
Architecture and Application of Traffic Safety Management Knowledge Graph Based on Neo4j

Abstract
:1. Introduction
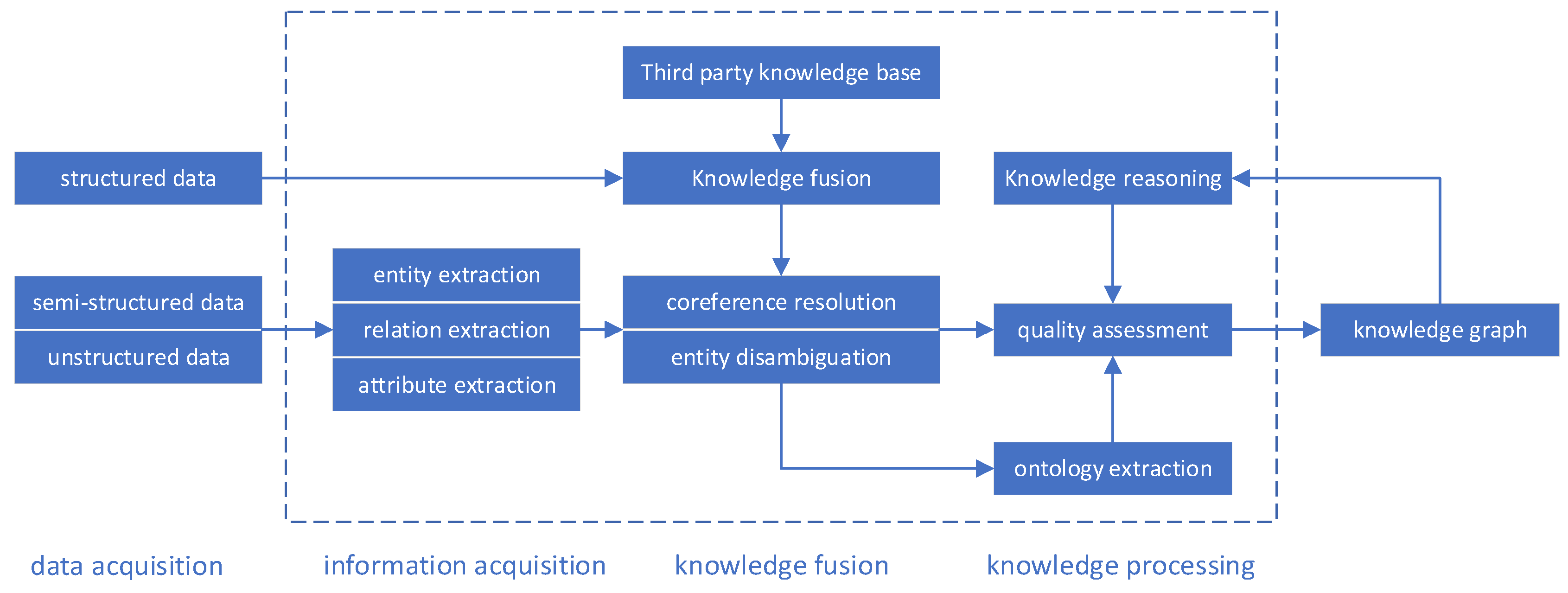
2. Overview of Knowledge Graph Construction
3. Design and Construction of Traffic Safety Management Knowledge Graph
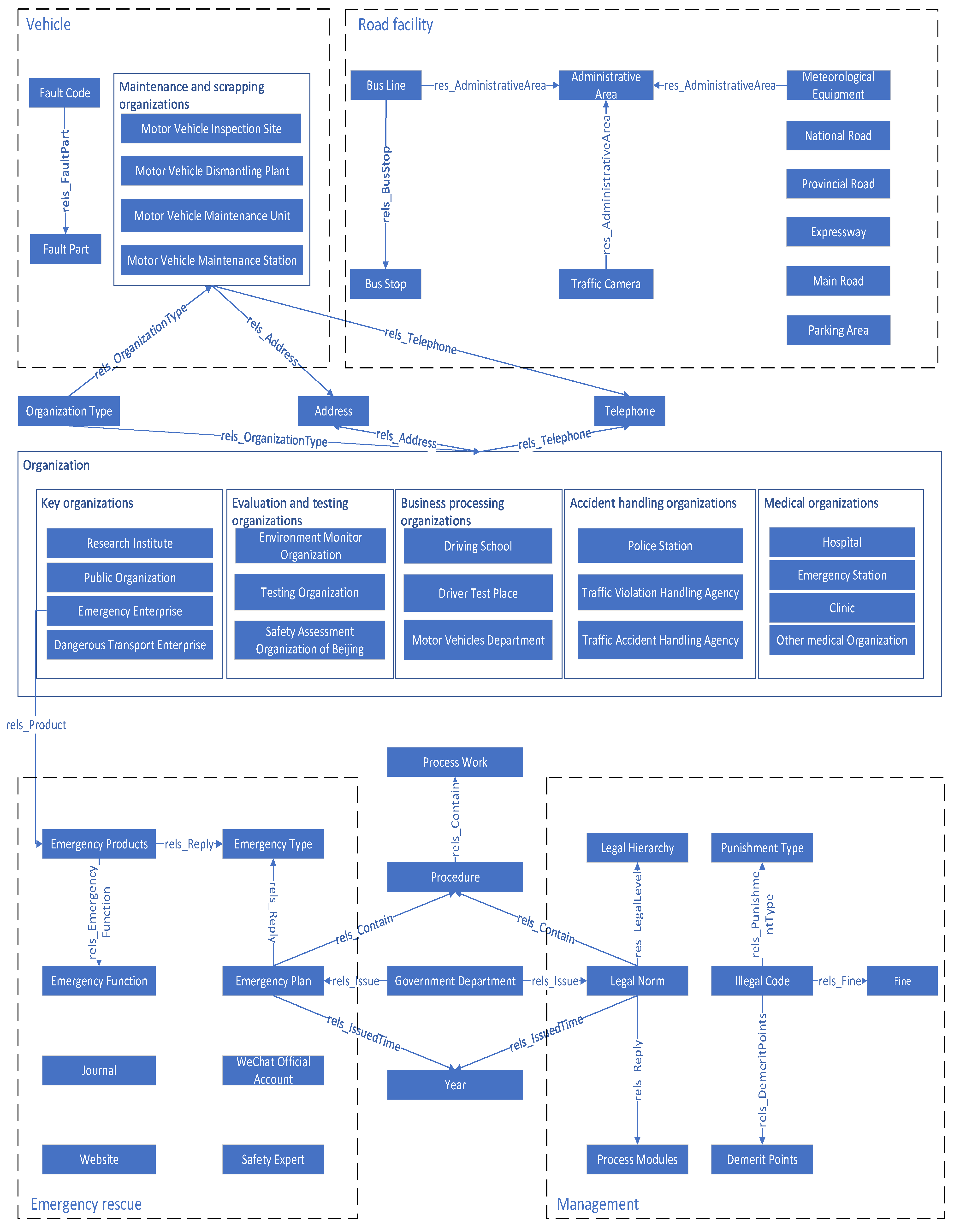
3.1. Design of Traffic Safety Management Knowledge Graph
- (1)
- The setting of the entity label ‘Organization Type’ divides 21 types of organizations into 6 categories based on 6 nodes about institutional functions. It further refines and summarizes the information. Record important attributes including phone number, address, and operation scope for each organization. The 6 types of organizations are explained as follows.
- (2)
- The setting of the entity label ‘Process Modules’ can divide 63 laws and regulations into 7 process modules based on 7 nodes about managed objects. It can realize an effective query by facilitating searching for managed objects to find relevant laws. The managed objects of the 7 process modules are related to the legal texts as follows:
- (3)
- The setting of the entity label ‘Procedure’ contributes to clarifying the context of documents by setting the chapter or section title information of laws, regulations, and emergency plans as nodes. Nodes labeled as ‘Process work’ are the detailed contents corresponding to the titles.
- (4)
- The entity label ‘Emergency Type’ includes seven nodes: gale disaster, snow disaster, rainstorm disaster, fire accident, geological disaster, ecological disaster, and traffic emergency. It mainly refers to the emergency plans made public by government departments. The setting can connect emergency plans to emergency products and create the information chain ‘Process Work—Procedure—Emergency Plan—Emergency Type—Emergency Products—Emergency Enterprise’.
- (5)
- The setting of the entity label ‘Administrative Area’ realizes the linkage of bus stops, bus lines, meteorological equipment, and traffic cameras. It mainly refers to the information on the website of Beijing Municipal Commission of Transport.
- (6)
- Set the entity label ‘Illegal Code’ to provide a basis for judging illegal behaviors. The illegal codes refer to the Road Traffic Management Information Code Part 31: Codes for Violations Categories, the Chinese industry standard. Set the violation, punishment basis, coercive measure, original law, and expanded knowledge as node attributes. The reference standards for the attributes are the Road Traffic Safety Law of the People’s Republic of China and the Regulations on the Procedures for Handling Road Traffic Safety Violations. To assist law enforcement, connect nodes labeled as ’Illegal Code’ with nodes labeled as ‘Demerit Points’, ‘Punishment Type’, or ‘Fine’. Demerit points refer to the Measures for Scoring Management of Road Traffic Safety Violations. Punishment types refer to Law of the People’s Republic of China on Administrative Penalty. Fines refer to the Road Traffic Safety Law of the People’s Republic of China.
- (7)
- The setting of entity label ‘Fault Code’ clearly divides complex vehicle fault types. To provide reference, set the fault name and fault description as attributes. Connect fault code to fault part to integrate it into the body system of a vehicle. The classification of vehicle fault codes adopts the OBD, a fault classification standard, issued by the Society of Automotive Engineers.
- (8)
- In order to expand information, set entity labels such as ‘Safety Expert’, ‘Journal’, ‘WeChat Official Account’, ‘Website’, ‘Research Institute’ in the knowledge map. Provide more references for traffic safety management work.
- (9)
- Set the entity label ‘Emergency Function’, including four nodes: safety protection, safety emergency service, monitoring and warning, and emergency rescue and disposal. Classifying emergency products can facilitate product inquiry according to needs. The reference is the Product Catalog of Key Safety and Emergency Enterprises in Beijing.
3.2. Knowledge Graph Data Results
- (1)
- The construction results for illegal acts are shown in Table 1, which includes the information on 452 types of illegal acts. The setting can be found in article (6) of Section 3.1. The traffic violation code consists of 5 digits. There are 6 types of demerit points: 0, 1, 2, 3, 6, and 12. The basic types of administrative penalties are divided into 7 categories: warnings, fines, confiscation of illegal gains, orders to suspend production or business, temporary suspension or revocation of permits or licenses, administrative detention, and other administrative penalties stipulated by laws and regulations. The 16 nodes labeled as ‘Punishment Type’ here include nodes representing combinations of basic penalty types.
- (2)
- There are 5419 types of vehicle fault. The construction results for relevant entities and relationships are shown in Table 2. The setting can be found in article (7) of Section 3.1. The OBD fault code consists of one letter and four digits. “P” represents the powertrain codes, “C” represents the chassis codes, “B” represents the body codes, and “U” represents the network codes. According to the OBD fault codes, the fault parts include 15 categories, which are specific fault parts of four systems.
- (3)
- Emergency response mainly includes the information about emergency plans, safety experts, key organizations, emergency rescue products, and safety media. The construction results are shown in Table 3.
- (4)
- There are a total of 63 legal norms imported into the knowledge graph. The construction results are shown in Table 4. According to the legal hierarchy, they can be divided into laws, departmental rules, and administrative regulations, with a total of 3, 52, and 8 documents, respectively. The reference is the Legislation Law of the People’s Republic of China. Additionally, the 63 laws and regulations are divided into 7 categories based on managed objects, as shown in articles (2) and (3) of Section 3.1.
- (5)
- A total of 12,946 organization nodes are created, and the detailed construction results are shown in Table 5. Telephone and address are basic information for most organizations, as detailed in Table 6. The setting can be found in article (1) of Section 3.1. The attribute ‘Company Type’ of the nodes labeled ‘Motor Vehicle Maintenance Station’ is explained as follows: According to the national standard Certification Requirements for Motor Vehicle Maintenance and Repair Enterprises, automobile maintenance enterprises are divided into three categories. The first kind of enterprises are engaged in major vehicle repair, routine vehicle repair, special vehicle repair, and vehicle maintenance. The second kind of enterprises are engaged in primary and secondary maintenance and routine vehicle repair. The third kind of enterprises are only engaged in special vehicle repair or maintenance.
- (6)
- Road-related information is mainly about roads, buses and facilities. The results are shown in Table 7. The setting can be found in article (5) of Section 3.1.
3.3. Query Implementation
3.3.1. Query Implementation Based on Cypher
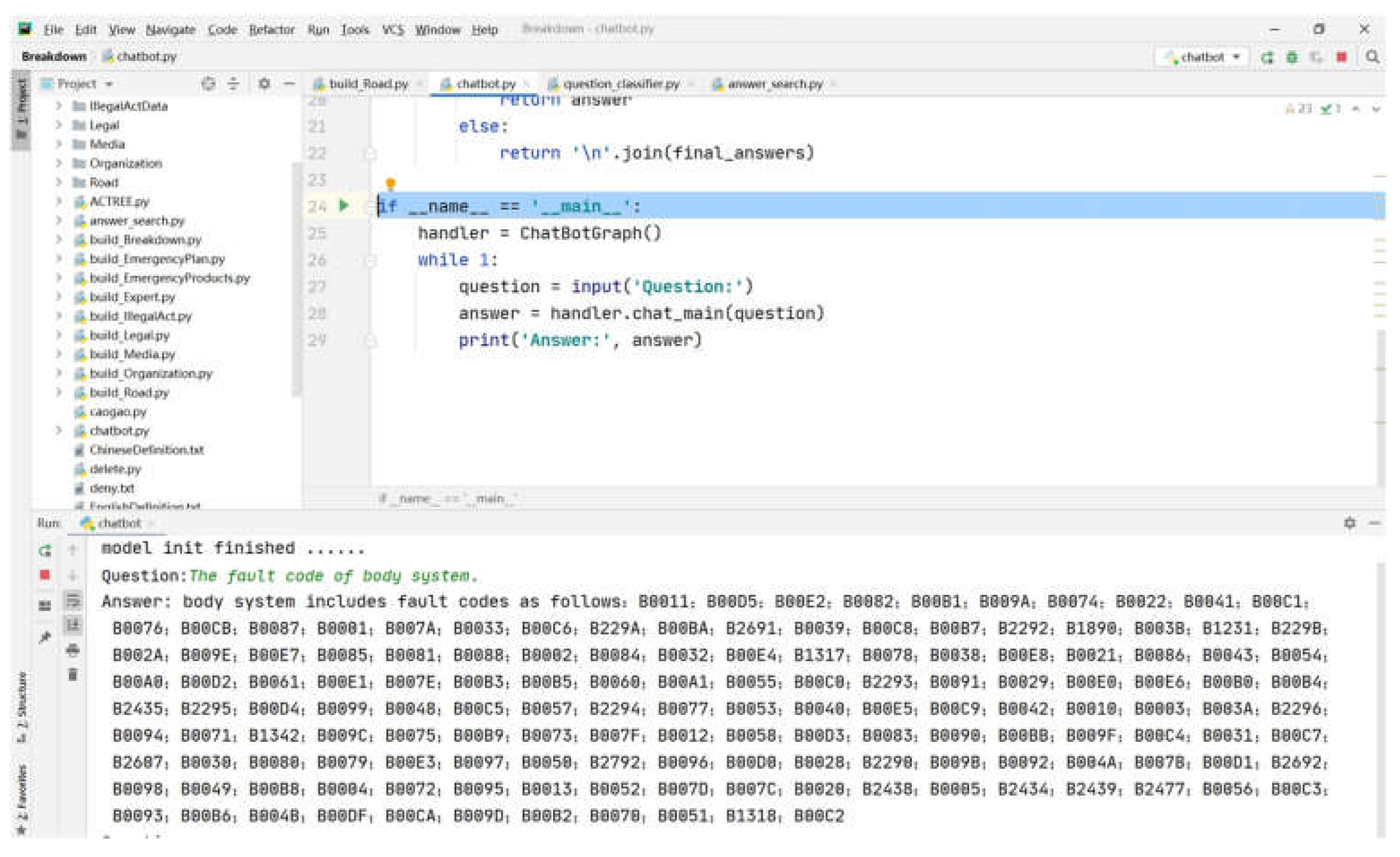
3.3.2. Query Implementation Based on Rule Matching—Taking Vehicle Failure as an Example
- (1)
- Build five types of dictionaries of query objects, including fault code, Chinese name, English name, fault description, and fault part. Build six types of question dictionaries, as shown in Table 9. Choose the AC automaton, a multi-pattern-matching algorithm. Add five types of dictionaries to the actree dictionary using the actree module of the ahocorasick library.
- (2)
- Decompose the input questions using the actree dictionary, and match the types of the words that are the query objects.
- (3)
- Loop the question vocabularies through the input questions for matching.
- (4)
- Construct 11 rules to classify the questions and determine the types of them based on the matching results of query objects and question words.
- (5)
- Modify the question sentences, that is, convert them into Cypher query templates. Then, modify the returned query results, that is, set the answer templates of the chat robot. Implement the final query function as shown in Figure 3.
4. Design and Construction of Traffic Accident Knowledge Graph
4.1. Characteristics of Traffic Accident Report Writing
- (1)
- Introduction
- (2)
- Basic information
- (3)
- Accident process and emergency response status
- (4)
- Reason for and nature of the accident
- (5)
- Suggestions for handling the persons and units responsible for the accident
- (6)
- Suggestions for accident prevention and rectification
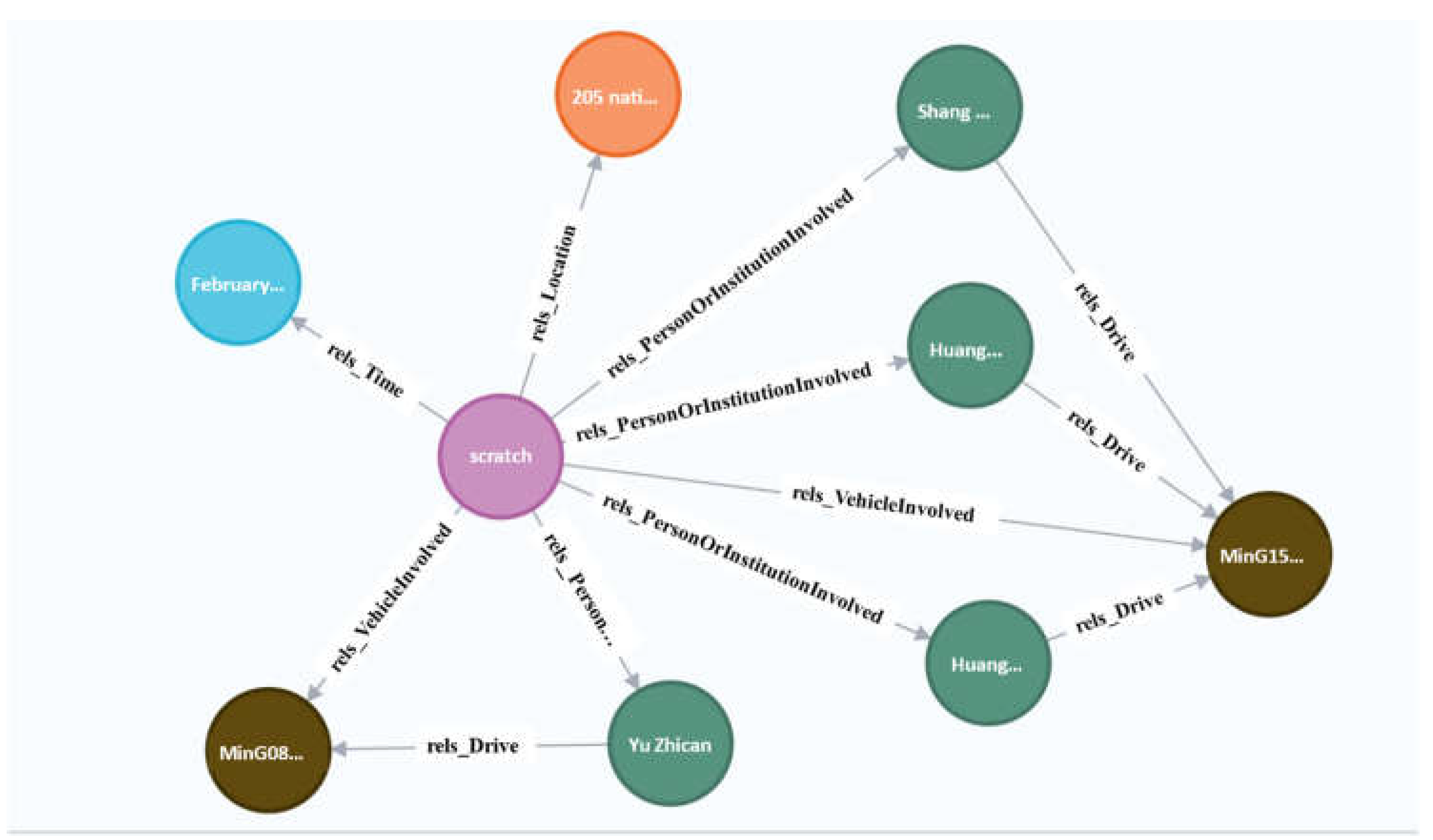
4.2. Entity and Relationship Settings for Traffic Accidents
- (1)
- Set node entities and relationship entities centered on accidents.
- (2)
- Set node entities and relationship entities centered on the vehicles involved
- (3)
- Set node entities and relationship entities centered on the people or institutions involved
4.3. Entity and Relationship Extraction Results
4.3.1. Named-Entity Recognition Results
4.3.2. Relationship Extraction Results
- (1)
- Data processing: (1) In terms of encoding, use special symbols to identify the positions of subjects and objects, and incorporate relationship label to improve learning effectiveness. (2) Data augmentation: Due to the lack of annotation for some relationships, data augmentation was performed on 8 types of relationships: ‘rels_AlcoholContent’, ‘rels_Age’, ‘rels_TraumaticCondition’, ‘rels_Speed’, ‘rels_Maker AndModel’, ‘rels_Load’, ‘rels_EconomicLoss’, and ‘rels_Stipulate’. Use Easy Data Augmentation, including synonym replacement, random insertion, random exchange, and random deletion methods. (3) Data shuffling: To prevent similar text from being continuously input, shuffle the data to make them more uniform.
- (2)
- Training parameters: The specific parameters are shown in Table 11.
- (3)
- The training results of the test set are shown in Table 12. Due to the uneven sample size, use macro-average to calculate the mean of each type result, which is beneficial for evaluating the performance of small data size.
4.4. Application of Traffic Accident Knowledge Graph
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Quillian, M.R. Word concepts: A theory and simulation of some basic semantic capabilities. Syst. Res. Behav. Sci. 1967, 12, 410–430. [Google Scholar] [CrossRef] [PubMed]
- Quillian, M.R. The teachable language comprehender: A simulation program and theory of language. Commun. ACM 1969, 12, 459–476. [Google Scholar] [CrossRef]
- Buchanan, B.; Duda, R.; Chen, Y.; Xu, Y. Rule-based expert systems principles. Comput. Sci. 1986, 22, 23–37. [Google Scholar]
- Guha, R.V.; Lenat, D.B. CYC: A mid-term report. Appl. Artif. Intell. 1991, 5, 45–86. [Google Scholar] [CrossRef]
- Miller, G.A.; Fellbaum, C. WordNet Then and Now. Lang. Resour. Eval. 2007, 41, 209–214. [Google Scholar] [CrossRef]
- Zeng, X.; Yang, C.; Tu, C.; Liu, Z.; Sun, M. Chinese LIWC lexicon expansion via hierarchical classification of word embeddings with sememe attention. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Jiang, Y.; Gao, X.; Su, W.; Li, J. Systematic Knowledge Management of Construction Safety Standards Based on Knowledge Graphs: A Case Study in China. Int. J. Environ. Res. Public Health 2021, 18, 10692. [Google Scholar] [CrossRef] [PubMed]
- Pedro, A.; Pham-Hang, A.-T.; Nguyen, P.T.; Pham, H.C. Data-Driven Construction Safety Information Sharing System Based on Linked Data, Ontologies, and Knowledge Graph Technologies. Int. J. Environ. Res. Public Health 2022, 19, 794. [Google Scholar] [CrossRef]
- Mao, S.; Zhao, Y.; Chen, J.; Wang, B.; Tang, Y. Development of process safety knowledge graph: A Case study on delayed coking process. Comput. Chem. Eng. 2020, 143, 107094. [Google Scholar] [CrossRef]
- Zheng, X.; Wang, B.; Zhao, Y.; Mao, S.; Tang, Y. A knowledge graph method for hazardous chemical management: Ontology design and entity identification. Neurocomputing 2020, 430, 104–111. [Google Scholar] [CrossRef]
- Nicholson, D.; Greene, C.S. Constructing knowledge graphs and their biomedical applications. Comput. Struct. Biotechnol. J. 2020, 18, 1414–1428. [Google Scholar] [CrossRef]
- Yu, T.; Li, J.; Yu, Q.; Tian, Y.; Shun, X.; Xu, L.; Zhu, L.; Gao, H. Knowledge graph for TCM health preservation: Design, construction, and applications. Artif. Intell. Med. 2017, 77, 48–52. [Google Scholar] [CrossRef]
- Zhang, Q.; Wen, Y.Q.; Han, D.; Zhang, F.; Xiao, C.S. Construction of knowledge graph of maritime dangerous goods based on IMDG code. J. Eng. 2020, 2020, 361–365. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, M.; Tang, J.; Ma, J.; Duan, X.; Sun, J.; Hu, X.; Xu, S. Analysis of Traffic Accident Based on Knowledge Graph. J. Adv. Transp. 2022, 2022, 3915467. [Google Scholar] [CrossRef]
- Liu, C.; Yang, S. Using text mining to establish knowledge graph from accident/incident reports in risk assessment. Expert Syst. Appl. 2022, 207, 117991. [Google Scholar] [CrossRef]
- Liu, J.; Schmid, F.; Li, K.; Zheng, W. A knowledge graph-based approach for exploring railway operational accidents. Reliab. Eng. Syst. Saf. 2020, 207, 107352. [Google Scholar] [CrossRef]
- Liu, Q.; Li, Y.; Duan, H.; Liu, Y.; Qin, Z.G. Knowledge Graph Construction Techniques. J. Comput. Res. Dev. 2016, 53, 582. [Google Scholar]
- Goyal, A.; Gupta, V.; Kumar, M. Recent Named Entity Recognition and Classification techniques: A systematic review. Comput. Sci. Rev. 2018, 29, 21–43. [Google Scholar] [CrossRef]
- Zhong, M.; Liu, G.; Xiong, J.; Zuo, J. DualNER: A Trigger-Based Dual Learning Framework for Low-Resource Named Entity Recognition. IEEE Intell. Syst. 2022, 37, 79–87. [Google Scholar] [CrossRef]
- Tuo, M.M.; Yang, W.Z. Review of entity relation extraction. J. Intell. Fuzzy Syst. 2023, 44, 7391–7405. [Google Scholar] [CrossRef]
- Qiao, B.; Zou, Z.; Huang, Y.; Fang, K.; Zhu, X.; Chen, Y. A joint model for entity and relation extraction based on BERT. Neural Comput. Appl. 2021, 34, 3471–3481. [Google Scholar] [CrossRef]
- Hang, T.; Feng, J.; Wu, Y.; Yan, L.; Wang, Y. Joint extraction of entities and overlapping relations using source-target entity labeling. Expert Syst. Appl. 2021, 177, 114853. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Label | Property | Example | Number of Entities Involved |
|---|---|---|---|---|
| Node entity | Legal Code | Name | 20010 | 452 |
| Violation | Article 70 (1) of the Road Traffic Safety Law of the People’s Republic of China | |||
| Punishment Basis | Article 99 of the Road Traffic Safety Law of the People’s Republic of China | |||
| Coercive Measure | Detain car. | |||
| Original Law | Article 70 (1): If a traffic accident occurs on the road, the driver of the vehicle shall immediately stop and protect the scene, and the driver of the vehicle shall immediately rescue the injured person and report promptly to the traffic police or the traffic management department of the public security organ on duty. Where the injured person changes location, their former position shall be marked. | |||
| Expanded Knowledge | Escape from a traffic accident refers to the illegal behavior of a party who, after a traffic accident, fails to protect the scene of the accident and intentionally escapes from it without reporting to the public security organs to escape responsibility. | |||
| Demerit Points | Name | 0 | 6 | |
| Punishment Type | Name | Fines, detention | 16 | |
| Fine | Name | 500 yuan | 20 | |
| Relation entity | rels_DemeritPoints (from Illegal Code to Demerit Points) | Name | rels_DemeritPoints | 452 |
| rels_PunishmentType (from Illegal Code to Punishment Type) | Name | rels_PunishmentType | 452 | |
| rels_Fine (from Illegal Code to Fine) | Name | rels_Fine | 452 |
| Type | Label | Property | Example | Number of Entities Involved |
|---|---|---|---|---|
| Node entity | Fault Code | Name | B2692 | 5419 |
| Chinese Definition | 前排乘客座椅安全带扣开关电路故障 | |||
| English Definition | Front Passenger’s Seat Belt Buckle Switch Circuit Fault | |||
| Fault Description | The function of the seat belt buckle switch/sensor is to monitor whether the seat belt is fastened. | |||
| Fault Part | Name | Body | 15 | |
| Relation entity | rels_Part (from Fault Code to Fault Part) | Name | rels_Part | 5419 |
| Type | Label | Property | Example | Number of Entities Involved |
|---|---|---|---|---|
| Node entity | Emergency Plan | Name | Highway Traffic Emergency Plan | 13 |
| Government Department | Name | Ministry of Transport | 5 | |
| Year | Name | 2009 | 7 | |
| Emergency Type | Name | Traffic emergency | 7 | |
| Introduction | Traffic emergencies include damage or potential damage to transportation facilities, traffic interruptions, and traffic jams. In addition, they include transportation support for natural disasters, accidents, public health incidents, and social security incidents that occur suddenly, as well as emergency measures to evacuate or rescue personnel. | |||
| Procedure | Name | Emergency organization_Highway Traffic Emergency Plan | 102 | |
| First Serial Number | Chapter 2 | |||
| Process Work | Name | Emergency leading group_Highway Traffic Emergency Plan | 392 | |
| Content | (omission) | |||
| Safety Expert | Name | Mr. Jia | 464 | |
| Sex | Male | |||
| Work Unit | National Center for Occupational Safety and Health, Beijing, China | |||
| Title | Senior engineer | |||
| Education Background | Postgraduate | |||
| Major | Policy research | |||
| Emergency Enterprise | Name | AKD Communication Technology Co., Ltd., Beijing, China | 111 | |
| Introduction | AKD Communication Technology Co., Ltd. was registered on 17 December 2001 in Beijing Zhongguancun Science and Technology Park with a registered capital of 39.36 million yuan. It is a high-tech enterprise specializing in the research and development, production, and sales of satellite communication antennas and terminal systems. This company provides customized satellite communication products. At the same time, this company also undertakes various satellite communication system integration projects. | |||
| slwang@akdtech.com.cn | ||||
| Fax | 010-63726086 | |||
| Website | www.akdtech.com.cn | |||
| Dangerous Transport Enterprise | Name | Beijing Ande Jingcheng Transportation Co., Ltd., Beijing, China | 229 | |
| Operation Scope | Transporting dangerous goods belonging to the third category | |||
| Public Organization | Name | China Society of Emergency Management, Beijing, China | 13 | |
| Introduction | China Society of Emergency Management is a primary organization under the leadership of the Party School of the Central Committee of C.P.C. It is a national, academic, and public welfare organization composed of experts; scholars; practitioners; relevant professional organizations, enterprises, and institutions; non-governmental organizations engaged in theoretical research, teaching, and training; and consulting services for emergency management. It is committed to developing and applying modern emergency management concepts, methods, and technologies and enhancing the ability of the entirety of society to prevent and respond to various emergencies. | |||
| Research Institute | Name | China Academy of Safety Science and Technology, Beijing, China | 38 | |
| Introduction | China Academy of Safety Science and Technology is a comprehensive scientific research institution for public welfare affiliated with the Ministry of Emergency Management of the People’s Republic of China. It focuses on fundamental, comprehensive, and forward-looking scientific research in the field of safety, as well as addressing major technical issues such as accident prevention, monitoring, early warning, and emergency rescue. | |||
| Emergency Products | Name | Mobile emergency communication vehicle | 269 | |
| Introduction | Mobile emergency communication vehicles are suitable for handling emergency situations related to mobile communication. In case of large-scale meetings, gatherings, or communication-related accidents, they can rapidly increase communication capacity. | |||
| Product Type | Emergency communication and command product | |||
| Emergency Function | Name | Emergency rescue and disposal | 4 | |
| Journal | Name | China Safety Science Journal | 74 | |
| WeChat Official Account | Name | Beijing Emergency | 98 | |
| Introduction | Interprets authoritative security policies. Transmits important security information. Disseminates practical security knowledge. | |||
| Website | Name | Safety Management Network | 19 | |
| Website | http://www.safehoo.com/, accessed on 12 December 2022 | |||
| Organizer | Orient Imagination Technology Co., Ltd., Beijing, China | |||
| Relation entity | rels_IssuedTime (from Emergency Plan to Year) | Name | rels_IssuedTime | 13 |
| rels_Reply (from Emergency Plan to Emergency Type) | Name | rels_Reply | 13 | |
| rels_Contain (from Emergency Plan to Procedure, from Procedure to Process Work) | Name | rels_Contain | 494 | |
| rels_Issue (from Government Department to Emergency Plan) | Name | rels_Issue | 13 | |
| rels_Product (from Emergency Enterprise to Emergency Products) | Name | rels_Product | 269 | |
| rels_EmergencyFunction (from Emergency Products to Emergency Function) | Name | rels_EmergencyFunction | 269 | |
| rels_Reply (from Emergency Products to Emergency Type) | Name | rels_Reply | 269 |
| Type | Label | Property | Example | Number of Entities Involved |
|---|---|---|---|---|
| Node entity | Legal Norm | Name | Road Traffic Safety Law of the People’s Republic of China | 63 |
| Legal Hierarchy | Name | Law | 3 | |
| Year | Name | 2021 | 20 | |
| Government Department | Name | The National People’s Congress | 12 | |
| Procedure | Name | Vehicles and Drivers_ Road Traffic Safety Law of the People’s Republic of China | 640 | |
| First Serial Number | Chapter II | |||
| Process Work | Name | Article 12 In case any of the following circumstances occur, the corresponding registration shall be made:
| 3845 | |
| Secondary Serial Number | Article 12 | |||
| Process Modules | Name | Duty | 7 | |
| Relation entity | rels_IssuedTime (from Legal Norm to Year) | Name | rels_IssuedTime | 63 |
| rels_Reply (from Legal Norm to Process Modules) | Name | rels_Reply | 63 | |
| rels_Contain (from Legal Norm to Procedure, from Procedure to Process Work) | Name | rels_Contain | 4456 | |
| rels_Issue (from Government Department to Legal Norm) | Name | rels_Issue | 63 | |
| res_LegalHierarchy (from Legal Norm to LegalHierarchy) | Name | res_LegalHierarchy | 63 |
| Type | Label | Property | Example | Number of Entities Involved |
|---|---|---|---|---|
| Node entity | Driving School | Name | Jingtian Driving School | 104 |
| Postal Code | 100022 | |||
| Work Time | 8:00–17:00 (from Monday to Sunday), excluding national holidays | |||
| Bus Line | Take bus 30, 34, or 801 to Qijiafen and get off. | |||
| Driving Test Location | Name | Laoshan Examination Hall | 29 | |
| Work Time | 8:00–12:00, 13:00–17:00 (from Monday to Sunday), excluding national holidays | |||
| Operation Scope | Holds examinations for motor vehicle drivers. | |||
| Motor Vehicles Department | Name | Chaoyang Traffic Division Vehicle Management Station | 29 | |
| Work Time | 8:30–18:00 (from Monday to Friday), 9:00–16:00 (Saturday and Sunday), excluding national holidays | |||
| Operation Scope | The verification, modification, and replacement of motor vehicle driving licenses and other business | |||
| Motor Vehicle Inspection Site | Name | Hongyuannankou Motor Vehicle Inspection Station | 36 | |
| Work Time | 8:00–12:00, 13:00–17:00 (from Monday to Saturday) | |||
| Operation Scope | Large, medium, small, and micro passenger vehicles; light and micro trucks; heavy, medium, light, and micro special work vehicles; and light trailers (except for diesel engines) | |||
| Motor-Vehicle-Dismantling Plant | Name | Beijing Motor Vehicle Dismantling Co., Ltd., Beijing, China | 7 | |
| Work Time | 8:00–16:00 (from Monday to Friday), excluding national holidays | |||
| Operation Scope | Mainly handles the following business: dismantling scrapped cars, leasing prop cars, and processing small metal objects. | |||
| Motor Vehicle Maintenance Unit | Name | Beijing Kedi Automobile Service Company | 1591 | |
| Juridical Person | Mr. Sun | |||
| Motor Vehicle Maintenance Station | Name | Beijing Shangdixinchen Automobile Sales and Service Co., Ltd. | 6189 | |
| Company Type | Class I motor vehicle maintenance station | |||
| Employer Address | 1 Sports University West Road, Haidian District, Beijing | |||
| Traffic-Accident-Handling Agency | Name | Dongcheng Traffic Division Temple of Heaven Branch | 57 | |
| Work Time | 8:30–18:00 (from Monday to Friday), 9:00–16:00 (Saturday and Sunday), excluding national statutory holidays | |||
| Operation Scope | Handles the extension of the Beijing Entrance Permit. Maintains traffic facilities, traffic order, and traffic safety and smoothness. Handles vehicle traffic accidents and violations. Creates publicity for traffic laws and regulations. | |||
| Traffic-Violation-Handling Agency | Name | Pinggu Traffic Division Law Enforcement Station | 46 | |
| Work Time | 8:30–18:00 (from Monday to Friday), 9:00–16:00 (Saturday and Sunday), excluding national statutory holidays | |||
| Operation Scope | Handles vehicle violations. | |||
| Police Station | Name | Chaoyang Gate Police Station | 351 | |
| Hospital | Name | Beijing Jishuitan Hospital | 724 | |
| Postal Code | 100035 | |||
| District Code | 110102 | |||
| District Name | Xicheng District | |||
| Hospital Level | Grade III | |||
| Hospital Rank | A | |||
| Big Class | A. hospital | |||
| Middle Class | A1. comprehensive hospital | |||
| Small Class | A100. comprehensive hospital | |||
| Economic Type | State-owned | |||
| Management Type | Non-profit medical institution | |||
| Clinic | Name | Beijing Chongren Clinic of Traditional Chinese Medicine | 4032 | |
| Postal Code | 100035 | |||
| District Code | 110102 | |||
| District Name | Xicheng Didtrict | |||
| Small Class | D212. Chinese medicine clinic | |||
| Economic Type | Stock cooperation | |||
| Management Type | For-profit medical institution | |||
| Other Medical Organization | Name | Beijing Adikang Medical Laboratory | 124 | |
| Postal Code | 100176 | |||
| District Code | 110115 | |||
| District Name | Daxing District | |||
| Economic Type | Other | |||
| Management Type | For-profit medical institution | |||
| Emergency Station | Name | Beijing Chaoyang District Chuiyangliu Aid Station | 12 | |
| Postal Code | 100022 | |||
| District Code | 110105 | |||
| District Name | Chaoyang District | |||
| Economic Type | State-owned | |||
| Management Type | Non-profit medical institution | |||
| Safety Assessment Organization of Beijing | Name | Beijing Long’an Kanghua Production Safety Research Center | 33 | |
| Introduction | The company has strong technical strength and rich management experience in safety evaluation, safety training, and safety production technology consulting. The company mainly provides services in the fields of safety films and television, safety management training, and safety evaluation. | |||
| Website | http://184255.71ab.com/, accessed on 12 December 2022. | |||
| Environment-Monitoring Organization | Name | Chinese Research Academy of Environmental Sciences | 16 | |
| Testing Organization | Name | National Safety Production Beijing Labor Protection Equipment Testing and Inspection Center | 4 | |
| Introduction | The National Safety Production Beijing Labor Protection Equipment Testing and Inspection Center is the first professional testing institution for labor protection equipment established in China. It has been engaged in various inspections, research, and service work for labor protection equipment for a long time, and it is a national inspection institution for public welfare. |
| Type | Label | Property | Example | Number of Entities Involved |
|---|---|---|---|---|
| Node entity | Telephone | Name | 84081551 | 2107 |
| Address | Name | 121 Chaonei South Street | 7273 | |
| Organization Type | Name | Medical Organization | 6 | |
| Relation entity | res_Telephone (from Organization to Telephone) | Name | res_Telephone | 7499 |
| res_Address (from Organization to Address) | Name | res_Address | 2407 | |
| res_OrganizationType (from Organization Type to Organization) | Name | res_OrganizationType | 12,946 |
| Type | Label | Property | Example | Number of Entities Involved |
|---|---|---|---|---|
| Node entity | Parking Area | Name | Daoxiangyuan Qiaonan Parking Lot | 502 |
| Park Type | The park area under the overpass | |||
| Park Address | Daoxiangyuan Bridge, Haidian District | |||
| Park Business Unit | Beijing Static Traffic Anda Parking Management Co., Ltd., Beijing, China | |||
| Bus Line | Name | 101 | 1219 | |
| Bus Stop | Name | Baiwanzhuang West Entrance | 8971 | |
| Administrative Area | Name | Dongcheng District | 16 | |
| Area | 41.84 km2 | |||
| Government Residence | Jingshan Subdistrict | |||
| Jurisdiction | Donghua Gate Subdistrict, Jingshan Subdistrict, Jiaodaokou Subdistrict, Anding Gate Subdistrict, Beixin Bridge Subdistrict, Dongsi Street, Chaoyang Gate Subdistrict, Jianguo Gate Subdistrict, Dongzhi Gate Subdistrict, Hepingli Street, Qianmen Subdistrict, Chongwenmenwai Subdistrict, Donghuashi Subdistrict, Longtan Street, Tiyuguan Road Subdistrict Street, Tiantan Street, Yongdingmenwai Subdistrict | |||
| National Road | Name | Beijing Harbin Expressway | 177 | |
| Route Code | G1 | |||
| Provincial Road | Name | Jingliang Road | 443 | |
| Route Code | S315 | |||
| Expressway | Name | East Fourth Ring South Road (main road) | 80 | |
| Start Point | Yaowa Lake Bridge | |||
| End Point | Shibalidian Bridge | |||
| Length | 4766.9 m | |||
| Main Road | Name | East Fourth Ring South Road (outer-ring auxiliary road) | 359 | |
| Start Point | Yaowa Lake Bridge | |||
| End Point | Shibalidian Bridge | |||
| Length | 4959.2 m | |||
| Meteorological Equipment | Name | 3110116001 | 39 | |
| Location Point | G111 Jingjia Road K84 Houshanpu Village | |||
| Traffic Camera | Name | Wuxing Intersection of National Road G103 | 31,504 | |
| Equipment Direction | East to West | |||
| North–South Intersection Road | Wuxing Road | |||
| East–West Intersection Road | National Road G103 | |||
| Relation entity | res_AdministrativeArea (from Bus Line, Meteorological Equipment, Traffic Camera to Administrative Area) | Name | res_AdministrativeArea | 25,417 |
| res_BusStop (from Bus Line to Bus Stop) | Name | res_BusStop | 31,911 |
| Order Number | Question Type |
|---|---|
| 1 | FaultPart_FaultCode |
| 2 | ChineseDefinition_FaultCode |
| 3 | FaultCode_FaultPart |
| 4 | ChineseDefinition_FaultPart |
| 5 | FaultCode_ChineseDefinition |
| 6 | FaultPart_ChineseDefinition |
| 7 | FaultCode_EnglishDefinition |
| 8 | ChineseDefinition_EnglishDefinition |
| 9 | FaultCode_FaultDescription |
| 10 | ChineseDefinition_FaultDescription |
| 11 | FaultSystem |
| Class | Question Vocabulary |
|---|---|
| system division | fault type, fault system, fault classification, fault part, division, segmentation, etc. |
| fault code | code, fault code, etc. |
| fault part | where, part, section, fault part, occur, etc. |
| Chinese definition | Chinese, name, fault name, performance, fault type, etc. |
| English definition | English, name, English name, etc. |
| fault description | phenomenon, performance, how, detail, fault description, content, detailed description, meaning, cause, etc. |
| Model | Precision | Recall | F1 |
|---|---|---|---|
| Bert | 84.87% | 89.96% | 87.34% |
| Bert-CRF | 85.98% | 90.71% | 88.28% |
| Bert-BiLSTM | 86.64% | 90.33% | 88.45% |
| Bert-BiLSTM-CRF | 86.93% | 91.20% | 89.01% |
| Parameters | Value |
|---|---|
| Max sentence length | 512 |
| Hidden size | 768 |
| Number of hidden layers | 12 |
| Number of epochs | 2 |
| Learning rate | 5e-5 |
| Batch size | 16 |
| Dropout rate | 0.5 |
| Average | Precision | Recall | F1 |
|---|---|---|---|
| macro-average | 0.9850 | 0.9657 | 0.9744 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, D.; Zhou, K.; Yang, C. Architecture and Application of Traffic Safety Management Knowledge Graph Based on Neo4j. Sustainability 2023, 15, 9786. https://doi.org/10.3390/su15129786
Yuan D, Zhou K, Yang C. Architecture and Application of Traffic Safety Management Knowledge Graph Based on Neo4j. Sustainability. 2023; 15(12):9786. https://doi.org/10.3390/su15129786
Chicago/Turabian StyleYuan, Danling, Keping Zhou, and Chun Yang. 2023. "Architecture and Application of Traffic Safety Management Knowledge Graph Based on Neo4j" Sustainability 15, no. 12: 9786. https://doi.org/10.3390/su15129786
APA StyleYuan, D., Zhou, K., & Yang, C. (2023). Architecture and Application of Traffic Safety Management Knowledge Graph Based on Neo4j. Sustainability, 15(12), 9786. https://doi.org/10.3390/su15129786