1. Introduction
Internet infrastructure provides equal access to education, essential services, and professional opportunities, affording users the potential to alleviate social or economic disparities. Moreover, important sectors of the economy and essential services rely on the internet for daily activities [
1]. This has led the internet (and its corresponding network infrastructure) to be recognized as vital to several critical infrastructures [
2,
3]. However, increased reliance on the internet has exacerbated the effects of outages, making internet resilience a growing concern [
4]. It is widely recognized that the internet is not sufficiently resilient [
5]—especially during natural disasters and pandemics (such as the ongoing COVID-19 crisis), because of the additional strain that they put on infrastructure [
6,
7].
Resilience is not equal across different spatial scales, locations, and critical infrastructure systems (e.g., [
8,
9,
10]). Differences in infrastructure conditions across regions hamper the comparison of resilience states. Some of a given infrastructure may be in excellent condition and use modern technologies, whereas other parts of the same infrastructure might be in poor condition with incompatible technology. This complicates the resilience assessment of large-scale critical infrastructure, including that of the internet, because the analysis has to consider these disparities. Unfortunately, such an assessment is a crucial step for stakeholders, especially to prioritize projects to confront infrastructural shortcomings across different locations (and, in the case of the internet, to mitigate digital divides). Beyond presenting a novel geospatial framework to assess the resilience of critical infrastructure and evaluate disparities, this study focuses on three key contributors—access flexibility, disruption risk, and disruption vulnerability—using a broad big data analysis approach. These resilience contributors are understudied for internet infrastructure, yet can have significant ramifications in terms of enhancing resilience. Beyond the lack of studies of each component, very few have assessed their geospatial interdependencies within the scope of critical infrastructure resilience—an issue that deserves further consideration. Moreover, the three contributors are crucially important to the resilience of internet infrastructure from the community-served perspective, as shown by this research, warranting their further study.
Resilience refers to a system’s ability to withstand disruptive events and recover quickly from an error state [
11]. With regard to the internet as a vital component of critical infrastructure, resilience refers to maintaining communications (i.e., internet access) despite a network disruption event, and restoring them quickly in case of an outage. The different factors that contribute to resilience have been identified in the literature, and have been used to assess resilience by several researchers [
4,
7,
11,
12,
13,
14,
15]. Some of the most widely accepted contributors to the resilience of systems such as the internet include system flexibility, failure risk, failure vulnerability, failure detection, failure response, and risk minimization [
5,
11,
15,
16]. In the context of internet resilience, previous studies have addressed network survivability. Network survivability studies the restoration of communications following a disruption, encompassing failure detection and response [
17,
18] and risk minimization [
12,
19,
20,
21,
22]. However, little research has been conducted on network access flexibility, failure risk, and failure vulnerability. The present study begins to address this gap using quantitative definitions and the significance of each of the resilience contributors.
Internet access flexibility refers to the availability and accessibility of internet services at a given location, and is an important component of internet resilience. Availability is the level to which service is provided at a location, while accessibility refers to whether the corresponding population can use the service. Access flexibility can be a crucial factor in disruption scenarios whereby the only (or one of the few) access pathway for people experiences an outage; this can be jointly hampered by a high disruption risk and vulnerability. Elena-Bucea et al. [
23] have shown important differences in quality of access based on education level, socioeconomic status, geography, and other factors. Failure risk (or risk of internet disruption) refers to the propensity of the internet service to be disrupted. To assess such a risk, which can significantly impact resilience, the concept of sudden-onset disasters [
24] has been used in previous work. Sudden-onset disasters (SODs) have the capability of disrupting network activities, and include natural disasters and anthropogenic activities [
25]. Natural disasters, in particular, can cause frequent and prolonged critical infrastructure outages. Network disruption risks can also be aggravated due to underlying technological limitations. Some examples of this include weather-dependent satellite-based services (or free-space optics) and the general interdependency with electric grids [
26,
27]. Vulnerability to internet disruption (or failure vulnerability) is best described as the factors exacerbating the harm caused by a service outage. It contrasts with disruption risk by studying the potential impacts of an outage, rather than its likelihood. In locations that rely on the internet for essential services and the subsistence of their local economies, the effects of prolonged outages can present with deleterious conditions and hamper economic growth. Such dependencies cause certain locations to be more vulnerable than others, making the vulnerability to service disruption an important contributor to study in a geospatial resilience context. The relationships between the resilience contributors underscore the necessity of incorporating them into a broad geospatial framework. For example, within a critical infrastructure resilience context, it is crucial to identify locations that are heavily dependent on infrastructure (i.e., high disruption vulnerability) while having a large amount of disruption events (i.e., high disruption risk) and few alternatives (i.e., low access flexibility).
There are significant challenges in assessing internet resilience [
5]. Some of these are related to the inherent difficulties of resilience analyses in general, such as the lack of standardized assessment methodologies [
11]. However, there are important added complexities for internet resilience. One of these is the variety of available network types, as technologies used within network infrastructure can vary significantly with geography. This can have significant impacts on the resilience of a network, as each technology is vulnerable to different external factors. Moreover, the direct competition for service populations results in a general disincentive for cooperation towards network resilience across different ISPs (internet service providers) and networks [
1]. The nontrivial nature of detecting and reporting network outages, in addition to variable delivery technologies, contributes to the lack of availability of datasets describing network outages.
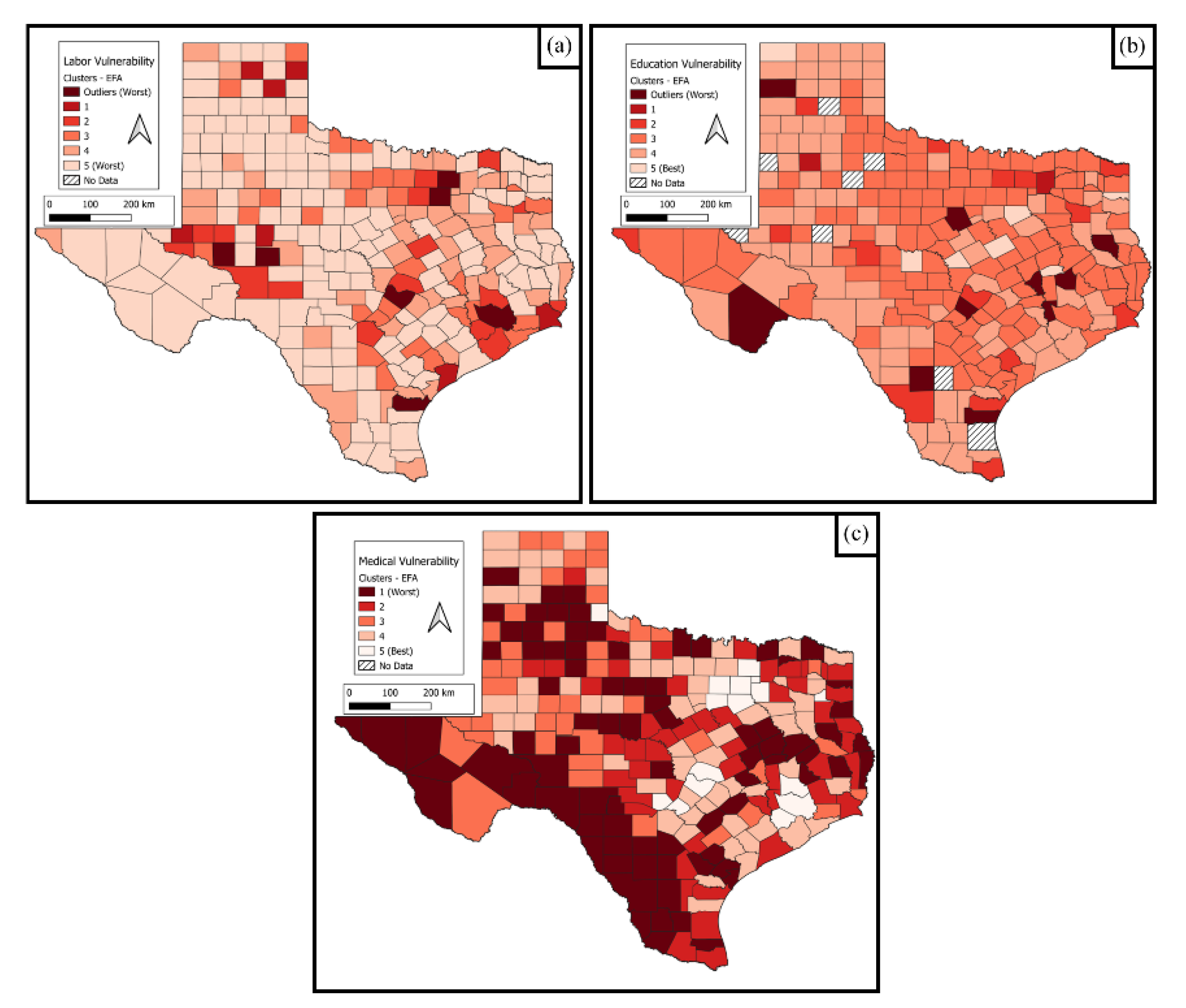
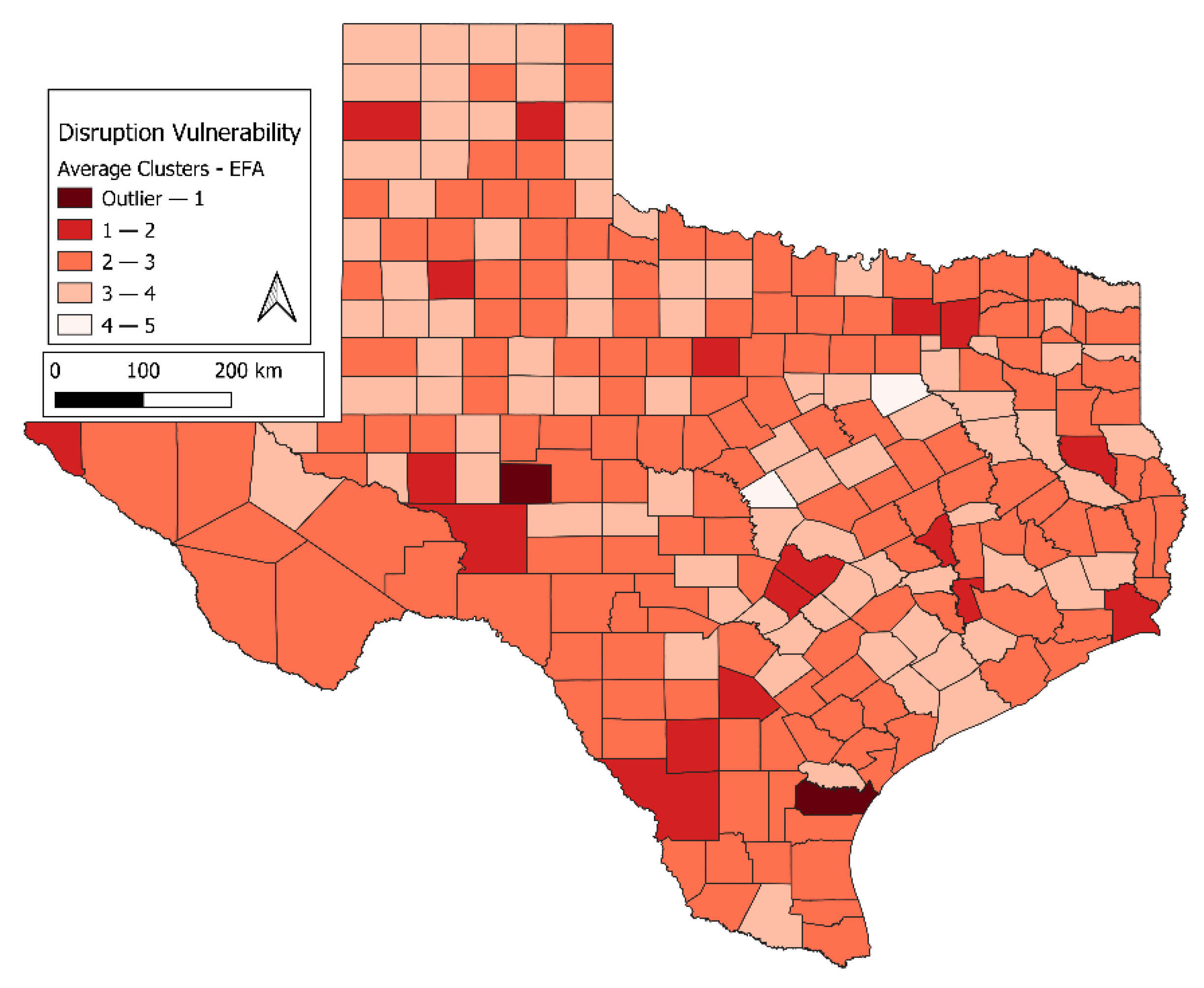
The rapid growth of network utilization, along with our increased reliance on critical infrastructures as a whole, makes it important to study geospatial disparities in resilience. The present study develops a new framework for such an analysis, and demonstrates the developed approach using the internet infrastructure in Texas as a testbed. Texas, despite being one of the most populated US states, has wide variation in population density, and is vulnerable to natural disasters. This makes Texas an ideal model study location to demonstrate the rigor of the framework developed in this research. Within the developed framework, internet access flexibility is addressed through the study of service availability and accessibility. The risk of internet disruption is addressed through the relative risk of sudden-onset disasters. Vulnerability to internet disruption is addressed by studying a subset of vulnerabilities based on the geospatial distributions of three regional user sectors: advanced industries, educational institutions, and telemedicine. These three sectors were carefully selected because of their far-reaching societal impacts when disrupted, and serve as a representative surrogate for overall vulnerability to internet outages in a region. While it is recognized that there may be other specific local vulnerabilities to internet disruption, studying these is beyond the scope of this demonstration of the proposed geospatial framework. The developed geospatial modeling framework presented in this study is novel; transferable and translatable to other regions, network topologies, and critical infrastructures; and readily expandable to incorporate additional vulnerabilities not specifically addressed in this paper.
2. Materials and Methods
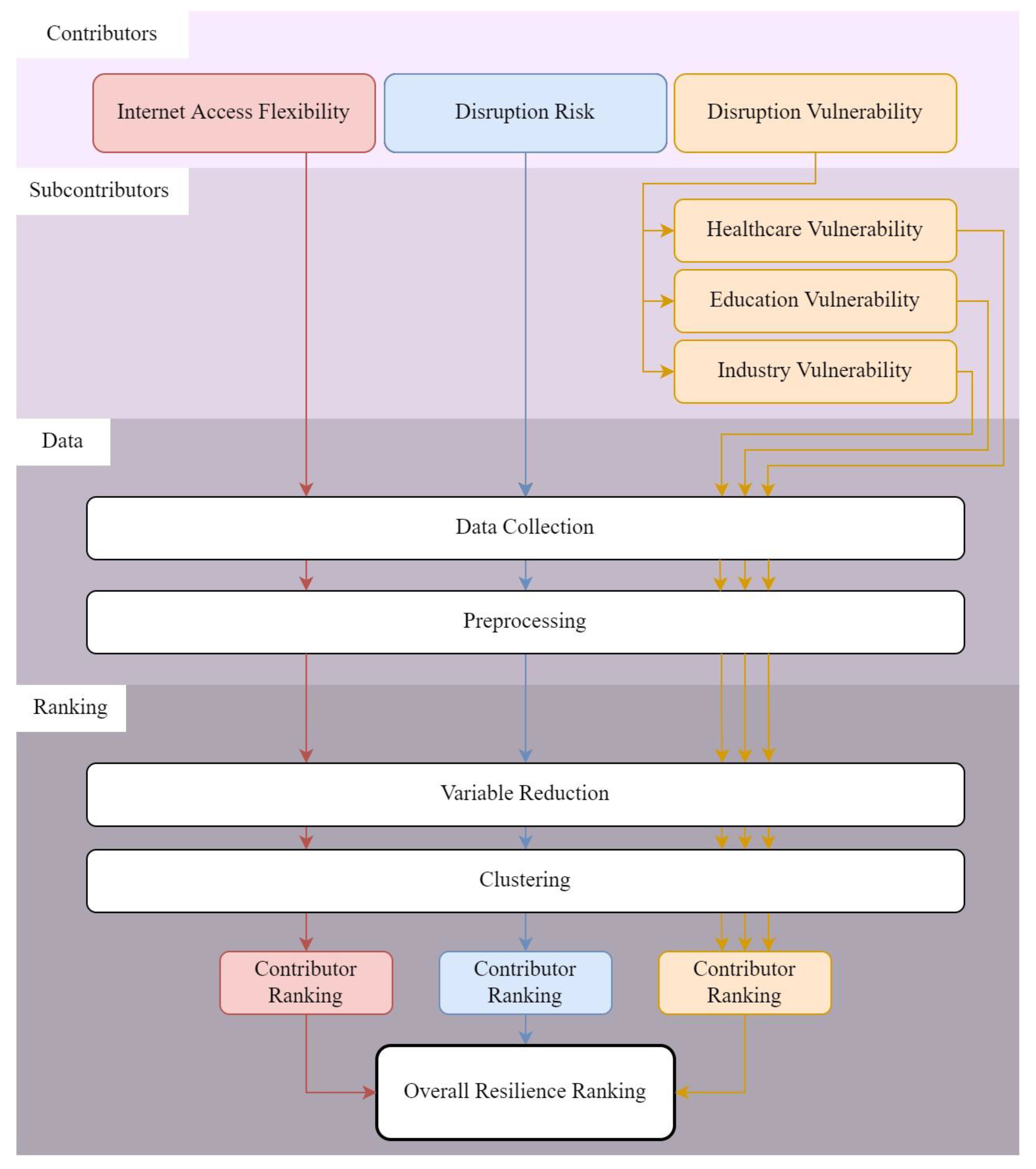
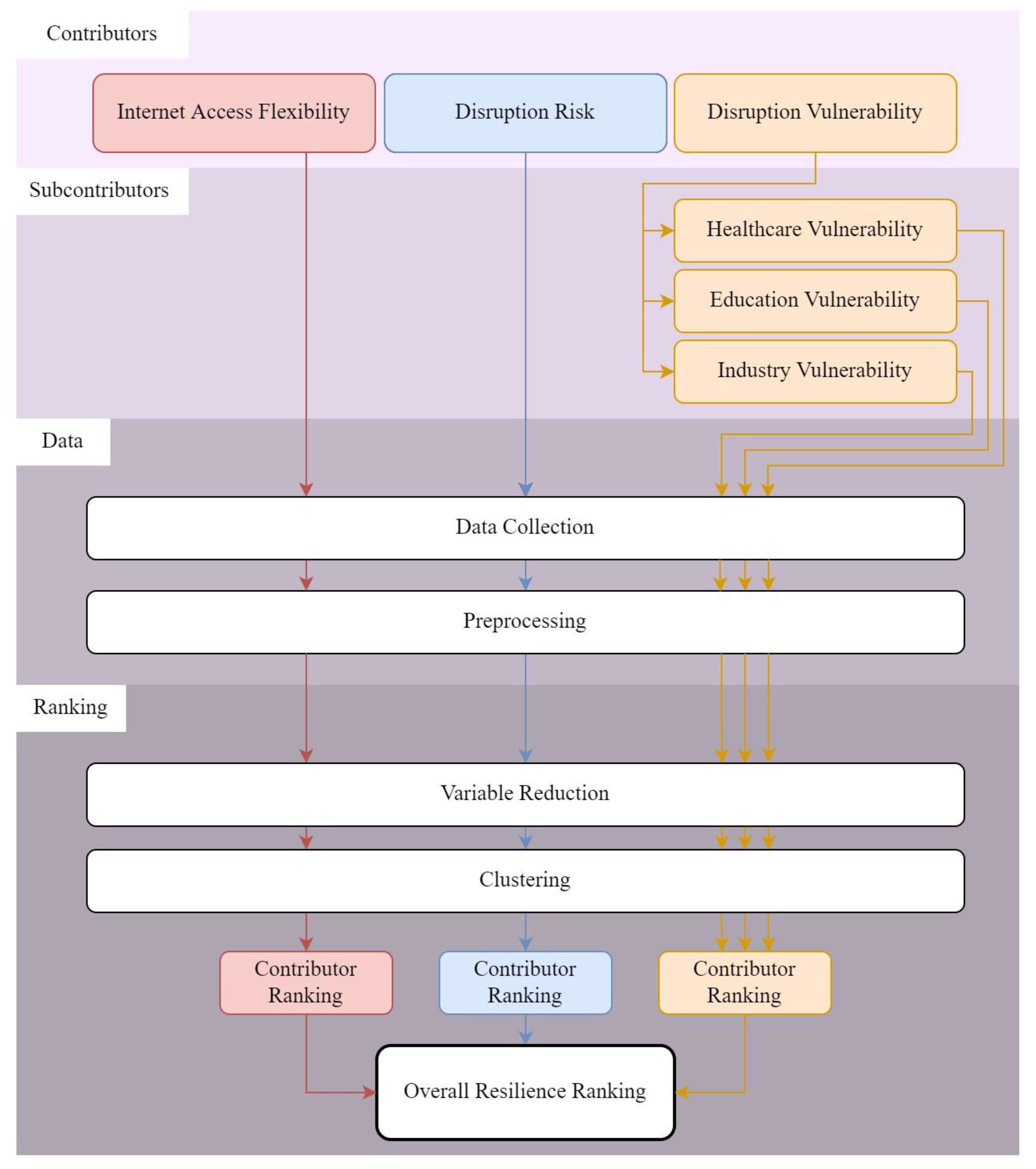
The developed framework is summarized in
Figure 1. First, the contributors and sub-contributors to the resilience of the critical infrastructure are identified—in this case, internet access flexibility, risk of service disruption, and vulnerability to service disruption. These three contributors, as mentioned previously, have been understudied but, as shown later in this manuscript, are critical aspects that can guide decision-making towards enhanced resilience of critical infrastructure. Sub-contributors—factors that fall within a contributor to resilience, but are not related to one another—are discussed in more detail in the
Supplementary Information (SI) (Sections S1.1–S1.3). Contributors to resilience are not reliably described by a few data points; therefore, the developed framework is designed to incorporate vast swaths of data through variable reduction. The reduced variables are then clustered to determine locations that behave similarly. Lastly, the attributes for each cluster are analyzed to provide individual rankings for each resilience contributor, and these rankings are then used to assign an overall resilience score, as discussed in more detail below. The methods constituting this framework are new within a critical infrastructure context, but have been commonly implemented in geospatial big data analyses (e.g., [
28,
29,
30]).
2.1. Study Region
Texas is the second largest (by area), second most productive (by gross domestic product (GDP)), and second most populated state in the US. Five of the fifteen most populated cities in the US are in Texas—the most of any state [
31]. This, however, should not mask the variation in population density in Texas as a consideration within a resilience context. The state is home to 3 of the 10 least populated counties in the United States [
32], being the only state to have a city in the top 15 and a county in the bottom 10. The combination of large populations in unevenly distributed areas makes Texas a challenging state in which to provide resilient internet services. The heterogeneous nature of population distribution in Texas is further exacerbated by its weather patterns and its location along the Gulf of Mexico, which make Texas susceptible to natural disasters.
Between 1980 and 2019, Texas experienced both the highest amount of billion-dollar climate disasters and the highest cumulative damage by natural disasters in any state [
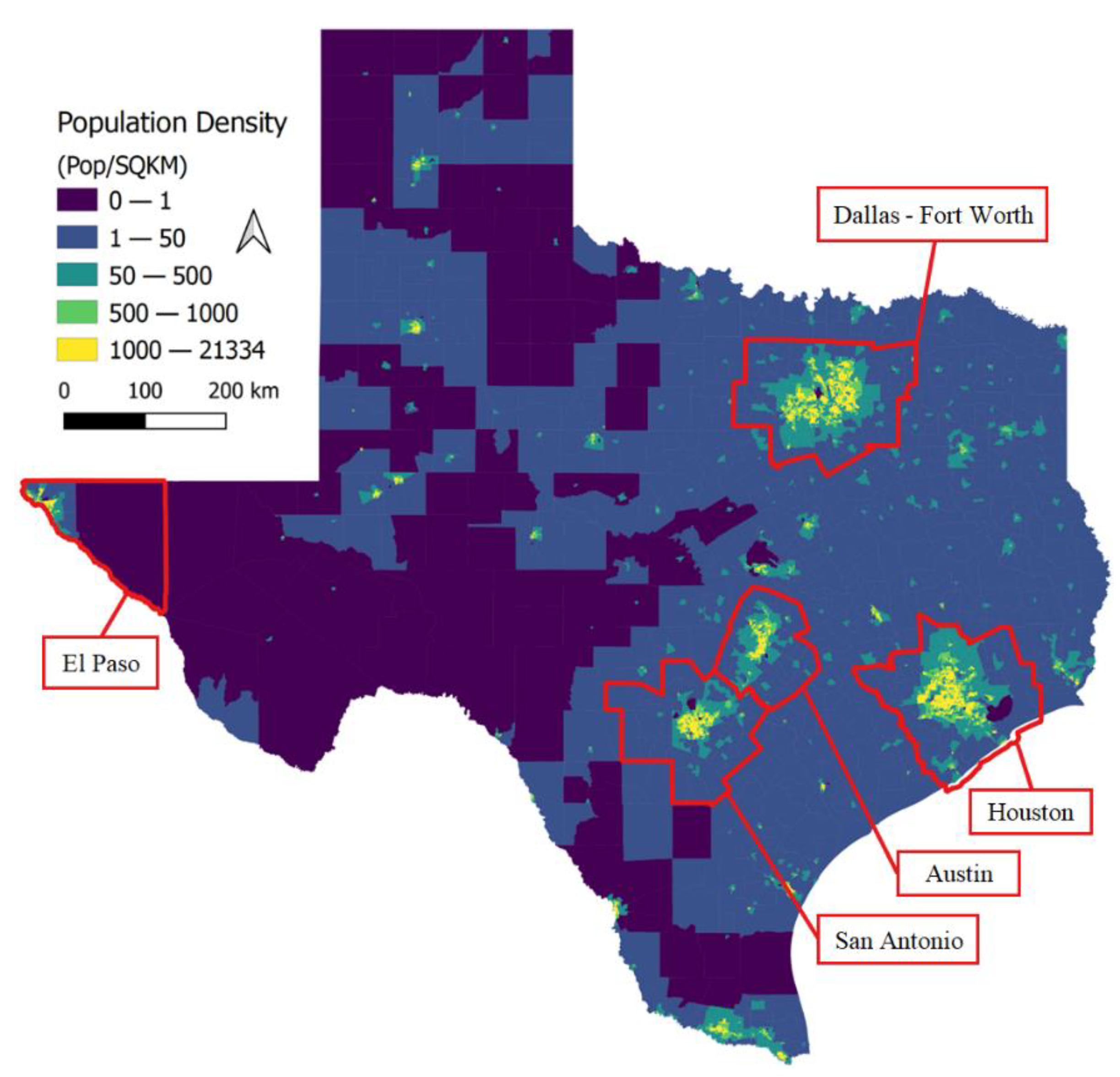
33]. Because of the combination of these factors, which are crucial to network resilience, the network infrastructure of Texas was selected as a case study for implementing the geospatial modeling framework developed herein. A map of Texas illustrating population density is shown in
Figure 2; as shown in the figure, much of West Texas and the panhandle have relatively low densities, whereas its coastal and near-coastal zones (in East and Central Texas) and its border valley region (in South Texas) exhibit much higher population densities, including its largest cities of Houston, Dallas, Austin, and San Antonio.
2.2. Data Collection
Since resilience contributors cannot be reliably interpreted by a few data points, diverse datasets were developed to analyze geospatial disparities in internet access, disruption risk, and disruption vulnerability. To assess internet access flexibility, datasets on ISPs (internet service providers) and cellular offerings were collected, along with governmental datasets on availability and accessibility complaints (a full description is available in
Supplementary Material SI Section S1.1). As a measure of disruption risk, data on natural disasters and storm events (which have been identified as a significant portion of sudden-onset disasters (SODs)) were sought [
24]. A full description of these datasets is available in
SI Section S1.2. To study disruption vulnerability, data sources for local dependency on the internet were investigated. As mentioned previously, three sectors of the economy with significant dependence on the internet for day-to-day activities were identified and chosen for detailed study: telemedicine, education, and advanced industries; data for these sectors were gathered. Detailed descriptions of the data on each of these sectors are available in
SI Section S1.3 Table S1 contains a complete listing of all of the datasets used in this study, and
Table S7 provides a listing of the economic sectors implemented for the advanced industries sub-contributor.
Past studies have found it beneficial to study lower-level data aggregations to ensure that important geospatial disparities are not overlooked [
34]. As such, data sources with high spatial resolution were sought, and efforts were made to keep their resolution as high as possible during the analysis. Because of the quality of the data sources, the internet access analysis was performed at the census tract level, while the disruption risk and disruption vulnerability analyses were performed at the county level. The possibility of interdependency with other critical infrastructures that may affect the assessment of disruption vulnerability is acknowledged; however, due to data limitations, this aspect was not incorporated in the study at this time.
2.3. Data Preprocessing
The first challenge in incorporating all datasets into a geospatial framework involved the different levels of aggregation of the data (i.e., at the county, ZIP code, or census tract levels). The 2010 ZIP Code Tabulation Areas (ZCTAs) from the Census Bureau were used to match ZIP code data with census tracts and counties. There are 5265 census tracts, 1782 ZCTAs, and 254 counties in Texas. Census tracts are always completely within a county; however, it is possible for a ZCTA to span multiple tracts and counties. To downscale internet access data, each census tract was assigned the most conservative value of overlapping ZIP-code-based data, along with the value for the county in which it is located. The data used for the remaining analyses did not need to be downscaled. It should be noted that all applicable county-based data were normalized by population, except in the cases of ratios (EG, percent medically underserved area) or unitless coefficients, such as location coefficients for labor data.
2.4. Data Analysis and Resilience Ranking
The contributors and sub-contributors to resilience are not reliably described by a few data attributes; thus, large amounts of data were collected for each location, as described in prior sections. However, such large datasets are challenging to analyze geospatially. Ideally, stakeholders should be able to glean actionable information by optimizing the observability of spatial differences within the datasets. Data-driven methods can be used to this end once the data have been preprocessed (as described in
Section 2.3). Specifically, the methods within the proposed geospatial framework include performing dimensional reduction on the datasets for each resilience contributor, clustering for all of the locations in the study domain, and ranking the clusters based on their attributes. This procedure enables the simple differentiation between different clusters through attribute analysis.
Dimensional reduction (DR) is a technique that can be used to simplify a dataset with a large number of covariates. Since the datasets compiled for each contributor and sub-contributor contained multiple related attributes, DR was performed through an exploratory factor analysis (EFA) [
35,
36]. EFA identifies underlying variables to the input dataset, which can then be used to summarize the overall data structure. These underlying variables are linear combinations of the input variables, weighted to group certain input variables into each underlying variable. However, because each underlying variable accounts for different amounts of variance within the dataset, not all of the underlying variables identified by EFA may be significant to analyze. To assess which variables are significant to retain in each case, Horn’s parallel analysis (HPA) was conducted for each EFA [
37]. The implemented version of HPA compares the eigenvalues from the input data covariance matrix to those generated from uncorrelated normal variables resampled 100 times. As is customary in the literature, the 95th percentile eigenvalue was used as a cutoff for significance [
31]. Code originally developed by Cai (2016) [
38], based on the HPA implementation by Ledesma and Valero-Mora (2007) [
39], was adapted for the HPA. Although these coupled processes drastically reduce the amount of data to analyze, they do not indicate which locations may share similar behavior across our study area, nor do they provide a clear path to an actionable resilience ranking from the input data. To this end, a data-driven clustering technique was implemented at this stage.
Clustering is a useful tool to group similarly behaving data objects in a dataset. Since the underlying variables in our datasets had been identified, the values for those underlying variables for each location were obtained by evaluating the corresponding linear combination, given the weights resulting from the EFA. These scores could then be put through a clustering algorithm to group similarly performing locations together. In this research, k-means clustering analyses were performed for the underlying variable values, with a maximum iteration value of 1000, and 5 clustering repetitions for new initial cluster positions. In some cases, outlier locations were identified; these are certain locations that were different from the rest of the data and, thus, could not be grouped.
The data characteristics for each cluster were examined to identify data differences in both the underlying and input variables of each dataset. Since the amount of data was greatly reduced, and similarly performing locations were grouped together, analyzing the cluster and outlier characteristics revealed a clear distinction in data parameters. This enabled the ranking of cluster conditions for each resilience contributor. Clusters were ranked from best to worst conditions. The lowest ranking among the three resilience contributors was assigned as the overall resilience score, and defined as the limiting factor for the resilience ranking of that census tract. While various other weighting schemes could be used to calculate a resilience score, the lowest score was used in this study to highlight the resilience shortcomings of the study area.
4. Discussion
The overall rankings shown in
Figure 7 display important trends for internet resilience. Generally, rural census tracts had lower resilience rankings than urban census tracts. This means that in prioritization efforts, a consideration of the causes of lower resilience between urban and rural settings would need to be undertaken. Practically speaking, isolating the specific causes of the lower resilience rankings in different regions can lead to informed decisions regarding corrective measures. This can be more clearly appreciated in
Figure 8, which shows the distribution of the rankings for urban and rural clusters (with urban clusters being defined as those with a population density greater than 500 people per square kilometer). Rural tracts generally had a lower cluster mean than urban tracts (
p < 0.01,
nrural = 1984,
nurban = 3269), indicating that rural areas generally have a lower resilience ranking than urban areas. Internet access was the driving contributor for the overall resilience rankings in 83.2% of rural tracts, with another 15.2% of rural tracts being limited by their disruption vulnerability. In contrast, disruption vulnerability was the limiting factor in 59.4% of urban areas, with internet access limiting 40.3% of urban tracts. Across both rural and urban tracts, disruption risk limited the resilience ranking of fewer than 2% of cases. This shows that a large majority of rural census tracts, and a portion of urban census tracts, are limited by their internet availability and accessibility, linking the improvement of infrastructure and access to potential benefits in resilience.
Important insights into the state of network resilience in Texas can be gleaned from the results of this study, and can be used to guide the improvement of vulnerabilities in the future. In the case of internet access, distinctions were made between availability and accessibility, with the Houston area being separated from other large cities (i.e., Dallas and San Antonio) due to lower accessibility rates. This shows that service accessibility is an important factor to consider in network resilience analyses, exemplifying the effects of pervasive digital divides (which are discussed in
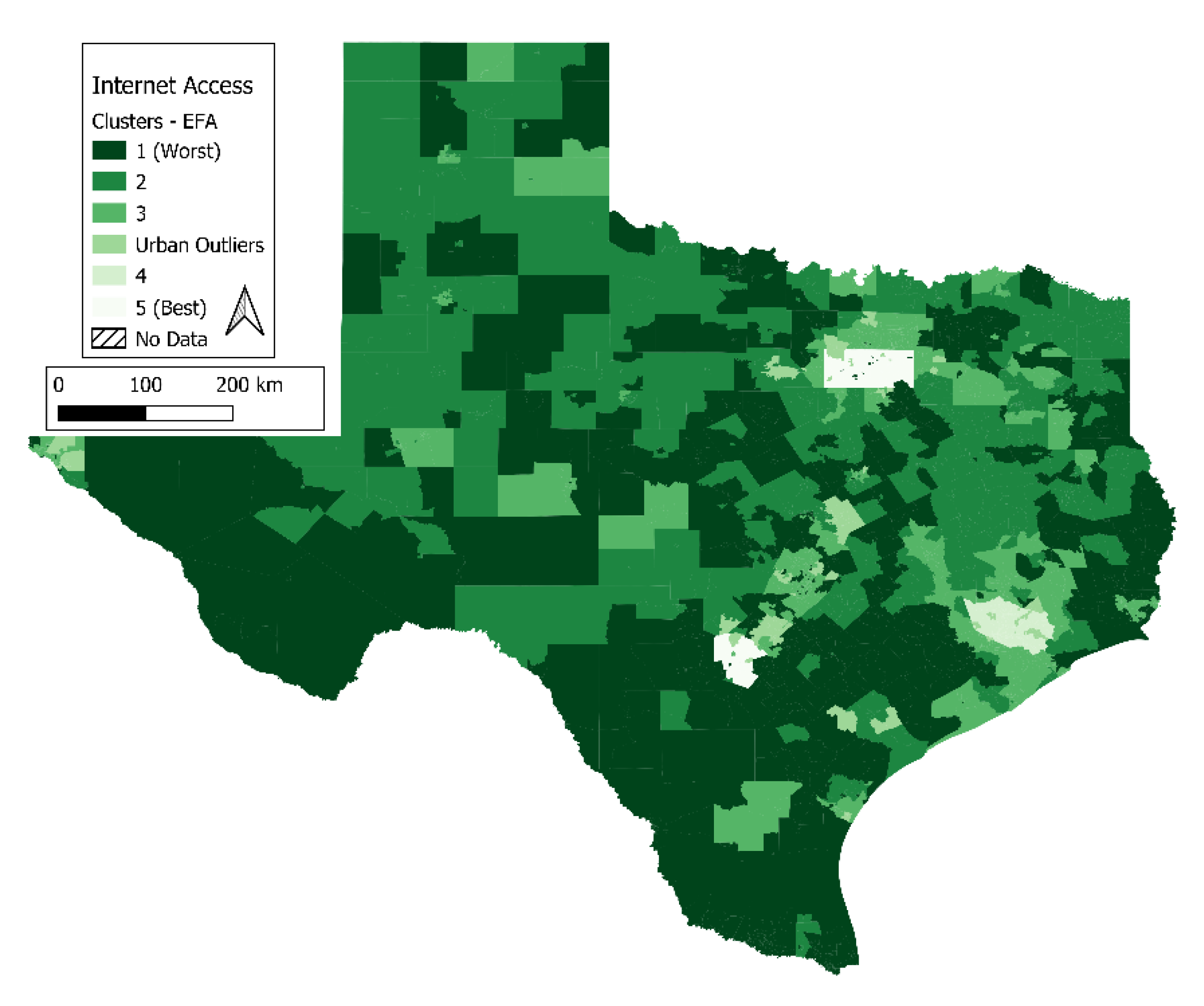
SI Section S2.0), and showing the necessity of targeted efforts to make reliable internet services more accessible. While the main distinguishing factor among urban clusters was service accessibility, rural areas were generally separated by the availability of non-satellite services. This brings into focus the important relationship between
Figure 2,
Figure 3 and
Figure 7.
Figure 3 (the results from the internet access EFA) generally shows South and West Texas with lower internet access rankings. This lowers their overall resilience classification (shown in
Figure 7). However, as can be observed in
Figure 2, there are higher population densities in South Texas than in West Texas. This could indicate that infrastructure investment focused in South Texas would improve the quality of access to wider populations—an observation that could not be drawn without the geospatial component of this resilience analysis.
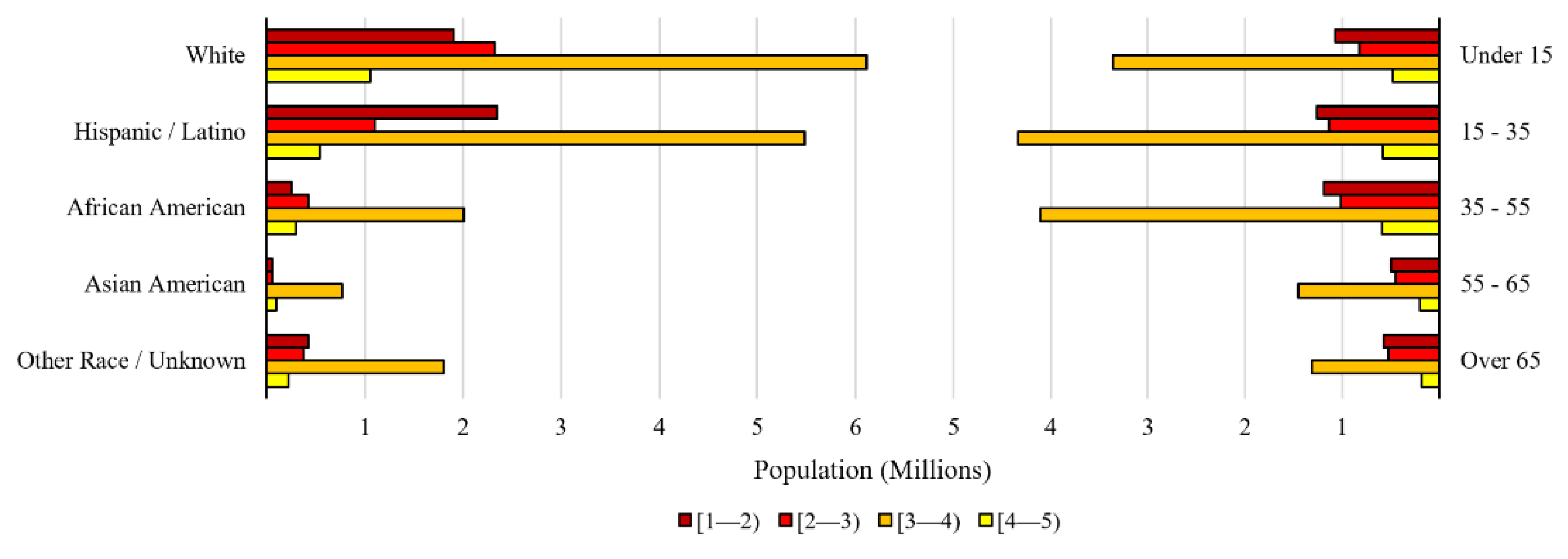
A demographic study of the internet resilience rankings also presents important insights.
Figure 9 shows the age and race distribution for the different rankings. The Hispanic/Latino population in the first (worst) rank is over twice that in the second—a trend that is not repeated across any other race or age group. This can be attributed to the large Hispanic/Latino populations in South Texas—a region that generally has low resilience rankings, as discussed in the previous paragraphs. Across all ages and races, over 50% of the population resides in locations ranked between 3 and 4—an indication that large populations live in moderately ranked areas. However, 18.2% of the population (of which 47.0% is Hispanic and 38% is white) lives in clusters ranked between 1 and 2, showing that an important portion of the population has low network resilience, and could benefit from targeted improvements to network conditions.
The DR in this study was performed by EFA; however, a number of alternatives exist for variable reduction—for example, principal component analysis (PCA). EFA requires a number of explanatory factors to be defined prior to analysis, while PCA outputs a number of principal components equal to the number of variables in the input dataset. In both cases, however, the number of variables (or principal components) to be retained is ultimately user-defined. In this study, HPA was used to determine the number of explanatory variables to retain. Beyond variable-reduction algorithms, machine learning and other novel data science developments could be implemented for the DR in similar analyses, and represent areas for future development.
The different spatial aggregations of underlying data are an important consideration for any geospatial analysis. In this case, the access flexibility contributor had data available at the census tract level, while the disruption risk and disruption vulnerability analyses were performed at the county levels. Data availability often determines the analysis resolution (as was the case in this study); however, the impacts of using different spatial aggregations in analysis should be recognized. Beyond preventing a detailed output for all resilience contributors, incorporating various spatial aggregations may exaggerate (or diminish) the observed resilience trends. Several strategies to mitigate these effects are available within the proposed framework; data within a contributor could be aggregated at the same level, data could be normalized by area or population, or contributors with lower data qualities could be assigned lower weights when combining the analysis results into an overall resilience ranking.
The methods introduced in this study assimilate large amounts of data into a comprehensive geospatial resilience analysis framework. The demonstration of the framework presented herein provides decision-makers with critical insights into the state of network resilience in Texas, underscoring the significance of the proposed framework to critical infrastructure analysis. This framework is easily transferrable to other locations, critical infrastructures, and resilience contributors. This presents a key novelty and usefulness over other geospatial frameworks in the literature, which are generally designed for specific critical infrastructure systems (such as electric [
43] or water [
44] infrastructure) or specific resilience contributors (such as vulnerability to climate change [
45]), limiting the scope of their analysis.
To further optimize the development of geospatial resilience analyses, several of the sub-processes presented in this study could be automated. The resilience of infrastructures changes with new population patterns, unforeseen risks, and changing vulnerabilities. As such, a system capable of automatically assimilating new geospatial data from distributed sources into an up-to-date comprehensive resilience analysis would be beneficial to stakeholders, as well as to society as a whole. This research provides a comprehensive geospatial framework that can be used to assess the resilience of critical infrastructure, and is distinct from prior work in the field in that the study considers geospatial resilience in the context of specific uses of the infrastructure and the sociodemographic characteristics of the user community.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}