

Using Social Media Analytics and Machine Learning Approaches to Analyze the Behavioral Response of Agriculture Stakeholders during the COVID-19 Pandemic





Abstract
1. Introduction
- i.
- Analyzing the influence of COVID-19 on the agricultural sector and its stakeholders.
- ii.
- Is this impact similar in each region of the country?
- iii.
- Is the related community happy with the government’s decisions during the lockdown period?
2. Related Work
3. Materials and Methods
| Algorithm 1: Sentiment Analyzer |
| Start 1. Create a Twitter Developer Account and Application with a set of permissions. 2. Use Twitter API to collect tweets based on Indian geolocation. 3. Pre-process the tweets: (a) Removing symbols and numbers. (b) Removing punctuation and English stopwords. (c) Removing URLs and whitespaces. (d) Removing keywords used to search for tweets. (e) Removing multiple tweets from a single person. 4. Performing sentiment analysis. (a) Use Meaning Cloud extension for polarity analysis. (b) Use R libraries for emotion analysis. 5. Calculate the score and plot it onto a bar graph. 6. Perform K-means clustering to discover the clusters in the data. End |
3.1. Data Collection
3.2. Data Pre-Processing
- i.
- Number removal: Only characters’ data had some significance in the sentiment analysis. The numbers did not represent any emotion of human behavior so the numerical data needed to be removed.
- ii.
- Removal of special symbols: special symbols such as (@ # ˆ * “/: ; > , < \ | ?) were removed in the data-cleaning process which may have led to inaccurate results.
- iii.
- Keyword removal: the keywords which were used to fetch the tweets needed to be removed as they certainly appeared in every tweet and may have distorted the accuracy of the results.
- iv.
- Punctuation removal: there was a need for the removal of punctuation as we were only focused on meaningful words that showed some emotions in the tweets.
- v.
- Hyperlink removal: the URL links also had to be removed from the tweet data as they did not show any kind of emotion and only led to the inaccuracy of the data.
- vi.
- Stopword removal: English stopwords are the most repetitive words in the text, their need is only to support the sentence and they do not show any type of sentiment hence they may also get removed in this processing of the data.
- vii.
- Removal of extra white spaces: Since we removed the unwanted data from the tweet, there were holes from where the data were deleted. These extra spaces would distort the meaning of the sentences; therefore, any extra white spaces in the text also had to be removed.
- viii.
- Removal of multiple tweets from a single person: If we included all the tweets of a single person, that may have led us to unbiased results; therefore, we kept only a single tweet from every unique person. From the list of 36,149 tweets, a total of 2310 such tweets were deleted and we were left with 33,839 unique tweets.
- ix.
- Removal of bot-generated tweets: There is a wide range of accounts existing on Twitter that are not handled by humans; rather, they are controlled using automated computer scripts normally known as bots (https://www.buzzfeednews.com/article/lamvo/twitter-bots-v-human (accessed on 6 November 2022)). The tweets generated by such accounts could influence the overall sentiments of the entire dataset, so it became necessary to identify and remove the tweets that appeared to be generated by the bots. There is no single method to identify such tweets but a group of steps may help in this process; it involves identifying the number of tweets generated by an account, all tweets following a fixed pattern, weird profile information, and reposting of the tweets.
3.3. WordCloud
3.4. Sentiment Analysis
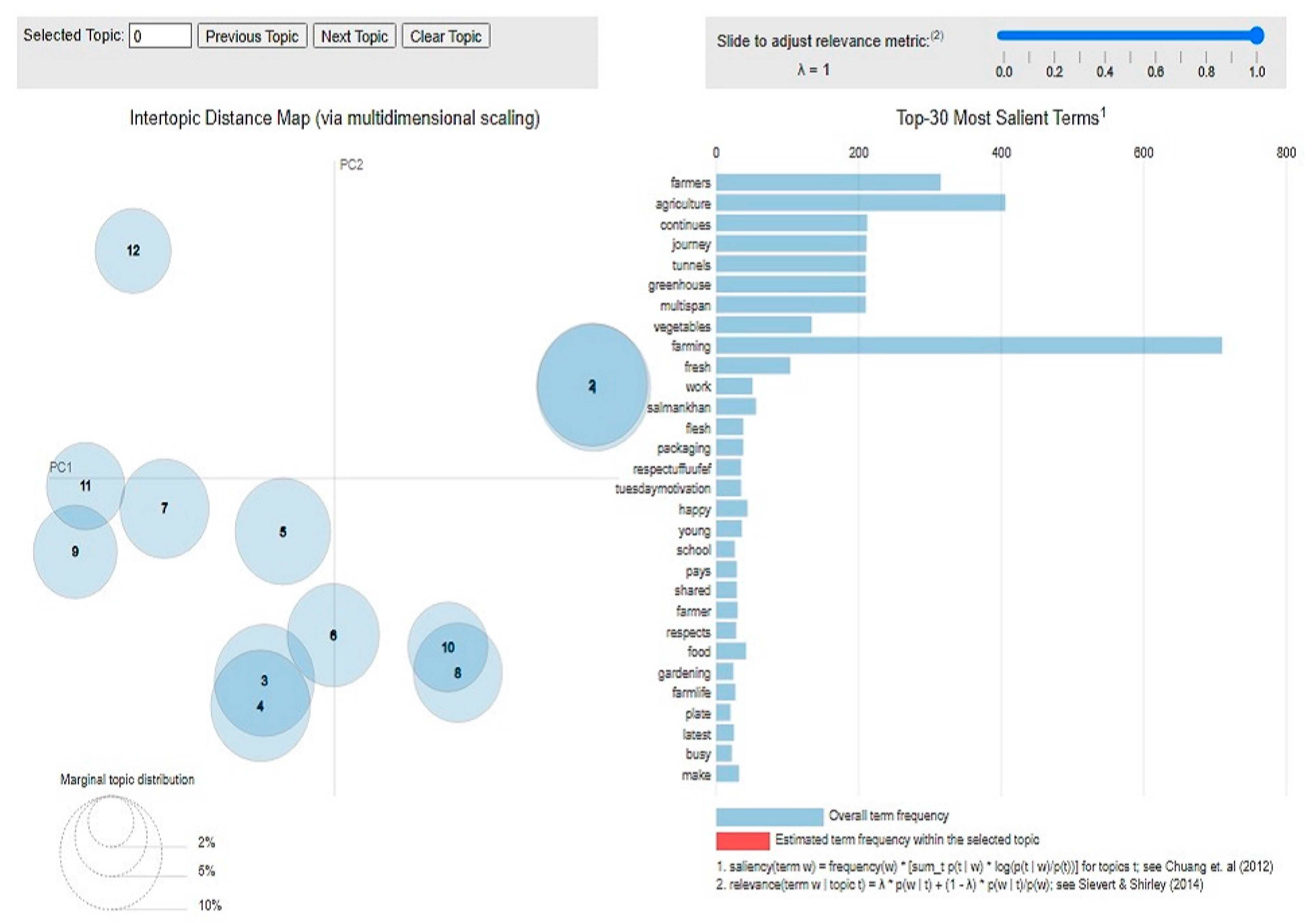
3.5. Topic Modeling
| Algorithm 2: Topic Modeling Algorithm |
| 1. Start. 2. Assume ‘x’ topics in the document(s). 3. For each document; Randomly assign each word to one of ‘x’ topics. 4. For each document; For each word ‘w’ Such that; and /* Where = total number of words in ith document in ‘xth’ topic. = Number of words in ith document. = corpus wide assignment of word to xth topic. = number of topics considered. = Vocabulary of the corpus. = Hyper parameters. is the current selected document among all the documents, yx is the selected topic from the current sentence. */ 5. Update q such that; 6. For each word in the document ‘d’; Find the topic ‘x’ such that; Reassign the word to the ‘xth’ topic 7. If iteration complete; Go to the last step of the algorithm Else Go to step 4 8. Stop |
4. Results and Analysis
4.1. Polarity Analysis
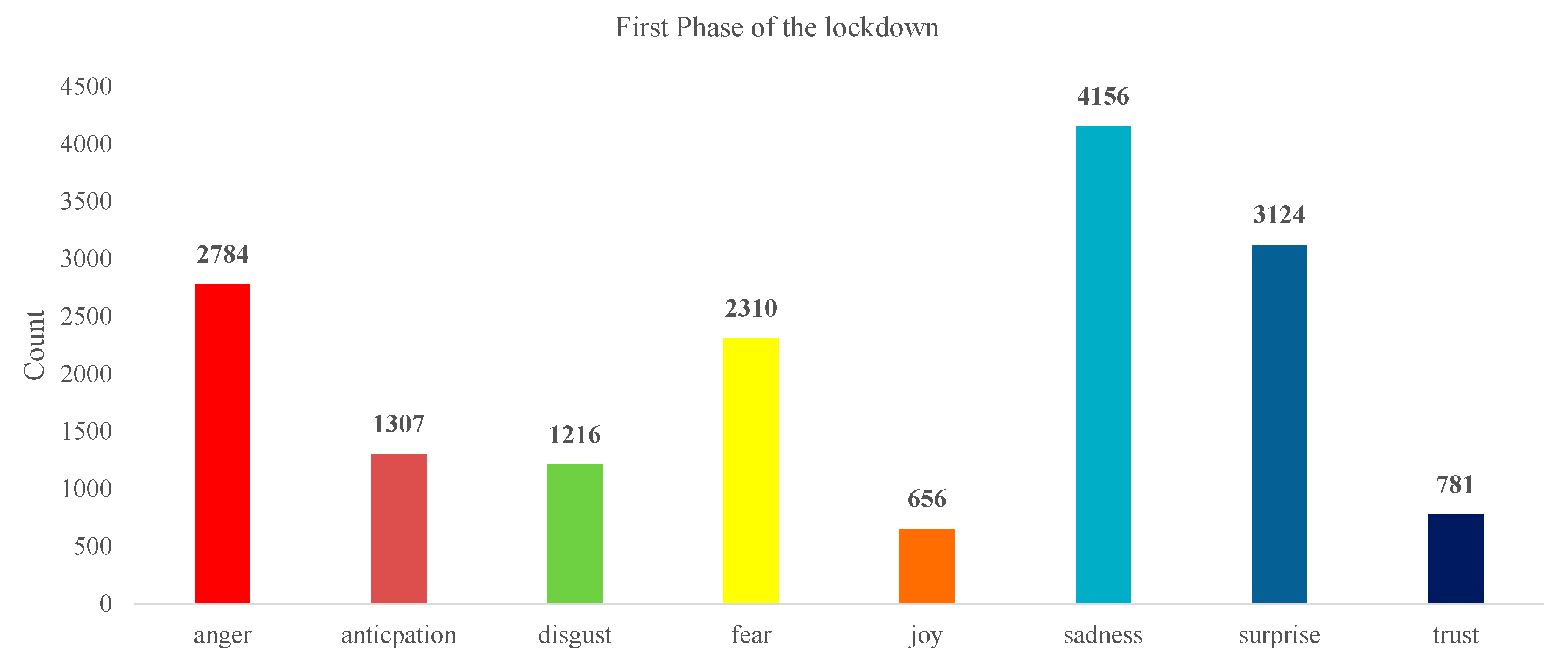
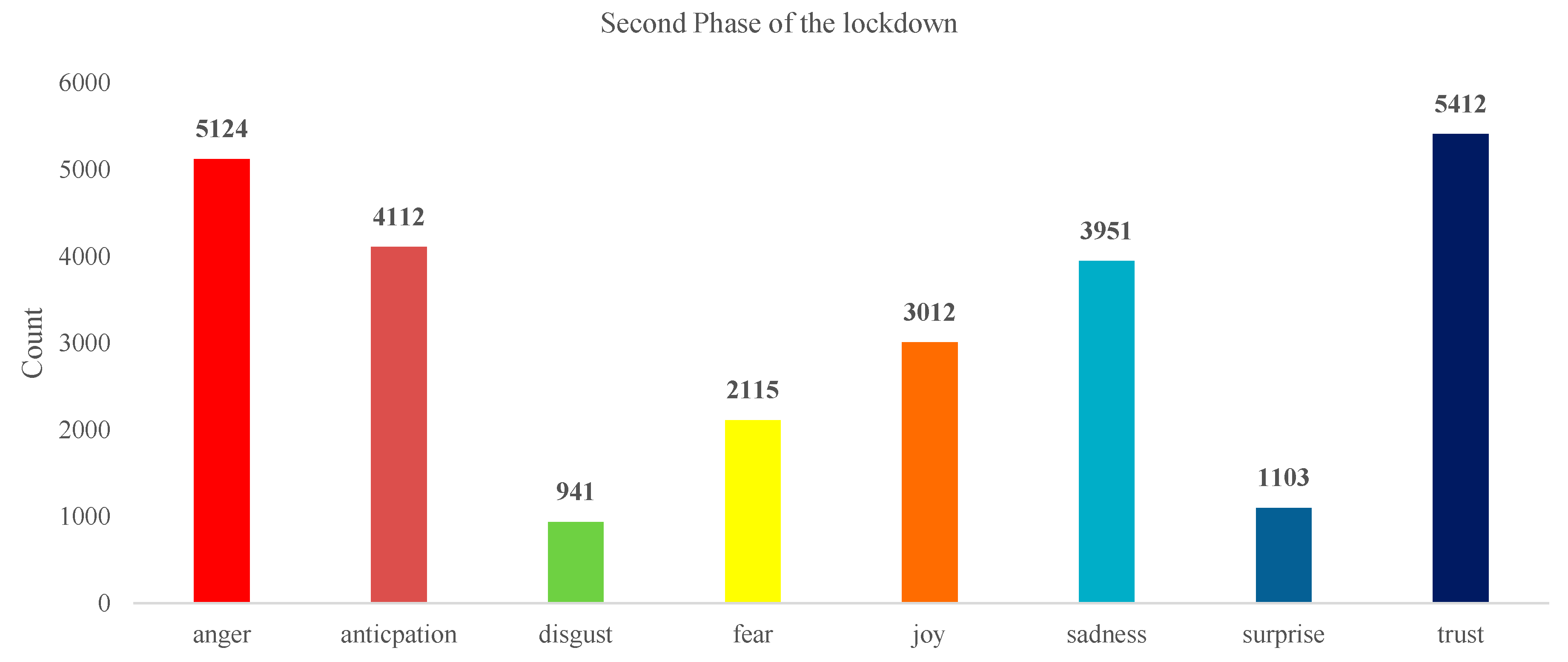
4.2. Emotion Analysis
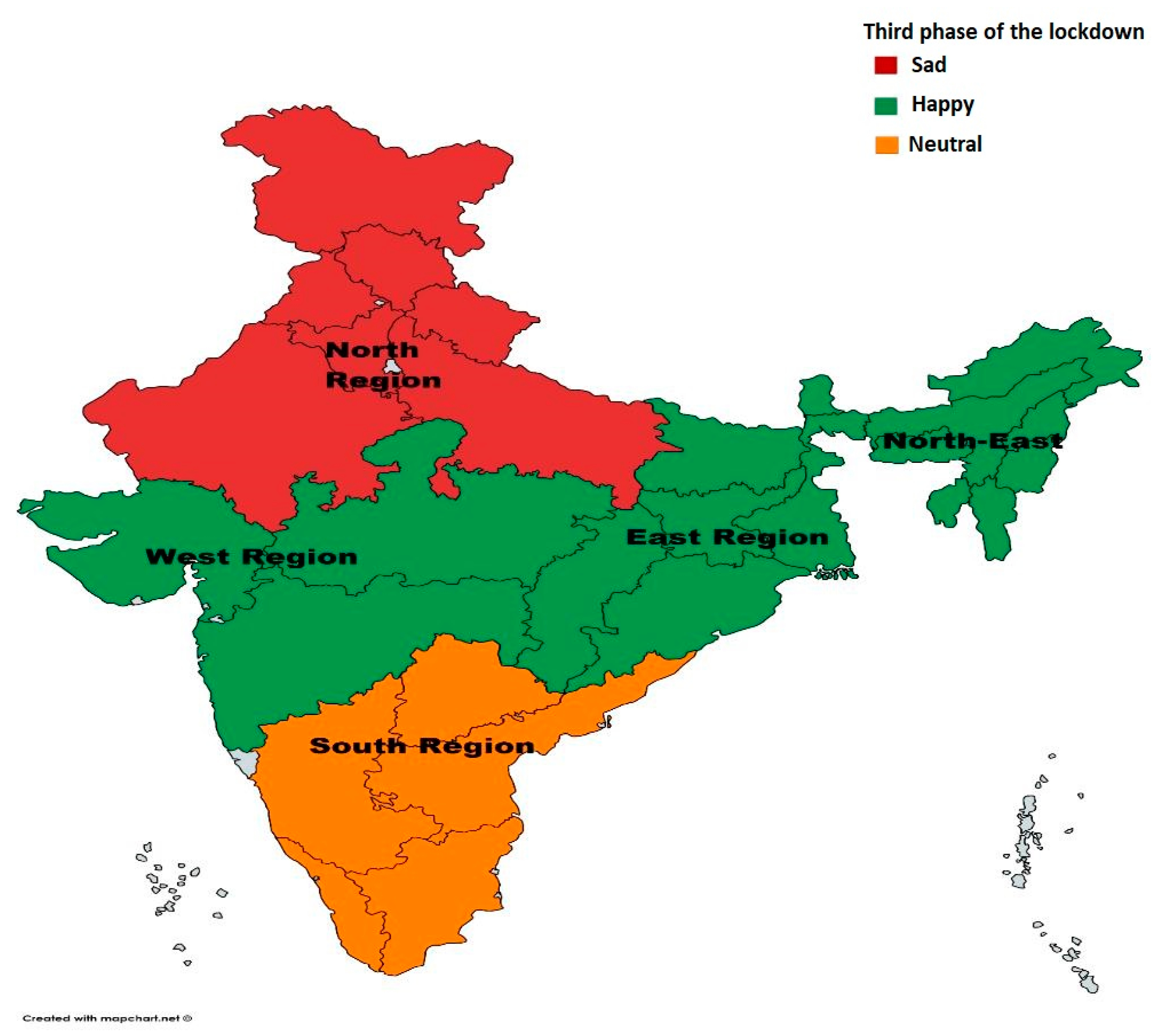
4.3. Region-Wise Analysis
5. Discussion
5.1. What May Be the Possible Causes of Unhappiness?
- (a)
- The government took the overnight decision to lock down [41]. People, especially farmers, were not ready for that. The time of the lockdown was the same as when the wheat crop was ready for harvesting. Due to restricted movement, it became harder for farmers to harvest the crop.
- (b)
- The government and people of the country were not ready for such a pandemic situation. The lack of planning and implementations was the key factor that made people suffer [42].
- (c)
- The unavailability of the machinery and labor that were needed for the harvesting of the crop was also a reason for unhappiness among the farmers [43]. Due to stringent movements, the supply of fertilizers, pesticides, and other necessary items was also affected.
- (d)
- A disturbance in food demand and supply was experienced during that period [44]. The sale of cereals, pulses, milk products, and vegetables was reduced by almost half. Due to the spread of the virus, people feared buying products from the market, and also the lack of money forced them to live on limited things.
- (e)
- Every section of the economy suffered almost the same kind of unhappiness as the agricultural sector. COVID-19 became a worldwide tragedy that equally affected every section of development.
5.2. Valuable Lesson for Policymakers
- (a)
- Agriculture is among the most important sectors for human survival; it should not be stopped in any condition and it must be among the least disaster-affected zones. So, special arrangements should be planned for the continuity of farming in the condition of any type of catastrophe.
- (b)
- The spread of rumors such as vegetables, fruits, and chickens being the carriers of COVID-19 greatly affected the consumption of these products [47]. Such false and misleading information should be monitored carefully and people should be made aware of these kinds of news.
- (c)
- Farming was much affected by the traveling restrictions imposed due to the lockdown and the shortage of laborers [48]. By keeping these problems in view, special arrangements should be made for agriculture if such a lockdown situation arises in the near future. Farmers must have continued access to markets to fulfill their requirements.
- (d)
- Agricultural workers and farmers must be included in the government’s aid package and any social safety programs addressing the disaster [49].
- (e)
- Food production and the supply chain should not be stopped under any circumstances.
- (f)
- Special arrangements should be made to keep an eye on the market to control the overpricing and storage of products during the pandemic period.
- (g)
- The trend in the home delivery of products, essential goods, and materials required for agriculture should be promoted in normal circumstances as well [50].
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Wang, Z.B.; Dong, Y.; Chang, R.; Xu, C.; Yu, X.; Zhang, S.; Tsamlag, L.; Shang, M.; Huang, J.; et al. Phase-adjusted estimation of the number of Coronavirus Disease 2019 cases in Wuhan. China Cell Discov. 2020, 6, 10. [Google Scholar] [CrossRef]
- Bhalekar, V. Novel Corona Virus Pandemic-Impact on Indian Economy, E-Commerce, Education and Employment. 2020. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3580342 (accessed on 28 August 2022).
- Hanashima, M.; Tomobe, K. Urbanization, industrialization, and mortality in modern Japan: A Spatio-temporal perspective. Ann. GIS 2012, 18, 57–70. [Google Scholar] [CrossRef]
- Arndt, C.; Lewis, J.D. The HIV/AIDS pandemic in South Africa: Sectoral impacts and unemployment. J. Int. Dev. 2001, 13, 427–449. [Google Scholar] [CrossRef]
- Bermejo, A. HIV/AIDS in Africa: International responses to the pandemic. New Econ. 2004, 11, 164–169. [Google Scholar] [CrossRef]
- Clemente, G.; Garcia-Prats, A.; Lisón, P.; Rubio, C.; Vidal-Puig, S.; Ricarte, B.; Estruch-Guitart, V.; Fenollosa, L.; Manzano, J.; Rovira-Más, F.; et al. COVID-19 Impact: A Case Study at the School of Agricultural Engineering and Environment of the Universitat Politècnica de València. Sustainability 2022, 14, 10607. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, Y.; Wu, S.; Peng, G.; Lv, B. Composite leading search index: A preprocessing method of internet search data for stock trends prediction. Ann. Oper. Res. 2015, 234, 77–94. [Google Scholar] [CrossRef]
- Oyekale, A.S. Poverty and Its Correlates among Kenyan Refugees during the COVID-19 Pandemic: A Random Effects Probit Regression Model. Sustainability 2022, 14, 10270. [Google Scholar] [CrossRef]
- Burgui, D. Coronavirus: How Action against Hunger Is Responding to the Pandemic. 2020. Available online: https://www.actionagainsthunger.org/story/coronavirus-how-action-against-hunger-responding-pandemic (accessed on 28 August 2022).
- Abdelhedi, I.T.; Zouari, S.Z. Agriculture and Food Security in North Africa: A Theoretical and Empirical Approach. J. Knowl. Econ. 2020, 11, 193–210. [Google Scholar] [CrossRef]
- Anik, A.R.; Rahman, S. Women’s Empowerment in Agriculture: Level, Inequality, Progress, and Impact on Productivity and Efficiency. J. Dev. Stud. 2020, 57, 930–948. [Google Scholar] [CrossRef]
- Siche, R. What is the impact of COVID-19 disease on agriculture? Sci. Agropecu. 2020, 11, 3–6. [Google Scholar] [CrossRef]
- Vatta, K.; Bhogal, S.; Green, A.S.; Sharma, H.; Petrie, C.A.; Dixit, S. COVID-19 Pandemic-Induced Disruptions and Implications for National Food Security and Farm Incomes: Farm-Level Evidence from Indian Punjab. Sustainability 2022, 14, 4452. [Google Scholar] [CrossRef]
- Rawal, V. COVID-19 Lockdown: Impact on Agriculture and Rural Economy. Soc. Sci. 2020, 48, 562–565. [Google Scholar]
- Agarwal, A.; Xie, B.; Vovsha, I.; Rambow, O.; Passonneau, R.J. Sentiment analysis of twitter data. In Proceedings of the Workshop on Languages in Social Media; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 30–38. [Google Scholar]
- Mohammad, S.M.; Turney, P.D. Emotions evoked by common words and phrases: Using Mechanical Turk to create an emotion lexicon. In Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in the Text, Los Angeles, CA, USA, 5 June 2010; pp. 26–34. [Google Scholar]
- Dev, S.; Sengupta, R. COVID-19: Impact on the Indian Economy; Indira Gandhi Institute of Development Research: Mumbai, India, 2020. [Google Scholar]
- Rawal, T.; Muris, J.W.; Mishra, V.K.; Arora, M.; Tandon, N.; van Schayck, O.C. Impact of the COVID-19 Pandemic Measures on the Number of Meals and the Types of Physical Activity of Adolescents: Cross-Sectional Study in Delhi, India. Recent Prog. Nutr. 2022, 2, 10. [Google Scholar] [CrossRef]
- Ponnusamy, K.; Padaria, R.N. Research in agricultural extension: Review of its contribution and challenges. Horticulture 2021, 305, 314–367. [Google Scholar] [CrossRef]
- Pokhrel, S.; Chhetri, R. A literature review on impact of COVID-19 pandemic on teaching and learning. High. Educ. Future 2021, 8, 133–141. [Google Scholar] [CrossRef]
- Verma, A.K.; Prakash, S. Impact of COVID-19 on environment and society. J. Glob. Biosci. 2022, 9, 7352–7363. [Google Scholar]
- Dairi, A.; Harrou, F.; Zeroual, A.; Hittawe, M.M.; Sun, Y. Comparative study of machine learning methods for COVID-19 transmission forecasting. J. Biomed. Inform. 2021, 118, 103791. [Google Scholar] [CrossRef]
- Yang, C.; Harkreader, R.; Zhang, J.; Shin, S.; Gu, G. Analyzing spammers’ social networks for fun and profit: A case study of cyber criminal ecosystem on twitter. In Proceedings of the 21st international conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 71–80. [Google Scholar]
- Gentry, J. TwitteR v1.1.9. Available online: https://www.rdocumentation.org/packages/twitteR/versions/1.1.9 (accessed on 18 June 2020).
- Mishra, N.; Singh, A. Use of twitter data for waste minimization in the beef supply chain. Ann. Oper. Res. 2016, 270, 337–359. [Google Scholar] [CrossRef]
- Singh, P.; Dwivedi, Y.K.; Kahlon, K.S.; Sawhney, R.S. Intelligent Monitoring and Controlling of Public Policies Using Social Media and Cloud Computing. In International Working Conference on Transfer and Diffusion of IT; Springer: Cham, Switzerland, 2018; pp. 143–154. [Google Scholar]
- Haddi, E.; Liu, X.; Shi, Y. The role of text pre-processing in sentiment analysis. Procedia Comput. Sci. 2013, 17, 26–32. [Google Scholar] [CrossRef]
- McNaught, C.; Lam, P. Using Wordle as a supplementary research tool. Qual. Rep. 2010, 15, 630. [Google Scholar] [CrossRef]
- Singh, P.; Sawhney, R.S.; Kahlon, K.S. Sentiment analysis of demonetization of 500 and 1000 rupee banknotes by the Indian government. ICT Express 2017, 4, 124–129. [Google Scholar] [CrossRef]
- Saif, H.; Fernandez, M.; He, Y.; Alani, H. Evaluation datasets for Twitter sentiment analysis: A survey and a new dataset, the STS-Gold. In Proceedings of the 1st Interantional Workshop on Emotion and Sentiment in Social and Expressive Media: Approaches and Perspectives from AI (ESSEM 2013), Turin, Italy, 3 December 2013. [Google Scholar]
- Setiawan, R.; Budiharto, W.; Kartowisastro, I.H.; Prabowo, H. Finding model through latent semantic approach to reveal the topic of discussion in discussion forum. Educ. Inf. Technol. 2020, 25, 31–50. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Arun, R.; Suresh, V.; Veni Madhavan, C.E.; Murthy, N. On finding the natural number of topics with latent dirichlet allocation: Some observations. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2021; pp. 391–402. [Google Scholar]
- Chuang, J.; Manning, C.D.; Heer, J.M. Termite: Visualization techniques for assessing textual topic models. In Proceedings of the International Working Conference on Advanced Visual Interfaces, Capri, Italy, 21–25 May 2012; pp. 74–77. [Google Scholar]
- Sievert, C.; Shirley, K. LDAvis: A method for visualizing and interpreting topics. In Proceedings of the Workshop on Interactive Language Learning Visualization, and Interfaces, Baltimore, MD, USA, 24 June 2014; pp. 63–70. [Google Scholar]
- Thakur, J.S.; Rao, B.T.; Rajwanshi, A.; Parwana, H.K.; Kumar, R. Epidemiological study of high cancer among rural agricultural community of Punjab in Northern India. Int. J. Environ. Res. Public Health 2008, 5, 399–407. [Google Scholar] [CrossRef]
- Fazal, S. The need for preserving farmland: A case study from a predominantly agrarian economy (India). Landsc. Urban Plan. 2001, 55, 1–13. [Google Scholar] [CrossRef]
- Guan, D.; Wang, D.; Hallegatte, S.; Huo, J.; Li, S.; Bai, Y.; Lei, T.; Xue, Q.; Davis, S.J.; Coffman, D.M.; et al. Global Economic Footprint of the COVID-19 Pandemic; University College London: London, UK, 2020. [Google Scholar]
- Kumar, A.; Priya, B.; Srivastava, S.K. Response to the COVID-19: Understanding implications of government lockdown policies. J. Policy Model. 2021, 43, 76–94. [Google Scholar] [CrossRef]
- Poudel, P.B.; Poudel, M.R.; Gautam, A.; Phuyal, S.; Tiwari, C.K.; Bashyal, N.; Bashyal, S. COVID-19 and its Global Impact on Food and Agriculture. J. Biol. Today’s World 2020, 9, 221. [Google Scholar]
- Virk, J.S.; Ali, S.A.; Kaur, G. Recent update on COVID-19 in India: Is locking down the country enough? medRxiv 2020. [Google Scholar] [CrossRef]
- Kumar, S.; Choudhury, S. Migrant workers and human rights: A critical study on India’s COVID-19 lockdown policy. Soc. Sci. Humanit. Open 2021, 3, 100130. [Google Scholar] [CrossRef]
- Chattopadhyay, S.; De, U.K.; Saha, B.; Kumar, A.; Ramachandran, M.; Mohanan, P.C.; Singh, R.; Saha, A.; Carreras, M.; Mazigo, A.; et al. Special Issue-The COVID-19 Pandemic and India. J. Dev. Policy Rev. 2020, 1, 138. [Google Scholar]
- Sukhwani, V.; Deshkar, S.; Shaw, R. COVID-19 lockdown, food systems and urban–rural partnership: Case of Nagpur, India. Int. J. Environ. Res. Public Health 2020, 17, 5710. [Google Scholar] [CrossRef] [PubMed]
- Ha, K.M. A Lesson Learned from the Outbreak of COVID-19 in Korea. Indian J. Microbiol. 2020, 60, 396–397. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Viral, R.; Deep, V.; Sharma, P.; Kumar, M.; Mahmud, M.; Stephan, T. Forecasting major impacts of COVID-19 pandemic on country-driven sectors: Challenges, lessons, and future roadmap. Pers. Ubiquitous Comput. 2021, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Tripathi, D.; Sindher, M.; Garg, T. The Aftermath of Pandemic COVID-19 on Food and Agri sector. Food Agric. Spectr. J. 2020, 1, 13–24. [Google Scholar]
- Kumar, P.; Singh, S.S.; Pandey, A.K.; Singh, R.K.; Srivastava, P.K.; Kumar, M.; Dubey, S.K.; Sah, U.; Nandan, R.; Singh, S.K.; et al. Multi-level impacts of the COVID-19 lockdown on agricultural systems in India: The case of Uttar Pradesh. Agric. Syst. 2021, 187, 103027. [Google Scholar] [CrossRef]
- Dev, S.M. Addressing COVID-19 impacts on agriculture, food security, and livelihoods in India. In IFPRI Book Chapters; IFPRI: Washington, DC, USA, 2020; pp. 33–35. [Google Scholar]
- Sheth, J. Impact of COVID-19 on consumer behavior: Will the old habits return or die? J. Bus. Res. 2020, 117, 280–283. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initial Phase | Mid-Phase | Lateral Phase | |||
|---|---|---|---|---|---|
| Date | No. of Tweets | Date | No. of Tweets | Date | No. of Tweets |
| 24 March 2020 | 190 | 14 April 2020 | 1719 | 14 May 2020 | 684 |
| 25 March 2020 | 450 | 17 April 2020 | 1626 | 15 May 2020 | 715 |
| 26 March 2020 | 389 | 21 April 2020 | 1851 | 20 May 2020 | 586 |
| 27 March 2020 | 969 | 23 April 2020 | 2152 | 23 May 2020 | 1562 |
| 28 March 2020 | 1785 | 24 April 2020 | 2232 | 24 May 2020 | 1411 |
| 29 March 2020 | 2481 | 30 April 2020 | 1543 | 27 May 2020 | 1225 |
| 30 March 2020 | 2288 | 4 May 2020 | 2561 | 2 June 2020 | 1774 |
| 31 March 2020 | 2145 | 5 May 2020 | 2487 | 10 June 2020 | 1324 |
| Total | 10,697 | Total | 16,171 | Total | 9281 |
| Raw Tweet Data | Tweet Data After Pre-Processing |
|---|---|
| RT @#####: In such a big epidemic many #businesses were closed for a while or given a time limit but #farming is a business which has not been closed yet or no time limit has been given. #agriculture #farmer #nature #agriculturelife #covid19 … https://t.co/v6lhi7zjpQ (accessed on 27 March 2020) | in such a big epidemic many businesses were closed for a while or given a time limit but farming is a business which has not been closed yet or no time limit has been given |
| Date | First Phase (24 March 2020 to 31 March 2020) | |||||
|---|---|---|---|---|---|---|
| Highly Positive (P+) | Positive (P) | Neutral | Negative (N) | Highly Negative (N−) | Total | |
| 24 March 2020 | 21 | 89 | 30 | 27 | 14 | 181 |
| 25 March 2020 | 65 | 119 | 71 | 107 | 25 | 387 |
| 26 March 2020 | 52 | 98 | 60 | 123 | 39 | 372 |
| 27 March 2020 | 169 | 324 | 86 | 243 | 91 | 913 |
| 28 March 2020 | 113 | 419 | 126 | 694 | 273 | 1625 |
| 29 March 2020 | 191 | 512 | 196 | 934 | 385 | 2218 |
| 30 March 2020 | 120 | 458 | 211 | 917 | 310 | 2016 |
| 31 March 2020 | 104 | 513 | 201 | 1005 | 276 | 2099 |
| Total | 835 | 2532 | 981 | 4050 | 1413 | 9811 |
| Combined Total | 3367 | 981 | 5463 | 9811 | ||
| Combined % | 34.32 | 10.00 | 55.68 | 100 | ||
| Date | Second Phase (14 April 2020 to 5 May 2020) | |||||
|---|---|---|---|---|---|---|
| Highly Positive (P+) | Positive (P) | Neutral | Negative (N) | Highly Negative (N−) | Total | |
| 14 April 2020 | 240 | 410 | 70 | 712 | 180 | 1612 |
| 17 April 2020 | 282 | 353 | 142 | 654 | 155 | 1586 |
| 21 April 2020 | 310 | 512 | 89 | 614 | 201 | 1726 |
| 23 April 2020 | 377 | 545 | 115 | 819 | 199 | 2055 |
| 24 April 2020 | 260 | 661 | 102 | 908 | 186 | 2117 |
| 30 April 2020 | 185 | 412 | 56 | 624 | 211 | 1488 |
| 4 May 2020 | 90 | 894 | 06 | 1204 | 145 | 2339 |
| 5 May 2020 | 220 | 1087 | 119 | 752 | 167 | 2345 |
| Total | 1964 | 4874 | 699 | 6287 | 1444 | 15,268 |
| Combined Total | 6838 | 699 | 7731 | 15,268 | ||
| Combined % | 44.79 | 4.58 | 50.63 | 100 | ||
| Date | Third Phase (14 May 2020 to 10 June 2020) | |||||
|---|---|---|---|---|---|---|
| Highly Positive (P+) | Positive (P) | Neutral | Negative (N) | Highly Negative (N−) | Total | |
| 14 May 2020 | 62 | 300 | 42 | 110 | 65 | 579 |
| 15 May 2020 | 53 | 267 | 35 | 296 | 51 | 702 |
| 20 May 2020 | 88 | 198 | 81 | 134 | 58 | 559 |
| 23 May 2020 | 154 | 773 | 63 | 345 | 124 | 1459 |
| 24 May 2020 | 267 | 652 | 26 | 213 | 96 | 1254 |
| 27 May 2020 | 72 | 698 | 55 | 294 | 82 | 1201 |
| 2 June 2020 | 97 | 1085 | 121 | 367 | 91 | 1761 |
| 10 June 2020 | 129 | 653 | 113 | 297 | 53 | 1245 |
| Total | 922 | 4626 | 536 | 2056 | 620 | 8760 |
| Combined Total | 5548 | 536 | 2676 | 8760 | ||
| Combined % | 63.33 | 6.12 | 30.55 | 100 | ||
| Sentiment Score Calculator |
|---|
| Positive tweets = 1 × 22 + 0.5 × 147 = 95.5 Negative tweets= 1 × 78 + 0.5 × 298 = 227 Neutral tweets = 45 Sentiment Score = (95.5 − 227) + 45 = −86.5 5% of the total 590 tweets are 29.5, and after adding this to the −86.5, we reach a result of −57, which is less than zero. So, the sentiment results here show that the overall emotion for that day for the northern region is sad. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, M.; Singh, A.; Bharti, S.; Singh, P.; Saini, M. Using Social Media Analytics and Machine Learning Approaches to Analyze the Behavioral Response of Agriculture Stakeholders during the COVID-19 Pandemic. Sustainability 2022, 14, 16174. https://doi.org/10.3390/su142316174
Singh M, Singh A, Bharti S, Singh P, Saini M. Using Social Media Analytics and Machine Learning Approaches to Analyze the Behavioral Response of Agriculture Stakeholders during the COVID-19 Pandemic. Sustainability. 2022; 14(23):16174. https://doi.org/10.3390/su142316174
Chicago/Turabian StyleSingh, Madanjit, Amardeep Singh, Sarveshwar Bharti, Prithvipal Singh, and Munish Saini. 2022. "Using Social Media Analytics and Machine Learning Approaches to Analyze the Behavioral Response of Agriculture Stakeholders during the COVID-19 Pandemic" Sustainability 14, no. 23: 16174. https://doi.org/10.3390/su142316174
APA StyleSingh, M., Singh, A., Bharti, S., Singh, P., & Saini, M. (2022). Using Social Media Analytics and Machine Learning Approaches to Analyze the Behavioral Response of Agriculture Stakeholders during the COVID-19 Pandemic. Sustainability, 14(23), 16174. https://doi.org/10.3390/su142316174