
The New Prediction Methodology for CO2 Emission to Ensure Energy Sustainability with the Hybrid Artificial Neural Network Approach


Abstract
1. Introduction
- -
- First of all, the data set to be used was created by discussing the studies in the literature and the relevant sector representatives. Unlike many other studies, data on the use of renewable energy are also considered in this study.
- -
- A hybrid method was obtained by using SFLA and FA methods together.
- -
- This hybrid method has been improved by using the Levy flight method and a new optimization method has been proposed.
- -
- A new hybrid estimation method is proposed by using the proposed optimization method together with ANN.
- -
- In the last step, the CO2 emission estimation in Türkiye was made with the proposed estimation method.
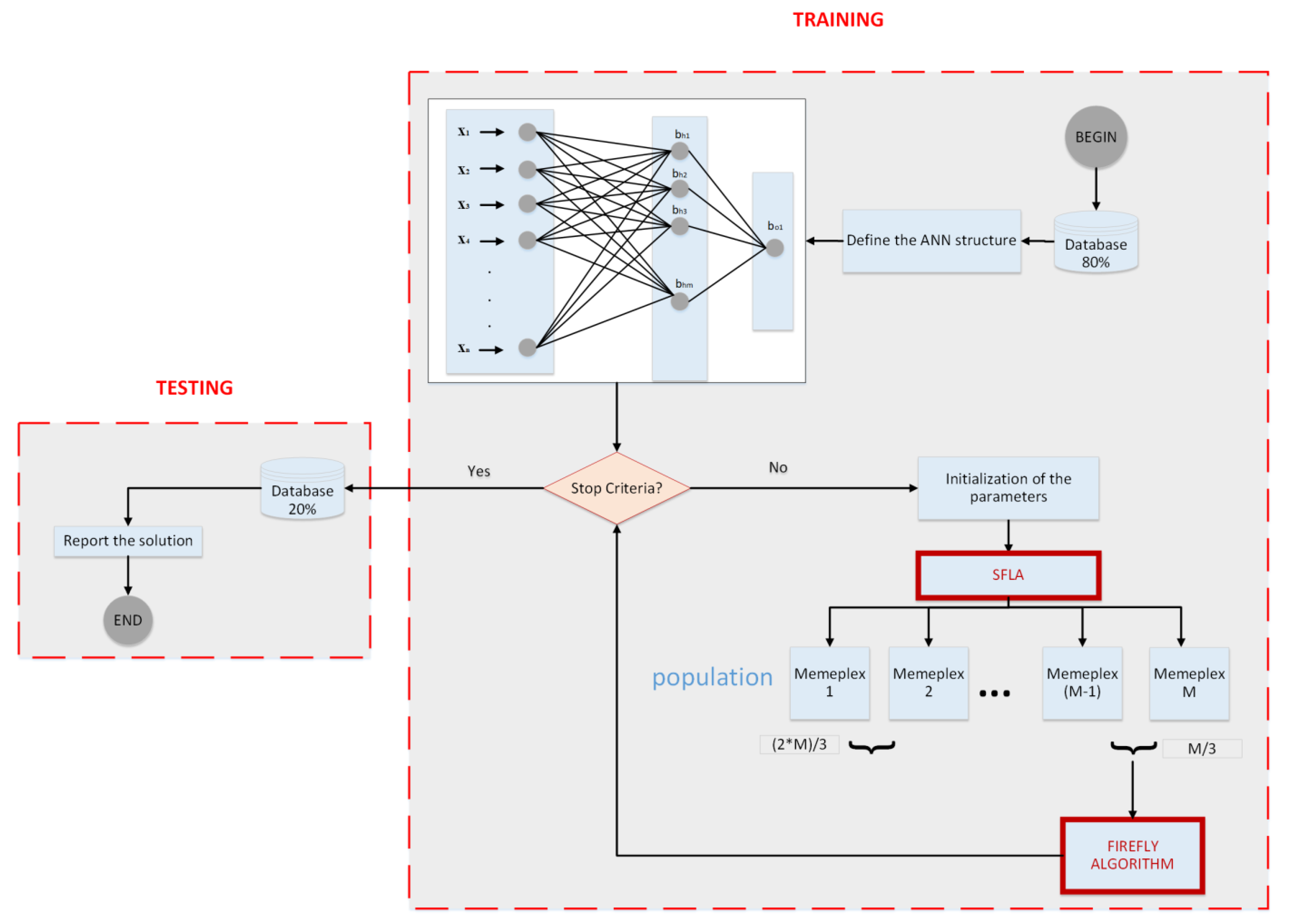
2. Proposed Estimation Method
2.1. Hybrid Optimization Algorithm
| Algorithm 1: The pseudo-code of the SFLA algorithm |
| 1. Begin define the fitness function f(x) set the initial value of the parameters generate the initial population P = (1, 2, …, p) calculate the fitness value of each frog 2. while (t < maximum_generation_number) Creating memeplexes for (i = 1:m) % for all memeplexes for (j = 1: z) % defined iteration number for local search Creating sub-memeplexes Determine the Xb, Xw and Xg Update new position with Equations (2)–(5) end for j end for i combine all memeplexes and rank the population according to their fitness value end_while 3. find the frog with the highest fitness and display it as optimal solution |
- All fireflies can communicate with each other regardless of sex;
- The attraction of any firefly is proportional to the glow brighter. Therefore, the one that emits lighter than the two fireflies attracts more attention and tends towards it;
- The brightness of the firefly is determined by the nature of the objective function.
| Algorithm 2: The pseudo-code of the FA algorithm |
| 1. Begin set the initial value of the parameters generate the initial population of the fireflies define the fitness function f(x) define the light intensity (Ii) associated with the fitness function 2. while (t < maximum_generation_number) for (I = 1: n) % for all fireflies for (j = 1: n) % for all fireflies if (f(xj) < f(xi)) move firefly i towards j end if update the attractiveness evaluate the new solutions and update the light intensity end for j end for i rank the population according to their fitness value and find the current optimal solution end_while 3. find the firefly with the highest fitness and display it as optimal solution |
2.2. Design of Proposed Estimation Method
- Improve forecasting performance;
- Increase the ability to train;
- Improve the speed of convergence;
- Find the optimum result in the search space.
3. Results
3.1. Comparison of the Proposed Estimation Method
3.2. Prediction of CO2 Emissions
3.2.1. Dataset
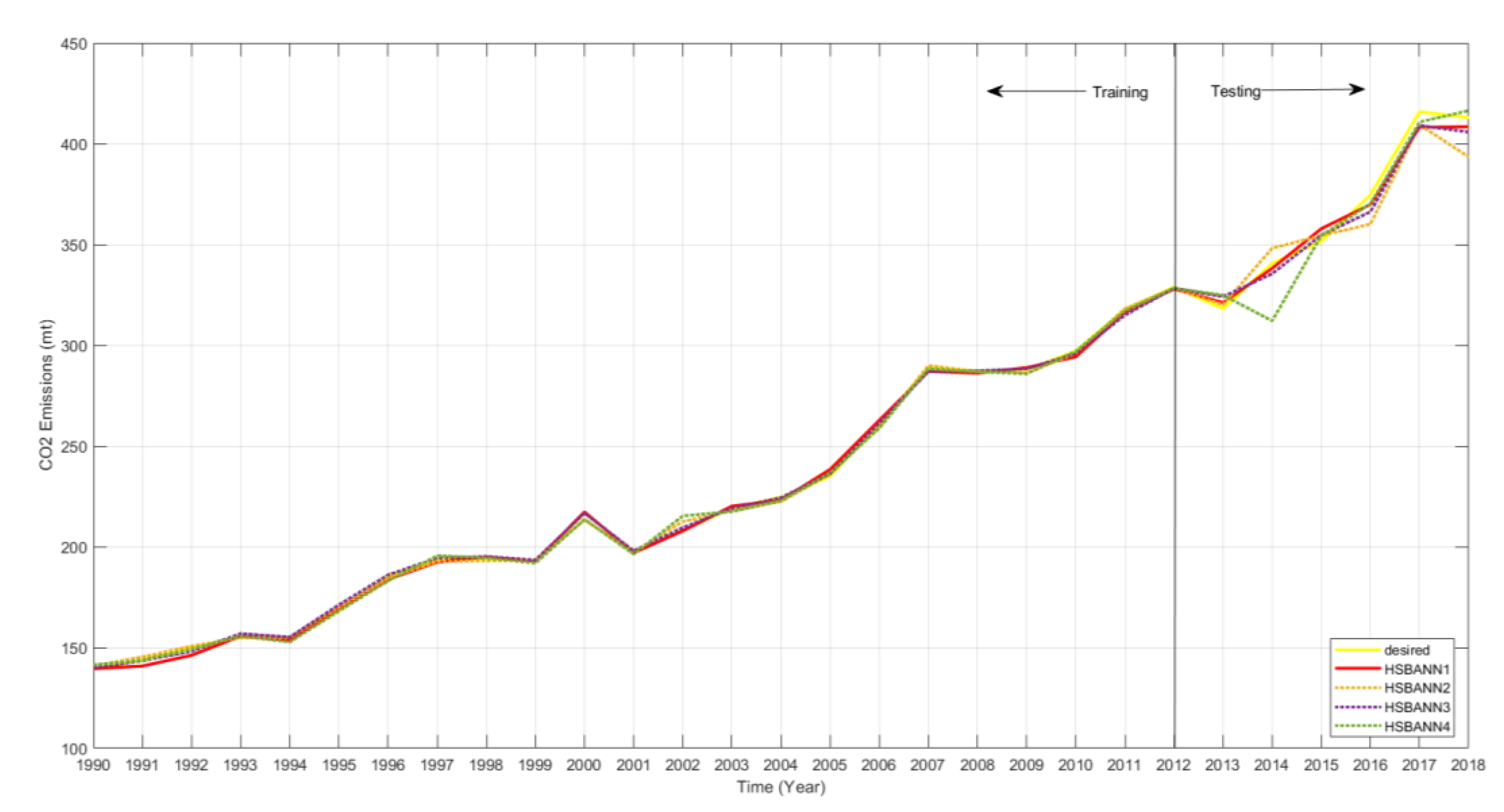
3.2.2. Prediction of the Türkiye’s CO2 Emissions
3.2.3. Future Prediction of the Türkiye’s CO2 emissions
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jenkinson, D.S.; Adams, D.E.; Wild, A. Model estimates of CO2 emissions from soil in response to global warming. Nature 1991, 351, 304–306. [Google Scholar] [CrossRef]
- Acaravci, A.; Ozturk, I. On the relationship between energy consumption, CO2 emissions and economic growth in Europe. Energy 2010, 35, 5412–5420. [Google Scholar] [CrossRef]
- Sadorsky, P. The effect of urbanization on CO2 emissions in emerging economies. Energy Econ. 2014, 41, 147–153. [Google Scholar] [CrossRef]
- Azomahou, T.; Laisney, F.; Van, P.N. Economic development and CO2 emissions: A nonparametric panel approach. J. Public Econ. 2006, 90, 1347–1363. [Google Scholar] [CrossRef]
- Gregg, J.S.; Andres, R.J.; Marland, G. China: Emissions pattern of the world leader in CO2 emissions from fossil fuel consumption and cement production. Geophys. Res. Lett. 2008, 35, 2887. [Google Scholar] [CrossRef]
- Ozturk, I.; Acaravci, A. CO2 emissions, energy consumption and economic growth in Turkey. Renew. Sustain. Energy Rev. 2010, 14, 3220–3225. [Google Scholar] [CrossRef]
- Arouri, M.E.H.; Youssef, A.B.; M’Henni, H.; Rault, C. Energy consumption, economic growth and CO2 emissions in Middle East and North African countries. Energy Policy 2012, 45, 342–349. [Google Scholar] [CrossRef]
- European Commission. Living Well, within the Limits of Our Planet. 7th EAP—The New General Union Environment Action Programme to 2020. 2014. Available online: https://ec.europa.eu/environment/pubs/pdf/factsheets/7eap/en.pdf (accessed on 2 March 2022).
- Ministry of Trade of the Republic of Türkiye. Available online: https://ticaret.gov.tr/data/60f1200013b876eb28421b23/MUTABAKAT%20YE%C5%9E%C4%B0L.pdf (accessed on 2 March 2022).
- Skjærseth, J.B. Towards a European Green Deal: The evolution of EU climate and energy policy mixes. Int. Environ. Agreem. Politi-Law Econ. 2021, 21, 25–41. [Google Scholar] [CrossRef]
- Hafner, M.; Raimondi, P.P. Priorities and challenges of the EU energy transition: From the European Green Package to the new Green Deal. Russ. J. Econ. 2020, 6, 374–389. [Google Scholar] [CrossRef]
- Shan, Y.; Ou, J.; Wang, D.; Zeng, Z.; Zhang, S.; Guan, D.; Hubacek, K. Impacts of COVID-19 and fiscal stimuli on global emissions and the Paris Agreement. Nat. Clim. Chang. 2020, 11, 200–206. [Google Scholar] [CrossRef]
- Zabojnik, S.; Hricovsky, M. Balancing the Slovak Energy Market After the Adoption of “Fit for 55 Package”. In SHS Web of Conferences. EDP Sci. 2021, 129, 05015. Available online: https://www.shs-conferences.org/articles/shsconf/pdf/2021/40/shsconf_glob2021_05015.pdf (accessed on 2 March 2022).
- Vinck, N. The Fit for 55 Package and the European Climate Ambitions An Assessment of Their Impacts on the European Metallurgical Silicon Industry. In Proceedings of the Silicon for the Chemical & Solar Industry XVI 2022, Trondheim, Norway, 14–16 June 2022. [Google Scholar]
- Bäckstrand, K. Towards a Climate-Neutral Union by 2050? The European Green Deal, Climate Law, and Green Recovery. In Routes to a Resilient European Union; Palgrave Macmillan: Cham, Switzerland, 2022; pp. 39–61. [Google Scholar] [CrossRef]
- Available online: https://data.tuik.gov.tr/Bulten/Index?p=Greenhouse-Gas-Emissions-Statistics-1990-2019-37196 (accessed on 2 March 2022).
- Ye, L.; Yang, D.; Dang, Y.; Wang, J. An enhanced multivariable dynamic time-delay discrete grey forecasting model for predicting China's carbon emissions. Energy 2022, 249, 123681. [Google Scholar] [CrossRef]
- Radojević, D.; Pocajt, V.; Popović, I.; Perić-Grujić, A.; Ristić, M. Forecasting of Greenhouse Gas Emissions in Serbia Using Artificial Neural Networks. Energy Sources Part A Recover. Util. Environ. Eff. 2013, 35, 733–740. [Google Scholar] [CrossRef]
- Bakay, M.S.; Ağbulut, Ü. Electricity production based forecasting of greenhouse gas emissions in Turkey with deep learning, support vector machine and artificial neural network algorithms. J. Clean. Prod. 2020, 285, 125324. [Google Scholar] [CrossRef]
- Antanasijević, D.Z.; Ristić, M.; Perić-Grujić, A.A.; Pocajt, V.V. Forecasting GHG emissions using an optimized artificial neural network model based on correlation and principal component analysis. Int. J. Greenh. Gas Control 2014, 20, 244–253. [Google Scholar] [CrossRef]
- Ren, F.; Long, D. Carbon emission forecasting and scenario analysis in Guangdong Province based on optimized Fast Learning Network. J. Clean. Prod. 2021, 317, 128408. [Google Scholar] [CrossRef]
- Qiao, W.; Lu, H.; Zhou, G.; Azimi, M.; Yang, Q.; Tian, W. A hybrid algorithm for carbon dioxide emissions forecasting based on improved lion swarm optimizer. J. Clean. Prod. 2019, 244, 118612. [Google Scholar] [CrossRef]
- Alam, T.; AlArjani, A. Forecasting CO2 Emissions in Saudi Arabia Using Artificial Neural Network, Holt-Winters Exponential Smoothing, and Autoregressive Integrated Moving Average Models. In Proceedings of the 2021 International Conference on Technology and Policy in Energy and Electric Power (ICT-PEP), Yogyakarta, Indonesia, 29–30 September 2021; pp. 125–129. [Google Scholar] [CrossRef]
- Jena, P.R.; Managi, S.; Majhi, B. Forecasting the CO2 Emissions at the Global Level: A Multilayer Artificial Neural Network Modelling. Energies 2021, 14, 6336. [Google Scholar] [CrossRef]
- Azadeh, A.; Sheikhalishahi, M.; Hasumi, M. A hybrid intelligent algorithm for optimum forecasting of CO2 emission in complex environments: The cases of Brazil, Canada, France, Japan, India, UK and US. World J. Eng. 2015, 12, 237–246. [Google Scholar] [CrossRef]
- Heydari, A.; Garcia, D.A.; Keynia, F.; Bisegna, F.; De Santoli, L. Renewable Energies Generation and Carbon Dioxide Emission Forecasting in Microgrids and National Grids using GRNN-GWO Methodology. Energy Procedia 2019, 159, 154–159. [Google Scholar] [CrossRef]
- Zhou, J.; Xu, X.; Li, W.; Guang, F.; Yu, X.; Jin, B. Forecasting CO2 Emissions in China’s Construction Industry Based on the Weighted Adaboost-ENN Model and Scenario Analysis. J. Energy 2019, 2019, 8275491. [Google Scholar] [CrossRef]
- Guo, J.; Liu, W.; Tu, L.; Chen, Y. Forecasting carbon dioxide emissions in BRICS countries by exponential cumulative grey model. Energy Rep. 2021, 7, 7238–7250. [Google Scholar] [CrossRef]
- Javed, S.A.; Cudjoe, D. A novel grey forecasting of greenhouse gas emissions from four industries of China and India. Sustain. Prod. Consum. 2021, 29, 777–790. [Google Scholar] [CrossRef]
- Ahmadi, M.H.; Jashnani, H.; Chau, K.-W.; Kumar, R.; Rosen, M.A. Carbon dioxide emissions prediction of five Middle Eastern countries using artificial neural networks. Energy Sources Part A Recover. Util. Environ. Eff. 2019, 16, 1–13. [Google Scholar] [CrossRef]
- Ma, X.; Jiang, P.; Jiang, Q. Research and application of association rule algorithm and an optimized grey model in carbon emissions forecasting. Technol. Forecast. Soc. Chang. 2020, 158, 120159. [Google Scholar] [CrossRef]
- Li, K.; Xiong, P.; Wu, Y.; Dong, Y. Forecasting greenhouse gas emissions with the new information priority generalized accumulative grey model. Sci. Total Environ. 2021, 807, 150859. [Google Scholar] [CrossRef] [PubMed]
- Şahin, U. Forecasting of Turkey’s greenhouse gas emissions using linear and nonlinear rolling metabolic grey model based on optimization. J. Clean. Prod. 2019, 239, 118079. [Google Scholar] [CrossRef]
- Liu, Z.; Jiang, P.; Wang, J.; Zhang, L. Ensemble system for short term carbon dioxide emissions forecasting based on multi-objective tangent search algorithm. J. Environ. Manag. 2021, 302, 113951. [Google Scholar] [CrossRef] [PubMed]
- Khoshnevisan, B.; Rafiee, S.; Omid, M.; Yousefi, M.; Movahedi, M. Modeling of energy consumption and GHG (greenhouse gas) emissions in wheat production in Esfahan province of Iran using artificial neural networks. Energy 2013, 52, 333–338. [Google Scholar] [CrossRef]
- Antanasijević, D.; Pocajt, V.; Ristić, M.; Perić-Grujić, A. Modeling of energy consumption and related GHG (green-house gas) intensity and emissions in Europe using general regression neural networks. Energy 2015, 84, 816–824. [Google Scholar] [CrossRef]
- Acheampong, A.O.; Boateng, E.B. Modelling carbon emission intensity: Application of artificial neural network. J. Clean. Prod. 2019, 225, 833–856. [Google Scholar] [CrossRef]
- Yang, H.; O’Connell, J.F. Short-term carbon emissions forecast for aviation industry in Shanghai. J. Clean. Prod. 2020, 275, 122734. [Google Scholar] [CrossRef]
- Ho, H.-X.T. Forecasting of CO2 Emissions, Renewable Energy Consumption and Economic Growth in Vietnam Using Grey Models. In Proceedings of the 2018 4th International Conference on Green Technology and Sustainable Development (GTSD), Ho Chi Minh City, Vietnam, 23–24 November 2018; pp. 452–455. [Google Scholar] [CrossRef]
- Eusuff, M.M.; Lansey, K. Optimization of Water Distribution Network Design Using the Shuffled Frog Leaping Algorithm. J. Water Resour. Plan. Manag. 2003, 129, 210–225. [Google Scholar] [CrossRef]
- Eusuff, M.; Lansey, K.; Pasha, F. Shuffled frog-leaping algorithm: A memetic meta-heuristic for discrete optimization. Eng. Optim. 2006, 38, 129–154. [Google Scholar] [CrossRef]
- Yang, X.S. Firefly algorithm. In Nature-Inspired Metaheuristic Algorithms, 2nd ed.; Luniver Press: Frome, UK, 2008; pp. 79–90. [Google Scholar]
- Senthilnath, J.; Omkar, S.; Mani, V. Clustering using firefly algorithm: Performance study. Swarm Evol. Comput. 2011, 1, 164–171. [Google Scholar] [CrossRef]
- Yang, X.-S.; Deb, S. Cuckoo Search via Lvy flights. In Proceedings of the 2009 World Congress Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar] [CrossRef]
- Senthilnath, J.; Das, V.; Omkar, S.N.; Mani, V. Clustering using levy flight cuckoo search. In Proceedings of the Seventh International Conference on Bio-Inspired Computing: Theories and Applications (BIC-TA 2012), Dehli, India, 3 July 2013; pp. 65–75. [Google Scholar]
- Baskan, O. Determining Optimal Link Capacity Expansions in Road Networks Using Cuckoo Search Algorithm with Lévy Flights. J. Appl. Math. 2013, 2013, 1–11. [Google Scholar] [CrossRef]
- Lan, K.; Liu, L.; Li, T.; Chen, Y.; Fong, S.; Marques, J.A.L.; Tang, R. Multi-view convolutional neural network with lead-er and long-tail particle swarm optimizer for enhancing heart disease and breast cancer detection. Neural Comput. Appl. 2020, 32, 15469–15488. [Google Scholar] [CrossRef]
- Hariya, Y.; Kurihara, T.; Shindo, T.; Jin’No, K. Lévy flight PSO. In Proceedings of the 2015 IEEE congress on evolutionary computation (CEC), Sendai, Japan, 25–28 May 2015; pp. 2678–2684. [Google Scholar] [CrossRef]
- Hassanzadeh, T.; Vojodi, H.; Moghadam, A.M.E. A Multilevel Thresholding Approach Based on Levy-Flight Firefly Algorithm. In Proceedings of the 2011 7th Iranian Conference on Machine Vision and Image Processing, Tehran, Iran, 16–17 November 2011; pp. 1–5. [Google Scholar] [CrossRef]
- Liu, S.; Wang, Y. A Lévy Flight Based Firefly Algorithm for Multilevel Thresholding Image Segmentation. J. Phys. Conf. Ser. 2021, 1865, 2098. [Google Scholar] [CrossRef]
- Rajpoot, V.; Chitrakoot, M.G.C.G.V.; Tiwari, A.; Mishra, B. AMSFLO: Optimization Based Efficient Approach For Assosia-tion Rule Mining. Int. J. Comput. Sci. Inf. Secur. (IJCSIS) 2018, 16, 147–154. [Google Scholar]
- Tang, D.; Yang, J.; Dong, S.; Liu, Z. A lévy flight-based shuffled frog-leaping algorithm and its applications for continuous optimization problems. Appl. Soft Comput. 2016, 49, 641–662. [Google Scholar] [CrossRef]
- Jensi, R.; Jiji, G.W. An enhanced particle swarm optimization with levy flight for global optimization. Appl. Soft Comput. 2016, 43, 248–261. [Google Scholar] [CrossRef]
- Zceylan, E. Forecasting CO2 emission of Turkey: Swarm intelligence approaches. Int. J. Glob. Warming 2016, 9, 337–361. [Google Scholar] [CrossRef]
- Indexmundi. Available online: https://www.indexmundi.com/facts/indicators/EN.ATM.CO2E.KT (accessed on 23 October 2014).
- Turkish Statistical Institute (TURKSTAT). Available online: https://data.tuik.gov.tr/Bulten/Index?p=Arastirma-Gelistirme-Faaliyetleri-Arastirmasi-2020-37439 (accessed on 2 March 2022).
- World Bank. Available online: https://data.worldbank.org/indicator/EG.FEC.RNEW.ZS?locations=TR (accessed on 2 March 2022).
- Indexmundi. Available online: https://www.indexmundi.com/Turkey/population.html (accessed on 2 March 2022).
- Available online: https://www.indexmundi.com/facts/Turkey/urban-population (accessed on 2 March 2022).
- Turkish Statistical Institute (TURKSTAT). Available online: https://data.tuik.gov.tr/Bulten/Index?p=Motorlu-Kara-Tasitlari-Aralik-2020-37410#:~:text=T%C3%9C%C4%B0K%20Kurumsal&text=T%C3%BCrkiye’de%202020%20y%C4%B1l%C4%B1nda%20bir,bin%20577%20adet%20art%C4%B1%C5%9F%20ger%C3%A7ekle%C5%9Fti (accessed on 2 March 2022).
- US Energy Information Administration (EIA). Available online: https://www.eia.gov/international/data/country/TUR/total-energy/total-energy-consumption?pd=44&p=0000000010000000000000000000000000000000000000000000000000u06&u=0&f=A&v=mapbubble&a=-&i=none&vo=value&&t=C&g=none&l=249--230&s=315532800000&e=1546300800000 (accessed on 2 March 2022).
- World Bank. Available online: https://data.worldbank.org/indicator/NY.GDP.MKTP.KD.ZG?locations=TR (accessed on 2 March 2022).
- World Bank. Available online: https://data.worldbank.org/indicator/EN.ATM.CO2E.KT?locations=TR (accessed on 2 March 2022).
- Uzlu, E. Estimates of greenhouse gas emission in Turkey with grey wolf optimizer algorithm-optimized artificial neural networks. Neural Comput. Appl. 2021, 33, 13567–13585. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Refs. | Proposed Model | Location | Error Criteria |
|---|---|---|---|
| [17] | Dynamic time-delay discrete grey forecasting model | China | MAPE < 1.5% RMSE 0.011 |
| [22] | Improved lion swarm optimizer | China, India, Canada, Brazil, Iran, United States, South Africa, Japan, German, Türkiye and Saudi Arabia | MAPE decreased by 0.726–1.878% |
| [19] | Deep learning, support vector machine and artificial neural network | Türkiye | R2 varies from 0.861 to 0.998 rRMSE values < 10%. |
| [21] | Optimized Fast Learning Network, Chicken Swarm Optimization | Guangdong in China | RMSE 27.755 MAPE 1.656% MAE 11.609 |
| [20] | Optimized artificial neural network | 28 European countries | MAPE 3.6% |
| [28] | Artificial Neural Networks | Serbia | R2 0.9125 |
| [29] | Artificial neural networks | Kuwait, Iran, Saudi Arabia, United Arab Emirates and Qatar | Average absolute relative error 2.3% R2 0.9998 |
| [30] | A novel grey forecasting model | China and India | MAPE < 11.24% RMSE < 299.9 |
| [18] | Exponential cumulative grey model | Brazil, Russia, India, China and South Africa | MAPE < 18.44% MAE < 0.384 RMSE < 0.479 |
| [31] | Gray model optimized by the Firefly Algorithm | China | MAPE 0.0499 |
| [32] | New information priority generalized accumulative gray model | Russia Kazakhstan, Kyrgyzstan, Tajikistan, Uzbekistan, Pakistan, India | MAPE < 6.36 |
| [33] | Optimized metabolic gray model and optimized nonlinear metabolic gray model | Türkiye | MAPE 5.19 |
| [34] | Multi-objective tangent search algorithm | America and China | MAPE (Dataset1) 1.1102% MAPE (Dataset2) 1.1382% |
| [35] | Artificial Neural Networks | Iran | R2 0.99 |
| [36] | General regression neural network | 26 European countries | MAPE 6.4% |
| [37] | Artificial neural Network | Australia, Brazil, China, India and USA | R2 < 0.99 |
| [38] | Autoregressive Integrated Moving Average linear model | Shanghai in China | RMSE 63.612 MAE 18.610 MAPE 2.634 |
| [26] | Generalized Regression Neural Network and Grey Wolf Optimization | Iran, Canada and Italy | RMSE 0.0111 MAE 0.0094 MAPE 2.2194 (The best values) |
| [23] | Autoregressive Integrated Moving Average, Holt-Winters Exponential Smoothing and Artificial Neural Network | Saudi Arabia’s | RMSE 1.44 MAE 1.12 MAPE 0.08 (The best values) |
| [39] | Grey Models | Vietnam | Mean relative error 1.21% (Model 1) Mean relative error 4.83% (Model 2) |
| Func. | Benchmark Problem | Formulation | Search Range | Initial Range | Global Min. |
|---|---|---|---|---|---|
| F1 | Sphere | [–100, 100] | [–100, 50] | 0 | |
| F2 | Schwefel 2.22 | [–10, 10] | [–10, 5] | 0 | |
| F3 | Sum Square | [–10, 10] | [–10, 10] | 0 | |
| F4 | Cigar | [–100, 100] | [–100, 100] | 0 |
| Parameters | FA | SFLA | ILSFLAFA |
|---|---|---|---|
| Population size | 24 | 24 | 24 |
| Fitness evaluations | 400 | 400 | 400 (100 × 4) |
| Number of decision variables | 30 | 30 | 30 |
| Light absorption coefficient | 2.0 | - | 2.0 |
| Attraction coefficient | 1.8 | - | 1.8 |
| Number of Memeplexes | - | 6 | 6 |
| Memeplex Size | - | 4 | 4 |
| Number of Fitness evaluations for local search | - | 4 | 4 |
| Levy index | - | - | 2.0 |
| FA | SFLA | ILSFLAFA | ||
|---|---|---|---|---|
| F1 | best | 5.37 × 10−18 | 8.38 × 10−9 | 0 |
| worst | 3.30 × 100 | 8.06 × 10−4 | 0 | |
| std | 7.37 × 10−1 | 2.93 × 10−4 | 0 | |
| Computation time | 1.5791 × 10−13 | 13.064510 | 83.375757 | |
| F2 | best | 2.74 × 10−16 | 2.44 × 10−5 | 0 |
| worst | 7.50 × 10−3 | 7.03 × 10−2 | 0 | |
| std | 2.27 × 10−3 | 2.14 × 10−2 | 0 | |
| Computation time | 3.024902 | 13.188631 | 87.217499 | |
| F3 | best | 5.42 × 10−201 | 3.11 × 10−282 | 0 |
| worst | 1.64 × 10−198 | 1.69 × 10−274 | 0 | |
| std | 0 | 0 | 0 | |
| Computation time | 2.898312 | 13.158265 | 80.099749 | |
| F6 | best | 2.85 × 10−203 | 3.90 × 10−280 | 0 |
| worst | 6.87 × 10−199 | 5.41 × 10−267 | 0 | |
| std | 0 | 0 | 0 | |
| Computation time | 2.877054 | 13.436169 | 81.848208 |
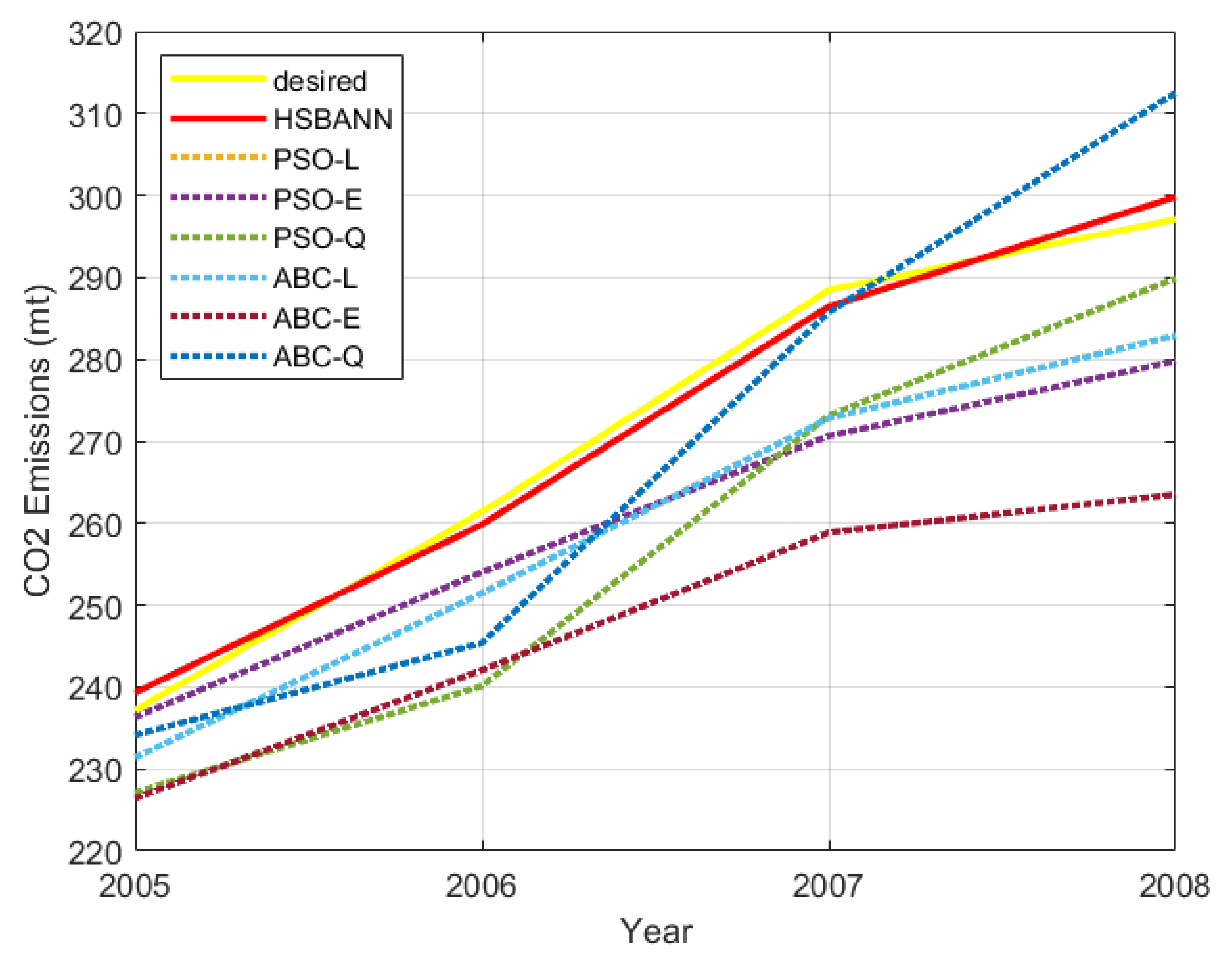
| 2005 | 2006 | 2007 | 2008 | |
|---|---|---|---|---|
| Actual data [55] | 237.174 | 261.357 | 288.445 | 297.120 |
| HSBNN | 239.3081 | 259.8382 | 286.4580 | 299.8035 |
| Relative Error % | 0.8998 | −0.5811 | −0.6889 | 0.9032 |
| PSOCO2 linear (PSO-L) | 231.399 | 251.480 | 272.824 | 282.906 |
| Relative Error % | −2.435 | −3.779 | −5.416 | −4.784 |
| PSOCO2 exponential (PSO-E) | 236.319 | 254.021 | 270.648 | 279.787 |
| Relative Error % | −0.361 | −2.807 | −6.170 | −5.834 |
| PSOCO2 quadratic (PSO-Q) | 227.135 | 240.122 | 273.136 | 289.881 |
| Relative Error % | −4.233 | −8.125 | −5.307 | −2.436 |
| ABCCO2 linear (ABC-L) | 231.399 | 251.468 | 272.806 | 282.888 |
| Relative Error % | −2.435 | −3.784 | −5.422 | −4.790 |
| ABCCO2 exponential (ABC- E) | 226.430 | 242.060 | 258.865 | 263.508 |
| Relative Error % | −4.530 | −7.383 | −10.255 | −11.313 |
| ABCCO2 quadratic (ABC-Q) | 234.139 | 245.389 | 285.749 | 312.542 |
| Relative Error % | −1.280 | −6.110 | −0.935 | 5.191 |
| Parameters | Value | Parameters | Value |
|---|---|---|---|
| Number of input neurons | 4 | Memeplex Size | 4 |
| Number of hidden neurons | 6 | Number of Fitness evaluations for local search | 5 |
| Number of output neurons | 1 | Levy index | 2.0 |
| Population size | 24 | Light absorption coefficient | 1.0 |
| Number of Memeplexes | 6 | Attraction coefficient | 2.0 |
| Prediction Models | Average Relative Errors |
|---|---|
| HSBNN | 0.7682 |
| PSOCO2 linear | 4.104 |
| PSOCO2 exponential | 3.793 |
| PSOCO2 quadratic | 5.025 |
| ABCCO2 linear | 4.108 |
| ABCCO2 exponential | 8.37 |
| ABCCO2 quadratic | 3.379 |
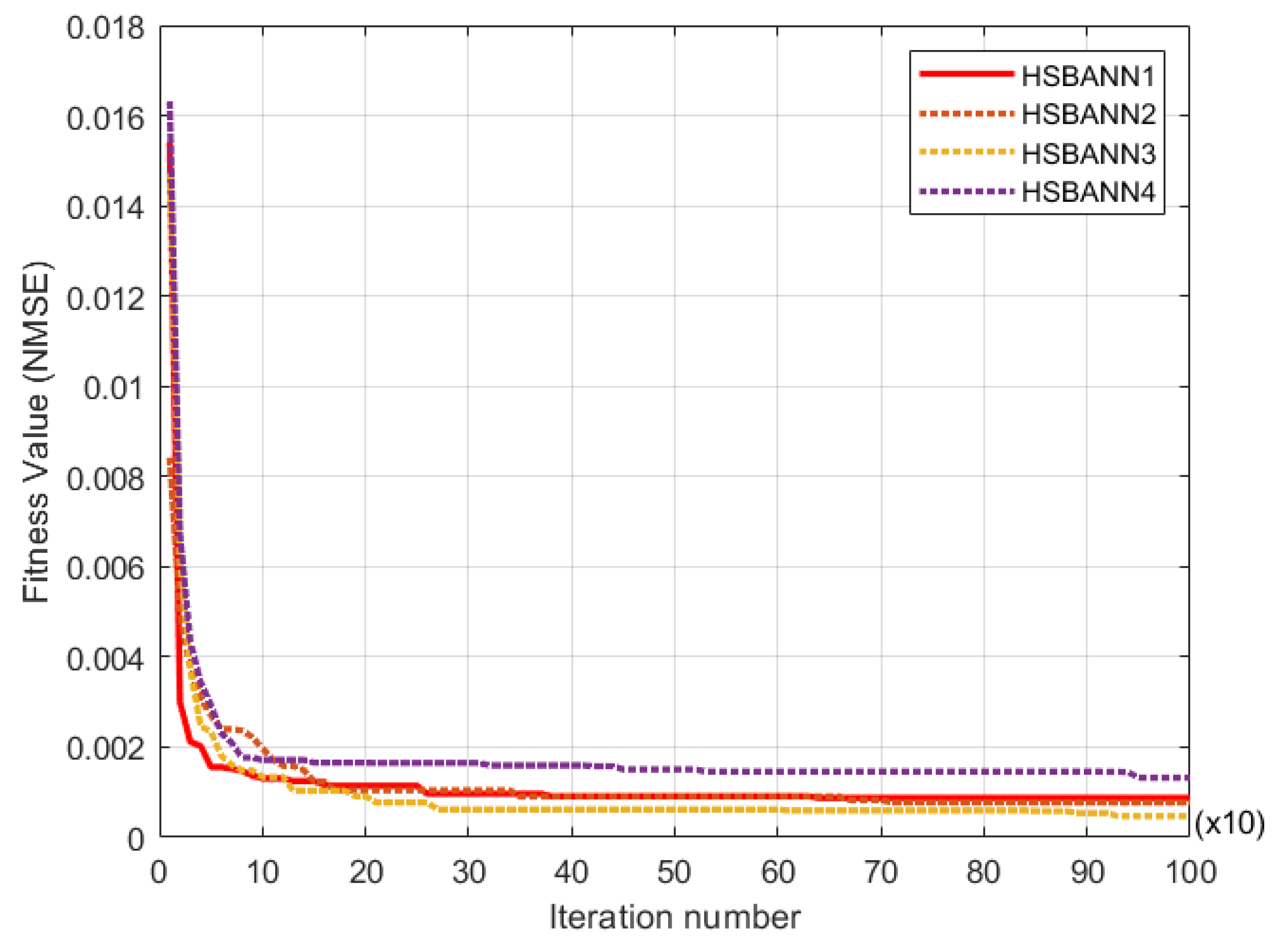
| No of Neuronsin 1st Hidden Layer | No of Neuronsin 2nd Hidden Layer | Error for Training Data Set | Error for Testing Data Set | ||||
|---|---|---|---|---|---|---|---|
| NMSE | MAPE (%) | RMSE | MAE | TIC | |||
| HSBNN1 | 12 | - | 0.000873 | 1.2752 | 5.1107 | 4.7789 | 0.0138 |
| HSBNN2 | 6 | 4 | 0.000774 | 2.2974 | 10.8183 | 8.8022 | 0.0295 |
| HSBNN3 | 6 | 6 | 0.000469 | 1.6456 | 6.3267 | 6.0970 | 0.0172 |
| HSBNN4 | 8 | 4 | 0.001321 | 2.4199 | 12.4193 | 8.5026 | 0.0338 |
| Regression | R2 | Relative Error (%) | |
|---|---|---|---|
| HSBNN1 | 0.99518 | 0.9904 | 1.2752 |
| HSBNN2 | 0.97661 | 0.9538 | 2.2974 |
| HSBNN3 | 0.99356 | 0.9872 | 1.6456 |
| HSBNN4 | 0.95556 | 0.9131 | 2.4199 |
| Scenario 1 | Scenario 2 | Scenario 3 | |
|---|---|---|---|
| R&D investments [56] | 19.42% | 22.64% | 21.72% |
| Renewable energy ratio [57] | 12.16% | 12.27% | 12.60% |
| Population [58] | TurkStat population forecasts | TurkStat population forecasts | TurkStat population forecasts |
| Urbanization [59] | 1.0% | 1.05% | 1.08% |
| Number of motor vehicles [54] | 3.0% | 3.5% | 4.0% |
| Energy consumption [54] | 2.0% | 2.5% | 3.0% |
| GDP [64] | 4.87% | 6.37% | 7.87% |
| Year | Scenario 1 | Scenario 2 | Scenario 3 |
|---|---|---|---|
| 2018 [63] | 412.9700 | 412.9700 | 412.9700 |
| 2019 | 419.7500 | 418.8049 | 419.2450 |
| 2020 | 427.1719 | 427.1067 | 426.2700 |
| 2021 | 434.7241 | 436.2368 | 433.4406 |
| 2022 | 442.1495 | 445.6232 | 440.4107 |
| 2023 | 449.3373 | 454.8216 | 447.0232 |
| 2024 | 455.8839 | 463.3066 | 452.8473 |
| 2025 | 460.7198 | 470.1485 | 457.0039 |
| 2026 | 464.1629 | 476.0640 | 467.5716 |
| 2027 | 469.7298 | 484.0587 | 473.9727 |
| 2028 | 478.7903 | 494.4381 | 483.6537 |
| 2029 | 490.7800 | 506.6813 | 496.0707 |
| 2030 | 504.6270 | 519.2656 | 510.0260 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aksu, İ.Ö.; Demirdelen, T. The New Prediction Methodology for CO2 Emission to Ensure Energy Sustainability with the Hybrid Artificial Neural Network Approach. Sustainability 2022, 14, 15595. https://doi.org/10.3390/su142315595
Aksu İÖ, Demirdelen T. The New Prediction Methodology for CO2 Emission to Ensure Energy Sustainability with the Hybrid Artificial Neural Network Approach. Sustainability. 2022; 14(23):15595. https://doi.org/10.3390/su142315595
Chicago/Turabian StyleAksu, İnayet Özge, and Tuğçe Demirdelen. 2022. "The New Prediction Methodology for CO2 Emission to Ensure Energy Sustainability with the Hybrid Artificial Neural Network Approach" Sustainability 14, no. 23: 15595. https://doi.org/10.3390/su142315595
APA StyleAksu, İ. Ö., & Demirdelen, T. (2022). The New Prediction Methodology for CO2 Emission to Ensure Energy Sustainability with the Hybrid Artificial Neural Network Approach. Sustainability, 14(23), 15595. https://doi.org/10.3390/su142315595