


Supervised Machine Learning Algorithms to Predict Provenance of Archaeological Pottery Fragments





Abstract
:1. Introduction
2. Materials and Methods
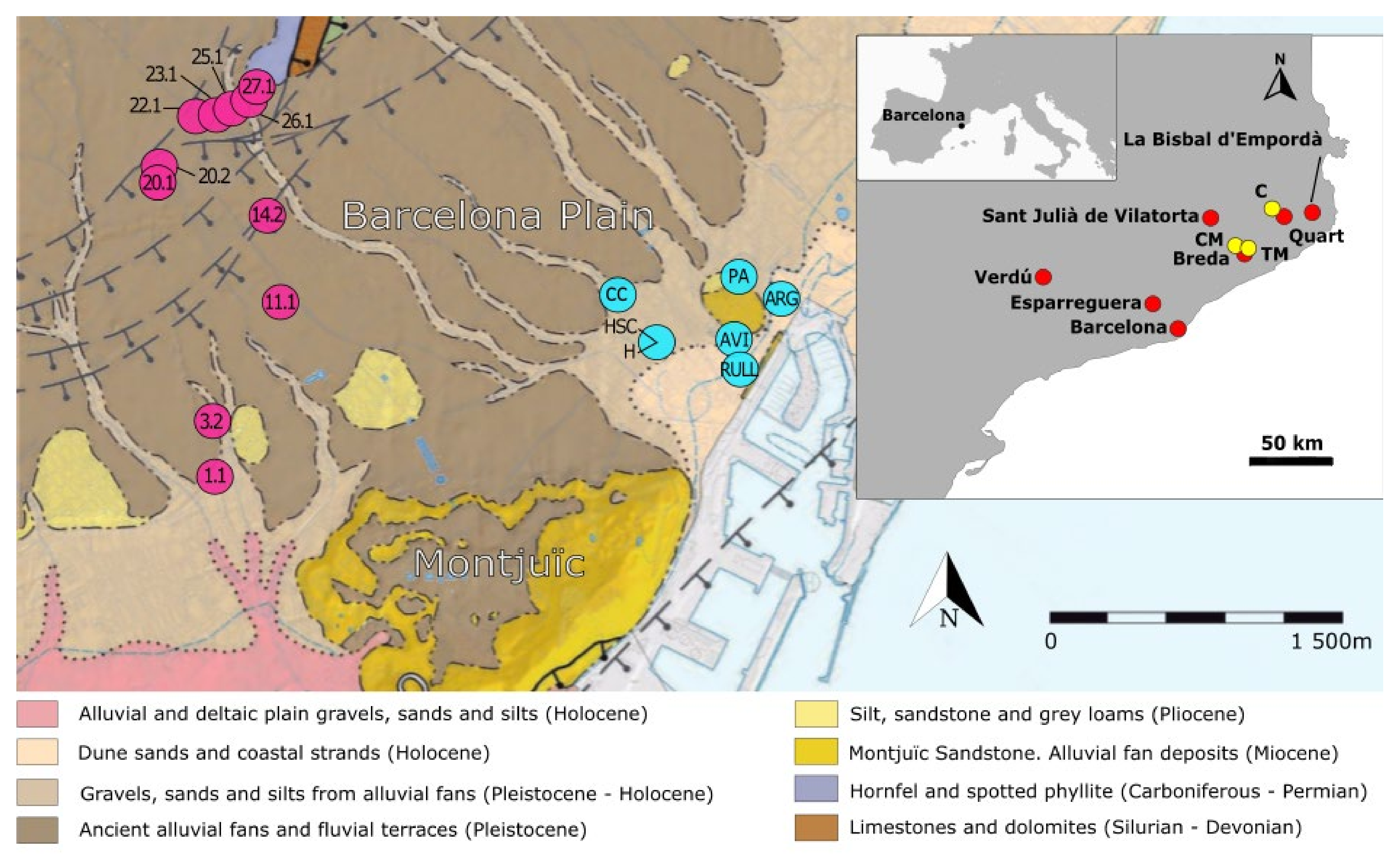
2.1. Reference Sampled Materials and Geochemical Data
- Esparreguera (~35 km northwest of Barcelona);
- Breda (~50 km northeast of Barcelona);
- Sant Julià de Vilatorta (~60 km north from Barcelona);
- Quart (~80 km northeast of Barcelona);
- Verdú (~90 km northwest of Barcelona);
- La Bisbal d’Empordà (~100 km northeast of Barcelona).
2.2. Archaeological Samples of Unknown Provenience
2.3. Data Processing, Modelling and Class Prediction
- Weighted k-nearest neighbors (kkNN); the samples are classified by taking into account the classes of their k-nearest neighbors;
- Random forest (RF); the algorithm is based on a combination of multiple and uncorrelated decision trees operating as an ensemble;
- Artificial neural network (ANN); this prognostic model uses an extensive network of nodes that exchange messages simulating the function of the human brain;
- Linear discriminant analysis (LDA); similar to PCA, is a linear transformation used for dimensionality reduction, but LDA maximizes the separation between classes and not between individual samples;
- Generalized linear models (GLM); this is a collection of regression models with the possibility to introduce a penalty term for the maximum likelihood (lambda) to move from a pure ridge model to a pure lasso model.
3. Results
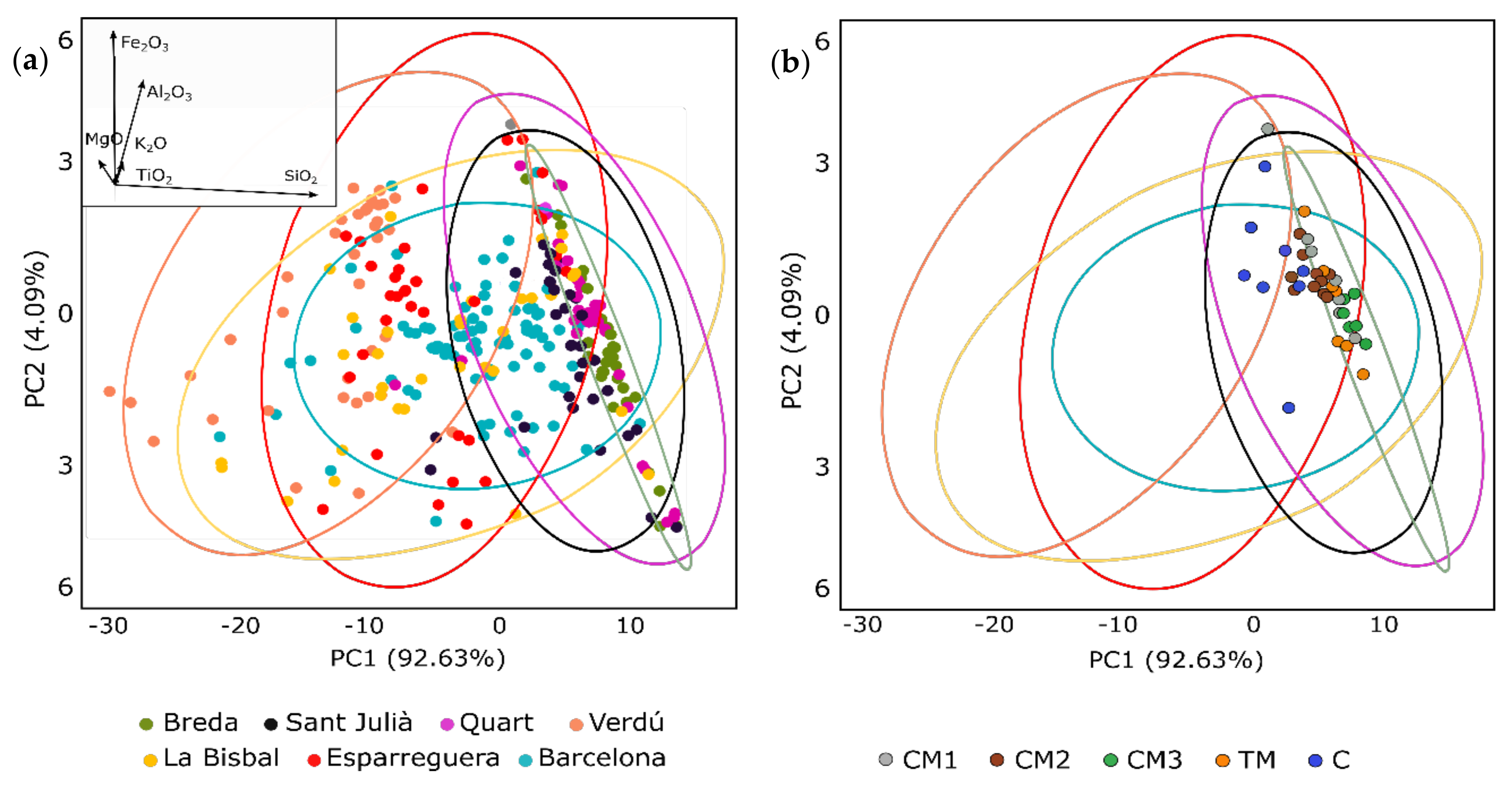
3.1. Unsupervised Approach
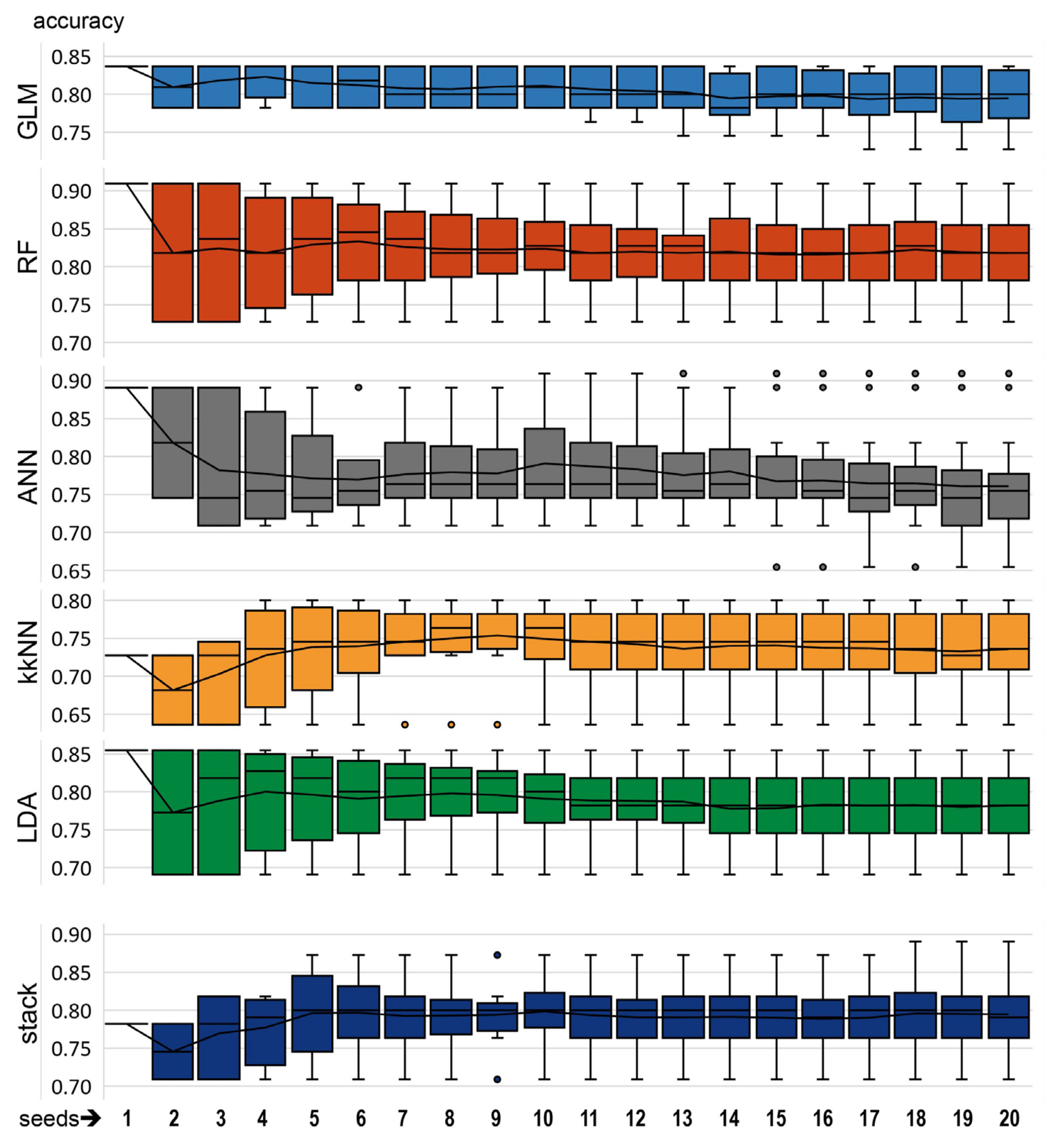
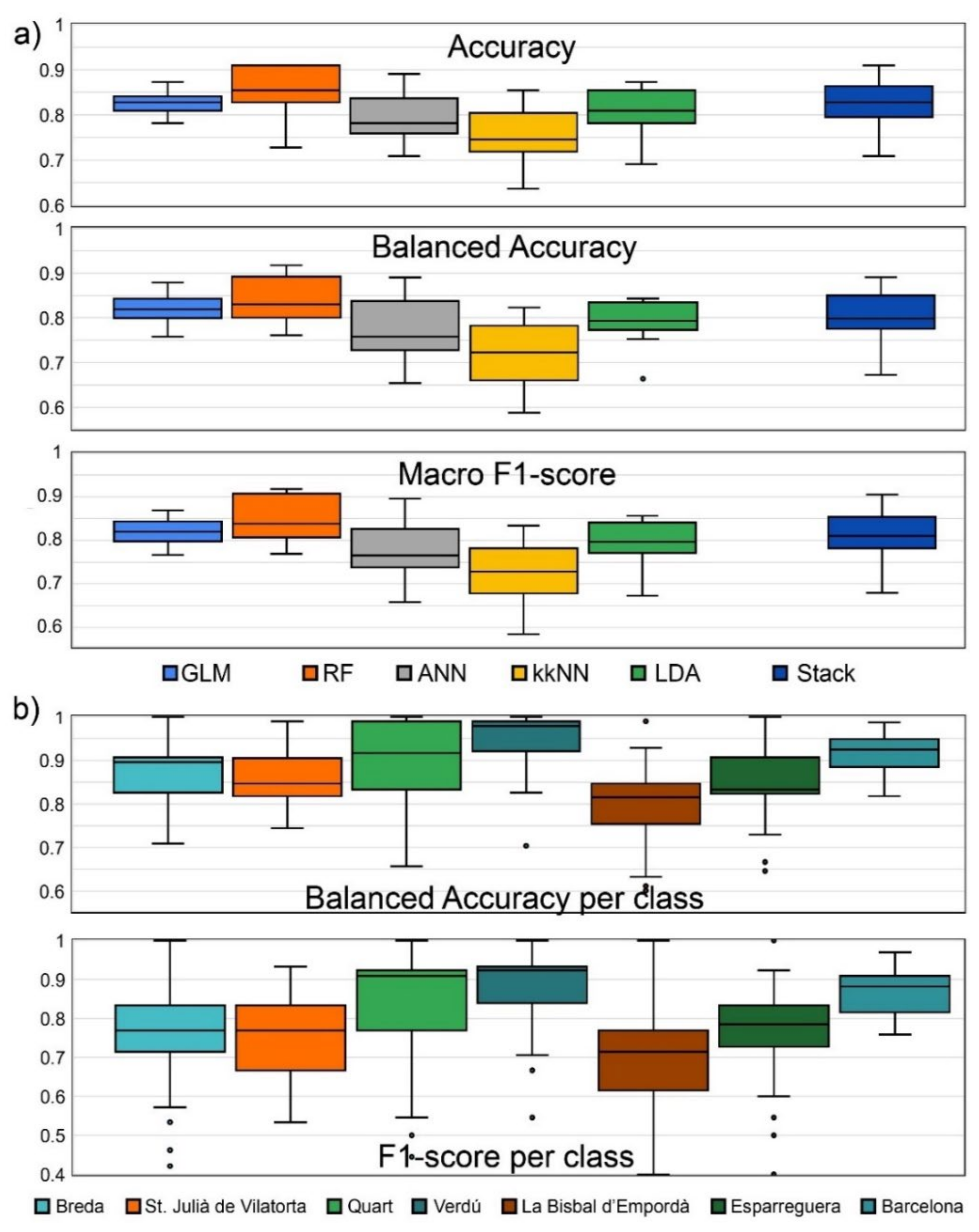
3.2. Supervised Classification Models
3.3. Cluster Prediction
4. Discussion
4.1. Cluster Prediction
4.2. Using and Exporting the Presented Approach to Other Contexts
4.3. Contribution to Sustainable Archaeology
4.3.1. Free and Open-Source Software
4.3.2. Open Access and Data Sharing
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Heimann, R.; Franklin, U. Archaeo-thermometry: The assessment of firing temperatures of ancient ceramics. J. Int. Inst. Conserv.-Can. Group 1979, 4, 23–45. [Google Scholar]
- Holakooei, P.; Tessari, U.; Verde, M.; Vaccaro, C. A new look at XRD patterns of archaeological ceramic bodies. J. Therm. Anal. Calorim 2014, 118, 165–176. [Google Scholar] [CrossRef]
- Aitken, M.J. Dating by archaeomagnetic and thermoluminescent methods. Philos. Trans. R. Soc. London. Ser. A Math. Phys. Sci. 1970, 269, 77–88. [Google Scholar]
- Howard, S. Understanding the concept of sustainability as applied to archaeological heritage. Rosetta 2013, 14, 1–19. [Google Scholar]
- Carman, J. Educating for sustainability in archaeology. Archaeologies 2016, 12, 133–152. [Google Scholar] [CrossRef]
- Reedy, C.L. Thin-Section Petrography of Stone and Ceramic Cultural Materials; Archetype Publications Ltd.: London, UK, 2008; ISBN 9781904982333. [Google Scholar]
- Quinn, P.S. (Ed.) Interpreting Silent Artefacts: Petrographic Approaches to Archaeological Ceramics; Archaeopress Publishing Ltd.: Oxford, UK, 2009; ISBN 9781905739295. [Google Scholar]
- Quinn, P.S. Ceramic Petrography: The Interpretation of Archaeological Pottery & Related Artefacts in Thin Section; Archaeopress Publishing Ltd.: Oxford, UK, 2013; ISBN 978-1-905-73959-2. [Google Scholar]
- Neff, H. (Ed.) Chemical Characterization of Ceramic Pastes in Archaeology; Prehistory Press: Madison, WI, USA, 1992; ISBN 0962911062. [Google Scholar]
- Hein, A.; Tsolakidou, A.; Iliopoulos, I.; Mommsen, H.; Garrigós, J.; Montana, G.; Kilikoglou, V. Standardisation of elemental analytical techniques applied to provenance studies of archaeological ceramics: An inter laboratory calibration study. Analyst 2002, 127, 542–553. [Google Scholar] [CrossRef]
- Baxter, M.J. Exploratory Multivariate Analysis in Archaeology; Eliot Werner Publications-Inc.: Clinton Corners, NY, USA, 2015. [Google Scholar]
- Ricca, M.; Paladini, G.; Rovella, N.; Ruffolo, S.A.; Randazzo, L.; Crupi, V.; Fazio, B.; Majolino, D.; Venuti, V.; Galli, G. Archaeometric characterisation of decorated pottery from the archaeological site of villa dei quintili (Rome, Italy): Preliminary study. Geosciences 2019, 9, 172. [Google Scholar] [CrossRef]
- Buxeda, I.; Garrigós, J.; Ontiveros, M.A.C.; Kilikoglou, V. Chemical variability in clays and pottery from a traditional cooking pot production village: Testing assumptions in pereruela. Archaeometry 2003, 45, 1–17. [Google Scholar] [CrossRef]
- Brorsson, T.; Blank, M.; Fridén, I.B. Mobility and exchange in the middle neolithic: Provenance studies of pitted ware and funnel beaker pottery from Jutland, Denmark and the West Coast of Sweden. J. Archaeol. Sci. Rep. 2018, 20, 662–674. [Google Scholar] [CrossRef]
- Papachristodoulou, C.; Oikonomou, A.; Ioannides, K.; Gravani, K. A study of ancient pottery by means of X-ray fluorescence spectroscopy, multivariate statistics and mineralogical analysis. Anal. Chim. Acta 2006, 573–574, 347–353. [Google Scholar] [CrossRef]
- Aquilia, E.; Barone, G.; Mazzoleni, P.; Ingoglia, C. Petrographic and chemical characterisation of fine ware from three archaic and hellenistic kilns in gela, sicily. J. Cult. Herit. 2012, 13, 442–447. [Google Scholar] [CrossRef]
- Munita, C.S.; Paiva, R.P.; Alves, M.A.; de Oliveira, P.M.S.; Momose, E.F. Provenance study of archaeological ceramic. J. Trace Microprobe Tech. 2003, 21, 697–706. [Google Scholar] [CrossRef]
- Scarpelli, R.; Robustelli, G.; Clark, R.J.H.; Francesco, A.M.D. Scientific investigations on the provenance of the black glazed pottery from Pompeii: A case study. Mediterr. Archaeol. Archaeom. 2017, 17, 1–10. [Google Scholar]
- Buxeda i Garrigós, J.; Kilikoglou, V.; Day, P.M. Chemical and mineralogical alteration of ceramics from a late bronze age kiln at Kommos, Crete: The effect on the formation of a reference group. Archaeometry 2001, 43, 349–371. [Google Scholar] [CrossRef] [Green Version]
- Maritan, L.; Holakooei, P.; Mazzoli, C. Cluster analysis of XRPD data in ancient ceramics: What for? Appl. Clay Sci. 2015, 114, 540–549. [Google Scholar] [CrossRef]
- Medeghini, L.; Mignardi, S.; Vito, C.D.; Conte, A.M. Evaluation of a FTIR data pretreatment method for principal component analysis applied to archaeological ceramics. Microchem. J. 2016, 125, 224–229. [Google Scholar] [CrossRef]
- Parisotto, S.; Leone, N.; Schönlieb, C.-B.; Launaro, A. Unsupervised clustering of Roman potsherds via variational autoencoders. J. Archaeol. Sci. 2022, 142, 105598. [Google Scholar] [CrossRef]
- Bratitsi, M.; Liritzis, I.; Vafiadou, A.; Xanthopoulou, V.; Palamara, E.; Iliopoulos, I.; Zacharias, N. Critical assessment of chromatic index in archaeological ceramics by Munsell and RGB: Novel contribution to characterization and provenance studies. Mediterr. Archaeol. Archaeom. 2018, 18, 175–212. [Google Scholar]
- Visiedo, J.P.; Madrid i Fernández, M.; Buxeda i Garrigós, J. The case of black and green tin glazed pottery from Barcelona between 13th and 14th century: Analysing its production and its decorations. J. Archaeol. Sci. Rep. 2021, 38, 103100. [Google Scholar] [CrossRef]
- Calparsoro, E.; Arana, G.; Iñañez, J.G. Pottery from orduña village in the 17th–19th centuries: An archaeometrical approach. J. Archaeol. Sci. Rep. 2019, 23, 304–323. [Google Scholar] [CrossRef]
- Baklouti, S.; Maritan, L.; Ouazaa, N.L.; Casas, L.; Joron, J.-L.; Kassaa, S.L.; Moutte, J. Provenance and reference groups of African Red Slip ware based on statistical analysis of chemical data and REE. J. Archaeol. Sci. 2014, 50, 524–538. [Google Scholar] [CrossRef]
- Mackensen, M.; Schneider, G. Production centres of African red slip ware (2nd-3rd c.) in northern and central Tunisia: Archaeological provenance and reference groups based on chemical analysis. J. Rom. Archaeol. 2006, 19, 163–190. [Google Scholar] [CrossRef]
- Monette, Y.; Richer-LaFlèche, M.; Moussette, M.; Dufournier, D. Compositional analysis of local redwares: Characterizing the pottery productions of 16 workshops located in southern québec dating from late 17th to late 19th-century. J. Archaeol. Sci. 2007, 34, 123–140. [Google Scholar] [CrossRef]
- Montana, G.; Randazzo, L.; Tsantini, E.; Fourmont, M. Ceramic production at Selinunte (Sicily) during the 4th and 3rd century BCE: New archaeometric data through the analysis of kiln wastes. J. Archaeol. Sci. Rep. 2018, 22, 154–167. [Google Scholar] [CrossRef]
- Maritan, L.; Gravagna, E.; Cavazzini, G.; Zerboni, A.; Mazzoli, C.; Grifa, C.; Mercurio, M.; Mohamed, A.A.; Usai, D.; Salvatori, S. Nile river clayey materials in Sudan: Chemical and isotope analysis as reference data for ancient pottery provenance studies. Quat. Int. 2021, in press. [Google Scholar] [CrossRef]
- Baklouti, S.; Maritan, L.; Casas, L.; Ouazaa, N.L.; Jàrrega, R.; Prevosti, M.; Mazzoli, C.; Fouzaï, B.; Kassaa, S.L.; Fantar, M. Establishing a new reference group of keay 25.2 amphorae from Sidi Zahruni (Nabeul, Tunisia). Appl. Clay Sci. 2016, 132–133, 140–154. [Google Scholar] [CrossRef]
- Montana, G.; Ontiveros, M.Á.C.; Polito, A.M.; Azzaro, E. Characterisation of clayey raw materials for ceramic manufacture in ancient sicily. Appl. Clay Sci. 2011, 53, 476–488. [Google Scholar] [CrossRef]
- Gutsuz, P.; Kibaroğlu, M.; Sunal, G.; Hacıosmanoğlu, S. Geochemical characterization of clay deposits in the Amuq Valley (Southern Turkey) and the implications for archaeometric study of ancient ceramics. Appl. Clay Sci. 2017, 141, 316–333. [Google Scholar] [CrossRef]
- Efenberger-Szmechtyk, M.; Nowak, A.; Kregiel, D. Implementation of chemometrics in quality evaluation of food and beverages. Crit. Rev. Food Sci. Nutr. 2018, 58, 1747–1766. [Google Scholar] [CrossRef]
- Anglisano, A.; Casas, L.; Anglisano, M.; Queralt, I. Application of supervised machine-learning methods for attesting provenance in Catalan traditional pottery industry. Minerals 2020, 10, 8. [Google Scholar] [CrossRef]
- Fiorucci, M.; Khoroshiltseva, M.; Pontil, M.; Traviglia, A.; Bue, A.D.; James, S. Machine learning for cultural heritage: A survey. Pattern Recognit. Lett. 2020, 133, 102–108. [Google Scholar] [CrossRef]
- McKeague, P.; van‘t Veer, R.; Huvila, I.; Moreau, A.; Verhagen, P.; Bernard, L.; Cooper, A.; Green, C.; van Manen, N. Mapping our heritage: Towards a sustainable future for digital spatial information and technologies in European archaeological heritage management. J. Comput. Appl. Archaeol. 2019, 2, 89–104. [Google Scholar] [CrossRef]
- Bickler, S.H. Machine learning arrives in archaeology. Adv. Archaeol. Pract. 2021, 9, 186–191. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Resler, A.; Yeshurun, R.; Natalio, F.; Giryes, R. A deep-learning model for predictive archaeology and archaeological community detection. Humanit. Soc. Sci. Commun. 2021, 8, 295. [Google Scholar] [CrossRef]
- Navarro, P.; Cintas, C.; Lucena, M.; Fuertes, J.M.; Delrieux, C.; Molinos, M. Learning feature representation of iberian ceramics with automatic classification models. J. Cult Herit. 2021, 48, 65–73. [Google Scholar] [CrossRef]
- Wilczek, J.; Monna, F.; Navarro, N.; Chateau-Smith, C. A computer tool to identify best matches for pottery fragments. J. Archaeol. Sci. Rep. 2021, 37, 102891. [Google Scholar] [CrossRef]
- Derech, N.; Tal, A.; Shimshoni, I. Solving archaeological puzzles. Pattern Recognit. 2021, 119, 108065. [Google Scholar] [CrossRef]
- Chetouani, A.; Treuillet, S.; Exbrayat, M.; Jesset, S. Classification of engraved pottery sherds mixing deep-learning features by compact bilinear pooling. Pattern Recognit. Lett. 2020, 131, 1–7. [Google Scholar] [CrossRef]
- Domínguez-Rodrigo, M.; Cifuentes-Alcobendas, G.; Jiménez-García, B.; Abellán, N.; Pizarro-Monzo, M.; Organista, E.; Baquedano, E. Artificial intelligence provides greater accuracy in the classification of modern and ancient bone surface modifications. Sci. Rep. 2020, 10, 18862. [Google Scholar] [CrossRef]
- Oonk, S.; Spijker, J. A supervised machine-learning approach towards geochemical predictive modelling in archaeology. J. Archaeol. Sci. 2015, 59, 80–88. [Google Scholar] [CrossRef]
- Barone, G.; Mazzoleni, P.; Spagnolo, G.V.; Raneri, S. Artificial neural network for the provenance study of archaeological ceramics using clay sediment database. J. Cult. Herit. 2019, 38, 147–157. [Google Scholar] [CrossRef]
- Lopez-Garcia, P.A.; Argote, D.L.; Thrun, M.C. Projection-based classification of chemical groups for provenance analysis of archaeological materials. IEEE Access 2020, 8, 152439–152451. [Google Scholar] [CrossRef]
- Ma, Q.; Yan, A.; Hu, Z.; Li, Z.; Fan, B. Principal component analysis and artificial neural networks applied to the classification of Chinese pottery of neolithic age. Anal. Chim. Acta 2000, 406, 247–256. [Google Scholar] [CrossRef]
- Díez-Pastor, J.F.; Jorge-Villar, S.E.; Arnaiz-González, Á.; García-Osorio, C.I.; Díaz-Acha, Y.; Campeny, M.; Bosch, J.; Melgarejo, J.C. Machine learning algorithms applied to Raman spectra for the identification of variscite originating from the mining complex of Gavà. J. Raman Spectrosc. 2020, 51, 1563–1574. [Google Scholar] [CrossRef]
- Salazar, A.; Safont, G.; Vergara, L.; Vidal, E. Pattern recognition techniques for provenance classification of archaeological ceramics using ultrasounds. Pattern Recognit. Lett. 2020, 135, 441–450. [Google Scholar] [CrossRef]
- Buxeda, J.; Iñañez, J.; Madrid, M.; Beltrán, J. La ceràmica de Barcelona. Organització i producció entre els segles XIII i XVIII a través de la seva caracterització arqueomètrica. Quarhis 2011, 7, 192–207. [Google Scholar]
- Serra, J. Ceràmica de rebuig al carrer d’Avinyó. Un possible nou taller barceloní en el primer quart del segle XIII. Quad. D’arqueologia Història Ciutat Barcelona. Quarhis 2016, 12, 194–209. [Google Scholar]
- Miró, N. Excavació de les voltes de la sala de reserva de la biblioteca de Catalunya, antic hospital de la Santa Creu, Barcelona (el Barcelonès). In 15 Anys D’Intervencions Arqueològiques: Mancanes i Resultats, Proceedings of 1r Congrés d’Arqueologia Medieval i Moderna a Catalunya, Igualada, Spain, 13–15 November 1998; Associació Catalana per a la Recerca en Arqueologia Medieval: Barcelona, Spain, 2000; pp. 168–176. Available online: https://dialnet.unirioja.es/servlet/libro?codigo=782515 (accessed on 30 July 2022).
- Nebot, N. La botiga de Josep Barba: Un terrisser a la Barcelona del segle XVIII. Quad. D’arqueologia Història Ciutat Barcelona. Quarhis 2015, 11, 184–199. [Google Scholar]
- Madrid, M.; Marcos, C.F.D.; Barrachina, C.P.; Heredia, J.B.D.; Escribano-Ruiz, S.; Ibáñez, J.G.; Ferrer, S.G.; Febo, R.D.; Amores, F.D.; Buxeda, J. Ceràmica, tecnologia i transferències. Els centres productius del projecte tecnolonial. Quad. D’arqueologia Història Ciutat Barcelona. Quarhis 2017, 13, 16–67. [Google Scholar]
- Caixal, A.; Fierro, X.; López, A. Resultats de l’excavació arqueològica en la galeria alta del pati Manning de l’antiga Casa de Caritat. In Actuacions en el Patrimoni Edificat Medieval i Modern (Segles X al XVIII) = Actuaciones en el Patrimonio Edificado Medieval y Moderno (Siglos X al XVIII); Servei del Oatrimoni Arquitectònic: Barcelona, Spain, 1991; pp. 13–15. [Google Scholar]
- Oriol, J. Memòria de la Intervenció Arqueològica a Pia Almoina, Barcelona; Generalitat de Catalunya: Barcelona, Spain, 1993. [Google Scholar]
- Miró, N. Memòria de la Intervenció Realitzada als Carrers de l’Argenteria i Manresa de Barcelona (Barcelonès); Ajuntament de Barcelona: Barcelona, Spain, 1997. [Google Scholar]
- Font, G.; Mateu, J.; Pujadas, S.; Tura, J.; Llorens, J.M. Montsoriu al Segle XVI. Testimonis Arqueològics de L’abandonament d’un Gran Castell. Tribuna D’arqueologia 2011–2012. 2014, pp. 244–263. Available online: http://calaix.gencat.cat/handle/10687/91795#page=1 (accessed on 30 July 2022).
- Tura, J.; Font, G.; Pujadas, S.; Mateu, J.; Llorens, J.M. El conjunt arqueològic del segle XVI localitzat a la cisterna est del castell de Montsoriu. Rodis J. Mediev. Post-Mediev. Archaeol. 2022, 25–46. [Google Scholar]
- Tura, J.; Mateu, J. Torre de la Mora o del Far (Sant Feliu de Buixalleu, la Selva): Una ocupació alt-medieval al Montseny. In Fars de L’islam: Antigues Alimares d’al-Andalus, Proceedings of the Jornades Científiques Ocorde; Barcelona, Spain, 9–10 November 2006, Martí, R., Ed.; Edar Press: Barcelona, Spain, 2008; pp. 139–154. Available online: https://cataleg.parcs.diba.cat/cgi-bin/koha/opac-detail.pl?biblionumber=10093 (accessed on 30 July 2022).
- Pericot y García, L.; Corominas Planellas, J.M.; Oliva Prat, M.; Riuró Ilapat, F.; Padrol Salellas, P. La Labor de La Comisaria Provincial de Excavaciones Arqueologicas de Gerona. Informes y Memorias; Ministerio de educación nacional. Comisaria general de excavaciones arqueológicas: Madrid, Spain, 1952; Volume 27. [Google Scholar]
- Zhao, Y. R and Data Mining. In R and Data Minig; Zhao, Y., Ed.; Academic Press: Cambridge, MA, USA, 2013; Chapter 5; pp. 41–50. ISBN 978-0-12-396963-7. [Google Scholar]
- Praveena, M.; Jaiganesh, V. A literature review on supervised machine learning algorithms and boosting process. Int. J. Comput. Appl. 2017, 169, 32–35. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Supervised machine learning: A review of classification techniques. In Proceedings of the 2007 Conference on Emerging Artificial Intelligence Applications in Computer Engineering: Real Word AI Systems with Applications in EHealth HCI, Information Retrieval and Pervasive Technologies, Amsterdam, The Netherlands, 10 June 2007; IOS Press: Amsterdam, The Netherlands, 2007; pp. 3–24. [Google Scholar]
- Kuhn, M. Building predictive models in r using the caret package. J. Stat. Softw. Artic. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for multi-class classification: An overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Bibby, D.; Ducke, B. Free and open source software development in archaeology. Two interrelated case studies: GvSIG CE and survey2GIS. Internet Archaeol. 2017, 43. [Google Scholar] [CrossRef]
- Van der Loo, M.P.J.; de Jonge, E. Learning RStudio for R Statistical Computing; Packt publishing: Birmingham, UK, 2012; ISBN 1782160604. [Google Scholar]
- Morin, A.; Urban, J.; Adams, P.D.; Foster, I.; Sali, A.; Baker, D.; Sliz, P. Research priorities. shining light into black boxes. Science 2012, 336, 159–160. [Google Scholar] [CrossRef]
- Marwick, B. CRAN Task View: Archaeological Science. Available online: https://github.com/benmarwick/ctv-archaeology (accessed on 29 August 2022).
- Kintigh, K. The promise and challenge of archaeological data integration. Am. Antiq. 2006, 71, 567–578. [Google Scholar] [CrossRef]
- Derudas, P.; Dell’Unto, N.; Callieri, M.; Apel, J. Sharing archaeological knowledge: The interactive reporting system. J. Field Archaeol. 2021, 46, 303–315. [Google Scholar] [CrossRef]
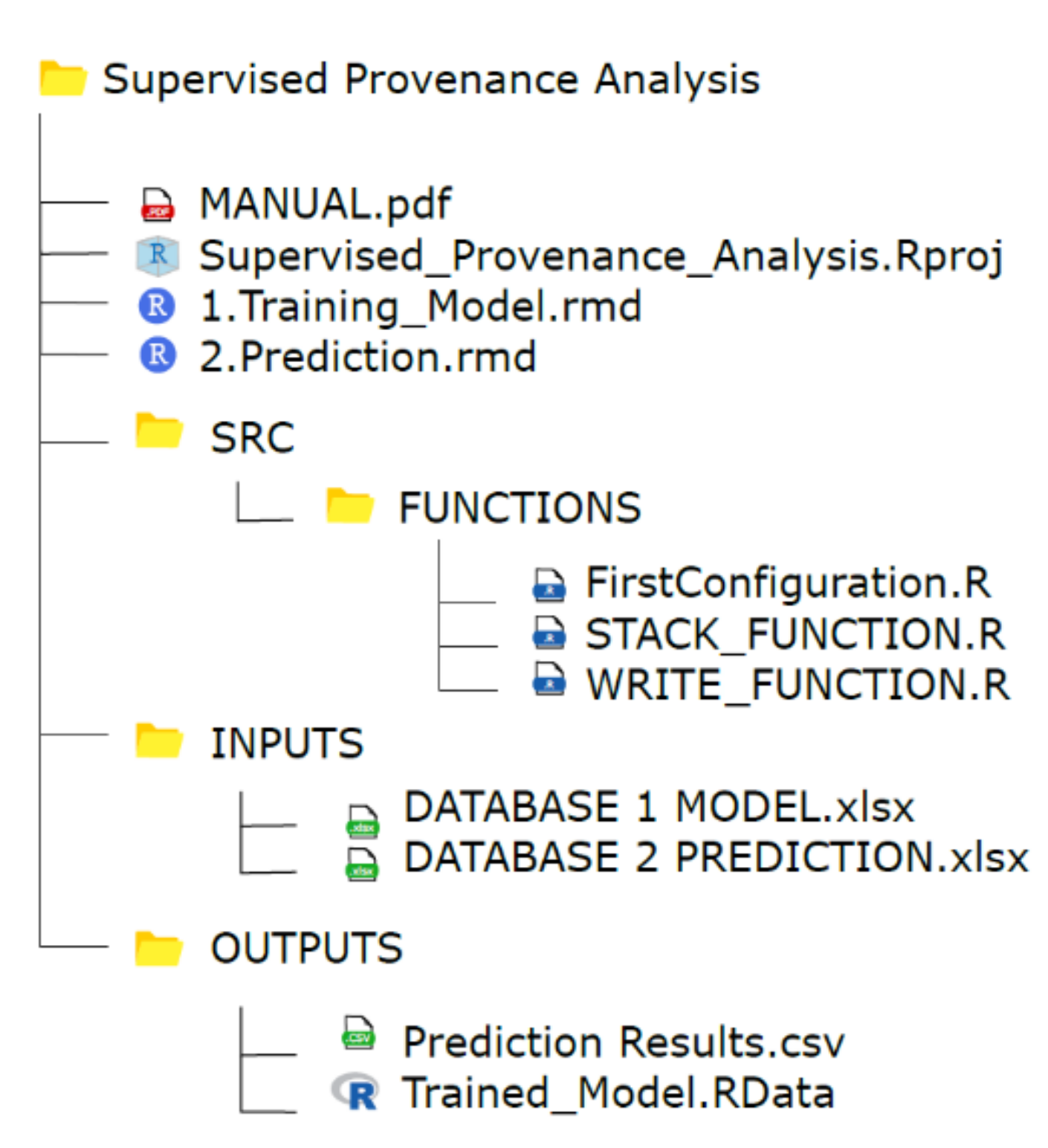
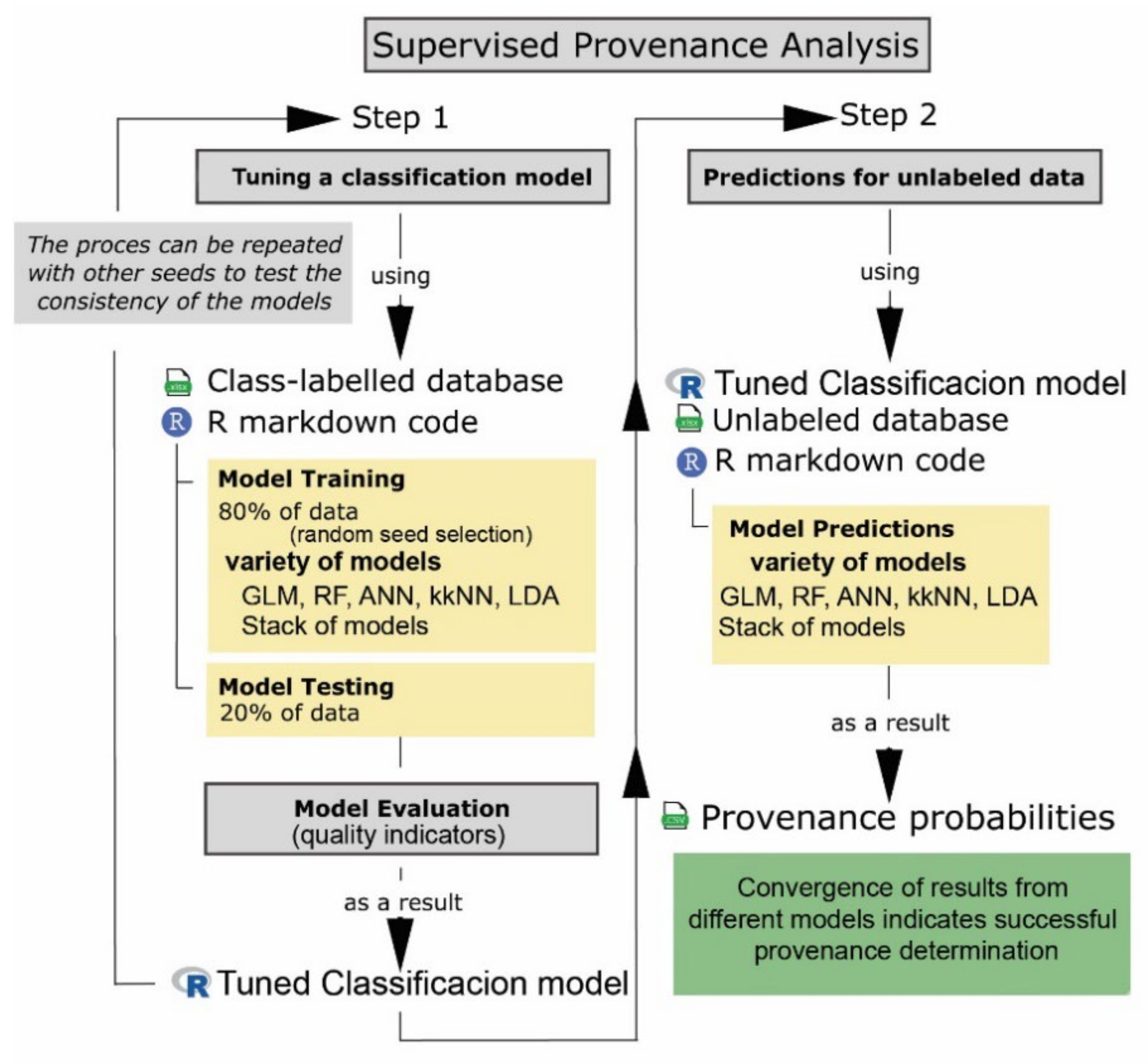

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Archaeological Site | N. of Samples | Age | References |
|---|---|---|---|
| Avinyó (AVI) | 7 | 13th CE | [53] |
| Hospital (H) | 6 | 13th CE–14th CE | [54] |
| Rull (RULL) | 3 | 14th CE–18th CE | [55,56] |
| Hospital de la Santa Creu (HSC) | 27 | 17th CE | [54] |
| Casa de la Caritat (CC) | 9 | mid 17th CE–18th CE | [57] |
| Pia almoina (PA) | 6 | early 18th CE | [58] |
| Argenteria (ARG) | 6 | 19th CE | [59] |
| Archaeological Site | Typology | Chronology | Tag | No. Samples | References |
|---|---|---|---|---|---|
| Castell de Montsoriu | gray ware | 1475–1560 CE | CM1 | 7 | [60] |
| lead-glazed cooking ware | CM2 | 10 | |||
| green-glazed cooking ware | CM3 | 6 | |||
| Torre de la Mora | cooking ware | late 9th CE–early 10th CE | TM | 7 | [62] |
| La Creueta | hand-built cooking pots | 4th BCE | C | 8 | [63] |
| Model | Locality | CM1 | CM2 | CM3 | TM | C | |||||
| Linear Discriminant Analysis | Breda | 1 | 23 ± 18 | 5 | 7 ± 9 | 100 | 75 ± 30 | 88 | 50 ± 25 | 100 | 100 ± 0 |
| Sant Julià | 5 | 16 ± 12 | 2 | 1 ± 0 | 0 | 1 ± 0 | 1 | 27 ± 28 | 0 | 0 ± 0 | |
| Quart | 85 | 45 ± 25 | 1 | 1 ± 0 | 0 | 14 ± 26 | 0 | 2 ± 5 | 0 | 0 ± 0 | |
| Verdú | 1 | 0 ± 0 | 0 | 0 ± 0 | 0 | 0 ± 0 | 0 | 0 ± 0 | 0 | 0 ± 0 | |
| La Bisbal | 3 | 3 ± 0 | 10 | 7 ± 3 | 0 | 3 ± 3 | 0 | 15 ± 23 | 0 | 0 ± 0 | |
| Esparreguera | 3 | 6 ± 4 | 12 | 6 ± 3 | 0 | 0 ± 0 | 1 | 3 ± 7 | 0 | 0 ± 0 | |
| Barcelona | 2 | 5 ± 8 | 69 | 78 ± 13 | 0 | 7 ± 10 | 9 | 3 ± 5 | 0 | 0 ± 0 | |
| Model | Locality | CM1 | CM2 | CM3 | TM | C |
| Linear Discriminant Analysis | Breda | 29 ± 21 | 9 ± 13 | 76 ± 28 | 58 ± 25 | 97 ± 10 |
| Sant Julià | 17 ± 12 | 1 ± 1 | 1 ± 1 | 22 ± 23 | 2 ± 7 | |
| Quart | 40 ± 24 | 0 ± 0 | 13 ± 23 | 1 ± 2 | 0 ± 0 | |
| Verdú | 2 ± 2 | 0 ± 0 | 0 ± 0 | 0 ± 0 | 0 ± 0 | |
| La Bisbal | 5 ± 3 | 7 ± 5 | 3 ± 5 | 11 ± 17 | 1 ± 2 | |
| Esparreguera | 4 ± 3 | 7 ± 5 | 0 ± 0 | 5 ± 12 | 0 ± 1 | |
| Barcelona | 4 ± 7 | 75 ± 16 | 7 ± 8 | 3 ± 5 | 0 ± 0 | |
| Random Forest | Breda | 11 ± 10 | 8 ± 4 | 37 ± 17 | 25 ± 22 | 13 ± 16 |
| Sant Julià | 20 ± 7 | 6 ± 2 | 5 ± 2 | 16 ± 8 | 21 ± 7 | |
| Quart | 33 ± 12 | 4 ± 2 | 46 ± 8 | 10 ± 4 | 11 ± 6 | |
| Verdú | 0 ± 0 | 0 ± 0 | 0 ± 0 | 0 ± 0 | 2 ± 1 | |
| La Bisbal | 16 ± 7 | 11 ± 5 | 5 ± 2 | 18 ± 7 | 17 ± 4 | |
| Esparreguera | 7 ± 4 | 3 ± 1 | 1 ± 1 | 3 ± 3 | 13 ± 6 | |
| Barcelona | 11 ± 5 | 68 ± 10 | 2 ± 1 | 21 ± 6 | 19 ± 7 | |
| Stack of Models | Breda | 11 ± 16 | 0 ± 2 | 50 ± 37 | 57 ± 37 | 35 ± 31 |
| Sant Julià | 17 ± 34 | 0 ± 0 | 0 ± 1 | 7 ± 20 | 21 ± 29 | |
| Quart | 62 ± 39 | 0 ± 0 | 48 ± 37 | 0 ± 2 | 0 ± 1 | |
| Verdú | 0 ± 0 | 0 ± 1 | 0 ± 2 | 0 ± 0 | 3 ± 7 | |
| La Bisbal | 6 ± 18 | 0 ± 2 | 0 ± 0 | 8 ± 21 | 3 ± 8 | |
| Esparreguera | 3 ± 8 | 0 ± 0 | 0 ± 1 | 1 ± 2 | 6 ± 15 | |
| Barcelona | 1 ± 5 | 99 ± 4 | 2 ± 6 | 28 ± 33 | 32 ± 33 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anglisano, A.; Casas, L.; Queralt, I.; Di Febo, R. Supervised Machine Learning Algorithms to Predict Provenance of Archaeological Pottery Fragments. Sustainability 2022, 14, 11214. https://doi.org/10.3390/su141811214
Anglisano A, Casas L, Queralt I, Di Febo R. Supervised Machine Learning Algorithms to Predict Provenance of Archaeological Pottery Fragments. Sustainability. 2022; 14(18):11214. https://doi.org/10.3390/su141811214
Chicago/Turabian StyleAnglisano, Anna, Lluís Casas, Ignasi Queralt, and Roberta Di Febo. 2022. "Supervised Machine Learning Algorithms to Predict Provenance of Archaeological Pottery Fragments" Sustainability 14, no. 18: 11214. https://doi.org/10.3390/su141811214
APA StyleAnglisano, A., Casas, L., Queralt, I., & Di Febo, R. (2022). Supervised Machine Learning Algorithms to Predict Provenance of Archaeological Pottery Fragments. Sustainability, 14(18), 11214. https://doi.org/10.3390/su141811214