1. Introduction
The rapidly growing global population has made freshwater resources scarce and compelled hydrologists to explore methods for better river management and water resource conservation [
1]. Accurate modeling of suspended sediment load (SSL) plays a vital role in river restoration, pollution, and soil erosion reduction, thus solving challenges related to water quality, channel design, and the operation of hydraulic structures [
2,
3]. However, precise forecasting of SSL is challenging due to the concurrent effects of many meteorological and hydrological factors on sediment processes, such as wind speed, evaporation, precipitation, river discharge, water temperature, and ice packs. The variations of these parameters in space and time make the sediment dynamics highly complicated and nonlinear [
4,
5]. Many SSL estimation models have been developed in the literature, ranging from physically based to data-driven models. Physically based models require a large volume of different kinds of data and information for reliable estimation of SSL. However, such a large amount of data is difficult to obtain in data-scarce catchments, especially for developing countries [
6]. For such cases, data-driven models have demonstrated success in modeling different hydrological phenomena, especially streamflow and sediment load, by capturing the non-stationarity and nonlinear behavior of SSL with fewer data [
3,
7,
8]. Several data-driven modeling approaches, including artificial neural networks (ANN), adaptive neuro-fuzzy inference systems (ANFIS), support vector machines (SVM), the M5 model tree (M5Tree), and multivariate adaptive regression splines (MARS), have shown their efficiency in precise modeling of different hydrological variables [
9,
10,
11,
12]. Some of those algorithms, such as ANN, have also demonstrated their success in modeling SSL [
13].
Different ANN models have been utilized to estimate SSL during the last two decades [
13,
14,
15]. The studies showed some inherent drawbacks of ANN, including limited regularization and plunging to local minima. The rapid learning and adaptation capacity of ANFIS has made it capable of overcoming the weaknesses of ANN significantly. Therefore, it has been widely employed in recent years for SSL prediction [
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29]. Kisi and Yaseen [
16] applied three different ANFIS models, including ANFIS subtractive clustering (ANFIS-SC), ANFIS grid partition (ANFIS-GP), and ANFIS fuzzy c-means (ANFIS-FCM), to predict the suspended sediment concentration of Eel River. Results indicated the satisfactory performance of ANFIS based models in estimating sediment concentration. Bakhtyar et al. [
17] and Kabiri-Samani et al. [
18] evaluated the prediction accuracy of ANFIS compared to different empirical formulas such as Walton–Bruno (WB), Van Rijn (VR), and CERC in forecasting longshore sediment transport rate (LSTR). They found less error in estimating LSTR using ANFIS models than that obtained using empirical formulas. Mianaei and Keshavarzi [
19] examined the ANFIS prediction capability in assessing suspended sediment discharge at the Escanaba River mouth station. They found the ANFIS model’s prediction very close to observation. For daily streamflow and sediment discharge estimation at Polavaram and Pathagudem gauging stations of the Godavari catchment, Kumar et al. [
20] applied ANFIS and ANN models. As results, they found that the ANFIS model with three membership functions provided the best results for daily streamflow and sediment discharge. Kisi and Kermani [
21] utilized the ANFIS-FCM, ANN, and sediment rating curve methods to determine the daily sediment amount at two hydraulic stations operated by the United States Geological Survey. They reported the ANFIS model’s capability to improve prediction accuracy by 10% to 16% compared to the ANN model. Vafakhah [
22] applied the ANFIS model to sediment load prediction of the Kojor forest watershed near the Caspian Sea using rainfall and streamflow as inputs. He compared the selected method with cokriging (CK), ordinary kriging (OK), and ANN models and reported a better performance of ANFIS compared to CK and OK models. For daily and monthly SSL modeling of the Little Black River and the Great Menderes basin, Rajaee et al. [
23] and Firat and Gungor [
24] compared the performance of the ANFIS model with ANN and multiple linear regression (MLR). Results demonstrated the dominancy of the ANFIS model over the ANN and MLR models. In dam operation management, the precise calculation of the sediment input to the dam reservoir is very critical. Therefore, Samet et al. [
25] used the ANFIS model with ANN and genetic algorithm (GA) models for SSL estimation from temperature, runoff, and CM (three-section method of sediment sampling) data in the Maku dam reservoir of Iran as a case study. Results indicated that the ANFIS model has a “gauss” membership function, which provides more accurate results than the ANN and GA models, with only a 0.968% percentage error. In addition to success in SSL prediction, the ANFIS models also performed well in estimating riverbed load. For forecasting the bed load of three Malaysian rivers (Kurau, Langat, and Muda of Peninsular Malaysia), Chang et al. [
26] utilized the ANFIS model. The literature also showed that coupling the wavelet technique with the ANFIS model produces more accurate results than standalone ANFIS models. Mirbagheri et al. [
27], Rajaee. [
28], and Rajaee et al. [
29] applied the ANFIS hybrid model coupled with the wavelet method. They found that the hybrid ANFIS model provided more accurate results than the standalone ANFIS models in estimating SSL at a USA gauging station.
This study selected the MARS model due to its shorter training process and better ability to model complex nonlinear processes without strong model assumptions than ANN models [
30]. Another selected method was the M5Tree model due to its large data handling capability and smaller computational cost than the ANN and SVM models [
29]. In recent years, MARS and M5Tree have been applied successfully in modeling runoff and sediment load [
31,
32,
33,
34,
35,
36,
37,
38,
39]. Malik et al. [
37] compared the performance of the MARS model with the SVM-based model (least square SVM) and two ANN models (radial basis and self-organizing map neural network) for estimating daily SSL at different gauging stations in Godavari catchment, India. Results indicated that the radial basis neural network and MARS models provided more satisfactory results than other data-driven models. Senthil Kumar et al. [
38] evaluated the accuracy of the M5Tree model in predicting SSL and compared its performance with ANN coupled with backpropagation and Levenberg–Marquardt algorithms, fuzzy logic, and REPTree models. They obtained the most precise sediment concentration simulations using M5Tree.
Although the MARS and M5Tree models demonstrated promising results in previous studies for sediment modeling, both models could not efficiently capture the uncertainties in sediment time series data due to their complex behavior. The literature found that hybrid MARS and M5Tree models can provide more precise results than standalone data-driven models. A hybrid of the wavelet method and the M5Tree model (WM5Tree) was introduced by Goyal et al. [
39] to estimate the sediment yield, and they found that the wavelet M5Tree provided more accurate results than ANN models. Nourani et al. [
35] endorsed the findings of Goyal et al. [
39]. They predicted the daily sediment load of the Lighvanchai and Upper Rio Grande rivers by comparing the WM5Tree with ANN and standalone M5Tree models and found that the hybrid M5Tree model outperformed the other models. Rahgoshay et al. [
36] applied M5Tree, MARS, and hybrid of SVM with GA and particle swarm optimization (PSO) models to predict the sediment load of two earth dams. They found that SVM hybrid models (SVM with GA and SVM with PSO) provided more precise results than the MARS and M5Tree models.
The abovementioned literature revealed hybrid models still need improvement for precise modeling of suspended sediment. In this study, a new model is developed through hybridization of MARS with the Kmeans method (MARS–KM) to overcome standalone MARS models’ weakness in precisely capturing uncertainties in sediment dynamics. The MARS model and many other machine learning models’ main disadvantage is that they are very time-consuming, especially for large amounts of data with high variance, as in sediment load. For this purpose, the K means clustering method is utilized in this study. Therefore, the main contributions of this study are to (1) develop a novel model that introducing the K-means clustering into the MARS model for more accurate and faster estimation; (2) compare the prediction accuracy of the proposed MARS–KMeans model with the commonly used machine learning models, e.g., MARS, M5Tree, and ANFIS in sediment load estimation; and (3) select methods based on 50–50% data division.
K-means has been successfully used in recent literature to improve machine learning models’ prediction accuracy due to its robust nature in estimation [
40,
41,
42,
43,
44]. The application of hybrid the MARS–KMeans method is rarely found in the literature for prediction [
45]. There is no published study in the literature that uses the MARS–KM method for modeling any variables in hydrology to the best of our knowledge. This gave impetus to this study.
3. Application and Results
3.1. Modeling Approaches and Accuracy Assessments
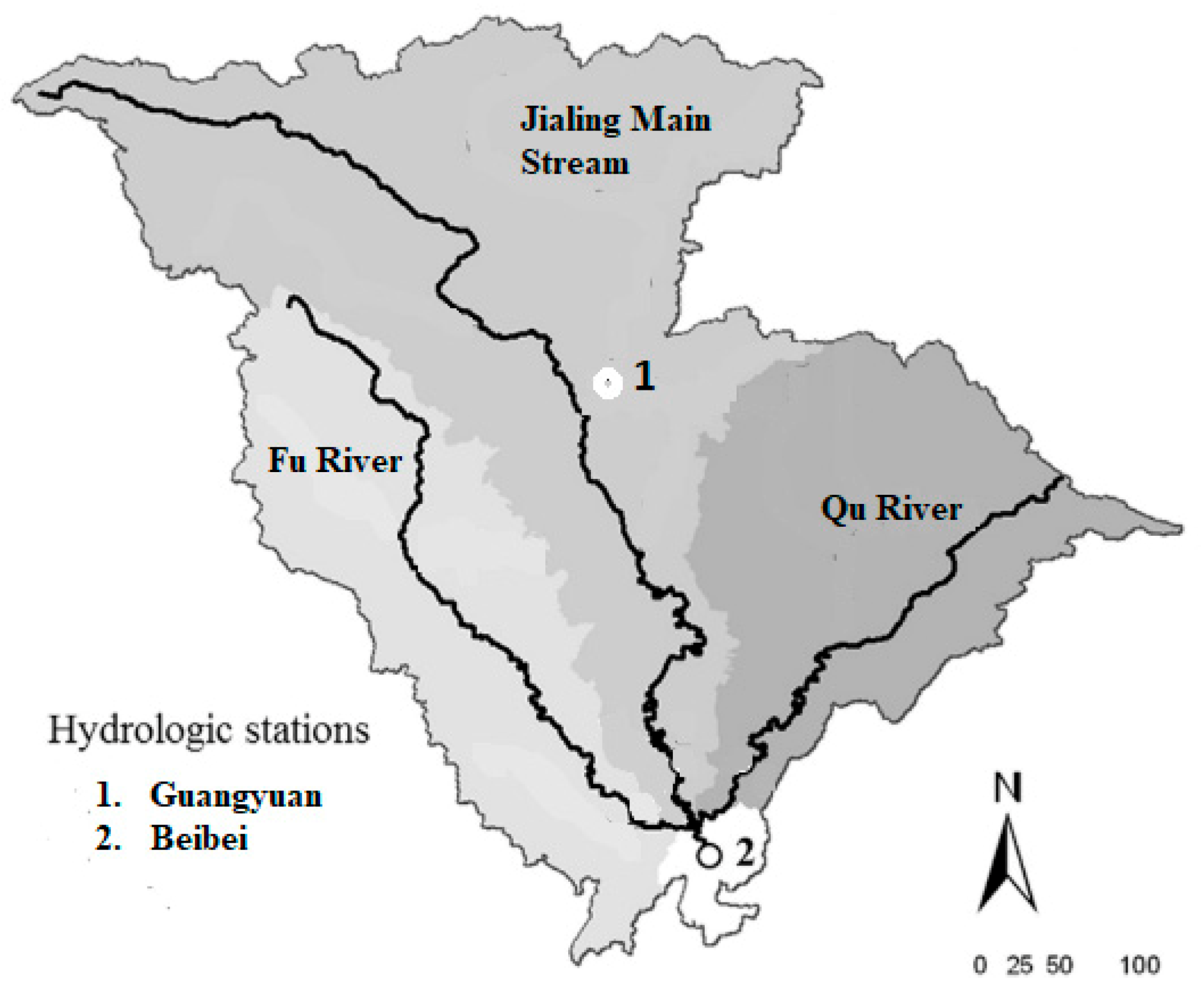
Four approaches, adaptive neuro-fuzzy inference system (ANFIS), multivariate adaptive regression splines (MARS), M5 model tree (M5Tree), and MARS with k-means clustering algorithm (MARS–KM), were used for modeling suspended sediment using various input combinations of sediment load (St: kg/s) and streamflow (Q: m3/s). The proposed models were developed using MATLAB software and compared using data at two stations, Guangyuan and Beibei. For each modeling approach, the sediment (kg/s) was modeled either separately using only the Q (m3/s) measured at previous lags or combined with St (kg/s) estimated at previous lags. Here, the sediment (St: kg/s) is the response variable. The explanatory variables considered were varied from one to more inputs, formed by a combination of several Q and St lag values. In total, seven input combinations were compared, denoted as combinations (i), (ii) … etc. In the first four input combinations, only streamflow inputs were considered: (i) Qt; (ii) Qt and Qt-1; (iii) Qt, Qt-1, and Qt-2; and (iv) Qt, Qt-1, Qt-2, and Qt-3. After selecting the best Q-based input combination, after the fourth combination, sediment inputs were added to the best Q-based combination. For example, for the ANFIS method, the input combinations considered are (v) Qt and St-1; (vi) Qt, St-1, and St-2, and (vi) Qt, St-1, St-2, and St-3, where Qt-1 and St-1 indicate the streamflow and sediment load at time t-1 (one previous day in this study). Performance assessment using different input combinations allows importance evaluation of variables and determining the lag values as inputs. Additionally, two different training scenarios were compared: splitting the dataset into two equal subsets having 50% of total data in each subset and a permutation between the two. Here, the two scenarios are denoted as the first training-test (scenario 1) and second training-test (scenario 2). In the first scenario, data from 4 January 2007, to 3 July 2011, were used for models’ training, while the remaining data from 4 July 2011, to 31 December 2015, were used for model testing at both stations. In the second scenario, the training and test data sets were swapped (data from 4 July 2011, to 31 December 2015, were used for the models’ training and data from 4 January 2007, to 3 July 2011, were used for the models’ testing). These two scenarios allowed comparing the overall models’ accuracy for the total range of the dataset. Model accuracy was computed by comparing the measured and the modeled data at each station separately using Nash–Sutcliffe efficiency (NSE), root mean squared error (RMSE: kg/s), and mean absolute error (MAE: kg/s).
3.2. Comparison of Accuracy among Models: Guangyuan Station
Table 1 shows the results obtained using ANFIS models for seven input combinations and two scenarios. In
Table 1, Qt-1 and St-1 indicate the streamflow and sediment load at time t-1 (one previous day in this study) and vice versa. For only the
Q as input, i.e., from input combination (i) Qt to input combination (iv) Qt, Qt-1, Qt-2, and Qt-3, the models showed a moderate to low accuracy, with mean NSE, RMSE, and MAE of 0.514, 1856.25 kg/s, and 346.75 kg/s, respectively.
The strong contribution of Qt is apparent, since there is no improvement in the models’ performance after input combination (i). Instead, the mean NSE value dropped sharply from 0.608 to 0.382 (37.17%) after including time lags of Q as input in combinations (ii) to (iv). The mean RMSE also increased from 1663 to 2104 kg/s (20.96%) and the mean MAE from 326 to 382 kg/s or by 14.65%. This indicates that only Qt should be considered as a predictor for modeling St. The comparison of model performance for two scenarios, namely, the first training-test and the second training-test, showed little difference in the models’ performance. The three statistical indices were relatively close to each other for the two scenarios.
Table 1 shows a strong impact of sediment (St) on the ANFIS model accuracy. Beyond the input combination (iv), i.e., input combinations (v), (vi), and (vii), the ANFIS model showed a gradual performance improvement. The (St-1) combined with Qt (input combination (v)) provided the highest accuracy compared to the ANFIS model with only Qt as input (input combination (i)). The mean NSE increased by 8.85% for combination (v) compared to input combination (i). However, it should be noted that the importance of St depends greatly on the number of lags included. Including more lags as predictors, i.e., the inclusion of two lags, St-1 and St-2 (input combination (vi)) or three lags, St-1, St-2, and St-3 (input combination (vi)), leads to a reduction in mean NSE by 6.44 and 29.68%, and an increase in mean RMSE by 24.11%, respectively. Overall, the best accuracy using the ANFIS model was achieved for input combination (v) with a mean NSE of 0.667.
The results obtained using the M5Tree model are reported in
Table 2. The improvement achieved using the M5Tree model compared to the ANFS model was marginal. The M5Tree with the second input combination (Qt and Qt-1) yielded the best accuracy among the Q input-based models, with an average NSE value of 0.581. The prediction accuracy for the second input combination was higher than 1.20%, 11.87%, and 4.17% compared to that obtained using the input combinations of (i), (iii), and (iv), respectively. The difference in RMSE between the second and the fourth combination was the largest, an increase from 1716 to 1870 kg/s (8.23%.). To assess the impact of St on the model’s performance, one to three St lags were combined with Qt and Qt-1 in input combinations (v) to (vii) (
Table 2). The RMSE showed a slight decrease by ~1.87% and ~8.31% for input combination (iv) and (v) (models without St and with St), respectively.
Nearly the same accuracy was achieved for all models using input combinations (vi) and (vii). The NSE was markedly higher and ranged from 0.663 to 0.672, with an average of 0.668 for those two input combinations. The accuracy increased most distinctly, with a decrease in RMSE and MAE by ~10.25 and ~18.80%, on average, between input combination (ii) and (vi). However, the inclusion of St-3 did not increase the NSE or decrease the RMSE and MAE. Consequently, M5Tree using the sixth and seventh combinations can be considered as the best models.
The statistical performance of the MARS model for both training scenarios is shown in
Table 3. The results showed moderate MARS model accuracy for the first four input combinations (i, ii, iii, and iv), with a mean NSE value ranging from 0.567 to 0.595. It indicates a marginal gradual increase, yet more significant than that observed using ANFIS and M5Tree models. However, the improvement in the models’ accuracy by increasing the number of inputs from one (Qt) to four (Qt, Qt-1, Qt-2, and Qt-3) was almost marginal, less than ~4.70% in NSE and ~3.37% and ~8.00%, in RMSE and MAE, respectively.
Table 3 shows that the accuracy of the MARS models was higher for the second training-test dataset than the first training-test dataset for all input combinations. It means no substantial improvement with the increased number of inputs beyond two. Therefore, the combination (ii), having only Qt and Qt-1, was deemed for model development. The performances of MARS models improved significantly after the fourth input combination (
Table 3). The mean NSE increased from 0.595 to 0.759 or by ~21.60%, the mean RMSE decreased from 1691 to 1312 kg/s or by ~22.41%, and the mean MAE dropped from 350 to 241 kg/s or by ~31.14%. The MARS model for the input combination (v) showed an overall higher accuracy than the sixth and seventh input combinations, having a slightly larger NSE value of 0.759. The MARS models’ performance for the sixth and seventh combination was similar, with equal mean RMSE and MAE values of 1357 and 256 kg/s and a negligible mean NSE value of only 0.002. Overall, the MARS model for input combination (v) was the best model.
The statistical performance of the MARS–KM model for different input combinations and training scenarios is given in
Table 4. Good accuracy using MARS–KM was observed for all the input combinations in terms of all three statistical metrics. The performance was higher compared to the ANFIS, M5Tree, and MARS models. The mean RMSE was higher (1342 kg/s) for the first four input combinations ((i) to (iv)) than for the last four input combinations ((v) to (vii)) (1158 kg/s). The differences observed for the four first input combinations were as follows: (1) good prediction accuracy using the MARS–KM model for the fourth input combination (Qt, Qt-1, Qt-2, and Qt-3) with a mean NSE value of 0.813, a mean RMSE value of 1158 kg/s, and a mean MAE value of 210 kg/s; (2) a slight to significant difference of mean RMSE, equal to 3.105% and 13.711% between the fourth and first combinations, and second and third combinations, respectively; and (3) the MAE of MARS–KM models’ accuracy dropped significantly for the fourth input combination. The inclusion of different lags of St as input showed a marked improvement in the models’ accuracy. For the three last input combinations (v, vi, and vii), the mean RMSE and MAE values rapidly decreased (dropped from 1158 to 1144 kg/s), while the NSE slightly increased from 0.813 to 0.818. Overall, MARS–KM also showed better performance for the fifth input combination.
The comparison of four machine learning methods with the corresponding best input combination is shown in
Table S2. The four models exhibited different accuracy varying with mean NSE ranging from 0.608 to 0.818, mean RMSE between 1143 and 1663 kg/s, and mean MAE between 177 and 332 kg/s. The MARS–KM enhanced the St prediction significantly, while the ANFIS showed the least accuracy compared to the other models. The results highlight that, although the models were developed using the same input variables, their capabilities in capturing the major variability and uncertainty in the dataset were variable. The most apparent difference between the models was between MARS–KM and the ANFIS. The MARS–KM improved accuracy compared to ANRIS by 21%, 31.27%, and 44.53% in terms of NSE, RMSE, and MAE, respectively. The M5Tree and MARS models lie between the two extremes. The differences between the two showed that the MARS algorithm generally enhanced the M5Tree accuracy by an average of 14.80% and 6.95% reduction of RMSE and MAE, respectively.
Table S2 indicates that, on average, the results obtained using different models differ significantly in terms of different metrics. For example, the variation of RMSE was lower than 12% between MARS and MARS–KM and 31% between ANFIS and MARS–KM. Overall, the models can be ranked in decreasing performance order as MARS–KM, MARS, M5Tree, and ANFIS.
3.3. Comparison of Accuracy among Models: Beibei Station
The results obtained using the ANFIS model for all input combinations and training scenarios at the Beibei Station are presented in
Table 5. The results showed ANFIS models for the first four input combinations, (i) Qt; (ii) Qt and Qt-1; (iii) Qt, Qt-1, and Qt-2; and (iv) Qt, Qt-1, Qt-2, and Qt-3, yielded relatively similar mean RMSE and MAE, ranging from 3553 to 3628 kg/s and 610 to 710 kg/s, respectively, whereas the fourth input combination showed the highest mean RMSE and lowest NSE.
Therefore, only
Qt was combined with different lags of
S to form the input combinations of (v), (vi), and (vii). The results showed a strong to moderate improvement in accuracy, with mean NSE value ranging from 0.602 to 0.693, mean RMSE ranging from 3130 to 3582 kg/s, and a mean MAE between 595 and 663 kg/s. The highest mean NSE value of 0.693 was found for the input combination (v). Relatively low mean NSE of 0.602 and large mean RMSE and MAE were found for the input combination (vii), highlighting the negligible contribution of St-2 and St-3 (
Table 5). The increasing number of input variables showed a minimal contribution to ANFIS model performance improvement at this station.
Results obtained for the M5Tree model are reported in
Table 6. Suspended sediment simulated from the first four input combinations showed a weak and insignificant difference between the models, with a slight superiority of the first input combination (only the Qt).
Table 6 shows the variation of the RMSE, MAE, and NSE values averaged for different input combinations.
The results showed an apparent decrease in the model’s performances from the input combination (i) to the input combination (iv). The mean RMSE and MAE values increased from 3892 to 4309 kg/s (9.67%) and from 566 to 612 kg/s (7.51%), respectively, and the mean NSE value gradually declined to its lowest value of 0.423. This negligible difference in the models’ accuracy might be due to the marginal effect of the higher lag streamflow data, which have already been highlighted in the previous discussion. Therefore, the inclusion of only Qt was sufficient for predicting suspended sediment. The effect of an increasing number of input variables on M5Tree performances can also be observed in
Table 6. There was a positive effect of St on model accuracy. Interestingly, the suspended sediment was more sensitive to its antecedent values than the Q. The lowest RMSE and MAE values of 3087 and 473 kg/s, respectively, and the mean NSE of 0.705 were obtained using the input combination (vii) (Qt, St-1, St-2, and St-3). The significant increase in the NSE value from 0.522 to 0.705 (18.3%) indicates that the inclusion of St-1, St-2, and St-3 has significantly contributed to M5Tree performances. Nevertheless, the sensitivity of the M5Tree model to the inclusion of the St was not the same for both training-test scenarios. The improvement was more significant for the second training-test data set.
The performances of the MARS model for different input combinations are shown in
Table 7. An overall maximum mean NSE value of 0.545 was obtained using only the Qt as the input (input combination (i)), suggesting a weak level of agreement between measured and predicted suspended sediment. Mean RMSE and MAE values of 3822 and 631 kg/s were achieved using only the Qt, and the level of accuracy remained very low regardless of the number of Q lags included from one to four.
Table 7 revealed Qt as the most dominant input variable. Therefore, only the first combination was coupled with different lag values of sediment. The St simulations for the input combinations (v), (vi), and (vii) showed better performance (
Table 7). The NSE ranged from 0.706 to 0.728, with a mean of 0.720. The performances of the input combination (vi) (Qt, St-1, and St-2) and input combination (vii) (Qt, St-1, St-2, and St-3) were quite similar, where the input combination (v) performed less well with a lower mean NSE (0.706) and higher RMSE (3070 kg/s) and MAE (534 kg/s) values. The above results indicate that the input combination (vii) should be used to obtain the best accuracy.
Table 8 summarizes the statistics of MARS–KM models. MARS–KM at Beibei Station showed exceptional performance compared to other models. The results indicated the model’s higher ability to predict the suspended sediment independently and successfully, even without the inclusion of St lags as input. The NSE values for the seven input combinations were in the range of 0.810 to 8.17 with a mean of ~0.754. The best accuracy was achieved using only the Qt and Qt-1 as inputs (input combination (ii)), with a mean NSE of 0.817. The RMSE and MAE for the best model (input combination (ii)) were much smaller, ~2428 and ~2428 kg/s, respectively. The results described above indicate the MARS–KM model’s effectiveness in predicting suspended sediment.
The relative performance of the four models with the best input combinations is presented in
Table S3. The results demonstrated that the performances of the models were relatively far from excellent. None of the models, i.e., ANFIS, M5Tree, MARS, and MARS–KM, achieved an NSE higher than 0.90. Overall, the performances of MARS–KM were remarkably superior. The MARS–KM improved the mean NSE of ANFIS, M5Tree, and MARS by 12.4%, 11.2%, and 8.9%, respectively. Additionally, it reduced the RMSE of ANFIS, M5Tree, and MARS by 22.42%, 21.34%, and 19.91%, respectively, and the MAE by 32.60%, 15.22%, and 22.73%, respectively.
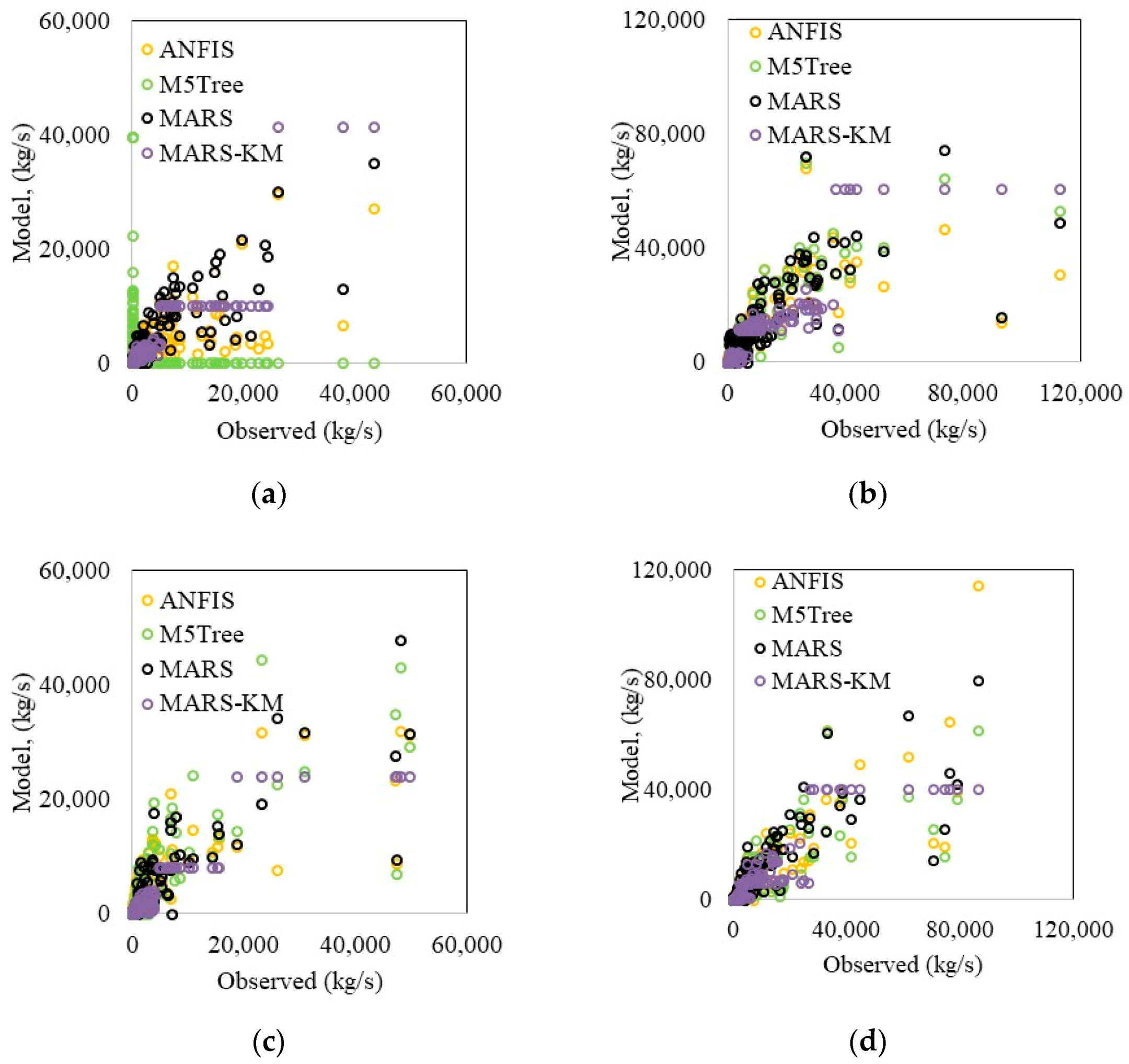
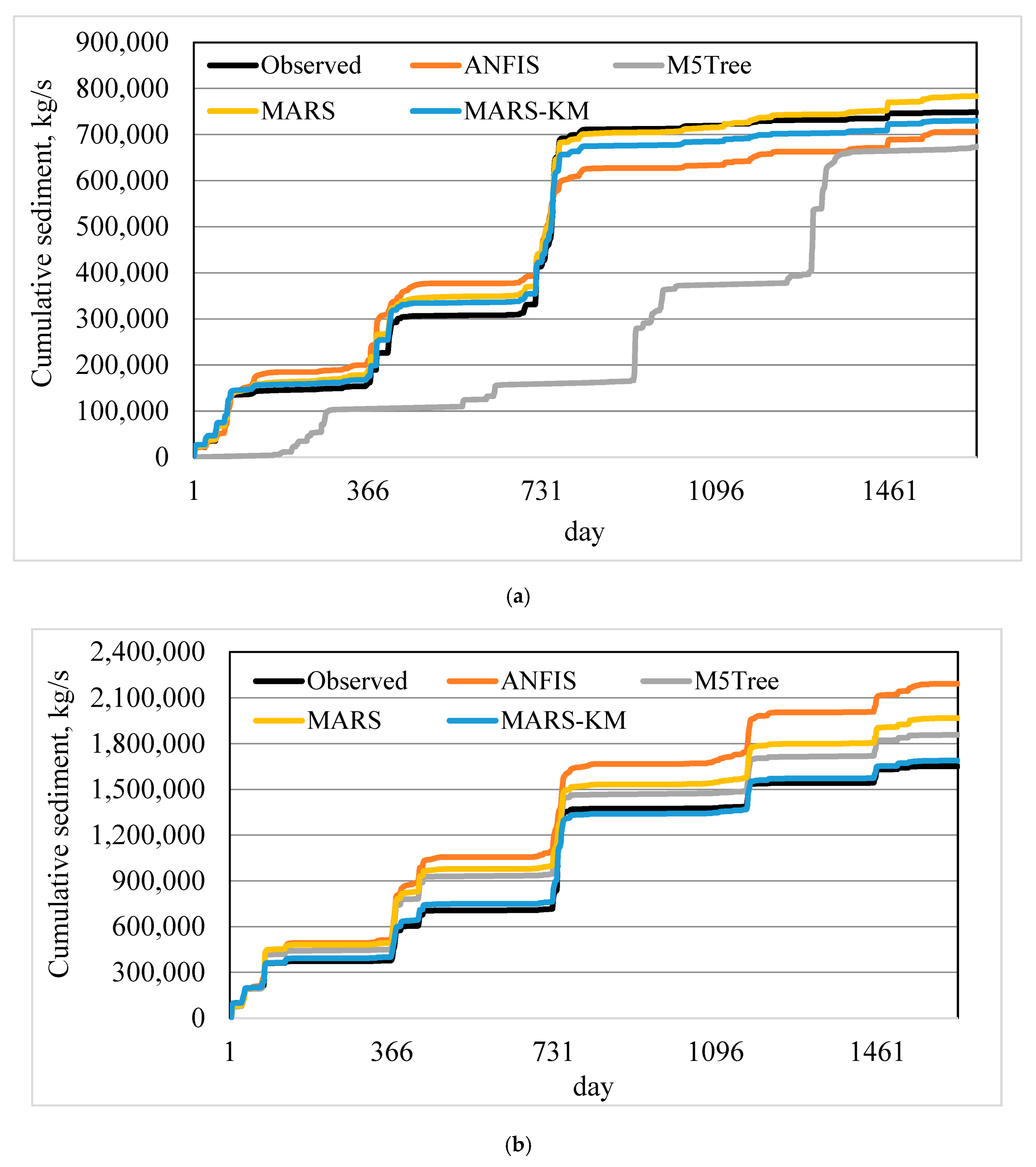
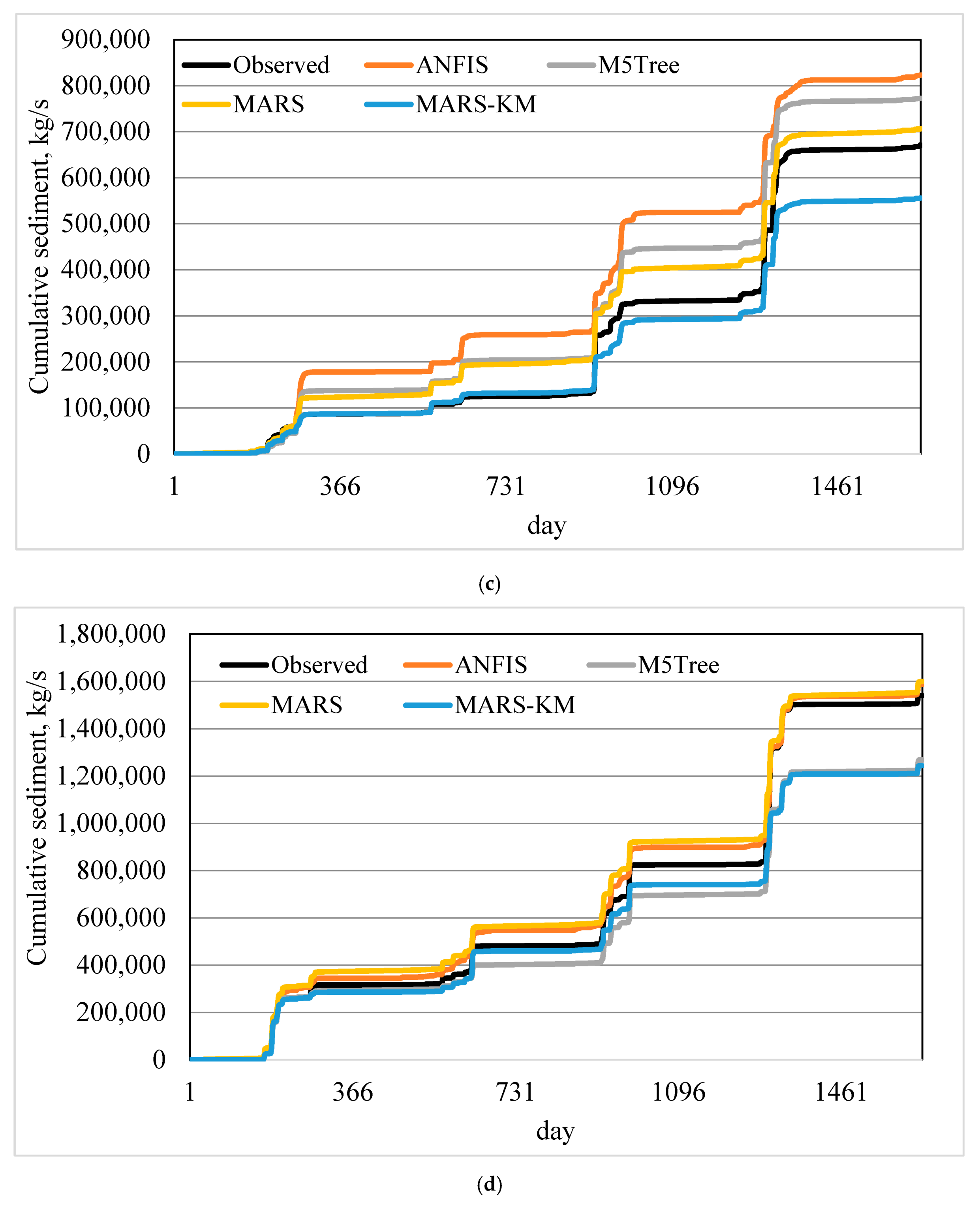
The suspended sediment estimation ability of machine learning models was further assessed through visual comparison with the in-situ data (
Figure 5a–d). MARS–KM and MARS reproduced suspended sediment variation much better and thus enhanced M5Tree and ANFIS models’ prediction accuracy. The scatterplots (
Figures S2–S5, see Supplementary Materials) revealed that (i) the underestimated data points were much higher than the overestimated data points, and (ii) all the models failed to simulate large suspended sediment values. It is apparent from
Figure 6 that the MARS–KM shows superiority in simulating cumulative sediment amounts compared to other alternatives.
In a recently published paper, Juez et al. [
59] studied the sediment hysteresis, a direct link among sediment size, distal sediment supply, and proximal sediment data obtained through a laboratory experiment. The authors demonstrated that sediment in the channel downstream depends mainly on the time-varying sediment load with different hysteresis types. The study also highlighted that sediment availability is governed by the evolution of two important morphological parts of the riverbed, degradation and aggradation. The shapes of hysteresis loops have often been intrinsically correlated to these two morphological processes. Finally, one of the important findings of the above-reported investigation is that the sediment concentration–discharge hysterical behavior is increasingly likely to amount between the distal sediment supply and the proximal sediment availability.
Suspended sediment concentration (SSC) and discharge (Q) are two variables with a temporal shift; consequently, it is important to focus on these approaches’ weaknesses and limitations in modeling these kinds of variables. Based on the direct linking of SSC to Q, the empirical models can estimate SSC reasonably. However, data-driven models resulted in slightly better performances in predicting the amount of SSC. Interpretation of the empirical models is more straightforward, as physical, morphological, and hydrological processes are explicitly expressed with simplified equations. However, it is appropriate for data-driven black-box models to examine whether it is possible to simulate SSC with input values outside the data range used during their calibration. Indeed, both the empirical and data-driven models showed encouraging results in terms of model accuracy; physical interpretation of the data-driven models is a challenge, thus requiring further analysis in quantifying the correlation between the input and output variables in a more meaningful way. When extending the models to another watershed, the empirical models may be more practical because of local calibration. Additionally, most input variables (i.e., the Q) undergo a rapid momentary fluctuation, which is very hard to capture with data-driven models. This deficiency makes the data-driven models unable to generate a durable and continuous response. Clearly, although the advantages exist, the limitations are always existing, which should be addressed in future studies.
4. Conclusions
In this investigation, a new method was developed by hybridizing MARS and the K-means clustering algorithm to improve the accuracy of suspended sediment prediction. The models were developed using daily discharge and sediment data at two stations in China. The MARS–KM models’ performance was compared with ANFIS, MARS, and M5Tree models using three statistical metrics, RMSE, MAE, and NSE, and graphical comparison. The following conclusions were reached from the outcomes of the presented work:
The proposed MARS–KM considerably improved the accuracy of the ANFIS, MARS, and M5Tree methods. The increments in the RMSE of the three mentioned methods were by 39%, 30%, and 18%, and 24%, 22%, and 8% for the first and second scenarios at the Guangyuan Station, and by 34%, 26%, and 27%, and 7%, 16%, and 6% for the first and second scenarios at the Beibei Station, respectively.
The suspended sediment in the studied region is generally sensitive to its lagged values rather than the lag discharge values. However, the MARS–KM models could estimate suspended sediment satisfactory using only discharge (Q) as inputs. It is very important in practical applications, because the measurement of suspended sediment is often very difficult.
Comparison of models’ ability in simulating cumulative suspended sediment loads also showed the superiority of MARS–KM compared to ANFIS, MARS, and M5Tree methods.
In this study, seasonality in the sediment load and discharge time series was not considered. It can be addressed in future studies. The methods may produce better estimates when season information is included in the models.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}