
A Heterogeneous Geospatial Data Retrieval Method Using Knowledge Graph

 , ,
, ,
Abstract
1. Introduction
- A KG construction method is proposed to integrate heterogeneous geospatial data. In this paper, KG is firstly constructed through mined knowledge to integrate semantics and relationships. Furthermore, the knowledge graph constructed from a bottom-up way can narrow down the retrieval domain and improve retrieval quality.
- A query expansion method considering relationships between concepts and entities is proposed, by which entities belonging to related concepts are returned. Moreover, for entities with low conceptual similarity, their associated entities are obtained to expand retrieval results coverage.
- A retrieval method automatically building Structured Query Language (SQL) statements is proposed, by which SQL retrieval statements are built through the semantic knowledge of search terms.
2. Related Work
2.1. Geospatial Data Analysis
2.1.1. Geographical Vector Model
2.1.2. OSM Data Model
2.1.3. Free Tagging Mechanism of OSM
2.2. Traditional Data Retrieval Method
2.2.1. Attribute Information Retrieval
2.2.2. Spatial Information Retrieval
2.3. Semantic-Oriented Data Retrieval Method
2.3.1. Semantic-Oriented Data Integration
2.3.2. Query Expansion
3. Approach
3.1. Retrieval Technology Framework
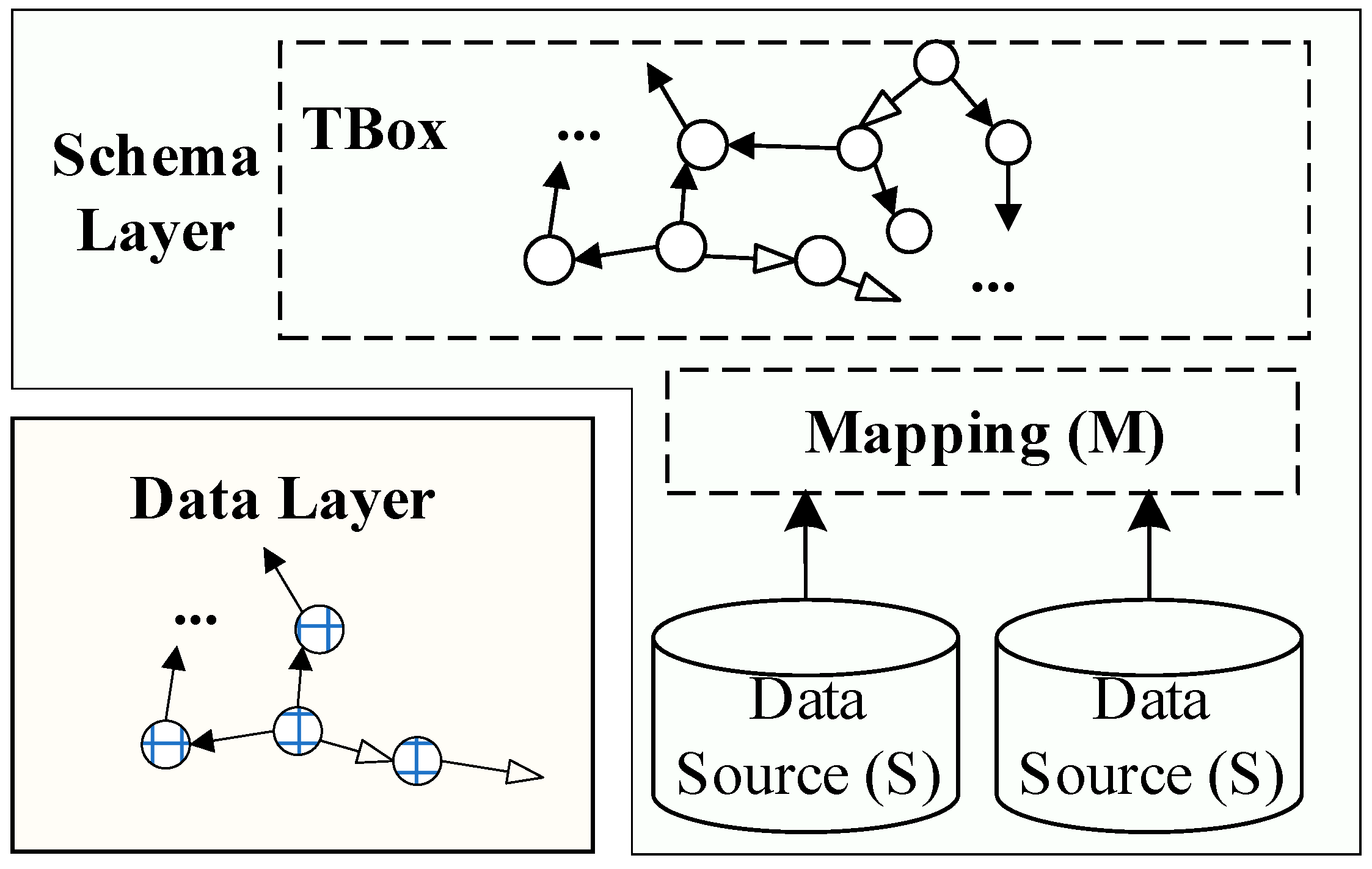
3.1.1. Basic Abstract Technology Framework
3.1.2. Retrieval Process
- Knowledge graph construction. The correlation is established between schema layer and geospatial database. The data layer relationships are completed by extracting knowledge from the database, including map layers, geographic features, and property fields.
- Semantic query expansion. The concept of a search term (Q) is matched with the concepts in schema layer. Based on conceptual hierarchical relationships and description logic axioms, query expansion rewrites the search term into related concepts (Q’) to reflect query intention.
- Mapping design. Mapping rules represent the correlation between geospatial databases and concepts. Based on these rules, SQL statements (Q”) are automatically constructed by mapping search terms onto table names, property fields and values.
- Entity query expansion. Q” is delegated to geospatial database after designing mapping rules. Moreover, data layer can expand the entities associated with search terms based on the constraints of concept types, administrative divisions, and cognitive styles.
- Retrieve database and return results. The geospatial database is retrieved through the above steps, and retrieval results are displayed in a multi-view mode. Hence, the method can provide more implicit information and meet query requirements.
3.1.3. Retrieval Method Characteristics
- Data-Centered Knowledge Graph Construction
- Relationship-Dependent Retrieval Process
- Knowledge-Centered Retrieval Result
3.2. Data Integration
3.2.1. Standard Ontology
- Concepts of GeoEntity, GeoGraphicDatasetEntity, and GeoBaikeEntity are created to integrate geospatial features and represent geospatial entities’ origins.
- Relationship hasFeature inheriting from owl:ObjectProperty is used to represent the association between geographic entities and geographic features.
- Relationship hasProperty inheriting from owl:ObjectProperty can associate database with schema layer.
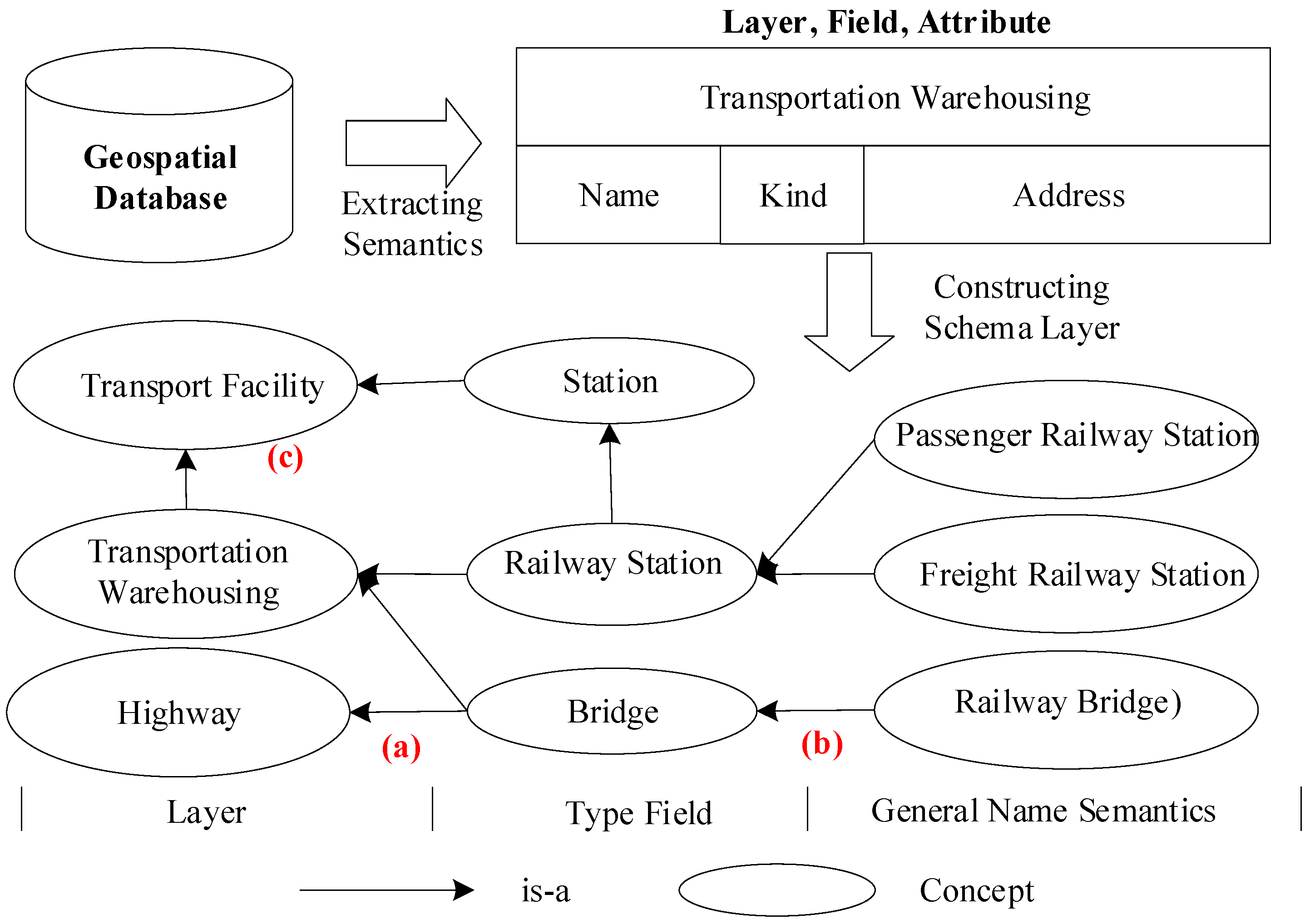
3.2.2. Semantic Knowledge Extraction
3.2.3. OSM Semantic Knowledge Extraction
3.3. Semantic Query Expansion
3.3.1. Semantic Similarity Calculating
3.3.2. Semantic Query Expansion Type
3.3.3. Semantic Query Expansion Principle
3.4. Mapping Design
3.4.1. Mapping Rules Type
3.4.2. Representing Tables and Property Fields
3.4.3. Mapping Relationships Construction
- m1:
- Transportation Facility ⊆∃MappingToTable.Transportation Warehousing.
- m2:
- Name ⊆∃MappingToFiled.Name.
- m3:
- Type ⊆∃MappingToFiled.Kind.
- m4:
- sf:Geometry ⊆∃MappingToFiled.Geometry.
- m5:
- Transportation Facility ⊆∃hasProperty. Name.
- m6:
- Transportation Facility ⊆∃hasProperty. Type.
- m7:
- Railway Station ⊆∃ hasProperty.Type∩(Type(“230103”)∪......).
- m8:
- v_station ⊆∃ hasProperty.Type∩(Type(“230103”)∪......).
3.4.4. SQL Statement Construction
3.5. Geographic Entity Query Expansion
4. Experiment and Analysis
4.1. Evaluation Index
4.2. Retrieval Result Analysis
4.2.1. Retrieval Efficiency
4.2.2. Retrieval Quality
4.3. Geospatial Data Retrieval Example
4.3.1. Conventional Retrieval Method
4.3.2. Proposed Method
4.3.3. Entity Query Expansion Example
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hahmann, S.; Burghardt, D. How Much Information is Geospatially Referenced? Networks and Cognition. Int. J. Geogr. Inf. Sci. IJGIS 2013, 27, 1171–1189. [Google Scholar] [CrossRef]
- Aloteibi, S.; Sanderson, M. Analyzing Geographic Query Reformulation: An Exploratory Study. J. Assoc. Inf. Sci. Technol. 2014, 65, 13–24. [Google Scholar] [CrossRef]
- Ding, L.; Xiao, G.; Calvanese, D.; Meng, L. A Framework Uniting Ontology-Based Geodata Integration and Geovisual Analytics. ISPRS Int. J. Geo Inf. 2020, 9, 474. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, X.; Ji, L.; Wang, H. Relation Mapping between Generic Terms of Place Names and Geographical Feature Types. Geomat. Inf. Sci. Wuhan Univ. 2011, 36, 857–861. [Google Scholar]
- Zhang, X.; Liu, J.; Wang, Y.; Luo, A. An Semantics Extended Framework for Spatial Direction Relation Query Based on Natural Language. Geogr. Geo Inf. Sci. 2018, 34, 7–14. [Google Scholar]
- Lim, S.C.J.; Liu, Y.; Lee, W.B. Multi-Facet Product Information Search and Retrieval Using Semantically Annotated Product Family Ontology. Inf. Process. Manag. 2010, 46, 479–493. [Google Scholar]
- Yoo, D. Hybrid Query Processing for Personalized Information Retrieval on the Semantic Web. Knowl. Based Syst. 2012, 27, 211–218. [Google Scholar] [CrossRef]
- Haklay, M.; Weber, P. Openstreetmap: User-Generated Street Maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Xie, M.; Zhou, G.; Li, D.; Gong, J. Design and Implementation of Attribute Database Management System in a Gis System: Geostar. Geogr. Inf. Sci. 2000, 6, 170–180. [Google Scholar] [CrossRef]
- Brüggemann, S.; Bereta, K.; Xiao, G.; Koubarakis, M. Ontology-Based Data Access for Maritime Security. In European Semantic Web Conference; Springer: New York, NY, USA, 2016; pp. 741–757. [Google Scholar]
- Giese, M.; Soylu, A.; Vega-Gorgojo, G.; Waaler, A.; Haase, P.; Jiménez-Ruiz, E.; Lanti, D.; Rezk, M.; Xiao, G.; Özçep, Ö. Optique: Zooming in on Big Data. Computer 2015, 48, 60–67. [Google Scholar] [CrossRef]
- Lenat, D.B. Cyc: A Large-Scale Investment in Knowledge Infrastructure. Commun. ACM 1995, 38, 33–38. [Google Scholar] [CrossRef]
- Miller, G.A. Wordnet: A Lexical Database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Wu, T.; Qi, G.; Li, C.; Wang, M. A Survey of Techniques for Constructing Chinese Knowledge Graphs and their Applications. Sustainability 2018, 10, 3245. [Google Scholar] [CrossRef]
- Larson, R.R. Geographic Information Retrieval and Spatial Browsing. In Geographic Information Systems and Libraries: Patrons, Maps, and Spatial Information; Library Applications of Data Processing: Urbana-Champaign, IL, USA, 1996. [Google Scholar]
- Jensen, J.; Saalfeld, A.; Broome, F.; Cowen, D.; Price, K.; Ramsey, D.; Lapine, L.; Usery, E.L. A Research Agenda for Geographic Information Science; CRC Press: Boca Raton, FL, USA, 2004; pp. 17–60. [Google Scholar]
- Li, L.; Wang, Q.; Wang, H. GIS Data Management Based on Spatialite Database. Geomat. World 2010, 8, 71–75. [Google Scholar]
- Soden, R.; Palen, L. From crowdsourced mapping to community mapping: The post-earthquake work of openstreetmap Haiti. In Proceedings of the 11th International Conference on the Design of Cooperative Systems (COOP 2014), Nice, France, 27–30 May 2014; pp. 311–326. [Google Scholar]
- Luxen, D.; Vetter, C. Real-time routing with openstreetmap data. In Proceedings of the 19th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 1–4 November 2011; pp. 513–516. [Google Scholar]
- Huber, S.; Rust, C. Calculate Travel Time and Distance with Openstreetmap Data Using the Open Source Routing Machine (OSRM). Stata J. 2016, 16, 416–423. [Google Scholar] [CrossRef]
- Chen, J.; Deng, S.; Chen, H. Crowdgeokg: Crowdsourced geo-knowledge graph. In Proceedings of the China Conference on Knowledge Graph and Semantic Computing, Chengdu, China, 26–29 August 2017; pp. 165–172. [Google Scholar]
- Wang, X.; Li, Z.; Jian, Y.; Liu, J. Machine Translation Dictionary Based on Hash Method. J. Dalian Univ. Technol. 1996, 3, 108–111. [Google Scholar]
- Sun, M.; Zuo, Z.; Huang, C. An Experimental Study on Dictionary Mechanism for Chinese Word Segmentation. J. Chin. Inf. Process. 2000, 14, 1–6. [Google Scholar]
- Li, J.; Zhou, Q.; Chen, Z. A Study on Fast Algorithm for Chinese Dictionary Lookup. J. Chin. Inf. Process. 2006, 20, 31–39. [Google Scholar]
- Ye, P.; Zhang, X.; Du, M. Query Method of Chinese Gazetteer Based on the Character Features. J. Geo Inf. Sci. 2018, 20, 880–886. [Google Scholar]
- Tanaka, S. Performance Improvement of MX-CIF Quadtree by Reducing the Query Results. Int. J. Comput. Theory Eng. 2012, 4, 902–906. [Google Scholar]
- Jin, P.; Xie, X.; Wang, N.; Yue, L. Optimizing R-Tree for Flash Memory. Expert Syst. Appl. 2015, 42, 4676–4686. [Google Scholar] [CrossRef]
- Roumelis, G.; Vassilakopoulos, M.; Corral, A.; Manolopoulos, Y. Efficient Query Processing on Large Spatial Databases: A Performance Study. J. Syst. Softw. 2017, 132, 165–185. [Google Scholar] [CrossRef]
- Xiang, L.; Gao, M.; Wang, D.; Gong, J. A Quadtree Spatial Index Method with Inclusion Relations for Complex Polygons. Geomat. Inf. Sci. Wuhan Univ. 2019, 44, 436–442. [Google Scholar]
- Wang, H.; Zhou, X. A Quadtree Spatial Index Method with Inclusion Relations for Complex Polygons. J. Hunan Univ. Nat. Sci. 2020, 47, 99–109. [Google Scholar]
- Yang, Y.; Du, J.; Ping, Y. Ontology-Based Intelligent Information Retrieval System. J. Softw. 2015, 26, 1675–1687. [Google Scholar]
- Guha, R.; McCool, R.; Miller, E. Semantic Search. In Proceedings of the 12th International Conference on World Wide Web, Budapest, Hungary, 20–24 May 2003; pp. 700–709. [Google Scholar]
- Ding, L.; Finin, T.; Joshi, A.; Pan, R.; Cost, R.S.; Peng, Y.; Reddivari, P.; Doshi, V.; Sachs, J. Swoogle: A Semantic Web Search and Metadata Engine. In Proceedings of the 13th ACM Conference on Information and Knowledge Management, Washington, DC, USA, 8–13 November 2004; pp. 10–1145. [Google Scholar]
- Sabou, M.; Dzbor, M.; Baldassarre, C.; Angeletou, S.; Motta, E. Watson: A gateway for the semantic web. In Proceedings of the Poster Session of the European Semantic Web Conference, ESWC, Innsbruck, Austria, 3–7 June 2007. [Google Scholar]
- Cheng, G.; Ge, W.; Qu, Y. Falcons: Searching and Browsing Entities on the Semantic Web. In Proceedings of the 17th international conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 1101–1102. [Google Scholar]
- Zhang, L.; Yu, Y.; Zhou, J.; Lin, C.; Yang, Y. An Enhanced Model for Searching in Semantic Portals. In Proceedings of the 14th international conference on World Wide Web, Chiba, Japan, 10–14 May 2005; pp. 453–462. [Google Scholar]
- Hong, J.-H.; Kuo, C.-L. A Semi-Automatic Lightweight Ontology Bridging for the Semantic Integration of Cross-Domain Geospatial Information. Int. J. Geogr. Inf. Sci. 2015, 29, 2223–2247. [Google Scholar] [CrossRef]
- Hu, Y.; Janowicz, K.; Carral, D.; Scheider, S.; Kuhn, W.; Berg-Cross, G.; Hitzler, P.; Dean, M.; Kolas, D. A Geo-Ontology Design Pattern for Semantic Trajectories. In Proceedings of the International Conference on Spatial Information Theory, Scarborough, UK, 2–6 September 2013; pp. 438–456. [Google Scholar]
- Xu, J.; Nyerges, T.L.; Nie, G. Modeling and Representation for Earthquake Emergency Response Knowledge: Perspective for Working with Geo-Ontology. Int. J. Geogr. Inf. Sci. 2014, 28, 185–205. [Google Scholar] [CrossRef]
- Wilcke, X.; Bloem, P.; De Boer, V. The Knowledge Graph as the Default Data Model for Learning on Heterogeneous Knowledge. Data Sci. 2017, 1, 39–57. [Google Scholar] [CrossRef]
- Poggi, A.; Lembo, D.; Calvanese, D.; De Giacomo, G.; Lenzerini, M.; Rosati, R. Linking Data to Ontologies. In Journal on Data Semantics X; Springer: New York, NY, USA, 2008; pp. 133–173. [Google Scholar]
- Zhang, Y.; Li, C.; Liu, S.; Wen, F.; Du, L.; He, H. A Unified Approach to Automate Geospatial Data Retrieval Using Semantic Web Technologies. In Proceedings of the 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), Okayama, Japan, 26–29 June 2016; pp. 1–6. [Google Scholar]
- Calvanese, D.; De Giacomo, G.; Lembo, D.; Lenzerini, M.; Poggi, A.; Rodriguez-Muro, M.; Rosati, R.; Ruzzi, M.; Savo, D.F. The Mastro System for Ontology-Based Data Access. Semant. Web 2011, 2, 43–53. [Google Scholar] [CrossRef]
- Sequeda, J.; Priyatna, F.; Villazón-Terrazas, B. Relational Database to Rdf Mapping Patterns. In Proceedings of the 3rd International Conference on Ontology Patterns-Volume 929, Boston, MA, USA, 12 November 2012; pp. 97–108. [Google Scholar]
- Van Rijsbergen, C.J. Acm Sigir Forum. In A New Theoretical Framework for Information Retrieval; ACM: New York, NY, USA, 1986; pp. 23–29. [Google Scholar]
- Voorhees, E.M. SIGIR’94. In Query Expansion Using Lexical-Semantic Relations; Springer: New York, NY, USA, 1994; pp. 61–69. [Google Scholar]
- Xu, J.; Croft, W.B. Acm Sigir Forum. In Quary Expansion Using Local and Global Document Analysis; ACM: New York, NY, USA, 2017; pp. 168–175. [Google Scholar]
- Cui, H.; Wen, J.; Li, M. A Statistical Query Expansion Model Based on Query Logs. J. Softw. 2003, 14, 1593–1599. [Google Scholar]
- Navigli, R.; Velardi, P. An Analysis of Ontology-Based Query Expansion Strategies. In Proceedings of the 14th European Conference on Machine Learning, Workshop on Adaptive Text Extraction and Mining, Cavtat-Dubrovnik, Croatia, 22 September 2003; pp. 42–49. [Google Scholar]
- Lopez, V.; Stephenson, M.; Kotoulas, S.; Tommasi, P. Data Access Linking and Integration with Dali: Building a Safety Net for an Ocean of City Data. In Proceedings of the International Semantic Web Conference, Bethlehem, PA, USA, 11–15 October 2015; pp. 186–202. [Google Scholar]
- Ji, P.; Xiao, Y.; Hou, R.; Zhang, N. Application of Data Integration Technology to Forestry in China and Its Progress. World For. Res. 2018, 31, 49–54. [Google Scholar]
- Zhu, J.; You, X.; Xia, Q. A Semantic Similarity Calculation Method for Battlefield Environment Elements Based on Operational Task Ontology. Geomat. Inf. Sci. Wuhan Univ. 2019, 44, 1407–1415. [Google Scholar]
- Calvanese, D.; De Giacomo, G.; Lembo, D.; Lenzerini, M.; Poggi, A.; Rosati, R. Ontology-Based Database Access. In Proceedings of the Fifteenth Italian Symposium on Advanced Database Systems, SEBD 2007, Fasano, Italy, 17–20 June 2007; pp. 324–331. [Google Scholar]
- Zhang, Y. Design and Implementation of an Ontology-based Data Access and Integration System; Zhejiang University: Hangzhou, China, 2018. [Google Scholar]
- Liu, J.; Liu, H.; Chen, X.; Guo, X.; Guo, W.; Zhu, X.; Zhao, Q. The Construction of Knowledge Graph towards Multi-Source Geospatial Data. J. Geo Inf. Sci. 2020, 22, 1476–1486. [Google Scholar]
- Chen, Y.; Wu, C.; Guo, X.; Xie, M.; Long, F. Augmenting Collaborative Recommendation by Grouping Synonymy Tags. J. Comput. Inf. Syst. 2011, 7, 1350–1357. [Google Scholar]
- Aleman-Meza, B.; Halaschek-Weiner, C.; Arpinar, I.B.; Ramakrishnan, C.; Sheth, A.P. Ranking Complex Relationships on the Semantic Web. IEEE Internet Comput. 2005, 9, 37–44. [Google Scholar] [CrossRef]
- Díaz-Galiano, M.C.; Martín-Valdivia, M.T.; Ureña-López, L. Query Expansion with a Medical Ontology to Improve a Multimodal Information Retrieval System. Comput. Biol. Med. 2009, 39, 396–403. [Google Scholar] [CrossRef]
- Calvanese, D.; De Giacomo, G.; Lembo, D.; Lenzerini, M.; Rosati, R. Tractable Reasoning and Efficient Query Answering in Description Logics: The Dl-Lite Family. J. Autom. Reason. 2007, 39, 385–429. [Google Scholar] [CrossRef]
- Cao, H.; Chen, J.; Du, D. Qualitative Extended Description of Spatial Target Orientation Relationship. Acta Geod. Cartogr. Sin. 2001, 162–167. [Google Scholar]
- Zhang, Y.; Yang, P.; Li, C.; Zhang, G.; Wang, C.; He, H.; Hu, X.; Guan, Z. A Multi-Feature Based Automatic Approach to Geospatial Record Linking. Int. J. Semant. Web Inf. Syst. IJSWIS 2018, 14, 73–91. [Google Scholar] [CrossRef]
- Saracevic, T. Evaluation of Evaluation in Information Retrieval. In Proceedings of the 18th Annual International Acm Sigir Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 9–13 July 1995; pp. 138–146. [Google Scholar]
- Lancaster, F.W. Information Retrieval Systems; Characteristics, Testing, and Evaluation; John Wiley and Sons: New York, NY, USA, 1979; pp. 57–58. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prefix | URL |
|---|---|
| xml: | http://www.w3.org/XML/1998/namespace/, accessed on 1 January 2020 |
| xsd: | http://www.w3.org/2001/XMLSchema#, accessed on 1 January 2020 |
| rdf: | http://www.w3.org/1999/02/22-rdf-syntax-ns#, accessed on 1 January 2020 |
| rdfs: | http://www.w3.org/2000/01/rdf-schema#, accessed on 1 January 2020 |
| owl: | http://www.w3.org/2002/07/owl#, accessed on 1 January 2020 |
| sf: | http://www.opengis.net/ont/sf#, accessed on 1 January 2020 |
| geo: | http://www.opengis.net/ont/geosparql#, accessed on 1 January 2020 |
| Query Expansion Type | Description |
|---|---|
| Synonymous extension | Obtaining concepts by equivalentClass, which are equivalent to the concept extracted from the search term. |
| Attribute extension | Obtaining concepts by hasProperty, which are related to the concept extracted from the search term. |
| Hierarchical extension | Expanding or narrowing the scope of concepts by parent-child relationships. |
| Mapping Tag | Mapping Relation Description |
|---|---|
| MappingToTable | Mapping concepts onto tables in a database. |
| MappingToField | Mapping concepts onto property fields in a table. |
| hasProperty | Mapping concepts of tables onto the concepts of property fields. |
| Mapping Type | Database Representation | Schema Layer Representation |
|---|---|---|
| Table name and concept | {x|Transportation Warehousing(x)} | {x|Transportation Facility(x)} |
| Spatial field and concept | {x|Geometry(x)} | {x|sf:Geometry(x)} |
| Property field and concept | {x|Name(x)} | {x|Name(x)} |
| {x|Kind(x)} | {x|Type(x)} | |
| … | … |
| Concept | Relationship | SQL Statement |
|---|---|---|
| Transportation Facility (x) | Transportation Facility ⊆∃MappingToTable.Transportation Warehousing | Select * From ‘Transportation Warehousing’ |
| Railway Station(x) or v_station(x) | Railway Station⊆ Transportation Facility | Select * From ‘Transportation Warehousing’ Where Kind = ‘230103’… |
| v_station⊆ Transportation Facility | ||
| Transportation Facility ⊆∃MappingToTable.Transportation Warehousing | ||
| Railway Station⊆∃ hasProperty.Type ∩ (Type(“230103”))… | ||
| v_station⊆∃ hasProperty.Type ∩ (Type(“230103”))… |
| Relationship Description | Data Types |
|---|---|
| Road affiliation | Roads contain service areas, toll stations, gas stations, etc. |
| Railway affiliation | Railways contain railway stations, railway bridges, etc. |
| River affiliation | Rivers contain bridges, ferries, etc. |
| No. | Retrieval Concept | Type Code | Features Number | Time (ms) | |
|---|---|---|---|---|---|
| Conventional Method | Proposed Method | ||||
| 1 | Bridge | 230201, 230202 | 202,112 | 429 | 183 |
| 2 | Flyover | 230202 | 21,944 | 439 | 34 |
| 3 | Toll station | 230209 | 19,223 | 428 | 14 |
| 4 | Charging station | 230218 | 14,884 | 462 | 23 |
| 5 | Gasoline station | 230215, 230217 | 104,036 | 428 | 113 |
| 6 | Gas station | 230216, 230217 | 7489 | 420 | 32 |
| 7 | Station | 230100, 230103, 20107 | 13,522 | 429 | 30 |
| 8 | Railway station | 230103, 230107 | 10,771 | 426 | 22 |
| 9 | Freight railway station | 230107 | 1413 | 421 | 5 |
| 10 | Parking lot | 230212, 230225, 230211 | 258,211 | 424 | 333 |
| Experiment Type | Search Term | Features (A) | Features (B) | Proposed Method | Method (A) | Method (B) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R (%) | P (%) | F | R (%) | P (%) | F | R (%) | P (%) | F | ||||
| Entities in multiple layers | Hong Kong-Zhuhai Bridge | 39 | 1 | 100 | 100 | 1 | 97.5 | 100 | 0.98 | 2.5 | 100 | 0.04 |
| Entities in a single layer | Zhengzhou Railway Station | 0 | 1 | 100 | 100 | 1 | 0 | 0 | 0 | 100 | 100 | 1 |
| Lianhuo Highway | 10,344 | 0 | 100 | 100 | 1 | 100 | 100 | 1 | 0 | 0 | 0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Liu, H.; Chen, X.; Guo, X.; Zhao, Q.; Li, J.; Kang, L.; Liu, J. A Heterogeneous Geospatial Data Retrieval Method Using Knowledge Graph. Sustainability 2021, 13, 2005. https://doi.org/10.3390/su13042005
Liu J, Liu H, Chen X, Guo X, Zhao Q, Li J, Kang L, Liu J. A Heterogeneous Geospatial Data Retrieval Method Using Knowledge Graph. Sustainability. 2021; 13(4):2005. https://doi.org/10.3390/su13042005
Chicago/Turabian StyleLiu, Junnan, Haiyan Liu, Xiaohui Chen, Xuan Guo, Qingbo Zhao, Jia Li, Lei Kang, and Jianxiang Liu. 2021. "A Heterogeneous Geospatial Data Retrieval Method Using Knowledge Graph" Sustainability 13, no. 4: 2005. https://doi.org/10.3390/su13042005
APA StyleLiu, J., Liu, H., Chen, X., Guo, X., Zhao, Q., Li, J., Kang, L., & Liu, J. (2021). A Heterogeneous Geospatial Data Retrieval Method Using Knowledge Graph. Sustainability, 13(4), 2005. https://doi.org/10.3390/su13042005