1. Introduction
Urban rail transit has developed rapidly in the twenty-first century. As a safe, convenient, and green transport tool, the subway is the preferred choice for most people to travel [
1]. However, the increase in passenger demand often leads to congestion in subways. Passenger flow prediction plays a vital role in relieving congestion, especially short-term passenger flow prediction (STPFP) [
2]. On the one hand, STPFP can assist station managers in organizing and guiding passengers, relieving congestion, and avoiding accidents. On the other hand, operators can draw up corresponding passenger flow control tactics and optimize train schedules to promote the operational efficiency of the subway systems. Moreover, it can also provide convenience for passengers. Therefore, it is of great significance to predict the short-term subway passenger flow by using the passenger flow data collected by the automatic fare collection (AFC) equipment.
Many methods have been utilized for STPFP, which can be generally divided into parametric models and non-parametric models [
3]. The parametric models include the Kalman filtering model [
4], grey prediction [
5], history average [
6], and autoregressive integrated moving average and its variant models [
7,
8]. The parametric models seek a linear mapping relation based on statistical principles that are suitable for predicting linear and stationary time series. This kind of method has a weak ability to learn nonlinear relations in passenger flow data, and the prediction error is remarkable. To improve prediction accuracy, researchers apply non-parametric models to STPFP, which are better than parametric models at capturing features in historical ridership data. The random forest model [
9], support vector machine (SVM) [
10], shallow neural networks [
11], and the Bayesian method [
12] are a few examples. Although the non-parametric methods can learn more nonlinear relationships of time series, the prediction performance of non-parametric methods relies too much on complicated artificial feature engineering. Recently, deep learning technologies based on deep neural networks have shown good performance without feature engineering. Some researchers have used them for STPFP, such as deep belief networks [
13], recurrent neural networks (RNN) [
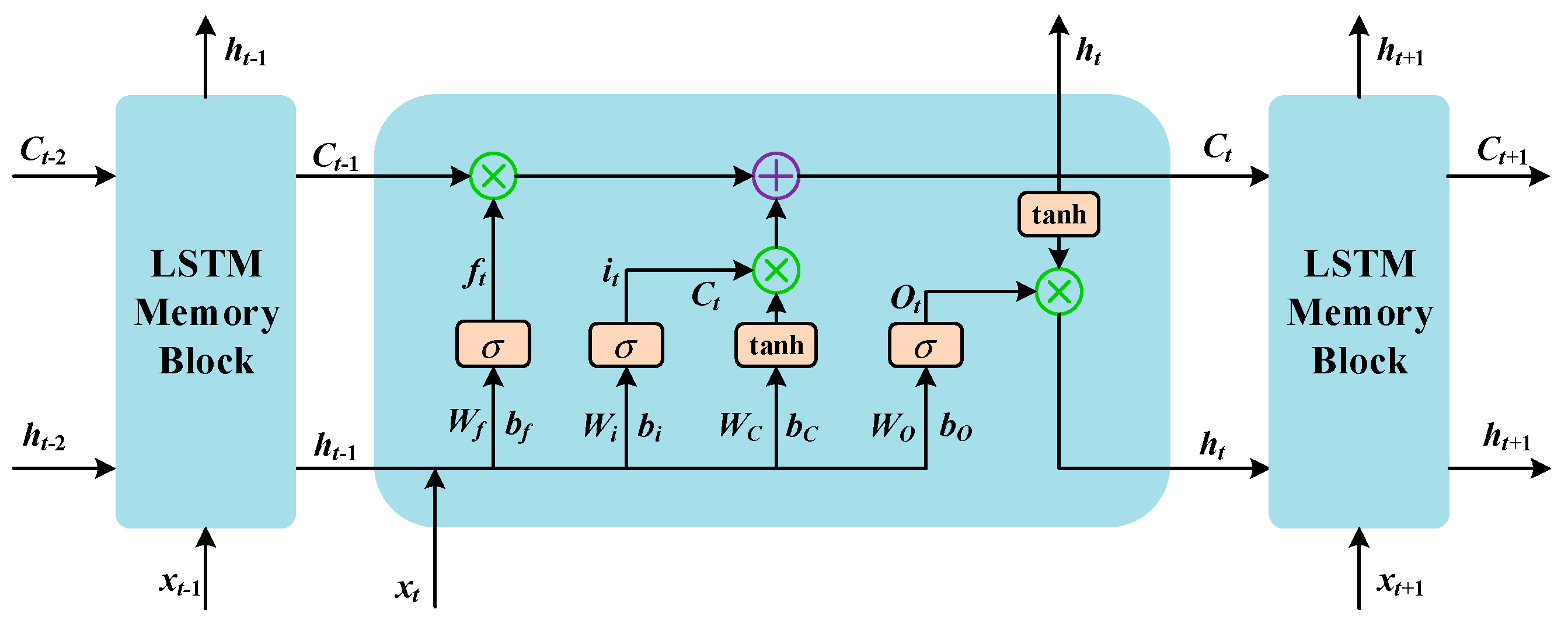
14], long short-term memory (LSTM) [
15], convolutional neural networks [
16], and graph convolutional neural networks [
17]. Due to their strong generalization ability and big data training ability, deep learning models have become the mainstream model for STPFP.
However, in practice, the process of collecting subway passenger flow data is often interfered by many factors such as weather or emergencies, and there is a lot of noise in the original passenger flow data. This leads to the highly nonlinear and nonstationary nature of the passenger flow time series, which seriously affects the prediction performance of the models [
18]. Recently, some data preprocessing techniques have been applied to passenger flow prediction. The idea is to reduce the influence of noise in the data through decomposition methods and improve the prediction accuracy of the model [
19]. Wei et al. [
3] used empirical mode decomposition (EMD) to decompose the subway passenger flow time series and proved that data preprocessing technology could significantly improve the prediction accuracy. Shen et al. [
20] applied EMD to process volatility and nonlinear passenger flow data. Li et al. [
21] conducted a secondary decomposition of bus passenger flow based on EMD to perform STPFP. Their experimental results showed that the model mixed with the data preprocessing method was a reliable and promising prediction method. Although the hybrid model based on EMD can significantly improve prediction accuracy, EMD has the disadvantage of mode mixing. Wu and Huang [
22] proposed ensemble EMD (EEMD) based on adding Gaussian white noise to overcome the above shortcomings. Liu et al. [
23] and Cao et al. [
24] adopted the EEMD to decompose passenger flow and further indicated that the EEMD had better decomposition and denoising ability than the EMD. Although the prediction accuracy based on EEMD is better than that of EMD, the computational scale of EEMD is large, and there is residual noise. Yeh et al. [
25] proposed a complementary EEMD (CEEMD). On the basis of EEMD, the added white noise is in the form of positive and negative pairs, which offset the residual components in the reconstructed signal and reduce the calculation time. Jiang et al. [
26] combined CEEMD and machine learning models for STPFP. Their experimental results showed that CEEMD could not only solve the problem of mode mixing but also reduce white noise interference and save computing time. However, EEMD and CEEMD can easily generate different numbers of sub-series. Torres et al. [
27] then proposed the complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN). This method adds adaptive white noise, which effectively avoids this problem. Li et al. [
28] used the CEEMDAN to decompose parking demand time series, and the experimental results proved that the CEEMDAN could effectively reduce the complexity and nonlinearity of time series. Huang et al. [
29] used CEEMDAN to decompose the original passenger flow data and reconstruct it into random parts, deterministic parts, and trend parts for STPFP. Huang et al. [
30] compared several conventional decomposition methods and concluded that the prediction accuracy and anti-noise performance of the CEEMDAN were better than those of the EMD and EEMD methods. Moreover, some scholars applied wavelet decomposition (WD) to STPFP. Sun et al. [
31] combined WD and SVM to STPFP in the Beijing subway. Yang et al. [
32] designed a WD-LSTM model for the STPFP of Beijing Subway Dongzhimen Station. Ozger et al. [
33] compared EMD and WD through experiments and concluded that the correct selection of wavelet type would make the hybrid model combined with WD have higher accuracy than the hybrid model combined with EMD. Unfortunately, the wavelet basis function of the WD needs to be predefined and is essentially non-adaptive. These limitations will affect the final prediction results. Afterward, Dragomiretskiy and Zosso [
34] put forward variational mode decomposition (VMD), which can overcome the drawbacks of WD and EMD. As an adaptive time-frequency analysis method, VMD has better time-series signal decomposition ability than EMD and WD [
35]. Zhang et al. [
36] mixed VMD and machine learning models for subway passenger flow prediction. Zhou et al. [
37] proposed the VMD-LSTM method for bus travel speed prediction in urban traffic networks, and experiments showed that this method can effectively improve the reliability of bus services. Due to the fact that VMD has a solid mathematical theory foundation, it can decompose signals more accurately, and has good anti-noise performance and high operating efficiency. VMD has achieved great success in wind power prediction [
38], wind speed prediction [
39], and price prediction [
40].
However, VMD needs to obtain the modal component and quadratic penalty factors in advance, which have a significant impact on the decomposition accuracy and the prediction accuracy of the hybrid model. There is no mature method to determine these two parameters. Generally, the selection of VMD parameters mainly comes from experience [
41] and the center frequency observation method [
42], which cannot fundamentally solve the shortcomings of relying on empirical knowledge. Recently, with the development of the swarm intelligence optimization algorithm, more and more scholars have applied it to VMD parameter optimization. In other time-series prediction fields, Huang et al. [
43] used a genetic algorithm to optimize VMD parameters. Liu et al. [
44] employed the particle swarm optimization (PSO) algorithm to find the best parameter combination for VMD. Li et al. [
45] realized the adaptive determination of VMD parameters through the seagull optimization algorithm. Yang et al. [
46] used a grey wolf optimizer (GWO) to overcome the problem of empirical selection of VMD parameters. However, these traditional optimization algorithms are generally limited by slow convergence speeds and poor stability, which has a certain impact on the accuracy of VMD parameter optimization. When these optimization algorithms are used to optimize the parameters of VMD, the phenomenon of over-decomposition or under-decomposition of VMD will occur, which seriously affects the prediction accuracy of subsequent models. The sparrow search algorithm (SSA) is a novel optimization algorithm. In the study of Xue and Shen [
47], it was proved that SSA has surprising advantages in convergence speed, stability, and robustness compared with other optimization algorithms. However, when SSA search approaches the global optimum, it still faces the problems of population diversity reduction, an easy fall into a local optimum, and slow convergence speed. To solve these problems, a mixed-strategy improved sparrow search algorithm (MSSA) is proposed in this paper. At the beginning of the iteration, the elite opposition learning [
48] strategy is used to initialize the population, making it more evenly distributed in the search space. Then, combined with the butterfly flight mode in the butterfly optimization algorithm (BOA) [
49], the position update strategy of the discoverer is improved to enhance the global exploration ability of the algorithm. In the latter stage of iteration, the adaptive T distribution mutation [
50] method is used to perturb the individual position and improve the ability of the algorithm to jump out of the local optimum. In order to adaptively select the parameters of VMD, the MSSA algorithm is used to search for the optimal parameter combination of VMD with the minimum envelope entropy of modal components as the objective function. Thus, an improved VMD (IVMD) method based on MSSA is proposed to decompose the original subway passenger flow time series to reduce the non-linear and non-stationary nature of the passenger flow series.
In addition, sub-series with different complexity after decomposition will lead to different prediction results. Most studies use a fixed model to predict all sub-series. However, a fixed model will inevitably cause underfitting phenomena for the sub-series with high complexity and overfitting phenomena for the sub-series with low complexity. Although Duan et al. [
51] believed that different models should be used to predict sub-series with different complexity, they did not give criteria for judging the complexity of sub-series. Liu and Zhang [
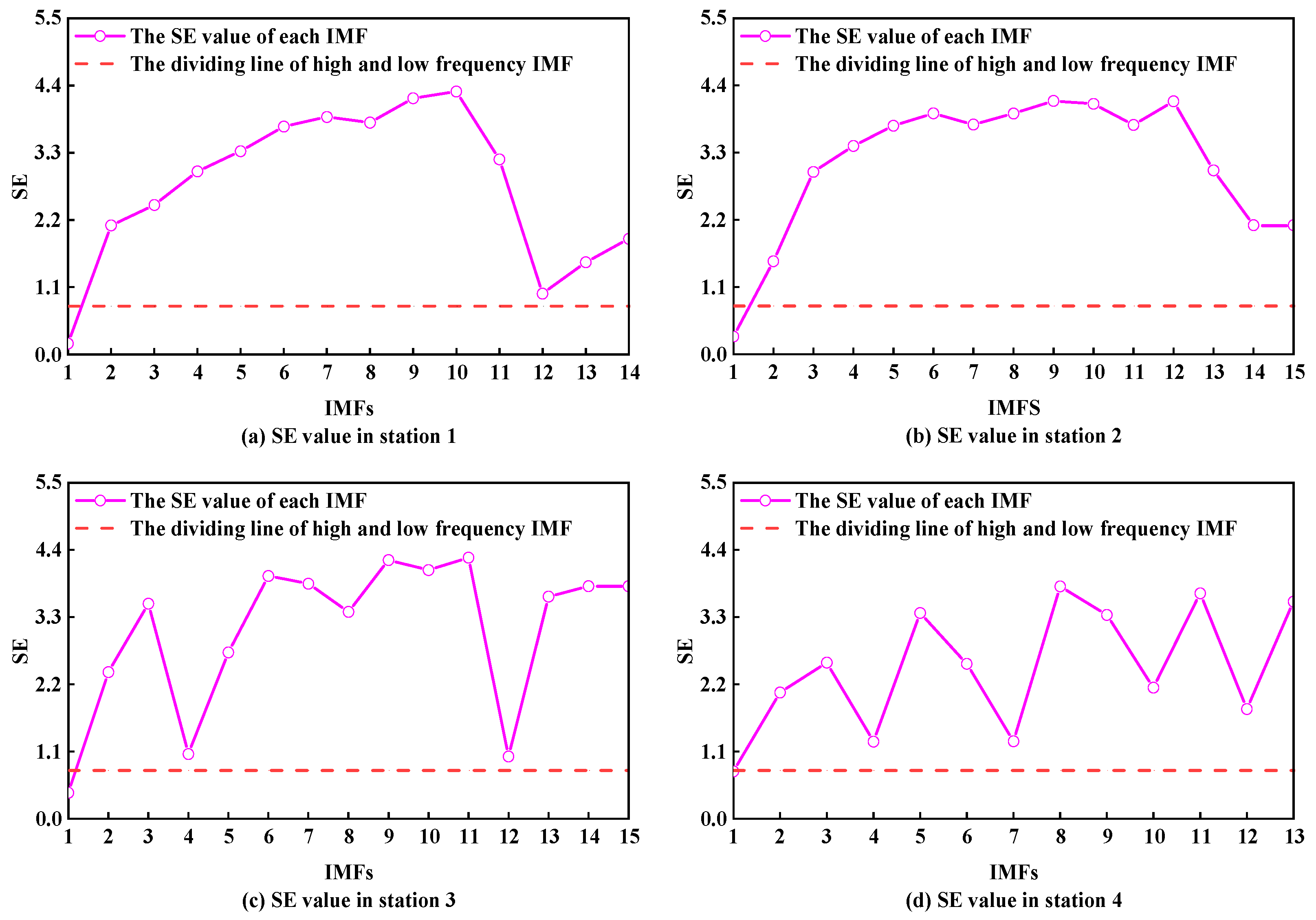
52] adopted sample entropy (SE) to measure the complexity of sub-series. Li et al. [
53] performed a second decomposition of the sub-series with the largest SE value. Drawing on their research, SE is applied to STPFP in this paper. The sub-series is divided into high-frequency and low-frequency components by calculating the SE values of each sub-series after decomposition. Different prediction models are used for high-frequency and low-frequency components to improve the prediction accuracy. Furthermore, after obtaining the prediction results of each sub-series, the existing research generally directly superimposes the prediction results of the sub-series to obtain the final prediction results. However, this approach will accumulate the prediction error of each sub-series, which will affect the final prediction results. To further improve the prediction accuracy, after obtaining the prediction results of each sub-series, the MSSA algorithm is used to automatically assign the best weight coefficient to each sub-series. The prediction results of each sub-series are combined by the best weight coefficient to get the final prediction results.
In summary, the nonlinear and nonstationary interference of the original subway passenger flow time series makes it difficult to improve the accuracy of the STPFP. A prediction method called IVMD-SE-MSSA based on IVMD time series decomposition and multi-model combination is proposed. Firstly, the elite opposition strategy, the new location update method, and the adaptive T distribution are introduced into SSA. The MSSA is used to optimize VMD parameters. Then, the IVMD is applied to decompose the original nonlinear and non-stationary passenger flow time series, and several stationary sub-series containing local features are obtained. The sub-series is divided into high-frequency and low-frequency components by SE. The low-frequency components are predicted by a back propagation (BP) neural network, and the high-frequency components are predicted by an attention LSTM (ALSTM). Finally, to further improve the prediction accuracy, the MSSA algorithm is used to combine the prediction results of each sub-series to obtain the final passenger flow prediction results. The major contributions of this paper are as follows:
(1) A mixed-strategy improved SSA algorithm is proposed to optimize the parameters of VMD. IVMD is applied to decompose the original passenger flow data to reduce the time variability and complexity of the passenger flow time series and improve predictability.
(2) The decomposed sub-series is divided into high-frequency and low-frequency components by SE, and different prediction models are used for different frequency components to avoid the limitation of one model.
(3) To further improve the prediction accuracy, a combination method based on MSSA is proposed to reduce the error superposition of the sub-series.
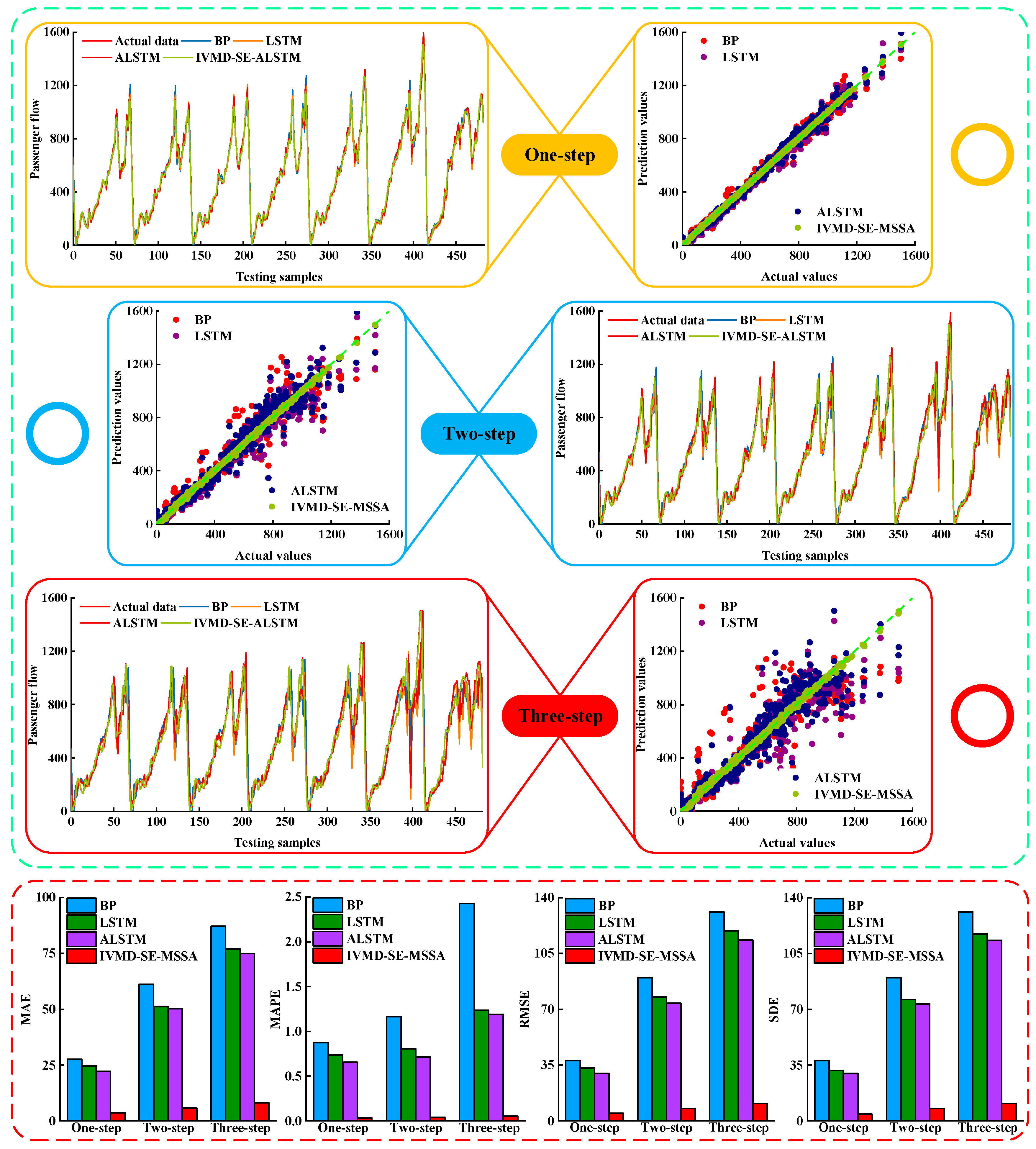
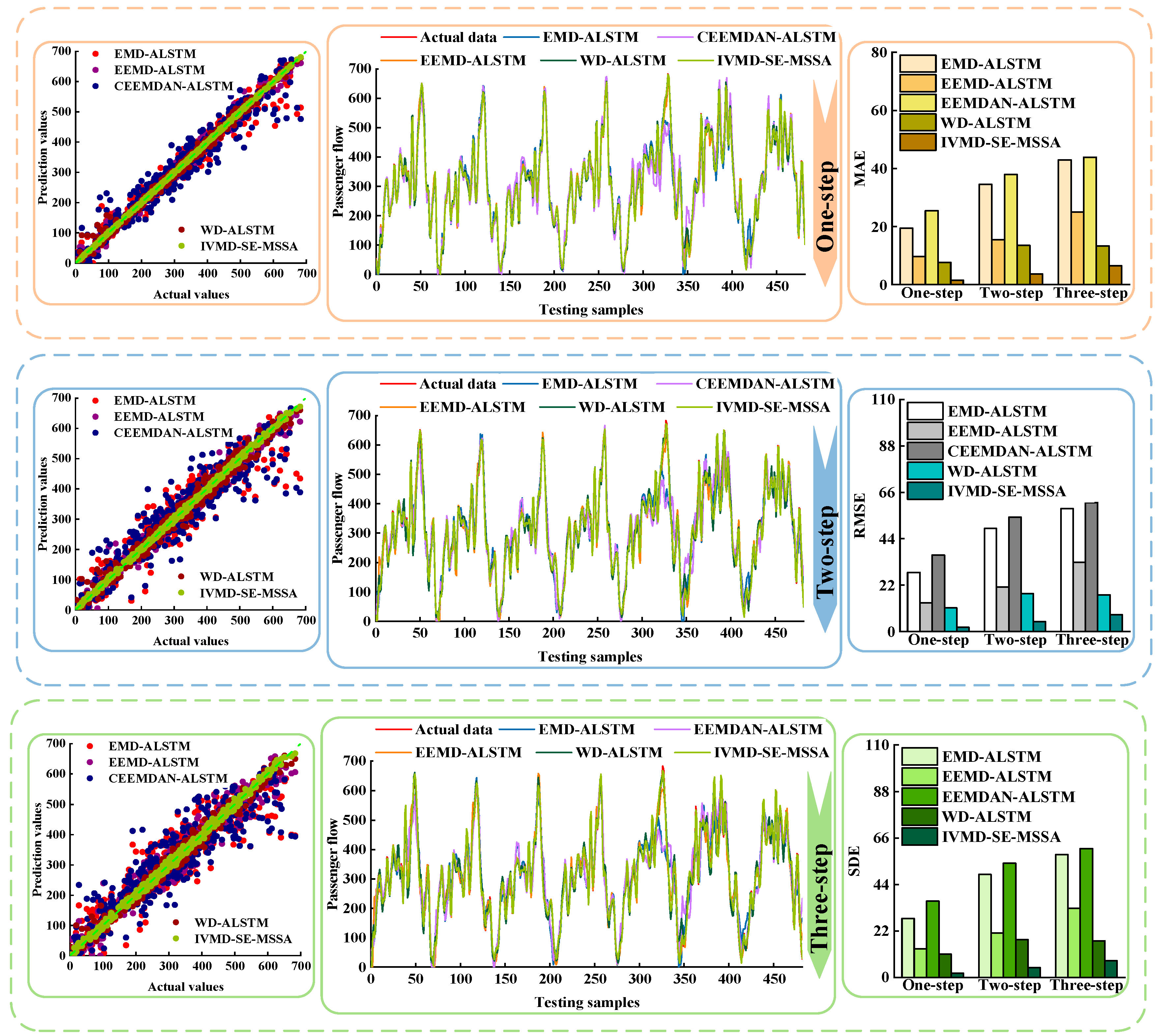
(4) To verify the validity of the established model, the passenger flow of four stations on the Nanning Metro was used to predict and four groups of comparative experiments were carried out. The experimental results showed that the prediction results of the established model were accurate and universal.
The rest of this paper is organized as follows. The theoretical background of the method used in this paper is introduced in
Section 2. The proposed IVMD-SE-MSSA model is described in
Section 3. The experiments and analysis are written in
Section 4. Some conclusions and future work are given in
Section 5.
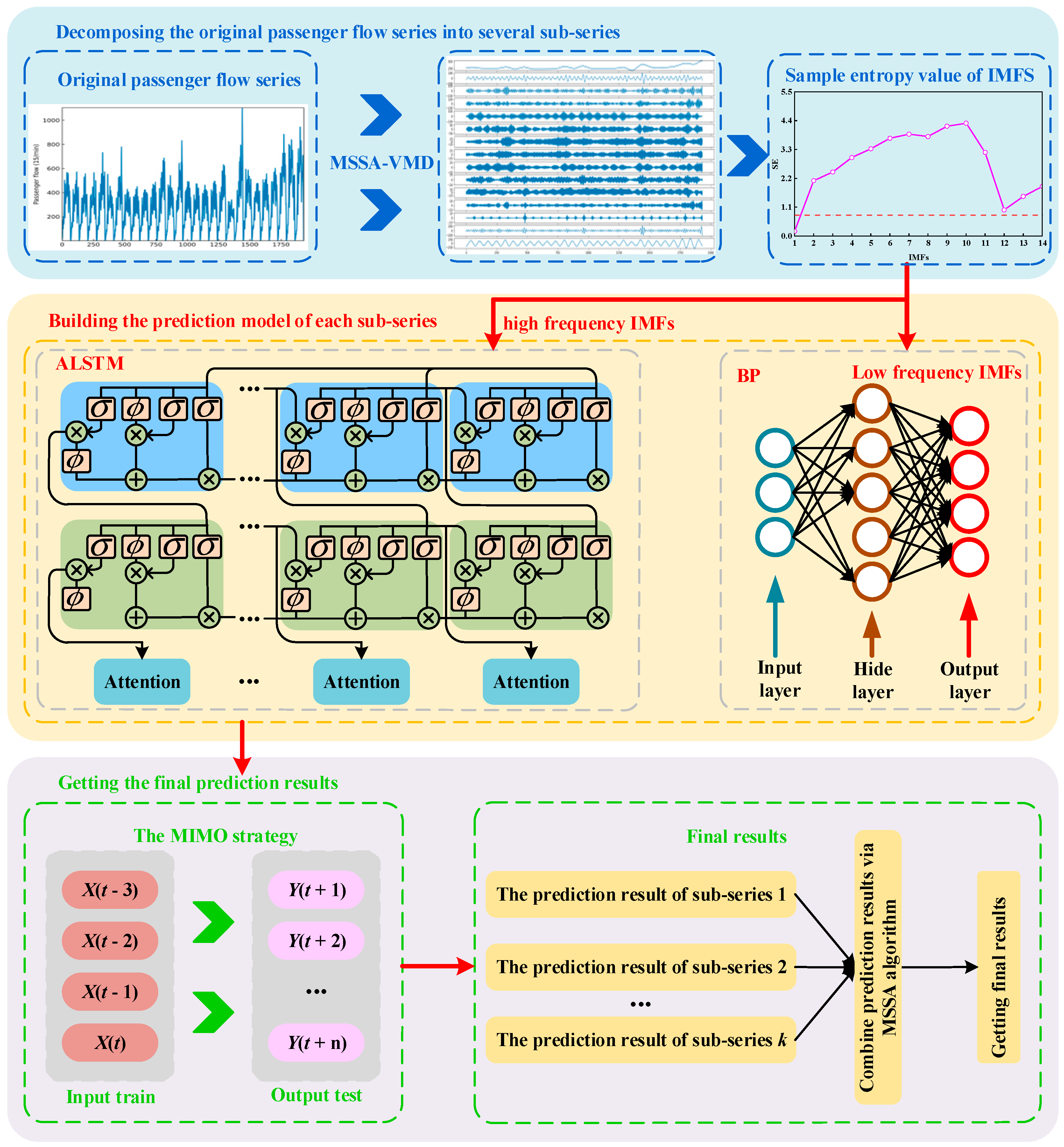
3. The Process of the Proposed Model
The proposed IVMD-SE-MSSA model architecture is shown in
Figure 3. The modeling steps of the whole process are as follows:
Step 1: Taking the minimum envelope entropy as the optimization objective, the MSSA algorithm is used to search for the parameters of VMD.
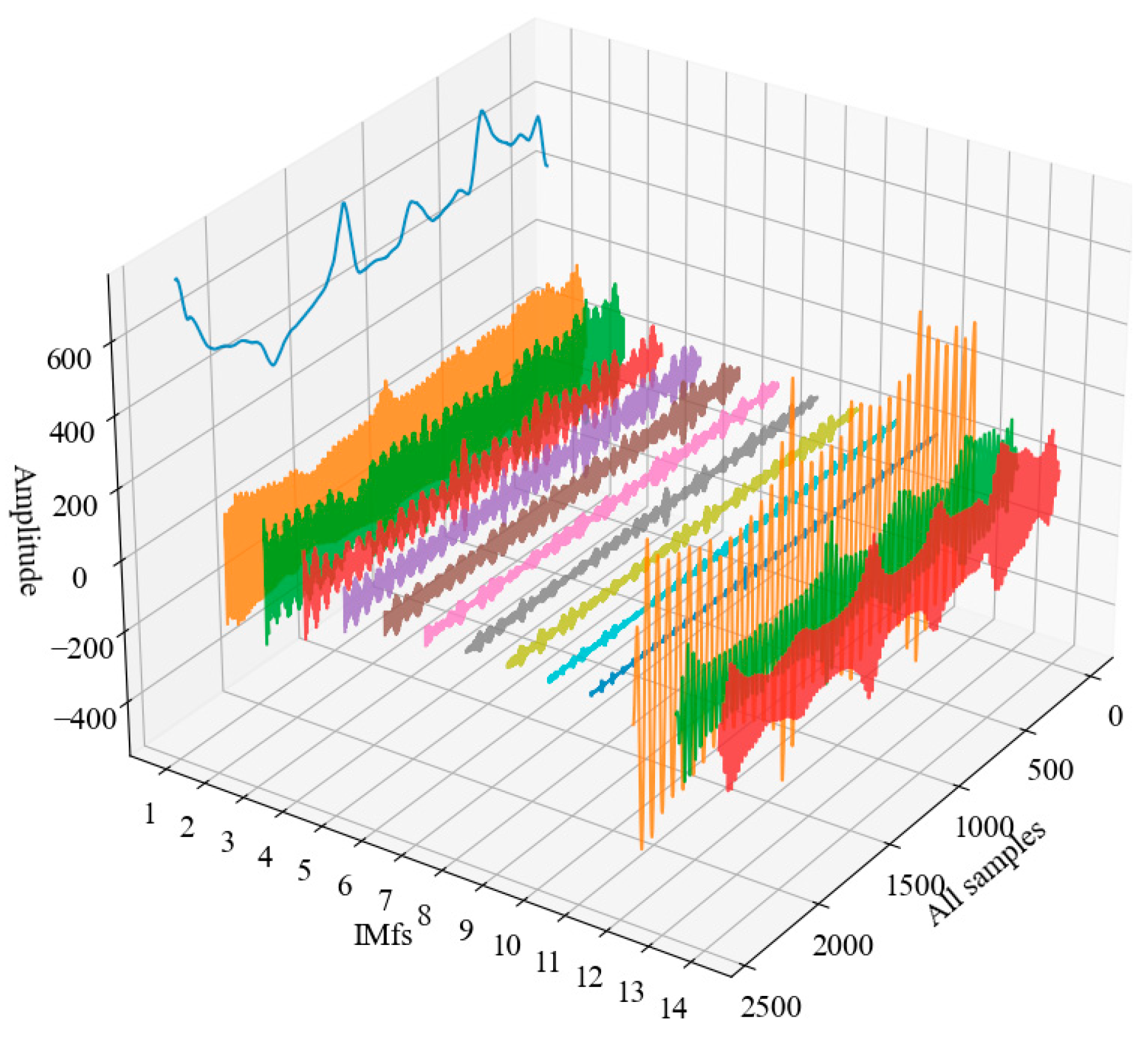
Step 2: After searching for the optimal parameters, the IVMD is used to decompose the passenger flow time series, and k IMF components are obtained.
Step 3: Calculate the SE value of each IMF component. The IMF is divided into high-frequency and low-frequency IMFs by SE value.
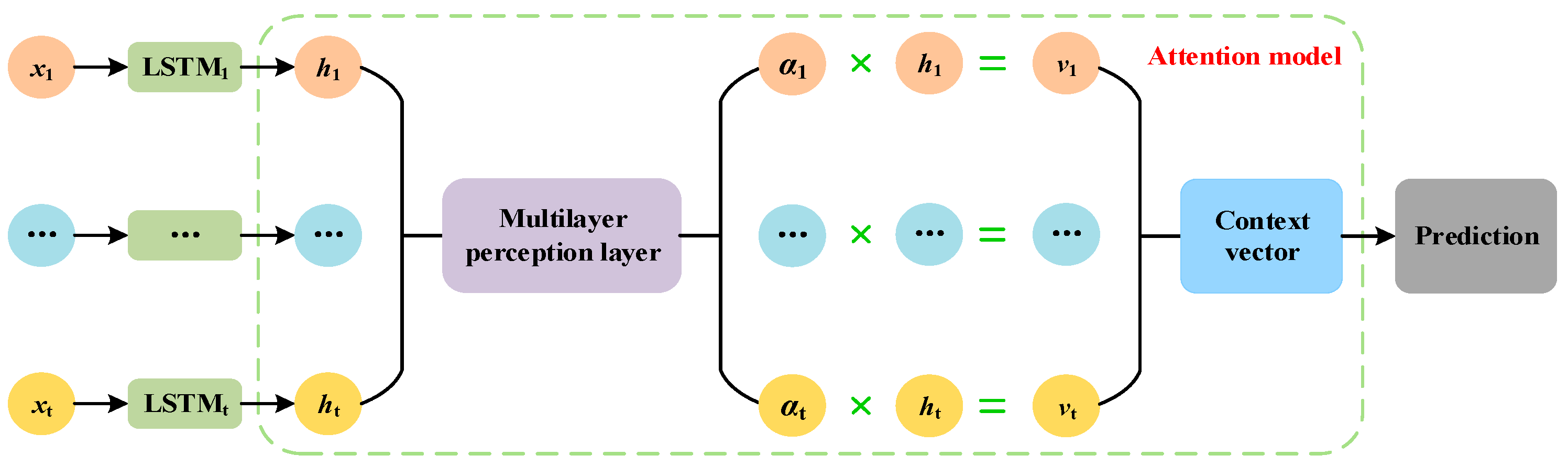
Step 4: BP is used to predict the low-frequency components, and ALSTM is used to predict the high-frequency components. Besides, in the prediction process, a multi-input multi-output (MIMO) strategy [
59] is used for multi-step prediction. In the field of time series prediction, the cumulative error of the MIMO strategy is very small [
60].
Step 5: MSSA is used to combine the prediction results of each component to obtain the final prediction results. In the study of pattern decomposition and multi-model combination forecasting methods, the weight of each prediction model is set to 1. This means that all prediction models have the same importance or prediction performance. However, the prediction accuracy of each prediction model is different, and the importance of different models in accumulating final prediction values is also different. Therefore, if each prediction model assigns appropriate weight coefficients according to certain rules, the final prediction accuracy can be improved. Based on the work of Zsuzsa et al. [
61], Precup et al. [
62], and Sawulski et al. [
63], the root mean square error between the actual value and the predicted value is taken as the optimization object, and the MSSA algorithm is introduced to optimize the weight coefficient of each prediction model. The optimization problem can be regarded as a nonlinear constrained optimization problem.
Assuming that
yt (
t = 1, 2, …,
N) is the actual passenger flow time-series data, and
N is the number of sample points.
is the predicted value of the
ith sub-series, and
is the prediction error.
wi is the weight coefficient of the
ith sub-series prediction model. Then, the optimization problem of the combination prediction model can be defined as:
The optimization process stops when the maximum number of iterations is reached, and it can be terminated according to predefined conditions. At this time, the weight coefficient of each subsequence is obtained, and the prediction result of the final model can be expressed as:
where
is the prediction result of the combined model, and
wi is the weight coefficient of the ith sub-sequence prediction model optimized by the final MSSA.
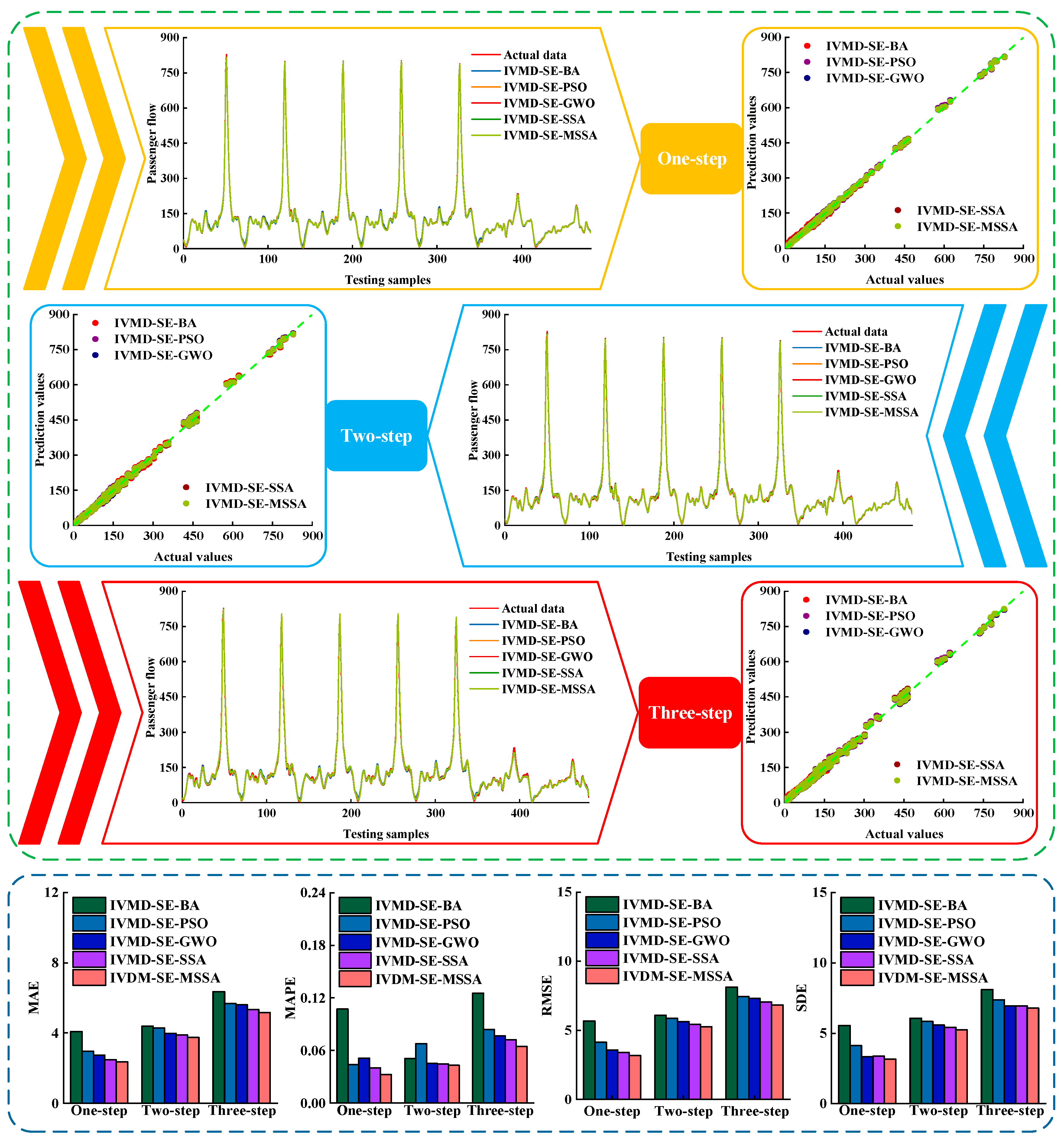
5. Conclusions
Aiming at the nonlinear and nonstationary interference of subway passenger flow time series, it is difficult to improve the accuracy of short-term passenger flow prediction. A hybrid prediction method IVMD-SE-MSSA is proposed. Specifically, IVMD technology is used to decompose the original passenger flow series to improve the predictability of the sequence. Then, the complexity of sub-series is divided by SE, and sub-series with different complexity are predicted, respectively. Finally, the MSSA is applied to combine the prediction results of each sub-series to get the final prediction results. In addition, some comparative models are designed to verify the performance of the proposed model. The main conclusions are summarized as follows:
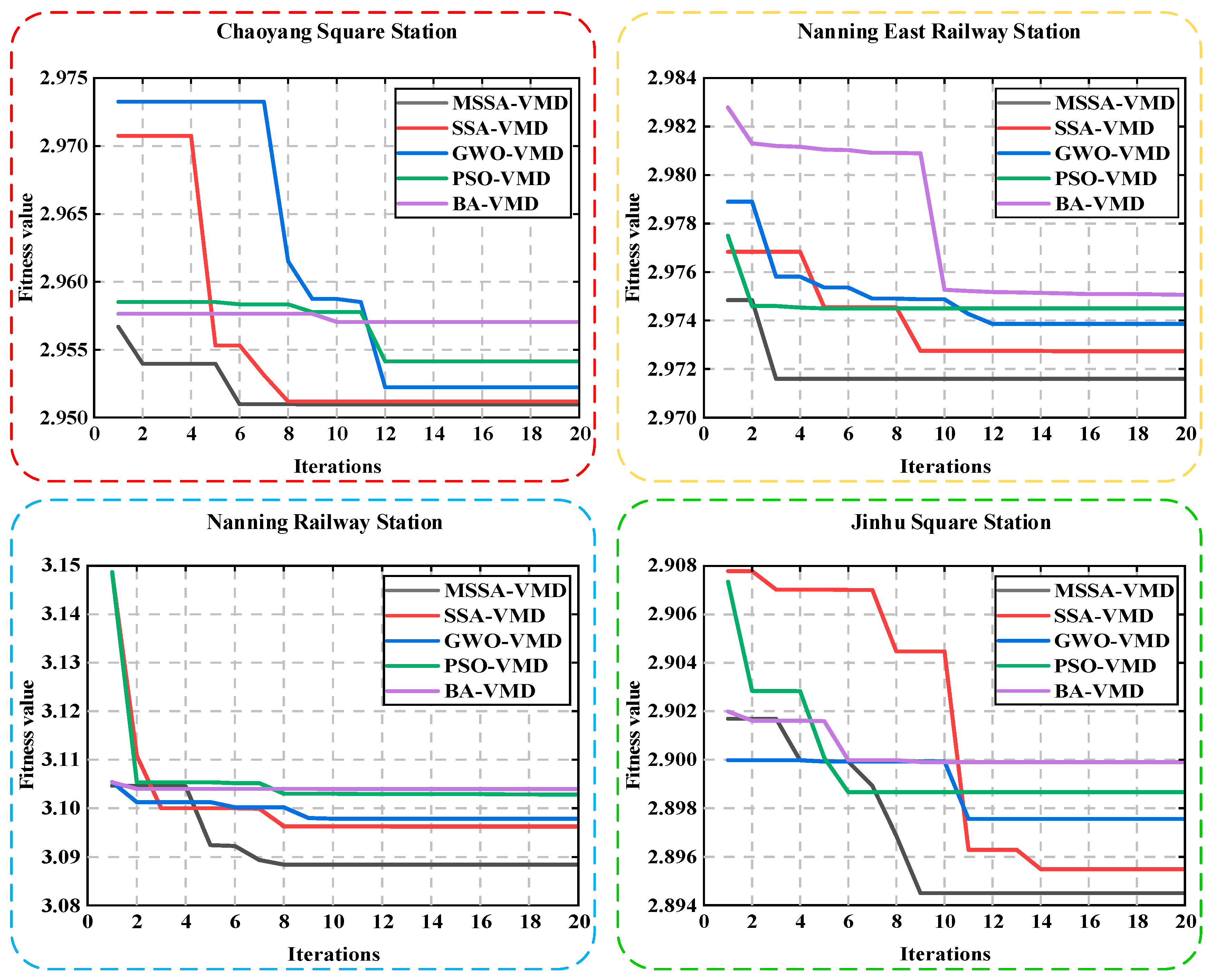
(1) The elite opposition strategy, the new position update method, and the adaptive T distribution mutation are introduced into SSA, and MSSA is proposed to optimize VMD. Compared with other optimization algorithms, MSSA has a faster convergence speed and higher optimization accuracy.
(2) The optimized adaptive VMD is used to decompose the original passenger flow time series. The experimental results showed that IVMD has a more stable prediction effect than other data preprocessing methods.
(3) The sub-series are divided by SE, and the prediction results of the sub-series are combined by MSSA. Experimental results show that both of them can further improve the prediction accuracy.
(4) Experiments are carried out on four subway station passenger flow datasets. The experimental results show that IVMD-SE-MSSA has the best prediction accuracy. This method has good applicability for different types of stations.
However, this study also has some limitations. Although IVMD-SE-MSSA has good prediction accuracy, the impact of weather conditions on passenger flow is not explicitly considered in the study. Moreover, although MSSA is used to combine sub-series prediction results, it is essentially a linear combination. How to adopt a better nonlinear combination method while considering the influence of weather is also a problem to be solved in future research.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}