
Cyclic Weighted k-means Method with Application to Time-of-Day Interval Partition


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Problem Description
3. Methodology
3.1. Cyclic Distance
3.2. Cyclic Weighted k-means Method
| Algorithm 1. The cyclic weighted k-means algorithm | |
| Require: iterations , number of sampling units , cluster number . | |
| Ensure: Determine the centroids and breakpoints in i-th iteration. | |
| 1: | Initialize the iterative number and centroids (see Algorithm 2). |
| 2: | for to do |
| 3: | for to do |
| 4: | Class label of t-th timescale in i-th iteration where , i.e., assign a centroid to timescale in i-th iteration. |
| 5: | End for |
| 6: | for to do |
| 7: | Update the centroids: . |
| 8: | End for |
| 9: | Ifthen |
| 10: | Output centroids and class labels . |
| 11: | Obtain subscripts which satisfy (let , ). |
| 12: | Obtain the corresponding breakpoints . |
| 13: | Ranking from small to large, the final breakpoints are obtained. |
| 14: | Break |
| 15: | End if |
| 16: | End for |
3.3. Initialization of Centroids
| Algorithm 2. Initialization of the centroids under given | |
| Require: Number of sampling units , cluster number , traffic flow series . | |
| Ensure: Obtain the initialized centroids . | |
| 1: | Initialize the set of centroids to empty set, i.e., |
| 2: | Find the maximum from , whose corresponding timescale is . |
| 3: | Add into , i.e., . |
| 4: | for to do |
| 5: | Find -th timescale outside cyclic neighborhood of all elements in , satisfying , where . |
| 6: | Add into , i.e., . |
| 7: | End for |
| 8: | Sort the elements of set in ascending order and obtain the initialized centroids . |
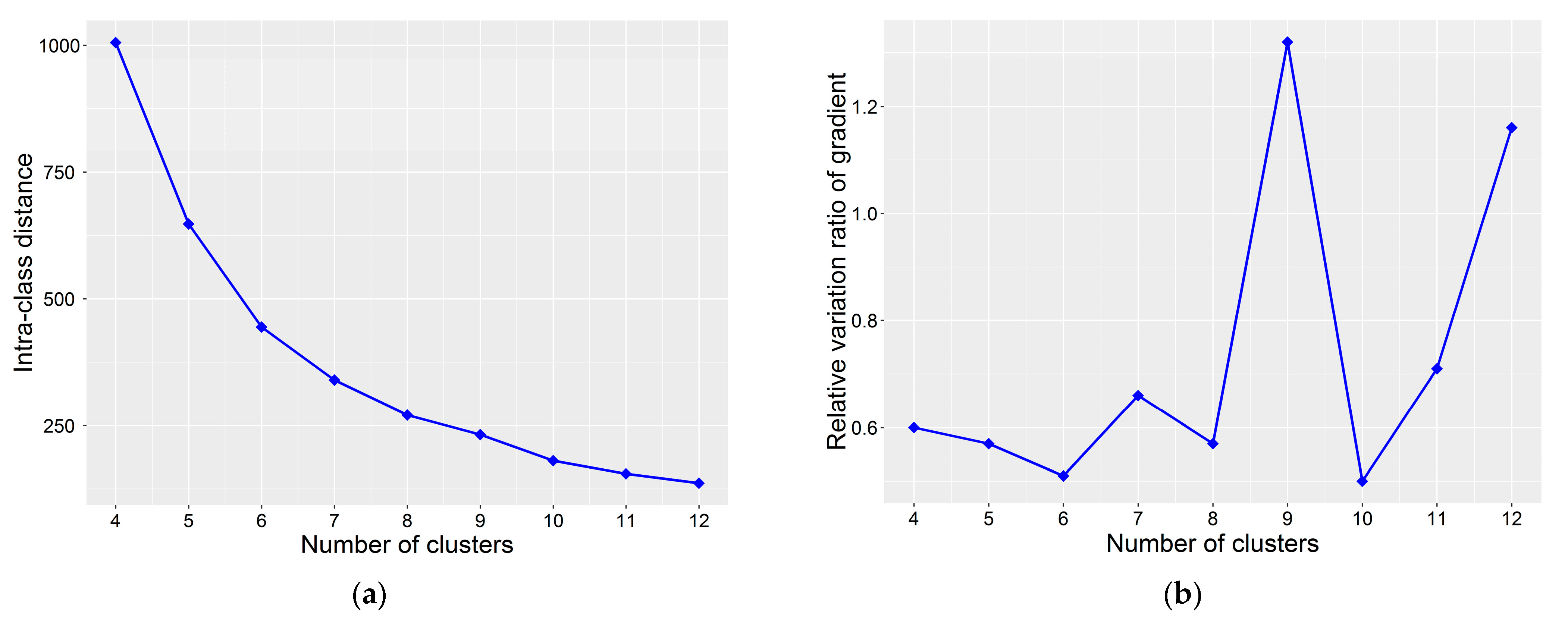
3.4. Determination of K
3.5. Adjustment of Breakpoints
4. Case Study
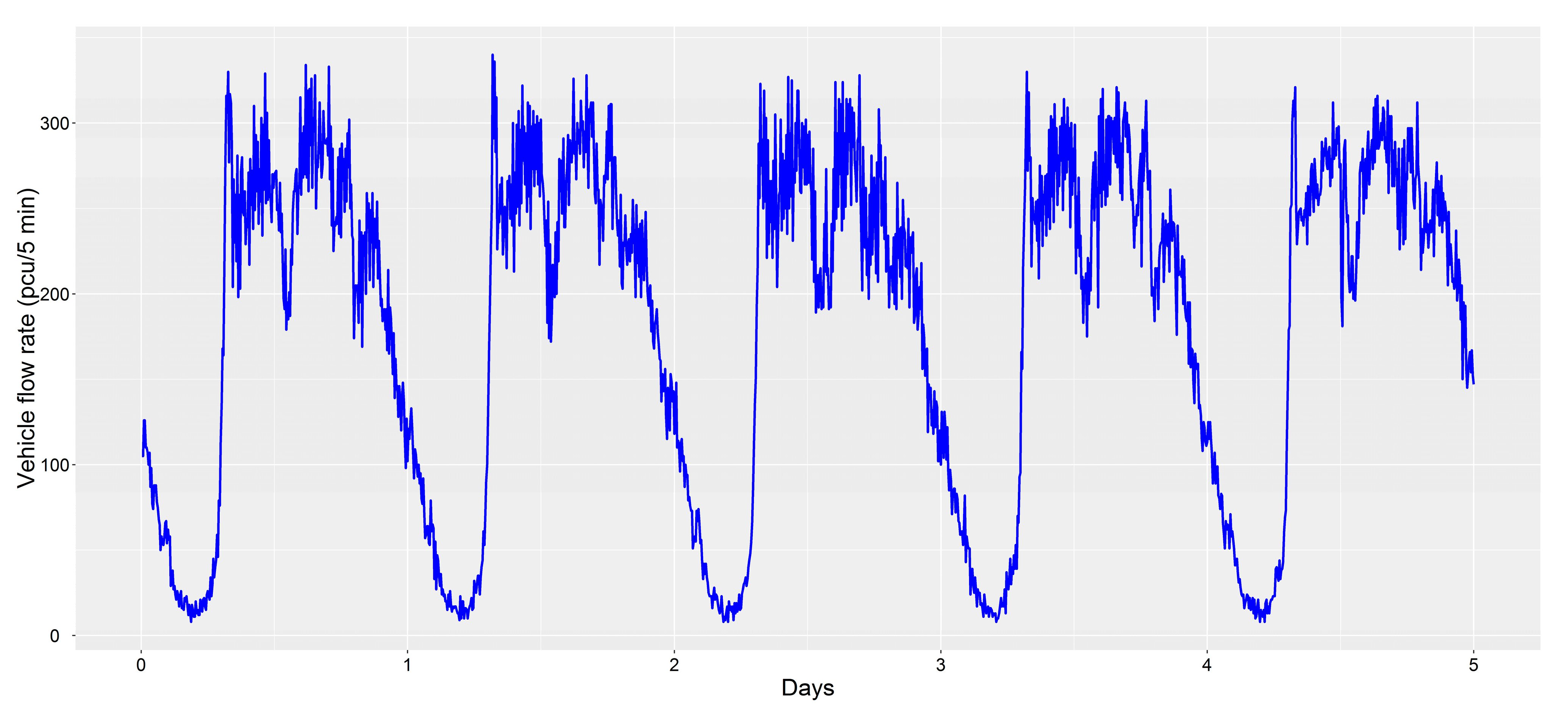
4.1. Empirical Data
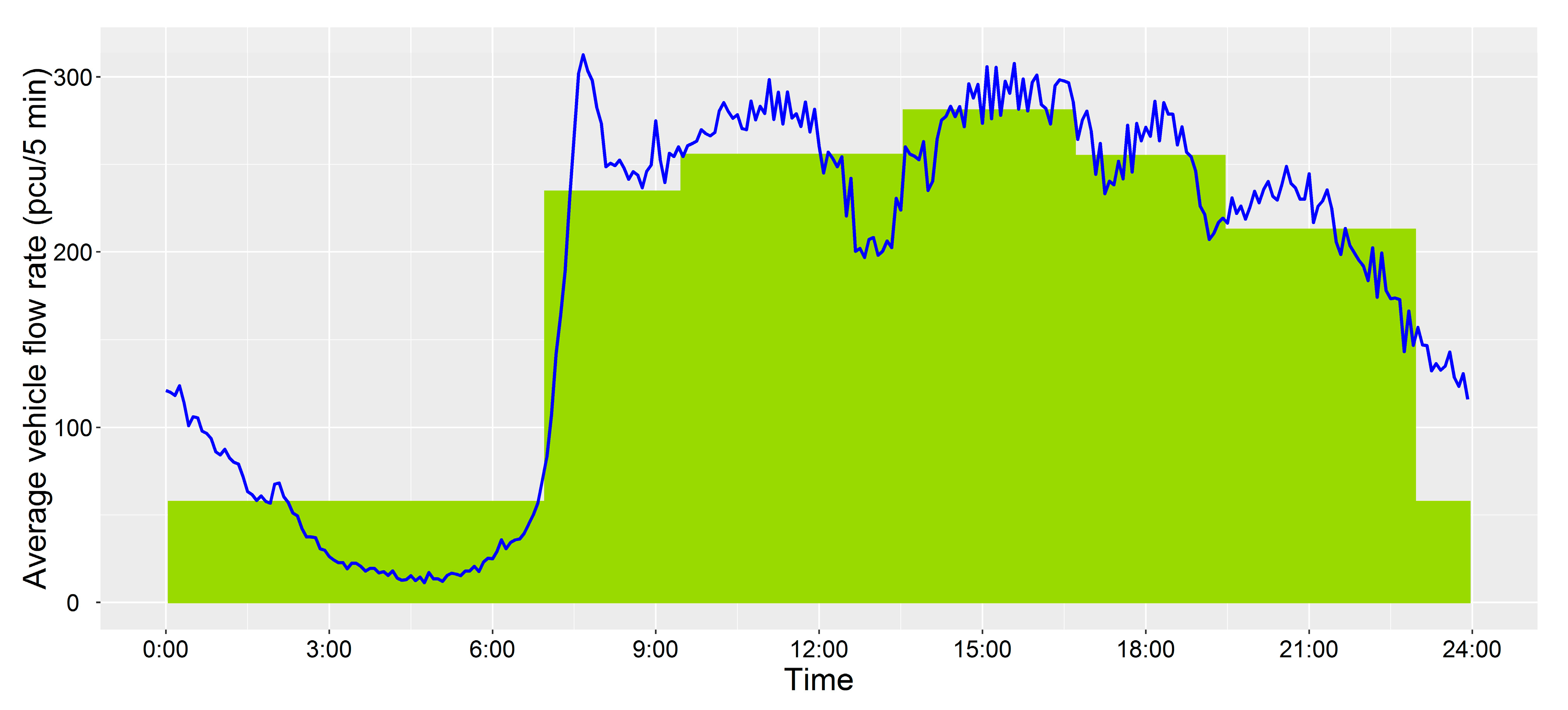
4.2. Results of Clustering
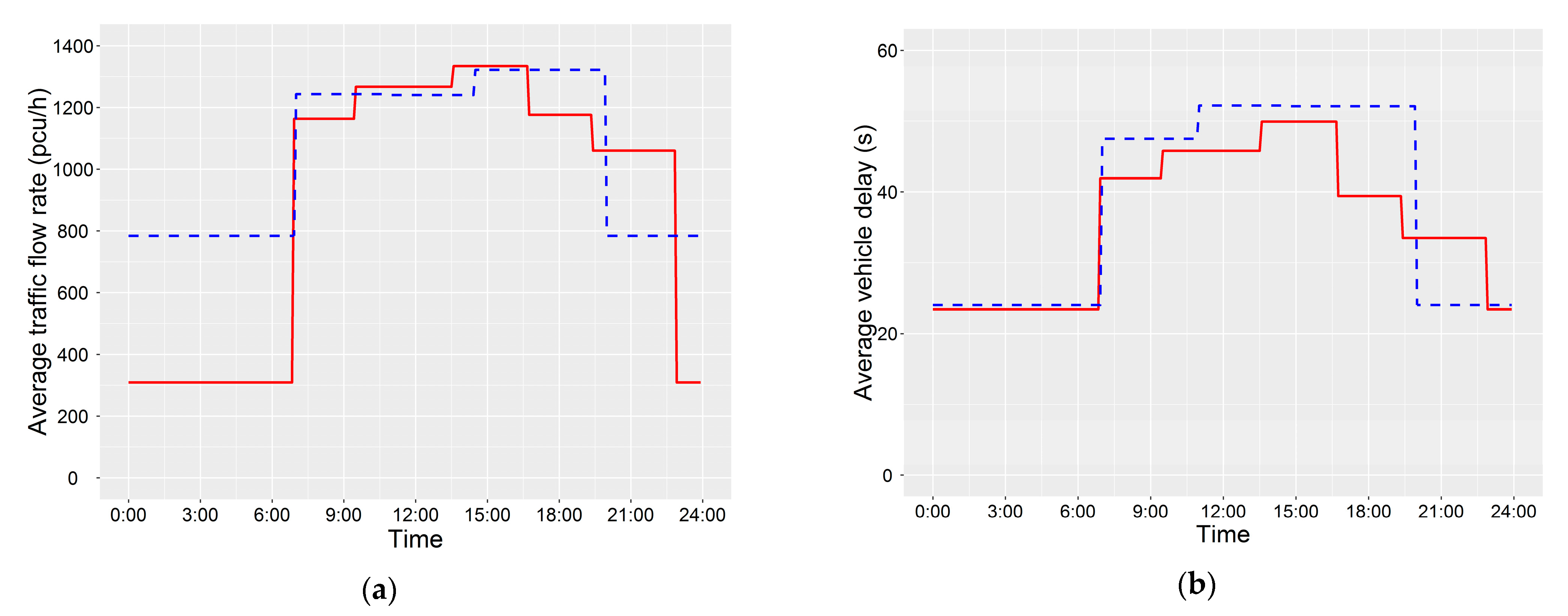
4.3. Evaluation of Methods
5. Conclusions
- i.
- The cyclic distance is the key for the cyclic weighted k-means algorithm, which makes it possible that the end point of the previous cycle and the start point of the current cycle are connected in the clustering result, and a complete cycle of data has been considered rather than separation from tail to head.
- ii.
- Some attached algorithms, i.e., centroid initialization, cluster number selection, and breakpoint adjustment, are helpful for further improvement of the cyclic weighted k-means algorithm to solve the TIP problem.
- iii.
- The feasibility of the proposed method is confirmed by empirical study. It is noted that the practical evaluation criteria (such as the average vehicle delay in benefits of traffic signal control) should serve the practice. From the perspective of application, the proposed method can also be applied to other scenes. For example, it can be applied to the inventory adjustment of e-commerce according to the daily sales, and the seat optimization of a call center according to the volume of calls.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Ma, D.; Luo, X.; Jin, S.; Wang, D.; Guo, W.; Wang, F. Lane-Based Saturation Degree Estimation for Signalized Intersections Using Travel Time Data. IEEE Intell. Transp. Syst. Mag. 2017, 9, 136–148. [Google Scholar] [CrossRef]
- Mirchandani, P.; Head, L. A Real-Time Traffic Signal Control System: Architecture, Algorithms, and Analysis. Transp. Res. Part C: Emerg. Technol. 2001, 9, 415–432. [Google Scholar] [CrossRef]
- Di Febbraro, A.; Giglio, D.; Sacco, N. A Deterministic and Stochastic Petri Net Model for Traffic-Responsive Signaling Control in Urban Areas. IEEE Trans. Intell. Transp. Syst. 2015, 17, 510–524. [Google Scholar] [CrossRef]
- Schmöcker, J.-D.; Ahuja, S.; Bell, M.G. Multi-Objective Signal Control of Urban Junctions—Framework and a London Case Study. Transp. Res. Part C: Emerg. Technol. 2008, 16, 454–470. [Google Scholar] [CrossRef]
- Keyvan-Ekbatani, M.; Yildirimoglu, M.; Geroliminis, N.; Papageorgiou, M. Multiple Concentric Gating Traffic Control in Large-Scale Urban Networks. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2141–2154. [Google Scholar] [CrossRef]
- Papageorgiou, M.; Kiakaki, C.; Dinopoulou, V.; Kotsialos, A.; Wang, Y. Review of Road Traffic Control Strategies. Proc. IEEE 2003, 91, 2043–2067. [Google Scholar] [CrossRef]
- Chang, T.-H.; Lin, J.-T. Optimal Signal Timing for an Oversaturated Intersection. Transp. Res. Part B: Methodol. 2000, 34, 471–491. [Google Scholar] [CrossRef]
- Lertworawanich, P.; Kuwahara, M.; Miska, M. A New Multiobjective Signal Optimization for Oversaturated Networks. IEEE Trans. Intell. Transp. Syst. 2011, 12, 967–976. [Google Scholar] [CrossRef]
- Liu, Z.; Bie, Y. Comparison of Hook-Turn Scheme with U-Turn Scheme Based on Actuated Traffic Control Algorithm. Transp. A Transp. Sci. 2015, 11, 484–501. [Google Scholar] [CrossRef]
- Zhao, L.; Peng, X.; Li, L.; Li, Z. A Fast Signal Timing Algorithm for Individual Oversaturated Intersections. IEEE Trans. Intell. Transp. Syst. 2010, 12, 280–283. [Google Scholar] [CrossRef]
- Bie, Y.; Liu, Z. Evaluation of a Signalized Intersection with Hook Turns under Traffic Actuated Control Circumstance. J. Transp. Eng. 2015, 141, 04014093. [Google Scholar] [CrossRef]
- Bie, Y.; Gong, X.; Liu, Z. Time of Day Intervals Partition for Bus Schedule Using GPS Data. Transp. Res. Part C Emerg. Technol. 2015, 60, 443–456. [Google Scholar] [CrossRef]
- Chen, P.; Zheng, N.; Sun, W.; Wang, Y. Fine-Tuning Time-of-Day Partitions for Signal Timing Plan Development: Revisiting Clustering Approaches. Transp. A Transp. Sci. 2019, 15, 1195–1213. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; The MIT Press: Cambridge, MA, USA; London, UK, 2012. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. Ser. B Methodol. 1977, 39, 1–22. [Google Scholar]
- Wu, C.F.J. On the Convergence Properties of the EM Algorithm. Ann. Stat. 1983, 11, 95–103. [Google Scholar] [CrossRef]
- Fraley, C.; Raftery, E.A. Model-Based Clustering, Discriminant Analysis, and Density Estimation. J. Am. Stat. Assoc. 2002, 97, 611–631. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by Passing Messages between Data Points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, A.; Laio, A. Clustering by Fast Search and Find of Density Peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef]
- Huang, W.; Cao, X.; Biase, F.H.; Yu, P.; Zhong, S. Time-Variant Clustering Model for Understanding Cell Fate Decisions. Proc. Natl. Acad. Sci. USA 2014, 111, E4797–E4806. [Google Scholar] [CrossRef]
- Shah, S.A.; Koltun, V. Robust Continuous Clustering. Proc. Natl. Acad. Sci. USA 2017, 114, 9814–9819. [Google Scholar] [CrossRef]
- Smith, B.L.; Scherer, W.T.; Hauser, T.A. Data-Mining Tools for the Support of Signal-Timing Plan Development. Transp. Res. Rec. J. Transp. Res. Board 2001, 1768, 141–147. [Google Scholar] [CrossRef]
- Ratrout, N.T. Developing Optimal Timing Plans for Cyclic Traffic along Arterials Using Pre-Timed Controllers. Proc. Urban Trans. 2011, 116, 367. [Google Scholar]
- Ratrout, N.T. Subtractive Clustering-Based K-means Technique for Determining Optimum Time-of-Day Breakpoints. J. Comput. Civ. Eng. 2011, 25, 380–387. [Google Scholar] [CrossRef]
- Xia, J.; Chen, M. Defining Traffic Flow Phases Using Intelligent Transportation Systems-Generated Data. J. Intell. Transp. Syst. 2007, 11, 15–24. [Google Scholar] [CrossRef]
- Wang, X.; Cottrell, W.D.; Mu, S. Using K-Means Clustering to Identify Time-of-Day Break Points for Traffic Signal Timing Plans. In Proceedings of the 2005 IEEE Intelligent Transportation Systems, Vienna, Austria, 16 September 2005; pp. 586–591. [Google Scholar]
- Guo, R.; Zhang, Y. Identifying Time-of-Day Breakpoints Based on Nonintrusive Data Collection Platforms. J. Intell. Transp. Syst. 2013, 18, 164–174. [Google Scholar] [CrossRef]
- Dong, C.; Su, Y.; Liu, X. Research on TOD Based on Isomap and K-means Clustering Algorithm. In Proceedings of the 2009 Sixth International Conference on Fuzzy Systems and Knowledge Discovery, Tianjin, China, 14–16 August 2009; Volume 1, pp. 515–519. [Google Scholar]
- Ma, D.; Li, W.; Song, X.; Wang, Y.; Zhang, W. Time-of-Day Breakpoints Optimisation through Recursive Time Series Partitioning. IET Intell. Transp. Syst. 2019, 13, 683–692. [Google Scholar] [CrossRef]
- Lee, J.; Kim, J.; Park, B. A Genetic Algorithm-Based Procedure for Determining Optimal Time-of-Day Break Points for Coordinated Actuated Traffic Signal Systems. KSCE J. Civ. Eng. 2010, 15, 197–203. [Google Scholar] [CrossRef]
- Park, B.; Santra, P.; Yun, I.; Lee, D.-H. Optimization of Time-of-Day Breakpoints for Better Traffic Signal Control. Transp. Res. Rec. J. Transp. Res. Board 2004, 1867, 217–223. [Google Scholar] [CrossRef]
- Park, B.; Lee, H.; Yun, I. Enhancement of Time of Day Based Traffic Signal Control. In Proceedings of the 2003 IEEE International Conference on Systems, Man and Cybernetics, Washington, DC, USA, 8 October 2003. [Google Scholar] [CrossRef]
- Yang, J.; Yang, Y. Using Kohonen Cluster to Identify Time-of-Day Break Points of Intersection. Lect. Notes Electr. Eng. 2013, 236, 889–896. [Google Scholar]
- Jia, L.; Yang, L.; Kong, Q.; Lin, S. Study of Artificial Immune Clustering Algorithm and its Applications to Urban Traffic Control. Int. J. Inf. Technol. 2006, 12, 1–6. [Google Scholar]
- Erman, J.; Arlitt, M.; Mahanti, A. Traffic Classification using Clustering Algorithms. In Proceedings of the 2006 Sigcomm Workshop on Mining Network Data-MineNet ’06; ACM: Nashville, TN, USA, 2006; pp. 281–286. [Google Scholar]
- Michalopoulos, P.G.; Stephanopoulos, G. Oversaturated Signal Systems with Queue Length Constraints—I: Single Intersection. Transp. Res. 1977, 11, 413–421. [Google Scholar] [CrossRef]
- Ban, X.; Hao, P.; Sun, Z. Real Time Queue Length Estimation for Signalized Intersections using Travel Times from Mobile Sensors. Transp. Res. Part C Emerg. Technol. 2011, 19, 1133–1156. [Google Scholar] [CrossRef]
- Farahani, R.Z.; Miandoabchi, E.; Szeto, W.; Rashidi, H. A Review of Urban Transportation Network Design Problems. Eur. J. Oper. Res. 2013, 229, 281–302. [Google Scholar] [CrossRef]
- Bräysy, O.; Gendreau, M. Vehicle Routing Problem with Time Windows, Part I: Route Construction and Local Search Algorithms. Transp. Sci. 2005, 39, 104–118. [Google Scholar] [CrossRef]
- Calderón, F.; Miller, E.J. Modelling within-Day Ridehailing Service Provision with Limited Data. Transp. B Transp. Dyn. 2021, 9, 62–85. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, W.; Bie, Y.; Wang, K.; Diabat, A. Mixed-Integer Second-Order Cone Programming Model for Bus Route Clus-tering Problem. Trans. Res. Part C Emerg. Technol. 2019, 102, 351–369. [Google Scholar] [CrossRef]
- Bie, Y.; Hao, M.; Guo, M. Optimal Electric Bus Scheduling Based on the Combination of All-Stop and Short-Turning Strategies. Sustainability 2021, 13, 1827. [Google Scholar] [CrossRef]
- Crainic, T.G.; Gendreau, M.; Potvin, J.-Y. Intelligent Freight-Transportation Systems: Assessment and the Contribution of Op-erations Research. Trans. Res. Part C Emerg. Technol. 2009, 17, 541–557. [Google Scholar] [CrossRef]
- Gordon, R.L.; Tighe, W. Traffic Control Systems Handbook; FHWA Office of Operations: Washington, DC, USA, 2005. [Google Scholar]
- Klein, L.A.; Gibson, D.; Mills, M.K. Traffic Detector Handbook; Federal Highway Admin: Washington, DC, USA, 2006. [Google Scholar]
- Webster, F. Traffic Signal Settings. In Road Research Technique Paper No. 39; Road Research Laboratory: London, UK, 1958. [Google Scholar]
- Wang, L.; Wang, Y.; Bie, Y. Automatic Estimation Method for Intersection Saturation Flow Rate Based on Video Detector Data. J. Adv. Transp. 2018, 2018, 1–9. [Google Scholar] [CrossRef]
- Council, N.R. Highway Capacity Manual; Transportation Research Board: Washington, DC, USA, 2000. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Qin, W.; Wang, Y. Cyclic Weighted k-means Method with Application to Time-of-Day Interval Partition. Sustainability 2021, 13, 4796. https://doi.org/10.3390/su13094796
Wang G, Qin W, Wang Y. Cyclic Weighted k-means Method with Application to Time-of-Day Interval Partition. Sustainability. 2021; 13(9):4796. https://doi.org/10.3390/su13094796
Chicago/Turabian StyleWang, Gaizhen, Wei Qin, and Yunhao Wang. 2021. "Cyclic Weighted k-means Method with Application to Time-of-Day Interval Partition" Sustainability 13, no. 9: 4796. https://doi.org/10.3390/su13094796
APA StyleWang, G., Qin, W., & Wang, Y. (2021). Cyclic Weighted k-means Method with Application to Time-of-Day Interval Partition. Sustainability, 13(9), 4796. https://doi.org/10.3390/su13094796