1. Introduction
A combined sewer system (CSS) collects domestic sewage, industrial wastewater, and rainwater runoff in the same pipe. Normally, these systems will convey the total volume of sewage to a wastewater treatment plant (WWTP) for treatment. However, during transport, some of the particulate compounds suffer sediment processes and accumulate in the sewers. Solids accumulated in sewer systems together with fat, oil, and grease (FOG) deposits and flash flooding constitute major problems in terms of blockages, reduction of sewer capacity [
1,
2] and in terms of pollutant discharge to receiving water bodies during wet weather periods through combined sewer overflow structures [
3]. Corrective interventions to remove sediments and FOG deposits are costly. As a reference value, in the United Kingdom, over 25,000 flooding events per year are due to sewer blockages, and the estimated annual control cost of clearing these blockages was 50 m£ [
4]. Instead, water utilities could better invest resources by taking a proactive maintenance approach, which involves periodic inspections in multiple points of the CSS and jetting whenever sediment levels are high to prevent blockages to happen. The prediction of sediment levels in CSS would result in enormous savings in resources for their maintenance as a reduced number of inspections would be needed. Several mechanistic models based on the better conceptual understanding of physical and biological processes have been presented in the literature [
1]. Nonetheless, most reported in-sewer studies produce results that relate only to the site or immediate vicinity within which the work has been carried out. Data-driven models have been applied to the enhancement of the operation of urban water infrastructure [
5,
6,
7,
8,
9]. Data-driven models have been applied as well for the prediction of blockages (caused or not by sediments). Simple statistical approaches have been applied in [
10] to understand the readily available catchment, hydraulic, and network parameters that appear to influence the likelihood of blockage occurrence.
A model that describes sediment level allows identifying critical points in the sewer, not only in terms of potential blockages but also in terms of bad odors as a result of biochemical processes occurring in the sediments layer. Having the capacity of predicting sediments levels allows wastewater utilities better plan for the maintenance activities and optimize human resources. Increasing prediction capabilities of sediment level models results in more accurate decisions with less uncertainty.
Machine learning techniques have been applied for CSS condition prediction (e.g., blockages or collapses) to model pipe condition and provide insight on inspections done by the Water and Sewerage Companies [
11,
12,
13]. Focusing on blockage prediction, some studies focused on the prediction of failure having into account pipe, choke, climate, soil, tree, and specifical data regarding the geographical position and social environment [
14]. Furthermore, Bailey et al. [
15] predicted the blockage likelihood without social, soil type, and vegetation data, achieving remarkable results with the available data.
The methods previously studied for blockage prediction include a wide range of solutions. Chughtai and Zayed [
16] applied a multiple regression algorithm to predict the degradation of the sewer structural and operational conditions, while [
17] had success with a Multinomial Logistic Regression to develop probabilistic deterioration models. The authors of [
18] used an Evolutionary Polynomial Regression to predict the blockage likelihood in a time period and study the importance of the different properties related to the sewer. Syachrani et al. [
19] compared the predictions of a Decision Tree with conventional regression algorithms and Neural Networks, with better performance by the Decision Tree when predicting the deterioration of sewer pipes, and Harvey and McBean [
20] compared decision trees with Support Vector Machines (SVM) to select the better algorithm when classifying the state of a sanitary sewer pipe, where the Decision Tree outperformed the SVMs, but [
21] get good performance using SVM to predict a condition grade to sewer assets. Furthermore, Harvey and McBean [
22] also studied the use of Random Forests to predict the condition of sanitary sewer pipes achieving excellent results. Bailey et al. [
13] studied different Decision Tree models to predict blockage likelihood in sewers obtaining beneficial results.
The different studies report different models with a performance that varies greatly depending on the number of features used, register length, and machine learning algorithms used. In classification models, Harvey and McBean [
20] accomplished the best performance with an accuracy of 0.76, and Chughtai et al. [
16] had the best performance when predicting the deterioration curve with an 0.88 R
2 score. A gap in the field is the comparison of machine learning algorithms.
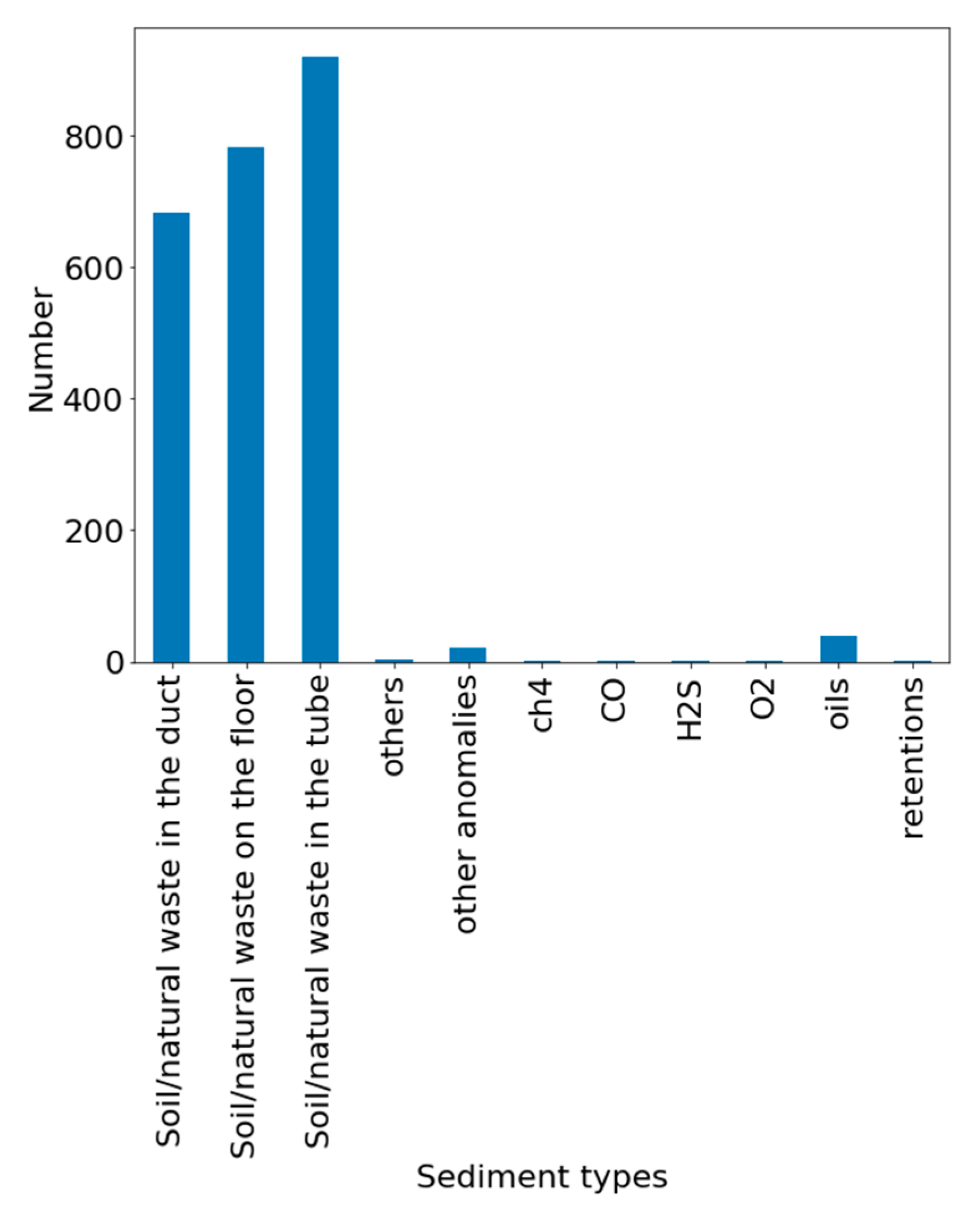
The goal of this paper is to benchmark machine learning algorithms for the prediction of sediment levels in CSS. It involves not only algorithms studied in the past, but also introduces innovative data modelling methodologies that can increase the performance of the predictions in comparison to the previous methods used. The benchmarking exercise is conducted with real data obtained from the historical records of the public water authority BCASA managing the CSS of Barcelona. The explored methods are the modelling of spatial features to predict the currently occupied percentage of the section by the sediment level, the prediction of the occupied percentage in ten days, and finally, a prediction of the cleaning condition in a section using spatial features.
The paper sections are organized as follows.
Section 2 introduces the data used in the research, the idea behind each methodology and the process of algorithm selection and evaluation.
Section 3 shows the results of the trained models in each methodology, compares them using the explained metrics and selects the best one.
Section 4 discusses the results of the methodologies and introduces some discussion regarding the overall solution. Finally,
Section 5 gives a global conclusion and provides the next steps of the research.
4. Discussion
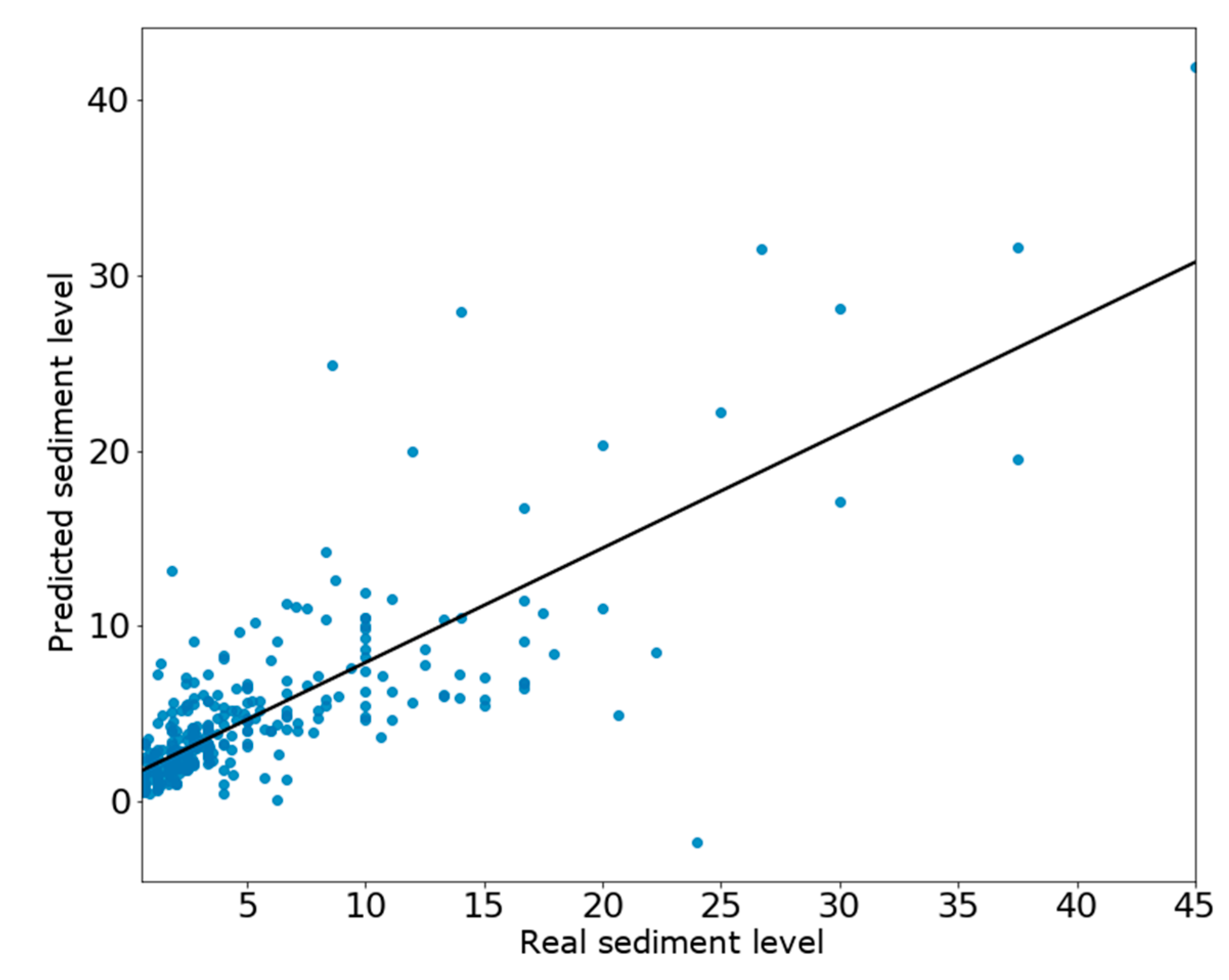
The three methodologies show different results and, despite they cannot be fully compared, the score of the models indicate which one can be considered more reliable for the final goal, the monitoring of the sewer network state. Out of the three methodologies, the second methodology is the only one which did not work well; in that case, the R2 score produced by the ANN model is 0.61, meaning there is a large deviation between the predictions and the real observations. This second methodology used a time interpolation to create a feature indicating the sediment level 10 days before the objective variable. Although it is a linear transformation which makes the trained model not trustable, it should not harm the model score; quite the opposite, benefiting the predictions thanks to the creation of an interpolated feature that grows linearly in the face of the goal. For a further study of the short-term prediction of sediment level, short-term gathered data should be available. Furthermore, a short-term prediction of 10 days is the bare minimum to start assisting the water utility, since most of the cleaning services generally have a planned schedule, and ten days can be problematic when optimizing maintenances. A goal should be to increase the time horizon and add more days in the prediction, giving more maneuver to act.
The models following the first and third methodologies offer the best results. The first methodology is of high importance in the study, as it allows to know an approximate level of sediments in any section, including those where access is almost impossible and requires many resources to carry out an inspection. While the third methodology can also be used on critical sections, a binary prediction outputs less information than a continuous variable, so the maintenance services cannot profit as much as in the first methodology. Nevertheless, this prediction can assist in situations where resources are limited and cleaning services are difficult to dispatch optimally, giving insight on which sections are in critical status.
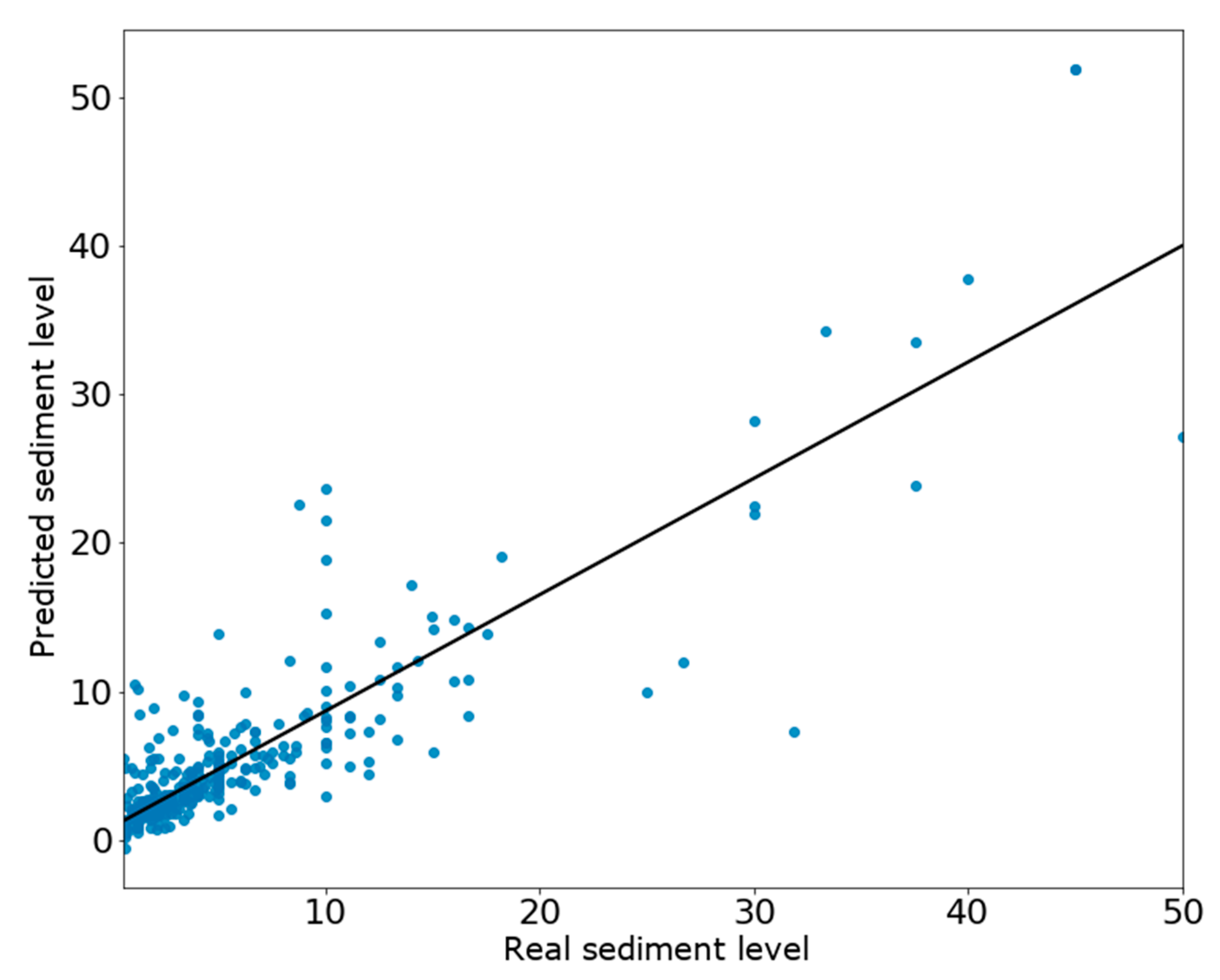
The ANN was the model which best worked for the first methodology, with an R
2 score of 0.76 being good enough [
27] to recognize it as a model to use in this predicting methodology, a 1.5 MAE and an MSE value of 10.31. The scoring and the analyzed errors from
Figure 2 indicate a good result that should be further improved in the future, adding more data in the training step, and optimizing the process of feature and hyperparameter selection.
Two models worked well for the third methodology, showing good scoring. The Gradient Boosting model classified better the cleaning cases, while the Extra Trees model perfectly classified the non-cleaning cases. Observe that it is more desirable to not miss any real cleaning needed, so it is better to have false positives than false negatives. Therefore, the Gradient Boosting model is the most suited to predict cleanings if the objective is to miss less critical situations in the sewer network.
The Gradient Boosting model performs better than other models reported in similar studies. The AUC of the model is good, with a value of 0.909, while in [
15] the maximum tested model approaches an AUC of 0.71 using predictions of geographical aggregations. In the case of the condition of sanitary sewer pipes, Harvey and McBean [
20,
22] predicted an AUC of 0.77 and 0.85, respectively. The accuracy of the model was 88%, while in other studies involving the prediction of the condition in sanitary sewers [
11,
20,
22] the accuracy was 0.62, 0.76, and 0.76, respectively. The recall has a lower scoring than in other studies, being 0.53 in this study, and 0.78 and 0.89 when predicting sewer condition [
20,
22].
It is also important to consider the imbalance of the datasets in the different studies to further compare the models. The test set used in this study contains 20% of positive registers (cleaning applied), while in other studies the imbalance is different. For example, in [
17], different conditions are being predicted using a multiple-output classification and the imbalance variates on each condition, achieving the best prediction on the first condition, classifying 201 registers correctly out of 223, but unable to predict the fifth with three registers wrongly predicted. The imbalance in the data for this classification task could explain partly why the recall is so low, but this needs future analysis.
In the past, numerous studies modelled each section individually, and maintenance routines were not considered [
14]. This study shows methodologies that use spatial features from near sections and information about the maintenance routines in the data model, providing a positive impact on the predictions.
The study can be used in the implementation of aid tools in Water and Sewerage companies. Predictions can provide important help in making decisions about section inspections. The predictions focused on the sediment level percentage offer an informative output that, although it does contain some error, it can provide enough data to make flexible decisions not only focused on cleaning routines. The binary classification predicts if the section pipe needs a cleaning looking at its past states, but the model does not consider other factors such as raining seasons or social events in the city. The output of the model should be considered as an indicator when managing the CSS.
5. Conclusions
Machine learning methods are suitable to predict sediment levels in CSS. From the studied methodologies, the predictions of the present situation in a section have proven to be more effective than the short-term predictions and the go-to. Furthermore, a model trained to predict the occupied percentage (or even the sediment level) in a short-term period requires the use of data in a small-time interval, meaning the increase of the number of inspections to do in a section, having to invest more money and resources. Moreover, this type of predictions needs to estimate the evolution of the sediment level taking into account rainy days and possible flash floods during the period. The addition of this data would increase the model scoring.
The Artificial Neural Network model is a clear winner when predicting the occupied percentage in a section, resulting in a focus point to study in the near future. With the addition of external features like pluviometry data, the expected results should improve.
Regarding the usefulness of our model in different scenarios, we should be careful with situations that show a different pattern of activity in cities. For example, the COVID-19 pandemic has affected society’s routine [
28,
29,
30], and therefore models trained with past data will not be able to make such good predictions during this period. The impact of the pandemic on sewer systems is an important topic to study in the future, as is the creation of models that can adapt to this change.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}