemble Model
- Support Vector Machine (SVM)
- b.
- Decision Tree (DT)
- c.
- Logistic Regression (LR)
- d.
- K-Nearest Neighbor (KNN)
- e.
- Neural Network (NN)
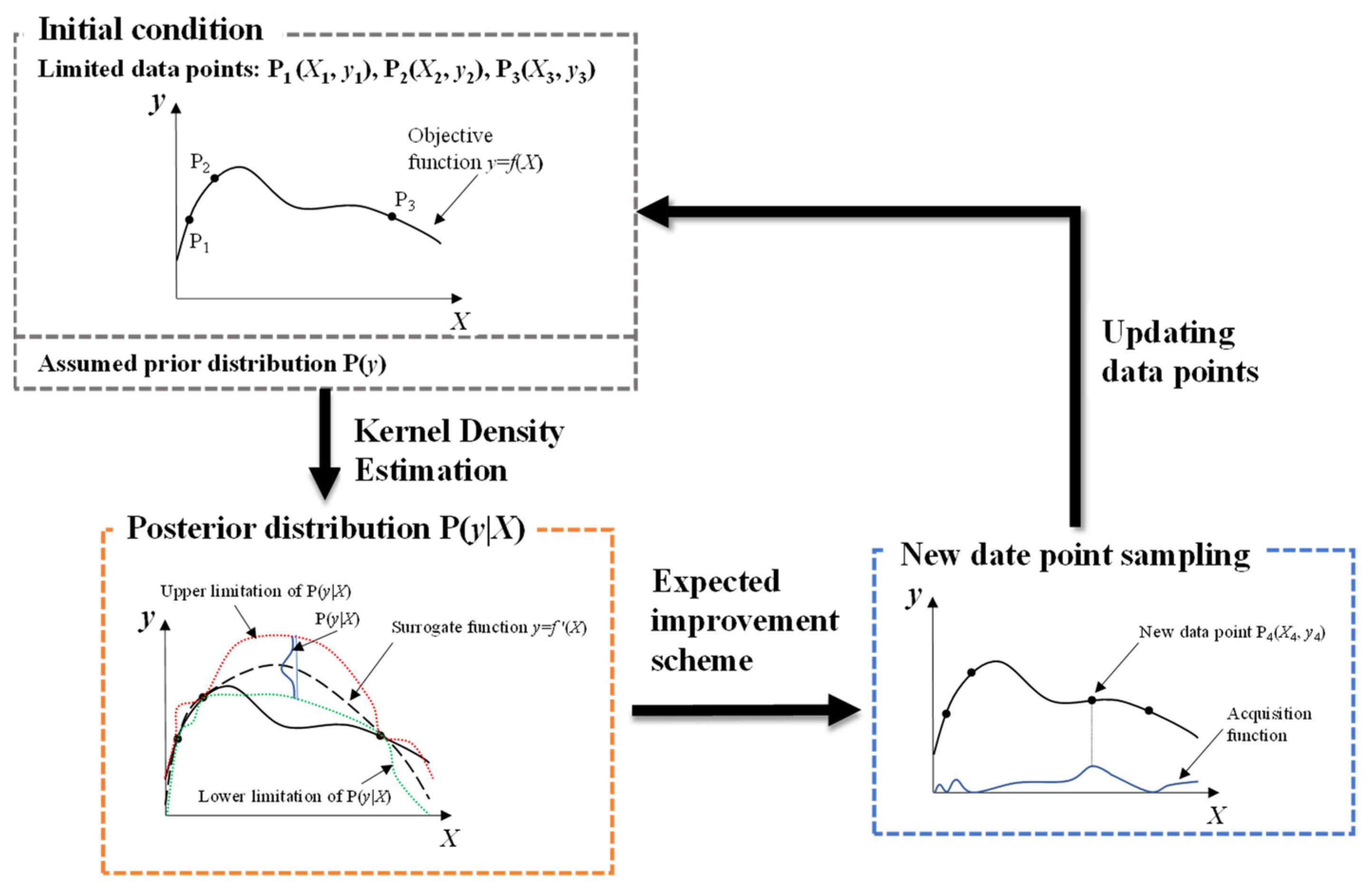
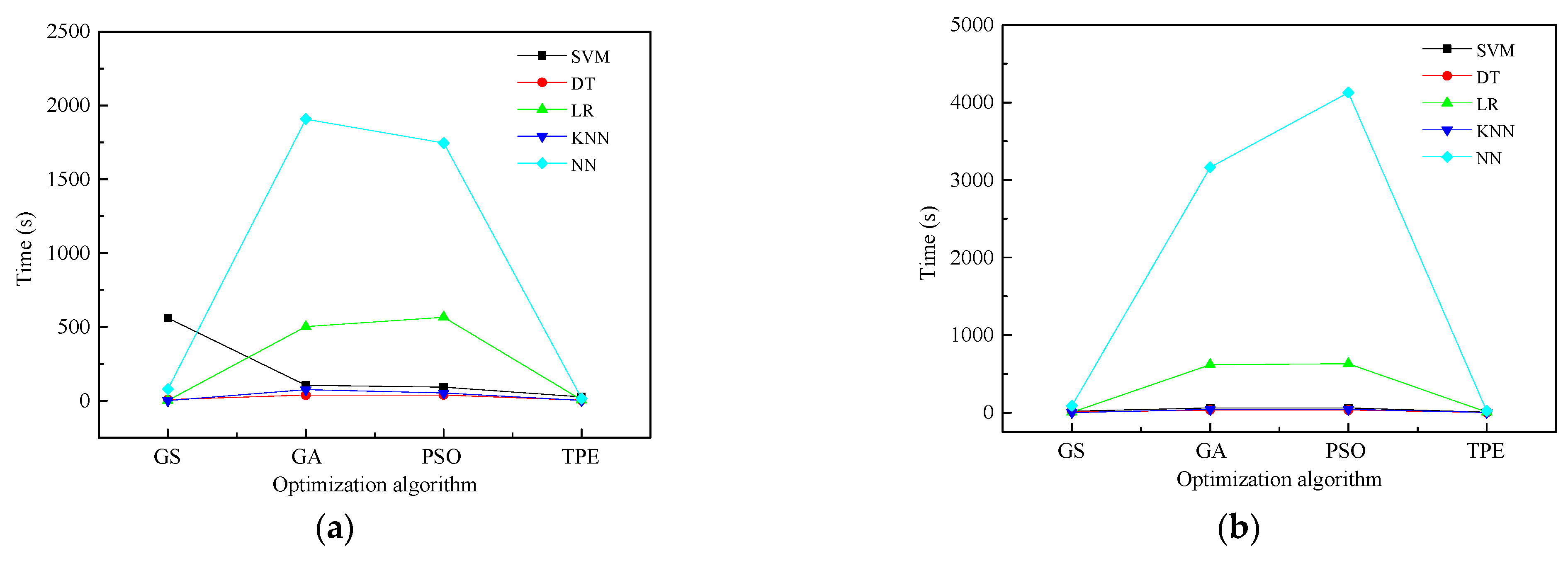
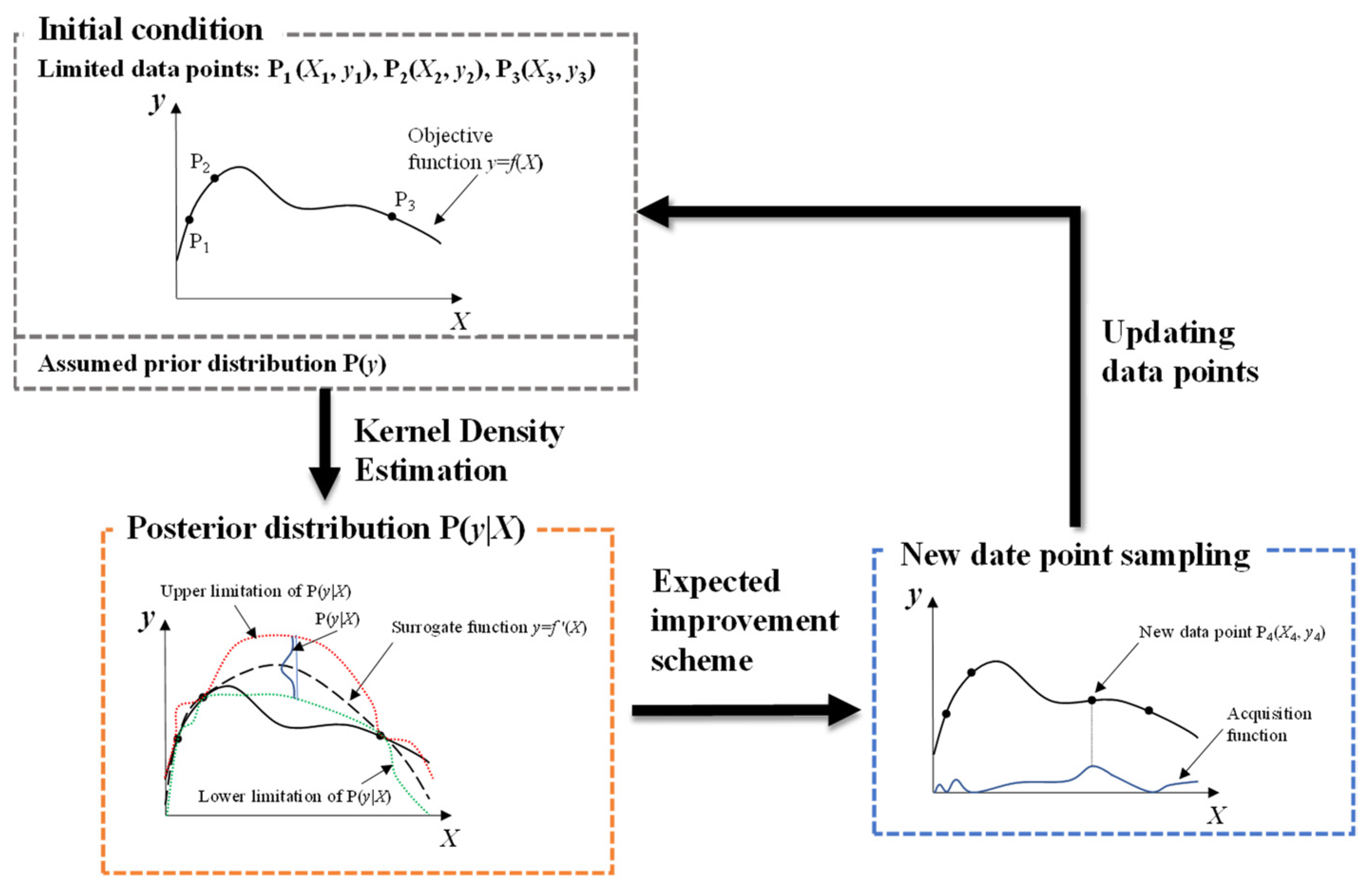
3.3. Hyperparameters Optimization
4. Results of Prediction and the Performance Evaluation
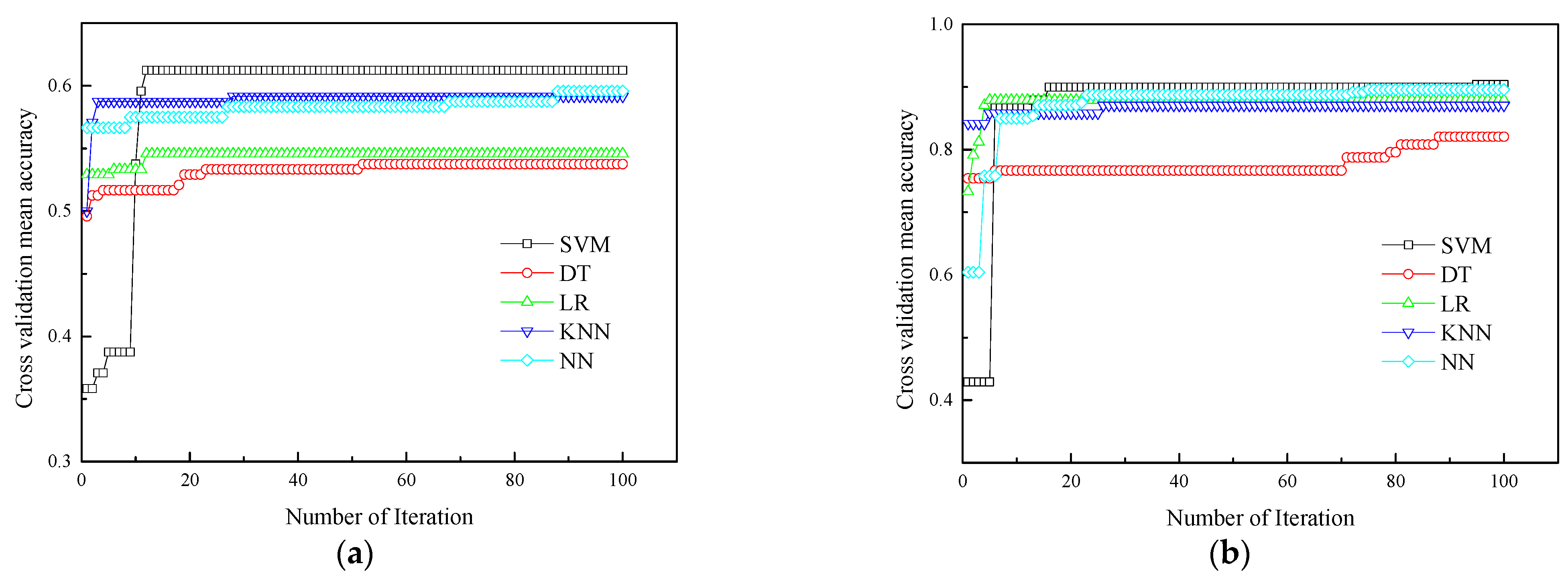
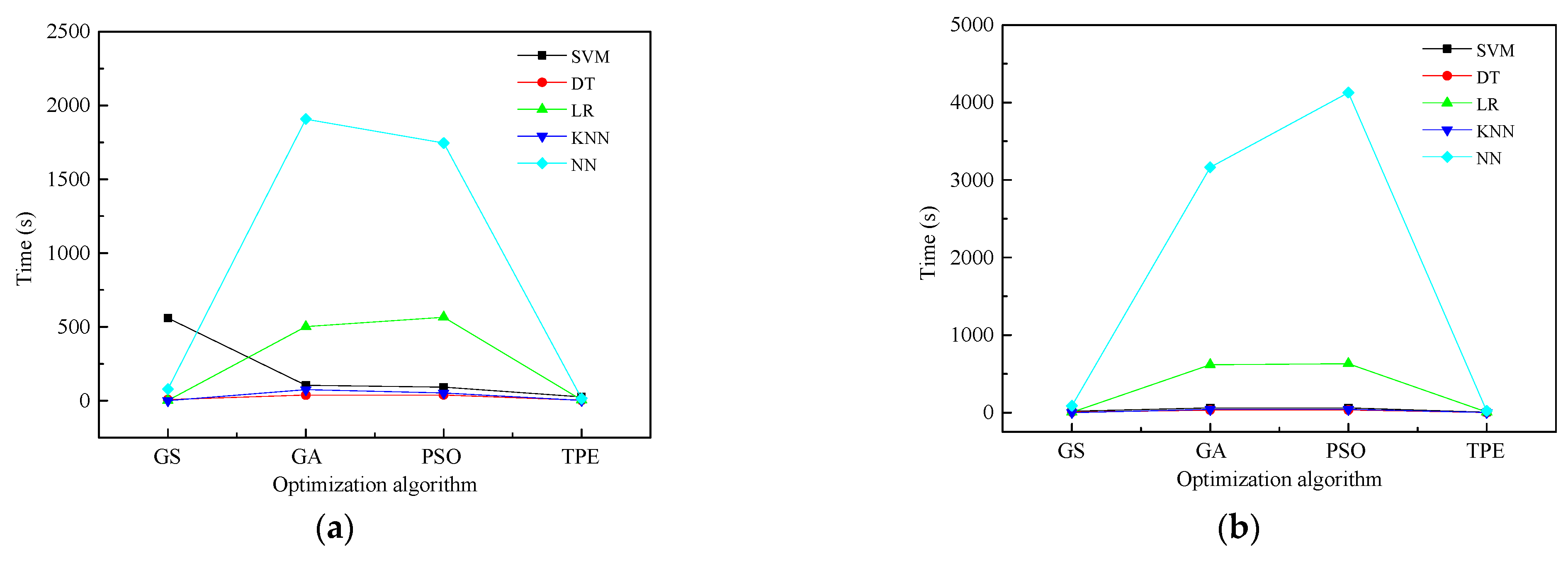
4.1. Results of Hyperparameter Optimization
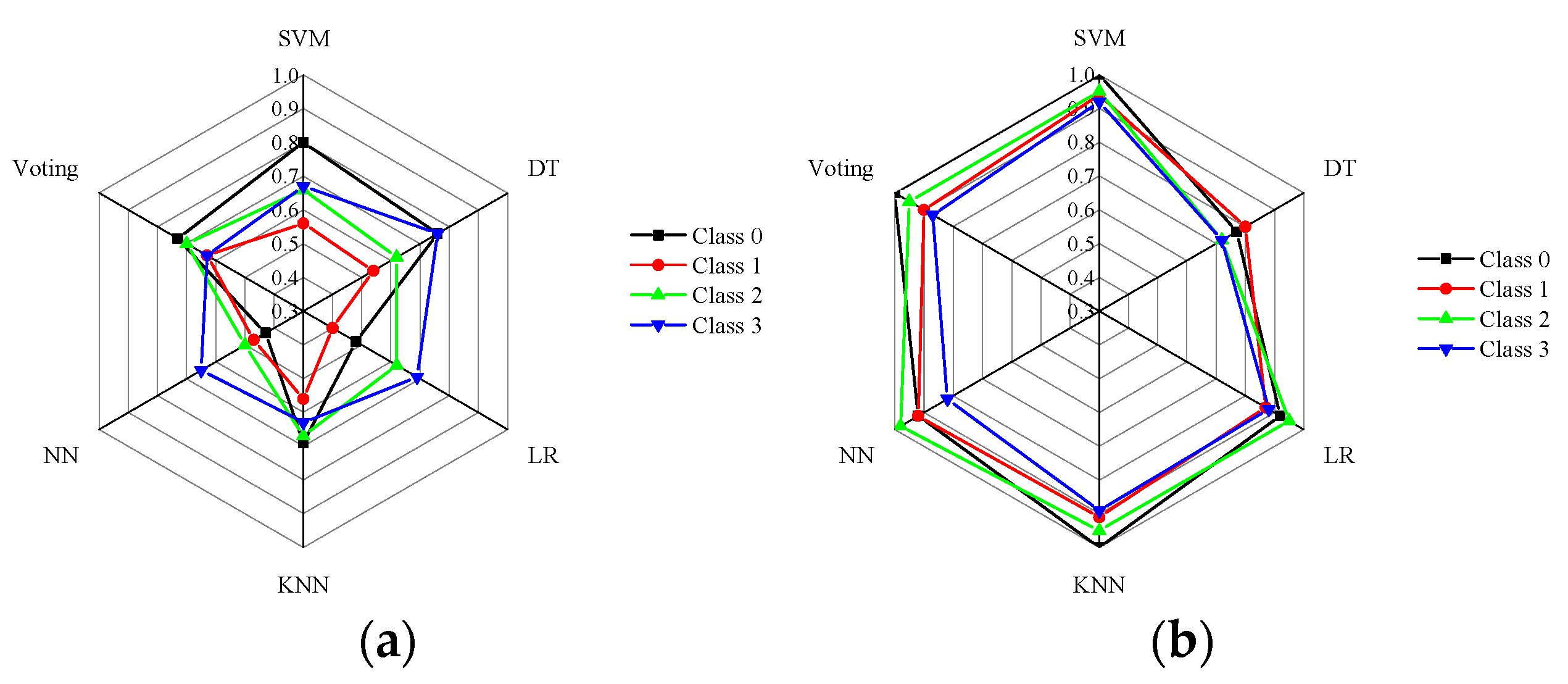
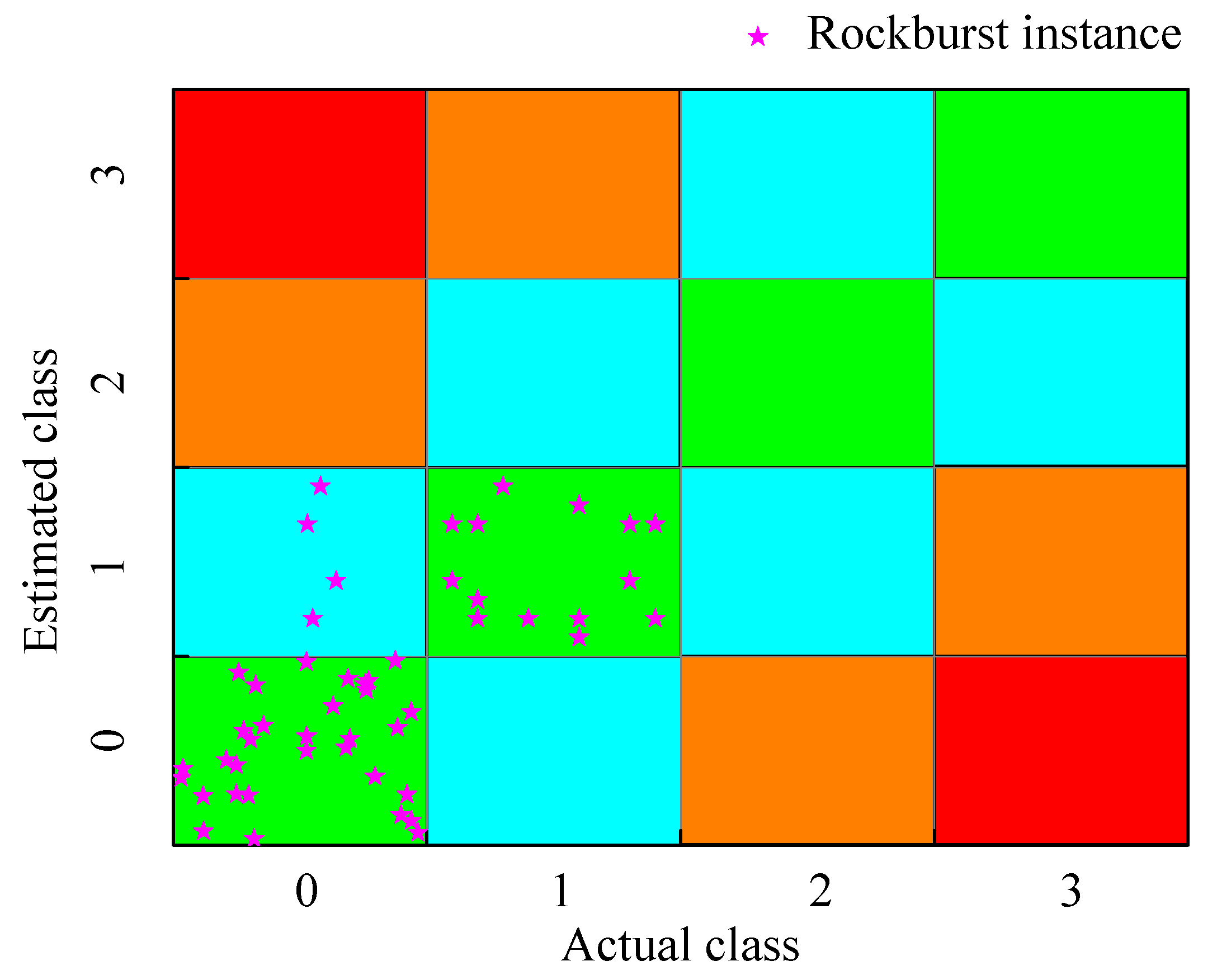
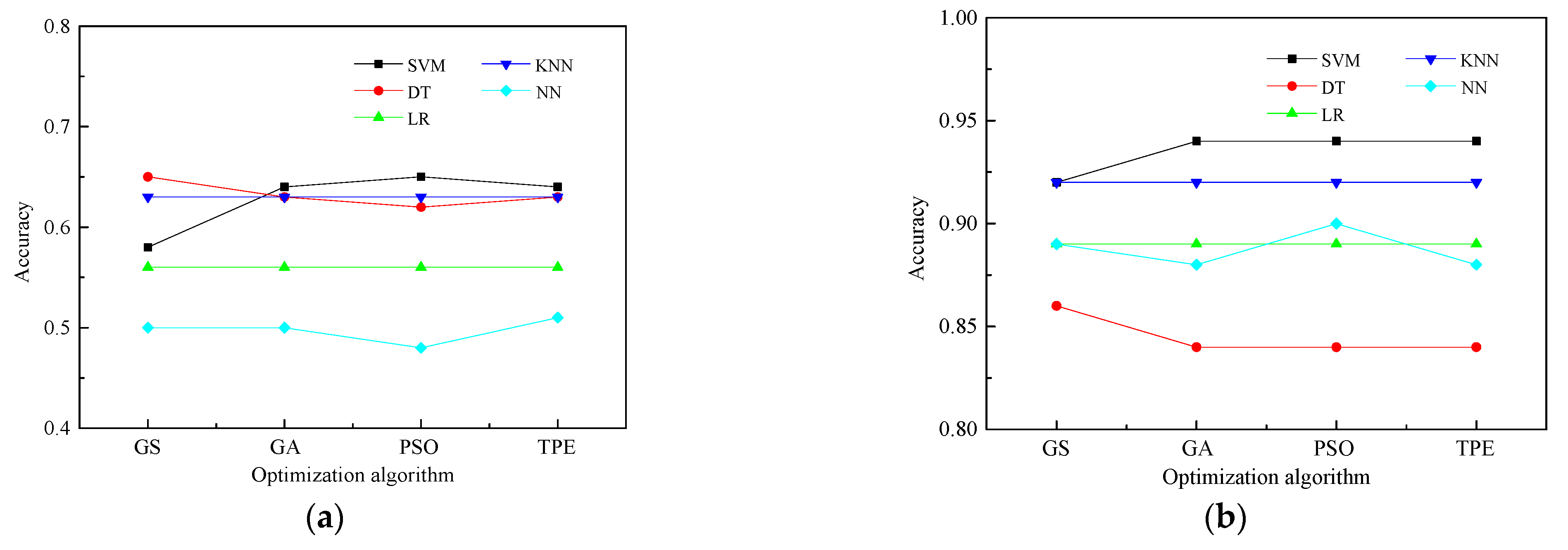
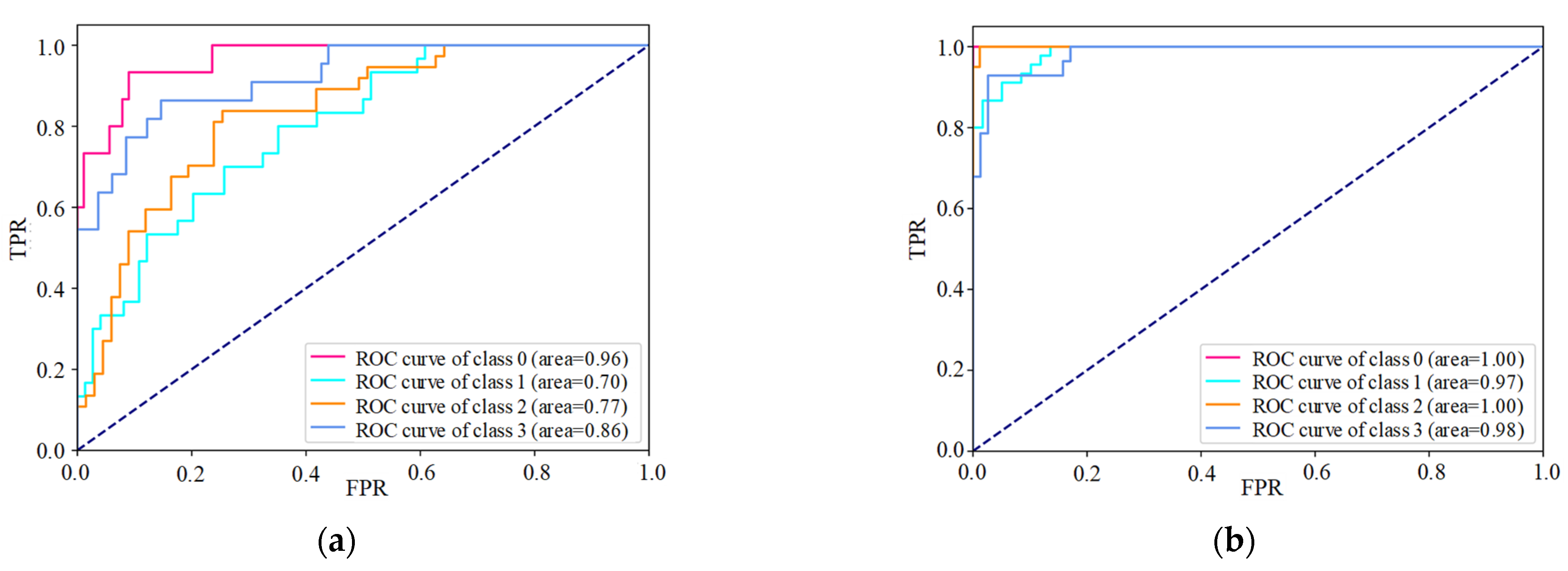
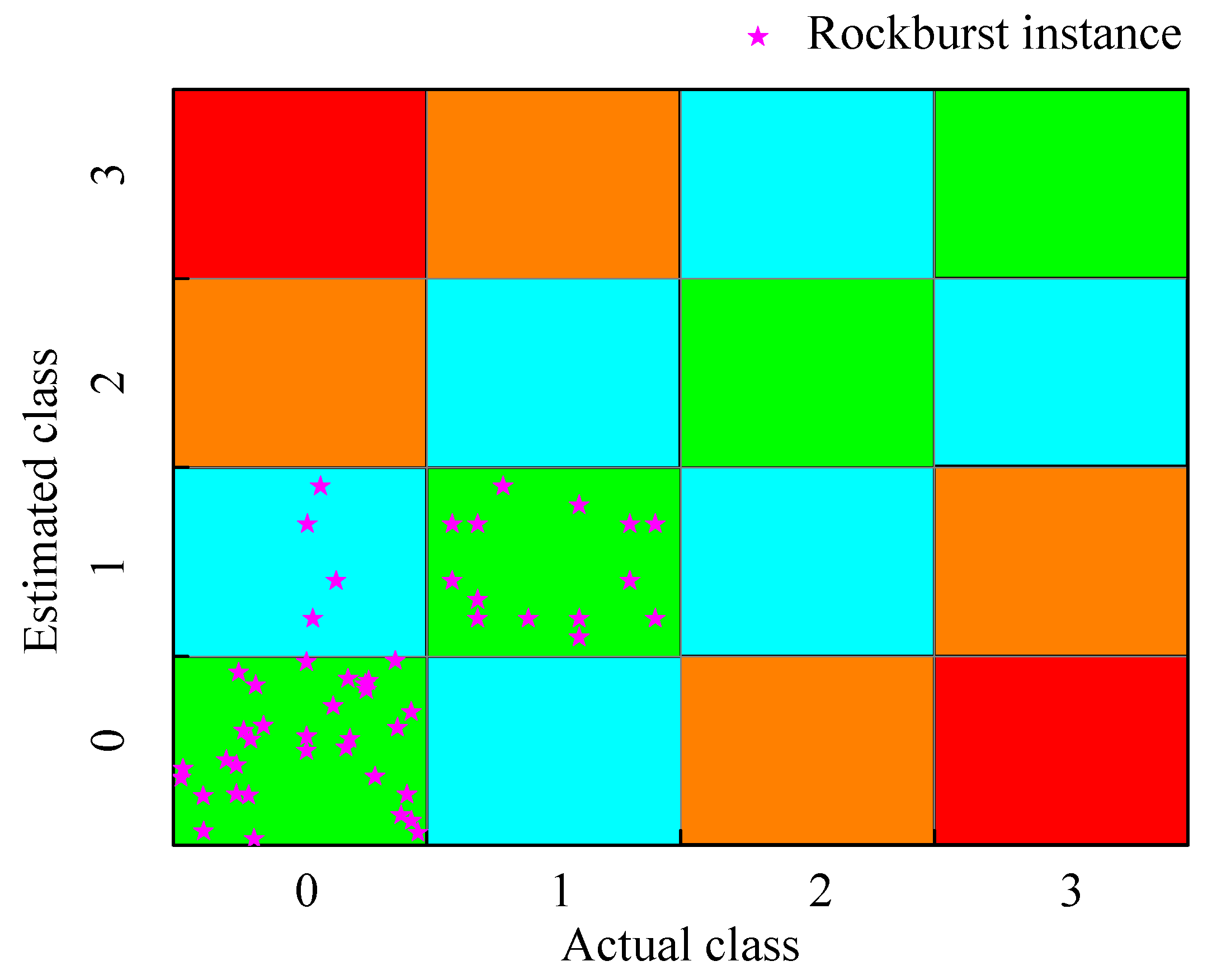
4.2. Prediction Results of the Machine Learning Model
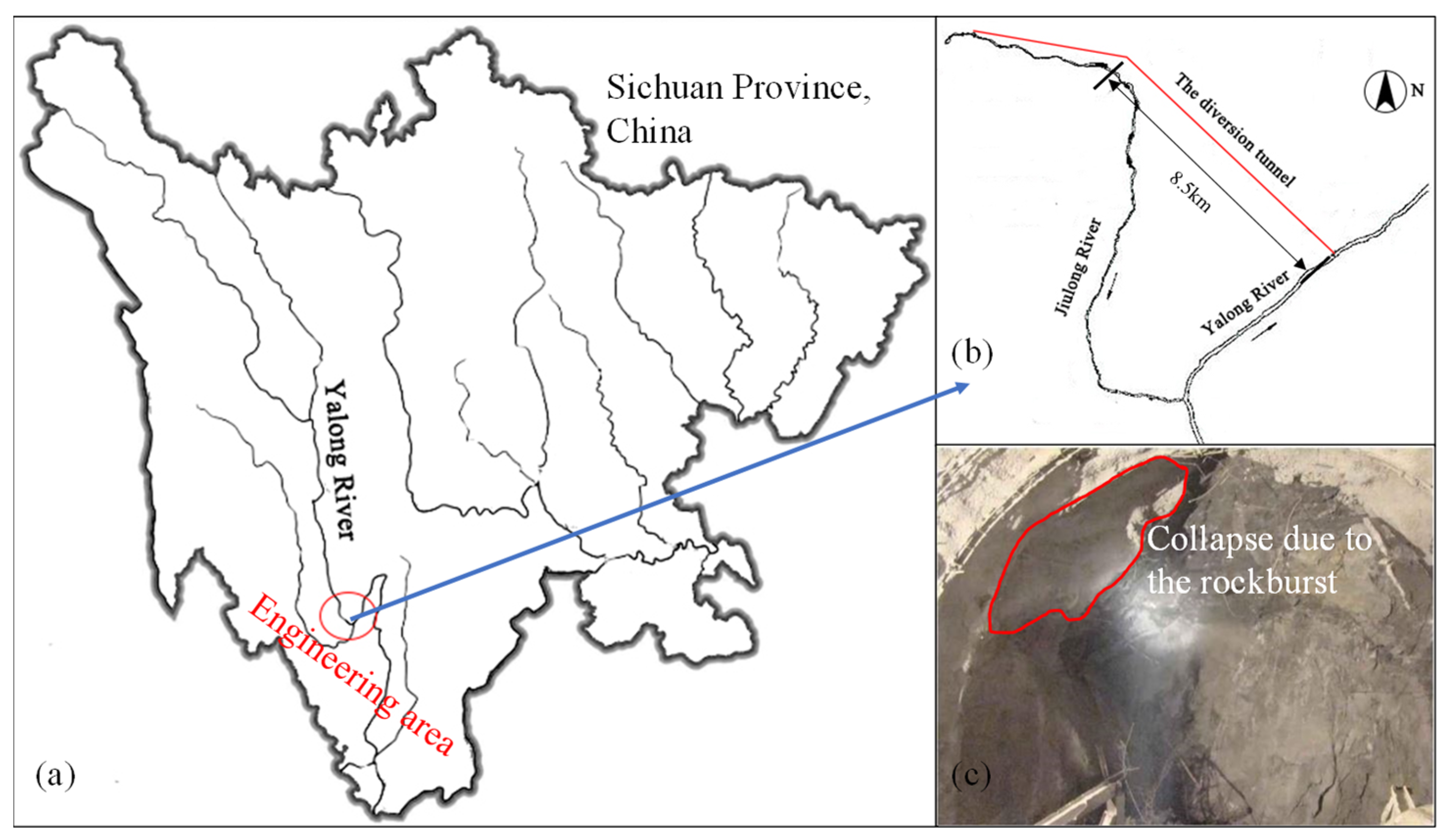
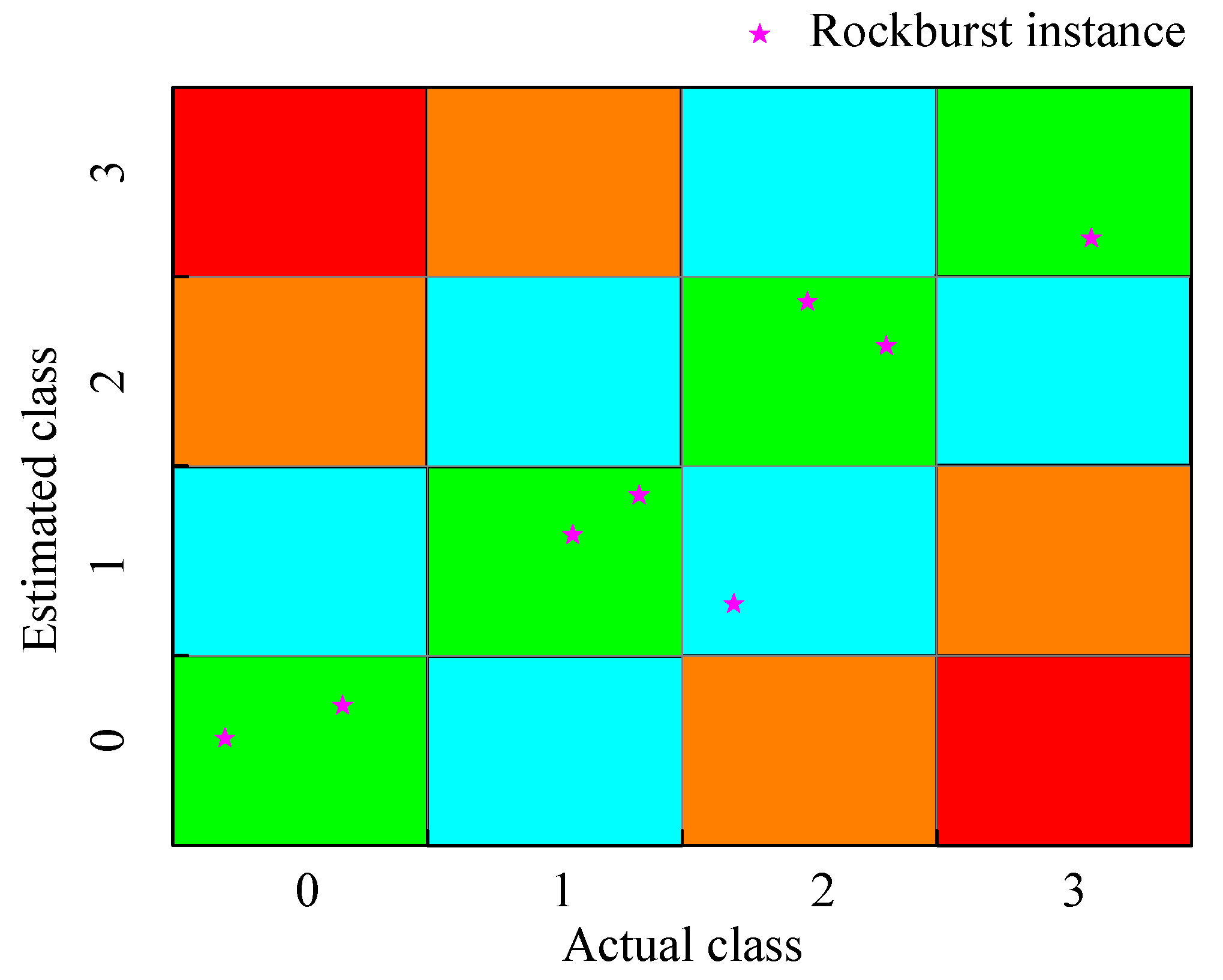
5. Validation on Practical Engineering Case
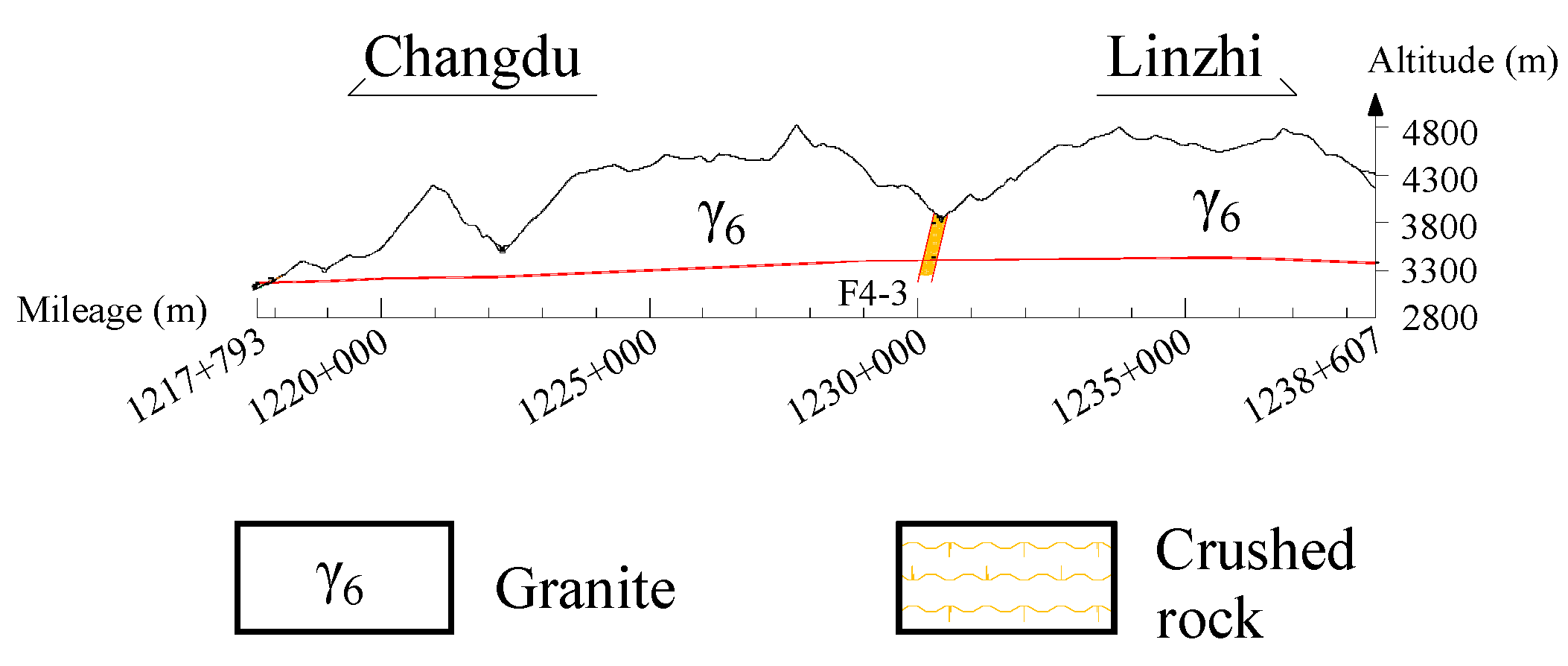
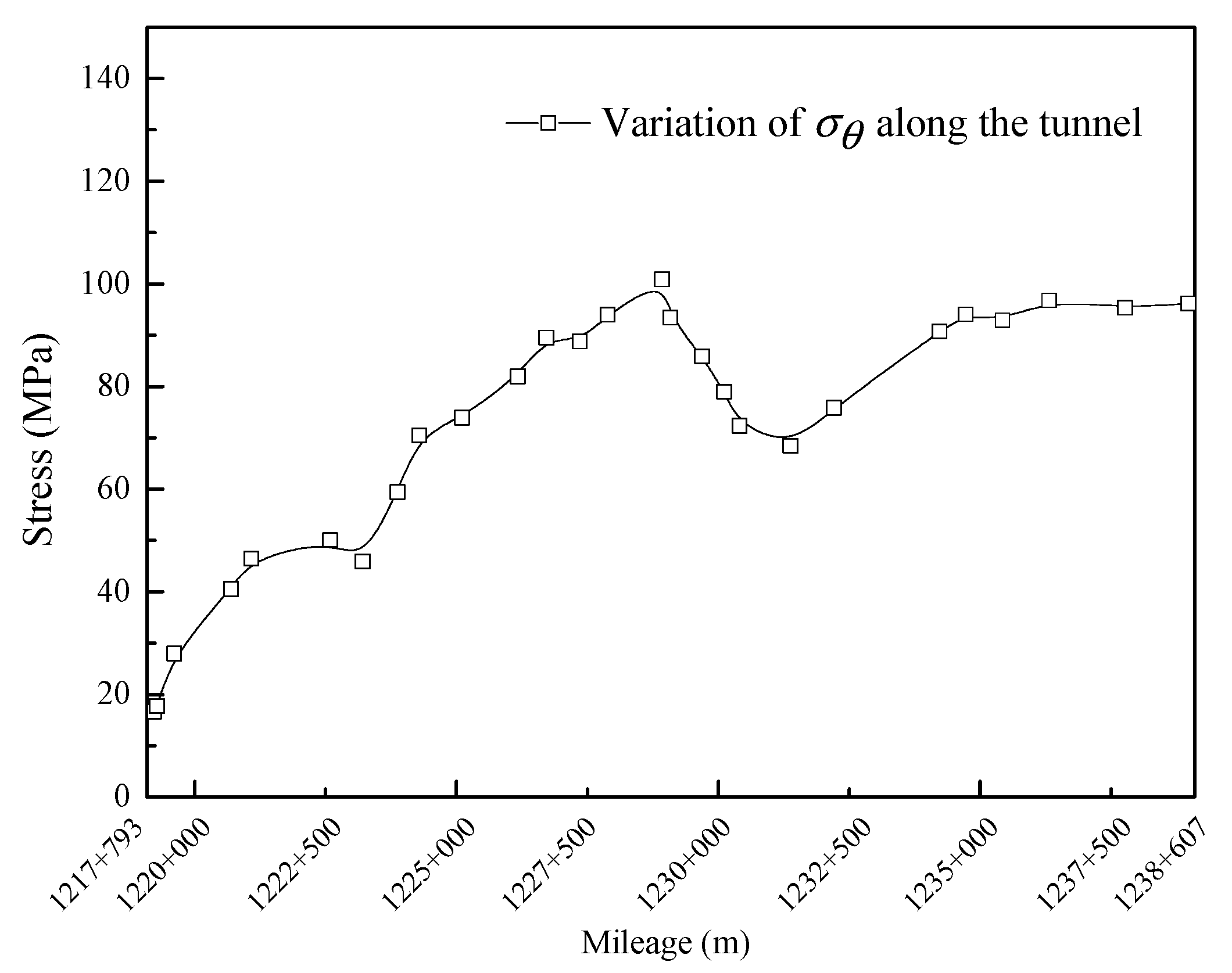
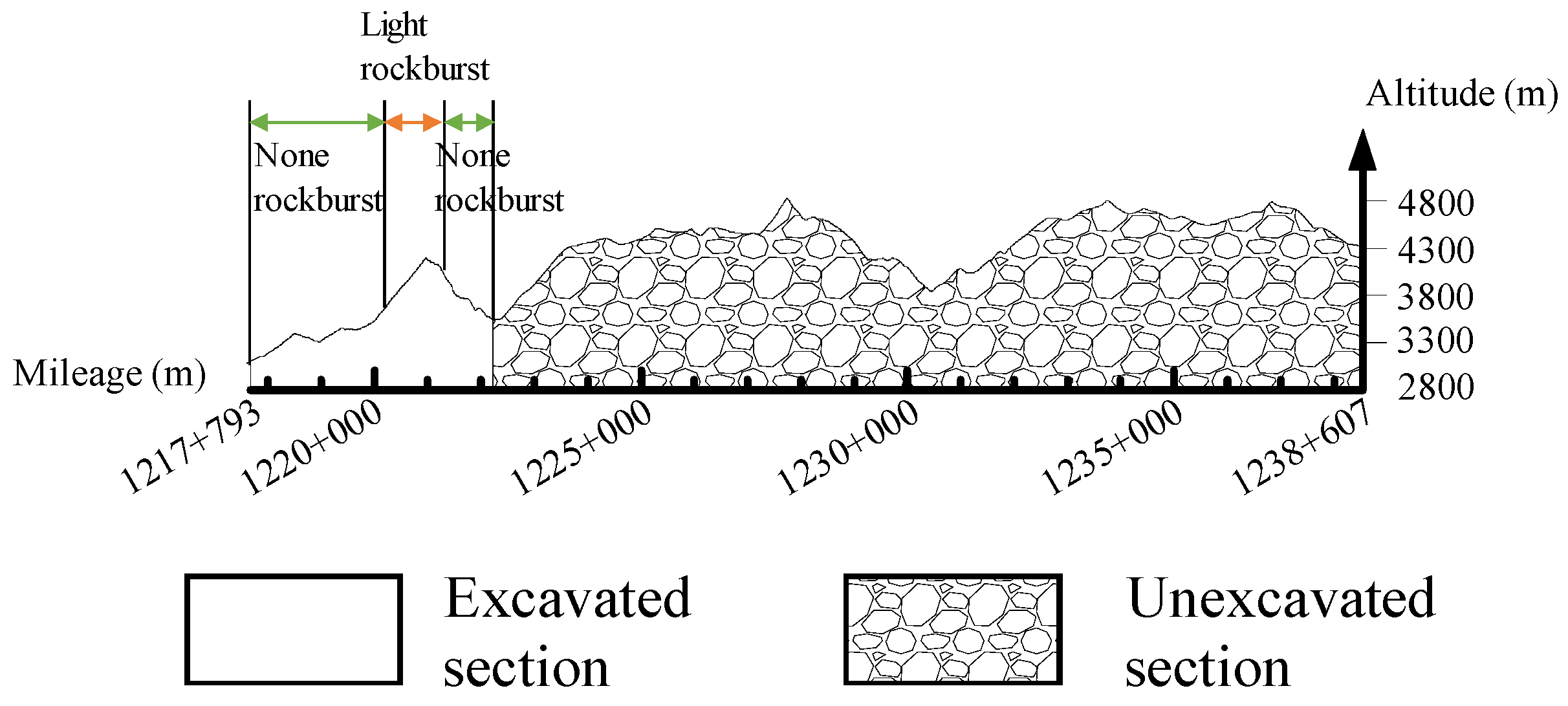
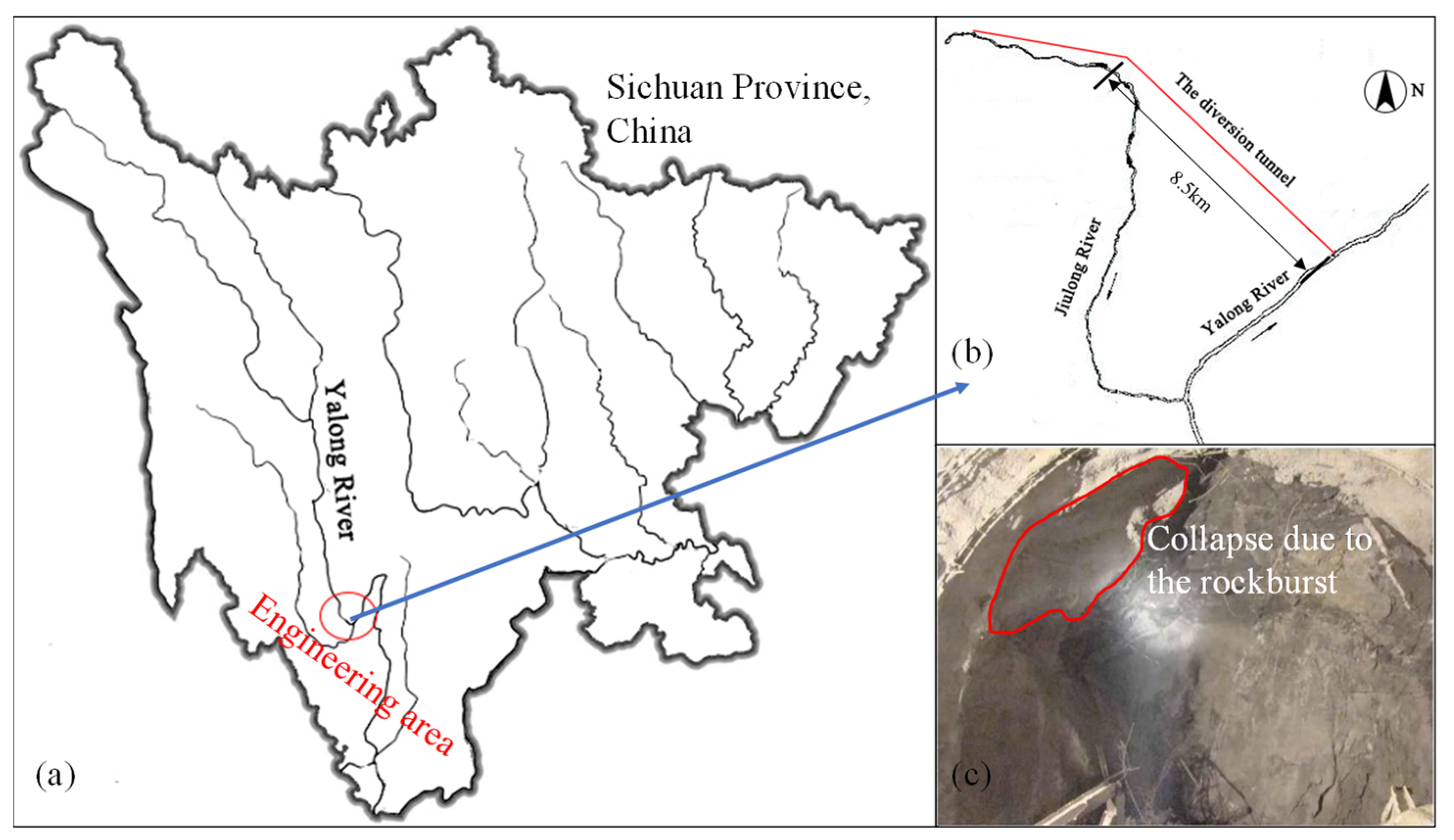
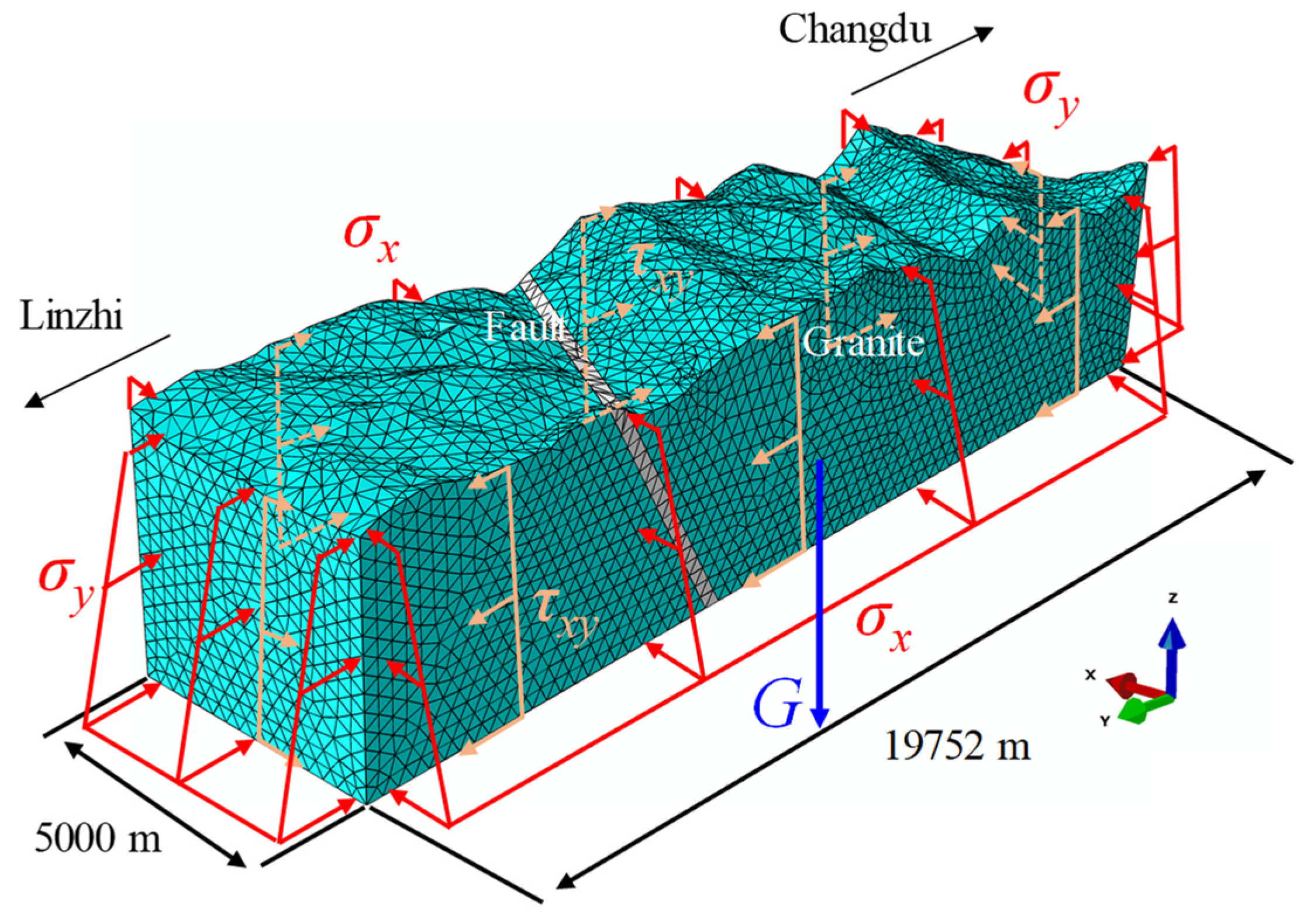
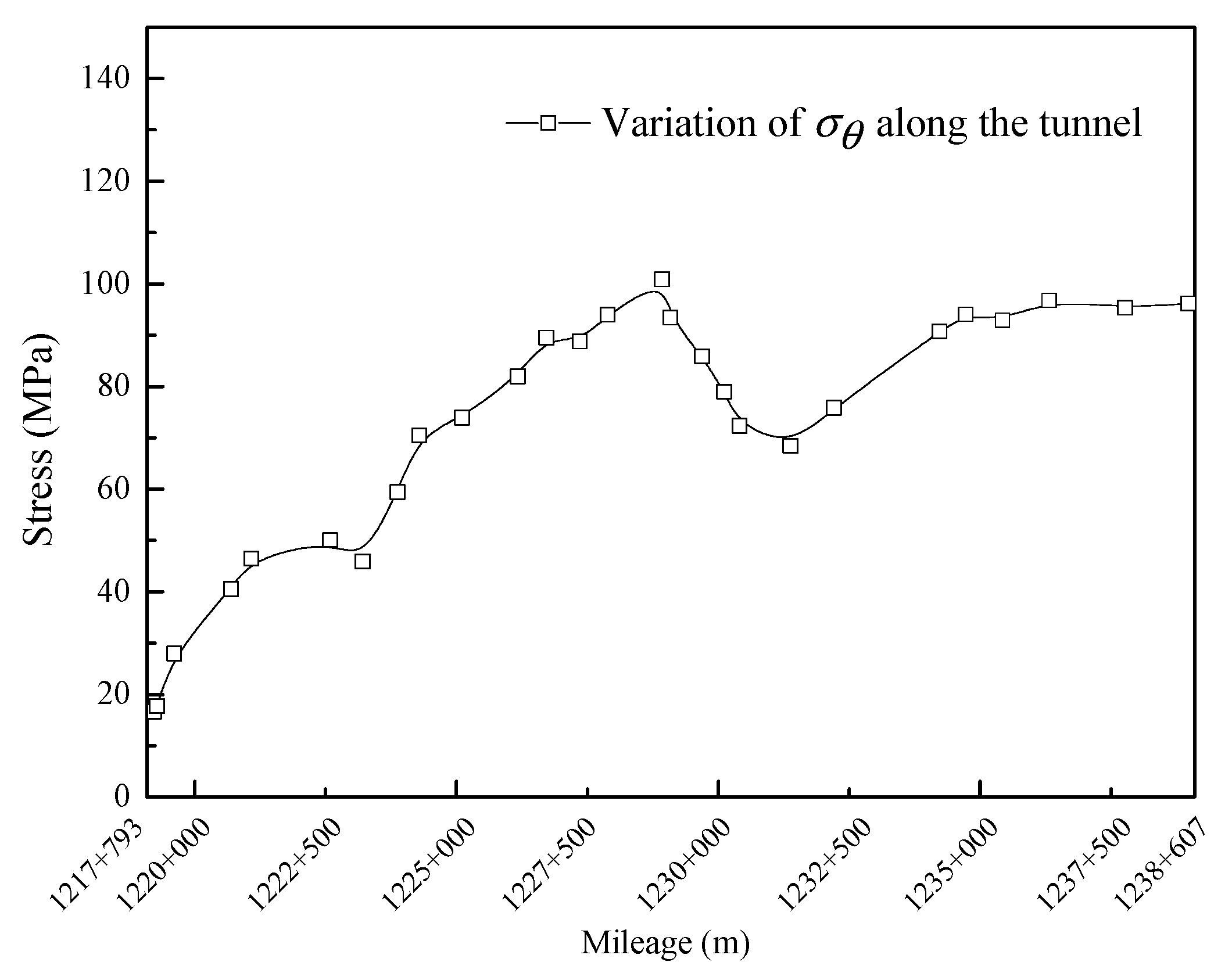
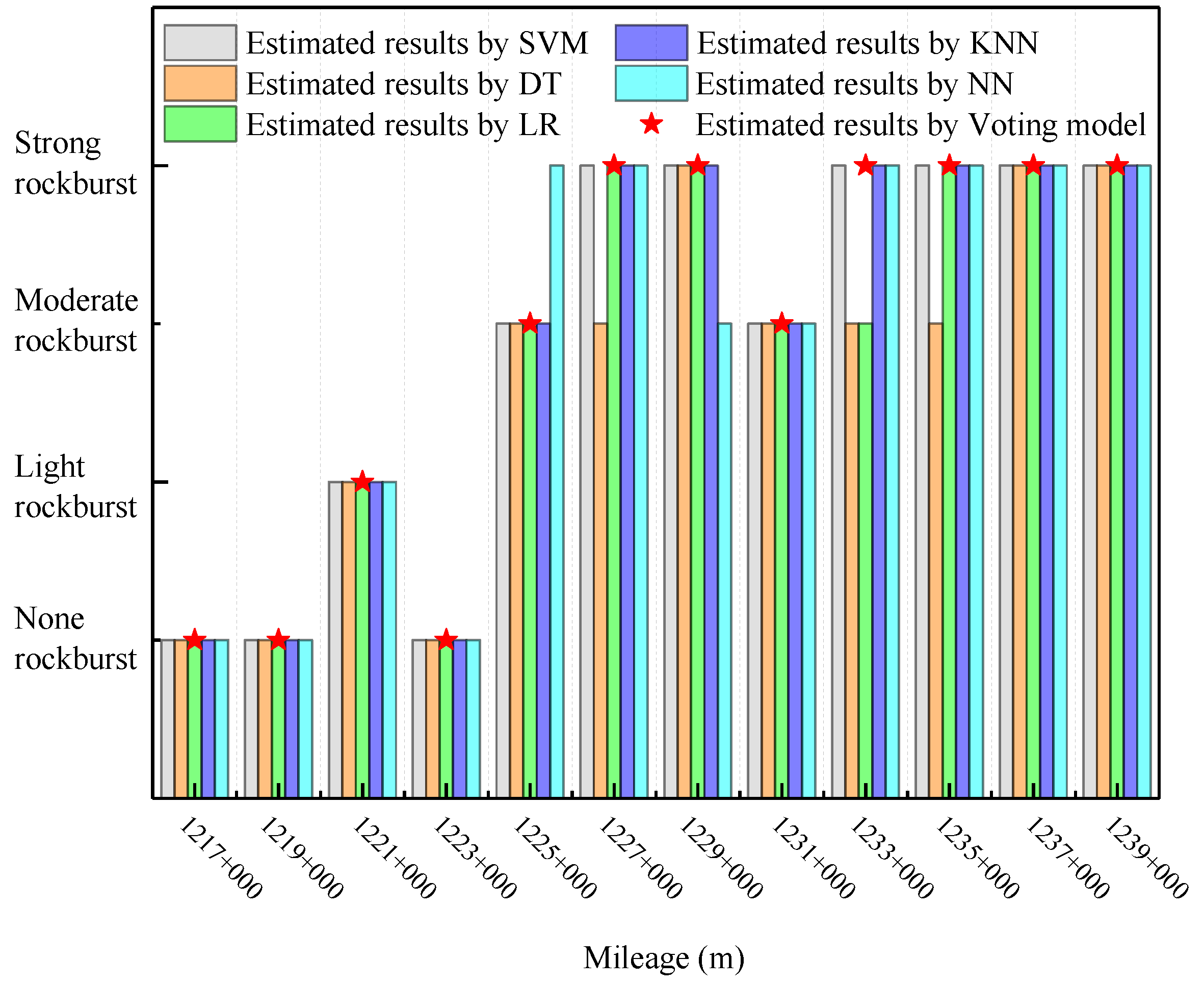
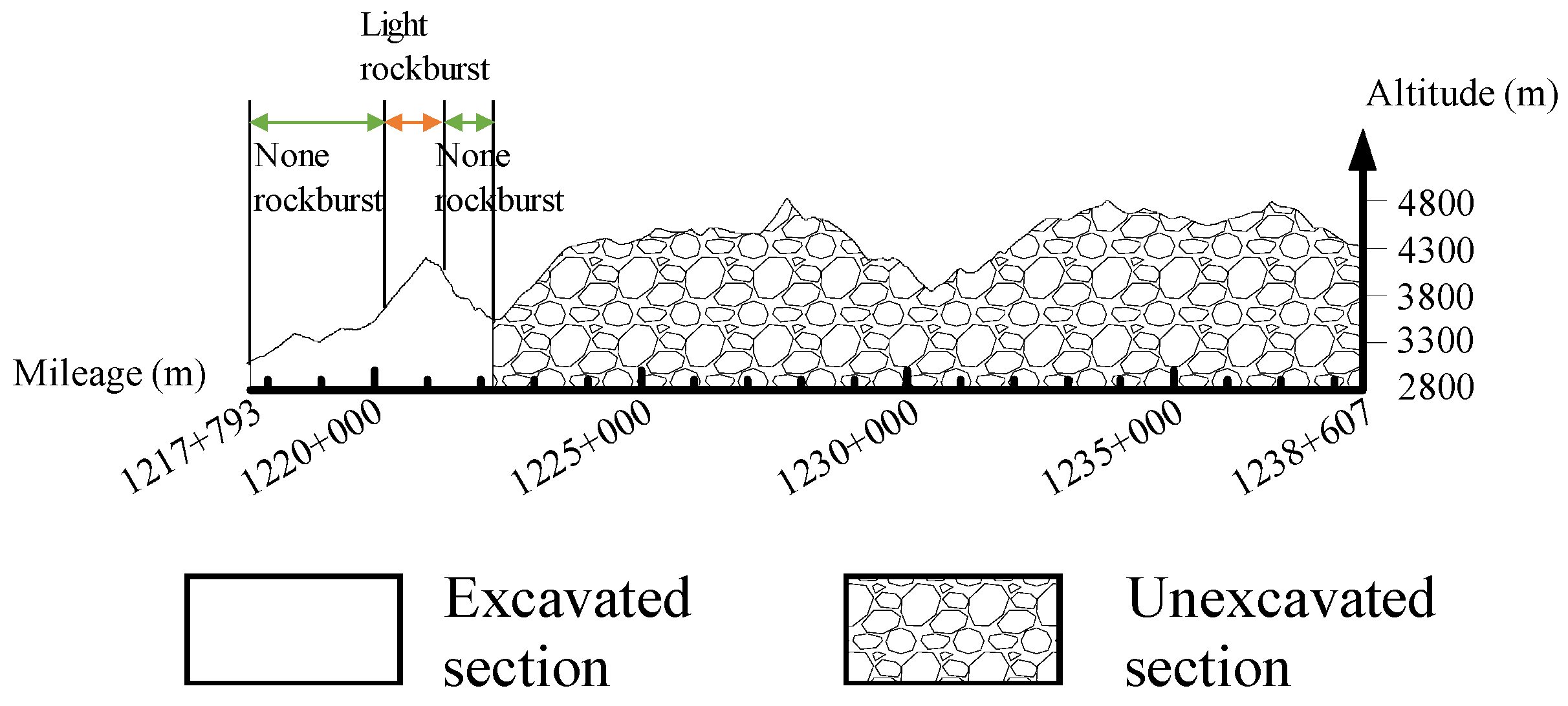
5.1. Case 1
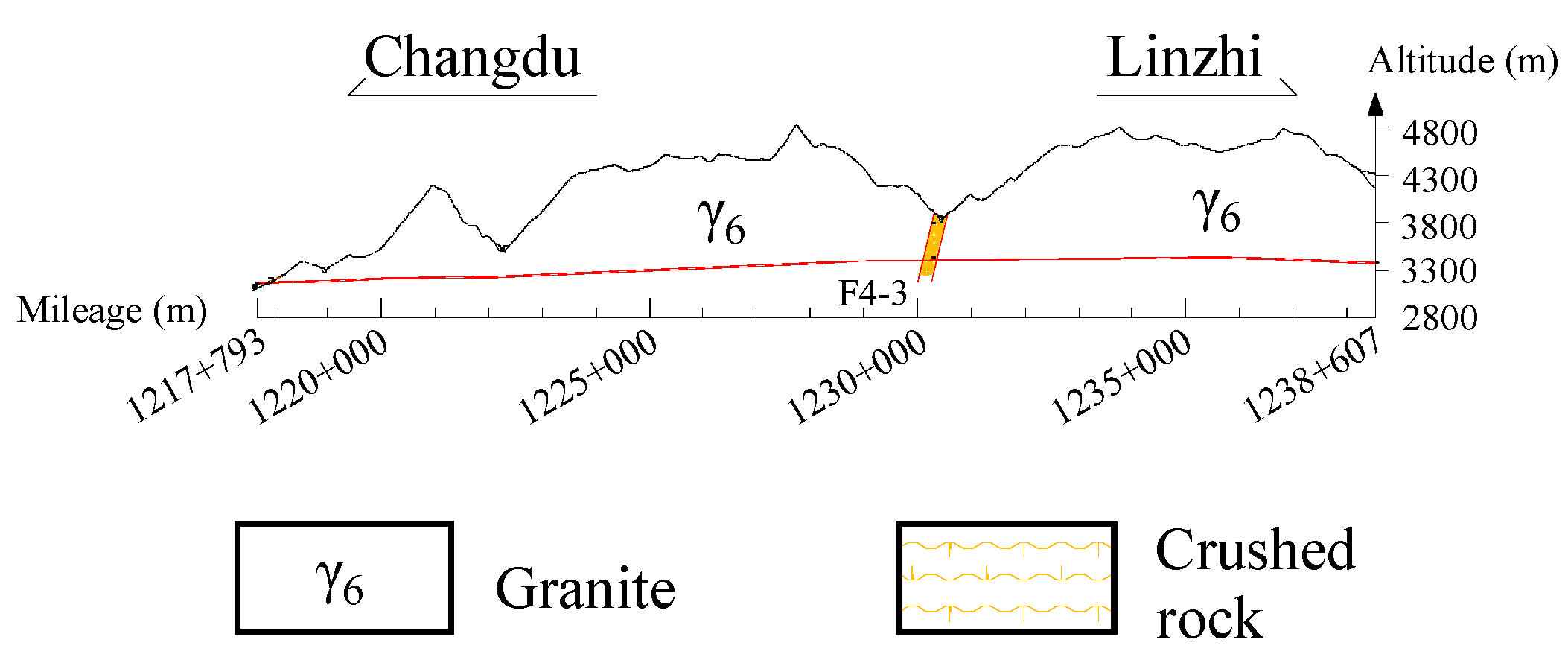
5.2. Case 2
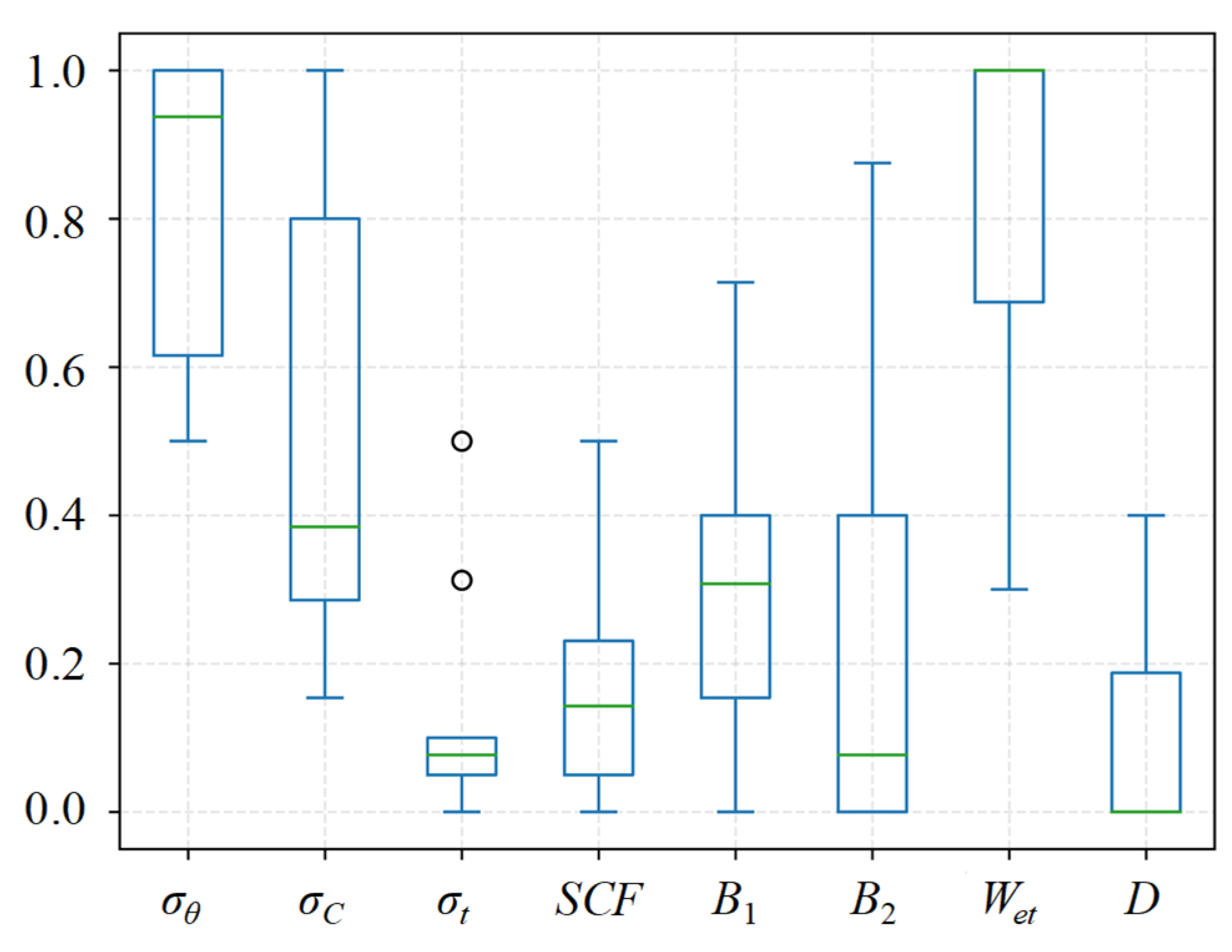
6. Sensitivity Analysis of Features
7. Discussion
8. Conclusions
- (1)
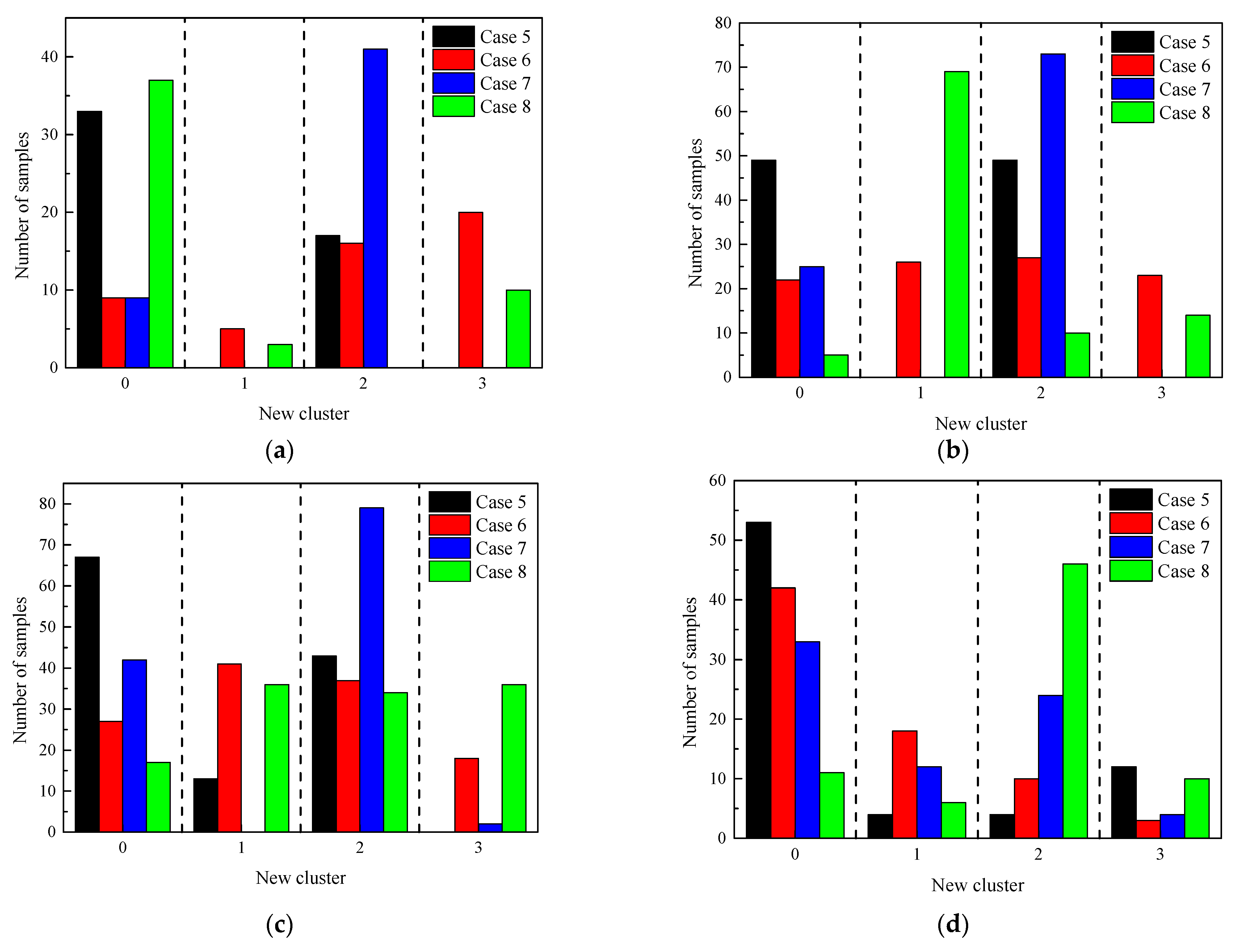
- In the process of relabeling the dataset, we used four combination methods (PCA + GMM, PCA + t-SNE + GMM, FS + GMM, and FS + t-SNE + GMM) to reduce the dimensionality of features and perform clustering. It was observed that PCA + t-SNE + GMM and FS + t-SNE + GMM outperformed the other two methods. This is because t-SNE can effectively handle outliers, leading to better clustering results. Moreover, the clustering effect of FS + t-SNE + GMM showed closer agreement with the practical labels compared with PCA + t-SNE + GMM. This is attributed to the susceptibility of PCA to the distribution of sample points and its inability to consider the physical meaning of features. Additionally, the relabeling of the dataset significantly improved both the prediction accuracy of machine learning models and their generalization ability.
- (2)
- When comparing prevalent hyperparameter optimization algorithms (GS, GA, and PSO), the TPE estimator demonstrated an equal capability in searching for the optimal solution. Notably, TPE’s distinct search strategy, which focuses on the direction of expected improvement, resulted in significant time savings during the optimization process.
- (3)
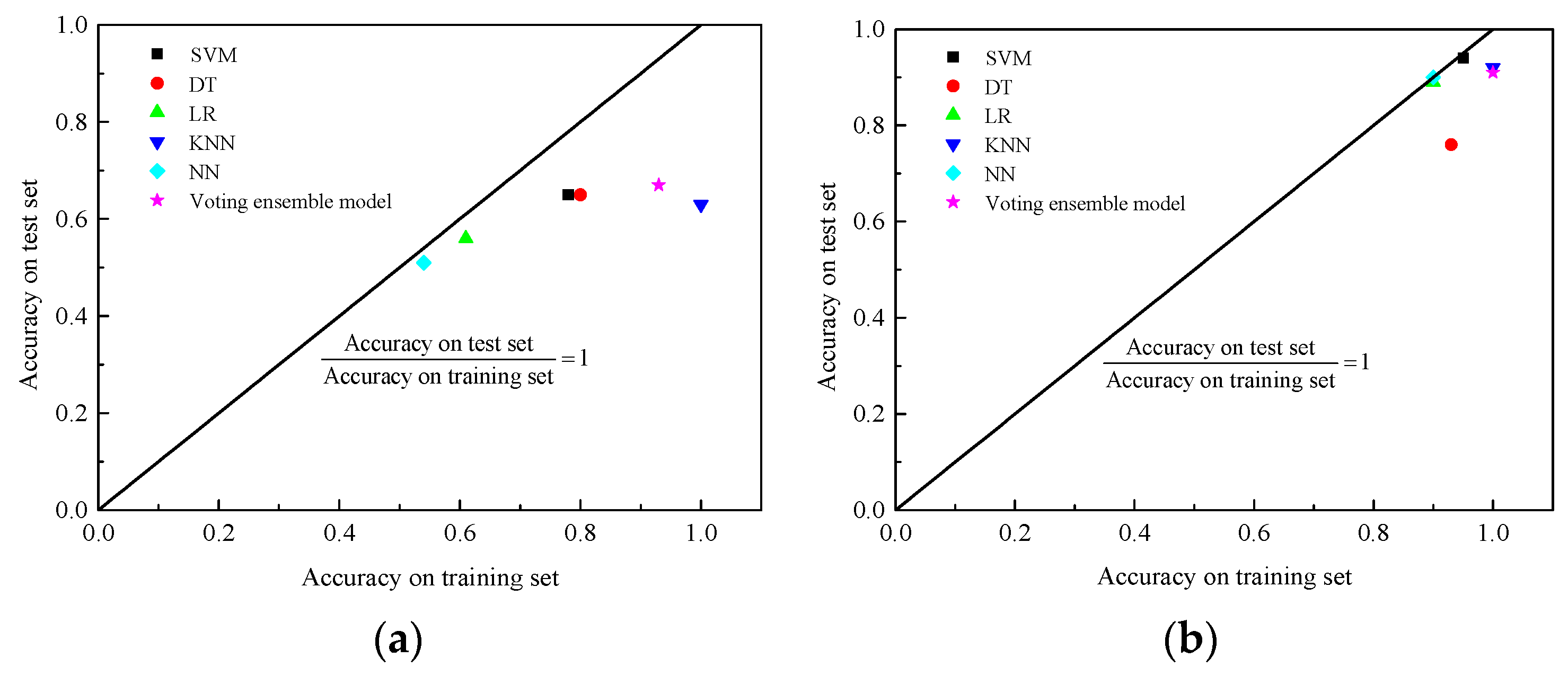
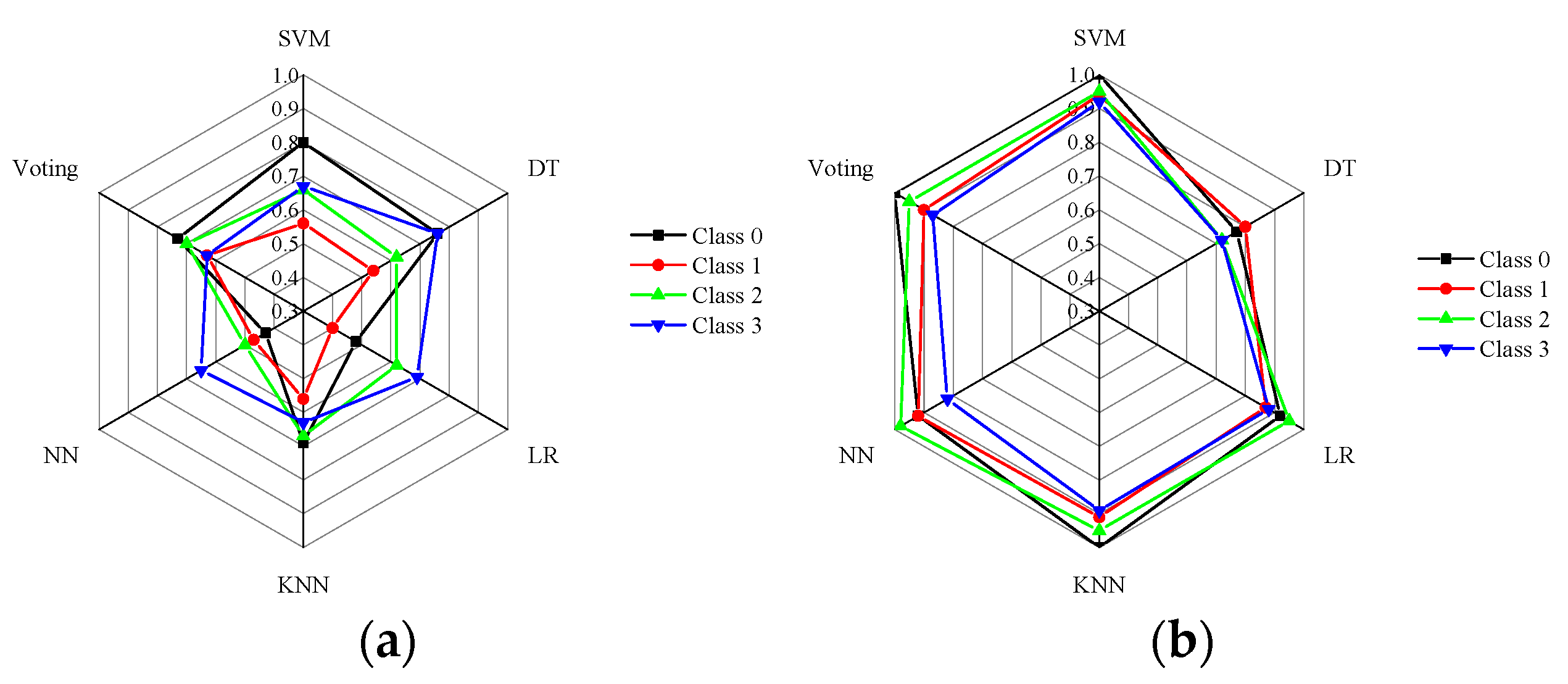
- When considering the dataset without preprocessing, the voting ensemble model outperforms the single learners. However, for high-quality datasets, some single learners may exhibit slightly higher precision accuracy compared with the voting ensemble model. Despite this observation, the voting ensemble model consistently achieves satisfactory prediction accuracy by effectively balancing out the weaknesses of individual base learners.
- (4)
- To assess the sensitivity of features to rockburst prediction, we analyzed the contribution rate of each feature. The results indicate that Wet has the most significant impact on rockburst prediction, followed by σθ and σc. Specifically, a high value (>5) of Wet often indicates a high rockburst intensity, which is typically more severe than a light rockburst. Conversely, a high value (>150 MPa) of σc usually implies a lower likelihood of rockburst occurrences. Additionally, light rockbursts and moderate rockbursts often tend to occur when Wet < 5 and σc < 150 MPa.
- (5)
- The proposed combination model was applied to two engineering cases for rockburst prediction. The minor discrepancies between the prediction results and actual rockburst situations underscore the reliability and effectiveness of the model. It is important to note that the proposed model demonstrates particular efficacy in estimating strainbursts. Furthermore, it has the potential to be extended to predict fracture-related rockbursts by incorporating some features related to pre-existing geological structures into the dataset. This presents an avenue for future research and development.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, S.C.; Wu, Z.G.; Zhang, C.X. Rock burst prediction probability model based on case analysis. Tunn. Undergr. Space Technol. 2019, 93, 103069. [Google Scholar] [CrossRef]
- Durrheim, R.J. Mitigating the risk of rockbursts in the deep hard rock mines of South Africa: 100 years of re-search. In Extracting the Science: A Century of Mining Research; SME: Southfield, MI, USA, 2010; pp. 156–171. [Google Scholar]
- Zhang, C.Q.; Feng, X.-T.; Zhou, H.; Qiu, S.L.; Wu, P. Case Histories of Four Extremely Intense Rockbursts in Deep Tunnels. Rock Mech. Rock Eng. 2012, 45, 275–288. [Google Scholar] [CrossRef]
- Ma, Z.K.; Li, S.; Zhao, X.D. Energy Accumulation Characteristics and Induced Rockburst Mechanism of Roadway Surrounding Rock under Multiple Mining Disturbances: A Case Study. Sustainability 2023, 15, 9595. [Google Scholar] [CrossRef]
- Pu, Y.Y.; Apel, D.B.; Lingga, B. Rockburst prediction in kimberlite using decision tree with incomplete data. J. Sustain. Min. 2018, 17, 158–165. [Google Scholar] [CrossRef]
- Frid, V.; Vozoff, K. Electromagnetic radiation induced by mining rock failure. Int. J. Coal Geol. 2005, 64, 57–65. [Google Scholar] [CrossRef]
- Rasskazov, I.Y.; Migunov, D.S.; Anikin, P.A.; Gladyr’, A.V.; Tereshkin, A.A.; Zhelnin, D.O. New-Generation Portable Geoacoustic Instrument for Rockburst Hazard Assessment. J. Min. Sci. 2015, 51, 614–623. [Google Scholar] [CrossRef]
- Hudyma, M.; Potvin, Y.H. An Engineering Approach to Seismic Risk Management in Hardrock Mines. Rock Mech. Rock Eng. 2010, 43, 891–906. [Google Scholar] [CrossRef]
- Mathew, T.J.; Sherly, E.; Alcantud, J.C.R. A multimodal adaptive approach on soft set based diagnostic risk prediction system. J. Intell. Fuzzy Syst. 2018, 34, 1609–1618. [Google Scholar] [CrossRef]
- Eremenko, A.; Timonin, V.; Bespalko, A.; Karpov, V.; Shtirts, V. Effect of vibro-impact exposure on intensity of geo-dynamic events in rock mass. In Proceedings of the Conference on Geodynamics and Stress State of the Earth’s Interior (GSSEI), Novosibirsk, Russia, 2–6 October 2017. [Google Scholar]
- Turchaninov, I.A.; Markov, G.A.; Gzovsky, M.V.; Kazikayev, D.M.; Frenze, U.K.; Batugin, S.A.; Chabdarova, U.I. State of stress in the upper part of the Earth’s crust based on direct measurements in mines and on tectonophysical and seis-mological studies. Phys. Earth Planet. Inter. 1972, 6, 229–234. [Google Scholar] [CrossRef]
- Brown, E.T.; Hoek, E. Underground Excavations in Rock; CRC Press: Boca Raton, FL, USA, 1980. [Google Scholar]
- Kidybiński, A. Bursting liability indices of coal. Int. J. Rock Mech. Min. Sci. Geomech. Abstr. 1981, 18, 295–304. [Google Scholar] [CrossRef]
- Aubertin, M.; Gill, D.E.; Simon, R. On the use of the brittleness index modified (BIM) to estimate the post-peak behavior of rocks. In Proceedings of the 1st North American Rock Mechanics Symposium, Austin, TX, USA, 1–3 June 1994; pp. 945–952. [Google Scholar]
- Gong, F.Q.; Wang, Y.L.; Wang, Z.G.; Pan, J.F.; Luo, S. A new criterion of coal burst proneness based on the residual elastic energy index. Int. J. Min. Sci. Technol. 2021, 31, 553–563. [Google Scholar] [CrossRef]
- Liang, W.Z.; Zhao, G.Y. A review of research on long-term and short-term rockburst risk evaluation in deep hard rock. Chin. J. Rock Mech. Eng. 2022, 41, 19–39. [Google Scholar]
- Salamon, M.D.G. Energy considerations in rock mechanics: Fundamental results. J. S. Afr. Inst. Min. Metall. 1984, 84, 233–246. [Google Scholar]
- Jiang, Q.; Feng, X.-T.; Xiang, T.-B.; Su, G.-S. Rockburst characteristics and numerical simulation based on a new energy index: A case study of a tunnel at 2,500 m depth. Bull. Eng. Geol. Environ. 2010, 69, 381–388. [Google Scholar] [CrossRef]
- Wiles, T.D. Loading system stiffness-a parameter to evaluate rockburst potential. In Proceedings of the 1st International Seminar on Deep and High Stress Mining, Perth, Australia, 6–8 November 2002. [Google Scholar]
- Zhang, C.Q.; Zhou, H.; Feng, X.T. An Index for Estimating the Stability of Brittle Surrounding Rock Mass: FAI and its Engineering Application. Rock Mech. Rock Eng. 2011, 44, 401–414. [Google Scholar] [CrossRef]
- Xu, J.; Jiang, J.D.; Xu, N.; Liu, Q.S.; Gao, Y.F. A new energy index for evaluating the tendency of rockburst and its engineering application. Eng. Geol. 2017, 230, 46–54. [Google Scholar] [CrossRef]
- Li, F.; Korgesaar, M.; Kujala, P.; Goerlandt, F. Finite element based meta-modeling of ship-ice interaction at shoulder and midship areas for ship performance simulation. Mar. Struct. 2020, 71, 102736. [Google Scholar] [CrossRef]
- Sun, Q.Y.; Zhang, M.; Zhou, L.; Garme, K.; Burman, M. A machine learning-based method for prediction of ship performance in ice: Part I. ice resistance. Mar. Struct. 2022, 83, 103181. [Google Scholar] [CrossRef]
- Ma, Y.Z.; Royer, J.J.; Wang, H.; Wang, Y.; Zhang, T. Factorial kriging for multiscale modelling. J. S. Afr. Inst. Min. Metall. 2014, 114, 651–659. [Google Scholar]
- Nivlet, P.; Fournier, F.; Royer, J.J. A New Nonparametric Discriminant Analysis Algorithm Accounting for Bounded Data Errors. J. Int. Assoc. Math. Geol. 2002, 34, 223–246. [Google Scholar] [CrossRef]
- Kim, J.-H.; Kim, Y.; Lu, W.J. Prediction of ice resistance for ice-going ships in level ice using artificial neural network technique. Ocean Eng. 2020, 217, 108031. [Google Scholar] [CrossRef]
- Yin, X.; Liu, Q.; Huang, X.; Pan, Y. Real-time prediction of rockburst intensity using an integrated CNN-Adam-BO algorithm based on microseismic data and its engineering application. Tunn. Undergr. Space Technol. 2021, 117, 104133. [Google Scholar] [CrossRef]
- Yin, X.; Liu, Q.S.; Pan, Y.C.; Huang, X.; Wu, J.; Wang, X.Y. Strength of Stacking Technique of Ensemble Learning in Rockburst Prediction with Imbalanced Data: Comparison of Eight Single and Ensemble Models. Nat. Resour. Res. 2021, 30, 1795–1815. [Google Scholar] [CrossRef]
- Xue, Y.G.; Li, G.K.; Li, Z.; Wang, P.; Gong, H.M.; Kong, F.M. Intelligent prediction of rockburst based on Copula-MC oversampling architecture. Bull. Eng. Geol. Environ. 2022, 81, 209. [Google Scholar] [CrossRef]
- Li, N.; Feng, X.D.; Jimenez, R. Predicting rock burst hazard with incomplete data using Bayesian networks. Tunn. Undergr. Space Technol. 2017, 61, 61–70. [Google Scholar] [CrossRef]
- Pu, Y.Y.; Apel, D.B.; Xu, H.W. Rockburst prediction in kimberlite with unsupervised learning method and support vector classifier. Tunn. Undergr. Space Technol. 2019, 90, 12–18. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.B.; Mitri, H.S. Classification of Rockburst in Underground Projects: Comparison of Ten Supervised Learning Methods. J. Comput. Civ. Eng. 2016, 30. [Google Scholar] [CrossRef]
- Faradonbeh, R.S.; Taheri, A.; Sousa, L.R.E.R.; Karakus, M. Rockburst assessment in deep geotechnical conditions using true-triaxial tests and data-driven approaches. Int. J. Rock Mech. Min. Sci. 2020, 128, 104279. [Google Scholar] [CrossRef]
- Guo, D.P.; Chen, H.M.; Tang, L.B.; Chen, Z.X.; Samui, P. Assessment of rockburst risk using multivariate adaptive regression splines and deep forest model. Acta Geotech. 2022, 17, 1183–1205. [Google Scholar] [CrossRef]
- Liang, W.Z.; Sari, A.; Zhao, G.Y.; McKinnon, S.D.; Wu, H. Short-term rockburst risk prediction using ensemble learning methods. Nat. Hazards 2020, 104, 1923–1946. [Google Scholar] [CrossRef]
- Zhang, J.F.; Wang, Y.H.; Sun, Y.T.; Li, G.C. Strength of ensemble learning in multiclass classification of rockburst intensity. Int. J. Numer. Anal. Methods Géoméch. 2020, 44, 1833–1853. [Google Scholar] [CrossRef]
- Cheng, W.-C.; Bai, X.-D.; Sheil, B.B.; Li, G.; Wang, F. Identifying characteristics of pipejacking parameters to assess geological conditions using optimisation algorithm-based support vector machines. Tunn. Undergr. Space Technol. 2020, 106, 103592. [Google Scholar] [CrossRef]
- Xue, Y.G.; Bai, C.H.; Qiu, D.H.; Kong, F.M.; Li, Z.Q. Predicting rockburst with database using particle swarm optimization and extreme learning machine. Tunn. Undergr. Space Technol. 2020, 98, 103287. [Google Scholar] [CrossRef]
- Zhang, M.C. Prediction of rockburst hazard based on particle swarm algorithm and neural network. Neural Comput. Appl. 2022, 34, 2649–2659. [Google Scholar] [CrossRef]
- Sun, Y.T.; Li, G.C.; Zhang, J.F.; Huang, J.D. Rockburst intensity evaluation by a novel systematic and evolved approach: Machine learning booster and application. Bull. Eng. Geol. Environ. 2021, 80, 8385–8395. [Google Scholar] [CrossRef]
- Van Buuren, S.; Groothuis Oudshoorn, K. mice: Multivariate Imputation by Chained Equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef]
- Russenes, B.F. Analysis of Rock Spalling for Tunnels in Steep Valley Sides. Master’s Thesis, Norwegian Institute of Technology, Trondheim, Norway, 1974. [Google Scholar]
- Zhou, J.; Li, X.B.; Shi, X.Z. Long-term prediction model of rockburst in underground openings using heuristic algorithms and support vector machines. Saf. Sci. 2012, 50, 629–644. [Google Scholar] [CrossRef]
- Feng, X.T.; Chen, B.R.; Zhang, C.Q.; Li, S.J.; Wu, S.Y. Mechanism, Warning and Dynamic Control of Rockburst Development Process; Science Press: Beijing, China, 2013. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis. In Springer Series in Statistics; Springer: New York, NY, USA, 2002; ISBN 978-0-387-95442-4. [Google Scholar] [CrossRef]
- Bouwmans, T.; Zahzah, E.H. Robust PCA via Principal Component Pursuit: A review for a comparative evaluation in video surveillance. Comput. Vis. Image Underst. 2014, 122, 22–34. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing Data using, t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Guofei9987. Scikit-opt. 2020. Available online: https://github.com/guofei9987/scikit-opt (accessed on 1 January 2020).
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]
- Kost, S.; Rheinbach, O.; Schaeben, H. Using logistic regression model selection towards interpretable machine learning in mineral prospectivity modeling. Geochemistry 2021, 81, 125826. [Google Scholar] [CrossRef]
- Peng, N.; Zhang, Y.; Zhao, Y. A SVM-kNN method for quasar-star classification. Sci. China Phys. Mech. Astron. 2013, 56, 1227–1234. [Google Scholar] [CrossRef]
- Li, Y.L.; Chen, H.; Lv, M.Q.; Li, Y. Event-based k-nearest neighbors query processing over distributed sensory data using fuzzy sets. Soft Comput. 2019, 23, 483–495. [Google Scholar] [CrossRef]
- Jiao, S.B.; Geng, B.; Li, Y.X.; Zhang, Q.; Wang, Q. Fluctuation-based reverse dispersion entropy and its applications to signal classification. Appl. Acoust. 2021, 175, 107857. [Google Scholar] [CrossRef]
- Bergstra, J.; Yamins, D.; Cox, D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 115–123. [Google Scholar]
- Fu, H.L.; Li, J.; Li, G.L.; Chen, J.J.; An, P. Determination of In Situ Stress by Inversion in a Superlong Tunnel Site Based on the Variation Law of Stress—A Case Study. KSCE J. Civ. Eng. 2023, 27, 2637–2653. [Google Scholar] [CrossRef]
- Meng, W.; He, C.; Zhou, Z.H.; Li, Y.Q.; Chen, Z.Q.; Wu, F.Y.; Kou, H. Application of the ridge regression in the back analysis of a virgin stress field. Bull. Eng. Geol. Environ. 2021, 80, 2215–2235. [Google Scholar] [CrossRef]
- Brown, E.T.; Hoek, E. Trends in relationships between measured in-situ stresses and depth. Int. J. Rock Mech. Min. Sci. Geomech. Abstr. 1978, 15, 211–215. [Google Scholar] [CrossRef]
- Shcherbakov, S.S. State of Volumetric Damage of Tribo-Fatigue System. Strength Mater. 2013, 45, 171–178. [Google Scholar] [CrossRef]
- Sherbakov, S.S.; Zhuravkov, M.A. Interaction of several bodies as applied to solving tribo-fatigue problems. Acta Mech. 2013, 224, 1541–1553. [Google Scholar] [CrossRef]
- Sosnovskiy, L.A.; Bogdanovich, A.V.; Yelovoy, O.M.; Tyurin, S.A.; Komissarov, V.V.; Sherbakov, S.S. Methods and main results of Tribo-Fatigue tests. Int. J. Fatigue 2014, 66, 207–219. [Google Scholar] [CrossRef]
- Sosnovskiy, L.A.; Sherbakov, S.S. On the Development of Mechanothermodynamics as a New Branch of Physics. Entropy 2019, 21, 1188. [Google Scholar] [CrossRef]
- Du, Z.J.; Xu, M.G.; Liu, Z.P.; Wu, X. Laboratory integrated evaluation method for engineering wall rock rock-burst. Gold 2006, 27, 26–30. (In Chinese) [Google Scholar]
- Jia, Q.J.; Wu, L.; Li, B.; Chen, C.H.; Peng, Y.X. The Comprehensive Prediction Model of Rockburst Tendency in Tunnel Based on Optimized Unascertained Measure Theory. Geotech. Geol. Eng. 2019, 37, 3399–3411. [Google Scholar] [CrossRef]
- Li, T.Z.; Li, Y.X.; Yang, X.L. Rock burst prediction based on genetic algorithms and extreme learning machine. J. Cent. South Univ. 2017, 24, 2105–2113. [Google Scholar] [CrossRef]
- Liu, R.; Ye, Y.C.; Hu, N.Y.; Chen, H.; Wang, X.H. Classified prediction model of rockburst using rough sets-normal cloud. Neural Comput. Appl. 2018, 31, 8185–8193. [Google Scholar] [CrossRef]
- Xue, Y.G.; Zhang, X.L.; Li, S.C.; Qiu, D.H.; Su, M.X.; Li, L.P.; Li, Z.Q.; Tao, Y.F. Analysis of factors influencing tunnel deformation in loess deposits by data mining: A deformation prediction model. Eng. Geol. 2019, 232, 94–103. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
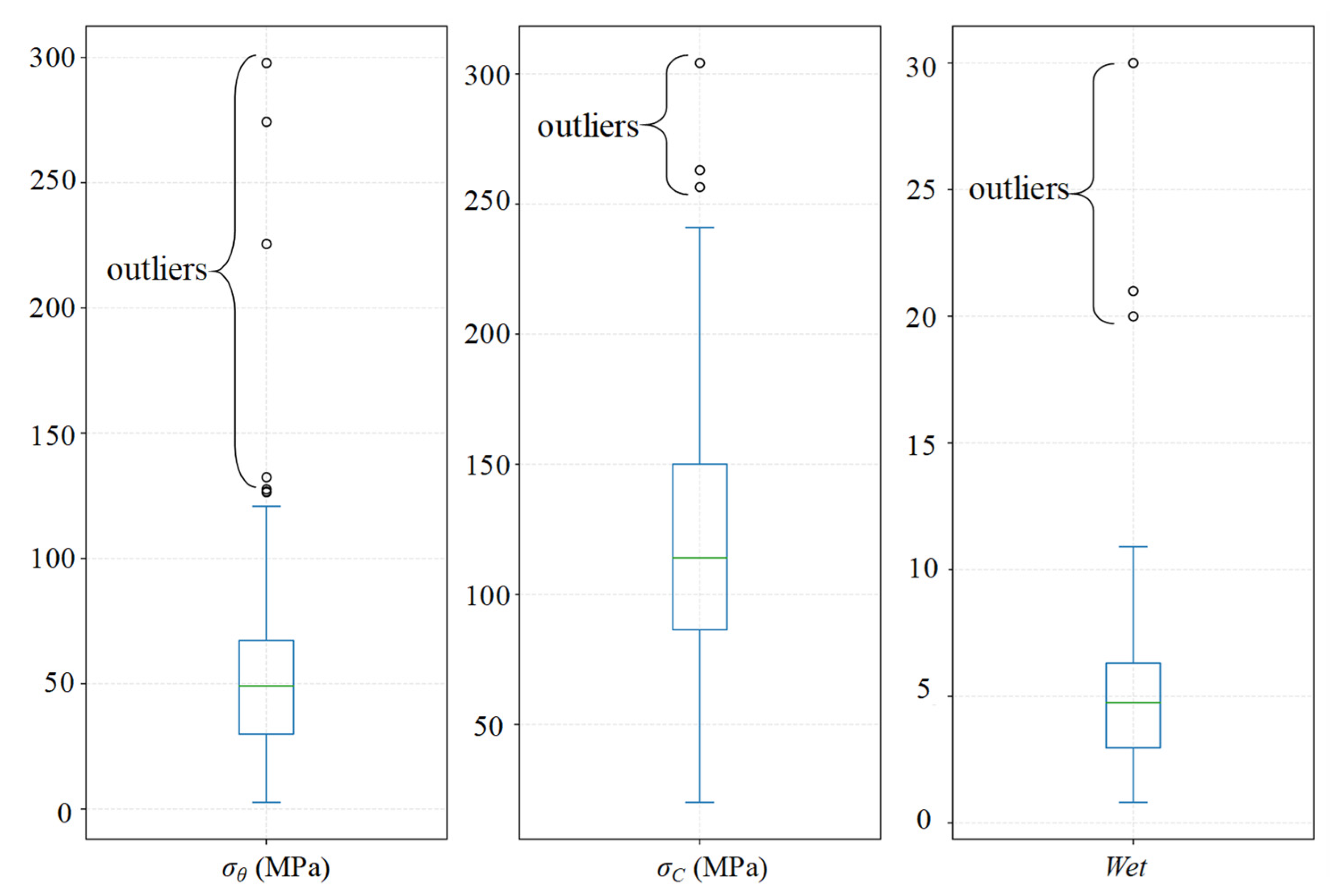
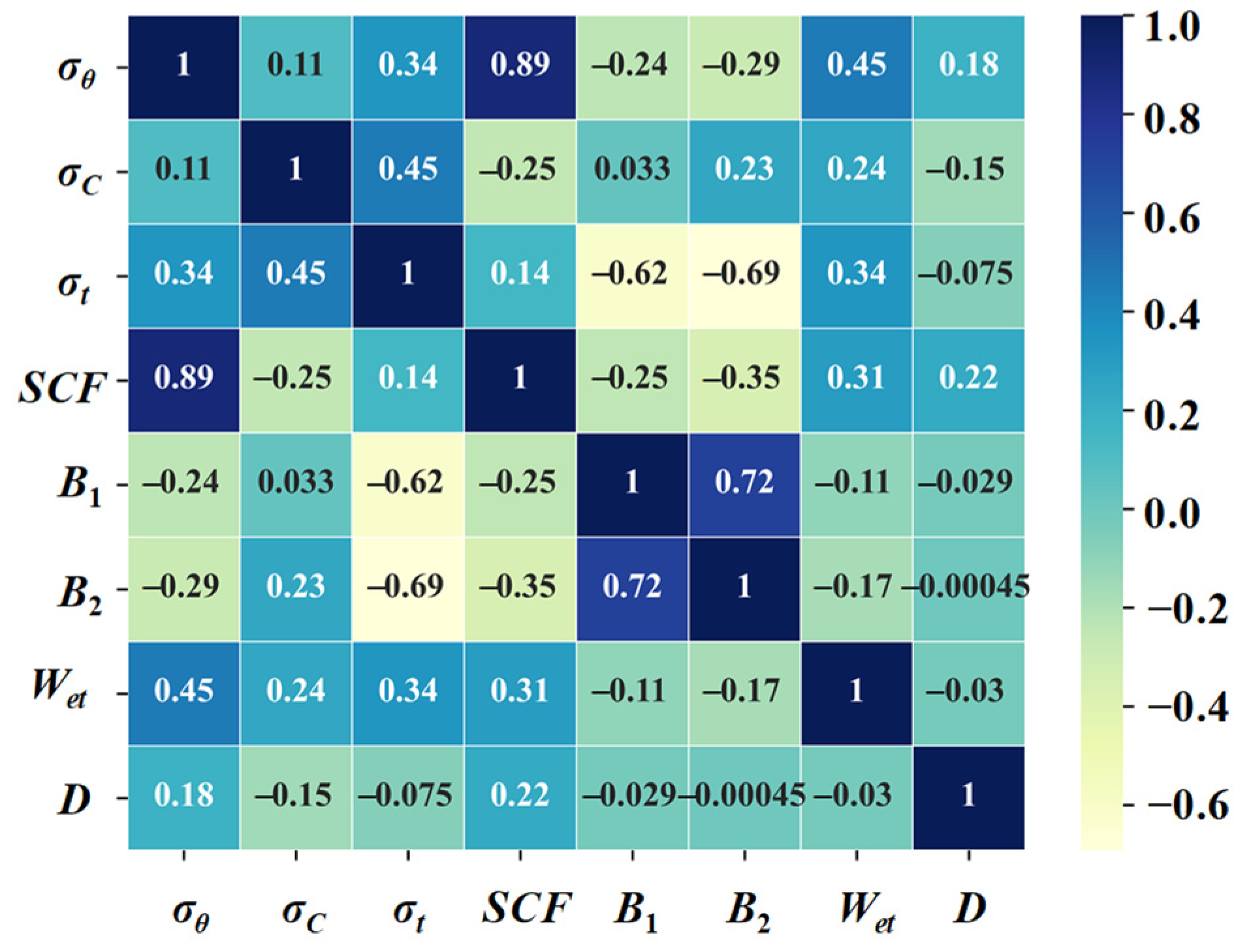
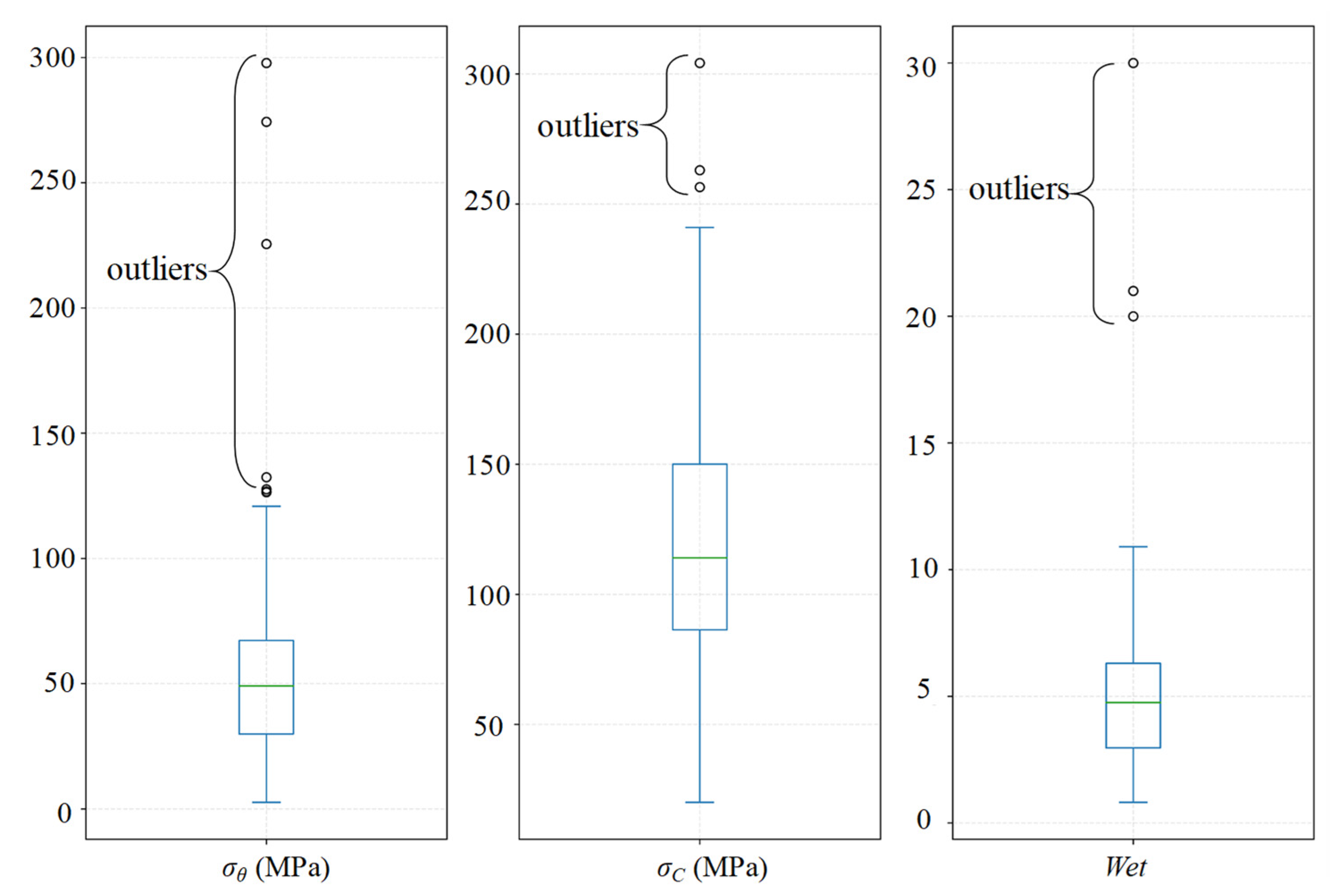
| σθ (MPa) | σc (MPa) | σt (MPa) | SCF | B1 | B2 | Wet | D (m) | |
|---|---|---|---|---|---|---|---|---|
| Mean | 57.73 | 119.34 | 7.00 | 0.54 | 22.05 | 0.89 | 5.12 | 701.64 |
| Standard deviation | 48.07 | 46.91 | 4.20 | 0.58 | 14.00 | 0.067 | 3.66 | 264.88 |
| Skewness | 3.00 | 0.66 | 1.00 | 4.46 | 1.97 | −1.93 | 3.44 | 1.41 |
| Kurtosis | 11.29 | 0.62 | 0.96 | 23.46 | 5.03 | 7.15 | 17.14 | 6.97 |
| Min | 2.60 | 20.00 | 0.40 | 0.05 | 0.15 | 0.43 | 0.81 | 100.00 |
| Max | 297.80 | 304.20 | 22.60 | 4.87 | 80.00 | 1.00 | 30.00 | 2372.00 |
| Class | Training Set | Prediction Set | Total Number of Samples |
|---|---|---|---|
| 0 | 74% | 26% | 50 |
| 1 | 67% | 33% | 98 |
| 2 | 55% | 45% | 123 |
| 3 | 58% | 42% | 73 |
| Case 1 | Case 2 | Case 3 | Case 4 | Case 5 | Case 6 | Case 7 | Case 8 | |
|---|---|---|---|---|---|---|---|---|
| Relabeling method | Russenes criterion | E.Hoek criterion | Wet | B1 | PCA + GMM | PCA + t-SNE + GMM | FS + GMM | FS + t-SNE + GMM |
| Russenes Criterion | E.Hoek Criterion | Wet | B1 | |
|---|---|---|---|---|
| None rockburst | σθ/σc < 0.2 | σθ/σc < 0.42 | Ee/Ep < 2 | σc/σt < 10 |
| Light rockbust | 0.2 ≤ σθ/σc < 0.3 | 0.42 ≤ σθ/σc < 0.56 | 2 ≤ Ee/Ep < 3.5 | 10 ≤ σc/σt < 14 |
| Moderate rockburst | 0.3 ≤ σθ/σc < 0.55 | 0.56 ≤ σθ/σc < 0.7 | 3.5 ≤ Ee/Ep < 5 | 14 ≤ σc/σt < 18 |
| Strong rockburst | 0.55 ≤ σθ/σc | 0.7 ≤ σθ/σc | 5 ≤ Ee/Ep | 18 ≤ σc/σt |
| F1 | F2 | F3 | F4 | F5 | |
|---|---|---|---|---|---|
| Feature | σt | σc | σθ | D | Wet |
| RF1 | RF2 | RF3 | RF4 | RF5 | |
|---|---|---|---|---|---|
| Factor | σt, B1, B2 | σc | σθ, SCF | Wet | D |
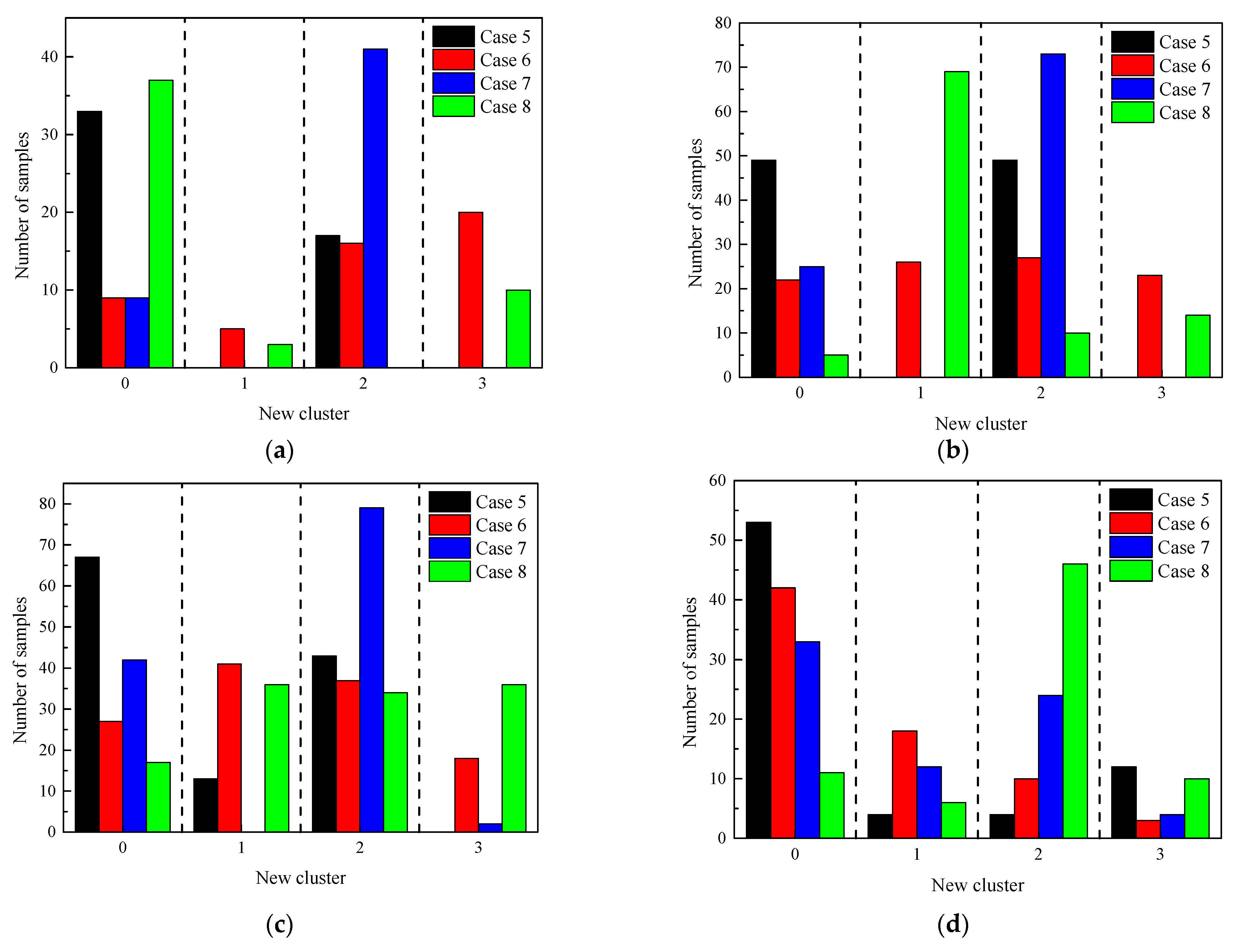
| New Class Label | Cluster in Case 6 | Cluster in Case 8 |
|---|---|---|
| 0 | 3 | 0 |
| 1 | 2 | 1 |
| 2 | 1 | 3 |
| 3 | 0 | 2 |
| Original Class Label | New Class Label | Rejection Score |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | |
| 2 | 2 | |
| 3 | 3 | |
| 1 | 0 | 1 |
| 1 | 0 | |
| 2 | 1 | |
| 3 | 2 | |
| 2 | 0 | 2 |
| 1 | 1 | |
| 2 | 0 | |
| 3 | 1 | |
| 3 | 0 | 3 |
| 1 | 2 | |
| 2 | 1 | |
| 3 | 0 |
| Class | Case 1 | Case 2 | Case 3 | Case 4 | Case 6 | Case 8 |
|---|---|---|---|---|---|---|
| 0 | 51 | 25 | 50 | 88 | 57 | 57 |
| 1 | 103 | 69 | 69 | 137 | 93 | 39 |
| 2 | 71 | 151 | 96 | 119 | 100 | 106 |
| 3 | 40 | 97 | 12 | 93 | 58 | 55 |
| Sum | 265 | 362 | 227 | 437 | 297 | 257 |
| Classifier | Hyperparameters | Empirical Scope |
|---|---|---|
| SVM | Penalty coefficient c | [2−10, 210] |
| Gamma in RBF kernel function g | [2−10, 210] | |
| DT | Maximum depth of tree Dt | [3, 15] |
| Minimum number of samples at leaf node nl | [1, 10] | |
| Minimum number of samples at split node ns | [2, 10] | |
| LR | Inverse of regularization strength C | [0.01, 50] |
| KNN | Number of neighbors nk | [3, 15] |
| Weight strategy | “Uniform” or “Distance” | |
| NN | Number of elements in hidden layer ne | [5, 15] |
| Strength of the L2 regularization α | [0.00001, 1] | |
| Initial learning rate η | [0.0001, 0.5] |
| Classifier | Hyperparameter | Dataset with Original Label | Dataset with New Label | ||||||
|---|---|---|---|---|---|---|---|---|---|
| GS | GA | PSO | TPE | GS | GA | PSO | TPE | ||
| SVM | c | 2000.00 | 3.93 | 3.21 | 32.02 | 2.00 | 67.70 | 69.26 | 100.48 |
| g | 0.20 | 9.34 | 9.40 | 9.38 | 20.00 | 5.21 | 5.11 | 4.22 | |
| DT | Dt | 10.00 | 14.00 | 12.00 | 13.00 | 8.00 | 12.00 | 13.00 | 10.00 |
| nl | 5.00 | 4.00 | 7.00 | 8.00 | 2.00 | 2.00 | 2.00 | 2.00 | |
| ns | 7.00 | 5.00 | 4.00 | 5.00 | 2.00 | 4.00 | 2.00 | 5.00 | |
| LR | C | 6.10 | 4.96 | 5.00 | 4.90 | 32.66 | 32.13 | 34.19 | 32.70 |
| KNN | nk | 9.00 | 9.00 | 9.00 | 9.00 | 5.00 | 5.00 | 5.00 | 5.00 |
| Weight strategy | distance | distance | distance | distance | distance | distance | distance | distance | |
| NN | ne | 7 | 10 | 5 | 10 | 9 | 10 | 12 | 8 |
| α | 10−4 | 0.05 | 0.75 | 0.61 | 0.001 | 0.14 | 10−5 | 0.01 | |
| η | 0.13 | 0.12 | 0.06 | 0.03 | 0.13 | 0.02 | 0.10 | 0.11 | |
| Lithology | Density ρ (g/cm3) | Young’s Modulus E (GPa) | Poisson’s Ratio μ | Cohesion Yield Stress C (MPa) | Friction Angle φ (°) |
|---|---|---|---|---|---|
| Granite | 2.7 | 23.53 | 0.27 | 2 | 56 |
| Fault | 2.63 | 12 | 0.35 | 0.6 | 35 |
| σc (MPa) | σt (MPa) | Wet |
|---|---|---|
| 150 | 4.82 | 3.82 |
| Number | σθ (MPa) | σc (MPa) | σt (MPa) | SCF | B1 | B2 | Wet | Actual Class | Prediction of Class |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 19.14 | 106.31 | 2.76 | 0.18 | 38.52 | 0.95 | 2.03 | 0 | 0 |
| 2 | 58.05 | 147.85 | 6.98 | 0.39 | 21.18 | 0.91 | 3.62 | 2 | 2 |
| 3 | 34.89 | 151.7 | 7.47 | 0.23 | 20.31 | 0.91 | 3.17 | 1 | 1 |
| 4 | 16.21 | 135.07 | 7.05 | 0.12 | 19.16 | 0.90 | 2.49 | 2 | 1 |
| 5 | 40.56 | 140.83 | 8.39 | 0.29 | 16.79 | 0.89 | 3.63 | 3 | 3 |
| 6 | 33.15 | 106.94 | 5.84 | 0.31 | 18.31 | 0.90 | 2.15 | 2 | 2 |
| 7 | 9.74 | 88.51 | 2.16 | 0.11 | 40.98 | 0.95 | 1.77 | 0 | 0 |
| 8 | 33.94 | 117.48 | 4.23 | 0.29 | 27.77 | 0.93 | 2.37 | 1 | 1 |
| Classifier | σθ | σc | σt | SCF | B1 | B2 | Wet | D |
|---|---|---|---|---|---|---|---|---|
| SVM | 0.07 | 0.01 | −0.01 | −0.01 | 0.03 | −0.03 | 0.17 | 0.02 |
| DT | 0.05 | 0.02 | −0.06 | −0.03 | 0 | 0.03 | 0 | −0.11 |
| LR | 0.12 | 0.2 | 0.01 | 0.01 | 0.02 | 0.01 | 0.14 | 0 |
| KNN | 0.09 | 0.07 | 0.04 | 0.01 | 0.03 | 0.03 | 0.02 | −0.01 |
| NN | 0.17 | 0.08 | 0.02 | 0.02 | 0.02 | 0.02 | 0.18 | 0.05 |
| Voting method | 0.11 | 0.03 | −0.01 | −0.02 | 0.02 | −0.02 | 0.03 | −0.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Fu, H.; Hu, K.; Chen, W. Data Preprocessing and Machine Learning Modeling for Rockburst Assessment. Sustainability 2023, 15, 13282. https://doi.org/10.3390/su151813282
Li J, Fu H, Hu K, Chen W. Data Preprocessing and Machine Learning Modeling for Rockburst Assessment. Sustainability. 2023; 15(18):13282. https://doi.org/10.3390/su151813282
Chicago/Turabian StyleLi, Jie, Helin Fu, Kaixun Hu, and Wei Chen. 2023. "Data Preprocessing and Machine Learning Modeling for Rockburst Assessment" Sustainability 15, no. 18: 13282. https://doi.org/10.3390/su151813282
APA StyleLi, J., Fu, H., Hu, K., & Chen, W. (2023). Data Preprocessing and Machine Learning Modeling for Rockburst Assessment. Sustainability, 15(18), 13282. https://doi.org/10.3390/su151813282