Distribution-Free Approaches for an Integrated Cargo Routing and Empty Container Repositioning Problem with Repacking Operations in Liner Shipping Networks


Abstract
1. Introduction
- (1)
- This work studies a new integrated cargo routing and empty container repositioning problem with repacking operations and uncertain laden and empty container demands in liner shipping networks.
- (2)
- For the problem, a chance-constrained programming model based on moment-based ambiguous sets is proposed.
- (3)
- To solve the problem, four distribution-free solution methods including Sample Average Approximation (SAA), enhanced SAA (eSAA), Approximation based on Markov’s Inequality (AMI) and Mixed Integer Second-Order Cone Program (MI-SOCP) are adopted to solve the problem.
2. Literature Review
2.1. Cargo Routing and Empty Container Repositioning Problems
2.2. Moment-Based Ambiguity Set and Chance Constrained Programming
2.3. Distribution-Free Approach
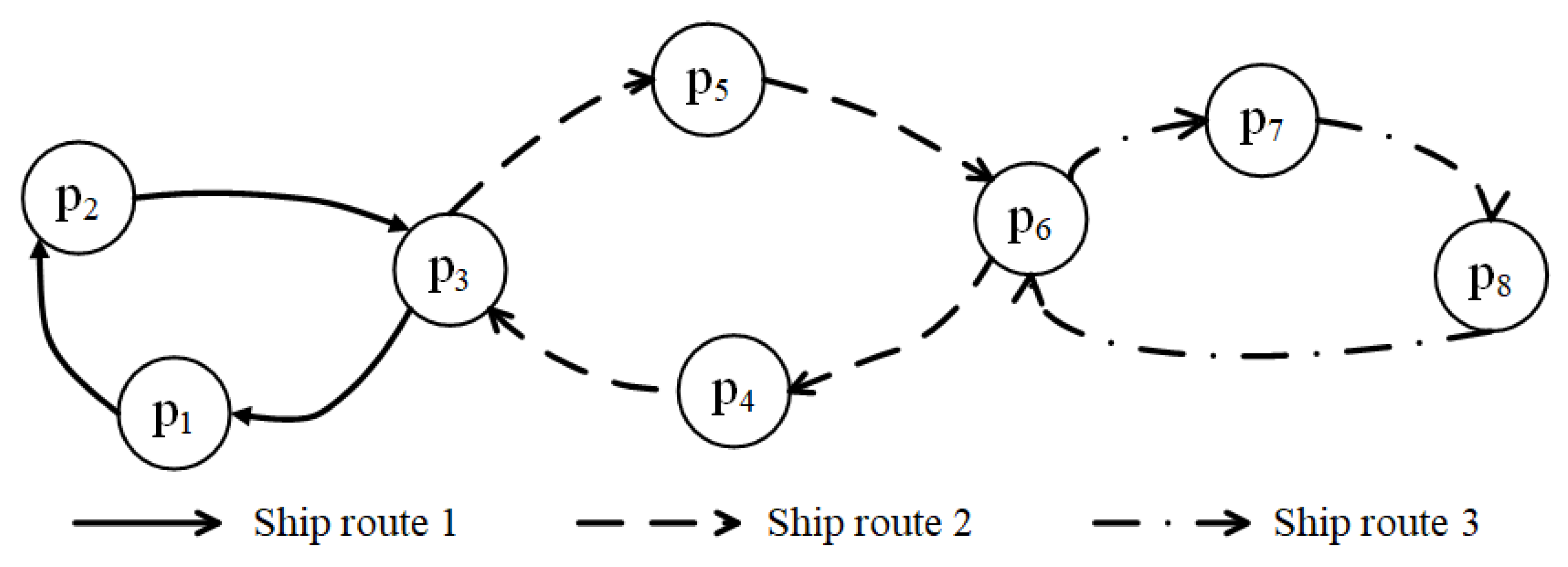
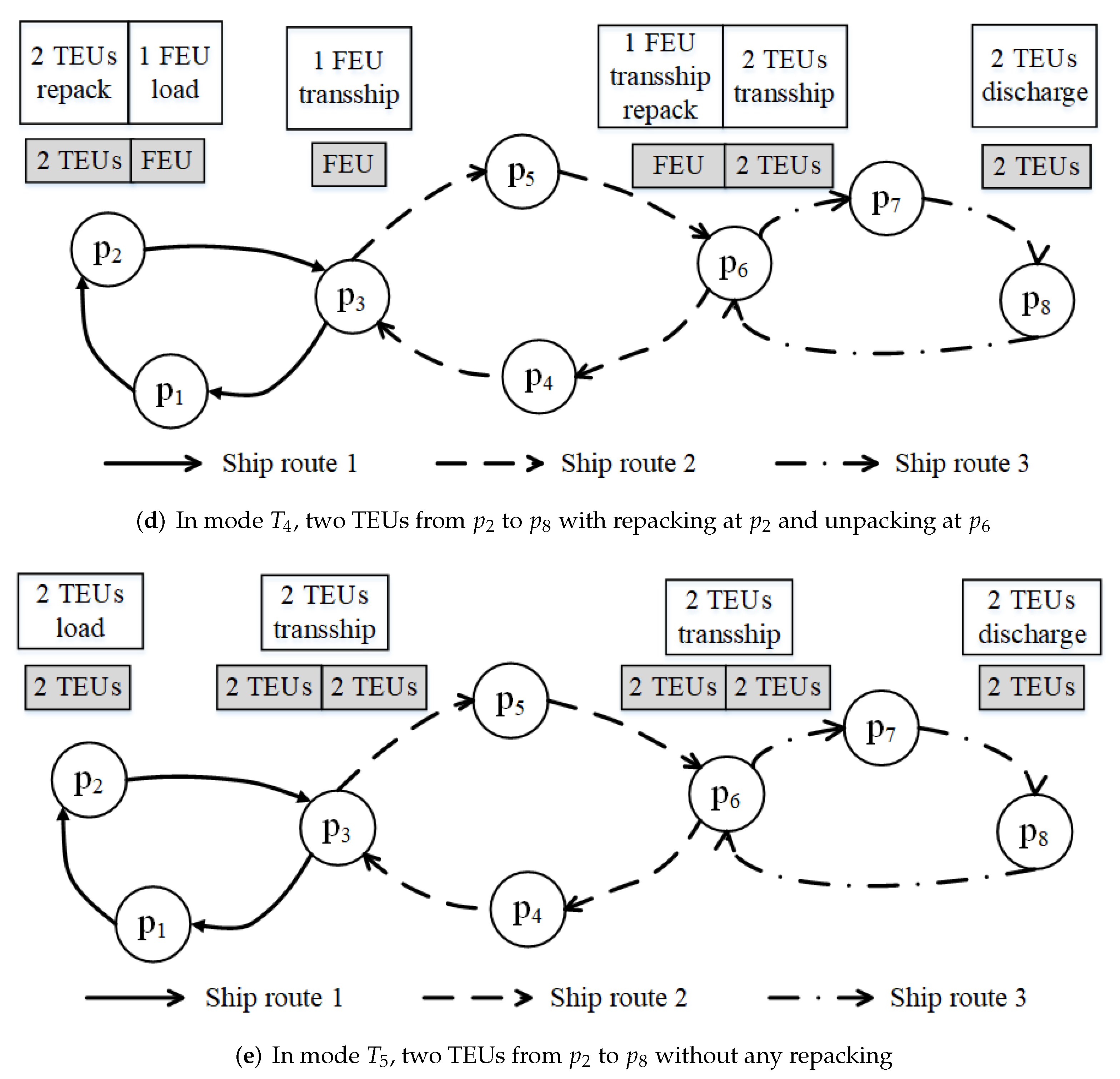
3. Problem Statement
- (1)
- The repacking operations can only be executed at container yards. Therefore, before TEUs are repackaged into FEUs, containers need to be discharged from the liner ship, and then unload costs are incurred.
- (2)
- Each TEU and FEU are repacked at most once for a cargo route .
- (3)
- The uncertain demand of each cargo route is considered, and it is assumed to be not over the capacity of a cargo route.
- (4)
- Repacking operations can occur at transshipment ports, origin and destination ports.
- (5)
- The capacity of a shipping route is limited. That is, the numbers of transported TEUs and FEUs at each leg are less than or equal to the capacity of the shipping route. Note that we consider the capacity of the shipping route but not the capacity of the liner ship, because a shipping route has a group of liner ships to provide services.
4. Mathematical Formulation
4.1. Notations and Moment-Based Ambiguity Set
4.2. Formulation
- :
- the capacity of both empty and laden TEUs in shipping route ;
- :
- the capacity of both empty and laden FEUs in shipping route ;
- :
- the laden TEU demand of cargo route , random parameter;
- :
- the empty TEU demand of cargo route , random parameter;
- :
- the empty FEU demand of cargo route , random parameter;
- :
- the maximum probability of failing to meet the demand of the laden TEUs in cargo route ; Note that laden FEUs derived from repacking operations are finally unpacked to laden TEUs in cargo route s;
- :
- the maximum probability of failing to meet the demand of the empty TEUs in cargo route ;
- :
- the maximum probability of failing to meet the demand of the empty FEUs in cargo route .
- :
- the number of laden TEUs that are repacked at port p () and unpacked at port q () while transshipping the laden containers, where are the origin and destination ports of cargo route , respectively;
- :
- the number of laden TEUs without repacking operations from o to d in cargo route ;
- :
- the number of empty TEUs from o to d in cargo route ;
- :
- the number of empty FEUs from o to d in cargo route ;
- :
- TEU flow of leg () of shipping route j, where ;
- :
- FEU flow of leg () of shipping route j, where ;
- :
- TEU flow of leg () of cargo route s, where ;
- :
- FEU flow of leg () of cargo route s, where ;
- :
- the quantity of laden and empty TEUs transshipped at port ;
- :
- the quantity of laden and empty FEUs transshipped at port ;
- :
- the quantity of laden TEUs repacked into FEUs at port ;
- :
- the quantity of laden FEUs unpacked into TEUs at port ;
- :
- the transshipment cost of all ports;
- :
- the total packing cost incurred at all ports in the transshipment port set H;
- :
- the cost for loading, discharge, repacking and unpacking operations at the origin and destination ports;
- :
- the costs of both empty TEU and FEU containers for loading, discharge, repacking and unpacking operations at the origin and destination ports.
5. Distribution-Free Approximation Approaches
5.1. Sample Average Approximation (SAA)
- :
- a sufficiently large positive number;
- :
- the laden TEU demand of cargo route s in scenario ;
- :
- the empty TEU demand of cargo route s in scenario ;
- :
- the empty FEU demand of cargo route s in scenario ;
- :
- binary variable, equal to 0 if the number of transshipment laden TEU containers meets the demand of cargo route s in scenario , 1 otherwise;
- :
- binary variable, equal to 0 if the number of empty TEU containers meets the demand of cargo route s in scenario , 1 otherwise;
- :
- binary variable, equal to 0 if the number of empty FEU containers meets the demand of cargo route s in scenario , 1 otherwise.
5.2. Enhanced Sample Average Approximation (eSAA)
| Algorithm 1: SAA with K-means clustering (eSAA with K-means) |
Step 1: Set parameters: the number of scenarios; number of clusters; set of points that belongs to cluster k, where k = 1, 2, 3, …, K. Step 2: Generate N scenarios: , where n = 1, 2, 3, …, N. Step 3: Randomly select K initial cluster centers recorded as from , where n = 1, 2, 3, …, N, k = 1, 2, 3, …, K, . Step 4: Attribute the nearest cluster to each data point: , where k = 1, 2, 3, …, K. Step 5: Fix the position of each cluster by calculating the mean of all points belonging to that cluster: . Step 6: Repeat Step 4 and Step 5 until convergence. Step 7: Randomly select one sample of each cluster as input. Step 8: Solve the model by CPLEX. |
| Algorithm 2: SAA with K-means++ clustering (eSAA with K-means++) |
Step 1: The same as Step 1 of Algorithm 1. Step 2: The same as Step 2 of Algorithm 1. Step 3: Randomly select one cluster center, recorded as , from , where n = 1, 2, 3, …, N; set ; Step 4: Calculate the core of m cluster center(s) recorded as : Step 5: Select one sample () apart from as cluster center recorded as with probability: . Step 6: Set , repeat Step 4 and Step 5 when . Step 7: The same as Step 4 of Algorithm 1. Step 8: The same as Step 5 of Algorithm 1. Step 9: Repeat Step 7 and Step 8 until convergence. Step 10: The same as Step 7 of Algorithm 1. Step 11: The same as Step 8 of Algorithm 1. |
5.3. An Approximation Based on Markov’s Inequality (AMI)
5.4. Mixed Integer Second-Order Cone Program (MI-SOCP)
6. Computational Experiments
6.1. Parameter Settings
6.2. Experiment Results
7. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Meng, Q.; Wang, T.; Wang, S. Short-term liner ship fleet planning with container transshipment and uncertain container shipment demand. Eur. J. Oper. Res. 2012, 223, 96–105. [Google Scholar] [CrossRef]
- Meng, Q.; Wang, T. A scenario-based dynamic programming model for multi-period liner ship fleet planning. Transp. Res. Part E Logist. Transp. Rev. 2011, 47, 401–413. [Google Scholar] [CrossRef]
- Song, D.P.; Dong, J.X. Empty container repositioning. In Handbook of Ocean Container Transport Logistics; Springer: Berlin/Heidelberg, Germany, 2015; pp. 163–208. [Google Scholar]
- Rodrigue, J.P. The Geography of Transport Systems; Routledge: London, UK, 2020. [Google Scholar]
- Epstein, R.; Neely, A.; Weintraub, A.; Valenzuela, F.; Hurtado, S.; Gonzalez, G.; Beiza, A.; Naveas, M.; Infante, F.; Alarcon, F.; et al. A strategic empty container logistics optimization in a major shipping company. Interfaces 2012, 42, 5–16. [Google Scholar] [CrossRef]
- Wang, S.; Qu, X.; Wang, T.; Yi, W. Optimal container routing in liner shipping networks considering repacking 20 ft containers into 40 ft containers. J. Adv. Transp. 2017, 2017, 8608032. [Google Scholar] [CrossRef]
- Wang, S.; Meng, Q.; Sun, Z. Container routing in liner shipping. Transp. Res. Part E Logist. Transp. Rev. 2013, 49, 1–7. [Google Scholar] [CrossRef]
- Li, C.; Qi, X.; Song, D. Real-time schedule recovery in liner shipping service with regular uncertainties and disruption events. Transp. Res. Part B Methodol. 2016, 93, 762–788. [Google Scholar] [CrossRef]
- Liu, M.; Liu, R.; Zhang, E.; Chu, C. Eco-friendly container transshipment route scheduling problem with repacking operations. J. Comb. Optim. 2020, 43, 1010–1035. [Google Scholar] [CrossRef]
- Song, D.P.; Dong, J.X. Cargo routing and empty container repositioning in multiple shipping service routes. Transp. Res. Part B Methodol. 2012, 46, 1556–1575. [Google Scholar] [CrossRef]
- Dong, J.X.; Lee, C.Y.; Song, D.P. Joint service capacity planning and dynamic container routing in shipping network with uncertain demands. Transp. Res. Part B Methodol. 2015, 78, 404–421. [Google Scholar] [CrossRef]
- Tran, N.K.; Haasis, H.D. Literature survey of network optimization in container liner shipping. Flex. Serv. Manuf. J. 2015, 27, 139–179. [Google Scholar] [CrossRef]
- Ng, M. Distribution-free vessel deployment for liner shipping. Eur. J. Oper. Res. 2014, 238, 858–862. [Google Scholar] [CrossRef]
- Shintani, K.; Imai, A.; Nishimura, E.; Papadimitriou, S. The container shipping network design problem with empty container repositioning. Transp. Res. Part E Logist. Transp. Rev. 2007, 43, 39–59. [Google Scholar] [CrossRef]
- Song, D.P.; Dong, J.X. Long-haul liner service route design with ship deployment and empty container repositioning. Transp. Res. Part B Methodol. 2013, 55, 188–211. [Google Scholar] [CrossRef]
- Wang, S. A novel hybrid-link-based container routing model. Transp. Res. Part E Logist. Transp. Rev. 2014, 61, 165–175. [Google Scholar] [CrossRef][Green Version]
- Jeong, Y.; Saha, S.; Chatterjee, D.; Moon, I. Direct shipping service routes with an empty container management strategy. Transp. Res. Part E Logist. Transp. Rev. 2018, 118, 123–142. [Google Scholar] [CrossRef]
- Kuzmicz, K.A.; Pesch, E. Approaches to empty container repositioning problems in the context of Eurasian intermodal transportation. Omega 2019, 85, 194–213. [Google Scholar] [CrossRef]
- Delage, E.; Ye, Y. Distributionally robust optimization under moment uncertainty with application to data-driven problems. Oper. Res. 2010, 58, 595–612. [Google Scholar] [CrossRef]
- Cheng, J.; Delage, E.; Lisser, A. Distributionally robust stochastic knapsack problem. SIAM J. Optim. 2014, 24, 1485–1506. [Google Scholar] [CrossRef]
- Zhang, Y.; Shen, S.; Erdogan, S.A. Distributionally robust appointment scheduling with moment-based ambiguity set. Oper. Res. Lett. 2017, 45, 139–144. [Google Scholar] [CrossRef]
- Zhang, Y.; Shen, S.; Erdogan, S.A. Solving 0–1 semidefinite programs for distributionally robust allocation of surgery blocks. Optim. Lett. 2018, 12, 1503–1521. [Google Scholar] [CrossRef]
- Liu, M.; Liu, X.; Chu, F.; Zheng, F.; Chu, C. Robust disassembly line balancing with ambiguous task processing times. Int. J. Prod. Res. 2020, 58, 5806–5835. [Google Scholar] [CrossRef]
- Liu, M.; Liu, X.; Chu, F.; Zhu, M.; Zheng, F. Liner ship bunkering and sailing speed planning with uncertain demand. Comput. Appl. Math. 2020, 39, 22. [Google Scholar] [CrossRef]
- Maini, P.; Sujit, P. Path Planning Algorithms for Single and Multiple Mobile Robot Systems. Ph.D. Thesis, IIIT-Delhi, New Delhi, India, 2020. [Google Scholar]
- Bahubalendruni, M.R.; Biswal, B.B. An intelligent approach towards optimal assembly sequence generation. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2018, 232, 531–541. [Google Scholar] [CrossRef]
- Bahubalendruni, M.; Gulivindala, A.K.; Varupala, S.; Palavalasa, D.K. Optimal assembly sequence generation through computational approach. Sādhanā 2019, 44, 174. [Google Scholar] [CrossRef]
- Bahubalendruni, M.R.; Gulivindala, A.; Kumar, M.; Biswal, B.B.; Annepu, L.N. A hybrid conjugated method for assembly sequence generation and explode view generation. Assem. Autom. 2019, 39, 211–225. [Google Scholar] [CrossRef]
- Charnes, A.; Cooper, W.W.; Symonds, G.H. Cost horizons and certainty equivalents: An approach to stochastic programming of heating oil. Manag. Sci. 1958, 4, 235–263. [Google Scholar] [CrossRef]
- Simic, V. Interval-parameter chance-constraint programming model for end-of-life vehicles management under rigorous environmental regulations. Waste Manag. 2016, 52, 180–192. [Google Scholar] [CrossRef]
- Kınay, Ö.B.; Kara, B.Y.; Saldanha-da Gama, F.; Correia, I. Modeling the shelter site location problem using chance constraints: A case study for Istanbul. Eur. J. Oper. Res. 2018, 270, 132–145. [Google Scholar] [CrossRef]
- Kepaptsoglou, K.; Fountas, G.; Karlaftis, M.G. Weather impact on containership routing in closed seas: A chance-constraint optimization approach. Transp. Res. Part C Emerg. Technol. 2015, 55, 139–155. [Google Scholar] [CrossRef]
- Ng, M. Container vessel fleet deployment for liner shipping with stochastic dependencies in shipping demand. Transp. Res. Part B Methodol. 2015, 74, 79–87. [Google Scholar] [CrossRef]
- Meng, Q.; Wang, T. A chance constrained programming model for short-term liner ship fleet planning problems. Marit. Pol. Mgmt. 2010, 37, 329–346. [Google Scholar] [CrossRef]
- Sun, H.; Gao, Z.; Szeto, W.; Long, J.; Zhao, F. A distributionally robust joint chance constrained optimization model for the dynamic network design problem under demand uncertainty. Netw. Spat. Econ. 2014, 14, 409–433. [Google Scholar] [CrossRef]
- Liu, M.; Liu, X.; Chu, F.; Zheng, F.; Chu, C. Distributionally robust inventory routing problem to maximize the service level under limited budget. Transp. Res. Part E Logist. Transp. Rev. 2019, 126, 190–211. [Google Scholar] [CrossRef]
- Xie, Y.; Chen, X.; Wu, Q.; Zhou, Q. Second-order conic programming model for load restoration considering uncertainty of load increment based on information gap decision theory. Int. J. Electr. Power Energy Syst. 2019, 105, 151–158. [Google Scholar] [CrossRef]
- Escudero, L.F.; Monge, J.F.; Morales, D.R. An SDP approach for multiperiod mixed 0–1 linear programming models with stochastic dominance constraints for risk management. Comput. Oper. Res. 2015, 58, 32–40. [Google Scholar] [CrossRef]
- Bertsimas, D.; Gupta, V.; Kallus, N. Robust sample average approximation. arXiv 2014, arXiv:1408.4445. [Google Scholar] [CrossRef]
- Emelogu, A.; Chowdhury, S.; Marufuzzaman, M.; Bian, L.; Eksioglu, B. An enhanced sample average approximation method for stochastic optimization. Int. J. Prod. Econ. 2016, 182, 230–252. [Google Scholar] [CrossRef]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-Means++: The Advantages of Careful Seeding; Technical Report; The Stanford InfoLab: Stanford, CA, USA, 2006. [Google Scholar]
- Wagner, M.R. Stochastic 0–1 linear programming under limited distributional information. Oper. Res. Lett. 2008, 36, 150–156. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Problem Setting | Modeling Method | Solution Method | |||
|---|---|---|---|---|---|---|
| Demand | Cargo Routing | Empty Container Repositioning | Repacking Operations | Chance Constrained | ||
| Meng et al. [1] | Known distribution | √ | √ | SAA | ||
| Ng [13] | Distribution-free | √ | √ | AMI | ||
| Dong et al. [11] | Known distribution | √ | SAA, PHA | |||
| Li et al. [8] | Known distribution | √ | DPA | |||
| Wang et al. [6] | Deterministic | √ | √ | Cplex | ||
| Liu et al. [9] | Distribution-free | √ | √ | √ | AMI, MI-SOCP | |
| Song and Dong [15] | Deterministic | √ | Cplex | |||
| Jeong et al. [17] | Deterministic | √ | HOP | |||
| Kuzmicz and Pesch [18] | Deterministic | √ | Cplex | |||
| Song and Dong [10] | Deterministic | √ | √ | TSP, THR | ||
| Our work | Distribution-free | √ | √ | √ | √ | SAA, eSAA, AMI, MI-SOCP |
| Modes | Origin Port | Transshipment Port | Destination Port |
|---|---|---|---|
| 2TEUs→1FEU | None | 1FEU→2TEUs | |
| None | 2TEUs→1FEU | 1FEU→2TEUs | |
| None | 2TEUs→1FEU 1FEU→2TEUs | None | |
| 2TEUs→1FEU | 1FEU→2TEUs | None | |
| 2TEUs | None | 2TEUs |
| Port Type | Ship Type | Loading | Discharge | Transship |
|---|---|---|---|---|
| A | TEU | 248 | 324 | 183 |
| FEU | 256 | 332 | 198 | |
| 51.61% | 51.23% | 54.10% | ||
| B | TEU | 118 | 118 | 145 |
| FEU | 148 | 148 | 145 | |
| 62.71% | 62.71% | 50.00% | ||
| C | TEU | 110 | 110 | 71 |
| FEU | 156 | 156 | 106 | |
| 70.91% | 70.91% | 74.65% |
| Method | Comb | Mixed | Normal | Uniform | |||
|---|---|---|---|---|---|---|---|
| obj() | Time(s) | obj() | Time(s) | obj() | Time(s) | ||
| SAA | 4–8 | 198.24 | 211.97 | 191.60 | 216.52 | 187.86 | 211.30 |
| 5–8 | 201.40 | 213.83 | 195.25 | 215.42 | 185.72 | 213.96 | |
| 6–8 | 205.63 | 217.55 | 195.63 | 219.41 | 187.55 | 217.70 | |
| 4–10 | 181.36 | 243.33 | 166.52 | 246.48 | 171.20 | 243.40 | |
| 5–10 | 182.18 | 244.89 | 169.95 | 244.69 | 172.06 | 245.39 | |
| 6–10 | 184.44 | 249.54 | 170.69 | 248.22 | 177.12 | 249.96 | |
| 4–12 | 185.86 | 274.51 | 172.46 | 274.58 | 176.90 | 275.71 | |
| 5–12 | 186.42 | 276.23 | 176.78 | 275.01 | 179.87 | 278.28 | |
| 6–12 | 188.90 | 280.43 | 177.22 | 278.32 | 183.67 | 281.55 | |
| average | 190.49 | 245.81 | 179.57 | 246.52 | 180.22 | 246.36 | |
| eSAA with K-means | 4–8 | 195.28 | 211.42 | 191.86 | 212.56 | 188.92 | 211.45 |
| 5–8 | 194.42 | 202.73 | 202.14 | 213.70 | 192.03 | 213.75 | |
| 6–8 | 194.68 | 217.37 | 196.97 | 217.77 | 191.15 | 216.51 | |
| 4–10 | 185.10 | 243.07 | 171.01 | 243.43 | 178.58 | 242.60 | |
| 5–10 | 183.25 | 245.00 | 174.71 | 245.48 | 178.83 | 245.31 | |
| 6–10 | 185.58 | 248.75 | 169.91 | 249.58 | 177.05 | 248.61 | |
| 4–12 | 187.11 | 274.53 | 179.98 | 274.49 | 183.42 | 274.75 | |
| 5–12 | 189.64 | 276.88 | 179.90 | 276.69 | 180.63 | 276.92 | |
| 6–12 | 188.56 | 280.16 | 182.75 | 280.18 | 183.29 | 280.37 | |
| average | 189.29 | 244.43 | 183.25 | 245.98 | 183.77 | 245.59 | |
| eSAA with K-means++ | 4–8 | 193.86 | 214.26 | 202.48 | 213.98 | 190.28 | 214.03 |
| 5–8 | 192.53 | 217.14 | 206.22 | 216.10 | 188.98 | 216.79 | |
| 6–8 | 194.77 | 220.81 | 197.26 | 219.19 | 188.99 | 220.78 | |
| 4–10 | 186.13 | 246.49 | 169.87 | 245.24 | 175.56 | 245.83 | |
| 5–10 | 184.07 | 248.71 | 170.01 | 248.62 | 179.66 | 248.92 | |
| 6–10 | 185.27 | 252.48 | 171.99 | 252.07 | 178.86 | 252.15 | |
| 4–12 | 188.44 | 279.57 | 178.99 | 278.24 | 188.16 | 278.61 | |
| 5–12 | 186.04 | 281.97 | 182.16 | 281.79 | 179.76 | 282.15 | |
| 6–12 | 186.38 | 285.79 | 184.43 | 285.12 | 184.29 | 286.61 | |
| average | 188.61 | 249.69 | 184.82 | 248.93 | 183.84 | 249.54 | |
| Method | Comb | Mixed | Normal | Uniform | |||
|---|---|---|---|---|---|---|---|
| obj() | Time(s) | obj() | Time(s) | obj() | Time(s) | ||
| SAA | 4–8 | 198.24 | 214.78 | 191.60 | 214.60 | 187.86 | 214.94 |
| 5–8 | 201.40 | 216.93 | 195.25 | 216.61 | 185.72 | 217.10 | |
| 6–8 | 205.63 | 221.11 | 195.63 | 219.91 | 187.55 | 221.15 | |
| 4–10 | 200.96 | 246.24 | 191.10 | 245.80 | 188.59 | 246.83 | |
| 5–10 | 210.19 | 248.91 | 204.54 | 249.30 | 190.16 | 249.98 | |
| 6–10 | 210.14 | 252.95 | 201.35 | 253.02 | 193.67 | 253.50 | |
| 4–12 | 206.53 | 279.40 | 199.37 | 278.01 | 191.64 | 278.19 | |
| 5–12 | 211.06 | 281.31 | 205.81 | 280.17 | 194.84 | 281.10 | |
| 6–12 | 212.42 | 284.80 | 206.74 | 284.22 | 196.29 | 285.07 | |
| average | 206.28 | 249.60 | 199.04 | 249.07 | 190.70 | 249.76 | |
| eSAA with K-means | 4–8 | 195.28 | 213.67 | 191.86 | 214.28 | 188.92 | 213.96 |
| 5–8 | 194.42 | 216.58 | 202.14 | 216.26 | 192.03 | 216.67 | |
| 6–8 | 194.68 | 220.67 | 196.97 | 220.16 | 191.15 | 219.81 | |
| 4–10 | 199.26 | 245.22 | 195.15 | 244.81 | 192.59 | 245.42 | |
| 5–10 | 196.15 | 248.88 | 204.85 | 247.75 | 195.35 | 248.41 | |
| 6–10 | 197.35 | 252.50 | 204.21 | 251.40 | 192.99 | 251.60 | |
| 4–12 | 200.64 | 276.89 | 209.17 | 276.85 | 197.47 | 276.94 | |
| 5–12 | 200.00 | 281.18 | 207.64 | 280.20 | 194.05 | 279.99 | |
| 6–12 | 198.56 | 284.04 | 210.73 | 283.97 | 196.50 | 283.24 | |
| average | 197.37 | 248.85 | 202.52 | 248.41 | 193.45 | 248.45 | |
| eSAA with K-means++ | 4–8 | 193.86 | 215.45 | 202.48 | 214.67 | 190.28 | 216.01 |
| 5–8 | 192.53 | 218.59 | 206.22 | 218.00 | 188.98 | 219.14 | |
| 6–8 | 194.77 | 222.08 | 197.26 | 221.88 | 188.99 | 223.08 | |
| 4–10 | 197.94 | 248.09 | 200.11 | 248.10 | 192.36 | 249.60 | |
| 5–10 | 196.47 | 251.15 | 202.55 | 251.32 | 192.76 | 251.38 | |
| 6–10 | 199.88 | 254.81 | 201.69 | 254.49 | 193.02 | 254.96 | |
| 4–12 | 202.06 | 282.66 | 205.74 | 281.21 | 198.24 | 282.34 | |
| 5–12 | 198.54 | 285.05 | 209.39 | 284.70 | 193.27 | 284.07 | |
| 6–12 | 197.71 | 288.22 | 210.50 | 287.91 | 196.31 | 287.87 | |
| average | 197.08 | 251.79 | 203.99 | 251.36 | 192.69 | 252.05 | |
| Method | Comb | Mixed | Normal | Uniform | |||
|---|---|---|---|---|---|---|---|
| obj() | Time(s) | obj() | Time(s) | obj() | Time(s) | ||
| SAA | 4–8 | 198.24 | 217.07 | 191.60 | 219.01 | 187.86 | 217.41 |
| 5–8 | 201.40 | 219.08 | 195.25 | 222.83 | 185.72 | 220.20 | |
| 6–8 | 205.63 | 223.00 | 195.63 | 224.05 | 187.55 | 223.98 | |
| 4–10 | 200.96 | 249.08 | 191.10 | 249.77 | 188.59 | 250.02 | |
| 5–10 | 210.19 | 252.23 | 204.54 | 251.51 | 190.16 | 252.09 | |
| 6–10 | 210.14 | 255.49 | 201.35 | 254.90 | 193.67 | 256.27 | |
| 4–12 | 206.53 | 281.55 | 199.37 | 281.35 | 191.64 | 282.02 | |
| 5–12 | 211.06 | 284.30 | 205.81 | 283.87 | 194.84 | 284.54 | |
| 6–12 | 212.42 | 288.10 | 206.74 | 287.80 | 196.29 | 288.10 | |
| average | 206.28 | 252.21 | 199.04 | 252.79 | 190.70 | 252.74 | |
| eSAA with K-means | 4–8 | 195.28 | 217.79 | 191.86 | 217.55 | 188.92 | 217.83 |
| 5–8 | 194.42 | 219.97 | 202.14 | 220.07 | 192.03 | 219.74 | |
| 6–8 | 194.68 | 223.77 | 196.97 | 223.66 | 191.15 | 224.19 | |
| 4–10 | 199.26 | 251.05 | 195.15 | 250.20 | 192.59 | 250.25 | |
| 5–10 | 196.15 | 252.38 | 204.85 | 252.55 | 195.35 | 252.76 | |
| 6–10 | 197.35 | 255.75 | 204.21 | 255.76 | 192.99 | 256.30 | |
| 4–12 | 200.64 | 283.32 | 209.17 | 283.22 | 197.47 | 282.78 | |
| 5–12 | 200.00 | 286.21 | 207.64 | 285.17 | 194.05 | 284.71 | |
| 6–12 | 198.56 | 288.37 | 210.73 | 288.76 | 196.50 | 288.38 | |
| average | 197.37 | 253.18 | 202.52 | 252.99 | 193.45 | 252.99 | |
| eSAA with K-means++ | 4–8 | 193.86 | 233.29 | 202.48 | 219.24 | 190.28 | 217.61 |
| 5–8 | 192.53 | 221.91 | 206.22 | 221.48 | 188.98 | 219.89 | |
| 6–8 | 194.77 | 225.41 | 197.26 | 225.41 | 188.99 | 223.24 | |
| 4–10 | 197.94 | 252.25 | 200.11 | 252.57 | 192.36 | 250.84 | |
| 5–10 | 196.47 | 255.03 | 202.55 | 254.98 | 192.76 | 252.23 | |
| 6–10 | 199.88 | 259.06 | 201.69 | 259.50 | 193.02 | 256.72 | |
| 4–12 | 202.06 | 286.34 | 205.74 | 285.73 | 198.24 | 283.85 | |
| 5–12 | 198.54 | 287.83 | 209.39 | 288.63 | 193.27 | 286.25 | |
| 6–12 | 197.71 | 290.15 | 210.50 | 292.30 | 196.31 | 289.45 | |
| average | 197.08 | 256.81 | 203.99 | 255.54 | 192.69 | 253.34 | |
| obj() | Time(s) | obj() | Time(s) | obj() | Time(s) | |
|---|---|---|---|---|---|---|
| 361.53 | 107.83 | 419.23 | 116.85 | 547.00 | 128.89 | |
| 423.76 | 107.88 | 521.85 | 115.65 | 718.53 | 131.81 | |
| 476.12 | 107.24 | 600.11 | 117.19 | 847.34 | 135.03 | |
| 355.10 | 108.46 | 406.18 | 118.74 | 517.14 | 131.82 | |
| 422.45 | 107.67 | 515.40 | 118.34 | 702.00 | 134.81 | |
| 476.85 | 109.00 | 596.82 | 119.51 | 836.13 | 134.01 | |
| 344.53 | 111.09 | 387.99 | 121.43 | 479.07 | 170.19 | |
| 418.71 | 110.72 | 505.86 | 120.47 | 681.74 | 355.96 | |
| 475.08 | 112.32 | 590.85 | 122.33 | 821.95 | 188.90 | |
| 323.10 | 104.34 | 363.25 | 125.78 | 495.63 | 153.27 | |
| 413.35 | 114.07 | 494.13 | 124.89 | 658.56 | 335.38 | |
| 471.85 | 114.87 | 583.32 | 126.16 | 805.79 | 253.89 | |
| obj() | Time(s) | Rel | obj() | Time(s) | Rel | obj() | Time(s) | Rel | |
|---|---|---|---|---|---|---|---|---|---|
| AMI | 398.05 | 107.41 | 100.00% | 407.54 | 99.95 | 100.00% | 568.82 | 119.21 | 100.00% |
| MI-SOCP | 326.91 | 106.55 | 100.00% | 385.51 | 121.28 | 100.00% | 483.68 | 177.94 | 100.00% |
| SAA-M | 185.07 | 284.86 | 87.05% | 211.42 | 284.16 | 91.68% | 212.68 | 287.54 | 94.77% |
| SAA-N | 174.45 | 253.17 | 81.55% | 205.16 | 248.56 | 92.71% | 201.52 | 266.71 | 92.47% |
| SAA-U | 171.07 | 246.93 | 78.44% | 203.08 | 251.37 | 85.76% | 200.43 | 260.11 | 87.06% |
| eSAA-K-M | 181.09 | 256.94 | 85.92% | 204.10 | 252.64 | 89.64% | 195.29 | 242.73 | 89.64% |
| eSAA-K-N | 185.77 | 268.92 | 87.08% | 204.38 | 268.95 | 91.93% | 216.03 | 269.07 | 91.93% |
| eSAA-K-U | 174.47 | 271.45 | 81.56% | 191.15 | 279.49 | 86.88% | 198.49 | 271.75 | 86.88% |
| eSAA-K+M | 180.31 | 287.82 | 84.71% | 198.52 | 244.01 | 89.04% | 204.47 | 258.39 | 89.69% |
| eSAA-K+N | 180.56 | 284.39 | 85.06% | 206.82 | 265.94 | 92.86% | 226.51 | 274.01 | 92.26% |
| eSAA-K+U | 173.75 | 269.15 | 81.70% | 196.57 | 263.59 | 86.77% | 195.28 | 255.31 | 88.74% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Liu, Z.; Liu, R.; Sun, L. Distribution-Free Approaches for an Integrated Cargo Routing and Empty Container Repositioning Problem with Repacking Operations in Liner Shipping Networks. Sustainability 2022, 14, 14773. https://doi.org/10.3390/su142214773
Liu M, Liu Z, Liu R, Sun L. Distribution-Free Approaches for an Integrated Cargo Routing and Empty Container Repositioning Problem with Repacking Operations in Liner Shipping Networks. Sustainability. 2022; 14(22):14773. https://doi.org/10.3390/su142214773
Chicago/Turabian StyleLiu, Ming, Zhongzheng Liu, Rongfan Liu, and Lihua Sun. 2022. "Distribution-Free Approaches for an Integrated Cargo Routing and Empty Container Repositioning Problem with Repacking Operations in Liner Shipping Networks" Sustainability 14, no. 22: 14773. https://doi.org/10.3390/su142214773
APA StyleLiu, M., Liu, Z., Liu, R., & Sun, L. (2022). Distribution-Free Approaches for an Integrated Cargo Routing and Empty Container Repositioning Problem with Repacking Operations in Liner Shipping Networks. Sustainability, 14(22), 14773. https://doi.org/10.3390/su142214773