1. Introduction
Traffic signal control is widely studied as an effective means to improve the operational and safety performance of intersections. Traffic control systems can be roughly divided into three types: fixed timing (FT), traffic actuated control (TAC), and adaptive traffic signal control (ATSC). Recent research focuses on ATSC, while the other two control algorithms are mainly used as the research baseline [
1]. ATSC needs a lot of accurate data to optimize the operational and safety performance of intersections in real-time [
2].
The traffic flow data required by traditional TAC and ATSC are usually collected by loop detectors, which is a common and economical method at present [
3]. With the development of connected and automated vehicles (CAVs), the way ATSC obtains real-time data have been expanded compared with human-driven vehicle (HDV) [
4,
5,
6,
7]. Existing studies generally believe that only CAV data can realize intelligent vehicle infrastructure cooperative systems [
8,
9,
10]. Yet, Yang et al. [
11] found that the integration of loop detectors data and CAVs data can improve the performance of traffic control algorithms. In addition, as mentioned above, the loop detector is widely used, and it is feasible and economical to integrate its data with CAVs data in the proposed traffic control algorithm. However, it can be considered that the data collected by the loop detector at a low market penetration rate (MPR) is more accurate than CAVs data, and the conclusion is the opposite at a high MPR. Therefore, how to balance them is a crucial problem in traffic signal control.
In the development and researches of ATSC, various algorithms, such as heuristic algorithm and reinforcement learning, are applied to improve the operational and safety performance of intersections [
12]. Among all algorithms, the Q-learning algorithm has been widely studied and achieved satisfactory performance [
13,
14,
15]. Guo and Harmati [
16] proposed an ATSC based on Q-learning and considered Nash equilibriums to improve traffic control performance at intersections. Abdoos et al. [
17] presented a two-level hierarchical control of traffic signals based on Q-learning, and the results show that the proposed hierarchical control improves the Q-learning efficiency of the bottom level agents. Wang et al. [
18] proposed a multi-agent reinforcement learning traffic control system based on Q-learning, and the results show that their algorithm outperforms the other multi-agent reinforcement learning algorithms in terms of multiple traffic metrics. Their research provides an idea for testing ATSC based on Q-learning, that is, comprehensive analysis from multiple perspectives. In addition, the model of reward function in Q-learning is the key to the implementation of the algorithm, that is, the optimization object. Essa and Sayed [
19] designed an ATSC based on Q-learning to optimize the conflict rate. However, their algorithm requires a large amount of complex data and is not suitable for low-level detectors (such as loop detectors). Abdoos [
20] proposed an ATSC with the object of optimizing the queue length and achieved good results in the simulation. The queue length used in her algorithm is the traffic data that the existing detectors can collect. However, the algorithm lacks comprehensive analysis, such as testing under different traffic demands and unbalanced traffic flow.
The existing research on intersection optimization attempts to improve the operation and safety performance at the same time [
19,
21,
22]. In recent years, robustness testing has been widely used in the research of traffic control [
23,
24,
25]. At the same time, the impact of unbalanced traffic flow on the operation and safety performance of intersections has also been widely concerned by scholars [
26]. In addition, the test of traffic control at irregular intersections has been proved necessary [
27]. Thus, comprehensive tests need to be carried out in the above environment to make the research more convincing.
To fill the above gaps, we proposed an ATSC based on a Q-learning algorithm that integrates data obtained by existing loop detectors and CAVs. In addition, a comprehensive analysis was conducted to test the performance of the proposed algorithm in various traffic conditions.
2. Algorithm Design
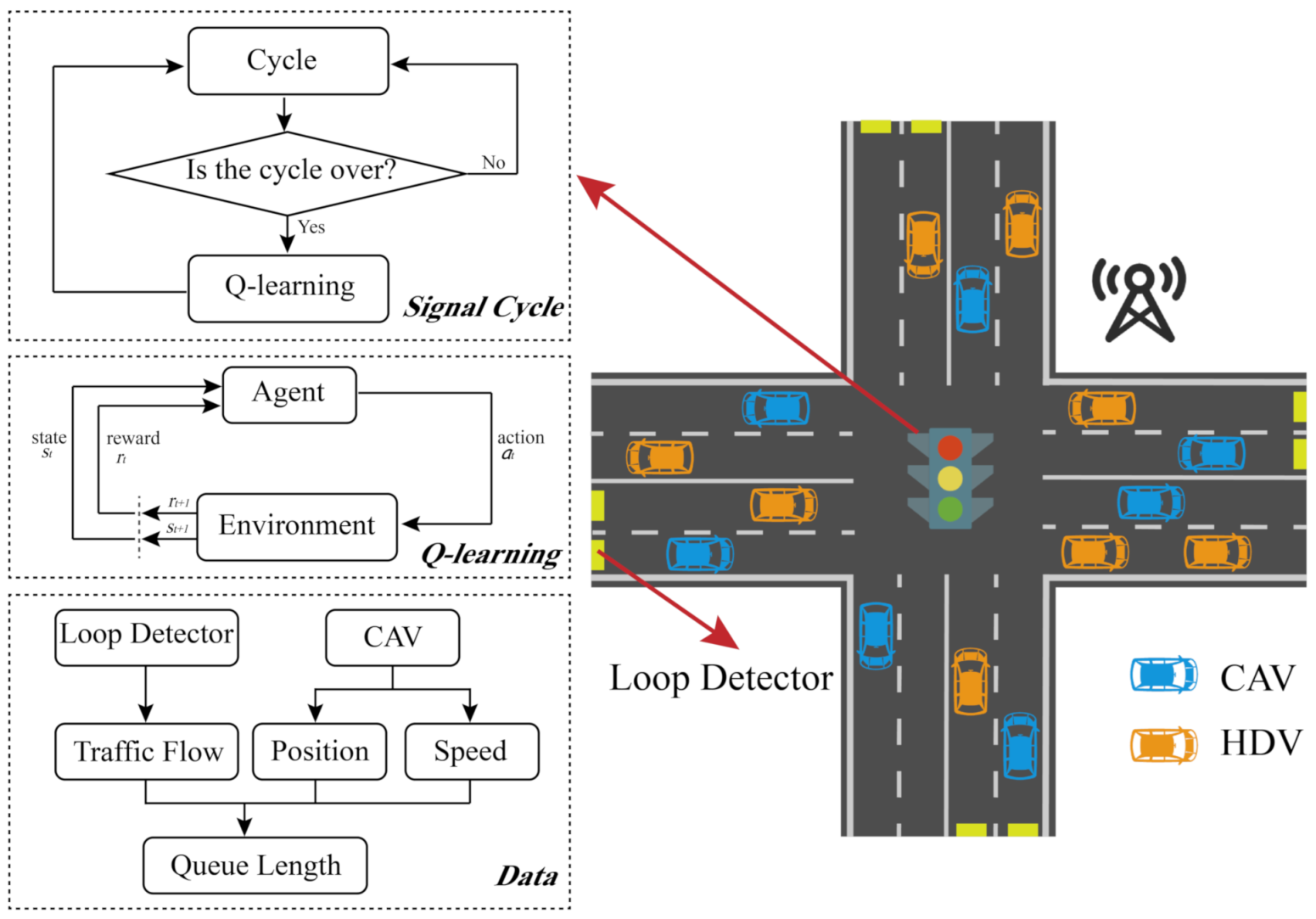
In this section, we designed an ATSC algorithm using Q-learning to optimize the operational performance of intersections in terms of the data obtained by loop detectors and CAVs. Specifically, the queue length estimated by loop detectors and CAVs is the optimized objective to enhance the operational and safety performance of intersections. The general flow of the proposed algorithm is represented in
Figure 1. As shown in the figure, loop detectors or CAVs collect data during the operation of the current cycle. When the cycle ends, the Q-learning algorithm is conducted to calculate the signal timing of the next cycle. So back and forth.
Q-learning is a value-based algorithm in the reinforcement learning algorithms. Q is
, which is the expectation that taking action
a in the state
s at a certain time can obtain income. The environment will feedback the corresponding reward
r according to the action of the agent. Therefore, the main idea of the algorithm is to build states and actions into a q-table to store the Q value and then select the action that can obtain the maximum income according to the Q value. Q-learning is one of reinforcement learning algorithms, and the process of it can be as follows:
where
is the update
Q value;
is the
Q value which selected action
under state
in the last episode;
is the learning rate;
is the reward under
;
is the discount rate and it is 0.7 in this study;
is the set of actions;
is the
Q value in next step.
2.1. State Representation
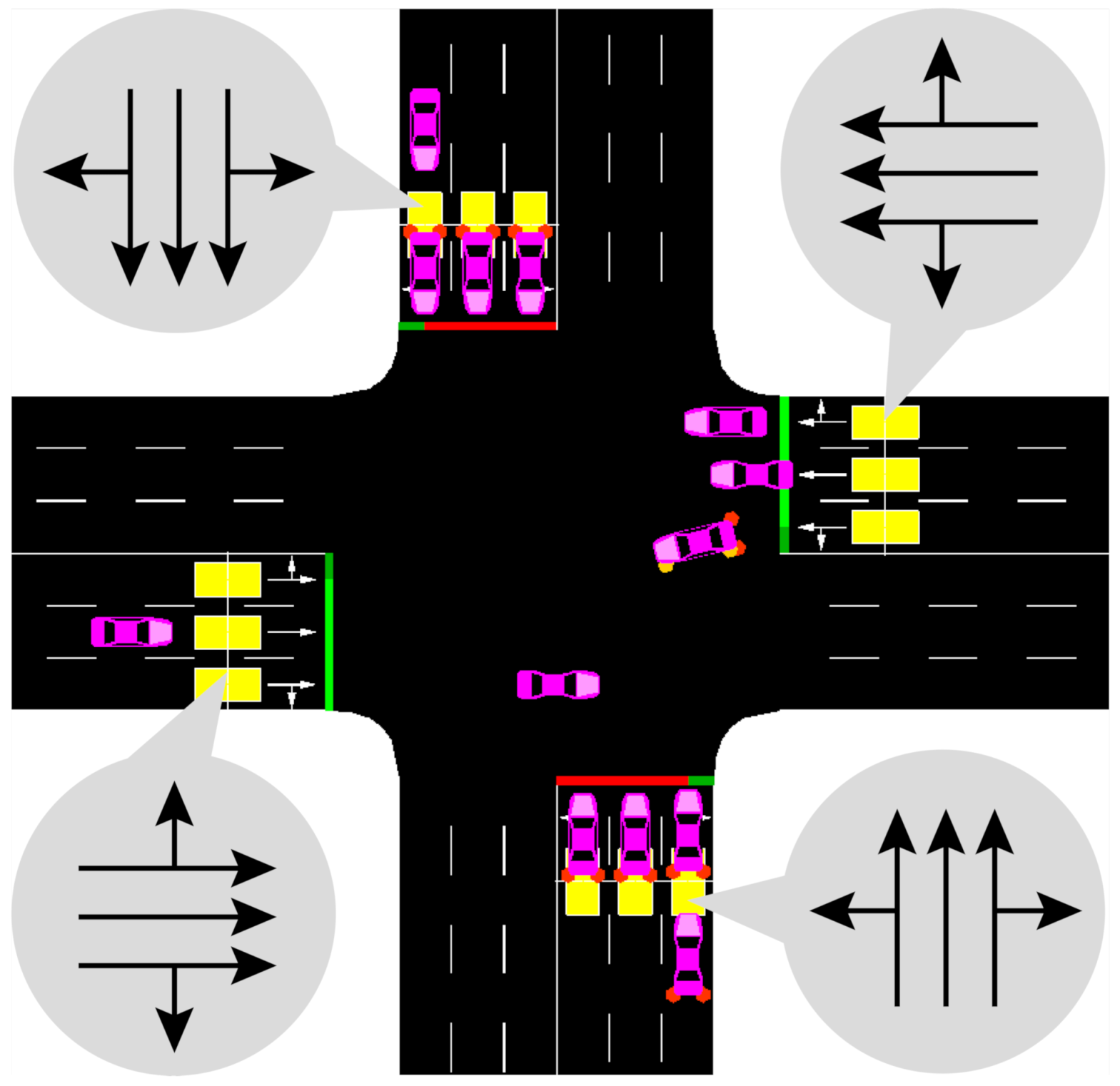
In the Q-learning algorithm, states are constantly changing according to the choice of actions. Therefore, each loop in Q-learning needs to redefine the current state. As mentioned above, the order of queue length of each approach in the intersection estimated by loop detectors and CAVs is used as the state set. In this study, the state set is presented in
Table 1, which is the same as [
20]. Firstly, we number the approaches. Specifically, we take the four-legs intersection as an example, and the number of each approach is 1–4.
is the queue length in the
l-th approach. After selecting each action, the queue length of each approach is sorted to correspond to each state in
Table 1. A boundary state is needed to make the program break in Q-learning, and three constraints are set in this study. When the queue length of two approaches under the red phase is higher than the others simultaneously, or one of the queue lengths is higher than the length of the lane, the current state is marked as terminal. In addition, The selection of action is limited by the maximum green time, as shown below.
2.2. Action Representation
There are 200 loops in the proposed algorithm to search for the optimal scheme. It needs to keep adjusting the signal timing until the current state is terminal. During each time step of one loop, two actions can be chosen to adjust the current signal timing as follows:
where,
is the length of the
l lane.
Specifically, actions can be selected 1 or 0, representing the extension time (1 s or 0 s). In other words, the current green time could be extended to 1 s or 0 s if the respective condition is true. However, the queue length estimated by loop detectors and low MPR CAVs is inaccurate, so we adjust the reward function in the next section to improve accuracy. In this study, the maximum cycle is 120 s, and the minimum green time is 20 s, so the maximum green time is set to 100 s.
2.3. Reward Function
As mentioned, the proposed algorithm aims to improve the performance of intersections according to the queue length of each approach. In each loop, the proposed algorithm predicts the queue length of each approach in the time step, which uses the data detected by loop detectors and CAVs as the initial state. The queue length of each approach can be estimated as follows:
where,
is the queue length of the
l lane;
n is the number of vehicles in queue.
is the length of the
i-th vehicle;
is the gap between the
i-th and the
-th vehicle.
Furthermore, the number of vehicles in queue
n is inaccurate when estimated by loop detectors and CAVs under low MPRs. As Equation (
4) shows that the traffic flow
m is the key parameter to calculate
n. However,
m detected by loop detectors could not adapt to the real-time traffic demand. In addition, there is limited data to calculate
m under low MPRs.
where
is the red time;
m is the traffic flow per second;
is the selection function, and if the
is true, the value is 1;
p is the current phase;
is the set of red phase.
In the prediction process, the green time and red time of each phase change one after another. The duration of the red phase will increase with the increase in the green time. Thus, the red time
can be determined as follows:
where,
is the minimum green time, it is 20 s in this study;
is the time step, and it is 1 s due to the selection of actions mentioned above.
The queue length detected by two methods is conducted in the reward function to enhance the accuracy. Under low MPR, there are few CAVs in intersections, and the amount of data detected is not enough, resulting in insufficient accuracy. At this time, it is wise to predict the queue length through the loop detector data rather than CAV. On the other hand, when high MPR is reached, the amount and accuracy of data detected by CAVs will meet the demand, making the predicted queue length more accurate than loop detectors. Therefore, we can conclude that the key to algorithm ability lies in MPR. In this study, we proposed a reward function to adjust the weight of the two methods through MPR as follows:
where
is the value of reward at
;
is the queue length estimated by the loop detector;
is the queue length detected by CAVs;
is the current MPR.
5. Conclusions
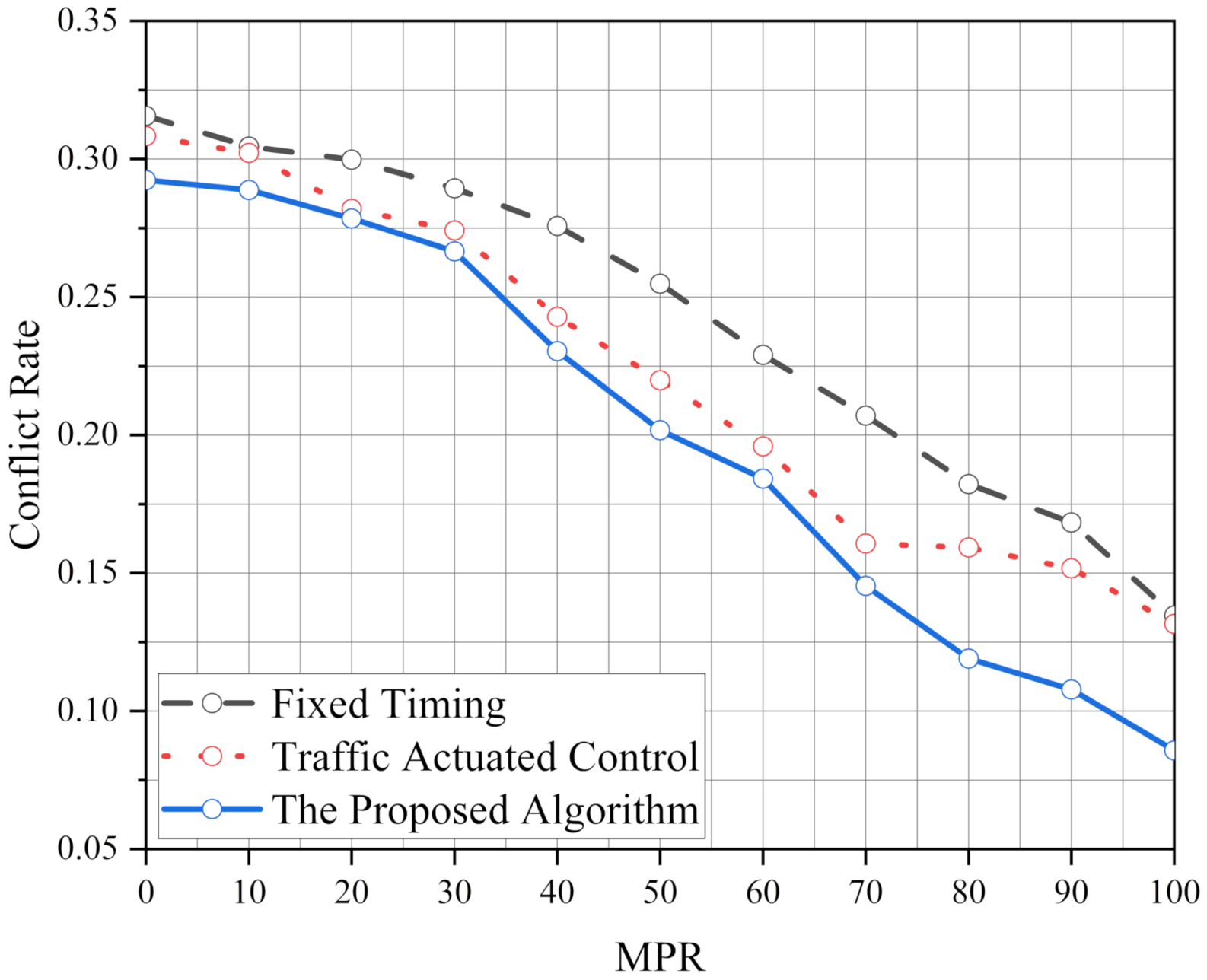
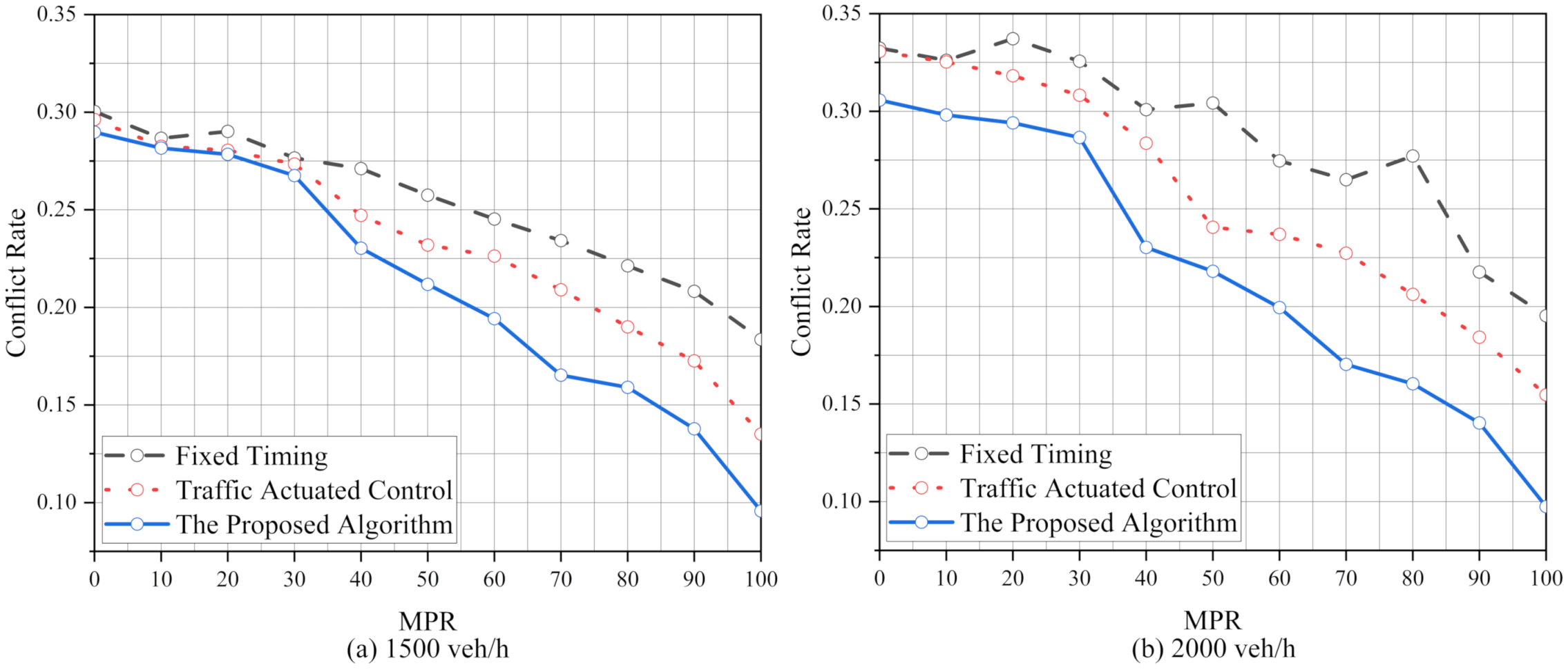
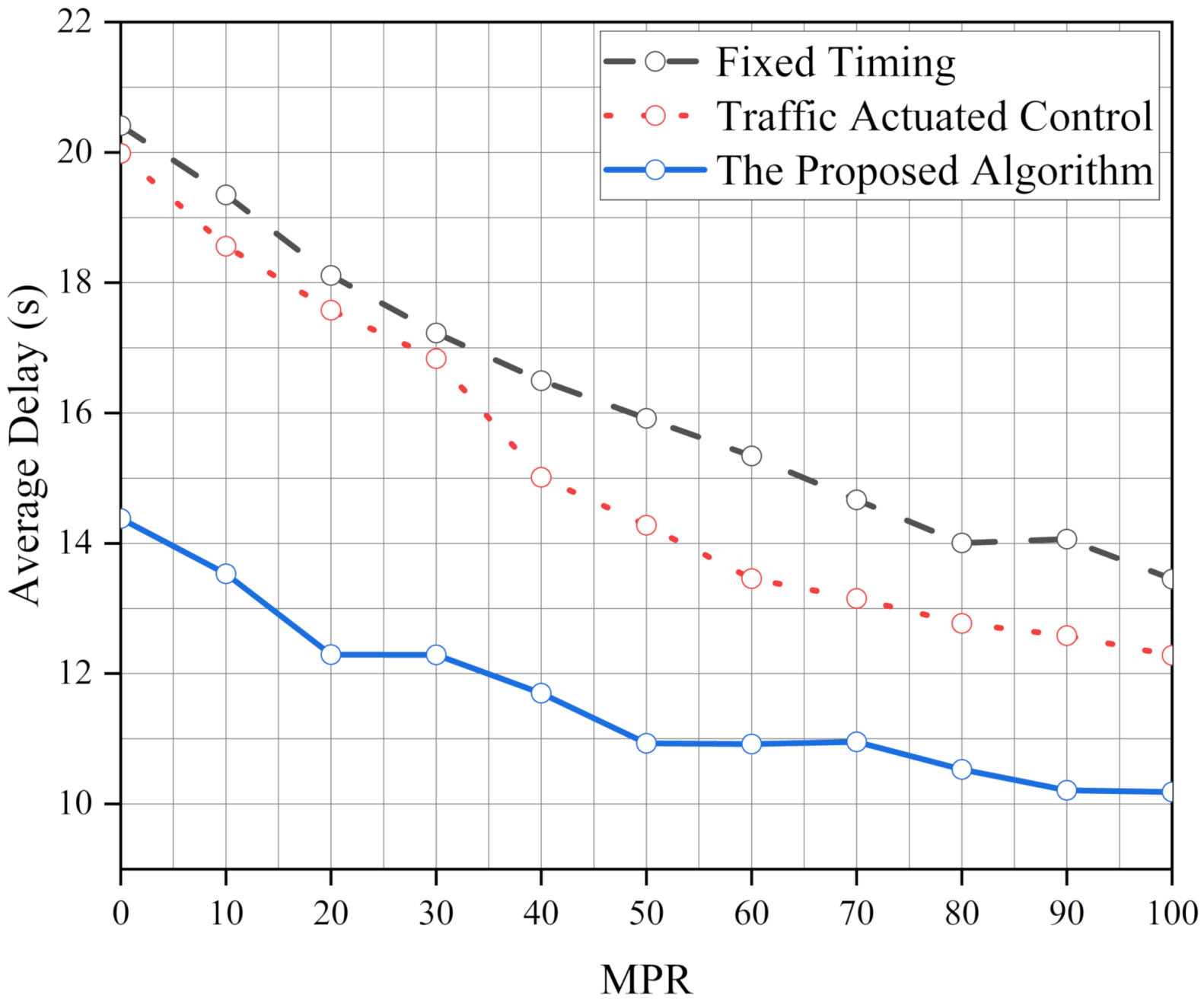
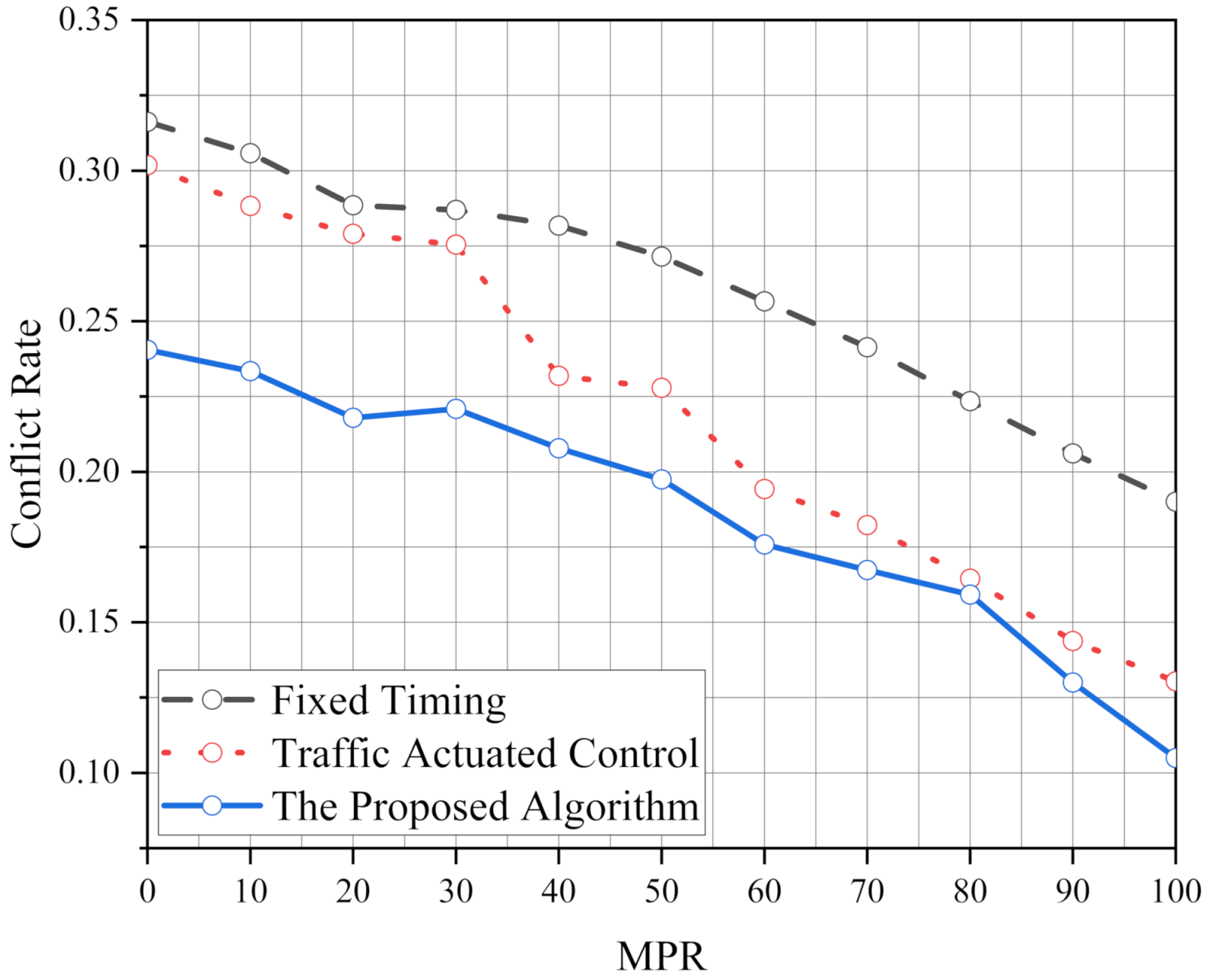
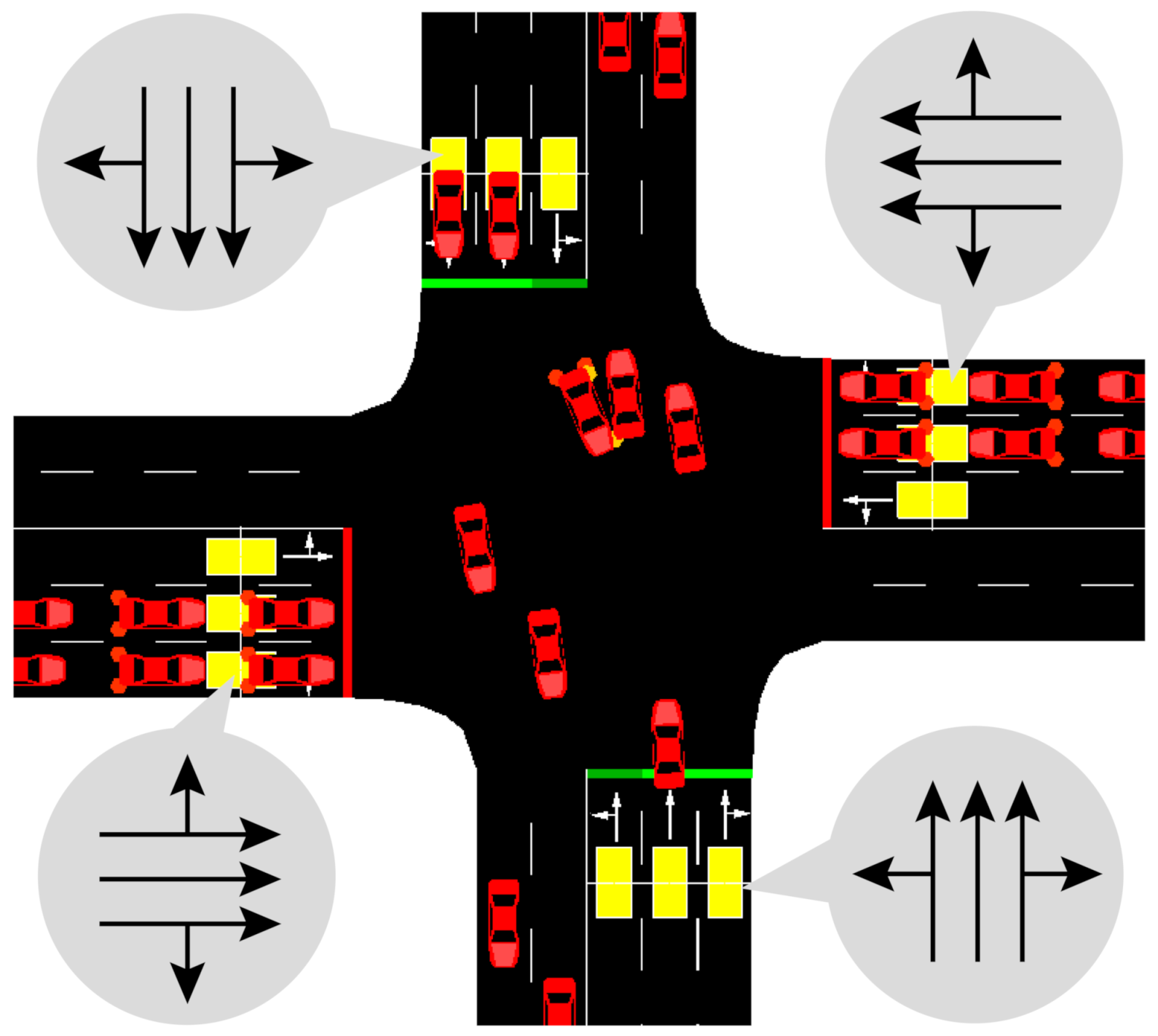
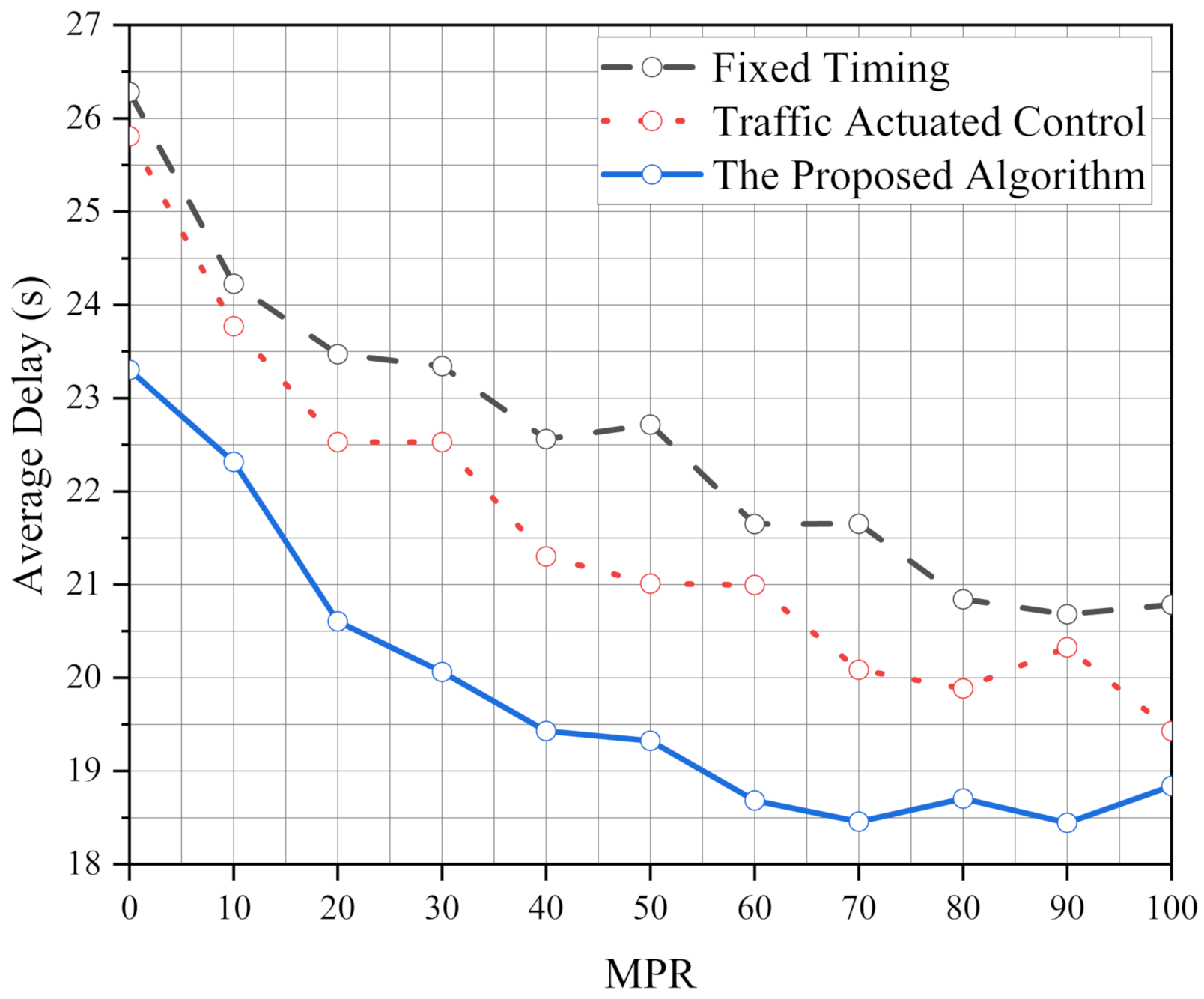
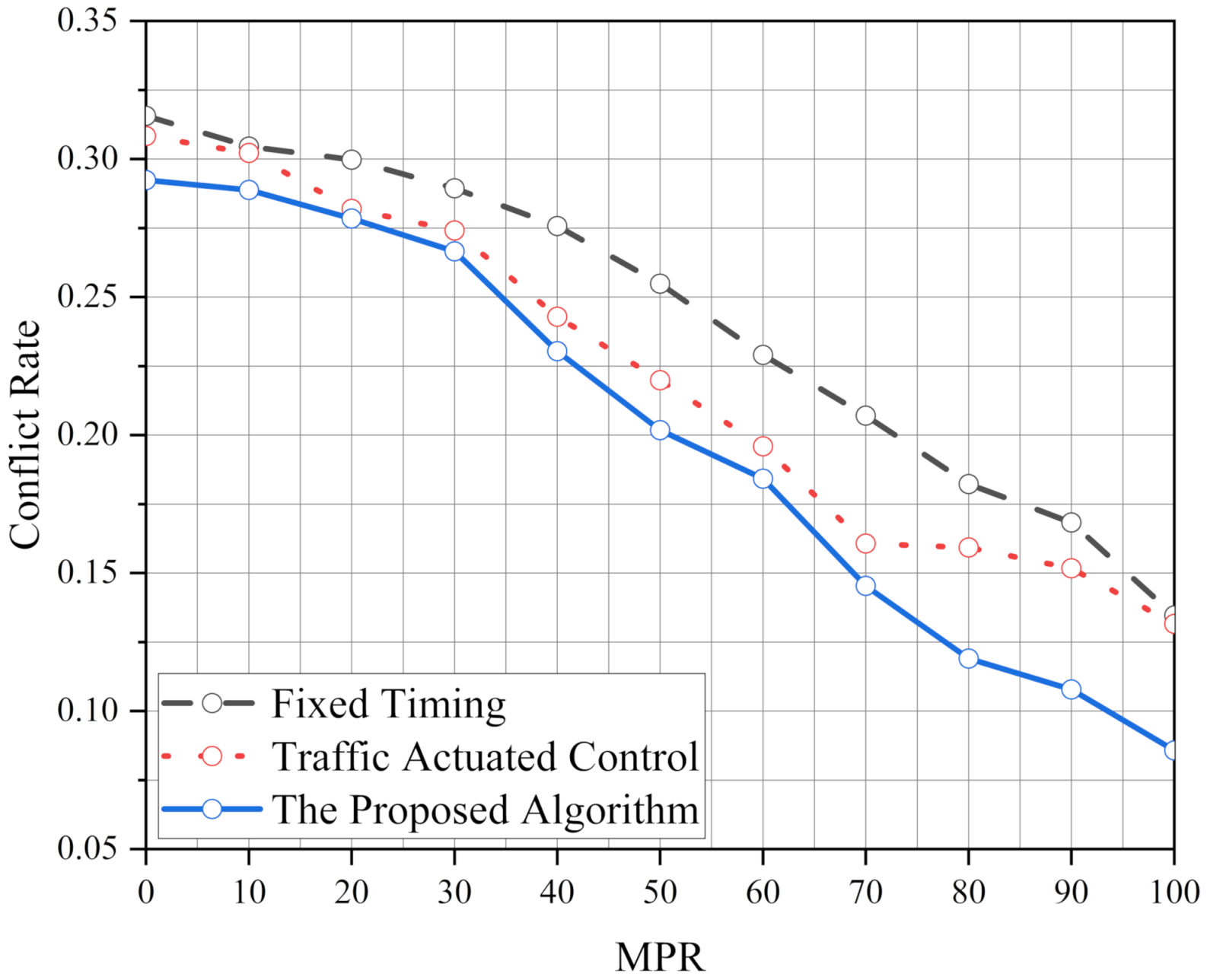
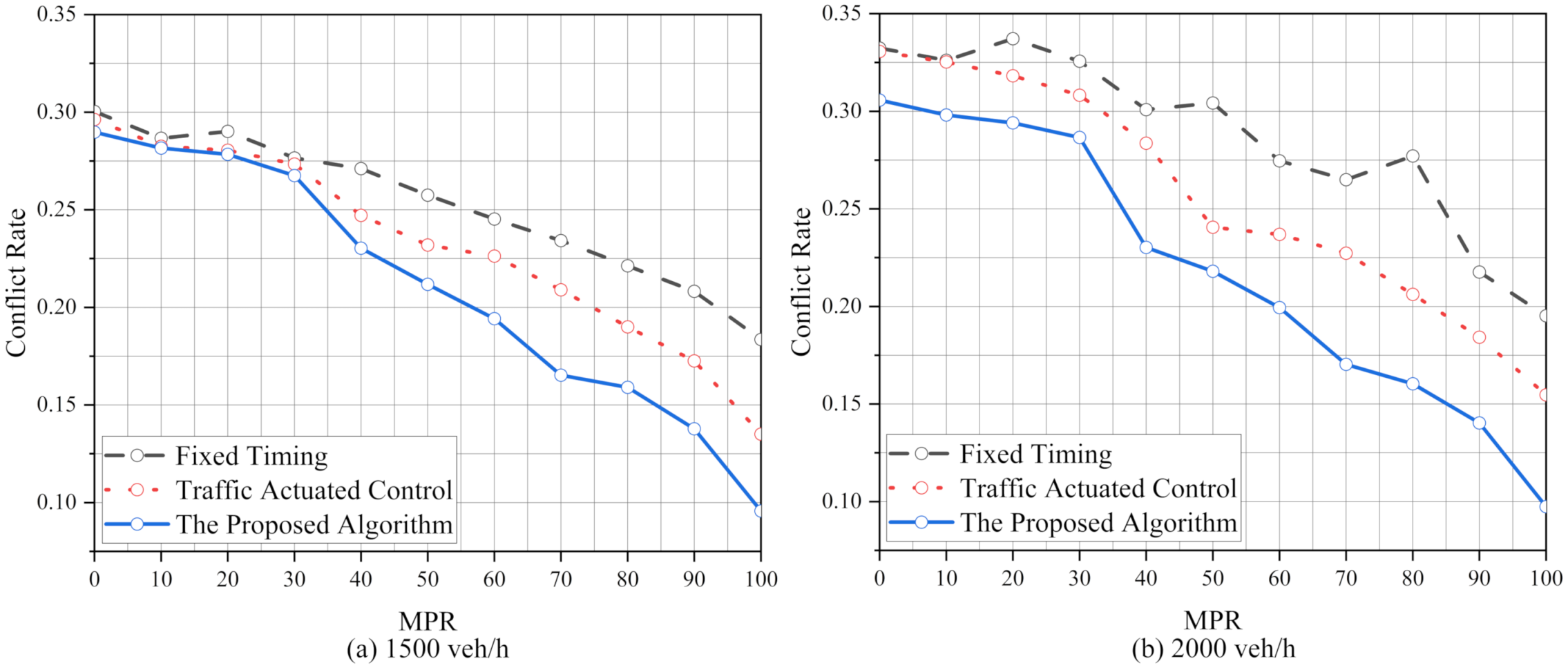
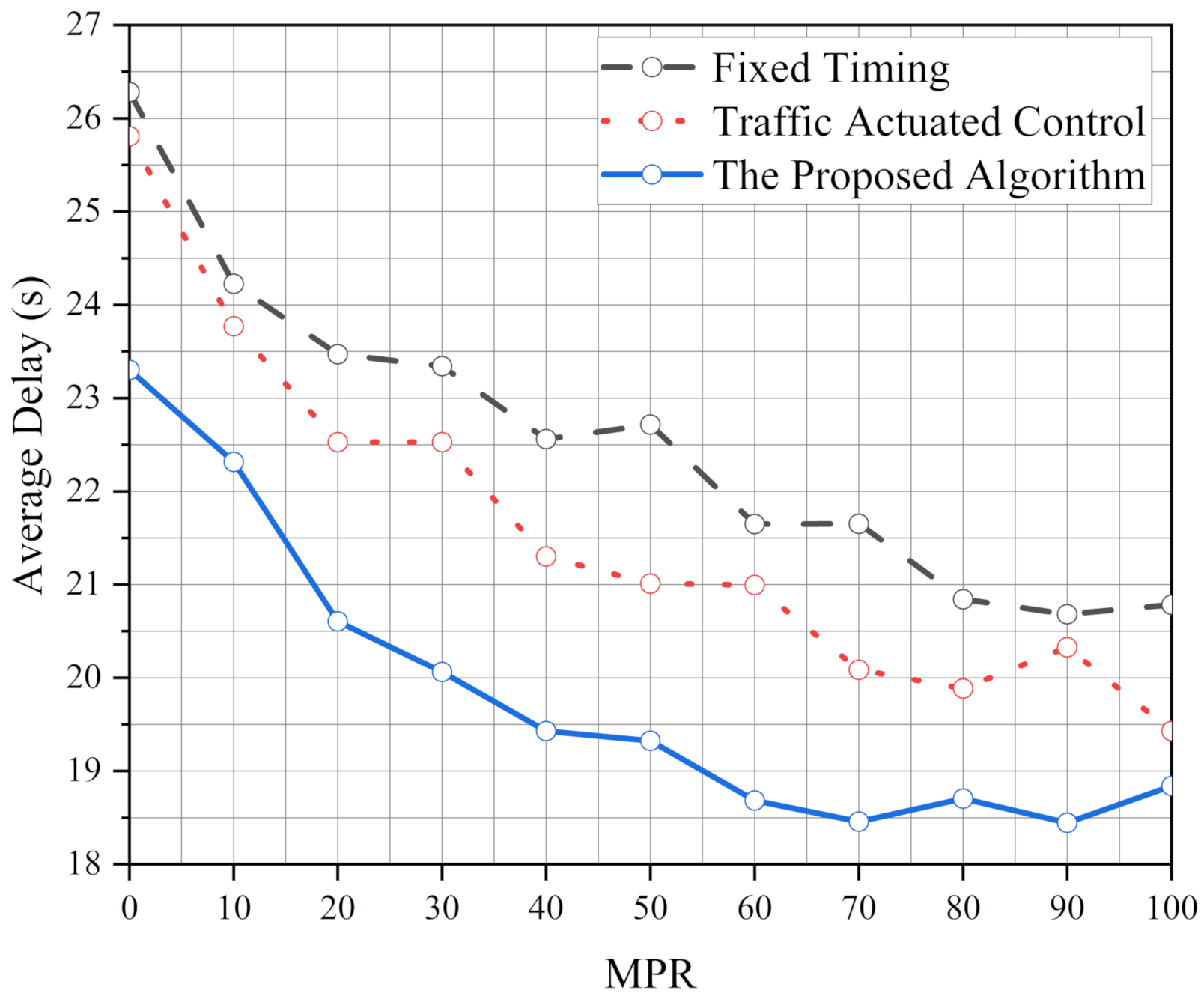
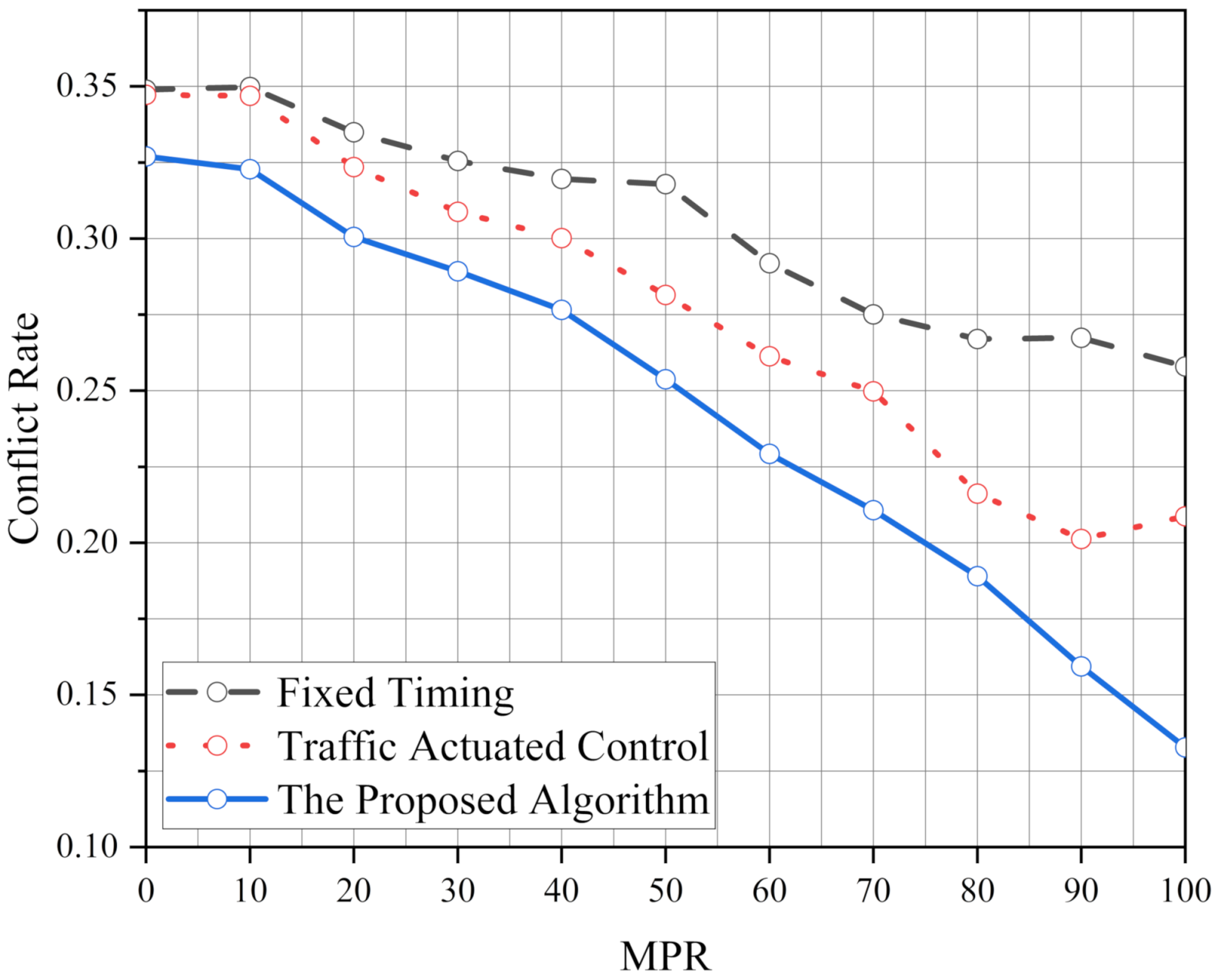
We proposed an ATSC based on the Q-learning algorithm to optimize the operational and safety performance of the intersection. The proposed algorithm has significant benefits for traffic control systems at isolated intersections. In addition, to meet the operational and safety performance of standard traffic demand, the robustness of the proposed algorithm is analyzed. The results show that the robustness of the proposed algorithm is better than FT and TAC. We also test the performance of the proposed algorithm in various traffic demands per approach (1000 veh/h, 1500 veh/h and 2000 veh/h) and its optimization ability increases with the increase in the traffic pressure. Moreover, it also shows excellent performance in an unbalanced traffic flow environment. After simulating, we find the operational and safety performance of our algorithm is more stable than FT and TAC. Finally, the effect of the intersection geometry is considered to verify the implementation of the proposed algorithm. It is found that the performance of the proposed algorithm is better than FT and TAC, and the ability of the proposed algorithm has been brought into full play under high MPRs.
The algorithm provides a new idea for the intelligent control of isolated intersections under the condition of mixed traffic flow. It also provides a research basis for collaborative control of multiple intersections.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}