1. Introduction
Extreme weather events including hurricanes, floods, and droughts have become more common in recent years, and the accompanying issues of rising sea levels, food security, and diminished biodiversity pose severe challenges to productive human existence [
1]. Due to the severity of the climate, immediate and extensive action is needed to reduce the global warming process. After the Kyoto Protocol was signed at the United Nations Climate Change Conference (UNFCC) in 1997, the Paris Agreement adopted at the 2015 Paris Climate Change Conference broke the negotiation deadlock and reached an extremely significant milestone in terms of the general arrangements for the international community to address climate change after 2020 [
2]. Since then, representatives from various nations have discussed issues such as achieving emission reduction goals and creating clean energy at the UN Climate Change Conference every year to further implement the Paris Agreement. At the same time, they will also look into more all-encompassing and coordinated ways to address climate change. In particular, economists believe that reasonable carbon pricing is the most effective means of achieving this goal [
3]. A carbon trading system can guide companies to adopt more ecological behaviors, effectively reduce social costs of emission reductions, drive low-carbon technology innovation, as well as investment financing, and allow for better policy choices [
4]. Since 2013, China has selected eight provinces and cities, including Beijing, Shanghai, Tianjin, Chongqing, Hubei, Guangdong, Fujian, and Shenzhen, as carbon trading pilots and opened a national carbon trading market in 2021.
In the carbon trading market, carbon prices are affected by various complex factors, such as changes in supply and demand, thus being nonlinear and unstable [
5]. Therefore, the accurate prediction of carbon prices can dig deeper into the intrinsic fluctuation law of carbon prices, accelerating the establishment of an efficient and perfect price system [
6]. As a result, establishing a high-precision carbon price prediction model is essential.
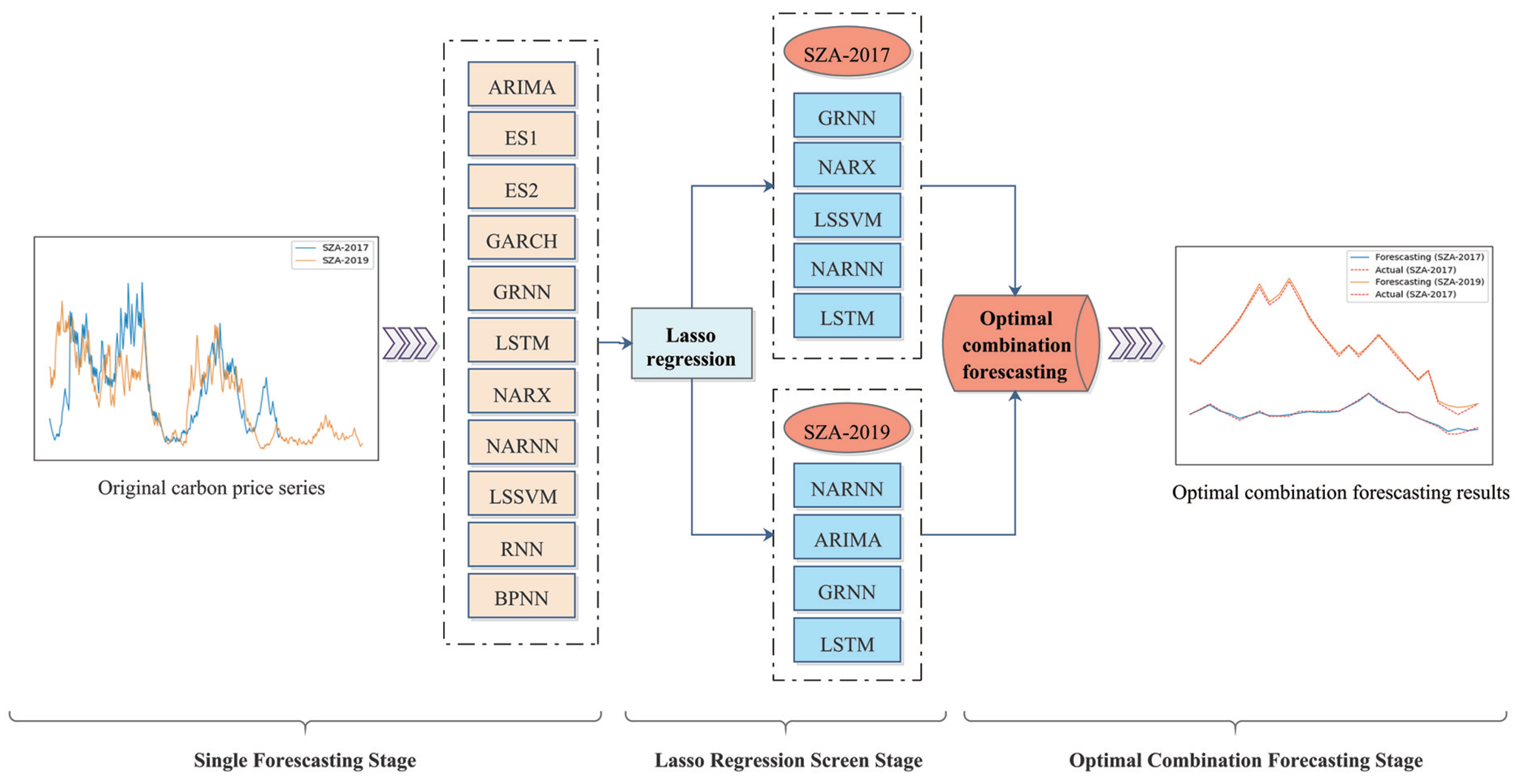
Nevertheless, existing methods for combination forecasting typically use one or a few specific methods. Specifically, various forecasting methods can provide practical information for carbon price forecasting from different perspectives due to the varying model settings. This study combines various models for carbon price forecasting. Eleven single forecasting models, namely, the autoregressive integrated moving average model (ARIMA), the exponential smoothing prediction method (ES1), Holt’s exponential smoothing prediction method (ES2), the generalized autoregressive conditional heteroscedasticity prediction model (GARCH), the generalized regression neural network prediction model (GRNN), the long short-term memory prediction model (LSTM), the nonlinear autoregression with external input prediction model (NARX), the nonlinear autoregressive neural network prediction model (NARNN), the least square support vector machine prediction model (LSSVM), the recurrent neural network model (RNN), and the back propagation neural network prediction model (BPNN), are employed to fully exploit the information provided by each method and establish the optimal combination forecasting model based on the least absolute shrinkage and selection operator (Lasso) regression.
The qualitative analysis method is commonly used for the first investigation of carbon price forecasting [
7]. With the swift progress of statistics and economics, as well as the rapid penetration of machine learning technology, researchers are gradually exploring more accurate methods to capture the evolution of carbon price series. In general, the current research on carbon price forecasting is slowly shifting focus from single forecasting methods to hybrid forecasting methods.
Specifically, the single prediction method mainly refers to classical measurement and excellent artificial intelligence models. The former is based on a traditional econometric model to predict the time series. For instance, ARIMA, the most traditional time series prediction model, was used to forecast the linear components of the European Union’s carbon pricing series with favorable performance [
8]. In addition, based on the second-stage carbon price data of the European Climate Exchange (ECX) from 2008 to 2011, GARCH [
9,
10] was found to have a better fitting degree than the k-nearest neighbor model and implied volatility. Furthermore, the improved ARIMA-GARCH model also made a good prediction of the carbon price fluctuation in the European Union, which effectively captured the skewness and the fluctuation behavior in different stages [
11]. To sum up, these models are all based on comprehensive statistics and can make sound predictions for stationary time series under certain assumptions. Notwithstanding, considering the prominent non-stationary and nonlinear features of carbon trading price series, the econometric prediction model cannot capture such elements accurately, so the prediction accuracy needs further improvement. Fortunately, the artificial intelligence model makes up for this defect to some extent.
With the swift advancement of machine learning, a growing number of artificial intelligence models are being used to forecast carbon prices. Compared with the econometric prediction model, these models have more robust adaptability and generalization ability. Furthermore, they can more accurately mine the nonlinear laws between data. The BP neural network, for example, is an artificial neural model that conducts reverse training based on errors, can modify any complexity mapping relationship, and has a strong nonlinear prediction ability [
12]. Nevertheless, it is easy for the model to suffer from premature convergence caused by local minima. To solve this problem, Sun and Huang [
13] combined the genetic algorithm (GA) with the BP model to further improve the training speed. At the same time, they applied this model to predict carbon price series in three Chinese markets, Beijing, Shanghai, and Hubei. Moreover, the prediction effectiveness of the model was proven using three error indicators. Likewise, LSSVM has also achieved good results in carbon price prediction, the core problem of which is determining the kernel function and the optimal parameters. In comparison to the BP neural network, this model can successfully solve the volatility of training effectiveness. Zhu et al. [
14] used empirical mode decomposition (EMD) to improve the LSSVM model’s resilience. In addition, Atsalakis et al. [
15] creatively proposed three-carbon price prediction methods: the neuro-fuzzy hybrid controller (NFHC), the adaptive neuro-fuzzy inference system (ANFIS), and the artificial neural system. According to the findings, the second method has the highest forecast accuracy and the largest development potential. However, these artificial intelligence models also have their limitations, for example, that they cannot completely capture various feature information of time series. When the time series fluctuates wildly, this kind of model cannot deliver ideal prediction results.
On the other hand, considering that the single forecasting model has certain limitations and cannot accurately capture the practical characteristics of the carbon price series, the existing carbon price research gradually adopts the combination forecasting method [
16]. This method may fully exploit the benefits of each individual prediction model, hence increasing forecast accuracy in particular. Zhu et al. [
17] combined LSSVM, GARCH, and EMD to set up a new nonlinear integrated combination forecasting model. Firstly, the carbon price series was decomposed using EMD into a residual value and multiple intrinsic modal functions, which are classified as high-frequency, low-frequency, and trend functions. After this, they considered using the GARCH model to predict the high-frequency function and using the LSSVM model to predict the low-frequency as well as trend functions. Finally, they employed LSSVM to integrate the predicted values. Nevertheless, modal mixing may interfere with EMD decomposition, so functions with the same frequency cannot be accurately decomposed. For this reason, researchers created the variational modal decomposition (VMD) model [
18]. By combining this model, modal reconstruction (MR), and the optimal combination forecasting model (CFM), Zhu et al. [
19] developed a novel combination forecasting method that increased the carbon price prediction accuracy substantially. In addition, Sun et al. [
20] also created a new integrated forecasting model, which combined weighted least squares support vector machine (WLS-SVM), linear particle swarm optimization (LDWPSO), and integrated empirical mode decomposition (EEMD). Moreover, they apply it to the empirical research of carbon trading markets in Hubei, Guangdong, and Shanghai. Similarly, by combining fractal Brownian motion (FBM) with GARCH, Liu et al. [
21] successfully predicted the carbon trading price of the European Energy Exchange (EUA).
After carefully analyzing the current carbon price combination forecasting models, we can see that each individual prediction method can extract sufficient information from various perspectives. Nonetheless, the accuracy of each method’s forecast varies over time. That is, the “high and low” condition emerges. Consequently, combined forecasting can incorporate the benefits of each forecasting method while also improving model forecasting accuracy. However, because there are a host of single prediction methods, some of them supply repeated information, increasing prediction error and computational complexity if they are all utilized together. As a result, one of the significant difficulties in this study is effectively picking suitable approaches among the single prediction models for combination.
Generally, linear and nonlinear algorithms are the most common data dimensionality reduction techniques. Researchers studied linear dimension reduction methods such as principal component analysis (PCA), independent component analysis (ICA), and factor analysis (FA) in the early research [
22,
23,
24]. These methods, based on feature extraction, translate data from a high-dimensional to a low-dimensional space and use the extracted variables to represent the original whole. Furthermore, scholars are gradually adopting nonlinear dimensionality reduction approaches such as isometric mapping (Isomap), kernel-based principle component analysis (KPCA), and stochastic neighborhood embedding (SNE) [
25,
26,
27] as data structures become more complicated. KPCA is a PCA-based method for improving nonlinear data processing [
28]. Simultaneously, SNE is a fantastic learning tool with excellent visualization functions. Laurens et al. [
29] devised the
t-SNE model on this foundation. The algorithm pays more attention to the correlation between neighboring sample points to better demonstrate the nonlinear relationship between variables. While these solutions can be used for a wide range of problems, they do have some limitations. Other issues, such as the selection of sample size, inability to detect outliers, and estimation of intrinsic dimensionality, have not been addressed. Considering the nonlinearity of carbon pricing data and the possibility of multiple co-linearities in a single forecasting model, we chose to eliminate collinearity statistically. In particular, the Lasso regression model is used to reduce the data dimensionality.
The Lasso regression model, on the other hand, has become a popular linear regression model in recent years [
30], which is widely used in computer science, biomedicine, engineering, and other fields [
31,
32,
33,
34]. The essence of this model is a kind of compressed estimation. By constructing a penalty function, the sum of absolute values of regression coefficients is less than a specific constant. Meanwhile, the sum of residual squares is minimized so that some coefficients are selected as 0. Finally, the coefficients of each explanatory variable are determined. Furthermore, scholars have gradually introduced the Lasso regression model into economics research. For example, Anuja et al. [
35] explored which factor is the key to becoming an influencer on social platforms with this method. Theodore et al. [
36] used the Lasso regression model to analyze bitcoin income. They concluded that both the gold return rate and search intensity have the most significant impact on the bitcoin return rate. Similarly, Liu et al. [
37] used the Lasso method to determine the variables affecting the efficiency of green innovation in high-tech industries.
Furthermore, Lasso regression models have also begun to be used by current academics to establish the weights of the combined models, thus improving the prediction accuracy. Among these, Diebold et al. [
38] propose an approach based on “partial equality LASSO” (peLASSO), which outperforms other models in terms of forecasting results by decreasing the weights of the remaining portfolio weights to the average level and setting some weights to zero. This study was even applied to the European Central Bank Survey of Professional Forecasters, demonstrating its potential for practical application. In addition, Zhang et al. [
39] compared the Lasso model with other models, such as ridge regression, principal component regression, and partial least squares in forecasting oil prices. The experimental findings demonstrate the Lasso model’s capacity to choose reliable predictors that add information beyond that offered by rival models. Similar to this, Zhang et al. [
40] suggested using a time autocorrelation-based regression model to estimate the concentration of suspended sediment. By using the “shrinkage” effect of the Lasso model, the model was able to identify the most significant factor among the analyzed parameters and compress the contributions of other factors to zero. The results show that the Lasso method is able to obtain prediction results with minimum root mean square error and standard deviation. In conclusion, these studies demonstrate that the use of the Lasso model can increase forecasting accuracy and identify the most crucial predictors, giving decision makers more precise and dependable forecasting findings. In particular, no one has used this method to forecast carbon prices.
Accordingly, this research presents a Lasso regression-based carbon price combination forecasting model. First, nine well-behaved single prediction models are selected to separately predict the carbon price series. Thus, the initial prediction values are obtained. In addition, the optimal weights of each model can be derived after filtering each model using a Lasso regression-based combined forecasting model. Lastly, the product of the predicted values of each model and the optimal weight is added to obtain the final combined prediction result. In addition, we use the carbon price data of Shenzhen for empirical research and consider four error indicators to corroborate the model’s prediction effectiveness.
This study contributes to the literature in following ways:
(1) For the first time, the Lasso regression model is used to investigate carbon price combination prediction, which partially solved the challenge of calculating the weight of the combination forecast.
(2) Past research on carbon price combination forecasting usually considered three or four single forecasting models. In comparison, eleven excellent single prediction models are selected in this study, which can capitalize on the advantages of different carbon price prediction models and internalize the characteristics of carbon price series more comprehensively, thus improving the prediction accuracy.
The remainder of this research is as follows.
Section 2 introduces eleven commonly used single prediction models and Lasso regression models, which lays a solid theoretical foundation for proposing new models later. Then, the combination forecasting model of the carbon price based on Lasso regression is constructed. Additionally,
Section 3 describes the data and the evaluation index.
Section 4 contains the empirical analysis. Finally,
Section 5 elaborates on the study’s primary findings and discusses future research.
5. Conclusions and Discussion
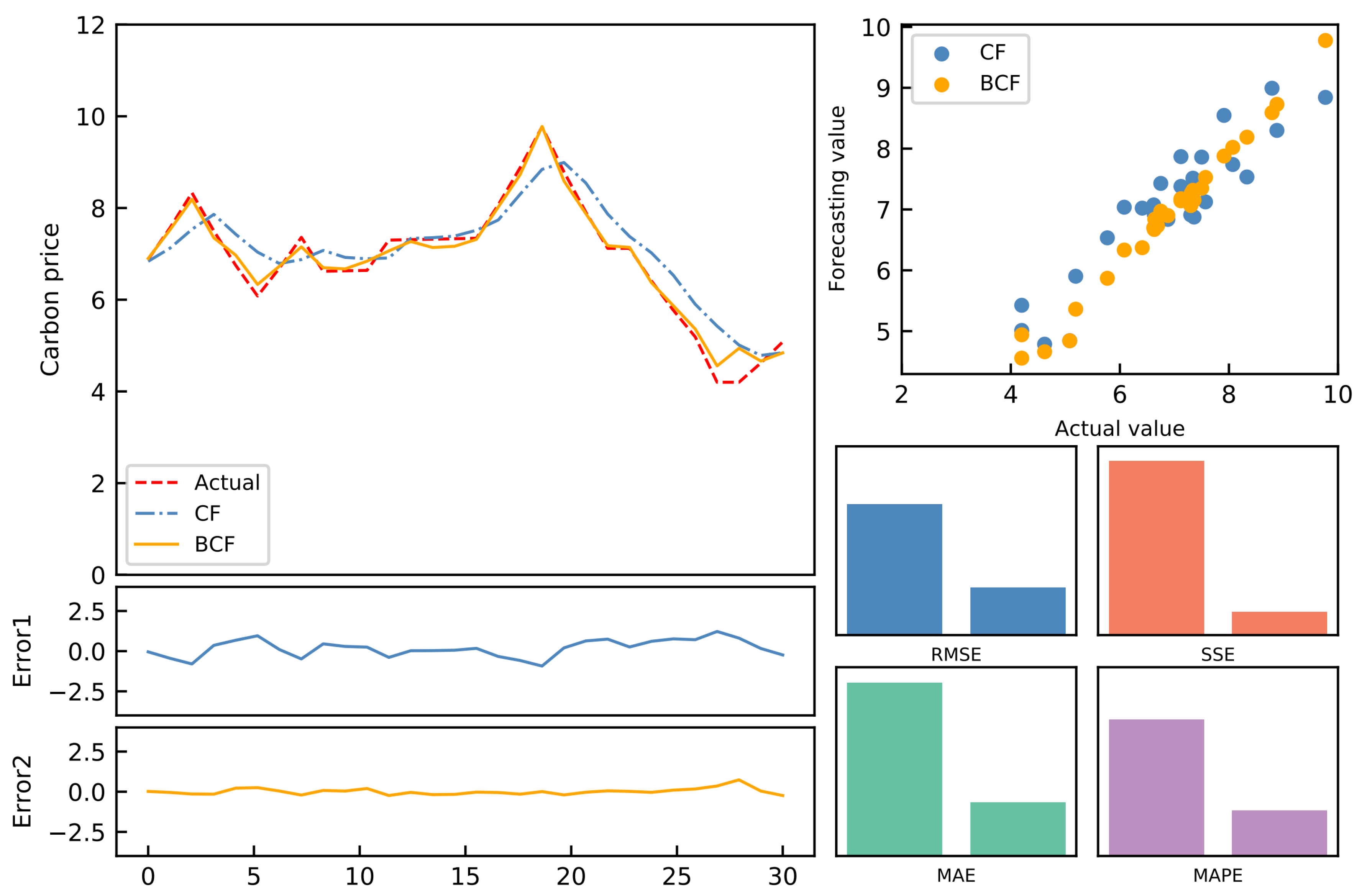
Forecasting an accurate carbon price trend is crucial for the growth of the carbon emission trading market. Given the current carbon price forecasting constraints, an optimal combination carbon price forecasting model based on the Lasso regression model is developed. First, 11 single forecasting models are chosen to forecast the relevant data sets. After that, the Lasso regression model is employed to reduce the dimensionality. Thus, the weights of some models are set to 0. Moreover, the best combination prediction model based on the IOWA operator is used to forecast the remaining models. As a result, the optimal weight can be calculated to obtain the final prediction value. In addition, using the Shenzhen SZA-2017 and SZA-2019 data sets as samples, eight evaluation indices and the DM test are applied to assess the model’s prediction effectiveness from various perspectives. The following breakthroughs and strengths of this paradigm have been identified through empirical and extensive analysis:
(1) Compared to existing benchmark models, the suggested model outperforms them in terms of prediction accuracy, generalization ability, and effectiveness. It introduces a novel strategy for predicting carbon prices.
(2) For the first time, the Lasso regression model is used in carbon price prediction, resolving the challenge of selecting a single prediction model in a combination prediction model.
(3) The simple average combination model’s suboptimal properties are empirically tested, and then the ideal weight is established.
In addition, the study also has some academic significance and practical benefits. On the one hand, the study builds a combined model for predicting carbon trading prices based on Lasso regression and optimal integration, as well as forecasts two different types of carbon trading prices in the Shenzhen carbon trading market, enhancing theoretical research on carbon trading price forecasting and the carbon trading market while also furthering forecasting results and their accuracy. Nevertheless, this study has significant practical implications for the policy making of government agencies, the strategic positioning of emission control businesses, and the decision making of investors. First and foremost, since China’s carbon trading market is currently in a stage of gradual improvement, the accurate price prediction of carbon trading is conducive to a deeper exploration of the intricate patterns of carbon trading prices, providing a reference for government departments to formulate policies related to the carbon trading market and accelerating the establishment of an effective and complete carbon price trading system, further improving the market regulatory mechanism. The study will also assist emission control businesses in predicting the trajectory of carbon trading prices and allocating resources more sensibly and effectively to cut costs and achieve sustainable development. The study can also give investors market information estimates, which can result in more useful investment and financing guidance, given that carbon emission rights are also a financial asset.
Nevertheless, there are still certain restrictions that need to be addressed. First, all of the forecasts in this research are based on historical carbon price data but do not take into account unstructured data, causing the prediction results to lag. More research is needed to determine how to mix this type of data with the combined forecasting model. Furthermore, the combination prediction model used combines traditional measurement methods with artificial intelligence methodologies. However, the decomposition and integration models are not taken into account. As a result, in the future, it may be essential to combine these methodologies with the optimal combination forecasting model to create a more general and robust forecasting model. Ultimately, to optimize its utility, the suggested model can be applied to the prediction of business cycles, economic growth, policy formulation, stock price forecasting, and other relevant domains.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}